Wstęp do programowania/Wstęp do algorytmów
Wprowadzenie do algorytmów
Najważniejszym pojęciem w informatyce jest algorytm. Nazwa ta ma swoje korzenie w średniowieczu i wzięła się ze zniekształconego nazwiska wielkiego uczonego arabskiego Al Chuwarizmiego, który żył na przełomie VIII i IX wieku i pochodzącego z Chorezmu. Al Chuwarizmi, działając w Domu Nauk kalifa Al Mamuna w Bagdadzie, opublikował ważne dzieła matematyczne, wśród nich Hisab al dżabr w'al muqabala – traktat o rozwiązywaniu równań, z którego wzięła nazwę algebra – jeden z głównych działów matematyki. W traktacie tym, poza wprowadzeniem systemu zapisu pozycyjnego, zaczerpniętego od Hindusów, a zwanego arabskim, podał między innymi metody rozwiązywania równań kwadratowych. Metody te odwoływały się do pojęć geometrycznych; utożsamiano wtedy liczby i działania z miarami obiektów geometrycznych. Liczby rzeczywiste to były długości odcinków, dodawanie to było sklejanie odcinków, mnożenie odpowiadało wyliczaniu pola prostokąta o danych bokach, a pierwiastkowanie wyznaczaniu boku kwadratu o zadanym polu. Arabowie, podobnie jak starożytni Grecy, nie znali pojęcia liczby ujemnej, stąd, gdy dziś patrzymy na metody Al Chuwarizmiego, poza oczywistym pięknem, wydają się nam one nieco dziwaczne. Ale cóż – wtedy inaczej po prostu się nie dało.
W pierwszym kroku rozwiązania Al Chuwarizmi polecał podzielić wszystkie współczynniki trójmianu kwadratowego przez współczynnik przy \( x^{2} \), aby uwolnić się od jednego z nich; w końcu pierwiastki przez takie podzielenie nie zmieniają się, a metoda staje się prostsza. Al Chuwarizmi rozważał zatem równania postaci \( x^{2}+bx+c \) dla różnych klas b i c: dodatnich, ujemnych i równych zero. Miał zatem do czynienia z 9 różnymi przypadkami i dla każdego z nich podał metodę wyznaczania pierwiastka takiego równania. Przyjrzyjmy się jednemu z nich: dane są zaczerpnięte bezpośrednio z omawianej księgi. Rozwiązujemy równanie
\( x^{2}+10x = 39 \)
Jest to zatem równanie z klasy równań, w których współczynnik przy x jest dodatni, a wyraz wolny ujemny (dla wygody przenieśliśmy go na prawą stronę, więc po tamtej stronie jawi się nam jako c dodatnie). Oto co proponował Al Chuwarizmi.
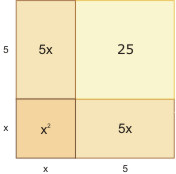
Rysujemy kwadrat o boku x. Po jednej jego stronie doklejamy prostokąt o bokach x oraz \( 10/2 = 5 \), po drugiej pod kątem prostym identyczny prostokąt. Uzupełniamy powstały kąt prosty wyznaczony przez 2 odcinki długości 5 do kwadratu i otrzymujemy duży kwadrat, którego pole wynosi
\( x^{2} + 5x + 5x + 25= 39 + 25 = 64 \)
Bok tego dużego kwadratu ma więc długość 8, a że powstał on przez sklejenie odcinka o długości x oraz odcinka o długości 5, więc \( x = 3 \). Drugi pierwiastek w tym przypadku nas nie interesuje: jest ujemny, a więc go "nie ma" – liczby ujemne nie istniały wówczas w świadomości współczesnych.
Zauważmy, że konstrukcję tę, a zatem i stosowne obliczenia, można powtórzyć dla każdej pary (b,c) w której b > 0, zaś c < 0. Wyrażając jednym wzorem efekt obliczeń uzyskalibyśmy wyrażenie
\( x=\sqrt{c+(\frac{b}{2})^2}-\frac{b}{2} \)
Obliczenie wartości x mogłoby się odbywać według następującego schematu:
- podziel \( b \) przez \( 2 \) i zapamiętaj wynik na zmiennej pomocniczej \( b' \)
- podnieś \( b' \) do kwadratu
- dodaj do otrzymanej liczby wartość \( c \)
- wyciągnij z otrzymanej sumy pierwiastek kwadratowy
- odejmij od tego, co uzyskałeś uprzednio zapamiętaną wartość \( b' \)
- otrzymana liczba jest szukanym (nieujemnym) pierwiastkiem równania \( x^{2}+bx=c \).
