Zarządzanie wersjami - Subversion
Wprowadzenie
Narzędzia zarządzające wersjami (zwane też systemami kontroli wersji) mają na celu wspomaganie pamiętania źródeł projektu wraz z jego historią i możliwymi wersjami.
Czego możemy się spodziewać od zarządzania wersjami?
Przyjrzyjmy się, czego możemy się spodziewać od zarządzania wersjami z punktu widzenia zarządzającego projektem programistycznym. Otóż w skład projektu wchodzą pliki źródłowe programu. Pliki te są modyfikowane na ogół przez wielu programistów. W najprostszym przypadku chcemy, aby te pliki znajdowały się w jednym miejscu. Takie miejsce nazwiemy repozytorium. Często jest ono umieszczane na zdalnym serwerze dostępnym dla wszystkich programistów. W takim repozytorium powinny być najświeższe wersje źródeł. W ten sposób programiści mieliby dostęp do ostatniej wersji i na niej mogli by pracować. Zmiany przez nich nanoszone powinny być umieszczane w repozytorium, aby pozostali programiści mieli do nich wgląd. Skoro mamy wgląd do ostatniej wersji, to czemu by nie mieć wglądu do wszystkich wersji, jakie się uprzednio pojawiły, najlepiej wraz z historią dokonanych zmian. W ten sposób można by przeglądać historię projektu. Pozwoliłoby to na odtworzenie poprzednich wersji, co jest przydatne w przypadkach, gdy ostatnio naniesione zmiany zostały wprowadzone przez pomyłkę lub spowodowały, że aktualna wersja programu przestała działać. Ponadto czasami mile widziana by była też możliwość rozwijania kilku wersji na raz, bądź też praca równoległa nad różnymi częściami projektu. Oczywiście zmiany w różnych częściach projektu powinny dać się zintegrować w celu ostatecznego utworzenia produktu. Powinna być możliwa równoległa praca nad źródłami, wykonywana przez wielu programistów na raz, nawet wtedy, gdy dwie osoby pracują nad jednym plikiem. Do tego jeden programista, który modyfikuje jakieś pliki, powinien mieć w tych plikach możliwość obejrzenia zmian dokonanych w międzyczasie przez innych. Nawet powinien mieć możliwość uaktualniania plików, nad którymi pracuje, o zmiany innych programistów, nie tracąc przy tym swoich zmian. Większość powyższych wymagań jest realizowana w systemach kontroli wersji. Wygoda i szybkość realizacji tych operacji jest wyznacznikiem jakości takich systemów.
Do czego może się to przydawać?
Przyjrzyjmy się paru przykładom. Przy pisaniu programu zdarza się nam, że wprowadzamy bezsensowną modyfikację, która bardziej coś psuje niż ulepsza. Wtedy chcemy powrócić do stanu z przed dokonanych zmian. Normalnie należałoby zrobić kopię, zanim zaczęliśmy wprowadzać naszą zmianę. A co, jak byśmy chcieli się cofnąć do jeszcze innej wersji? Pewnie wypadało by robić kopię co jakiś czas. Takie rzeczy znacznie ułatwiają systemy kontroli wersji. Inna sytuacja. Mamy gdzieś błąd w programie i trzeba go poszukać. Błąd jest na tyle złośliwy, że narzędzia do śledzenia kodu są niewystarczające. Wtedy dopisujemy wypisywanie różnych informacji albo nawet całe nowe programy testujące, które mają na celu znalezienie najprostszych przypadków, kiedy ten błąd występuje. Po żmudnej pracy dodaliśmy dużo kodu debugującego do naszego programu i w końcu znaleźliśmy błąd, który usuwamy. Co zrobić teraz z całym tym kodem debugującym? Można go wykomentować, ale wtedy źródła robią się bardzo brzydkie. Jeśli ktoś inny też będzie zaglądał do tego kodu, to pewnie o wiele wygodniej będzie mu się pracować, gdy nie będzie całego tego śmietnika. Zatem najlepiej jest usunąć cały kod debugujący. Alternatywnie można by przepisać źródła inaczej, aby programy testujące nie mieszały się z kodem, ale to zazwyczaj wymaga dużo pracy. Załóżmy, że usunęliśmy kod debugujący, ale po krótkich dalszych modyfikacjach okazuje się, że znowu jest gdzieś bug. Co wtedy zrobić? Napisać kod debugujący od nowa? Za pomocą narzędzia zarządzania wersjami sprawa wygląda dosyć prosto. Otóż w momencie stwierdzenia, że mamy błąd w programie, zapamiętujemy aktualną wersję. Następnie wprowadzamy kod debugujący. Po znalezieniu błędu w repozytorium zapamiętujemy wersję z kodem debugującym. Przywracamy wersję bez kodu debugującego i poprawiamy tam błąd. Po dalszych modyfikacjach, jak pojawi się nowy błąd, to zazwyczaj (zależnie od możliwości systemu i zmian dokonanych w kodzie) możemy wprowadzić kod debugujący odtwarzając go z repozytorium, przy czym modyfikacje, które zrobiliśmy ostatnio zostają zachowane. Takie możliwości daje również kontrola wersji! Rozważmy teraz kolejną sytuację. Załóżmy, że piszemy nową funkcję naszego programu. Przy czym jest to złożone zajęcie. Modyfikacje w kodzie okazują się być dosyć duże. Na tyle duże, że postanawiamy zawiesić tą modyfikację i powrócić do niej za jakiś czas. W międzyczasie jednak chcemy dalej zająć się prostszymi elementami programu i go trochę pozmieniać. Później, jak wrócimy do naszej większej modyfikacji, chcemy jednak, aby te prostsze elementy były również uwzględnione. Normalnie trzeba by się zastanawiać, jak to wszystko zrobić, a z kontrolą wersji takie procesy są zupełnie naturalne. Oczywiście jedną z funkcji, którą umożliwia zarządzanie wersjami jest możliwość pracy w wiele osób. Jest to dużo wygodniejsze niż przesyłanie między sobą zaktualizowanych plików, które często prowadzi do błędów, gdyż łatwo się pomylić i wysłać nie ten plik, albo nie tą wersję pliku.
Narzędzia
Informacje o różnych narzędziach zarządzających wersjami można znaleźć na stronie Better SCM Initiative. Najbardziej rozpowszechniony jest CVS, jednak ze względu na jego ograniczenia, dzisiaj lepiej używać nowych, młodszych narzędzi, które nie mają już wad swojego poprzednika. My będziemy używać bardzo popularnego Subversion znanego też pod nazwą SVN. Subversion składa się z kilku poleceń, które umożliwiają tworzenie, modyfikowanie repozytorium oraz komunikację z repozytorium w celu uaktualniania, pobieranie różnych wersji, czy też historii zmian. Zatem praca polega na wpisywaniu poleceń. Istnieją też wygodne interfejsy graficzne, jak na przykład RapidSVN, jednak nie będziemy ich omawiać.Początek projektu
Tworzenie repozytorium
Wpierw trzeba zdecydować, gdzie repozytorium ma się znajdować - czy na serwerze zdalnym, czy też w lokalnym systemie plików. SVN udostępnia różne protokoły do komunikacji z serwerem wraz autoryzacją. My jednak będziemy stosować tutaj repozytorium lokalne bez autoryzacji. Utwórzmy wpierw katalog (z poziomu root'a):host:~# mkdir -p /var/local/reposhost:~# svnadmin create /var/local/reposhost:~# chgrp -R staff /var/local/repos host:~# chmod -R g+rw /var/local/repos
Co zawiera repozytorium?
