Ściany ogniowe z użyciem netfilter
Systemy programowych zapór sieciowych
Podstawowym sposobem zwiększania bezpieczeństwa systemów komputerowych od strony sieci jest wprowadzenie mechanizmów kontroli ruchu w sieci. Najważniejszą metodą zabezpieczającą jest tutaj kształtowanie ruchu: ruch niepożądany jest zabroniony lub, jeśli zabronić się nie da, ograniczany. Narzędziem pozwalającym na takie działanie są umieszczane w różnych punktach sieci (ruterach, końcówkach komputerowych, serwerach) zapory sieciowe z filtracją pakietów.
Zapora sieciowa ma za zadanie filtrować ruch przychodzący i wychodzący z danego urządzenia sieciowego (na przykład komputera). Dzięki filtrowaniu ruchu możemy zapewniać różnego rodzaju zasady bezpieczeństwa związane z danym urządzeniem sieciowym. Obsługa sieci w Linuksie jest obecnie wbudowana w jądro. Jednym z jej elementów jest netfilter, zestaw modułów do filtrowania pakietów.
Netfilter posiada narzędzia dostępne zewnętrznie, służące do określenia reguł przesyłania pakietów – przesyłania, a nie filtrowania, bo nie tylko o filtrowanie chodzi – pakiety mogą być też zmieniane podczas przechodzenia przez zaporę. Obecnie nft (poprzednio były to wciąż popularne <xx>tables, gdzie <xx> to jeden z prefiksów: ip, ip6, arp, eb, oraz mające już wyłącznie historyczne znaczenie ipchains). Narzędzie nft pozwala ustalać reguły przetwarzania pakietów przechodzących przez maszynę. Na najwyższym poziomie narzędzie to grupuje pakiety w rodziny (ang. families), które to rodziny są ściśle związane z protokołem bazowym, którego dotyczą:
- ip – będzie zawierało reguły filtrujące pakiety przekazywane za pomocą protokołu IPv4;
- ip6 – będzie zawierało reguły filtrujące pakiety przekazywane za pomocą protokołu IPv6;
- inet – będzie zawierało reguły filtrujące pakiety przekazywane za pomocą protokołu IPv4 oraz IPv6; rozwiązanie to służy do obsługi sytuacji, gdy w jednej maszynie łączona jest komunikacja w obu protokołach warstwy sieci (L3); łatwiej jest utrzymać spójność konfiguracji, gdy reguły dla obu protokołów są konfigurowane w jednym miejscu;
- arp – będzie zawierało reguły filtrujące pakiety związane z protokołem ARP;
- bridge – będzie zawierało reguły filtrujące pakiety przekazywane, gdy maszyna służy za mostek (ang. bridge) między dwoma sieciami, czyli urządzenie przeźroczyście dla wyższych warstw protokołów przekazujące pakiety z jednego segmentu ethernetowego do drugiego;
- netdev – będzie zawierało reguły filtrujące pakiety związane z konkretnym interfejsem sieciowym (lub ich grupą połączoną za pomocą wirtualnego interfejsu) – wszystkie pakiety przechodzące przez wskazany interfejs będą przetwarzane z pomocą reguł umieszczonych w tej rodzinie.
Podstawowa funkcjonalność zapory polega na filtrowaniu pakietów, które przepuszcza tylko te pakiety odpowiadające wyznaczonym przez nas zasadom bezpieczeństwa. Pakiety, które nie są przepuszczane mogą być porzucane po cichu lub też odrzucane z komunikatem do nadawcy. Przy czym to drugie zachowanie powinno być zawsze przemyślane - takie zachowanie może być wykorzystywane przez atakujących do monitorowania konfiguracji czy stanu sieci. W zaporze sieciowej możemy filtrować zarówno ruch przychodzący, jak i wychodzący. Reguły filtrowania mogą być dosyć skomplikowane, w tym mogą uwzględniać stan protokołu, dla którego wykonywane jest filtrowanie.
Kolejną ważną funkcjonalnością zapory jest możliwość wykonywania translacji adresów. Istnieją dwa główne rodzaje translacji adresów:
- SNAT pozwala komputerom w sieci wewnętrznej na dostęp do różnego rodzaju serwerów z Internetu,
- DNAT pozwala komputerom z sieci zewnętrznej (Internetu) na dostęp do różnego rodzaju serwerów umieszczonych w sieci wewnętrznej.
