Wstęp do programowania
Opis
Podstawowy przedmiot pierwszego semestru studiów, mający zapoznać studentów z pojęciami algorytmu i programu. Celem zajęć jest nauczenie projektowania, zapisywania, dowodzenia poprawności i uwzględniania złożoności algorytmów.
Sylabus
Autor
- Piotr Chrząstowski-Wachtel — Uniwersytet Warszawski, Wydział Matematyki, Informatyki i Mechaniki
Zawartość
- Pojęcie algorytmu:
- historia powstania pojęcia algorytmu
- algorytmy znane ze szkoły (Euklidesa, Hornera, rozwiązywanie równań liniowych i kwadratowych)
- Języki formalne:
- alfabet, składnia i semantyka
- gramatyki bezkontekstowe jako narzędzie definiowania składni
- definiowanie semantyki przez interpretację wyrażeń poprawnych składniowo
- Reprezentacja liczb w komputerze:
- stałe całkowite i rzeczywiste
- reprezentacje binarne stało- i zmiennopozycyjne
- systemy znak-moduł i uzupełnieniowy
- rachunek zmiennopozycyjny — pojęcie zakresu i błędu zaokrągleń
- Zmienne i wyrażenia:
- typ zmiennej i wartościowanie zmiennych
- wyrażenia arytmetyczne i logiczne: składnia i semantyka
- Instrukcje while-programów:
- pusta, przypisania, warunkowa, iteracji, wyboru, czytania, pisania, wywołania procedury
- składnia i semantyka powyższych instrukcji
- obliczenia skończone i nieskończone
- błędy obliczeń
- przykłady algorytmów
- Asercje w programach i niezmienniki pętli:
- formuły Hoare'a
- uzasadnianie poprawności programów
- własność stopu i metody jej dowodzenia
- Typy danych:
- tablice
- rekordy
- zbiory
- pliki
- typy wyliczeniowe i okrojone
- typy wskaźnikowe
- Pliki:
- pliki o dostępie bezpośrednim
- pliki tekstowe
- Funkcje i procedury:
- składnia i semantyka
- sposoby przekazywania parametrów: przez wartość i przez zmienną
- widoczność zmiennych w zagnieżdżonych procedurach
- Miary złożoności algorytmów:
- koszty algorytmu: czasowy i pamięciowy, pesymistyczny i średni
- rozmiar danych
- przykłady wyznaczania kosztów
- koszt zamortyzowany
- Rekursja
Literatura
- Wstęp do programowania systematycznego, N.Wirth, Wydawnictwa Naukowo - Techniczne 1999.
- Elementy analizy algorytmów, L. Banachowski, A.Kreczmar, Wydawnictwa Naukowo - Techniczne 1987.
- Projektowanie programów poprawnych i dobrze zbudowanych, S.Alagić, M.Arbib, Wydawnictwa Naukowo - Techniczne 1982.
Wstęp do programowania/Wstęp do algorytmów
Wprowadzenie do algorytmów
Najważniejszym pojęciem w informatyce jest algorytm. Nazwa ta ma swoje korzenie w średniowieczu i wzięła się ze zniekształconego nazwiska wielkiego uczonego arabskiego Al Chuwarizmiego, który żył na przełomie VIII i IX wieku i pochodzącego z Chorezmu. Al Chuwarizmi, działając w Domu Nauk kalifa Al Mamuna w Bagdadzie, opublikował ważne dzieła matematyczne, wśród nich Hisab al dżabr w'al muqabala – traktat o rozwiązywaniu równań, z którego wzięła nazwę algebra – jeden z głównych działów matematyki. W traktacie tym, poza wprowadzeniem systemu zapisu pozycyjnego, zaczerpniętego od Hindusów, a zwanego arabskim, podał między innymi metody rozwiązywania równań kwadratowych. Metody te odwoływały się do pojęć geometrycznych; utożsamiano wtedy liczby i działania z miarami obiektów geometrycznych. Liczby rzeczywiste to były długości odcinków, dodawanie to było sklejanie odcinków, mnożenie odpowiadało wyliczaniu pola prostokąta o danych bokach, a pierwiastkowanie wyznaczaniu boku kwadratu o zadanym polu. Arabowie, podobnie jak starożytni Grecy, nie znali pojęcia liczby ujemnej, stąd, gdy dziś patrzymy na metody Al Chuwarizmiego, poza oczywistym pięknem, wydają się nam one nieco dziwaczne. Ale cóż – wtedy inaczej po prostu się nie dało.
W pierwszym kroku rozwiązania Al Chuwarizmi polecał podzielić wszystkie współczynniki trójmianu kwadratowego przez współczynnik przy \( x^{2} \), aby uwolnić się od jednego z nich; w końcu pierwiastki przez takie podzielenie nie zmieniają się, a metoda staje się prostsza. Al Chuwarizmi rozważał zatem równania postaci \( x^{2}+bx+c \) dla różnych klas b i c: dodatnich, ujemnych i równych zero. Miał zatem do czynienia z 9 różnymi przypadkami i dla każdego z nich podał metodę wyznaczania pierwiastka takiego równania. Przyjrzyjmy się jednemu z nich: dane są zaczerpnięte bezpośrednio z omawianej księgi. Rozwiązujemy równanie
\( x^{2}+10x = 39 \)
Jest to zatem równanie z klasy równań, w których współczynnik przy x jest dodatni, a wyraz wolny ujemny (dla wygody przenieśliśmy go na prawą stronę, więc po tamtej stronie jawi się nam jako c dodatnie). Oto co proponował Al Chuwarizmi.
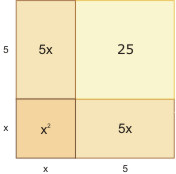
Rysujemy kwadrat o boku x. Po jednej jego stronie doklejamy prostokąt o bokach x oraz \( 10/2 = 5 \), po drugiej pod kątem prostym identyczny prostokąt. Uzupełniamy powstały kąt prosty wyznaczony przez 2 odcinki długości 5 do kwadratu i otrzymujemy duży kwadrat, którego pole wynosi
\( x^{2} + 5x + 5x + 25= 39 + 25 = 64 \)
Bok tego dużego kwadratu ma więc długość 8, a że powstał on przez sklejenie odcinka o długości x oraz odcinka o długości 5, więc \( x = 3 \). Drugi pierwiastek w tym przypadku nas nie interesuje: jest ujemny, a więc go "nie ma" – liczby ujemne nie istniały wówczas w świadomości współczesnych.
Zauważmy, że konstrukcję tę, a zatem i stosowne obliczenia, można powtórzyć dla każdej pary (b,c) w której b > 0, zaś c < 0. Wyrażając jednym wzorem efekt obliczeń uzyskalibyśmy wyrażenie
\( x=\sqrt{c+(\frac{b}{2})^2}-\frac{b}{2} \)
Obliczenie wartości x mogłoby się odbywać według następującego schematu:
- podziel \( b \) przez \( 2 \) i zapamiętaj wynik na zmiennej pomocniczej \( b' \)
- podnieś \( b' \) do kwadratu
- dodaj do otrzymanej liczby wartość \( c \)
- wyciągnij z otrzymanej sumy pierwiastek kwadratowy
- odejmij od tego, co uzyskałeś uprzednio zapamiętaną wartość \( b' \)
- otrzymana liczba jest szukanym (nieujemnym) pierwiastkiem równania \( x^{2}+bx=c \).
Zróbmy parę obserwacji.
Po pierwsze powyższa procedura jest wykonywalna dla każdych danych b,c>0. Zauważmy, że jedyna operacja, która mogłaby sprawić kłopoty z wykonaniem, to odejmowanie w punkcie 5 naszej procedury. Jednak można łatwo sprawdzić, że daje ono zawsze wynik dodatni:
w końcu dla \( c >0 \) mamy \( \sqrt{c+(\frac{b}{2})^2} > \sqrt{(\frac{b}{2})^2}=\frac{b}{2} \).
Po drugie, zastosowaliśmy tu pewne niewielkie, ale ważne uproszczenie algorytmu: użyliśmy w jego opisie pomocniczej zmiennej \( b' \), dzięki której nie musieliśmy dwukrotnie dzielić wartości \( b \) przez \( 2 \). Po trzecie, zapisując wzór na równanie kwadratowe skorzystaliśmy z tradycji notacyjnej, w myśl której w wyrażeniach arytmetycznych zawsze wiadomo, w jakiej kolejności wykonuje się działania. W szczególności w wyrażeniu podpierwiastkowym najpierw dzieliliśmy b przez 2, potem podnosiliśmy wynik do kwadratu, a na końcu dodawaliśmy do niego c. To, co w podanym przez Al Chuwarizmiego przepisie wymagało uściślenia kolejności, można wyrazić wzorem w zwartej formie, umówiwszy się zawczasu co do interpretacji podanej notacji. Niezwykle ważne jest, aby używana notacja była jednoznaczna i abyśmy nie popełniali błędu przy interpretacji wyrażeń, w szczególności żebyśmy byli zgodni co do kolejności wykonywanych działań. Wrócimy do tego zagadnienia w wykładzie o gramatykach.
Ćwiczenie
- Jak będzie działała podana metoda, dla c<realnowiki><realnowiki> = </realnowiki></realnowiki>0?
- Zaprojektuj geometryczną metodę w stylu Al Chuwarizmiego dla równania \( x^{2}= 5x + 6 \). Czy metoda ta da poprawne wyniki dla wszystkich równań postaci \( x^{2} = bx + c \) przy dodatnich b, c?
Co to są zatem algorytmy? Ogólnie określamy tym mianem wszelkie przepisy postępowania, które doprowadzają do uzyskania pożądanego efektu – rozwiązania zadania. W potocznej mowie mówimy czasem o algorytmach postępowania niewiele mających wspólnego z komputerami, jednak dla informatyków algorytmy wiążą się nierozerwalnie z programowaniem.
Prawdziwe problemy pojawiają się, gdy chcemy algorytm zakodować w taki sposób, żeby był dobrze wykonany przez maszynę. Nie możemy sobie pozwolić na odwoływanie się do doświadczenia, machanie rękami, domysły. Komputer niczego się nie domyśla, ba, nie rozumie języka naturalnego i potrzebna będzie nam precyzyjna notacja do komunikacji z nim. Istotą programowania jest bowiem wyrażanie algorytmów w sposób ścisły, podlegający rygorom skończonej liczby reguł, których znaczenie w jednoznaczny sposób jesteśmy określić.
Al Chuwarizmi nie był oczywiście pierwszym człowiekiem, który stosował podejście algorytmiczne do rozwiązywania problemów. W rzeczywistości każdy z nas stosuje algorytmy w rozmaitych sytuacjach życiowych. Człowiek pierwotny miał algorytm polowania na mamuty, czy rozpalania ognia. Dzisiaj często wykonujemy pewne algorytmy, nie zdając sobie sprawy. Warto przytoczyć parę przykładów algorytmów z życia codziennego:
Przepisy kucharskie Typowy przepis zawiera deklaracje obiektów (składników pichcenia) ich początkowe wartości (miary) oraz opis działań doprowadzający do przyrządzenia potrawy.
Zapis nutowy muzyki. Za pomocą szczególnego systemu notacyjnego określa się wysokości i względne czasy trwania nut i pauz między nimi. Można również i tu określić dane: są to zazwyczaj określenia instrumentów, które w partyturze występują, oraz dane początkowe, takie jak metrum czy dynamika poszczególnych części. Zauważmy, że poza standardowymi znakami na pięciolinii, kompozytorzy często stosują dodatkowe określenia takie jak crescendo, poco allegretto, piano, con fuoco itp, pozwalające wykonawcy lepiej wyczuć ich intencje. Szczególnie atrakcyjnie wyglądają niektóre nuty kompozytorów współczesnych, którzy odchodzą czasem od tradycyjnego zapisu nutowego i starają się niekiedy wymyślić i opisać własny system notacyjny, wyrażający ich intencje.
Instrukcje montażu Często do zestawów mebli, czy klocków lego, dołączona jest kartka z instrukcją montażu zapisaną za pomocą sekwencji rycin obrazujących kolejne fazy powstawania składanego obiektu. Użytkownik, porównując zmiany na poszczególnych obrazkach, ma się domyślić, jakie czynności, w jakiej kolejności i za pomocą jakich części ma wykonywać. Zauważmy, że i tu występuje charakterystyczny dla algorytmów opis danych: najczęściej zestaw części składowych jest wyrysowany obok historyjki obrazkowej z zaznaczeniem liczby poszczególnych elementów.
Opisy dojazdu Wyjaśniając jak dotrzeć do danego miejsca (mappy.com), wiele serwisów udostępnia opis drogi z zaznaczeniem kluczowych punktów i decyzji.
Opis układów choreograficznych, scenopisy przedstawień Tutaj też stosuje się specyficzną symbolikę i skróty notacyjne.
Takich przykładów można przytaczać tysiące. Właściwie niemal wszystko, co robimy, podlega jakiemuś algorytmowi działania – przy czym warto podkreślić, że ludzie nie muszą mieć algorytmów objaśnianych dokładnie: wiele mogą wywnioskować z kontekstu, doświadczenia, po prostu domyślając się, o co może chodzić. Kucharce nie trzeba wyjaśniać, co to znaczy "zeszklić cebulkę na ciemnozłoty kolor", a monterowi - co znaczy "zaizolować przewody".
Z komputerami jest jednak inaczej. Są to wyjątkowo głupie urządzenia i jeśli dokładnie nie wytłumaczymy, co mają zrobić, stają się bezradne. Między bajki należy włożyć rozmaite sytuacje znane z literatury fantastyczno-naukowej, w których komputery są równorzędnymi partnerami intelektualnymi dla ludzi. Sztuczna inteligencja, nawet jeśli istnieje, bazuje na ściśle określonych algorytmach działania i nie ma tam miejsca na intuicję, domyślenie się czegokolwiek czy nagłe olśnienie, które są doskonale znane istotom myślącym. Ludzie często nie zdają sobie sprawy, jak wiele w algorytmach, którymi się posługują, zależy od nieuświadamianego kontekstu, jak dużo muszą dopowiadać do rzekomo precyzyjnych procedur działania. Komputery bezlitośnie wyłapują luki w specyfikacji procedur i nie ma mowy, żeby domyśliły się, że wykonują jakąś bezsensowną akcję, typu wydrukowanie żądania zapłacenia 0 zł. Jeśli wyraźnie nie zapiszemy w algorytmie, że takich żądań nie należy generować, to komputer ślepo wykona nasze polecenie, choćby było ono w oczywisty sposób bezsensowne. W dalszych wykładach zobaczymy przykłady, w których algorytmy z pozoru wyglądające na poprawne i kompletne, będą miały luki powodujące błędne działanie.
Ćwiczenie
Znajdź w Internecie przykłady bezsensownego zachowania się komputerów. Spróbuj domyślić się, jakiego rodzaju błąd programisty był przyczyną kompromitacji.
Spróbujmy przymierzyć się do problemu znanego jeszcze ze starożytności. Przy dodawaniu sprowadza się mianowniki do najmniejszej wspólnej wielokrotności. Wyznaczenie jej najczęściej polega na tym, że oblicza się największy wspólny dzielnik, dzieli się jedną z liczb przez niego i wynik mnoży przez drugą. Jak jednak znaleźć największy wspólny dzielnik?
Operacja dzielenia z resztą
Algorytm Euklidesa
Dziedzina algorytmiczna
Dziedzina algorytmiczna
Ważnym pojęciem przy określaniu algorytmu jest pojęcie dziedziny algorytmicznej. Algorytmy wykonują pewne operacje na argumentach i wyrażenie własności algorytmu, a w tym określenie jego złożoności, dokonywane jest za pomocą tych operacji. Dziedziną algorytmiczną nazwiemy zatem system relacyjny \( \langle A,\{o_i\}_{i\in I}, \{r_{j}\}_{j\in J}\rangle \), gdzie \( A \) nazywany jest nośnikiem, a zbiory \( \{o_i\}_{i\in I}, \{r_{j}\}_{j\in J} \), odpowiednio zbiorem operacji i relacji określonych w \( A \), których można używać w algorytmie. Zauważmy, że od tego, jakimi operacjami i relacjami dysponujemy zależą nasze możliwości opisywania algorytmów. Zawsze musimy wiedzieć, z jakich operacji można korzystać, zanim zabierzemy się za programowanie. Czasami takie operacje przyjmują postać bibliotek gotowych procedur i funkcji – cegiełek, z których składamy nasze algorytmy.
W przypadku naszych trzech algorytmów Euklidesa te trzy dziedziny, to:
- Euklides1: \( \langle {\cal N}, -,\le, =_0 \rangle \)
- Euklides2: \( \langle {\cal N}, \bmod, =_0 \rangle \)
- Euklides3: \( \langle {\cal N}, -,\div_2, *_2,\le, \in_P,=_0 \rangle \),
gdzie \( - \), to zwykłe odejmowanie, \( \bmod \) operacja znajdowania reszty, \( \div_2 \) - jednoargumentowa operacja dzielenia przez 2, \( *_2 \) jednoargumentowa operacja mnożenia przez 2 (zauważmy, że przez nic innego nie musimy dzielić ani mnożyć), \( \le \) relacja dwuargumentowa niemniejszości, \( \in_P \) jednoargumentowa relacja parzystości, zaś \( =_0 \) relacja jednoargumentowa bycia zerem.
Uświadomienie sobie, w jakiej dziedzinie algorytmicznej operujemy, jest ważne między innymi z punktu widzenia porównywania algorytmów. Łatwo jest bowiem "skrzywdzić" jakiś algorytm nie zauważając, że działa on w uboższej dziedzinie niż rzekomo lepszy, a przyjrzenie się kosztowi operacji podstawowych daje lepszy wgląd w istotę złożoności.
Jeszcze parę słów na temat złożoności algorytmów. Jak mogliśmy to zauważyć, brak analizy złożoności może doprowadzić do porażki – algorytm, nawet poprawny, może stać się praktycznie bezużyteczny, jeśli będzie miał zbyt dużą złożoność. Dokładniej o złożoności będzie jeszcze mowa na dalszych wykładach z bardziej zaawansowanej algorytmiki. Podkreślmy parę podstawowych spraw.
- Złożoność określamy obliczając liczbę operacji dominujących, czyli takich, które najczęściej będą wykonywane.
- Złożoność wyznacza się zazwyczaj z dokładnością do rzędu wielkości, a więc zaniedbując czynnik stały. Czasami czynnik ten bierze się pod uwagę, ale dopiero wtedy, gdy porównujemy algorytmy o podobnym rzędzie złożoności. Najczęściej do określenia złożoności używa się notacji \( O \), która pozwala uwolnić się od czynnika stałego i skupia się właśnie na rzędzie wielkości. #MatematykaDyskretna.xxx
Definicja [Definicja notacji \( O \)]
Mówimy, że funkcja \( f:{\cal N} arrow R \) jest \( O(g) \), jeśli istnieją stała \( c>0 \) oraz liczba \( m\in {\cal N} \) takie, że dla każdego \( n>m \) zachodzi \( f(n)\le cg(n) \). - Złożoność zależy od rozmiaru danych. Przez rozmiar danych najczęściej rozumiemy liczbę bitów (czy bajtów) potrzebnych do zakodowania danych; znowu chodzi o rząd wielkości. Na przykład jeśli mówimy o sortowaniu liczb, to ważne jest ile ich jest, a nie to, z jaką dokładnością je podajemy – zwiększenie takiej dokładności w końcu rozmiar danych powiększy o stały czynnik. Stąd na przykład
- gdy sortujemy n obiektów, rozmiarem danych jest n;
- gdy rozważamy graf, rozmiarem danych jest suma liczby krawędzi i wierzchołków (czasem rozważamy osobno liczbę krawędzi i wierzchołków);
- gdy rozważamy algorytmy liczbowe – tak jak w naszych przykładach obliczania największego wspólnego dzielnika – rozmiarem danych jest długość zapisu cyfrowego liczby, bo tak złożone jest podanie jej wartości
- Czasami do wykonania algorytmu potrzeba dodatkowej pamięci na pomocnicze struktury. Wtedy również zastanawiamy się, ile tej pamięci potrzeba i wynik nazywamy złożonością pamięciową
- Dla różnych danych algorytm może różnie się wykonywać. W praktyce rozważa się dwa rodzaje danych: pesymistyczne (czyli najbardziej złośliwe) i losowe, czyli typowe. Mówimy wtedy odpowiednio o złożoności pesymistycznej i złożoności średniej.
Dobrzy informatycy wyrabiają sobie przy programowaniu nawyk myślenia o złożoności.
Liczby Fibonacciego
Liczby Fibonacciego
rycina
Fibonacci (ok. 1170-1250)
Aby rozwiązać ten problem doboru najbardziej złośliwych danych, należy spojrzeć na problem od drugiej strony: jak za pomocą najmniejszych liczb uzyskać z góry zadaną liczbę obrotów pętli? Widać, że aby pętla wykonała się raz, wystarczą dane \( (1, 1) \). Ale te dane nie mogą być wynikiem wcześniejszego obrotu pętli: pamiętajmy, że pierwszy z argumentów jest zawsze dzielnikiem z poprzedniego obrotu pętli, a skoro jest nim jedynka, to reszta nie mogła być równa jeden. Zatem przy więcej niż jednym obrocie pętli najmniejsze dane dla ostatniego obrotu pętli, to \( (2, 1) \) (po czym dostajemy od razu parę \( (1, 0) \) kończącą pętlę). Jakie były zatem dane przedostatnie? Widać, że dzieliliśmy przez \( 2 \) i dostaliśmy resztę \( 1 \). Zatem w poprzednim kroku mogliśmy mieć pary \( (3, 2) \) lub \( (5, 2) \) lub \( (7, 2),\ldots \). Z nich para \( (3, 2) \) jest najoszczędniejsza – są to liczby, które dają najmniejszą sumę, a liczba obrotów naszej pętli jest równa \( 2 \). Jak wyglądała zatem para dwa kroki wstecz? Dzielnik musiał być równy \( 3 \), a reszta równa \( 2 \), więc w grę wchodzą pary \( (5, 3), (8, 3), (11, 3),\ldots \). Z nich znów najoszczędniejsza jest para \( (5, 3) \). Dalej, cofając się i rozumując w analogiczny sposób, dostaniemy pary \( (8,5) \) i kolejno \( (13, 8), (21, 13),\ldots \). Widać zatem, że zawsze najoszczędniej będzie tak dobierać kolejną parę, aby wynik dzielenia był równy \( 1 \), czyli innymi słowy, jeśli w kolejnym obrocie pętli argumenty są równe \( a \) i \( b \), to w poprzednim powinny być równe \( a + b \) i \( a \). Wtedy bowiem \( b \) jest resztą z dzielenia \( a + b \) przez \( a \), natomiast iloraz równy jest 1.
Zbadajmy zatem, jakie najmniejsze argumenty dają zadaną liczbę obrotów pętli.
| Liczba obrotów | a | b |
|---|---|---|
| 0 1 2 3 4 5 6 ... |
1 1 3 5 8 13 21 |
0 1 2 3 5 8 13 |
Liczby, które występują w tabeli, są znane pod nazwą liczb Fibonacciego. Mają one w informatyce duże znaczenie i warto znać podstawowe fakty o nich. Definiuje się je następująco:
Liczby Fibonacciego
\( F_{0}=0 \) \( F_{1}=1 \) \( F_n = F_{n-1}+F_{n-2} \) dla \( n \ge 2 \)
Każda kolejna liczba Fibonacciego jest sumą dwóch swoich poprzedniczek. Parę początkowych wyrazów tego ciągu warto znać na pamięć.
| \( n \) | \( F_{n} \) |
|---|---|
| 0 1 2 3 4 5 6 7 8 ... |
0 1 1 2 3 5 8 13 21 |
{kind=link}
rycina
Jacques Philippe Marie Binet (1786-1856)
Widzimy więc, że poczynając od drugiego wiersza tabeli (\( n\ge 1 \)), najbardziej złośliwych danych dla algorytmu Euklides2 mamy zawsze \( a = F_{n+2}, b= F_{n+1} \). Aby wymusić \( n \) obrotów pętli musimy wziąć zatem co najmniej \( n + 2 \)-gą i \( n + 1 \)-wszą liczbę Fibonacciego.
{kind=link}
rycina
Leonhard Euler (1707-1783)
Liczby Fibonacciego rosną szybko. Konkretnie znany jest ogólny wzór na \( n \)-tą liczbę Fibonacciego przypisywany Binetowi, a znany jeszcze na pewno Eulerowi 100 lat przed Binetem.
\( F_n=\frac{1}{\sqrt{5}}((\frac{1+\sqrt{5}}{2})^n-(\frac{1-\sqrt{5}}{2})^n) \)
Dowód tego wzoru można znaleźć w #MatematykaDyskretna-xxx.
Wprowadzając oznaczenia \( \varphi = \frac{1+\sqrt{5}}{2}, \hat{\varphi} = \frac{1-\sqrt{5}}{2} \), otrzymujemy wzór w nieco bardziej czytelnej postaci
\( F_n=\frac{1}{\sqrt{5}}(\varphi^n-\hat{\varphi}^n) \).
Biorąc pod uwagę to, że \( \varphi = 1,618... \), zaś \( \hat{\varphi} = -0,318... \) i to, że w związku z tym składnik \( \hat{\varphi}^{n} \) w naszym wzorze bardzo szybko dąży do zera, możemy łatwo pokazać, że n-ta liczba Fibonacciego jest równa
\( F_n=[\frac{1}{\sqrt{5}}\varphi^n] \),
gdzie przez \( [x] \) oznaczamy zaokrąglenie \( x \), czyli liczbę całkowitą najbliższą danej liczby rzeczywistej \( x \). Zatem n-ta liczba Fibonacciego jest prawie dokładnie równa n-tej potędze \( \varphi \) podzielonej przez \( {\sqrt{5}} \). Zauważmy jeszcze, że skoro tak, to po zlogarytmowaniu obustronnie wzoru przy podstawie \( \varphi \) otrzymujemy wzór
\( \log_{\varphi} F_n = n - log_{\varphi}\sqrt{5} \).
Zatem indeks \( n \) zadanej liczby Fibonacciego \( F_{n} \) wynosi
\( n=\log_{\varphi}F_n + log_{\varphi}\sqrt{5} \).
Zapamiętajmy sobie niezwykle ważny wniosek:
Wniosek
Liczby Fibonacciego rosną wykładniczo szybko. Ich wzrost jest prawie identyczny, jak funkcji wykładniczej \( \frac{1}{\sqrt{5}} \varphi^n \).
