Celem zajęć jest przedstawienie roli i zadań systemu operacyjnego w oprogramowaniu komputera oraz omówienie zagadnień realizacji — algorytmów, struktur danych i ich implementacji. Prezentowane są techniki zarządzania podstawowymi zasobami sprzętowymi komputera — procesorem, pamięcią operacyjną oraz wirtualną i urządzeniami wejścia-wyjścia — oraz ich wpływ na efektywność funkcjonowania systemu jako całości. W kontekście zarządzania zasobami wprowadzana jest również koncepcja procesu oraz wątku. Omawiana jest koncepcja pliku oraz realizacja systemu plików — warstwy logicznej i fizycznej — wraz z przykładami konkretnych implementacji. Osobnym zagadnieniem, integralnie związanym z realizacją systemu operacyjnego, jest współbieżność i synchronizacja. W kontekście podstawowych problemów synchronizacji, takich jak wzajemne wykluczanie oraz ograniczone buforowanie, omawiane są podejścia do synchronizacji procesów, bazujące na współdzielonych zmiennych, podejścia wspierane przez system operacyjny — semafory, oraz podejścia wymagające wsparcia w konstrukcjach programowych języków wysokopoziomowych — monitory, regiony krytyczne i spotkania (ang. rendezvous). Ilustruje się zastosowanie omawianych mechanizmów do rozwiązywania klasycznych problemów synchronizacji (problem producenta-konsumenta, czytelników i pisarzy, pięciu filozofów itp.). Omawiany jest również problem wynikający z dostępu współbieżnych procesów do zasobów — zakleszczenie oraz podejścia do rozwiązywania tego problemu. Ważnym elementem zajęć jest ilustracja omawianych zagadnień na przykładzie współczesnych systemów operacyjnych.
Laboratorium jest poświęcone aspektom praktycznym korzystania z systemów operacyjnych, administrowania systemami, tworzenia pakietów z oprogramowaniem, rekompilowania i konfigurowania jądra systemu operacyjnego, a także robienia zmian w jądrze. Ponadto studenci nabywają umiejętność programowania współbieżnego z zastosowaniem wielowątkowości i różnych mechanizmów synchronizacji procesów.
Wykład
Przykłady zastosowania wymienionych mechanizmów pokazuje się w rozwiązaniach klasycznych problemów synchronizacji: producenta i konsumenta, czytelników i pisarzy, pięciu filozofów.
Laboratorium
| Załącznik | Wielkość |
|---|---|
| Laboratoria | 389.81 KB |
Celem wykładu jest przedstawienie ogólnych informacji o systemie operacyjnym jako składowej oprogramowania komputera. Omawiana jest zatem jego rola i zadania, klasyfikacja oraz specyficzny sposób wykonywania, wynikający ze ścisłej integracji z poziomem maszynowym procesora.
Wykład rozpoczyna się od przedstawienia kilku ogólnych definicji systemu operacyjnego, z których wynika jego rola i miejsce w oprogramowaniu komputera. Omówiona jest też ogólna struktura systemu operacyjnego. Następnie przedstawiona jest klasyfikacja systemów operacyjnych według różnych kryteriów. Ostatnia część dotyczy wykonywania systemu operacyjnego jako programu w komputerze, czyli przekazywania sterowania do kodu jądra. Poruszone przy tej okazji są kwestie zabezpieczenia jądra systemu przed niekontrolowaną ingerencją ze strony oprogramowania aplikacyjnego.
System operacyjny jest zbiorem ręcznych i automatycznych procedur, które pozwalają grupie osób na efektywne współdzielenie urządzeń maszyny cyfrowej. Per Brinch Hansen.
Pojęcie systemu operacyjnego jest trudne do zdefiniowania w zwartej, lakonicznej formie. Najczęściej krótki opis jest zbyt ogólny, żeby uzyskać wyobrażenie o roli i sposobie działania tego specyficznego oprogramowania. Podobnie, trudne jest określenie elementów składowych systemu operacyjnego, czyli jednoznaczne oddzielenie oprogramowania systemowego od aplikacyjnego.
System operacyjny (nadzorczy, nadrzędny, sterujący) jest to zorganizowany zespół programów, które pośredniczą między sprzętem a użytkownikiem, dostarczając użytkownikom zestawu środków ułatwiających projektowanie, kodowanie, uruchamianie i eksploatację programów oraz w tym samym czasie sterują przydziałem zasobów dla zapewnienia efektywnego działania. Alan Shaw
System operacyjny jest programem, który działa jako pośrednik między użytkownikiem komputera a sprzętem komputerowym. Zadaniem systemu operacyjnego jest tworzenie środowiska, w którym użytkownik może wykonywać programy w sposób wygodny i wydajny. Abraham Silberschatz
System operacyjny jest warstwą oprogramowania operującą bezpośrednio na sprzęcie, której celem jest zarządzanie zasobami systemu komputerowego i stworzenie użytkownikowi środowiska łatwiejszego do zrozumienia i wykorzystania. Andrew Tanenbaum
W niemal wszystkich tych definicjach przewijają się dwie zasadnicze kwestie:
System operacyjny pośredniczy pomiędzy użytkownikiem a sprzętem, dostarczając wygodnego środowiska do wykonywania programów. Użytkownik końcowy korzysta z programów (aplikacji), na potrzeby których przydzielane są zasoby systemu komputerowego. Przydziałem tym zarządza system operacyjny, dzięki czemu można uzyskać stosunkowo duży stopień niezależności programów od konkretnego sprzętu oraz odpowiedni poziom bezpieczeństwa i sprawności działania.
Nie ma precyzyjnego określenia, które składniki wchodzą w skład systemu operacyjnego jako jego części. Najczęściej akceptuje się definicję „marketingową”, zgodnie z którą to wszystko, co producent udostępnia w ramach zbioru oprogramowania nazywanego systemem operacyjnym , stanowi jego cześć. (Podejście takie było przyczyną wielu problemów prawnych firmy Microsoft).
W ogólnym przypadku w strukturze systemu operacyjnego wyróżnia się jądro oraz programy systemowe, które dostarczane są razem z systemem operacyjnym, ale nie stanowią integralnej części jądra. Jądro jest zbiorem modułów, które ukrywają szczegóły sprzętowej realizacji systemu komputerowego, udostępniając pewien zestaw usług, wykorzystywanych między innymi do implementacji programów systemowych. W dalszej części system operacyjny będzie rozumiany głównie jako jądro, ewentualnie inne elementy oprogramowania integralnie związane z funkcjonowaniem jądra.
Z punktu widzenia kontaktu z użytkownikiem istotny jest interpreter poleceń, który może być częścią jądra lub programem systemowym (np. w systemie UNIX). Interpreter wykonuje pewne polecenia wewnętrznie, tzn. moduł lub program interpretera dostarcza implementacji tych poleceń. Jeśli interpreter nie może wykonać wewnętrznie jakiegoś polecenia, uruchamia odpowiedni program (tzw. polecenie zewnętrzne), jako odrębny proces.
Udostępnianie systemu plików: system operacyjny organizuje i ułatwia dostęp do informacji np. w postaci hierarchicznego systemu plików.
Udostępnianie środowisko do wykonywania programów: system operacyjny dostarcza struktur danych do organizacji wykonywania programu oraz zachowywania i odtwarzania stanu przetwarzania (procesy i przełączanie kontekstu). System operacyjny udostępnia też programistom mechanizmy komunikacji pomiędzy procesami (kolejki komunikatów, strumienie, pamięć współdzielona) oraz mechanizmy synchronizacji procesów (np. semafory).
Sterowanie urządzeniami wejścia-wyjścia: odpowiednie moduły sterujące, integrowane z systemem operacyjnym, inicjalizują pracę urządzeń zewnętrznych oraz pośredniczą w efektywnym przekazywaniu danych pomiędzy jednostką centralną a tymi urządzeniami.
Obsługa podstawowej klasy błędów: system operacyjny reaguje na błędy użytkowników (np. niedostępność zasobów, brak prawa dostępu), programistów (np. błąd dzielenia przez 0, naruszenie ochrony pamięci, nieprawidłowy kod rozkazu) oraz systemu (np. błąd braku strony, błąd magistrali).
Efektywność zarządzania zasobami oraz wygodny interfejs dla użytkownika są dwoma ogólnymi, niezależnymi celami projektowymi systemów operacyjnych. Pierwszy z tych celów był kluczowy w rozwoju rodziny systemów uniksowych. Dopiero w późniejszych etapach ich rozwoju pojawił się intuicyjny okienkowy interfejs użytkownika. Systemy rodziny MS Windows zorientowane były natomiast przede wszystkim na interfejs użytkownika, na bazie którego w późniejszych etapach rozwoju powstawał pełnowartościowy system operacyjny, uwzględniający szerzej rozumiane zarządzanie zasobami.
W ramach zarządzania ogólnie rozumianymi zasobami można wyróżnić następujące operacje:
Procesor jest zasobem współdzielonym przez wiele procesów, w związku z czym zadaniem systemu operacyjnego jest przydział kwantu czasu procesora i wywłaszczanie zadania, które:
Pamięć jest zasobem, który przydzielany jest na wyłączność danego przetwarzania. Zadaniem systemu jest zatem utrzymywanie informacji o zajętości przestrzeni adresowej, znajdowanie i przydzielanie odpowiednich fragmentów wolnej pamięci na żądanie aplikacji użytkownika lub innych modułów systemu operacyjnego oraz reagowanie na naruszenie ochrony pamięci. System operacyjny pośredniczy również w transformacji adresów wirtualnych na fizyczne w systemach z segmentacją lub stronicowaniem przez organizację tablicy segmentów lub stron oraz obsługę błędów strony.
Urządzenia zewnętrzne są stosunkowo wolne, w związku z czym, w celu poprawy efektywności, zarządzanie tymi urządzeniami wymaga odpowiedniej organizacji systemu przerwań oraz buforowania danych, ewentualnie spoolingu. Osobnym zagadnieniem jest zarządzanie urządzeniami pamięci masowej, zwłaszcza odpowiednia organizacja przestrzeni dyskowej oraz optymalizacja ruchu głowic dyskowych.
Informacja jest z punktu widzenia użytkownika najważniejszym zasobem, gdyż jej przetwarzanie jest celem systemu komputerowego. System operacyjny odpowiada za organizację gromadzenia i udostępniania informacji, jej ochronę przed nieuprawnioną ingerencją, spójność w przypadku awarii itp.
W przypadku systemu przetwarzania bezpośredniego użytkownik wprowadza zadanie do systemu i oczekuje na wyniki. W trakcie przetwarzania jest zatem możliwa interakcja pomiędzy użytkownikiem a systemem (aplikacją). Użytkownik może być na przykład poproszony o wprowadzenie jakiś danych na terminalu, wybranie czegoś z menu itp.
W przypadku przetwarzania pośredniego zadanie jest realizowane w czasie wybranym przez system. Po przedłożeniu zadania ingerencja użytkownika jest niemożliwa. Wszystkie dane muszą być zatem dostępne w momencie przedkładania zadania, a jakikolwiek błąd programowy (np. niekompletność danych) oznacza konieczność przedłożenia i wykonania zadania ponownie.
Systemy jednoprogramowe, zwane też jednozadaniowymi, umożliwiają uruchomienie jednego zadania użytkownika, które ewentualnie może być wykonywane współbieżnie z pewnymi procedurami systemu operacyjnego.