Uwaga: By korzystać z translacji adresów, zwykle trzeba zezwolić na przekazywanie pakietów IP przez jądro. W przypadku IPv4 konfiguracja jądra sprowadza się do zapisania wartości 1 do pliku /proc/sys/net/ipv4/ip_forward:
echo 1 > /proc/sys/net/ipv4/ip_forward
Jeszcze inną ważną funkcjonalnością jest możliwość modyfikowania różnych fragmentów przechodzących pakietów (w istocie translacja adresów jest też przykładem tego rodzaju funkcjonalności). Dzięki temu możemy pakiety tak modyfikować, że poruszają się po sieci w bardziej regularny lub łatwiej sterowalny sposób.
Często w praktyce administracyjnej przydaje się także możliwość rejestrowania różnego rodzaju sytuacji sieciowych. Zapory pozwalają na śledzenie i rejestrowanie wielu sytuacji. Przydaje się to do optymalizowania ruchu w sieci oraz wykrywania usterek w jej konfiguracji.
Tablice w netfilter i ich zawartość
Organizacja pracy filtrującej ściany ogniowej wymaga wprowadzenia bardzo dużej liczby szczegółowych reguł. Szybkie, precyzyjne i bezbłędne reagowanie na pojawiające się potrzeby i sytuacje jest kwestią kluczową przy tworzeniu bezpiecznego rozwiązania. Jest to możliwe do osiągnięcia przy pomocy mechanizmów strukturalizacji, za pomocą których można reguły podzielić na mniejsze zestawiki zajmujące się dobrze określonymi zadaniami (czyli zadaniami, dla których mamy jednoznaczne kryteria przynależności danej akcji – jeśli nie wiemy, do jakiego zestawiku włożyć określoną regułę, to znaczy, że podział na zestawiki jest niewłaściwy). Na najwyższym poziomie struktury reguł w netfilter znajdują się tablice. W związku z tym, że nie ma zbyt dużo możliwości ich kształtowania, warto utrzymywać w systemie niewielką ich liczbę (7 będzie zapewne już na granicy tego, co przy ludzkich zasobach poznawczych, pozwala na szybkie uczenie się i bezpośrednie pojmowanie utworzonego systemu). Na przykład w Fedorze 35 jest jedna tablica firewalld. Z kolei we wcześniejszych wersjach netfilter stosowane były trzy tablice: filter, gdzie znajdowały się reguły filtrowania, nat, gdzie znajdowały się reguły przetwarzające pakiety, ale wyłącznie w celu dokonania translacji adresów, oraz mangle, gdzie znajdowały się wszystkie pozostałe reguły związane ze zmienianiem pakietów. Ważnym kryterium dla utworzenia tablicy jest możliwość utrzymywania lokalnych dla tablicy struktur danych (zbiorów, map. tablic przepływu i obiektów ze stanem wewnętrznym), które decydują o wspólnym zakresie działania danej tablicy. Tablice w netfilter tworzy się za pomocą poleceniacreate table <rodzina> <nazwa>gdzie <rodzina> to jedno z powyżej wspomnianych: ip. ip6, inet, arp, bridge, netdev, zaś <nazwa> to dosyć dowolnie dobrana nazwa, która będzie się łatwo kojarzyła z tym, jakie reguły mają trafiać do tej tablicy (zob. wyżej: filter, nat, mangle itp.).
Łańcuchy
Podstawową jednostką organizującą przetwarzanie w ramach tablicy jest łańcuch. Mamy dwa rodzaje łańcuchów (poniżej używamy tylko łańcuchów w rodzinie inet):- Łańcuchy bazowe (ang. base chains) - działanie ich jest przywiązywane do konkretnych haczyków obecnych w jądrze. Takie łańcuchy tworzy się za pomocą wywołania postaci
sudo nft add chain inet <nazwa tablicy> <nazwa łańcucha> '{type <rodzaj łańcucha> hook <nazwa haczyka> priority <priorytet>; [policy <domyślna obsługa>] }'gdzie nazwa tablicy i nazwa łańcucha wskazują, jaki łańcuch jest dokładany do jakiej tablicy, z kolei rodzaj łańcucha określa jeden z trzech rodzajów (filter, route, nat), haczyk wskazuje, skąd biorą się pakiety przetwarzane przez regułę łańcucha, priorytet określa numer kolejny łańcucha przy przetwarzaniu związanym ze wskazanym haczykiem, wreszcie domyślna obsługa wskazuje, co się ma dziać z pakietami, jeśli operacja na nich nie zostanie jawnie wskazana. Więcej wyjaśnień znajdziemy poniżej. - Łańcuchy regularne (ang. regular chains) - działanie ich służy do sterowania przepływem przetwarzania. Takie łańcuchy tworzy się za pomocą wywołania postaci
sudo nft add chain inet <nazwa tablicy> <nazwa łańcucha>
W tego typu łańcuchach nie wskazujemy, jak pakiety do nich trafiają. Pakiety trafiają do takich łańcuchów w wyniku wykonania akcji skoku z łańcuchów bazowych. Po wykonaniu takiego skoku pakiet jest przetwarzany, jak zwykle w wypadku łańcuchów bazowych.