Wprowadźmy oznaczenie \( \text{FIB}(a) \) na największą liczbę Fibonacciego mniejszą od \( a \), a przez \( [n]\text{FIB}(a) \) jej indeks. Ponieważ dla dowolnych argumentów \( (a, b) \) liczba obrotów pętli algorytmu Euklides2 nie przekracza liczby obrotów pętli dla argumentów najbardziej złośliwych, czyli \( \text{FIB}(a)=F_{[n]\text{FIB}(a)} \) oraz poprzedniej liczby Fibonacciego \( F_{[n]\text{FIB}(a)-1} \), a liczba obrotów pętli dla tych argumentów jest o \( 2 \) mniejsza, niż indeks większej z nich, to otrzymujemy szacowanie na liczbę obrotów pętli \( M(a, b) \) dla dowolnych argumentów \( a \) i \( b \):
\( M(a,b) \le M(\text{FIB}(a)), \text{FIB}(\text{FIB}(a)) = [n]\text{FIB}(a)-2, \)
skąd
\( M(a, b)+ 2 \le \log_{\varphi}F_n + log_{\varphi}\sqrt{5} \),
a biorąc pod uwagę, że
\( log_{\varphi}\sqrt{5}=1,67... \)
otrzymujemy
\( M(a,b)\le \log_{\varphi}a \log_{\varphi}a \le log_{\varphi}(\text{FIB}(a)) \).
Zapamiętajmy jeszcze jedną ważną prawidłowość.
Uwaga
Indeksy liczb Fibonacciego rosną logarytmicznie wolno w stosunku do wartości tych liczb.
Zatem funkcja [n]FIB(x) rośnie logarytmicznie ze względu na x.
Wracając do naszych danych trzydziestocyfrowych: możemy oszacować liczbę obrotów pętli przez \( log_{\varphi} 10^{30} = 148,33... \). Zatem wykonamy nie więcej niż 150 obrotów pętli, co oczywiście będzie w zasięgu nawet bardzo wolnego komputera. Pamiętajmy, że przy dużych liczbach możemy zapomnieć o wbudowanych w języki programowania procedurach arytmetycznych. O arytmetykę musimy zadbać sami. Własną arytmetyką dużych liczb zajmiemy się później.
Zauważmy pewną niedogodność. W algorytmie Euklides2 jeden krok pętli jest nieco trudniejszy. W poprzednim algorytmie Euklides1 mieliśmy tylko porównywanie liczb i ich odejmowanie. Tutaj musimy zaprogramować dzielenie z resztą. Jest to nie tylko trudniejsze, ale i ogólnie wolniejsze od odejmowania. Jeśli zdecydujemy się na algorytm szkolny dzielenia słupkowego, to trzeba będzie wykonać całą serię obliczeń realizujących kolejne kroki wyznaczania cyfr ilorazu. Każdy z tych kroków wymaga wyznaczenia stosownej cyfry wyniku, przemnożenia jej wartości przez dzielnik, a następnie odjęcia od fragmentu dzielnej tego wyniku. Robimy to z grubsza tyle razy, ile cyfr ma iloraz.
Jeżeli za miarę wielkości liczby przyjmiemy długość jej reprezentacji w systemie pozycyjnym (czyli liczbę cyfr), to o ile porównywanie oraz odejmowanie można zrobić w czasie proporcjonalnym do długości tej reprezentacji, to dzielenie może wymagać kwadratowego czasu. Niech długość dzielnej wynosi \( n \). Zauważmy, że jeśli dzielnik jest o połowę krótszy od dzielnej, (czyli mając długość \( n/2 \) jest mniej więcej równy pierwiastkowi kwadratowemu z dzielnej), to iloraz będzie miał długość podobną jak dzielnik, czyli \( n/2 \) i tyle razy będzie się musiała wykonać zasadnicza pętla algorytmu dzielącego, bo tyle cyfr trzeba wyznaczyć. Z kolei wyznaczenie każdej cyfry ilorazu wymaga odjęcia jakiejś niewielkiej wielokrotności dzielnika, a więc liczby również z grubsza \( n/2 \)-cyfrowej. A odejmowanie jest proporcjonalnie kosztowne do długości argumentów. Łącznie zatem \( n/2 \) cyfr ilorazu razy \( n/2 \) jednocyfrowych kroków przy odejmowaniu daje nam łącznie \( {n^2/4} \), więc kwadratowo wiele w stosunku do \( n \).
Liczba obrotów głównej pętli algorytmu jest też proporcjonalna do \( n \), bo w dowolnym systemie pozycyjnym liczba cyfr jest proporcjonalna do logarytmu z danej liczby przy podstawie będącej bazą systemu, czyli również proporcjonalna do logarytmu przy podstawie \( \varphi \), bo logarytmy o różnych podstawach różnią się od siebie tylko o czynnik stały.
Jeśli skupimy się na operacjach na pojedynczych cyfrach, to łączna liczba wszystkich operacji będzie rzędu co najwyżej \( n^3 \). W rzeczywistości możemy się pokusić o przypuszczenie, że będzie to nawet mniej. Zauważmy bowiem, że złośliwe dane dla głównej pętli, to kolejne liczby Fibonacciego, a te długością różnią się co najwyżej o 1, natomiast złośliwe dane dla algorytmu dzielenia z resztą, to dane różniące się długością dwukrotnie; liczby Fibonacciego można podzielić w czasie liniowym, a nie kwadratowym. I to liczby Fibonacciego będą się pojawiały cały czas, w każdym kroku algorytmu. Jeżeli zatem zaczniemy od pary kolejnych liczb Fibonacciego, to \( O(n) \)-krotnie wykonamy dzielenie kosztujące \( O(n) \), co nam da \( O(n^{2}) \). Jeśli natomiast będziemy się starali wywindować koszt dzielenia, to długości kolejnych par powinny być równe \( (n,n/2), (n/2,n/4 ), (n/4, n/8),\ldots \). Ale wtedy łączny koszt dzieleń będzie równy
\( \frac{n^2}{4}+\frac{n^2}{16}+ \frac{n^2}{64}+\ldots =O(n^2) \).
Zatem obie skrajności: złośliwe dane dla zewnętrznej i dla wewnętrznej pętli dają koszt kwadratowy. Ale czy nie można wypośrodkować złośliwości tak, aby uzyskać jednak złożoność sześcienną?
Ćwiczenie
Czy można tak dobrać dane, żeby wymusić sześcienną złożoność algorytmu Euklides2?
Odpowiedź
NIE. Złożoność algorytmu Euklides2 jest jednak kwadratowa.
Powstaje pytanie, czy nie dałoby się znaleźć takiego algorytmu znajdowania największego wspólnego dzielnika tak, aby zachowując złożoność kwadratową korzystać z łatwiejszych operacji niż dzielenia z resztą. Rozwiązanie jest zaskakująco proste, jeśli zauważymy parę dość oczywistych faktów. Będziemy rozważać parzystość argumentów i redukować problem ze względu na tę właśnie własność. Oznaczmy zbiór liczb parzystych przez \( P \). Kluczem do algorytmu jest spostrzeżenie, że jeśli jedna liczba jest parzysta, a druga nie, to największy wspólny dzielnik nie zmieni się, jeśli parzysty argument podzielimy przez 2.
Euklides3
\( (a,b) = \begin{cases} a & \mbox{jeśli }b=0 \\ 2(\frac{a}{2},\frac{b}{2}) & \mbox{jeśli }a,b\in P \\ (\frac{a}{2},b) & \mbox{jeśli }a\in P, b\notin P \\ (a,\frac{b}{2}) & \mbox{jeśli }a\notin P, b\in P \\ (a-b,b) & \mbox{jeśli }a,b\notin P \end{cases} \)
Oczywiście, podobnie jak poprzednio, dbamy zawsze o to, żeby pierwszy argument nie był mniejszy od drugiego i w razie czego zamieniamy je miejscami.
Euklides 3
<b>Read</b>(a,b); //Wczytujemy a i b, zakładając że użytkownik wie, że a>=b, a+b>0 wynik:=1; <b>while</b> b > 0 <b>do</b> <b>begin</b> <b>if</b> a< b <b>then</b> zamień(a,b); //po wykonaniu tej instrukcji zawsze a>=b <b>if</b> parzyste(a) <b>and</b> parzyste(b) <b>then</b> <b>begin</b> wynik:=wynik*2 a:=a div 2; b:=b div 2 <b>end</b> <b>else</b> // w przeciwnym razie <b>if</b> parzyste(a) <b>and</b> <b>not</b> parzyste(b) <b>then</b> a:=a div 2 <b>else</b> <b>if</b> <b>not</b> parzyste(a) <b>and</b> parzyste(b) <b>then</b> b:=b div 2 <b>else</b> a:=a-b <b>end</b>; wynik:=wynik*a; Write(a)
W kodzie tym posługujemy się predykatem parzyste(x), który przyjmuje wartość true (prawda), jeśli x jest parzyste i false (fałsz) jeśli jest nieparzyste. Operacja div daje nam wynik dzielenia całkowitego (z ucięciem reszty).
Przyjrzyjmy się naszemu algorytmowi pod kątem liczby obrotów pętli. Zauważmy, że w każdym obrocie we wszystkich przypadkach, poza sytuacją obu argumentów nieparzystych, co najmniej jeden z argumentów jest połowiony. Natomiast w przypadku obu argumentów nieparzystych jeden z argumentów stanie się parzysty w wyniku odejmowania i w następnym obrocie pętli zostanie podzielony przez 2. Zatem co najmniej raz na dwa obroty pętli, co najmniej jeden z argumentów jest dzielony przez 2. Ale dzieleń przez 2 można wykonać tylko logarytmicznie dużo.
Uwaga
W dziedzinie całkowitoliczbowej możemy spojrzeć na logarytm jak na liczbę możliwych dzieleń przez 2, zanim dojdziemy do jedynki. Liczba ta jest równa podłodze z logarytmu rzeczywistego przy podstawie 2.
Zatem łączna liczba obrotów pętli nie przekracza \( 2(\log_2a + \log_2b) \). Co się dzieje w każdym obrocie pętli? Każda z operacji ma złożoność liniową. Sprawdzenie parzystości liczby wymaga zajrzenia do ostatniej cyfry. Sprawdzenie, czy liczba jest równa zero wymaga przejrzenia w najgorszym razie wszystkich jej cyfr jednokrotnie. Dzielenie przez 2 i mnożenie przez dwa, podobnie jak odejmowanie, mają złożoność liniową (czyli proporcjonalną do logarytmu z wartości a i b). Zatem złożoność algorytmu na poziomie operacji na cyfrach jest kwadratowa, czyli w tym przypadku proporcjonalna do kwadratu z logarytmu \( a \).
Wstęp do algorytmów - Ćwiczenia
Wprowadzenie do programowania
Nieformalny wstęp do programowania
W poprzednim wykładzie rozważaliśmy algorytmy znajdowania największego wspólnego dzielnika. Po precyzyjnym wyrażeniu definicji istoty algorytmu za pomocą wzorów rekurencyjnych, zostały one zilustrowane w postaci kodu programu, jednak bez głębszego komentarza dotyczącego tego, jak zastosowane konstrukcje programistyczne działają. W uproszczonej wersji programy konstruujemy z trzech rodzajów instrukcji:
Instrukcji przypisania
Przykład
a:=a-b;
Instrukcji warunkowej
Przykład
if a < b then c:=a else c:=b;
Instrukcji pętli
Przykład
<b>while</b> b > 0 <b>do</b> b:=b div 2;
Instrukcje oddzielamy średnikami i wykonujemy po kolei.
Kolejno omówimy te konstrukcje.
Instrukcja przypisania
Instrukcja przypisania jest postaci v:=E, gdzie przez v oznaczamy zmienną, czyli obiekt, który może przyjmować wartości typu określonego przy wcześniejszej deklaracji, a przez E wyrażenie pochodzące z dziedziny algorytmicznej, której nośnikiem jest typ zmiennej. Wyrażenie jest termem, w skład którego wchodzą stałe, zmienne i operacje dostępne w tej dziedzinie.
Wykonanie instrukcji przypisania odbywa się na dwa takty. Najpierw wyliczana jest wartość wyrażenia E występującego po prawej stronie instrukcji przypisania (w wyrażeniu może wystąpić w szczególności zmienna v z lewej strony przypisania i wtedy bierze się jej starą wartość), a potem obliczoną wartość przypisuje się zmiennej v.
Przykład ilustrujący ilustruje kolejność czynności przy wykonaniu instrukcji przypisania. Zakładamy w nim, że w pamięci komputera są zarezerwowane komórki na wartości wszystkich zmiennych programu. W animacji odwołujemy się do wartości tych komórek. Znaki zapytania oznaczają, że zmienna nie ma jeszcze nadanej wartości. Zakładamy, że ten mały fragment programu jest częścią większej całości i pomijamy szczegóły dotyczące kontekstu.
animacja flash
Instrukcja warunkowa
Instrukcja warunkowa jest postaci if B then I1 else I2 gdzie warunek B jest wyrażeniem logicznym, dającym wartości true lub false (prawda lub fałsz), a I1 oraz I2 są instrukcjami. Instrukcja warunkowa pozwala nam wybrać jeden z dwóch wariantów dalszego wykonania programu w zależności od tego, czy warunek b jest spełniony, czy nie.
Wykonanie instrukcji warunkowej odbywa się również na dwa takty: najpierw obliczana jest wartość warunku B i jeśli jest ona równa true, to wykonujemy I1, a jeżeli nie, wykonujemy I2. Gdy nie chcemy, aby cokolwiek wykonywało się w tym drugim przypadku, wówczas nie piszemy „else I2” i wtedy w przypadku, gdy wartość warunku jest false, nic się nie dzieje. Przykład takiej instrukcji mieliśmy w algorytmie Euklides1 i Euklides3: gdy zmienna a miała wartość większą od b, nie trzeba było niczego zamieniać.
Przykład ilustrujący kolejność czynności przy wykonaniu instrukcji warunkowej.
animacja flash
Instrukcja pętli
Instrukcja pętli jest postaci while B do I gdzie B jest warunkiem logicznym, a I instrukcją, którą pętla ma powtarzać, aż do spełnienia warunku B. Wykonanie pętli zaczyna się od obliczenia wartości warunku. Jeśli wartość ta wynosi false, to pętla nie robi niczego i kończy swoje działanie, ale jeśli wynosi true, to pętla wykonuje instrukcję I, a następnie wraca do sprawdzenia warunku B. Wykonuje tę sekwencję tak długo, aż warunek B przestanie być spełniony. Może się zdarzyć, że warunek B nigdy nie przestanie być spełniony i pozostanie prawdziwy na zawsze. Program wtedy nie zatrzyma się nigdy i mówimy o takiej sytuacji, jako o zapętleniu programu.
Jeśli chcemy zaznaczyć, że zależy nam na wykonaniu ciągu instrukcji, to ciąg ten ujmujemy w nawiasy begin ... end.
Na razie będziemy używali jedynie zmiennych o wartościach całkowitoliczbowych, a w dziedzinie algorytmicznej będą się znajdowały operacje \( +,-,-,*,\div,\) \(mod\) (gdzie dwa minusy nie są pomyłką, tylko zgodnie z tradycją oznaczają dwie różne operacje: jednoargumentową tworzenia liczby przeciwnej i dwuargumentową odejmowania; niestety są one tradycyjnie oznaczane tym samym znakiem) oraz relacje \( < , < =,>,>=,= \) oraz \( < > \), przy czym znaki relacji kolejno oznaczają mniejszość, mniejszość lub równość, większość, większość lub równość, równość i różność. Umawiamy się ponadto, że zachowane są tradycyjne priorytety działań (czyli mnożenie i dzielenie wiąże mocniej niż dodawanie i odejmowanie, minus jednoargumentowy wiąże silniej od mnożenia i dzielenia, a działania są wykonywane od lewej do prawej). W wyrażeniach logicznych używamy standardowych spójników logicznych not, and, or z umową, że not wiąże najsilniej, and słabiej, a or najsłabiej. Wolno nam tworzyć wyrażenia logiczne przez porównanie wartości całkowitoliczbowych za pomocą jednego z powyższych sześciu operatorów relacji. Dopuszczamy także użycie nawiasów, które służą do wymuszania właściwej kolejności obliczeń zarówno w wyrażeniach arytmetycznych, jak i logicznych. Oto kilka przykładów poprawnych wyrażeń logicznych:
i>=0 (i>=0) <b>and</b> (j>=i) <b>not</b> ((k<n) <b>or</b> (j<n))
Przykład ilustrujący kolejność czynności przy wykonaniu instrukcji pętli.
animacja flash
Zmienne indeksowane (tablice)
Często działamy na ciągach zmiennych tego samego typu. Przykładowo taka sytuacja występuje gdy chcemy posortować jakieś dane, albo sprawdzić, czy w zestawie danych znajduje się zadana wartość. Wygodnie wtedy jest używać zmiennych indeksowanych, które realizują pojęcie skończonego ciągu. Zmienna taka ma wtedy jeden wspólny identyfikator, a kolejne elementy oznacza się kolejnymi indeksami, które zazwyczaj są liczbami naturalnymi, choć nie jest to konieczne i w niektórych językach programowania dopuszcza się indeksowanie również innymi typami dyskretnymi (np. znakami).
Zmienne indeksowane nazywają się tablicami. Jeśli A jest tablicą, to A[i] jest jej i-tym elementem. Umawiamy się, że indeksem tablicy może być dowolne poprawne wyrażenie, ale pod warunkiem, że jego wartość mieści się w zakresie określoności tablicy. Zatem odwołanie do elementu spoza zakresu indeksów traktowane jest jako poważny błąd. Często powoduje przerwanie programu bez ostrzeżenia.
W przykładowych zadaniach poniżej proponujemy przećwiczenie podstawowych algorytmów na tablicach. Zakładamy zazwyczaj, że tablica jest zadeklarowana w zakresie \( 1..n \). Dla ułatwienia zrozumienia zapisu pewnych algorytmów stosujemy skrót notacyjny
<b>for</b> k:=1 <b>to</b> n <b>do</b> I
na oznaczenie następującego równoważnego kodu
k:=1; <b>while</b> k<=n <b>do</b> <b>begin</b> I; k:=k+1 <b>end</b>
Konwencja ta powoduje, że dla każdej wartości indeksu, poczynając od \( 1 \), a kończąc na \( n \), wykonamy instrukcję I. Zakresy pętli for mogą być dowolnymi wyrażeniami dającymi wartości całkowite.
Ćwiczenia
Gramatyki – definiowanie składni i semantyki wyrażeń
Drzewa wywodu
Liczby całkowite
Liczby całkowite
Zacznijmy od zdefiniowania liczb całkowitych. Po pierwsze określmy, co będziemy chcieli nazywać liczbami całkowitymi. Przyjmijmy, że poprawnymi liczbami są wszystkie skończone ciągi cyfr dziesiętnych poprzedzone pojedynczym znakiem \( + \) lub \( - \). Dopuścimy zatem jako poprawne napisy \( 123,-22,00,+013 \), ale jako niepoprawne uznamy np. napisy \( ++12,-+0,2+3,XVI,+,\varepsilon \). Oto propozycja gramatyki:
W ten sposób napisana gramatyka daje jednoznaczne wyprowadzenie każdej liczby całkowitej, zgodnej z naszymi założeniami. Zauważmy, że na samym początku wyprowadzania decydujemy, czy liczba ma być ze znakiem, czy bez – o tym decyduje wybór \( L \) lub \( ZL \) spośród dwóch wariantów, które daje nam symbol \( S \). Z symbolu pomocniczego \( L \) możemy wygenerować dowolny niepusty ciąg cyfr, a z symbolu \( Z \) znak. Przykładowe wyprowadzenie liczby -120 wygląda następująco:
\begin{Rysunek}[rys3-120] \end{Rysunek}Reguły semantyczne
Wyrażenia całkowitoliczbowe
Ćwiczenia
Reprezentacja liczb
Wcale nie jest oczywiste, jak należy reprezentować liczby w komputerze. Powszechnie wiadomo, że bardzo wygodny technologicznie jest układ dwójkowy, zwany też binarnym. Łatwiej jest bowiem reprezentować i rozróżniać dwie wartości, niż jakąkolwiek większą ich liczbę: wystarczy przecież rozróżnić "brak sygnału" od "jest sygnał", żeby reprezentować dwie cyfry binarne. Jakakolwiek próba zwiększenia liczby cyfr, które trzeba by było rozróżniać, wymusiłaby analizę ilościową sygnału, a nie tylko jakościową.
Liczby naturalne
Liczby naturalne
grafika
Gottfried Wilhelm von Leibniz (1646–1716)
System dwójkowy, zbadany i spopularyzowany przez Wilhelma Gotfrieda Leibniza w wieku XVII, ma wiele zalet. Podobnie jak w dziesiętnym systemie pozycyjnym, liczby naturalne przedstawiamy jako sumę potęg bazy (2) z odpowiednimi wagami reprezentowanymi przez cyfry – w tym przypadku tylko dwie: 0 i 1. Każda liczba naturalna dodatnia ma zatem reprezentację postaci
\( \sum_{k=0}^{m} a_k2^k \), gdzie \( a_k\in\{0,1\} \).
Reprezentacja ta jest jednoznaczna, jeśli przyjmiemy, że nie stosujemy wiodących zer. Warto zapamiętać pierwszych 16 wartości:
| \( k \) | \( (k)_2 \) |
| 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ... |
0 1 10 11 100 101 110 111 1000 1001 1010 1011 1100 1101 1110 1111 |
Jeśli ustalimy z góry pewną liczbę \( n \) cyfr, za pomocą których będziemy reprezentowali liczby naturalne, to w automatyczny sposób uzyskamy \( n \)-cyfrowe reprezentacje, uzupełniając je do pełnych \( n \) cyfr zerami z lewej strony. Kolejno mielibyśmy np. dla \( n=8:00000000,00000001,00000010,\ldots,11111111 \). Widać, że różnych wartości \( n \)-cyfrowych jest \( 2^n \): od \( 0 \) do \( 2^n-1 \).
Jak w prosty sposób znajdować reprezentacje dwójkowe liczb naturalnych? Są dwie proste metody. Załóżmy, że chodzi nam o przedstawienie dwójkowe liczby \( m>0 \).
- Znajdujemy największą liczbę \( d=2^k \) nieprzekraczającą \( m \). Piszemy jedynkę, odejmujemy od \( m \) wartość \( d \), a następnie kolejno dla wszystkich mniejszych potęg dwójki sprawdzamy, czy mieszczą się one w tym, co zostało z \( m \). Jeśli dana potęga dwójki nie mieści się, to dopisujemy zero, a jeśli mieści się, to dopisujemy jedynkę i odejmujemy tę wartość od tego, co zostało z \( m \). Przykładowo dla \( m=13: \)
| zostało z \( m \) | potega dwójki | wypisano |
| 13 5 1 1 0 |
8 4 2 1 |
1 11 110 1101 |
- Zaczynamy od liczby \( m \), a następnie dopóki m jest większe od zera dzielimy \( m \) przez 2, zapisując kolejno otrzymywane reszty. Ciąg reszt odczytany od końca da nam poszukiwaną reprezentację. Przykładowo dla tego samego \( m=13: \)
| zostało z \( m \) po dzieleniu przez 2 | reszta z dzielenia \( m \) przez 2 |
| 13 6 3 1 0 |
1 0 1 1 |
Ciąg reszt z ostatniej kolumny czytany od dołu do góry daje właśnie \( 1101 \), czyli reprezentację dwójkową \( 13 \).
W odwrotną stronę trudno podać lepszą metodę niż proste dodanie kolejnych potęg dwójki, zatem np. 10101, to
\( 1\cdot 16+0\cdot 8 + 1 \cdot 4 + 0 \cdot 2 + 1\cdot 1=21 \).
Teoretycznie jesteśmy więc w stanie reprezentować każdą liczbę naturalną. Musimy jednak zdać sobie sprawę z tego, że to jest tylko ułuda. W rzeczywistości trzeba by mieć nieograniczoną pamięć, aby reprezentować bardzo duże liczby, a w każdym komputerze, ba, we wszystkich komputerach świata łączna pamięć jest i będzie ograniczona i skończona. Musimy zatem pogodzić się z tym, że będziemy w stanie reprezentować jedynie skończony podzbiór liczb naturalnych. Zazwyczaj robi się to tak, że do reprezentacji liczb całkowitych używa się standardowo określonej z góry liczby bitów (typowo 8, 16, 32 lub 64). Jeżeli chcemy reprezentować liczby o większej długości, to musimy sami sobie to zaprogramować, ale i tak wszystkich liczb naturalnych nie będziemy w stanie wyrazić.
Z tych prostych uwag wynikają ważne wnioski. Po pierwsze może nam zabraknąć liczb do realizacji założonych celów. Po drugie, świat liczb naturalnych różni się od świata liczb naturalnych reprezentowanych w komputerze choćby tym, że nie wszystkie działania będą wykonalne. I to nie tylko chodzi o dzielenie. W szczególności, skoro zbiór liczb reprezentowanych w komputerze jest skończony, to istnieją w nim dwie największe i dodanie ich do siebie spowoduje, że wynik będzie niereprezentowalny.
Liczby całkowite
Liczby całkowite
Umówmy się zatem, że przeznaczymy określoną liczbę \( n \) bitów, aby reprezentować liczby całkowite. Powstaje pytanie, jak zapisywać liczby ujemne? Istnieją co najmniej trzy sposoby, stosowane zresztą przez producentów różnych procesorów do dziś. Pokrótce je omówimy.
Znak – moduł
Sposób ten jest bardzo naturalny. Spośród \( n \) dostępnych bitów wyróżniamy jeden – umówmy się, że pierwszy z lewej – i rezerwujemy go na określenie znaku liczby. Pozostałe \( n-1 \) bitów reprezentuje moduł liczby w tradycyjny sposób omówiony powyżej. Jeśli pierwszy bit znaku jest równy \( 0 \), to liczba jest nieujemna, a jeśli \( 1 \), to jest niedodatnia.
Oto tabela 16 liczb 4-bitowych zakodowanych tą metodą:
| bity | wartość |
| 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111 |
0 1 2 3 4 5 6 7 -0 -1 -2 -3 -4 -5 -6 -7 |
Kod znak – moduł
Zauważmy, że podane kodowanie prowadzi do dość dziwnej sytuacji, że zero reprezentujemy na 2 sposoby: nieujemne zero (0000) i niedodatnie zero (1000). To dość duża wada tego systemu kodowania; w szczególności trzeba uważać porównując wartości dwóch liczb, żeby nie stwierdzić, że \( 0\neq-0 \), o co bardzo łatwo porównując tradycyjnie bit po bicie zawartości bitowe takich reprezentacji.
W kodzie tym dla liczb \( n \)-bitowych mamy zakres \( -2^{n-1}+1\ldots 2^{n-1}-1 \) i różnych liczb reprezentowanych jest w związku z tym \( 2^n-1 \).