Systemy wieloprogramowe (wielozadaniowe) dostarczają mechanizm przełączania kontekstu, umożliwiając w ten sposób zachowanie stanu wykonywania określonego programu (stanu procesu), a następnie odtworzenie stanu wykonywania innego programu (w szczególności innego wykonywania tego samego programu). Przełączenie kontekstu jest skutkiem zwolnienia procesora, które z kolei następuje w wyniku:
W systemach dla jednego użytkownika nie ma problemu autoryzacji, czyli konieczności identyfikowania zleceniodawcy poszczególnych zadań. Mechanizmy ochrony są ograniczone w tym sensie, że nie ma potrzeby ochrony zasobów jednego użytkownika przed drugim użytkownikiem tego samego systemu operacyjnego, ale w czasie powszechności sieci rozległych istnieje jednak problem ochrony zasobów przed ingerencją z zewnątrz.
System operacyjny w przypadku wielodostępu musi zagwarantować, że jeden użytkownik nie jest w stanie zakłócić pracy innych użytkowników. Jest to problem właściwego udostępniania zasobów oraz dostępności mechanizmów ochrony „prywatnych” zasobów jednego użytkownika przed ingerencją innego.
W systemach czasu rzeczywistego priorytetem jest minimalizacja czasu odpowiedzi (reakcji) lub czasu realizacji zadania, gdyż po przekroczeniu pewnego czasu wartość wyników albo jest znacznie mniejsza (np. przewidywanie kursów akcji na giełdzie) albo są one całkowicie bezużyteczne (np. prognozowanie pogody). Szczególnym przypadkiem, gdzie czas jest krytyczny, są wszelkiego rodzaju systemy sterowania w czasie rzeczywistym (np. w komputerach pokładowych samochodów, samolotów, jednostek pływających itp.). Systemy operacyjne czasu rzeczywistego są więc budowane pod kątem szybkości reakcji na zdarzenie zewnętrzne. Ich zadaniem jest minimalizować czas oczekiwania na zasoby dla czasowo krytycznych zadań, dlatego unika się w ich przypadku rozwiązań, które zmniejszają przewidywalność tego czasu (np. pamięci wirtualnej).
Rozproszone systemy operacyjne zapewniają, że system komputerowy, złożony z autonomicznych jednostek przetwarzających połączonych siecią komputerową, postrzegany jest jako całość. Zasoby tego systemu udostępniane są w jednolity sposób niezależnie od ich fizycznej lokalizacji — niezależnie od tego, czy są to zasoby lokalne danej jednostki, czy zasoby związane integralnie z jednostką zdalną. Cecha ta odróżnia systemy rozproszone od systemów sieciowych, które również umożliwiają dostęp do zdalnych zasobów, ale nie ukrywają faktu fizycznego rozproszenia tych zasobów. Inaczej mówiąc, w systemie sieciowym odróżnia się dostęp lokalny i dostęp zdalny do zasobów.
Rozwiązania dla systemów naręcznych nie muszą tworzyć środowiska dla zaawansowanego przetwarzania wielozadaniowego, ale ze względu na niewielkie rozmiary urządzeń podlegają dość rygorystycznym ograniczeniom zasobowym. W przypadku tego typu rozwiązań, jak również rozwiązań dla innych urządzeń mobilnych, dość istotnym zasobem, którym należy odpowiednio zarządzać jest energia.
System operacyjny jest programem, jednak jego działanie jest dość specyficzne, gdyż musi on nadzorować (monitorować) pracę komputera nawet wówczas, gdy wykonywany jest jakiś program aplikacyjny. System operacyjny musi reagować na błędy w programach aplikacyjnych, porządkować system komputerowy po awariach, z kolei błędy w kodzie jądra systemu operacyjnego mogą zdestabilizować funkcjonowanie całego systemu komputerowego.
Działanie współczesnych systemów operacyjnych jest rezultatem ewolucji w architekturze sprzętowo-programowej, w której potrzeby w zakresie implementacji pewnych mechanizmów systemu operacyjnego wymuszały wprowadzanie stosownych rozwiązań na poziomie architektury komputera (procesora, jednostki zarządzania pamięcią, układu bezpośredniego dostępu do pamięci, procesorów wejścia-wyjścia itp.). Rozwiązania na poziomie architektury komputera otwierały z kolei drogę do dalszego rozwoju oprogramowania systemowego.
Działanie systemu komputerowego można opisywać na różnych poziomach abstrakcji, począwszy od zjawisk fizycznych na poziomie układów półprzewodnikowych, czy też propagacji sygnałów logicznych na poziomie układów techniki cyfrowej. Tak niski poziom abstrakcji jest jednak na ogół mało interesujący dla informatyka, dlatego na najniższym poziomie abstrakcji na slajdzie umieszczona została mikroarchitektura. Poziom mikroarchitektury jest jednak zastrzeżony dla twórców procesorów, natomiast dla programistów systemów komputerowych najniżej dostępny jest poziom maszynowy procesora. Na poziomie tym definiowana jest lista rozkazów procesora, tryby adresowania pamięci, rejestry procesora. Na poziomie tym nie istnieją jednak takie elementy, jak pliki, procesy, mechanizmy komunikacji i synchronizacji. Te elementy uzupełniane są przez system operacyjny, który współtworzy wraz poziomem maszynowym hybrydową warstwę usług dla programów użytkowych. Na bazie tej warstwy budowane są kolejne poziomy abstrakcji, związane z językami programowania niższego lub wyższego poziomu.
W praktyce rzadko kiedy korzysta się bezpośrednio z poziomu maszynowego. Jeśli rzeczywiście istnieje potrzeba pisania programu na tak niskim poziomie, wykorzystywany jest raczej asembler, który nie ogranicza możliwości poziomu maszynowego, a usprawnia tworzenie programu dzięki mnemonikom rozkazów zamiast ich kodów, etykietom zamiast adresów itp.
W celu wyjaśnienia, w jaki sposób wykonywany jest program jądra, istotne jest uświadomienie sobie, w jaki sposób w ogóle wykonywany jest program przez procesor.
Działanie współczesnych procesorów opiera się w dużej części na modelu von Neumanna. Architektura komputera, której nazwa przyjęła się od nazwiska jej popularyzatora — Johna von Neumanna, zakłada, że zarówno dane, jak i program (kod instrukcji/rozkazów) znajdują się w pamięci operacyjnej (dziś wydaje się to dość oczywiste). Rozkazy umieszczane są pod kolejnymi adresami w pamięci. Wykonywanie takiego programu sprowadza się zatem do pobierania rozkazów z kolejnych komórek. Adres komórki pamięci, od której rozpoczyna się kod następnego rozkazu do wykonania, przechowywany jest w odpowiednim rejestrze procesora, zwanym licznikiem programu (PC — program counter) lub wskaźnikiem instrukcji (IP — instruction pointer). Zawartość tego rejestru wystawiana jest na szynę adresową magistrali systemowej w celu pobrania z pamięci kodu rozkazu. Po zdekodowaniu operacji licznik ten zwiększany jest odpowiednio do długości pobranego rozkazu, w ten sposób wskazuje następny rozkaz do wykonania. Opisany schemat — domyślny przepływ sterowania — oznacza wykonywanie rozkazów w pewnej sekwencji, wynikającej z ich uporządkowania w programie i tym samym w pamięci. Schemat ten może ulec zmianie w wyniku wykonania specjalnego rozkazu (skoku, wywołania podprogramu, powrotu z podprogramu). Zmiana domyślnego przepływu sterowania jest więc zdefiniowana przez sam program.
Działania procesora, zmierzające do wykonania rozkazu, powtarzają się cyklicznie, w związku z czym określa się je jako cykl rozkazowy. Realizacja cyklu rozkazowego wymaga na ogół kilku interakcji procesora z pamięcią. Każdą taką interakcję określa się mianem cyklu maszynowego. W każdym cyklu rozkazowym występuje cykl maszynowy pobrania kodu rozkazu (fetch). W zależności od trybu dostępności operandów mogą też wystąpić cykle pobrania operandu z pamięci (albo rejestrów wejścia-wyjścia) lub składowania operandu w pamięci (albo rejestrach wejścia-wyjścia) . (Operandy są argumentami operacji wykonywanej w ramach rozkazu.) Każdy cykl maszynowy oznacza zatem zapis lub odczyt pamięci, przy czym cykl pobrania kodu rozkazu oznacza zawsze odczyt.
Cykl rozkazowy rozpoczyna się od wystawienia kodu rozkazu. W reakcji na towarzyszący temu sygnał sterujący odczytu pamięci na szynie danych udostępniana jest zawartość zaadresowanej komórki, a procesor pobiera ją i zapamiętuje w odpowiednim rejestrze. Następnie zostaje zdekodowana operacja i w zależności od wymaganych operandów następuje odczyt pamięci lub rejestrów wejścia-wyjścia. Odczyt taki wymaga oczywiście wystawienia odpowiedniego adresu na magistrali, a następnie przekazania sygnału sterującego odczytu pamięci. Adres operandu w zależności od trybu adresowania jest częścią kodu rozkazu lub znajduje się w rejestrze procesora (rzadziej w innej komórce pamięci). W przypadku rozkazów wymagających kilku operandów wejściowych cykl maszynowy pobrania operandów może powtórzyć się kilkakrotnie. W szczególnym przypadku rozkaz nie wymaga żadnego operandu wejściowego. Może się też okazać, że operand dostępny jest w rejestrze procesora, w związku z czym nie jest wymagana interakcja z pamięcią albo rejestrami wejścia-wyjścia. W takich przypadkach cykl maszynowy pobrania operandów zostanie pominięty.
Po zdekodowaniu operacji i skompletowaniu operandów wejściowych można wykonać operację, a następnie umieścić w pamięci albo rejestrach wejścia-wyjścia operandy wyjściowe. Podobnie jak w przypadku operandów wejściowych ten cykl maszynowy może być wykonany wielokrotnie lub w szczególnym przypadku pominięty. Na tym kończy się ciąg działań związany z wykonaniem bieżącego rozkazu i można by przejść do następnego cyklu rozkazowego.
Jeśli w taki sposób byłby wykonywany program użytkownika, to nasuwa się pytanie: „Gdzie jest miejsce na wykonywanie programu jądra systemu operacyjnego?”, „W jaki sposób następuje przekazanie sterowania do jądra systemu operacyjnego?”.
W czasie wykonywania rozkazu mogły nastąpić pewne zdarzenia zewnętrzne w stosunku do procesora, nie związane z bieżącym cyklem rozkazowym, ale wymagające od procesora jakiejś reakcji. Konieczność reakcji zgłaszana jest poprzez sygnał na odpowiedniej linii wejściowej procesora. Ostatnia faza cyklu rozkazowego polega zatem na sprawdzeniu, czy wystąpiło takie zgłoszenie. Jeśli nie było zgłoszenia, rozpoczyna się następny cykl maszynowy. Jeśli jednak było zgłoszenie — nazywane przerwaniem, następuje ciąg działań, zmierzających do zidentyfikowania źródła przerwania, a następnie przekazania sterowania do stosownej procedury obsługi. Procedury obsługi przerwań są częścią programu jądra systemu operacyjnego.
Ogólnie, sterowanie przekazywane jest do jądra systemu operacyjnego poprzez przerwania. Program jądra jest więc zbiorem procedur obsługi przerwań i wywoływanych przez nie innych podprogramów. Przerwania, wspomniane na poprzednim slajdzie, pochodzą z układów na zewnątrz procesora, czyli od urządzeń wejścia-wyjścia, czasomierzy, układu bezpośredniego dostępu do pamięci itp. Inny rodzaj to przerwania zgłaszane wewnętrznie przez procesor, będące następstwem wykrycia jakiegoś stanu wyjątkowego. Jeszcze inny rodzaj to przerwania programowe, wynikające z wykonania specjalnej instrukcji procesora, umożliwiające programom użytkownika dostęp do wybranych funkcji jądra systemu operacyjnego.
