Automat ze stosem
W tym wykładzie określimy automat ze stosem rozpoznający języki bezkontekstowe. Wprowadzimy dwie definicje rozpoznawania języków przez automat ze stosem oraz omówimy ważną podklasę języków bezkontekstowych, mianowicie języków rozpoznawanych przez deterministyczne automaty ze stosem. Uzasadnimy też fakt, iż rodzina języków rozpoznawana przez automaty ze stosem pokrywa się z rodziną jezyków bezkontekstowych.
Automaty ze stosem to systemy rozpoznające języki bezkontekstowe. Ich działanie jest nieco bardziej skomplikowane niż działanie automatu skończenie stanowego. Poza możliwością zmiany stanu pod wpływem czytanego symbolu umieszczonego na taśmie wejściowej automat ten posiada także taśmę stosu, na którą może wpisywać słowa, jak i odczytywać pojedynczy symbol znajdujący się na wierzchu stosu.
Definicja 1.1
Automatem ze stosem nad alfabetem \(\displaystyle A\) nazywamy system \(\displaystyle \mathcal{AS}=(A,A_{S},Q,f,s_{0},z_{0},Q_{F})\) , w którym:
\(\displaystyle A\) - jest alfabetem,
\(\displaystyle A_{S}\) - jest dowolnym skończonym i niepustym zbiorem zwanym alfabetem stosu (niekoniecznie rozłącznym z \(\displaystyle A\) ),
\(\displaystyle Q\) - jest dowolnym, skończonym i niepustym zbiorem zwanym zbiorem stanów,
\(\displaystyle f:A_{S}\times Q\times (A\cup \left\{ 1\right\} )\longrightarrow \mathcal{P}_{sk}(A_{S}^{*}\times Q)\) jest funkcją przejść, której wartościami są skończone podzbiory \(\displaystyle A_{S}^{*}\times Q\) (także zbiór pusty),
\(\displaystyle q_{0}\in Q\) jest stanem początkowym,
\(\displaystyle z_{0}\in A_{S}\) symbolem początkowym stosu,
\(\displaystyle Q_{F}\subset Q\) zbiorem stanów końcowych.
Badając działanie automatu ze stosem, wygodniej jest, zamiast funkcji przejść \(\displaystyle f\), rozważać skończoną relację \(\displaystyle P\subset (A_{S}\times Q\times (A\cup \left\{ 1\right\} ))\times (A_{S}^{*}\times Q)\) zwaną relacją przejść. Elementy tej relacji nazywane są prawami. Relacja \(\displaystyle P\) jest zatem skończonym zbiorem praw o następującej postaci:
- \(\displaystyle zq_i \longrightarrow uq_j\) dla \(\displaystyle z \in A_S, \;\; u \in A_S^*, \;\; q_i ,q_j \in Q\),
- \(\displaystyle zq_i a \longrightarrow uq_j\) dla \(\displaystyle z \in A_S, \;\; u \in A_S^*, \;\; a \in A, \;\;q_i ,q_j \in Q\).
Często, używając relacji przejść, oznaczamy automat ze stosem jako układ:
Prawo \(\displaystyle zq_{i}a\longrightarrow uq_{j}\) będziemy reprezentować grafem:
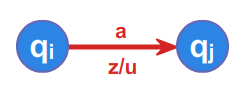
Napis \(\displaystyle z/u\) oznacza, iż symbol \(\displaystyle z\) pobrany ze stosu wymieniany jest na słowo \(\displaystyle u\) utworzone nad alfabetem stosu \(\displaystyle A_S\).
Natomiast prawo \(\displaystyle zq_{i}\rightarrow uq_{j}\) interpretowane jest graficznie jako:
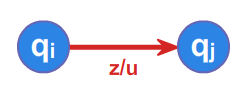
Działanie automatu ze stosem \(\displaystyle \mathcal{AS}\) zależne jest, jak wspomnieliśmy we wstępie wykładu, nie tylko od czytanego przez automat słowa, ale także od symbolu znajdującego się na wierzchu stosu. Poniżej przedstawiamy graficznie te zależności.