Zróbmy parę obserwacji.
Po pierwsze powyższa procedura jest wykonywalna dla każdych danych b,c>0. Zauważmy, że jedyna operacja, która mogłaby sprawić kłopoty z wykonaniem, to odejmowanie w punkcie 5 naszej procedury. Jednak można łatwo sprawdzić, że daje ono zawsze wynik dodatni:
w końcu dla \( c >0 \) mamy \( \sqrt{c+(\frac{b}{2})^2} > \sqrt{(\frac{b}{2})^2}=\frac{b}{2} \).
Po drugie, zastosowaliśmy tu pewne niewielkie, ale ważne uproszczenie algorytmu: użyliśmy w jego opisie pomocniczej zmiennej \( b' \), dzięki której nie musieliśmy dwukrotnie dzielić wartości \( b \) przez \( 2 \). Po trzecie, zapisując wzór na równanie kwadratowe skorzystaliśmy z tradycji notacyjnej, w myśl której w wyrażeniach arytmetycznych zawsze wiadomo, w jakiej kolejności wykonuje się działania. W szczególności w wyrażeniu podpierwiastkowym najpierw dzieliliśmy b przez 2, potem podnosiliśmy wynik do kwadratu, a na końcu dodawaliśmy do niego c. To, co w podanym przez Al Chuwarizmiego przepisie wymagało uściślenia kolejności, można wyrazić wzorem w zwartej formie, umówiwszy się zawczasu co do interpretacji podanej notacji. Niezwykle ważne jest, aby używana notacja była jednoznaczna i abyśmy nie popełniali błędu przy interpretacji wyrażeń, w szczególności żebyśmy byli zgodni co do kolejności wykonywanych działań. Wrócimy do tego zagadnienia w wykładzie o gramatykach.
Ćwiczenie
- Jak będzie działała podana metoda, dla c<realnowiki><realnowiki> = </realnowiki></realnowiki>0?
- Zaprojektuj geometryczną metodę w stylu Al Chuwarizmiego dla równania \( x^{2}= 5x + 6 \). Czy metoda ta da poprawne wyniki dla wszystkich równań postaci \( x^{2} = bx + c \) przy dodatnich b, c?
Co to są zatem algorytmy? Ogólnie określamy tym mianem wszelkie przepisy postępowania, które doprowadzają do uzyskania pożądanego efektu – rozwiązania zadania. W potocznej mowie mówimy czasem o algorytmach postępowania niewiele mających wspólnego z komputerami, jednak dla informatyków algorytmy wiążą się nierozerwalnie z programowaniem.
Prawdziwe problemy pojawiają się, gdy chcemy algorytm zakodować w taki sposób, żeby był dobrze wykonany przez maszynę. Nie możemy sobie pozwolić na odwoływanie się do doświadczenia, machanie rękami, domysły. Komputer niczego się nie domyśla, ba, nie rozumie języka naturalnego i potrzebna będzie nam precyzyjna notacja do komunikacji z nim. Istotą programowania jest bowiem wyrażanie algorytmów w sposób ścisły, podlegający rygorom skończonej liczby reguł, których znaczenie w jednoznaczny sposób jesteśmy określić.
Al Chuwarizmi nie był oczywiście pierwszym człowiekiem, który stosował podejście algorytmiczne do rozwiązywania problemów. W rzeczywistości każdy z nas stosuje algorytmy w rozmaitych sytuacjach życiowych. Człowiek pierwotny miał algorytm polowania na mamuty, czy rozpalania ognia. Dzisiaj często wykonujemy pewne algorytmy, nie zdając sobie sprawy. Warto przytoczyć parę przykładów algorytmów z życia codziennego:
Przepisy kucharskie Typowy przepis zawiera deklaracje obiektów (składników pichcenia) ich początkowe wartości (miary) oraz opis działań doprowadzający do przyrządzenia potrawy.