Znak – moduł odwrotny
Sposób ten jest bardzo podobny do poprzedniego. Tak samo pierwszy bit oznacza znak, ale jeśli pierwszy bit jest 1 (co oznacza liczbę niedodatnią), to pozostałe \( n-1 \) bitów reprezentuje negatyw modułu liczby. Podobnie, jak poprzednio, jeśli pierwszy bit znaku jest równy \( 0 \), to liczba jest nieujemna, a jeśli \( 1 \), to jest niedodatnia.
Oto tabela 16 liczb 4-bitowych zakodowanych tą metodą w kodzie znak – moduł odwrotny:
| bity | wartość |
| 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111 |
0 1 2 3 4 5 6 7 -7 -6 -5 -4 -3 -2 -1 -0 |
Kod znak – moduł odwrotny
Zauważmy, że liczby nieujemne są reprezentowane dokładnie w taki sam sposób jak poprzednio, oraz że i tu podane kodowanie prowadzi do podwójnej reprezentacji zera. W kodzie tym dla liczb \( n \)-bitowych mamy ten sam zakres \( -2^{n-1}+1\ldots 2^{n-1}-1 \) i różnych liczb reprezentowanych jest w związku z tym \( 2^n-1 \).
Po co sobie utrudniać kodowanie przez branie odwrotności modułu? Okazuje się, że system ten jest wygodniejszy, przynajmniej jeśli chodzi o dodawanie. W systemie znak-moduł, aby dodać dwie liczby przeciwnych znaków trzeba by najpierw ustalić znak wyniku i zdecydować, od którego modułu odjąć który. Okazuje się, że w kodzie znak-moduł odwrotny wystarczy, nie przejmując się znakami, dodać bitowo reprezentacje i, jeśli ostatecznie pojawi się w przeniesieniu całego wyniku jedynka, dodać ją jeszcze raz do otrzymanego rezultatu.
Przykładowo dodajmy w kodzie znak-moduł odwrotny \( -4 \) do \( 6 \). Otrzymamy
1011
0110
-- ---
(1) 0001i teraz jedynkę przeniesienia \( (1) \) dodajemy do wyniku 0001 i otrzymujemy 0010, czyli reprezentację dwójki, czyli prawidłowego wyniku.
Kod uzupełnieniowy
Jest to najczęściej stosowany kod. Ma bardzo prostą interpretację – po prostu najstarszy bit \( n \)-bitowej reprezentacji traktujemy jako \( -2^{n-1} \), a pozostałe tradycyjnie jako wartości, kolejno \( 2^{n-2},\ldots,2^0 \). Popatrzmy, jak wygląda nasza tabela czterobitowych wartości zapisanych w kodzie uzupełnieniowym. Kolejno od lewej bity nają wartości \( -8,4,2,1 \).Z trzech młodszych bitów generujemy wszystkie wartości od 0 do 7, a jeśli włączymy bit \( -8 \), to dodanie do niego tych wartości da nam liczby od \( -8 \) do \( -1 \).
| bity | wartość |
| 0000 0001 0010 0011 0100 0101 0110 0111 1000 1001 1010 1011 1100 1101 1110 1111 |
0 1 2 3 4 5 6 7 -8 -7 -6 -5 -4 -3 -2 -1 |
Kod uzupełnieniowy
W n-bitowym kodzie uzupełnieniowym mamy następujące własności:
- Wartości są z przedziału \( [-2^{n-1},2^{n-1}-1] \)
- Każda wartość jest reprezentowana jednoznacznie
- Liczb ujemnych jest o jeden więcej niż dodatnich
- \( 000\ldots 0 \) to zawsze \( 0 \), a \( 111\ldots 1 \) to zawsze \( -1 \)
Kod uzupełnieniowy ma jeszcze jedną miłą cechę: dodawanie w nim nie wymaga żadnych specjalnych czynności. Po prostu dodaje się bitowo reprezentacje i jeśli pojawia się bit przepełnienia, to się go ignoruje. Na przykład: jeśli chcemy dodać \( -4 \) do \( 6 \), to w naszym 4-bitowym systemie dostaniemy
1100 (-4)
0110 (6)
-- ---
(2) 0010Od tej pory, jeśli wyraźnie tego nie zaznaczymy, to będziemy używali reprezentacji uzupełnieniowej. Zapamiętajmy. Uwaga
We wszystkich stosowanych systemach liczby dodatnie reprezentuje się identycznie.
Powstaje jeszcze jeden problem. Co się dzieje, jeśli w wyniku wykonania jakiegoś działania wynik wyjdzie spoza zakresu reprezentowalności? Oczywiście cudów nie ma. Musimy pogodzić się z tym, że jakkolwiek to ustalimy, zawsze będzie możliwa taka właśnie sytuacja, że pewnych liczb, będących legalnymi wynikami działań, przedstawić się nie da. Mówimy w takiej sytuacji o problemie przepełnienia i uznajemy ją za błędną. Warto pamiętać jednak o jednej niezwykle istotnej rzeczy: niektóre systemy komputerowe nie zauważają sytuacji przepełnienia i wtedy może zajść dziwna sytuacja, w której np. dodanie dwóch liczb dodatnich daje ujemny wynik. Oto przykładowo w naszej reprezentacji 4-bitowej spróbujmy dodać \( 4 \) do \( 6 \). dostaniemy
0100 (4)
0110 (6)
-- ---
(0) 1010 (-6)
<code>
<p>Bit przeniesienia jest równy 0, ale wynik jest absurdalny. Czegóż innego jednak można się było spodziewać? Przecież liczby 10 nie umiemy w naszym czterobitowym systemie wyrazić. W rzeczywistości dodanie jedynki do największej liczby dodatniej w kodzie uzupełnieniowym (czyli do \( 0111\ldots 1 \) daje nam najmniejszą liczbę ujemną, czyli \( 1000\ldots 0 \), zatem cały reprezentowany przedział się w ten sposób zacykla. Te same uwagi dotyczą rzecz jasna innych działań. Rozpoznać sytuację przepełniania można automatycznie i wiele systemów to robi, ale są środowiska programistyczne, które przechodzą nad tym problemem do porządku dziennego i wykonują błędnie działania bez kontroli przepełnienia. </p>Ułamki
Ułamki
Jak reprezentować liczby rzeczywiste? W tym przypadku mamy jeszcze większy problem, gdyż nie dość, że jest ich nieskończenie wiele, nie dość, że tworzą zbiór gęsty, to jeszcze jest ich nieprzeliczalnie wiele. Stoimy zatem przed problemem, jak wybrać skończony ich podzbiór tak, żeby jak najlepiej reprezentował nasze potrzeby. Działania, które będziemy wykonywali dadzą wyniki tylko w ramach tego podzbioru, więc może się zdarzyć, że wynik będzie odbiegał od rzeczywistości. Fenomen ten znamy dobrze z doświadczeń z kalkulatorami: zwykle, jeśli najpierw podzielimy jedynkę przez trzy, a potem pomnożymy wynik przez 3, otrzymamy coś w rodzaju \( 0,99999999 \). Błąd się wziął stąd, że w zestawie wartości reprezentowanych przez kalkulator brakuje jednej trzeciej. Zamiast niej mamy jej przybliżenie \( 0,33333333 \), które pomnożone przez \( 3 \) daje właśnie to, co widzimy na wyświetlaczu. Dzieje się tak nie tylko dlatego, że kalkulatory są prymitywnymi urządzeniami. Duże komputery cierpią na te same dolegliwości (choć akurat powyższe działanie mogą wykonać lepiej). Zajmiemy się teraz doborem właściwego podzbioru reprezentującego liczby rzeczywiste (a tak naprawdę wymierne, bo to takich wartości nasz podzbiór się będzie ograniczał).
Zacznijmy od reprezentacji binarnej ułamków. Podobnie jak w systemie dziesiętnym korzystamy z ujemnych potęg dziesiątki po przecinku, tak tu będziemy rozważali binarne rozwinięcia ułamków za pomocą ujemnych potęg dwójki. Zatem po kropce binarnej, oddzielającej część całkowitą od ułamkowej, kolejne pozycje będą odpowiadały bitom reprezentującym kolejno wartości \( \frac{1}{2},\frac{1}{4},\frac{1}{8},\ldots \). Liczba \( \frac{1}{2} \) będzie zatem miała przedstawienie \( 0.1 \), liczba \( \frac{1}{4} \) będzie miała przedstawienie \( 0.01 \), liczba \( \frac{3}{4} \) będzie miała przedstawienie \( 0.11 \) itd. Wszystko jest proste, jeśli w mianowniku ułamka są potęgi dwójki. Wystarczy bowiem zapisać licznik binarnie, a następnie kropkę binarną przesunąć w prawo o tyle pozycji, ile wynosi potęga dwójki w mianowniku. Na przykład \( \frac{5}{16} \) ma przedstawienie \( 0.0101 \): jest to po prostu \( 5 \) czyli \( 101 \) przesunięte o 4 pozycje w prawo.
Co jednak począć z mianownikami niebędącymi potęgami dwójki? W systemie dziesiętnym mamy podobny problem. Jeśli jedynymi dzielnikami mianownika są \( 5 \) i \( 2 \), to otrzymujemy skończone rozwinięcie ułamka. W przeciwnym razie rozwinięcia są nieskończone i dla liczb wymiernych okresowe (można się umówić, że wszystkie rozwinięcia liczb wymiernych są okresowe, tylko niektóre mają okres złożony z samego zera!).
Jak zatem znajdować binarne rozwinięcia ułamków wymiernych? Oto algorytm, którego nieskomplikowany (ale i nieoczywisty) dowód poprawności można przeprowadzić indukcyjnie, i który działa również dla systemu dziesiętnego (oczywiście rolę dwójki pełni tam dziesiątka) – proszę sprawdzić.
Algorytm przedstawiania ułamka \( u \) w binarnym systemie pozycyjnym. Założenie: \( 0\le u < 1 \). Napisz \( 0 \).. Kolejne cyfry rozwinięcia binarnego będziemy generować w następujący sposób: Dopóki otrzymujesz nienapotkane wcześniej wartości \( u \) wykonuj 1. Pomnóż \( u \) przez 2 2. Jeżeli otrzymana wartość jest mniejsza od 1, to dopisz cyfrę \( 0 \) 3. Jeżeli otrzymana wartość jest równa co najmniej 1, dopisz cyfrę \( 1 \) i odejmij od wyniku 1. Z chwilą, gdy powtórzy się wartość \( u \), zakończ procedurę; wypisany ciąg jest okresowy, a jego okresem jest ciąg bitów między powtórzeniami.
| bity | wartość |
| 0. 0 1 0 0 |
\( \frac{2}{7} \) \( \frac{4}{7} \) \( \frac{1}{7} \) \( \frac{2}{7} \) \( \frac{4}{7} \) |
Binarne rozwinięcie \( \frac{2}{7}=0.(010) \)
Widzimy, że \( \frac{2}{7} \) ma rozwinięcie binarne \( 0.010010010\ldots \). Okresem jest \( (010) \).
Spróbujmy znaleźć jeszcze rozwinięcie binarne dla \( \frac{1}{10} \).
| bity | wartość |
| 0. 0 0 0 1 1 |
\( \frac{1}{10} \) \( \frac{2}{10} \) \( \frac{4}{10} \) \( \frac{8}{10} \) \( \frac{6}{10} \) \( \frac{2}{10} \) |
Binarne rozwinięcie \( \frac{1}{10}=0.0(0011) \)
Zauważmy jeden wstrząsający fakt: nawet tak prosta liczba jak \( \frac{1}{10} \) ma nieskończone binarne rozwinięcie okresowe. Oczywiście takie rozwinięcia mają także \( \frac{2}{10},\frac{3}{10},\frac{4}{10}\frac{6}{10}\frac{7}{10},\frac{8}{10}\frac{9}{10} \). I rzeczywiście, gdy chcemy w komputerze (a nawet w kalkulatorach) reprezentować \( \frac{1}{10} \), jesteśmy zmuszeni do zaokrąglenia tej wartości i w rzeczywistości otrzymujemy tylko coś koło jednej dziesiątej. Przynajmniej tak to widzi komputer.
Zaokrąglenie
Zaokrąglenie
Skoro nie da się dokładnie reprezentować wartości wymiernych w komputerze, trzeba się pogodzić z ich przybliżaniem. Robimy to za pomocą zaokrąglania, przy czym reguły są bardzo proste: jeżeli mamy ochotę zaokrąglić na \( k \)-tej pozycji, to patrzymy się na następną cyfrę i jeśli jest ona zerem, to po prostu cały ogon odrzucamy (zaokrąglenie w dół), a jeśli jest jedynką, to dodajemy ją do uciętego na \( k \)-tym miejscu przybliżenia (zaokrąglenie w górę). Oto kolejne przybliżenia \( \frac{1}{10} \) w zależności od stopnia dokładności, czyli określenia, ile cyfr po kropce binarnej chcemy mieć.
| Numer bitu zaokrąglenia | reprezentacja |
| 1 2 3 4 5 6 7 8 9 ... |
0.0 0.00 0.001 0.0010 0.00011 0.000110 0.0001101 0.00011010 0.000110011 |
Kolejne zaokrąglenia \( \frac{1}{10} \)
To, co uzyskujemy, postępując w pokazany sposób, jest ciągiem najlepszych przybliżeń zadanej wartości za pomocą ułamków o mianownikach będących kolejnymi potęgami dwójki. W przypadku jednej dziesiątej są to kolejno \( \frac{0}{2},\frac{0}{4},\frac{1}{8},\frac{2}{16},\frac{3}{32},\frac{6}{64},\frac{13}{128},\frac{26}{256},\frac{51}{512} \). Nie ma liczników, które przy tych mianownikach lepiej przybliżałyby \( \frac{1}{10} \).
Doszliśmy do momentu, w którym trzeba podjąć wyjątkowo ważną decyzję. Musimy określić, ile bitów będziemy potrzebowali na część całkowitą, a ile na część ułamkową przybliżenia liczby rzeczywistej. Decyzja wcale nie jest łatwa, szczególnie że komputerów używają ludzie potrzebujący zarówno operować liczbami bardzo małymi, jak i bardzo dużymi. Weźmy choćby fizyków kwantowych – ci działają na wielkościach rzędu \( 10^{-34} \). Astrofizycy z kolei używają wielkości astronomicznych; promień Wszechświata choćby to jest wielkość rzędu \( 10^{23}m \). Gdybyśmy chcieli zadowolić i jednych i drugich, trzeba by dysponować mniej więcej 70 bitami na część całkowitą i ponad setką bitów na część ułamkową. Łącznie na każdą liczbę rzeczywistą, biorąc pod uwagę pewien zapas, trzeba by przeznaczyć pewnie około 200 bitów, czyli 25 bajtów. Znając życie, skończyłoby się na 32 bajtach.
Warto zauważyć przy tym, że astronomowie w ogóle nie byliby zainteresowani tymi częściami ułamkowymi, a kwantowcy tymi całkowitymi. W ich obliczeniach na tych pozycjach stałyby zera i komputery niepotrzebnie mieliłyby zerowe bity przy każdych działaniach. Biorąc pod uwagę to, że choćby mnożenie (nie mówiąc o bardziej skomplikowanych procedurach liczących pierwiastki, sinusy czy logarytmy) tradycyjną metodą wymaga przemnożenia każdego bitu przez każdy, co oznaczałoby \( 40000 \) mnożeń jednobitowych na każdą parę liczb rzeczywistych. Tym niemniej w niszowych zastosowaniach można stosować układ nazywany stałopozycyjnym.
Uwaga
W układzie stałopozycyjnym z góry określamy, ile bitów przeznaczamy na część całkowitą (k), a ile na ułamkową (u). Cały przedział określoności rozciąga się między \( -2^{k-1} \) a \( 2^{k-1}-2^{-u} \) i wartości w nim reprezentowane są równomiernie rozłożone co \( 2^{-u} \).
System zmiennopozycyjny
System zmiennopozycyjny
We współczesnych komputerach właściwie bez wyjątku spotykamy inną metodę zapisu liczb rzeczywistych. Pomysł zaczerpnięto od fizyków właśnie, którzy nie kwapią się, aby używać tak niewygodnej jak stałopozycyjna notacji, po to, żeby np. wyrazić wielkości typu stałej Plancka. Wielkość ta, zapisana w dziesiętnej notacji stałopozycyjnej, wygląda mniej więcej tak: \( h=0,000000000000000000000000000000000663 Js \). Gdyby podręczniki mechaniki kwantowej zawierały tak zapisywane wielkości kwantowe, byłyby nieczytelne. Zamiast takiego zapisu stosuje się znacznie poręczniejszy: \( 6,63 \cdot 10^{-34} Js \). W zapisie tym podajemy kilka cyfr znaczących oraz określamy rząd wielkości poprzez podanie o ile należy je przesunąć w lewo lub w prawo. Przy takim przedstawieniu cyfry znaczące nazywamy mantysą, a potęgę podstawy obrazującą, o ile należy przesunąć przecinek dziesiętny - cechą. Umówmy się ponadto, że w przypadku zapisów binarnych będziemy używali znaku kropki dla oddzielenia części całkowitej od ułamkowej i nazywali go kropką binarną.
Musimy rozwiązać jeszcze jeden mały problem. Sposobów przedstawienia konkretnej wartości jest nieskończenie wiele. Na przykład liczbę \( \frac{3}{8} \) można przedstawić jako
\( \frac{3}{8}\cdot 2^0 = \frac{3}{4}\cdot 2^{-1} = \frac{3}{2}\cdot 2^{-2}= 3\cdot 2^{-3} = \ldots \)
i podobnie w drugą stronę:
\( \frac{3}{8}= \frac{3}{16}\cdot 2^{1} = \frac{3}{32}\cdot 2^{2}= \ldots \).
Niewygodne byłoby używać kilku reprezentacji tej samej wartości. Stąd pomysł, żeby wybrać jedną z nich jako standardową i zapamiętywać wartości w takiej znormalizowanej postaci. Powszechnie przyjmuje się, że dobieramy tak mantysę, aby jej wartość mieściła się w przedziale \( (\frac{1}{2},1] \) dla wartości dodatnich oraz \( [-1,-\frac{1}{2}) \) dla wartości ujemnych. Zero reprezentuje się w specyficzny sposób i zajmiemy się tym problemem później.
Podsumujmy zatem nasze ustalenia.
Każdą niezerową liczbę rzeczywistą reprezentujemy za pomocą przybliżenia wymiernego w postaci
pary \( (m,c) \), gdzie \( m\in[-1,-\frac{1}{2})\cup[\frac{1}{2},1) \) jest mantysą,
zaś \( c \), nazywane cechą, określa o ile pozycji w prawo (dla \( c \) ujemnych) bądź w lewo (dla \( c \) dodatnich) należy przesunąć mantysę, aby uzyskać żądaną wartość. Interpretacja takiej reprezentacji wyraża się wzorem
\( x=m2^c \)System o 3 bitach cechy i 4 mantysy
Zero
Zero
Pozostała sprawa zera. Nie da się zera przedstawić w podanej postaci, gdyż żadna z liczb \( m2^c \) zerem być nie może dla mantys co do modułu większych od 1/2. Najczęściej stosowane rozwiązanie polega na tym, że wyłącza się jedną z cech (najmniejszą) i ustala, że jeśli liczba ma tę cechę, to jest równa zero niezależnie od mantysy. W naszym systemie więc przyjęcie tego rozwiązania prowadziłoby do wyłączenia grupy 8 liczb o cesze -4 z naszego repertuaru. Tu jest to dużo, ale w przypadku cech większych ta strata jest niezauważalna.
Ukrywanie bitu
Ukrywanie bitu
Częstym rozwiązaniem jest też oszczędzanie jednego bitu na drugiej pozycji. Skoro znak liczby determinuje kolejny bit (musi być przeciwny), to nie ma sensu go osobno pamiętać. Zatem reprezentując liczby po bicie znaku mamy od razu bit 1/4 i tylko pamiętamy, że ukryty bit dotyczy wartości 1/2. Przy omówieniu naszego systemu tego aspektu nie braliśmy pod uwagę. Wszystkie wnioski, które wyciągnęliśmy przenoszą się również na system z ukrytym bitem.
Dodawanie w systemie zmiennopozycyjnym
Ćwiczenia
Składnia i semantyka instrukcji
Składnia i semantyka instrukcji
Na wykładzie 2 wprowadziliśmy nieformalnie podstawowe instrukcje naszego języka programowania. Dzięki poznanemu mechanizmowi gramatyk, jesteśmy gotowi do precyzyjnego określenia, czym są instrukcje. Interesują nas dwie rzeczy: składnia i semantyka, czyli określenie postaci zapisu instrukcji oraz samego znaczenia. Obie rzeczy zrealizujemy za pomocą gramatyk – tak jak się to stało z wyrażeniami; byliśmy w końcu w stanie zarówno określić postać wyrażeń, jak ich znaczenie.
Zacznijmy od zastanowienia się, w jakiej dziedzinie semantycznej będziemy interpretować instrukcje. Zakładamy tu, że w naszym programie będziemy korzystali ze zmiennych i ich wartości będą wpływały na wykonanie programu: w zależności od wartości zmiennych, programy będą wybierały odpowiednie ścieżki wykonania. Na razie rozważamy jedynie zmienne liczbowe, ale wkrótce przekonamy się, że nie jest to jakieś istotne ograniczenie. Przynajmniej z punktu widzenia instrukcji powinno być nam z grubsza obojętne, na jakich obiektach działamy, jeżeli tylko będzie jasne, co i w jakim porządku zamierzamy wykonać.
We wszystkich poważnych językach programowania zmienne deklarujemy przed ich użyciem (czasem – jak to bywało np. w językach FORTRAN czy BASIC – deklaracja zmiennej była automatyczna wraz z jej pierwszym użyciem; rozwiązanie tyleż wygodne, co niebezpieczne; później je zarzucono). Zestaw wartości zmiennych jest czymś, co nazywamy stanem programu. Instrukcje będą te stany zmieniały, nadając nowe wartości poszczególnym zmiennym. Całe wykonanie programu będzie zatem ciągiem stanów, a rolą instrukcji będzie przeprowadzenie obliczeń od stanu początkowego do stanu końcowego dokładnie zgodnie z życzeniem programisty. Przez stan zatem rozumiemy pewne wartościowanie \( V:Zarrow D \), przeprowadzające zbiór zmiennych Z w odpowiadającą im dziedzinę algorytmiczną (jest to w naszym ujęciu zbiór wektorów wszystkich możliwych wartości zmiennych). Rzecz jasna chcielibyśmy, żeby instrukcja wykonana przy wartościowaniu \( V \) dała jednoznacznie określone nowe wartościowanie \( V' \), w którym pewne zmienne przybiorą nowe wartości, a inne pozostaną przy starych. Jednoznaczność oznacza, że chcemy, aby semantyka instrukcji była funkcją. Oznaczmy przez \( {\cal V} \) zbiór wszystkich możliwych wartościowań, a przez \( {\cal P} \) zbiór wszystkich możliwych instrukcji. Chcielibyśmy, aby semantyka posiadała następującą własność.
Semantyka instrukcji, to funkcja \( I:{\cal V}\times {\cal P} arrow {\cal V} \)Rzeczywistość pokaże, że będziemy to nasze życzenie musieli lekko zmodyfikować, ale z grubsza nam na razie wystarczy. Cały problem polega teraz na tym, żeby precyzyjnie tę funkcję zdefiniować. Będziemy musieli zatem podać składnię instrukcji \( P \), a potem dla każdej instrukcji i każdego wartościowania \( V \) określić, do jakiego wartościowania \( V' \) wykonanie tej instrukcji prowadzi. Wprowadźmy następującą notację
\( I_V(P)=V' \) oznacza, że w stanie \( V \) wykonanie instrukcji \( P \) prowadzi do stanu \( V' \).
Zatem samo \( I_V \) będzie oznaczało funkcję ze zbioru \( {\cal P} \) w zbiór \( {\cal V} \). Funkcja ta związana z wartościowaniem \( V \) będzie mówiła, do czego doprowadzi nas wykonanie w tym stanie instrukcji \( P \). Podamy teraz składnię instrukcji naszych programów.
<instrukcja>. ::=<instrukcja pusta>|<instrukcja przypisania>|<instrukcja złożona>| <instrukcja warunkowa>|<instrukcja pętli>|<instrukcja pisania>|<instrukcja czytania>| <wywołanie procedury>
Po kolei będziemy teraz objaśniali składnię i semantykę poszczególnych typów instrukcji.
Instrukcja pusta
Składnia: <instrukcja pusta> ::= \( \varepsilon \). Semantyka: \( I_V(\varepsilon)=V \). Na dobry początek coś bardzo łatwego. Zażyczyliśmy sobie instrukcji pustej, która nie ma widzialnej postaci – jest pustym ciągiem znaków i nic nie robi: wykonana dla każdego wartościowania \( V \), pozostawia je niezmienionym. Jest to może mało ambitne zadanie, ale nie jest zabronione i w pewnych sytuacjach może być wygodne. Odłóżmy na później dyskusję dlaczego.
Instrukcja przypisania
Składnia: <instrukcja przypisania> ::= <zmienna>:=<wyrażenie>. Zauważmy, że wszystkie instrukcje przypisania są postaci x:=E, gdzie x jest symbolem zmiennej, a E wyrażeniem, które umiemy już i zapisywać i interpretować. Semantyka: \( I_V({\tt x:=E})=V' \), gdzie. \( V'(z) = \begin{cases}V(z) & \textrm{\ jeśli } z \neq x \\ I_V(E) & \textrm{\ jeśli } z = x\end{cases} \) Czyli instrukcja przypisania x:=E nie zmienia wartości żadnej zmiennej poza \( x \), której to wyróżnionej zmiennej przypisuje wartość wyrażenia \( E \) przy wartościowaniu \( V \). Widzimy więc, że w wyrażeniu w szczególności może wystąpić ta sama zmienna \( x \), która znajduje się z lewej strony przypisania i jedyne, czego wymagamy, to żeby wartość tego wyrażenia była obliczona dla starego wartościowania.
Instrukcja złożona
Składnia: <instrukcja złożona> ::= begin <ciąg instrukcji> end
<ciąg instrukcji>::=\( \varepsilon \)|<instrukcja>;<ciag instrukcji>
Semantyka:
Zauważmy, że wszystkie instrukcje złożone są postaci begin \( \ P_1;\ldots;P_n\ \)end, gdzie \( P_1,\ldots P_n \) są instrukcjami.