Prawo \(\displaystyle zq_{i}a\longrightarrow uq_{j}\) dla słowa \(\displaystyle u=z_{1}\ldots z_{m}\) określające działanie automatu \(\displaystyle \mathcal{AS}\) interpretujemy w ten sposób, że automat, będąc w stanie \(\displaystyle q_{i}\) po przeczytaniu litery \(\displaystyle a\) (ze słowa wejściowego) i symbolu \(\displaystyle z\) ze stosu, zmienia stan na \(\displaystyle q_{j}\) oraz zastępuje na stosie literę \(\displaystyle z\) słowem \(\displaystyle u\) w ten sposób, że ostatnia litera tego słowa, symbol \(\displaystyle z_{m}\) , jest na wierzchu stosu. Ten właśnie symbol będzie pobrany ze stosu przy kolejnym "ruchu" automatu, zgodnie z zasadą last in, first out. Ilustruje tę zasadę animacja, która jest zamieszczona będzie w dalszej części tego wykładu.
Dla precyzyjnego opisu działania automatu ze stosem wprowadza się pojęcie konfiguracji automatu, poprzedzając to pojęcie określeniem konfiguracji wewnętrznej.
Definicja 1.2
Konfiguracją wewnętrzną automatu ze stosem \(\displaystyle AS\) nazywamy dowolną parę \(\displaystyle (u,q)\in A_{S}^{*}\times Q\) taką, że \(\displaystyle q\) jest stanem, w którym automat znajduje się aktualnie, a \(\displaystyle u\) słowem zapisanym na stosie tak, że litera będąca na wierzchu stosu jest ostatnią literą tego słowa.
Konfiguracją automatu ze stosem \(\displaystyle AS\) nazywamy trójkę
gdzie \(\displaystyle (u,q)\) jest konfiguracją wewnętrzną, a \(\displaystyle w\) słowem wejściowym.
Wprowadzone pojęcia wykorzystamy do określenia działania automatu ze stosem dla dowolnych słów wejściowych i dowolnych słów znajdujących się na stosie. W tym celu rozszerzymy odpowiednio relację przejść \(\displaystyle P\) , określając ją na zbiorze konfiguracji i oznaczając symbolem \(\displaystyle |\! \! \! \Longrightarrow\) . Przyjmujemy dla dowolnych słów \(\displaystyle u_{1},u_{2}\in A_{S}^{*}\) i litery \(\displaystyle z\in A_{S}\) , dla dowolnego słowa \(\displaystyle w\in A^{*}\) i \(\displaystyle a\in A\cup \left\{ 1\right\}\) oraz dla dowolnych stanów \(\displaystyle q_{1},q_{2}\in Q\) , że zachodzi relacja
wtedy i tylko wtedy, gdy \(\displaystyle zq_{1}a\longrightarrow u_{2}q_{2}\in P\) .
Zwrotne i przechodnie domknięcie tej relacji nazywamy przejściem lub poprawnym obliczeniem automatu \(\displaystyle AS\) i oznaczamy symbolem \(\displaystyle |\! \! \! \Longrightarrow ^{*}\) .
Dla dowolnego słowa \(\displaystyle w\in A^{*}\) przyjmujemy oznaczenie \(\displaystyle (u,q)\, \mid \! \Longrightarrow ^{w}\, (u_{1},q_{1})\) , jeśli ma miejsce \(\displaystyle (u,q,w)|\! \! \! \Longrightarrow ^{*}(u_{1},q_{1},1)\) . Prawdziwa jest wówczas następująca równość:
Mówimy, że konfiguracja wewnętrzna \(\displaystyle (u,q)\) automatu ze stosem \(\displaystyle AS\) jest osiągalna z konfiguracji wewnętrznej \(\displaystyle (u_{1},q_{1})\), jeśli istnieje takie słowo \(\displaystyle w\in A^{*}\), że
Zdefiniujemy teraz język rozpoznawany przez automat ze stosem. W literaturze spotkać można kilka równoważnych definicji rozpoznawania. W naszym wykładzie wprowadzimy dwie, używane najczęściej:
- rozpoznawanie poprzez stany końcowe (wyróżniony zbiór stanów końcowych \(\displaystyle Q_{F}\) ),
- rozpoznawanie poprzez pusty stos.
