Zadanie Uruchamiamy współbieżnie dwa egzemplarze następującego procesu:
var
y : integer := 0;
process P1;
var
x, i: integer;
begin
for i := 1 to 5 do
begin
x := y;
x := x + 1;
y := x
end;
end;Jaką wartość będzie miała zmienna y po zakończeniu działania obu?
Zadanie Uruchamiamy współbieżnie dwa następujące procesy:
process P1;
begin
repeat
sekcja_lokalna;
protokół_wstępny;
rejon_krytyczny;
protokół_końcowy
until false
end;
process P2;
begin
repeat
sekcja_lokalna;
protokół_wstępny;
rejon_krytyczny;
protokół_końcowy
until false
end;Chcemy zapewnić, że w tym samym czasie co najwyżej jeden z nich wykonuje fragment programu oznaczony jako rejon_krytyczny. Jakie instrukcje należy umieścić w protokołach, aby zrealizować ten cel? Zakładamy, że nie dysponujemy żadnymi mechanizmami synchronizacyjnymi.
Rozwiązanie W rozwiązaniu będziemy korzystać ze zmiennych globalnych i lokalnych. Zmienna lokalna może znajdować się w prywatnej przestrzeni adresowej procesu. Pozostałe procesy nie mają do niej dostępu, nie mogą jej zatem ani odczytywać ani modyfikować. Inaczej sytuacja wygląda ze zmiennymi globalnymi. Są one współdzielone między procesami, co oznacza, że w dowolnej chwili każdy z nich może takie zmienne zmodyfikować lub je odczytywać. Co dzieje się, gdy dwa wykonujące się równolegle procesy w tej samej chwili chcą uzyskać dostęp do tej samej zmiennej, a zatem do tej samej komórki (tych samych komórek) pamięci? Konflikt rozwiązuje sprzęt za pomocą arbitra pamięci. Jest to układ sprzętowy, który realizuje wzajemne wykluczanie przy dostępie do pojedynczych komórek pamięci. Jednoczesne odwołania do tej samej komórki pamięci zostaną w jakiś nieznany z góry sposób uporządkowane w czasie i wykonane. W dalszej części rozważań zakładamy istnienie arbitra pamięci i jego poprawne działanie.
Spróbujmy najpierw rozwiązać problem wprowadzając zmienną globalną ktoczeka. Będzie ona przyjmować wartości 1 lub 2. Wartość 1 oznacza, że proces pierwszy musi teraz poczekać a prawo wejścia do rejonu krytycznego ma proces drugi. Treść procesów wygląda następująco:
var
ktoczeka: 1..2 := ?;
process P1;
begin
repeat
sekcja_lokalna;
while ktoczeka = 1 do
{ instrukcja pusta };
rejon_krytyczny;
ktoczeka := 1;
until false
end;
process P2;
begin
repeat
sekcja_lokalna;
while ktoczeka = 2 do
{ instrukcja pusta };
rejon_krytyczny;
ktoczeka := 2
until false
end;Czy jest to rozwiązanie poprawne? Własność bezpieczeństwa jest zachowana — nigdy oba procesy nie będą jednocześnie w rejonie krytycznym. A co z własnością żywotności? Przypomnijmy o założeniu, że proces nie przebywa nieskończenie długo w rejonie krytycznym. Zatem po wyjściu z niego (które na pewno w końcu nastąpi) rozpocznie się wykonanie sekcji_lokalnej. I tu pojawia się problem, bo o tym fragmencie programu nic założyć nie możemy. Jeśli proces utknie w tym fragmencie kodu (bo nastąpi błąd, zapętlenie, itp.) to drugi z procesów będzie mógł wejść do sekcji krytycznej jeszcze co najwyżej raz. Kolejna próba zakończy się wstrzymaniem procesu „na zawsze". Zatem przedstawione rozwiązanie nie ma własności żywotności. Inną wadą tego rozwiązania jest zbyt ścisłe powiązanie ze sobą procesów. Muszą one korzystać z sekcji krytycznej naprzemiennie, a przecież potrzeby obu procesów mogą być różne. Jeśli ponadto działają one z różną „szybkością" (bo na przykład sekcja lokalna jednego z nich jest bardziej złożona od sekcji lokalnej drugiego), to proces „szybszy" będzie równał tempo pracy do wolniejszego.
Spróbujmy zatem zaatakować problem inaczej. Wprowadźmy dwie logiczne zmienne globalne: jest1 oznaczającą, że proces P1 jest w sekcji krytycznej i analogiczną zmienną jest2 dla procesu P2. Przed wejściem do rejonu krytycznego proces sprawdza, czy jego partner jest już w rejonie krytycznym. Jeśli tak, to czeka. Gdy rejon krytyczny będzie wolny to proces ustawia swoją zmienną sygnalizując, że jest w rejonie krytycznym, po czym wchodzi do niego.
var jest1: boolean := false; jest2: boolean := false;
process P1;
begin
repeat
sekcja_lokalna;
while jest2 do
{ instrukcja pusta };
jest1 := true;
rejon_krytyczny;
jest1 := false;
until false
end;
process P2;
begin
repeat
sekcja_lokalna;
while jest1 do
{ instrukcja pusta };
jest2 := true;
rejon_krytyczny;
jest2 := false
until false
end;Zauważmy, że to rozwiązanie nie uzależnia już procesów od siebie. Jeśli jeden z nich nie chce korzystać z sekcji krytycznej lub awaryjnie zakończy swoje działanie w sekcji lokalnej, to drugi może swobodnie wchodzić do rejonu krytycznego, ile razy zechce. Nie ma też problemu z żywotnością. Jeśli jakiś proces utknął w pętli w protokole wstępnym, to drugi proces musi znajdować się gdzieś między przypisaniem jest2 := true a przypisaniem jest2 := false. Po skończonym czasie wyjdzie zatem z rejonu krytycznego i ustawi swoją zmienną jest na false pozwalając partnerowi wyjść z jałowej pętli i wejść do rejonu krytycznego. Niestety, przy pewnych złośliwych przeplotach może się zdarzyć, że do rejonu krytycznego wejdą oba procesy:
jest1 = false, jest2= false
P1: P2
while jest2 do
{warunek jest teraz falszywy
więc nie czeka w pętli}
while jest1 do
{warunek jest teraz falszywy
więc nie czeka w pętli}
jest1 := true;
rejon_krytyczny;
jest2:= true;
rejon_krytyczny;
{ oba procesy są w rejonie krytycznym }Przyczyną takiej sytuacji było zbyt późne ustawienie zmiennych logicznych. Proces już był w rejonie krytycznym (bo przeszedł przez wstrzymującą go pętlę), a jeszcze nie poinformował partnera o tym, że jest w rejonie krytycznym. Zgodnie z definicją poprawności (musi być dobrze dla każdego przeplotu) stwierdzamy, że powyższy program jest niepoprawny. Spróbujmy zatem zmienić kolejność czynności i najpierw ustawmy zmienne logiczne, a potem próbujmy przechodzić przez pętle. Teraz zmienne logiczne oznaczają chęć wejścia do rejonu krytycznego:
var chce1: boolean := false; chce2: boolean := false;
process P1;
begin
repeat
sekcja_lokalna;
chce1 := true;
while chce2 do
{ instrukcja pusta };
rejon_krytyczny;
chce1 := false;
until false
end;
process P2;
begin
repeat
sekcja_lokalna;
chce2 := true;
while chce1 do
{ instrukcja pusta };
rejon_krytyczny;
chce2 := false
until false
end;Teraz mamy program bezpieczny. Faktycznie w rejonie krytycznym może znajdować się co najwyżej jeden proces. Ale ... nie ma żywotności! Z łatwością można doprowadzić do zakleszczenia:
chce1 = false, chce2 = false
P1: P2
chce1 := true;
chce2 := true;
while chce2 do; while chce1 do
{ i oba procesy są w pętlach nieskończonych }Zatem znowu program jest niepoprawny. Można próbować ratować sytuację zmuszając procesy do chwilowej rezygnacji z wejścia do sekcji i ustąpienia pierwszeństwa partnerowi:
var chce1: boolean := false; chce2: boolean := false;
process P1;
begin
repeat
sekcja_lokalna;
chce1 := true;
while chce2 do
begin
chce1 := false;
chce1 := true
end;
rejon_krytyczny;
chce1 := false;
until false
end;
process P2;
begin
repeat
sekcja_lokalna;
chce2 := true;
while chce1 do
begin
chce2 := false;
chce2 := true
end;
rejon_krytyczny;
chce2 := false
until false
end;Niestety znów istnieje (bardzo) złośliwy przeplot, który powoduje brak żywotności:
chce1 = false, chce2 = false
P1: P2
chce1 := true;
chce2 := true;
while chce2 do
{warunek policzony i prawdziwy}
chce1:=false;
chce1 := true;
while chce1 do
{warunek policzony i prawdziwy}
chce2 := false;
chce2 := true
{ itd. }Nie pomoże argumentacja, że taki przeplot jest „w zasadzie" nieprawdopodobny. Zgodnie z definicją poprawności, skoro istnieje scenariusz powodujący brak żywotności, to program jest niepoprawny.
Poprawne rozwiązanie znane pod nazwą algorytmu Petersona jest połączeniem pierwszego pomysłu z przedostatnim. Utrzymujemy zmienne chce1 i chce2, które oznaczają chęć wejścia procesu do rejonu krytycznego. W razie gdy oba procesy chcą wejść do rejonu krytycznego rozstrzygamy konflikt za pomocą zmiennej ktoczeka:
var chce1: boolean := false; chce2: boolean := false; ktoczeka: 1..2 := ?
process P1;
begin
repeat
sekcja_lokalna;
chce1 := true;
ktoczeka := 1;
while chce2 and (ktoczeka = 1) do
{ instrukcja pusta };
rejon_krytyczny;
chce1 := false;
until false
end;
process P2;
begin
repeat
sekcja_lokalna;
chce2 := true;
ktoczeka := 2;
while chce1 and (ktoczeka = 2) do
{ instrukcja pusta };
rejon_krytyczny;
chce2 := false
until false
end;Wady algorytmu Petersona:
Problem 1 Wzajemne wykluczanie. Stosujemy notację z wykładu oraz zakładamy, że bufor jest nieograniczony.
Pomysł polega na umieszczeniu początkowo w buforze jednego egzemplarza komunikatu Bilet. Proces wejdzie do sekcji krytycznej o ile w buforze jest komunikat, w przeciwnym razie będzie czekał. Wchodząc do sekcji krytycznej oczywiście wyjmuje komunikat z buforu a umieszcza go w nim zwalniając sekcję.
type
Komunikaty = (Bilet)
var
b: buffer;
process P (i: integer);
var
k: Komunikaty;
begin
repeat
sekcja_lokalna;
GetMessage (b, k)
rejon_krytyczny;
SendMessage (b, k)
until false
end;
begin
SendMessage (b, Bilet);
cobegin P(1); P(2) coend
endZwróćmy uwagę, że dla poprawności tego rozwiązania kluczowa jest żywotność operacji pobrania z bufora. Ponieważ pracujemy w modelu rozproszonym zmienne nie mogą być współdzielone między żadnymi procesami (w tym także zmienne występujące w głównym programie, który traktujemy jako jeszcze jeden proces, muszą być rozłączne ze zmiennymi, które występują w procesach). Wyjątkiem są zmienne buforowe, które zawsze są globalne. Rozwiązanie to nie zmieni się, jeśli uruchomimy więcej procesów:
type
Komunikaty = (Bilet)
var
b: buffer;
process P (i: integer);
var
k: Komunikaty;
begin
repeat
sekcja_lokalna;
GetMessage (b, k)
rejon_krytyczny;
SendMessage (b, k)
until false
end;
const
ileP = ...;
var i: integer;
begin
SendMessage (b, Bilet);
cobegin for i := 1 to ileP do P(i) coend
endCzasami zachodzi jednak konieczność ograniczenia liczby procesów jednocześnie przebywających w sekcji krytycznej niekoniecznie do jednego procesu, ale ogólnie do pewnej ustalonej wielkości M < ileP. Wtedy wystarczy umieścić w buforze odpowiednią liczbę „biletów wstępu".
Inne możliwe rozwiązanie polega na wprowadzeniu dodatkowego procesu Dozorcę, który będzie nadzorował wykorzystanie sekcji krytycznej. Proces, który chce skorzystać z sekcji krytycznej musi wysłać zamówienie do dozorcy i oczekiwać na potwierdzenie. Do komunikacji wykorzystamy zatem dwa bufory: jeden do wysyłania komunikatów do dozorcy, a drugi do odbierania zezwoleń (dlaczego muszą to być dwa oddzielne bufory?):
type
Komunikaty = (Chce, Mo»esz, Zwalniam)
var
zam, zezw: buffer;
process P (i: integer);
var
k: Komunikaty;
begin
repeat
sekcja_lokalna;
SendMessage (zam, Chce);
GetMessage (zezw, k);
rejon_krytyczny;
SendMessage (zam, Zwalniam);
until false
end;
const
M = ...;
process Dozorca;
var
k: Komunikaty;
ileWolnych: integer := M;
iluChce: integer := 0;
begin
repeat
GetMessage (zam, k);
case k of
Chce: if ileWolnych > 0 then
begin
dec (ileWolnych);
SendMessage (zezw, Mo»esz)
end
else
inc (iluChce)
Zwalniam: if iluChce > 0 then
begin
SendMessage (zezw, Mo»esz);
dec (iluChce)
end else
inc (ileWolnych)
end
until false
end;
const
ileP = ...;
var i: integer;
begin
cobegin Dozorca; for i := 1 to ileP do P(i) coend
endTen algorytm ma pewną subtelność: procesy nie muszą wchodzić do sekcji krytycznej w kolejności jej zamawiania. Może się zdarzyć, że zezwolenie „przeznaczone" dla jednego procesu odbierze proces, który zgłosił zapotrzebowanie później. Na mocy żywotności operacji pobierania z bufora nie dojdzie jednak do zagłodzenie żadnego procesu.
Obsługa procesów zgodnie z kolejnością zgłoszeń wymagałaby wykorzystania dodatkowych informacji umieszczanych w bilecie.
Problem 2. Producenci i konsumenci Problem producentów i konsumentów ma kilka odmian. W notacji z wykładu najłatwiej zapisać rozwiązanie w wersji z nieograniczonym buforem. Wszelkie komentarze są tu chyba zbyteczne:
var
b: buffer;
process Producent;
var
p: Porcja;
begin
repeat
Produkuj (p);
SendMessage (b, p)
until false
end;
process Konsument;
var
p: Porcja;
begin
repeat
GetMessage (b, p);
Konsumuj (p)
until false
end;
begin
cobegin Producent; Konsument coend
endPowyższe rozwiązanie jest także poprawne dla wielu producentów i wielu konsumentów. Trudniej jest uzyskać rozwiązanie w wariancie problemu z buforem o pojemności M porcji. Trzeba wtedy „symulować" ograniczoność bufora w sposób podobny do pierwszego rozwiązania problemu wzajemnego wykluczania. W osobnym buforze umieszczamy „bilety", z których każdy reprezentuje jedno wolne miejsce w buforze. Producent przed umieszczeniem porcji w buforze pobiera bilet:
type
Bilety = (Bilet);
var
b: buffer;
bpom: buffer;
process Producent;
var
p: Porcja;
bil: Bilety;
begin
repeat
Produkuj (p);
GetMessage (bpom, bil);
SendMessage (b, p)
until false
end;
process Konsument;
var
p: Porcja;
begin
repeat
GetMessage (b, p);
SendMessage (bpom, Bilet)
Konsumuj (p)
until false
end;
var
i: 1..M;
begin
for i := 1 to M do SendMessage (bpom, Bilet);
cobegin Producent; Konsument coend
endJeszcze innego rozwiązania wymaga żądanie, żeby producent przekazywał porcję „bezpośrednio" do konsumenta (tzn. że możliwa jest produkcja kolejnej porcji dopiero gdy konsument odbierze dane). Konsument musi wtedy potwierdzać fakt odebrania komunikatu:
type
Potw = (Potwierdzenia);
var
b: buffer;
bpom: buffer;
process Producent;
var
p: Porcja;
pot: Potw;
begin
repeat
Produkuj (p);
SendMessage (b, p);
GetMessage (bpom, pot)
until false
end;
process Konsument;
var
p: Porcja;
begin
repeat
GetMessage (b, p);
SendMessage (bpom, Potwierdzenie)
Konsumuj (p)
until false
end;
begin
cobegin Producent; Konsument coend
endProblem 3. Czytelnicy i Pisarze Wydaje się, że rozwiązanie tego problemu można ująć następującym algorytmem. Czytelnik, który chce czytać sprawdza, czy w czytelni nie ma pisarza. Jeśli nie ma, to rozpoczyna czytanie. Pisarz, który chce pisać czeka aż czytelnia będzie pusta i rozpoczyna pisanie. Implementując taki algorytm dobrze jest wprowadzić dodatkowy proces Czytelnia synchronizujący dostęp do czytelni. Proces ten przechowuje informacje o tym, kto jest w czytelni i decyduje, kogo można wpuścić. Do komunikacji wprowadzimy trzy bufory: jeden do komunikacji z czytelnią, jeden do wysyłania zezwoleń dla pisarzy, jeden do wysyłania zezwoleń dla czytelników:
type
Komunikaty = (ChceCzytac, ChcePisac, Wychodze);
Zezwolenia = (Wejdz)
var
czytelnia, czyt, pis: buffer;
process Czytelnik (i: integer);
var
z: Zezwolenia;
begin
repeat
Sekcja_lokalna;
SendMessage (czytelnia, ChceCzytac);
GetMessage (czyt, z);
CZYTANIE;
SendMessage (czytelnia, Wychodze)
until false
end;
process Pisarz (i: integer);
var
z: Zezwolenia;
begin
repeat
sekcja_lokalna;
SendMessage (czytelnia, ChcePisac);
GetMessage (pis, z);
PISANIE;
SendMessage (czytelnia, Wychodze)
until false
end;
process Czytelnia;
var
dc, dp : integer; { liczba odp. czytelnikow i pisarzy
w czytelni. Dla symetrii dp jest
typu integer, choć mogłaby być typu
boolean }
ac, ap : integer; { liczba czyt. i pis., którzy się
pojawili, więc ac - dc czytelników
oczekuje na wejście do czytelni }
kom: Komunikaty;
begin
dc := 0; dp := 0;
repeat
GetMessage (czytelnia, kom);
case kom of
ChceCzytac: begin
inc (ac);
(*) if dp = 0 then
begin
inc (dc);
SendMessage (czyt, Wejdz);
end
end;
ChcePisac: begin
inc (ap);
if dp + dc = 0 then
begin
inc (dp);
SendMessage (pis, Wejdz)
end
end
Wyjdz : if dp > 0 then { wychodzi pisarz }
begin
dec (dp); dec (ap);
if dc < ac then
while dc < ac do
begin
SendMessage (czyt, Wejdz)
inc (dc)
end
else if dp < ap then begin
inc (dp);
SendMessage (pis, Wejdz)
end
end else { wychodzi czytelnik }
begin
dec (dc); dec (ac);
if (dc = 0) and (dp < ap) then begin
inc (dp);
SendMessage (pis, Wejdz)
end
end
end {case}
until false
end;Zwróćmy uwagę na sposób obsługi wychodzenia z czytelni. Pisarz, który wychodzi sprawdza najpierw, czy czekają czytelnicy. Jeśli tak, to wpuszcza wszystkich czekających. Dopiero gdy upewni się, że nie ma oczekujących czytelników sprawdza, czy czekają pisarze i jeśli tak, to wpuszcza jednego z nich. Odwrotna kolejność mogłaby spowodować zagłodzenie czytelników w razie ciągłego zgłaszania się pisarzy. Analogicznie czytelnik, który jako ostatni wychodzi z czytelni wpuszcza jednego z oczekujących pisarzy (jeśli są). Czytelnicy na pewno w tym momencie nie czekają (skoro w czytelni byli czytelnicy to nowi czytelnicy mogli od razu wejść do czytelni).