\( I_V ({\tt begin }\ P_1; \ldots;P_n\ {\tt end}) = \begin{cases}V & \textrm{\ jeśli } n = 0 \\ I_V(P_1) & \textrm{\ jeśli } n = 1 \\ I_{I_V(P_1)} ({\tt begin}\ P_2; \ldots;P_n\ {\tt end}) & \textrm{\ jeśli } n > 1\end{cases} \)
Zatem jeśli między nawiasami begin a end nie ma żadnej instrukcji, to semantyka jest taka, jak instrukcji pustej; jeśli jest dokładnie jedna instrukcja, to semantyka jest dokładnie taka, jak tej jedynej instrukcji, a jeśli wewnątrz nawiasów występuje więcej niż jedna instrukcja, to po kolei wykonujemy je przechodząc od stanu \( V=V_0 \) kolejno przez stany \( V_1,\ldots,V_n \), tak że dla każdego \( 1\le i\le n \) zachodzi \( I_{V_{i-1}}(P_i)=V_i \). Wykonanie instrukcji złożonej polega więc na przejściu przez ciąg stanów pośrednich powstających przez wykonanie kolejnych instrukcji składowych. Z przyjętych założeń wynika, że jeśli którakolwiek z instrukcji składowych spowoduje błąd, to wartością całej instrukcji złożonej jest również błąd.
Instrukcja warunkowa
Do zdefiniowania instrukcji warunkowej będzie nam potrzebne rozróżnienie jej dwóch postaci: będziemy je nazywali instrukcją warunkową bez else'a oraz instrukcją warunkową z else.
Składnia:
<instrukcja warunkowa>::=<instrukcja warunkowa bez else>|<instrukcja warunkowa z else>
<instrukcja warunkowa bez else>::= if <wyrażenie logiczne> then <instrukcja>
<instrukcja warunkowa z else>::= if <wyrażenie logiczne> then <instrukcja, ale jeśli warunkowa to tylko z else> else <instrukcja>.
Rzecz jasna symbol <instrukcja, ale jeśli warunkowa to tylko z else> przechodzi na wszystkie instrukcje poza jedną: instrukcją warunkową bez else'a. Może zdziwić nieco ten łamaniec: na pierwszy rzut oka wydaje się niepotrzebną komplikacją wyłączenie w instrukcji z „else” jednego rodzaju instrukcji jako tej, która następuje po „then”. W rzeczywistości był to jeden z poważniejszych błędów koncepcyjnych w historii tworzenia języków programowania: tak właśnie myśleli twórcy znanego i bardzo popularnego w latach 60. języka programowania Algol 60 i przez parę lat programiści programowali za pomocą niejednoznacznych instrukcji. Problem ten stanie się widoczny po zdefiniowaniu semantyki.
Semantyka:
Zauważmy, że wszystkie instrukcje warunkowe są jednej z dwóch postaci: if \( \ B\ \) then \( \ P\ \) lub if \( \ B\ \) then \( \ P_1\ \) else \( \ P_2\ \), gdzie \( B \) jest wyrażeniem logicznym, \( P_1 \) jest dowolną instrukcją poza instrukcja warunkową bez else'a, a \( P_2 \) dowolną instrukcją. Dla pierwszego rodzaju instrukcji określamy semantykę następująco:
\( I_V({\tt if }\ B\ {\tt then }\ P) = \begin{cases}I_V(P) & \textrm{\ jeśli } I_V(B) = true \\ V & \textrm{\ jeśli } I_V(B) = false \end{cases} \)
Dla drugiego rodzaju instrukcji określamy semantykę następująco:
\( I_V({\tt if }\ B\ {\tt then }\ P_1\ {\tt else }\ P_2) = \begin{cases}I_V(P_1) & \textrm{\ jeśli } I_V(B) = true \\ I_V(P_2) & \textrm{\ jeśli } I_V(B) = false\end{cases} \)
Sprawdźmy teraz, że wyłączenie instrukcji warunkowej bez else'a było konieczne w drugim rodzaju instrukcji warunkowej. Rozważmy następującą instrukcję:
Przykład programu:
<b>if</b> x>0 <b>then</b> <b>if</b> y>0 <b>then</b> x:=1 <b>else</b> x:=0
Gdybyśmy dopuścili instrukcję warunkową bez else'a jako możliwą dla tego, co pojawia się po „then”, wówczas możliwy byłby dwojaki rozbiór gramatyczny tej instrukcji:
- albo „else” odnosiłby się do „if y>0” i wtedy cała instrukcja warunkowa byłaby pierwszego rodzaju – bez else, a po then pojawiłaby się instrukcja warunkowa drugiego rodzaju.
- albo „else” odnosiłby się do „if x>0” i wtedy instrukcja ta byłaby drugiego rodzaju, z tym że po „then” pojawiłaby się instrukcja warunkowa pierwszego rodzaju, bez else'a
W pierwszym przypadku na przykład dla danych początkowych \( x=-1, y=-2 \) wartością zmiennej \( x \) po wykonaniu tej instrukcji byłoby \( -1 \) - nic by się nie zmieniło, gdyż warunek \( x>0 \) byłby niespełniony i w ogóle nie przeszlibyśmy do wykonania tego, co jest po „then”. W drugim przypadku wykonałaby się instrukcja po „else”, czyli x:=0, co spowodowałoby przypisanie zmiennej x wartości \( 0 \). Zatem, w zależności od widzimisię kompilatora, nasz program mógłby dawać dwie różne wartości. Tak określona semantyka nie byłaby więc funkcją.
W naszej gramatyce niejednoznaczności już nie ma. Jedynym możliwym odczytem rozważanej wyżej instrukcji jest pierwszy. Zapamiętajmy
Jeżeli mamy kaskadę if'ów, to „else” zamyka zawsze ostatnio otwarty „if”.
Proszę sprawdzić, że nie ma możliwości innego odczytu kaskady ifów, niż przez zamykanie else'ami najbardziej aktualnych warunków.
Instrukcja pętli
Często spotykamy się z sytuacją, w której pewien ciąg czynności będziemy chcieli wykonywać, aż zostanie spełniony pewien warunek. W takiej sytuacji stosujemy instrukcję pętli, która musi określić, co ma spowodować zakończenie pętli oraz co w każdym obrocie pętli powinno się wykonać. W zasadzie wystarczyłaby jedna postać instrukcji pętli, ale że jest to bardzo często stosowana instrukcja, dozwolimy aby stosować wygodne składniowo warianty.
Składnia:
<instrukcja pętli>::=<instrukcja while> | <instrukcja repeat> | <instrukcja for>
<instrukcja while> ::= while <wyrażenie logiczne> do <instrukcja>
<instrukcja repeat> ::= repeat <ciąg instrukcji> until <wyrażenie logiczne>
<instrukcja for> ::= for <zmienna> := <wyrażenie> to <wyrażenie> do <instrukcja> |
for <zmienna> := <wyrażenie> downto <wyrażenie> do <instrukcja>
Pętla while
Skupimy się na instrukcji while, a następnie pozostałe instrukcje zdefiniujemy korzystając z semantyki pętli while. Semantyka instrukcji while wymaga wprowadzenia dodatkowej kategorii semantycznej. Pętle while są postaci while \( B \) do \( P \). Intencją naszą jest wykonywanie instrukcji \( P \) tak długo, jak długo będzie spełniony warunek \( B \). Co jednak, gdy warunek \( B \) zawsze będzie spełniony? Zgodnie z naszym życzeniem program powinien działać bez końca. I tak właśnie chcielibyśmy, żeby było. Zatem mamy tu do czynienia z nową sytuacją: program ani nie kończy się błędem, ani czymkolwiek innym, co można by nazwać stanem końcowym. Po prostu {zapętla się}. Dla takiej sytuacji wprowadzamy kolejne rozszerzenie dziedziny semantycznej: już nie tylko wektor wartościowań lub błąd może być wynikiem wykonania programu, ale również uznajemy za poprawną wartość semantyczną zapętlenie, które będziemy oznaczali przez loop.
Zatem dodajemy jeszcze jedną wartość do możliwych wyników programu. Poza stanem programu (czyli wektorem wartościowań zmiennych) oraz błędem, mamy też {\em zapętlenie}. Powstaje pytanie, jak określić, czy – zgodnie z warunkiem definiującym semantykę pętli – program zapętli się, czy nie. W końcu chcielibyśmy wiedzieć, którą z wartości końcowych nasz program przyjmie: czy się zapętli, czy dojdzie do stanu końcowego. I tu niespodzianka! Nasza ciekawość nie może zostać zaspokojona, przynajmniej w automatyczny sposób. Nie ma bowiem procedury rozstrzygającej, czy dany program się zatrzyma dla konkretnych danych. Własność tę odkrył w latach 30-tych XX wieku Alan Turing. Turing udowodnił, że nie ma metody sprawdzenia, czy program zatrzyma się, czy nie.
Wkrótce dowiemy się, jak można w wielu przypadkach taki problem rozstrzygnąć. Nauczymy się dowodzenia tego, że program się zatrzyma, ale nie będzie to ogólna metoda, tylko ograniczona do na szczęście dość szerokiej klasy programów.
Semantyka:
Zauważmy, że instrukcja pętli ma postać: while \( \ B\ \) do \( \ P\ \), gdzie \( B \) jest wyrażeniem logicznym, a \( P \) jest dowolną instrukcją. Dla pętli while określamy semantykę następująco:
\( I_V({\tt while }\ B\ {\tt do }\ P) = \begin{cases}V & \textrm{\ jeśli } I_V(B) = false \\ I_{I_V(P)}(\tt while)\ B\ {\tt do }\ P) & \textrm{\ jeśli } I_V(B) = true \end{cases} \)
Widzimy więc, że gdy przy wartościowaniu \( V \) warunek \( B \) ma wartość false, wówczas nic się nie dzieje: pozostajemy przy wartościowaniu \( V \) i idziemy dalej, tak jak gdybyśmy wykonali instrukcję pustą. Jeśli natomiast warunek \( B \) ma wartość true, wówczas wykonujemy instrukcję P i wracamy do punktu wyjścia. Żeby ta definicja była formalnie poprawna, potrzebne jest jeszcze jedno ustalenie. Widać bowiem, że mamy do czynienia z dwiema mozliwościami. Albo po skończonej liczbie obrotów pętli warunek B stanie się fałszywy i wtedy przerywamy wykonanie pętli wychodząc z niego z otrzymanym wartościowaniem, albo warunek B nie stanie się fałszywy nigdy i wtedy właśnie mamy do czynienia z sytuacją zapętlenia się programu. Ustalmy więc, że gdy program się zapętla, to jego semantyką jest pętla - trzecia z możliwości (oprócz wartościowania i błędu). Zapętlenie się programu jest zaraźliwe: wystarczy, żeby choć jedna instrukcja pętli nie zakończyła działania, a wartością całego programu będzie pętla.
Podamy teraz parę przykładów pętli while.
l:=0; <b>while</b> b <> 0 <b>do</b> <b>begin</b> b:=b div 2; l:=l+1 <b> end</b>
Ten fragment programu działa różnie w zalezności od tego, czy b jest liczbą ujemną, czy nieujemną. Dla liczb dodatnich oblicza logarytm z b zaokrąglony w dół. Dla zera pozostawia wartość 0. dla liczb ujemnych otrzymujemy zapętlenie, gdyż -1 div 2 = -1 .
Zauważmy, że pętla może ani razu się nie wykonać, jeśli warunek dozoru będzie miał wartość false od razu na początku działania pętli. Często zdarzają się nam sytuacje, kiedy chcielibyśmy, aby pętla wykonała się co najmniej raz i żeby o tym, czy dalej ma się wykonywać, czy nie, decydować pod jej koniec. Taka sytuacja występuje na przykład wtedy, gdy żądamy od użytkownika podania jakiejś danej, na przykład hasła. Powinniśmy tak długo żądać od niego wprowadzenia danej, aż spełni ona pewien warunek (na przykład poprawności hasła lub przekroczenia limitu prób). Ponieważ taka sytuacja jest bardzo typowa, więc wprowadzimy konstrukcję, która umożliwia zrobienie tego prościej niż za pomocą pętli while.
Pętla repeat
Pętla repeat wygląda następująco:
<b>repeat</b>
P1;
P2;
...
Pn
<b>until</b> BJej semantyka jest równoważna następującemu fragmentowi
<b>begin</b> P1; P2; ... Pn <b>while</b> not B <b>do</b> <b>begin</b> P1; P2; ... Pn <b>end</b> {<b>while</b> not b} <b>end</b>
Widzimy więc, że zgodnie z tym, co napisaliśmy wcześniej, najpierw jednokrotnie wykonuje się ciąg instrukcji \( P1; \ldots;Pn \), a potem dopóki warunek \( B \) nie będzie spełniony, powtarzamy ten sam ciąg instrukcji. Warto zwrócić uwagę na to, że używając pętli while negujemy warunek z pętli repeat. Pętla while bowiem działa dopóki podany warunek dozoru jest spełniony, a pętla repeat kończy działanie w pierwszej chwili, w której warunek dozoru jest spełniony przy jego sprawdzaniu.
Pętla for
Kolejny rodzaj pętli, bardzo często stosowany, wiąże się najczęściej z przetwarzaniem kolejnych liczb całkowitych, na przykład przy przetwarzaniu tablic, kiedy nimi indeksujemy elementy. Użycie tego rodzaju pętli umożliwia kompilatorowi optymalizację kodu i przyspieszenie jego działania, ale wiąże się z pewnymi niebezpieczeństwami, o których zaraz opowiemy.
Najpierw przyjrzyjmy się postaci pętli. Może być ona dwojakiego rodzaju: for i:=E1 to E2 do P lub for i:=E1 downto E2 do P. W pierwszym przypadku semantyką tej pętli jest semantyka równoważnej jej postaci
i:=E1;
<b>while</b> i<=E2 <b>do</b>
<b>begin</b>
P;
i:=i+1
<b>end</b>Zaczynamy zatem od przypisania zmiennej sterującej i wartości E1, a następnie wykonujemy instrukcję P oraz zwiększamy i o 1 tak długo, aż przekroczymy wartość E2. W drugim przypadku robimy to samo, tylko w drugą stronę, zmniejszając wartości zmiennej i o 1. Zatem semantyką instrukcji for i:=E1 downto E2 do P jest semantyka następującego kodu
i:=E1;
<b>while</b> i>=E2 <b>do</b>
<b>begin</b>
P;
i:=i-1
<b>end</b>W rzeczywistości kompilatory często odbiegają nieco od tej semantyki i wprowadzają usprawnienia, które mogą dawać wyniki różniące się od siebie. Rzecz w tym, że gdy uruchamiamy pętlę for, to kompilator stara się z góry przewidzieć, ile obrotów pętla wykona. Oblicza więc wartości wyrażeń \( E1,E2 \) na początku działania pętli i z góry ustawia stosowny rejestr, który będzie odliczał liczbę wykonanych obrotów pętli, aż ta spadnie do zera. Podobnie będzie postępował z tablicami indeksowanymi zmienną sterującą. Normalnie, gdy odwołujemy się do i-tego elementu tablicy A, to kompilator ustala adres stosownej komórki w następujący sposób. Pobiera adres \( a \) początku tablicy z tabeli symboli, którą sam tworzy na etapie deklaracji, wylicza wartość wyrażenia indeksującego – w tym przypadku \( i \) - oraz dodaje do \( a \) wartość \( i-1 \) przemnożoną przez wielkość w bajtach pojedynczego elementu tablicy.
W przypadku pętli for, gdybyśmy chcieli odwoływać się w każdym kroku do i-tego elementu, to wystarczy wiedzieć, że w poprzednim obrocie pętli byliśmy w poprzednim elemencie, więc uzyskanie aktualnego adresu jest znacznie prostsze – wystarczy wziąć poprzedni adres i dodać do niego liczbę bajtów przypadającą na 1 element tablicy. Jeśli mamy nawet bardziej skomplikowane wyrażenie indeksujące pętli, np. zamiast \( i \) powiedzmy \( 3*i+2 \), to nadal różnica między poprzednim, a bieżącym adresem będzie stała i tę wartość można raz ustalić na początku pętli, a następnie kolejne adresy wyznaczać dodając ją do poprzednich. Stosowne wartości – ostatnio używanego adresu oraz skoku – zazwyczaj przechowywane są w rejestrach procesora i w związku z tym dostęp do nich jest znacznie szybszy.
Aby to wszystko się udało, nie powinno się zmieniać ani wartości zmiennej sterującej pętlą, ani ograniczenia wartości, czyli \( E2 \). Zrobienie jednej z tych dwóch rzeczy powoduje nieobliczalne skutki, więc pętle w stylu for i:=1 to n do begin i:=i+1; n:=n-1 end są przejawem niezrozumienia o co chodzi w pętli for. Na szczęście praktyka pokazuje, że tego typu konstrukcje nie mają żadnego zastosowania, więc po prostu pamiętajmy:
W pętlach for nie wolno zmieniać wartości zmiennej sterującej ani wartości końcowego ograniczenia pętli.
Ciekawe jest pytanie, jaka jest wartość zmiennej sterującej po wykonaniu pętli for. Przyjmijmy, że jest ona nieokreślona. W każdym razie nie powinno się niczego o niej zakładać. W niektórych bowiem kompilatorach zmienna ta pod koniec pętli przyjmuje wartość równą wartości \( E2, \), a w niektórych o jeden większą, jak to by wynikało z semantyki określonej za pomocą pętli while. W naszym narzędziu do uruchamiania programów zmienna sterująca różni się o 1 od wartości \( E2 \), ale nie należy z tego w żadnym wypadku korzystać.
Instrukcja czytania
Gdyby nasz program nie komunikował się w czasie działania ze światem zewnętrznym, musiałby wszystkie dane mieć wpisane przed uruchomieniem w kodzie. W rzeczywistości komputery wymieniają informację ze światem zewnętrznym i często w trakcie ich działania trzeba podawać pewne dane. Bardzo często jesteśmy w sytuacji, w której komputer żąda od nas podania imienia, nazwiska, wieku, dokonania jakichś wyborów. Co to znaczy, że wprowadzimy takie dane? Program musi je jakoś zapamiętać, czyli nadać pewnym zmiennym wartości przez nas podane. Do tego służy właśnie instrukcja czytania.
Mamy tu jednak zupełnie nową sytuację. Jak uwzględnić w semantyce programu to, co użytkownik poda jako dane wejściowe? Jest to o tyle trudne, że liczba możliwych reakcji użytkownika jest potencjalnie nieograniczona. W związku z tym musimy zmienić znowu nieco naszą dziedzinę semantyczną. Ciąg kolejno podawanych danych będziemy reprezentowali w liście zwanej wejściową. Zakładamy, że wszystko co użytkownik przygotuje, niezależnie od tego, czy zrobi to w momencie, gdy dane są potrzebne, czy zawczasu, zostaje dopisywane na końcu tej listy. Program natomiast pobiera wartości z początku listy – te, które były tam umieszczone jako pierwsze. Technikę, w której dane są podawane nieco wcześniej niż trzeba i wykorzystywane we właściwym momencie nazywamy buforowaniem, a część pamięci wykorzystywaną do przechowywania takich danych buforem.
Składnia:
<instrukcja czytania> ::= Read(<ciąg zmiennych>).
<ciąg zmiennych> ::= <zmienna> | <zmienna>,<ciag zmiennych>
Semantyka:
Zauważmy, że wszystkie instrukcje wejścia są postaci Read(x1,...,xm), gdzie x1,...,xm są zmiennymi.
Aby określić semantykę instrukcji czytania, przyjmijmy, że zawartość listy wejściowej jest równa \( L_{in}=(v_1,\ldots,v_n); n\ge m \). W tej sytuacji jako stan komputera przyjmujemy parę \( (V,L_{in}) \).
Mamy wtedy \( I_{(V,L_{in})}({\tt Read(x1,...,xm))}= (V',L'_{in}) \), gdzie
\( V'(z) = \begin{cases}V(z) & \textrm{\ jeśli } z \notin \{x1,\ldots,xm\} \\ v_k & \textrm{\ jeśli } z = x_k\end{cases} \)
oraz
\( L'_{in}=v_{m+1},\ldots,v_n. \)
W wyniku wykonania instrukcji czytania Read(x1,...,xm) lista wejściowa \( L_{in}=\{v_1,\ldots,v_m\} \) zostanie skrócona o \( m \) początkowych wartości, a wartości \( v_1,\ldots,v_m \) zostają przypisane zmiennym \( x1,\ldots, xm \). Dodajmy jeszcze, że jeśli lista wejściowa jest krótsza niż \( m \), to program zawiesza działanie i czeka aż zostanie uzupełniona o brakujące wartości.
Instrukcja pisania
W przypadku instrukcji czytania musieliśmy wziąć pod uwagę listę wejściową, aby określić semantykę. Podobnie teraz będziemy się musieli odnieść do listy wyjściowej, służącej jako medium komunikacyjne ze światem zewnętrznym. Standardową realizacją takiej listy są monitory ekranowe, ale równie dobrze mogą to być pliki oraz inne urządzenia wyjścia takie jak drukarka czy ploter. Zakładamy zatem istnienie listy wyjściowej, która na początku działania programu jest pusta i w miarę jego działania zapełnia się napisami wygenerowanymi przez program.
Składnia:
<instrukcja pisania> ::= Write(<ciąg wyrażeń>).
<ciąg wyrażeń> ::= <wyrażenie> | <wyrażenie>,<ciag wyrażeń>
Semantyka:
Zauważmy, że wszystkie instrukcje pisania są postaci Write(e1,...,em), gdzie e1,...,em są wyrażeniami.
Aby określić semantykę instrukcji pisania przyjmijmy, że zawartość listy wyjściowej jest równa \( L_{out}=(v_1,\ldots,v_n) \). W tej sytuacji jako stan komputera przyjmujemy trójkę \( (V,L_{in},L_{out}) \). Instrukcja pisania nie zmieni ani wartościowania zmiennych \( V \), ani listy wejściowej \( L_{in} \). Zmieni natomiast listę wyjściową, dopisując na jej końcu wartości wyrażeń.
Formalnie:
\( I_{(V,L_{in},L_{out})}({\tt Write(e1,...,em))}= (V',L'_{in},L'_{out}) \),
gdzie
\( V'=V \)
\( L'_{in}=L_{in} \)
\( L'_{out}=v_1, \ldots, v_n, I_V (e1) , \ldots , I_V(em) \)
W wyniku wykonania instrukcji pisania Write(e1,...,em) lista wyjściowa \( L_{out}=\{v_1,\ldots,v_n\} \) zostanie wydłużona o \( m \) wartości wyrażeń wyliczonych przy wartościowaniu \( V \). Ani wartościowanie \( V \), ani lista wejściowa \( L_{in} \) nie ulegają zmianie przy wykonywaniu instrukcji pisania.
Instrukcja procedury
Wykonywaniu procedur poświęcony będzie osobny wykład. Przyjmijmy na razie, że gdy wywołujemy procedurę, wyliczamy wartości parametrów dla aktualnego wartościowania, a następnie wykonujemy kod procedury, używając wyliczonych wartości jako początkowych w naszych obliczeniach.
Ćwiczenia
Dowodzenie poprawności programów
Wprowadzenie
Wiemy, jak bardzo nasze życie zaczyna zależeć od komputerów, a dokładniej od programów komputerowych. Chodzi tu nie tylko o wygodę. Niekiedy działanie komputerów ma krytyczne znaczenie, gdy mówimy o takich zastosowaniach jak transport (nie tylko lotniczy), loty kosmiczne, nadzorowanie życia pacjenta w czasie operacji, dozowanie leków. Wszelkie zastosowania komputerów, gdzie trzeba mieć zaufanie do programu sprawiają, że trzeba zapytać z czego wynika nasze zaufanie, że program komputerowy napisany jest dobrze?
Mija właśnie epoka, w której poprawność programu można było ustalić na podstawie słowa honoru danego przez programistę, że się nie pomylił. Typowym zachowaniem programisty po napisaniu programu to oczywiście jego gruntowne przetestowanie. Gruntowne to nie znaczy całkowite. Rzadko bowiem w czasie testowania mamy wyobraźnię tak bogatą, żeby przedstawić sobie wszystkie możliwe sytuacje, szczególnie wtedy, gdy jest ich potencjalnie nieskończenie wiele. Owszem, testy mogą wykazać, że program jest niepoprawny, ale prawie nigdy (poza przypadkami, kiedy liczba przypadków jest skończona i mała – wielka rzadkość) nie mogą wykazać jego poprawności. Informatycy od dawna próbują skonstruować metody wnioskowania o programach i stają się one coraz popularniejsze, szczególnie że raz udowodnione fragmenty programu mogą być włączane do bibliotek jako poprawne moduły, do których już nie trzeba wracać.
Jak zatem udowodnić, że program robi to, o co nam chodzi? Mniej więcej widać, że gdy wykonamy instrukcję i:=i+1 dla \( i=1 \) będziemy mieli \( i=2 \). Czy możliwe jest jednak opracowanie ogólnej teorii? Okazuje się, że dla ogromnej większości algorytmów jesteśmy w stanie udowodnić ich poprawność korzystając z metod logiki opracowanych na początku lat 60-tych XX wieku. Jak się wkrótce okaże, ta teoria nie tylko pozwala udowodnić poprawność algorytmu, ale i daje metodologię wymyślania algorytmów. Za jej pomocą będziemy wiedzieli, na czym się skupić, gdy zaczynamy projektować pętle.
Częściowa poprawność programów
Częściowa poprawność programów
Będziemy poszukiwali takiej teorii, która pozwoli nam ustalić pewną relację między trzema obiektami: stanem początkowym, instrukcją i stanem końcowym. Relacja ta intuicyjnie ma oznaczać, że jeśli w pierwszym stanie, zwanym początkowym, wykonamy badaną instrukcję, to przejdziemy do stanu drugiego, który nazwiemy końcowym. W rzeczywistości, żeby móc wnioskować o nieskończonej przestrzeni stanów, będziemy agregować wiele z nich za pomocą formuł logicznych. Zatem będziemy rozważali pewien zbiór stanów początkowych, instrukcję oraz pewien zbiór stanów końcowych, które będą względem siebie w odpowiedniej relacji. Stany początkowe i końcowe będziemy określali za pomocą formuł.
Przykładowo możemy sobie wyobrazić formułę \( \varphi_1 =k\ge 0 \), instrukcję j:=k+1 oraz formułę \( \varphi_2 =j > 0 \) i próbować udowodnić dość oczywisty fakt, że jeśli stan początkowy spełnia formułę \( \varphi_1 \), to po wykonaniu naszej instrukcji stan końcowy będzie spełniał formułę \( \varphi_2 \). Wprowadźmy zatem oznaczenie Formuła częściowej poprawności programu \( P \) Trójka \( (\{\varphi_1\},P, \{\varphi_2\}) \) to formuła logiczna, która jest prawdziwa wtedy i tylko wtedy, gdy zachodzi następujący warunek. Dla każdego stanu spełniającego \( \varphi_1 \), jeżeli program \( P \) zakończy swoje działanie, to stan końcowy będzie spełniał formułę \( \varphi_2 \). Takie formuły nazywamy trójkami Hoare'a albo formułami częściowej poprawności programu. Zostały wprowadzone przez jednego z największych informatyków, Anthony'ego Hoare'a, w połowie lat 60.
rycina
C.A.R. Hoare (1934– )
Zauważmy, że o poprawności formuły Hoare'a możemy mówić w dwóch przypadkach:
- Kiedy dla danych spełniających \( \varphi_1 \) program się zatrzyma i dane po zatrzymaniu się programu spełniają \( \varphi_2 \)
Kiedy dla danych spełniających \( \varphi_1 \) program się nie zatrzyma.