Definicja 1.3
Niech \(\displaystyle \mathcal{AS}=(A,A_{S},Q,P,s_{0},z_{0},Q_{F})\) będzie automatem ze stosem. Językiem rozpoznawanym przez automat \(\displaystyle \mathcal{AS}\) poprzez stany końcowe nazywamy zbiór
Językiem rozpoznawanym przez automat \(\displaystyle \mathcal{AS}\) poprzez pusty stos nazywamy zbiór
Używając drugiego określenia rozpoznawania, w definicji automatu ze stosem pomija się zbiór stanów końcowych \(\displaystyle Q_{F}\) .
Przykład 1.1
Poniższa animacja ilustruje działanie automatu ze stosem. Przedstawiony grafem automat ze stosem \(\displaystyle \mathcal{AS}=(A,A_{S},\{q_0,q_F\},P,q_{0},z_{0},\{q_{F}\})\), w którym alfabet stosu \(\displaystyle A_{S}=\{z_{0},a,b\}\) rozpoznaje język bezkontekstowy
Animacja 2
Zauważmy, że automat ten rozpoznaje ten sam język zarówno zarówno przez stany końcowe ( \(\displaystyle Q_{F}=\{q_{F}\}\) ), jak i w sensie rozpoznawania przez pusty stos.
W ogólności dla ustalonego automatu ze stosem \(\displaystyle \mathcal{AS}\) wprowadzone wyżej dwa sposoby rozpoznawania niekoniecznie prowadzą do tego samego języka. Jednak są one równoważne, o czym przekonuje następujące twierdzenie, w dowodzie którego konstruujemy odpowiednie automaty ze stosem.
Twierdzenie 1.1
Język \(\displaystyle L\subset A^{*}\) jest rozpoznawany przez automat ze stosem przez stany końcowe wtedy i tylko wtedy, gdy jest rozpoznawany przez automat ze stosem poprzez pusty stos.
Dowód
Załóżmy, że automat \(\displaystyle \mathcal{AS}=(A,A_{S},Q,P,s_{0},z_{0},Q_{F})\) rozpoznaje przez stany końcowe język \(\displaystyle L=L_{F}(\mathcal{AS})\) . Wówczas automat
w którym symbol \(\displaystyle x_{0}\) jest spoza alfabetu \(\displaystyle A_{S}\) , stany \(\displaystyle q_{0}',q_{e}\) nie należą do \(\displaystyle Q\) , a relacja przejść \(\displaystyle P'\) określona jest poniżej
rozpoznaje język \(\displaystyle L\) przez pusty stos.
Na odwrót, jeśli automat ze stosem \(\displaystyle \mathcal{AS}=(A,A_{S},Q,P,q_{0},z_{0})\) rozpoznaje poprzez pusty stos język \(\displaystyle L=L_{e}(\mathcal{AS})\) , to automat
w którym symbol \(\displaystyle x_{0}\) jest spoza alfabetu \(\displaystyle A_{S}\) , stany \(\displaystyle q_{0}',q_{F}\) nie należą do \(\displaystyle Q\) , a relacja przejść \(\displaystyle P'\) określona jest poniżej
rozpoznaje język \(\displaystyle L\) poprzez stany końcowe.
Zdefiniujemy i omówimy teraz deterministyczne automaty ze stosem. W odróżnieniu od automatów skończenie stanowych deterministyczne automaty ze stosem posiadają mniejsze możliwości rozpoznawania języków niż automaty, które dopuszczają przejścia niedeterministyczne.