Wiedza o tym, co przechowuje repozytorium i w jaki sposób, nie jest potrzebna do korzystania z narzędzia, jednakże może ułatwić zrozumienie działania niektórych poleceń SVNa. Dzięki temu będzie można lepiej zrozumieć, dlaczego są dostępne właśnie takie polecenia i jak za pomocą nich dokonać operacji, które sobie zaplanowaliśmy. Można w miarę w intuicyjny sposób przedstawić, co SVN pamięta w swoim repozytorium. W uproszczony sposób przedstawia to poniższy rysunek.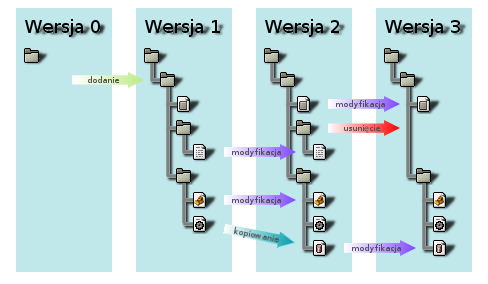 SVN pamięta wszystkie kolejne wersje poczynając od numeru 0. Wersja 0 jest wersją powstałą tuż po utworzeniu repozytorium i zawiera ona tylko katalog główny, który z początku jest pusty. Dla każdej wersji pamiętana jest cała struktura plików i katalogów, jakie zawiera dana wersja. Ponadto dla każdego pliku lub katalogu jest pamiętana informacja, w jaki sposób dany zbiór się tutaj znalazł. Otóż możliwe są trzy sposoby.
SVN pamięta wszystkie kolejne wersje poczynając od numeru 0. Wersja 0 jest wersją powstałą tuż po utworzeniu repozytorium i zawiera ona tylko katalog główny, który z początku jest pusty. Dla każdej wersji pamiętana jest cała struktura plików i katalogów, jakie zawiera dana wersja. Ponadto dla każdego pliku lub katalogu jest pamiętana informacja, w jaki sposób dany zbiór się tutaj znalazł. Otóż możliwe są trzy sposoby.
- Zbiór został właśnie dodany w tej wersji. W przypadku pliku trzeba więc zapamiętać całą zawartość, a w przypadku katalogu wszystkie pliki i katalogi w nim się znajdujące.
- Plik został zmodyfikowany. W takim wypadku wystarczy zapamiętać tylko zmiany, które zostały dokonane (można to robić całkiem efektywnie) oraz poprzednią wersję pliku, który był wyjściem dla dokonania tych zmian. Na ogół jest to wersja poprzednia, jak mamy to na rysunku, ale w ogólności podstawą, dla której dokonano modyfikacji, może być plik z dowolnej wcześniejszej wersji.M
- Zbiór jest kopią jakiegoś innego zbioru. Wtedy wystarczy pamiętać tylko nazwę zbioru, którego jest on kopią. Kopia może dotyczyć całego katalogu wraz z jego zawartością. Później zobaczymy, że operacja kopiowania ma wiele ciekawych zastosowań.
Przykładowy projekt
Przepuśćmy, że mamy już zaczęty projekt. Naszym przykładowym projektem będzie projekt o nazwie słownik, którego celem jest napisanie bardzo uproszczonego słownika ortograficznego. Utworzyliśmy już kilka plików i porozmieszczaliśmy je w katalogach w następujący sposób:
slownik/
bin/
data/
slowa.txt
src/
Makefile
sprawdz.c- W katalogu
binbędą umieszczane pliki wykonywalne. Na razie mamy jeden program o nazwiesprawdz. Makefilepowinien być napisany tak, aby plik wykonywalny o nazwiesprawdzbył umieszczany właśnie w katalogubin. - W katalogu
databędą pliki z danymi. Na razie mamy tam plikslowa.txt, który ma zawierać wszystkie poprawne wyrazy języka polskiego. - W katalogu src znajdują się źródła programów
(sprawdz.c)orazMakefile. Działanie programu sprawdz.c ma być następujące. Wczytuje on ze standardowego wejścia wszystkie słowa i wypisuje na standardowe wyjście wszystkie te słowa, które nie występują w słowniku, czyli w plikuslowa.txt.PlikMakefilema być taki, aby wynikowy program sprawdz był umieszczany w katalogubin.
slowa.txt Zawiera tylko parę przykładowych słów dla testów.
abecadło
słowo
coś
raz
dwa
trzyMakefile.
CC=gcc CFLAGS=-Wall DEST=../bin/sprawdz all: $(DEST) $(DEST): sprawdz.c $(CC) $(CFLAGS) -o $@ $^ $(LDFLAGS) clean: rm -f $(DEST)
sprawdz.c. Jest to prosta implementacja. Duże i małe litery nie są rozróżniane. Kontrola błędów jest tylko na podstawowym poziomie.
#include <stdio.h> #include <stdlib.h> #include <string.h> const char * SLOWNIK = "slowa.txt"; int slow; char **slownik; void wczytaj_slownik(FILE *f) { char buf[128]; slow = 0; while (fscanf(f, "%127s", buf) > 0) { if (slow == 0) slownik = (char **) malloc(sizeof(char *)); else slownik = (char **) realloc(slownik, (slow + 1) * sizeof(char *)); slownik[slow] = (char *) malloc((strlen(buf) + 1) * sizeof(char)); strcpy(slownik[slow], buf); slow++; } } int inicjuj_slownik() { FILE *f = fopen(SLOWNIK, "r"); if (!f) { fprintf(stderr, "Nie można otworzyć pliku '%s' do odczytu\n", SLOWNIK); return 0; } wczytaj_slownik(f); fclose(f); return 1; } int w_slowniku(char *s) { int i; for (i = 0; i < slow; i++) if (!strcmp(s, slownik[i])) return 1; return 0; } void obrob_wejscie() { char buf[128]; while (scanf("%127s", buf) > 0) if (!w_slowniku(buf)) printf("%s\n", buf); } int main() { if (!inicjuj_slownik()) return 1; obrob_wejscie(); return 0; }
Wybór struktury katalogów
Dany projekt możemy wrzucić do repozytorium w takiej postaci, w jakiej go trzymamy. Jednakże ze względu na specyfikę Subversion, zostało powszechnie przyjęte stosowanie dodatkowych katalogów. Wiąże się to z tym, że w trakcie trwania projektu będziemy chcieli od czasu do czasu robić kopię wszystkich plików. Zdarza się to na przykład wtedy, gdy mamy już gotową, działającą wersję i chcemy ją sobie zapamiętać. Później możemy powprowadzać dalsze zmiany, ale dzięki kopii zawsze będziemy mogli odtworzyć tą daną wersję. Zazwyczaj przyjmuje się następującą strukturę katalogów:
trunk/ tags/ branches/
- W katalogu
trunkbędzie główna ścieżka rozwoju projektu. W tym katalogu będą trzymane wszystkie zbiory i tutaj będzie umieszczana większość zmian. - W katalogu
tagsbędą umieszczane kopie projektu. Będziemy tam kopiować określone wersje projektu, na ogół takie, które osiągnęły już pewien planowany stopień rozwoju. Przyjmuje się, że dla takich kopii nie wprowadza się już żadnych zmian (mimo, że system nie zabrania takowych). - W katalogu
branchespodobnie jak wtagsbędziemy umieszczać kopie projektu, ale w tym przypadku z zamiarem wprowadzenia zmian w tej kopii. Są to tak zwane gałęzie i o ich przeznaczeniu powiemy więcej później.