Niestety zachowanie odpowiedniej kolejności wpuszczania do czytelni przy wychodzeniu z niej nie wystarcza do uniknięcia zagłodzenia. W powyższym rozwiązaniu czytelnicy mogą z łatwością zagłodzić pisarzy: wystarczy, że czytelnia będzie wiecznie okupowana przez czytelników. Aby temu zapobiec czytelnia przestaje wpuszczać nowych czytelników, gdy pojawi się oczekujący pisarz. W tym celu warunek z wiersza oznaczonego gwiazdką zmieniamy na ap= 0.
Rozwiązanie tego problemu można znacznie uprościć zakładając, że liczba miejsc w czytelni jest ograniczona i wynosi M. Wtedy ponownie wykorzystujemy pomysł „biletów" na wejście do sekcji krytycznej: czytelnik przed rozpoczęciem czytania musi pobrać jeden bilet, a pisarz musi uzyskać komplet biletów. Dodatkowy proces jest wtedy niepotrzebny, wystarczy też jeden bufor:
type
Bilety = (Bilet);
var
czytelnia : buffer;
process Czytelnik (i: integer);
var
bil: Bilety;
begin
repeat
Sekcja_lokalna;
GetMessage (czytelnia, bil);
CZYTANIE;
SendMessage (czytelnia, Bilet)
until false
end;
process Pisarz (i: integer);
var
bil: Bilety;
i: 1..M;
begin
repeat
sekcja_lokalna;
for i := 1 to M do
GetMessage (czytelnia, bil);
PISANIE;
for i := 1 to M do
SendMessage (czytelnia, Bilet)
until false
end;Niestety powyższe rozwiązanie nie jest poprawne. Może dojść do zakleszczenia, jeśli dwóch pisarzy będzie jednocześnie próbować dostać się do czytelni. Wtedy jeden z nich może zabrać część biletów, a drugi pozostałe i obydwaj będą czekać w nieskończoność na pozostałe bilety blokując siebie i inne procesy. Prostym rozwiązaniem tego problemu jest umieszczenie pierwszej pętli pisarza w sekcji krytycznej:
type
Bilety = (Bilet);
var
czytelnia, pis : buffer;
process Czytelnik (i: integer);
var
bil: Bilety;
begin
repeat
Sekcja_lokalna;
GetMessage (czytelnia, bil);
CZYTANIE;
SendMessage (czytelnia, Bilet)
until false
end;
process Pisarz (i: integer);
var
bil: Bilety;
i: 1..M;
begin
repeat
sekcja_lokalna;
GetMessage (pis, bil);
for i := 1 to M do
GetMessage (czytelnia, bil);
SendMessage (pis, bil);
PISANIE;
for i := 1 to M do
SendMessage (czytelnia, Bilet)
until false
end;Oczywiście początkowo w buforze czytelnia musi być M biletów, a w buforze pis — jeden bilet.
Problem 1. Implementacja różnych odmian semaforów.
(a) Implementacja semafora dwustronnie ograniczonego.
var S : semaphore := K; {wartosc poczatkowa, 0 <= K <= N} T : semaphore := N - K; procedure PD; {operacja P na semaforze dwustronnie ograniczonym} begin P(S); V(T); end; procedure VD; {operacja V na semaforze dwustronnie ograniczonym} begin P(T); V(S); end;
Uwaga. Warto zauważyć, że zmiana kolejności wywołań w procedurze VD prowadzi do niepoprawnego rozwiązania (bardzo często podawanego przez studentów). Najlepiej to widać na przykładzie zastosowania powyższego schematu do rozwiązania problemu producentoów i konsumentóow z ograniczonym buforem.
Zastosowanie — producent i konsument, bufor cykliczny.
var bufor : array[0..N-1] of porcja; {bufor cykliczny} Wolne : semaphore := N; {bufor inicjalnie pusty} Zajete : semaphore := 0; process Producent; process Konsument; var k : integer := 0; var k : integer := 0; p : porcja; p : porcja; begin begin while true do begin while true do begin produkuj(p); P(Zajete); P(Wolne); p:= bufor[k]; bufor[k]:= p; V(Wolne); V(Zajete); k:= (k + 1) mod N; k:= (k + 1) mod N konsumuj(p) end end end; end;
(b) Implementacja semafora uogólnionego.
Należy zdefiniować dwie operacje, nazwijmy je PG(n) oraz VG(n), oznaczające odpowiednio opuszczenie oraz podniesienie semafora uogólnionego.
W przedstawionym, prostym i zwiezłym, rozwiazaniu semafor (tzn. zmienna pomocnicza) przyjmuje czasowo wartości ujemne (sic!). Sposób działania procesów (wstrzymywanie procesów) jest jednak całkowicie prawidłowy (i o to przecież chodzi). Rozwiązanie, w którym zmienna pomocnicza nie przyjmuje wartości ujemnych jest znacznie bardziej złożone (por. Z. Weiss, T. Gruźlewski).
var mutex : binary semaphore := 1; {wylaczny dostep} ochrona : binary semaphore := 1; {ochrona wspolnej zmiennej} Sczekaj : semaphore := 0; {oczekiwanie} ile : integer; {aktualna wartosc semafora} procedure PG(n : integer); {operacja P na semaforze uogolnionym} begin P(mutex); {co najwyzej jeden proces czeka na P} P(ochrona); ile:= ile - n; if ile < 0 then {wstrzymanie} begin V(ochrona); P(Sczekaj); end else V(ochrona); V(mutex) end; procedure VG(n : integer); {operacja V na semaforze uogolnionym} begin P(ochrona); ile:= ile + n; if (ile >= 0) and (ile < n) then {ktos czeka i juz sie doczekal} V(Sczekaj); V(ochrona); end;
Problem 2. Czytelnicy i pisarze.
Rozwiązanie klasycznego problemu przy użyciu semaforów, bez żadnych priorytetów, czyli bez zagłodzenia. Treści obu rodzajów procesów są prawie identyczne — z dokład-nością do nazw zmiennych plus spełnienie wymagania, że tylko jeden pisarz może prze-bywać w czytelni.
Schemat działania procesu danej grupy jest następujący: jeśli nie ma procesów z grupy przeciwnej, to wchodzę do czytelni (pisarze pojedynczo), w przeciwnym przypadku czekam (na odpowiednim semaforze). Po zakończeniu korzystania z czytelni przez wszystkie procesy, które uzyskały takie prawo, ostatni wychodzący proces wpuszcza wszystkie oczekujące procesy ż grupy przeciwnej (podnosząc semafor odpowiednia liczbę razy).
Do realizacji powyższego schematu należy użyć:
var jest_cz, akt_cz, czeka_p, jest_p : integer := (0, 0, 0, 0); Ochrona : binary semaphore := 1; {ochrona wspolnych zmiennych} Czytelnia : binary semaphore := 1; {dostep dla jednego pisarza} Czytelnicy : semaphore := 0; {czekajacy czytelnicy} Pisarze : semaphore := 0; {czekajacy pisarze} process Czytelnik; begin while true do begin wlasne_sprawy; P(Ochrona); jest_cz:= jest_cz + 1; {licznik wszystkich czytelnikow} if jest_p = 0 then begin {nie ma pisarza, mozna czytac} akt_cz:= akt_cz + 1; {licznik czytelnikow w czytelni} V(Ochrona) end else begin {sa pisarze ... } V(Ochrona); P(Czytelnicy) { ... czytelnicy czekaja} end; CZYTAM; P(Ochrona); akt_cz:= akt_cz - 1; jest_cz:= jest_cz - 1; if akt_cz = 0 then {wychodzi ostatni czytelnik} while jest_p > akt_p do begin {wpuszczamy wszystkich pisarzy} akt_p:= akt_p + 1; {zaznaczajac, ze sa oni aktywni} V(Pisarze); end; V(Ochrona) end end;
Treści obu rodzajów procesów są prawie identyczne — zamiast CZYTAM pisarz wykonuje P(Pisarze); PISZE; V(Pisarze).
Czytelnicy i pisarze — priorytet dla pisarzy (zagłodzenie czytelników).
Rozwiązanie dające priorytet pisarzom można uzyskać modyfikując przedstawione powyżej rozwiązanie. Interesujące cechy poniższego rozwiązania:
Osoby zainteresowane innym rozwiązaniem tego problemu odsyłam do książki: W. Iszkowski, M. Maniecki, "Programowanie współbieżne", WNT 1982. Bardzo pouczające jest pełne zrozumienie przedstawionego tam rozwiązania (zwłaszcza sekwencji trzech operacji P).
var jest_cz, akt_cz, jest_p : integer := (0, 0, 0); Ochrona : binary semaphore := 1; {ochrona wspolnych zmiennych} Czytelnia : binary semaphore := 1; {dostep dla pisarza/czytelnikow} Czytelnicy : binary semaphore := 0; {czekajacy czytelnicy} process Pisarz; begin while true do begin wlasne_sprawy; P(Ochrona); jest_p:= jest_p + 1; V(Ochrona); P(Czytelnia); PISANIE; V(Czytelnia); P(Ochrona); jest_p:= jest_p - 1; if (jest_p = 0) and (jest_cz > 0) then {wchodza czytelnicy} begin P(Czytelnia); {czytelnie zajmuja czytelnicy; troche nieladne} V(Czytelnicy) {uwaga: dziedziczenie sekcji krytycznej} end else V(Ochrona) end end; process Czytelnik; begin while true do begin wlasne_sprawy; P(Ochrona); jest_cz:= jest_cz + 1; {licznik wszystkich czytelnikow} if jest_p = 0 then begin {nie ma pisarza, mozna czytac} akt_cz:= akt_cz + 1; {licznik czytelnikow w czytelni} if akt_cz = 1 then P(Czytelnia); {pierwszy czytelnik musi zajac} V(Ochrona) end else begin {sa pisarze ... } V(Ochrona); P(Czytelnicy) { ... czytelnicy czekaja} akt_cz:= akt_cz + 1; if jest_cz > akt_cz then V(Czytelnicy) {wpuszczam nastepnego} else V(Ochrona) {a ostatni zwalnia} end; CZYTAM; P(Ochrona); akt_cz:= akt_cz - 1; jest_cz:= jest_cz - 1; if akt_cz = 0 then {wychodzi ostatni czytelnik} V(Czytelnia); { - moze wejsc pisarz} V(Ochrona) end end;
Możliwe jest również zapisanie treści obu procesów w sposób jeszcze bardziej zbliżony do poprawnego rozwiązania (beż priorytetów) — ale mniej ciekawy :-). Pozostawiamy to zainteresowanym czytelnikom.
Zadanie 1.
W systemie działa N grup procesów. Każdy proces cyklicznie wykonuje procedurę własne_sprawy, a następnie procedurę OBLICZ, którą w tym samym czasie mogą wykonywać tylko procesy należące do tej samej grupy. Pierwszy proces z grupy może rozpocząć wykonywanie procedury OBLICZ tylko wówczas, gdy nikt inny jej nie wykonuje. Po zakończeniu wykonywania procedury OBLICZ procesy czekają aż wszystkie wykonujące ją procesy zakończą jej wykonywanie. Po zakończeniu procedury przez ostatni z wykonujących ją procesów działanie powinny rozpocząć oczekujące procesy z kolejnej grupy. Zapisz treść procesu process P (gr : 1..N) używając samaforów.
Uwagi wstępne.
W tym zadaniu synchronizacja działania procesów dotyczy dwóch kwestii: zapewnienia poprawnego wykonywania procedury OBLICZ oraz wspólnego zakończenia (jednego cyklu) przetwarzania.
Rozwiązanie tego zadania wymaga użycia następujących semaforów:
Niezbędne informacje o stanie systemu obejmują:
Rozwiązanie
var Ochrona : binary semaphore := 1; {ochrona wspolnych zmiennych} Pierwsi : binary semaphore := 0; {tu czekaja pierwsi z grup} Reszta : array[1..N] of binary semaphore := {all 0}; { tu pozostali} Koniec : binary semaphore := 0; {a tu procesy, ktore juz zakonczyly} kto : integer := 0; {numer dzialajacej grupy; 0 - brak} dziala : integer := 0; {liczba dzialajacych procesow} ile : array[1..N] of integer := {all 0}; {ile procesow czeka} ilegrup : integer := 0; {ile grup czeka} ilekon : integer := 0; {ilu czeka po zakonczeniu obliczen} process P (gr : 1..N); begin while true do begin wlasne_sprawy; P(Ochrona); if kto = 0 then kto:= gr {nikogo nie ma, moge dzialac} else if kto <> gr then begin {dziala moja grupa -> wchodze, wpp. czekam} inc(ile[gr]); if ile[gr] = 1 then begin {jestem pierwszy z grupy} inc (ilegrup); V(Ochrona); {zwalniam dostep do zmiennych} P(Pierwsi); { i grzecznie czekam} dec (ilegrup); kto:= gr; {a teraz dziala moja grupa} end else begin {kolejny proces z grupy} V(Ochrona); P(Reszta[gr]); {czekam razem z kolegami z grupy} end; dec(ile[gr]); {juz sie doczekalem} end; inc(dziala); {i zaraz zaczne dzialac} if ile[gr] > 0 then V(Reszta[gr]) {budze nastepnego} else V(Ochrona); {lub zwalniam dostep} OBLICZ; P(Ochrona); dec(dziala); if dziala > 0 then begin {koledzy jeszcze pracuja} inc(ilekon); { wiec musze poczekac} V(Ochrona); P(Koniec); dec(ilekon) {dziedziczenie sekcji!} end; if ilekon>0 then V(Koniec) {zwalniam czekajacego,} else { a ostatni proces z grupy} if ilegrup >0 then V(Pierwsi) { budzi pierwszego z innej grupy} else begin kto:= 0; { lub zwalnia, bo nikt nie czeka} V(Ochrona) end end end;
Komentarze do rozwiązania zadania 1.
W obydwu miejscach (czekanie na rozpoczęcie działania, czekanie po zakończeniu działania) procesy są budzone potokowo, czyli jeden proces budzi następny, przekazując mu sekcję krytyczną, a dopiero ostatni proces zwalnia sekcję krytyczną (tu: dostęp do zmiennych),
Pytanie: czy można (w tym rozwiązaniu lub w ogóle) zmienić sposób budzenia, tak aby jeden proces budził wszystkich? Czy dostaniemy poprawne i sprawne rozwiązanie, a jeśli tak, to jakie są wady i zalety obu podejść?
Przyjmujemy, że obowiązującą definicją semaforów jest definicja klasyczna. Analizę dla praktycznej definicji pozostawiamy czytelnikowi.
