Wykłady
Wprowadzenie do problematyki bezpieczeństwa systemów komputerowych
Wprowadzenie do problematyki bezpieczeństwa systemów komputerowych
Co to jest bezpieczeństwo?
Przedstawienie problematyki bezpieczeństwa systemów komputerowych systemów komputerowych należy rozpocząć od zdefiniowania pojęcia bezpieczeństwa. Niestety trudno skonstruować uniwersalną i jednoznaczną definicję tego pojęcia, która pokryłaby wszystkie oczekiwania stawiane w tej dziedzinie systemom komputerowym. Literatura przedmiotu podaje bardzo dużo, często znacznie odbiegających od siebie definicji. Przykład ciekawej definicji można znaleźć w [1]:
- Def.
- System komputerowy jest bezpieczny, jeśli jego użytkownik może na nim polegać, a zainstalowane oprogramowanie działa zgodnie ze swoją specyfikacją. W myśl tej definicji, możemy system uznać za bezpieczny, jeśli np. można od niego oczekiwać, że wprowadzone na stałe dane nie zostaną utracone, nie ulegną zniekształceniu i nie zostaną pozyskane przez nikogo nieuprawnionego - ufamy, że system będzie przechowywał i chronił dane.
Bezpieczeństwo jest elementem szerszego kontekstu, nazywanego wiarygodnością systemu komputerowego. W kontekście tym wyróżnia się w sumie cztery atrybuty wiarygodności:
- System wiarygodny =
- - dyspozycyjny (available) = dostępny na bieżąco
- - niezawodny (reliable) = odporny na awarie
- - bezpieczny (secure) = zapewniający ochronę danych
- - bezpieczny (safe) = bezpieczny dla otoczenia, przyjazny dla środowiska
Czynniki decydujące o znaczeniu bezpieczeństwa
O doniosłości problematyki bezpieczeństwa dla współczesnej cywilizacji decyduje przede wszystkim wszechobecność technik komputerowych. W szczególności rozważyć należy następujące zagadnienia:
- rola systemów informatycznych (szczególnie sieci) dla funkcjonowania współczesnej cywilizacji jest nie do przecenienia; nie ma już praktycznie obszaru działalności człowieka, w którym żadne elementy techniki komputerowej (bądź szerzej mikroprocesorowej) nie byłyby obecne. Jako drobny przykład niech posłuży telefonia komórkowa, towarzysząca dziś człowiekowi niemal ciągle i wszędzie;
- trudności związane ze skonstruowaniem i eksploatacją systemu spełniającego wysokie wymagania w zakresie bezpieczeństwa (niedoskonałości technologii, konfiguracji i polityki bezpieczeństwa) stwarzają niebezpieczeństwo niedopracowanego pod względem bezpieczeństwa i niezawodności produktu informatycznego lub nieodpowiedniego pod owym względem wykorzystania tego produktu;
- elementarny konflikt interesów występujący pomiędzy użytecznością systemu a ryzykiem związanym z jego wykorzystaniem rodzi szereg pragmatycznych problemów (często całkowicie pozatechnicznych) związanych z oczywistymi utrudnieniami we wdrożeniu i użytkowaniu systemów o podwyższonym bezpieczeństwie.
Zagrożenia bezpieczeństwa
Zagrożenia bezpieczeństwa mają różną naturę. Mogą być najzupełniej przypadkowe lub powstać w efekcie celowego działania. Mogą wynikać z nieświadomości lub naiwności użytkownika, bądź też mogą być motywowane chęcią zysku, poklasku lub odwetu. Mogą pochodzić z zewnątrz systemu lub od jego środka.
Większość działań skierowanych w efekcie przeciwko bezpieczeństwu komputerowemu jest w świetle aktualnego prawa traktowana jako przestępstwa. Możemy tu wyróżnić w szczególności:
- włamanie do systemu komputerowego
- nieuprawnione pozyskanie informacji
- destrukcja danych i programów
- sabotaż (sparaliżowanie pracy) systemu
- piractwo komputerowe, kradzież oprogramowania
- oszustwo komputerowe i fałszerstwo komputerowe
- szpiegostwo komputerowe
Istotne jest, iż w przypadku jurysdykcji większości krajów europejskich, praktycznie wszystkie przypadki naruszające bezpieczeństwo wyczerpują znamiona przestępstw określonych w obowiązującym prawie.
W Polsce w szczególności mają tu zastosowanie:
- artykuły 267-269 Kodeksu Karnego
- artykuł 287 Kodeksu Karnego
(http://www.gazeta-it.pl/prawo/przestepstwa_komputerowe.html)
Zazwyczaj przestępstwa te nie są ścigane z oskarżenia publicznego, lecz na wniosek pokrzywdzonego.
W kontekście bezpieczeństwa komputerowego powszechnie spotyka użycie popularnego terminu hacker na określenie osoby podejmującej atak. Termin ten oryginalnie nie posiadał wydźwięku pejoratywnego. Wg „The Hacker's Dictionnary" (Guy L. Steele et al.) hacker jest to (1) osoba, której sprawia przyjemność poznawanie szczegółowej wiedzy na temat systemów komputerowych i rozszerzanie tej umiejętności, w przeciwieństwie do większości użytkowników, którzy wolą uczyć się niezbędnego minimum; (2) osoba, która entuzjastycznie zajmuje się programowaniem i nie lubi teorii dotyczącej tej dziedziny. W związku z tym w niniejszych materiałach stosować będziemy bardziej odpowiednie terminy (zależnie od typu rozważanego ataku), takie jak: cracker, intruz, włamywacz, napastnik, wandal czy po prostu - przestępca.
Przykłady ataków na systemy informatyczne znaleźć można w wielu dziedzinach życia osobistego, gospodarki, przemysłu czy funkcjonowania organów państwowych. Przykładowo w 1997 r. CIWARS (Centre for Infrastructural Warfare Studies) odnotował 2 incydenty (w Brazylii i w Australii) zaciekłej konkurencji gospodarczej, w których zaatakowały się wzajemnie (omawianymi później atakami SYN flood) konkurujące ze sobą firmy ISP (operatorzy dostępu do Internetu). Jako działania anarchistyczne można sklasyfikować przykładowo incydent z 1997 r., w którym grupa Damage Inc. zastąpiła witrynę Urzędu Rady Ministrów stroną proklamującą utworzenie Hackrepubliki Polskiej i Centrum Dezinformacyjnego Rządu z odsyłaczami do playboy.com. Być może jako terroryzm natomiast - incydent z 1998 r., gdy w akcie protestu przeciwko próbom nuklearnym grupa Milw0rm zaatakowała systemy indyjskiego BARC (Bhabba Atomic Research Center).
Komponenty systemu informatycznego w kontekście bezpieczeństwa
Elementarne składniki systemu informatycznego jakie należy wyróżnić przy omawianiu problematyki bezpieczeństwa to:
- stanowisko komputerowe i infrastruktura sieciowa
- system operacyjny i usługi narzędziowe
- aplikacje użytkowe
Ogólne problemy konstrukcji zabezpieczeń
Problematyka bezpieczeństwa, jak każda dziedzina, podlega pewnym ogólnym prawom, niektórym sformalizowanym, innym - nieformalnym. Można wyróżnić pewne truizmy obowiązujące podczas projektowania i realizowania zabezpieczeń. Niektóre z nich to:
- Nie istnieje absolutne bezpieczeństwo. Wiąże się to z wieloma przyczynami. Jedną z nich jest fakt, iż nigdy nie jesteśmy w stanie przewidzieć z góry wszystkich możliwych zagrożeń, tym bardziej że często należy opracowywać zabezpieczenia z odpowiednim wyprzedzeniem. Szybki rozwój technologii informatycznych implikuje powstawanie coraz to nowych zagrożeń. Czas reakcji na nie nigdy nie jest zerowy i w związku z tym nawet dla najlepiej opracowanego systemu zabezpieczeń istnieje ryzyko powstania okresu dezaktualizacji zastosowanych mechanizmów bezpieczeństwa. Ewolucja zagrożeń pociąga za sobą wyścig atakujących i broniących („policjantów i złodziei"). Innym istotnym powodem niemożliwości osiągnięcia 100% bezpieczeństwa jest ludzka słabość, w szczególności omylność projektantów, programistów, użytkowników systemów informatycznych, skutkująca błędami w oprogramowaniu systemowym i aplikacyjnym oraz niewłaściwym lub niefrasobliwym jego wykorzystaniu.
Skoro zatem nie mamy 100% bezpieczeństwa, jaki jego poziom można uznać za zadowalający? Otóż wydaje się, że najwłaściwszą odpowiedzią na to pytanie jest - taki, który okaże się dla atakującego na tyle trudny do sforsowania, wymagając operacji żmudnych lub czasochłonnych, iż uczyni to atak nieatrakcyjnym lub nieekonomicznym (lub oczywiście nieopłacalnym wg innego kryterium obranego przez atakującego). Zatem należy na tyle utrudnić włamywaczowi atak, aby z niego zrezygnował widząc marne, choć nadal niezerowe, szanse powodzenia.
- Napastnik na ogół nie pokonuje zabezpieczeń, tylko je obchodzi. Przeprowadzenie skutecznego ataku na jakikolwiek aktywny mechanizm zabezpieczeń jest raczej czasochłonne i stosowane tylko w ostateczności. Zwykle mniej kosztowne i szybsze jest znalezienie luki w środowisku systemu informatycznego, zabezpieczanego owym mechanizmem niż łamanie jego samego, która to luka pozwoli skutecznie wtargnąć do systemu nie jako „z boku" zabezpieczeń. Przy tej okazji warto wspomnieć, że okazuje się niezmiennie od wielu lat, iż większość ataków przeprowadzanych na systemy informatyczne realizowana jest „od środka", czyli przez zaufanych, poniekąd, użytkowników systemu, którzy znając system jakim się posługują niewątpliwie łatwiej mogą znaleźć i wykorzystać luki bezpieczeństwa.
- Nie należy pokładać zaufania w jednej linii obrony. Z poprzedniej obserwacji wynika, że obejście aktywnego mechanizmu zabezpieczeń często bywa możliwe i może istotnie narażać bezpieczeństwo całego systemu. W związku z tym, naturalną konsekwencją tego jest konstruowanie wielopoziomowych zabezpieczeń poprzez budowanie kolejnych swoistych „linii obrony", z których każda po przejściu poprzedniej stanowić będzie, przynajmniej potencjalnie, kolejną zaporę dla atakującego.
- Złożoność jest najgorszym wrogiem bezpieczeństwa. Skomplikowane systemy są trudne do opanowania, również pod względem bezpieczeństwa. Istotnym usprawnieniem zarządzania systemem jest jego modularna konstrukcja, dająca szansę na zwiększenie kontroli nad konfiguracją i funkcjonowaniem systemu. Dotyczy to również wielopoziomowych zabezpieczeń.
- System dopóty nie jest bezpieczny, dopóki nie ma pewności że jest. Bardzo łatwo popełnić błąd zakładając zupełnie inaczej - dopóki brakuje odnotowanych symptomów, iż bezpieczeństwo systemu zostało naruszone, możemy spać spokojnie. Zaobserwowanie ataku nie jest trywialne nawet w systemie poprawnie monitorowanym. Ponadto symptomy ataku zwykle występują dopiero po jego zakończeniu, kiedy to może być zbyt późno by przeprowadzać akcję ratunkową, kiedy ucierpiały już newralgiczne składniki systemu, poufne dane lub reputacja firmy.
Wzrost poziomu bezpieczeństwa odbywa się kosztem wygody. Użytkownicy systemu pragną przede wszystkim efektywności i wygody swojej pracy.
Strategia bezpieczeństwa
Opracowanie skutecznych zabezpieczeń jest problemem bardzo złożonym. Wymaga uwagi i systematyczności na każdym etapie. Niewątpliwie decydujące znaczenia ma etap projektowy, na którym popełnione błędy mogą być nienaprawialne w kolejnych etapach. Etap projektowy powinien rozpocząć się od wypracowania strategii firmy dotyczącej bezpieczeństwa (i to nie wyłącznie systemu informatycznego). Polega to w ogólnym schemacie na odpowiedzi na następujące pytania:
- „Co chronić?” (określenie zasobów)
- „Przed czym chronić?” (identyfikacja zagrożeń)
- „Ile czasu, wysiłku i pieniędzy można poświęcić na należną ochronę” (oszacowanie ryzyka, analiza kosztów i zysku)
Określenie zasobów = „Co chronić?”
Zasoby jakie mogą podlegać ochronie obejmują m.in. (w zależności od typu instytucji, dziedziny działalności itp.):
- sprzęt komputerowy
- infrastruktura sieciowa
- wydruki
- strategiczne dane
- kopie zapasowe
- wersje instalacyjne oprogramowania
- dane osobowe
- dane audytu
- zdrowie pracowników
- prywatność pracowników
- zdolności produkcyjne
- wizerunek publiczny i reputacja
Identyfikacja zagrożeń = „Przed czym chronić?”
Zagrożenia jakie należy rozważyć stanowią m.in.:
- włamywacze komputerowi
- infekcje wirusami
- destruktywność pracowników / personelu zewnętrznego
- błędy w programach
- kradzież dysków / laptopów (również w podróży służbowej)
- utrata możliwości korzystania z łączy telekomunikacyjnych
- bankructwo firmy serwisowej / producenta sprzętu
- choroba administratora / kierownika (jednoczesna choroba wielu osób)
- powódź
Polityka bezpieczeństwa
Polityka bezpieczeństwa stanowi element polityki biznesowej firmy. Jest to formalny dokument opisujący strategię bezpieczeństwa. Jej realizacja podlega oczywistym etapom:
- zaprojektowanie
- zaimplementowanie
- zarządzanie (w tym monitorowanie i okresowe audyty bezpieczeństwa)
Szczególnie godnym podkreślenia jest etap 3. odzwierciedlający ciągłą ewolucję jaką przechodzą działalność firmy, środowisko rynkowe jej funkcjonowania, zagrożenia i technologie obrony. Wymaga to ciągłego "trzymania ręki na pulsie".
Zakres
Zakres tematyczny jaki powinna obejmować polityka bezpieczeństwa to:
- definicja celu i misji polityki bezpieczeństwa
- standardy i wytyczne których przestrzegania wymagamy
- kluczowe zadania do wykonania
- zakresy odpowiedzialności
Specyfikacja środków
Polityka bezpieczeństwa winna definiować środki jej realizacji obejmujące takie elementy jak:
- ochrona fizyczna
- polityka proceduralno-kadrowa (odpowiedzialność personalna)
- mechanizmy techniczne
Normy i zalecenia zarządzania bezpieczeństwem
Istnieje wiele dokumentacji poświęconej realizacji polityki bezpieczeństwa, w tym również norm i standardów międzynarodowych, którymi należy posiłkować się przy opracowywaniu własnej polityki bezpieczeństwa. Pod tym względem kanonem jest norma ISO/IEC Technical Report 13335 (ratyfikowana w naszym kraju jako PN-I-13335). Norma ta jest dokumentem wieloczęściowym obejmującym następujące zagadnienia:
- TR 13335-1 terminologia i modele
- TR 13335-2 metodyka planowania i prowadzenia analizy ryzyka, specyfikacja wymagań stanowisk pracy związanych z bezpieczeństwem systemów informatycznych
- TR 13335-3 techniki zarządzania bezpieczeństwem
- - zarządzanie ochroną informacji
- - zarządzanie konfiguracją systemów IT
- - zarządzanie zmianami
- TR 13335-4 metodyka doboru zabezpieczeń
- WD 13335-5 zabezpieczanie połączeń z sieciami zewnętrznymi
Jednakże norm ISO dotyczących bezpieczeństwa jest wiele. Można tu wymienić chociażby bogaty podzbiór (wycinek listy do roku 1995):
ISO 2382-8:1986 Information processing systems - Vocabulary - Part 08: Control, integrity and security ISO 6551:1982 Petroleum liquids and gases - Fidelity and security of dynamic measurement - Cabled transmission of electric and/or electronic pulsed data ISO 7498-2:1989 Information processing systems - Open Systems Interconnection - Basic Reference Model - Part 2: Security Architecture ISO/IEC 7816-4:1995 Information technology - Identification cards - Integrated circuit(s) cards with contacts - Part 4: Interindustry commands for interchange ISO/IEC 9796:1991 Information technology - Security techniques - Digital signature scheme giving message recovery ISO/IEC 9797:1994 Information technology - Security techniques - Data integrity mechanism using a cryptographic check function employing a block cipher algorithm ISO/IEC 9798-1:1991 Information technology - Security techniques - Entity authentication mechanisms - Part 1: General model ISO/IEC 9798-2:1994 Information technology - Security techniques - Entity authentication - Part 2: Mechanisms using symmetric encipherment algorithms ISO/IEC 9798-3:1993 Information technology - Security techniques - Entity authentication mechanisms - Part 3: Entity authentication using a public key algorithm ISO/IEC 9798-4:1995 Information technology - Security techniques - Entity authentication - Part 4: Mechanisms using a cryptographic check function ISO/IEC 10118-1:1994 Information technology - Security techniques - Hash-functions - Part 1: General ISO/IEC 10118-2:1994 Information technology - Security techniques - Hash-functions - Part 2: Hash-functions using an n-bit block cipher algorithm ISO/IEC 10164-7:1992 Information technology - Open Systems Interconnection - Systems Management: Security alarm reporting function ISO/IEC 10164-8:1993 Information technology - Open Systems Interconnection - Systems Management: Security audit trail function ISO/IEC DIS 10181-1 Information technology - Open Systems Interconnection - Security Frameworks for Open Systems: Overview ISO/IEC DIS 10181-2 Information technology - Open Systems Interconnection - Security frameworks for open systems: Authentication framework ISO/IEC DIS 10181-3 Information technology - Open Systems Interconnection - Security frameworks in open systems - Part 3: Access control ISO/IEC DIS 10181-4 Information technology - Open Systems Interconnection - Security frameworks in Open Systems - Part 4: Non-repudiation ISO/IEC DIS 10181-5 Information technology - Security frameworks in open systems - Part 5: Confidentiality ISO/IEC DIS 10181-6 Information technology - Security frameworks in open systems - Part 6: Integrity ISO/IEC DIS 10181-7 Information technology - Open Systems Interconnection - Security Frameworks for Open Systems: Security Audit Framework ISO/IEC 10736:1995 Information technology - Telecommunications and information exchange between systems - Transport layer security protocol ISO/IEC 10745:1995 Information technology - Open Systems Interconnection - Upper layers security model ISO 11166-1:1994 Banking - Key management by means of asymmetric algorithms - Part 1: Principles, procedures and formats ISO 11166-2:1994 Banking - Key management by means of asymmetric algorithms - Part 2: Approved algorithms using the RSA cryptosystem ISO 11442-1:1993 Technical product documentation - Handling of computer-based technical information - Part 1: Security requirements ISO/IEC 11577:1995 Information technology - Open Systems Interconnection - Network layer security protocol ISO/IEC DIS 11586-1 Information technology - Open Systems Interconnection - Generic upper layers security: Overview, models and notation ISO/IEC DIS 11586-2 Information technology - Open Systems Interconnection - Generic upper layers security: Security Exchange Service Element (SESE) service specification ISO/IEC DIS 11586-3 Information technology - Open Systems Interconnection - Generic upper layers security: Security Exchange Service Element (SESE) protocol specification ISO/IEC DIS 11586-4 Information technology - Open Systems Interconnection - Generic upper layers security: Protecting transfer syntax specification ISO/IEC DIS 11586-5 Information technology - Open Systems Interconnection - Generic Upper Layers Security: Security Exchange Service Element Protocol Implementation Conformance Statement (PICS) ISO/IEC DIS 11586-6 Information technology - Open Systems Interconnection - Generic Upper Layers Security: Protecting Transfer Syntax Implementation Conformance Statement (PICS) ISO/IEC DIS 11770-1 Information technology - Security techniques - Key management - Part 1: Framework ISO/IEC DIS 11770-2 Information technology - Security techniques - Key management - Part 2: Mechanisms using symmetric techniques ISO/IEC DISP 12059-7 Information technology - International Standardized Profiles - OSI Management - Common information for management functions - Part 7: Security alarm reporting ISO/IEC DISP 12059-8 Information technology - International Standardized Profiles - OSI Management - Common information for management functions - Part 8: Security audit trail ISO/IEC DISP 12060-6 Information technology - International Standardized Profiles - OSI Management - Management functions - Part 6: Security management capabilities ISO/IEC DTR 13335-1 Information technology - Guidelines for the management of IT security - Part 1: Concepts and models for IT security ISO/IEC DTR 13335-2 Information technology - Guidelines for the management of IT security - Part 2: Planning and managing IT security (Future Technical Report) ISO/IEC DTR 13335-3 Information technology - Guidelines for the management of IT security - Part 3: Techniques for the management of IT security ISO/IEC TR 13594:1995 Information technology - Lower layers security ISO/IEC DIS 14980 Information technology - Code of practice for information security management
[1] Simson Garfinkel, "Practical Unix and Internet Security", II ed., O'Reilly, 2003
Podstawowe definicje i problemy
Klasy ataków
pasywne / aktywne
Pod względem interakcji atakującego z atakowanym systemem wyróżniamy ataki:
- pasywne - atakujący ma dostęp do danych (komunikacji) w systemie, mogąc je odczytać, lecz ich nie modyfikuje - przykład: podsłuch komunikacji pomiędzy legalnymi użytkownikami systemu.

- aktywne - atakujący pośredniczy w przetwarzaniu danych (komunikacji) w systemie, mogąc je nie tylko odczytać, lecz również sfałszować czy spreparować z premedytacją, tak by uzyskać zamierzony cel ataku - taki atak nazywa się popularnie „człowiek w środku" (ang. „man in the middle").
lokalne / zdalne
Pod względem źródła rozpoczęcia ataku wyróżniamy ataki:
- lokalny - atakujący już ma dostęp do systemu (konto) i próbuje zwiększyć swe uprawnienia
- zdalny - atakujący nie posiada jeszcze żadnych uprawnień w systemie atakowanym
Ogólne formy ataku elektronicznego
Najczęściej spotykanymi formami ataku są:
- podszywanie (ang. masquerading) - atakujący (osoba, program) udaje inny podmiot, w domyśle zaufany systemowi atakowanemu, np. fałszywy serwer www podszywa się pod znaną witrynę internetową
- podsłuch (ang. eavesdropping) - pozyskanie danych składowanych, przetwarzanych lub transmitowanych w systemie - typowy przykład: przechwycenie niezabezpieczonego hasła klienta przesyłanego do serwera
- odtwarzanie (ang. replaying) - użycie ponowne przechwyconych wcześniej danych, np. hasła
- manipulacja (ang. tampering) - modyfikacja danych w celu zrekonfigurowania systemu lub wprowadzenia go do stanu, z którego atakujący może osiągnąć bezpośrednio lub pośrednio korzyść (np. zastosować skuteczny atak gotowym narzędziem)
- wykorzystanie luk w systemie (ang. exploiting) - posłużenie się wiedzą o znanej luce, błędzie w systemie lub gotowym narzędziem do wyeksploatowania takiej luki - bardzo częste w przypadku ataków zdalnych
Konkretne przypadki ataków ewoluują wraz z rynkiem informatycznym. Można np. przedstawić rys historyczny prawdopodobnie najbardziej typowych ataków przeprowadzanych w Internecie na przestrzeni ostatnich lat:

Podstawowe fazy ataku
W czasie przeprowadzania ataku pojawiają się zwykle mniej lub bardziej jawnie następujące ogólne fazy:
- skanowanie (wyszukanie słabości, np. sondowanie usług)
- wyznaczenie celu (np. niezabezpieczona usługa, znany exploit)
- atak na system
- modyfikacje systemu umożliwiające późniejszy powrót
- usuwanie śladów
- propagacja ataku
Podstawowe środki ostrożności
W celu zminimalizowania podatności na typowe ataki należy stosować elementarne zasady „higieny osobistej". Dotyczą one wszystkich komponentów systemu informatycznego, stanowisk komputerowych, infrastruktury sieciowej , usług aplikacyjnych.
Elementarna ochrona stacji roboczej
Do podstawowych środków ochrony stanowisk komputerowych można zaliczyć przykładowo:
- uniemożliwienie startowania systemu z nośników wymiennych
- ograniczenie wykorzystania przestrzeni lokalnych dysków twardych
- ograniczenie stosowania nośników wymiennych (stacji dyskietek, nagrywarek)
- rejestracja prób dostępu do systemu i ich limitowanie
(kontrola, kto i kiedy korzystał z systemu) - bezpieczne kasowanie poufnych danych
- uniemożliwienie usunięcia / wyłączenia zabezpieczeń, np. antywirusowych
- konsekwentna polityka haseł użytkowników
Elementarna ochrona sieci lokalnej
Do podstawowych środków ochrony infrastruktury sieciowej można zaliczyć przykładowo:
- dobór medium i topologii gwiazdy (okablowanie strukturalne)
- fizyczna ochrona pomieszczeń z węzłami sieci i serwerami
- zdefiniowanie listy stanowisk, z których dany użytkownik może uzyskać dostęp do systemu (adresy MAC lub IP)
- usuwanie nieużywanych kont użytkowników
Elementarna ochrona usług sieciowych
Procedura ochrony dostępu do usług sieciowych polega w ogólności na skrupulatnym przeprowadzeniu następującej sekwencji operacji:
- usunięcie z systemu wszystkich usług zbędnych, najlepiej poprzez całkowite odinstalowanie, a co najmniej - dezaktywację
- zastąpienie usług niezbędnych odpowiednikami o podwyższonym bezpieczeństwie (jeśli to możliwe i takie odpowiedniki są dostępne)
- kontrola dostępu do pozostałych usług (np. poprzez zapory sieciowe firewall)
Złożoność problemu stosowania zabezpieczeń
Z realizacją zabezpieczeń związany jest szereg problemów, stawiających broniących od razu na pozycji gorszej niż atakującego. Dotyczą one m.in. asymetrii obrony i ataku, konieczności uwzględniania kontekstu całego otoczenia celu zabezpieczeń oraz trudności utrzymania poprawności zabezpieczeń (zarządzania i pielęgnacji).
- asymetria
Aby skutecznie zabezpieczyć system należy usunąć ''wszystkie'' słabości,
aby skutecznie zaatakować - wystarczy znaleźć ''jedną''.
- kontekst otoczenia systemu
Bezpieczeństwo powinno być rozważane w kontekście nie pojedynczego systemu informatycznego, ale całego otoczenia, w którym on się znajduje.
- zarządzanie i pielęgnacja
Zabezpieczenie systemu nie jest pojedynczą operacją, ale ciągłym procesem.
Stosowanie mechanizmów bezpieczeństwa
W związku z w/w trudnościami realizacji zabezpieczeń istotne jest stosowanie kilku podstawowych reguł, w szczególności są to:
- zasada naturalnego styku z użytkownikiem
- zasada spójności poziomej i pionowej
- zasada minimalnego przywileju
- zasada domyślnej odmowy dostępu
Zasada naturalnego styku z użytkownikiem
Zabezpieczenie nie możne być postrzegane przez użytkowników jako nienaturalny element systemu, stanowiący utrudnienie w ich pracy. Jeśli wprowadzony zostanie nawet najbardziej wyrafinowany mechanizm bezpieczeństwa, którego jednak stosowanie będzie wymagało od użytkowników dodatkowo zbyt obciążających ich (czasochłonnych) operacji, to wkrótce wypracują oni sposób jego permanentnego obejścia i - w efekcie stanie się ów mechanizm bezużyteczny.
Zasada spójności poziomej i pionowej
Stosowanie zabezpieczeń w systemie musi zapewniać podstawowy warunek kompletności: spójność poziomą i pionową. Są one odpowiednikiem reguły „trwałości łańcucha", która mówi, iż cały łańcuch jest tak trwały, jak jego najsłabsze ogniwo. Spójność pozioma wymaga aby wszystkie, spośród potencjalnie wielu komponentów w danej warstwie systemu (jako dobry przykład modelu warstwowego można tu obrać model OSI obowiązujący w sieciach komputerowych), zostały zabezpieczone na jednakowym poziomie. W życiu codziennym spotykamy przykłady tej reguły - gdy zabezpieczamy okna pomieszczenia kratami, to wszystkie, a nie co drugie, gdy budujemy ogrodzenie, to do wysokości identycznie trudniej do sforsowania na całej jego długości. Gdy zabezpieczamy protokoły komunikacyjne danej warstwy modelu OSI, którymi posługuje się nasz system, to wszystkie niezbędne, a nie tylko jeden wybrany, choćby był on popularniejszy i częściej wykorzystywany od pozostałych.
Spójność pionowa mówi o konieczności zastosowania kompletnych zabezpieczeń „w pionie" - jak kraty w oknach na pierwszym piętrze, to i na parterze czy innej „dostępnej" z zewnątrz kondygnacji, analogicznie - jak jedna warstwa przez którą istnieje dostęp do systemu, to każda inna, w której niezależnie taki dostęp też jest możliwy.
Zasada minimalnego przywileju
Użytkownikom należy udzielać uprawnień w sposób zgodny z polityką bezpieczeństwa - tylko i wyłącznie takich, które są niezbędne do zrealizowania ich pracy. Zmianie zakresu obowiązków użytkownika powinna towarzyszyć zmiana zakresu uprawnień.
Zasada domyślnej odmowy dostępu
Jeśli na podstawie zdefiniowanych reguł postępowania mechanizmy obrony nie potrafią jawnie rozstrzygnąć, jaką decyzję podjąć wobec analizowanych operacji (np. nadchodzącego pakietu protokołu komunikacyjnego), to decyzją ostateczną powinna być odmowa dostępu (odrzucenie pakietu). Wiele urządzeń i protokołów jest jednak domyślnie konfigurowanych inaczej, czy to w celu wygody użytkownika, czy z założenia wynikającego z ich funkcji (por. routing).
Elementarne pojęcia
W celu przedstawienia problematyki ataku i obrony należy wprowadzić definicje niezbędnych pojęć. Dotyczyć one będą w szczególności użytkowników, ale także i innych komponentów systemu.
1.Identyfikacja (ang. identification)
- możliwość rozróżnienia użytkowników, np. użytkownicy są identyfikowani w systemie operacyjnym za pomocą UID (user identifier)
2.Uwierzytelnianie (ang. authentication)
- proces weryfikacji tożsamości użytkownika; najczęściej opiera się na tym:
- co użytkownik wie (proof by knowledge), np. zna hasło
- co użytkownik ma (proof by possession), np. elektroniczną kartę identyfikacyjną
3.Autoryzacja (ang. authorization)
- proces przydzielania praw (dostępu do zasobów) użytkownikowi
4.Kontrola dostępu (ang. access control)
- procedura nadzorowania przestrzegania praw (dostępu do zasobów)
5.Poufność (ang. confidentiality)
- ochrona informacji przed nieautoryzowanym jej ujawnieniem
6.Nienaruszalność (integralność; ang. data integrity)
- ochrona informacji przed nieautoryzowanym jej zmodyfikowaniem (ew. detekcja takiej modyfikacji)
7.Autentyczność (ang. authenticity)
- pewność co do pochodzenia (autorstwa i treści) danych
8.Niezaprzeczalność (ang. nonrepudiation)
- ochrona przed fałszywym zaprzeczeniem
- przez nadawcę - faktu wysłania danych
- przez odbiorcę - faktu otrzymania danych
Autoryzacja
Z procesem autoryzacji związane są kolejne pojęcia:
Zasób (obiekt)
- jest jednostką, do której dostęp podlega kontroli
- przykłady: programy, pliki, relacje bazy danych, czy całe bazy danych
- obiekty o wysokiej granulacji: poszczególne krotki bazy danych
Podmiot
- ma dostęp do zasobu
- przykłady: użytkownik, grupa użytkowników, terminal, komputer, aplikacja, proces
Prawa dostępu
- określają dopuszczalne sposoby wykorzystania zasobu przez podmiot
Filozofie przydziału uprawnień
W dowolnym modelu autoryzacji można stosować jedną z poniższych czterech możliwych filozofii:
- Wszystko jest dozwolone.
- Wszystko, co nie jest (jawnie) zabronione, jest dozwolone.
- Wszystko, co nie jest (jawnie) dozwolone, jest zabronione.
- Wszystko jest zabronione.
Z praktycznego punktu widzenia w grę wchodzić mogą środkowe dwie. Jak można zaobserwować, tylko trzecia jest zgodna z zasadą minimalnego przywileju i domyślnej odmowy dostępu.
Kontrola dostępu do danych
Wyróżnia się dwie ogólne metody kontroli dostępu do danych: uznaniową (DAC) i ścisłą. (MAC) Istnieją też ich różne warianty - jak np. kontrola oparta o role (RBAC) powszechnie spotykana np. systemach baz danych.
Uznaniowa kontrola dostępu (Discretionary Access Control)
Podstawowe własności tego podejścia są następujące:
- właściciel zasobu może decydować o jego atrybutach i uprawnieniach innych użytkowników systemu względem tego zasobu
- DAC oferuje użytkownikom dużą elastyczność i swobodę współdzielenia zasobów
- powszechnym zagrożeniem jest niefrasobliwość przydziału uprawnień (np. wynikająca z nieświadomości lub zaniedbań) i niewystarczająca ochrona zasobów
- najczęściej uprawnienia obejmują operacje odczytu i zapisu danych oraz uruchomienia programu
Ścisła kontrola dostępu (Mandatory Access Control)
Podstawowe własności tego podejścia są następujące:
- precyzyjne reguły dostępu automatycznie wymuszają uprawnienia
- nawet właściciel zasobu nie może dysponować prawami dostępu
- MAC pozwala łatwiej zrealizować (narzucić) silną politykę bezpieczeństwa i konsekwentnie stosować ją do całości zasobów
Ścisła kontrola dostępu operuje na tzw. poziomach zaufania wprowadzając etykiety poziomu zaufania (sensitivity labels) przydzielane w zależności np. od stopnia poufności. Mogą one być następjące:
ogólnie dostępne < do użytku wewn. < tylko dyrekcja < tylko zarząd
czy w innego typu instytucji:
jawne < poufne < tajne < ściśle tajne
Oprócz poziomu zaufania, każdy zasób posiada kategorię przynależności danych. Kategorie te nie są hierarchiczne i reprezentują jedynie rodzaj wykorzystania danych, np.:
FINANSOWE, OSOBOWE, KRYPTO, MILITARNE
W celu określenia uprawnień w systemach MAC są konstruowane etykiety ochrony danych. Składają się one z 2 parametrów: poziomu zaufania i kategorii informacji, np.
(tajne, {KRYPTO})
(ściśle tajne, {KRYPTO,MILITARNE})
Na zbiorze etykiet ochrony danych określona jest relacja wrażliwości:
(ściśle tajne, {KRYPTO,MILITARNE}) -> (tajne, {KRYPTO})
Jest to relacja częściowego porządku, nie wszystkie etykiety do niej należą. Przykładowo może nie być określona relacja pomiędzy etykietą:
(ściśle tajne, {KRYPTO,MILITARNE})
a etykietą:
(tajne, {FINANSOWE,KRYPTO})
Wobec podmiotów i zasobów w systemie MAC narzucone są niezmienne reguły, które wymusza system. Podmiot nie może mianowicie czytać danych o wyższej etykiecie (read-up) niż swoja aktualna. Podmiot nie może również zapisywać danych o niższej etykiecie (write-down) niż swoja aktualna. Zbiór reguł przedstawia rysunek:
MAC 1:Użytkownik może uruchomić tylko taki proces, który posiada etykietę nie wyższą od aktualnej etykiety użytkownika. MAC 2:Proces może czytać dane o etykiecie nie wyższej niż aktualna etykieta procesu. MAC 3:Proces może zapisać dane o etykiecie nie niższej niż aktualna etykieta procesu.
Reguły MAC
Klasy bezpieczeństwa systemów komputerowych
W historii dziedziny bezpieczeństwa systemów komputerowych od początku starano się stworzyć reguły klasyfikacji systemów. Opracowano standardy certyfikacji:
- Trusted Computer System Evaluation Criteria (TCSEC "Orange Book") - USA
http://www.radium.ncsc.mil/tpep/library/rainbow/5200.28-STD.html ; jest to standard opracowany w USA, ale stał się pierwszym powszechnym takim standardem w skali światowej. Owiązujący w latach 1983-2000 stał się podstawą opracowywania podobnych norm w Europie i na świecie. Bardzo często nawet współcześnie znajduje się odwołania do certyfikatów tego standardu. - Information Technology Security Evaluation Criteria (ITSEC) - EU
http://www.cesg.gov.uk ; obowiązywał w 1991-1997. Powstał głównie z angielskiego CESG2/DTIEC, francuskiego SCSSI i niemieckiego ZSIEC. - Common Criteria Assurance Levels (EAL) - aktualnie obowiązujący standard będący w istocie złączeniem ITSEC, TCSEC oraz CTCPEC (Kanada). Od 1996 powszechnie znany jako Common Criteria for Information Technology Security Evaluation (CC; http://www.commoncriteria.org). Od 1999 roku zaakceptowany jako międzynarodowa norma ISO15408 ( EAL v.2).
Poniżej zostaną przedstawione wymagania klas bezpieczeństwa systemów komputerowych wg oryginalnej propozycji TCSEC "Orange Book". Schematyczne porównanie klas różnych standardów można znaleźć w tablece 1.
KLASA WŁASNOŚCI
- D
- - minimalna ochrona (właściwie jej brak)
- C1
- - identyfikacja i uwierzytelnianie użytkowników,
- - hasła chronione
- - luźna kontrola dostępu na poziomie właściciela / grupy / pozostałych użytkowników
- - ochrona obszarów systemowych pamięci
- C2
- - kontrola dostępu na poziomie poszczególnych użytkowników
- - automatyczne czyszczenie przydzielanych obszarów pamięci
- - wymagana możliwość rejestracji dostępu do zasobów
- B1
- - etykietowane poziomy ochrony danych
- B2
- - ochrona strukturalna - jądro ochrony
- - weryfikacja autentyczności danych i procesów
- - informowanie użytkownika o dokonywanej przez jego proces zmianie poziomu bezpieczeństwa
- - wykrywanie zamaskowanych kanałów komunikacyjnych
- - ścisła rejestracja operacji
- B3
- - domeny ochronne
- - aktywna kontrola pracy systemu (security triggers)
- - bezpieczne przeładowanie systemu
- A1
- - formalne procedury analizy i weryfikacji projektu i implementacji systemu
Tabelka 1. Porównanie klas bezpieczeństwa systemów komputerowych

| TCSEC | ITCES | CC / EAL |
|---|---|---|
| D | E0 | EAL1 |
| C1 | E1, F-C1 | EAL2 |
| C2 | E2, F-C2 | EAL3 |
| B1 | E3, F-B1 | EAL4 |
| B2 | E4, F-B2 | EAL5 |
| B3 | E5, F-B3 | EAL6 |
| A1 | E6, F-B3 | EAL7 |
Popularne systemy operacyjne plasują się na różnych poziomach klas bezpieczeństwa. Trzeba zaznaczyć, iż uzyskanie certyfikatu danej klasy jest operacją formalną i odpłatną.