Zapis nutowy muzyki. Za pomocą szczególnego systemu notacyjnego określa się wysokości i względne czasy trwania nut i pauz między nimi. Można również i tu określić dane: są to zazwyczaj określenia instrumentów, które w partyturze występują, oraz dane początkowe, takie jak metrum czy dynamika poszczególnych części. Zauważmy, że poza standardowymi znakami na pięciolinii, kompozytorzy często stosują dodatkowe określenia takie jak crescendo, poco allegretto, piano, con fuoco itp, pozwalające wykonawcy lepiej wyczuć ich intencje. Szczególnie atrakcyjnie wyglądają niektóre nuty kompozytorów współczesnych, którzy odchodzą czasem od tradycyjnego zapisu nutowego i starają się niekiedy wymyślić i opisać własny system notacyjny, wyrażający ich intencje.
Instrukcje montażu Często do zestawów mebli, czy klocków lego, dołączona jest kartka z instrukcją montażu zapisaną za pomocą sekwencji rycin obrazujących kolejne fazy powstawania składanego obiektu. Użytkownik, porównując zmiany na poszczególnych obrazkach, ma się domyślić, jakie czynności, w jakiej kolejności i za pomocą jakich części ma wykonywać. Zauważmy, że i tu występuje charakterystyczny dla algorytmów opis danych: najczęściej zestaw części składowych jest wyrysowany obok historyjki obrazkowej z zaznaczeniem liczby poszczególnych elementów.
Opisy dojazdu Wyjaśniając jak dotrzeć do danego miejsca (mappy.com), wiele serwisów udostępnia opis drogi z zaznaczeniem kluczowych punktów i decyzji.
Opis układów choreograficznych, scenopisy przedstawień Tutaj też stosuje się specyficzną symbolikę i skróty notacyjne.
Takich przykładów można przytaczać tysiące. Właściwie niemal wszystko, co robimy, podlega jakiemuś algorytmowi działania – przy czym warto podkreślić, że ludzie nie muszą mieć algorytmów objaśnianych dokładnie: wiele mogą wywnioskować z kontekstu, doświadczenia, po prostu domyślając się, o co może chodzić. Kucharce nie trzeba wyjaśniać, co to znaczy "zeszklić cebulkę na ciemnozłoty kolor", a monterowi - co znaczy "zaizolować przewody".
Z komputerami jest jednak inaczej. Są to wyjątkowo głupie urządzenia i jeśli dokładnie nie wytłumaczymy, co mają zrobić, stają się bezradne. Między bajki należy włożyć rozmaite sytuacje znane z literatury fantastyczno-naukowej, w których komputery są równorzędnymi partnerami intelektualnymi dla ludzi. Sztuczna inteligencja, nawet jeśli istnieje, bazuje na ściśle określonych algorytmach działania i nie ma tam miejsca na intuicję, domyślenie się czegokolwiek czy nagłe olśnienie, które są doskonale znane istotom myślącym. Ludzie często nie zdają sobie sprawy, jak wiele w algorytmach, którymi się posługują, zależy od nieuświadamianego kontekstu, jak dużo muszą dopowiadać do rzekomo precyzyjnych procedur działania. Komputery bezlitośnie wyłapują luki w specyfikacji procedur i nie ma mowy, żeby domyśliły się, że wykonują jakąś bezsensowną akcję, typu wydrukowanie żądania zapłacenia 0 zł. Jeśli wyraźnie nie zapiszemy w algorytmie, że takich żądań nie należy generować, to komputer ślepo wykona nasze polecenie, choćby było ono w oczywisty sposób bezsensowne. W dalszych wykładach zobaczymy przykłady, w których algorytmy z pozoru wyglądające na poprawne i kompletne, będą miały luki powodujące błędne działanie.
Ćwiczenie
Znajdź w Internecie przykłady bezsensownego zachowania się komputerów. Spróbuj domyślić się, jakiego rodzaju błąd programisty był przyczyną kompromitacji.
Spróbujmy przymierzyć się do problemu znanego jeszcze ze starożytności. Przy dodawaniu sprowadza się mianowniki do najmniejszej wspólnej wielokrotności. Wyznaczenie jej najczęściej polega na tym, że oblicza się największy wspólny dzielnik, dzieli się jedną z liczb przez niego i wynik mnoży przez drugą. Jak jednak znaleźć największy wspólny dzielnik?