Jest to dość istotny szczegół techniczny, którym się jeszcze zajmiemy.
Jak zatem wnioskować o programach? Za chwilę podamy zbiór reguł dla podstawowych konstrukcji programistycznych, umożliwiający wnioskowanie na podstawie drzewa wywodu programu. Dla każdego węzła drzewa wywodu, albo dokładniej, dla każdej produkcji gramatyki podamy regułę wnioskowania pozwalającą wyprowadzić konsekwencję wykonania instrukcji na podstawie opisu działania instrukcji składowych. Reguły wnioskowania będziemy zapisywali w postaci
\( \frac{\mbox {Przesłanki oddzielone przecinkami}}{\mbox {Wniosek}} \)
Przesłanki tak są dobrane, aby wniosek wyrażał własność, że dana instrukcja jest częściowo poprawna względem dwóch formuł \( \alpha \) i \( \beta \).
Instrukcja pusta
Zacznijmy od najprostszej instrukcji pustej:
\( \frac{}{\{\alpha\} \varepsilon \{\alpha\}} \)
Czytamy to tak: bez żadnych warunków wstępnych (pusty "licznik"), jeśli dane początkowe spełniają warunek \( \alpha \), po wykonaniu instrukcji pustej (zauważmy, że nie może się wykonanie takiej instrukcji zapętlić) dane końcowe spełniają warunek \( \alpha \). Dość oczywiste, zważywszy że instrukcja pusta nie robi nic. Mamy tu pusty zbiór przesłanek.
Instrukcja przypisania
Umówmy się, że jeśli zmienna \( z \) jest parametrem formuły logicznej \( \alpha(z) \), zaś \( E \) jest wyrażeniem, przez \( \alpha(E) \) rozumiemy formułę, która powstaje przez zastąpienie wszystkich wystąpień zmiennej \( z \) w formule \( \alpha \) przez \( E \). Mamy zatem następującą regułę wnioskowania dla instrukcji przypisania:
\( \frac{}{\{\alpha(E)\}{\mbox{\tt z:=E}}\{\alpha(z)\}} \) która mówi nam, że jeśli przed wykonaniem przypisania zachodziła formuła \( \alpha \) dla wyrażenia \( E \), po wykonaniu instrukcji przypisania formuła ta będzie zachodziła dla zmiennej \( z \). Faktycznie, skoro \( z \) przyjęła wartość \( E \), dla której formuła \( \alpha \) była prawdziwa, nie ma powodu, dla którego formuła ta miała by nie zachodzić dla wartości \( z \).
Instrukcja złożona
Tym razem musimy wyrazić to co się dzieje, gdy wykonujemy sekwencję instrukcji. Intuicyjnie będziemy zakładali, że istnieje ciąg stanów pośrednich, spełniających pośrednie formuły \( \alpha_1,\ldots,\alpha_n \). Mamy zatem
\( \frac{\mbox {\alpha=\alpha_0,\{\alpha_0\}P1\{\alpha_1\}, \ldots,\{\alpha_{n-1}\} Pn \{\alpha_n\}, \alpha_n=\beta}}{\mbox {\{\alpha\}{\tt begin P1; \dots Pn end} \{\beta\}}} \)
Czyli jeśli umiemy udowodnić, że w stanie \( \alpha_0 \) po wykonaniu P1 przejdziemy do stanu \( \alpha_1 \), w stanie \( \alpha_1 \) po wykonianiu P2 przejdziemy do stanu \( \alpha_2 \dots \), a ze stanu \( \alpha_{n-1} \) po wykonaniu Pn przejdziemy do stanu \( \alpha_n \), to łącznie wykonanie wszystkich instrukcji ze stanu spełniającego \( \alpha_0 \) przeprowadzi nas do stanu spełniającego \( \alpha_n \).
Instrukcja warunkowa
Podamy dwie reguły: dla instrukcji bez "else" i dla instrukcji z "else".
\( \frac{\mbox {\{\alpha \land B\} P \{\beta\}, (\alpha \land \neg B) arrow \beta}}{\mbox {\{\alpha\}{\tt if B then P } \{\beta\}}} \) \( \frac{\mbox {\{\alpha \land B\} P \{\beta\}, \{\alpha \land \neg B\} Q \{ \beta\}}}{\mbox {\{\alpha\}{\tt if B then P else Q } \{\beta\}}} \)
Odczyt tych reguł jest bardzo naturalny i zgodny oczywiście z semantyką instrukcji warunkowych. W pierwszym przypadku bowiem (bez "else") albo instrukcja \( P \) wykona się albo nie, w zależności od prawdziwości warunku \( B \). Wystarczy zatem, żeby dla danych spełniających \( \alpha \) i takich, że warunek \( B \) jest spełniony wykonanie programu P doprowadziło nas do stanu \( \beta \), aby w tym przypadku cała instrukcja warunkowa była poprawna względem \( \alpha \) i \( \beta \). Również gdy dla takich danych warunek \( B \) nie jest spełniony, wówczas żądamy, aby \( \beta \) było automatycznie spełnione bez wykonywania jakiejkolwiek instrukcji – żeby było logiczną konsewkencją \( \alpha \) i \( \neg B \) i w obu przypadkach: odpowiednio wykonując instrukcję \( P \) lub nie, mamy zapewnione spełnienie warunku \( \beta \).
Dla instrukcji warunkowej z "else" mamy jednorodną sytuację: zależnie od tego, czy \( B \) jest spełnione czy nie, żądamy częściowej poprawności albo względem instrukcji \( P \), albo \( Q \).
Instrukcja pętli
Gdyby programy składały się tylko z dotychczas omówionych w tym rozdziale instrukcji, wówczas można by automatycznie dowodzić poprawność programów. Instrukcja pętli powoduje, że taka automatyzacja nie jest możliwa. Metoda dowodzenia poprawności pętli ma charakter indukcyjny. Podamy ją tylko dla pętli while, bowiem pozostałe typy instrukcji pętli dadzą się z niej wyprowadzić. Idea reguły dowodzenia leży w wymyśleniu warunku, który będzie zawsze spełniony na początku każdego obrotu pętli. Taki warunek będziemy nazywali 'niezmiennikiem' pętli. Od niezmiennika będziemy wymagali trzech rzeczy.
- żeby był spełniony przy wejściu do pętli przed jej pierwszym obrotem
- żeby jeden obrót pętli nie zmieniał jego wartości (czyli żeby niezmiennik pozostawał prawdziwy)
- żeby po wyjściu z pętli niezmiennik (nadal prawdziwy!) w koniunkcji z zaprzeczeniem dozoru pętli implikował warunek \( \beta \)
Ujmijmy nasze żądania w regułę dowodzenia.
\( \frac{\mbox {\alpha \Rightarrow N, \{N\land B\}P \{N\},N\land \neg B \Rightarrow \beta }}{\{\alpha\}{\mbox {\tt while B do P }} \{\beta\}} \)
Zauważmy, że w regule tej pojawia się - jakby znikąd - warunek \( N \). Musimy go sami wymyślić i jeżeli uda się nam znaleźć \( N \) takie, żeby spełniało wszystkie 3 przesłanki, udowodnimy częściową poprawność instrukcji pętli.
Zanim przejdziemy do przykładów zauważmy, że poprawne są również dwa schematy dowodzenia, z których często będziemy korzystali. Nazywane są one regułami osłabiania. Osłabić twierdzenie można albo wzmacniając założenie, albo osłabiając tezę.
Wzmacnianie założenia
\( \frac{\mbox {\alpha \Rightarrow \gamma, \{\gamma\}P \{ \beta\}}}{\mbox {\{\alpha\} P \{\beta\}}} \)
Osłabianie tezy
\( \frac{\mbox {\{\alpha\} P \{ \gamma\}, \gamma \Rightarrow \beta}}{\mbox {\{\alpha\} P \{\beta\}}} \)
Podajmy teraz parę przykładów zastosowania podanych reguł dowodzenia zastosowanych do stwierdzania poprawności instrukcji.
Przykład [1]
Na początek prosty przykład. Udowodnijmy, że jeśli \( k\ge 0 \), to po instrukcji j:=k+1 mamy \( j>0 \). Ponieważ mamy po prawej stronie instrukcji przypisania wyrażenie \( k+1 \), więc musimy warunek początkowy zapisać w równoważnej formie, w której miejsce zmiennej \( k \) zajmuje wyrażenie \( k+1 \). Zatem \( k\ge 0 \) jest rónoważne \( k+1\ge 1 \) i stosując regułę dla instrukcji przypisania otrzymujemy, że \( j\ge 1 \), co akurat w przypadku zmiennych całkowitych jest równoważne \( j>0 \). Gdyby jednak zmienne \( k \) oraz \( j \) były typu rzeczywistego, to końcowe stwierdzenie otrzymalibyśmy osłabiając tezę: wszak \( j\ge 1 \) implikuje \( j>0 \).
Przykład [2]
Tym razem spróbujmy przeanalizować fragment programu, w którym chcemy sprawdzić, czy w tablicy A[1..n] of Integer znajduje się zadana wartość \( x \). Zakładamy tu, że nie wiemy nic o uporządkowaniu tablicy, w szczególności nie możemy zakładać posortowania danych. Nie wiemy również, jaka jest wartość \( n \) poza tym, że jest nieujemna (dla n=0 mamy do czynienia z pustą tablicą). Przeszukiwanie zaczniemy od pierwszego elementu i będziemy sprawdzali, czy w kolejnych elementach tablicy jest szukane \( x \). Pierwszy pomysł polega na tym, że pętlą for przejdziemy przez całą tablicę i jeśli znajdziemy \( x \), zmienimy początkową waratość logicznej zmiennej jest z false na true.
jest := false; <b>for</b> k:=1 <b>to</b> n <b>do</b> if A[k]=x <b>then</b> jest:=true
Pomysł tyleż prosty, co niezbyt ambitny: jeśli element \( x \) jest na początku tablicy, to pętla for niepotrzebnie będzie wykonywała dalsze sprawdzanie. Spróbujmy udowodnić jednak, że program ten jest poprawny. Zacznijmy od zapisania go przy użyciu pętli while.
jest := false; k:=1;
jest=false, k=1
while k<=n do \( {\mbox{\neg jest \Leftrightarrow (\forall 1\le j < k: A[j] \neq x) \land (1\le k\le n+1)}} \)
begin
if A[k]=x then jest:=true;
k:=k+1
end
\( {\mbox {\neg jest \Leftrightarrow (\forall 1\le j \le n: A[j] \neq x)}} \)
Sprawdźmy, że podany niezmiennik pętli spełnia wszystkie warunki. Oznaczmy przez \( N(k) \) wartość formuły logicznej
\( (\neg jest \Leftrightarrow \forall 1\le j < k: A[j] \neq x) \land (1\le k\le n+1) \).
Zauważmy po pierwsze, że w trywialny sposób inicjalizuje się. Warunek \( N(1) \) jest zawsze prawdziwy: nie ma bowiem żadnej wartości \( j \) większej lub równej 1, a jednocześnie mniejszej od 1, wskutek czego pierwszy czynnik koniunkcji jest trywialnie prawdziwy. Wszelkie stwierdzenia poprzedzone kwantyfikatorem ogólnym dla elementów zbioru pustego są prawdziwe. Oczywiście dla \( n\ge 0 \) oraz \( k=1 \) mamy też \( 1\le k\le n+1 \), więc drugi czynnik też jest prawdziwy.
Po drugie wykonanie jednego obrotu pętli nie zmienia prawdziwości niezmiennika. Jeśli bowiem na początku pętli dla pewnej wartości k wartość zmiennej jest równa się false, to na mocy założenia indukcyjnego zachodzi
\( \forall 1\le j < k: A[j] \neq x \).
Teraz mamy dwa przypadki.
- Jeśli dodatkowo \( A[k] \neq x \), to możemy powiedzieć równoważnie, że \( \forall 1\le j < k: A[j] \neq x \land A[k] \neq x \), czyli \( \forall 1\le j \le k: A[j]\neq x \), a to jest równoważne \( \forall 1\le j < k+1: A[j]\neq x \). Warunek ten obrazuje stan obliczeń po wykonaniu badanej instrukcji warunkowej, gdyż wartość zmiennej {\tt jest} pozostanie równa false. W jednym kroku pętli wykonuje się jeszcze tylko instrukcja k:=k+1. Po tym przypisaniu warunek nasz będzie spełniony dla nowego k, czyli niezmiennik \( \neg jest = \forall 1\le j < k: A[j] \neq x \) zostaje odtworzony.
- Jeśli natomiast \( A[k]=x \), to wykona się instrukcja jest := true i wtedy, dla nowej wartości \( k \), formuła \( \forall 1\le j \le k: A[j]\neq x \) będzie fałszywa, czyli równoważna wartości \( \not jest \).
Podobnie gdy zmienna jest ma wartość true, na mocy założenia istnieje \( 1\le j < k \) takie, że \( A[j]=x \). Niezależnie od tego, czy przypisanie jest :=true zostanie wykonane w ramach instrukcji warunkowej, po wykonaniu instrukcji k:=k+1 niezmiennik się również odtworzy. To stwierdzenie kończy dowód niezmienniczości formuły \( N(k) \).
Zostało nam w końcu do udowodnienia, że po wyjściu z pętli, gdy mamy \( k>n \) oraz zachodzi \( N(k) \), otrzymamy tezę. Zatem ze względu na to, że \( k\le n+1 \) dochodzimy do wniosku, że \( k=n+1 \), co łącznie z pierwszym czynnikiem niezmiennika daje nam (po zastosowanu reguły osłabienia tezy) końcowy warunek
\( (\neg jest = \forall 1\le j < n+1: A[j] \neq x) \).
W naszym przypadku niezmiennik opisywał ogólną sytuację po kilku obrotach pętli: zmienna jest ma wartość true wtedy i tylko wtedy gdy na lewo od \( k \) znajduje się wartość \( x \). Kiedy szukamy niezmiennika, staramy się możliwie dokładnie wyobrazić sobie jak może wyglądać sytuacja, gdy już pętla wykona parę obrotów i zapisujemy to w postaci formuły logicznej. Jeśli nie mamy wystarczająco dużo wyobraźni, to niezmiennik wyjdzie za słaby i trudno będzie korzystając tylko z niego i z dozoru pętli jego niezmienniczość udowodnić (choć może być prawdziwy). Również za słaby niezmiennik może być powodem trudności pokazania trzeciej z implikacji, kończącej wywód. W naszym przypadku na przykład nieuwzględnienie w niezmienniku warunku \( k\le n+1 \) spowodowałoby kłopoty z przekształceniem niezmiennika do postaci \( N(n+1) \), z czego wynikała od razu teza. Z kolei za mocny niezmiennik oznacza kłopoty z jego inicjalizacją. Niezmiennik powienien być w sam raz.
Zauważmy jeszcze jedną rzecz. W momencie, gdy zmienna jest przyjmuje wartość true, możemy dalsze przeszukiwanie zakończyć, gdyż na false już zmienić swojej wartości nie może z powrotem. Zatem dozór pętli możemy wzmocnić o dodatkowy warunek tak, aby przerwać obliczenia, gdy tylko \( x \) znajdziemy. Tym razem, ponieważ liczba obrotów pętli będzie dynamicznie zależała od danych, nie można użyć pętli for, tylko od razu użyjemy pętli while.
jest := false; k:=1; jest=false, k=1 <b>while</b> (not jest) and ( k<=n) do \( {\mbox{\neg jest \Leftrightarrow (\forall 1\le j < k: A[j] \neq x \land 1\le k\le n+1)}} \) <b>begin</b> <b>if</b> A[k]=x <b>then</b> jest:=true; k:=k+1 <b>end</b>
Dowód poprawności przebiega identycznie jak poprzednio. Zmienia się tylko złożoność algorytmu: ten wykona być może mniej kroków, choć w najgorszym przypadku – gdy x w tablicy A nie ma - w obu przypadkach wykonamy tę samą liczbę obrotów pętli. Zauważmy, że to są kroki trochę droższe, bo mamy bardziej skomplikowany warunek dozoru. Czy skórka jest warta wyprawki?
Powiedzmy tak: jeśli mamy podejrzenie, że znalezienie x jest prawdopodobne, a danych jest dużo, warto zastosować wcześniejsze przerwanie pętli. Kiedy jednak danych jest niewiele lub przypuszczalnie wartości x nie ma w tablicy, wtedy pętla for jest sensowniejszym rozwiązaniem. Nie ma sensu optymalizować tego typu pętli, gdy mamy np. do czynienia z tablicą kilkunastoelementową. W każdym razie to, od kiedy zaczyna się opłacać robić tego typu optymalizacje, zależy często od testów – wystarczy napisać obie wersje programu i sprawdzić, czy zyskujemy coś na którejś z nich. Na pewno jednak dobry programista powinien umieć napisać obie wersje.
Problem jest co prawda prosty, ale bardzo ważny, więc pokażemy jeszcze dwa ulepszenia tego algorytmu. Oto pierwsze z nich.
Wyszukiwanie liniowe proste
Wyszukiwanie liniowe proste
Tym razem musimy założyć, że tablica jest niepusta, czyli że \( n\ge 1 \). Oto kolejna wersja rozwiązania problemu wyszukiwania liniowego.
{\( {\mbox{ n\ge 1}} \)} k:=1; {\( {\mbox{ k=1, n\ge 1}} \)} <b>while</b> (k<n) and (A[k]<> x) <b>do</b> {\( {\mbox{(\forall 1\le j < k: A[j] \neq x) \land (1\le k\le n)}}\)} k:=k+1; {\( {\mbox{ (A[k]=x) \Leftrightarrow ((\exists 1\le j \le n: A[j] = x) \land (1\le k\le n))}} \)} jest := A[k]=x {\( {\mbox{ (jest) \Leftrightarrow ((\exists 1\le j \le n: A[j] = x) \land (k\le n))}} \)}
Ulepszenie polega na uproszczeniu treści pętli. Zauważmy, że pętla przerwie swoje działanie, gdy tylko k dojdzie do n lub \( A[k] \) będzie równe \( x \). Możliwe jest też, że pętla przerwie działanie z obu powodów na raz. Pozbywamy się tu też dodatkowej zmiennej logicznej jest i działamy bezpośrednio na elementach tablicy \( A \).
Sprawdzenie, że warunki początkowe dobrze inicjalizują niezmiennik jest proste. Również nieskomplikowany jest dowód niezmienniczości. Najtrudniejsze tym razem będzie pokazanie, że negacja dozoru i niezmiennik implikują warunek
\( {\mbox{ (A[k]=x) \Leftrightarrow ((\exists 1\le j \le n: A[j] = x) \land (1\le k\le n))}} \).
Zanim to zrobimy, zauważmy, że zachodzą następujące tożsamości logiczne.
\( ((p \land q) \Rightarrow r) \Leftrightarrow ((p\Rightarrow r) \lor (q\Rightarrow r)) \) \( ((p \lor q) \Rightarrow r) \Leftrightarrow ((p\Rightarrow r) \land (q\Rightarrow r)) \)
Sprawdzenie prawdziwości tych tautologii pozostawiamy jako ćwiczenie. Są one o tyle ważne, że bardzo często dowodzimy wynikania czegoś z koniunkcji albo alternatywy warunków i tautologie te pozwalają nam zredukować dowody do prostszych przypadków. Zauważmy charakterystyczną zamianę rolami spójników logicznych \( \land \) oraz \( \lor \). Kiedy dowodzimy, że coś wynika z koniunkcji warunków, wystarczy że udowodnimy, że wynika z jednego z nich. Natomiast gdy dowodzimy, że coś wynika z alternatywy warunków, wówczas musimy pokazać, że wynika z każdego z nich.
Dowiedziemy zatem prawdziwości następującej formuły:
\( (((k\ge n)\lor(A[k]=x)) \land (\forall 1\le j < k: A[j] \neq x) \land (k\le n)) \Rightarrow ((A[k]=x) \Leftrightarrow ((\exists 1\le j \le n: A[j] = x) \land (1\le k\le n))) \).
Lewa strona implikacji to zaprzeczenie dozoru i niezmiennik, a prawa strona implikacji to warunek, który jest nam konieczny do dowodu ostatecznej formuły: wyraża on fakt, że to czy w tablicy \( A \) znajduje się wartość \( x \) zależy wyłącznie od tego, czy \( x \) równa się \( A[k] \) po wyjściu z pętli. W poprzedniku implikacji mamy alternatywę i dwie koniunkcje. Korzystając z praw de Morgana rozbijamy alternatywę otrzymując równoważny poprzednikowi implikacji warunek
\( ((k\ge n) \land (\forall 1\le j < k: A[j] \neq x) \land (1\le k\le n)) \lor ((A[k]=x) \land (\forall 1\le j < k: A[j] \neq x) \land (1\le k\le n)) \).
Mamy tu do czynienia z postacią właśnie omawianej tautologii, kiedy to z alternatywy \( p \) oraz \( q \) wynika \( r \). Rolę \( p \) pełni tu formuła
\( ((k\ge n) \land (\forall 1\le j < k: A[j] \neq x) \land (1\le k\le n)) \), rolę \( q \)
formuła \( ((A[k]=x) \land (\forall 1\le j < k: A[j] \neq x) \land (1\le k\le n)) \),
zaś rolę \( r \) pełni formuła
\( (A[k]=x) \Leftrightarrow ((\exists 1\le j \le n: A[j] = x) \land (1\le k\le n)) \).
Osobno udowodnimy więc dwie implikacje:
\( p \Rightarrow r \) i \( q\Rightarrow r \).
Zacznijmy od \( p\Rightarrow r \). Załóżmy, że zachodzi \( p \). Wtedy, ponieważ \( k\le n \) oraz \( k\ge n \), więc \( k=n \). Skoro tak, to w trzecim czynniku koniunkcji wchodzącej w skład \( p \) mamy \( (\forall 1\le j < n: A[j] \neq x) \). Zatem istnieje \( j \) pomiędzy \( 1 \) a \( n \) takie, że \( A[j]=x \) wtedy i tylko wtedy, gdy \( A[n]=x \), czyli \( A[k]=x \), co było do pokazania. Oczywiście drugi czynnik koniunkcji w formule \( r \) jest trywialnie prawdziwy dla \( k=n \).
Pozostało nam do pokazania, że \( q \Rightarrow r \). Z \( q \) wynika, że \( 1\le k \le n \) oraz że \( A[k]=x \). Zatem istnieje takie \( j \) (równe \( k \)), że \( A[j]=x \).
Pokazana implikacja kończy cały dowód.
Oczywiście możemy tu narzekać, że dość prosty program, którego poprawność była "oczywista", miał tak skomplikowany dowód poprawności. Nie zapominajmy jednak, że
- Po pierwsze, gdy już udowodnimy poprawność takiego kodu, możemy opakować go w procedurę i więcej do niego nie zaglądać, wiedząc, że na pewno dobrze zadziała.
- Po drugie, co można zaproponować poza takim dowodem? Solenne przyrzeczenie programisty, że się nie pomylił?
- Po trzecie, jak się wkrótce okaże, technika niezmienników służy nie tylko do dowodzenia poprawności programów, ale też do prawidłowego konstruowania pętli.
- Po czwarte, często przeprowadzając dowody nie zauważa się szczególnych przypadków. W analizowanym programie na przykład można łatwo przeoczyć konieczność założenia \( n\ge 1 \). Puste tablice też się zdarzają i akurat w naszym przypadku mógłby wystąpić błąd na samym początku przy sprawdzaniu pierwszego dozoru pętli. Jest tam bowiem wyrażenie A[k]=x i gdyby wartość A[1] byłaby nieokreślona, to mógłby wystąpić błąd. Również po zakończeniu pętli zaglądamy do A[1] i jeśli przypadkiem znajdzie się tam \( x \), to otrzymamy błędną odpowiedź (powinna być false, a byłaby true). Co gorsza, tego typu błąd może w żadnych testach nie wyjść!
Zauważmy, że dla \( n\ge 1 \) wszystko jest w porządku: wszędzie tam, gdzie odwołujemy się do indeksu tablicy \( A \), mieści się on w zakresie określoności [1..n], a gwarantuje nam to właśnie niezmiennik. Zapamiętajmy
Ilekroć odwołujemy się do tablicy, powinniśmy móc udowodnić, że indeks tablicy mieści się w dziedzinie określoności.
Wyszukiwanie liniowe ze strażnikiem
Wyszukiwanie liniowe ze strażnikiem
Podany wyżej algorytm wydaje się tak prosty, że trudno jest cokolwiek uprościć. Pokażemy jego dość istotne ulepszenie, którego wiele odmian stosuje się w podobnych sytuacjach. Zauważmy, że gdybyśmy wiedzieli, że \( x \) znajduje się gdzieś w tablicy i na przykład chcieli poznać jego indeks, to nie trzeba byłoby się zabezpieczać przed końcem tablicy i jedynym warunkiem dozoru byłoby A[k]<>x. Pomysł jest następujący. Dodajmy jeden element na końcu tablicy deklarując ją na początku dłuższą o 1 niż potrzeba. Zatem tablica będzie miała zakres [1..n+1], ale prawdziwe wartości, wśród których będziemy szukali \( x \), będą tylko pomiędzy 1 a n.
Oto propozycja programu:
\( \{ {\mbox{ n\ge 1}}\} \) k:=1; A[n+1]:=x; \( \{{\mbox{ n\ge 1, k=1, A[n+1]=x}}\} \) <b>while</b> A[k]<> x <b>do</b> \( {\mbox{\{(\forall 1\le j < k: A[j] \neq x) \land (1\le k\le n+1) \land (A[n+1]=x)}}\} \) k:=k+1; \( \{{\mbox{ (k\le n) \Leftrightarrow (\exists 1\le j \le n: A[j]=x)}}\} \) jest := k<=n \( \{{\mbox{ (jest) \Leftrightarrow (\exists 1\le j \le n: A[j] = x) }}\} \)
Zobaczmy jak uprościł się nam program. W warunku dozoru zniknęła koniunkcja oraz konieczność wyliczania jednego warunku logicznego ( k<n). Przez to dowód poprawności też będzie prostszy. Skupmy się na samej pętli. Widać, że przy wejściu do pętli niezmiennik jest prawdziwy – wynika wprost z warunku wstępnego.