slownik/
trunk/
bin/
data/
src/
tags/
branches/slownik/ bin/ data/ src/
slownik w katalogu głównym repozytorium. Moglibyśmy pliki projektu umieścić od razu w katalogu głównym repozytorium:
trunk/ ... tags/ branches/
Umieszczenie projektu w repozytorium.
Ustaliliśmy, jak chcemy trzymać nasz projekt, więc trzeba przeorganizować to, co aktualnie mamy do postaci, w jakiej chcemy mieć to w repozytorium. W katalogu domowym użytkownika ala mamy:
slownik/ bin/ data/ src/
ala@host:~$ mkdir -p do_repozytorium/slownik ala@host:~$ cp -a slownik/ do_repozytorium/slownik/trunk ala@host:~$ mkdir -p do_repozytorium/slownik/tags ala@host:~$ mkdir -p do_repozytorium/slownik/branches ala@host:~$
staff:
ala@host:~$ groups users staff ala@host:~$
ala@host:~$ svn import do_repozytorium/ file:///var/local/repos/ -m "Import pierwszej wersji" Adding do_repozytorium/slownik Adding do_repozytorium/slownik/trunk Adding do_repozytorium/slownik/trunk/src Adding do_repozytorium/slownik/trunk/src/sprawdz.c Adding do_repozytorium/slownik/trunk/src/Makefile Adding do_repozytorium/slownik/trunk/bin Adding do_repozytorium/slownik/trunk/data Adding do_repozytorium/slownik/trunk/data/slowa.txt Adding do_repozytorium/slownik/branches Adding do_repozytorium/slownik/tags Committed revision 1. ala@host:~$
file://. Dodatkowo użyliśmy opcji -m, której argumentem jest komentarz, który będzie zapamiętany jako opis wprowadzonej zmiany w repozytorium. W rezultacie otrzymaliśmy wersję o numerze 1. Wersja ta różni się tym od wersji 0, że dodaliśmy katalog slownik. Upewnijmy się jeszcze, że właściwe katalogi znajdują się w repozytorium za pomocą komendy list:
ala@host:~$ svn list -R file:///var/local/repos slownik/ slownik/branches/ slownik/tags/ slownik/trunk/ slownik/trunk/bin/ slownik/trunk/data/ slownik/trunk/data/slowa.txt slownik/trunk/src/ slownik/trunk/src/Makefile slownik/trunk/src/sprawdz.c ala@host:~$
ala@host:~$ rm -rf do_repozytorium/
ala@host:~$Podstawowe operacje
Kopia robocza
Aby móc pracować na wersji znajdującej się w repozytorium, trzeba pobrać kopię roboczą. Posiadanie kopii roboczej pozwala na łatwe wprowadzanie zmian do repozytorium, porównywanie z wersją w repozytorium, czy też aktualizowanie zbiorów o zmiany znajdujące się już w repozytorium. Tworzymy sobie katalogsvn, w którym będziemy przechowywać kopie robocze.
ala@host:~$ mkdir svn ala@host:~$ cd svn/ ala@host:~$
checkout lub w skrócie co. Pobierzemy sobie z repozytorium główną wersję, czyli tą znajdującą się w katalogu trunk:
ala@host:~/svn$ svn co file:///var/local/repos/slownik/trunk slownik A slownik/src A slownik/src/sprawdz.c A slownik/src/Makefile A slownik/bin A slownik/data A slownik/data/slowa.txt Checked out revision 1. ala@host:~/svn$
slownik a w nim te pliki, które są w pierwszej wersji naszego projektu. Można zobaczyć, że SVN utworzył również ukryty katalog o nazwie .svn:
ala@host:~/svn$ cd slownik/ ala@host:~/svn/slownik$ ls -a . .. bin data src .svn ala@host:~/svn/slownik$
Wprowadzanie zmian
Modyfikacja plików
Popracujmy teraz na kopii roboczej znajdujące się w katalogusvn/slownik. Wprowadźmy jakieś proste modyfikacje.
W pliku dane/slowa.txt usuńmy słowo abecadło i dodajmy przed słowem raz słowo zero. Plik slowa.txt po modyfikacjach.
słowo
coś
zero
raz
dwa
trzysrc/Makefile dodajmy opcję -g do zmiennej CFLAGS.
CC=gcc CFLAGS=-Wall -g DEST=../bin/sprawdz all: $(DEST) $(DEST): sprawdz.c $(CC) $(CFLAGS) -o $@ $^ $(LDFLAGS) clean: rm -f $(DEST)
Sprawdzanie dokonanych zmian
Do podsumowania stanu naszej kopii roboczej służy komenda
status:
ala@host:~/svn/slownik$ svn status
M src/Makefile
M data/slowa.txt
ala@host:~/svn/slownik$M zostały zmodyfikowane.
Do sprawdzenia, jakich zmian dokonaliśmy, służy komenda diff:
ala@host:~/svn/slownik$ svn diff Index: src/Makefile =================================================================== --- src/Makefile (revision 1) +++ src/Makefile (working copy) @@ -1,5 +1,5 @@ CC=gcc -CFLAGS=-Wall +CFLAGS=-Wall -g DEST=../bin/sprawdz all: $(DEST) Index: data/slowa.txt =================================================================== --- data/slowa.txt (revision 1) +++ data/slowa.txt (working copy) @@ -1,6 +1,6 @@ -abecadło słowo coś +zero raz dwa trzy ala@host:~/svn/slownik$
Wycofywanie zmian
Jeśli uznamy, że wprowadzone zmiany nie są w jakiś sposób właściwe i będziemy chcieli się cofnąć do wersji sprzed zmian, z pomocą przychodzi na komenda revert. Na przykład stwierdziliśmy, że zmiany wslowa.txt są bez sensu. Przywracamy wersję z przed zmian następująco:
ala@host:~/svn/slownik$ svn revert data/slowa.txt Reverted 'data/slowa.txt' ala@host:~/svn/slownik$
diff lub za pomocą komendy status:
ala@host:~/svn/slownik$ svn status M src/Makefile ala@host:~/svn/slownik$
revert wymaga jako argumentów zbiorów, dla których chcemy przywrócić wersję z przed zmian.