Operacja dzielenia z resztą
Algorytm Euklidesa
Dziedzina algorytmiczna
Dziedzina algorytmiczna
Ważnym pojęciem przy określaniu algorytmu jest pojęcie dziedziny algorytmicznej. Algorytmy wykonują pewne operacje na argumentach i wyrażenie własności algorytmu, a w tym określenie jego złożoności, dokonywane jest za pomocą tych operacji. Dziedziną algorytmiczną nazwiemy zatem system relacyjny \( \langle A,\{o_i\}_{i\in I}, \{r_{j}\}_{j\in J}\rangle \), gdzie \( A \) nazywany jest nośnikiem, a zbiory \( \{o_i\}_{i\in I}, \{r_{j}\}_{j\in J} \), odpowiednio zbiorem operacji i relacji określonych w \( A \), których można używać w algorytmie. Zauważmy, że od tego, jakimi operacjami i relacjami dysponujemy zależą nasze możliwości opisywania algorytmów. Zawsze musimy wiedzieć, z jakich operacji można korzystać, zanim zabierzemy się za programowanie. Czasami takie operacje przyjmują postać bibliotek gotowych procedur i funkcji – cegiełek, z których składamy nasze algorytmy.
W przypadku naszych trzech algorytmów Euklidesa te trzy dziedziny, to:
- Euklides1: \( \langle {\cal N}, -,\le, =_0 \rangle \)
- Euklides2: \( \langle {\cal N}, \bmod, =_0 \rangle \)
- Euklides3: \( \langle {\cal N}, -,\div_2, *_2,\le, \in_P,=_0 \rangle \),
gdzie \( - \), to zwykłe odejmowanie, \( \bmod \) operacja znajdowania reszty, \( \div_2 \) - jednoargumentowa operacja dzielenia przez 2, \( *_2 \) jednoargumentowa operacja mnożenia przez 2 (zauważmy, że przez nic innego nie musimy dzielić ani mnożyć), \( \le \) relacja dwuargumentowa niemniejszości, \( \in_P \) jednoargumentowa relacja parzystości, zaś \( =_0 \) relacja jednoargumentowa bycia zerem.
Uświadomienie sobie, w jakiej dziedzinie algorytmicznej operujemy, jest ważne między innymi z punktu widzenia porównywania algorytmów. Łatwo jest bowiem "skrzywdzić" jakiś algorytm nie zauważając, że działa on w uboższej dziedzinie niż rzekomo lepszy, a przyjrzenie się kosztowi operacji podstawowych daje lepszy wgląd w istotę złożoności.
Jeszcze parę słów na temat złożoności algorytmów. Jak mogliśmy to zauważyć, brak analizy złożoności może doprowadzić do porażki – algorytm, nawet poprawny, może stać się praktycznie bezużyteczny, jeśli będzie miał zbyt dużą złożoność. Dokładniej o złożoności będzie jeszcze mowa na dalszych wykładach z bardziej zaawansowanej algorytmiki. Podkreślmy parę podstawowych spraw.
- Złożoność określamy obliczając liczbę operacji dominujących, czyli takich, które najczęściej będą wykonywane.
- Złożoność wyznacza się zazwyczaj z dokładnością do rzędu wielkości, a więc zaniedbując czynnik stały. Czasami czynnik ten bierze się pod uwagę, ale dopiero wtedy, gdy porównujemy algorytmy o podobnym rzędzie złożoności. Najczęściej do określenia złożoności używa się notacji \( O \), która pozwala uwolnić się od czynnika stałego i skupia się właśnie na rzędzie wielkości. #MatematykaDyskretna.xxx
Definicja [Definicja notacji \( O \)]
Mówimy, że funkcja \( f:{\cal N} arrow R \) jest \( O(g) \), jeśli istnieją stała \( c>0 \) oraz liczba \( m\in {\cal N} \) takie, że dla każdego \( n>m \) zachodzi \( f(n)\le cg(n) \). - Złożoność zależy od rozmiaru danych. Przez rozmiar danych najczęściej rozumiemy liczbę bitów (czy bajtów) potrzebnych do zakodowania danych; znowu chodzi o rząd wielkości. Na przykład jeśli mówimy o sortowaniu liczb, to ważne jest ile ich jest, a nie to, z jaką dokładnością je podajemy – zwiększenie takiej dokładności w końcu rozmiar danych powiększy o stały czynnik. Stąd na przykład
- gdy sortujemy n obiektów, rozmiarem danych jest n;
- gdy rozważamy graf, rozmiarem danych jest suma liczby krawędzi i wierzchołków (czasem rozważamy osobno liczbę krawędzi i wierzchołków);
- gdy rozważamy algorytmy liczbowe – tak jak w naszych przykładach obliczania największego wspólnego dzielnika – rozmiarem danych jest długość zapisu cyfrowego liczby, bo tak złożone jest podanie jej wartości
- Czasami do wykonania algorytmu potrzeba dodatkowej pamięci na pomocnicze struktury. Wtedy również zastanawiamy się, ile tej pamięci potrzeba i wynik nazywamy złożonością pamięciową
- Dla różnych danych algorytm może różnie się wykonywać. W praktyce rozważa się dwa rodzaje danych: pesymistyczne (czyli najbardziej złośliwe) i losowe, czyli typowe. Mówimy wtedy odpowiednio o złożoności pesymistycznej i złożoności średniej.