Ogólne własności bezpieczeństwa informacji
Podstawowe własności bezpieczeństwa
Często wyróżnia się 3 podstawowe własności bezpieczeństwa informacji, których zachowanie jest konieczne w większości zastosowań systemów informatycznych. Są to poufność, nienaruszalność i dostępność informacji (rysunek 1).
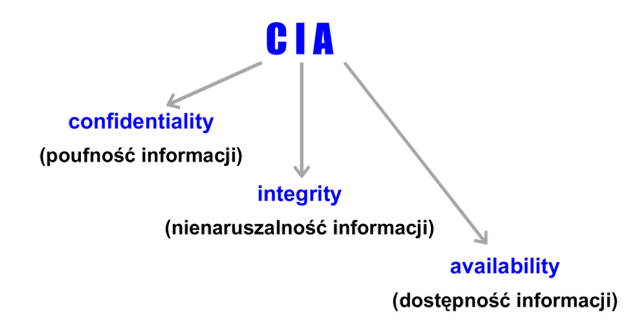
Rysunek '1'. Trzy podstawowe własności bezpieczeństwa informacji
Zajmiemy się teraz omówieniem wybranych zagrożeń związanych z tymi trzema własnościami oraz krótkim przedstawieniem mechanizmów stosowanych w celu osiągnięcia tych własności.
Poufność informacji
Zagrożenia
Poufność, rozumiana - jak wiemy - jako ochrona przed nieautoryzowanym ujawnieniem (odczytem) informacji, narażona jest na ataki poprzez:
- nieuprawniony dostęp do danych w miejscu składowania w systemie, np. w bazie danych
- nieuprawniony dostęp do danych w miejscu przetwarzania, np. w aplikacji końcowej użytkownika
- podsłuchanie danych przesyłanych w sieci
Szczególny nacisk można położyć na szeroko rozumiany podsłuch, który dotyczy nie tylko oczywistego przypadku transmisji danych. Należy podkreślić techniczną możliwość podsłuchu zdalnego większości urządzeń infrastruktury systemu komputerowego, poprzez tzw. receptory Van Ecka. Dotyczy to urządzeń emitujących promieniowanie elektromagnetyczne (jak np. monitory ekranowe, szczególnie starszego typu - CRT). Zatem ten rodzaj podsłuchu stanowi teoretyczne zagrożenie również dla danych składowanych oraz przetwarzanych na stanowiskach komputerowych, niezależnie od komunikacji sieciowej.
Mechanizmy obrony
W celu ochrony informacji przed jej nieautoryzowanym odczytem należy przede wszystkim umieć określić czy zamierzony odczyt jest autoryzowany oraz zminimalizować prawdopodobieństwo „wycieku" danych poza mechanizmem kontroli dostępu (w transmisji). Zatem mechanizmy obrony stosowane do zapewnienia poufności realizować będą następujące zadania:
- uwierzytelnianie
- autoryzację i kontrolę dostępu do zasobów
- utrudnianie podsłuchu
Omówimy kolejno problematykę wymienionych zadań i pokażemy przykłady mechanizmów, które je realizują.
Uwierzytelnianie
W systemach informatycznych stosuje się następujące rodzaje uwierzytelniania:
- uwierzytelnianie jednokierunkowe – polega na uwierzytelnieniu jednego podmiotu (uwierzytelnianego), np. klienta aplikacji, wobec drugiego (uwierzytelniającego) – serwera. Obrazuje to rysunek 2. Uwierzytelnienie następuje poprzez zweryfikowanie danych uwierzytelniających przekazanych przez podmiot uwierzytelniany. Typowymi danymi uwierzytelniającymi są np. identyfikator użytkownika i jego hasło dostępu.

Rysunek '2'. Uwierzytelnianie jednokierunkowe - uwierzytelnianie dwukierunkowe – polega na kolejnym lub jednoczesnym uwierzytelnieniu obu podmiotów (które są wzajemnie i naprzemiennie uwierzytelnianym oraz uwierzytelniającym). Obrazuje to rysunek 3. Jeżeli wzajemne uwierzytelnianie następuje sekwencyjnie (np. najpierw klient wobec serwera, a później serwer wobec klienta), mówimy o uwierzytelnianiu dwuetapowym, natomiast jednoczesne uwierzytelnienie obu stron nazywamy jednoetapowym.

Rysunek '3'. Uwierzytelnianie dwukierunkowe - uwierzytelnianie z udziałem zaufanej trzeciej strony – włącza w proces uwierzytelniania trzecią zaufaną stronę, która bierze na siebie ciężar weryfikacji danych uwierzytelniających podmiotu uwierzytelnianego. Po pomyślnej weryfikacji podmiot uwierzytelniany otrzymuje poświadczenie, które następnie przedstawia zarządcy zasobu, do którego dostępu żąda (serwerowi). Schemat ten pokazuje rysunek 4. Podstawową zaletą tego podejścia jest przesunięcie newralgicznej operacji uwierzytelniania do wyróżnionego stanowiska, które można poddać szczególnie podwyższonemu zabezpieczeniu. Należy też podkreślić potencjalną możliwość wielokrotnego wykorzystania wydanego poświadczenia (przy dostępie klienta do wielu zasobów, serwerów). Zaufana trzecia strona może być lokalna dla danej sieci komputerowej (korporacyjnej) lub zewnętrzna (wykorzystująca infrastrukturę uwierzytelniania dostępną w sieci rozległej np. publiczne urzędy certyfikujące).
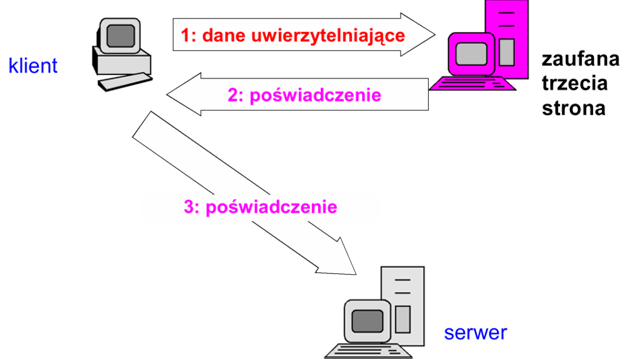
Rysunek '4'. Uwierzytelnianie z udziałem zaufanej trzeciej strony
Mechanizmy uwierzytelniania użytkowników
Klasyczne uwierzytelnianie użytkownika
W przypadku wielu współczesnych środowisk informatycznych, systemów operacyjnych lub systemów zarządzania bazami danych, funkcjonuje klasyczny mechanizm uwierzytelniania poprzez hasło. Proces uwierzytelniania rozpoczyna klient żądając zarejestrowania w systemie (login). Serwer pyta o identyfikator (nazwę) użytkownika, a następnie o hasło
i decyduje o dopuszczeniu do sieci. W większości przypadków nazwa użytkownika i hasło są przesyłane tekstem jawnym, co stanowić może kolejny problem zapewnienia poufności, jaką właśnie mamy osiągnąć stosując opisywany mechanizm. Stąd też takie klasyczne podejście nadaje się do wykorzystania jedynie w ograniczonej liczbie przypadków, kiedy np. mamy uzasadnioną skądinąd pewność wykluczenia możliwości podsłuchu danych uwierzytelniających.

Rysunek '5'. Klasyczne uwierzytelnianie użytkownika
Hasła nie są najefektywniejszą, ani najbezpieczniejszą formą weryfikacji tożsamości użytkownika, z następujących powodów
- hasło można złamać:
- odgadnąć, np. metodą przeszukiwania wyczerpującego (brute-force attack) lub słownikową (dictionary attack) - często hasła są wystarczająco nieskomplikowane by ułatwiło to odgadnięcie ich przez atakującego
- podsłuchać w trakcie niezabezpieczonej transmisji
- wykraść z systemowej bazy haseł użytkowników - zwykle hasła nie są przechowywane w systemie w postaci jawnej, często są zakodowane funkcją jednokierunkową lub zaszyfrowane, jednak niekiedy można stosunkowo łatwo jest pobrać i następnie starać się odzyskać ich oryginalną postać
- pozyskać inną metodą (np. kupić)
- hasła się starzeją - czas przez który możemy z dużą pewnością polegać na tajności naszego hasła skraca się nieustannie, przez co hasła wymagają systematycznych zmian na nowe
- w niektórych środowiskach aplikacyjnych stosuje się predefiniowane konta użytkowników (również o charakterze administracyjnym) i przypisuje się im dość powszechnie znane hasła domyślne - usuwanie lub dezaktywowanie takich kont czy zmiany haseł wymagają dużej staranności
Hasła są przedmiotem ataków - słownikowego i metodą przeszukiwania wyczerpującego. Słownikowy atak polega na podejmowaniu kolejnych prób zweryfikowania czy hasło wybierane ze zbioru popularnie stosowanych haseł (tzw. słownika) odpowiada hasłu aktualnie ustawionemu dla konta będącego celem ataku. Wariantem tego ataku jest wykradzenie nawet zakodowanych danych uwierzytelniających z systemu, aby po weryfikować czy kolejne hasła ze słownika dają po odpowiednim zakodowaniu którąś z postaci przechowywanych w systemie.
Przykładem analizy podatności haseł na atak słownikowy jest kilkukrotnie wykonane badanie, znane powszechnie jako raport Kleina. Operacje wykonywane w tym badaniu doskonale odzwierciedlają metodologię tworzenia słownika i mogą być doskonałą ilustracją zagrożeń wynikających z wyboru słabych haseł. W skrócie opisując Klein wykonał następujące operacje służące do uzyskania słownika haseł:
- wejściową postać słownika utworzyły nazwy użytkowników w systemie, ich inicjały oraz inne dostępne informacje (np. daty urodzin)
- następnie dodane zostały imiona i ich permutacje, nazwy miejsc, nazwiska sławnych ludzi, tytuły filmów i książek S-F oraz nazwiska postaci, dziedziny sportu i terminy sportowe
- wejściowy rozmiar słownika objął w efekcie ok. 1 500 haseł
- na tej zawartości słownika wykonane zostały przekształcenia powszechnie stosowane przez użytkowników: np. zmiana pierwszej litery na wielką, zastąpienie pierwszej litery znakiem sterującym, zamianę litery o na 0 czy l na 1, utworzenie liczby mnogiej, dodanie przed- i przyrostków
- dalej dołączone zostały kombinacje małych i wielkich liter haseł
- co dało łącznie ok. 1 000 000 słów
Z tak przygotowanym słownikiem zrealizowano atak na hasła użytkowników w rzeczywistym systemie. Efekty przedstawia poniższa lista trafień haseł (fragment) ze słownika wg poszczególnych kategorii (bez uwzględniania wśród nich przekształceń i kombinacji):
- nazwa użytkownika: ponad 10%
- nazwy pospolite: ponad 16%
- imiona żeńskie: 4,8%
- imiona męskie: 4%
- mity i legendy: 2%
- sport: 0,8%
- słownik środowiska korekty językowej dostępny w systemie operacyjnym (/usr/dict/words): blisko 30%
Wszystkie wymienione kategorie (nie jest to lista kompletna) należy uznać, jak widać, za słabe hasła i wystrzegać się ich przy wyborze własnego.
Przeszukiwanie wyczerpujące („atak brutalny") polega kolejnym weryfikowaniu całej przestrzeni haseł, czyli wybieraniu wszystkich możliwych permutacji znaków z alfabetu wykorzystywanego przy ustawianiu hasła użytkownika. Taki atak jest oczywiście kosztowny czasowo - wymaga prób dopasowania każdej permutacji do odgadywanego hasła, co zależy od wielkości alfabetu i długości hasła (rozmiaru przestrzeni haseł).
Prawdopodobieństwo odgadnięcia hasła wyraża wzór (1):
\(P = \frac{L \cdot R}{S}\) (0)
- gdzie
- L = czas obowiązywania hasła
- R = współczynnik szybkości (ilość prób na jednostkę czasu)
- S = przestrzeń haseł - dla haseł o długości k z alfabetu N znaków: S = N k
Uwzględniając zagrożenia wynikające z przedstawionych ataków na hasła, można zaproponować następujące „żelazne reguły" higieny haseł:
- czego nie wolno
- wybierać hasła o długości krótszej niż 6 znaków
- wybierać jako hasło znanego słowa, imienia, nazwiska, daty urodzenia, numeru telefonu, numeru rejestracyjnego
- zmieniać hasła tak, by nowe było zależne od starego
(np. z 012345 na 123456) - zapisywać hasła w widocznych lub łatwo dostępnych miejscach
(jak np. fragment biurka zakryty klawiaturą, wnętrze szuflady
czy płyta z danymi) - informować nikogo o swoim haśle
- co należy
- wybierać długie i mało znane słowo lub frazę (kombinacja różnych znaków)
- wybrać hasło w sposób na tyle losowy na ile tylko możliwe
- zmieniać hasło możliwie często, lecz w nieprzewidywalny sposób
- zmienić hasło natychmiast, jak tylko rodzi się podejrzenie, że ktoś mógł je poznać
- co warto
- opracować własny algorytm generowania haseł - wybór pierwszych liter słów ulubionej fraszki, ostatnich znaków z wersów wiersza lub wybranej strony książki itp.
- zlecić systemowi wygenerowanie trudnego hasła
Zdalne potwierdzanie tożsamości użytkownika
W środowisku sieci TCP/IP wypracowano mechanizm prostego potwierdzania tożsamości użytkownika, który żąda zdalnego uwierzytelniania. W tym celu powstał standard RFC 1413 opisujący usługę o nazwie ident. Niezależnie od jej aktualnej przydatności i powszechności warto zdawać sobie sprawę z istoty jej działania, którą łatwo opisać w następujący sposób:
- użytkownik uruchamia klienta usługi i nawiązuje połączenie z serwerem
- serwer kontaktuje się z wydzielonym serwerem - identd, pracującym na stacji klienta (113/tcp) w celu poświadczenia nazwy (lub identyfikatora) użytkownika wykorzystującego usługę

Rysunek '6'. Klasyczne uwierzytelnianie użytkownika
Należy też zdawać sobie sprawę z potencjalnych zagrożeń jakie niesie udostępnianie przez usługę ident informacji o przynależności procesów dokonujących komunikacji sieciowej (nie tylko klientów). W standardzie RFC 1413 oraz w praktycznych implementacjach nie realizuje się bowiem uwierzytelniania podmiotu żądającego informacji z tej usługi, może ona być zatem również nadużyta przez potencjalnego włamywacza.
Uwierzytelnianie jednokrotne (SSO – single sign-on)
Procedury uwierzytelniania jednokrotnego są częściowym rozwiązaniem problemu ochrony danych uwierzytelniających przed złamaniem w systemie wielozasobowym, np. sieci komputerowej z wieloma serwerami.
Ideą procedury uwierzytelniania jednokrotnego jest minimalizacja ilości wystąpień danych uwierzytelniających w systemie - hasło powinno być podawana jak najrzadziej. Zgodnie z tą zasadą, jeśli jeden z komponentów systemu (np. system operacyjny) dokonał pomyślnie uwierzytelniania użytkownika, pozostałe komponenty (np. inne systemy lub zarządcy zasobów) ufać będą tej operacji i nie będą samodzielnie wymagać podawania ponownie danych uwierzytelniających. Przy tym jest możliwe teoretycznie, że wszystkie komponenty samodzielnie korzystają z odmiennych mechanizmów uwierzytelniana. Wówczas, dodatkowo po pierwszorazowym uwierzytelnieniu użytkownika, system może oddelegować specjalny moduł do przechowywania odrębnych danych uwierzytelniających użytkownika i poświadczania w przyszłości jego tożsamości wobec innych komponentów systemu.
Schemat SSO przedstawia rysunek 7. W przedstawionej na rysunku sytuacji tylko jeden serwer dokonuje uwierzytelniania klienta, reszta ufa uwierzytelnianiu dokonanemu przez ten serwer.
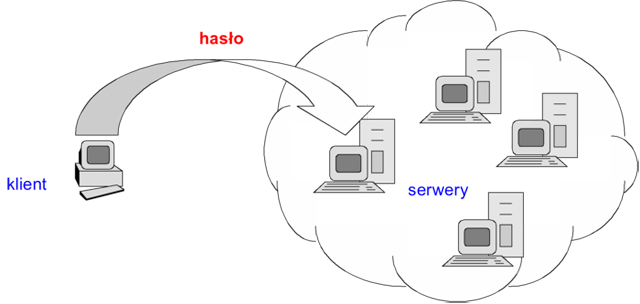
Rysunek '7'. Uwierzytelnianie jednokrotne (SSO)
Hasła jednorazowe (OTP – one-time passwords)
Istota wykorzystania haseł jednorazowych wynika zamiaru ochrony ich przed przechwyceniem i nieautoryzowanym wykorzystanie, w przyszłości. Jednak nie polega na zapewnieniu ich poufności w transmisji lecz na uczynieniu ich de facto bezwartościowymi po przechwyceniu. Opiera się na, jak sama nazwa wskazuje, tylko użyciu danej postaci hasła tylko raz. Hasła jednorazowe mają przy każdym kolejnym uwierzytelnieniu inną postać. Raz przechwycone hasło jednorazowe nie jest przydatne, bowiem przy kolejnym uwierzytelnieniu będzie obowiązywać już inne. Komunikacja między podmiotami procesu uwierzytelniania może być zatem jawna. Stosujące takie hasła procedury uwierzytelniania muszą jedynie oferować brak możliwości odgadnięcia na podstawie jednego z haseł, hasła następnego.
Hasła jednorazowe generowane są przy pomocy listy haseł, synchronizacji czasu lub metody zawołanie-odzew. Dostępne są najczęściej w następujących postaciach: listy papierowe, listy-zdrapki, tokeny programowe i tokeny sprzętowe.
Listy haseł to najprostsza i najtańsza metoda identyfikacji metodą haseł jednorazowych. Użytkownik otrzymuje listę zawierająca ponumerowane hasła. Ta sama lista zostaje zapisana w bazie systemu identyfikującego. W trakcie logowania użytkownik podaje swój identyfikator, a system prosi o podanie hasła z odpowiednim numerem. Klient za każdym razem posługuje się kolejnym niewykorzystanym hasłem z listy.
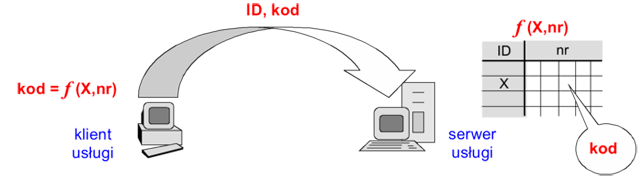
Rysunek '8'. Uwierzytelnianie metodą listy haseł jednorazowych
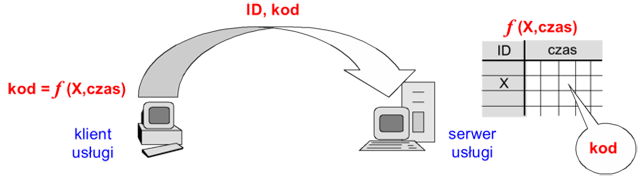
W metodzie z synchronizacją czasu (time synchronization) klient generuje unikalny kod w funkcji pewnego parametru X użytkownika (identyfikatora, kodu pin, hasła, numeru seryjnego karty identyfikacyjnej) oraz bieżącego czasu. Serwer następnie weryfikuje otrzymany od klienta kod korzystając z identycznej funkcji (z odpowiednią tolerancją czasu).
Rysunek '9'. Uwierzytelnianie metodą z synchronizacją czasu
Natomiast w metodzie zawołanie-odzew (challenge-response) serwer pyta o nazwę użytkownika, a następnie przesyła unikalny ciąg („zawołanie"). Klient koduje otrzymany ciąg (np. swoim hasłem lub innym tajnym parametrem pełniącym rolę klucza) i odsyła jako „odzew". Serwer posługując się identycznym kluczem weryfikuje poprawność odzewu.
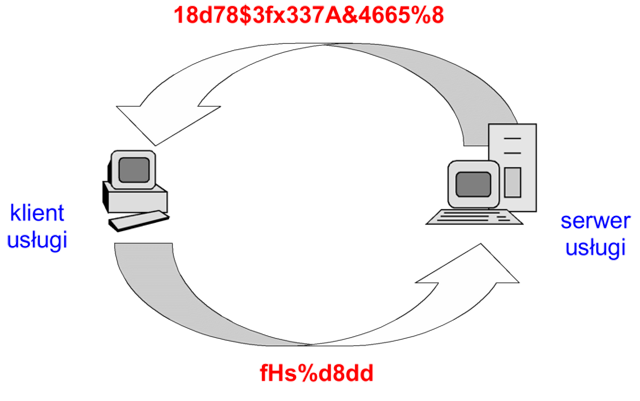
Rysunek '10'. Uwierzytelnianie metodą listy haseł jednorazowych
Tokeny programowe to specjalne programy generujące hasła. W zależności od implementacji program na podstawie kwantu czasu lub zawołania serwera generuje hasło jednorazowe, które weryfikuje serwer.
Token sprzętowy jest małym przenośnym urządzeniem spełniającym wszystkie funkcje tokenu programowego.
Pewną ciekawostką zyskującą na popularności jest wykorzystanie telefonu komórkowego w uwierzytelnianiu za pomocą haseł jednorazowych. Cały proces polega przesłaniu hasła jednorazowego z serwera na telefon w postaci wiadomości SMS. W tym przypadku rola telefonu jako swoistego tokena sprowadza się tylko do medium odbierającego i wyświetlającego dane.
Inne mechanizmy uwierzytelniania
Do uwierzytelniania użytkowników można wykorzystać również przedmioty, których posiadaniem musi się wykazać uwierzytelniany. Mogą to być np. karty magnetyczne, karty elektroniczne czy tokeny USB. Ponadto, w przypadku ludzi, można posłużyć się również cechami osobowymi wynikającymi z odmienności parametrów niektórych naturalnych składników organizmu (uwierzytelnianie biometryczne), takich jak m.in.:
- klucz DNA
- małżowina uszna
- geometria twarzy
- termogram twarzy
- termogram dłoni
- obraz żył krwionośnych na zaciśniętej pięści
- odcisk palca (dermatoglify)
- chód
- geometria dłoni
- tęczówka oka
- odcisk dłoni
- obraz siatkówki
- podpis odręczny
- głos
Autoryzacja i kontrola dostępu do zasobów
Mechanizmy ochrony dostępu do danych
Zadania autoryzacji i kontroli dostępu legalnych użytkowników należą do podstawowych funkcji systemów operacyjnych czy systemów zarządzania bazą danych oraz środowisk przetwarzania rozproszonego. W większości przypadków te funkcje są realizowane podobnie.
Aktualnie jednym z najczęściej stosowanych mechanizmów weryfikacji praw dostępu jest lista kontroli dostępu, której implementacje, w zależności od konkretnego systemu, noszą nazwy ACL (Access Control List), ARL (Access Rights List) lub Trustees. Ogólna koncepcja działania mechanizmu listy kontroli polega na wyspecyfikowaniu dla każdego udostępnianego zasobu listy indywidualnych użytkowników lub ich grup bądź kategorii oraz przydzieleniu im podzbiorów uprawnień wybranych ze zbioru wszystkich uprawnień dostępnych dla danego zasobu (rysunek 11).

Rysunek '11'. Lista kontroli dostępu do pliku
W kolejnych modułach (<A HREF="bsk-m6.doc">moduł 6</A> i (<A HREF="bsk-m11.doc">moduł 11</A>) omówione zostaną przykłady realizacji autoryzacji i kontroli dostępu użytkowników wybranych systemów operacyjnych oraz systemów zarządzania bazą danych.
Utrudnianie podsłuchu
Atak poprzez podsłuch jest zwykle skierowany przeciwko określonym zasobom i ma konkretny cel (np. przechwycenie hasła, lub zawartości konkretnych plików). Atak taki w istocie polega na wykonaniu operacji umożliwiających dostęp do kanału transmisyjnego (wpięcie się do medium transmisyjnego, podłączenie do stacji bazowej sieci bezprzewodowej itp.) a następnie wyłuskaniu z całego ruchu odbywającego się w tym kanale informacji poszukiwanych.
Ogólna koncepcja utrudniania podsłuchu polega zatem na uczynieniu możliwie jak najbardziej kłopotliwym obu kroków ataku - wpięcia się do kanału komunikacyjnego i wyłuskania użytecznych danych. Operacje utrudniania podsłuchu obejmują:
- stosowanie topologii sieciowej utrudniającej ewentualny posłuch lub ułatwiającej jego wykrycie, np. topologii gwiazdy (okablowanie strukturalne)
- stosowanie medium mniej podatnego na podsłuch; przykładowo popularne przewodowe media transmisyjne można uszeregować wg łatwości i skuteczności ich ewentualnego podsłuchu: UTP -> FTP -> STP -> SSTP -> FO
- utrudnianie wyłuskania użytecznych danych poprzez sztuczne generowanie ruchu (traffic padding) - wypełnianie wolnego pasma przenoszenia sieci danymi bezużytecznymi, co czyni trudniejszym, przynajmniej potencjalnie, rozróżnienie danych użytecznych od reszty (w wyniku zwiększenia proporcji danych bezużytecznych w całym ruchu)
- tworzenie zamkniętych grup użytkowników, poprzez separację ruchu sieciowego kierowanego z i do odrębnych grup użytkowników systemu (wspierają to już dojrzałe technologie VLAN ACL, Wire-rate ACL i in.)
- kontrola dostępu do zasobów infrastruktury sieciowej, poprzez dopuszczanie do udziału w ruchu sieciowym tylko uwierzytelnionych stacji sieciowych (co realizuje np. protokół IEEE 802.1x)
- szyfrowanie danych - stanowiące niewątpliwie najbardziej uniwersalny mechanizm ochrony poufności danych (czy ja zobaczymy wkrótce - szerzej rozumianej ochrony danych)
- ograniczanie emisji elektromagnetycznej - atak przez przechwycenie promieniowania van Ecka jest nadal tańszy od innego typu ataków na poufność danych (np. ataku kryptoanalitycznego), mimo że wymaga bardzo specjalistycznego sprzętu. Skutecznie można utrudnić ten atak poprzez wykorzystanie materiałów pochłaniających istotnie dużą część promieniowania elektromagnetycznego. Mamy do dyspozycji ekranujące materiały konstrukcyjne (obudowy komputerów i urządzeń peryferyjnych) oraz ekranujące materiały elastyczne do przygotowania pomieszczeń (tapety, wykładziny podłogowe i sufitowe). W niektórych zastosowaniach, jak np. przetwarzanie danych niejawnych, obowiązuje standard TEMPEST (Transient Electromagnetic Pulse Emanation Standard), który definiuje wymagania stanowiska komputerowego o ograniczonej emisji elektromagnetycznej. Stanowiska komputerowe zgodne z TEMPEST to wydatek rzędu kilkunastu, kilkudziesięciu tysięcy złotych.
Nienaruszalność informacji (integralność)
Kolejnym po poufności aspektem bezpieczeństwa omawianym w tym module jest nienaruszalność informacji, rozumiana jako ochrona danych przed ich nieautoryzowanym zmodyfikowaniem (dostępem do zapisu, w odróżnieniu od poufności, która oznacza ochronę przed nieautoryzowanym dostępem do odczytu).
Zagrożenia
Zagrożeniem nienaruszalności informacji jest zatem celowa lub przypadkowa modyfikacja danych przez nieuprawnionych użytkowników bądź oprogramowanie (np. wirusowe).
Mechanizmy obrony
Mechanizmy obrony stosowane do zapewnienia nienaruszalności informacji obejmują w szczególności:
- kontrolę dostępu do danych - wymienione wcześniej mechanizmy list kontroli dostępu
- sumy kontrolne zbiorów danych (np. plików dyskowych)
- kryptograficzne sumy kontrolne i podpis elektroniczny
- rejestrację operacji na danych (auditing) - niezbędną dla formalnego wykrycia naruszeń integralności; zwykle spotyka się podział danych audytu co najmniej na rejestr zdarzeń systemowych oraz rejestr zdarzeń aplikacji.
- kontrolę antywirusową
Dostępność informacji
Zagrożenia
Wśród zagrożeń nienaruszalności informacji należy wymienić przede wszystkim:
Podstawowe elementy kryptografii
Podstawowe elementy kryptografii
Mechanizmy kryptografii są powszechnie wykorzystywane w dziedzinie bezpieczeństwa systemów komputerowych. Stanowią bardzo uniwersalne narzędzie osiągania poufności, integralności czy autentyczności, są stosowane w procedurach uwierzytelniania, do ochrony danych składowanych i komunikacji sieciowej. Należą niewątpliwie do najważniejszych mechanizmów bezpieczeństwa.
Bieżący moduł przedstawia elementarne pojęcia dziedziny kryptografii i prezentuje podstawowe koncepcje algorytmów szyfracji. Celem dydaktycznym modułu jest wyrobienie intuicji działania popularnych technik kryptograficznych i ich własności. Kolejny moduł przedstawi podstawowe zastosowania mechanizmów kryptograficznych w informatyce.
Podstawowe pojęcia
Kryptografia jest dziedziną kryptologii - nauki operującej bardzo formalnym i relatywnie skomplikowanym aparatem matematycznym. Nie jest celem tego modułu przedstawienie tego aparatu, lecz jedynie przybliżenie istoty operacji szyfrowania i deszyfrowania. Wymaga to jednak minimalnej ilości jasno definiowanych terminów. Niniejszy rozdział przedstawia podstawowe pojęcia, które wykorzystywane będą w dalszej części modułu.
Kryptologia jest to wiedza naukowa obejmująca kryptografię i kryptoanalizę.
Kryptografia jest dziedziną obejmująca zagadnienia związane z utajnieniem danych (w kontekście przesyłania wiadomości i zabezpieczenia dostępu do informacji) przed niepożądanym dostępem. Przez utajnienie należy tu rozumieć taką operację, która powoduje że wiadomość jest trudna do odczytania (rozszyfrowania) przez podmiot nie znający tzw. klucza rozszyfrowującego - dla takiego podmiotu wiadomość będzie wyłącznie niezrozumiałym ciągiem wartości (znaków).
Kryptoanaliza natomiast to dziedzina kryptologii zajmująca się łamaniem szyfrów, czyli odczytywaniem zaszyfrowanych danych bez posiadania kluczy rozszyfrowujących.
Dane, które poddawane będą operacjom ochrony kryptograficznej nazywać tu będziemy po prostu tekstem jawnym lub wiadomością czytelną.
Kryptogramem (szyfrogramem) będziemy nazywali zaszyfrowaną postać wiadomości czytelnej.
Klucz szyfrowania to ciąg danych służących do szyfrowania wiadomości czytelnej w kryptogram za pomocą algorytmu szyfrowania. Klucz ten jest odpowiednio ustalany (uzgadniany) przez nadawcę w fazie szyfrowania.
Klucz rozszyfrowujący jest z kolei ciągiem danych służących do rozszyfrowania kryptogramu do postaci wiadomości czytelnej za pomocą algorytmu deszyfrowania. Naturalnie, klucz ten odpowiada w pewien sposób kluczowi szyfrowania wykorzystanemu w fazie szyfrowania.
W niektórych przypadkach będziemy mieli do czynienia z ciekawą własnością przemienności kluczy. Przemienność kluczy oznacza, że role dwóch kluczy z pary mogą ulec przestawieniu. Mianowicie informację zaszyfrowaną jednym kluczem można rozszyfrować tylko przy pomocy odpowiadającego mu drugiego klucza z pary, i odwrotnie, informację zaszyfrowaną drugim kluczem można rozszyfrować wyłącznie przy pomocy klucza pierwszego.
Proste szyfry
Teraz przejdziemy do zademonstrowania prostych operacji kryptograficznych, które wykorzystywane są również w bardzo skomplikowanych procesach szyfrowania i deszyfrowania. Świadomość ich funkcjonowania jest niezbędna dla zrozumienia istoty aktualnie wykorzystywanych algorytmów szyfrowania.
Szyfrowanie metodą podstawiania
Szyfrowanie metodą podstawiania jest prawdopodobnie najprostszą koncepcją utajniania informacji. Było już stosowane w czasach antycznych. Przykładem a przykład może u posłużyć szyfr wykorzystywany przez Juliusza Cezara do utajniania korespondencji wojskowej, nazywany na jego cześć szyfrem Cezara (notabene jest to jedno z pierwszych nazwisk związanych z kryptografią).
Działanie tej metody szyfrowania polega na wykonaniu na każdym znaku wiadomości czytelnej przekształcenia szyfrującego polegającego na zastąpieniu tego znaku innym o pozycji w alfabecie przesuniętej o zadaną ilość znaków względem znaku szyfrowanego. Przy czym pozostajemy wyłącznie w dziedzinie alfabetu wejściowego (przesunięcie pozycji jest w istocie rotacją - „zapętla się" po osiągnięciu końcowego znaku alfabetu na jego początek). Operację taką nazywa się z tego powodu monogramem.
Operację szyfrującą na znaku x możemy zatem zapisać formalnie jako \(f(x) = x + \Delta\), gdzie dodawanie oznacza zmianę (rotację!) pozycji znaku w alfabecie, a symbol \(\Delta\) oznacza wartość przesunięcia przy podstawianiu. Należy zaobserwować, iż w istocie zatem wartość \(\Delta\) jest kluczem szyfrowania. Jest to również klucz deszyfrowania, gdzie deszyfrowanie polega na „odejmowaniu" pozycji znaku o wartość \(\Delta\). Dla szyfru Cezara wartość \(\Delta\) jest stała i wynosi 3. Natomiast dla kodu nazywanego Captain Midnight \(\Delta\) jest kluczem zmiennym.
szyfr Cezara: \("A" \Rightarrow ( "A" + 3 ) = "D"\)
kod Captain Midnight: \("A" \Rightarrow ( "A" + \Delta); \Delta = 1,...,26\)
Rysunek '1'. Przykłady monogramów
Szyfry monoalfabetyczne mogą być konstruowane i opisywane różnymi wzorami matematycznymi. W powyższym przykładzie funkcję podstawienie zapisywaliśmy \(f(x)\). W kryptologii częściej stosuje się zapis \(E[x|k]\), gdzie \(E[]\) jest operacją szyfrowania (ang. encryption), a k oznacza użyty klucz. W niniejszym module będziemy stosowali najczęściej uproszczony zapis postaci \(E_k[x]\)
Oto przykłady formalnych definicji przekształceń monoalfabetycznych:
- \(f(x) = x + k\)
\(E[x|k] = x + k\)
\(E_k[x] = x + k\) - \(f(x) = x \cdot k \bmod n\)
\(E[x|k] = x \cdot k \bmod n\) - \(f(x) = (x \cdot a + b) \bmod n\)
\(E[x|a,b] = (x \cdot a + b) \bmod n\)
Szyfrowanie metodą przestawiania
Inną podstawową operacją kryptograficzną jest przestawianie treści wiadomości czytelnej. Polega ono na przestawieniu kolejności wystąpienia znaków („wymieszaniu") testu jawnego. Kryptogram rozszyfrowujemy wykonując odwrotne przestawianie.
Najprostszym przypadkiem szyfrowania metodą przestawiania jest przestawienie losowe. W jego przypadku kolejne znaki wiadomości czytelnej przyjmują przypadkowe pozycje w kryptogramie. Takie szyfrowanie ma sens dla relatywnie niedużych wiadomości (rysunek 2).