Stabilność pracy systemu wymaga ochrony przynajmniej jądra systemu operacyjnego przed niekontrolowaną ingerencją użytkowników. Wymaga to monitorowania odniesień do pamięci i weryfikowania poprawności adresów. Ze względów wydajnościowych zadanie to realizowane jest sprzętowo, ale odpowiednie dane na potrzeby weryfikacji musi dostarczyć system. W celu zabezpieczenia tych (i innych) newralgicznych danych wyróżnione są pewne instrukcje uprzywilejowane, niedostępne dla programów aplikacyjnych. Powstaje jednak problem odróżnienia programów systemowych od aplikacyjnych, którego rozwiązaniem jest wyodrębnienie dwóch (w niektórych procesorach nawet większej liczby) poziomów pracy (trybów pracy). Możliwe staje się narzucenie sprzętowych restrykcji odnośnie wykonywania niektórych instrukcji na odpowiednich poziomach. Proces użytkownika uruchamiany jest w trybie nieuprzywilejowanym, w związku z czym nie może wykonać pewnych instrukcji, dostępnych tylko w trybie uprzywilejowanym, tym samym ma ograniczoną możliwość swobodnego ingerowania w „obszary” zastrzeżone dla jądra systemu operacyjnego.
System przerwań umożliwia niesekwencyjne (współbieżne) wykonywanie programów. Zmiana sekwencji wykonywania instrukcji polega na tym, że w reakcji na przerwanie następuje zapamiętanie bieżącego stanu przetwarzania (najważniejszych rejestrów procesora), przekazanie sterowania do ustalonej procedury obsługi i rozpoczęcie wykonywania instrukcji tej procedury. W szczególności może to prowadzić do przełączenia kontekstu, czyli przekazania sterowania po zakończeniu procedury obsługi przerwania do innego przetwarzania, niż to które zostało przerwane.
Przerwania od urządzeń zewnętrznych zgłaszane są po zakończeniu operacji wejścia-wyjścia i przekazywane na specjalne wejście procesora najczęściej przez sterownik przerwań. Tą samą ścieżką zgłaszane są również przerwania od układów ściśle współpracujących z procesorem — czasomierzy, układów bezpośredniego dostępu do pamięci itp. Są to typowe przerwania, gdyż ich źródło jest poza procesorem i jest od niego niezależne.
W przeciwieństwie do przerwań zewnętrznych, przerwania programowe są wynikiem wykonania specjalnej instrukcji procesora, np. int (interrupt) w procesorach firmy Intel, sc (system call) w procesorach PowerPC firm IBM, Motorola i Apple.
Przerwania diagnostyczne są z kolei generowane wewnętrznie przez procesor w sytuacji zajścia określonego stanu. Są zatem pośrednim skutkiem wykonania określonego ciągu rozkazów prowadzących do osiągnięcia tego stanu. Tego typu przerwania w literaturze określa się jako pułapki lub wyjątki. Przykładami tego typu przerwań są:
Przerwanie diagnostyczne ma swoje źródło na poziomie maszynowym procesora. Przerwanie programowe też ma swoje źródło na poziomie maszynowym procesora, ale bezpośrednią przyczyną jego wystąpienia jest rozkaz w programie wykonywanym przez procesor. Rozkaz taki najczęściej jest w programie aplikacyjnym, ale może również być w kodzie jądra systemu operacyjnego. Przerwanie zewnętrzne zgłaszane jest procesorowi poprzez podanie odpowiedniego sygnału na specjalne wejście. Procesor może mieć kilka takich wejść — w najprostszym przypadku ma jedno wejście przerwań maskowalnych (przerwanie zgłaszane na tym wejściu można ignorować) oraz jedno wejście przerwań niemaskowalnych (nie można go zignorować).
Kluczowa dla stabilnej pracy i bezpieczeństwa systemu komputerowego jest ochrona pamięci jądra systemu operacyjnego przed ingerencją programów wykonywanych w trybie użytkownika — przede wszystkim przed modyfikacją kodu lub danych, ale ze względów bezpieczeństwa również przed odczytem (np. haseł). W systemach wielozadaniowych ważna jest również ochrona pamięci jednego zadania (procesu) przed ingerencją innego zadania.
W najprostszym przypadku ochrona pamięci polega na ograniczeniu zakresu dostępnych adresów do pewnego podzbioru, opisanego przez podanie najniższego i najwyższego dopuszczalnego adresu. W przedstawionym schemacie najniższy dopuszczalny adres przechowywany jest w rejestrze bazowym. Rejestr graniczny z kolei określa wielkość dostępnego obszaru pamięci. Dopuszczalne adresy należą do zatem do przedziału
W środowisku wielozadaniowym z każdym przetwarzaniem mogą być związane inne ograniczenia na dostępność obszarów pamięci. Przełączanie między zadaniami wymaga zatem zmiany zawartości rejestrów, ograniczających zakres dostępności pamięci. W rozważaniach pominięte zostały też kwestie ograniczonego dostępu do określonych obszarów (np. tylko do odczytu). Dostępność obszaru w takim przypadku zależy od rodzaju cyklu maszynowego. Tego typu zagadnienia będą rozważane przy omawianiu zarządzania pamięcią.
Dla procesora program jest ciągiem instrukcji. Na tym poziomie nie ma rozróżnienia użytkownika, administratora, operatora itd. Narzucenie restrykcji odnośnie wykonywania niektórych instrukcji wymaga zatem wskazania trybu pracy (związanego z poziomem uprzywilejowania), który musi być czytelny dla procesora w celu weryfikowania dostępności instrukcji.
W najprostszym przypadku wystarczą dwa tryby, ale większa ich liczba może usprawnić tworzenie oprogramowania systemowego. Na rysunku wyszczególniono 3 tryby, zwane też pierścieniami ochrony. W architekturze Intel IA-32 wyróżniono 4 pierścienie. W trybie najbardziej uprzywilejowanym (trybie jądra, poziomie nr 0 w procesorach Intel) dostępne są wszystkie instrukcje i rejestry procesora. W każdym następnym (mniej uprzywilejowanym) trybie jest coraz mniej dostępnych instrukcji lub rejestrów.
Procesor pracuje zatem zawsze w jednym z trybów uprzywilejowania. Programu jądra wykonywany jest w trybie najbardziej uprzywilejowanym, z którego można się przełączyć w tryb mniej uprzywilejowany, co ma miejsce przy uruchamianiu programu aplikacyjnego. Powrót do trybu uprzywilejowanego możliwy jest poprzez odpowiednie przerwania (lub podobne mechanizmy), ale procedura obsługi przerwania dostarczona jest przez jądro. Program użytkownika nie może zatem zmienić trybu pracy na potrzeby wykonania dowolnego własnego kodu.
Czasomierz jest licznikiem, na wejście którego podawane są impulsy o stałej częstotliwości, niezależnej od częstotliwości zegara procesora. Do licznika wpisywana jest pewna wartość, która zmniejszana jest o 1 z każdym impulsem. Po osiągnięciu wartości 0 generowane jest przerwanie, zwane zegarowym. Jest to jedno z przerwań zewnętrznych. Wystąpienie tego przerwania nazywany jest taktem zegara i pojawia się zależnie od architektury kilkadziesiąt lub kilkaset razy na sekundę (zwykle około 100 razy).
W wyniku przerwania zegarowego system operacyjny przejmuje sterowanie, wykonuje pewne zadania okresowe (np. zbiera dane statystyczne w celu optymalizacji pracy systemu) i podejmuje decyzje, czy wznowić przerwane zadanie, czy przełączyć się na inne zadanie (dokonać przełączenia kontekstu). W ten sposób niemożliwe jest zawłaszczenie procesora przez program użytkownika.
Celem wykładu jest wprowadzenie fundamentalnych pojęć, integralnie związanych z systemem operacyjnym, na których opiera się przetwarzanie we współczesnych systemach komputerowych — pojęcia procesu i pojęcia zasobu. Oba pojęcia zostały zasygnalizowane we wprowadzeniu. Tutaj zostaną przedyskutowane związki pomiędzy procesami i zasobami.
Treść wykładu obejmuje przedstawienie koncepcji procesu i zasobu, ich obsługę, czyli podstawowe struktury danych oraz ogólną koncepcję zarządzania. Z relacji między procesami a zasobami wynikają stany procesu i związane ze stanem kolejkowanie procesów. Następnie przedstawiona zostanie klasyfikacja zasobów. Kolejnym istotnym zagadnieniem jest koncepcja wątku, wyodrębniona ze względu na specyfikę wykorzystywania niektórych zasobów systemu. Na koniec omówiony zostanie sposób realizacji koncepcji procesów i wątków we współczesnych systemach operacyjnych, czyli w systemie Linux oraz Windows 2000/XP.
Proces służy do organizowania wykonywania programu w ten sposób, że stanowi on powiązanie niezbędnych zasobów systemu komputerowego i umożliwia kontrolę stanu tych zasobów, związaną z wykonywaniem programu.
Istotne jest rozróżnienie pomiędzy procesem a programem. Program jest zbiorem instrukcji. W tym sensie jest tylko elementem procesu, znajdującym się w jego segmencie kodu (zwanym też segmentem tekstu). Poza tym do wykonania programu potrzebne są dodatkowe zasoby (procesor, pamięć itp.) Program najczęściej nie zmienia się w czasie wykonywania (nie ulega modyfikacji), podczas gdy stan procesu ulega zmianie: zmienia się stan wykonywania programu podobnie jak stan większości zasobów z tym związanych. Zmianie w wyniku wykonywania procesu ulega np. segment danych, segment stosu, stan rejestrów procesora itp. Procesem jest więc cały ten kontekst niezbędny do wykonania programu.
Wyodrębnienie procesu wiąże się z współbieżnością przetwarzania. W systemie może istnieć wiele procesów (wiele niezależnych przetwarzań), stąd ważne jest utrzymanie informacji o tym, które zasoby przedzielone na potrzeby każdego przetwarzania. W systemach jednozadaniowych (np. MS DOS) pojęcie procesu nie było wyodrębnione, gdyż nie było takiej potrzeby.
Zasobem jest każdy element systemu, który może okazać się niezbędny dla realizacji przetwarzania. Typowe zasoby kojarzone są z elementami sprzętowymi systemu komputerowego. Należy jednak podkreślić, że to dopiero system operacyjny definiuje taki element jako zasób, gdyż w jądrze systemu istnieją struktury do zarządzania i procedury realizacji przydziału, odzyskiwania itd.
Poza tym część zasobów tworzona jest przez jądro systemu operacyjnego. Zasoby takie często określa się jako wirtualne. Przykładem wirtualnego urządzenia wejścia-wyjścia jest plik. Pliki udostępnia system operacyjny. Na poziomie maszynowym pojęcie takie nie istnieje — można co najwyżej mówić o sektorach dysku, w których składowana są dane.
Operacje tworzenia i usuwania procesów bezpośrednio dotyczą procesów, ale pośrednio również często zasobów, gdyż utworzenie procesu wymaga przydziału pewnych zasobów. Proces tworzony jest przez inny proces i początkowo może współdzielić z nim większość zasobów.