Dobrzy informatycy wyrabiają sobie przy programowaniu nawyk myślenia o złożoności.
Liczby Fibonacciego
Liczby Fibonacciego
rycina
Fibonacci (ok. 1170-1250)
Aby rozwiązać ten problem doboru najbardziej złośliwych danych, należy spojrzeć na problem od drugiej strony: jak za pomocą najmniejszych liczb uzyskać z góry zadaną liczbę obrotów pętli? Widać, że aby pętla wykonała się raz, wystarczą dane \( (1, 1) \). Ale te dane nie mogą być wynikiem wcześniejszego obrotu pętli: pamiętajmy, że pierwszy z argumentów jest zawsze dzielnikiem z poprzedniego obrotu pętli, a skoro jest nim jedynka, to reszta nie mogła być równa jeden. Zatem przy więcej niż jednym obrocie pętli najmniejsze dane dla ostatniego obrotu pętli, to \( (2, 1) \) (po czym dostajemy od razu parę \( (1, 0) \) kończącą pętlę). Jakie były zatem dane przedostatnie? Widać, że dzieliliśmy przez \( 2 \) i dostaliśmy resztę \( 1 \). Zatem w poprzednim kroku mogliśmy mieć pary \( (3, 2) \) lub \( (5, 2) \) lub \( (7, 2),\ldots \). Z nich para \( (3, 2) \) jest najoszczędniejsza – są to liczby, które dają najmniejszą sumę, a liczba obrotów naszej pętli jest równa \( 2 \). Jak wyglądała zatem para dwa kroki wstecz? Dzielnik musiał być równy \( 3 \), a reszta równa \( 2 \), więc w grę wchodzą pary \( (5, 3), (8, 3), (11, 3),\ldots \). Z nich znów najoszczędniejsza jest para \( (5, 3) \). Dalej, cofając się i rozumując w analogiczny sposób, dostaniemy pary \( (8,5) \) i kolejno \( (13, 8), (21, 13),\ldots \). Widać zatem, że zawsze najoszczędniej będzie tak dobierać kolejną parę, aby wynik dzielenia był równy \( 1 \), czyli innymi słowy, jeśli w kolejnym obrocie pętli argumenty są równe \( a \) i \( b \), to w poprzednim powinny być równe \( a + b \) i \( a \). Wtedy bowiem \( b \) jest resztą z dzielenia \( a + b \) przez \( a \), natomiast iloraz równy jest 1.
Zbadajmy zatem, jakie najmniejsze argumenty dają zadaną liczbę obrotów pętli.
| Liczba obrotów | a | b |
|---|---|---|
| 0 1 2 3 4 5 6 ... |
1 1 3 5 8 13 21 |
0 1 2 3 5 8 13 |
Liczby, które występują w tabeli, są znane pod nazwą liczb Fibonacciego. Mają one w informatyce duże znaczenie i warto znać podstawowe fakty o nich. Definiuje się je następująco:
Liczby Fibonacciego
\( F_{0}=0 \) \( F_{1}=1 \) \( F_n = F_{n-1}+F_{n-2} \) dla \( n \ge 2 \)
Każda kolejna liczba Fibonacciego jest sumą dwóch swoich poprzedniczek. Parę początkowych wyrazów tego ciągu warto znać na pamięć.
| \( n \) | \( F_{n} \) |
|---|---|
| 0 1 2 3 4 5 6 7 8 ... |
0 1 1 2 3 5 8 13 21 |
{kind=link}
rycina
Jacques Philippe Marie Binet (1786-1856)
Widzimy więc, że poczynając od drugiego wiersza tabeli (\( n\ge 1 \)), najbardziej złośliwych danych dla algorytmu Euklides2 mamy zawsze \( a = F_{n+2}, b= F_{n+1} \). Aby wymusić \( n \) obrotów pętli musimy wziąć zatem co najmniej \( n + 2 \)-gą i \( n + 1 \)-wszą liczbę Fibonacciego.