Rysunek '2'. Przykład szyfrowania metodą przestawiania losowego
W rzeczywistych przypadkach, przestawienie nie jest losowe, lecz wynika z określonego wzoru zadanego np. figurą geometryczną. Najprostszą przydatną figurą transpozycji jest prostokąt. Dokładniej mamy do czynienia z macierzą prostokątną, w której pozycje wpisujemy wiadomość czytelną (lub też kolejne bloki całej wiadomości, których długości odpowiadają ilości elementów macierzy - czyli inaczej - jej rozmiarowi). Wiadomość wpisywana jest do macierzy, przyjmijmy, wierszami. Kryptogram tworzy się spisując zawartość tak wypełnionej macierzy, ale kolumnami (rysunek 3).
Rolę klucza szyfrowania pełnią wymiary figury transpozycji. W przykładzie z rysunku byłby to rozmiar macierzy: k = (5,4).
W celu utrudnienia złamania szyfru, operację transpozycji można powiązać w permutacją kolejności kolumn, przed spisaniem zawartości macierzy do krytpogramu. Innymi słowy, można przykładowo spisywać najpierw zawartość kolumny 2-giej, potem 5-tej, później 3-ciej, dopiero dalej 1-szej i na końcu 4-tej. Klucz szyfrowania przyjmuje tu postać: k = (5,4;2-5-3-1-4).
Dalsze wzmocnienie jakości szyfrowania można osiągnąć poprzez dodatkowe skomplikowanie operacji szyfrowania. Można stosować macierze o wierszach zmiennej długości bądź przestawienie przekątnokolumnowe, albo też szyfry siatkowe czy zastosować całkiem inną figurę transpozycji.
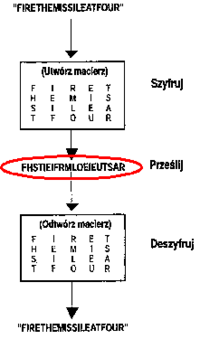
Rysunek '3'. Przykład szyfrowania metodą przestawiania losowego
Zasada Kerckhoffsa
Najprostsze z przedstawionych metod szyfrowania opierają swoją siłę na tajności procedury szyfrowania. Każdy, kto pozna tę procedurę, bez większego trudu i w relatywnie krótkim czasie jest w stanie odtworzyć wiadomość czytelną z dowolnego kryptogramu.
Szyfry najczęściej spotykane współcześnie w systemach informatycznych opierają swą siłę nie na tajności samego algorytmu lecz jedynie na tajności zmiennego parametru tego algorytmu, jakim jest klucz. Jest to zgodne z powszechnie uznaną regułą, nazywaną zasadą Kerckhoffsa:
Algorytm szyfrowania i deszyfrowania jest jawny
Rysunek '4'. Zasada Kerckhoffsa
Zgodnie z tą zasadą, algorytm może być, a nawet z wielu względów powinien być publicznie znany. Przemawia za tym ułatwienie publicznej oceny i dyskusji jakości, jakie potencjalnie oferuje powszechna dostępność każdego nowo-opracowanego algorytmu dla światowej rzeszy kryptoanalityków. Dzięki temu, łatwiej i wcześniej można wykryć ewentualne luki w koncepcji algorytmu bądź w samej jego konstrukcji.
Szyfrowanie z kluczem
Rysunek 5 przedstawia ogólny schemat szyfrowania z użyciem klucza, jaki stosować będziemy w niniejszym module. Użytkownicy uczestniczący w komunikacji, na tym schemacie - Alicja i Bolek, posługują się swoimi kluczami, odpowiednio - KA oraz KB, aby przesłać zaszyfrowaną wiadomość od Alicji do Bolka. Alicja poddaje szyfrowaniu wiadomość czytelną M z użyciem klucza szyfrowania KA operacją \(E_K_A[M]\) uzyskując szyfrogram S
Następnie szyfrogram S jest przesyłany do Bolka, który poddaje go operacji \(D_K_B[S]\) rozszyfrowania z kluczem KB.
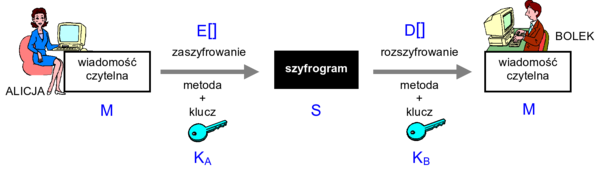
Rysunek '5'. Schemat ogólny szyfrowania z kluczem
Formalny zapis tych operacji przedstawia rysunek 6. Wynika z niego własność szyfrowania z kluczem: \(D_K_B[E_K_A[M]] = M\).
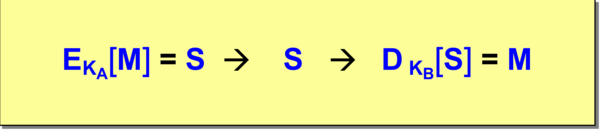
Rysunek '6'. Formalny zapis operacji szyfrowania z kluczem
W przypadku szyfrowania z kluczem spotykane są dwa schematy: szyfrowanie symetryczne i asymetryczne.
Szyfrowanie symetryczne
Szyfrowanie symetryczne jest schematem, który posiada następujące cechy
- występuje wspólny dla obu uczestników komunikacji tajny klucz KA-B (dalej oznaczany po prostu K)
- stąd zapis formalny operacji szyfrowania symetrycznego ma postać:
\(E_K[M] = S \rightarrow S \rightarrow D_K[S] = M\)

Rysunek '7'. Ogólny schemat szyfrowania symetrycznego
Własność szyfrowania symetrycznego ma zatem postać: \(D_K[E_K[M]] = M\).
Szyfrowanie symetryczne jest o tyle ciekawe, że wymaga posłużenia się tylko jednym kluczem, dla obu uczestników komunikacji i w obu jej kierunkach (choć można wyobrazić sobie wariant tego schematu z oddzielnym kluczem na każdy kierunek). Uczestników takiej komunikacji może oczywiście być więcej niż dwoje i wówczas cała grupa może posługiwać się wspólnym kluczem. Jednak my będziemy tu zakładali zachowanie poufności komunikacji w pojedynczym kanale komunikacyjnym łączącym tylko dwoje uczestników. W związku z tym, pojedynczy klucz przypisany jest wyłącznie do jednej pary użytkowników i musi on być utajniony wobec innych osób.
Konieczność utrzymania tajności klucza w obrębie jednej pary użytkowników rodzi szereg praktycznych problemów:
tożsamość problemu poufności wiadomości z problemem tajności klucza
- wiadomość jest bezpieczna dopóki osoba trzecia nie pozna tajnego klucza K
problem dystrybucji klucza
- jak uzgodnić wspólny klucz bez osób trzecich, będąc oddalonym o setki, a nawet tysiące kilometrów?
problem skalowalności
- dla 2 komunikujących się w systemie osób wymagane jest przechowywanie przez każdą z nich 1 klucza; dla 3 osób - 3 kluczy (przez każdą osobę); 4 os. = 6 kluczy; 10 os. = 45 kluczy; 100 os. = 4950 kluczy; ...
autentyczność
- tajność klucza nie zapewnia autentyczności - nie można wykazać formalnie która z dwóch stron jest rzeczywistym nadawcą wiadomości, skoro obie posługują się tym samym kluczem.
Przykłady algorytmów symetrycznych
Algorytm DES (Data Encryption Standard)
Algorytm DES (Data Encryption Standard) został opracowany w latach '70. przez firmę IBM na zamówienie NSA (National Security Agency) - rządowej agencji USA, będącej odpowiednikiem Agencji Bezpieczeństwa Wewnętrznego. Zespołem odpowiedzialnym za opracowanie DES w IBM kierował Horst Feistel. Zmodyfikowany przez NSA, algorytm DES został przyjęty jako standard krajowy w 1976 przez NBS (National Bureau of Standards, obecnie NIST = National Institute of Standards and Technology) i objęty ochroną patentową oraz ograniczeniami ekportowymi. Należy od razu podkreślić, iż ochrona patentowa tego algorytmu już wygasła. W 1977 DES został opublikowany przez nieporozumienie między NSA a NBS (NSA spodziewało się, że standardem stanie się sam układ sprzętowy, lecz NBS opublikowało na tyle dużo szczegółów, iż możliwe stały się implementacje programowe tego algorytmu).
Algorytm DES pracuje na 64-bitowych blokach tekstu jawnego, co odpowiada 8 znakom 8-bitowego kodu ASCII. Klucz składa się z 64 bitów, przy czym 8 z nich jest bitami parzystości. Zatem w istocie, w trakcie wyboru klucza można określić jedynie 56 bitów.
Aktualnie standard DES nie jest już uważany za dostatecznie silny mechanizm kryptograficzny dla większości zastosowań, jednak wciąż jest bardzo często demonstrowany jako bardzo reprezentatywny przykład algorytmu symetrycznego szyfrowania. Dalej przedstawiony zostanie uproszczony szkic działania algorytmu DES, którego celem jest umożliwienie nabrania pewnej intuicji co do sposobu konstrukcji i pracy współczesnych algorytmów kryptograficznych.
Algorytm działa w kilku wyraźnie zaznaczających się etapach nazywanych tu fazami. Fazy działania, znane dość powszechnie jako sieć Feistela, są następujące
- wstępna permutacja wejściowego bloku danych (na podstawie tabeli transpozycji)
- podział bloku na lewą i prawą połowę o długości 32 bitów każda
- 16 jednakowych rund - cykli operacji podstawiania i przestawiania wykorzystujących pewną funkcję f, w czasie których dane zostają połączone z kluczem
- połączenie lewej i prawej połowy bloku
- permutacja końcowa (odwrotność permutacji wstępnej)
Schematycznie sieć Feistela przedstawia rysunek 8.
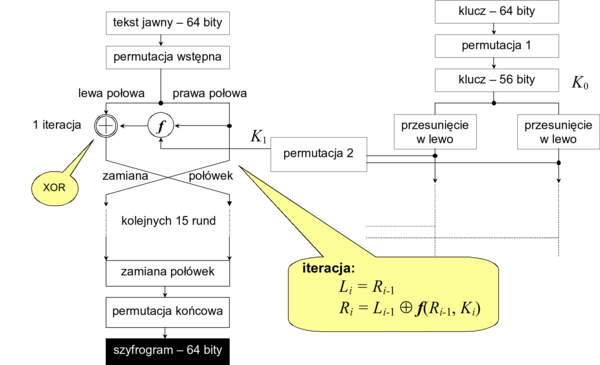
'Rysunek '8'. Sieć 'Feistela
Najbardziej skomplikowaną fazą jest każdy z 16 rund wykorzystujących funkcję f. Rundy te są w istocie iteracjami tych samych operacji. Każda kolejna runda, dokonuje tych samych obliczeń, ale na wynikach obliczeń z poprzedniej rundy i specjalnym podkluczu Ki generowanym z 56b klucza K0 (64-bitowego klucza powstałego po usunięciu 8 bitów parzystości z wejściowego klucza szyfrowania).
Początek każdej iteracji składa się z następujących kroków:
- 56 bitów klucza dzielone jest na dwie połowy po 28 bitów
- w każdej iteracji bity obu połówek są cyklicznie przesuwane w lewo o jeden lub dwa bity, w zależności od numeru iteracji
- ostatecznie wykonywana jest permutacja kompresująca, dzięki której z 56b klucza, otrzymujemy 48b podklucz Ki używany w funkcji f(Li, Ki)
- a połówki klucza podawane jest do następnej iteracji i+1
Kulminacyjnym etapem wykonania kolejnej rundy jest funkcja f. Jej działanie jest następujące:
- prawa połowa Ri-1 rozszerzana jest z 32 bitów do 48 bitów za pomocą permutacji rozszerzonej (e-blok) i sumowana mod 2 z 48 bitami podklucza Ki danego cyklu
- otrzymany wynik poddawany jest operacji podstawienia poprzez wykorzystanie bloków podstawień (S-bloki):
- ciąg 48 bitów dzielony jest na 8 bloków po 6 bitów
- każdy ciąg 6 bitów jest redukowany do 4 bitów funkcją podstawienia
- z 48 bitów otrzymujemy 32b ciąg, który poddawany jest permutacji zwykłej
- następnie sumowany mod 2 z lewą połową Li-1 bloku wejściowego
No koniec iteracji następuje zamiana lewej i prawej połowy bloku miejscami.
Bloki podstawień (S-bloki; z ang. Substitution blocks) są zdefiniowane w standardzie DES i można je znaleźć w literaturze przedmiotowej. Każdy z 8 S-bloków jest inny, jednak w ogólności S-blok należy postrzegać jako tabelę 4 wiersze na 16 kolumn. Element tabeli jest 4b liczbą (podstawiana wartość). Wybór wiersza i kolumny za pomocą 6b wejścia wygląda następująco:
- pierwszy i ostatni bit 6b ciągu tworzy 2b liczbę
- liczba ta wybiera wiersz
- pozostałe środkowe 4 bity wybierają kolumnę
Wskazany element tabeli (4 bity) jest podawany na wyjście jako wynik podstawienia.
Deszyfrowanie w algorytmie DES
Operacje deszyfrowania kryptogramu uzyskanego algorytmem DES są realizowane za pomocą tej samej sieci co operacje szyfrowania bloku tekstu jawnego. Różnica polega jedynie na tym, iż klucze stosowane są w kolejności odwrotnej od K16 do K1.
Kryptoanaliza algorytmu DES
Istotą trudności kryptoanalizy algorytmu DES metodą przeszukiwania wyczerpującego jest złożoność obliczeniowa procesu dopasowania kolejnych możliwych wartości klucza. W latach 80-tych ubiegłego wieku wymagała ona czasu liczonego w setki/tysiące lat. W efekcie uczyniła ten standard odpornym na atak metodą przeszukiwania wyczerpującego.
Tryby pracy algorytmu DES
Standard przewiduje wykorzystanie algorytmu DES w różnych trybach pracy nazywanych ECB, CBC, CFB i OFB. Dwa pierwsze to tryby blokowe, w których algorytm DES jest wykonywany wprost dokładnie tak jak na przedstawionym wcześniej szkicu, operując na kolejnych 8-znakowych blokach szyfrowanej wiadomości czytelnej.
Tryb ECB (Electronic CodeBook) jest to podstawowy tryb szyfrowania blokowego. Jego własności można przedstawić następująco:
- cały tekst jawny jest dzielony na bloki 64b (ostatni blok, jeśli nie jest 8 znakowy, zostaje uzupełniony do 8 znaków nieistotnym wypełnieniem - ang. padding)
- każdy 64b blok jest szyfrowany niezależnie
- dla danego bloku i danego klucza wynik szyfrowania będzie zawsze ten sam
- jeśli blok wystąpi w wiadomości częściej niż raz - za każdym razem otrzyma taki sam blok szyfrogramu ECB
- przy pewnym standardowym formacie wiadomości (np. rozpoczynających się od tych samych stałych pól) stanowi ten tryb istotne ułatwienie dla kryptoanalityka.
Tryb CBC (Cipher Block Chaining) jest wolny od tej ostatniej wady. Umożliwia on uzależnienie postaci bloku kryptogramu nie tylko od treści szyfrowanego bloku wiadomości jawnej, lecz również od pewnego dodatkowego parametru - wektora inicjującego. Jego własności można przedstawić następująco:
- na pierwszym 64b bloku jest wykonywana operacja XOR z pewnym wektorem początkowym (IV = Initialization Vector) znanym nadawcy i odbiorcy
\(S_1 = E_K [M_1 \oplus \; IV ]\) - wynikowy ciąg jest podawany na wejście algorytmu DES
- na każdym kolejnym 64b bloku jest wykonywany XOR z zaszyfrowanym poprzednim blokiem przed podaniem na wejście algorytmu DES
\(S_i = E_K [M_i \oplus S_{i-1}]\) - powtórzone takie same bloki 64b dadzą bloki zaszyfrowane różnej postaci
- deszyfrowanie:
\(M_i = D_K [S_i] \oplus S_{i-1}\)
Tryby blokowe nadają się doskonale do szyfrowania gotowych wiadomości, jednak nie są odpowiednia dla szyfrowania strumienia danych asynchronicznych, np. wprowadzanych z klawiatury lub pojawiających się w protokołach komunikacyjnych, w których nie można z góry określić tempa pojawiania się danych do przesłania (i zaszyfrowania) oraz ich ilości, w efekcie dających teksty zmiennej długości. W tym celu wprowadzono tryby szyfrowania strumieniowego szyfrujące każdorazowo po jednym znaku 8-bitowym: CFB (Cipher FeedBack) oraz OFB (Output FeedBack) - tzw. tryby sprzężenia zwrotnego. Opisują je następujące własności:
- w CFB na wejście funkcji szyfrującej podawana jest zawartość 64b rejestru przesuwnego - początkowo zawiera on IV, który jest szyfrowany: \(R_1 = E_K[ IV ]\)
- na ośmiu najstarszych bitach rejestru jest wykonywany XOR ze znakiem szyfrowanym \(M_i: S_i = R_i \oplus M_i\)
- zawartość rejestru jest przesuwana w lewo 8b, a jako 8 najmłodszych jest wpisywany szyfrogram \(S_i\) wprowadzonego znaku (\(R_{i+1}\))
- wadą tego podejścia jest fakt iż uszkodzenie 1 bitu (np. w transmisji) propaguje się na 9 kolejnych znaków szyfrogramu
- w OFB w miejsce 8 najmłodszych bitów wpisywany jest tylko szyfrogram 8 najstarszych (bez XOR z porcją tekstu szyfrowanego)
- w trybie OFB błędy się nie propagują - uszkodzenie 1 bitu wpłynie tylko na rozszyfrowanie 1 znaku (zawierającego ten bit) - kryptoanalityk kontrolujący szyfrowany strumień może kontrolować zmiany w tekście jawnym
Powyższa dyskusja oraz znajomość praktycznych implementacji standardu DES skłania do następujących wniosków:
- ECB jest trywialny - nie powinien być stosowany do szyfrowania sesji danych; może być wykorzystany do przesłania kluczy oraz IV
- w trybie CBC mogą z kolei występować problemy implementacyjne związane z IV
- celem IV jest upodobnienie bloków szyfrogramu do postaci losowych danych
- typowe IV wartości nijak nie przypominają losowych (często zawierają powtarzające się najstarsze bity lub mają inną łatwą do przewidzenia strukturę)
- nawet jeśli IV byłby prawdziwie losowy, to trzeba go przekazać odbiorcy (skoro jest losowy)
- np. wysyłając w pierwszym bloku szyfrogramu (wydłuża to szyfrogram stanowiąc problem z małymi porcjami szyfrowanych danych)
Algorytm CDMF (Commercial Data Masking Facility)
Stany Zjednoczone, ojczyzna standardu DES, jak zresztą również inne kraje, traktują technologie kryptograficzne na równi z militarnymi i stosują ograniczenia w ich wykorzystaniu. Jednym z nich jest embargo eksportowe na wszelkie algorytmy i systemy kryptograficzne opracowane w USA. Również standard DES był objęty tymi ograniczeniami, a dokładniej jego ustandaryzowana postać posługująca się kluczem 56-bitowym. Natomiast algorytm CDMF, opracowany również przez IBM, został przygotowany specjalnie z myślą o wykorzystaniu również poza Stanami Zjednoczonymi i jest wolny od ograniczeń eksportowych. W istocie jest to wersja uproszczona DES operująca kluczem 40b, a dokładniej jest to algorytm DES uzupełniony o wstępną metodę skracania klucza 56b do 40b.
Odporność algorytmu DES
Algorytm DES był przez wiele lat bezpieczny. Ze względu na złożoność obliczeniową kryptoanalizy, przy dostępnej mocy obliczeniowej, proces odnajdywania klucza metodą przeszukiwania wyczerpującego był wystarczająco nieefektywny, by uczynić ataki nieopłacalnymi. Jednak w 1998 r. algorytm DES z kluczem 56b został złamany w 56 godzin kryptoanalizy metodą przeszukiwania wyczerpującego. Koszt sprzętu (EFF DES Cracker) wówczas szacowano na 250 tys. USD. Rok później zajęło to już 22 godziny. Dziś to kwestia minut.
Algorytm 3DES (Triple DES)
Istnieją jednak propozycje wzmocnienia siły algorytmu DES, np. poprzez praktyczne zwiększanie długości klucza. I tak algorytm 3DES stosuje jednocześnie trzy kolejne iteracje szyfrowania i deszyfrowania tekstu jawnego oryginalnym algorytmem DES. Każda iteracja może używać innego klucza 56b, co w efekcie daje klucz 168b. W praktyce najczęściej spotykany jest tryb DES-EDE (encrypt-decrypt-encrypt) z dwoma kluczami (razem 112b), wg rysunku 9:
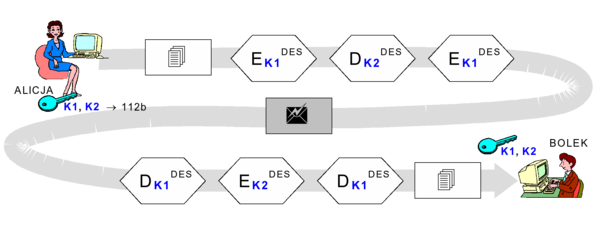
Rysunek '9'. Schemat działania algorytmu 3DES
Algorytm IDEA (International Data Encryption Algorithm)
Algorytm IDEA został opracowany w 1991r. przez Swiss Federal Institute of Technology
(w zespole, którym kierowali James L. Massey i Xuejia Lai). W ogólnej koncepcji jest dość podobny do algorytmu DES, występują jedynie różnice w szczegółach. Przykładowo algorytm IDEA charakteryzują:
- 64b bloki danych (jak DES)
- klucz 128b
- 64b blok dzielony na 16b podbloki
- a 128b klucz na 16b podklucze
- 8 iteracji (w DES jest 16, ale w IDEA 1 iteracja odpowiada 2 w DES)
Fazy działania algorytmu IDEA przedstawiają się następująco:
- w każdym kroku cztery 16b podbloki danych poddawane są operacji dodawania modulo 2, dodawania modulo 216 i mnożenia modulo 216 z innymi blokami i z sześcioma 16b podkluczami.
- pomiędzy każdym krokiem następuje zamiana drugiego i trzeciego podbloku.
Algorytm IDEA stosuje podklucze o następującej charakterystyce:
- 128-bitowy klucz jest dzielony na osiem 16-bitowych podkluczy
- pierwszych 6 podkluczy jest używanych w pierwszej iteracji,
2 pozostałe podklucze - w kolejnej - następnie cały 128b klucz rotuje o 25 pozycji w lewo
- tak otrzymany klucz jest ponownie dzielony na osiem 16b podkluczy, z których pierwsze 4 uzupełniają podklucze w drugiej iteracji, a kolejne 4 są przydzielane do trzeciej iteracji
- w kluczu jest powtarzana rotacja o 25 pozycji w lewo - klucz jest ponownie dzielony na 8 podkluczy używanych w kolejnych krokach.
Opisane wyżej czynności powtarzane są do momentu przydzielenia kluczy do wszystkich kroków, przy czym w fazie zakończenia zamiast sześciu podkluczy, stosuje się tylko cztery podklucze. Łącznie w algorytmie wykorzystuje się 52 podklucze, które generowane są z wejściowego klucza szyfrującego.

Rysunek '10'. Siatka operacji w pojedynczej iteracji algorytmu IDEA
Deszyfracja przebiega następująco:
- podklucze używane do deszyfrowania odpowiadają podkluczom szyfrowania podanym w odwrotnej kolejności,
- operacje arytmetyczne przy użyciu czterech podkluczy są wykonywane nie na początku, ale na końcu deszyfrowania.
Algorytm Rijndeal
Algorytm Rijndeal został opracowany w 1999 przez Belgów: Joana Daemena i Vincenta Rijmena. Bloki wejściowe mają po 128, 196 lub 256 bitów. Klucze również mają długość 128b, 196b lub 256b. W zależności od wielkości bloku stosowana jest różna liczba iteracji: 10 (128b), 12 (196b) lub 14 (256b). Każda iteracja to następująca sekwencja wykonywana na poszczególnych bajtach danych i klucza:
- podstawienie (S-bloki)
- przesuwanie (rzędów i kolumn bloku-macierzy)
- XOR.
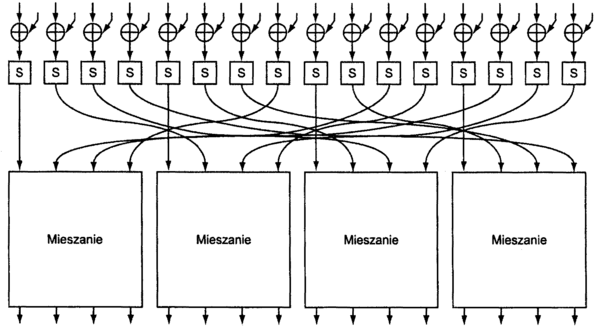
'Rysunek '11'. Uproszczony schemat pojedynczej iteracji algorytmu 'Rijndeal
Standard AES (Advanced Encryption Standard)
Standard AES jest następcą standardu DES obowiązującym w USA od 2001 r. Wykorzystuje algorytm Rijndeal. Algorytm ten wygrał oficjalną rywalizację z innymi zgłoszonymi do konkursu algorytmami, m.in. Serpent, Twofish, RC6, MARS. Stosuje tryb blokowy (blok 128b) i strumieniowy, klucze 128b, 192b, 256b (choć teoretycznie dopuszczalne również inne kombinacje). W standardzie wprowadzono też ciekawy nowy strumieniowy tryb licznikowy (CTR - Counter Mode), w którym dedykowany rejestr jest inkrementowany wraz z kolejnymi operacjami szyfrowania porcji danych. Tryb ten oferuje możliwość zrównoleglenia operacji na różnych porcjach danych.
Inne algorytmy symetryczne
Algorytmy RC2 / RC4 / RC5 / RC6
RC2, RC4, RC5 i RC6 to prawnie zastrzeżone algorytmy opracowane przez Ronalda Rivesta (pracownika MIT i jednocześnie założyciela firmy RSA Data Security), chociaż od 1994 kod źródłowy niektórych z nich jest szeroko dostępny w Internecie. Są to bardzo wydajne algorytmy symetryczne (ok. 10 razy szybsze od DES) o zmiennej długości klucza (do 2048b). RC2, RC5, RC6 to szyfry blokowe, natomiast RC4 jest szyfrem strumieniowym. Co ciekawe, niemal od samego początku swego istnienia posiadały specjalny status eksportowy USA dla kluczy 40b lub 56b (dla instytucji powiązanych z interesami USA). Dziś są powszechnie wykorzystywane w Lotus Notes, Apple OCE (Open Collaboration Enviromnent), Oracle, protokołach SSL i S-HTTP, sieciach bezprzewodowych i komórkowych.
Algorytmy z rodziny CAST
Określenie CAST opisuje schemat zastosowany w rodzinie zbliżonych do DES algorytmów kryptograficznych o zmiennej długości kluczy i bloków. Najpowszechniej znany reprezentant to szyfr CAST-128 opublikowany w 1997 [RFC 2144].
Algorytm SAFER
To algorytm blokowy opracowany przez kolejną ważną postać kryptografii komputerowej - Jamesa L. Masseya. Popularne są: wersja z kluczem 64b (SAFER-K64) obejmująca 6 rund oraz wersja z kluczem 128b (SAFER-K128) - do 12 rund (rekomendowane 10).
Algorytm Blowfish
Algorytm Blowfish, bardzo popularny zwłaszcza w produktach open source, został opracowany w 1994 r. przez Bruce'a Schneiera. Blok danych ma 64 bity, a klucz podstawowy długość do 448b. W algorytmie występuje 16 iteracji wykorzystujących 18 kluczy pomocniczych (wyznaczanych każdorazowo przed szyfrowaniem i deszyfrowaniem) i 4 S-bloki 256-elementowe o wartościach zależnych od: klucza podstawowego, danych oraz liczby \(\pi\). Deszyfrowanie jest operacją identyczną z szyfrowaniem - jedynie odwrotna zostaje kolejność kluczy pomocniczych.

Szyfrowanie asymetryczne
Istotą szyfrowania asymetrycznego jest wyodrębnienie dwóch kluczy o odmiennych rolach: klucz prywatny i klucz publiczny. I tak przyjmiemy dalej iż odbiorca Bolek posiada parę kluczy: prywatny klucz kb oraz publiczny klucz KB. Z założenia klucz prywatny jest tajny znany wyłącznie właścicielowi. Publiczny klucz, natomiast, może być powszechnie znany. Aby przekazać zaszyfrowaną postać wiadomości do tego odbiorcy należy zaszyfrować wiadomość czytelną jego kluczem publicznym. Odszyfrowanie jest możliwe tylko przy użyciu klucza prywatnego, odpowiadającego użytemu uprzednio kluczowi publicznemu.
Operacje szyfrowania opisuje zatem ogólny wzór:
\(E_K_B [M] = S\)
a deszyfrację:
\(D_k_b [S] = M\)
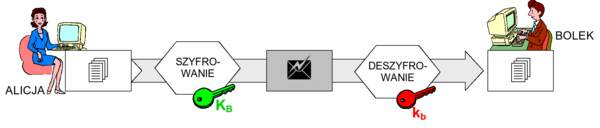
Rysunek '12'. Ogólny schemat szyfrowania asymetrycznego
Istotne jest iż znajomość klucza publicznego KB nie wystarcza do naruszenia poufności szyfrogramu uzyskanego przy zastosowaniu tego klucza.
Szyfrowanie asymetryczne idealnie nadaje się do zastosowania w następujących celach:
- zapewnienie poufności (rys. 13)
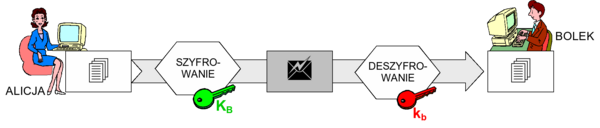
Rysunek '13'. Ogólny schemat zapewnienia poufności w szyfrowaniu asymetrycznym
- zapewnienie autentyczności (rys. 14)
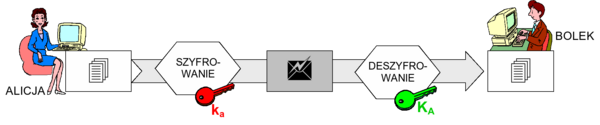
Rysunek '14'. Ogólny schemat zapewnienia autentyczności w szyfrowaniu asymetrycznym
Przykłady algorytmów asymetrycznych
Algorytm RSA (Rivest–Shamir–Adleman)
Algorytm RSA został opublikowany w 1978 roku przez Ronalda Rivesta, Adi Shamira i Leonarda Adlemana. Niedawno wygasła jego ochrona patentowa. Algorytm ten pozwala w zasadzie dowolnie ustalić długość klucza. Wymaga użycia 2 dużych liczb pierwszych (przez duże rozumiemy tu liczby co najmniej stucyfrowe w systemie dziesiętnym). Do szyfrowania i deszyfrowania wykorzystuje operacje potęgowania dyskretnego. W efekcie wymaga dużej liczby działań arytmetycznych (jest zdecydowanie wolniejszy od DES - nawet do 1000 razy).
Dobór kluczy jest najbardziej istotnym elementem pracy algorytmu. Schematycznie przedstawia ją rysunek 15.