Rozważmy najpierw kwestię wspólnego kończenia pracy przez wszystkie procesy z grupy. Przyjmijmy, że ostatni proces budzi wszystkich, czyli wykonuje instrukcję postaci: for i:= 1 to ilekon do V(Koniec); i kończy działanie. Semafor Koniec (ogólny, a nie binarny) ma poprawną wartość i każdy czekający proces może kontynuować pracę. Co się jednak stanie, gdy jakiś proces 'zaśpi'? Następna grupa zaczyna działać i może skończyć zanim ten 'śpioch' opuści podniesiony dla niego semafor. Konsekwencje: proces z nowej grupy nie czeka na kolegów, natomiast proces ze starej grupy ciągle czeka.
Konieczność dziedziczenia sekcji przy budzeniu pierwszego procesu z kolejnej grupy jest chyba oczywista. Gdyby nie było dziedziczenia, inny proces mógłby na podstawie stanu systemu (m.in, zmienna kto) stwierdzić, że może pracować i rozpocząć działanie. Chwilę później uprawniona grupa również rozpoczęłaby działanie. Nie możemy tego naprawić, gdyż nie wiemy który z oczekujących procesów zostanie obudzony.
Rozważmy teraz kwestię rozpoczęcia pracy przez grupę procesów z tej samej grupy. Pierwszy proces z grupy mógłby, po obudzeniu, budzić wszystkich swoich kolegów. Drobna wada (cecha?) takiego rozwiązania, to zrzucenie pewnej pracy na jeden z procesów, a nie równomierne obłożenie obowiązkami wszystkich (sprawność całości w zasadzie bez zmian). Odpowiednio operując licznikami (inaczej niż w przedstawionym rozwiązaniu!) można uniknąć sytuacji opisanej powyżej, czyli niepoprawnej pracy systemu.
Pozostaje jeszcze inna kwestia: proces może zostać wstrzymany zaraz po zwolnieniu dostępu do zmiennych >(V(0chrona)), a bezpośrednio przed wykonaniem operacji P, A wówczas mogłoby się zdarzyć, że pierwszy proces z grupy zostanie obudzony i podniesie semafor. Przy (nieco) niewłaściwej (a być może trudnej do zauważenia) modyfikacji liczników mogłoby się zdarzyć, że wszystkie procesy z grupy zakończyłyby działanie nie czekając na spóźnialskiego kolegę, który z kolei mógłby rozpocząć pracę w dowolnym terminie (bo semafor jest podniesiony).
Uwaga końcowa: przedstawione rozwiązanie jest poprawne, niezależnie od przyjętej definicji semaforów, jest jednakowo sprawne i bardziej sprawiedliwie dzieli obowiązki między wszystkie procesy.
Zadanie 2.
W systemie działa pewna liczba procesów zajmujących się przetwarzaniem danych. Każda praca jest wykonywana dokładnie przez K procesów (K > 1). Każdy proces (w nieskończonej pętli) zgłasza się do pracy, otrzymuje numer kolejny z przedziału od 1 do K, a następnie czeka na zgłoszenie się wszystkich K procesów. Ostatni (K-ty) proces inicjuje przetwarzanie (function inicjuj () : DANE)). Zainicjowane dane są następnie przetwarzane sekwencyjnie przez wszystkie procesy z tej grupy, począwszy od pierwszego procesu (tj, procesu, który przy zgłoszeniu otrzymał numer 1) aż do ostatniego (procedure przetwarzaj (var dane : DANE; nr : 1. .K)). Po zakończeniu przetwarzania każdy proces ponownie zgłasza się do pracy. Zakończenie całej pracy następuje po zakończeniu jej przetwarzania przez wszystkie procesy z grupy.
Równocześnie może być wykonywanych co najwyżej MAX prac (opisanych wyżej; MAX > 1). Przetwarzanie różnych prac może (i powinno) odbywać się równolegle, przy czym przetwarzanie danej pracy przez i-ty proces z danej grupy może rozpocząć się dopiero po zakończeniu przetwarzania poprzedniej pracy przez i-ty proces z poprzedniej grupy.
Zapisz przy użyciu semaforów treść procesów działających w tym systemie. Podaj początkowe wartości wszystkich semaforów.
Uwagi wstępne.
Zapewnienie wymaganej synchronizacji procesów oznacza konieczność użycia dwóch dwuwymiarowych tablic semaforów: semafory Faza służą do zapewnienia sekwencyjnego przetwarzania każdej pracy, natomiast semafory Dalej służą do właściwej synchronizacji procesów realizujących różne prace (nie za szybko).
Ograniczenie liczby jednocześnie wykonywanych prac może być zrealizowane (inaczej niż w przedstawionym rozwiązaniu) przy użyciu semafora ogólnego, zainicjowanego na liczbę prac dozwolonych do jednoczesnego wykonywania. Przedstawiona wersja rozwiązania jest nieco bardziej złożona, przedstawiam ją jednak dlatego, że wielu studentów wybierających tego typu rozwiązanie popełniało wiele podstawowych błędów synchronizacyjnych, Ponadto w tym drugim rozwiązaniu każdy proces musiałby najpierw opuścić semafor, a po stwierdzeniu, że nie jest ostatnim z grupy (tu akurat ostatni, a nie pierwszy proces to robi) musiałby podnosić niesłusznie opuszczony semafor. Alternatywne rozwiązanie jest w sumie nieco krótsze, ale mniej eleganckie i nieco bardziej złożone.
Przykładowe rozwiązanie.
const K = ...; MAX = ...; var Faza : array[1..K, 1..MAX] of binary semaphore = {all 0}; Dalej : array[1..K, 1..MAX] of binary semaphore = {K*1; others 0}; Prace : binary semaphore = 0; {tylko MAX prac, reszta czeka} Ochrona : binary semaphore = 1; {standardowa ochrona zmiennych} dane : array[1..MAX] of DANE; {przetwarzane dane} ilePrac : integer = 0; {liczba prac w toku} ileCzeka : integer = 0; {liczba procesow czekajacych na Prace} praca : integer = 1; {indeks w dane dla nastepnej pracy} ileProcesow : integer = 0; {liczba procesow do nastepnej pracy} process Proces; var nr : integer; {numer kolejny (1..K)} nrPracy : integer; {numer pracy (1..MAX)} begin while true do begin P(Ochrona); if ilePrac = MAX then begin {MAX prac w toku, czekamy} inc(ileCzeka); V(Ochrona); P(Prace); dec(ileCzeka) {sekcja odziedziczona} end; inc(ileProcesow); nr:= ileProcesow; {moj numer kolejny} nrPracy:= praca; {numer pracy} if nr = K then begin {grupa w komplecie} inc(ilePrac); praca:= praca mod MAX + 1; {nastepna praca} ileProcesow:= 0; {jeszcze nie ma do niej nikogo} dane[nrPracy]:= inicjuj(); V(Ochrona); V(Faza[1, nrPracy]); {pierwszy z mojej grupy do roboty} end else if ileCzeka > 0 then V(Prace) else V(Ochrona); P(Faza[nr, nrPracy]); {poprzednik z grupy zakonczyl} P(Dalej[nr, nrPracy]); {nie za szybko (poprzednia praca)} przetwarzaj( dane[nrPracy], nr ); {kolejne prace moga juz byc kontynuowane} V(Dalej[nr, nrPracy mod MAX + 1]); if nr < K then begin V(Faza[nr+1, nrPracy]) {nastepny z grupy do roboty} else begin {zakonczenie pracy} P(Ochrona); dec(ilePrac); if ileCzeka > 0 then V(Prace) else V(Ochrona) end end end;
Gdyby przyjąć (dospecyfikować), że rozpoczęcie pracy następuje już od zbierania procesów do jej wykonania, to wspomniane wcześniej alternatywne rozwiązanie nie-spełniałoby wymagań tego zadania, A wówczas przedstawione rozwiązanie byłoby (chyba) optymalne.
Zadanie 1 (Stolik dwuosobowy)
W systemie działa N par procesów. Procesy z pary są nierozróżnialne. Każdy proces cyklicznie wykonuje własne_sprawy, a potem spotyka się z drugim procesem z pary (randka) w kawiarni przy stoliku dwuosobowym. W kawiarni jest tylko jeden stolik. Procesy mogą zająć stolik tylko wtedy gdy obydwa są gotowe do spotkania, ale odchodzą od niego pojedynczo (w różnym czasie kończą wykonywanie procedury randka).
P(j : 1. .N) używając do synchronizacji semaforów.P(j : 1. .N) i monitor KAWIARNIA synchronizujący ich działanie.Rozwiązanie a
var NA_PARĘ : array [1..N] of binary semaphore := (0,...,0); para : array [1..N] of boolean := (False, ...,False); NA_STÓŁ : binary semaphore := 1; przy_stole : integer := 0; OCHRONA : binary semphore := 1; process P(j:1..N) begin repeat własne_sprawy; P(OCHRONA); if not para[j] then begin para[j] := True; V(OCHRONA); P(NA_PARĘ[j]); end else begin para[j] := False; V(OCHRONA); P(NA_STÓŁ); przy_stole := 2; V(NA_PARĘ[j]); end; randka; P(OCHRONA); dec(przy_stole); if przy_stole = 0 then begin V(OCHRONA); V(NA_STÓŁ); end else V(OCHRONA); until false; end;
Rozwiązanie b
monitor KELNER var NA_PARĘ : array [1..N] of condition; NA_STÓŁ : condition; przy_stole : integer; export procedure CHCĘ_STOLIK(j:integer) begin if empty(NA_PARĘ[j]) then wait(NA_PARĘ[j]) else begin if przy_stole > 0 then wait(NA_STÓ); przy_stole := 2; signal(NA_PAR[j]); end; end; export procedure ZWALNIAM begin dec(przy_stole); if przy_stole = 0 then signal(NA_STÓŁ); end; begin przy_stole := 0; end. process P(j:1..N) begin repeat własne_sprawy; KELNER.CHCĘ_STOLIK(j); randka; KELNER.ZWALNIAM; until false; end
Należy zwrócić uwagę na następujące różnice:
OCHRONA) dlatego, że procedur monitora nie może wykonywać wiele procesów jednocześniewait jest zawsze blokująca w przeciwieństwie do operacji P, która zależy od wartości semafora. Dlatego w rozwiązaniu a jest: P(NA_STÓŁ), a w rozwiązaniu b: if przy_stole > 0 then wait(NA_STÓŁ);signal na pustej kolejce nic nie robi w przeciwieństwie do operacji V, która wykonana na semaforze na którym żaden proces nie czeka powoduje jego podniesienie (zostawienie otwartej drogi)Zadanie 2 (Implementacja monitora przy pomocy semaforów)
Należy napisać odpowiedniki operacji monitorowych korzystając z semaforów:
waitsignalRozwiązanie a
Wersja prostsza: zakładamy, że signal jest ostatnią instrukcją w procedurze monitora.
var MONITOR: binary semaphore := 1; {żeby zapewnić wzajemne wykluczanie przy wykonywaniu procedur monitora} KOLEJKA: binary semaphore := 0; ilu_czeka: integer := 0; 1) P(MONITOR); 2) inc(ilu_czeka); V(MONITOR); P(KOLEJKA); dec(ilu_czeka); 3) if ilu_czeka > 0 then V(KOLEJKA) else V(MONITOR); 4) V(MONITOR);
Dziedziczenie sekcji krytycznej jest konieczne, aby zachować semantykę operacji monitorowych - po wykonaniu signal wykonuje się zwolniony proces.
Rozwiązanie b
Wersja pełna: signal może się pojawić w dowolnym miejscu w procedurze.
var MONITOR: binary semaphore := 1; {żeby zapewnić wzajemne wykluczanie przy wykonywaniu procedur monitora} KOLEJKA: binary semaphore := 0; STOS: binary semaphore := 0; ilu_czeka_k: integer := 0; ilu_czeka_s: integer := 0; 1) P(MONITOR); 2) inc(ilu_czeka_k); if ilu_czeka_s > 0 then begin dec(ilu_czeka_s); V(STOS); end else V(MONITOR); P(KOLEJKA); 3) if ilu_czeka_k > 0 then begin dec(ilu_czeka_k); inc(ilu_czeka_s); V(KOLEJKA); P(STOS); end; 4) if ilu_czeka_s > 0 then begin dec(ilu_czeka_s); V(STOS); end else V(MONITOR);
Procesy wykonujące wait i kończące procedurę monitora zwalniają procesy które wykonały signal (oczekujące na semaforze STOS).
Należy zwrócić uwagę, że nie jest to dokładna implementacja, ponieważ za pomocą semaforów nie można zasymulować kolejki (procesy wykonujące wait) ani stosu (procesy wykonujące signal) - procesy oczekujące na semaforze są zwalniane w kolejności zapewniającej żywotność, ale nie możemy powiedzieć dokładnie w jakiej.
Zadanie 1 (Bar)
Napisz monitor BAR synchronizujący pracę barmana obsługującego klientów przy kolistym barze z N stołkami. Każdy klient realizuje następujący algorytm:
var i : integer; begin repeat BAR.CZEKAJ_NA_STOŁEK_I_PIWO(i); <pije piwo na stołku i-tym> BAR.ZWALNIAM(i); until false; end;
Barman nalewa piwo nowo przybyłym klientom w kolejności wyznaczonej przez stołki przez nich zajmowane (chodzi "w kółko"):
var i : integer; begin repeat BAR.KTO_NASTĘPNY(i); <podejście do stołka i-tego i nalanie piwa> BAR.ZACZNIJ_PIĆ(i); until false; end;
Rozwiązanie
monitor BAR; var ilu_w: integer; { ilu klientów jest w barze } WEJŚCIE: condition; { tu klienci czekaj¡ na wej±cie do baru } stołek: array [0..N-1] of (wolny, nieobsłużony, obsłużony); { stan stołka: nieobsłużony - siedzący na nim klient czeka na piwo obsłużony - siedzący na nim klient pije piwo } czeka: array [0..N-1] of condition; { tu klient czeka na nalanie piwa } ilu_czeka: integer; { ilu klientów czeka na nalanie piwa } BARMAN: condition; { tu czeka barman, jeżeli nie ma nic do roboty } export procedure CZEKAJ_NA_STOŁEK_I_PIWO(var i: integer); begin if ilu_w = N then wait(WEJŚCIE); { nie ma wolnych stołków } inc(ilu_w); inc(ilu_czeka); i := 0; while stołek[i] <> wolny do { klient szuka wolnego stołka } i := (i + 1) mod N; stołek[i] := nieobsłużony; { i-ty stołek był wolny, klient go zajmuje } if ilu_czeka = 1 then signal(BARMAN); { zwalnia barmana, jeżeli ten czeka } wait(czeka[i]); { czeka na stołku i-tym na piwo } end; export procedure ZWALNIAM(i: integer); begin dec(ilu_w); stołek[i] := wolny; signal(WEJŚCIE); end; export procedure KTO_NASTĘPNY(var i:integer); begin if ilu_czeka = 0 then wait(BARMAN); { nie ma nieobsłużonych klientów } i := (i + 1) mod N; { barman szuka klienta począwszy od następnego miejsca po tym, które ostatnio obsługiwał } while stołek[i] <> nieobsłużony do i := (i + 1) mod N; end; export procedure ZACZNIJ_PIĆ(i: integer); begin stołek[i] := obsłużony; dec(ilu_czeka); signal(czeka[i]); end; begin for i:=0 to N do stołek[i] := wolny; end.
Uwagi
CZEKAJ_NA_STOŁEK_I_PIWO wykonuje wait( czeka [i] ) po signal (BARMAN). Zgodnie z semantyką operacji signal po wykonaniu signal (BARMAN) zaczyna działać barman, który sprawdzając kolejkę czeka [i] stwierdziłby, że jest ona pusta, ponieważ klient nie wykonał jeszcze wait(czeka[i])! Ten sam problem wystąpiłby, jeżeli przyjęlibyśmy założenie, że nalanie piwa jest wewnętrzną czynnością w monitorze, czyli procedury KTO_NASTĘPNY i ZACZNIJ_PIĆ złączylibyśmy w jedną.Zadanie 2 (Ładowanie cegieł)
Grupa N (N > 0) robotników ma załadować stertę cegieł na samochód. Każdy z nich musi wiedzieć od kogo ma odbierać cegły i komu podawać, czyli musi znać numery obu swoich sąsiadów (należy przyjąć, że sterta cegieł ma numer 0, a samochód N + 1). Pracę można rozpocząć dopiero wtedy, gdy zgłoszą się wszyscy robotnicy. Po zakończeniu załadunku robotnicy przychodzą po wypłatę. Każdy podaje swoją stawkę za pracę, na podstawie której wylicza się stawkę średnią, którą otrzymują wszyscy. Każdy robotnik działa według schematu:
procedura Robotnik (i: integer); const moja_stawka = ...; var lewy, prawy, wypłata: integer: begin repeat M.CHCĘ_PRACOWAĆ (i, lewy, prawy); podawaj_cegły (lewy, prawy); M.WYPŁATA (moja_stawka, wypłata); odpoczynek (wypłata); until false; end;
Należy napisać monitor M. Nie wolno deklarować żadnych struktur rozmiaru N lub większego.