Operacje przydziału i zwalniania jednostek zasobów dotyczą tworzenia powiązań między procesami i zasobami.
Elementarne operacje wejścia-wyjścia dotyczą również zasobów, ale nie są związane z ich przydziałem, czy zwalnianiem. Są to operacje dostępu do przydzielonych zasobów. Nie wszystkie operacje dostępu do przydzielonych zasobów wymagają jednak wsparcia ze strony jądra. Operacje dostępu do pamięci na przykład realizowane są na poziomie maszynowym, jądro natomiast angażowane jest dopiero w przypadku wykrycia jakichś nieprawidłowości.
Procedury obsługi przerwań z kolei są reakcją na zdarzenia zewnętrzne lub pewne szczególne stany wewnętrzne, mogą być zatem skutkiem ubocznym realizacji dostępu do zasobów. Reakcja na przerwanie może prowadzić do zmiany stanu procesu lub zasobu, nie zawsze jednak taka zmiana jest bezpośrednio spowodowana wykonaniem procedury obsługi. Procedury obsługi przerwań wykonywane muszą być szybko, dlatego ich bezpośrednim skutkiem jest czasami tylko odnotowanie faktu zajścia zdarzenia, natomiast właściwa reakcja systemu, w konsekwencji której nastąpi zmiana stanu procesu lub zasobu, wykonywana jest później.
Ze względów pojęciowych lub projektowych fragmenty kodu jądra związane z obsługą procesów i zasobów wyodrębnia się postaci zarządców. Można więc mówić o zarządcy procesów, który grupuje i wykonuje funkcje obsługi procesów oraz zarządcy zasobów, którego zadaniem jest kontrola stanu zajętości zasobów i realizacja żądań procesów.
Zarządzenie wymaga odpowiednich struktur dla danych na potrzeby ewidencji stanu procesów i zasobów, ich powiązań, potrzeb zasobowych procesów itp.
Strukturę danych na potrzeby opisu stanu procesu określa się jako deskryptor procesu lub blok kontrolny procesu . Zbiór takich informacji dla wszystkich procesów określa się jako tablicę procesów. Współcześnie na potrzeby deskryptorów rzadko wykorzystywana jest rzeczywiście statyczna tablica. Podejście takie gwarantuje szybki dostęp do informacji, ale jest mało elastyczne, gdyż narzuca górny limit na liczbę procesów w systemie, a w przypadku mniejszej ich liczby oznacza marnotrawstwo pamięci.
Zasoby mogą być bardzo zróżnicowane, dlatego ogólny określenie deskryptor zasobu ma raczej charakter pojęciowy, a nie definicyjny. W zależności od rodzaju zasobu struktura opisu może być bardzo różna. Często jest ona narzucona przez rozwiązanie przyjęte na poziomie architektury procesora (np. w przypadku pamięci), a czasami wynika z decyzji projektowych.
Zakres niezbędnych informacji, umożliwiających odpowiednie zarządzanie procesem może być różny w zależności od celów projektowych systemu operacyjnego lub przyjętych rozwiązań implementacyjnych. Np. w przypadku systemów dla komputerów osobistych identyfikator właściciela lub informacje do rozliczeń mogą okazać się zbędne. Prawa dostępu mogą by różnie zaimplementowane, zależnie od przyjętej koncepcji ochrony zasobów.
Część tych informacji jest jednak niezbędna w każdym deskryptorze. Stan procesu potrzebny jest do podjęcia decyzji odnośnie dalszego losu procesu (np. usunięcie procesu i zwolnienie zasobów, przesunięcie procesu z pamięci fizycznej do pamięci pomocniczej lub odwrotnie itp.). Licznik rozkazów i stan rejestrów niezbędne są do odtworzenia kontekstu danego procesu. Informacje na potrzeby planowania przydziału procesora umożliwiają właściwe szeregowanie procesów i podejmowanie decyzji przez planistów (ang. scheduler), chociaż część tych informacji może znajdować się poza właściwym deskryptorem. Informacje o zarządzaniu pamięcią umożliwiają ochronę obszarów pamięci, w szczególności powstrzymanie procesu przed ingerencją w obszary poza jego przestrzenią adresową. Informacje o stanie wejścia-wyjścia , obejmujące dane o przydzielonych urządzeniach, wykaz otwartych plików itp., umożliwiają odpowiednie zarządzanie tymi zasobami i dostępem do nich przez system operacyjny, ich odzyskiwanie po zakończeniu procesu itp.
W zależności od stanu wykonywania programu i dostępności zasobów można wyróżnić następujące, ogólne stany procesu:
Nowy — formowanie procesu, czyli gromadzenie zasobów niezbędnych do rozpoczęcia wykonywania procesu, z wyjątkiem procesora (kwantu czasu procesora), a po zakończeniu formowania oczekiwanie na przyjęcie do kolejki procesów gotowych.
Wykonywany — wykonywanie instrukcji programu danego procesu i wynikająca z ich wykonywania zmiana stanu odpowiednich zasobów systemu.
Oczekujący — zatrzymanie wykonywania instrukcji programu danego procesu ze względy na potrzebę przydziału dodatkowych zasobów, konieczność otrzymania danych lub osiągnięcia odpowiedniego stanu przez otoczenie procesu (np. urządzenia zewnętrzne lub inne procesy).
Gotowy — oczekiwanie na przydział kwantu czasu procesora (dostępność wszystkich niezbędnych zasobów z wyjątkiem procesora).
Zakończony — zakończenie wykonywania programu, zwolnienie większości zasobów i oczekiwanie na możliwość przekazania informacji o zakończeniu innym procesom lub jądru systemu operacyjnego.
Pozostawanie procesu z stanie zakończony (w systemach uniksopodobnych zwany zombi ) spowodowane jest przetrzymywaniem pewnych informacji o procesie po jego zakończeniu (np. statusu zakończenie). Całkowite usunięcie procesu mogłoby oznaczać zwolnienie pamięci i utratę tych informacji.
Przejście ze stanu gotowy do wykonywany wynika z decyzji modułu szeregującego procesy (planisty przydziału procesora), która oparta jest na priorytetach procesów. Jeśli w systemie jest jedna jednostka przetwarzająca (procesor), to w stanie wykonywany może być tylko jeden proces, podczas gdy pozostałe procesy znajdują się w innych stanach (w szczególności w stanie gotowy).
Przejście ze stanu wykonywany bezpośrednio do stanu gotowy oznacza wywłaszczenie procesu z procesora. Wywłaszczenie może być następstwem:
W systemie z podziałem czasu proces otrzymuje tylko kwant czasu na wykonanie kolejnych instrukcji. Upływ kwantu czasu odmierzany jest przez przerwanie zegarowe, a po stwierdzeniu wyczerpania kwantu czasu następuje przełączenie kontekstu i kolejny kwant czasu otrzymuje inny proces (rotacyjny algorytm planowania przydziału procesora).
W systemie z dynamicznymi priorytetami przerwanie zegarowe lub inne zdarzenie obsługiwane przez jądro wyznacza momenty czasu, w którym przeliczane są priorytety procesów. Jeśli stosowane jest wywłaszczeniowe podejście do planowania przydziału procesora, oparte na priorytecie, proces o najwyższym priorytecie otrzymuje procesor. Więcej szczegółów zostanie omówionych w następnym module.
Informacje o zasobie mogą obejmować zróżnicowane atrybuty, których omawianie w oderwaniu od konkretnego rodzaju zasobu, czy chociażby pewnych klas nie ma sensu. Ogólnie dany zasób może być dostępny w liczbie wielu jednostek (np. pamięć) i informacje o tych jednostkach muszą być dostępne w deskryptorze.
Istotne są też powiązania pomiędzy jednostkami zasobu, a procesami, którym są przydzielone lub które na przydział oczekują. W prezentowanym modelu założono, że informacje o przydzielonych zasobach umieszczone są w deskryptorze procesu, a informacje o oczekiwaniu na przydział umieszczone są w deskryptorze zasobu, ale założenie takie ma raczej charakter poglądowy, niż implementacyjny. W rzeczywistości informacje o powiązaniach mogą być jednocześnie w obu strukturach, jeśli jest to wymagane na potrzeby zarządzania.
Innym zagadnieniem jest implementacja kolejki procesów. Procesy można powiązać w kolejkę wykorzystując odpowiednie wskaźniki w deskryptorze procesu. W deskryptorze procesu oczekującego można więc przechować wskaźnik lub identyfikator następnego (również poprzedniego) procesu w kolejce. Atrybut lista procesów w deskryptorze zasobu może się zatem sprowadzić do czoła takiej kolejki, czyli wskaźnika na deskryptor pierwszego proces, a deskryptor ten będzie zawierał wskaźnik na deskryptor następnego procesu.
Na potrzeby wskazania ogólnych zasad zarządzania zasobami należy dokonać pewnej klasyfikacji. Sposób zarządzania w dużym stopniu zależy od przynależności zasobu do odpowiedniej klasy.
Jednostki pewnych zasobów można odzyskać po zakończonych procesach, np. pamięć. Są jednak zasoby, które proces zużywa w ramach przetwarzania, np. energia, istotna w urządzeniach przenośnych, lub czas procesora przed linią krytyczną (nie sam procesor, czy czas procesora ogólnie), istotny w systemach czasu rzeczywistego. Jednostki zasobów, podanych w przykładzie nie są wytwarzane przez procesy w systemie. Zasobem nieodzyskiwalnym wytwarzanym w wyniku przetwarzania mogą być dane lub sygnały synchronizujące.
Jeśli zasób można odzyskać, istotny z punktu widzenia pewnych problemów (np. zakleszczenia) może być sposób odzyskiwania. Zasób wywłaszczalny można odebrać procesowi (np. procesor). Natomiast jednostki zasobu niewywłaszczalnego proces sam musi zwrócić do systemu. Z punktu widzenia systemu oznacza to, że należy poczekać, aż proces, posiadający zasób, dojdzie do takiego stanu przetwarzania, w którym zasób nie będzie mu już potrzebny (np. po wydrukowaniu proces zwróci drukarkę, ale nie papier ani toner).
Pewne zasoby mogą być używane współbieżnie przez wiele procesów, np. segment kodu programu może być czytany i wykonywany przez wiele procesów w tym samym czasie. Są też zasoby dostępne w trybie wyłącznym, czyli dostępne co najwyżej dla jednego procesu w danej chwili czasu (np. drukarka, deskryptor procesu w tablicy procesów).
Stan procesu w dużym stopniu zależy od dostępności zasobów systemu. W zależności od tego, jakie zasoby są dostępne, proces jest albo wykonywany, albo na coś czeka (w stanach NOWY, GOTOWY, OCZEKUJĄCY). W czasie oczekiwania proces trafia do kolejki procesów oczekujących na dany zasób, a często opuszczając jedną kolejkę, trafia do innej, np. opuszczając kolejkę do urządzenia, trafia do kolejki procesów gotowych.
Kolejkowanie procesów polega na umieszczeniu ich na określonej liście. Jak już wspomniano, do budowy list procesów wykorzystywane są specjalne pola w tablicy procesów, w których dla każdego procesu na liście pamiętany jest identyfikator następnego procesu i/lub poprzedniego procesu.
W tym kontekście, określenie kolejka zadań może się okazać niezręczne — jest to raczej zbiór zadań lub tablica zadań.