Wprowadzanie zmian do repozytorium
Wprowadźmy dalsze zmiany. Przejdźmy do katalogu
src. Tym razem zmodyfikujmy plik sprawdz.c. Zmiana funkcjonalnie polega na tym, że będziemy rzadziej przydzielać pamięć tablicy slownik, nie tak jak dotychczas powiększać o jeden z każdym nowym słowem, ale jak tylko rozmiar będzie przekraczał potęgę dwójki, to będziemy zwiększać rozmiar tablicy dwa razy. Oto zmiany, jakich dokonamy. Po pierwsze dodamy funkcję potega2 zwracająca, czy liczba jest potęgą dwójki:
int potega2(int n) { return (n & (n - 1)) == 0; }
void wczytaj_slownik(FILE *f) { char buf[128]; slow = 0; while (fscanf(f, "%127s", buf) > 0) { if (slow == 0) slownik = (char **) malloc(sizeof(char *)); else if (potega2(slow)) slownik = (char **) realloc(slownik, (slow * 2) * sizeof(char *)); slownik[slow] = (char *) malloc((strlen(buf) + 1) * sizeof(char)); strcpy(slownik[slow], buf); slow++; } }
ala@host:~/svn/slownik/src$ svn diff sprawdz.c Index: sprawdz.c =================================================================== --- sprawdz.c (revision 1) +++ sprawdz.c (working copy) @@ -7,6 +7,11 @@ int slow; char **slownik; +int potega2(int n) +{ + return (n & (n - 1)) == 0; +} + void wczytaj_slownik(FILE *f) { char buf[128]; @@ -14,8 +19,8 @@ while (fscanf(f, "%127s", buf) > 0) { if (slow == 0) slownik = (char **) malloc(sizeof(char *)); - else - slownik = (char **) realloc(slownik, (slow + 1) * sizeof(char *)); + else if (potega2(slow)) + slownik = (char **) realloc(slownik, (slow * 2) * sizeof(char *)); slownik[slow] = (char *) malloc((strlen(buf) + 1) * sizeof(char)); strcpy(slownik[slow], buf); slow++; ala@host:~/svn/slownik/src$
ala@host:~/svn/slownik/src$ make
gcc -Wall -g -o ../bin/sprawdz sprawdz.c
ala@host:~/svn/slownik/src$ala@host:~/svn/slownik/src$ cd .. ala@host:~/svn/slownik$ svn status M src/sprawdz.c M src/Makefile ? bin/sprawdz ala@host:~/svn/slownik$
Makefile i sprawdz.c, a plik wykonywalny sprawdz w katalogu bin ma status nieznany (literka ?). Nie chcemy, żeby plik wykonywalny był w repozytorium, więc ignorujemy ten status.
Teraz wprowadźmy te zmiany do repozytorium. Służy do tego komenda commit lub w skrócie ci. Jej argumentem są pliki, dla których zmiany chcemy dodać do repozytorium. Ponadto należy dodać komentarz krótko charakteryzujący zmiany, które wprowadziliśmy. Można to zrobić używając opcji -m. W przypadku braku tej opcji zostanie uruchomiony edytor z prośbą o podanie komentarza.
Ponieważ charakterystyka zmian dla pliku Makefile i sprawdz.c jest różna, a SVN nie umożliwia różnych komentarzy dla osobnych plików, więc zrobimy dwa commity. Wpierw Makefile:
ala@host:~/svn/slownik$ cd src/ ala@host:~/svn/slownik/src$ svn ci Makefile -m "Dodanie opcji -g" Sending Makefile Transmitting file data . Committed revision 2. ala@host:~/svn/slownik/src$
src, czyli jeden plik sprawdz.c:
ala@host:~/svn/slownik/src$ svn ci -m "Szybsza alokacja tablic" Sending src/sprawdz.c Transmitting file data . Committed revision 3. ala@host:~/svn/slownik/src$
ala@host:~/svn/slownik/src$ cd ..
ala@host:~/svn/slownik$ svn status
? bin/sprawdz
ala@host:~/svn/slownik$Dodawanie zbiorów
Umiemy wprowadzać modyfikacje plików, a jak dodawać nowe pliki lub katalogi? Służy do tego komendaadd. Na przykład załóżmy, że postanowiliśmy pisać również dokumentację i umieszczać ją w katalogu doc. Na razie utworzymy tam jeden plik dokumentacja.txt o zawartości:
Dokumentacja projektu slownik ============================= Tutaj będzie dokumentacja
ala@host:~/svn/slownik$ svn status ? doc ? bin/sprawdz ala@host:~/svn/slownik$
ala@host:~/svn/slownik$ svn add doc
A doc
A doc/dokumentacja.txt
ala@host:~/svn/slownik$dokumentacja.txt został zaplanowany do dodania. Nie zostały umieszczone one w repozytorium, aby tak się stało trzeba użyć operacji komendy ci:
ala@host:~/svn/slownik$ svn ci -m "Dodanie dokumentacji" Adding doc Adding doc/dokumentacja.txt Transmitting file data . Committed revision 4. ala@host:~/svn/slownik$
Usuwanie zbiorów
Możemy chcieć też usuwać zbiory z projektu. Służy do tego komenda delete lub w skrócie del:
ala@host:~/svn/slownik$ svn del data/slowa.txt D data/slowa.txt ala@host:~/svn/slownik$
data/slowa.txt. Plik został usunięty z naszej kopii roboczej. Teraz, żeby usunięcie zostało dokonane także w repozytorium, trzeba by użyć commita. Powiedzmy jednak, że to była pomyłka i nie chcemy usuwać tego pliku. Możemy wycofać tą zmianę (dodawanie i usuwanie zbiorów też jest modyfikacją, tylko że struktury), używając komendy revert. Komenda ta oprócz cofania modyfikacji w plikach może być używana do cofania zaplanowanych dodawań, czy usunięć zbiorów.
ala@host:~/svn/slownik$ svn revert data/slowa.txt Reverted 'data/slowa.txt' ala@host:~/svn/slownik$
Praca równoległa
Zademonstrujemy teraz jak sobie radzi SVN, gdy więcej niż jeden użytkownik pracuje nad danym projektem. Przypuśćmy, że jest drugi użytkownik o loginie
bartek. Żeby pracować nad projektem musi pobrać on swoją wersję roboczą:
bartek@host:~$ mkdir svn bartek@host:~$ cd svn/ bartek@host:~/svn$ svn co file:///var/local/repos/slownik/trunk slownik A slownik/doc A slownik/doc/dokumentacja.txt A slownik/src A slownik/src/sprawdz.c A slownik/src/Makefile A slownik/bin A slownik/data A slownik/data/slowa.txt Checked out revision 4. bartek@host:~/svn$
sprawdz.c przyspieszyć wyszukiwanie słów w słowniku. Wpierw trzeba dopisać sortowanie słów w słowniku i tym się zajmie Bartek. Gdy tablica slownik jest posortowana, można do wyszukiwania słów zastosować wyszukiwanie binarne i tym zajmie się Ala.