Jeśli chodzi o niezmienniczość w czasie wykonywania pętli, podobnie jak zeszłym razem odtworzenie klauzuli
\( (\forall 1\le j < k: A[j] \neq x) \)
przy jednokrotnym obrocie pętli jest dość oczywiste. Ostatni warunek \( A[n+1]=x \) cały czas zachowuje prawdziwość, bo nic się w tablicy nie zmienia w czasie wykonywania pętli. Najbardziej ambitne będzie pokazanie, że \( k\le n+1 \). Dowód tego faktu polega na zauważeniu, że gdy wchodzimy do pętli, to – na mocy założenia indukcyjnego \( 1\le k \le n+1 \) - to mamy z poprzedniego obrotu pętli – oraz, że \( A[k] \neq x \) - to mamy z dozoru pętli. Stąd po uwzględnieniu tego, że \( A[n+1]=x \) dostajemy, że \( k \neq n+1 \). A skoro \( 1\le k \le n+1 \) oraz \( k\neq n+1 \), to oznacza, że \( 1\le k < n+1 \), czyli \( 2 \le k+1 < n+2 \), z czego wnioskujemy, że \( 1\le k+1 \le n+1 \), co po przypisaniu k:=k+1 staje się z powrotem \( 1\le k \le n+1 \) na mocy reguły przypisania.
Pozostaje udowodnienie, że zaprzeczenie dozoru i niezmiennik razem implikują warunek końcowy, czyli że
\( ((A[k]=x) \land (\forall 1\le j < k: A[j] \neq x) \land (1\le k\le n+1) \land (A[n+1]=x)) \Rightarrow ((k\le n) \Leftrightarrow (\exists 1\le j \le n: A[j] = x)) \).
Tym razem wygodnie będzie nam skorzystać z następującej klasycznej tautologii:
\( p \Rightarrow (q \Rightarrow r) \) jest równoważne \( (p \land q) \Rightarrow r \)
Ponieważ mamy udowodnić równoważność warunków \( k\le n \) oraz \( \exists 1\le j \le n: A[j] = x \), więc osobno pokażemy obie implikacje.
Pierwsza z nich
\( ((A[k]=x) \land (\forall 1\le j < k: A[j] \neq x) \land (1\le k\le n+1) \land (A[n+1]=x)) \land (k\le n)) \Rightarrow (\exists 1\le j \le n: A[j] = x) \).
Ta implikacja jest oczywista: wystarczą trzy warunki z przesłanek: \( (A[k]=x) \), \( 1\le k \) oraz \( k\le n \), żeby udowodnić tezę.
Druga implikacja:
\( ((A[k]=x) \land (\forall 1\le j < k: A[j] \neq x) \land (1\le k\le n+1) \land (A[n+1]=x)) \land (\exists 1\le j \le n: A[j] = x)) \Rightarrow (k\le n) \)
jest prawdziwa: ponieważ \( (\exists 1\le j \le n: A[j] = x) \), a \( k \) jest z przedziału \( [1..n+1] \), więc gdyby \( k \) było równe \( n+1 \), wówczas otrzymalibyśmy sprzeczność z warunkiem mówiącym o tym, że na lewo od \( k \) wartości \( x \) nie ma, czyli \( (\forall 1\le j < k: A[j] \neq x) \), który jest w poprzedniku implikacji.
To kończy dowód poprawności tego algorytmu.
Warto dla dużych tablic przekonać się, że metoda ze strażnikiem jest nieco szybsza niż poprzednia. Przyspieszenie powinno być rzędu kilkunastu procent. Zawsze coś!
Co jednak zrobić, gdy nie mamy wpływu na decyzję o deklaracji tablicy. Ktoś nam daje tablicę, w której mamy namierzyć wartość \( x \) i nie ma ekstra elementu o indeksie \( n+1 \). Mamy na to sposób.
\( {\mbox{ n\ge 1}} \) <b>if</b> A[n]=x <b>then</b> jest := true <b>else</b> <b>begin</b> v:=A[n] // zapamiętujemy ostatnią wartość tablicy k:=1; A[n]:=x; // i teraz możemy ją zamazać bez obawy o jej utracenie <b>while</b> A[k]<> x <b>do</b> // stosujemy znany algorytm ze strażnikiem k:=k+1; jest := k<n; // ten warunek nieco się zmienił A[n] := v // a tutaj odtwarzamy zamazaną wartość \( {\mbox{ (jest) \Leftrightarrow (\exists 1\le j \le n: A[j] = x)}} \)
Czasem bardzo proste pomysły są niezwykle skuteczne!
Całkowita poprawność programów
Całkowita poprawność programów
Jak na razie umiemy sobie poradzić z programami, które zatrzymają swoje działanie. Problem, czy dany program zatrzyma się dla konkretnych danych jest nierozstrzygalny, więc nie ma metody stwierdzania czy nie nastąpi zapętlenie. Nie oznacza to, że jesteśmy bezradni. W wielu przypadkach udowodnić własność stopu możemy i zajmiemy się teraz tym zagadnieniem.
Mnożenie chłopów rosyjskich
Rozważmy następujący program:
program ChlopiRosyjscy(x0,y0:Integer); var x,y,z:Integer; begin x:=x0; y:=y0; z:=0; while x<>0 do begin if odd(x) then z:=z+y; x:= x div 2; y:=y+y end; Write(z) end.
Fragment ten wyznacza pewną wartość z w zależności od początkowych wartości x0,y0. Spróbujmy określić tę zależność. Przeprowadźmy symulację dla paru wartości początkowych. Przekonamy się szybko, że np. dla pary wartości (x0,y0) równej (3,7) wynikiem jest 21, dla (5,6) wynikiem jest 30 i tak na oko końcowa wartość z jest wynikiem mnożenia x0 przez y0. Czy można ten fakt udowodnić?
Nazwa algorytmu pochodzi stąd, że etnografowie znaleźli na Syberii obszary, w których chłopi właśnie w ten sposób mnożyli w pamięci. Czy słusznie?
Znalezienie niezmiennika nie jest oczywiste, ale możliwe. Oto ten sam program z asercjami ułatwiającymi udowodnienie częściowej poprawności.
program ChlopiRosyjscy(x0,y0:Integer); var x,y,z:Integer; begin x:=x0; y:=y0; z:=0; {x=x0, y=y0, z=0} while x<>0 do {z+xy=x0y0} begin if odd(x) then z:=z+y; {(odd(x) \( \land \) z-y+xy=x0y0) \( \lor (\neg \)odd(x)\( \land \) z+xy=x0y0) x:= x div 2; {z+2xy=x0y0} y:=y+y {z+xy=x0y0} end; {z=x0y0} Write(z) end.
Łatwo się przekonać, że
- Niezmiennik z+xy=x0y0 inicjalizuje się dobrze po początkowych przypisaniach x:=x0; y:=y0; z:=0.
- Z niezmiennika z+xy=x0y0 i zaprzeczenia dozoru x=0 wynika natychmiast warunek końcowy z=x0y0.
- Niezmiennik z+xy=x0y0 odtwarza się po każdym obrocie pętli. Ten ostatni fakt może nie jest tak oczywisty, więc parę słów wyjaśnienia. Po pierwsze musimy przypomnieć sobie, że x div 2=x/2, gdy x jest parzyste oraz że x div 2=(x-1)/2, gdy x jest nieparzyste. Jeśli na początku pętli x jest parzyste, to pierwsza instrukcja jest równoważna pustej i w oczywisty sposób niezmiennik pozostaje prawdziwy. Po wykonaniu x:=x div 2 prawdziwy jest warunek z+2xy=x0y0, gdyż x jest już dokładnie dwa razy mniejsze (zgodnie z regułą dowodzenia dla instrukcji przypisania), a po wykonaniu instrukcji y:=y+y mamy z+2x(y/2)=x0y0, czyli niezmiennik odtwarza się. Jeśli natomiast na początku pętli x jest nieparzyste, to najpierw wykona się instrukcja z:=z+y, po której będzie spełniony warunek z-y+xy=x0y0. Teraz wykonanie instrukcji x:=x div 2 spowoduje, że będzie spełniony warunek z-y+(2x+1)y=x0y0, co jest równoważne warunkowi z+2xy=x0y0, co po przypisaniu y:=y+y doprowadza nas z powrotem do z+xy=x0y0, a to jest odtworzony niezmiennik.
Zatem pokazaliśmy, że nasz program jest częściowo poprawny dla każdych początkowych wartości x oraz y. Dla każdych dlatego, że nie zakładaliśmy niczego o wartościach początkowych x0 i y0. Teraz niespodzianka! Zbadajmy, jak zachowuje się program dla danych ujemnych. Jeżeli x0 jest dodatnie, a y0 ujemne, nie ma problemu. Jeśli jednak x0 będzie ujemne, mamy kłopot. Zobaczmy na przykład, jakie wartości pojawią się kolejno dla danych początkowych x0=-5, y0=2.
| Liczba obrotów | x | y | z |
|---|---|---|---|
| 0 1 2 3 4 ... |
-5 -3 -2 -1 -1 |
2 4 8 16 32 |
0 2 6 6 22 |
Widać, że program się zapętla. Wartość x zawsze będzie równa -1, gdyż zachodzi (-1) div 2 = -1. Zauważmy, że program jest nadal częściowo poprawny, gdyż z definicji każdy pętlący się program taki jest. Przy okazji zweryfikujmy poprawność naszego niezmiennika. W każdym wierszu tabeli, reprezentującym stan obliczeń na początku pętli, wartość wyrażenia z+xy jest stała i równa -10, czyli x0y0.
Rzecz jasna musimy wrócić do pytania jak wymusić zatrzymanie się programu: gdyby bowiem program był częściowo poprawny, a do tego wiedzielibyśmy, że program zatrzyma się, mielibyśmy gwarancję uzyskania żądanego wyniku. Jak zatem wywnioskować, czy program się zatrzyma?
Metoda Floyda dowodzenia warunku stopu
Metoda ta opracowana przez Roberta Floyda w latach sześćdziesiątych korzysta z zasady indukcji. Pomysł jest następujący. Chodzi o pokazanie, że pewna wartość, mówiąc intuicyjnie, maleje w każdym obrocie pętli, a zmniejszanie to nie może się ciągnąć w nieskończoność. Aby przedstawić tą metodę możliwie ogólnie, wprowadźmy pojęcie relacji dobrze ufundowanej. Załóżmy, że mamy określoną relację dwuargumentową r w zbiorze A.
Definicja 1
Łańcuchem relacji r nazwiemy każdy skończony bądź nieskończony ciąg \( a=a_1,a_2,\ldots \) elementów z A taki, że dla każdych \( a_i,a_{i+1} \) należących do \( a \) zachodzi \( (a_i,a_{i+1})\in r \). Czyli kolejne wyrazy ciągu są ze sobą w relacji r.
Definicja 2
Powiemy, że relacja r jest dobrze ufundowana (ang. well founded) w zbiorze A wtedy i tylko wtedy, gdy nie istnieje nieskończony łańcuch relacji r w zbiorze A.
Jeśli relacja r jest dobrze ufundowana w zbiorze A, taki zbiór nazwiemy dobrze ufundowanym (przez relację r).
Najprostszym zbiorem dobrze ufundowanym jest zbiór liczb naturalnych z relacją \( > \). Istotnie nie można w nieskończoność pomniejszać liczb naturalnych. Oczywiście relacja \( \ge \) dobrze ufundowana nie jest w tym zbiorze: można stworzyć nieskończony łańcuch składający się choćby z samych zer. Widać, że relacja dobrze ufundowana musi być przeciwzwrotna.
Będziemy się teraz starali znaleźć odwzorowanie wartości zmiennych w zbiór dobrze ufundowany tak, aby kolejne wartości tego odwzorowania dla kolejnych obrotów pętli tworzyły łańcuch. Jeśli się nam to uda, to bedzie to oznaczało, że pętla musi się zatrzymać po skończonej liczbie kroków. W naszych przykładach typowym zbiorem dobrze ufundowanym będzie właśnie zbiór liczb naturalnych z relacją większości.
W przypadku algorytmu mnożenia chłopów rosyjskich taką funkcją będzie \( f(x,y,z)=x \). Pokażemy, że jeśli początkowa wartość x jest dodatnia, to po jednym obrocie pętli kolejna wartość jest mniejsza od poprzedniej. Jest to oczywisty fakt związany z funkcją dzielenia przez 2. Mamy bowiem dla x>0 \( x \div 2 \le x/2 < x \). Dla pełności dowodu warto tu dodać do niezmiennika warunek \( x\ge 0 \). Dlaczego nie \( x>0 \)? Bo nie dałoby się go udowodnić. Po prostu przy wyjściu z pętli x=0, więc warunek ten nie byłby spełniony. Zauważmy, że nie ma problemu z dowodem ostrej większości kolejnych wartości, gdyż nigdy nie wejdziemy do pętli jeśli x=0. Dozór pętli zapewnia nam bowiem, że \( x\neq 0 \), co w połączeniu z niezmienniczym \( x\ge 0 \) daje \( x>0 \), a to już wystarcza do ostrej nierówności z następną wartością x.
To czego brakuje to poprawna inicjalizacja niezmiennika. Aby był on spełniony na samym początku, konieczne jest, żeby x było nieujemne. Zatem podany program jest całkowicie poprawny dla wszystkich par (x0,y0) takich, że \( x0\ge 0 \). Nadmieńmy, że program nie wykonuje żadnych operacji mogących spowodować błąd, więc zawsze zakończy się dając poprawny wynik.
Wyszukiwanie binarne
Gdyby trzeba było wybrać najważniejszy algorytm w całej informatyce, to wybrałbym chyba algorytm wyszukiwania binarnego. Dzięki niemu jesteśmy w stanie szybko odnajdywać dane w posortowanym ciągu. Załóżmy tu, że w tablicy A:array[1..n] of Integer mamy posortowane niemalejąco liczby całkowite. Naszym zadaniem jest stwierdzić, czy pośród nich znajduje się liczba x. Wykorzystamy tu następujący pomysł. Porównamy wartość x ze środkowym elementem tablicy A[(n+1) div 2]. I teraz albo x będzie od niego większy i wtedy na pewno x-a nie ma na lewo od tego elementu, albo będzie mniejszy lub równy i wtedy jeśli jest, to tylko w lewej połówce tablicy. Zatem możemy za pomocą jednego sprawdzenia sprowadzić zadanie do dwa razy mniejszego rozmiaru. Oto rozwiązanie:
l:=1; p:=n; <b>while</b> (l < p) <b>do</b> <b>begin</b> s:=(l+p) <b>div</b> 2; <b>if</b> x > A[s] <b>then</b> l := s+1 <b>else</b> p :=s <b>end</b>; jest := x = A[l] </pascale> <p>Zróbmy parę spostrzeżeń. Po pierwsze, nie sprawdzamy nigdzie, czy przypadkiem A[s] nie równa się x, tylko doprowadzamy za każdym razem do momentu, w którym badany przedział jest jednoelementowy. Moglibyśmy sprawdzić czy A[s]=x wprowadzając dodatkowe sprawdzenie, ale czy to się opłaca, przedyskutujemy później. Po drugie, wybraliśmy akurat ostrą nierówność prowadzącą do przesunięcia indeksu l na prawo od s i wydaje się na pierwszy rzut oka, że równie dobrze byłoby sprawdzić nieostrą nierówność, zastępując instrukcję warunkową następującą: </p> <pascal> <b>if</b> x>=A[s] <b>then</b> l:=s <b>else</b> p:=s-1
Sytuacja wygląda na zupełnie symetryczną. Przekonamy się za chwilę, że wcale tak nie jest.
Udowodnijmy poprawność tego fragmentu kodu. Ustalmy, że predykat Sort(A) mówi nam o tym, że tablica A jest posortowana niemalejąco.
l:=1; p:=n; <b>while</b> l < p <b>do</b> {Sort(A) \( \land (1\le l\le p\le n) \land \exists (1\le k \le n: A[k]=x \Leftrightarrow \exists (l\le k \le p: A[k]=x)} \) <b>begin</b> s:=(l+p) <b>div</b> 2; if x > A[s] <b>then</b> l:=s+1 <b>else</b> p:=s <b>end</b>; jest := x=A[l]
Niezmiennik mówi nam, że po pierwsze tablica jest posortowana cały czas, po drugie indeksy l oraz p są w zakresie indeksów tablicy i że l nie przekracza p, a trzecia część niezmiennika mówi nam, że jeśli element x jest gdzieś w tablicy, to jest między indeksami l oraz p.
Zauważmy, że niezmiennik inicjalizuje się dobrze, jeśli tylko \( 1\le n \) i jest to warunek, który musimy tu dodać jako warunek wstępny na dane (przy okazji sprawdźmy, że jest to warunek konieczny poprawności programu; dla n=0 dostalibyśmy błąd!). Po drugie ze względu na to, że dla \( k>1 \) zachodzi \( 1\le k \div 2 < k \) otrzymujemy nierówność \( l\le (l+p) \div 2 < p \) i ta ostatnia ostra nierówność jest bardzo istotna. Zauważmy więc, że przypisując zmiennej l wartość (l+p) div 2 +1 otrzymujemy wartość ostro większą od l, a przypisując zmiennej p wartość (l+p) div 2 otrzymujemy wartość mniejszą ostro od p. Zatem funkcja F(l,p)=p-l ma wartości w zbiorze liczb naturalnych i maleje z każdym obrotem pętli. Czyli pętla zawsze się zakończy.
Odtworzenie się trzeciego warunku niezmiennika też jest dość oczywiste, gdyż jeśli x>A[s], to ze względu na przechodniość relacji większości mamy x>A[k] dla 1<=k<s, więc jeśli istnieje x w tablicy, to istnieje między s+1 a p. Gdy zaś x<=A[s], wówczas jeśli istnieje x w tablicy, to w szczególności znajdziemy je w przedziale 1..s, zatem przypisanie p:=s nadal utrzymuje w prawdziwości ten warunek.
Powstaje pytanie czy zaprzeczenie dozoru w połączeniu z niezmiennikiem da nam końcowy warunek \( A[l]=x \Leftrightarrow \exists 1\le k \le n: A[k]=x \)? Jeśli tak, to ostatnie przypisanie ustali nam wartość zmiennej jest na to, czego chcemy, czyli \( \exists 1\le k \le n: A[k]=x \).
Spróbujmy przerachować. Zaprzeczenie dozoru to l>=p. W połączeniu z niezmiennikiem daje nam l=p. Z niezmiennika wiemy, że warunek \( \exists 1\le k \le n: A[k]=x \) jest równoważny warunkowi \( \exists l\le k \le p: A[k]=x \), ale że l=p, to jest to równoważne warunkowi A[l]=x.
Możemy się przekonać, że tak znaleziona wartość x będzie zawsze pierwsza od lewej. Jak to pokazać? Bardzo prosto. Wystarczy do niezmiennika dodać warunek \( \forall 1\le k < l: A[k]\neq x$ \). Widzimy, że inicjalizacja jest dobra (dla l=1 warunek ten jest trywialnie spełniony), odtworzenie warunku po każdym obrocie jest oczywiste: tylko gdy l się zmienia ten warunek mógłby zajść, a l zmienia się na s+1 tylko wtedy, gdy x>A[s], więc na lewo od s+1 nie ma x-ów. Zatem przy wyjściu z pętli również mamy niezmiennik spełniony, a ten nam gwarantuje, że na lewo od l nie ma żadnej wartości x. Czyli jeśli znaleźliśmy x, to jest on pierwszy od lewej.
Czytelnikom jako ćwiczenie pozostawiamy sprawdzenie, czy symetryczna wersja wyszukiwania binarnego jest błędna. Program zapewne się zapętli. Jest to bardzo częsty błąd popełniany przy kodowaniu tego algorytmu.
Ćwiczenia
Pliki
Wprowadzenie
Jak wiadomo, architektura powszechnie stosowanych komputerów charakteryzuje się tym, że pamięć operacyjna jest ulotna, a jej rozmiar jest niewystarczający do przechowywania dużej liczby danych. W związku z powyższym komputery wyposażane są w pamięci masowe (zewnętrzne) pozwalające na trwały zapis danych o dużych rozmiarach. W rozważaniach teoretycznych często przyjmuje się, że rozmiar pamięć masowej jest nieograniczony.
Konstrukcja nośników danych wykorzystywanych do realizacji pamięci masowych sprawia, że dane zapisywane są i odczytywane w postaci wielobajtowych bloków. Blok danych zgodny z fizyczną charakterystyką danego użadzenia zwany jest rekordem fizycznym. Typowy rozmiary rekordu fizycznego mieści się w zakresie od 512 bajtów do kilku kilobajtów.
Fizyczne właściwości urządzenia na jakim składowane są dane nie powinny rozpraszać uwagi programisty. Działanie programu nie może być zależne od rodzaju nośnika. W związku z tym na poziomie systemu operacyjnego wprowadzono pojęcie pliku. Plik jest logiczną jednostką przechowywania danych. Aby cokolwiek przechować w pamięci masowej, trzeba utworzyć co najmniej jeden plik. Warto w tym miejscu wspomnieć, że nie ma jednej uniwersalnej metody realizacji pojęcia pliku w systemie operacyjnym. Pliki realizowane są w strukturach zwanych systemami plików, które różnie wyglądają w różnych systemach operacyjnych. Często też w obrębie danego systemu operacyjnego mamy do wyboru wiele systemów plików o różnych właściwościach.
Model mentalny pliku
W pewnym uproszczeniu każdy plik możemy wyobrazić sobie jako ciąg kolejnych elementów. Za ostatnim znajduje się znacznik końca pliku. Element który zostanie przewożony przy kolejnym odczycie lub zapisie wskazywany jest przez wskaźnik pliku stojący na początku tego elementu. Proszę jednak pamiętać, że jest to bardzo uproszczony model mentalny pliku, bo choćby wskaźnik końca może być realizowane na różne sposoby. Czasami jest to wyróżniona wartość (inna niż dowolna przechowywana w pliku informacja) zapisana na końcu pliku, a w innych rozwiązaniach informacja o końcu pliku zapisana jest w strukturze systemu zbiorów zwanej FAT (file allocation table).
Typy plików
Ze względu na organizacje danych wewnątrz pliku (na poziomie logicznym), będziemy rozróżniać trzy typy plików: pliki binarne, pliki tekstowe i pliki ogólne.
Pliki binarne
Plik binarny to po prostu ciąg bajtów. Inaczej można powiedzieć, że jest to plik, w którym rekord logiczny ma rozmiar jednego bajta. Dane zawarte w pliku binarnym zawsze traktowane są jak ciąg bajtów, bez względu na rodzaj zapisanej w pliku informacji. Co więcej każdy plik możemy potraktować jak plik binarny i w pewnym sensie „ręcznie” (nie zdając się na system operacyjny) interpretować jego zawartość bajt po bajcie.
Pliki ogólne
Plik ogólny podzielony jest na mniejsze/równe porcje zwane rekordami logicznymi. Generalnie plik ogólny możemy wyobrazić sobie jako zbiór rekordów logicznych ułożonych jeden za drugim podobnie jak komórki w tablicy. W języku Pascal mamy nawet pewne podobieństwa w składni deklaracji typu tablicy i pliku ogólnego. W obydwu przypadkach nazwa typu składowego występuje po słowie kluczowym of. (array[1..n] of integer; file of integer;)
Elementami składowymi pliku nie mogą być inne pliki ani wskaźniki (patrz następny wykład).
Rozmiar rekordu logicznego nie musi być równy rozmiarowi rekordu fizycznego. W związku z tym do manipulowania danymi w pliku potrzebny jest wydzielony obszar pamięci operacyjnej zwany buforem, w którym rekordy fizyczne „przerabiane” są na rekordy logiczne. Bufor stosowany jest również w pozostałych typach plików z uwagi na efektywność zapisu. Jest ona większa, gdy zapis lub odczyt obywa się odpowiednio dużymi porcjami będącymi całkowitą wielokrotnością rekordu fizycznego. Zatem jeśli chcemy pobrać z pliku tylko małą ilość informacji, choćby jeden bajt, do bufora zostanie ściągnięta większa ich porcja: zazwyczaj od kilkuset do kilkunastu tysięcy bajtów i próba odczytu kolejnego bajtu nie będzie już wymagała drogiej komunikacji z urządzeniem zewnętrznym. Zakładamy bowiem, że typowe przetwarzanie plików polega na pobieraniu informacji kolejno bajt po bajcie i wtedy dodatkowe czynności związane z transmisją danych są tak kosztowne, że warto na zapas ściągnąć większą porcję danych, co średnio na pewno się opłaci, nawet jeśli w jakimś konkretnym przypadku tych dodatkowych danych nie wykorzystamy. Podobnie przy zapisywaniu danych program czeka, aż bufor się wypełni i dopiero gdy uzna, że już jest ich wystarczająco dużo, żeby zainicjować fizyczny transfer, uruchomi odpowiednie procedury. Jedną z ról zamknięcia pliku jest wyczyszczenie bufora wyjściowego, czyli spowodowanie wymuszonego transferu danych, które czekały w buforze na transmisję. Często w drukarkach wierszowych użytkownicy skarżą się, że ostatni wiersz się im nie wydrukował i że przy wyłączaniu drukarki nagle się coś jeszcze drukuje. Jest to nic innego jak wydrukowanie wiersza zalegającego w buforze drukarki.
Prędkość działania urządzeń zewnętrznych jest o kilka rzędów wielkości mniejsza niż pamięci operacyjnej. Jest bowiem często związana z fizycznym ruchem pewnego urządzenia (głowicy), a tu nie mamy aż takich możliwości przyspieszania jak w przypadku pamięci rdzeniowych. Mechanika rządzi się swoimi prawami.
Pliki tekstowe
Pliki tekstowe zasługują na szczególną uwagę, gdyż sposób kodowania informacji w tych plikach jest najbardziej rozpowszechnionym standardem, a także dlatego, że w wielu językach programowania stanowią one osobny wyróżniony typ danych z dodatkowym zestawem poleceń. Najprościej mówiąc, plik tekstowy to ciąg znaków z podziałem na wiersze. Można powiedzieć, że podstawową jednostką danych w pliku tekstowym jest jeden znak, co w plikach zakodowanych w ASCII przekłada się na 1 bajt. Ale nie zawsze jeden znak to 1 bajt. W standardzie unicode jeden znak ma dwa bajty, a dodatkowo w standardzie tym występują sekwencje kilku bajtów oznaczające jeden znak. Również koniec wiersza kodowany jest na różne sposoby. W systemie Mac OS X jest to znak powrotu karetki, w systemie UNIX znak przejścia do nowego wiersza, a w systemie MS Windows koniec wiersza oznaczony jest dwoma znakami przejściem do nowego wiersza i powrotem karetki.