Definicja 1.4
Automat ze stosem \(\displaystyle \mathcal{AS}=(A,A_{S},Q,f,s_{0},z_{0},Q_{F})\) nazywamy deterministycznym, jeśli dla każdej konfiguracji \(\displaystyle (z,q,a)\in A_{S}\times Q\times (A\cup \left\{ 1\right\} )\) wartość funkcji \(\displaystyle f(z,q,a)\) jest zbiorem co najwyżej jednoelementowym, czyli \(\displaystyle \sharp f(z,q,a)\leqslant 1\) oraz jeśli \(\displaystyle f(z,q,1)\neq \emptyset\) , to \(\displaystyle f(z,q,a)=\emptyset,\) dla każdego \(\displaystyle a\in A\) .
A więc deterministyczny automat ze stosem ma możliwość co najwyżej jednego przejścia z dowolnej konfiguracji \(\displaystyle (z,q,a)\in A_{S}\times Q\times (A\cup \left\{ 1\right\} )\) oraz jeśli istnieje przejście dla określonego stanu i symbolu ze stosu pod wpływem słowa pustego, to jest ono jedynym możliwym dla tego układu w tym automacie.
Język rozpoznawany przez deterministyczny automat ze stosem nazywamy językiem deterministycznym.
O tym, że, w przeciwieństwie do klasy języków regularnych, języki rozpoznawane przez deterministyczne automaty ze stosem stanowią właściwą podklasę wszystkich języków akceptowanych przez automaty ze stosem, przekonuje przykład.
Przykład 1.2
Język \(\displaystyle L=\{a^{n}b^{n}:\: n\geqslant 1\}\cup \{a^{n}b^{2n}:\: n\geqslant 1\}\) rozpoznawany przez automat ze stosem opisany grafem
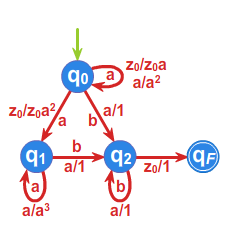
nie jest językiem deterministycznym. Zauważmy bowiem, że deterministyczny automat ze stosem, aby zaakceptować słowo \(\displaystyle a^{n}b^{n}\) , dla kontrolowania ilości liter \(\displaystyle a\) i \(\displaystyle b\) wykorzystuje stos, wprowadzając przy czytaniu każdej litery \(\displaystyle a\) ustalony symbol na stos, na przykład \(\displaystyle "a"\) i usuwając sekwencyjnie te symbole przy czytaniu liter \(\displaystyle b\) . Dla zaakceptowania słowa \(\displaystyle a^{n}b^{2n}\) podobne postępowanie prowadzi do wpisywania na stos słowa \(\displaystyle "aa"\) z alfabetu stosu dla każdej litery \(\displaystyle a\) i usuwaniu pojedynczego symbolu przy czytaniu \(\displaystyle b\) . Jest to jedyny sposób kontroli ilości liter, a opisane działanie automatu jest źródłem jego istotnej niedeterministyczności. Bez trudu można zauważyć, że każdy automat ze stosem rozpoznający język \(\displaystyle L\) będzie zawierać ten niedeterministyczny układ w swojej strukturze.
Aby lepiej uchwycić istotę tego niedeterminizmu, zauważmy, że automat ze stosem określony grafem
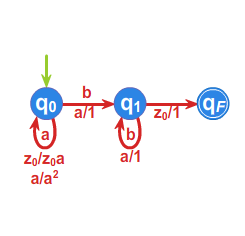
rozpoznaje język \(\displaystyle L=\{a^{n}b^{n}:\: n\geqslant 1\}\) i jest deterministyczny.
Każdy język rozpoznawany przez deterministyczny automat ze stosem
jest oczywiście (dlaczego?) jednoznaczny. Jednoznaczność języka nie implikuje jednak jego deterministyczności, o czym przekonuje zamieszczony poniżej przykład.
