Związek między procesem a systemem plików opisany jest przez dwa pola w strukturze danych procesu (task_struct):
W strukturze files_struct znajduje się tablica indeksowana liczbami naturalnymi, które odpowiadają deskryptorom otwartych plików. Wartościami poszczególnych pozycji w tej tablicy są dowiązania do systemowej tablicy otwartych plików.
Systemowa tablica otwartych plików
Każde wywołanie funkcji open() powoduje utworzenie nowej pozycji w systemowej tablicy otwartych plików. Natomiast wywołanie funkcji dup() i fork() powoduje, że do jednej pozycji mogą odnosić się różne deskryptory. Pozycja w systemowej tablicy otwartych plików jest opisana przez strukturę file. Pole f_count tej struktury odpowiada liczbie dowiązań do danej pozycji.
I-węzeł pliku
I-węzeł każdego otwartego pliku znajduje się w pamięci operacyjnej. Dla każdego pliku jest tylko jedna kopia i-węzła w pamięci niezależnie od tego ile razy dany plik był otwierany. Pole i_count w i-węźle informuje ile razy dla danego pliku wykonano funkcję open().
Uwaga: Przedstawiony tutaj opis jest oczywiście niepełny. Zawiera tylko wyrywkowe informacje pomocne przy wykonywaniu poniższych zadań.
Załóżmy, że pewien proces, który nie tworzył procesów potomnych, korzysta z n otwartych plików przy czym wszystkie one są różne (odpowiadają im różne i-węzły). Załóżmy również, że ten proces jest jedynym procesem w systemie posiadającym otwarte pliki. Czy jest możliwa sytuacja, w której liczba deskryptorów otwartych plików dla tego procesu jest:
Jeśli taka sytuacja jest możliwa, to kiedy może wystąpić? Opisz jak można taką sytuację wykryć znając jedynie zbiór obiektów plików file dla danego procesu, a nie wiedząc nic o liczbie deskryptorów plików otwartych przez ten proces.
Rozwiązanie
Proces P działa według następującego schematu (tablica plik[0..5] zawiera nazwy ścieżkowe plików):
fd=open(plik[0], ...);
for i in 1..5 do
{
if (!fork()) break;
fd=open(plik[i], ...);
}Jak będą wyglądały tablice deskryptorów plików procesu P i jego potomków?
Jak będzie wyglądała systemowa tablica otwartych plików (jakie wartości będą miały pola f_count)?
Rozwiązanie
Procesy potomne dziedziczą otwarte deskryptory ojca. Pierwszy proces potomny dziedziczy otwarty plik[0]. W momencie tworzenia drugiego procesu otwarte są pliki plik[0] i plik[1] itd.
Tablica deskryptorów procesu ojca:
| deskryptor | 0 | 1 | 2 | ... | j | j+1 | j+2 | j+3 | j+4 | j+5 |
| plik | STDIN | STDOUT | STDERR | ... | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] | plik[5] |