No dobrze, więc postawmy się wpierw w sytuacji Bartka, który pisze sortowanie. Przypuśćmy, że zmodyfikował on plik sprawdz.c w swojej kopii roboczej dopisując sortowanie z użyciem dostępnej funkcji qsort.
#include <stdio.h> #include <stdlib.h> #include <string.h> const char * SLOWNIK = "slowa.txt"; int slow; char **slownik; int potega2(int n) { return (n & (n - 1)) == 0; } void wczytaj_slownik(FILE *f) { char buf[128]; slow = 0; while (fscanf(f, "%127s", buf) > 0) { if (slow == 0) slownik = (char **) malloc(sizeof(char *)); else if (potega2(slow)) slownik = (char **) realloc(slownik, (slow * 2) * sizeof(char *)); slownik[slow] = (char *) malloc((strlen(buf) + 1) * sizeof(char)); strcpy(slownik[slow], buf); slow++; } } int inicjuj_slownik() { FILE *f = fopen(SLOWNIK, "r"); if (!f) { fprintf(stderr, "Nie można otworzyć pliku '%s' do odczytu\n", SLOWNIK); return 0; } wczytaj_slownik(f); fclose(f); return 1; } int w_slowniku(char *s) { int i; for (i = 0; i < slow; i++) if (!strcmp(s, slownik[i])) return 1; return 0; } void obrob_wejscie() { char buf[128]; while (scanf("%127s", buf) > 0) if (!w_slowniku(buf)) printf("%s\n", buf); } int main() { if (!inicjuj_slownik()) return 1; obrob_wejscie(); return 0; }
bartek@host:~/svn/slownik$ svn diff Index: src/sprawdz.c =================================================================== --- src/sprawdz.c (revision 4) +++ src/sprawdz.c (working copy) @@ -27,6 +27,12 @@ } } +static int +cmpstringp(const void *p1, const void *p2) +{ + return strcmp(* (char * const *) p1, * (char * const *) p2); +} + int inicjuj_slownik() { FILE *f = fopen(SLOWNIK, "r"); @@ -36,6 +42,7 @@ } wczytaj_slownik(f); fclose(f); + qsort(slownik, slow, sizeof(char *), cmpstringp); return 1; } bartek@host:~/svn/slownik$
bartek@host:~/svn/slownik$ svn up At revision 4. bartek@host:~/svn/slownik$
bartek@host:~/svn/slownik$ svn ci -m "Sortowanie słownika" Sending src/sprawdz.c Transmitting file data . Committed revision 5. bartek@host:~/svn/slownik$
Aktualizacja
Wróćmy do Ali. Ala ma napisać przeszukiwanie binarne. Sprawa wydaje się prosta, gdyż w standardowej bibliotece mamy dostępną funkcję
bsearch. Ala zmodyfikowała funkcję w_slowniku w programie sprawdz.c tak, że wygląda ona następująco:
int w_slowniku(char *s) { return bsearch(&s, slownik, slow, sizeof(char *), ???) != NULL; }
ala@host:~/svn/slownik/src$ svn diff Index: sprawdz.c =================================================================== --- sprawdz.c (revision 3) +++ sprawdz.c (working copy) @@ -41,11 +41,7 @@ int w_slowniku(char *s) { - int i; - for (i = 0; i < slow; i++) - if (!strcmp(s, slownik[i])) - return 1; - return 0; + return bsearch(&s, slownik, slow, sizeof(char *), ???) != NULL; } void obrob_wejscie() ala@host:~/svn/slownik/src$
??? powinna pojawić się funkcja porównująca elementy tablicy zgodna z typem, który jest spodziewany w nagłówku bsearch. Ala się zastanawia jak to zrobić, ale na razie zostawia ten problem. Sprawdzi wpierw, czy Bartek już coś wprowadził do repozytorium. Jak już wspomnieliśmy komenda update służy do aktualizacji kopii roboczej. Ala wykonuje to polecenie:
ala@host:~/svn/slownik/src$ svn up G sprawdz.c Updated to revision 5. ala@host:~/svn/slownik/src$
sprawdz.c i ma ona numer 5. Plik sprawdz.c został zaktualizowany , ale nasze zmiany nie zostały zapomniane. Świadczy o tym literka G mówiąca, że zmiany z repozytorium zostały naniesiony do pliku.
#include <stdio.h> #include <stdlib.h> #include <string.h> const char * SLOWNIK = "slowa.txt"; int slow; char **slownik; int potega2(int n) { return (n & (n - 1)) == 0; } void wczytaj_slownik(FILE *f) { char buf[128]; slow = 0; while (fscanf(f, "%127s", buf) > 0) { if (slow == 0) slownik = (char **) malloc(sizeof(char *)); else if (potega2(slow)) slownik = (char **) realloc(slownik, (slow * 2) * sizeof(char *)); slownik[slow] = (char *) malloc((strlen(buf) + 1) * sizeof(char)); strcpy(slownik[slow], buf); slow++; } } static int cmpstringp(const void *p1, const void *p2) { return strcmp(* (char * const *) p1, * (char * const *) p2); } int inicjuj_slownik() { FILE *f = fopen(SLOWNIK, "r"); if (!f) { fprintf(stderr, "Nie można otworzyć pliku '%s' do odczytu\n", SLOWNIK); return 0; } wczytaj_slownik(f); fclose(f); qsort(slownik, slow, sizeof(char *), cmpstringp); return 1; } int w_slowniku(char *s) { return bsearch(&s, slownik, slow, sizeof(char *), ???) != NULL; } void obrob_wejscie() { char buf[128]; while (scanf("%127s", buf) > 0) if (!w_slowniku(buf)) printf("%s\n", buf); } int main() { if (!inicjuj_slownik()) return 1; obrob_wejscie(); return 0; }
int w_slowniku(char *s) { return bsearch(&s, slownik, slow, sizeof(char *), cmpstringp) != NULL; }
ala@host:~/svn/slownik/src$ cd .. ala@host:~/svn/slownik$ svn up At revision 5. ala@host:~/svn/slownik$ svn ci -m "Użycie przeszukiwania binarnego" Sending src/sprawdz.c Transmitting file data . Committed revision 6. ala@host:~/svn/slownik$
bartek@host:~/svn/slownik$ svn up U src/sprawdz.c Updated to revision 6. bartek@host:~/svn/slownik$
Przeglądanie zmian
Do przeglądania logów ze zmian służy komendalog. Na przykład, aby przejrzeć historię zmian pliku src/sprawdz.c podajemy go jako argument:
ala@host:~/svn/slownik$ svn log src/sprawdz.c ------------------------------------------------------------------------ r6 | ala | 2006-08-30 23:05:39 +0200 (Wed, 30 Aug 2006) | 1 line Użycie przeszukiwania binarnego ------------------------------------------------------------------------ r5 | bartek | 2006-08-30 22:33:32 +0200 (Wed, 30 Aug 2006) | 1 line Sortowanie słownika ------------------------------------------------------------------------ r3 | ala | 2006-08-30 14:35:50 +0200 (Wed, 30 Aug 2006) | 1 line Szybsza alokacja tablic ------------------------------------------------------------------------ r1 | ala | 2006-08-30 14:22:39 +0200 (Wed, 30 Aug 2006) | 1 line Import pierwszej wersji ------------------------------------------------------------------------ ala@host:~/svn/slownik$
sprawdz.c.