Rysunek '15'. Ogólny schemat pracy algorytmu RSA
Schemat ten wymaga następujących wyjaśnień:
- liczba względnie pierwsza z (p-1) i (q-1) to inaczej Wykładnik Uniwersalny: dzieli się tylko przez 1, siebie oraz (p-1) i (q-1), czyli Najmniejsza Wspólna Wielokrotność, albo inaczej: Największy Wspólny Dzielnik (e, (p-1)(q-1)) = 1
- odwrotność e można łatwo wyznaczyć rozszerzonym algorytmem Euklidesa.
Złamanie tak ustalonego klucza wymagałoby znalezienia efektywnej metody faktoryzacji dużych liczb - póki co takowa nie istnieje.
Algorytm ElGamala (ELG)
Algorytm ten został opublikowany w 1985 roku, ale nie jest chroniony patentem. Brak również w jego przypadku ograniczeń eksportowych USA - wykorzystuje koncepcję (i patent) Diffiego-Helmana lecz ów patent wygasł w 1997 r. Szyfrowanie wymaga każdorazowo losowo wybranej wartość k, dlatego też ten sam tekst jawny każdorazowo daje inny szyfrogram. Niestety wadą tego algorytmu jest fakt, iż szyfrogram jest dwukrotnie dłuższy od tekstu jawnego.
Generowanie kluczy przebiega następująco:
- wybieramy losowo liczbę pierwszą p
- wykorzystujemy multiplikatywną grupę modulo p - \(\mathbb{Z}_p^*\)
- gdzie p jest liczbą pierwszą, a \(\mathbb{Z}_p\) jego ciałem skończonym (\(GF(p) lub \mathbb{Z} /p \mathbb{Z}\))
- wybieramy liczbę g, która jest elementem pierwotnym (generatorem) grupy \(\mathbb{Z}_p^*\)
- generator - generuje ciąg \(1, g, g^2, g^3, ...\)
- z którego tylko skończenie wiele należy do \(\mathbb{Z}_p^*\) (potem zaczną się powtarzać modulo p)
- w ogólności mamy q elementów: \(1, g, g^2, ... , g^{q-1} (g^q \bmod p = 1)\)
- istnieje przynajmniej jedno g generujące całą grupę! (tzn. \(q = p-1\))
- czyli zamiast 1, ..., p-1 możemy grupę traktować jako \(1, g, g^2, ... , g^{p-2}\)
W dalszej kolejności:
- wybieramy losowo liczbę \(x<p\)
- obliczamy \(y=q^x \bmod p\)
- klucz publiczny stanowią y, g i p - zarówno g, jak i p mogą być wspólnie wykorzystywane przez grupę użytkowników (mod p)
- kluczem prywatnym jest x
Szyfrowanie przebiega następująco:
- wybieramy losowo liczbę k względnie pierwszą z p
- obliczamy \(a=g^k \bmod p\)
- obliczamy \(b=y^k \cdot M \bmod p\)
- szyfrogram to para (a,b)
Deszyfrowanie przebiega następująco:
- \(M=b/a^x \bmod p\)
- ponieważ \(a^x \equiv g^{kx} \bmod p\)
- \(b/a^x \equiv y^k \cdot M/a^x \equiv g^{xk} \cdot M/g^{kx} \equiv M \bmod p\)
Literatura
[1] Janusz Stokłosa, Tomasz Bilski, Tadeusz Pankowski, "Bezpieczeństwo danych w systemach informatycznych", PWN, 2001
Zadania
- Na czym polega kodowanie ROT-13 powszechnie wykorzystywane w Internecie?
- Na czym polega i do czego służy kodowanie MIME?
- Jaki będzie szyfrogram dla przykładu z rysunku 3, w przypadku użycia klucza k = (5,4;2-5-3-1-4)?
- Wektor inicjujący IV powinien być każdorazowo unikalny, ale nie musi być tajny. Dlaczego?
- Dlaczego wersja 40b algorytmu DES była od początku wolna od ograniczeń eksportowych?
Wykorzystanie kryptografii
Wykorzystanie kryptografii
Bieżący moduł przedstawia koncepcje związane z wykorzystaniem mechanizmów kryptograficznych w systemach informatycznych.
Potwierdzanie autentyczności danych
Szyfrowanie asymetryczne, jak już wiemy z poprzedniego modułu, można wykorzystać do osiągnięcia własności autentyczności danych. Zastosować można potencjalnie 2 metody przedstawione poniżej.
Metoda 1:
- szyfrujemy całą wiadomość kluczem prywatnym nadawcy
- kosztowne obliczeniowo - koszt rośnie z wielkością wiadomości
Metoda 2:
- tworzymy skrót wiadomości o ustalonym z góry rozmiarze n
- szyfrujemy kluczem prywatnym nadawcy tylko skrót
- koszt mały - n małe
- koszt stały - nie rośnie z wielkością wiadomości i zależy tylko od n
Druga metoda wykorzystuje pojęcie skrótu, który jest wynikiem zastosowania pewnej funkcji matematycznej na treści wiadomości. Funkcja skrótu to jednokierunkowa funkcja \(h[M]\), a więc taka, która daje jednoznaczny wynik \(d=h[M]\) (skrót, ang. message digest, fingerprint) o stałym rozmiarze, przy wieloznacznym argumencie (M). Jej zadaniem w naszym przypadku jest dostarczyć odbiorcy narzędzia do zweryfikowania czy treść wiadomości nie została zmodyfikowana, przez osoby niepowołane.
W istocie, w dziedzinie transmisji danych skróty wiadomości, lub ich odpowiedniki, powszechnie wykorzystywane są w celu potwierdzania integralności wiadomości od lat 70-tych ubiegłego wieku, choć zwykle ukrywają się pod różnymi nazwami:
- suma kontrolna (checksum) - negatywne potwierdzenia, retransmisje
- funkcja kontrolna (data integrity check)
- funkcja kontrolna wiadomości (message integrity check)
- funkcja ściągająca (contraction function)
- kod uwierzytelniający informacji (data authentication code)
Własności jakie musi posiadać odpowiednia dla nas funkcja skrótu to:
- kompresja: oznaczająca, że rozmiar skrótu musi być mniejszy od rozmiaru samej wiadomości \(|d|<|M|\)
- łatwość obliczeń: czas wielomianowy wyznaczenia \(h[M]\) dla dowolnego \(M\)
- odporność na podmianę argumentu: dla danego \(h[M]\) obliczeniowo trudne znalezienie \(M^\prime\) takiego, że \(h[M] = h[M^\prime]\)
- odporności na kolizje: obliczeniowo trudne znalezienie dwóch dowolnych argumentów \(M \neq M^\prime\) takiego, że \(h[M] = h[M^\prime]\)
Zastosowania funkcji skrótu mogą obejmować:
- zapewnienie integralności wiadomości bez klucza kryptograficznego
- zapewnienie integralności oraz autentyczności wiadomości: MAC - message authentication code (z kluczem kryptograficznym)
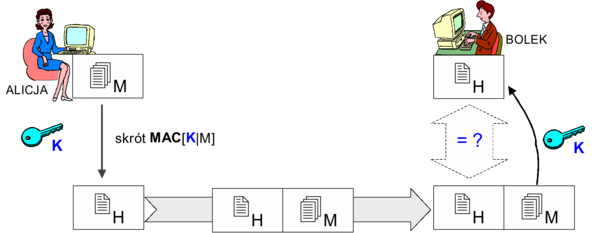
Rysunek '1'. Zastosowanie funkcji skrótu
Podpis cyfrowy
Funkcje skrótu można wykorzystać do zrealizowania ciekawego i niezwykle ważnego narzędzia, jakim jest podpis cyfrowy. Najczęściej wykorzystywana jest w tym celu jest funkcja mieszająca HMAC z kluczem k asymetrycznym (keying hash function) - \(h_k[M]\). Wartość skrótu HMAC jest zaszyfrowana kluczem prywatnym nadawcy, być może dodatkowo z wykorzystaniem ziarna (salt) lub zawołania (challenge).
Proces generowania i weryfikowania podpisu HMAC z kluczem przedstawia rysunek 2. Nadawca (Alicja) po przygotowaniu wiadomości M przygotowuje jej skrót H, który poddaje szyfrowaniu swoim kluczem prywatnym, który z założenia zna i posiada tylko nadawca. Po połączeniu M z zaszyfrowanym skrótem H' całość przekazuje do odbiorcy dowolnym kanałem komunikacyjnym. Tan następuje deszyfracja H' (przy użyciu otwarcie dostępnego klucza publicznego nadawcy) oraz niezależne wyliczenie skrótu H dla otrzymanego M. Porównanie H wyliczonego z odszyfrowanym wskazuje na autentyczność i nienaruszalność wiadomości M lub jej brak. Gdyby M została zmodyfikowana w trakcie transmisji do odbiorcy, wyliczony skrót nie pasowałby do odszyfrowanego z H'. Natomiast, gdyby nadawcą nie była Alicja, posłużenie się jej kluczem publicznym przy odszyfrowaniu H' nie dałoby skrótu identycznego z wyliczony przez odbiorcę H.
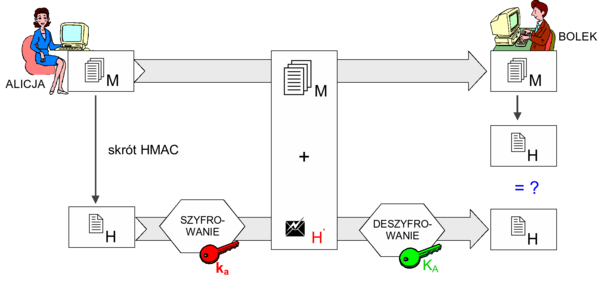
Rysunek '2'. Zastosowanie funkcji skrótu
Osiąganie poufności, autentyczności i nienaruszalności danych
Możliwe jest jednoczesne osiągnięcie własności poufności, autentyczności i nienaruszalności wiadomości. Uzyskuje się to poprzez znane już szyfrowanie (np. asymetryczne) pary M + H' z poprzedniego przykładu, przed przesłaniem do odbiorcy. Przy tym szyfrowaniu musi oczywiście być wykorzystany odpowiedni klucz publiczny odbiorcy. Schemat ten przedstawia rysunek 3.
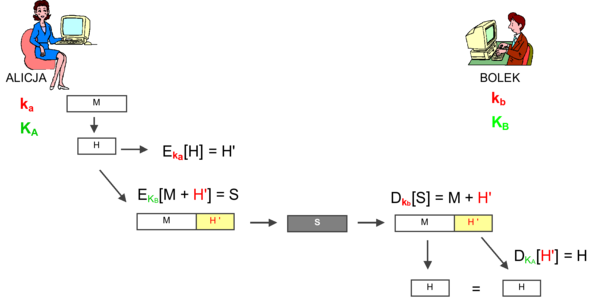
Rysunek '3'. Osiąganie poufności, autentyczności i nienaruszalności
Algorytmy skrótu
Pierwsze z powszechnie stosowanych algorytmów generowania skrótu na potrzeby ochrony autentyczności i nienaruszalności informacji - MD i MD2 (autorstwa Rona Rivesta) powstały w latach '80. Algorytm MD nie został nigdy oficjalnie opublikowany. Był wykorzystywany jako autorskie rozwiązanie w systemie pocztowym RSADSI. Natomiast MD2 został ustandaryzowany w dokumencie RFC 1319. W 1990 Ralph Merkle (Xerox) zaproponował algorytm HMAC o nazwie SNEFRU - kilkukrotnie szybszy od MD2. Na to Rivest odpowiedział algorytmem MD4 (RFC 1320). WWwww W roku 1992 złamano SNEFRU i wykryto pewną słabość MD4 w wersji 2-rund i wkrótce Rivest wzmocnił algorytm otrzymując trochę wolniejszy MD5 (RFC1321).
Algorytm MD5
Algorytm MD5 posiada następujące cechy charakterystyczne:
- wykorzystuje 128b wektor IV
- wykonuje 64 iteracje (4 rundy po 16 kroków)
- daje skrót 128b
- teoretyczna odporność na kolizje 264 jest współcześnie uznawana za zbyt słabą
Algorytm SHA (Secure Hash Algorithm)
Algorytm SHA został opracowany przez NSA (National Security Agency) i przyjęty przez NIST jako standard federalny w 1993r. Wersja oryginalna SHA (SHA-0) jest zbliżona do MD4. Algorytm ten posiada następujące cechy charakterystyczne:
- przekształca wiadomość o długości do 264b w skrót 160b
- wykorzystuje 160b wektor IV
- wykonuje 80 iteracji (4 rundy po 20 kroków)
Stosunkowo szybko wykryto słabości SHA-0 (choć ich natury nigdy nie opublikowano) i opracowano SHA-1 (ratyfikowany przez NIST), który jest często spotykany do dziś. Wykazuje odporność na kolizje 160b skrótu - 280 , która jest współcześnie uznawana również za zbyt słabą.
Algorytmy SHA-256 / SHA-384 / SHA-512
Niedawno zaproponowano zupełnie nowe funkcje skrótu: SHA-256, SHA-384 oraz SHA-512, przystosowane do współpracy z kluczami AES (odpowiednio 128b, 192b i 256b). Dają skróty odpowiednio 256b, 384b i 512b. Nie doczekały się jeszcze szerszej analizy jednak dość powszechnie uznawane są za bezpieczne. Mają większą złożoność obliczeniową od poprzedników wymienionych wyżej. W praktyce okazuje się, iż algorytm SHA-384 ma identyczny koszt obliczeniowy co SHA-512, co czyni SHA-384 w praktyce bezużytecznym. Powszechnie spotykane są zatem jedynie SHA-256 oraz SHA-512.
Algorytm RIPE-MD
Algorytm ten powstał w ramach europejskiego (EU) projektu RACE Integrity Primitives Evaluation - Message Digest. W uproszczeniu mówiąc jest to ulepszony wariant MD4 (zmodyfikowane rotacje i kolejność słów wiadomości) Oferuje skrót 128b. Wykorzystuje rejestr strumieniowy. Podczas generowania skrótu wykonuje równoległe 2 przebiegi (za każdym razem z innym zadanym parametrem) w każdej iteracji. Po każdej iteracji oba wyniki łączone z rejestrem strumieniowym. Prawdopodobnie posiada dużą odporność na ataki.
Algorytm HAVAL
Algorytm HAVAL generuje skrót o zmiennej długości: 128b, 160b, 192b, 224b lub 256b. Można i jego uznać za wariant MD4, względem oryginału zmodyfikowano operacje rotacji. Stosuje wyrafinowane funkcje nieliniowe (o własności lawinowości), w każdej iteracji wykonuje inne permutacje. I posiada prawdopodobnie duża odporność na ataki.
Algorytm ElGamal
Ostatnim z wymienionych algorytmów jest ElGamal. Algorytm ten początkowo opracowano właśnie dla realizacji podpisu cyfrowego HMAC. Podpisem wiadomości M jest para (a, b), taka że:
\(a=g^k \bmod p\)
\(b:: M = (xa + kb) \bmod p-1\)
Weryfikacja podpisu cyfrowego następuje pomyślnie jeśli \((y^a a^b) \bmod p == g^M \bmod p\).
Standardy podpisu cyfrowego
W systemach informatycznych powszechnie spotykane są standardy podpisu cyfrowego opracowane w USA. Należą do nich starszy DSS i nowszy SHS
Standard DSS (Digital Signature Standard)
DSS jest to standard NIST z kategorii FIST (Federal Information processing STandard) w wersjach z 1991 i 1993 roku. Obejmuje użycie skrótu SHA-1 oraz algorytmu DSA (Digital Signature Algorithm).
Standard SHS (Secure Hash Standard)
Standard SHS to nowszy projekt NIST z 2001. Obejmuje użycie rodziny SHA-256 / SHA-384 / SHA-512.
Ataki na funkcje skrótu
Najpowszechniej znanym atakiem na funkcje skrótu jest atak urodzinowy. Poniżej przedstawiona zostanie koncepcja tego ataku.
Atak urodzinowy
Paradoks dnia urodzin po lega na dokonaniu następujących obserwacji:
Obserwacja 1:
- pytanie: ile osób potrzeba na tej sali, aby z prawdopodobieństwem 50% znalazła się wśród nich taka, która obchodzi urodziny tego samego dnia co autor tych slajdów? (funkcja mieszająca odwzorowuje zbiór ludzi na 365 lub 366 dni roku)
- odpowiedź: oczywiście 183.
Obserwacja 2:
- pytanie: a ile potrzeba osób, aby wśród nich znalazły się 2 obchodzące urodziny tego samego dnia?
- odpowiedź: tylko 23.
Uogólnienie tego paradoksu przebiega następująco. Mamy dany rozmiar n danych wejściowych (ludzi - w przykładzie urodzin) oraz rozmiar k zbioru wynikowego (daty urodzin). Dla n mamy możliwych n(n-1)/2 par danych wejściowych i dla każdej pary oba elementy dadzą ten sam wynik z prawdopodobieństwem 1/k. Zatem, potrzeba k/2 par aby z prawdopodobieństwem 50% wśród nich była taka jak szukamy - gdzie oba elementy mają tę samą wartość wyniku (datę urodzin). W efekcie jeśli \(n>\sqrt{k}\) to szanse powodzenia są duże. Dla skrótu 128b potrzeba 2128 wiadomości aby znaleźć tę, która dała określony skrót, ale wystarczy 264 wiadomości aby znaleźć 2 o identycznym skrócie (znaleźć tzw. kolizję).
Jako komentarz można podać, iż w połowie 2004 r. zespół kryptoanalityków pod kierunkiem Xuejia Lai wykazał zaskakujące kolizje w MD5 podając 2 ciągi po 128 B różniące się zaledwie 6-cioma bajtami. Natomiast na początku 2005 r. zespół kierowany przez Xiaoyuna Wanga wykazał w rodzinie SHA kolizje łatwiejsze niż należy oczekiwać z teoretycznej odporności. Mianowicie w przypadku SHA-1: kolizje dla 269 operacji (przy teoretycznej 280), dla SHA-1 w uproszczonej wersji (58-rund): kolizje dla 233 operacji i dla SHA-0: kolizje dla 239 operacji.
Zarządzanie kluczami
W procesie pozyskiwania i wykorzystania kluczy kryptograficznych występują pewne istotne problemy. Należą do nich poniższe:
problem przekazania klucza
- jak partnerowi komunikacji przekazać w sposób bezpieczny klucz niezbędny do szyfrowania / deszyfrowania?
problem zmiany klucza
- jak go regularnie zmieniać?
problem doboru systemu szyfrowania
- czy wybrać tajny klucz symetryczny? - występuje w tym przypadku, jak pamiętamy, problem skalowalności: 10 osób = 45 kluczy, 100 osób = 4950 kluczy
- czy raczej wybrać publiczny klucz asymetryczny? - tu występuje problem autentyczności skąd pewność jego prawdziwości
Nie istnieje uniwersalne rozwiązanie wszystkich wymienionych problemów, jednak poniżej przedstawiona metoda zaproponowana przez Whitfielda Diffiego i Martina Hellmana jest częściowym rozwiązaniem problemu przekazania klucza. Jest to metoda ciekawa i powszechnie spotykana, dlatego warta bliższego poznania.
Metoda Diffiego-Hellmana (DH)
Metoda Diffiego-Hellmana pozwala partnerom uzgodnić tajny klucz bez ryzyka ujawnienia go podsłuchującym. Początkowo ustalamy wspólny jednorazowy symetryczny klucz sesji (dla każdej sesji inny). Na potrzeby ustalenia klucza sesji wykorzystamy model asymetryczny.
DH wykorzystuje multiplikatywną grupę modulo p - oznaczaną \(\mathbb{Z}_p^*\).
Przez \(\alpha\\) oznaczmy element pierwotny grupy \(\mathbb{Z}_p^*\). Zatem \(\alpha\\) generujące całą grupę.
Czyli zamiast 1, ..., p-1 możemy grupę traktować jako 1, \(\alpha\, \alpha^2, ... , \alpha^{p-2}\).
Schemat postępowania w metodzie DH przedstawia rysunek 4.
Każdy z użytkowników wybiera sobie w nieistotny sposób wartość klucza prywatnego k. Natomiast klucz publiczny K dobiera jako \(\alpha^k\). Klucz ten jest swobodnie i otwarcie przykazywany drugiej stronie komunikacji.
Klucz sesji dobierany jest przez każdą ze stron w taki sposób, że obie uzyskują identyczną wartość \(\Phi\\), przy czym przechwycenie obu transmitowanych kluczy publicznych nie wystarcza do jego uzyskania.
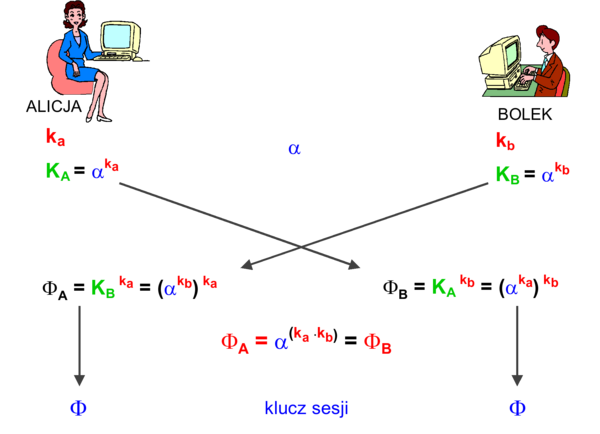
Rysunek '4'. Schemat postępowania w metodzie DH
Metoda D-H nie jest, jak już zaznaczono, idealnym rozwiązaniem. Jest m.in. podatna n atak man-in-the-middle. Przyjmijmy, iż Edziu, znając \(\alpha\\), może skutecznie wkroczyć na etapie negocjacji klucza. Alicja i Bolek będą porozumiewać się poprzez Edzia za pomocą kluczy,
które - jak im się będzie wydawać - wymienili ze sobą.
Dystrybucja kluczy publicznych
Rozważmy możliwe sposoby pozyskiwania kluczy publicznych szyfrowania asymetrycznego. Istnieją następujące warianty:
- pobranie klucza bezpośrednio od właściciela
- pobranie klucza z centralnej bazy danych
- pobranie z własnej prywatnej bazy danych zapamiętanego wcześniej klucza pozyskanego sposobem 1 lub 2
Należy zwrócić uwagę, iż w ogólności istnieje ryzyko podstawienia przez nieuczciwą osobę (atakującego) własnego klucza pod klucz domniemanego użytkownika.
Rozwiązaniem tego problemu, które zyskało dotychczas największą akceptację jest certyfikacja kluczy publicznych.
Certyfikacja
Certyfikację stosuje się w celu uniknięcia podstawienia fałszywego klucza publicznego. Certyfikat jest poświadczeniem autentyczności podpisanym przez osobę (instytucję) godną zaufania, nazywaną urzędem poświadczającym CA (Certification Authority). certyfikat ma najczęściej formę dokumentu elektronicznego. Certyfikat zawiera podstawowe dane identyfikujące właściciela. W ogólnym przypadku, urząd poświadczający CA potwierdza, iż informacja opisująca właściciela klucza jest prawdziwa, a klucz publiczny faktycznie do niego należy. Certyfikat posiada też okres ważności wyznaczający czas przez który certyfikowane dane można uważać za poprawne. Niezależnie od okresu ważności certyfikowane klucze mogą zostać uznane za niepoprawne, np. gdy zaistnieje podejrzenie, iż ktoś nieuprawniony wszedł w posiadanie tajnego klucza prywatnego, odpowiadającego certyfikowanemu kluczowi publicznemu. Urząd poświadczający CA musi przechowywać listę niepoprawnych i nieaktualnych certyfikatów. Oczywiście, unieważnienie klucza jest także rodzajem certyfikatu.
Struktura podstawowa typowego certyfikatu jest przedstawiona na rysunku 5. Oprócz wymienionych tam pól poszczególne certyfikaty mogą zawierać dodatkowe, specyficzne dla konkretnego urzędu CA lub zastosowań, do których certyfikaty są przeznaczone. Przykłady rzeczywistych certyfikatów możemy znaleźć w każdej przeglądarce internetowej.
Jednym z najpopularniejszych współcześnie rodzajów certyfikatów są te zgodne ze standardem ITU-T X.509. Budowa certyfikatu X.509 v.3 obejmuje szereg elementów. Należą do nich:
- struktura podstawowa uzupełniona o zestaw danych identyfikacyjnych podmiotu certyfikatu
- sposób wykorzystania klucza (przeznaczenie, np. do szyfrowania danych, do szyfrowania kluczy, do uzgadniania kluczy, do podpisywania danych, do osiągnięcia niezaprzeczalności)
- informacje o polityce certyfikacji wydawcy certyfikatu (np. ograniczenia długości ścieżki certyfikacji, punkty dystrybucji list certyfikatów unieważnionych).
Ponadto istnieje opcjonalna możliwość tworzenia dodatkowych pól / parametrów identyfikacyjnych, wg potrzeb komunikujących się podmiotów.

Rysunek '5'. Schematyczna struktura typowego certyfikatu
Dystrybucja kluczy przy wykorzystaniu certyfikatów przebiega następująco:
- w celu uzyskania certyfikatu użytkownik zwraca się do urzędu certyfikującego CA dostarczając mu swój klucz publiczny
- do zweryfikowania certyfikatu niezbędny jest tylko i wyłącznie klucz publiczny urzędu certyfikującego
- alternatywnie użytkownik może przesłać swój certyfikat do innych użytkowników z prośbą o poświadczenie jego autentyczności.
W tym ostatnim przypadku mówimy o systemie wzajemnej certyfikacji (sieci wzajemnego zaufania, ang. web of trust). Certyfikat użytkownika, dajmy na to - Alicji, poświadcza (podpisuje) z reguły kilko (kilkunastu) użytkowników. Jeśli po pobraniu przez Bolka, stwierdza on, że wśród podpisów znajdują się jakieś należące do zaufanych mu osób, uznaje on certyfikat za poświadczony.
Zarówno rozwiązania instytucjonalne z urzędami certyfikującymi, jaki i system wzajemnego zaufania mają swoich zwolenników.
W każdym przypadku istnieje dylemat, komu na tyle zaufać, aby mógł być on w pełni wiarygodny i poświadczać (wydawać) certyfikaty? Problem ten dotyczy przede wszystkim pierwszego kontaktu, zwłaszcza w relatywnie anonimowej sieci globalnej Internet, gdzie wzajemne kontakty, „w cztery oczy", nie są raczej najbardziej typowym sposobem komunikacji. Skąd zatem pewność, że certyfikat został pobrany z właściwego urzędu, czy że podpisy poświadczające jego autentyczność rzeczywiście są godne zaufania. ile może istnieć instytucji cieszących takim zaufaniem, iż certyfikaty przez nie podpisane możemy śmiało uznawać za rzetelnie zweryfikowane i autentyczne.
Rozwiązaniem tego problemu jest system, w którym certyfikat musi przebyć pewną kilkuetapową procedurę uwierzytelniającą, a urzędy CA mogą tworzyć wielopoziomową hierarchię. Urzędy danego poziomu hierarchii wystawiają certyfikaty kluczy publicznych urzędom lub użytkownikom znajdującym się na niższym poziomie. Na szczycie znajduje jeden z nielicznych urzędów centralnych, który swym powszechnie uznanym autorytetem ostatecznie poświadcza poprawność całej procedury uwierzytelniającej certyfikat.
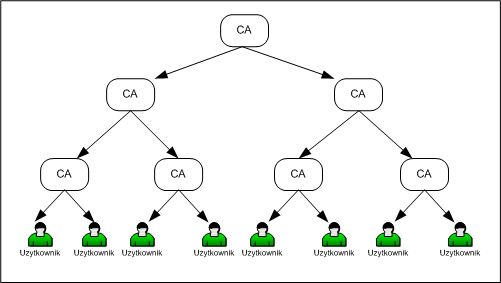
Rysunek '6'. Hierarchia urzędów poświadczających
Taka hierarchia urzędów poświadczających jest podstawą funkcjonowania niezwykle ważnego współcześnie mechanizmu informatycznego - infrastruktury kluczy publicznych - PKI (Public Key Infrastructure). Infrastruktura kluczy publicznych obejmuje sprzęt, oprogramowanie, ludzi, polityki bezpieczeństwa i procedury konieczne do utworzenia, zarządzania, przechowywania, dystrybucji i unieważniania certyfikatów kluczy publicznych w skali najczęściej ogólnonarodowej lub światowej. PKI oferuje często dodatkowe certyfikaty, np. Certyfikaty Znacznika Czasu (dla wiarygodnego potwierdzania czasu). W sieci Internet, PKI wykorzystuje specyfikację X.509 (PKIX, RFC 2459).
PKI jest hierarchicznym systemem urzędów certyfikujących oferujących publicznie swoje usługi. Do usług tych należy między innymi:
- weryfikacja tożsamości użytkowników ubiegających się o certyfikaty
- zarządzanie kluczami kryptograficznymi
- generowanie par kluczy dla użytkowników
- bezpieczne przechowywanie kluczy
- zarządzanie certyfikatami
- wystawienie certyfikatów kluczy publicznych
- generowanie list certyfikatów unieważnionych CRL (Certificate Revocation List)
Komponenty systemu PKI to:
- urzędy CA
- punkty rejestrujące, poręczające zgodność kluczy z identyfikatorami (lub innymi atrybutami) posiadaczy certyfikatów
- użytkownicy certyfikatów podpisujący cyfrowo dokumenty
- klienci weryfikujący podpisy cyfrowe i ścieżki certyfikacji do zaufanego CA
- repozytoria przechowujące i udostępniające certyfikaty i listy unieważnień.
Repozytoriami certyfikatów i list unieważnień mogą być np.:
- serwery LDAP
- respondery OCSP
- serwery WWW
- serwery FTP
- serwery DNS (DNSsec)
- agenci systemu katalogowego X.500 (DSA - Directory System Agents)
- korporacyjne bazy danych
Mimo wysokiej przydatności systemów PKI, nie wszystkie problemy związane z certyfikacją zostały w pełni rozwiązane. Pozostaje przykładowo problem jednoznacznej identyfikacji podmiotu - jaki jest adekwatny kompromis pomiędzy pełnymi danymi identyfikującymi a prywatnością podmiotu? Rozwiązanie tego problemu na ogół przybliża się wprowadzając różne klasy certyfikacji o różnym poziomie zaufania.
Inny problem to problem pierwszego certyfikatu - jak bezpiecznie certyfikować CA? Możliwym rozwiązaniem jest wzajemna certyfikacja różnych urzędów z PKI. Wielość hierarchicznych ośrodków certyfikacji umożliwia współpracę pomiędzy niezależnymi strukturami, również w zakresie wzajemnej certyfikacji. Innym powszechnie spotykanym rozwiązaniem są certyfikaty wybranych urzędów najwyższego poziomu hierarchii wbudowane na stałe w aplikacje (przeglądarki WWW, np. Netscape Navigator ma ponad 30 predefiniowanych certyfikatów urzędów CA). Wówczas, zakładając, iż integralność wersji binarnej aplikacji dystrybuowanej przez producenta nie została naruszona (co, notabene, można weryfikować również technikami kryptograficznymi), można przyjąć autentyczność kluczy publicznych zawartych w tych wbudowanych certyfikatach i bezpiecznie się nimi posługiwać do potwierdzania autentyczności urzędów niższego szczebla hierarchii.
Mechanizmem pobierania certyfikatów CA powszechnie uznanym za standardowy jest przekazywanie ich jako typ MIME application/x-x509-ca-cert. Z kolei do popularnych protokołów wymiany informacji niezbędnych do właściwego zarządzania infrastrukturą kluczy publicznych zaliczyć można CMP (Certificate Management Protocol) oraz SCVP (Simple Certificate Validation Protocol).
W myśl polskiego ustawodawstwa wyróżnia się dwa rodzaje certyfikatów:
Certyfikaty zwykłe (tzw. powszechne)
- obejmują takie zastosowania jak szyfrowanie danych, poczta, www, urządzenia sieciowe, oprogramowanie
Certyfikaty kwalifikowane:
- wywołują skutki prawne równoważne podpisowi własnoręcznemu
(Ustawa z dn. 18.09.2001 o podpisie elektronicznym) - przeznaczone dla osób fizycznych, wydawane na podstawie umowy i po (osobistej) weryfikacji tożsamości w Punkcie Rejestracji CA
- znajdują zastosowanie w każdym przypadku składania oświadczenia woli (również e‑faktury)
- nie służą do szyfrowania dokumentów
W naszym kraju istnieje wiele urzędów certyfikacji. Jedne z najstarszych to np.:
- Unizeto Certum www.certum.pl
- Signet www.signet.pl
- Sigillum www.sigillum.pl
Kryptograficzne zabezpieczenie danych
Współcześnie dostępna jest ogromna ilość aplikacji szyfrowania plików i całych katalogów (fragmentów systemu plików). Można tu wymienić np. moduł jądra Linux loop-AES (od wersji 2.4 jądra nosi nazwę cryptoloop). Oferuje on szyfrowanie całego systemu plików na poziomie jądra za pomocą urządzenia blokowego /dev/loop[1-8]. Przykładowe polecenie montowania zaszyfrowanego systemu plików pokazuje poniższa komenda powłoki systemu operacyjnego:
mount -t ext3 crypto.raw /mnt/crypto -oencryption=aes-256
Innym przykładem środowiska szyfrowania plików jest EncFS. Tworzy ono z wybranego katalogu wirtualny system plików w przestrzeni użytkownika, korzystając ze standardowego modułu jądra FUSE (Filesystem in USErspace). Przykładowe wywołanie operacji tego środowiska jest przedstawione poniżej:
encfs ~/.crypto.vfs ~/tajne_dane
Wykonanie tego polecenia za pierwszym razem powoduje utworzenie pliku .crypto.vfs z zaszyfrowanym systemem plików, na podstawie zawartości katalogu tajne_dane. Przy kolejnych wywołaniach następuje podmontowanie .crypto.vfs z do katalogu tajne_dane. Odmontowanie niepotrzebnego już katalogu tajne_dane przebiega standardowo:
fusermount -u ~/tajne_dane
W systemie MS Windows z kolei zawarty jest moduł EFS (Encrypted File System), działający na partycjach NTFS od wersji Windows 2000. EFS działa jako usługa systemowa - przeźroczyście dla aplikacji użytkownika. Usługa ta wykorzystuje algorytm DESX, będący autorską odmianą 3DES firmy Microsoft. Przykład uaktywnienia funkcji szyfrowania pliku poprzez graficzny interfejs użytkownika pokazuje rysunek 7.
Występują dwa rodzaje kluczy EFS tworzonych automatycznie przy pierwszym uaktywnieniu usługi (rysunek 8):
- klucz właściciela pliku przechowywany w certyfikacie użytkownika (na rysunku należy do użytkownika Administrator)
- klucz uniwersalny usługi systemowej odtwarzania danych z kopii zapasowych - Data Recovery Agent (na rysunku również wystawiony przez i dla użytkownika Administrator, lecz nie jest dostępny ani dla niego, ani dla żadnego innego konta poza usługą Data Recovery Agent).
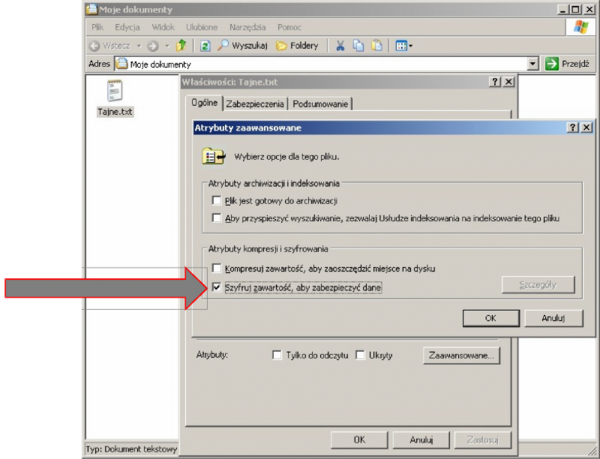
Rysunek '7'. Uaktywnienie funkcji szyfrowania pliku w MS Windows
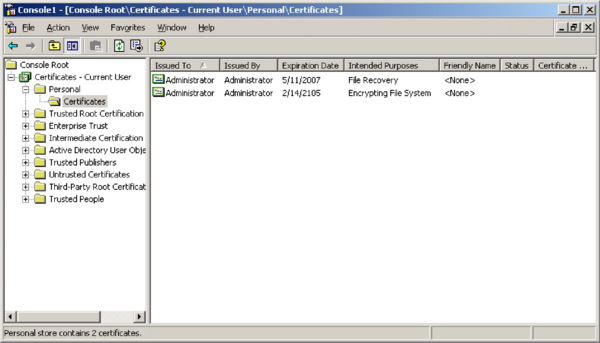
Rysunek '8'. Uaktywnienie funkcji szyfrowania pliku w MS Windows
Ponadto istnieje wiele narzędzi kryptograficznego zabezpieczania komunikacji. Do najpopularniejszych rozwiązań należą protokoły komunikacyjne:
- SSH (Secure Shell)
- SSL (Secure Sockets Layer) i TLS (Transport Layer Security)
- PCT (Private Communication Technology)
oraz komponenty aplikacji użytkowych, takie jak:
- dla poczty elektronicznej: PGP, PEM, S/MIME, MIME/PGP, MSP
- dla usługi www: S-HTTP
- dla systemów e-commerce: SET (Secure Electronic Transactions).
Rozwiązania te i ich implementacje będą szerzej przedstawione w następnych modułach.
Zadania
- Dlaczego nadal wykorzystywane są oba systemy kryptograficzne: symetryczny i asymetryczne? Inaczej mówiąc: dlaczego szyfrowanie asymetryczne, oferujące więcej własności bezpieczeństwa, nie wyparło całkowicie szyfrowania symetrycznego?
- Rozważmy przypadek szczególny ataku man-in-the-middle na realizację metody D-H: co się stanie jeśli Edziu przechwytując komunikację pomiędzy Alicją i Bolkiem zastąpi \(K_A=\alpha^{ka}\) oraz \(K_B=\alpha^{kb}\) przez wartość 1?
Podstawowe problemy bezpieczeństwa sieci komputerowych
Bieżący moduł przedstawia wybrane zagadnienia bezpieczeństwa związane bezpośrednio z niedoskonałościami współczesnych technologii sieci komputerowych. Omówione zostaną problemy bezpieczeństwa podstawowych protokołów sieciowych, klasyfikacja i przykłady ataków na środowiska sieciowe, podstawowe metody obrony oraz przykłady narzędzi podnoszących poziom bezpieczeństwa sieci
Rysunek 1 przedstawia schemat prostej sieci komputerowej analizowany w dalszej części modułu jako przykładowy scenariusz ataków na środowisko sieciowe i obrony przed tymi atakami. Rozważać będziemy sieć lokalną hipotetycznego przedsiębiorstwa lub instytucji, obejmującą serwer aplikacyjny, np. z systemem bazy danych zawierającej dane przetwarzane w firmie, zbiór stacji roboczych, na których działają klienckie aplikacje użytkowników wykorzystujące informacje z bazy danych. Oprócz infrastruktury sieci lokalnej wyróżnimy jeszcze łącze do sieci rozległej. Przyjmijmy dla uatrakcyjnienia rozważań, iż jest to sieć publiczna, np. Internet. Utrzymywanie łącza do sieci rozległej może być wymagane chociażby z tego powodu, że pewne ograniczone informacje z bazy danych firma chce publicznie udostępniać swoim klientom poprzez usługę WWW. Oczywiście możliwych jest kilka punktów dostępowych do sieci rozległej, mogą to być np. łącza modemowe, analogowe lub cyfrowe typu xDSL, lub sieci bezprzewodowe z dostępem do Internetu.
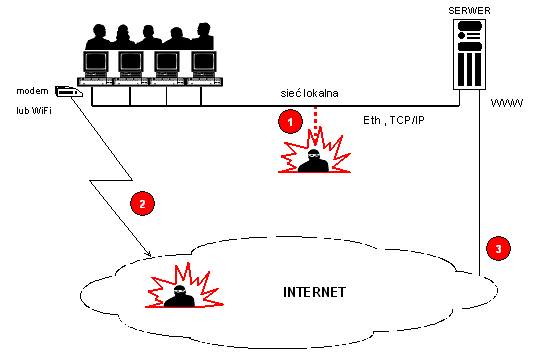
Rysunek 1. Schemat sieci komputerowej analizowany jako scenariusz zagrożeń
Rozważany scenariusz zagrożeń bezpieczeństwa obejmuje następujące przypadki:
- Uzyskanie dostępu do konta w systemie / bazie danych, z czym wiąże się możliwość:
- naruszenia własności poufności / integralności / dostępności przechowywanych w systemie danych
- rekonfiguracji systemu (co w istocie jest też naruszeniem własności integralności)
- Pozyskanie / modyfikacja transmitowanych danych
- naruszenia własności poufności / integralności / dostępności danych transmitowanych między serwerem a stacjami roboczymi
- Rekonfiguracja sieci (urządzeń sieciowych, protokołów) – naruszenie integralności
- Zablokowanie funkcjonowania stacji / urządzeń sieciowych i w efekcie naruszenie własności dostępności informacji
Przyczyn tych zagrożeń należy przede wszystkim szukać w niedoskonałościach technologii sieciowych wykorzystywanych aktualnie. Należy od razu zaznaczyć, niejako tytułem usprawiedliwienia, iż większość tych technologii zostało zaprojektowanych wiele lat temu (pierwotne wersje niektórych rozważanych standardów datują się na wczesne lata 70-te ubiegłego wieku) i do dziś były zaledwie modernizowane na ogół w celu usprawnienia działania, dostosowania do nowych wymagań, a raczej rzadko dla nieznacznego podniesienia bezpieczeństwa.
Obserwując właściwości technologii należących do kolejnych warstw modelu referencyjnego OSI, interesujących odkryć możemy dokonać już w warstwie pierwszej – fizycznej. Poniżej przypomniane zostaną, raczej jedynie hasłowo, tytułem zaakcentowania, najistotniejsze z tych właściwości.
Elementami specyfikacji funkcjonalnej tej warstwy są topologie fizyczne i media komunikacyjne.
Ze względu na własności zarówno poufności, integralności jak i dostępności możemy łatwo uszeregować typowe topologie sieciowe o najmniej do najbardziej bezpiecznej (zastanów się jak wygląda to uszeregowanie). Szczęśliwie najkorzystniej wypada tu najpowszechniej dziś spotykana topologia gwiazdy (przypomnij sobie jej własności).
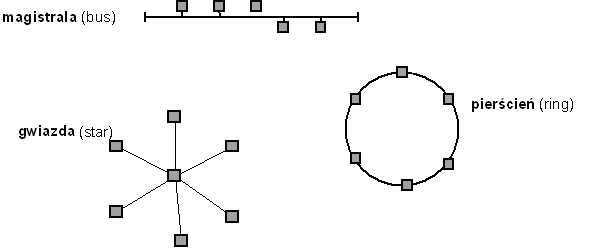
Rysunek 2. Modele typowych topologii sieciowych
Również typowo dziś spotykane media można podobnie uszeregować, od najmniej bezpiecznych z natury – mediów bezprzewodowych, poprzez różne technologie skrętki komputerowej, niechaj wymienić tu: UTP, FTP, STP czy SSTP, aż po światłowód.
W warstwie łącza danych pojawiają się już elementy inteligencji sieciowej – protokoły komunikacyjne. Najistotniejszym współcześnie jest niewątpliwie protokół Ethernet w różnych stosowanych standardach.
Z punktu widzenia bezpieczeństwa architekturę sieci Ethernet wyróżniają następujące cechy:
- ruch niejawnie rozgłoszeniowy, współdzielenie medium (topologia logiczna)
- komunikacja jawnie rozgłoszeniowa (adresy rozgłoszeniowe i grupowe)
- możliwość pracy sterownika sieciowego w trybie diagnostycznym (ang. promiscuous)
- stosowane proste liniowe sumy kontrolne (CRC) dla kontroli integralności transmitowanych ramek
Funkcjonujące w tej warstwie urządzenia sieciowe (mosty i przełączniki) charakteryzują następujące cechy:
- mostowanie transparentne (TB) i źródłowe (SR) i związana z tymi funkcjami selektywna propagacja danych (prosta lecz podatna na nadużycia odmiana filtracji)
- automatyka obsługi dowolnych stacji i współpracy z innymi urządzeniami (np. protokół drzewa rozpinającego STP)
Z racji szczególnej roli wszechobecnej dziś rodziny protokołów TCP/IP, spośród kolejnych warstw modelu OSI najistotniejsze są te, które odwzorowują się najdokładniej na model internetowy. Dotyczy to warstwy sieciowej, transportowej oraz aplikacyjnej.
W warstwie sieciowej szczególną uwagę należy zwrócić na problematykę:
- bezpołączeniowa semantyki i zawodnej transmisji pakietów (datagramów) IP
- mechanizmów zautomatyzowanego wsparcia dla adresacji: ARP, RARP
- funkcjonalności routingu dynamicznego
- kapsułkowania (kopertowania) pakietów.
Zagadnienia dotyczące warstwy sieciowej są na tyle ważne, iż wymienione wyżej problemy zostaną omówione szerzeń w dalszej części bieżącego modułu. Wcześniej jednak podkreślone zostaną istotne cechy pozostałych ważnych warstw.
Warstwa transportowa cechuje się funkcjonalnością której najistotniejsze elementy określa się mianem sterowania przepływem.
Natomiast w warstwie aplikacyjnej pojawiają się problemy związane z niedoskonałościami popularnych protokołów (telnet, ftp, SMTP, POP, IMAP) na ogół nie dysponujących mechanizmami ochrony poufności oraz integralności i stosującymi mało wiarygodne mechanizmy uwierzytelniania.
Warstwa sieciowa
Protokół IP, jest najpowszechniej spotykanym protokołem sieciowym i analizę problemów bezpieczeństwa ograniczamy wyłącznie do aspektów dotyczących tego protokołu.