{kind=link}
rycina
Leonhard Euler (1707-1783)
Liczby Fibonacciego rosną szybko. Konkretnie znany jest ogólny wzór na \( n \)-tą liczbę Fibonacciego przypisywany Binetowi, a znany jeszcze na pewno Eulerowi 100 lat przed Binetem.
\( F_n=\frac{1}{\sqrt{5}}((\frac{1+\sqrt{5}}{2})^n-(\frac{1-\sqrt{5}}{2})^n) \)
Dowód tego wzoru można znaleźć w #MatematykaDyskretna-xxx.
Wprowadzając oznaczenia \( \varphi = \frac{1+\sqrt{5}}{2}, \hat{\varphi} = \frac{1-\sqrt{5}}{2} \), otrzymujemy wzór w nieco bardziej czytelnej postaci
\( F_n=\frac{1}{\sqrt{5}}(\varphi^n-\hat{\varphi}^n) \).
Biorąc pod uwagę to, że \( \varphi = 1,618... \), zaś \( \hat{\varphi} = -0,318... \) i to, że w związku z tym składnik \( \hat{\varphi}^{n} \) w naszym wzorze bardzo szybko dąży do zera, możemy łatwo pokazać, że n-ta liczba Fibonacciego jest równa
\( F_n=[\frac{1}{\sqrt{5}}\varphi^n] \),
gdzie przez \( [x] \) oznaczamy zaokrąglenie \( x \), czyli liczbę całkowitą najbliższą danej liczby rzeczywistej \( x \). Zatem n-ta liczba Fibonacciego jest prawie dokładnie równa n-tej potędze \( \varphi \) podzielonej przez \( {\sqrt{5}} \). Zauważmy jeszcze, że skoro tak, to po zlogarytmowaniu obustronnie wzoru przy podstawie \( \varphi \) otrzymujemy wzór
\( \log_{\varphi} F_n = n - log_{\varphi}\sqrt{5} \).
Zatem indeks \( n \) zadanej liczby Fibonacciego \( F_{n} \) wynosi
\( n=\log_{\varphi}F_n + log_{\varphi}\sqrt{5} \).
Zapamiętajmy sobie niezwykle ważny wniosek:
Wniosek
Liczby Fibonacciego rosną wykładniczo szybko. Ich wzrost jest prawie identyczny, jak funkcji wykładniczej \( \frac{1}{\sqrt{5}} \varphi^n \).
Wprowadźmy oznaczenie \( \text{FIB}(a) \) na największą liczbę Fibonacciego mniejszą od \( a \), a przez \( [n]\text{FIB}(a) \) jej indeks. Ponieważ dla dowolnych argumentów \( (a, b) \) liczba obrotów pętli algorytmu Euklides2 nie przekracza liczby obrotów pętli dla argumentów najbardziej złośliwych, czyli \( \text{FIB}(a)=F_{[n]\text{FIB}(a)} \) oraz poprzedniej liczby Fibonacciego \( F_{[n]\text{FIB}(a)-1} \), a liczba obrotów pętli dla tych argumentów jest o \( 2 \) mniejsza, niż indeks większej z nich, to otrzymujemy szacowanie na liczbę obrotów pętli \( M(a, b) \) dla dowolnych argumentów \( a \) i \( b \):
\( M(a,b) \le M(\text{FIB}(a)), \text{FIB}(\text{FIB}(a)) = [n]\text{FIB}(a)-2, \)
skąd
\( M(a, b)+ 2 \le \log_{\varphi}F_n + log_{\varphi}\sqrt{5} \),
a biorąc pod uwagę, że
\( log_{\varphi}\sqrt{5}=1,67... \)
otrzymujemy
\( M(a,b)\le \log_{\varphi}a \log_{\varphi}a \le log_{\varphi}(\text{FIB}(a)) \).
Zapamiętajmy jeszcze jedną ważną prawidłowość.
Uwaga
Indeksy liczb Fibonacciego rosną logarytmicznie wolno w stosunku do wartości tych liczb.
Zatem funkcja [n]FIB(x) rośnie logarytmicznie ze względu na x.
Wracając do naszych danych trzydziestocyfrowych: możemy oszacować liczbę obrotów pętli przez \( log_{\varphi} 10^{30} = 148,33... \). Zatem wykonamy nie więcej niż 150 obrotów pętli, co oczywiście będzie w zasięgu nawet bardzo wolnego komputera. Pamiętajmy, że przy dużych liczbach możemy zapomnieć o wbudowanych w języki programowania procedurach arytmetycznych. O arytmetykę musimy zadbać sami. Własną arytmetyką dużych liczb zajmiemy się później.