Konflikty
Przy pracy równoległej nie zawsze jest tak dobrze, że aktualizacja jest bezproblemowa. W sytuacji, gdy dwaj użytkownicy modyfikują tą samą część tego samego pliku, może dojść do tak zwanych konfliktów. Prześledźmy to na przykładzie.
Powstawanie konfliktów
Przypuśćmy, że Ala i Bartek jednocześnie dodają nowe słowa do słownika, czyli do pliku
data/slowa.txt.
Bartek modyfikuje plik następująco:
abecadło
słowo
coś
zero
raz
dwa
trzy
ananas
banan
japkozero, ananas, banan i japko, a następnie wprowadza do repozytorium:
bartek@host:~/svn/slownik$ svn ci -m "Nowe słowa" Sending data/slowa.txt Transmitting file data . Committed revision 7. bartek@host:~/svn/slownik$
abecadło słowo coś raz dwa trzy cztery banan jabłko kokos
cztery, banan, jabłko i kokos. Aktualizuje swoją kopie roboczą:
ala@host:~/svn/slownik$ svn up C data/slowa.txt Updated to revision 7. ala@host:~/svn/slownik$
slowa.txt został zaktualizowany do wersji 7, ale z konfliktami, o czym świadczy literka C. Zobaczmy co się stało.
ala@host:~/svn/slownik$ cd data/ ala@host:~/svn/slownik/data$ ls slowa.txt slowa.txt.mine slowa.txt.r6 slowa.txt.r7 ala@host:~/svn/slownik/data$
slowa.txt. Znaczenie ich jest następujące:
slowa.txt.minezawiera plikslowa.txtz naszej kopii roboczej sprzed dokonania aktualizacji,slowa.txt.r6zawiera plikslowa.txtw wersji 6 z repozytorium, czyli w wersji, na której pracowaliśmy przed aktualizacją,slowa.txt.r7zawiera plikslowa.txtw wersji 7 z repozytorium, czyli wersji, która jest ostatnią w repozytorium.
slowa.txt wygląda tak:
abecadło słowo coś zero raz dwa trzy <<<<<<< .mine cztery banan jabłko kokos ======= ananas banan japko >>>>>>> .r7
Rozwiązywanie konfliktów
Stajemy przed trudnym zadaniem, które polega na zdecydowaniu, co powinno powstać w wyniku zmian Ali i Bartka. To zadanie może być czasami dosyć oczywiste (jak to jest w tym przypadku), ale może też być nieoczywiste i wymagać bezpośredniej komunikacji między Alą, a Bartkiem. W tym przypadku z punktu widzenia Ali, Bartek chciał dodać trzy słowa na końcu pliku. Jedno, którego my nie dodaliśmy -
ananas, jedno, które my też dodaliśmy - banan oraz jedno, które my też dodaliśmy, a Bartek wprowadził z błędem. Jasne jest, że powinny znaleźć się wszystkie nowe słowa, ale te napisane bez błędów, zatem plik slowa.txt powinien wyglądać tak:
abecadło słowo coś zero raz dwa trzy cztery ananas banan jabłko kokos
resolved:
ala@host:~/svn/slownik/data$ svn resolved slowa.txt Resolved conflicted state of 'slowa.txt' ala@host:~/svn/slownik/data$ ls slowa.txt ala@host:~/svn/slownik/data$
ala@host:~/svn/slownik/data$ svn diff Index: slowa.txt =================================================================== --- slowa.txt (revision 7) +++ slowa.txt (working copy) @@ -5,6 +5,8 @@ raz dwa trzy +cztery ananas banan -japko +jabłko +kokos ala@host:~/svn/slownik/data$
ala@host:~/svn/slownik/data$ svn ci -m "Nowe słowa" Sending data/slowa.txt Transmitting file data . Committed revision 8. ala@host:~/svn/slownik/data$
Etykiety i gałęzie
Oznaczanie wybranych wersji
W pewnym stadium projektu uzyskujemy wersję, która spełnia stawiane przez nas wymagania. Taką wersję warto sobie zapamiętać. Najprościej jest zapamiętać numer wersji w repozytorium danej wersji. Jednak ten numer trzeba by wtedy gdzieś opisać. Dlatego najwygodniej jest zrobić kopię tej wersji pod nazwą mówiącą, co to jest za wersja. Kopiowanie umożliwia komendacopy.
Przykładowo spójrzmy na nasz projekt. Uzyskaliśmy szybką wersję programu sprawdz.c i chcemy ją sobie oznaczyć jako wersja o symbolicznym numerze 1.0. Później jeszcze dokonaliśmy jakichś zmian w słowniku slowa.txt, ale to nas nie interesuje i chcemy, aby w tej wersji 1.0 znalazły się słowa nie zawierające ostatnich dodań. Żeby sprawdzić, o jaki numer wersji chodzi, możemy posłużyć się komendą log:
ala@host:~/svn/slownik$ svn log | head -13 ------------------------------------------------------------------------ r7 | bartek | 2006-08-31 14:19:26 +0200 (Thu, 31 Aug 2006) | 1 line Nowe słowa ------------------------------------------------------------------------ r6 | ala | 2006-08-30 23:05:39 +0200 (Wed, 30 Aug 2006) | 1 line Użycie przeszukiwania binarnego ------------------------------------------------------------------------ r5 | bartek | 2006-08-30 22:33:32 +0200 (Wed, 30 Aug 2006) | 1 line Sortowanie słownika ------------------------------------------------------------------------ ala@host:~/svn/slownik$
tags, którego zadaniem jest tak naprawdę przechowywanie kopii wybranych przez nas wersji.
ala@host:~/svn/slownik$ svn copy -r 6 file:///var/local/repos/slownik/trunk \ > file:///var/local/repos/slownik/tags/1.0 -m "Utworzenie etykiety '1.0'" Committed revision 9. ala@host:~/svn/slownik$
slownik/tags/1.0, który jest kopią katalogu slownik/trunk, ale z wersji o numerze 6. Gdybyśmy pominęli opcję -r 6 byłaby to kopia z ostatniej wersji, czyli z wersji o numerze 8. Widzimy teraz, czemu warto było na początku umieścić cały projekt w dodatkowym katalogu trunk - po to, aby wygodnie można było robić jego kopie.