Przykład 1.3
Język \(\displaystyle L=\{a^{n}b^{n}:\: n\geqslant 1\}\cup \{a^{n}b^{2n}:\: n\geqslant 1\}\) , który jest rozpoznawany przez automat ze stosem z poprzedniego przykładu, nie jest, jak wiemy, deterministyczny, ale jest jednoznaczny.
Gramatyki bezkontekstowe i automaty ze stosem
Automaty ze stosem charakteryzują rodzinę języków bezkontekstowych w tym samym sensie, w jakim automaty skończenie stanowe charakteryzują języki regularne.
Twierdzenie 2.1
Rodzina języków rozpoznawanych przez automaty ze stosem jest równa rodzinie języków bezkontekstowych \(\displaystyle \mathcal{L}_{2}\) .
Dowód
(szkic)
Dla dowodu, że każdy język bezkontekstowy jest rozpoznawany przez odpowiedni automat ze stosem, rozważmy gramatykę \(\displaystyle G=(V_{N},V_{T},v_{0},P_{G})\) bezkontekstową w postaci normalnej Greibach i załóżmy, że słowo puste \(\displaystyle 1\) nie należy do języka \(\displaystyle L(G)\) generowanego przez tę gramatykę. Podamy konstrukcję automatu ze stosem \(\displaystyle AS\) , który, jak można wykazać, akceptuje poprzez pusty stos język \(\displaystyle L(G)\) . Niech
gdzie funkcja \(\displaystyle f:(V_{N}\cup V_{T})\times \{q\}\times (V_{T}\cup \left\{ 1\right\} )\longrightarrow \mathcal{P}_{sk}((V_{N}\cup V_{T})^{*}\times \{q\})\) określona jest następująco. Dla dowolnych \(\displaystyle v\in V_{N},\: a\in V_{T}\)
oraz ma wartość równą zbiorowi pustemu \(\displaystyle \emptyset\) we wszystkich pozostałych przypadkach.
Jest to więc automat o jednym stanie \(\displaystyle q\) , alfabetem wejściowym jest alfabet terminalny \(\displaystyle V_{T}\) , alfabetem stosu jest suma mnogościowa alfabetu symboli nieterminalnych \(\displaystyle V_{N}\) i terminalnych \(\displaystyle V_{T}\) , a symbol początkowy stosu jest symbolem startowym gramatyki. Istotą działania automatu \(\displaystyle AS\) jest symulacja lewostronnego wyprowadzenia w gramatyce \(\displaystyle G.\) Pełne uzasadnienie podanej konstrukcji znajduje sie na końcu tego wykładu, w części "dla zainteresowanych".
Załóżmy teraz, że automat \(\displaystyle \mathcal{AS}=(A,A_{S},Q,f,q_{0},z_{0})\) akceptuje poprzez pusty stos język \(\displaystyle L(\mathcal{AS})\) . Konstrukcja gramatyki bezkontekstowej \(\displaystyle G\) , która generuje ten sam język przebiega następująco. Niech \(\displaystyle G=((Q\times A_{S}\times Q)\cup \left\{ v_{0}\right\} ,A,v_{0},P_{G})\) , gdzie \(\displaystyle v_{0}\notin Q\cup A_{S}\cup A\) . Wprowadzamy do zbioru praw \(\displaystyle P_{G}\) wyłącznie następujące prawa:
- \(\displaystyle v_{0}\rightarrow (q_{0},z_{0},q)\) dla wszystkich stanów \(\displaystyle q\in Q\) ,
- \(\displaystyle (q,z,q_{1})\rightarrow a(q_{k+1},z_{k},q_{k})(q_{k},z_{k-1},q_{k-1})\ldots (q_{2},z_{1},q_{1})\) dla dowolnych stanów \(\displaystyle q,q_{1},\ldots ,q_{k+1}\in Q, \displaystyle \, a\in A\cup \left\{ 1\right\} ,\, z,z_{1},\ldots z_{k}\in A_{S}\) jeśli \(\displaystyle (z_{1}...z_{k},q_{k+1})\in f(z,q,a)\) ,
- \(\displaystyle (q,z,q_{1})\rightarrow a\in P_{G}\) jeśli \(\displaystyle (1,q_{1})\in f(z,q,a)\) .