Po wyjściu ze stanu wykonywany (po opuszczeniu procesora), w zależności od przyczyny zaprzestania wykonywania programu, proces trafia do jednej z kolejek. Po upłynięciu kwantu czasu proces (w stanie gotowy ) trafia po prostu na koniec kolejki procesów gotowych, a z czoła tej kolejki pobierany jest proces do wykonywania. Następuje więc przełączenie procesora w kontekst nowego procesu. Odpowiednio częste przełączanie kontekstu przy niezbyt długim oczekiwaniu w kolejce procesów gotowych umożliwia na bieżąco (ang. on-line) interakcję procesu z użytkownikiem, dzięki czemu użytkownik ma wrażenie, że wyłącznie jego zadania są wykonywane przez system. Użytkownik nie ma zatem poczucia dyskomfortu nawet, gdy zasoby systemu są w rzeczywistości współdzielone przez współbieżnie działające procesy wielu użytkowników.
Jeśli proces opuszcza procesor z innych przyczyn, niż upłynięcie kwantu czasu, przechodzi do stanu oczekujący , co wiąże się z umieszczeniem go w kolejce procesów oczekujących na zajście określonego zdarzenia. Kolejek takich może być wiele, np. kolejka może być związana z każdym urządzeniem zewnętrznym, z mechanizmami synchronizacji itp.
Jak już wspomniano, opuszczenie stanu wykonywany przez jeden proces udostępnia procesor innemu procesowi i następuje przełączenie kontekstu . Przełączenie kontekstu polega na zachowaniu stanu przetwarzania procesu oddającego procesor (zachowaniu kontekstu) i załadowaniu stanu przetwarzania innego procesu (odtworzenie kontekstu). Na ogólnie rozumiany kontekst składa się stan tych zasobów, z których jeden proces w ramach przełączania rezygnuje na rzecz drugiego. W najprostszym przypadku jest to stan procesora, czyli zawartość rejestrów. W procesorze mogą być rejestry, które nie są elementem kontekstu procesu, ale przechowują wartości, stanowiące element definicji stanu całego systemu. Wartości takich rejestrów nie trzeba zachowywać ani odtwarzać, ale też nie można dopuścić do ich swobodnej modyfikacji przez proces.
Tak rozumiany kontekst zajmuje niewiele miejsca w pamięci i przechowywany jest w deskryptorze procesu. Przełączanie kontekstu sprowadza się zatem do zaktualizowania we właściwym deskryptorze informacji o kontekście procesu wywłaszczanego z procesora, a następnie załadowaniu rejestrów procesora odpowiednimi wartościami z deskryptora procesu, który ma być wykonywany jako następny.
Czas przełączania kontekstu jest marnowany z punktu widzenie wykorzystania procesora, gdyż żaden program użytkowy nie jest w tym czasie wykonywany. W celu skrócenia czasu przełączania, procesory oferują często wsparcie dla tej operacji w postaci odpowiednich instrukcji lub bardziej złożonych mechanizmów na poziomie architektury.
Ogólnym zadaniem planistów (programów szeregujących) jest wybieranie procesów z pewnego zbioru tak, aby dążyć do optymalizacji przetwarzania w systemie. Kryteria optymalizacji mogą być jednak bardzo zróżnicowane.
W kontekście optymalizacji wykorzystania zasobów mówi się o równoważeniu obciążenia systemu, czyli ogólnie procesora i urządzeń zewnętrznych. Zrównoważenie takie umożliwia osiągnięcie odpowiedniego poziomu wykorzystania zasobów systemu. W przeciwnym razie w systemie może powstać wąskie gardło, którym będzie procesor lub urządzenie zewnętrzne. O procesach, które wykorzystują głównie procesor (np. związane są z realizacją dużej liczby obliczeń) mówi się, że są ograniczone procesorem. Procesy, które większość czasu w systemie spędzają w oczekiwaniu na realizację operacji wejścia-wyjścia, określane są jako ograniczone wejściem-wyjściem (np. edytor tekstu). Wybór procesów tylko z jednej z tych grup może spowodować powstanie wąskiego gardła na intensywnie wykorzystywanym zasobie i tym samym zmniejszyć wykorzystania pozostałych zasobów. W systemach interaktywnych istotny jest tzw. czas odpowiedzi. Zbyt długi czas odpowiedzi grozi zniecierpliwieniem użytkowników i ich irracjonalnym zachowaniem.
W różnego typu systemach rola poszczególnych planistów może być większa lub mniejsza. W systemach interaktywnych zmniejsza się (lub zupełnie znika) rola planisty długoterminowego, a rośnie rola planisty krótkoterminowego. W systemach wsadowych jest dokładnie odwrotnie.
Z analizy przełączania kontekstu wynikało, że proces oddaje procesor, w związku z tym stan procesora należy zapisać w bloku kontrolnym. Wymiana procesów w pamięci oznacza usunięcie z pamięci jednego procesu, żeby zasób pamięci oddać innemu procesowi. Umożliwienie wznowienia przetwarzania uwarunkowane jest zapisaniem zwolnionych obszarów pamięci w celu późniejszego odtworzenia. Zapis wykonywany jest na dysku w specjalnie do tego przygotowanym obszarze lub pliku, zwanym obszarem (plikiem) wymiany. Z pamięci usuwany jest najczęściej jakiś proces oczekujący, ale możliwe jest też usunięcie procesu gotowego. Dla odróżnienia stanów procesu w pamięci od stanów na urządzeniu wymiany, proces w pamięci określany będzie jako aktywny , a proces na urządzeniu wymiany jako zawieszony.
W grafie zmian stanów procesu, oprócz stanów wynikających z wymiany uwzględniono role planistów. Decyzję o przyjęciu nowego procesu do systemu podejmuje planista długoterminowy (PD). Przejście ze stanu gotowy do wykonywany wynika z decyzji planisty krótkoterminowego (PK). Planista średnioterminowy (PS) odpowiada natomiast za wymianę, czyli decyduje o tym, które procesu usunąć z pamięci, a które ponownie załadować. Uwzględniając wymianę, można powiedzieć, że pamięć jest zasobem wywłaszczalnym. W przypadku braku wymiany, odebranie procesowi pamięci oznaczałoby jego usunięcie — pamięć byłaby więc zasobem niewywłaszczalnym.
Elementarne operacje na procesach obejmują: tworzenie, usuwanie, zmianę stanu, zmianę priorytetu. Nie wszystkie operacje na procesach są dostępne dla aplikacji.
Dostępne są operacje tworzenia i usuwania. Proces jest tworzony przez inny proces, w wyniku czego tworzą się zależności przodek-potomek pomiędzy procesami. W systemach uniksopodobnych, zgodnie ze standardem POSIX, do tworzenia służy funkcja fork, która w Linuksie implementowana jest za pomocą bardziej ogólnej funkcji clone. W systemach Windows 2000/XP wykorzystywana do tego celu jest jedna z funkcji: CreateProcess, CreateProcessAsUser, CreateProcessWithLogonW lub (w najnowszych wersjach) CreateProcessWithTokenW.
Usunięcie procesu jest skutkiem zakończenia wykonywania programu, albo wynika z interwencji zewnętrznej. W systemach zgodnych z POSIX proces informuje system o swoim zakończeniu, wywołując funkcję exit lub abort. Do usuwania procesu przez inny proces, albo przez jądro systemu operacyjnego wykorzystywana jest funkcja kill. W systemach Windows 2000/XP dostępne są 2 funkcje: ExitProcess, TerminateProcess.
W interfejsie aplikacji nie ma funkcji umożliwiających swobodną zmianę stanu procesu. Operacje zawieszania i aktywacji (związane z wymianą) są dostępne wewnątrz zarządcy procesów. Mogą być natomiast udostępnione funkcje wstrzymania i wznawiania procesów. Ich skutkiem jest przejście odpowiednio w stan oczekiwania i gotowości. Zdarzeniem oczekiwanym po wstrzymaniu jest wywołanie funkcji wznowienia. W systemach zgodnych ze standardem POSIX efekt ten można uzyskać przez użycie funkcji kill, przekazując odpowiednie sygnały. W systemach Windows tego typu funkcje dostępne są dla wątków.
Nie zawsze też możliwa jest swobodna zmiana priorytetu. Funkcja nice w systemach standardu POSIX zmienia np. tylko pewną składową priorytetu procesu, podczas gdy właściwa wartość priorytetu zależy od kilku innych czynników. Zostanie to omówiony przy okazji szeregowania procesów.
Elementarne operacje na zasobach nie muszą być bezpośrednio dostępne dla aplikacji. Tworzenie lub usuwanie deskryptora jest wewnętrzną sprawą zarządcy. Realizacja przydziału jednostki zasobu jest skutkiem żądania ze strony procesu, ale bardzo często jest pośrednim skutkiem innych operacji (np. tworzenia procesu). Odzyskiwanie jednostek jest najczęściej skutkiem zakończeniu procesu.
Koncepcja wątku (ang. thread) wiąże się ze współdzieleniem zasobów. Każdy proces (ciężki proces w odróżnieniu od lekkiego, czyli wątku) otrzymuje zasoby od odpowiedniego zarządcy i utrzymuje je do swojej dyspozycji. Zasoby przydzielone procesowi wykorzystywane są na potrzeby sekwencyjnego wykonania programu, ale w wyniku wykonania programu mogą się pojawić kolejne żądania zasobowe. Niedostępność żądanego zasobu powoduje zablokowanie procesu (wejście w stan oczekiwania). W programie procesu może być jednak inny niezależny fragment, do wykonania którego żądany zasób nie jest potrzebny. Można by zatem zmienić kolejność instrukcji w programie i wykonać ten niezależny fragment wcześniej, jednak do jego wykonania może być potrzebny inny zasób. Dostępność zasobów zależy od stanu całości system i w czasie tworzenia programu nie wiadomo, które z nich będą dostępne, gdy będą potrzebne do wykonania jednego czy drugiego fragmentu.
W programie dobrze jest zatem wówczas wyodrębnić takie niezależne fragmenty i wskazać systemowi, że można je wykonać w dowolnej kolejności lub nawet współbieżnie, w miarę dostępnych zasobów. Taki wyodrębniony fragment określa się jako wątek. Wątek korzysta głównie z zasobów przydzielonych procesowi — współdzieli je z innymi wątkami tego procesu. Zasobem, o który wątek rywalizuje z innymi wątkami, jest procesor, co wynika z faktu, że jest on odpowiedzialny za wykonanie fragmentu programu. Wątek ma więc własne sterowanie, w związku z czym kontekst każdego wątku obejmuje licznik rozkazów, stan rejestrów procesora oraz stos. Każdy wątek musi mieć swój własny stos, gdzie odkładane są adresy powrotów z podprogramów oraz alokowane lokalne zmienne.
Tworzenie dodatkowych wątków w ramach tego samego procesu oraz przełączanie kontekstu pomiędzy nimi jest ogólnie mniej kosztowne, niż w przypadku ciężkich procesów, gdyż wymaga przydziału lub odpowiedniej zmiany stanu znacznie mniejszej liczby zasobów. Wynika to z faktu, że wątki tego samego procesu współdzielą większość przestrzeni adresowej (segment danych, segment kodu), otwarte pliki i sygnały. Nie jest zatem konieczne wykonywanie dodatkowych działań związanych z zarządzaniem pamięcią. Wątki mogą być nawet tak zorganizowane, że jądro nie jest świadome ich istnienia. Deskryptory wątków utrzymywane są w pamięci procesu (a nie jądra) i cała obsługa wykonywana jest w trybie użytkownika.
Alternatywą jest zarządzanie wątkami w trybie systemowym przez jądro, które utrzymuje deskryptory i odpowiada za przełączanie kontekstu pomiędzy wątkami.