Rozwiązanie niepoprawne
Podajemy rozwiązanie niepoprawne, ponieważ studenci najczęściej próbują je rozwiązać w taki właśnie sposób:
monitor M; var ilu, ostatni, stawka: integer; na_pozostałych: condition; export procedure CHCĘ_PRACOWAŁ (i: integer, var lewy, prawy: integer); begin inc(ilu); lewy := ostatni; ostatni := i; if ilu < N then wait(na_pozostałych) else ostatni:=N+1; prawy := ostatni; ostatni := i; dec(ilu); if not empty(na_pozostałych) then signal(na_pozostałych); end; export procedure WYPŁATA(moja_stawka: integer, var wypłata: integer); begin inc(ilu); if ilu = 1 then ostatni := 0; stawka := stawka + moja_stawka; if ilu < N then wait(na_pozostałych) else stawka := stawka div N; wypłata : = stawka; signal(na_pozostałych); end; begin ilu := 0; ostatni := 0; stawka := 0; end.
Każdy z procesów musi poznać swoich sąsiadów: lewego, czyli proces, który zgłosił się bezpośrednio przed nim (wystarczy zapamiętać numer ostatniego procesu, który wykonywał procedurę) i prawego, czyli proces, który zgłosił się bezpośrednio po nim - ten właśnie warunek nie jest spełniony.
Przeanalizujmy następujący scenariusz:
N = 4, kolejność zgłaszania się robotników: 2 4 3 1
2 4 3 1 lewy:=0 ostatni:=2 wait lewy:=2 ostatni:=4 wait lewy:=4 ostatni:=3 wait lewy:=3 ostatni:=1 ostatni:=N+1 prawy:=N+1 ostatni:=1; signal prawy:=1 (?!) ostatni:=2 signal prawy:=2 (?!) ostatni:=4; signal prawy:=4 (?!) ostatni:=3 signal (pusty)
Rozwiązanie poprawne
Aby poznać numer prawego sąsiada nie używając dodatkowych struktur danych należy odwrócić kolejność procesów wykorzystując do tego operację signal. Przypominamy, że signal wstrzymuje działanie procesu do momentu, gdy zwalniany przez niego proces opuści monitor. Procesy wstrzymane przy wykonaniu operacji signal zwalniane są w kolejności odwrotnej do tej w jakiej ją wykonywały.
export procedure CHCĘ_PRACOWAĆ(i: integer, var lewy, prawy: integer); begin inc(ilu); lewy := ostatni; ostatni := i; if ilu < N then begin export procedure CHCĘ_PRACOWAĆ(i: integer, var lewy, prawy: integer); begin inc(ilu); lewy := ostatni; ostatni := i; if ilu < N then begin wait(na_pozostałych); signal(na_pozostałych); prawy := ostatni; ostatni := i; end else begin prawy := N + 1; ilu := 0; signal(na_pozostałych); end; end;
Przeanalizujmy to na naszym przykładzie:
2 4 3 1 lewy:=0 ostatni:=2 wait lewy:=2 ostatni:=4 wait lewy:=4 ostatni:=3 wait lewy:=3 ostatni:=1 prawy:=N+1 signal signal signal signal (pusty) prawy:=1 ostatni:=3 prawy:=3 ostatni:=4 prawy:=4 ostatni:=2
Należy zwrócić uwagę, że nie potrzeba osobnych kolejek do wstrzymywania procesów czekających na pracę i na wypłatę, ponieważ nie ma niebezpieczeństwa, że procesy z tych dwóch grup się przemieszają.
Zadanie 1 (Biuro)
W pewnym biurze grupa urzędników obsługuje grupę klientów. Każdy urzędnik ma unikatowy identyfikator z zakresu od 1 do N. Algorytmy urzędników i klientów są następujące:
process Urzędnik (u:integer, r:1..2) process Klient begin var u1,u2:integer; repeat begin BIURO.CHCĘ_PRACOWAĆ(u,r); repeat rozmawiam_z_klientem; BIURO.CHCĘ_ZAŁATWIĆ_SPRAWĘ(u1,u2); BIURO.SKOŃCZYŁEM; rozmawiam_z_urządnikiem(u1,u2); odpoczywam; BIURO.ZAŁATWILEM; until false; własne_sprawy; end; until false; end;
Rozwiązanie
monitor BIURO var ile_krzeseł: integer; ilu_u2: integer; { ilu jest gotowych urzędników II } u: array [1..2] of condition; { tu czekają urzędnicy I i II } k: condition; { tu czekają klienci } z_kim1, z_kim2: integer; { identyfikatory urzędników } export procedure CHCĘ_PRACOWAĆ(ranga: 1..2, id: integer); begin if ranga = 1 then begin { czeka, jeżeli nie ma klientów lub wystarczającej liczby krzeseł } if empty(k) or ile_krzeseł < 2 then wait u[1]; ile_krzeseł := ile_krzeseł - 2; z_kim1 := id; { zapisuje swój identyfikator } z_kim2 := 0; { informuje, ze nie będzie drugiego urzędnika } signal(k); { zwalnia klienta } end else begin { czeka, jeżeli nie ma klientów lub wystarczającej liczby krzeseł lub oczekującego urzędnika II } if empty(k) or ile_krzeseł < 3 or empty(u[2]) then begin inc(ilu_u2) wait u[2]; dec(ilu_u2); end; { jeżeli jest pierwszym urzędnikiem, to zapisuje swój identyfikator i budzi drugiego urzędnika } if z_kim1 = 0 then begin ile_krzeseł := ile_krzeseł - 3; z_kim1 := id; signal(u[2]); end { jeżeli jest drugim urzędnikiem, to zapisuje swój identyfikator i budzi klienta } else begin z_kim2 := id; signal(k); end; end; export procedure CHCĘ_ZAłATWIĆ_SPRAWĘ(var id1, id2: integer); begin { klient czeka jeżeli } if (empty(u[1]) or ile_krzeseł < 2) and { nie ma urzędnika I lub 2 krzeseł } (ilu_u2 < 2 or ile_krzeseł < 3) { nie ma dwóch urzędników II lub 3 krzeseł } then wait(k) else if not empty(u[1]) then signal(u[1]) { budzi urzędnika I } else signal(u[2]); { budzi pierwszego urzędnika II } id1 := z_kim1; { odczytuje identyfikatory } id2 := z_kim2; z_kim1 := 0; end; export procedure SKOŃCZYŁEM/ZAŁATWIŁEM; begin inc(ile_krzeseł); { jeżeli może dojść do rozmowy, to zwalnia odpowiedniego urzędnika } if not empty(k) then if not empty(u[1]) and ile_krzeseł >= 2 then signal(u[1]) else if ilu_u2 >= 2 and ile_krzeseł >= 3 then signal(u[2]); end; begin ile_krzeseł := K; ilu_u2 := 0; z_kim1 := 0; end.
Uwagi
Schemat rozwiązania jest następujący: kiedy nie może dojść do rozmowy (z powodu braku jednej ze stron lub miejsc do siedzenia), wtedy proces czeka w odpowiedniej kolejce. Jeżeli pojawi się brakujący urzędnik pierwszej rangi, to zwalnia klienta. Jeżeli pojawi się brakujący urzędnik drugiej rangi, to zwalnia drugiego urzędnika, który zwalnia klienta. Jeżeli pojawi się brakujący klient, to zwalnia urzędnika i jeżeli jest to urzędnik drugiej rangi, to zwalnia swojego kolegę, który zwolniłby klienta, ale tego nie robi, bo kolejka klientów jest pusta (gdyby nie była, to nie brakowało by klienta - patrz: początek zdania). Jeżeli pojawiają się brakujące krzesła, to zwalniani są odpowiedni urzędnicy, którzy zwalniają klienta.
Warto zwrócić uwagę na przekazywanie identyfikatorów klientowi. Jeżeli to klient zwalnia urzędników, to identyfikatory zostają przekazane w momencie, kiedy klient wykonuje signal.
Priorytetowym wymaganiem w tym zadaniu jest obsłużenie jak największej ilości klientów. Aby je spełnić należy w pierwszej kolejności wybierać urzędników pierwszej rangi, ponieważ zajmują oni mniej krzeseł. Oczywiście może dojść do zagłodzenia drugiej grupy urzędników, ale jest to zagłodzenie wynikające z treści zadania.
Zadanie 2 (Zasoby)
W systemie są dwie grupy procesów korzystające z N zasobów typu A i M zasobów typu B (N + M > 1). Procesy z pierwszej grupy cyklicznie wykonują własne sprawy, po czym wywołują procedurę zamieńAB, która konsumuje jeden zasób A i produkuje jeden zasób B. Procesy z grupy drugiej cyklicznie wykonują własne sprawy, po czym wywołują procedurę zamień, która konsumuje jeden zasób dowolnego typu i produkuje zasób przeciwny. Zsynchronizuj procesy za pomocą monitora tak, aby:
zamieńAB i zamień były wywoływane przez procesy jedynie pod warunkiem dostępności odpowiednich zasobówzamieńAB parami, tzn. proces z grupy pierwszej może rozpocząć jej wykonanie jedynie wtedy, gdy jest inny proces z grupy pierwszej, gotowy do jej wykonania (i oczywiście niezbędne zasoby)Monitor powinien udostępniać jedynie procedury wywoływane przez procesy przed i po rozpoczęciu korzystania z zasobów.
Rozwiązanie
monitor Zasoby; var ileA, ileB, iluNaA: Integer; zasóbA, zasób, partner: condition; export procedure ChceA; begin inc(iluNaA); if iluNaA mod 2 = 1 then { pierwszy z pary } wait (partner); { czeka na partnera } else begin { drugi z pary } if ileA < 2 then { jeżeli nie ma dwóch zasobów A } wait (zasóbA); { czeka na co najmniej dwa zasoby A } ileA := ileA - 2; signal (partner) { zwalnia partnera } end dec(iluNaA); end; export procedure ChceZasób (var z: Zasob); begin if (ileB = 0) and (ileA = 0 or not empty(zasóbA)) then wait (zasób); { czeka na cokolwiek } if ileB > 0 then { najpierw B, żeby produkować A } begin z := B; dec (ileB) end else begin z := A; dec (ileA) end end; export procedure Wyprodukowalem (z: Zasób); begin if z = B then { jeżeli wyprodukowano B } begin inc (ileB); signal (Zasób) end else begin inc (ileA); if empty (ZasóbA) then { tylko jeżeli nie ma par w pierwszej grupie } signal (Zasób) { to zwalniamy swoją grupę } else { czeka para na zasób A } if ileA > 1 then { zwalniamy ja jeśli można lub } signal (ZasóbA) { czekamy na drugi egzemplarz zasobu A } end end; begin iluNaA := 0; ileA := N; ileB := M; end.
Uwagi
Aby nie zagłodzić procesów pierwszej grupy, proces który wyprodukował A, zwalnia procesy drugiej grupy tylko wtedy, gdy nie ma pary gotowych procesów z grupy pierwszej, nawet jeżeli jest tylko jeden zasób, który na razie jest dla tej pary bezużyteczny.
Na potrzeby kilku następnych ćwiczeń zakładamy dostępność następujących typów danych oraz operacji na nich:
wait_queuesleep(q) wstawiająca wykonujący ją proces do kolejki qprocesów zawieszonych, zmieniająca jego stan na wstrzymany oraz inicjująca przełączenie kontekstu wakeup(q) zmieniająca stan wszystkich procesów zawieszonych w kolejce q na gotowy i przenosząca je do kolejki procesów gotowych disable_interrupts wyłącza przerwania enable_interrupts włącza przerwania Czy synchronizacja globalnych struktur danych w jednoprocesorowym systemie operacyjnym z jądrem niewywłaszczalnym (takim jak tradycyjne jądro Uniksa) jest w ogóle potrzebna?
Nawet w niewywłaszczalnym jądrze działającym na komputerze jednoprocesorowym może być w danej chwili aktywnych wiele procesów. Oczywiście wykonuje się jeden z nich, a pozostałe oczekują na procesor lub jakiś zasób. Dzieje się tak, gdyż proces mógł rozpocząć wykonanie funkcji systemowej, po czym zrzec się dobrowolnie procesora (bo na przykład musi poczekać na zajście jakiegoś zdarzenia na przykład zainicjowanej operacji wejścia-wyjścia).
Takie jądro nazywamy wielowejściowym.
Wszystkie te procesy współdzielą tę samą kopię struktur danych jądra, więc jądro musi dbać o zachowanie ich spójności. Szczęśliwie niewywłaszczalność bardzo mu w tym pomaga. Przypomnijmy niewywłaszczalność jądra oznacza, że proces wykonujący się w trybie jądra nie może zostać wywłaszczony przez inny proces, nawet jeśli upłynie przeznaczony dla niego kwant czasu. Proces może jednak dobrowolnie oddać procesor. Ponieważ dzieje się to w konkretnym punkcie programu wykonywanego przez proces, więc proces może zadbać o pozostawienie jądra w stanie spójnym. Dzięki temu jądro może na przykład swobodnie manipulować wskaźnikami listy dwukierunkowej bez blokowania dostępu do niej, gdyż nie grozi wywłaszczenie po modyfikacji wskaźnika w przód, a przed modyfikacją wskaźnika w tył.
Są jednak dwa powody, w których synchronizacja w jednoprocesorowym systemie z niewywłaszczalnym jądrem jest jednak niezbędna:
Jak zapewnić spójność struktur danych, z których korzystają podprogramy obsługi przerwań?
Wyłączając przerwania na czas modyfikacji tych struktur danych, z których może również korzystać podprogram obsługi przerwania. W ten sposób kod modyfikujący kluczowe struktury danych jest w istocie sekcją krytyczną.
Należy jednak przy tym pamiętać, że:
Rozważmy następujący przykład. W pewnym systemie operacyjnym pula wolnych buforów wejścia-wyjścia jest przechowywana w jednokierunkowej liście bufcache. Rozpoczynając operację wejścia-wyjścia jądro wywołuje funkcję GetBuffer, która znajduje pierwszy wolny bufor i usuwa go z listy wolnych buforów. Jeśli w puli nie ma wolnych buforów, to proces jest wstrzymywany w kolejce procesów zawieszonych nobuffers. Po zakończeniu operacji wejścia-wyjścia podprogram obsługi przerwania wywołuje procedure ReleaseBuffer (b). Dane są następujące deklaracje:
type Buffer = ^ record next: Buffer; data: array[0..BUFFERSIZE] of byte; ... end; var bufcache: Buffer; {pierwszy bufor w puli buforów}
Zaimplementuj funkcję GetBuffer oraz ReleaseBuffer.
function GetBuffer: Buffer; begin while bufcache = nil do sleep (nobuffers); disable_interrupts; GetBuffer := bufcache; bufcache := bufcache^.next; enable_interrupts; end; procedure ReleaseBuffer (b: Buffer); begin b^.next := bufcache; bufcache := b; wakeup (nobuffers) end;
Wyłączenie przerwań w GetBuffer jest tu kluczowe! Niestety, nie daje ono jeszcze poprawności rozwiązania, pojawia się bowiem tzw. problem zagubionej pobudki. Zaobserwuj, co się stanie, jeśli przerwanie pojawi się po sprawdzeniu warunku pętli, a przed uśpieniem. Proces zostanie wówczas uśpiony, choć tak naprawdę jest dla niego bufor. Co więcej, pobudka dla niego (w postaci wakeup z ReleaseBuffer została wygenerowana ... zanim został on uśpiony!
Odłóżmy na razie rozwiązanie tego problemu i nie przejmując się nim przyjrzyjmy się drugiej sytuacji wymagającej synchronizacji w jądrze niewywłaszczalnym na jednoprocesorze. Zauważmy jeszcze tylko, że o ile disable_interrupt blokuje także przerwania zegarowe nie dopuszczając tym samym do wywłaszczenia procesu z powodu upływu kwantu czasu oraz o ile w trakcie obsługi przerwań blokowane są przerwania, to rozwiązania to zadziała poprawnie (z dokładnością do zagubionej pobudki) także w systemie z jądrem wywłaszczalnym (ale nie na wieloprocesorze).
Jak zapewnić spójność struktur danych w czasie wykonywania operacji blokującej?
Przypuśćmy, że w poprzednim zadaniu bufory znalezione przez GetBuffer są jedynie blokowane i nie usuwa się ich z puli wolnych buforów. Zmodyfikuj treść funkcji GetBuffer i procedury ReleaseBuffer. Nie przejmuj się problemem zagubionej pobudki.
Tym razem w ogóle nie musimy blokować przerwań, a właściwą synchronizację zapewni dodatkowe pole blocked związane z każdym buforem oraz niewywłaszczalność jądra.
function GetBuffer: Buffer; var found: boolean; p: Buffer; begin found := false; while not found do begin p := bufcache; while (p <> nil) and not found do if p^.blocked then p := p^.next else begin found := true; GetBuffer := p; p^.blocked := true end; if not found then sleep (nobuffers) end; end; procedure ReleaseBuffer (p: Buffer); begin p^.blocked := false; wakeup (nobuffers) end;
Choć struktura danych nie straci spójności, to jednak jeszcze dobitniej widać tu problem zagubionej pobudki, który drastycznie ujawni się, gdy podczas poszukiwania wolnego bufora zostanie zwolniony bufor, który już sprawdzaliśmy.