Zauważmy pewną niedogodność. W algorytmie Euklides2 jeden krok pętli jest nieco trudniejszy. W poprzednim algorytmie Euklides1 mieliśmy tylko porównywanie liczb i ich odejmowanie. Tutaj musimy zaprogramować dzielenie z resztą. Jest to nie tylko trudniejsze, ale i ogólnie wolniejsze od odejmowania. Jeśli zdecydujemy się na algorytm szkolny dzielenia słupkowego, to trzeba będzie wykonać całą serię obliczeń realizujących kolejne kroki wyznaczania cyfr ilorazu. Każdy z tych kroków wymaga wyznaczenia stosownej cyfry wyniku, przemnożenia jej wartości przez dzielnik, a następnie odjęcia od fragmentu dzielnej tego wyniku. Robimy to z grubsza tyle razy, ile cyfr ma iloraz.
Jeżeli za miarę wielkości liczby przyjmiemy długość jej reprezentacji w systemie pozycyjnym (czyli liczbę cyfr), to o ile porównywanie oraz odejmowanie można zrobić w czasie proporcjonalnym do długości tej reprezentacji, to dzielenie może wymagać kwadratowego czasu. Niech długość dzielnej wynosi \( n \). Zauważmy, że jeśli dzielnik jest o połowę krótszy od dzielnej, (czyli mając długość \( n/2 \) jest mniej więcej równy pierwiastkowi kwadratowemu z dzielnej), to iloraz będzie miał długość podobną jak dzielnik, czyli \( n/2 \) i tyle razy będzie się musiała wykonać zasadnicza pętla algorytmu dzielącego, bo tyle cyfr trzeba wyznaczyć. Z kolei wyznaczenie każdej cyfry ilorazu wymaga odjęcia jakiejś niewielkiej wielokrotności dzielnika, a więc liczby również z grubsza \( n/2 \)-cyfrowej. A odejmowanie jest proporcjonalnie kosztowne do długości argumentów. Łącznie zatem \( n/2 \) cyfr ilorazu razy \( n/2 \) jednocyfrowych kroków przy odejmowaniu daje nam łącznie \( {n^2/4} \), więc kwadratowo wiele w stosunku do \( n \).
Liczba obrotów głównej pętli algorytmu jest też proporcjonalna do \( n \), bo w dowolnym systemie pozycyjnym liczba cyfr jest proporcjonalna do logarytmu z danej liczby przy podstawie będącej bazą systemu, czyli również proporcjonalna do logarytmu przy podstawie \( \varphi \), bo logarytmy o różnych podstawach różnią się od siebie tylko o czynnik stały.
Jeśli skupimy się na operacjach na pojedynczych cyfrach, to łączna liczba wszystkich operacji będzie rzędu co najwyżej \( n^3 \). W rzeczywistości możemy się pokusić o przypuszczenie, że będzie to nawet mniej. Zauważmy bowiem, że złośliwe dane dla głównej pętli, to kolejne liczby Fibonacciego, a te długością różnią się co najwyżej o 1, natomiast złośliwe dane dla algorytmu dzielenia z resztą, to dane różniące się długością dwukrotnie; liczby Fibonacciego można podzielić w czasie liniowym, a nie kwadratowym. I to liczby Fibonacciego będą się pojawiały cały czas, w każdym kroku algorytmu. Jeżeli zatem zaczniemy od pary kolejnych liczb Fibonacciego, to \( O(n) \)-krotnie wykonamy dzielenie kosztujące \( O(n) \), co nam da \( O(n^{2}) \). Jeśli natomiast będziemy się starali wywindować koszt dzielenia, to długości kolejnych par powinny być równe \( (n,n/2), (n/2,n/4 ), (n/4, n/8),\ldots \). Ale wtedy łączny koszt dzieleń będzie równy
\( \frac{n^2}{4}+\frac{n^2}{16}+ \frac{n^2}{64}+\ldots =O(n^2) \).
Zatem obie skrajności: złośliwe dane dla zewnętrznej i dla wewnętrznej pętli dają koszt kwadratowy. Ale czy nie można wypośrodkować złośliwości tak, aby uzyskać jednak złożoność sześcienną?
Ćwiczenie
Czy można tak dobrać dane, żeby wymusić sześcienną złożoność algorytmu Euklides2?