- filter - jest wykorzystywany do filtrowania pakietów.
- route - jest wykorzystywany do przekazywania pakietu do ponownego przejścia przez proces wyznaczania jego trasy. Jest to przydatne, gdy zmieniliśmy jakieś pola nagłówka IP i mogło to zdecydować o zmianie trasy.
- nat - jest wykorzystywany do wykonywania operacji translacji adresów NAT (ang. Networking Address Translation). Tylko pierwszy pakiet z danego strumienia trafia do takiego łańcucha, następne omijają go. Dlatego nie należy łączyć łańcuchów z takimi operacjami z filtrowaniem.
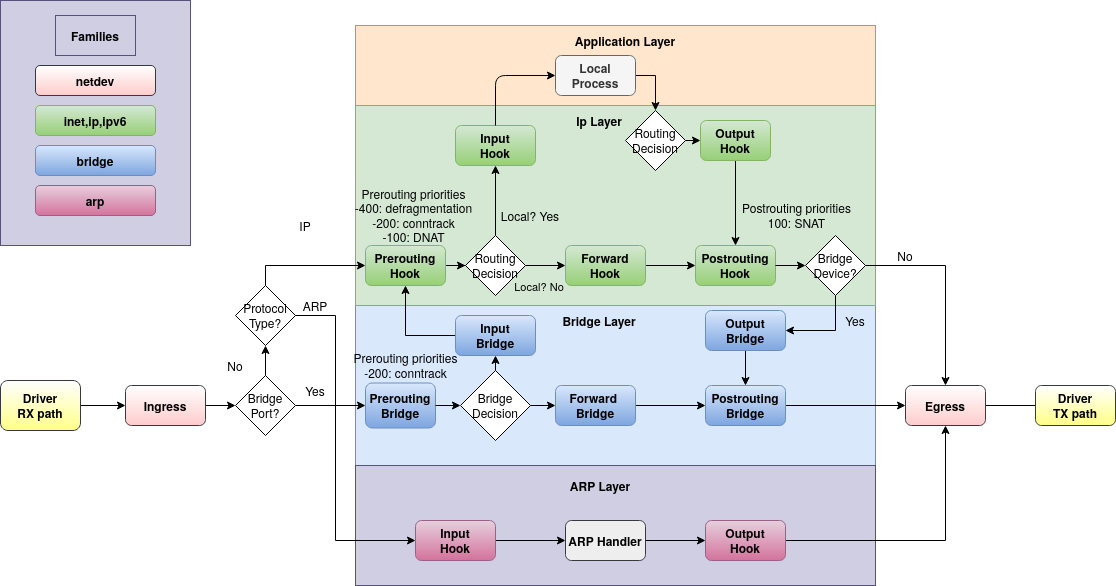 Najbardziej dla nas interesujące są haczyki związane z warstwą trzecią protokołów (barwa zielona na obrazku). Mamy tutaj następujące haczyki
Najbardziej dla nas interesujące są haczyki związane z warstwą trzecią protokołów (barwa zielona na obrazku). Mamy tutaj następujące haczyki
- prerouting: to miejsce, przez które przechodzą wszystkie pakiety wchodzące do stosu internetowego zanim nastąpi jakakolwiek decyzja związana z określeniem tracy pakietu. Pakiety tutaj mogą być adresowane do maszyny lokalnej, ale też i do innych komputerów.
- input: to miejsce, przez które przechodzą wszystkie pakiety, które mają wejść do lokalnego systemu i zostały tam skierowane przez procedury rutowania, ale jeszcze nie trafiły do procesów lokalnej maszyny
- forward: to miejsce, przez które przechodzą wszystkie pakiety, które przeszły przez proces rutowania, ale nie mają wejść do lokalnej maszyny.