Zauważmy przy okazji, że w jądrze wywłaszczalnym oraz na wieloprocesorze powyższe rozwiązanie nie zapewni spójności danych.
W praktyce powyższe rozwiązanie zapisalibyśmy unikając przeszukiwania, gdy wiadomo, że buforów brakuje. Wystarczy, aby jądro utrzymywało globalną zmienną freebuffers zliczającą wolne bufory. Dla uproszczenia załóżmy, że operacje zwiększania i zmniejszanie tej zmiennej są atomowe:
function GetBuffer: Buffer; p: Buffer; begin while freebuffers = 0 do sleep (nobuffers); freebuffers--; p := bufcache; while p^.blocked do p := p^.next; GetBuffer := p; p^.blocked := true end; procedure ReleaseBuffer (p: Buffer); begin p^.blocked := false; freebuffers++; wakeup (nobuffers) end;
W dalszym ciągu jest to rozwiązanie, które nie zadziała ani z jądrem wywłaszczalnym ani z wieloprocesorem, a w przypadku jądra wywłaszczalnego mamy problem z zagubioną pobudką.
Czy można poradzić sobie jakoś z problemem zagubionej pobudki?
Nie. Proces musi odblokować przerwania zanim zostanie uśpiony, ale odblokowanie przerwań przed uśpieniem może spowodować, że przerwanie pojawi się zanim proces zostanie uśpiony. Chyba, że zmienimy semantykę operacji sleep. Niech teraz sleep atomowo zmienia stan procesu, przenosi go do kolejki procesów zatrzymanych i odblokowuje przerwania. Dzięki temu można go wywołać przy wyłączonych przerwaniach, a nasz ostatni program wyglądałby tak:
function GetBuffer: Buffer; p: Buffer; begin disable_interrupts; while freebuffers = 0 do begin sleep (nobuffers); disable_interrupts; end; freebuffers--; enable_interrupts; p := bufcache; while p^.blocked do p := p^.next; GetBuffer := p; p^.blocked := true end; procedure ReleaseBuffer (p: Buffer); begin p^.blocked := false; freebuffers++; wakeup (nobuffers) end;
Teraz już nie trzeba zakładać niepodzielności operacji zwiększania i zmniejszania zmiennej freebuffers.
Zaimplementuj operacje P i V na semaforze ogólnym w systemie jednoprocesorowym bez wywłaszczania. Załóż, że żadna procedura obsługi przerwania nigdy nie manipuluje semaforem.
type semaphore = record count: integer; wait: wait_queue; end; procedure P (var s: semaphore); { tryb jądra} begin while (s.count <= 0) do sleep (s.wait); s.count--; end; procedure V (var s: semaphore); { tryb jądra } begin inc (s.count); wakeup (s.wait); end;
Oczywiście w systemie z jądrem wywłaszczalnym i na wieloprocesorze rozwiązanie jest niepoprawne - brakuje nawet bezpieczeństwa, bo wiele procesów może wykonywać jednocześnie procedurę P.
Niektóre procesory (na przykład MIPS R4000, Alpha AXP firmy Digital oraz mikrokontrolery rodziny ARM) oferują parę specjalnych rozkazów:
load-locked (adres) przekazuje w wyniku wartość z komórki pamięci o podanym adresie i ustawia znacznik sprzętowy związany z konkretnym procesorem. Ten znacznik sprzętowy oznacza, że jedynie procesor wykonujący load-locked(adres) ma prawo wykonać na tym adresie operację store-condstore-cond (adres, wartość)wpisuje wartość do pamięci, o ile jest ustawiony znacznik wykonującego procesora. Jeśli zapis się udał, to przekazuje w wyniku true, w przeciwnym razie wynikiem jest false. Znacznik jest zerowany.Zaimplementuj blokadę wirującą dla wieloprocesora za pomocą pary rozkazów load-locked i store-cond. (Implementacja za pomocą xchng oraz test-and-set była na wykładzie). Załóż, że spin_lock jest niewywłaszczalny.
var lock: boolean := false; procedure spin_lock (var lock: boolean); begin repeat while load-locked (lock) do {nic}; until store-cond (lock, true) end; procedure spin_unlock (var lock: boolean); begin lock := false; end;
Czy blokady wirujące w kodzie jądra mają sens:
Blokady wirujące mają sens na wieloprocesorze, gdzie oczekiwanie w sposób aktywny na zasób zablokowany przez aktualnie wykonujący się (na innym procesorze) proces, może okazać się efektywniejsze niż wstrzymywanie procesu.
W systemach jednoprocesorowych z jądrem wywłaszczalnym blokady wirujące są nieefektywne, choć jeszcze niczego nie psują. Natomiast w jądrze niewywłaszczalnym "zawieszenie" się na blokadzie wirującej oznacza zakleszczenie.
Z tego powodu operacje spin_lock oraz spin_unlock są w takich systemach implementowane jako operacje puste.
Spróbujmy teraz uzupełnić poprzednią implementację semafora o wzajemne wykluczanie realizowane za pomocą blokad wirujących. Czy otrzymamy w ten sposób poprawną implementację semafora?
type semaphore = record count: integer; wait: wait_queue; lock: boolean; end; procedure P (var s: semaphore); { tryb jądra} begin spin_lock(s.lock); while (s.count <= 0) do begin spin_unlock(s.lock); sleep (s.wait); spin_lock(s.lock); end; s.count--; spin_unlock(s.lock); end; procedure V (var s: semaphore); { tryb jądra } begin spin_lock (s.lock); s.count++; wakeup (s.wait); spin_unlock (s.lock) end;
W systemie jednoprocesorowym jest OK (o ile operacje na blokadach wirujących są implementowane jako puste w przypadku jądra niewywłaszczalnego). Natomiast w systemie wieloprocesorowym mamy znów problem z zagubioną pobudką - tym razem jednak na nieco innym poziomie niż poprzednio.
Żeby sobie z tym problemem poradzić potrzebujemy niepodzielną operacje spin_unlock i sleep. Implementacja semafora w wieloprocesorowym jądrze Linuksa korzysta na przykład z wariantu funkcji sleep, której jednym z parametrów jest semafor s. Operacja sleep jest wywoływana bez zwalniania blokady wirującej i dopiero po faktycznym umieszczeniu procesu w odpowiedniej kolejce tuż przed przełączeniem kontekstu, wywołuje ona spin_unlock (s.lock).
W pewnym systemie z czterema typami zasobów A, B, C i D działa równocześnie pięć procesów: P1, P2, ..., P5. W pewnej chwili stan przydziału zasobów jest następujący:
| Przydzielone | Maksymalne | Dostępne | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | A | B | C | D | A | B | C | D | |
| P1 | 0 | 0 | 1 | 2 | 0 | 0 | 1 | 2 | 2 | 1 | 0 | 0 |
| P2 | 2 | 0 | 0 | 0 | 2 | 7 | 5 | 0 | ||||
| P3 | 0 | 0 | 3 | 4 | 6 | 6 | 5 | 6 | ||||
| P4 | 2 | 3 | 5 | 4 | 4 | 3 | 5 | 6 | ||||
| P5 | 0 | 3 | 3 | 2 | 0 | 6 | 5 | 2 | ||||
Potrzebne?(0, 1, 0,0) zgłoszone przez proces P3?Potrzebne jest różnicą macierzy Maksymalne i Przydzielone. Zatem aktualna wartość macierzy Potrzebne to:
| Potrzebne | ||||
|---|---|---|---|---|
| A | B | C | D | |
| P1 | 0 | 0 | 0 | 0 |
| P2 | 0 | 7 | 5 | 0 |
| P3 | 6 | 6 | 2 | 2 |
| P4 | 2 | 0 | 0 | 2 |
| P5 | 0 | 3 | 2 | 0 |
| Przydzielone | Potrzebne | Dostępne | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | A | B | C | D | A | B | C | D | ||
| P1 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | 0 | P1 | 2 | 1 | 0 | 0 |
| P2 | 2 | 0 | 0 | 0 | 0 | 7 | 5 | 0 | P4 | 2 | 1 | 1 | 2 |
| P3 | 0 | 0 | 3 | 4 | 6 | 6 | 2 | 2 | P5 | 4 | 4 | 6 | 6 |
| P4 | 2 | 3 | 5 | 4 | 2 | 0 | 0 | 2 | P2 | 4 | 7 | 9 | 8 |
| P5 | 0 | 3 | 3 | 2 | 0 | 3 | 2 | 0 | P3 | 6 | 7 | 9 | 8 |
| Przydzielone | Potrzebne | Dostępne | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | A | B | C | D | A | B | C | D | ||
| P1 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | 0 | P1 | 2 | 0 | 0 | 0 |
| P2 | 2 | 0 | 0 | 0 | 0 | 7 | 5 | 0 | P4 | 2 | 0 | 1 | 2 |
| P3 | 0 | 1 | 3 | 4 | 6 | 5 | 2 | 2 | P5 | 4 | 3 | 6 | 6 |
| P4 | 2 | 3 | 5 | 4 | 2 | 0 | 0 | 2 | 4 | 6 | 9 | 8 | |
| P5 | 0 | 3 | 3 | 2 | 0 | 3 | 2 | 0 | |||||
Zatem żądanie nie zostanie zrealizowane, choć zasoby potrzebne procesowi P3 są dostępne.
W pewnym systemie z trzema typami zasobów A, B i C działa równocześnie pięć procesów: P1, P2, ..., P5. W pewnej chwili stan przydziału zasobów jest następujący:
| Przydzielone | Maksymalne | Dostępne | |||||||
|---|---|---|---|---|---|---|---|---|---|
| A | B | C | A | B | C | A | B | C | |
| P1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 5 | 3 |
| P2 | 1 | 0 | 0 | 1 | 7 | 5 | |||
| P3 | 1 | 3 | 5 | 2 | 6 | 10 | |||
| P4 | 0 | 6 | 3 | 0 | 6 | 5 | |||
| P5 | 0 | 0 | 1 | 0 | 6 | 5 | |||
Potrzebne?(0, 4, 2) zgłoszone przez proces P2?Analogicznie do poprzedniego zadania.
Wykaż, że strategia SJF jest optymalna ze względu na średni czas obrotu dla ustalonego (w chwili 0) zbioru procesów w klasie strategii bez wywłaszczania.
Bez straty ogólności rozwiązania przyjmijmy, że procesy są ponumerowane zgodnie z rosnącymi czasami zapotrzebowania na kolejną fazę procesora, tzn. ti <= tj dla i < j, gdzie ti jest czasem trwania kolejnej fazy dla procesu Pi.
Rozpatrzymy teraz dowolną kolejność wykonania procesów, w której istnieje 1 <= i < n takie, że
Pi+1 wykonuje się przed Pi. Zamiana miejscami tych procesów powoduje zmianę czasów zakończenia jedynie procesu Pi oraz Pi+1. Proces Pi kończy się teraz o ti+1 wcześniej niż poprzednio, a proces Pi+1 o ti później. Zatem suma czasów obrotów wszystkich procesów zmienia się o ti - ti+1 <= 0. Średni czas obrotu jest więc teraz nie gorszy niż poprzednio.
Widać zatem, że możemy zawsze zlikwidować "inwersję" w ciągu procesów nie pogarszając średniego czasu obrotu zadania. Wynika z tego, że przydział procesora w kolejności wzrastających numerów procesów jest nie gorszy niż jakakolwiek inna kolejność. Czyli SJF jest optymalny.
W pewnym systemie jednoprocesorowym na wykonanie czekają następujące procesy:
| Proces | Czas przybycia | Zapotrzebowanie na CPU |
|---|---|---|
| P1 | 0 | 10 |
| P2 | 0 | 5 |
| P3 | 0 | 4 |
| P4 | 6 | 8 |
| P5 | 6 | 3 |
Jaki jest średni czas obrotu procesu dla strategii PS?
Do chwili 6 wykonują się procesy P1, P2 i P3 i każdy wykorzystuje procesor przez 2 jednostki czasu.
Następnie działają wszystkie procesy aż do zakończenie procesu P3, co nastąpi w chwili 16. Do tego czasu każdy proces wykorzysta procesor przez kolejne 2 jednostki czasu. W chwili 20 skończą się procesy P2 i P5. Pozostałe procesy P1 i P4 potrzebują jeszcze 5 jednostek czasu procesora, skończą się więc w chwili 30. Otrzymujemy zatem:
| Proces | Czas przybycia | Czas zakończenia | Czas obrotu |
|---|---|---|---|
| P1 | 0 | 30 | 30 |
| P2 | 0 | 20 | 20 |
| P3 | 0 | 16 | 16 |
| P4 | 6 | 30 | 24 |
| P5 | 6 | 20 | 14 |
Średni czas obrotu wynosi 104/5 = 20,8
W pewnym systemie jednoprocesorowym na wykonanie czekają cztery procesy. Zapotrzebowanie na CPU każdego z nich wynosi 10. Jaki będzie średni czas obrotu dla tej grupy procesów przy strategiach szeregowania:
Wyciągnij wnioski z tego przykładu.
Okazuje się zatem, że dla procesów o podobnym charakterze obliczeniowym, które nie wymagają szybkiego czasu reakcji, najprostsza implementacyjnie strategia FCFS daje także najlepszy czas obrotu! W dodatku narzut na przełączanie kontekstu jest tu najmniejszy.
Studenci rejestrujący się na pewien przedmiot muszą uzyskać zgodę prowadzącego i opłacić czesne. Oba te wymagania można wypełniać niezależnie od siebie w różnych miejscach kampusu. Limit miejsc wynosi 20 osób i przestrzega go zarówno prowadzący, jak i sekcja finansowa. Przypuśćmy, że opisany powyżej system rejestracji spowodował, że 19 studentów zarejestrowało się na przedmiot bez problemu, a o ostatnie miejsce rywalizuje dwóch studentów, z których jeden opłacił już czesne, ale nie uzyskał jeszcze zgody prowadzącego, a drugi uzyskał zgodę prowadzącego, ale nie opłacił czesnego. Który z warunków koniecznych powstawania zakleszczenia usuwa każde z następujących rozwiązań problemu:
W tym zadaniu dwóch feralnych studentów gra rolę procesów ubiegających się o dwa zasoby: miejsce na liście prowadzącego oraz miejsce na liście w sekcji finansowej. Zasoby te są niepodzielne.
Pewien bankier dysponuje kwotą 100 000 zł. Udziela on kredytu dwóm kredytobiorcom - każdemu po 50 000 zł. Po pewnym czasie obaj kredytobiorcy informują bankiera, że potrzebują jeszcze po 10 000 zł na dokończenie interestów i wtedy dopiero będą mogli oddać dług. Bankier radzi sobie z tym zakleszczeniem pożyczając potrzebną gotówkę z innego źródła i przekazując ją kredytobiorcom (zwiększając oprocentowanie kredytu:-). Który z warunków koniecznych powstawania zakleszczeń został usunięty przez bankiera?
Rozważmy następujące stategie przydziału pamięci w sposób ciągły:
Pokaż trzy przykłady ciągów działań, dla których każda z tych stategii okaże się lepsza od pozostałych. W każdym przykładzie podaj zapotrzebowanie na pamięć, określ kiedy pamięć jest zajmowana i zwalniana, a także podaj wielkość pamięci traconej w wyniku fragmentacji.
Przy okazji przyjrzyjmy się wadom i zaletom poszczególnych strategii. Porównajmy algorytmy, starając się dla każdego wskazać, w jakich sytuacjach będzie miał przewagę nad innymi, a w jakich będzie się zachowywał gorzej. Weźmy pod uwagę także narzut systemowy każdej z nich (np. sposób przechowywania informacji o wolnych obszarach pamięci i czas przeglądania tych danych).
Dostępna pamięć to spójny blok 2000B (2 kawałki po 1000B). Ciąg żądań:
X:=alloc(900B), Y:=alloc(900B), release(X), Z:=alloc(1000B)
Podany ciąg żądań zostanie bez czekania obsłużony tylko przez metodę stref statycznych. W przypadku stref dynamicznych - mimo, że pozostanie 1100B wolnej pamięci, to nie może ona być wykorzystana do spełnienia ostatniego żądania ze względu na fragmentację zewnętrzną.
Dostępna pamięć to spójny kawałek wielkości 400B. Ciąg żądań:
X:=alloc(200B), Y:=alloc(100B), release(X),
X:=alloc(50B), Z:=alloc(150B), W:=alloc(100B)
W przypadku metody pierwszy pasujący ten ciąg zostanie obsłużony bez czekania. Ze względu na fragmentację zewnętrzną (100B), w przypadku metody najlepszy pasujący ostatnie żądanie nie zostanie wykonane od razu. W strategii stref statycznych musielibyśmy mieć strefy wielkości 200B (żeby móc obsłużyć największe żądanie). W takiej sytuacji nie można przydzielić dwóch ostatnich fragmentów,
a fragmentacja wewnętrzna wynosi 250B.
Jak poprzednio dostępna pamięć to spójny blok wielkości 400B. Ciąg żądań:
X:=alloc(200B),Y:=alloc(100B), release(X),
X:=alloc(50B), Z:=alloc(50B), W:=alloc(200B)
W przypadku metody najlepiej pasujący ten ciąg zostanie obsłużony bez czekania. Ze względu na fragmentację zewnętrzną (200B) w przypadku metody pierwszy pasujący ostatnie żądanie nie zostanie wykonane od razu. Dla stref statycznych jest tak samo jak w poprzednim punkcie.