Mamy więc następującą równoważność:
\(\mbox{(1)}\)
która w szczególności dla \(\displaystyle k=0\) przyjmuje postać
i oznacza dla gramatyki wymazywanie symboli nieterminalnych, a dla automatu wymazywanie symboli stosu.
Skonstruowana gramatyka \(\displaystyle G\) odtwarza działanie automatu \(\displaystyle AS\) działającego pod wpływem słowa wejściowego \(\displaystyle w\) . Pełne uzasadnienie podanej konstrukcji znajduje się na końcu tego wykładu, w części "dla zainteresowanych".
Z konstrukcji przedstawionej w szkicu dowodu twierdzenia wynika, że każdy język bezkontekstowy może być rozpoznawany poprzez pusty stos przez automat ze stosem o jednym stanie. Określenie algorytmów na podstawie powyższego twierdzenia proponujemy jako ćwiczenie.
Powróćmy na moment do języka Łukasiewicza. Język ten oraz jego gramatyka zostały wprowadzone podczas pierwszego wykładu poświęconego językom bezkontekstowym. Każde słowo, generowane przez tę gramatykę, jest pewnym wyrażeniem algebraicznym zapisanym w notacji polskiej, prefiksowej, bez użycia nawiasów. Bez trudności można określić gramatykę bezkontekstową, która generuje język Łukasiewicza, w którym słowa zapisywane są w wersji postfiksowej. Wystarczy bowiem przyjąć: \(\displaystyle G = (V_N,V_T,v_0,P)\), gdzie \(\displaystyle V_N=\{v_0 \}\), \(\displaystyle V_{T}=\left\{ a,b,+,*\right\}\) , \(\displaystyle v_{0}=v\) oraz \(\displaystyle P= \{v \rightarrow a, v \rightarrow b, v \rightarrow vv+, v \rightarrow vv* \}\). Język Łukasiewicza jest więc teraz zbiorem
Oczywiście język ten jest rozpoznawany przez odpowiedni automat ze stosem. Określeniem takiego automatu zajmiemy się podczas ćwiczeń. Warto zauważyć, że rozpoznając słowa języka Łukasiewicza w postfiksowej postaci, automat ze stosem działa dokładnie tak, jak obliczane są wartości wyrażeń arytmetycznych we współczesnych procesorach. Automat ze stosem, czytając wyrażenie od lewej do prawej, zapisuje wyniki częściowe na stosie, a operacje wykonywane są zawsze na ostatnich elementach stosu.
Dla bardziej dociekliwych studentów proponujemy poniżej pełny dowód twierdzenia 2.1 orzekajacego, że języki rozpoznawane przez automaty ze stosem to dokładnie języki bezkontekstowe.
Dowod
Dla dowodu, że każdy język bezkontekstowy jest rozpoznawany przez odpowiedni automat ze stosem, rozważmy gramatykę \(\displaystyle G=(V_{N},V_{T},v_{0},P_{G})\) bezkontekstową, w postaci normalnej Greibach i załóżmy, że słowo puste \(\displaystyle 1\) nie należy do języka \(\displaystyle L(G)\) generowanego przez tę gramatykę. Konstruujemy teraz automat ze stosem \(\displaystyle AS\) , który, jak udowodnimy, akceptuje poprzez pusty stos język \(\displaystyle L(G)\) . Niech
gdzie funkcja \(\displaystyle f:(V_{N}\cup V_{T})\times \{q\}\times (V_{T}\cup \left\{ 1\right\} )\longrightarrow \mathcal{P}_{sk}((V_{N}\cup V_{T})^{*}\times \{q\})\) określona jest następujaco. Dla dowolnych \(\displaystyle v\in V_{N},\: a\in V_{T}\)
oraz równa jest zbiorowi pustemu \(\displaystyle \emptyset\) we wszystkich pozostałych przypadkach.