Odpowiedź
NIE. Złożoność algorytmu Euklides2 jest jednak kwadratowa.
Powstaje pytanie, czy nie dałoby się znaleźć takiego algorytmu znajdowania największego wspólnego dzielnika tak, aby zachowując złożoność kwadratową korzystać z łatwiejszych operacji niż dzielenia z resztą. Rozwiązanie jest zaskakująco proste, jeśli zauważymy parę dość oczywistych faktów. Będziemy rozważać parzystość argumentów i redukować problem ze względu na tę właśnie własność. Oznaczmy zbiór liczb parzystych przez \( P \). Kluczem do algorytmu jest spostrzeżenie, że jeśli jedna liczba jest parzysta, a druga nie, to największy wspólny dzielnik nie zmieni się, jeśli parzysty argument podzielimy przez 2.
Euklides3
\( (a,b) = \begin{cases} a & \mbox{jeśli }b=0 \\ 2(\frac{a}{2},\frac{b}{2}) & \mbox{jeśli }a,b\in P \\ (\frac{a}{2},b) & \mbox{jeśli }a\in P, b\notin P \\ (a,\frac{b}{2}) & \mbox{jeśli }a\notin P, b\in P \\ (a-b,b) & \mbox{jeśli }a,b\notin P \end{cases} \)
Oczywiście, podobnie jak poprzednio, dbamy zawsze o to, żeby pierwszy argument nie był mniejszy od drugiego i w razie czego zamieniamy je miejscami.
Euklides 3
<b>Read</b>(a,b); //Wczytujemy a i b, zakładając że użytkownik wie, że a>=b, a+b>0 wynik:=1; <b>while</b> b > 0 <b>do</b> <b>begin</b> <b>if</b> a< b <b>then</b> zamień(a,b); //po wykonaniu tej instrukcji zawsze a>=b <b>if</b> parzyste(a) <b>and</b> parzyste(b) <b>then</b> <b>begin</b> wynik:=wynik*2 a:=a div 2; b:=b div 2 <b>end</b> <b>else</b> // w przeciwnym razie <b>if</b> parzyste(a) <b>and</b> <b>not</b> parzyste(b) <b>then</b> a:=a div 2 <b>else</b> <b>if</b> <b>not</b> parzyste(a) <b>and</b> parzyste(b) <b>then</b> b:=b div 2 <b>else</b> a:=a-b <b>end</b>; wynik:=wynik*a; Write(a)
W kodzie tym posługujemy się predykatem parzyste(x), który przyjmuje wartość true (prawda), jeśli x jest parzyste i false (fałsz) jeśli jest nieparzyste. Operacja div daje nam wynik dzielenia całkowitego (z ucięciem reszty).
Przyjrzyjmy się naszemu algorytmowi pod kątem liczby obrotów pętli. Zauważmy, że w każdym obrocie we wszystkich przypadkach, poza sytuacją obu argumentów nieparzystych, co najmniej jeden z argumentów jest połowiony. Natomiast w przypadku obu argumentów nieparzystych jeden z argumentów stanie się parzysty w wyniku odejmowania i w następnym obrocie pętli zostanie podzielony przez 2. Zatem co najmniej raz na dwa obroty pętli, co najmniej jeden z argumentów jest dzielony przez 2. Ale dzieleń przez 2 można wykonać tylko logarytmicznie dużo.
Uwaga
W dziedzinie całkowitoliczbowej możemy spojrzeć na logarytm jak na liczbę możliwych dzieleń przez 2, zanim dojdziemy do jedynki. Liczba ta jest równa podłodze z logarytmu rzeczywistego przy podstawie 2.
Zatem łączna liczba obrotów pętli nie przekracza \( 2(\log_2a + \log_2b) \). Co się dzieje w każdym obrocie pętli? Każda z operacji ma złożoność liniową. Sprawdzenie parzystości liczby wymaga zajrzenia do ostatniej cyfry. Sprawdzenie, czy liczba jest równa zero wymaga przejrzenia w najgorszym razie wszystkich jej cyfr jednokrotnie. Dzielenie przez 2 i mnożenie przez dwa, podobnie jak odejmowanie, mają złożoność liniową (czyli proporcjonalną do logarytmu z wartości a i b). Zatem złożoność algorytmu na poziomie operacji na cyfrach jest kwadratowa, czyli w tym przypadku proporcjonalna do kwadratu z logarytmu \( a \).