Rysunek 3. Format datagramu IP
Adresacja
Adresacja jest jednym z zadań podstawowych protokołów warstwy sieciowej. Pola adresowe ustawiane są w nagłówku datagramu IP przez stację nadawczą (źródło, ang. source). Z zawartością pól adresowych wiążą się następujące problemy:
- nie ma gwarancji, że pakiet został wysłany z adresu wpisanego w polu Source Address
- wiele systemów kontroluje to pole w momencie wysyłania datagramu
- niektórzy operatorzy dostępu do Internetu stosują filtry blokujące pakiety z nieprawidłowym adresem źródłowym
- mimo tego nie można polegać na poprawności adresu źródłowego odebranego pakietu.
Problemy te dyskwalifikują uwierzytelnianie poprzez wartość pola adresu źródłowego. Niestety wiele protokołów aplikacyjnych posiada wbudowane takie mechanizmy. Ewentualny atak na system może zatem polegać sfałszowaniu adresu źródłowego (IP spoofing). Kompromituje to procedury uwierzytelniania ofiary.
Trasowanie
Trasowanie (routing) polegające na wyznaczaniu drogi do adresata. W przypadku protokołu IP trasowanie jest wykonywane pojedynczymi etapami. Zadanie to wykonuje router. Trasowanie jest niezwykle istotnym elementem działania warstwy sieciowej i związanych z nim jest kilka problemów:
- przeciążony router może odrzucać nadchodzące pakiety
- za retransmisję odpowiadać muszą protokoły warstw wyższych
- jeśli router zostanie „zalany” bardzo dużą masą pakietów (nieistotne czy prawidłowych), to ewentualne przeciążenie doprowadzi do zablokowania komunikacji (pakietów należących do aktywnych sesji – asocjacji IP)
Przeciążenie routera implikuje zagrożenia dostępności danych transmitowanych w pakietach kierowanych do niego. Co więcej, potencjalny atak zdalny skierowany przeciwko innym stacjom sieciowym może wykorzystywać chwilową niedostępność pakietów z oryginalnego źródła celem podszycia się pod źródłowy komputer.
Fragmentacja pakietów
Fragmentacja datagramów IP jest często realizowaną funkcją, pierwotnie zamierzoną jako mechanizm optymalizacji kosztu przetwarzania pakietów. O wielkości fragmentów decyduje wartość MTU (Maximum Transfer Unit) związana z wielkością pola danych ramek warstwy drugiej OSI. Do fragmentacji dochodzić może na dowolnym etapie drogi między nadawcą a odbiorcą. Oryginalny datagram otrzymuje unikalny (w przybliżeniu) identyfikator, którym opatrywane są kolejne fragmenty. Kolejność fragmentów determinuje względny numer pierwszego bajtu przekazywanego w polu danych fragmentu liczony od początkowego bajtu oryginalnego datagramu (Fragment Offset). Scalanie fragmentów odbywa się na węźle odbiorcy.
Fragmentacja może stanowić potencjalne źródło zagrożenia a następujących powodów:
- każdy fragment jest również datagramem i jako taki może mieć, teoretycznie, do 64 kB wielkości – z premedytacją spreparowane fragmenty przekraczające w sumie 64 kB mogą powodować błędy scalania
- podobnie manipulacje wartościami pola Fragment Offset
- niektóre stacje IP, w tym zabezpieczenia (filtry pakietów), mogą zachowywać się niepoprawnie atakowane przez niewłaściwie pofragmentowane pakiety – zjawisko to wykorzystuje np. teardrop attack [Ziemba, RFC 1858]
- często filtry przetwarzają właściwie (np. odrzucają) tylko pierwszy fragment pakietu – wynika to z faktu iż w praktyce informacje niezbędne do przeprowadzenia filtracji znajdują się tylko w pierwszym pakiecie, a ponadto jest to działanie wystarczające do wykluczenia poprawnego scalenia niepożądanego datagramu w węźle odbiorcy, jednak powoduje to mimowolne przepuszczanie kolejnych fragmentów należących do (będących przecież kontynuacją) ruchu sklasyfikowanego jako niepożądany. Fakt przepuszczania takich pakietów może zostać wykorzystany do realizacji niektórych typów ataków.
Rysunek 4. Schemat fragmentacji IP
Pakiety rozgłoszeniowe
Mechanizmy rozgłoszeniowe oferuje wiele protokołów, również IP. Ukierunkowane rozgłoszenie często jest wykorzystywane do przeprowadzenia ataków na dostępność informacji (typu Denial of Service – DoS). Stanowi to najistotniejsze zagrożenie związane z mechanizmem rozgłaszania. Szczęśliwie, wiele routerów posiada funkcję blokowania ruchu rozgłoszeniowego.
Odwzorowanie adresów
Odwzorowanie adresów IP na adresy MAC (np. Ethernet) jest niezbędne dla realizacji operacji nadawczych, a dokładniej do konstrukcji prawidłowej ramki MAC. Zadaniem odwzorowania adresów na ogół zajmuje się protokół ARP (Address Resolution Protocol). Stosuje on transmisję rozgłoszeniową zapytań i zbiera odpowiedzi bez zapewnienia poufności i autentyczności. W celu poprawy efektywności, protokół wykorzystuje pamięć podręczną do temporalnego składowania informacji pozyskanych z docierających zapytań i odpowiedzi ARP.
W efekcie z protokołem ARP wiążą się następujące zagrożenia:
- stacja w sieci lokalnej może wysyłać fałszywe zapytania lub odpowiedzi ARP
- kierując w efekcie inne pakiety w swoim kierunku (ARP spoofing)
- dzięki czemu napastnik może:
- modyfikować strumienie danych
- podszywać się pod wybrane komputery
Często można skonfigurować lokalne statyczne mapowanie ARP wyłączając przy tym automatyczną obsługę zapytań i odpowiedzi ARP, co uwalnia od w/w problemów. Jednak w praktyce okazuje się, że wyłączenie obsługi komunikacji sieciowej nie jest możliwe w każdej implementacji stacji protokołu ARP.
Rysunek 5. Format zapytania ARP
Warstwa transportowa
Jak wiadomo, w rodzinie protokołów internetowych występują 2 protokoły transportowe. Protokół TCP (Transmission Control Protocol) jest to protokół strumieniowy zorientowany połączeniowo. Zestawienie komunikacji w protokole TCP wymaga wykonania 3-etapowej procedury nawiązania połączenia (3-way handshake). Bodaj najistotniejszym zadaniem tej procedury jest ustalenie inicjalnych numerów sekwencyjnych, rozpoczynających numerowanie bajtów strumienia danych przekazywanego w każdym z dwu kierunków połączenia A-B (rysunek 7).