Powstały katalog 1.0 w katalogu slownik/tags nazywamy etykietą. Za pomocą tej etykiety (czyli tak naprawdę katalogu) możemy się później odwoływać w celu uzyskania konkretnej wersji.
Komenda copy jest bardzo tania i nie musimy sie martwić, że jeśli wykonamy za dużo kopii, to zapchamy dostępną przestrzeń dyskową. SVN nie kopiuję całego drzewa katalogów plik po pliku, a jedynie zapamiętuje w sposób leniwy informację, że dany katalog jest kopią takiego katalogu z takiej wersji. Robi to w czasie i pamięci O(1).
Eksportowanie
Aby docenić wartość etykiet, spróbujmy wyeksportować paczkę z daną wersją z repozytorium. Chodzi oczywiście o wersję z etykietą 1.0. Do wyciągania z repozytorium plików bez tworzenia już żadnych katalogów administracyjnych (np. katalogów .svn tak jak ma się to przy komendzie
checkout) służy komenda export:
ala@host:~$ svn export file:///var/local/repos/slownik/tags/1.0 slownik-1.0 A slownik-1.0 A slownik-1.0/doc A slownik-1.0/doc/dokumentacja.txt A slownik-1.0/src A slownik-1.0/src/sprawdz.c A slownik-1.0/src/Makefile A slownik-1.0/bin A slownik-1.0/data A slownik-1.0/data/slowa.txt Exported revision 9. ala@host:~$
slownik-1.0 z żądaną przez nas wersją, która zawiera wyłącznie interesujące nas pliki. Jeśli byśmy nie mieli etykiety, to dokładnie ten sam efekt osiągnęlibyśmy poleceniem:
ala@host:~$ svn export -r 6 file:///var/local/repos/slownik/trunk slownik-1.0
Rozgałęzianie projektu
W trakcie tworzenia projektu możemy chcieć wprowadzać równolegle kilka różnych modyfikacji. Jedne modyfikacje mogą być bardziej skomplikowane i trwać dłużej, inne mogą być znacznie prostsze i można je wprowadzać bardzo szybko. Możliwe jest, że dodanie pewnej nowej funkcjonalności może trwać tygodniami, a kod programu, który będzie powstawał podczas takiej zmiany, nie będzie funkcjonalny, tzn. może się nawet nie kompilować. Tu pojawia się problem, gdyż jeśli więcej osób pracuje nad projektem, to pozostali autorzy powinni mieć dostępny kod stabilny. Mogą oni chcieć wprowadzać prostsze zmiany, skompilować sobie program i przetestować go. Jedne rozwiązanie jest takie, że osoby odpowiedzialne, za wprowadzenie większej zmiany, będą ją robiły u siebie lokalnie i nie będą nic wprowadzały do repozytorium dopóki, dopóty modyfikacja nie będzie w pełni gotowa. W ten sposób jednak, przy wprowadzaniu tej większej modyfikacji, pozbawiamy możliwości korzystania z kontroli wersji w Subversion. Właściwym podejściem w takiej sytuacji jest stworzenie kopii projektu w repozytorium i nanoszenie modyfikacji pracując na tej kopii. W ten sposób praca nad nową funkcjonalnością nie będzie kolidowała z główną ścieżką projektu, a dodatkowo można wprowadzać zmiany do repozytorium. Później przy zakończeniu tej modyfikacji, można nanieść zmiany, które zostały wprowadzone w tej kopii, do właściwych źródeł projektu. Taką kopię nazywamy gałęzią. Prześledźmy to na przykładzie naszego projektu. Chcemy wprowadzić modyfikację polegającym na tym, że program sprawdz sprawdzałby swoje argumenty i w przypadku, gdy zostałyby one podane czytałby wejście z plików podanych w argumentach zamiast ze standardowego wejścia. Zakładając, że ta modyfikacja będzie większa, chcemy wprowadzać ją w nowej gałęzi. Możliwe są dwa sposoby przejścia do pracy w gałęzi. Wpierw omówimy jak wygląda pierwszy sposób opisując tylko jak wyglądają odpowiednie polecenia. Następnie omówimy drugą metodę stosując ją bezpośrednio na naszym projekcie. Aby utworzyć gałąź można użyć polecenia:$ svn copy file:///var/local/repos/slownik/trunk \ > file:///var/local/repos/slownik/branches/uzycie_argumentow -m "Utworzenie gałęzi 'uzycie_argumentow'"
$ svn co file:///var/local/repos/slownik/branches/uzycie_argumentow slownik-uzycie_argumentowslownik-uzycie_argumentow powinniśmy teraz mieć już odpowiednią gałąź. Możemy pracować w tym katalogu. Naniesione zmiany będą wprowadzane w repozytorium w katalogu branches/uzycie_argumentow, a zatem główna ścieżka projektu trunk pozostanie nienaruszona.
Omówmy teraz drugą metodę w praktyce na uproszczonym przykładzie. Pracujemy cały czas na kopii roboczej głównej ścieżki projektu, tj. kopii roboczej katalogu trunk. Załóżmy, że zaczeliśmy modyfikować już program sprawdz.c pod kątem dodania obsługi argumentów. Przypuśćmy, że Ala zmieniła funkcję main następująco:
int main(int argc, char *argv[]) { if (!inicjuj_slownik()) return 1; if (argc == 0) /* po staremu */ obrob_wejscie(); else { /* tutaj obrobimy pliki znajdujące się w argumentach */ } return 0; }
ala@host:~/svn/slownik$ svn copy file:///var/local/repos/slownik/trunk \ > file:///var/local/repos/slownik/branches/uzycie_argumentow -m "Utworzenie gałęzi 'uzycie_argumentow'" Committed revision 10. ala@host:~/svn/slownik$
branches/uzycie_argumentow, ale aktualna kopia robocza jest wzięta z katalogu trunk. Według pierwszej metody trzeba by utworzyć nową kopię roboczą z odpowiedniego katalogu, ale wtedy stracilibyśmy swoje zmiany. Można by je oczywiście ewentualnie nanieść jeszcze raz. Jest na szczęście prostsza metoda. Otóż możemy przełączyć kopię roboczą na inny katalog w repozytorium za pomocą komendy switch:
ala@host:~/svn/slownik$ svn switch file:///var/local/repos/slownik/branches/uzycie_argumentow . At revision 10. ala@host:~/svn/slownik$
ala@host:~/svn/slownik$ svn diff Index: src/sprawdz.c =================================================================== --- src/sprawdz.c (revision 10) +++ src/sprawdz.c (working copy) @@ -59,10 +59,14 @@ printf("%s\n", buf); } -int main() +int main(int argc, char *argv[]) { if (!inicjuj_slownik()) return 1; - obrob_wejscie(); + if (argc == 0) /* po staremu */ + obrob_wejscie(); + else { + /* tutaj obrobimy pliki znajduące się w argumentach */ + } return 0; } ala@host:~/svn/slownik$
ala@host:~/svn/slownik$ svn ci -m "Przygotowanie obróbki argumentów" Sending src/sprawdz.c Transmitting file data . Committed revision 11. ala@host:~/svn/slownik$
bartek@host:~/svn/slownik$ svn update U data/slowa.txt Updated to revision 11. bartek@host:~/svn/slownik$
slowa.txt. Jest to jeszcze zaległa aktualizacja, w której Ala dodawała nowe słowa. Jak się można było spodziewać, plik src/sprawdz.c nie został zaktualizowany. Jest to logiczne, gdyż Ala zmieniała tak naprawdę plik w repozytorium slownik/branches/uzycie_argumentow/src/sprawdz.c, a nie slownik/trunk/src/sprawdz.c.