Tablica deskryptorów pierwszego potomka:
| deskryptor | 0 | 1 | 2 | ... | j |
| plik | STDIN | STDOUT | STDERR | ... | plik[0] |
Tablica deskryptorów piątego potomka:
| deskryptor | 0 | 1 | 2 | ... | j | j+1 | j+2 | j+3 | j+4 |
| plik | STDIN | STDOUT | STDERR | ... | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] |
Systemowa tablica otwartych plików:
| plik | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] | plik[5] |
| f_count | 6 | 5 | 4 | 3 | 2 | 1 |
(trudniejszy wariant poprzedniego zadania)
Proces P działa według następującego schematu (tablica plik[0..4] zawiera nazwy ścieżkowe plików):
fd=open(plik[0], ...);
for i in 1..4 do
{
fd=open(plik[i-1]);
if (!fork()) break;
fd=open(plik[i], ...);
dup(fd);
}Ile będzie pozycji odpowiadających plikom: plik[0], ..., plik[4]:
Jakie będą wartości liczników:
Rozwiązanie
Liczba pozycji odpowiadających poszczególnym plikom:
| plik | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] |
| tablica deskryptorów procesu P | 2 | 3 | 3 | 3 | 2 |
| tablica otwartych plików | 2 | 2 | 2 | 2 | 1 |
| tablica i-węzłów | 1 | 1 | 1 | 1 | 1 |
Wartości liczników w tablicy otwartych plików:
| plik | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] | ||||
| f_count | 5 | 5 | 8 | 4 | 6 | 3 | 4 | 2 | 2 |
Wartości liczników w tablicy i-węzłów:
| plik | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] |
| i-count | 2 | 2 | 2 | 2 | 1 |
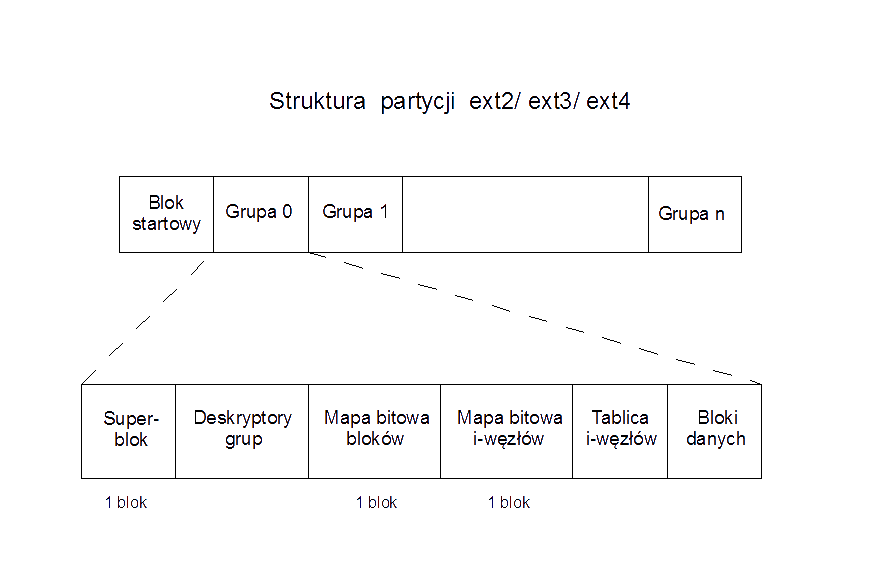
W omawianych systemach plików pierwszy blok partycji jest zarezerwowany dla sektora startowego. Reszta partycji jest podzielona na grupy bloków tego samego rozmiaru o ustalonej strukturze. Liczba grup zależy od rozmiaru partycji i od wielkości bloku. Głównym ograniczeniem jest to, że mapa bitowa opisująca stan zajętości bloków wewnątrz grupy musi zmieścić się w jednym bloku.
Jak widać na rysunku również mapa bitowa opisująca zajętość i-węzłów oraz superblok zajmują po jednym bloku. Pozostałe struktury są zmiennej długości.
Superblok zawiera informacje o całym systemie plików (m. in rozmiar bloku, łączną liczbę bloków i i-węzłów, łączną liczbę wolnych bloków i i-węzłów). Deskryptor grupy przechowuje podstawowe informacje dotyczące grupy, takie jak liczbę wolnych bloków oraz i-węzłów w danej grupie, numery bloków map bitowych i numer pierwszego bloku tablicy i-węzłów.
Tablica i-węzłów to zbiór bloków, w ramach których przydzielane są i-węzły. Ich liczba jest ustalana podczas tworzenia systemu plików.