Rysunek 6. Format segmentu TCP
Na schemacie z rysunku 7 zastosowano następujące oznaczenia:
SN = Numer sekwencyjny w nagłówku segmentu określa numer pierwszego oktetu danych przesyłanych w tym segmencie ACK = Numer potwierdzenia – numer sekwencyjny następnego oktetu danych po ostatnim pomyślnie odebranym (numer oczekiwanego oktetu) ISN = Inicjalny numer sekwencyjny (Initial Sequence Number) – początkowy numer sekwencyjny danych przesyłanych w danym połączeniu, ustalany w procesie nawiązania połączenia (w segmencie SYN). Każde połączenie może rozpocząć numerację oktetów danych od arbitralnej wartości (jeśli ISN=0, to pierwszy oktet w całym połączeniu ma numer ISN+1=1). Inicjalny numer sekwencyjny jest ustalany oddzielnie dla obu stron połączenia (w ogólności ISNA ≠ ISNB )
Rysunek 7. Schemat nawiązania połączenia (3-way handshake)
Nawiązanie połączenia TCP charakteryzują następujące cechy:
- możliwe jest zdalne wymuszenie połączenia i przechwycenie legalnej komunikacji nawet bez odbioru segmentu SYN+ACK
- wymaga to odgadnięcia ISN zawartego w tym segmencie
- na szczęście numery ISN są wybierane pseudolosowo
- na ogół z rozkładem bardzo dalekim od losowego
- wg sugestii z RFC 793 – licznik ISN jest inkrementowany co 4 μs
- starsze jądra wywodzące się z BSD (4.2) dokonują inkrementacji o wartość stałą co 1 sek i przy każdym nowym połączeniu
- więc łatwo przewidzieć ISN dla nowych połączeń
Stopień randomizacji wyboru ISN graficznie reprezentuje się wykresem fazowym. Wykresy fazowe prawidłowego generatora ISN zgodny ze standardem RFC 1948 oraz generatorów w popularnych (mniej i bardziej) systemach operacyjnych można znaleźć w <A HREF=”http://alon.wox.org/tcpseq/”>[Zalewski]</A>. Jak pokazują przykłady wykresów fazowych, coraz więcej systemów operacyjnych stosuje generatory zbliżone do wzorcowego, jednak nadal wiele jest implementacji dalece od wzorca odbiegających. Skutkuje to możliwością przeprowadzenia pewnych ataków, o których będzie mowa dalej.
Procedura nawiązania połączenia TCP może być wykorzystana do realizacji następujących ataków:
- ataki zalewające ofiarę nowonawiązywanymi połączeniami – dla każdego nawiązanego połączenia system przydziela pewne zasoby, w szczególności pamięć. Zasoby zwalniane są po zamknięciu połączenia. Jeśli zamknięcie nie następuje, wówczas zasoby pozostają zajęte (mimo iż mogły w ogóle nie być wykorzystane). Odpowiednio duża liczba zestawionych połączeń może doprowadzić do przydzielenia im całej dostępnej pamięci nie pozostawiając żadnych dostępnych zasobów do pracy systemu i powodując załamanie jego pracy.
- ataki zalewające ofiarę segmentami SYN (wykorzystujące stan half-opened) – w praktyce system operacyjny przydziela zasoby dla nowozestawianego połączenia, jak tylko pojawia się pierwszy segment SYN, jeszcze zanim 3-etapowa procedura nawiązywania zostanie zakończona. Zasoby zajmowane są zatem nawet jeśli połączenie nie zostanie w pełni zestawione. Duża liczba na wpół nawiązanych połączeń może wyczerpać zasoby i ostatecznie blokuje stację protokołu TCP i cały system. Co więcej, takie ataki są trudno wykrywalne, bowiem typowe implementacje TCP nie raportują wyższym warstwom OSI (systemowi operacyjnemu) żadnych zdarzeń związanych z połączeniem, które nie jest jeszcze w pełni nawiązane.
Warstwa aplikacyjna
W warstwie aplikacyjnej występują m.in. problemy trywialnego uwierzytelniana na podstawie identyfikacji usług oraz braku odpowiednich zabezpieczeń usług narzędziowych.
Identyfikacja usług
Identyfikacja usług w modelu internetowym odbywa się zwykle jedynie na podstawie numer portu źródłowego lub docelowego. Z wykorzystaniem wartości numeru portu wiążą się następujące obserwacje:
- lokalny numer portu klienta jest niemal zawsze wybierany przypadkowo przez system operacyjny (choć klient może go wybrać sam)
- w systemie Unix występują tzw. porty uprzywilejowane (systemowe) – są to porty o numerach do wartości 1024. Pod tymi portami system pozwala uruchomić proces sieciowy tylko administratorowi (root). Teoretycznie zatem, można domniemywać iż uruchomione pod systemowymi portami procesy należą do zaufanych i bezpiecznych. Jednak w praktyce, nie ma oczywiście pewnego sposobu zweryfikowania prawdziwości tego domniemania zdalnie.
- niestety nadal w wielu przypadkach systemy zdalne polegają na zaufaniu do asocjacji obejmujących te porty (połączeń z tymi portami)
- w istocie restrykcja wykorzystania portów uprzywilejowanych tylko przez administratora jest wyłącznie konwencją – nie należy do specyfikacji protokołów usług, a co więcej – nie dotyczy systemów innych niż Unix
- poleganie na niej absolutnie nie jest bezpieczne
Usługi narzędziowe infrastruktury sieciowej
Jednym z najpopularniejszych przykładów usług narzędziowych jest DNS (Domain Name Service). Jak wiadomo, system DNS to swoista rozproszona baza danych odwzorowań nazwa domenowa - adres sieciowy. Baza DNS ma strukturę drzewiastą, poddrzewa odpowiadają poszczególnym domenom niższego poziomu (poddomenom). Zarządzanie poddrzewami może być delegowane innym serwerom DNS. Aktualizacje bazy DNS mogą obejmować pojedyncze rekordy RR (resource records), jak i całe poddrzewa. Poprzez protokół DNS można dokonywać prostych zapytań o pojedyncze odwzorowania, jak i zrealizować pozyskanie pełnej kopii fragmentu obszaru nazw (tzw. transfer stref – zone transfer) np. w celu aktualizacji serwerów zapasowych. Protokół DNS dostępny jest poprzez oba internetowe protokoły transportowe: UDP – tak realizowane są proste zapytania DNS, TCP – tak odbywa się transfer stref DNS. Z punktu widzenia bezpieczeństwa istotne jest, iż niektóre zapisy RR dostarczają informacji użytecznych dla włamywaczy, np. HINFO (może zawierać m.in. informacje o systemie operacyjnym), WKS (well-known-services). Pola te, na szczęście, rzadko są dziś stosowane.
Baza DNS składa się z dwóch oddzielnych drzew mapowań – dla mapowania nazw na adresy (zapytania proste) i adresów na nazwy (zapytania odwrotne – inverse queries). Nie ma wymuszonej relacji między drzewami – każde z nich jest w praktyce utrzymywanie niezależnie. Przy tym drzewo mapowań odwrotnych zwykle nie jest równie często aktualizowane a do tego w ogóle jest utrzymywane w gorszym stanie. Niestety stanowi to potencjalne ułatwienie w przejęciu kontroli nad częściami drzewa mapowań odwrotnych i, w efekcie, skutecznym podszywaniu się pod autoryzowane nazwy.
W przypadku usługi DNS można wyróżnić następujące podstawowe problemy dotyczące bezpieczeństwa:
- udostępnianie użytecznych informacji atakującym
- brak uwierzytelniania w protokole zapytań DNS i transferu stref, co umożliwia fałszowanie danych (pharming)
- podszywanie się pod autoryzowne nazwy kompromituje system uwierzytelniania przez nazwę – w tym przypadku możliwa jest jednak prosta obrona przez dodatkową weryfikację w drzewie mapowań nazw i wykrycie fałszerstwa
- możliwość „zatruwania” fałszywymi odpowiedziami lokalnej pamięci cache usługi DNS stacji uwierzytelniającej jeszcze zanim wyśle ona zapytanie o mapowanie – wówczas fałszerstwo nie wyjdzie na jaw
Usługi inne popularne usługi narzędziowe BOOTP i DHCP również udostępniają informacje o infrastrukturze sieciowej, i to często bardzo bogate informacje, praktycznie bez uwierzytelniania. Na szczęście dostępne są one na ogół tylko w obrębie sieci lokalnej, zatem mogą być wykorzystane tylko przez atakujących, którzy wdarli się już do atakowanej podsieci. Istotny jest jednak problem bezpiecznej wymiany danych pomiędzy serwerami DHCP a DNS, a ta z kolei może przechodzić przez kilka podsieci.
Typowe ataki na infrastrukturę sieciową
Powszechne techniki ataków na infrastrukturę sieciową wykorzystują głównie niedoskonałości protokołów oraz technologii sieciowych w celu:
- uzyskania danych (information recovery)
- podszycia się pod inne systemy w sieci (host impersonation)
- manipulacji mechanizmami dostarczania pakietów (temper with delivery mechanisms)
Poniżej wymienione zostaną najczęściej spotykane współcześnie techniki ataków zebrane w następujące 4 klasy:
- Sniffing/scanning:
- network sniffing – jest to pasywny podgląd medium transmisyjnego, np. w celu przechwycenia interesujących ramek (packet snooping)
- network scanning – jest to wykorzystanie specyfiki implementacji protokołów do sondowania (enumeration) urządzeń aktywnych w sieci, aktywnych usług, konkretnych wersji systemu operacyjnego i poszczególnych aplikacji (sztandarowym przykładem narzędzi realizujących taki atak jest program nmap)
- Spoofing:
- session hijacking – przejmowanie połączeń poprzez „wstrzelenie” odpowiednio dobranych pakietów – wymaga dostępu do uprzednio legalnie zestawionego połączenia TCP
- TCP spoofing – podszywanie bazujące na oszukaniu mechanizmu generowania numerów ISN; wykorzystanie ataku np. w celu oszukania mechanizmów uwierzytelniania usług r* (które dokonują uwierzytelniania przy użyciu funkcji rusersok())
- UDP spoofing – prostsze od TCP w realizacji (ze względu na brak mechanizmu szeregowania i potwierdzeń ramek w protokole UDP), użyteczne podczas atakowania usług i protokołów bazujących na UDP np. DNS.
- Poisoning:
- ARP spoofing/poisoning – wykorzystuje zasady działania protokołu ARP, umożliwiając zdalną modyfikację wpisów w tablicach ARP systemów operacyjnych oraz przełączników, a przez to przepełnianie tablic ARP
- DNS cache poisoning (pharming, także znany jako birthday attack) – umożliwia modyfikację wpisów domen w dynamicznym cache DNS, co jest niezwykle dużym zagrożeniem w połączeniu z atakami pasywnymi
- ICMP redirect – wykorzystanie funkcji ICMP do zmiany trasy routingu dla wybranych adresów sieciowych
- ataki na urządzenia sieciowe przy pomocy protokołu SNMP
- Denial of Service (DoS)
w tej kategorii mieszczą się wszystkie te ataki, których ostatecznym celem jest unieruchomienie poszczególnych usług, całego systemu lub całej sieci komputerowej.
- oto przykłady kilku najpopularniejszych ataków:
- SYN flood
- smurf, fraglle
- land
- tribal flood (trin00, trinio, trinity v3)
- subseven, stacheldracht
- UDP storms (teardrop, bonk)
- ICMP destination unreachable
- istnieją też ataki na wyższe warstwy modelu OSI, np. e-mail bombing.
- oto przykłady kilku najpopularniejszych ataków:
Atak session hijacking
Rysunek 8 przedstawia wyjściowy stan ataku session hijacking, którego celem jest nieuprawnione wpięcie segmentów protokołu transportowego w strumień wymieniany w autoryzowanym (poprawnie zestawionym) połączeniu między systemem A (przyszłą ofiarą ataku) i zaufanym systemem B. Atakujący E, mając wgląd w dotychczasową zawartość strumienia w kierunku do B do A (poprzez sniffing), może spreparować poprawny i oczekiwany przez A segment, który podsunie jako rzekomo autentyczny segment wysłany przez B (rysunek 9).
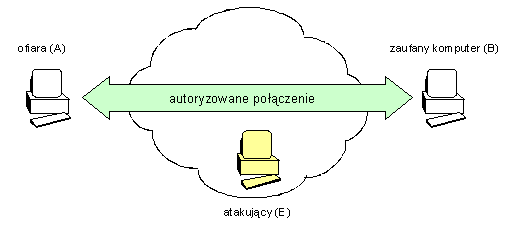
Rysunek 8. Schemat ataku session hijacking (1)
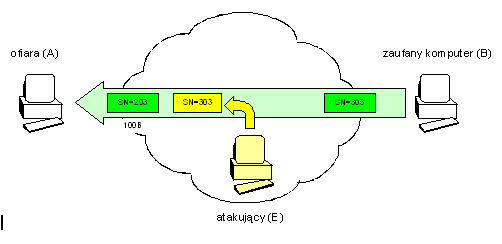
Rysunek 9. Schemat ataku session hijacking (2) – w strumieniu przesyłane są segmenty po 100 B
Atak TCP spoofing
Rysunek 10 przedstawia początek ataku TCP spoofing, którego celem jest nieuprawnione zestawienie połączenia z systemem A (ofiarą ataku) w imieniu zaufanego systemu B. Atakujący E tym razem nie ma wglądu komunikację między A i B, co czyni atak znacznie trudniejszym niż session hijacking. Atak wymaga nie tylko sfałszowania adresu źródłowego (w szczególności w pierwszym segmencie SYN, nawiązującym połączenie), ale dodatkowo poprawnego przewidzenia numeru ISNA (który zaproponuje system A w drugim segmencie SYN/ACK) i być może jeszcze zablokowania poprawnej komunikacji z rzeczywistym systemem B (co może wymagać przeprowadzenia ataku DoS skierowanego przeciw B), aby B nie mógł zakończyć (zresetować) niechcianego połączenia. Mimo tych utrudnień E może spreparować poprawny i oczekiwany przez A segment ACK – kończący poprawnie procedurę nawiązania połączenia, (rysunek 11).
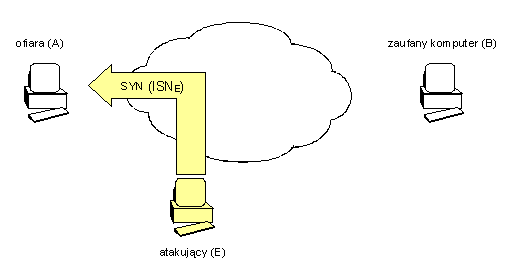
Rysunek 10. Schemat ataku TCP spoofing (1)
Najtrudniejszym krokiem ataku jest wysłanie poprawnego segmentu trzeciego zawierającego potwierdzenie inicjalnego numeru sekwencyjnego ISNA wybranego przez A. Ze względu na brak możliwości podglądu przez E komunikacji z A do prawdziwego B, wymaga to przewidzenia wartości ISNA przez E. Jest to prawdopodobne przy wygenerowaniu relatywnie niedużej liczby segmentów ACK, jeśli system A nie posiada poprawnego generatora ISN. Wówczas jest szansa, iż jeden z wygenerowanych przez E segmentów będzie przenosił poprawną wartość potwierdzenia i zostanie przez A uznany za oczekiwany.
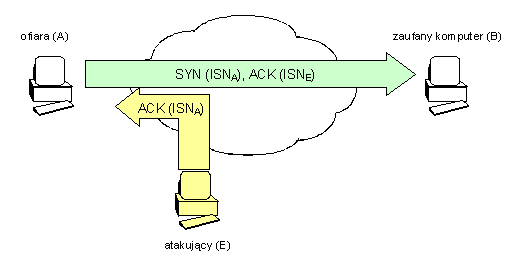
Rysunek 11. Schemat ataku TCP spoofing (2)
Można wyróżnić następujące elementy ataku TCP spoofing:
- wytypowanie właściwego ISNA – np. poprzez uprzednie nawiązanie autoryzowanego połączenia na inny port (pozyskanie wcześniejszego numeru ISN'A)
- celowe uniemożliwienie przetwarzania segmentu drugiego, zawierającego wartości SYN (ISNA) i ACK (ISNE)
Poczynić można w związku z tym następujące obserwacje:
- atakujący nie musi mieć dostępu do segmentów autoryzowanego połączenia
- jeśli ma (sniffing) – może podejrzeć numer sekwencyjny (nie musi zgadywać)
- i podpiąć się na dowolnym etapie już zestawionego połączenia
Atak Denial of Service (DoS)
Celem ataku DoS jest unieruchomienie całego systemu ofiary lub jego komponentów (rysunek 12). W tym celu stosowane są różne techniki ataku. Niektóre z nich zostaną krótko przedstawione poniżej.
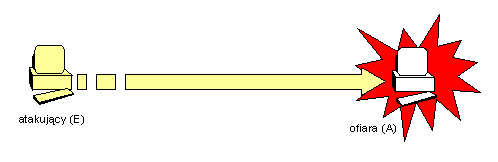
Rysunek 12. Schemat ataku Denial of Service (DoS)
Szczególnie niebezpieczną odmianą ataku jest rozproszony DoS (Distributed Denial of Service – DdoS), w którym atakujący nie przeprowadza ataku bezpośrednio, lecz doprowadza do skomasowanego natarcia wykorzystując inne systemy (często w dużej liczbie). Zwykle owe systemy uczestniczące mimowolnie w skomasowanym ataku, zostały wcześniej opanowane przez atakującego i tak odpowiednio zmodyfikowane by ułatwić mu w przyszłości przeprowadzanie ataku DDoS.
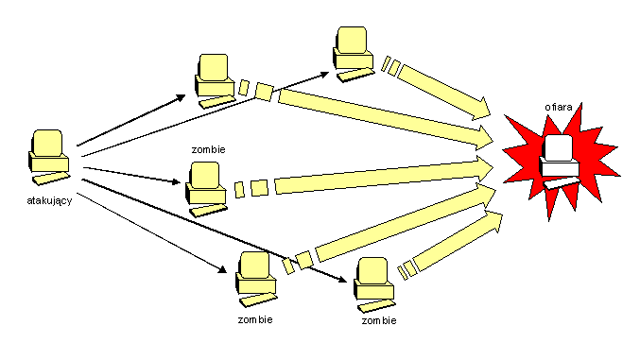
Rysunek 13. Schemat ataku Distributed DoS (DDoS)
Atak SYN flood
W przypadku ataku SYN flood atakujący (E) wysyła na adres ofiary (A) dużą liczbę segmentów SYN protokołu TCP adresowanych z dowolnych (nieistniejących) adresów IP. Nieświadomy tego A odpowiada segmentami SYN/ACK i rozpoczyna bezowocne oczekiwanie na segmenty ACK (stacja protokołu TCP ofiary jest w stanie na wpół otwartym). W trakcie oczekiwania wyczerpują się zasoby stacji protokołu TCP i systemu operacyjnego A.
W 1997 r. atak SYN flood na WebCom wyłączył z użycia ponad 3000 witryn WWW
Ping of Death
Atak ten przeprowadza się poprzez wygenerowanie pofragmentowanych pakietów ICMP przekraczających w sumie 64kB. Wówczas scalanie może w niektórych implementacjach powodować błędy prowadzące do zawieszenia stacji IP.
Smurf attack
Jest to atak DDoS. Polega na wygenerowaniu dużej ilości rozgłoszeniowych (directed broadcast) pakietów ICMP echo (ping) z adresem IP ofiary ataku jako źródłowym. Ofiara zostanie zalana odpowiedziami ping. Atak ten jest skuteczny jedynie jeśli brzegowy dla sieci ofiary router przepuszcza ping w ukierunkowanym rozgłoszeniu, a system operacyjny stacji odpowiada na taki ping.
Fraglle attack
To atak posiadający identyczny schemat postępowania, lecz wykorzystuje usługę echo na UDP.
Land attack
W tym przypadku, atakujący wysyła segment SYN na adres ofiary podając jej własny adres jako źródłowy i nadając ten sam numer portu źródłowego i docelowego. Stacja TCP ofiary nigdy nie zestawi połączenia zapętlając się w nieskończoność. W niektórych implementacjach może to prowadzić do jej zawieszenia.
Metody obrony przed atakami DoS/DDoS
Nie ma uniwersalnych metod obrony przez atakami odmowy dostępu. Na ogół wymagają one przygotowania przez producenta systemu operacyjnego odpowiednich poprawek (łat) i zastosowania ich w podatnym na atak systemie. Poniżej przedstawione zostaną dwa mechanizmy obrony przed atakiem SYN flood, które systematycznie zyskują coraz większą popularność.
Obrona przed atakiem SYN flood – SYN Defender
SYN Defender jest komponentem kilku kompleksowych systemów ochrony (takich jak np. CheckPoint Firewall-1). Jego ogólna koncepcja działania polega na wprowadzeniu pomiędzy atakującego i ofiarę wyspecjalizowanego obrońcę (na rysunku 14 oznaczonego na czerwono), który przejmuje wszystkie segmenty SYN skierowane do ochranianego systemu i propaguje połączenia dopiero gdy wykluczy atak (czyli, gdy dotrze do obrońcy trzeci segment nawiązania połączenia, co oznacza, że nie mamy do czynienia z atakiem SYN flood).
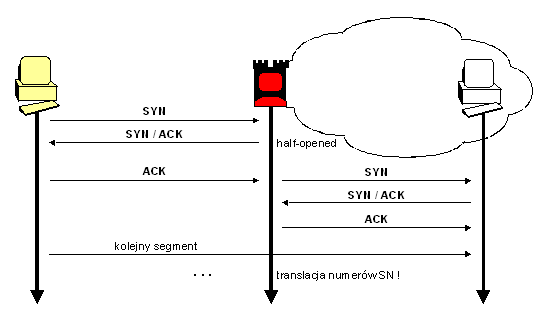
Rysunek 14. Schemat działania mechanizmu SYN Defender
Jeśli SYN Defender rozpoznaje atak (nie doczeka się trzeciego segmentu) po prostu zapomina o parametrach połączenia, a system ochraniany nawet nie dowie się o ataku. Jeśli SYN Defender wykluczy atak, to wówczas samodzielnie zestawia nowe połączenie z systemem ochranianym, które posłuży to retransmitowania segmentów odebranych od nadawcy. Oczywiście owo nowe połączenie nie będzie miało identycznych parametrów (np. numer ISN wybrany przez ochranianego będzie z pewnością inny, niż uprzednio zaproponowany nadawcy segmentu SYN przez obrońcę). W związku z tym, segmenty propagowane muszą być poddane konwersji parametrów (nagłówka) przy przejściu przez węzeł obrońcy).
Istotą ochrony przed atakiem jest przeniesienie punktu obrony z ofiary na zewnętrzny system, który przygotowany na okoliczność ewentualnego ataku nie pozwoli na przeciążenie siebie poprzez zużycie wszystkich zasobów. Właściwie ilość zasobów potrzebna obrońcy na obsługę połączeń jest tu minimalna, a system ofiary obsługuje wyłącznie połączenia, które nie są elementem ataku SYN flood.
Obrona przed atakiem SYN flood – SYN cookies
Inną metodą obrony przed atakiem SYN flood jest wykorzystanie dość sprytnego mechanizmu o nazwie SYN cookies. Umożliwia on realizację obrony w samym węźle potencjalnej ofiary. Przy zastosowaniu tego mechanizmu, węzeł broniący się nie musi rezerwować zasobów dla połączenia już w momencie odebrania segmentu SYN. Miast tego, węzeł ten generuje specjalną wartość, przekazywaną nadawcy segmentu SYN, i tak spreparowaną, by po ewentualnym otrzymaniu w przyszłości trzeciego segmentu (ACK), rozpoznać że jest to kontynuacja wcześniej rozpoczętego nawiązywania połączenia. Dopiero po otrzymaniu segmentu ACK rezerwowane są zasoby.
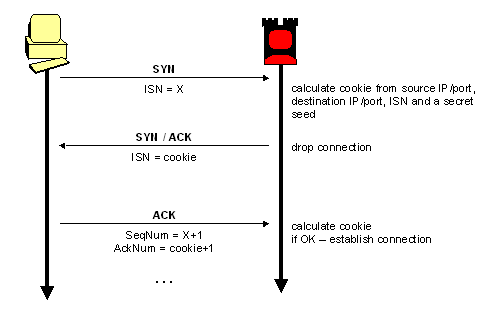
Rysunek 15. Schemat działania mechanizmu SYN cookies
Dla rozpoznania poprawności późniejszego segmentu ACK, broniący po odebraniu segmentu SYN generuje wartość cookie uzależnioną od parametrów segmentu ACK. Wartość ta jest wpisywana następnie jako ISN do segmentu SYN/ACK, a zatem powróci (faktycznie zinkrementowana) w polu potwierdzenia w segmencie ACK, umożliwiając detekcję poprawności procedury zestawiania połączenia.
Mechanizm SYN cookies posiada niestety pewne ograniczenia, np. nie można korzystać niektórych użytecznych rozszerzeń specyfikacji protokołu TCP, np. Large Window.
Więcej informacji o SYN cookies można znaleźć pod adresem http://cr.yp.to/syncookies.html
Mechanizmy bezpieczeństwa zdalnego dostępu
Rysunek 16 przedstawia schemat uwierzytelniania przy zdalnym dostępie do sieci komputerowej. Przyjmujemy tu scenariusz, w którym system A uzyskuje dostęp zdalny do sieci poprzez publiczną sieć operatora dostępu do Internetu. Po stronie A wykorzystywany jest adapter łącza do sieci publicznej, wbudowany w system komputerowy A lub zewnętrzny (modem telefoniczny, modem kablowy, adapter ISDN lub modem DSL). Operator posiada infrastrukturę złożoną w łączy i systemów przełączających (np. cyfrowych centralek telefonicznych). Natomiast po stronie sieci docelowej połączenie jest obsługiwane przez serwer dostępowy RAS. Serwer dostępu zezwala tylko na autoryzowane połączenia, które muszą zostać uwierzytelnione. Uwierzytelnieniu podlega na ogół adapter reprezentujący system A wobec serwera RAS. Najprostsze mechanizmy uwierzytelniania (PAP, CHAP) wykorzystują hasła.
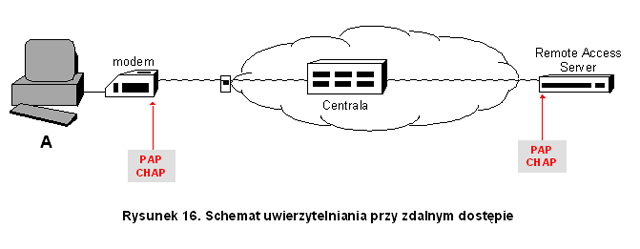
Rysunek 16. Schemat uwierzytelniania przy zdalnym dostępie
PAP (PPP Authentication Protocol) RFC1334
W protokole PAP, serwer RAS pyta o nazwę (ID) użytkownika, a następnie o hasło i na tej podstawie decyduje o dopuszczeniu do sieci. W tym protokole nazwa użytkownika i hasło są przesyłane tekstem jawnym! Istnieje też odmiana tego protokołu – SPAP (Shiva PAP), która stosuje proste szyfrowanie procedury uwierzytelniania.
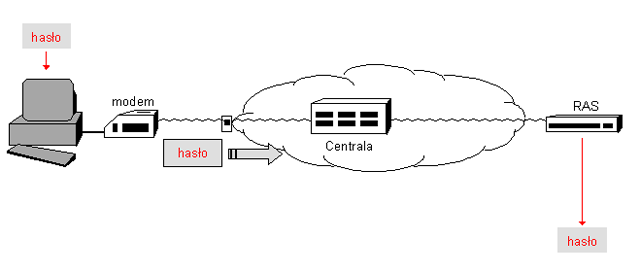
Rysunek 17. Schemat uwierzytelniania PAP
CHAP (Challenge Handshake Authentication Protocol) RFC1994
W przypadku tego protokołu, RAS pyta o ID użytkownika, a następnie przesyła unikalne „zawołanie”. Klient koduje zapytanie hasłem (MD5) i odsyła jako „odzew” decydujący o dopuszczeniu do sieci.
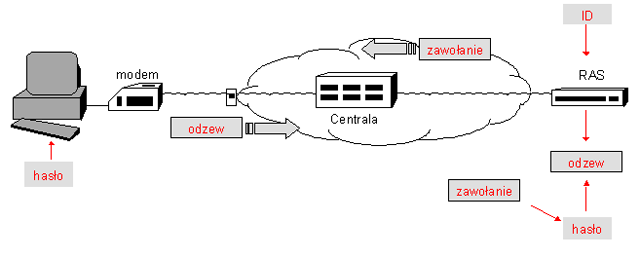
Rysunek 18. Schemat uwierzytelniania CHAP
EAP (PPP Extensible Authentication Protocol) RFC2284
W tym przypadku RAS wysyła kilka zapytań do uwierzytelnianego podmiotu, każdorazowo specyfikując typ żądania (np. żądanie hasła lub skrótu MD5). Oferuje tym samym możliwość korzystania z wielu protokołów uwierzytelniania bez potrzeby uprzedniego ich negocjowania. Istnieje tez możliwość dwustronnego uwierzytelniania.
Protokół RADIUS (Remote Access Dial-In User Service) – RFC2138
Protokół RADIUS oferuje własności AAA (Authentication + Authorization + Accounting) zdalnego dostępu i pozwala na centralizację zarządzania tymi własnościami. Pozwala na przechowywanie jednej globalnej bazy procedur i informacji uwierzytelniających, i umożliwia utrzymywanie wielu punktów dostępowych wykorzystujących tę globalną konfigurację. Ułatwia to tworzenie złożonych sieci z wieloma serwerami dostępowymi RAS. Serwer RADIUS stanowi centrum uwierzytelniania i kontroli dostępu. Natomiast punkty dostępowe RAS realizują proces uwierzytelniania na podstawie informacji pozyskanych z centralnego serwera RADIUS za pomocą protokołu RADIUS.
Rysunek 19. Konfiguracja środowiska RADIUS
Na podobnej zasadzie działają także protokoły TACACS (Terminal Access Control – Access Control System), XTACACS czy TACACS+.
Uwierzytelnianie stanowisk infrastruktury sieciowej
Standard IEEE 802.1x umożliwia ochronę infrastruktury sieciowej przed nieautoryzowanym dostępem poprzez centralne uwierzytelnianie poszczególnych stacji sieciowych. Przykładowo przy wykorzystaniu tego standardu przełącznik wymusza uwierzytelnienie nowo wpiętej lub właśnie uruchomionej stacji, zanim rozpocznie przełączanie pakietów przez nią wysyłanych. Do zweryfikowania danych uwierzytelniających może wykorzystać protokoły RADIUS czy TACACS+.
Bezpieczny system nazw
W 1999 zaproponowano rozszerzenie DNS o mechanizmy kryptograficznego uwierzytelniania i kontroli integralności (RFC 2535). Zaproponowano dodanie rekordów SIG zawierających podpisy cyfrowe podpisujące zbiory rekordów informacyjnych (RRset). Rolę certyfikacji pełni umieszczenie klucza publicznego w samym zbiorze. Klucz przechowują rekordy nowego typu –DNSkey. Usługa DNSsec również może służyć przechowywaniu samych kluczy publicznych dla innych celów, np. PKI. Niestety wdrożenie DNSsec wciąż napotyka trudności. Przykładowym problemem jest m.in. kwestia pełnego lub częściowego podpisywana zbiorów dla dużych domen, takich jak .com)
Narzędzia bezpieczeństwa
Niżej przedstawione zostaną dwa wybrane narzędzia ochrony środowisk sieciowych.
DoS guard
DoS guard jest nazwą osobnego narzędzia lub modułu większej aplikacji zabezpieczającej, realizującego ochronę przed atakami DoS. Funkcje DoS guard posiada większość zapór sieciowych (również osobistych), a także wiele systemów operacyjnych routerów, np. TCPintercept w CiscoIOS lub Finesse (PiX). Niektóre z dostępnych narzędzi są nawet dość zaawansowane, np. SYN defender w Checkpoint Firewall-1 lub SYN cookies w PiX-ach.
Kryptograficzne zabezpieczenie komunikacji
Jednym z najbardziej reprezentatywnych przykładów narzędzia kryptograficznej ochrony komunkacji sieciowej jest protokół SSH – Secure Shell. SSH to protokół szyfrowanej transmisji dedykowanej dla emulacji wirtualnego terminala lecz nie tylko. Protokół SSH obsługuje usługa TCP, której przydzielono port 22. W domyślnej konfiguracji zastępuje telnet, rlogin, rsh, rexec, rcp, ftp. Ponadto umożliwia tunelowanie ruchu (VPN – tryb port forwarding).
Protokół SSH to standard de facto. Istnieją jego dwie specyfikacje – SSH1 i SSH2). Dostępnych jest wiele implementacji, w tym darmowych dla większości systemów z rodziny Unix/Linux (Open SSH). Natomiast dla systemów MS Windows, MacOS dostępnych jest wielu klientów protokołu SSH.
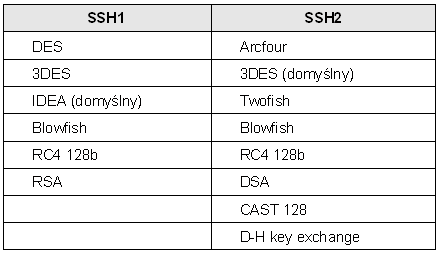
Rysunek 20. SSH – wykorzystywane algorytmy krytpograficzne. Implementacje mogą domyślnie używać inne algorytmy niż wskazane w specyfikacji protokołu (np. OpenSSH).
SSH oferuje różnorodne metody uwierzytelniania, m.in. tradycyjne – hasłem konta systemu zdalnego, kryptograficzne – zapytanie odzew z kluczem publicznym i prywatnym RSA, czy wykorzystanie zewnętrznych systemów uwierzytelniania, jak Kerberos lub S/Key. Istnieją implementacje wykorzystujące tokeny elektroniczne.
Pytania problemowe
- W bieżącym module stwierdzono, iż często filtry przetwarzają właściwie tylko pierwszy fragment pakietu ponieważ informacje niezbędne do przeprowadzenia filtracji znajdują właśnie w pierwszym pakiecie. Spróbuj wyjaśnić dlaczego.
- Dlaczego akurat usługi r* są szczególnie upodobanym celem ataków TCP spoofing?
Podstawowe problemy bezpieczeństwa systemów operacyjnych
Bieżący moduł przedstawia wybrane zagadnienia bezpieczeństwa dotyczące systemów operacyjnych. Przedstawione zostaną naruszenia bezpieczeństwa systemu operacyjnego, w tym w szczególności typowe formy ataku na system operacyjny oraz komponenty systemu szczególnie podatne na ataki. Omówione zostaną również problemy uwierzytelniania i kontroli dostępu, zagadnienia ochrony antywirusowej oraz zagrożenia związane z zamaskowanymi kanałami komunikacyjnymi.
Naruszenia bezpieczeństwa systemu operacyjnego przybierają różne formy. Typowo związane są z nimi następujące zagrożenia:
- włamania i kradzieże danych
- destrukcja systemu operacyjnego lub jego komponentów czy aplikacji
- wykorzystanie systemu operacyjnego do realizacji ataku na inny cel (jako zombie)
Różne formy ataku posiadają zwykle nieco odmienne realizacje (przebieg), jednak można wyróżnić pewien ogólny scenariusz ataku na system operacyjny. Obejmuje on zwykle następujące kroki:
- zlokalizowanie systemu do zaatakowania
- wtargnięcie na konto legalnego użytkownika (wykorzystując brak hasła, złamanie łatwego hasła, podsłuchanie hasła)
- wykorzystanie błędów i luk w komponentach systemu lub w ich konfiguracji w celu uzyskania dostępu do konta uprzywilejowanego
- wykonanie nieuprawnionych działań
- zainstalowanie furtki dla bieżącego lub przyszłego wykorzystania
- zatarcie śladów działalności (usunięcie zapisów z rejestrów systemowych)
- ataki na inne komputery
Przyczyny naruszeń bezpieczeństwa tkwią najczęściej w trudności osiągnięcia pełnej kontroli nad poprawnością implementacji i konfiguracji tak złożonego i wielokomponentowego oprogramowania, jakim są współczesne systemy operacyjne. Zwykle trudności te powodują:
- błędy i luki bezpieczeństwa („dziury”) w komponentach systemu lub w ich konfiguracji
- furtki (ang. backdoor)
- konie trojańskie
- wirusy oraz bomby logiczne i czasowe
Jako konkretne przykłady najczęstszych obszarów błędów implementacyjnych możemy wymienić chociażby sieciowe komponenty systemu, np.:
- stos TCP/IP
- przykładem może być atak Bonk na implementację stosu protokołów TCP/IP firmy Microsoft, który może spowodować awarię systemu zaatakowanego komputera
- lub NetBIOS:
- WinNuke – atak umożliwiający wywołanie awarii starszych wersji systemu Windows przy użyciu usług systemu NetBIOS
- albo RPC:
- RDS_Shell – metoda wykorzystania składnika Remote Data Services, należącego do MDAC (Microsoft Data Access Components), umożliwiająca zdalnemu napastnikowi uruchamianie poleceń z uprawnieniami systemowymi
Wrażliwe usługi systemowe i narzędziowe nie ograniczają się oczywiście do wymienionych wyżej przypadków i obejmują szerokim kręgiem m.in. usługi informacyjne (jak netstat, systat, nbtstat, finger, rusers, showmount, ident), usługi konfiguracyjne (bootparam, dhcp, zdalne zarządzanie), zdalne wywołanie procdur RPC (rpcinfo, rexec), rozproszone systemy plików (np. NFS), usługi zdalnego dostępu, mechanizm domen zaufania czy usługi komunikacyjne i pocztowe
W rożnych systemach operacyjnych, a nawet w różnych ich wersjach, można zaobserwować różną podatność komponentów na poszczególne rodzaje ataków. W wielu przypadkach istnieją gotowe i łatwo dostępne narzędzia ataków skierowane na wybrane wersje systemu lub jego konkretnych komponentów. Skuteczne przeprowadzenie ataku staje się rzeczą relatywnie prostą i nie wymagającą praktycznie żadnej wiedzy technicznej. Istotna dla tej skuteczności jest niewątpliwie możliwość zdalnej detekcji systemu operacyjnego, jego wersji i dostępnych w nim komponentów (szczególnie sług dostępnych zdalnie).
http://www.insecure.org/nmap/nmap-fingerprinting-article.html
Metody rozpoznawania systemu możemy podzielić na aktywne i pasywne. Metody aktywne realizowane są poprzez inicjowanie a następnie analizowanie połączeń (na ogół specjalnie spreparowanych) i są wobec tego skierowane wobec konkretnych stanowisk. Natomiast pasywne metody realizowane są poprzez podsłuch pakietów pochodzących z analizowanego systemu. Metody pasywne są naturalnie dużo mniej precyzyjne niż aktywne, lecz są trudno wykrywalne i mogą być skierowane przeciw celom jeszcze nie określonym ostatecznie (np. całej sieci).
Do zdalnego rozpoznawania systemu operacyjnego najczęściej wykorzystywane są usługi informacyjne dostępne w rozpoznawanym systemie oraz implementacje stosu TCP/IP.
Usługi informacyjne, jak np. ident oferują typowo charakterystyczne powitanie (banner), choć nie tylko informacyjne: dobrym przykładem może być serwer usługi pocztowej sendmail. Powitanie bardzo często zawiera informacje o typie i dokładnej wersji systemu operacyjnego, wersji usługi (co też istotnie przyczynia się do wyboru skutecznego narzędzia ataku). Szczęśliwie problem powitań jest już dobrze znany i coraz więcej usług stara się unikać publicznego podawania newralgicznych informacji o systemie. Z tych też powodów, często świadomie rezygnuje się z oferowania takich nadmiernie „gadatliwych” usług lub ogranicza się zdalny dostęp do nich. Osobnym sposobem ograniczania zagrożenia jest kamuflaż, polegający na spreparowaniu celowo nieprawdziwych informacji w powitaniu, co nie jest niestety gwarancją ochrony systemu przed wprawnym intruzem, jednak może utrudnić i wydłużyć realizację ataku (security trough obscurity).
W przypadku stosu TCP/IP najskuteczniejszą aktualnie metodą zdiagnozowania typu i wersji systemu okazuje się być analizowanie zachowania protokołu implementacji TCP w przypadku retransmisji – tzw. badanie RTO. Badanie RTO (Retransmission Time-Out) jest to pomiar czasów pomiędzy retransmisjami pakietów SYN+ACK w trakcie nawiązywania odpowiednio spreparowanego przez atakującego połączenia. Badanie obejmuje ilość retransmisji i odstępy między nimi, co, jak się okazuje, należy do „cech osobniczych” systemu operacyjnego. Przykładowo system MacOS X wysyła po 5 nieskutecznych retransmisjach segment RST, a systemy Windows i Linux milcząco zamykają wpółotwarte połączenie, różniąc się istotnie liczbą i interwałami retransmisji.
Również w przypadku tej metody detekcji systemu stosować można kamuflaż. Przykladem zaawansowanego narzędzia do kamuflażu jest łata stealth patch na jądro systemu Linux, która m.in.:
- blokuje nieprawidłowe pakiety ACK
- blokuje pakiety z flagami SYN i FIN
- blokuje pakiety z niepoprawnymi flagami i kombinacjami flag
- blokuje pakiety ICMP (za wyjątkiem echo)
Podobną funkcjonalność ma pakiet IP Personality – zestaw łat na jądro Linuksa i iptables, niestety już nierozwijany.
Uwierzytelnianie
Jednym z najistotniejszych mechanizmów ochrony systemu operacyjnego jest uwierzytelnianie użytkowników, niezbędne dla określania ich uprawnień oraz zdiagnozowania ewentualnej próby niepowołanego dostępu.
Uwierzytelnianie w systemie Unix/Linux
W większości systemów operacyjnych, również w systemach z rodziny Unix/Linux, podstawowym narzędziem uwierzytelniania jest weryfikacja hasła użytkownika. W tym punkcie przedstawimy najpierw klasyczny mechanizm przechowywania haseł w systemie Unix.
Działanie klasycznego mechanizmu tworzenia i rejestrowania w systemie Unix hasła przebiega następująco:
- użytkownik wybiera 8 znakowe hasło
- hasło jest zamieniane na 56b ciąg za pomocą 7b kodu ASCII
- powstały 56b ciąg jest kluczem algorytmu DES
- e-blok algorytmu DES jest modyfikowany za pomocą 12b wartości – ziarna (ang. salt) ustalanego na ogół na podstawie bieżącego czasu
- tak zmodyfikowany algorytm DES jest wykonywany na 64b bloku złożonym z samych zer
- wyjście podaje się na wejście kolejnej iteracji (25 iteracji)
- 64b wynik transformowany na 11-znaków z alfabetu 64 znakowego (A-Z, a-z, 0-9, ‘.’, ‘/’)
Wynikowa postać hasła jest zapamiętywania w pliku konfiguracyjnym (klasycznie był to /etc/passwd) i każdorazowo porównywana przez narzędzie login, rejestrujące sesję użytkownika w systemie, z przetransformowanym hasłem wprowadzanym przez logującego się użytkownika.
Jak wiemy, mechanizm haseł jest podatny na problem złamania hasła. W przypadku klasycznego mechanizmu uwierzytelniania metoda przeszukiwania wyczerpującego (brut-force attack) może być przykładowo wykonana następująco:
- 8 znaków z 36-znakowego alfabetu daje 368 czyli ok. 2,8 biliona kombinacji
- załóżmy moc obliczeniową o wydajności 6,4 miliona iteracji DES na sekundę
- 25 iteracji dla każdej kombinacji hasła – 1 milion kombinacji w 4 sek.
- dowolne hasło zostanie złamane (2,8 biliona kombinacji) w 4 miesiące
Przykład ten, aczkolwiek hipotetyczny, jednak obnaża wyraźnie tempo starzenia się haseł oraz uzmysławia dobitnie konieczność i doniosłość systematycznych zmian hasła dla wszystkich kont w systemie operacyjnym.
Wobec problemu złamania hasła, we współczesnych systemach z rodziny Unix/Linux stosuje się pewne usprawnienia. Obejmują one dodatkowo ochronę haseł przed ich pozyskaniem (w celu utrudnienia przeszukiwania wyczerpującego oraz wymuszanie odpowiednio wysokiego stopnia skomplikowania hasła (w celu utrudnienia ataku słownikowego). Ochrona haseł przed ich pozyskaniem sprowadza się do ukrycia ich postaci składowanej w systemie haseł poza dostępem zwykłego użytkownika – w przypadku systemu Unix/Linux jest to przeniesienie haseł do oddzielnej lokalizacji (pliku /etc/shadow). Realizuje to albo sam system operacyjny (konkretna dystrybucja), albo oddzielne pakiety, np. shadow-in-a-box, Linux Shadow Password Suite, itp. W praktyce okazuje się, iż czasami nadal możliwe ataki na pliki shadow (wykorzystują głównie luki w usługach, obrazy core dump), co umożliwia przechwycenie postaci składowanej haseł i ich późniejsze dekodowanie. Rozwiązaniem skuteczniejszym i bardziej uniwersalnym dla ochrony haseł mogą być zatem centralne bazy katalogowe, np. NIS, NIS+, czy bazy dostępne poprzez protokół LDAP.
W celu kontroli poziomu trudności haseł stosuje się różnorodne testery jakości haseł uaktywniane w momencie ustawiania nowego hasła przez użytkownika. Często spotykane są np. passwd+ (zastępuje passwd) lub anlpasswd, czy npasswd.
W bieżących wersjach systemów tej rodziny odchodzi się od wykorzystania algorytmu DES na korzyść silniejszych mechanizmów kryptograficznych i pozwalających wybierać hasła bez górnego limitu znaków (lub z wysokim limitem), np. z wykorzystaniem algorytmów MD5 czy Blowfish.
Uwierzytelnianie w systemie MS Windows NT 4.0
W systemie MS Windows NT 4.0 użytkownik otrzymuje losowo wygenerowany SID (Security ID). Procedura logowania wymaga wywołania przerwania sprzętowego (poprzez kombinację Ctrl-Alt-Del), co ułatwia kontrolę nad poprawnym wywołaniem właściwego programu logującego. Ze względu na złożoną ewolucję systemu Windows, hasła w systemie są przechowywane w różnych postaciach. Niezakodowane hasła, przetwarzane przez system, przechowywane są w zastrzeżonym obszarze LSA (Local Security Authority) rejestru: HKEY_LOCAL_MACHINE\SECURITY\Policy\Secrets, dostępnym tylko dla usługi Security Accounts Manager. Od wersji NT 4.0 hasła mogą być również zakodowane (w postaci tzw. hash) funkcją MD5 z ziarnem i z 40b kluczem RSA i przechowywane w rejestrze: HKLM\SAM oraz w zastrzeżonym obszarze systemu plików NTFS: %SYSTEMROOT%\SYSTEM32\CONFIG\SAM. Jednak dla zachowania zgodności wstecz (z linią 9x) obok postaci hash MD5 umieszczane są kopie haseł – LM hash – zakodowane autorskim algorytmem LanMan (z protokołu NT Lan Manager), bez ziarna. Postać ta jest dużo mniej bezpieczna i jej dostępność drastycznie podnosi skuteczność złamania hasła. Na szczęście w systemie Windows przechowywanie postaci LM hash można wyłączyć. Rysunek 1 przedstawia obraz ekranu narzędzia Zasad lokalnych zabezpieczeń, które umożliwia uaktywnienie wyłączenia LM hash – tak, widoczną na ekranie opcję trzeba włączyć, aby postać LM hash nie była tworzona i to dopiero od chwili następnej zmiany hasła (do kiedy to dotychczasowe LM hashe pozostają w systemie).
Rysunek 1. Uaktywnienie opcji wyłączenia przechowywania postaci LM hash haseł
W poprawkach serwisowych SP2 i SP3 do systemu wprowadzono następujące usprawnienia:
- opcję syskey (SP2) – postacie hash można zaszyfrować kluczem SYSTEM KEY (128b klucz RSA zamiast klucza 40b) co znacznie utrudnia łamanie haseł (jednak nadal dostępne są gotowe narzędzia wyłuskiwania i łamania haseł, choć bardziej złożone niż uprzednio)
- filtr słabych haseł Passfilt.dll (SP3)
- dodatkowe restrykcje
- ograniczenia czasowe (pory dnia, data ważności konta)
- ograniczenia stanowisk logowania
- limit ilości błędnych uwierzytelnień lub korzystania z nieaktualnego hasła
- rozszerzenia procedury uwierzytelniania
- API opublikowane przez Microsoft umożliwia wykorzystanie inteligentnych kart uwierzytelniających lub biometrii
Niestety ciągle istnieje w module zarządzania hasłami wiele luk i dostępnych jest wiele gotowych narzędzi exploit (wykorzystują uprawnienia administracyjne do importu plików SAM, luki w systemie tworzenia kopii zapasowych systemu RDISK, itp.)
Uwierzytelnianie w systemie MS Windows 2000, XP, 2003
W systemie MS Windows 2000 i jego następcach algorytm uwierzytelniania NTLM został zastąpiony przez Kerberos TGP. Ponadto opcja syskey jest domyślnie włączona, a przechowywanie postaci LM hash jest domyślnie wyłączone. Należy jednak mieć na uwadze, iż w środowiskach heterogenicznych istniejące starsze wersje Windows nie obsługują Kerberosa, stąd mogą nadal wymagać obsługi LM hash, co osłabia bezpieczeństwo całego srodowiska.
Uwierzytelnianie w systemie Novell NetWare
W systemie Novell NetWare stosuje się od wczesnych jego wersji dość wyrafinowaną I powszechnie uważaną za bezpieczną procedurę uwierzytelniania. Wykorzystuje ona mechanizmy kryptograficzne i przebiega w uproszczeniu następująco:
- w bazie katalogowej NDS (NetWare Directory Service) przechowywany jest skrót hasła użytkownika z ziarnem (jest nim identyfikator użytkownika) oraz para kluczy RSA
- najpierw stacja sieciowa uwierzytelnia się w imieniu użytkownika wobec wybranego serwera (NetWare od wersji 4 stosuje SSO) metodą zawołanie-odzew
- następnie serwer przesyła klucz publiczny NDS (KNDS), a stacja losuje klucz jednorazowy K1, który prześle serwerowi zaszyfrowany kluczem KNDS
- K1 posłuży serwerowi do bezpiecznego przekazania klucza prywatnego RSA użytkownika
- stacja przekształca klucz RSA do postaci GQ – Gillou-Quisquater (asymetryczny algorytm uwierzytelniania – NetWare od wersji 4 nie stosuje RSA) i natychmiast usuwa z pamięci hasło wraz z kluczem RSA
- klucz GQ posłuży do uwierzytelniania użytkownika w dostępie do zasobów sieci
Relacja zaufania
Jak wiemy z poprzednich modułów, pewnym ograniczeniem ryzyka pozyskania hasła przez intruza, jest zastosowanie mechanizmu SSO (Single Sign-On). Systemy Unix/Linux i Windows (w konfiguracji domenowej, od wersji NT Advanced Server) pozwalają wykorzystać mechanizm SSO w postaci tzw. relacji zaufania. Dzięki jej istnieniu uwierzytelniony użytkownik systemu (domeny) zaufanego może mieć dostęp do zasobów systemu ufającego bez konieczności ponownego uwierzytelniania. A wobec tego, hasło nie zostaje ponownie przesyłane ani przetwarzane przy zdalnym dostępie do kolejnego systemu operacyjnego. Relacje zaufania mogą mieć charakter jednostronny lub dwustronny i, co ważne, nie są przechodnie.
Prawa dostępu do zasobów
Standard POSIX (Portable Operating System Interface) 1003.1
Standard POSIX 1003.1 jest powszechnie wspierany przez współczesne systemy operacyjne. Wymaga on obsługi następujących elementów procesu autoryzacji i kontroli dostępu do zasobów:
- prawa: r (read – odczyt), w (write – zapis), x (execute – wykonanie)
- kategorie użytkowników: u (user – właściciel zasobu), g (group), o (others)
- dodatkowo prawa Set User Id, Set Group Id, Sticky, znane z systemu Unix.
Niektóre aplikacje oferują własne rozszerzenia tego modelu uprawnień,
np. ProFTPD (http://proftpd.linux.co.uk/). Również w samych systemach operacyjnych spotyka się rozszerzone implementacje modelu POSIX. Rozszerzenia te obejmują na ogół:
- listy kontroli dostępu ACL: np. w systemach AIX, Solaris
- model ścisłej kontroli dostępu MAC: w systemach Trusted Solaris, Trusted IRIX, Ultrix, HP-UX czy Xenix.
Standard POSIX 1003.1e/1003.2c
Ponieważ wcześniejsza wersja tego standardu dobrze odpowiadała w praktyce tylko klasycznym systemom Unix i w wielu nowszych systemach implementowano różnorodne rozszerzenia standardu, zaproponowano nowe wersje standardu. obejmujące m.in.:
- mechanizmy ACL, CAP, RBAC, MAC
- audyt kontroli dostępu
W implementacji nowego standardu prym wiedzie projekt TrustedBSD (http://www.trustedbsd.org/) – dla systemu FreeBSD. Dostępne są również implementacje dużej części standardu w systemie Linux z jądrem w wersjach od 2.5.46 (do jądra 2.4 jest łata obsługująca ACL standardowo dystrybuowana np. w SuSE Linux). Standard POSIX 1003.1e/1003.2c wspierają różne systemy plików Ext2, Ext3, IBM JFS, ReiserFS oraz SGI XFS. Dostępne jest też wsparcie NFS – w wersji NFSv3 możliwe jest przekazywanie list ACL (chociaż brak specyfikacji metody przekazywania skutkuje różnymi implementacjami), a wersja NFSv4 posiada mechanizm NFS ACL, lecz niestety niezgodny z POSIX. Istotne jest zachowanie wymagań standardu również w przypadku takich operacji na zasobach jak archiwizacja i tworzenie kopii zapasowych – tu popularne jest chociażby narzędzie pax (portable archive interchange), które zachowuje wszystkie wymagane standardem parametry.
Listy dostępu ACL
Listy ACL są w praktyce dostępne we wszystkich popularnych współcześnie systemach.
ACL w jądrze Linux
System Linux obsługuje dwa rodzaje uprawnień ACL:
- minimal ACL – prawa r w x dla u g o
- extended ACL – rozszerzone prawa i maski praw
Rysunek 2 przedstawia kombinację uprawnień do zasobu KATALOG1 dla użytkownika joe należącego do grupy students. Prawa efektywne są wyznaczane za pomącą algorytmu opisanego niżej. Uprawnienia defaults określają maskę dziedziczenia uprawnień w głąb – ustawianą tylko dla katalogów i dotyczącą tylko nowotworzonych obiektów.

Rysunek 2. Schemat wyznaczania uprawnień mechanizmu ACL w systemie Linux
Rysunek 3 przedstawia przykład wykorzystania narzędzi systemu Linux operujących na uprawnieniach extended ACL. Są to polecenia getfacl i setfacl.