Rodzaje dostępu do pliku
Budowa pamięci masowej może też powodować ograniczenia w sposobie dostępu do poszczególnych części pliku. Ze względu na te ograniczenia pliki możemy podzielić na pilik sekwencyjne i pliki o dostępie bezpośrednim.
Pliki o dostępie sekwencyjnym
Pliki o dostępie sekwencyjnym charakteryzują się ograniczoną swobodą poruszania się po rekordach. Aby przeczytać k-ty rekord trzeba przeczytać poprzedzające go k-1 rekordów. Dodatkowo możemy przeskoczyć na początek albo na koniec pliku, ale nigdy w dowolne miejsce wewnątrz pliku.
Pliki o dostępie bezpośrednim
Pliki o dostępie bezpośrednim charakteryzują się tym, że rekordy logiczne są ponumerowane i można odczytywać je w dowolnym porządku dzięki operacji pozwalającej na przeskoczenie do rekordu o podanym numerze. W tego rodzaju plikach wszystkie rekordy logiczne muszą mieć taki sam rozmiar. Pliki o dostępie bezpośrednim realizuje się na takich urządzeniach, w których łatwo można się fizycznie dostać do dowolnego miejsca, niezależnie od jego położenia. Przykładami takich urządzeń są twarde dyski, pamięci flash.
Przetwarzanie plików
Generalnie każde przetwarzanie pliku odbywa się według schematu:
1. Otwarcie pliku 2. Operacje na danych w pliku 3. Zamknięcie pliku.
Otwarcie pliku
W momencie otwarcia pliku system tworzy deskryptor pliku (jeżeli wcześniej plik nie został otworzony), w którym przechowywane są między innymi takie informacje jak: określenie urządzenia pamięci masowej, na którym znajduje się plik, nazwa pliku, położenie bufora do przesyłania danych z pliku i do pliku oraz inne informacje. W programie odwołujemy się do pliku przez zmienną, w której umieszczony jest wskaźnik (uchwyt) do deskryptora pliku. W Pascalu operacja otwarcia pliku rozbita jest na dwie instrukcje. Pierwsza Assign(f, nazwa_pliku) wiąże zmienną f z plikiem o podanej nazwie. Tworzony jest deskryptor i umieszczany wskaźnik do niego w zmiennej f. Następnie drugą instrukcją plik otwierany jest od odczytu reset(f), zapisu rewrite(f) lub dopisywania danych append(f); Reset ustawia wskaźnik pliku na początku i przygotowuje plik do odczytu. Rewrite kasuje zawartości pliku (wskaźnik jest na początku) i przygotowuje plik do zapisu. Append nie kasuje zawartości pliku, ustawia wskaźnik na końcu pliku i przygotowuje plik do dopisania kolejnych elementów.
Operacje na danych w pliku (odczyt lub zapis)
W Pascalu jest to odpowiednio instrukcja read(f, zmienna), która powoduje odczyt danych z bieżącego rekordu logicznego (w pliku ogólnym) do zmiennej i przesuniecie wskaźnika pliku na początek kolejnego rekordu logicznego. W przypadku pliku tekstowego zachowanie instrukcji read jest zależne od typu zmiennej. Dla zmiennej typu char odczytywany jest jeden znak, a wskaźnik pliku przesuwa się do następnego zanku. Jeżeli zmienna jest typu liczbowego wtedy następuje odczytanie ciagu znaków odpowiadającego składniowo jednej liczbie danego typu. Jeżeli zmienna jest typu string, to odczytywany jest ciąg znaków, aż do końca bieżącego wiersza, a wskaźnik pliku zatrzymuje się przed znakiem końca wiersza. Aby przetworzyć znak końca wiersza, należy wykonać polecenie readln(f). Po jego wykonaniu wskaźnik pliku ustawia się na początku kolejnego wiersza. Aby zapisać informacje w pliku należy użyć polecenia write(f, zmienna). Polecenie to spowoduje zapisanie zawartości zmiennej do pliku i ustawi wskaźnik pliku na końcu zapisanego rekordu (w pliku ogólnym). W przypadku pliku tekstowego liczba zapisanych znaków zależna jest od typu zmiennej. I tak odpowiednie dla typu char zapisze się jeden znak, a wskaźnik pliku ustawi się za zapisanym znakiem. Dla typu liczbowego zapisze się ciąg znaków opowiadający danej liczbie. Dla typu string zapisane zostaną wszystkie znaki znajdujące się w zmiennej, a wskaźnik pliku ustawi się za ostatnim z zapisanych znaków. Aby zapisać znacznik końca linii, należy użyć polecenia writeln(f).
Zamknięcie pliku
W Pascalu zamknięcie pliku realizowane jest poleceniem Close(f). Uwaga, należy pamiętać o zamknięciu pliku nie tylko ze względu na zwolnienie pamięci zajmowanej przez deskryptor i bufor danych. Zamknięcie pliku ważne jest też ze względu na opóźniony zapis. Opóźniony zapis ma na celu zwiększenie efektywności zapisu danych w pamięci masowej. Polega on na tym, że dane z bufora nie są zapisywane dopóki nie zgromadzi się na tyle duża porcja, by zapis był efektywny (np. porcja równa rozmiarowi rekordu fizycznego). Wiąże się z tym niebezpieczeństwo utraty danych, jeżeli plik nie zostanie poprawnie zamknięty. Wtedy mogą zostać utracone dane, które gromadziły się w buforze i nie zostały jeszcze zapisane. Zamknięcie piku gwarantuje zapisanie danych zalegających w buforze. Czasami twórcy systemu operacyjnego stosują zabezpieczenie, które polega na tym, że w momencie gdy program kończy swoje działanie, automatycznie zapisywane są dane z buforów dla wszystkich niezamkniętych plików używanych przez dany program. Podobne rozwiązanie stosowano kiedyś w drukarkach igłowych, co przejawiało się dosyć zaskakującym zachowaniem drukarki, która czasami w momencie wyłączania, ku zaskoczeniu użytkownika, dodrukowywała brakującą część wiersza.
Dostęp bezpośredni
Warto jeszcze wspomnieć, że w plikach ogólnych i binarnych o dostępie bezpośrednim możliwe jest bezpośrednie przejście do dowolnego rekordu logicznego. Operacje tę realizuje polecenie seek(f, N). Powoduje przejście do rekordu o numerze N, przy czym pierwszy rekord w pliku ma numer 0. Wykonanie instrukcji seek(f, 0) jest równoważne instrukcji Reset(f). Operacja seek nie może być stosowana w plikach tekstowych.
Pliki szczególne input i output
W większości języków programowania definiuje się szczególne pliki: standardowe wejście i wyjście, które w momencie uruchomienia programu są otwarte i gotowe do pracy. Standardowe wejście nazywa się input, a standardowe wyjście output; pierwsze z nich otwarte jest do czytania, drugie do pisania. Plik input jest związany z klawiaturą, a plik output z monitorem ekranowym. Jeśli chcemy przeczytać coś ze standardowego pliku wejściowego, albo wypisać coś do standardowego pliku wyjściowego, to nie musimy ani otwierać ich, ani nawet nazywać w instrukcjach czytania i pisania. Zakładamy, że jeśli w instrukcjach Read/Write nie pojawi się wśród argumentów jako pierwsza zmienna plikowa, to mamy do czynienia z czytaniem/pisaniem w plikach standardowych, tak jak to się dzieje w VIPie.
Przykład przetwarzania plików ogólnego lub binarnego
Przykład
<b>var</b> f:file <b>of</b> integer; zmienna:integer; <b>begin</b> Assign(f, nazwa_pliku); Reset(f); <b>while</b> <b>not</b> Eof(f) <b>do</b> <b>begin</b> Read(f, zmienna); Przetwórz(zmienna) <b>end</b>; Close(f); <b>end</b>.
Przykład przetwarzania plików tekstowych
Przykład
<b>var</b> f:text; ch:char; <b>begin</b> Assign(f, nazwa_pliku); Reset(f); <b>while</b> <b>not</b> Eof(f) <b>do</b> <b>begin</b> <b>while</b> <b>not</b> Eoln(f) <b>do</b> <b>begin</b> Read(f, ch) Przetwórz(ch) <b>end</b>; <b>if</b> <b>not</b> Eof(f) <b>then</b> Readln(f); <b>end</b>; Close(f); <b>end</b>.
Powyższy fragment programu należy uznać za wzorcową metodę przetwarzania plików tekstowych znak po znaku. Warto zwrócić uwagę na fakt, który często przyjmujemy za oczywisty. Powyższy program jest poprawny tylko przy założeniu, że Eof(f) \( \Rightarrow \) Eoln(f). Gdyby ta implikacja nie zachodziła, wówczas powyższy program wchodziłby w nieskończona pętlę po dojściu do końca pliku. Jeśli nie mamy pewności, że w realizacji języka programowania, z której korzystamy, ta implikacja nie zachodzi, trzeba tę pętlę zapisać inaczej. W większości realizacji języków programowania to założenie jest prawdziwe.
Przykład użycia wirtualnego czytania
Przy przetwarzaniu plików często mamy problem z tym, że aby poznać wartość elementu, trzeba go wpierw przeczytać. Przy czym należy pamiętać o tym, że element przeczytany z pliku niekoniecznie od razu wykorzystamy i będzie nam psuł czytelnośc algorytmu, gdyż będziemy go przechowywali poza plikiem do dalszego przetworzenia. Przykładowym programem, w którym wspomniany problem może wystąpić, jest następujące zadanie.
Przykład:
Usuń z posortowanego niemalejąco pliku f wszystkie wartości występujące w posortowanym niemalejąco pliku g i wynik zapisz w pliku h.
Bez utraty ogólności istoty rozwiązania możemy założyć, że wszystkie 3 pliki są typu file of Integer i zawierają liczby całkowite. Zauważmy, że całkiem prawdopodobnym wynikiem jest plik pusty, gdy się okaże, że wszystkie wartości z f występują w g. Zadanie to chciałoby się rozwiązać za pomocą liniowego algorytmu takiego jak na tablicach. Gdyby dane były zapisane w tablicach F,G,H:array[1..n] of integer, wówczas moglibyśmy zastosować następujący kod:
i:=1; j:=1; k:=1; <b>while</b> (i<=n) <b>and</b> (j<=n) <b>do</b> {W H[1..k-1] są elementy F[1..i-1] których nie ma w G[1..j-1] <b>if</b> F[i]<G[j] <b>then begin</b> {Nie ma w tablicy G elementu F[i]} H[k]:=F[i]; i:=i+1; k:=k+1; <b>end</b> <b>else if</b> F[i]>G[j] <b>then</b> {G[j] już nie dotyczy żadnego z elementów F[i..n]} j:=j+1 <b>else</b> {F[i]=G[j]) i:=i+1; {zostawiamy j, żeby wytłuc z F[i..n] wszystkie elementy o wartości G[j]} <b>if</b> i<=n <b>then</b> {skończyła się tablica G, a w F są jeszcze elementy do skopiowania} <b>for</b> i:=i <b>to</b> n <b>do</b> <b>begin</b> H[k]:=F[i]; k:=k+1 <b>end</b>
Spróbujmy teraz wykonać podobny algorytm z plikami. Musimy zacząć od sprawdzenia, czy oba są niepuste.
Przykład
<b>var</b> f,g,h:file of Integer; fx,gx:Integer; <b>begin</b> Assign(f, nazwa_pliku1); Assign(g, nazwa_pliku2); Reset(f); Reset(g); Rewrite(h); <b>if</b> eof(g) <b>then</b> {Niczego nie wyrzucamy z f; kopiujemy wszystko do h} <b>while</b> <b>not</b>(eof(f) <b>do</b> <b>begin</b> Read(f,fx); Write(h,fx) <b>end</b> <b>else</b> <b>if not</b> eof(f) <b>then</b> <b>begin</b> Read(f,fx); Read(g,gx); {teraz jesteśmy gotowi wystartować z porównywaniem decydującym o tym, który plik awansujemy} <b>while</b> (<b>not</b> Eof(f)) <b>and</b> (<b>not</b> eof(g)) <b>do</b> <b>if</b> fx < gx <b>then begin</b> Write(h,fx); {nie ma w g elementu fx} Read(f,fx) <b>end</b> <b>else if</b> fx > gx <b>then</b> Read(g,gx) {stary element fg już był bezużyteczny} <b>else</b> {fx=gx} Read(f,fx} {stary fx nie powinien być przepisany do h}
Jak na razie idzie nieźle. Wyjdziemy z pętli albo wtedy gdy z pliku f przeczytamy ostatni element, albo z g. Zauważmy, że dalsze przetwarzanie, gdyby którykolwiek z plików sie skończył, mogłoby doprowadzic do błędu czytania poza końcem pliku.
Teraz stoimy w obliczu sytuacji, kiedy jeden z plików się skończył (a może oba? - czy jest to możliwe?), trzymamy w ręce ostatni element z tego pliku i musimy jakoś zakończyć algorytm. Nie wolno nam już czytać z pliku, którego ostatni element został przeczytany. Spróbujmy kontynuwać
<b>if</b> eof(f) <b>then</b> {trzeba sprawdzić, czy w pliku g nie ma wartości fx} <b>begin</b> <b>while</b> (gx < fx) <b>and</b> (not eof(g) <b>do</b> Read(g,gx); <b>if</b> gx<>fx <b>then</b> Write(h,fx) <b>end</b> <b>else</b> {w pliku g już nie ma niczego, więc tylko wartość gx trzeba wykluczyć z f} <b>begin</b> <b>while</b> (fx <> gx) <b>and</b> (<b>not</b> eof(f)) <b>do</b> <b>begin</b> Write(h,fx); Read(f,fx) <b>end</b>; <b>while</b> (fx = gx) <b>and</b> (<b>not</b> eof(f)) <b>do</b> Read(f,fx); {elementów równych gx nie wypisujemy} <b>while</b> <b>not</b> eof(f) <b>do</b> {kopiujemy resztę pliku f - elementy większe od gx} <b>begin</b> Write(h,fx); Read(f,fx) <b>end</b>; <b>if</b> fx<>gx <b>then</b> Write(h,fx) {i nie zapominamy o ostatnim elemencie} <b>end</b> Close(f); Close(g); Close(h); <b>end</b>;
Uff! Okazało się, że najżmudniejsza część programu pojawiła się wtedy, gdy wydawało się, że jesteśmy już blisko końca. Być może da się usprawnić jakoś ten kod w miarę normalnie, my jednak zajmiemy się nieco trikową metodą, ale za to niezwykle skracającą cały kod. Do tego załóżmy, że
- istnieje największa liczba całkowita; nazwijmy ją MAXINT
- w zadanych ciągach jej nie ma.
Napiszemy następującą procedurę
<b>procedure</b> Czytaj(var p:plik; var x:Integer); {procedura przypisuje zmiennej x wartość MAXINT, jeśli jesteśmy na końcu pliku lub czyta z pliku p kolejną wartość i podaje ją jako wartość zmiennej x} <b>begin</b> <b>if</b> eof(p) <b>then</b> x:=MAXINT <b>else</b> Read(p,x) <b>end;</b>
Teraz wszystko jest bardzo proste. Dzięki procedurze Czytaj uzyskaliśmy pewność, że nie wystąpi błąd przy próbie czytania, nawet jeśli będziemy stali na końcu pliku. Zastosowaliśmy wirtualne czytanie, które nie zawsze daje wartość znajdującą się w pliku. Oto kod po deklaracjach i inicjalizacjach plików.
Czytaj(f,fx); Czytaj(g,gx); <b>while</b> (fx < MAXINT) <b>or</b> (g < MAXINT) <b>do</b> <b>if</b> fx < gx <b>then begin</b> Write(h,fx); {nie ma w g elementu fx} Czytaj(f,fx) <b>end</b> <b>else if</b> fx > gx <b>then</b> Czytaj(g,gx) {stary element fg już był bezużyteczny} <b>else</b> {fx=gx} Czytaj(f,fx} {stary fx nie powinien być przepisany do h}
I już! Nic więcej nie trzeba robić poza zamknięciem plików! Warto zapamiętać ten sposób uproszczenia kodu.
Ćwiczenia
Pamięć dynamiczna
Pamięć dynamiczna
Dotychczas używając pamięci trzeba było z góry znać jej wielkość, aby zadeklarować odpowiednią strukturę danych. Takie rozwiązanie bywa niewygodne, gdy nie wiemy z jak dużymi danymi będziemy mieli do czynienia. Często bowiem wraz z danymi pojawia się ich rozmiar i dopiero wtedy chcielibyśmy ustalać wielkość struktury danych. W tym celu użyjemy tzw. pamięci dynamicznej, czyli takiej, której rezerwacja i zwalnianie odbywa się w czasie działania programu.
System operacyjny, uruchamiając program, przeznacza na jego obsługę fragment pamięci zapewniając wyłączność tak, aby żaden inny proces nie mógł się do niej dostać. W tym fragmencie przydzielonej pamięci mieści się kod programu, dane statyczne (czyli zadeklarowane na etapie deklaracji) oraz dane dynamiczne, czyli takie, dla których pamięć jest rezerwowana i zwalniana na bieżąco. W naszym języku będzie można deklarować zmienne dynamiczne, które będą rozpoznawane dzięki poprzedzeniu typu przy deklaracji symbolem ^, na przykład deklaracja
var px:^Integer;będzie traktowana jako deklaracja zmiennej wskaźnikowej do obiektu typu całkowitego.
Alokacja i zwalnianie pamięci dynamicznej
Przydział (alokacja) i zwalnianie (dealokacja) pamięci dynamicznej odbywa się za pomocą dwóch procedur: New(z) oraz Dispose(z). Obie te procedury mają jeden argument: zmienną. Wykonanie procedury New(z) powoduje następujące czynności
1. Określenie wielkości elementu alokowanego typu (wielkość ta musi być znana na etapie kompilacji programu) 2. Znalezienie adresu w pamięci, począwszy od którego jest dostępnych tyle kolejnych komórek, ile potrzeba na zaalokowanie żądanego elementu 3. Zarezerwowanie alokowanego obszaru 4. Przypisanie znalezionego adresu zmiennej z
Jeśli nie ma spójnego fragmentu pamięci, w którym można by zaalokować żądany element, to procedura New(z) powoduje błąd.
Procedura Dispose(z) powoduje tylko jedną rzecz
1. Odblokowanie zarezerwowanego obszaru pamięci i zwrócenie go do puli niewykorzystanych obszarów.
Przyjmijmy, że po wykonaniu Dispose(z) wartość zmiennej z jest nieokreślona. W rzeczywistości często kompilatory po zwolnieniu zaalokowanego obszaru pozostawiają starą wartość adresu na zmiennej, której dealokacja dotyczyła. Bardzo niebezpieczne jest używanie tej wartości do czegokolwiek i nie należy nigdy tego robić.
Zatem zmienne dynamiczne operują w rzeczywistości na adresach. W konsekwencji pamięć rezerwowana na zmienną dynamiczną jest taka sama (zazwyczaj 4 bajty) i niezależna od tego, na co ta zmienna wskazuje.
Operacje na zmiennych dynamicznych
Zmienne dynamiczne mają ograniczone możliwości wykonywania na nich działań. Możliwe jest porównanie ich wartości, ale tylko pod kątem równości, czyli z operatorów relacyjnych mamy jedynie dwa, a mianowicie = oraz <>. Nie wolno zatem porównywać zmiennych dynamicznych za pomocą operatorów <,<=,>,>=.
Zmiennym dynamicznym można przypisywać wartości, ale jest to ograniczone do innych zmiennych dynamicznych; nie można budować za ich pomocą żadnych wyrażeń. Odwołanie się do wartości elementu wskazywanego przez zmienną dynamiczną odbywa się za pomocą operatora ^. Zatem
z^, to element wskazywany przez zmienną zNależy bardzo uważać, żeby odróżniać przypisanie z:=x od przypisania z^:=x^. W pierwszym przypadku nastąpi przypisanie zmiennej z wartości adresu wskazywanego przez zmienną x. W drugim przypadku nastąpi skopiowanie wartości elementu wskazywanego przez zmienną x elementowi wskazywanemu przez zmienną z. Przyjmijmy w poniższych przykładach, że zmienne x oraz z są zadeklarowane jako var x,z:^Integer. Wykonanie następującej sekwencji instrukcji
New(x); z:=x; z^:=5; Write(x^)
spowoduje wypisanie wartości 5, gdyż obie zmienne wskazują na ten sam obszar pamięci.
Jeśli natomiast wykonalibyśmy następującą sekwencję
New(x); New(z); z^:=5; x^:=z^; z^:=3; Write(x^);
to wypisałaby się wartość 5, gdyż każda z naszych zmiennych wskazuje na inny obszar pamięci i działa na nim autonomicznie. Zastanówmy się, co stałoby się, gdybyśmy tę sekwencję zakończyli przypisaniem z:=x.
Niebezpieczeństwa stosowania zmiennych dynamicznych
Zmienne dynamiczne stwarzają niebezpieczeństwo nieudolnego wykorzystania tego mocnego mechanizmu programistycznego. Wykonanie ostatniego przypisania w powyższym przykładzie spowodowałoby uratę zaalokowanego obszaru pamięci dla zmiennej z. Po prostu zmienna z po przypisaniu z:=x wskazywałaby na ten sam obszar pamięci, co zmienna x i jakiekolwiek odwołanie do x byłoby teraz równoważne odwołaniu do z (włącznie z Dispose). Pamięć przydzielona wcześniej zmiennej z pozostałaby od tej pory niedostępna. Co gorsza, nie udałoby się już nam jej zwolnić, bowiem wykonanie instrukcji Dispose(z) spowodowałoby zwolnienie pamięci przydzielonej zmiennej x! Obszaru przydzielonego zmiennej z nie wskazywałaby już żadna zmienna i nie można byłoby go zwolnić.
Tego typu działanie powoduje powstanie groźnego w skutkach zaśmiecenia pamięci. System operacyjny bowiem będzie rezerwował zajęty obszar do końca działania programu, nie zauważając, że nikt z tego obszaru nie jest już w stanie skorzystać.
Równie groźne są efekty wzajemnego działania na tym samym obszarze. Wyobraźmy sobie następującą sekwencję instrukcji.
New(x); x^:=5; z:=x; ... Dispose(z); ... New(z); z^:=3; Write(x^);
Efekt działania tego kodu jest nieokreślony. Może się zdarzyć, że zostanie wypisana piątka, może trójka (jeśli przez przypadek zmienna z dostałaby ten sam obszar, który wcześniej zwolniła), a może jeszcze coś innego, jeśli po wykonaniu Dispose(z) jakaś inna zmienna dostałaby zwolniony obszar i coś tam w nim zapisała.
Tego typu błędy są trudne do wykrycia, bo w testach w ogóle mogą nie zostać zauważone. Niedeterministyczny charakter alokacji daje tu ogromną gamę możliwych wyników i nie sposób przewidzieć, jak w konkretnym przebiegu programu będą wyglądały wyniki.
Ćwiczenia
Procedury i funkcje
Procedury i funkcje
Gdyby jakiś tyran zabronił stosowania procedur i funkcji, wówczas cała informatyka by padła. Są one tak ważnym narzędziem, że trudno sobie wyobrazić programowanie bez stosowania procedur i funkcji.
Procedury i funkcje stanowią podstawową konstrukcję programistyczną umożliwiającą modularyzację programu. Wiemy, że programy komputerowe mogą mieć dziesiątki czy setki tysięcy wierszy kodu, więc zapanowanie nad tak potężnymi tekstami graniczyłoby z cudem. Konieczne staje się wyodrębnianie fragmentów kodu stanowiących logiczną całość oraz poprzez odpowiednie nazywanie ich - doprowadzenie do tego, że czytając tekst programu nie będziemy wchodzili od razu w szczegóły implementacji, a poprzez nazwę sugerującą rolę ukrytego fragmentu kodu będziemy się mogli zorientować, co spowoduje jego wykonanie.
Poza tą fundamentalną cechą procedur, nie mniej ważną jest możliwość jednokrotnego zapisania ciągu rozkazów, który może być wielokrotnie używany. Korzystaliśmy z tej możliwości np. już przy zadaniach o flagach: polskiej i holenderskiej. Napis Z(i,j) traktowaliśmy jako skrót sekwencji zamieniającej zawartości pól i-tego i j-tego. Zauważmy, że nie tylko nazywamy pewne sekwencje rozkazów, ale umożliwiamy też parametryzację niektórych zmiennych. W tym przypadku kod zamiany dwóch elementów jest bardzo podobny, niezależnie od tego, dla jakich indeksów dokonujemy zamiany.
Dodatkowo jeszcze zyskujemy możliwość rekurencyjnego definiowania kodu, gdy potrafimy wyrazić rozwiązanie w zależności od innych wartości zmiennych, które są parametrami. Przykładowo w zadaniach o największym wspólnym dzielniku mieliśmy możliwość zdefiniowania wartości (a,b) w zależności od mniejszych wartości argumentów.
Procedury zatem są mechanizmem 'abstrakcji', umożliwiającym wyodrębnienie fragmentów kodu i użycie ich na zasadzie 'czarnych skrzynek'. Funkcja to procedura, która poza wykonaniem kodu oblicza pewną wartość - wynik funkcji - nadawany w trakcie wykonania jej identyfikatorowi, tak jak zmiennej.
Najprostsze użycie procedury, to po prostu nazwanie fragmentu kodu i użycie tej nazwy do późniejszego wykonania tego fragmentu. Powiedzmy, że chcemy wypisać rząd gwiazdek. Normalnie robimy to za pomocą pętli
PRZYKŁAD
<b>for</b> i:=1 <b>to</b> n <b>do</b> Write('*')
Jeśli chcielibyśmy ująć tę instrukcję w procedurę, to możemy zrobić to w następujący sposób. W części deklaracyjnej programu, a więc tak, gdzie definiuje się stałe, typy i zmienne umieszczamy deklarację procedury.
PRZYKŁAD
procedure Gwiazdki; <b>begin</b> <b>for</b> i:=1 <b>to</b> n <b>do</b> Write('*') <b>end</b>;
Od tej chwili użycie gdziekolwiek identyfikatora Gwiazdki będzie oznaczało wykonanie zaszytego pod tą nazwą kodu powodującego wypisanie n gwiazdek. W momencie deklaracji procedury musi być jasne, o jakie zmienne chodzi. W naszym przypadku mamy do czynienia ze zmiennymi i oraz n. Muszą one być zadeklarowane zanim przystąpimy do pisania kodu procedury lub ich deklaracje powinny wystąpić w jej wnętrzu. Zmienna i jest tutaj zdecydowanie zmienną pomocniczą - jej zadaniem jest jedynie sterowanie liczbą obrotów pętli. Ze względu jednak na to, że w momencie wykonywania procedury jej wartość ulegnie zmianie (zgodnie z naszą semantyką po wykonaniu pętli będzie nieokreślona), nie chcielibyśmy, aby taka ingerencja pozostawała nieodnotowana. Programista widząc taki fragment kodu:
PRZYKŁAD
i:=5; Gwiazdki; Write(i)
mógłby się spodziewać wypisania wartości 5, a tego nie powinniśmy się spodziewać. Mamy tu do czynienia z tzw. efektem ubocznym , czyli zmianą wartości zmiennej nieuwidocznioną bezpośrednio w kodzie. Występowanie efektów ubocznych jest uważane za wadę i przykład złego stylu programistycznego. Utrudnia zrozumienie tekstu i jego analizę poprawnościową.