Bartek wprowadzi jakieś drobne modyfikacje. Powiedzmy, że pododaje słowa kluczowe static przed wszystkimi symbolami globalnymi (zmienne i funkcje oprócz main). Zamieszczamy diffa, aby pokazać zmiany.
bartek@host:~/svn/slownik$ svn diff Index: src/sprawdz.c =================================================================== --- src/sprawdz.c (revision 11) +++ src/sprawdz.c (working copy) @@ -2,17 +2,17 @@ #include <stdlib.h> #include <string.h> -const char * SLOWNIK = "slowa.txt"; +static const char * SLOWNIK = "slowa.txt"; int slow; char **slownik; -int potega2(int n) +static int potega2(int n) { return (n & (n - 1)) == 0; } -void wczytaj_slownik(FILE *f) +static void wczytaj_slownik(FILE *f) { char buf[128]; slow = 0; @@ -33,7 +33,7 @@ return strcmp(* (char * const *) p1, * (char * const *) p2); } -int inicjuj_slownik() +static int inicjuj_slownik() { FILE *f = fopen(SLOWNIK, "r"); if (!f) { @@ -46,12 +46,12 @@ return 1; } -int w_slowniku(char *s) +static int w_slowniku(char *s) { return bsearch(&s, slownik, slow, sizeof(char *), cmpstringp) != NULL; } -void obrob_wejscie() +static void obrob_wejscie() { char buf[128]; while (scanf("%127s", buf) > 0) bartek@host:~/svn/slownik$
bartek@host:~/svn/slownik$ svn ci -m "Dodanie brakujących static" Sending src/sprawdz.c Transmitting file data . Committed revision 12. bartek@host:~/svn/slownik$
ala@host:~/svn/slownik$ svn update At revision 12. ala@host:~/svn/slownik$
sprawdz.c.
void obrob_wejscie(FILE *f) { char buf[128]; while (fscanf(f, "%127s", buf) > 0) if (!w_slowniku(buf)) printf("%s\n", buf); } int main(int argc, char *argv[]) { if (!inicjuj_slownik()) return 1; if (argc == 0) obrob_wejscie(stdin); else { int i; for (i = 1; i <= argc; ++i) { FILE *f = fopen(argv[i], "r"); if (!stdin) { fprintf(stderr, "Nie można otworzyć pliku '%s'\n", argv[i]); return 1; } obrob_wejscie(f); fclose(f); } } return 0; }
ala@host:~/svn/slownik/src$ svn ci -m "Dodanie obrabiania plików w argumentach" Sending src/sprawdz.c Transmitting file data . Committed revision 13. ala@host:~/svn/slownik/src$
Scalanie
Ala zamknęła nanoszenie zmian w gałęzi. Modyfikacja została ostatecznie zakończona. Teraz przyszedł czas na naniesienie zmian z gałęzi do głównej ścieżki projektu. Taką operacją nazywamy scalaniem. Wpierw trzeba przejść do wersji roboczej, która odpowiada katalogowi trunk. Można to zrobić poprzez zrobienie checkout odpowiedniego katalogu z repoztorium. W naszym przykładzie użyjemy ponownie komendyswitch:
ala@host:~/svn/slownik$ svn switch file:///var/local/repos/slownik/trunk . U src/sprawdz.c Updated to revision 13. ala@host:~/svn/slownik$
sprawdz.c zawiera teraz tylko modyfikacje Bartka (bez kodu z obsługą argumentów). W tej kopii roboczej naniesiemy jeszcze raz zmiany, które Ala nanosiła pracowicie w gałęzi uzycie_argumentow. Oczywiście nie trzeba już tu pisać kodu ponownie, a jedynie pobrać odpowiednie zmiany z repozytorium. W tym celu musimy znać wersję sprzed zmian w danej gałęzi i wersję, w której już wszystkie zmiany są naniesione. SVN mając ustalone dwie wersje, potrafi zobaczyć jaka jest między nimi różnica i nanieść te zmiany do bieżącej kopii roboczej. Do tego służy komenda merge. Wersja, w której już wszystkie zmiany w gałęzi są wprowadzone to w tym przypadku po prostu ostatnia wersja znajdująca się w repozytorium, którą reprezentuje słowo HEAD. Musimy jeszcze znaleźć numer wersji, w której nie było jeszcze naniesionych żadnych zmian, czyli najlepiej wersję, w której dana gałąź powstała. Numer ten mogliśmy sobie zapamiętać, ale w przypadku, gdy go zapomnimy z pomocą przychodzi komenda log.
ala@host:~/svn/slownik$ svn log file:///var/local/repos/slownik | grep -B 2 "uzycie_argumentow" r10 | ala | 2006-09-06 13:51:10 +0200 (Wed, 06 Sep 2006) | 1 line Utworzenie gałęzi 'uzycie_argumentow' ala@host:~/svn/slownik$
log z argumentem z lokalizacją znajdujacą się w repozytorium, gdyż chcieliśmy otrzymać komunikaty dotyczące wszystkich zmian w projekcie slownik, a nie tylko te, które są w katalogu trunk. W wyniku widzimy, że szukaną wersją początku gałęzi jest 10. Teraz mamy już wszystkie dane, aby użyć komendy merge.
ala@host:~/svn/slownik$ svn merge -r 10:HEAD file:///var/local/repos/slownik/branches/uzycie_argumentow C src/sprawdz.c ala@host:~/svn/slownik$
sprawdz.c. Taka sytuacja może często się pojawiać w wyniku scalania większych zmian. Konflikty trzeba poprawić. W tym przypadku konflikt jest dosyć oczywisty. Pojawił on się w nagłówku funkcji obrob_wejscie:
<<<<<<< .working static void obrob_wejscie() ======= void obrob_wejscie(FILE *f) >>>>>>> .merge-right.r13
static, a my dodaliśmy argument. Jasne zatem jest, że po scaleniu nagłówek funkcji powinien wyglądać tak:
static void obrob_wejscie(FILE *f)
ala@host:~/svn/slownik$ svn resolved src/sprawdz.c Resolved conflicted state of 'src/sprawdz.c' ala@host:~/svn/slownik$
ala@host:~/svn/slownik$ svn ci -m "Dodanie zmian z gałęzi 'uzycie_argumentow'" Sending src/sprawdz.c Transmitting file data . Committed revision 14. ala@host:~/svn/slownik$