Rysunek 3. Przykładowe wywołanie poleceń getfacl i setfacl w systemie Linux
System operacyjny weryfikuje po kolei kategorie uprawnionych podmiotów (właściciel zasobu, grupa, wyróżnieni użytkownicy), aby określić, do której kategorii należy podmiot żądający zasobu i jakie prawa z listy ACL należy zaaplikować. Kolejność weryfikacji kategorii uprawnień w celu określenia praw z listy ACL jest następująca:
- właściciel zasobu (user)
- wyszczególniony użytkownik (filtrowane przez maskę)
- grupa zdefiniowana (jeśli zawiera żądane prawa filtrowane przez maskę)
- dowolna z wyszczególnionych grup (jeśli zawiera żądane prawa filtrowane przez maskę)
- jeśli żadna dopasowana grupa nie zawiera praw – żądanie jest odrzucane
- pozostali użytkownicy (others) bez maski
Implementacje ACL w systemie Unix
W systemach z rodziny Unix, listy ACL mogą być przechowywane na różne sposoby. Zwykle definicje ACL przechowuje:
- węzeł przysłonięty (shadow inode) – wiele i-węzłów może być związanych z tym samym węzłem przysłoniętym (Solaris UFS file system)
- rozszerzone atrybuty EA obiektów (Extended Attributes) – są to struktury informacyjne związane z plikami i in. obiektami w systemie (Linux)
Maksymalna ilość pozycji możliwych do przechowania na liście ACL zależy oczywiście od miejsca przechowywania. Ilość tę dla wybranych systemów plików przedstawia rysunek 4.
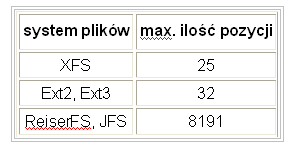
Rysunek 4. Przykładowe wywołanie poleceń getfacl i setfacl w systemie Linux
Prawa dostępu ACL w MS Windows
W systemie Windows wprowadzono mechanizm ACL (odbiegający od POSIX) w systemie plików NTFS. Lista możliwych praw i kategorii uprawnionych podmiotów jest imponująco duża. Wśród ciekawych praw można znaleźć takie atrybuty jak np. append, delete, change permissions, take ownership, change ownership, i in. (istnieją podobne atrybuty dla niektórych systemów plików z rodziny Unix, np. w systemie Linux narzędzie chattr oferuje takie atrybuty dla systemu plików Ext2/Ext3). Dzięki oddzielnie stosowanym przypisaniom GRANT i unieważnieniom DENY praw możliwa jest do osiągnięcia duża elastyczność konfiguracji uprawnień. W definicji uprawnień na liście można wykorzystywać statyczne oraz dynamiczne grupy użytkowników (np. All Authenticated Users). Ponadto Windows oferuje dla ACL wsparcie protokołu CIFS (Common Internet File System) umożliwiając tym samym tworzenie rozproszonych systemów plików uwzględniających definicje ACL. Z kolei niezależny pakiet Samba dostępny dla systemu Linux, będący implementacją wcześniejszego protokołu współdzielenia zasobów w Windows – SMB, oferuje listy ACL zgodne z POSIX.
Uprawnienia specjalne w systemie Unix
Flaga suid
W systemach z rodziny Unix wykorzystuwana jest często flaga suid = Set User Id oznaczająca specjalne uprawnienie do przejmowania przez proces (uruchomiony z programu z takim atrybutem) praw dostępu zdefiniowanych dla właściciela tego programu. Mechanizm ten jest w niektórych sytuacjach niezbędny do poprawnej pracy systemu, korzystają z niego takie programy narzędziowe jak np. passwd.
Niestety, mechanizm ten może stanowić potencjalne zagrożenie dla bezpieczeństwa systemu operacyjnego, zwłaszcza jeśli właścicielem programu z flagą suid jest administrator. Często spotykany atak polega na wyszukiwaniu programów z atrybutem suid należących do superużytkownika root, w celu wykorzystania błędów lub nieodpowiedniej konfiguracji systemu i uzyskania uprawnień administracyjnych. Zatem programy z ustawionym bitem suid powinny być szczególnie chronione.
Podobny mechanizm, o podobnym zagrożeniu, wprowadzono również dla grupy – flaga sgid = Set Group Id.
Redukcja przywilejów (privilege reduction)
Procesy uruchomione z podwyższonymi uprawnieniami (głównie administracyjnymi) stanowią łakomy kąsek dla intruza. Jest to szczególnie istotne w systemie Unix, gdzie przewidziano jedno konto administracyjne – superużytkownika root, które umożliwia wykonanie praktycznie wszelkich działań w systemie.
Jednak w większości przypadków, nawet ważne dla systemu procesy wymagają wysokich uprawnień tylko przez krótki okres czasu (zwykle początkowy). Koncepcja redukcji przywilejów sprowadza się do ograniczania zagrożenia przejęcia uprawnień procesu mogącego stać się potencjalnym celem ataku. Ograniczenie zagrożenia osiągane jest poprzez świadomą rezygnację z wyższych uprawnień (administracyjnych) natychmiast gdy newralgiczne operacje zostaną przez proces zakończone. W czasie dalszej pracy proces działa z niskimi (możliwie najniższymi) uprawnieniami.
Innym sposobem ograniczenia zagrożenia, jest wyodrębnienie wielu szczegółowych uprawnień administracyjnych i przydzielanie do procesu tylko niezbędnych, zamiast wszechwładnego prawa superużytkownika. Standard POSIX przewiduje taki mechanizm nazywany capabilities (CAP), dostępny w systemie Linux od jądra 2.2 (ftp://linux.kernel.org/pub/linux/libs/security/linux-privs). CAP pozwala na rozdzielenie uprawnień administracyjnych superużytkownika root na zbiór szczegółowych uprawnień i powiązanie ich z systemem plików poprzez dodatkowe bity praw dostępu.
Popularną implementacją mechanizmu CAP w systemie Linux jest narzędzie LCAP (http://pweb.netcom.com/~spoon/lcap/). Oferuje on m.in. następujące uprawnienia szczegółowe:
- administrowanie modułami jądra
- administrowanie siecią
- dowiązywanie do gniazd numerów portów zarezerwowanych dla serwisów systemowych
- realizacja komunikacji rozgłoszeniowej i grupowej w sieci
- omijanie ograniczeń dotyczących kontroli dostępu do plików
- zmiana informacji o właścicielu i grupie plików
- kontrola plików specjalnego rodzaju
- kontrola flag suid oraz sgid
- omijanie ograniczeń dotyczących wysyłania sygnałów do procesów
- blokowanie stron w pamięci fizycznej
- omijanie limitów zasobowych
Separacja przywilejów (privilege separation)
Kolejnym sposobem ograniczania zagrożeń związanych z nadużyciem praw dostępu jest separacja przywilejów posiadanych przez uruchomiony proces. Koncepcja separacji przywilejów polega na wyodrębnieniu zadań wymagających wysokich uprawnień w postaci odrębnego procesu. Błędy w programie procesu głównego, działającego z uprawnieniami zwykłego użytkownika, nie umożliwiają już tak łatwego uzyskania wysokich uprawnień. Istotne jest, iż ta koncepcja nadaje również się do systemów z klasycznym przydziałem uprawnień administracyjnych (bez CAP). Przykład sztandarowy wykorzystania separacji przywilejów to m.in. OpenSSH.
Malware
Pod pojęciem malware należy rozumieć wszelkie niepożądane (złośliwe) w systemie oprogramowanie, którego pojawienie się w systemie było niezamierzone i działanie jego przynosi systemowi wymierne straty. Infekcje systemu operacyjnego mogą być spowodowane różnymi typami oprogramowania malware, do którego należą:
- wirusy
- konie trojańskie
- spyware
- dialery
Poniżej zajmiemy się przedstawieniem pierwszej klasy oprogramowania malware – wirusami.
Wirusy i inne robactwo
Wirus (łac. virus – trucizna) to – najprościej definiując – kod samopowielający się w systemie operacyjnym. Istnieje wiele bardzo odmiennych rodzajów wirusów w tym w szczególności tak specyficzne jak:
- wirusy skryptowe i w makrodefinicjach (np. w dokumentach edytorów tekstu)
- wirusy sieciowe (worms) – przenoszone poprzez sieć (uruchamiane lokalnie)
- wirusy w poczcie elektronicznej (przesyłane jako załączniki)
- wirusy atakujące programy pocztowe (np. Win.Redteam), które przenoszą się tradycyjnie (przez system operacyjny), a jako ofiary wybierają klientów poczty elektronicznej (np. Eudorę) – zarażają klienta, wykonując makrodefinicje i rozsyłając się do wszystkich osób z listy adresowej.
- wirusy bujdy (hoax-viruses) – udające ostrzeżenia zwykłe żarty rozpowszechniane pocztą elektroniczną (często przez nieświadomych użytkowników).
Efekty działania wirusów to najczęściej:
- utrudnienie pracy systemu (zużywanie zasobów: CPU, pamięci, przestrzeni dyskowej, pasma sieci)
- destrukcja danych
- wyciek danych na zewnątrz (np. poprzez zamaskowany kanał komunikacyjny).
Obserwacja ewolucji oprogramowania wirusowego w ostatnich latach skłania do wyróżnienia pewnych trendów. Można przykładowo wybrać następujące obserwacje:
- 2002 r.: pojawiają się pierwsze wirusy wieloplatformowe, atakujące pliki wykonywalne w popularnych formatach zarówno exe (MS Windows) oraz elf (Linux)
- 2003 r.: wirusy typu blended threats – łączą cechy różnych klas: wirusów, koni trojańskich, robaków sieciowych (np. MS Blaster)
- 2004 r.: ataki na systemy wbudowane: np. wirus nazwany Ratter atakujący Windows CE, wirus Cabir atakujący telefony komórkowe z systemem Symbian
- 2005 r.: wzmaga się aktywność wirusowa w systemach wbudowanych – pojawił się Lasco, wirus telefonów komórkowych z możliwością infekowania plików (od 2005 McAfee i TrendMicro oferują antywirusy dla systemów mobilnych)
W oprogramowaniu wirusowym pojawiają się zaawansowane mechanizmy, takie jak kamuflaż i techniki anty-antywirusowe:
- polimorfizm
- metamorfizm
- maskowanie (stealth) oraz opancerzenie (armor) – techniki różnorodnej ochrony kodu, np. uniemożliwienie debugowania.
Wzmaga się aktywność retrowirusów stosujących obronę agresywną przed detekcją, poprzez ataki skierowane przeciw oprogramowaniu antywirusowemu. Najbardziej zaawansowane wirusy sieciowe posiadają strukturę modułową, w której występują moduły zdalnie aktualizowane (przez Internet).
Oprogramowanie malware może stosować też przeróżne sztuczki w celu ukrycia się w systemie plików i uniemożliwienia skutecznego wyszukania przez oprogramowanie antywirusowe. W tym kontekście ciekawe możliwości oferuje, dotąd mało znany i wykorzystywany mechanizm ADS (Alternate Data Stream) w systemie NTFS. Teoretycznie miał on zapewniać wsparcie międzyplatformowe (np. z systemem Macintosh). Jednak istotne z naszego punktu widzenia jest to, iż system Windows w bieżących wersjach pozwala tworzyć pliki (programy) w ADS, choć sam nie zwraca na nie uwagi (nawet ich nie pokazuje), co z kolei pozwala skutecznie ukrywać malware przed użytkownikiem, a nawet przed większością skanerów antywirusowych.
Nakłady poniesione na usunięcie infekcji i zwalczanie skutków są całkiem pokaźne. Przykładowo wg Computer Economics (2001r.) w roku 1999 osiągnęły w sumie 12,1 mld USD, a w roku 2000 – w sumie 17,1 mld USD. Jedne z najkosztowniejszych pod tym względem wirusów w historii to z pewnością:
- Love Bug (łącznie ok. 50 odmian), 2000 r.: 8,7 mld USD
- Code Red, 2001 r.: 2,6 mld USD
- Melissa, 1999 r.: 1,2 mld USD
- Explorer, 1999 r.: 1 mld USD
- SirCom, 2001 r.: 460 mln USD
Ochrona przed wirusami
Ochrona przed wirusami jest realizowana przez różnorodne oprogramowanie nazywane ogólnie antywirusowym, a obejmujące jedną lub kilka z wymienionych poniżej kategorii.
- Programy wyszukujące programy zarażone (skanery)
przed ich uruchomieniem
- wymagające znajomości kodu wirusa
- wyszukujące identyfikator wirusa (fingerprint)
- wyszukujące fragment charakterystyczny wirusa
- nie wymagające znajomości kodu wirusa
- stosujące analizę zmian struktury programu
- wymagające znajomości kodu wirusa
na podstawie efektów
- metodą "przynęty"
- poprzez analizę zmian w systemie plików po zakończeniu programu
- Programy wzbogacające możliwości ochronne systemu
- monitory operacji wykonywanych w systemie wyszukujące działania wirusa albo w trakcie instalacji lub powielenia wirusa, albo w trakcie wykonywania zadań
- destruktywnych
- demonstracyjnych
- skanery usług sieciowych (np. poczty elektronicznej, WWW)
- system plików zabezpieczony przed zapisem
- monitory operacji wykonywanych w systemie wyszukujące działania wirusa albo w trakcie instalacji lub powielenia wirusa, albo w trakcie wykonywania zadań
- Programy usuwające:
- kod wirusa
- skutki działania wirusa
Poniżej wymienione są przykładowe narzędzia ochrony przed malware.
- Zdalne skanery internetowe
- Programy anty-spyware
- Ad-aware: http://www.snapfiles.com/get/adaware.html
- Spybot: http://www.safer-networking.org/pl/download/
- Bazooka: http://www.kephyr.com
- SpywareBlaster: http://javacoolsoftware.com/downloads.html
Zamaskowane kanały komunikacji
Zamaskowane kanały komunikacji (covered channels) są pojęciem ściśle powiązanym z malware, choć nie ograniczają się wyłącznie do tego przypadku. Poprzez zamaskowany kanał komunikacji (covered channel) rozumie się wykorzystanie w celu przekazania informacji takiego mechanizmu systemu operacyjnego, które został opracowany w celu nie związanym z komunikacją i na ogół nie jest z nią w ogóle kojarzony. Kanał ten może być wykorzystywany do nieujawnionego przekazywania wiadomości, tak aby ukryć nie tylko treść tej wiadomości, ale i sam fakt dokonywania transmisji. Przykładami zamaskowanych kanałów komunikacji są:
- kanał czasowy (obciążenie systemu) – transmisja bitu następuje poprzez wzmożenie obciążenia systemu w danym kwancie czasu (bit 1) lub obniżenie obciążenia (bit 0)
- kolejka wydruku (wstawianie do niej i usuwanie określonego zadania wydruku)
- kanał poprzez tworzenie / usuwanie ogólnodostępnego pliku w systemie plików
Tunele wirtualne VPN
Tunel wirtualny (Virtual Private Network, VPN) jest to kanał komunikacyjny chroniony przez niepowołanym dostępem (odczytem i modyfikacją) poprzez zastosowanie kryptografii. Tunel wirtualny VPN umożliwia chronioną transmisję w obszarze publicznej sieci rozległej, np. w celu realizacji bezpiecznego połączenia pomiędzy różnymi jednostkami, najczęściej geograficznie odległymi (rysunek 1). W sieci publicznej należy się liczyć z potencjalnymi naruszeniami poufności, integralności i autentyczności transmitowanych danych. Poznane we wcześniejszych modułach mechanizmy kryptograficzne umożliwiają skuteczną ochronę wszystkich tych własności informacji.
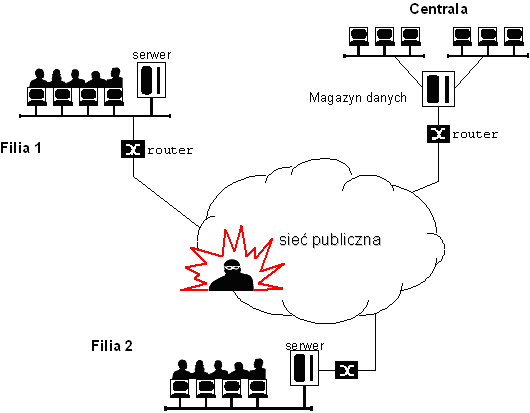
Rysunek 1. Schemat sieci publicznej analizowany jako scenariusz zagrożeń
Konfiguracje sieci VPN
Konfiguracja host-to-host
W konfiguracji tej końcami tunelu są pojedyncze stanowiska, wyposażone w odpowiednie oprogramowanie lub sprzęt (karty sieciowe) umożliwiające szyfrowanie i deszyfrowanie transmisji pomiędzy nimi.
Rysunek 2. Konfiguracja host-to-host
Konfiguracja net-to-net
W konfiguracji tej końcami tunelu są pojedyncze węzły międzysieciowe (np. dedykowane urządzenia szyfrujące, routery brzegowe z modułami kryptograficznymi). Mogą one szyfrować całą transmisję wychodzącą ze swoich sieci lokalnych lub wybrany ruch sieciowy. Transmisja odbywająca się wewnątrz poszczególnych sieci nie jest szyfrowana.
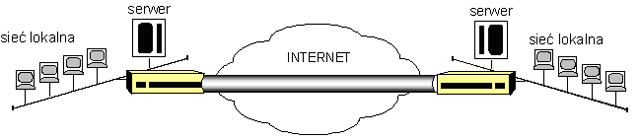
Rysunek 3. Konfiguracja net-to-net
Konfiguracja host-to-net
W konfiguracji tej jednym z końców tunelu jest pojedyncze stanowisko, które uzyskuje dostęp do zasobów pewnej sieci lokalnej (np. korporacyjnej). Cała komunikacja lub wybrany ruch (wybrane usługi) poddawane są szyfrowaniu. Jest to model typowy dla środowisk pracy zdalnej.
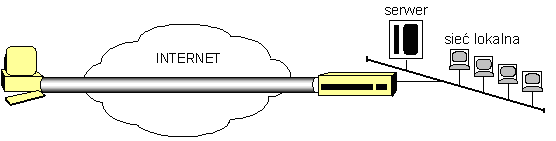
Rysunek 4. Konfiguracja host-to-net
Protokół IPsec
Jak wiemy w protokole IPv4 brak praktycznie jakichkolwiek mechanizmów bezpieczeństwa. W związku z rosnącymi wymagani bezpieczeństwa, w 1995 r. przedstawiono (IETF) pierwszą wersję specyfikacji protokołu sieciowego IPsec (RFC 1825), zawierającego dwie składowe
- Authentication Header (AH) – protokół nr 51
- Encapsulating Security Payload (ESP) – protokół nr 50
Zadaniem protokołu IPsec operującego w warstwie sieciowej jest transparentne dla aplikacji wykorzystanie narzędzi kryptograficznych w celu osiągnięcia
- integralności – poprzez funkcje protokołu AH
- poufności – poprzez funkcje protokołu ESP
Jednak wkrótce rozszerzono funkcje ESP o ochronę również integralności. W efekcie funkcje ochrony integralności zostały powielone w obu składowych protokołu IPsec. Dlaczego zatem utrzymano oddzielne składniki AH i ESP? Z jednej strony przemawiają za tym trudności merytoryczne, zrozumiałe w tak złożonym projekcie jak ESP. Ponadto przemawiały pierwotnie za tym ograniczenia natury polityczno-prawnej, związane ze stosowaniem kryptografii – AH wykorzystując wyłącznie kryptograficzne funkcje skrótu, z reguły był traktowany bardziej liberalnie. Ostatecznie jednak należy przyznać, iż funkcjonalność AH wystarcza w wielu zastosowaniach, np. w przypadku ochrony usługi DNS, gdzie informacje udostępniane przez tę usługę są z reguły publiczne i nie ma potrzeby ich szyfrowania, ważne jest natomiast by nie zostały one po drodze sfałszowane.
Ostateczna wersja IPsec (RFC 2401, 1998 r.) obejmuje zatem specyfikacje dwu protokołów:
http://www.ipsec.pl/
- AH (Authentication Header, RFC 2402)
- który realizuje kontrolę integralności i autentyczności datagramu IP oraz umożliwia uwierzytelnianie
- ESP (Encapsulating Security Payload, RFC 2406)
- który zapewnia integralność i poufność treści datagramu
Uwierzytelnianie stron jest realizowane do pewnego stopnia przez sam protokół IPsec i może być rozszerzane przez dodatkowe mechanizmy.
Tryby pracy protokołów IPsec
Tryb transportowy (transport mode), inaczej nazywany bezpośrednim, charakteryzuje się tym, że do datagramu dodany jest nagłówek AH / ESP i dane datagramu (ramka TCP, UDP, ICMP, ...) zostają zabezpieczone (podpisane / zaszyfrowane) bezpośrednio za nim.
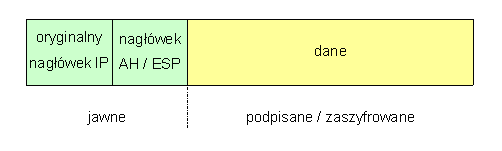
Rysunek 5. Postać chronionego datagramu w trybie transportowym
W trybie tunelowym (tunnel mode) natomiast oryginalny datagram IP zostanie zabezpieczony (podpisany / zaszyfrowany) w całości z nagłówkiem w ramkę protokołu AH / ESP, a następnie umieszczony w niezabezpieczonym datagramie IP jako jego dane.
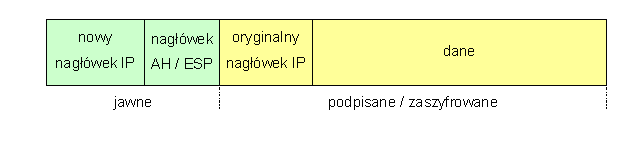
Rysunek 6. Postać chronionego datagramu w trybie tunelowym
Protokół AH (Authentication Header)
Protokół AH przenosi wartość jednokierunkowej funkcji skrótu treści datagramu oraz stałych pól nagłówka (zarówno w trybie transportowym jak i tunelowym). W tym celu wykorzystywane są funkcje HMAC: MD5, SHA-1, RIPEMD-160 lub inne (negocjowane). Ewentualna fragmentacja datagramu jest dokonywana wcześniej (podpisywany jest każdy fragment oddzielnie). Niezaprzeczalność osiągana jest poprzez silne algorytmy kryptograficzne, np. RSA.

Rysunek 7. Schemat budowy datagramu protokołu AH
Protokół ESP (Encapsulating Security Payload)
Protokół ESP Umożliwia podpisywanie datagramu (stosuje te same algorytmy co w AH – uwzględnia w podpisie statyczne pola nagłówka podstawowego IP) oraz zaszyfrowanie datagramu – wykorzystuje szyfry blokowe w trybie CBC, np. DES, 3DES (z 3-ma kluczami), Blowfish, CAST-128 czy Rijndael/AES, aktualnie również 3-IDEA (z 3-ma kluczami).
Nagłówek ESP jest umieszczany bezpośrednio przed zaszyfrowanymi danymi. Format i długość zaszyfrowanych danych zależy od wybranej metody kryptograficznej.
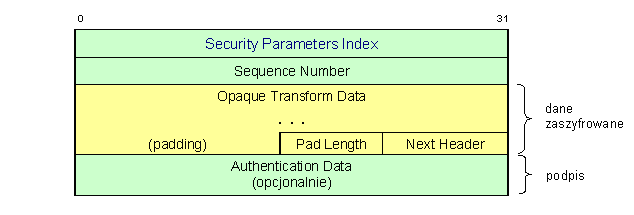
Rysunek 8. Schemat budowy datagramu protokołu ESP
Możliwe jest połączenie mechanizmów AH i ESP. Przykładowo, najpierw szyfrowane są dane za pomocą ESP, a następnie cały datagram jest zabezpieczony przez AH. Alternatywnie, najpierw wyznacza się nagłówek AH i umieszcza się go datagramie, a następnie szyfruje w całości przez ESP (tuneluje).
Asocjacja bezpieczeństwa (Security Association)
Asocjacja bezpieczeństwa SA jest to zbiór parametrów charakteryzujących bezpieczną komunikację między nadawcą a odbiorcą (kontekst), utrzymywany przez nadawcę i unikalnie identyfikowany przez SPI (Security Parameters Index). Blok parametrów asocjacji obejmuje następujące dane:
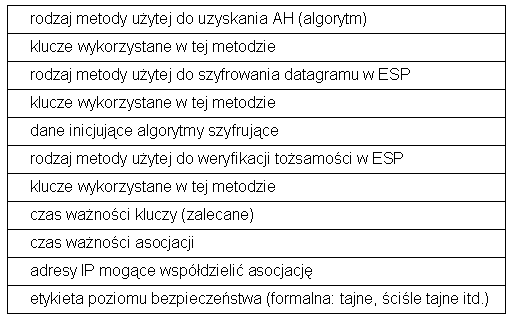
Asocjacja bezpieczeństwa (a dokładniej blok parametrów asocjacji) nie jest przesyłana siecią – przesyłany jest tylko numer SPI. Asocjacja bezpieczeństwa jest jednokierunkowa – w łączności obukierunkowej wymagane są dwie asocjacje – daje to dużą elastyczność ruch w każdym kierunku może być szyfrowany innym kluczem i może mieć inny okres ważności. Kanały SA mogą się wzajemnie w sobie zawierać i nie muszą się zaczynać w tych samych miejscach (na tych samych stacjach).
Poniżej przedstawiony zostanie schemat działania stacji protokołu IPsec. Działania wykonywane przy wysyłaniu pakietu są następujące:
- Sprawdzenie czy i w jaki sposób wychodzący pakiet ma być zabezpieczony:
- sprawdzenie polityki bezpieczeństwa w SPD (Security Policy Database)
- jeśli polityka bezpieczeństwa każe odrzucić pakiet to pakiet jest odrzucany
- jeśli pakiet nie musi być zabezpieczany to jest wysyłany
- Ustalenie, które SA powinno być zastosowane do pakietu:
- odszukanie SA w bazie SAD (SA Database) lub
- nawiązanie odpowiedniego SA jeśli nie jest jeszcze nawiązane
- Wykonanie zabezpieczeń wykorzystując algorytmy, parametry i klucze zawarte w SA:
- wynikiem jest stworzenie nagłówka AH lub ESP
- dodatkowo może zostać również utworzony nowy nagłówek IP (w trybie tunelowym)
- Wysłanie powstałego pakietu IP
Natomiast działania wykonywane przy odbieraniu pakietu są następujące:
- Sprawdzenie nagłówka IPsec:
- odszukanie odpowiedniego SA w SAD na podstawie SPI zawartego w nagłówku
- i postępowanie zgodnie z informacjami zawartymi w SA
- jeśli SA wskazywany przez SPI nie istnieje, to pakiet jest odrzucany
- Sprawdzenie czy i jak pakiet powinien był być zabezpieczony:
- sprawdzenie polityki bezpieczeństwa w SPD
- jeśli polityka bezpieczeństwa każe odrzucić pakiet to pakiet jest odrzucany
- jeśli zabezpieczenia pakietu nie odpowiadają polityce bezpieczeństwa to pakiet jest odrzucany
- jeśli pakiet był zabezpieczony prawidłowo to przekazywany jest wyżej
Zarządzanie kluczami
Zarządzanie i dystrybucja kluczy nie są uwzględnione w specyfikacji samego standardu IPsec. Możliwe jest jednak wykorzystanie kluczy dwojakiego typu:
- klucze przypisane do użytkownika
- klucze przypisane do stacji sieciowej
Możliwe są też bardzo różnorodne sposoby dystrybucji:
- dystrybucja ręczna – administrator (małej sieci lokalnej) wyznacza wszystkie klucze
- wykorzystanie istniejących systemów dystrybucji (np. systemu Kerberos)
- automatyczne – początkowo myślano o DNS jako repozytorium kluczy
- ostatecznie wprowadzono nowe protokoły i specyfikacje serwerów kluczy (niezależne od IPsec): np. SKIP (Sun), Photuris, IKE (Internet Key Exchange)
- integracja serwerów kluczy z usługami katalogowymi (DNSsec, LDAP)
Protokoły zarządzania kluczami mają na celu wzajemne uwierzytelnianie podmiotów nawiązujących asocjacje IPsec oraz uzgadnianie kluczy sesji na potrzeby poszczególnych kanałów SA. Obie te funkcje realizowane są na podstawie skonfigurowanych na stałe danych uwierzytelniających. Może to być np. hasło wspólne dla pary stacji (shared secret), certyfikaty X.509, klucze PGP. Niektóre implementacje (SKIP, Photuris) umożliwiają wyłącznie uwierzytelnienie na podstawie haseł, a popularny protokół IKE obsługuje natomiast wszystkie wyżej wymienione metody i umożliwia jeszcze prywatne rozszerzenia.
Protokół IKE (Internet Key Exchange)
Protokół IKE obejmuje 2 składniki:
- ISAKMP (Internet Security Association and Key Management Protocol) – faktyczny protokół negocjacji parametrów IPSec
- Oakley – kryptograficzny protokół wymiany kluczy za pomocą algorytmu Diffiego-Hellmana
ISAKMP (RFC 2408) stanowi trzon całości i z tego powodu nazwy tej używa się niekiedy zamiennie z IKE. Protokół ISAKMP korzysta z UDP (port 500).
Wymiana kluczy następuje dwuetapowo: najpierw ustalana jest tożsamość komunikujących się węzłów i tworzony jest bezpieczny kanał (tzw. ISAKMP SA), utrzymywany przez cały czas trwania sesji i służący następnie do właściwej negocjacji parametrów asocjacji. Negocjacja obejmuje m.in. listę obsługiwanych algorytmów szyfrujących, co ułatwia obsługę środowisk heterogenicznych.
Uwierzytelnianie może być realizowane na ogół na dwa sposoby. W najprostszym przypadku każda para węzłów musi mieć ustalone wspólne hasło, które służy do obliczania kluczy metodą Diffiego-Hellmana. Oznacza to konieczność konfigurowania haseł na wszystkich węzłach, co jest istotnym ograniczeniem tej metody i może okazać się zbyt pracochłonne w przypadku dużych sieci. Alternatywną metodą jest zastosowanie kluczy publicznych podpisanych przez nadrzędny urząd certyfikujący CA (np. certyfikatów X.509), które jest wolne od ograniczeń ręcznej definicji haseł.
protokół ISAKMP jest łatwo rozszerzalny. Pewne parametry (Domain of Interpretation, DOI) można przystosować całkowicie do potrzeb własnej instytucji:
- własny zestaw szyfrów
- własne mechanizmy uwierzytelnienia
PKI (Public Key Infrastructure)
Protokół IKE pozwala wykorzystać możliwości PKI. Po nawiązaniu komunikacji, ale przed uzgodnieniem ISAKMP SA węzeł może zweryfikować autentyczność certyfikatu drugiej strony dzięki podpisowi CA. W skrajnym przypadku węzeł nie musi wiedzieć nic o innych węzłach z którymi będzie się łączył, lub które będą się łączyć z nim. Wymaga to jedynie lokalnego dostępu (zainstalowania w tym węźle) klucza publicznego urzędu CA – będzie to jeden i ten sam klucz na wszystkich węzłach. Znacznie ułatwia to realizację złożonych topologii.
Co istotne, IKE umożliwia też automatyczną renegocjację kluczy kryptograficznych co określony interwał (nawet często). W takim przypadku, w razie złamania bieżącego klucza, dane zaszyfrowane poprzednimi kluczami nie są narażone. Cecha ta, określana jako Perfect Forward Security, chroni przed sytuacją gdy atakujący zapisuje wszystkie przechwycone w przeszłości dane w nadziei, że kiedyś uda mu się zdobyć klucz do ich rozszyfrowania. Implementacja obligowana jest by w przypadku renegocjacji klucza poprzedni klucz był usuwany z pamięci. Wówczas włamywacz nie znajdzie go w systemie nawet w przypadku opanowania systemu operacyjnego węzła.
Ograniczenia
Protokół IPsec dobrze nadaje się do realizacji tuneli wirtualnych VPN. Jednak nie jest idealnym rozwiązaniem problemu bezpiecznej komunikacji. Praktycznie od początku był IPsec krytykowany za niekonsekwencje projektowe i nadmierne skomplikowanie. Wytykano, iż np. ochrona integralności zapewniana jest niemal w równym stopniu przez ESP, jak i AH. Niektóre odkryte błędy zostały usunięte w wersji z 1998 r. (np. część potencjalnych furtek do ataków DoS). Gwoli ścisłości należy zaznaczyć, iż zdiagnozowane usterki nie mają raczej charakteru otwartych dziur, grożących złamaniem bezpieczeństwa sieci, ale są za to dość liczne i ułatwiają powstawanie potencjalnych słabości w samych implementacjach.
Mimo tego jednak, IPsec jest wykorzystywany powszechnie i praktycznie nie ma dla niego alternatywy. Jako reprezentatywną opinię można przytoczyć tu podsumowanie analizy IPsec dokonanej w 1999 r. przez znanych kryptologów Nielsa Fergussona i Bruce’a Schneiera:
,,Nawet pomimo dość poważnych zarzutów jakie wysunęliśmy wobec IPSec, jest on prawdopodobnie najlepszym protokołem bezpieczeństwa z obecnie dostępnych.
W przeszłości przeprowadziliśmy podobne analizy innych protokołów o analogicznym przeznaczeniu (w tym PPTP). Żaden ze zbadanych protokołów nie spełnił swojego celu, ale IPSec zbliżył się do niego najbliżej. (...) Mamy ambiwalentne odczucia wobec IPSec. Z jednej strony IPSec jest znacznie lepszy niż jakikolwiek protokół bezpieczeństwa IP stworzony w ostatnich latach: Microsoft PPTP, L2TP itp. Z drugiej strony nie wydaje nam się, by zaowocował on kiedykolwiek stworzeniem w pełni bezpiecznego systemu.”
IPsec w Windows
W Windows 2000 i XP wbudowano obsługę IPsec (ESP) zintegrowaną z usługą Active Directory. Sam IPsec tuneluje tylko ruch IP.
Rysunek 9. Uaktywnienie obsługi protokołu IPsec w Windows
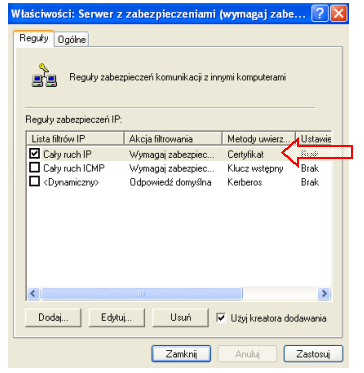
Rysunek 10. Przykład definicji tunelowania ruchu IP
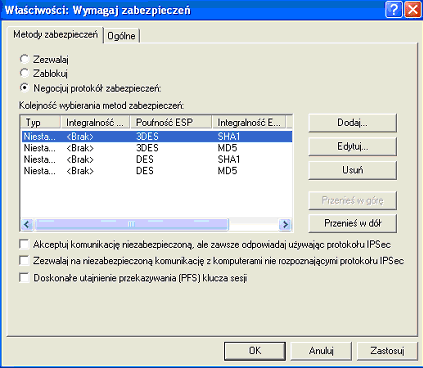
Rysunek 11. Szczegóły definicji tunelowania ruchu (zmienne parametry SA)
Bezpieczeństwo w IPv6
Uzupełniając wiadomości o protokole IPsec, należy dodać, iż jest on zintegrowaną częścią specyfikacji protokołu IP w wersji 6. Zatem w protokole IPv6 możliwe jest korzystanie z nagłówków AH i ESP jak z dowolnych innych opcji protokołu.
Propagowanie połączeń aplikacyjnych (port forwarding)
Aczkolwiek najbardziej uniwersalny tunel wirtualny osiągnąć można na poziomie warstwy sieciowej, to jednak mechanizmy kryptograficznej ochrony komunikacji można zaprząc do pracy w innych warstwach.
Szyfrowane propagowanie połączeń jest metodą realizacji tuneli wirtualnych na poziomie warstwy aplikacji. Oferuje je np. protokół SSH. Działanie mechanizmu propagowanie połączeń można przedstawić następująco (rysunek 12).
- połączenia na port A bramy 1 są tunelowane do bramy 2
- i dalej propagowane na port S serwera w sieci lokalnej za bramą 2
- tunel między bramą 1 a bramą 2 jest szyfrowany
- komunikacja poza tunelem (w obu sieciach lokalnych – czyli od klienta do bramy 1 oraz od bramy 2 do serwera nie jest szyfrowana
Rysunek 12. Schemat działania propagacji połączeń
Tunele SSL
Tunele wirtualne można realizować na poziomie warstwy sesji. Znanym powszechnie przykładem jest SSL (Secure Socket Layer) – połączeniowy protokół oferujący dwupunktowy tunel kryptograficzny z wykorzystaniem certyfikatów, zaprojektowany z myślą o ochronie sesji takich protokołów jak HTTP, POP/IMAP, SMTP. SSL oferuje ochronę poufności, integralności i autentyczności danych. I tak przykładowo HTTPS – protokół HTTP tunelowany poprzez SSL – jest powszechnie wykorzystywaną w sieci internetowej usługą (port 443). Odpowiednio istnieją wersje tunelowane innych usług (POPS, IMAPS). W praktyce SSL potrafi tunelować dowolny ruch (stunnel, OpenVPN).
Aktualna wersja SSL nosi numer 3.0. Równolegle z tą wersją występuje jego następca – protokół TLS (Transport Layer Security). TLS v.1.0 jest standardem IETF – RFC 2246.
Pytania problemowe
- Który tryb pracy protokołów IPsec – transportowy czy tunelowy – jest dogodniejszy dla konfiguracji: host-to-host, net-to-net, host-to-net?
- Wyjaśnij dlaczego najbardziej uniwersalny tunel wirtualny osiągnąć można na poziomie warstwy sieciowej.
Zapory sieciowe (firewall) i translacja adresów
W dziedzinie zabezpieczeń ruchu sieciowego dużą rolę odgrywają systemy kontroli komunikacji nazywane w języku ang. firewall. W języku polskim ścierają się na ogół dwa terminy: zapora sieciowa oraz ściana przeciwogniowa. Drugi z nich jest tłumaczeniem rdzennego pojęcia amerykańskiego (rysunek 1)