Istotne w obsłudze wielowątkowości, niezależnie od sposobu realizacji, jest dostarczenie odpowiednich mechanizmów synchronizacji wątków wewnątrz procesu. Potrzeba synchronizacji wynika z faktu współdzielenia większości zasobów procesu. Problemy synchronizacji będą przedmiotem rozważań w innym module.
Obsługa wielowątkowości na poziomie jądra systemu (w trybie systemowym) oznacza, że wszelkie odwołania do mechanizmów obsługi wątków wymagają dostępu do usług jądra, co zwiększa koszt czasowy realizacji. Jądro musi też utrzymać bloki kontrolne (deskryptory) wątków, co w przypadku wykorzystania statycznych tablic może stanowić istotny koszt pamięciowy.
Z drugiej strony, świadomość istnienia wątków procesu umożliwia uwzględnienie tego faktu w zarządzaniu zasobami przez jądro i prowadzi do poprawy ich wykorzystania.
Realizacja wątków przez odpowiednią bibliotekę w trybie użytkownika zwiększa szybkość przełączania kontekstu, ale powoduje, że jądro, nie wiedząc nic o wątkach, planuje przydział czasu procesora dla procesów. Oznacza to, że w przypadku większej liczby wątków procesu czas procesora, przypadający na jeden wątek jest mniejszy, niż w przypadku procesu z mniejszą liczbą wątków.
Problemem jest też wprowadzanie procesu w stan oczekiwania, gdy jeden z wątków zażąda operacji wejścia-wyjścia lub utknie na jakimś mechanizmie synchronizacji z innymi procesami. Planista traktuje taki proces jako oczekujący do czasu zakończenia operacji, podczas gdy inne wątki, o których jądro nie wie, mogłyby się wykonywać.
W niektórych systemach operacyjnych wyróżnia się zarówno wątki trybu użytkownika, jak i wątki trybu jądra. W systemie Solaris terminem wątek określa się wątek, istniejący w trybie użytkownika, a wątek trybu jądra określa się jako lekki proces. W systemie Windows wprowadza się pojecie włókna , zwanego też lekkim wątkiem (ang. fiber, lightweight thread), które odpowiada wątkowi trybu użytkownika, podczas gdy termin wątek odnosi się do wątku trybu jądra. Takie rozróżnienie umożliwia operowanie pewną liczbą wątków trybu jądra, a w ramach realizowanych przez te wątki programów może następować przełączanie pomiędzy różnymi wątkami trybu użytkownika bez wiedzy jądra systemu. Wątek trybu jądra można więc traktować jako wirtualny procesor dla wątku trybu użytkownika.
Kontekst pomiędzy dwoma lekkimi procesami przełączany jest przez jądro. Każdy z lekkich procesów wykonuje jakiś wątek trybu użytkownika (włókno), co obrazuje ciągła linia ze strzałką. Dla każdego lekkiego procesu istnieje zatem bieżące włókno. W ramach wykonywanego kodu takiego włókna może nastąpić wywołanie funkcji zachowania bieżącego kontekstu, a następnie funkcji odtworzenia innego (wcześniej zachowanego) kontekstu, o ile tylko w miejscu wywołania dostępny jest odpowiedni deskryptor, opisujący odtwarzany kontekst. Potencjalnie więc każdy z lekkich procesów może wykonywać dowolne z włókien, co symbolizuje przerywana linia.
Proces potomny tworzony jest w systemie Linux poprzez wywołanie funkcji clone. Funkcja ta wykorzystywana jest między innymi do implementacji funkcji fork, ujętej w standardzie POSIX.
Tworząc nowy proces z użyciem funkcji clone można określić, które zasoby procesu macierzystego mają być współdzielone z potomkiem. W zależności od zakresu współdzielonych zasobów, nowo utworzony proces może być uznawany za wątek lub za ciężki proces. Typowe wątki będą współdzielić przestrzeń adresową, otwarte pliki i inne informacje związane z systemem plików (np. katalog bieżący, korzeń drzewa katalogów) i procedury obsługi sygnałów.
Rozróżnienie proces ciężki – proces lekki sprowadza się zatem do określenia zakresu współdzielenia zasobów.
Cykl zmian stanów w Linuksie jest bardzo prosty — odpowiada dość dokładnie ogólnemu schematowi. Jedyna różnica to wyodrębnienie dwóch stanów oczekiwania — w jednym następuje reakcja na sygnały, w drugim sygnały są ignorowane. Jako specyficzny rodzaj oczekiwania można też traktować stan wstrzymania TASK_STOP. Specyficzną cechą jest również brak rozróżnienia pomiędzy stanem gotowości a stanem wykonywania. Są to oczywiście dwa różne stany, ale w deskryptorze procesu oznaczone w taki sam sposób.
Proces w systemie Windows gromadzi zasoby na potrzeby wykonywania wątków, wchodzących w jego skład. Informacje o procesie znajdują się w strukturze EPROCESS, której częścią jest właściwy blok kontrolny (KPROCESS). Zawartość obu tych struktur dostępna jest w trybie jądra. W ich skład wodzi wiele wskaźników do innych struktur (między innymi struktur opisujących wątki). Część opisu procesu — blok środowiska procesu PEB — znajduje się w części przestrzeni adresowej, dostępnej w trybie użytkownika.
Podstawowe zasoby na potrzeby wykonania wątku (np. pamięć) przydzielone są procesowi. Są one zatem wspólne dla wszystkich wątków danego procesu. Najważniejszym zasobem przydzielanym wątkowi jest procesor. Wszelkie przetwarzanie i wynikająca stąd zmiana stanu procesu odbywa się w wątku. Struktury opisu wątku są analogiczne do struktur opisu procesu.
W systemie Windows zarówno stan gotowości, jak i czuwania odpowiada stanowi gotowości w odniesieniu do ogólnego schematu zmian stanów.
Omawiane podejścia ograniczone są do środowiska z jedną jednostką przetwarzającą i dotyczą procesów niezależnych. Kwestia zależności przewija się jedynie w problemie odwrócenia (inwersji) priorytetów, który został tylko zasygnalizowany, gdyż wybiega nieco poza planowanie przydziału samego procesora (dotyczy planowania dostępu do zasobów).
W nawiązaniu do poprzedniego wykładu krótko scharakteryzowane są komponenty jądra, istotne w realizacji szeregowania procesów. Następnie omawiana jest ogólna koncepcja szeregowania, umożliwiająca matematyczny opis podstawowych algorytmów. Przy jej omawianiu scharakteryzowane są parametry czasowe procesów, które są podstawą omawianych dalej kryteriów oceny algorytmów planowania. Ostatecznie omawiane są algorytmy planowania, wraz z niektórymi aspektami ich dostrajania, konsekwencjami stosowania oraz kwestiami implementacyjnymi.
W różnych systemach operacyjnych stosowana jest różna terminologia do określania komponentów jądra, istotnych w szeregowaniu zadań. Nie zawsze też komponenty te da się wyodrębnić strukturalnie. Funkcjonalnie jednak można oddzielić samo planowanie od realizacji decyzji, wynikających z tego planowania. Za planowanie, czyli utrzymywanie odpowiednich danych o procesach i ich powiązaniach, na podstawie których można wybrać następny proces do wykonania, odpowiedzialny jest planista krótkoterminowy (planista przydziału procesora, ang. scheduler). Zmiany wykonywanego proces, czyli przełączenia kontekstu, dokonuje ekspedytor.
Planowanie opiera się na trzech elementach, z których dwa zasadnicze to tryb decyzji oraz funkcja priorytetu.
Funkcja priorytetu jest zbiorem wytycznych dla planisty. Zadaniem planisty jest po prostu realizacja funkcji priorytetu, ewentualnie rozwiązywanie problemów, wynikających z takiej samej wartości priorytetów dla więcej niż jednego procesu.
Wartość funkcji priorytetu jest jakąś liczbą, przy czym w niektórych systemach większa wartość tej liczby oznacza wyższy priorytet (np. w Windows), w innych wyższy priorytet to mniejsza wartość funkcji (np. w tradycyjnym systemie UNIX).
Tryb decyzji jest z kolei zbiorem wytycznych odnośnie uruchamiania ekspedytora. Szczegółowe wytyczne mogą obejmować również wartość funkcji priorytetu, gdyż jedną z okoliczności zmiany przydziału procesora jest wzrost lub spadek priorytetu procesów gotowych lub wykonywanego.
W schemacie niewywłaszczeniowym procesor traktowany jest jako zasób niewywłaszczalny. Nie można go odebrać procesowi, ale proces może się go zrzec dobrowolnie (służy do tego np. funkcja yield, dostępna w niektórych systemach) lub się zakończyć. Rezygnacja z procesora jest też uboczną konsekwencją wejścia w stan oczekiwania (np. w wyniku zażądania operacji wejścia-wyjścia).
W schemacie wywłaszczeniowym, w ramach kontrolnego przekazania sterowania do jądra systemu operacyjnego może zostać podjęta decyzja o przełączeniu kontekstu pomimo, że wykonywany proces nie zażądał żadnej usługi, oznaczającej rezygnację z procesora. Przechodzi on wówczas do stanu gotowy, a rozpoczyna się wykonywanie innego procesu.
Najprostsze algorytmy planowania (szeregowania) wynikają z konstrukcji funkcji priorytetu w oparciu o parametry czasowe procesu, takie jak czas oczekiwania, czas obsługi, czy czas przebywania w systemie.
Określenie czas oczekiwania może być mylące i kojarzyć się ze stanem oczekiwania. W rzeczywistości jest to czas spędzony w stanie gotowości, a więc czas oczekiwania na procesor. Czas oczekiwania nie obejmuje więc czasu spędzonego przez proces w oczekiwaniu na przydział zasobów, związanych z realizacją operacji wejścia-wyjścia, czy synchronizacją. Na rzeczywisty czas spędzony w systemie składa się czas obsługi (przez procesor), czas oczekiwania (na procesor) i czas realizacji żądań zasobowych, podczas którego proces znajduje się w stanie oczekiwania.
Istotnym parametrem procesu, stanowiącym argument funkcji priorytetu, jest priorytet zewnętrzny. Nadając różne priorytety, można pewne procesy uprzywilejować, a inne, mało istotne, degradować. Jądro systemu dostarcza mechanizm uruchamiania procesów, ale nie zna ich specyfiki i roli, stąd priorytet taki musi być ustalony przez użytkownika lub administratora poza jądrem systemu.
W priorytecie procesu można też uwzględnić bilans żądań procesu i możliwości systemu w bieżącym jego stanie. Taka regulacja priorytetu ma na celu wczesne przeciwdziałanie nadmiernemu obciążeniu systemu w czasie niedostępności zasobów w bezpiecznej ilości lub szybkie zwalnianie zasobów, potrzebnych innym, wysokopriorytetowym procesom (problem inwersji priorytetu).
W przedstawionym przykładzie w chwili 0 w systemie istnieją 2 procesy. Proces P2 otrzymuje procesor i jest wykonywany przez 2 jednostki czasu, po czym wybierany jest proces P1 , a po kolejnych 2 jednostkach czasu proces P3 . W chwili 6 wszystkie procesy są w stanie oczekiwania, procesor jest więc bezczynny (wykonuje nieskończoną pętlę zwaną procesem/wątkiem bezczynności). W chwili 8 przydzielane są zasoby, oczekiwane przez proces P1 i P2 (np. kończą się operacje wejścia-wyjścia, docierają sygnały synchronizacji itp.). Proces P1 otrzymuje procesor, a proces P2 przechodzi w stan gotowości. W międzyczasie w stan gotowości po zakończonym oczekiwaniu wchodzi proces P3 . Każdy z procesów do zakończenie potrzebuje jeszcze 2 jednostek czasu procesora (czasu obsługi). Proces P1 kończy się zatem w chwili 10, proces P2 w chwili 12, a proces P3 w chwili 14.