- output: to miejsce, przez które przechodzą pakiety, które są wygenerowane przez procesy na maszynie lokalnej.
- postrouting: to miejsce, przez które przechodzą pakiety, które mają wyjść z maszyny, tzn. pakiety, które są forwardowane przez procedury rutowania oraz pakiety wygenerowane przez lokalne procesy na maszynie lokalnej.
Reguły
Reguły mają dosyć dużo możliwości opisywania tego, co za ich pomocą można zrobić. W związku z tym podamy tutaj tylko kilka przykładów.sudo nft add rule inet example_table example_chain tcp dport 22 counter acceptPolecenie powyższe spowoduje dodanie reguły do łańcucha example_chain w tablicy example_table (obie te rzeczy muszą być już utworzone). Oprócz tego
- Podwyrażenie tcp dport 22 zawiera dwa wyrażenia podstawowe i określa filtrowanie, w którym obecna reguła zostanie uruchomiona, jeśli pakiet będzie niósł w sobie segment TCP i to w dodatku skierowany do portu 22.
- Podwyrażenie counter określa, że pakiet zostaje dodany do licznika reguły, który zawiera liczbę pakietów przetworzonych przez daną regułę.
- Wreszcie podwyrażenie accept wskazuje, co ma się stać z pakietem w ostateczności. Tutaj wskazane działanie to przyjęcie pakietu, ale możliwe byłoby też jego porzucenie (podwyrażenie drop) i inne operacje, zob. poniżej. Takie podwyrażenie decydujące o końcowym losie pakietu musi znajdować się na końcu reguły.
- accept: zaakceptowanie pakietu i zakończenie przetwarzania dalszymi regułami.
- drop: porzucenie pakietu i zakończenie przetwarzania dalszymi regułami.
- queue: zakolejkowanie pakietu do przetwarzania w przestrzeni użytkownika i zakończenie przetwarzania dalszymi regułami.
- continue: przejście do następnej reguły w łańcuchu.
- return: powrót z obecnego łańcucha do łańcucha poprzedniego. W łańcuchach bazowych równoważne jest to akcji accept.
- jump <łańcuch>: przejście do pierwszej reguły wskazanego łańcucha. Gdy we wskazanym łańcuchu wykonana zostanie akcja return, to przetwarzanie w obecnym łańcuchu jest kontynuowane od następnej reguły.
- goto <łańcuch>: nieco podobnie jak w jump następuje przejście do pierwszej reguły wskazanego łańcucha. Jednak w tym wypadku zakończenie przetwarzania we wskazanym łańcuchu oznacza zastosowanie domyślnego sposobu obsługi pakietu zgodnego z domyślnym sposobem obsługi zdefiniowanym w pierwotnym łańcuchu bazowym, od którego zaczęło się przetwarzanie pakietu.
sudo nft add rule inet example_table example_chain position 3 tcp dport 22 counter acceptspowoduje dodanie reguły działającej jak ta poprzednia, ale na pozycji nr 3 w łańcuchu example_chain.
Inne typy danych w tablicach
O innych typach danych można przeczytać więcej na stronach o:Przykładowa tablica z łańcuchami
table firewall {
chain incoming {
type filter hook input priority 0; policy drop;
# established/related connections
ct state established,related accept
# loopback interface
iifname lo accept
# icmp
icmp type echo-request accept
# open tcp ports: sshd (22), httpd (80)
tcp dport {ssh, http} accept
}
}
Dalsze informacje do przeczytania przed zajęciami:
- przejrzyj man nft.
- przejrzyj http://www.netfilter.org/
- zajrzyj do tutorialu https://www.linkedin.com/pulse/comprehensive-guide-nftables-leading-pack...
- przydatna ściągawka: https://wiki.nftables.org/wiki-nftables/index.php/Quick_reference-nftabl...
Ćwiczenia - zapory sieciowe
- Ogranicz za pomocą nft maksymalną wielkość pakietu ICMP-echo do 1kB.
- Ogranicz do 3 na minutę liczbę pakietów ICMP-echo.
- Ogranicz żądania HTTP do 2kB wielkości i do 3 na minutę.
- Każ systemowi logować pakiety HTTP większe niż 2kB i częstsze niż 3 na minutę, ale ich nie usuwać.
- Spraw, żeby były usuwane pakiety większe niż 3 kB, zwracając komunikat błędu ICMP-net-unreachable.