Rysunek 1. Etymologia pojęcia firewall
Inną analogią tego pojęcia jest kontrola paszportowa i celna na granicy – w naszym przypadku granicy sieci komputerowej.
Podstawowe funkcje systemów firewall
Podstawowe funkcje systemów firewall obejmują filtrację ruchu oraz pośredniczenie w dostępie do usług sieciowych
Filtracja pakietów to podstawowa forma zabezpieczenia sieci. Polega na analizie pakietów (a dokładniej parametrów ruchu zawartych w nagłówkach pakietów) warstwa 3 (czasami 2-4) modelu OSI. Możliwa jest:
- filtracja pakietów nadchodzących
- filtracja pakietów wychodzących
- filtracja pakietów propagowanych przez moduł routingu (dotyczy oczywiście wyłącznie węzłów międzysieciowych)
Ruch sieciowy jest filtrowany (przepuszczany lub blokowany) w zależności od decyzji podjętych na podstawie analizy pakietów, przy zastosowaniu zdefiniowanych reguł (reguł filtracji).
Pośredniczenie w dostępie do usług jest realizowane poprzez odseparowanie świata wewnętrznego i zewnętrznego względem zapory sieciowej (brak funkcji routingu). Komunikacja poprzez zaporę nie jest możliwa w żadnej warstwie poza aplikacyjną (warstwa 7 modelu OSI). Na zaporze uruchomione są aplikacje pośredniczące (proxy services) w komunikacji końcowych aplikacji użytkowych (np. klient-serwer). Oznacza to, iż klient, uruchomiony – przyjmijmy – w sieci wewnętrznej, nie może nawiązać połączenia bezpośrednio z serwerem pracującym w sieci zewnętrznej. Może tylko nawiązać połączenie z aplikacją proxy. Ruch może przechodzić przez zaporę, jedynie gdy zostanie pozytywnie sklasyfikowany przez aplikację proxy. Zaakceptowane połączenie od klienta jest następnie zestawiane w imieniu klienta przez aplikację proxy z serwerem. W istocie zatem utrzymywane są dwa połączenia: klient-proxy i proxy-serwer dolecowy.
Rysunek 2. Model pośredniczenie w realizacji usług (firewall typu proxy)
Podstawowe komponenty systemów firewall
Systemy firewall konstruowane są ze złożenia wymienionych poniżej komponentów.
- Specjalizowany węzeł międzysieciowy (router)
Jest to rozwiązanie najprostsze i najłatwiejsze w utrzymaniu. Można je zrealizować przy pomocy następujących urządzeń:
- router filtrujący (screening router)
- router szyfrujący (ciphering router)
- Komputer Twierdza (Bastion Host)
Jest to dedykowana stacja lub węzeł międzysieciowy, na którym uruchomione są usługi proxy.
- Strefa Zdemilitaryzowana (Demilitarized Zone – DMZ)
Jest to dedykowana podsieć obejmująca jedno lub kilka stanowisk o złagodzonych wymaganiach względem ochrony. Typowo umieszcza się tam stanowiska oferujące pewne wybrane informacje publicznie, w odróżnieniu od stacji sieciowych pracujących wewnątrz sieci chronionej.
Router filtrujący
Podstawowym zagadnieniem dotyczącym realizacji zapory sieciowej tego typu jest kwestia definicji reguł filtracji. Reguły filtracji operują w ogólności na parametrach analizowanych pakietów, takich jak:
- adresy z nagłówka protokołu sieciowego (źródłowy i docelowy)
- typ protokołu (PDU i SDU, np. protokołu transportowego)
- rodzaj usługi (numer portu z nagłówka protokołu transportowego)
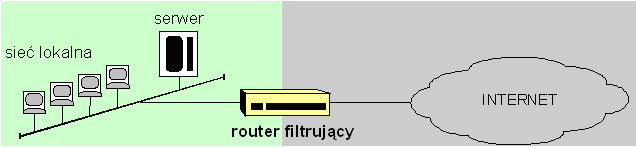
Rysunek 3. Model systemu z zaporą sieciową typu router filtrujący
Schemat wewnętrznej kompozycji urządzenia filtrującego jest przedstawiony na rysunku 4. Możliwe jest utrzymywanie oddzielnych list filtracji dla ruchu wchodzącego i wychodzącego z zapory sieciowej.
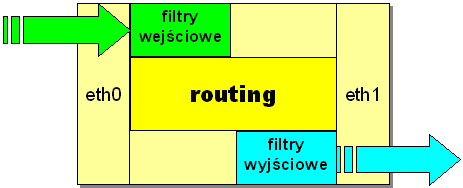
Rysunek 4. Model modułu filtracji
Filtry można zdefiniować na następujące sposoby:
- filtry statyczne – definicje reguł filtracji są dokonane z wyprzedzeniem i obowiązują aż do jawnej ich zmiany
- filtry kontekstowe – realizują dynamiczne reguły filtracji (SPF = Stateful Packet Filtering)
- w trakcie pracy aktualizowane są informacje o bieżących sesjach (asocjacjach protokołu sieciowego)
- decyzje o filtracji pakietów podejmowane są z uwzględnieniem stanu sesji, do której przynależą
- filtracja nieliniowa:
- elastyczne definiowanie wyrażeń warunkowych (zagnieżdżone reguły logiczne)
Przykład statycznych reguł filtracji pokazuje rysunek 5. Opisuje on filtrację przypadku z rysunku 6. Na nim mamy hipotetyczną sieć wewnętrzną, której stacjom zezwala się na nawiązywanie połączeń tylko wybranej usługi (w przykładzie – telnet) i jedynie z wybranym serwerem zewnętrznym.
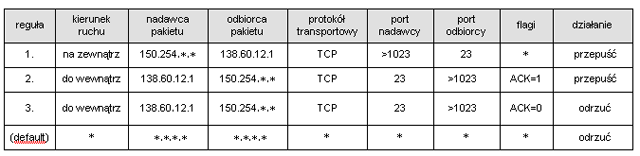
Rysunek 5. Przykładowe statyczne reguły filtracji
Reguły zdefiniowane na statycznej liście filtracji są przeglądane sekwencyjnie do pierwszego trafienia. Dla pasującej reguły jest aplikowane zdefiniowane w niej działanie (na ogół akceptacja lub odrzucenie pakietu). Reguła nr 1 zezwala na ruch wychodzący na zewnątrz jeśli adres nadawcy należy do zakresu adresów sieci wewnętrznej, odbiorcą pakietu jest wyróżniony serwer zewnętrzny, port nadawcy nie jest portem systemowym, a port odbiorcy zgadza się z portem usługi telent. Druga reguła zezwala na ruch w przeciwnym kierunku, pod warunkiem odwrotnej kombinacji parametrów, lecz jedynie pod warunkiem, że w nagłówku TCP ustawiona jest flaga ACK. Natomiast w przypadku, gdy flaga ta jest wyzerowana, ruch wchodzący z serwera jest blokowany. Jest konsekwencją faktu, iż flaga ACK jest wyzerowana jedynie w pierwszym segmencie TCP – nawiązującym połączenie (segment SYN). Nie jest oczywiście naturalne, by serwer usługi telent próbował zestawić połączenie z klientem ochranianej sieci, zatem taką sytuację należy rozpoznać jako podejrzaną i odrzucić pakiet (najprawdopodobniej oprogramowanie podszywające się za serwer próbuje nawiązać połączenie ze stacjami wewnątrz chronionej sieci). Reguła ostatnia jest realizacją zasady domyślnej reguły dostępu – blokuje jakikolwiek ruch, który nie został zdefiniowany w poprzednich regułach.
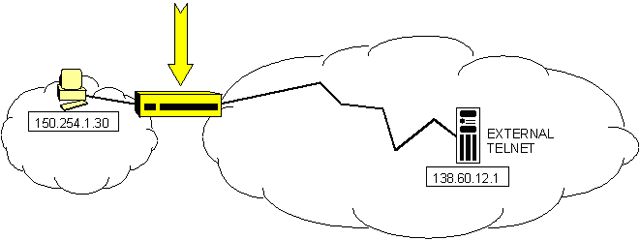
Rysunek 6. Schemat sieci do przykładu definicji statycznych reguł filtracji
Statyczne reguły filtracji posiadają kilka ograniczeń. Przykładowo niektóre usługi trudno poddają się filtracji statycznej (np. FTP, X11, DNS). Rozważmy jak w trybie aktywnym pracy serwera FTP (przypomnij sobie jaki to tryb) ochronić się przed nadużyciem, w którym oprogramowanie podszywające się za serwer próbuje nawiązać połączenie ze stacjami wewnątrz chronionej sieci. Z pomocą przychodzą pewne nowe rozwiązania proponowane w samych protokołach aplikacyjnych. Coraz powszechniej wprowadza się i stosuje tryby pracy zmodyfikowane pod kątem usprawnienia filtracji, np. tryb passive w protokole FTP (skądinąd użyteczny także np. przy korzystaniu z dostępu xDSL)
Komputer Twierdza
Komputer Twierdza to stacja z odseparowanymi interfejsami sieciowymi (Dual Homed Host Gateway) zajmująca miejsce węzła międzysieciowego (rysunek 7). Oferuje fizyczną i logiczną separację prywatnej sieci lokalnej od zewnętrznej sieci publicznej. Dzięki separacji interfejsów tylko Komputer Twierdza jest widoczny z sieci publicznej. Zatem, aby wtargnąć do sieci prywatnej trzeba uprzednio zawładnąć Komputerem Twierdzą. Komputer Twierdza pełni rolę bramy aplikacyjnej – usługi pośredniczące i zastępcze (proxy) rozwiązują problem usług trudnych do filtracji. Dzięki temu, iż jest on pełnym stanowiskiem komputerowym, potencjalnie wyposażonym w dowolne żądane oprogramowanie i praktycznie nieograniczone zasoby pamięci masowej, możliwa jest szczegółowa rejestracja zdarzeń (auditing), ułatwiająca diagnozowanie ewentualnie pojawiających się nowych zagrożeń i niedoskonałości konfiguracji.
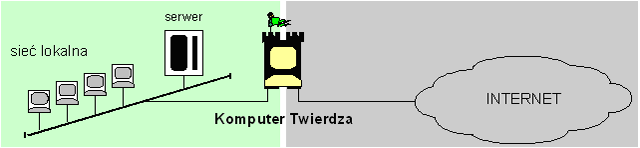
Rysunek 7. Model systemu z zaporą sieciową typu Komputer Twierdza
Filtracja podwójna
Rysunek 8 pokazuje schematyczne połączenie w jedną linię obrony różnych typów zapór sieciowych, dokładniej jest to brama aplikacyjna poprzedzona routerem filtrującym (Screened Host Gateway).
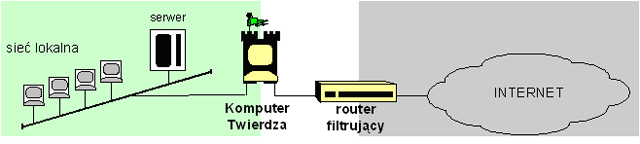
Rysunek 8. Model systemu z filtracją podwójną
Możliwe jest dalej „rozciągnięcie” Twierdzy na całą dedykowaną podsieć (Screened Network), co pokazuje z kolei rysunek 9, a nawet kaskadę podsieci.
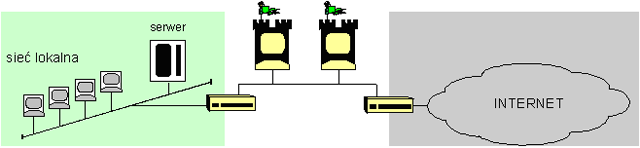
Rysunek 9. Model systemu z podsiecią ochronną
Strefa Zdemilitaryzowana
Konfiguracja która przyjęła się pod nazwą Strefa Zdemilitaryzowana (DMZ = Demilitarized Zone) to wydzielona podsieć zawierająca komponenty świadomie wyjęte spod kontroli obejmującej całą resztę sieci wewnętrznej, takie jak np.:
- publiczne zasoby (np. ogólnodostępny serwis WWW)
- przynęty, pułapki
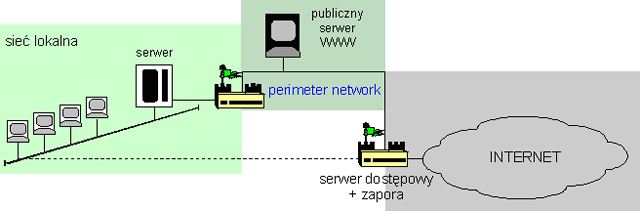
Rysunek 10. Model systemu ze Strefą Zdemilitaryzowaną DMZ
Translacja adresów – Network Address Translation (NAT)
Translacja adresów jest powszechnym w sieciach komputerowych mechanizmem, który ma różne cele, a są to:
- rozszerzenie dostępu do sieci publicznej na stanowiska nie posiadające przydziału adresów publicznych (posiadające tylko adresy prywatne – RFC 1918)
- wykorzystanie wewnątrz sieci nieprzydzielonych publicznych adresów IP
(za cenę braku możliwości komunikacji z takimi oficjalnymi adresami)
- ukrycie wewnętrznej struktury sieci przed światem zewnętrznym
- przekierowanie ruchu (portów: NAPT = Network Address Port Translation)
Metody wzajemnego odwzorowania adresów są ustandaryzowane i opisane w dokumentach:
- RFC1631 (translacja na pojedynczy adres, tj. N:1)
- RFC1597,1918 (translacja na pulę adresową, tj. N:M)
Wyróżnia się przy tym translację adresów źródłowych – Source NAT (SNAT) – oraz docelowych – Destination NAT (DNAT).
Translacja adresów źródłowych (SNAT)
W tym przypadku pakiety wychodzące z sieci wewnętrznej otrzymują nowy adres źródłowy w nagłówku (rysunek 11). W przykładzie, pakiet wychodzący w rzeczywistości z adresu IP równy 10.1.1.1 otrzymuje po translacji adres źródłowy serwera translacji (jest nim brzegowy węzeł międzysieciowy), mianowicie 150.254.1.100. Numer portu źródłowego też ulega zmianie.
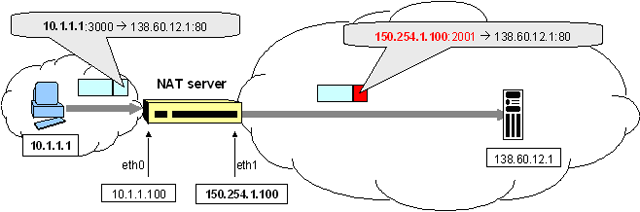
Rysunek 11. Schemat translacji adresów źródłowych (SNAT)
Translacja adresów docelowych (DNAT)
W mechanizmie Destination NAT (DNAT) pakiety przychodzące ze strony inicjującej (na ogół – sieci zewnętrznej) otrzymują nowy adres docelowy (w tym w szczególności – port). Celem może być przekierowanie ruchu określonej usługi pod rzeczywisty, nie ujawniany na zewnątrz, adres wewnętrznego serwera tej usługi. Na rysunku 12 adres serwera (o jaką usługę chodzi w tym przykładzie?) upubliczniony na zewnątrz jest równy 150.254.1.1, podczas gdy rzeczywisty adres to 150.254.1.200.
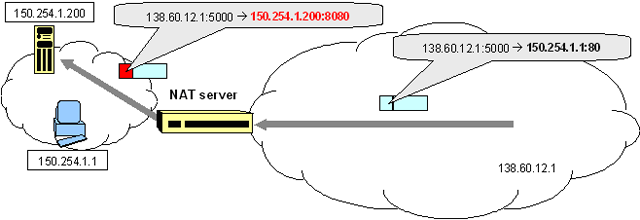
Rysunek 12. Schemat translacji adresów źródłowych (SNAT)
Dodatkowa funkcjonalność zapór sieciowych
Łańcuch funkcji realizowanych przez zapory sieciowe wyglądać może następująco:
- jedynie funkcje podstawowe:

- również funkcje dodatkowe:

Dodatkowymi funkcjami mogą być
- obrona przed atakami DoS (flood-wall) – specyfikowanie dopuszczalnego rozmiaru strumienia wejściowego (np. w pakietach na sek.)
- kontrola fragmentacji IP i śledzenie numerów sekwencyjnych TCP (kontrola czy znajdują się w oczekiwanym zakresie)
- wsparcie dla IPv6: fragmentacja, ICMPv6, ochrona przed atakami DoS analogicznymi jak dla IPv4
- filtry IPv6, np. ipf (FreeBSD), rozpoznawanie tunelowania IPv6 w IPv4
(tzn. takich protokołów jak 6to4, 6over4, Toredo)
- integracja z różnymi zewnętrznymi modułami, np. systemami antywirusowymi, modułami sieciowej detekcji intruzów (IDS), czy ograniczenia dostępu (parental control)
Filtry kontekstowe
Standardowy przepływ ruchu poddawanego filtracji (round-trip) można przedstawić schematycznie postaci poniższej:
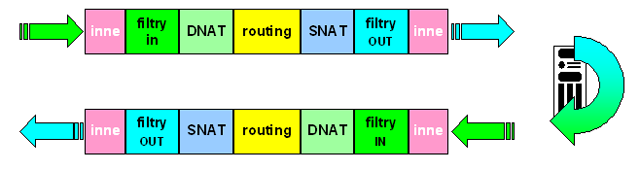
Filtry kontekstowe podejmują dynamicznie zmienne decyzje na podstawie weryfikacji kontekstu (stateful inspection):
- każda zainicjowana poprawnie sesja jest pamiętana na dynamicznych listach
- w drodze powrotnej pakiet jest sprawdzany na przynależność do zapamiętanej sesji – filtracja może być pominięta:
Przedstawia to poniższy schemat:
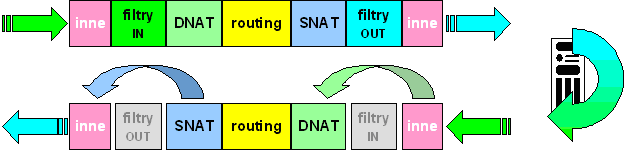
Problemy realizacji zapór sieciowych
Zapory sieciowe cierpią na wiele problemów, zarówno technologicznych jak i realizacyjnych. Problemy technologiczne dotyczą np. usług takich jak FTP. Przykładowo, jeśli filtr kontekstowy w zaporze obsłuży komendę PORT 23 protokołu FTP, to czy będzie to naruszenie polityki bezpieczeństwa? Problemy technologiczne związane są również z wykorzystaniem w ruchu sieciowym mechanizmów takich jak fragmentacja IP. Z filtracją pakietów pofragmentowanych związane są następujące problemy:
- odrzucanie tylko pierwszych fragmentów umożliwia wyciek informacji w strumieniu wyjściowym
- istnieją narzędzia do tak perfidnego fragmentowania, by flagi ACK i SYN nagłówka TCP nie pojawiały się w pierwszym fragmencie
- można scalać fragmenty na zaporze – uwaga na błędy przy scalaniu
- można narzucić wymóg, aby pierwszy fragment zawierał co najmniej 16B danych (a najlepiej cały nagłówek TCP)
Istotne problemy niesie ze sobą pielęgnacja reguł filtracji. Szczególnie trudna jest ona do sprawnego przeprowadzenia w przypadku dużych zbiorów reguł. Dodatkowo potęgują trudności częste na naszym rynku informatycznym zmiany personelu i brak dokumentacji uniemożliwiający pielęgnację starych reguł (odziedziczonych po poprzednim administratorze). Często występują również problemy wewnętrzne: duże organizacje posiadają często złożoną politykę bezpieczeństwa, co implikuje wielość nachodzących na siebie domen bezpieczeństwa i trudności w definicji i pielęgnacji spójnych reguł filtracji.
Ostrożnie należy też postępować z tunelami wirtualnymi. Autoryzowane tunele VPN mogą być potencjalnym nośnikiem nieautoryzowanych treści poza kontrolą zapór ogniowych. Zatem powinny być zaplanowane i zrealizowane w sposób przemyślany. Podobnie jak VPN, również propagowanie połączeń (port forwarding) może przyczynić się do skutecznego ominięcia kontroli na zaporze. Podobnie trudności sprawia dość rozpowszechniony protokół SOAP (Simple Object Access Protocol), służący, mówiąc kolokwialnie, do tunelowania jakiegokolwiek ruchu w HTTP. Pod tym względem skrajnie wywrotowy jest httptunnel (http://www.noccrew.org/software/httptunnel.html)
Pytania problemowe
- W przykładzie statycznych reguł filtracji z rysunku 5 zdefiniowano 4 reguły. Jedna z nich jest jednak nadmiarowa i można ją usunąć bez żadnych konsekwencji dla przebiegu filtracji. Która to reguła?
Bezpieczeństwo aplikacji i usług sieciowych
Bieżący moduł przedstawia wybrane zagadnienia bezpieczeństwa dotyczące aplikacji użytkowych i usług sieciowych. Najpierw omówiony zostanie dość uniwersalny mechanizm ochrony stosowalny wobec dowolnych aplikacji – ograniczanie środowiska wykonania. Następnie przedstawione zostaną najistotniejsze problemy dotyczące popularnych usług aplikacyjnych – WWW i poczty elektronicznej.
Bezpieczne środowisko aplikacyjne
Jednym z najważniejszych środków ochrony aplikacji użytkowych przed zagrożeniami płynącymi z zewnątrz i skutkującymi przejęciem kontroli nad aplikacją, a potencjalnie dalej – nad całym systemem operacyjnym, jest stworzenie bezpiecznego środowiska aplikacyjnego, czyli takiego, w którym aplikacja zostaje uruchomiona w specjalnie spreparowanym podsystemie, który minimalizuje zagrożenia.
Ograniczanie środowiska wykonania aplikacji ma na celu w istocie nie tyle uniemożliwienie ataku w ogóle, co minimalizowanie szkód po ewentualnym ataku. Koncepcja działania tego mechanizmu jest następująca:
- zawsze uruchamiamy proces z najmniejszymi wystarczającymi mu uprawnieniami
- ograniczamy przestrzeń aktywności procesu (dozwolonych modyfikacji) do wybranego zawężonego fragmentu systemu, w szczególności systemu plików – tworząc tzw. piaskownicę (ang. sandbox)
W systemach z rodziny Unix popularnym narzędziem służącym do tworzenia piaskownic jest systemowa funkcja chroot(). Jest to uprzywilejowana funkcja systemowa ograniczająca proces do określonego poddrzewa systemu plików. Blokuje jedynie dostęp do plików, tworząc tzw. więzienie. Uwięziony proces nie może otworzyć (w tym utworzyć) pliku poza ograniczonym obszarem, chociaż może dziedziczyć deskryptory wskazujące na pliki spoza tego obszaru.
Tworząc piaskownicę w systemie Unix trzeba stworzyć więzionemu procesowi iluzję pracy w pełnoprawnym systemie. W tym celu w piaskownicy należy zainstalować odpowiednie pliki i katalogi potrzebne programowi i używanym przez niego bibliotekom (na ogół bardzo ograniczone fragmenty /etc, /lib czy /usr/lib).
Mimo ogromnej przydatności funkcji chroot(), związane są z jej wykorzystaniem pewne problemy. Większość z nich dotyczy ataków DoS. I tak przykładowo, mimo ograniczenia środowiska wykonania:
- dysk może się przepełnić (np. zrzutami obrazu pamięci, plikami raportów) – na szczęście w systemie Unix możemy ograniczać programy do oddzielnej partycji
- może nastąpić przepełnienie pamięci – proces może zagarnąć tyle pamięci, że zablokuje to urządzenie z plikiem wymiany – przeważnie możemy ograniczać użycie pamięci
- zużywanie czasu procesora – tu do obrony mamy do dyspozycji polecenie nice
- brak automatycznej kontroli nad komunikacją sieciową pozwala potencjalnie wyzwolić się częściowo z uwięzienia
W systemie Unix istnieje polecenie chroot (dostępne z powłoki), które wywołuje funkcję chroot(). Polecenie to ma też pewne ograniczenia, z których najważniejsze to:
- polecenie chroot musi znajdować się w piaskownicy
- chroot wymaga uprawnień superużytkownika
- brak mechanizmu zmiany UID i GID procesu – proces uwięziony wykonuje się z prawami superużytkownika root (ew. sam musi zmienić efektywny UID/GID)
- potencjalne luki umożliwią ucieczkę z piaskownicy (prawa superużytkownika)
W nowszych wydaniach systemów Unix/Linux istnieją inne, doskonalsze narzędzia – np. chrootuid, jail – które przed wywołaniem funkcji chroot() pozwalają zmienić UID oraz GID
jail –u nobody –g www –l /tmp/jail.log –d / /usr/apache /bin/httpd
Usługa WWW
Uwierzytelnianie
Jednym z ważniejszych problemów zapewnienia podstawowych własności bezpieczeństwa jest, jak wiemy, poprawne uwierzytelnianie. Prosty mechanizm uwierzytelniania został wbudowany w protokół usługi WWW – HTTP. Uwierzytelnianie podstawowe w protokole HTTP przebiega następująco:
- serwer WWW może w dowolnym momencie zażądać od przeglądarki dokonania uwierzytelnienia użytkownika
- przeglądarka wyświetla stosowne okno dialogowe lub podobny obiekt (rysunek 1),
który pozwoli użytkownikowi na wprowadzenie danych uwierzytelniających
- po ich pierwszym wpisaniu przeglądarka zapamięta je i automatycznie prześle do serwera na każde następne żądanie
- dane przesyłane są w postaci jawnej
- dane te zostaną usunięte z pamięci z chwilą zamknięcia okna przeglądarki
Rysunek 1. Okienko uwierzytelniania wyświetlane w przykładowej przeglądarce www
Wiele implementacji serwerów usługi www umożliwia automatyzację operacji uwierzytelniania, pozwalając na weryfikację otrzymanych danych uwierzytelniających poprzez zewnętrzne bazy danych, przechowujące konfigurację kont użytkowników. Przykładowo, serwer Apache posiada rodzinę modułów mod_auth służacych do tego celu (np. mod_auth_mysql), a serwer IIS pozwala na starowanie automatyzają poprzez ustawienia opcji Panel Sterowania -> Narzędzia Administracyjne -> Menedżer Usług Internetowych (można zdefiniować np. uwierzytelnianie użytkownika przez domenę)
W standardzie HTTP 1.1 uwzględniono uwierzytelnianie kryptograficzne, realizowane najczęściej z wykorzystaniem algorytmu MD5. Niestety nie przewidziano w specyfikacji dwustronnego uwierzytelniania.
Rozwiązaniem problemów uwierzytelniania, które przyjęło się w praktyce jest zastosowanie niezależnie od protokołu aplikacyjnego HTTP, protokołu sesji – SSL.
Protokół SSL (Secure Sockets Layer)
W istocie protokół SSL tworzy tunel kryptograficzny usługi www. Tak zabezpieczona usługa znana jest pod nazwą https (port 443/tcp). Jednym z podstawowych komponentów protokołu SSL jest protokół uzgadniania, który realizuje zadania uwierzytelniania stron.
Protokół uzgadniania (handshake protocol) działa wg poniższego schematu:
- klient wysyła do serwera komunikat ClientHello (wersja protokołu, identyfikator sesji, listę obsługiwanych szyfrów i metod kompresji, dane losowe)
- serwer odsyła komunikat ServerHello (wersja protokołu, identyfikator sesji, wybrany szyfr i metodę kompresji, dane losowe oraz swój certyfikat X.509) oraz opcjonalnie – żądanie certyfikatu klienta (wraz z losowym zawołaniem)
- klient uwierzytelnia serwer na podstawie odebranego certyfikatu i w razie niepowodzenia przerywa połączenie
- po pomyślnym uwierzytelnieniu klient tworzy pierwotny sekret główny (premaster secret), który szyfruje kluczem publicznym serwera i wysyła do serwera
- jeśli serwer żądał uwierzytelnienia klienta, to klient wysyła też swój certyfikat oraz podpisane zawołanie odebrane wcześniej od serwera
- po ewentualnym uwierzytelnieniu klienta serwer deszyfruje pierwotny sekret główny i na jego podstawie uzyskuje sekret główny (master secret), podobnie czyni w tym czasie klient
- z wygenerowanego sekretu głównego obie strony tworzą (zależny od ustalonego algorytmu szyfrującego) klucz sesji (lub klucze sesji – do szyfrowania i podpisywania)
- klient i serwer wysyłają do siebie nawzajem zaszyfrowany kluczem sesji komunikat o zakończeniu fazy uzgadniania
- protokół uzgadniania kończy się i (o ile wzajemna weryfikacja przebiegła pomyślnie) rozpoczyna się sesja SSL
Poprawność procedury uwierzytelniania wynika z następujących obserwacji:
- jeśli serwer nie posiadałby klucza prywatnego odpowiadającego kluczowi publicznemu ze swojego certyfikatu:
- nie rozszyfruje poprawnie sekretu i nie wygeneruje tego samego klucza sesji co klient
- wówczas połączenie zastanie przerwane w fazie uzgadniania
- stąd klient ma pewność, że serwer jest tym, czyją autentyczność poświadcza certyfikat (po weryfikacji jego poprawności)
- jeśli klient nie posiadałby klucza prywatnego odpowiadającego kluczowi publicznemu ze swojego certyfikatu:
- serwer pobierze jego klucz publiczny z certyfikatu i rozszyfruje podpisane kluczem prywatnym klienta zapytanie
- nie otrzyma tego, które sam wysłał
- zatem klient nie jest tym, czyją autentyczność poświadcza certyfikat
Newralgiczna w tym procesie jest weryfikacja certyfikatów – SSL jest podatny na atak man-in-the-middle. Sposobem redukcji zagrożenia może być np. weryfikacja czy adres IP asocjacji z nawiązanego połączenia zgadza się z adresem IP w certyfikacie.
Luki bezpieczeństwa w usłudze WWW
Luki bezpieczeństwa w usłudze WWW dotyczą wielu komponentów systemu, w szczególności klientów (przeglądarek), serwerów czy środowiska wykonania (systemu operacyjnego).
Przeglądarki WWW
Wśród typowych problemów bezpieczeństwa klientów usługi WWW należy wymienić chociażby
- problemy z losową generacją kluczy SSL
- błędy implementacji S/MIME (Secure/Multi-purpose Internet Mail Extension)
- problemy specyficzne dla konkretnych przglądarek, np. Internet Explorer
- BHO (Browser Helper Objects) – pozwala na integrację z przeglądarką np. toolbarów (praktycznie dowolnych aplikacji) – często wykorzystywane przez malware do cichej instalacji (zagrożenia browser hijacking – podmiana parametrów pracy przeglądarki, takich jak adres strony domowej, tracking – śledzenie pracy użytkownika, niechciane wyskakujące okienka pop-ups)
- konie trojańskie / wirusy w dokumentach hipertekstowych – ochronę tu stanowić może wiele mechanizmów
- zamknięte środowisko uruchomieniowe (sandbox)
- korzystanie wyłącznie z poprawnie zdefiniowanego zbioru zaufanych serwerów źródłowych
- certyfikaty cyfrowe
Z ostatnim z powyższych problemów związanych jest szereg zagrożeń niesionych przez języki automatyzacji operacji na dokumentach hipertekstowych i definicji dynamicznych stron DHTML czy .NET. Języki te to przede wszystkim Java i ActiveX
Java charakteryzuje się w tym kontekście następującymi własnościami:
- jest to język stosunkowo bezpieczny (brak wskaźników i problemu przepełnienia bufora)
- jest językiem interpretowanym (aplety mają format byte code) – możliwe są luki bezpieczeństwa w programie interpretera
- maszyna wirtualna JVM posiada wbudowany system ochronny: analizatory kodu (code verifier i class loader), sandbox, security manager, certyfikacja serwerów
ActiveX posiada następujące istotne w naszych rozważaniach cechy:
- program jest dystrybuowany w postaci skompilowanej – praktycznie brak tu możliwości analizy bezpieczeństwa
- system ochronny: certyfikacja kontrolek ActiveX (mechanizm authenticode) – praktyka pokazuje, iż generalnie zaufanie jedynie certyfikacji jest złudne.
W praktyce, najczęściej wbudowane w usługę WWW i dostępne w przeglądarkach mechanizmy ochrony są uzupełniane o filtrację treści ruchu HTTP na zaporze firewall (osobistej lub sieciowej).
Serwery WWW
Do charakterystycznych problemów bezpieczeństwa, na które cierpią implementacje serwerów usługi WWW można zaliczyć w szczególności np.:
- tylne furtki
- błędy przepełnienia bufora, np. w ism.dll (uruchamianym przez IIS dla URL *.htr) pozwala na uruchomienie kodu w kontekście procesu serwera z jego uprawnieniami
Środowisko wykonania
Problemy środowiska wykonania szczególnie często ujawniają się w przypadku systemu MS Windows. Tu wymienimy chociażby:
- mechanizm LSP (Layered Service Provider) oferujący możliwość podpinania się modułów LSP (praktycznie dowolnych aplikacji, w tym malware) pod stos protokołów w bibliotece Winsock 2
- luki w implementacjach protokołów MHTML, MS-ITS, XMLHTTP i VBScript (wykorzystywane przez Outlook, WindowsUpdate oraz rozliczne malware)
Umożliwiają one instalację niechcianego oprogramowania pobieranego nieświadomie poprzez usługę WWW.
Poczta elektroniczna
Rysunek 2 przedstawia model komunikacji systemu internetowej usługi pocztowej standardu SMTP (RFC 821). Wyróżnione na nim elementy systemu to:
- MUA = Mail User Agent
- MTA = Mail Transfer Agent
- MDA = Mail Delivery Agent
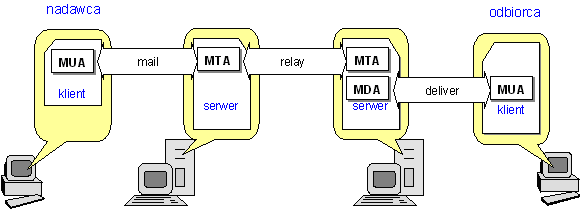
Rysunek 2. Model komunikacji SMTP
Podstawowe problemy bezpieczeństwa dotyczące poczty obejmują:
- niepożądane przesyłki (spam)
- niebezpieczne załączniki (wirusy)
- potwierdzanie dostarczenia
- naruszenie poufności / integralności / autentyczności
Spam
Pojęcie spam dotyczy ogółu niechcianych przesyłek pocztowych zajmujących zasoby pamięciowe (skrzynka pocztowa odbiorcy) i czasowe systemu. Ochrona anty-spamowa sprowadza się do odfiltrowania takich przesyłek z całości ruchu pocztowego i może być realizowana na kilku poziomach modelu komunikacji SMTP.
Na poziomie MTA filtracja jest dokonywana poprzez analizę nagłówka SMTP, np.
- adresów: czy są weryfikowalne w DNS, czy odpowiadają rekordom MX
czy nie jest na czarnej liście
- weryfikacja konta nadawcy (komenda VRFY protokołu SMTP)
Posiada ona istotną zaletę – oszczędność zasobów – odrzucamy spam na pierwszej linii obrony. Wadą tego rozwiązania jest mała precyzja wynikająca z faktu, iż na tak wczesnym etapie posiadamy mało informacji do dyspozycji. Stąd występuje duże prawdopodobieństwo pomyłki – sklasyfikowania niechcianej przesyłki jako pożądanej i odwrotnie.
Stosunkowo dużą skuteczność i małe efekty uboczne (opóźnienie) wykazuje tu mechanizm znany jako szare listy (greylisting). Mianowicie, po odebraniu przesyłki MTA odsyła na adres nadawcy kod 452 „czasowa niedostępność” i czeka na powtórną transmisję. Automaty spamerskie z założenia nie retransmitują, stąd akceptowane jako pożądane są wszystkie retransmitowane listy.
Poziom MDA pozwala stosować do realizacji możliwie skutecznej filtracji takie rozwiązania jak:
- analiza heurystyczna (na podstawie przygotowanej bazy danych charakterystycznych)
- analiza statystyczna (samouczące się filtry Bayesa)
Również klienci pocztowi MUA posiadają często wbudowane narzędzia filtrujące, które, niekiedy automatycznie, pozwalają użytkownikowi klasyfikować wybrane listy jako spam.
Ochrona kryptograficzna poczty
Powszechnie spotykane są następujące standardy ochrony kryptograficznej
- PEM – Privacy Enhanced Mail
- PGP – Pretty Good Privacy
- S/MIME – Secure MIME
Istnieje wiele kompleksowych systemów i standardów pocztowych wykorzystujących kryptografię, w tym przykładowo:
- X.400 MHS – Message Handling System
- EDI (EDIFACT – X.435) – Electronic Data Interchange
System PEM (Privacy Enhanced Mail)
PEM to jeden z pierwszych standardów zaproponowanych do ochrony przesyłek protokołu SMTP i posiadający zgodny z pierwotnymi wymaganiami tego protokołu format RFC822 (rysunek 3). W PEM możliwa jest przede wszystkim kontrola integralności przy wykorzystaniu MD2 lub MD5 (128b) – zgodnie ze standardem RFC1421. Opcjonalnie możliwe jest szyfrowanie wiadomości – DES-ECB, 3DES (RFC1423). PEM wspiera zarządzanie kluczami i certyfikację wg ISO X.509 (RFC1422, RFC1424).
Rysunek 3. Schematyczna struktura przesyłki pocztowej zabezpieczonej kryptograficznie
Przykładowe implementacje to chociażby RIPEM czy TIS-PEM. Jednak w szerszej skali PEM nie uzyskał dużej popularności.
PGP (Pretty Good Privacy)
PGP powstał jako projekt akademicki prowadzony przez Phila Zimmermanna (z MIT). Prace uwieńczyły standard IETF RFC1991 (PGP 2.6.x) i wielka popularność jaką zyskał on w Internecie. W 1998 IETF zatwierdził standard OpenPGP (RFC2440) opracowany przez Network Associates, bazujący na PGP 5.x. Istnieje również alternatywny projekt PGPi (www.pgpi.org) = International PGP – przeniesiony poza USA. Z najpopularniejszych implementacji wymienić należy Desktop PGP – jest to komercyjna wersja rozprowadzana przez Network Associates (rozszerzona np. o IDS) – oraz GnuPG – wersję dystrybuowaną na licencji GNU. Ponadto wiele aplikacji wykorzystuje PGP (np. enigmail – rozszerzenie klientów pocztowych Mozilli).
PGP umożliwia:
- szyfrowanie wiadomości pocztowej
- wykorzystywany jest jednorazowy klucz symetryczny generowany dla każdego szyfrowanego listu
- następnie klucz ten szyfrowany jest metodą asymetryczną – kluczem publicznym odbiorcy – Diffie-Hellman/DSS, RSA (768b, 1024b, ...)
- i tak zaszyfrowany klucz jest dołączany do zaszyfrowanego listu
- kontrolę integralności – MD5, SHA-1
- symetryczne szyfrowanie dowolnych plików
S/MIME
Standard Secure MIME umożliwia wygodną integrację mechanizmu kryptograficznego zabezpieczenia korespondencji pocztowej z protokołem SMTP, poprzez wykorzystanie rozszerzenia uznanego mechanizmu obsługi załączników MIME. Wersja S/MIME 1 została opracowana przez RSA Security w 1995r. i wykorzystywała mechanizmy kryptograficzne wchodzące w skład PKCS (Public Key Cryptography Standards). Wersja S/MIME 2 (RFC2311/12) powstała w 1998r., a wkrótce później S/MIME 3 (RFC 2630-34). S/MIME 3 oferuje m.in. rozszerzone funkcje bazujące na mechanizmach MSP (Message Security Protocol protokołu opracowanego pierwotnie dla Defense Message System).
Należy nadmienić istnienie również protokołów PGP/MIME i OpenPGP/MIME.
Pytania problemowe
- W przykładzie statycznych reguł filtracji z rysunku 5 zdefiniowano 4 reguły. Jedna z nich jest jednak nadmiarowa i można ją usunąć bez żadnych konsekwencji dla przebiegu filtracji. Która to reguła?