Rozważmy teraz system, w którym pamięć podzielona jest na strony. Załóżmy, że tablica stron jest przechowywana w pamięci głównej, czas dostępu do tej pamięci wynosi t.
Rozwiązanie
Przypuśćmy, że zawartość tablicy stron dla aktualnie wykonywanego procesu jest następująca:
| Numer strony | Numer ramki |
|---|---|
| 0 | - |
| 1 | 4 |
| 2 | - |
| 3 | 2 |
| 4 | 1 |
| 5 | 0 |
Strony i ramki są numerowane od zera, adresy są adresami bajtów w pamięci, a strona ma rozmiar 1024 bajty.
Jakim adresom fizycznym odpowiadają podane adresy wirtualne (nie należy obsługiwać błędów braku strony):
W pewnym systemie ze stronicowaniem: strona ma rozmiar 512 bajtów, pozycja w tablicy stron (adres) zajmuje 4 bajty, a tablica stron dowolnego poziomu zajmuje 1 stronę.
64KB > 8KB, czyli do zarządzania pamięcią o rozmiarze 8KB wystarczy stronicowanie 1-poziomowe.
Załóżmy, że funkcja mem(x) przekazuje liczbę 32-bitową, znajdującą się pod adresem x wyrażonym w bajtach. Napisz funkcję f(x), która dla założeń z poprzedniego zadania i 3 poziomów stronicowania przekształca adres liniowy w adres fizyczny. Przyjmij, że zmienna R przechowuje adres bazowy katalogu 3-ciego poziomu.
Struktura adresu liniowego dla podanych założeń
| 2 zarezerwowane bity | indeks 3 poziomu (7 bitów) |
indeks 2 poziomu (7 bitów) |
indeks 1 poziomu (7 bitów) |
przesunięcie (najmłodsze 9 bitów) |
Skorzystamy z poniższych makr:
#define PAGE_SIZE 512
#define CATALOG_BITS 7
#define DIRECTORY_BITS 7
#define TABLE_BITS 7
#define OFFSET_BITS 9
#define CATALOG_FIRST_BIT (DIRECTORY_BITS+TABLE_BITS+OFFSET_BITS)
#define DIRECTORY_FIRST_BIT (TABLE_BITS+OFFSET_BITS)
#define TABLE_FIRST_BIT (OFFSET_BITS)
#define SIZE_OF_CATALOG_ENTRY 4
#define SIZE_OF_DIRECTORY_ENTRY 4
#define SIZE_OF_TABLE_ENTRY 4
#define OFFSET_MASK ~(~0 << OFFSET_BITS)
#define getbits(x, start_position, field_size) ((x >> start_position) & (~(~0 << field_size)))
Makro getbits przekazuje pole o długości field_size wycięte z x od pozycji start_position, dosunięte to prawej strony. Przyjmujemy, że zerową pozycją bitu jest prawy koniec x.
Na przykład, getbits(x, 4, 3) przekazuje 3 bity - z pozycji 4, 5 i 6 dosunięte do prawej strony wyniku.
Oto funkcja f tłumacząca adres liniowy na adres fizyczny:
u32 f(u32 lin_addr) {
u32 address, offset;
/* wyznaczam indeks w katalogu stron najwyższego (tzn. trzeciego) poziomu */
offset = getbits(lin_addr, CATALOG_FIRST_BIT, CATALOG_BITS);
/* wyznaczam adres katalogu stron drugiego poziomu */
address = mem(R + SIZE_OF_DIRECTORY_ENTRY * offset);
/* wyznaczam indeks w katalogu stron drugiego poziomu */
offset = getbits(lin_addr, DIRECTORY_FIRST_BIT, DIRECTORY_BITS);
/* wyznaczam adres tablicy stron (pierwszy poziom) */
address = mem(address + SIZE_OF_DIRECTORY_ENTRY * offset);
/* wyznaczam indeks w tablicy stron */
offset = getbits(lin_addr, TABLE_FIRST_BIT, TABLE_BITS);
/* wyznaczam adres strony */
address = mem(address + SIZE_OF_TABLE_ENTRY * offset);
address *= PAGE_SIZE;
return address + (lin_addr & OFFSET_MASK);
}
Algorytm bliźniaków
Funkcja alloc_pages() (wykorzystywana między innymi przez kmalloc()) służy do przydzielania spójnych fragmentów pamięci na potrzeby jądra w systemach uniksowych.
Pamięć jest przydzielana i zwalniana w blokach o rozmiarze 2i ramek (i=0..MAX_ORDER-1).
Zarządzanie przydziałem i zwalnianiem wolnych fragmentów pamięci jest oparte na algorytmie bliźniaków (w literaturze angielskojęzycznej: buddy algorithm).
System przechowuje tablicę list adresów wolnych obszarów pamięci fizycznej o różnych
rozmiarach. Pierwsza lista zawiera obszary pamięci o wielkości jednej strony, a ostatnia o wielkości 2MAX_ORDER-1 stron. Każdy taki fragment pamięci, mimo że może składać się z wielu stron, jest spójnym blokiem pamięci fizycznej.
Zajmowanie obszaru o rozmiarze 2i
Szukanie obszaru do przydzielenia zaczyna się od listy i-tej. Jeśli nie jest ona pusta, to wyjmemy z niej jeden element i przekazujemy go
jako wynik funkcji. Jeśli lista jest pusta, to szukamy najbliższej niepustej listy zawierającej większe obszary pamięci i z niej wyjmujemy jeden element. Ponieważ znaleziony obszar jest większy od poszukiwanego, więc należy go podzielić. Dzielimy go zatem na połowy dopóty, dopóki otrzymany fragment jest żądanej wielkości. Pozostałe po dzieleniu obszary wstawanie są do odpowiednich list.
Zwalnianie obszaru o rozmiarze 2i
Zwalniany obszar musiał być kiedyś przydzielony, czyli musiał być wydzielony z bloku dwa razy większego. Być może jego bliźniak (czyli druga połowa tego większego bloku) też jest wolny i dwa bliźniacze obszary będzie można połączyć w jeden większy spójny obszar. Jeśli to się uda, to można szukać bliźniaka dla tego większego fragmentu itd. Postępuje się tak aż do momentu, kiedy szukany bliźniak okaże się być zajęty (lub cała dostępna pamięć jest wolna) i dodaje się utworzony blok do odpowiedniej listy, a także aktualizuje informacje o przynależności obszarów do pozostałych list.
Analiza
Zaletą algorytmu bliźniaków jest to, że jest on elastyczny i zapobiega fragmentacji, ponieważ te same fragmenty pamięci są wykorzystywane w obszarach o różnym rozmiarze. Jego wadą może wydawać się wydajność z uwagi na konieczność dzielenia i scalania obszarów.
Z drugiej strony dzięki indeksowaniu tablicy obszarów potęgami dwójki, większość operacji arytmetycznych polega na przesunięciu dwójkowym lub zamianie bitu, więc są one bardzo szybkie.
Zadanie
Przyjmiemy dla uproszczenia, że MAX_ORDER=5. W rzeczywistości jest to większa wartość: we współczesnych systemach Linux wynosi ona 11. Początkowo cała dostępna pamięć jest wolna i tworzy spójny obszar o rozmiarze 16 ramek o adresach od 0 do 15.
Jaka będzie odpowiedź, jeżeli zmienimy kolejność kroków (4) i (5)?
Jaki ciąg zleceń powoduje najgorsze możliwe zachowanie algorytmu bliźniaków?
| 4 | -> 0 | 3 | | 2 | | 1 | | 0 |
Sytuacja po operacji A:=allocate(1) :
| 4 | | 3 | -> 8 | 2 | -> 4 | 1 | -> 2 | 0 | -> 1
Sytuacja po operacji B:=allocate(2) :
| 4 | | 3 | -> 8 | 2 | -> 4 | 1 | | 0 | -> 1
Sytuacja po operacji C:=allocate(2) :
| 4 | | 3 | -> 8 | 2 | | 1 | -> 6 | 0 | -> 1
Sytuacja po operacji release(A) :
| 4 | | 3 | -> 8 | 2 | | 1 | -> 0, 6 | 0 |
Fragmenty o adresach 0 i 6 nie są bliźniakami, ponieważ nie tworzą spójnego obszaru.
Sytuacja po operacji D:=allocate(2) :
| 4 | | 3 | -> 8 | 2 | | 1 | -> 6 | 0 |
Jeśli zamienimy kolejność ostatnich 2 operacji, to otrzymamy:
Sytuacja po operacji D:=allocate(2) :
| 4 | | 3 | -> 8 | 2 | | 1 | | 0 | -> 1
Sytuacja po operacji release(A) :
| 4 | | 3 | -> 8 | 2 | | 1 | -> 0 | 0 |
Oblicz optymalny rozmiar strony minimalizujący fragmentację wewnętrzną.
(Wg. Brinch Hansena)
Niech p oznacza rozmiar strony (w słowach), a s przeciętny rozmiar programu (w słowach). Na każdą stronę potrzeba jednej pozycji w tablicy stron, a więc s/p pozycji. Średnio jest marnowana połowa (ostatniej) strony, a więc p/2. Optymalny rozmiar strony (minimalizujący fragmentację wewnętrzną) można zatem opisać wzorem:
f(p)=(p/2 + s/p)/s = p/2s + 1/p
f(p)' = 1/2s - 1/(p ^ 2)
f(p)' = 0 dla p = sqrt(2s), f(sqrt(2s)) = sqrt(2/s)
Wnioski: duża strona oznacza większe straty wynikające z niewykorzystania reszty ostatniej strony, ale mniejsze straty wynikające z rozmiaru tablicy stron. Warto też skomentować rozmiar strony w kontekście czasu poświęcanego na transmisje wejścia-wyjścia: im większa strona, tym narzuty w przeliczeniu na bajt są mniejsze) oraz w kontekście "fragmentacji logicznej" (ściągamy do pamięci większą stronę, potencjalnie ryzykujemy, że zawiera ona więcej niepotrzebnych bajtów).
(Jeszcze raz algorytm bliźniaków)
Zakładając, że MAX_ORDER=6 i początkowo cała wolna pamięć tworzy spójny obszar o rozmiarze 32 ramki, opisz stan pamięci po wykonaniu każdej z następujących operacji:
getpages(2); getpages(1); getpages(2); getpages(2);
freepages(8,2); freepages(4,1); freepages(0,2)Funkcja getpages(i) przydziela blok o rozmiarze i ramek, natomiast funkcja freepages(k,i) zwalnia blok rozpoczynający się od strony o numerze k i o rozmiarze i ramek. Ramki są numerowane od 0. Spośród dwóch obszarów uzyskanych w wyniku podziału zajmowany jest ten o mniejszym adresie.
Sytuacja początkowa:
| 5 | -> 0 | 4 | | 3 | | 2 | | 1 | | 0 |
Sytuacja po operacji getpages(2) :
| 5 | | 4 | -> 16 | 3 | -> 8 | 2 | -> 4 | 1 | -> 2 | 0 |
Sytuacja po operacji getpages(1) :
| 5 | | 4 | -> 16 | 3 | -> 8 | 2 | -> 4 | 1 | | 0 | -> 3
Sytuacja po operacji getpages(2) :
| 5 | | 4 | -> 16 | 3 | -> 8 | 2 | | 1 | -> 6 | 0 | -> 3
Sytuacja po operacji getpages(2) :
| 5 | | 4 | -> 16 | 3 | -> 8 | 2 | | 1 | | 0 | -> 3
Sytuacja po operacji freepages(6,2) :
| 5 | | 4 | -> 16 | 3 | -> 8 | 2 | | 1 | -> 6 | 0 | -> 3
Sytuacja po operacji freepages(4,1) :
| 5 | | 4 | -> 16 | 3 | -> 8 | 2 | | 1 | -> 6 | 0 | -> 3, 4
Fragmenty o adresach 3 i 4 nie są bliźniakami mimo, że tworzą spójnego obsza, ponieważ nie można z nich zbudować obszaru dwa razy większego o wyrównanym adresie.
Sytuacja po operacji freepages(0,2) :
| 5 | | 4 | -> 16 | 3 | -> 8 | 2 | | 1 | -> 0, 6 | 0 | -> 3, 4
Niech index_of_page oznacza indeks strony w tablicy ramek, index_of_buddy oznacza indeks bliźniaka, a order rząd, gdzie rozmiar wolnego obszaru w systemie bliźniaków to 2^order ramek. W jaki sposób obliczamy indeks bliźniaka? Wypełnij puste pola podanej tabeli:
index_of_page: 0 1 2 3 0 2 0 index_of_buddy: order: 0 0 0 0 1 1 2
Indeks bliźniaka wylicza się za pomocą formuły:
index_of_buddy = index_of_page XOR (1 << order).
index_of_page: 0 1 2 3 0 2 0 index_of_buddy: 1 0 3 2 2 0 4 order: 0 0 0 0 1 1 2
Zapisz formułę wyznaczającą dla obszaru o indeksie index_of_page rzędu order indeks zawierającego go bliźniaka rzędu order + 1. Sprawdź jej działanie dla przykładowych danych.
index_of_parent = index_of_page & ~(1 << order)
index_of_page: 0 1 2 3 0 2 0 index_of_parent: 0 0 2 2 0 0 0 order: 0 0 0 0 1 1 2
Rozważmy pamięć wirtualną ze stronicowaniem na żądanie. Tablica stron jest przechowywana w rejestrach. Obsługa przerwania braku strony zajmuje 8 milisekund, gdy jest dostępna pusta ramka lub strona usuwana z pamięci nie była modyfikowana i 20 milisekund, gdy usuwana strona była modyfikowana. Czas dostępu do pamięci wynosi 1 mikrosekundę.
Załóżmy, że 70% usuwanych stron to strony, które były modyfikowane. Jaki jest maksymalny akceptowalny współczynnik przerwań braku strony, aby efektywny czas dostępu do pamięci nie przekraczał 2 mikrosekund?
Rozwiązanie
2 mikrosekundy >= (1 - p) * 1 mikrosekunda + p * (0.3 * 8 milisekund + 0.7 * 20 milisekund) p <= 0.00006
Rozważmy następujący ciąg odwołań do stron:
4, 5, 3, 1, 4, 5, 2, 4, 5, 3, 1, 2
Zakładając, że dostępna dla procesów pamięć fizyczna składa się z:
które początkowo są wolne, podaj, które strony i w jakiej kolejności zostaną usunięte oraz jaka jest w każdej chwili zawartość pamięci przy zastosowaniu następujących strategii usuwania stron:
Rozwiązanie
4 5 3 1 4 5 2 4 5 3 1 2
* * * * * * * * * *
4 5 3 1 4 5 2 4 5 3 1 2
4 5 3 1 4 5 2 4 5 3 1
4 5 3 1 4 5 2 4 5 3 4 5 3 1 4 5 2 4 5 3 1 2
* * * * * * * * *
4 4 4 1 1 1 2 2 2 2 2 2
5 5 5 4 4 4 4 4 3 3 3
3 3 3 5 5 5 5 5 1 1 4 5 3 1 4 5 2 4 5 3 1 2
* * * * * * *
4 4 4 4 4 4 4 4 4 4 1 1
5 5 5 5 5 5 5 5 3 3 3
3 1 1 1 2 2 2 2 2 2 4 5 3 1 4 5 2 4 5 3 1 2
* * * * * * * *
4 5 3 1 4 5 2 4 5 3 1 2
4 5 3 1 4 5 2 4 5 3 1
4 5 3 1 4 5 2 4 5 3
4 5 3 1 1 1 2 4 5 4 5 3 1 4 5 2 4 5 3 1 2
* * * * * * * * * *
4 4 4 4 4 4 2 2 2 2 1 1
5 5 5 5 5 5 4 4 4 4 2
3 3 3 3 3 3 5 5 5 5
1 1 1 1 1 1 3 3 3Anomalia Belady'ego: wystąpiło więcej błędów braku strony mimo, że jest więcej dostępnej pamięci.
4 5 3 1 4 5 2 4 5 3 1 2
* * * * * *
4 4 4 4 4 4 4 4 4 4 1 1
5 5 5 5 5 5 5 5 5 5 5
3 3 3 3 3 3 3 3 3 3
1 1 1 2 2 2 2 2 2Pewien proces wygenerował następujący ciąg odwołań do stron:
1, 4, 1, 2, 5, 3, 1, 2, 6, 4, 3, 2
Zakładając, że dostępna dla procesów pamięć fizyczna składa się z 4 ramek, które początkowo są wolne, podaj, które strony i w jakiej kolejności zostaną usunięte oraz jaka jest w każdej chwili zawartość pamięci przy zastosowaniu następujących strategii usuwania stron:
Rozwiązanie
1 4 1 2 5 3 1 2 6 4 3 2
* * * * * * * *
1 4 1 2 5 3 1 2 6 4 3 2
1 4 1 2 5 3 1 2 6 4 3
4 1 2 5 3 1 2 6 4
4 1 2 5 3 1 2 6 1 4 1 2 5 3 1 2 6 4 3 2
* * * * * * * * *
>1.>1.>1.>1.>1. 3. 3. 3.>3. 3 3. 3
4. 4. 4. 4.>4 1. 1. 1. 1 1 2.