Parametry czasowe procesów, wynikające z tego przetwarzania są następujące:
Przy okazji można też stwierdzić, że średnie wykorzystanie procesora w czasie tego przetwarzania wynosi 12/14 = 86% (w przybliżeniu).
Arbitraż losowy przy małej zmienności priorytetów mógłby prowadzić do głodzenia procesów.
Arbitraż cykliczny jest trudny w realizacji przy zmiennych priorytetach. Można go z powodzeniem realizować przy stałych priorytetach przy odpowiednim wsparciu ze strony struktur danych.
Arbitraż chronologiczny wydaję się być najbardziej sprawiedliwym, ale wymaga utrzymania odpowiednich atrybutów procesów lub użycia pewnych struktur danych do powiązania procesów w celu ustalenia kolejności przyjmowania ich do systemu.
W ocenie jakości planowania można przyjąć różne kryteria. Kryteria te bardzo często są ze sobą w sprzeczności w tym sensie, że poprawa uszeregowania z punktu widzenie jednego kryterium powoduje pogorszenie z punktu widzenia innego kryterium (trade-off pomiędzy kryteriami).
Część kryteriów ma charakter ilościowy — można je zmierzyć i obiektywnie ocenić. Przykładem jest wykorzystanie procesora lub przepustowość. W innych przypadkach ocena ilościowa jest trudna, a ewentualne miary nie jednoznaczne i nie zawsze obiektywne. Przykładem może być sprawiedliwość, co zostało zasygnalizowane przy omawianiu zagadnień synchronizacji procesów.
Sprzeczność występuje najczęściej pomiędzy kryteriami, istotnymi z punktu widzenie interesów użytkowników, a kryteriami oceny całego systemu. Dla użytkownika istotna jest minimalizacja czasu odpowiedzi, czasu cyklu przetwarzania lub czasu oczekiwania. W przypadku ustalenia czasowej linii krytycznej istotna jest również minimalizacja opóźnienia, zakładając że jest dopuszczalne (np. w systemach łagodnego czasu rzeczywistego). Dla systemu istotna jest natomiast maksymalizacja wykorzystania zasobów (np. procesora) lub przepustowość. Obciążenie procesora przez dużą liczbę zadań może jednak wpływać na zwiększenie czasu cyklu przetwarzania, czasu oczekiwania, czasu odpowiedzi oraz opóźnienia.
Interes użytkownika powinien być przedkładany w systemach interakcyjnych. Istotnym parametrem w tych systemach jest czas odpowiedzi. Odpowiedź przekazywana jest za pośrednictwem jakiegoś urządzenia wejścia-wyjścia, a więc z punktu widzenia planowania przydziału procesora istotny jest czas przetwarzania do momentu zażądania odpowiedniej operacji wejścia-wyjścia. Obok minimalizacji tego czasu, ważna jest też jego przewidywalność. Do oceny przewidywalności można użyć jakieś statystycznej miary rozrzutu (np. wariancji), ale wykorzystanie takiej miary w optymalizacji uszeregowania jest trudne. W systemach wsadowych dąży się z kolei przede wszystkim do optymalizacji wykorzystania zasobów. Próbę optymalizacji w tego typu systemach można podjąć, gdyż znany jest najczęściej zbiór zadań do zrealizowania. Nawet jeśli spontanicznie pojawia się nowe zadanie, nie ma potrzeby podejmowani natychmiastowej obsługi.
FCFS jest naturalnym algorytmem w systemach obsługi masowej, takich jak kasy sklepowe, kasy biletowe, banki, urzędy itp. Procesy otrzymują procesor w kolejności, w jakiej zgłosiły się do systemu. Specyficzną cechą w systemach komputerowych, nie zawsze mającą odpowiednik w systemach masowej obsługi, jest możliwość oddania procesora innemu procesowi na czas oczekiwania na przydział dodatkowego zasobu, np. wykonania operacji wejścia-wyjścia.
Algorytm LCFS obsługuje procesy w kolejności odwrotnej do kolejności zgłoszeń. Algorytm nie wywłaszcza procesów, więc nowo przychodzący proces jest pierwszy w kolejce i czeka na zwolnienie procesora przez bieżąco wykonywany proces. Algorytm ten wymieniany jest dla porządku, nie ma natomiast praktycznego zastosowania we współczesnych koncepcjach planowania przydziału procesora.
Algorytm SJF preferuje procesy, które mają najmniejsze wymagania odnośnie czasu procesora, potrzebnego na realizację przetwarzania. W kontekście systemów komputerowych preferencje te należałoby raczej określić jako najpierw zadanie z najkrótszą następną fazą procesora, gdyż po odwołaniu do jądra w celu przydziału dodatkowych zasobów nastąpi zwolnienie procesora. Algorytm ten ma sens również w systemach masowej obsługi (często w kolejce do kasy w sklepie przepuszczamy kogoś, kto ma niewiele produktów w koszyku). Problemem praktycznej stosowalności jest określenie przyszłego zapotrzebowania na procesor.
Zakładając, że procesy kolejkowane są zgodnie z kolejnością zgłoszeń, w algorytmie FCFS wybierany jest proces z czoła kolejki, w algorytmie LCFS wybierany jest proces z ogona (końca) kolejki, a w algorytmie SJF kolejkę należy przejrzeć w celu znalezienia procesu, który najmniej zaabsorbuje procesor.
Typowym algorytmem planowania wywłaszczającego jest algorytm rotacyjny. Każdy proces wykonywany jest co najwyżej przez pewien okres czasu, po czym następuje przełączenie kontekstu na inny proces. Po jakimś czasie nastąpi wznowienie procesu przerwanego. Proces może przed upływem kwantu czasu zgłosić żądanie zasobowe, zrezygnować dobrowolnie z procesora lub zakończyć się, co skutkuje przydzieleniem nowego kwantu dla następnego procesu. W planowaniu rotacyjnym wszystkie procesy mają ten sam priorytet. Zasadniczym kosztem stosowania algorytmu rotacyjnego jest zużycie czasu procesora na przełączanie kontekstu. Z punktu widzenia przetwarzania użytkowego czas ten jest marnowany. Taki algorytm trudno byłoby wdrożyć w systemach masowej obsługi, ale w czasach kryzysu, gdy każdy towar podlegał reglamentacji, właściwie coś takiego funkcjonowało...
SRT jest wywłaszczającą wersją algorytmu SJF. Zakładając, że znany jest czas następnej fazy procesora dla każdego procesu, sprawdza się, czy jakiś proces gotowy ma mniejsze wymagania odnośnie czasu procesora, niż proces aktualnie wykonywany. Jeśli tak, to podejmowana jest decyzja o wywłaszczeniu.
Na slajdzie po lewej stronie zobrazowano działanie algorytmu RR, w którym proces po wykorzystaniu przysługującego mu kwantu czasu przechodzi na koniec kolejki procesów gotowych i czeka na kolejny przydział procesora.
W algorytmie SRT (po prawej) proces, który ma mniejsze potrzeby odnośnie czasu procesora wywłaszcza proces obsługiwany. Ponieważ procesy obsługiwane są wg. zapotrzebowania na czas procesora, polityka porządkowania w zbiorze procesów gotowych nie ma większego znaczenia, chyba że kolejność uwzględnia to zapotrzebowanie.
Interpretacja priorytetu procesu jest taka, że większa wartość oznacza wyższy priorytet. W implementacjach mechanizmów planowania w systemach operacyjnych czasami jest odwrotnie (np. w systemie UNIX lub Linux).
W przypadku wywłaszczeniowego trybu decyzji moment zmiany kontekstu zależy ogólnie od priorytetów. W algorytmie SRT priorytetem jest czas, pozostały do zakończenia. Momentem, w którym analiza priorytetu ma sens, jest przyjęcie procesu do systemu lub zakończenie procesu. W algorytmie RR, gdzie priorytet jest stały (w najprostszym przypadku równy dla wszystkich), momentem podejmowania decyzji jest upływ kwantu czasu.
Oczywiście niezależnie od algorytmu i trybu decyzji zmiana kontekstu następuje w przypadku zakończenia procesu lub wejścia procesu w stan oczekiwania. W tych przypadkach stosowane są takie same reguły wyboru następnego procesu do wykonania.
Na diagramie zaprezentowano uszeregowanie 3 procesów P1 , P2 i P3 , które zgłaszają się do systemu w odstępie 1 jednostki czasu (przyjmijmy sekundę, jako jednostkę). Proces P1 potrzebuje 5 jednostek czasu procesora na obsługę, P2 potrzebuje 4 jednostek, a P3 — 2 jednostek. Dla uproszczenia założono, że procesy nie generują żądań zasobowych i tym samym nie wchodzą w stan oczekiwania.
W pierwszym uszeregowaniu zgodnym z algorytmem FCFS procesy wykonują się w kolejności P1 , P22 , P3 . Czasy oczekiwania tych procesów wynoszą odpowiednio 0, 4, 7. Średni czas oczekiwania wynosi wynosi 11/3≈3,67. Czasy cyklu przetwarzania wynoszą odpowiednio 5, 8, 9, co daje średni czas cyklu przetwarzania 22/3≈7,33.
Drugie uszeregowanie jest dla algorytmu SJF, chociaż zupełnie przypadkowo takie samo uszeregowanie byłoby dla algorytmu LCFS. Dokonując podobnej analizy uzyskujemy średni czas oczekiwania (0+6+3)/3 = 3, a średni czas cyklu przetwarzania (5+10+5)/3≈6,67.
Z indywidualnej perspektywy każdego procesu należałoby określić relacje pomiędzy czasem oczekiwania i czasem obsługi. Przyjmując stosunek czasu obsługi do sumy czasu oczekiwania i czasu obsługi jako miarę efektywności z punktu widzenia procesu otrzymujemy:
W algorytmie SRT w chwili uzyskania gotowości przez proces P2 oba procesy (P1 i P2 ) mają ten sam priorytet. Optymalizując liczbę przełączeń kontekstu wykonywany jest w dalszym ciągu proces P1 , co jest również zgodne z arbitrażem chronologicznym.
Kontynuując analizę dla algorytmu SRT otrzymujemy średni czas oczekiwania (2+6+0)/3≈2,67, a średni czas cyklu przetwarzania — (7+10+2)/3≈6,33. Stosunek czasu obsługi do czasu cyklu przetwarzania wynosi: 71%, 40%, 100% odpowiednio dla procesów P1 , P2 i P3 .
Analogiczne wyliczenia dla algorytmu RR przy kwancie 1 jednostki czasu dają następujące wyniki: średni czas oczekiwania (6+5+2)≈4,33, a średni czas cyklu przetwarzania (11+9+4)/3≈8 oraz współczynnik efektywności dla procesów P1 , P2 i P3 odpowiednio 45%, 44%, 50%. W formie ćwiczenia proponuje się przeprowadzanie podobnej analizy przy kwancie czasu 2 jednostki. W analizie pominięto koszt przełączania kontekstu, które zależnie od wielkości kwantu może być częstym zjawiskiem w algorytmie RR.
