Selekcja
Rozważmy następujący problem:
Dany jest zbiór \( A \) składający się z \( n \) liczb oraz liczba \( k \). Należy wyznaczyć \( k \)-ty co do wielkości element zbioru \( A, \) tzn. takie \( a\in A \), że \( |\{ x\in A : x < a \}|=k-1 \).
Dla niektórych wartości \( k \) (np. 1 lub n) problem jest bardzo prosty i wymaga jedynie wyznaczenia minimalnej lub maksymalnej wartości w A, co możemy zrobić w czasie \( O(n) \). Znacznie ciekawszym problemem jest np. znajdowanie mediany, czyli \( \lfloor \frac{n}{2} \rfloor \)-tego co do wielkości elementu. Tu niestety problem jest bardziej skomplikowany.
Możemy zauważyć, że szybkie (np. o złożoności \( O(n) \)) znajdowanie mediany pozwoliłoby tak poprawić algorytm sortowania QuickSort, żeby nawet w pesymistycznym przypadku działał w czasie \( O(n\log n) \).
Najprostszym rozwiązaniem naszego problemu może być uporządkowanie zbioru, np. algorytmem MergeSort, i wskazanie k-tego elementu. Takie postępowanie wymaga czasu \( \Omega(n\log n) \).
Jednak można łatwo zauważyć, że nasz problem jest znacznie prostszy od problemu sortowania. Czy można rozwiązać go szybciej? Okazuje się, że jest to możliwe. W następnej części wykładu przedstawimy dwa algorytmy, które rozwiązują nasz problem znacznie sprytniej.
Algorytm Hoare'a
Algorytm jest oparty na tym samym pomyśle, co algorytm sortowania QuickSort.
Dla danej tablicy A[1..n] oraz liczby k, algorytm wybiera element dzielący m (np. pierwszy element z tablicy), a następnie używa go do podzielenia tablicy na dwie części. Do pierwszej części tablicy - A[1..r] - zostają przeniesione elementy o wartościach mniejszych lub równych m. Do drugiej części (A[r+1..n]) - elementy o wartościach większych lub równych m.
Ponieważ naszym zadaniem jest jedynie wyznaczenie k-tego co do wielkości elementu tablicy, możemy zamiast 2 wywołań rekurencyjnych (jak to było w przypadku algorytmu QuickSort) wykonać tylko jedno wywołanie rekurencyjne.
Jeśli \( k\le r \), to poszukiwana wartość znajduje się w pierwszej części tablicy, wpp. możemy zawęzić poszukiwania do drugiej części tablicy, jednak zamiast wyszukiwać k-tej wartości musimy poszukiwać (k-r)-tej wartości.
Algorytm Hoare'a
function AlgHoara(A[1..n],k); begin if n=1 and k=1 then return A[1]; // Partition m:=A[1]; l:=1; r:=n; while(l<r) do begin while (A[l]<m) do l++; while (m<A[r]) do r--; if (l <=r) then begin tmp:=A[l]; A[l]:=A[r]; A[r]:=tmp; l++; r--; end; end; if (k<=r) then return AlgHoara(A[1..r],k) else return AlgHoara(A[r+1..n],k-r) 18 end;
Analiza algorytmu
Niestety, w pesymistycznym przypadku ten algorytm może zachowywać się bardzo źle. Dla uporządkowanego ciągu i k=n czas działania algorytmu wynosi \( O(n^2) \). Jednak tak jak w przypadku algorytmu QuickSort, w średni koszt działania algorytmu jest znacznie lepszy i wynosi O(n).
Algorytm magicznych piątek
Algorytm Hoare'a w pesymistycznym przypadku może wymagać bardzo długiego czasu działania. Możemy tak zmodyfikować poprzedni algorytm, aby zapewnić liniowy czas działania nawet w najgorszym przypadku.
Kluczem do nowego algorytmu jest lepszy wybór elementu dzielącego (zmienna m z 5-linii algorytmu Hoare'a). Element ten jest obliczany w następujący sposób:
- dzielimy ciąg \( A \) na podciągi 5-elementowe \( P_1,\ldots,P_{\lceil |A|/5 \rceil} \),
- każdy z podciągów sortujemy, otrzymując \( P'_1,\ldots,P'_{\lceil |A|/5 \rceil} \),,
- wybieramy z każdego podciągu 3-ci co do wielkości element otrzymując krótszy ciąg \( M \),
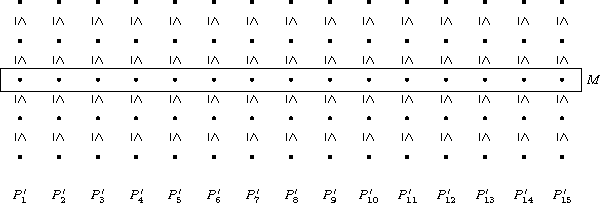
- jako m wybieramy medianę ciągu \( M \) (którą to obliczamy rekrurencyjnie).
Dzięki takiemu znacznie bardziej skomplikowanemu wyborowi możemy zagwarantować bardziej równomierny podział ciągu \( A \) na podciągi elementów mniejszych (\( A_{ < } \)), oraz większych (\( A_{>} \)) od m.
Algorytm
function AlgorytmMagicznychPiatek(A[1..n], k); begin if n<=10 then posortuj tablicę A return A[k] else begin podziel elementy z tablicy A na podciągi 5-elementowe: P(1),...,P(n/5) (jeśli n nie jest wielokrotnością 5, uzupełnij ostatni podciąg wartościami infty) Niech M={ P_i [3] : 1 <= i <= n/5} (zbiór median ciągów P(i)); m:=AlgorytmMagicznychPiatek(M, ceil(|M|/2)); A_< :={ A[i] : A[i] < m}; A_= :={ A[i] : A[i] = m}; A_> :={ A[i] : A[i] > m}; if |A_<| <= k then return AlgorytmMagicznychPiatek(A_<,k) else if |A_< |+|A_=| <= k then return m else return AlgorytmMagicznychPiatek(A_>, k-|A_<|-|A_=|); end end
Analiza złożoności czasowej
Na pierwszy rzut oka algorytm wygląda bardzo podobnie do algorytmu Hoare'a. Nowy algorytm jest jednak znacznie bardziej efektywny: nawet w pesymistycznym przypadku algorytm kończy działanie po \( O(n) \) krokach.
Złożoność algorytmu możemy opisać następującym równaniem rekurencyjnym.
- rozmiar zbioru |M| możemy ograniczyć przez \( \lceil n/5 \rceil \)
- ze względu na dodatkowy czas poświęcony na obliczanie mediany m, możemy podać lepsze ograniczenia na rozmiary zbiorów \( A_{ < },\ A_{>} \):

Ćwiczenia
- Podaj algorytm wyznaczający drugi co do wielkości element zbioru, używający przy tym minimalnej liczby porównań.
- Podaj algorytm sprawdzający, czy dany ciąg zawiera element występujący co najmniej n/k razy (np. n/3 razy). !!todo: trzeba to trochę jaśniej napisać!!
- Czy liczbę 5 w algorytmie "Magicznych piątek" można zastąpić przez inną wartość, np. 3,4,6,7?
- Dane są trzy tablice A[1..n], B[1..n], C[1..n]. Elementy każdej z tych tablic są uporządkowane rosnąco. Podaj efektywny sposób na znajdowanie mediany wśród wszystkich elementów.