2. 2. 2 >2 >2. 2 4. 4.>4.
5. 5 5 5 6.>6.>6. 6. oznacza ustawiony bit
Rozważmy następujący ciąg odwołań do stron:
2, 4, 3, 4, 4, 4, 3, 4, 2, 1, 5, 2, 5
Podaj zawartość pola roboczego oraz liczbę przerwań braku strony dla wskazanego ciągu odwołań w strategii pola roboczego z okienkiem o rozmiarze:
Rozwiązanie
2 4 3 4 4 4 3 4 2 1 5 2 5
* * * * * * *
2 2 2 4 4 4 4 4 3 4 2 1 5
4 4 3 3 3 3 4 2 1 5 2
3 2 1 5 2
2 4 3 4 4 4 3 4 2 1 5 2 5
* * * * * *
2 2 2 2 4 4 4 4 4 3 4 2 1
4 4 4 3 3 3 3 3 4 2 1 5
3 3 2 2 1 5 2
1 5Rozważmy dwuwymiarową tablicę A:
var A: array [1..page_size] of array [1..page_size] of byte;
Ile przerwań braku strony wygeneruje wykonanie każdego z podanych dwóch algorytmów zerowania tablicy A?
for i:= 1 to page_size do
for j:= 1 to page_size do
A[i, j] := 0;
for i:= 1 to page_size do
for j:= 1 to page_size do
A[j, i] := 0;Można założyć, że:
Rozwiązanie
Algorytm pierwszy wygeneruje page_size przerwań braku strony, a drugi: page_size2.
Wniosek: struktura programu może mieć istotny wpływ na efektywność wykonywania tego programu w systemie z pamięcią wirtualną.
Algorytm WSClock zarządzania pamięcią działa następująco. Jeśli są puste ramki, to przydziela pierwszą wolną.
Jeśli nie ma, to przegląda cyklicznie wszystkie ramki (począwszy od miejsca, w którym ostatnio zakończono przeglądanie). Jeśli do strony zapamiętanej w ramce było odwołanie od ostatniego sprawdzenia, to za czas tego odwołania przyjmuje się czas bieżący. Jeśli do strony nie było odwołania od ostatniego sprawdzenia, to można usunąć tę stronę, jeśli od czasu ostatniego sprawdzenia minęło co najmniej T jednostek czasu. Jeśli strona była modyfikowana podczas pobytu w pamięci operacyjnej, to inicjuje się usunięcie strony i szuka się dalej. Jeśli w wyniku przejrzenia wszystkich ramek nie znajdzie się żadnej wolnej, to:
Dane są następujące deklaracje:
const lramek = ...;
maxproc = ...;
T = ...;
type ramki = 0..lramek-1;
procesy = 0..maxproc;
function Zegar: real; (* wirtualny zegar *)
procedure UsuńStronę (nrramki: ramki);
(* inicjuje przesłanie strony z danej ramki z pamięci operacyjnej do pomocniczej *)
function CzekajNaRamkę: ramki;
(* wstrzymuje działanie procesu aż do chwili najbliższego zakończenia usuwania
strony z pamięci operacyjnej do pomocniczej - przekazuje numer zwolnionej ramki *)
function UsuńProces: procesy
(* przekazuje numer procesu wyznaczonego do usunięcia *)Należy zadeklarować wszystkie potrzebne struktury danych oraz napisać procedurę WSClock implementującą strategię zarządzania pamięcią WSClock i przekazującą numer wolnej ramki w pamięci operacyjnej.
Uwaga: jeśli na porządne zapisanie tego algorytmu nie wystarczy czasu, to należy przynajmniej dokładnie omówić działanie algorytmu WSClock.
Rozwiązanie
type wramki = -1 .. lramek -1; (* wolne ramki; -1 <=>; NIL *)
var PaO: array [ramki] of
record
było_odwołanie: boolean;
czas_odwołania: real;
modyfikowana: boolean;
trwa_transmisja: boolean; (* strona jest usuwana,
była modyfikowana *)
proces: procesy;
następna_wolna: wramki; (* następna wolna *)
end;
strzałka: ramki;
wolna: wramki; (* wskaźnik do listy wolnych *)
usuwane: integer; (* liczba usuwanych stron zmodyfikowanych;
transmisja mogła zostać zainicjowana podczas
poprzednich wywołań procedury WSClock *)
czekający: integer; (* liczba procesów czekających na stronę *)
bieżący_proces: integer; (* numer bieżącego procesu *)
procedure ZwolnijRamkę (nrramki: ramki);
begin
PaO[nrramki].następna_wolna := wolna; wolna := nrramki;
with PaO[nrramki] do
begin
proces := 0; trwa_transmisja := false; było_odwołanie := false
end
end;
procedure WSClock (var nrramki: ramki);
var znaleziono: boolean;
ostatni: nrramki;
nrproc: procesy;
begin
if wolna <> -1 then begin
nrramki := wolna; wolna := PaO[wolna].następna_wolna
end
else begin
znaleziono := false;
ostatni := strzałka;
repeat
strzałka := (strzałka + 1) mod lramek;
with PaO[strzałka] do
if not trwa_transmisja then
if było_odwołanie then begin
było_odwołanie := false; czas_odwołania := Zegar(bieżący_proces);
end
else if Zegar(bieżący_proces) - czas_odwołania > T then
if modyfikowana then begin
usuwane := usuwane + 1;
trwa_transmisja := true;
UsuńStronę(strzałka)
end else begin
znaleziono := true;
proces := bieżący_proces;
nrramki := strzałka;
end
until znaleziono or (strzałka = ostatni);
if not znaleziono then begin
if czekający >= usuwane then begin
nrproc := UsuńProces;
for ostatni:=0 to lramek-1 do
with PaO[ostatni] do
if proces = nrproc then
if modyfikowana then begin
trwa_transmisja:=true;
usuwane := usuwane + 1;
UsuńStronę(ostatni)
end
else ZwolnijRamkę(ostatni);
end;
if wolna <> -1 then begin
nrramki := wolna; wolna := PaO[wolna].następna_wolna
end
else begin czekający := czekający + 1; nrramki := CzekajNaRamkę end
end;
end
end (* WSClock *)Dodatkowe pytania:
Rozważmy plik złożony ze 100 bloków. Załóżmy, że struktury danych opisujące położenie pliku na dysku są w pamięci operacyjnej. Przyjmijmy także, że blok fizyczny poprzedzający pierwszy blok pliku na dysku jest zajęty, a blok fizyczny położony za ostatnim blokiem pliku jest wolny. Ile operacji dyskowych wymaga:
Rozwiązanie
| alokacja ciągła | alokacja listowa | alokacja indeksowa | |
| a | 201=100+101 | 1 | 1 |
| b | 101=50+51 | 52=50+1+1 | 1 |
| c | 1 | 102=100+1+1 | 1 |
| d | 198=99+99 albo 0 | 1 | 0 |
| e | 98=49+49 | 52=51+1 | 0 |
| f | 0 | 100=99+1 | 0 |
I-węzeł pliku w systemach ext2 i ext3 zawiera numery pierwszych 12 bloków z danymi oraz numery jednego bloku pośredniego, jednego bloku podwójnie pośredniego i jednego bloku potrójnie pośredniego (tablica i-block).
Plik o rozmiarze logicznym 15000 B został umieszczony na partycji, dla której rozmiar bloku ustalono na 1 KB.
Policz ile operacji dyskowych wymaga:
fragmentu pliku o wielkości 1000 B (uwaga: nie 1 KB) położonego:
W obu przypadkach plik jest otwarty, ale żaden blok danych nie został jeszcze sprowadzony do pamięci. W pamięci znajduje się jedynie i-węzeł pliku. Możemy założyć, że wszystkie bloki pliku są zapisane (plik nie jest dziurawy).
Jak zmienią się odpowiedzi bez ostatniego założenia?
W jakiej sytuacji uzyskamy najmniejszą liczbę operacji dyskowych?
Rozwiązanie
Gdyby był to pierwszy zapis do bloku o numerze 14 (na przykład w sytuacji, gdy dopisywane jest 1000B na końcu pliku), to jeszcze doszedłby zapis bloku pojedynczo pośredniego, bo trzeba by przydzielić blok fizyczny na ten blok logiczny i wstawić jego adres do bloku indeksowego. Nie potrzeba natomiast odczytywać wcześniej bloku o numerze 14, więc liczba operacji dyskowych również wyniosłaby 5 (2 odczyty i 3 zapisy).
Najmniejsza liczba operacji odczytu i zapisu będzie w sytuacji, w której dokonujemy pierwszego zapisu do obydwu bloków i nie został jeszcze przydzielony blok z adresami pośrednimi (tylko 3 operacje zapisu). W tej sytuacji trzeba jednak przydzielić 3 nowe bloki dyskowe.
Załóżmy, że rozmiar bloku w systemie plików ext3 został ustalony na 1KB. Ile maksymalnie, a ile minimalnie bloków dyskowych może być potrzebne do zapamiętania pliku o rozmiarze 2GB?
Wskazówka: Pliki mogą być rozrzedzone (dziurawe).
Rozwiązanie
Przypadek maksymalnej liczby bloków dyskowych odpowiada np. plikowi całkowicie zapisanemu. Dla takiego pliku trzeba alokować wszystkie bloki z danymi, a więc także wszystkie bloki indeksowe.
Plik ma rozmiar 2 GB, co daje 2GB /1KB = 2M bloków z danymi.
Każdy blok pośredni może pomieścić 1024/4=256 numerów bloków.
Gdyby wszystkie bloki były indeksowane przez bloki pośrednie, to potrzeba na to 2M /256 = 8 K bloków pośrednich. Ponieważ adresy pierwszych 12 bloków znajdują się w i-węźle ostatni z tych bloków będzie indeksował 256 - 12 = 244 bloki z danymi.
Bloki pośrednie dzielą się na 1 blok samodzielny i 31 * 256 + 255 bloków indeksowanych przez bloki podwójnie pośrednie (ostatni niepełny). Te ostatnie z kolei dzielą się na 1 blok samodzielny i 31 bloków indeksowanych przez blok potrójnie pośredni (oczywiście niepełny).
Łącznie potrzeba: 2 M bloków z danymi, 8 K bloków pośrednich, 32 bloki podwójnie pośrednie i 1 blok potrójnie pośredni.
Przypadek minimalnej liczby bloków dyskowych odpowiada np. plikowi, który powstał przez zapisanie jednego bajtu pod adresem 2^31-1 (za pomocą operacji lseek()). W tym przypadku trzeba alokować po jednym bloku pośrednim każdego poziomu i jeden na blok danych (łącznie 3 + 1 = 4 bloki).
Kiedy rozmiar pliku w i-węźle systemu ext2 był opisywany liczbą 32-bitową i jej najstarszy bit był zarezerwowany, plik mógł mieć wielkość co najwyżej 2GB. We współczesnych systemach ext2 i ext3 32-bitowe pole i-węzła o nazwie i-blocks przechowuje rozmiar pliku wyrażony w liczbie 512 bajtowych porcji. Rozmiar bloków na dysku zależy od konfiguracji. Dopuszczalne są bloki o wielkości 512 B, 1KB, 2KB, 4KB, a nawet 8KB (o ile architektura na to pozwala). Numery bloków fizycznych są 32-bitowe.
Wiedząc to wszystko i biorąc pod uwagę sposób adresowania bloków uzupełnij poniższą tabelkę dla systemów ext2/3:
| rozmiar bloku | maksymalny rozmiar pliku | maksymalny rozmiar partycji |
| 1 KB | ||
| 2 KB | ||
| 4 KB | ||
| 8 KB |
Rozwiązanie
| rozmiar bloku | maksymalny rozmiar pliku | maksymalny rozmiar partycji |
| 1 KB | 16 GB | 4 TB |
| 2 KB | 256 GB | 8 TB |
| 4 KB | 2 TB | 16 TB |
| 8 KB | 2 TB | 32 TB |
Maksymalny rozmiar pliku jest ograniczony przez:
min(((b/4)3 + (b/4)2 + b/4 + 12)*b, 241),
gdzie b jest rozmiarem bloku.
Pierwsza część ograniczenia wynika ze sposobu adresowania, czyli maksymalnej liczby bloków jaką możemy zaadresować mając
3 poziomowe indeksowanie.
Druga część to ograniczenie wynikające z 32-bitowej postaci i-blocks oznaczającej liczbę 512 bajtowych porcji pliku:
232 * 29 = 241, czyli 2TB.
Dla b=210 maksymalny rozmiar pliku to
min(((28)3 + ...) * 210, 241)= w przybliżeniu 234
Dla b=211 maksymalny rozmiar pliku
to min(((29)3 + ...) * 211, 241)= w przybliżeniu 238
Dla b=212 maksymalny rozmiar pliku
to min(((210)3 + ...) * 212, 241) =241
Maksymalny rozmiar partycji jest zdeterminowany przez 32-bitowe numery bloków na dysku. Na przykład dla bloku o rozmiarze 1 KB:
232 * 210=242, czyli partycja może mieć wielkość co najwyżej 4 TB.
Napisz funkcję int bmap(struct inode *inode, int block), która tłumaczy logiczny numer bloku w pliku na fizyczny numer bloku na dysku, w systemach plików ext2/3.
Dane: wskaźnik do i-węzła pliku i logiczny numer bloku w pliku.
Wynik: fizyczny numer bloku na dysku w przypadku sukcesu lub 0, gdy nie znaleziono bloku.
Załóżmy, że są dostępne następujące makrodefinicje:
#define EXT2_BLOCK_SIZE 4096 #define EXT2_NDIR_BLOCKS 12 #define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS #define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1) #define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1) #define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1)
Ponadto można założyć, że są dostępne następujące funkcje pomocnicze:
Jest to makro, które przekazuje numer bloku zapisany na pozycji nr w tablicy bloków pliku w i-węźle wskazywanym przez inode. Parametr nr powinien zatem należeć do przedziału [0..EXT2_N_BLOCKS-1] (czyli [0..14]). Makro to jest używane przy pobieraniu adresu fizycznego jednego z bloków bezpośrednich, bloku pojedynczego, podwójnego bądź potrójnego pośredniego.
Funkcja ta przekazuje wskaźnik do nagłówka bufora, do którego wczytano blok o numerze fizycznym i z urządzenia dev.
Funkcja ta przekazuje liczbę zapisaną w bloku z bufora o nagłówku bh, w komórce o numerze nr. Po odczytaniu zwalnia bufor (wykonując brelse()). Jest używana przy odczytywaniu adresów w blokach pojedynczych, podwójnych i potrójnych pośrednich.
Rozwiązanie
Warto wprowadzić dwie zmienne pomocnicze:
Jej wartością jest stale liczba adresów mieszczących się w bloku (czyli rozmiar_bloku/rozmiar_adresu).
Jej wartością jest stale logarytm przy podstawie 2 z wartości zmiennej N. Zmienna ta jest wykorzystywana przy wykonywaniu różnych operacji na bitach.
Przy przekształcaniu adresów zachodzi potrzeba obliczenia liczby bloków, które mieszczą się w poszczególnych strefach pośredniości. Oto jak radzi sobie z tym problemem algorytm bmap():
Maksymalna liczba bloków dająca się zaadresować w i-węźle jest sumą wymienionych czterech liczb.