Aby temu zapobiec, wszelkie pomocnicze zmienne będziemy deklarowali wewnątrz procedury.
PRZYKŁAD
procedure Gwiazdki; <b>var</b> i: Integer; {deklaracja lokalnej zmiennej i} <b>begin</b> <b>for</b> i:=1 <b>to</b> n <b>do</b> Write('*') <b>end</b>;
Zmienna i jest teraz zadeklarowana lokalnie i nawet jeśliby występowała inna zmienna i na zewnątrz procedury, to ta deklaracja przesłoni tamtą, wskutek czego użycie procedury Gwiazdki nie będzie ingerować w wartość tej zewnętrznej zmiennej. Za chwilę o mechanizmie przesłaniania opowiemy dokładniej, gdyż jest to sprawa ważniejsza i bardziej skomplikowana, niż mogłoby się to na pozór wydawać.
Wywołanie naszej nowej procedury wygląda tak samo. Na przykład, gdyby nam zależało na wypisaniu najpierw w pierwszym wierszu 5 gwiazdek, a potem w kolejnym wierszu 6 gwiazdek, to moglibyśmy to zrobić następująco:
n:=5; Gwiazdki; Writeln; n:=6; Gwiazdki
Parametry procedur
Zauważmy, że poradziliśmy sobie na razie tylko z jedną z dwóch zmiennych - zmienna n nadal musi być zadeklarowana jakoś inaczej. Dlaczego nie zdecydowaliśmy się na umieszczenie jej również pośród zmiennych lokalnych? Po prostu dlatego, że wartość zmiennej n jest istotna dla wyniku działania procedury (wartość zmiennej i była zupełnie nieistotna; i tak inicjalizowała się ona na początku działania pętli). W tego typu przypadkach, kiedy chcemy wykorzystać wartość pewnej zmiennej, przyjęło się podawać ją, jako parametr procedury . Przy deklaracji procedury, w nagłówku - zaraz po nazwie procedury - podamy listę parametrów wraz z określeniem ich typu. Będzie to równoważne z deklaracją zmiennych występujących jako parametry, których zasięg będzie ograniczony jedynie do treści procedury. Ograniczenie zasięgu takich zmiennych jest niezwykle ważną cechą programowania z użyciem procedur.
Deklaracja naszej procedury będzie wyglądać teraz następująco:
PRZYKŁAD
procedure Gwiazdki(n: Integer); <b>var</b> i: Integer; {deklaracja lokalnej zmiennej i} <b>begin</b> <b>for</b> i:=1 <b>to</b> n <b>do</b> Write('*') <b>end</b>;
Tym razem wywołanie procedury będzie się nieco różniło. W miejsce parametru można wstawić przy wywołaniu dowolną wartość, również będącą wynikiem wyrażenia. Wyglądać to może przykładowo w taki sposób:
n:=5;
Gwiazdki(n); Writeln; Gwiazdki(n+1)
Przy wywołaniu wylicza się wartość wszystkich parametrów zanim zaczniemy wykonywać jakiekolwiek instrukcje procedury. Efektem tego wywołania będzie zatem wypisanie najpierw 5 gwiazdek, a potem 6. Zauważmy, że zmienna n użyta jako parametr procedury ma inne znaczenie, niż ta, która jest zadeklarowana na zewnątrz i której jest nadana wartość 5. Sposób przekazywania wartości do wnętrza procedury przez parametry jest uznawany za wzorcowy. Czyni on kod czytelniejszym i pozwala na wyraźne zaznaczenie, które wartości są dla procedury ważne.
Wprowadźmy jeszcze nomenklaturę dotyczacą parametrów. Ponieważ parametry występują w dwóch różnych odsłonach: przy deklaracji procedury i przy jej wywołaniu, więc nazwijmy inaczej parametry występujące w tych kontekstach. Parametry przy deklaracji nazywa się formalnymi, a przy wywołaniu aktualnymi.
Czasami zadaniem procedury ma być obliczenie jakiejś złożonej wartości i wtedy też zamiast korzystać z efektów ubocznych lepiej jest wprowadzić do nagłówka informację o tym, które zmienne będą miały nadawane nowe wartości. Twórcy wielu języków programowania uznali tę potrzebę za tak istotną, że wprowadzili specjalne mechanizmy rozróżniające tryby wywoływania parametrów. Do tej pory poznaliśmy wywołanie przez wartość: przekazujemy procedurze pewną wartość, a ona na jej podstawie wykonuje stosowne działania.
Drugim trybem w Pascalu jest tzw. wywołanie parametru przez zmienną. Omówimy te dwie metody nieco dokładniej.
Parametry wołane przez wartość
W przypadku wywołania parametru przez wartość w nagłówku procedury podajemy identyfikator zmiennej i jej typ, a w momencie wywołania przekazujemy procedurze wyrażenie, którego wartość przypisujemy osobnej zmiennej powołanej na użytek tego konkretnego wywołania procedury. Zatem jesli nawet nazwa parametru formalnego i aktualnego są identyczne, to w rzeczywistości przy wykonywaniu kodu procedury działamy na kopii wartości - dokładnie w momencie wywołania procedury rezerwowana jest dodatkowa pamięć rozmiaru odpowiadającego typowi parametru i do tej pamięci kopiowana jest wartość wyrażenia odpowiadającego temu parametrowi, wyliczona w momencie wywołania procedury. Późniejsze zmiany wartości tego parametru aktualnego sa możliwe, ale po zakończeniu wywołania procedury oryginalne wartości pozostają niezmienione.
Parametry wołane przez zmienną
Parametry wołane przez stałą
Funkcje
Zdarza się, że w efekcie wywołania procedury chcemy wyznaczyć jakąś wartość. W takiej sytuacji korzystamy najczęściej z jednego z dwóch mechanizmów: życia funkcji lub specjalnego typu parametrów, którym będziemy nadawali wartość w trakcie wykonania procedury.
Zacznijmy od sposobu pierwszego. Jeżeli wartością procedury jest liczba, wartość logiczna, znak, napis lub wskaźnik, możemy użyć funkcji , czyli procedury z wartością. Deklaracja wygląda podobnie, jak w przypadku procedur, z tym że w nagłówku dodajemy na końcu po dwukropku typ wyniku funkcji. Tak więc funkcja, która podwaja wartość całkowitej liczby mogłaby wyglądać tak:
PRZYKŁAD
function Dubluj(n: Integer):Integer; <b>begin</b> Dubluj := 2*n <b>end</b>;
Widzimy więc, że w pewnym momencie w tekście funkcji następuje przypisanie wartości jej identyfikatorowi. Późniejsze wywołanie zadeklarowanej funkcji polega na użyciu identyfikatora z odpowiednią liczbą argumentów po prawej stronie wyrażenia. Na przykład wywołanie
n2:=Dubluj(n)
spowoduje nadanie zmiennej n2 podwojonej wartości zmiennej n.
Uważa się, że szczególnie w przypadku funkcji efekty uboczne, choć podobnie jak w przypadku procedur możliwe do wywołania, stanowią poważny problem. Nie chcielibyśmy przecież, aby wykonanie instrukcji y:=sin(x) spowodowało np. zmiane zmiennej x czy n . Byłoby to sprzeczne z przyzwyczajeniami matematycznymi. Gorąco odradzam tego typu styl programowania.
Składnia procedur i funkcji
Składnia procedur i funkcji jest podobna do składni całego programu. Najpierw mamy nagłówek, w którym określamy nazwę procedury oraz jej parametry, a następnie deklaracje i instrukcje. Deklaracje dotyczą zmiennych lokalnych dla procedury, niewidocznych z zewnątrz i zajmujących pamięć tylko w czasie wykonywania procedury. Część deklaracyjna jest identyczna jak w wypadku programu: mogą w niej być zdefiniowane stałe, typy, zmienne, procedury i funkcje. W przypadku procedur lub funkcji występujących w deklaracjach innej procedury lub funkcji mówimy o zagnieżdżeniu . Ponieważ zagnieżdżenia mogą być wielostopniowe (podprocedura podprocedury procedury...), więc ważne jest, aby określić reguły zasłaniania widoczności identyfikatorów. Zajmiemy się tym w następnym rozdziale.
Zobaczmy, jak mechanizm procedur można wykorzystać w prostym przykładzie rysowania ramki złożonej z symboli jednego rodzaju. Załóżmy, że chcemy wydrukować ramkę o bokach wypełnionych znakami ch, o i wierszach, oraz j kolumnach, oddaloną od lewego brzegu ekranu o m pozycji.
PRZYKŁAD
<b>procedure</b> ramka(i,j,m:Integer; ch:char); {procedura narysuje ramkę ze znaków ch o i wierszach, j kolumnach oddaloną od lewego brzegu ekranu o m pozycji. Zakładamy, że kursor jest na początku wiersza} <b>procedure</b> powiel (n:integer; ch:znak); {to jest wewnętrzna procedura procedury ramka} {Drukujemy znak ch n razy} <b>var</b> k:Integer; <b>begin</b> <b>for</b> k:=1 <b>to</b> n <b>do</b> Write(ch) <b>end</b>; <b>procedure</b> margines(m:Integer); {to jest wewnętrzna procedura procedury ramka} {Drukujemy m spacji} <b>begin</b> powiel(m,' ') <b>end</b>; <b>procedure</b> BokPoziomy (j,m:integer; ch:char); {to jest wewnętrzna procedura procedury ramka} {Drukujemy oddalony o m spacji od lewego brzegu ekranu ciąg j znaków ch} <b>begin</b> margines(m); powiel(j,ch); Writeln {Po wydrukowaniu przechodzimy do nowego wiersza} <b>end</b>; <b>procedure</b> BokiPionowe (i,j,m:integer; ch:char); {to jest wewnętrzna procedura procedury ramka} {Drukujemy dwa boki pionowe wysokości i-2 oddalone od siebie o j-2 spacje Lewy bok jest oddalony od lewego brzegu ekranu o m spacji} <b>var</b> k:Integer; <b>begin</b> <b>for</b> k:=1 <b>to</b> i-2 <b>do</b> <b>begin</b> margines(m); Write(ch); powiel(j-2,' '); Write(ch); <b>end</b>; Writeln <b>end</b>; <b>begin</b>{ramka} {ponieważ często kod procedury jest dość daleko od nagłówka, więc do dobrych obyczajów należy komentowanie, czego dotyczy nadchodzący fragment kodu} BokPoziomy (j,m,ch); BokiPionowe(i,j,m,ch); BokPoziomy (j,m,ch) <b>end</b>
Jeśli teraz np. w tekście programu użyjemy wywołania
ramka(7,6,0,'*'),
to narysuje się ramka siedem na sześć, złożona z gwiazdek i przylegająca do lewego brzegu ekranu.
Parę słów komentarza. Zauważmy, że procedura ramka zawiera 4 podprocedury, przy czym one nawzajem sie wywołują. Podprocedury margines i powiel nie są w dodatku w ogóle wykorzystywane bezpośrednio przez ramkę. Procedura margines wygląda dziwnie: mogłoby się wydawać, że jest niepotrzebna, gdyż jej wywołanie sprowadza się do prostego wywołania procedury powiel. Jednak do dobrego stylu programowania należy wyodrębnianie i nazywanie inaczej tych fragmentu kodu, które służą innym celom. Procedura powiel jest niewątpliwie ogólniejsza od procedury margines. Ma też inne parametry - w przypadku marginesu zakładamy, że wypisujemy spacje, a nie dowolne znaki. W takim przypadku asekurujemy się np. przed sytuacją, kiedy zmieni się nam koncepcja marginesu i - powiedzmy - każdy wiersz będzie poprzedzony dwoma wykrzyknikami. Gdybyśmy w kodzie zamiast margines(m) pisali powiel(m,' '), to musielibyśmy odszukać wszystkie wywołania procedury powiel, które dotyczyły marginesu i wstawić przed nimi stosowne instrukcje. A tak wystarczy, że w jednym miejscu - wewnątrz procedury margines - zmienimy fragment kodu na .
<b>procedure</b> margines(m:Integer); <b>begin</b> Write('!!'); powiel(m,' ') <b>end</b>;
i o nic więcej nie musimy się martwić.
Ważne jest, aby procedury były skomentowane. Do standardów należy opisanie, co procedura robi oraz wyjaśnienie roli wszystkich parametrów. Jeśli czynimy jakieś nieoczywiste założenie, to musi ono być umieszczone w komentarzu (np. założenie o pozycji kursora)
Konieczne jest, aby parametry przy wywołaniu były podane w tej samej kolejności, co przy deklaracji i aby typy ich były zgodne. W przypadku niezgodności typów wystąpi błąd kompilacji.
Realizacja procedur i funkcji
Rekursja
Rekursja
Częstokroć stajemy przed problemem, który łatwo byłoby rozwiązać, gdybyśmy mieli w ręku odpowiedź dla mniejszych danych. Dla przykładu, obliczenie silni liczby \( n \) wymaga przemnożenia silni \( (n-1) \) przez \( n \). Wiemy zatem, że:
\( 0!=1; n!=n*(n-1)! \) dla \( n>0 \)
Możemy tę parę wzorów przyjąć za definicję funkcji silnia. Takie definiowanie nazywamy rekurencyjnym lub indukcyjnym. My jednak słowo indukcja wolimy zachować do określenia sposobu dowodzenia. Będziemy więc mówili o rekurencyjnych definicjach i indukcyjnych dowodach.
Dla przykładu, jeżeli ciąg \( T_0,T_1,\ldots \) zdefiniujemy rekurencyjnie następująco:
\( T_0=0; T_n = 2T_{n-1}+1, \) dla \( n>0 \),
to używając metody indukcji matematycznej, możemy łatwo udowodnić, że \( T_n = 2^n-1 \).
Napotykamy jednak często na problemy, które w odróżnieniu od funkcji silnia, czy ciągu \( T_n \), nie mają prostej, nierekurencyjnej postaci, albo wręcz nie jest ona nam znana. Dla przykładu liczby Fibonacciego znane są co najmniej od 1202 roku, i generowanie kolejnych liczb \( F_n \) bezpośrednio ze wzoru rekurencyjnego nie stanowi żadnego problemu, jednak dopiero Euler, a niezależnie od niego w 100 lat później w roku 1843 francuski matematyk J.Binet udowodnił wzór bezpośrednio wyliczający n-tą liczbę Fibonacciego:
\( F_n=\frac{1}{\sqrt{5}}((\frac{\sqrt{5}+1}{2} )^n -( \frac{1-\sqrt{5}}{2})^n ) \)
Znajomość tego wzoru wcale nie rozwiązuje nam wszystkich problemów związanych z wyliczeniem n-tej liczby Fibonacciego. Przede wszystkim komputer mógłby mieć trudności ze stwierdzeniem, że wynik jest liczbą naturalną, choć w istocie powyższy wzór Eulera-Bineta generuje jedynie liczby naturalne.
Gdyby bowiem próbował wyciągać pierwiastek z pięciu, to nieuniknione stałoby się zaokrąglenie wyniku i w rezultacie moglibyśmy otrzymać wartość lekko różniącą się od liczby naturalnej, która byłaby spodziewanym wynikiem obliczeń. Poza tym lekką przesadą możnaby nazwać używanie tak skomplikowanych operacji jak potęgowanie liczb niewymiernych w celu uzyskania w miarę prostej liczby naturalnej.
Ponieważ stosujemy zasadę, że to komputer powinien dostosowywać się w miarę możliwości do potrzeb człowieka, więc mechanizmy pozwalające na korzystanie z rekurencji istnieją w większości współczesnych języków programowania. W Pascalu użycie rekurencji jest niezwykle naturalne:
<b>function</b> silnia(n:Integer):Integer; <b>begin</b> <b>if</b> n=0 <b>then</b> silnia := 1 <b>else</b> silnia := n*silnia(n-1) <b>end</b>;
Wywołanie tej funkcji od pewnego naturalnego argumentu \( n\ge 0 \) spowoduje, że identyfikatorowi silnia zostanie nadana wartość \( n! \). Stanie się to w następujący sposób. Najpierw sprawdzimy, czy \( n \) równa się zero. Jeżeli tak, to wynik wyniesie 1. Jeżeli nie, to wywołana zostanie funkcja silnia od parametru \( n-1 \), a jej wynik przemnożony zostanie przez \( n \) dając ostateczną wartość funkcji. Wykonanie instrukcji mnożenia przez \( n \) zostanie więc zawieszone na czas obliczenia wartości \( {silnia}(n-1) \). Zawartość sumatora i wszystkich rejestrów używanych przez komputer do obliczeń zostaną więc automatycznie zapamiętane przez system wykonujący program tak, że \({silnia}(n-1) \) wykona się w czystym środowisku. Po obliczeniu silni z \( n-1 \), zawartość stanu komputera zostanie odtworzona i mnożenie przez \( n \) będzie mogło zostać zakończone.
Rzecz jasna \( {silnia}(n-1) \) zostanie obliczona w analogiczny sposób. Rolę wartości \( n \) przejmie \( n-1 \), zatem wywoła się w miarę potrzeby \( {silnia}(n-2) \) itd. Widać więc, że do wywołania funkcji silnia od jakiegoś dużego parametru wymaga się zawieszenia wykonywania mnożeń na wielu poziomach wywołań rekurencyjnych (po jednym dla każdego \( 1 \le k \le n \)).
Zauważmy, że podobnie jak w przypadku źle skonstruowanych pętli, możemy nabawić się kłopotów wywołując funkcję silnia od argumentu ujemnego. System zacznie wtedy wywoływać kaskadę silni wołanych dla parametrów ujemnych coraz bardziej oddalonych od zera. Gdyby pamięć komputera była nieskończona, spowodowałoby to nieskończone zapętlenie się programu. Każde wywołanie funkcji wymaga jednak zapamiętania aktualnego stanu komputera. Zużywa to dostępną pamięć blokując potrzebny jej fragment do końca wywołania funkcji; w naszym przypadku ten koniec nigdy nie nastąpi. Program zostanie zatem zerwany przez system wykonujący z powodu braku pamięci. Nie jest to jednak jedyna groźba, którą napotykamy stosując rekurencję. Znacznie poważniejszym problemem może okazać się nieprawidłowa organizacja rekurencji powodująca brzemienne w skutkach zużycie czasu wykonywanego programu.
Spróbujmy zastosować technikę rekurencyjną do napisania funkcji obliczającej n-tą liczbę Fibonacciego \( F_n \).
<b>function</b> Fibo(n:integer):Integer; {funkcja liczy n-ta liczbe Fibonacciego dla n>=0} <b>begin</b> <b>if</b> n <= 1 <b>then</b> Fibo := n <b>else</b> Fibo := Fibo(n-2) + Fibo(n-1) <b>end</b>; {Fibo}
Na pierwszy rzut oka widać, że funkcja powinna dobrze zadziałać. Została napisana zgodnie z podaną wyżej definicją liczb Fibonacciego. Spróbujmy zatem prześledzić, jak będzie się wykonywać dla \( n=4 \). Aby obliczyć wartość \( F_4 \), będziemy musieli wywołać Fibo dla \( n=2 \) i dla \( n=3 \), a następnie dodać te wartości. Zauważmy jednak, że obliczywszy \( { Fibo}(2) \) weźmiemy się za liczenie \( { Fibo}(3) \) od nowa. Do policzenia \( {Fibo}(3) \) będziemy jednak potrzebowali wartości \( {Fibo}(1) \) oraz \( {Fibo}(2) \). Ponieważ komputer nie otrzymał od nas żadnych wskazówek dotyczących wykorzystania raz już obliczonych wartości, więc zacznie od nowa obliczać \( {Fibo}(2) \).
Ta drobna niegospodarność będzie nas dużo kosztować. Liczba wywołań funkcji Fibo będzie bowiem proporcjonalna do wartości wykładniczej ze względu na \( n \). Oznacza to, jak już wiemy, że nawet dla niewielkich stosunkowo danych, rzędu 100, żaden komputer na świecie nie poradzi sobie z zakończeniem obliczeń, niezależnie od tego jak jest szybki i jak wiele czasu mu damy.
Cały problem będzie rozwiązany bezboleśnie, jeżeli tylko nie dopuścimy do więcej niż jednokrotnego wywołania funkcji dla tych samych danych. Wystarczy zatem stworzyć bank danych o obliczonych już wartościach \( F_n \). W tym celu zadeklarujemy sobie tablicę \( F \), w której będziemy przechowywali obliczone już wartości \( F_n \). Aby zaznaczyć, że dana wartość nie została jeszcze obliczona, wypełnimy tablicę minus jedynkami. Funkcję Fibo będziemy zatem liczyli rekurencyjnie jedynie w miarę potrzeby, czyli wtedy, gdy dla danego argumentu liczymy ją po raz pierwszy. Zmodyfikujmy zatem naszą funkcję.
<b>var</b> F:array[0..m] <b>of</b> Integer; <p><b>function</b> Fibo1(n:integer): Integer; { funkcja liczy n-ta liczbe Fibonacciego dla n>=0, korzystając przy tym z globalnej tablicy F, przy czym F[i] = F_i, jezeli F_i jest juz obliczone F[i] = -1, jezeli nie jest jeszcze obliczone Założenie: n>=0 } <b>begin</b> <b>if</b> F[n]<0 <b>then</b> {Wartosc F[n] nie jest jeszcze obliczona, więc zaczniemy od wypełnienia tablicy właściwą wartością} <b>if</b> n <= 1 <b>then</b> F[n]:=n <b>else</b> F[n] := Fibo1(n-2) + Fibo1(n-1); {i teraz dopiero nadamy odpowiednią wartośc identyfikatorowi Fibo. W tablicy F[n] znajduje się zawsze własciwa wartość} Fibo1 := F[n] <b>end</b>;{Fibo1}
Wykonanie tego programu dla paru danych szybko przekona nas o skuteczności tego ulepszenia. Tym razem powinniśmy także uważać na stosunkowo nieduży zakres typu integer, i jeżeli chcemy obliczać większe liczby Fibonacciego, musimy użyć innego typu (np. longint).
Rzecz jasna istnieją znacznie prostsze metody pozwalające nam na obliczenie n-tej liczby Fibonacciego. Podobnie jak w przypadku silni, można to zrobić jedną prostą pętlą z czterema przypisaniami. Są jednak problemy, dla których znalezienie nierekurencyjnego rozwiązania ani nie jest proste, ani warte zachodu ze względu na elegancję i efektywność rekurencji w tych przypadkach.
Wielu znane jest zapewne zadanie o wieżach z Hanoi. Legenda głosi, że w pewnej świątyni buddyjskiej w Hanoi znajdują się trzy wbite w ziemię pręty. Na jednym z nich początkowo umieszczono 64 koła o malejących średnicach. Należy te koła przenieść z pierwszego pręta na drugi przy pomocy trzeciego, respektując następujące zasady:
- jednorazowo można przenieść jeden krążek
- krążek można nałożyć na dowolny z prętów pod
warunkiem, że kładzie się go na pusty pręt lub na krążek o większej średnicy. Ponoć mnisi przekładają od jakiegoś czasu te krążki, a gdy skończą, nastąpi koniec świata.
Jak można wyobrazić sobie najprostszy algorytm przekładający w możliwie szybki sposób krążki? Przenieść jeden krążek to żadna sztuka. Jak jednak poradzić sobie z ich większą liczbą? Załóżmy indukcyjnie, że umiemy tego dokonać dla \( n-1 \) krążków. Rekurencyjnie nasz algorytm formułuje się bardzo prosto. Aby przełożyć wieżę złożoną z n krążków z jednego pręta na drugi przy pomocy trzeciego, należy \( n-1 \) krążków przełożyć na pręt trzeci, następnie przełożyć krążek \( n \) na pręt drugi, a następnie \( (n-1) \)-elementową wieżę przełożyć z pręta trzeciego na drugi przy pomocy pierwszego.
Zauważmy przy okazji, że liczba przenosin \( n \) krążków, \( T_n \), wymaga dwukrotnego przeniesienia wieży złożonej z \( n-1 \) krążków oraz jednokrotnego przeniesienia jednego krążka. Mamy więc wzór:
\( T_1 = 1; \ T_n=2T_{n-1}+1 \)
zatem
\( T_n=2(2^{n-1}-1)+1=2^n-1 \). Liczba przenosin jest więc wykładnicza ze względu na \( n \). Możemy spać spokojnie. Nawet jeżeli mnisi będą bardzo wydajni, to prędzej nastąpi koniec Układu Słonecznego, aniżeli przełożenie tych 64 krążków (zakładając, że mnisi zaczęli w czasach historycznych).
Procedura, która dokona wygenerowania kolejnych ruchów przenoszących n-elementową wieżę może więc wyglądać następująco. Zakładamy, że zamiast dźwigania krążków komputer będzie wypisywał kolejne ruchy w postaci przenieś krążek z pręta \( i \) na pręt \( j \).
<b>procedure</b> Hanoi (n, skad, dokad:integer); { procedura przenosi n krążkow z wieży skąd na wieżę dokąd } <b>procedure</b> przenies (co, skad, dokad:integer); { Tu rzecz jasna można wpisać dowolnie inteligentną procedurę} <b>begin</b> writeln ('PRZENIES ', CO, ' Z ', skad, ' NA ', dokad) <b>end</b>; <b>begin</b> <b>if</b> n<=1 then przenies (1, skad, dokad) <b>else</b> <b>begin</b> {zauważmy, że jeżeli jeden pręt ma numer i, a drugi j, to trzeci z nich ma numer 6-i-j} hanoi (n-1, skad, 6-skad-dokad); przenies (n, skad, dokad ); hanoi (n-1, 6-skad-dokad, dokad) <b>end</b> <b>end</b>;
Nasza procedura będzie teraz działała w czasie wykładniczym ze względu na \( n \). Dzieje się tak w zasadzie zawsze, gdy bez żadnych finezji dokonujemy we wnętrzu procedury więcej niż jednokrotnego wywołania rekurencyjnego tej procedury. Tym razem jednak nie będzie to stanowiło wady rozwiązania - taka jest natura problemu: odpowiedź w postaci ciągu ruchów do wykonania ma długość wykładniczą ze względu na \( n \), więc trudno tu cokolwiek poprawić. Rzecz jasna procedurę należy wywoływać dla danych znacznie mniejszych niż 64.