A zatem jest to automat o jednym stanie \(\displaystyle q\) , alfabetem wejściowym jest alfabet terminalny \(\displaystyle V_{T}\) , alfabetem stosu jest suma mnogościowa alfabetu symboli nieterminalnych \(\displaystyle V_{N}\) i terminalnych \(\displaystyle V_{T}\) , a symbol początkowy stosu jest symbolem startowym gramatyki. Działanie automatu \(\displaystyle AS\) symuluje lewostronne wyprowadzenie w gramatyce \(\displaystyle G.\)
Dla dowolnego słowa \(\displaystyle w\in L(G)\) istnieje lewostronne wyprowadzenie
gdzie \(\displaystyle a_{i}\in V_{T}\) , \(\displaystyle v_{i}\in V_{N}\) oraz \(\displaystyle y_{i}\in V_{N}^{*}\) , gdyż gramatyka jest w postaci Greibach. Odpowiada temu wyprowadzeniu następujące działanie automatu \(\displaystyle \mathcal{AS}\) :
A to oznacza zaakceptowanie słowa \(\displaystyle w\) poprzez pusty stos. Zatem \(\displaystyle L(G)\subset L(\mathcal{AS})\) . Dla dowodu inkluzji w przeciwną stronę wykorzystamy implikację
która ma miejsce dla dowolnego \(\displaystyle w\in V_{T}^{*}\) . Implikację tę udowodnimy indukcyjnie ze względu na długość słowa \(\displaystyle w\) . Dla słowa pustego \(\displaystyle 1\) oraz dla \(\displaystyle w=a\in V_{T}\) powyższa implikacja wynika bezpośrednio z definicji automatu ze stosem. Załóżmy teraz, że \(\displaystyle (v_{0},q)\mid \! \Longrightarrow ^{w}(\overleftarrow{x},q)\) w \(\displaystyle \mathcal{AS}\) i niech \(\displaystyle w=w_{1}a\) dla \(\displaystyle a\in V_{T}\) i \(\displaystyle w_{1}\in V_{T}^{*}\) . Mamy więc \(\displaystyle (v_{0},q)\mid \! \Longrightarrow ^{w_{1}}(\overleftarrow{y},q)\) i \(\displaystyle (\overleftarrow{y},q)\mid \! \Longrightarrow ^{a}(\overleftarrow{x},q)\) w automacie \(\displaystyle \mathcal{AS}\) . Z założenia indukcyjnego wnioskujemy, że \(\displaystyle v_{0}\mapsto_{L}^{*}w_{1}y\) w \(\displaystyle G\) . W przypadku, gdy \(\displaystyle y=a\) , wnioskujemy z określenia automatu ze stosem, że \(\displaystyle x=1\) i wtedy \(\displaystyle v_{0}\mapsto_{L}^{*}w_{1}a=w\) w \(\displaystyle G\) . Jeśli natomiast \(\displaystyle y=vy'\) dla \(\displaystyle v\in V_{N}\) i \(\displaystyle y'\in V_{N}^{*}\) , to w automacie \(\displaystyle \mathcal{AS}\) ma miejsce wyprowadzenie
gdzie \(\displaystyle x'=az,\; \displaystyle a\in V_{T}\) i \(\displaystyle z\in V_{N}^{*}\) i prawo \(\displaystyle v\rightarrow x'\in P_{G}\) . W dalszym ciągu działania automatu następuje krok \(\displaystyle (\overleftarrow{y'}\overleftarrow{x',}q)\mid \! \Longrightarrow ^{a}(\overleftarrow{x},q)\) , a to w konsekwencji oznacza, że w gramatyce \(\displaystyle G\) ma miejsce wyprowadzenie