Różnice w strukturze partycji pomiędzy kolejnymi wersjami systemu plików od ext2 do ext4 są niewielkie. W oryginalnej wersji systemu ext2, kopia superbloku oraz deskryptory grup znajdowały się w każdej grupie (redundacja miała na celu zabezpieczenie danych przed awarią). W nowszych wersjach wprowadzono możliwość pominięcia kopii w niektórych grupach. Kopie superbloku i deskryptorów grup znajdują się wtedy w grupach o numerach 0, 1 oraz będących potęgą 3, 5 lub 7.
Zauważmy, że dla bardzo dużych partycji taki sposób organizacji staje się nieefektywny, ponieważ zbyt wiele miejsca jest przeznaczone na (redundantne) metadane. Chodzi tutaj przede wszystkim o deskryptory grup, których liczba rośnie wraz z rozmiarem partycji (szczegółowe wyjaśnienie w zadaniu 7). Dlatego w późniejszych wersjach systemu ext3 i w systemie ext4 wprowadzono tak zwane metagrupy. Metagrupa jest zbiorem grup, o tak dobranym rozmiarze, aby deskryptory grup w obrębie jednej metagrupy mieściły się w pojedynczym bloku dyskowym. Deskryptory grup danej metagrupy są przechowywane w jej pierwszej grupie i dodatkowo - w drugiej i w ostatniej.
Dla partycji ext2 o wielkości 4 GB rozmiar bloku został ustalony na 4 KB. Załóżmy, że rozmiar deskryptora grupy wynosi 48 B, rozmiar i-węzła na dysku wynosi 128 B, a na grupę przypada 4096 i-węzłów.
Rozwiązanie
W sumie 528 KB, co stanowi 0.4% rozmiaru grupy: 528 KB / 128 MB =0.4% (rozmiar metadanych dzielony przez rozmiar grupy - dane i metadane).
W obrębie całego dysku straty będą takie same - 0.4% (pomijamy rozmiar bloku startowego).
Załóżmy, że w pewnym systemie plików ext2:
Jak należy skonfigurować system plików na tej partycji, żeby metadane nie zajęły więcej niż 2% partycji?
Opisz szczegółowo ile będzie grup dyskowych, ile bloków zajmie jedna grupa, co będzie się znajdowało w kolejnych blokach dyskowych partycji, jakie metadane będą przechowywane w kolejnych (ilu) blokach, ile bloków będzie przypadało średnio na jeden plik. Blok startowy można zaniedbać w rozważaniach.
Rozwiązanie
(4+x) * 64 * 4KB /8GB = (4+x)*32 /1M < 0.02
x < 651.36, czyli np. x=650
Czyli i-węzłów będzie 650*32=20 800 (w mapie bitowej da się opisać więcej, bo 32K, więc taka konfiguracja jest możliwa)
0111 1111 1101 1010 0110 ...
1011 0000 0000 0000 0000 ...
1101 1111 1111 1111 1111 ...
Rozwiązanie
Jaki jest maksymalny rozmiar partycji dla systemu plików, w którym pierwsza grupa przechowuje wszystkie deskryptory grup danej partycji. Przyjmijmy, że deskryptor grupy ma rozmiar 64B, a blok dyskowy - 4 KB. Jaki byłby w takiej sytuacji rozmiar metagrupy?
Rozwiązanie
Dla bloku o rozmiarze 4 KB grupa będzie miała rozmiar 8 * 212 * 212 = 227, czyli 128 MB.
Zatem w grupie zmieści się nie więcej niż 227/64 = 221 deskryptorów grup, a więc partycja może mieć rozmiar co najwyżej 221 * 227 = 248, czyli 256TB (a nawet jeszcze mniej, bo nie wzięliśmy pod uwagę superbloku, map bitowych i tablicy i-węzłów, które znajdują się w każdej grupie).
Wniosek: w przypadku dużych partycji konieczne staje się zastosowanie metagrup. Dla podanych założeń jedna metagrupa zawierałaby 212/64 =64 grupy.
| Załącznik | Wielkość |
|---|---|
| struktura-partycji.gif | 9.9 KB |
{kind=link}
{kind=link}