Implementacja funkcji bmap():
{
/* Sprawdz czy parametr wywołania, block, jest poprawny */
if (block < 0) return 0; /* Nie znaleziono bloku */
if (block >= maksymalna liczba bloków możliwa do zaadresowania
w i-węźle) return 0;
/* Numer block jest poprawny; dalsze działanie zależy od
poziomu pośredniości, w którym znajduje się block */
DIR:
/* Poziom bezpośredni */
/* Blok jest w poziomie bezpośrednim, gdy jego numer jest
mniejszy od liczby blokow bezpośrednich */
if (block < EXT2_NDIR_BLOCKS) return inode_bmap(inode,block);
/* Blok jest w strefach pośrednich;pomijamy bloki bezpośrednie*/
block -= EXT2_NDIR_BLOCKS;
IND:
/* Pierwszy poziom pośredniości */
/* Blok jest w pierwszym poziomie pośredniości, gdy zmienna
block w tej chwili jest mniejsza od liczby bloków
dostępnych poprzez pojedynczy blok pośredni */
if (block < N)
{
/* Pobierz numer bloku pojedynczego pośredniego */
i = inode_bmap(inode, EXT2_IND_BLOCK);
if (i == 0) return 0;
/* Wczytaj blok o numerze i ( bread(inode->i_dev, i) ),
a nastepnie przekaż go jako pierwszy argument
do funkcji pomocniczej block_bmap */
return block_bmap( bread(inode->i_dev, i), block );
}
/* Blok jest w poziomie pośredniości wyższym od pierwszego;
pomijamy bloki w pierwszym poziomie pośredniości */
block -= N;
DIND:
/* Drugi poziom pośredniości */
if (block < liczba bloków dostępnych poprzez blok
podwójny pośredni)
{
/* Blok jest w drugim poziomie pośredniości */
/* Pobierz numer bloku podwójnego pośredniego */
i = inode_bmap(inode, EXT2_DIND_BLOCK);
if (i == 0) return 0;
/* Pobierz numer bloku pojedynczego pośredniego,
w którym znajduje się szukany blok; ten blok pojedynczy
pośredni ma numer block/N (część całkowita
ilorazu */
i = block_bmap(bread(inode->i_dev,i), block >> N_bits);
if (i == 0) return 0;
/* W bloku o numerze i, na pozycji (block mod N)
znajduje się szukany adres bloku */
return block_bmap(bread(inode->i_dev,i), block & (N - 1));
}
/* Pomijamy bloki w strefie drugiej pośredniości */
block -= liczba bloków dostępnych poprzez podwójny blok pośredni;
TIND:
/* Trzeci poziom pośredniości */
/* Pobierz numer bloku potrójnego pośredniego */
i = inode_bmap(inode, EXT2_TIND_BLOCK);
if (i == 0) return 0;
/* Pobierz numer bloku podwójnego pośredniego, w którym znajduje się szukany blok;
ten blok podwójny pośredni ma numer równy całości z dzielenia liczby block przez
kwadrat liczby N */
i = block_bmap( bread(inode->i_dev, i), block >> (N_bits * 2));
if (i == 0) return 0;
/* Z bloku i pobierz numer bloku pojedynczego pośredniego, w
którym znajduje się szukany blok; ten numer można otrzymać
biorąc część całkowitą z ilorazu block przez N,
a następnie z tego wyniku resztę modulo N */
i = block_bmap( bread(inode->i_dev,i), (block >> N_bits) & (N - 1) );
if (i == 0) return 0;
/* Teraz w bloku i na pozycji block mod N znajduje
się szukany adres bloku */
return block_bmap(bread(inode->i_dev, i), block & (N - 1))
}Jak widać ten klasyczny w świecie uniksowym sposób adresowania jest dobrze przystosowany do niewielkich plików lub plików rozrzedzonych. Jego zastosowanie w przypadku dużych plików wiąże się ze wzrastającymi nakładami. Konwersja numeru bloku o wysokim numerze, korzystająca z bloków
pośrednich (zwłaszcza podwójnie i potrójnie) jest dosyć kosztowna, wymaga od jądra kilku dostępów do bloków dyskowych (to może prowadzić do oczekiwania w stanie uśpienia podczas wykonania funkcji bmap).
Nasuwa się wniosek, że system plików ext3 dochodzi do granic swoich możliwości. Maksymalna wielkość partycji, czyli 16 TB (ew. 32 TB) jest już często przekraczana (np. w macierzach RAID), a ze względu na 32-bitowe numery bloków dyskowych więcej osiągnąć się nie da. Od 2006 roku trwają prace nad dwoma zasadniczymi zmianami dla ext3 dostępnymi w postaci łat a także obecnymi w jego następcy, czyli w systemie ext4.
Pierwsza i najważniejsza zmiana polega na zwiększeniu wielkości numeru bloku do 48 bitów, a druga na zamianie mechanizmu pośredniego adresowania bloków na tzw. ekstenty (ang. extent), czyli ciągłe zbiory (zakresy) bloków danych.
struct ext4_extent {
__le32 ee_block; /* first logical block extent covers */
__le16 ee_len; /* number of blocks covered by extent */
__le16 ee_start_hi; /* high 16 bits of physical block */
__le32 ee_start_lo; /* low 32 bits of physical block */
};Pojedynczy ekstent opisuje:
W strukturze i-węzła tablica i-block, która w systemach ext2/3 jest wykorzystywana do zapisywania numerów bloków, w ext4 służy do zapisania czterech ekstentów i jednego nagłówka ekstentu. W przypadku dużych plików system ext4 tworzy drzewo ekstentów. Dodatkowa struktura - indeks ekstentu - zawiera pozycję początkową ekstentu w pliku i numer bloku na dysku. Mechanizm ekstentów jest obecny także w innych popularnych systemach plików m. in w XFS, JFS, Reiser4, a nawet w NTFS.
Wiedząc, że w systemie ext4 numery logiczne bloków są 32-bitowe, a numery fizyczne bloków są 48 bitowe wypełnij tabelkę jak w zadaniu 3 dla rozmiaru bloku: 1, 2 i 4 KB.
Rozwiązanie
| rozmiar bloku | maksymalny rozmiar pliku | maksymalny rozmiar partycji |
| 1 KB | 4 TB | 256 PB |
| 2 KB | 8 TB | 512 PB |
| 4 KB | 16 TB | 1 EB |
232 * 210 = 242
232 * 211 = 243
232 * 212 = 244
248 * 210 = 258
248 * 211 = 259
248 * 212 = 260
Ustalmy, że rozmiar bloku wynosi 4KB. Porównaj, ile bloków dyskowych jest potrzebne do zapamiętania pełnego pliku (bez dziur) o rozmiarze 512MB w systemie ext3 i ext4.
Rozwiązanie
ext3:
Plik ma rozmiar 512 MB, co daje 512 MB/ 4 KB = 128 K bloków z danymi.
Każdy blok pośredni może pomieścić 4096/4=1024 numery bloków.
Gdyby wszystkie bloki były indeksowane przez pewien blok pośredni, to trzeba by na to 128 K/ 1024 = 128 bloków pośrednich. W rzeczywistości potrzeba 128 bloków pośrednich z tym, że ostatni jest niepełny i zawiera 1024 - 12 = 1012 numerów bloków z danymi. Ze 128 bloków pośrednich jeden jest wskazywany w i-węźle, a adresy pozostałych 127 bloków znajdują się w bloku podwójnie pośrednim.
Do przechowywania pliku wielkości 512MB potrzeba zatem 128 K bloków z danymi, 128 bloków pośrednich i 1 blok podwójnie pośredni. Oprócz bloków z danymi potrzeba dodatkowo 129 bloków, czyli 128 * 4KB + 4KB = 516KB.
ext4:
Jak poprzednio: 128 K bloków z danymi i w optymistycznej sytuacji (jeżeli plik nie jest pofragmentowany) nic więcej.
Za pomocą jednego ekstentu można zaadresować maksymalnie 215 * 4 KB = 128 MB danych, a zatem 4 ekstenty mieszczące się w i-węźle adresują cały plik.
Związek między procesem a systemem plików opisany jest przez dwa pola w strukturze danych procesu (task_struct):
W strukturze files_struct znajduje się tablica indeksowana liczbami naturalnymi, które odpowiadają deskryptorom otwartych plików. Wartościami poszczególnych pozycji w tej tablicy są dowiązania do systemowej tablicy otwartych plików.
Systemowa tablica otwartych plików
Każde wywołanie funkcji open() powoduje utworzenie nowej pozycji w systemowej tablicy otwartych plików. Natomiast wywołanie funkcji dup() i fork() powoduje, że do jednej pozycji mogą odnosić się różne deskryptory. Pozycja w systemowej tablicy otwartych plików jest opisana przez strukturę file. Pole f_count tej struktury odpowiada liczbie dowiązań do danej pozycji.
I-węzeł pliku
I-węzeł każdego otwartego pliku znajduje się w pamięci operacyjnej. Dla każdego pliku jest tylko jedna kopia i-węzła w pamięci niezależnie od tego ile razy dany plik był otwierany. Pole i_count w i-węźle informuje ile razy dla danego pliku wykonano funkcję open().
Uwaga: Przedstawiony tutaj opis jest oczywiście niepełny. Zawiera tylko wyrywkowe informacje pomocne przy wykonywaniu poniższych zadań.
Załóżmy, że pewien proces, który nie tworzył procesów potomnych, korzysta z n otwartych plików przy czym wszystkie one są różne (odpowiadają im różne i-węzły). Załóżmy również, że ten proces jest jedynym procesem w systemie posiadającym otwarte pliki. Czy jest możliwa sytuacja, w której liczba deskryptorów otwartych plików dla tego procesu jest:
Jeśli taka sytuacja jest możliwa, to kiedy może wystąpić? Opisz jak można taką sytuację wykryć znając jedynie zbiór obiektów plików file dla danego procesu, a nie wiedząc nic o liczbie deskryptorów plików otwartych przez ten proces.
Rozwiązanie
Proces P działa według następującego schematu (tablica plik[0..5] zawiera nazwy ścieżkowe plików):
fd=open(plik[0], ...);
for i in 1..5 do
{
if (!fork()) break;
fd=open(plik[i], ...);
}Jak będą wyglądały tablice deskryptorów plików procesu P i jego potomków?
Jak będzie wyglądała systemowa tablica otwartych plików (jakie wartości będą miały pola f_count)?
Rozwiązanie
Procesy potomne dziedziczą otwarte deskryptory ojca. Pierwszy proces potomny dziedziczy otwarty plik[0]. W momencie tworzenia drugiego procesu otwarte są pliki plik[0] i plik[1] itd.
Tablica deskryptorów procesu ojca:
| deskryptor | 0 | 1 | 2 | ... | j | j+1 | j+2 | j+3 | j+4 | j+5 |
| plik | STDIN | STDOUT | STDERR | ... | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] | plik[5] |
Tablica deskryptorów pierwszego potomka:
| deskryptor | 0 | 1 | 2 | ... | j |
| plik | STDIN | STDOUT | STDERR | ... | plik[0] |
Tablica deskryptorów piątego potomka:
| deskryptor | 0 | 1 | 2 | ... | j | j+1 | j+2 | j+3 | j+4 |
| plik | STDIN | STDOUT | STDERR | ... | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] |
Systemowa tablica otwartych plików:
| plik | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] | plik[5] |
| f_count | 6 | 5 | 4 | 3 | 2 | 1 |
(trudniejszy wariant poprzedniego zadania)
Proces P działa według następującego schematu (tablica plik[0..4] zawiera nazwy ścieżkowe plików):
fd=open(plik[0], ...);
for i in 1..4 do
{
fd=open(plik[i-1]);
if (!fork()) break;
fd=open(plik[i], ...);
dup(fd);
}Ile będzie pozycji odpowiadających plikom: plik[0], ..., plik[4]:
Jakie będą wartości liczników:
Rozwiązanie
Liczba pozycji odpowiadających poszczególnym plikom:
| plik | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] |
| tablica deskryptorów procesu P | 2 | 3 | 3 | 3 | 2 |
| tablica otwartych plików | 2 | 2 | 2 | 2 | 1 |
| tablica i-węzłów | 1 | 1 | 1 | 1 | 1 |
Wartości liczników w tablicy otwartych plików:
| plik | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] | ||||
| f_count | 5 | 5 | 8 | 4 | 6 | 3 | 4 | 2 | 2 |
Wartości liczników w tablicy i-węzłów:
| plik | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] |
| i-count | 2 | 2 | 2 | 2 | 1 |
W omawianych systemach plików pierwszy blok partycji jest zarezerwowany dla sektora startowego. Reszta partycji jest podzielona na grupy bloków tego samego rozmiaru o ustalonej strukturze. Liczba grup zależy od rozmiaru partycji i od wielkości bloku. Głównym ograniczeniem jest to, że mapa bitowa opisująca stan zajętości bloków wewnątrz grupy musi zmieścić się w jednym bloku.
Jak widać na rysunku również mapa bitowa opisująca zajętość i-węzłów oraz superblok zajmują po jednym bloku. Pozostałe struktury są zmiennej długości.
Superblok zawiera informacje o całym systemie plików (m. in rozmiar bloku, łączną liczbę bloków i i-węzłów, łączną liczbę wolnych bloków i i-węzłów). Deskryptor grupy przechowuje podstawowe informacje dotyczące grupy, takie jak liczbę wolnych bloków oraz i-węzłów w danej grupie, numery bloków map bitowych i numer pierwszego bloku tablicy i-węzłów.
Tablica i-węzłów to zbiór bloków, w ramach których przydzielane są i-węzły. Ich liczba jest ustalana podczas tworzenia systemu plików.
Różnice w strukturze partycji pomiędzy kolejnymi wersjami systemu plików od ext2 do ext4 są niewielkie. W oryginalnej wersji systemu ext2, kopia superbloku oraz deskryptory grup znajdowały się w każdej grupie (redundacja miała na celu zabezpieczenie danych przed awarią). W nowszych wersjach wprowadzono możliwość pominięcia kopii w niektórych grupach. Kopie superbloku i deskryptorów grup znajdują się wtedy w grupach o numerach 0, 1 oraz będących potęgą 3, 5 lub 7.
Zauważmy, że dla bardzo dużych partycji taki sposób organizacji staje się nieefektywny, ponieważ zbyt wiele miejsca jest przeznaczone na (redundantne) metadane. Chodzi tutaj przede wszystkim o deskryptory grup, których liczba rośnie wraz z rozmiarem partycji (szczegółowe wyjaśnienie w zadaniu 7). Dlatego w późniejszych wersjach systemu ext3 i w systemie ext4 wprowadzono tak zwane metagrupy. Metagrupa jest zbiorem grup, o tak dobranym rozmiarze, aby deskryptory grup w obrębie jednej metagrupy mieściły się w pojedynczym bloku dyskowym. Deskryptory grup danej metagrupy są przechowywane w jej pierwszej grupie i dodatkowo - w drugiej i w ostatniej.
Dla partycji ext2 o wielkości 4 GB rozmiar bloku został ustalony na 4 KB. Załóżmy, że rozmiar deskryptora grupy wynosi 48 B, rozmiar i-węzła na dysku wynosi 128 B, a na grupę przypada 4096 i-węzłów.
Rozwiązanie
W sumie 528 KB, co stanowi 0.4% rozmiaru grupy: 528 KB / 128 MB =0.4% (rozmiar metadanych dzielony przez rozmiar grupy - dane i metadane).
W obrębie całego dysku straty będą takie same - 0.4% (pomijamy rozmiar bloku startowego).
Załóżmy, że w pewnym systemie plików ext2:
Jak należy skonfigurować system plików na tej partycji, żeby metadane nie zajęły więcej niż 2% partycji?
Opisz szczegółowo ile będzie grup dyskowych, ile bloków zajmie jedna grupa, co będzie się znajdowało w kolejnych blokach dyskowych partycji, jakie metadane będą przechowywane w kolejnych (ilu) blokach, ile bloków będzie przypadało średnio na jeden plik. Blok startowy można zaniedbać w rozważaniach.
Rozwiązanie
(4+x) * 64 * 4KB /8GB = (4+x)*32 /1M < 0.02
x < 651.36, czyli np. x=650
Czyli i-węzłów będzie 650*32=20 800 (w mapie bitowej da się opisać więcej, bo 32K, więc taka konfiguracja jest możliwa)
0111 1111 1101 1010 0110 ...
1011 0000 0000 0000 0000 ...
1101 1111 1111 1111 1111 ...
Rozwiązanie
Jaki jest maksymalny rozmiar partycji dla systemu plików, w którym pierwsza grupa przechowuje wszystkie deskryptory grup danej partycji. Przyjmijmy, że deskryptor grupy ma rozmiar 64B, a blok dyskowy - 4 KB. Jaki byłby w takiej sytuacji rozmiar metagrupy?
Rozwiązanie
Dla bloku o rozmiarze 4 KB grupa będzie miała rozmiar 8 * 212 * 212 = 227, czyli 128 MB.
Zatem w grupie zmieści się nie więcej niż 227/64 = 221 deskryptorów grup, a więc partycja może mieć rozmiar co najwyżej 221 * 227 = 248, czyli 256TB (a nawet jeszcze mniej, bo nie wzięliśmy pod uwagę superbloku, map bitowych i tablicy i-węzłów, które znajdują się w każdej grupie).
Wniosek: w przypadku dużych partycji konieczne staje się zastosowanie metagrup. Dla podanych założeń jedna metagrupa zawierałaby 212/64 =64 grupy.
| Załącznik | Wielkość |
|---|---|
| struktura-partycji.gif | 9.9 KB |
{kind=link}
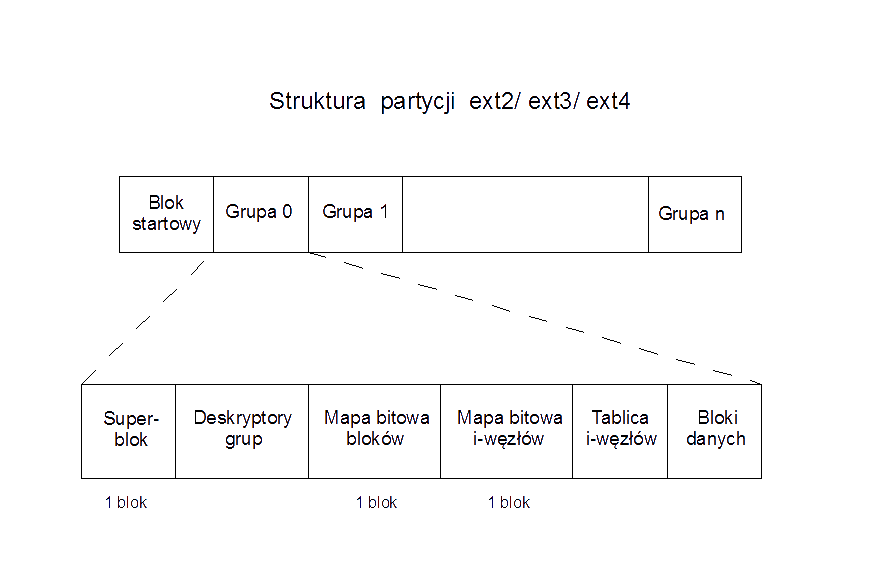{kind=link}