Załóżmy teraz, że automat \(\displaystyle \mathcal{AS}=(A,A_{S},Q,f,q_{0},z_{0})\) rozpoznaje z pustym stosem język \(\displaystyle L(\mathcal{AS})\) . Skonstruujemy gramatykę bezkontekstową \(\displaystyle G\) , generującą ten sam język. Niech \(\displaystyle G=((Q\times A_{S}\times Q)\cup \left\{ v_{0}\right\} ,A,v_{0},P_{G})\) , gdzie \(\displaystyle v_{0}\notin Q\cup A_{S}\cup A\) . Do zbioru praw \(\displaystyle P_{G}\) zaliczymy wyłącznie następujące prawa:
- \(\displaystyle v_{0}\rightarrow (q_{0},z_{0},q)\) dla wszystkich stanów \(\displaystyle q\in Q\) ,
- \(\displaystyle (q,z,q_{1})\rightarrow a(q_{k+1},z_{k},q_{k})(q_{k},z_{k-1},q_{k-1})\ldots (q_{2},z_{1},q_{1})\) dla dowolnych stanów \(\displaystyle q,q_{1},\ldots ,q_{k+1}\in Q, \displaystyle \, a\in A\cup \left\{ 1\right\} ,\, z,z_{1},\ldots z_{k}\in A_{S}\) jeśli \(\displaystyle (z_{1}...z_{k},q_{k+1})\in f(z,q,a)\) ,
- \(\displaystyle (q,z,q_{1})\rightarrow a\in P_{G}\) jeśli \(\displaystyle (1,q_{1})\in f(z,q,a)\) .
Mamy więc następującą równoważność:
\(\mbox{(2)}\)
która w szczególności dla \(\displaystyle k=0\) przyjmuje postać
i oznacza dla gramatyki wymazywanie symboli nieterminalnych, a dla automatu wymazywanie symboli stosu.
Skonstruowana gramatyka \(\displaystyle G\) odtwarza działanie automatu \(\displaystyle AS\) działającego pod wpływem słowa wejściowego \(\displaystyle w,\) co udowodnimy poniżej. W tym celu wykażemy indukcyjnie ze względu na długość słowa \(\displaystyle w\in A^{*}\) następującą równoważność:
Dla \(\displaystyle w=a\in A\) równoważność redukuje się do obserwacji (2). Załóżmy teraz, że słowo \(\displaystyle w=w_{1}a\) oraz że w gramatyce \(\displaystyle G\) mamy wyprowadzenie \(\displaystyle (q,z,q_{1})\Rightarrow _{G}^{*}w_{1}a(q_{k+1},z_{k},q_{k})\ldots (q_{2},z_{1},q_{1})\) . Z postaci gramatyki \(\displaystyle G\) wynika, że to wyprowadzenie można przedstawić nastepująco:
dla pewnego \(\displaystyle p\leqslant k\) i odpowiednich \(\displaystyle q,q',q_{1},\ldots ,q_{k+1}\in Q,\, z,z',z_{1},\ldots z_{k}\in A_{S}\) .
Z założenia indukcyjnego wynika, iż pierwszy fragment wyprowadzenia jest w automacie \(\displaystyle AS\) zastąpiony równoważnie poprawnym obliczeniem
a drugi
A to oznacza, że w automacie \(\displaystyle AS\) mamy poprawne obliczenie
co kończy dowód indukcyjny równoważności. Na jej podstawie, przyjmując \(\displaystyle q=q_{0},\: z=z_{0}\) , otrzymujemy:
Uwzględniając, iż dla dowolnego stanu \(\displaystyle q\) mamy w gramatyce \(\displaystyle G\) prawo \(\displaystyle v_{0}\rightarrow (q_{0},z_{0},q)\) oraz że automat \(\displaystyle AS\) akceptuje słowa przez pusty stos (stan \(\displaystyle q'\) jest nieistotny), ostatnia równoważność kończy dowód twierdzenia.