Przedstawione przykłady są ilustracja niektórych własności podstawowych algorytmów planowania. Algorytm FCFS gwarantuje efektywność przetwarzania całego systemu, gdyż nie wymaga częstego przełączania kontekstu, ale jest niesprawiedliwy dla procesów. Algorytmy SJF/SRT minimalizują średni czas oczekiwania (SJF dla zbioru procesów, znanego z góry) i poprawiają przepustowość, ale dyskryminują (w skrajnym przypadku głodzą) procesy wymagające dużego czasu obsługi. Na sprawiedliwe traktowanie procesów zorientowany jest algorytm RR, ale wymaga kompromisu pomiędzy długością kwantu czasu, a kosztem działania.
W przedstawionych przykładach uszeregowania nie rozważano przypadku wejścia procesu w stan oczekiwania w wyniku zażądania operacji wej.wyj. lub innych żądań zasobowych. Z punktu widzenia algorytmu SJF lub SRT oznacza to, że całkowity czas obsługi musi być znany w momencie zgłoszenia procesu do systemu. Tak sytuacja jest potencjalnie możliwa w systemach wsadowych, gdzie użytkownik specyfikuje ten czas. Jego zaniżenie może skutkować odrzuceniem zadania w trakcie przetwarzania po przekroczeniu zadeklarowanej wielkości, więc nie należy spodziewać się nadużyć w tym zakresie.
Z drugiej strony sytuacja, w której proces wymaga przez większość czasu wyłącznie obsługi ze strony procesora jest nieprawdopodobna w realnym przetwarzaniu. Dlatego w algorytmach SJF lub SRT uwzględnia się czas następnej (przyszłej) fazy procesora. W ogólnym przypadku czas taki trudno oczywiście wydedukować z atrybutów procesu, można jedynie próbować estymować go na podstawie czasu obsługi wcześniejszych faz.
Jedno podejście polega na wyznaczeniu średniego czasu obsługi poprzednich faz procesu. Dla pierwszego okresu można przyjąć średnią po wszystkich procesach w systemie. Dotychczasową średnią można utrzymywać jako jeden z atrybutów procesu i wykorzystać do szybszego wyliczenia średniej, uwzględniającej kolejny okres, zgodnie z równoważnym wzorem.
Charakterystyka procesu może się jednak zmieniać i ważniejsze mogą się okazać przesłanki z ostatniego okresu, niż z bardziej odległej przeszłości. Można więc zastosować średnią wykładniczą, w której współczynnik α (0≤α≤1) określa poziom istotności ostatniej fazy. Jak wynika z przedstawionego rozwinięcia, im wyższa potęga przy wartości 1–α, tym mniejsza istotność czasu z tego okresu. Tego typu podejścia określa się jako postarzanie.
Pomimo wsparcia na poziomie maszynowym, przełączanie kontekstu jest operacją wymagającą pewnej ilości czasu procesora na wykonanie odpowiednich instrukcji, związanych z zachowaniem kontekstu procesu przerywanego i odtworzeniem kontekstu procesu wznawianego. Sam czas przełączania kontekstu nie jest jedynym kosztem tej operacji, jest nim również zwiększony czas dostępu do pamięci po przełączaniu kontekstu, wynikający z braku odpowiednich danych w pamięci podręcznej. Zbyt częste przełączanie kontekstu może więc spowodować spadek znaczenia pamięci podręcznej i tym samym spadek efektywności przetwarzania.
Algorytm RR jest właściwy dla systemów interaktywnych, ale zbyt częste przełączanie kontekstu ma również bezpośredni wpływ na najistotniejszy parametr czasowy w tych systemach — czas odpowiedzi (reakcji).
Rozważmy przykład, w którym proces interaktywny został wznowiony w wyniku operacji wejścia-wyjścia, związanej z żądaniem użytkownika. Załóżmy, że proces ten otrzymuje właśnie kwant czasu procesora. Jeśli czas procesora, potrzebny na uzyskanie odpowiedzi, mieści się w jednym kwancie, odpowiedź będzie przekazana tak szybko, jak to tylko było możliwe. Jeśli jednak kwant czasu jest zbyt krótki na uzyskanie odpowiedzi, należy poczekać, aż wszystkie inne procesy gotowe wykorzystają swój kwant. Czas uzyskania odpowiedzi przez użytkownika może się więc wydłużyć wielokrotnie.
Każdy rodzaj planowania można opisać funkcją priorytetu, chociaż w realizacji strategii szeregowania nie zawsze funkcja ta jest odrębnym fragmentem kodu, realizującym matematyczną definicję. Ze względu na wymaganą szybkość działania planisty jest to wręcz niewskazane. W tym sensie każde planowanie można by nazwać priorytetowym. Planowanie priorytetowe jest tu zatem rozumiane jako oparcie strategii szeregowania na arbitralnie przyjętym priorytecie, nie wynikającym z parametrów czasowych ani innych obiektywnych parametrów procesów. Jest to wiec priorytet zewnętrzny względem procesu. Priorytet taki może być nadany przez użytkownika, nadzorcę (administratora) lub może wynikać z konfiguracji, czy też wewnętrznych uwarunkowań systemu (np. w przypadku procesów systemowych). W praktyce stosowane są często rozwiązania hybrydowe, w których priorytet zewnętrzny jest jedną ze składowych. Planowanie priorytetowe może być wywłaszczające lub niewywłaszczające.
Planowanie wielokolejkowe, zwane również planowaniem wielopoziomowych kolejek, polega na zarządzaniu wieloma kolejkami, które mogą być w różny sposób obsługiwane, tzn. przy użyciu różnych strategii, czy przypisaniu różnych priorytetów kolejkom lub przydzielaniu różnych kwantów czasu. Koncepcje wykorzystania wielu kolejek zostaną przedstawione w dalszej części.
Planowanie przed liniami krytycznymi związane jest najczęściej z systemami czasu rzeczywistego. Optymalizacja uszeregowania zależy od charakteru linii krytycznej i ewentualnych kosztów jej przekroczenia oraz wymaganych czasów obsługi. Ze znajomością czasów obsługi wiążą się podobne problemy, jak opisane przy algorytmach SJF i SRT. Szeregowanie w opisywanym tutaj zakresie sprowadza się do wyboru procesu gotowego, natomiast zasadniczym problemem w systemach czasu rzeczywistego jest odpowiednie zarządzanie zasobami, gwarantujące jak najszybsze osiąganie stanu gotowości przez procesy.
Problemem związanym z zarządzaniem zasobami, który można rozwiązać poprzez odpowiednie planowanie przydziału procesora, jest tzw. problem inwersji priorytetów. Problem powstaje wówczas, gdy proces o wysokim priorytecie jest w stanie oczekiwania na zasób, przetrzymywany przez inny proces. Proces przetrzymujący krytyczny zasób jest wprawdzie gotowy, ale ma niski priorytet, w związku z czym jest pomijany przez planistę. Wysoki priorytet procesu oczekującego na zasób nie ma znaczenia wobec niskiego priorytetu procesu przetrzymującego. Rozwiązaniem problemu jest nadanie równie wysokiego (lub wyższego) priorytetu procesowi gotowemu, żeby mógł on uzyskać procesor, wykonać kolejny fragment przetwarzania, w wyniku którego zwolni krytyczny zasób i tym samym umożliwi dalsze przetwarzanie procesu wysokopriorytetowego.
W szeregowaniu procesów ograniczonych wejściem-wyjściem chodzi głównie o to, żeby jak najszybciej zgłaszać żądania do urządzeń zewnętrznych, które są stosunkowo powolne. Jeśli proces będzie przetrzymywany w stanie gotowości, to z braku dostępu do procesora nie będzie mógł zgłosić żądania obsługi, co z kolei może powodować przestój urządzania. Po otrzymaniu czasu procesora natomiast, bardzo szybko wygeneruje on żądanie, po czym i tak zwolni procesor, wchodząc w stanu oczekiwania na powolne urządzenie.
Właściwym algorytmem szeregowania byłby tu SJF lub SRT, który promuje procesy z krótką fazą procesora. Konieczność estymowania czasu obsługi jest jednak dość kosztowna, a identyfikacja procesów ograniczonych wejściemwyjściem możliwa jest również na podstawie innych przesłanek. W najprostszym przypadku każdy proces przechodzący ze stanu oczekiwania do stan gotowości można potraktować jako proces ograniczony wejściem-wyjściem. Takie podejścia stwarzają jednak ryzyko głodzenie procesów ograniczonych procesorem.
Algorytm FCFS nie uwzględnia oczywiście potrzeb procesów ograniczonych wejściemwyjściem, co może prowadzić do niezrównoważenia obciążenia. Algorytm RR, który jest sprawiedliwy dla procesów ograniczonych procesorem, gdyż daje preferencje dla zadań krótkich, nie jest jednak sprawiedliwy dla procesów ograniczonych wejściemwyjściem. Procesy te muszą rywalizować o kolejny kwantu czasu na równy zasadach z procesami ograniczonymi procesorem, chociaż w większości sytuacji nie wykorzystują tego kwantu do końca.
Rozwiązanie problemu procesów ograniczonych wejściemwyjściem można uzyskać przez zwiększenie preferencji dla procesów, które wchodzą w stan gotowości po zakończeniu oczekiwania na urządzenie zewnętrzne. Można w tym celu zastosować planowanie dwukolejkowe z obsługą obu kolejek zgodnie z algorytmem rotacyjnym. Jedna z tych kolejek — pomocnicza — przeznaczona jest na procesy gotowe po zakończeniu operacji wejściawyjścia, a druga — główna — na procesy, które wykorzystały kwant czasu lub z innych powodów oddały procesor. Kolejkę pomocniczą obsługiwać należy oczywiście w pierwszej kolejności. Taka bezwzględna preferencja dla jednej grupy procesów mogłaby spowodować głodzenie drugiej grupy. W tym przypadku procesy z kolejki głównej mogłyby nigdy nie dostać procesora. Procesy z kolejki pomocniczej otrzymują jednak do dyspozycji tylko tę część kwantu czasu, której nie wykorzystały w wyniku zażądania operacji wejściawyjścia. Jeśli zatem proces po wykorzystaniu połowy kwantu czasu zażądał operacji wejściawyjścia, po zakończeniu tej operacji trafi do kolejki pomocniczej z drugą połową kwantu czasu do dyspozycji. W ten sposób każdy proces, nawet jeśli wielokrotnie zażąda operacji wejściawyjścia w ramach jednego kwantu, ostatecznie wykorzysta swój kwant czasu i trafi na koniec kolejki głównej.
Zaprezentowane podejście jest przykładem wykorzystania kolejki dwupoziomowej ze sprzężeniem zwrotnym. Podobny efekt można uzyskać różnicując względne priorytety procesów, co jednak najczęściej i tak implementowane jest za pomocą kolejek wielopoziomowych ze sprzężeniem zwrotnym.
Wielopoziomowa kolejka ze sprzężeniem zwrotnym polega na tym, że tak jak w systemie wielokolejkowym, obsługiwanych jest wiele kolejek, ale procesy nie są na stałe związane z konkretną kolejką, tylko mogą się przemieszczać pomiędzy nimi. Typowy scenariusz zastosowania wielopoziomowych kolejek polega na wybieraniu procesów z najwyższej niepustej kolejki, wykonywaniu przez określony czas (zależny od kwantu i zdarzeń w systemie), a po uzyskaniu stanu gotowości umieszczaniu w któreś z kolejek, w szczególności tej samej. Każda kolejka może być inaczej obsługiwana, np. z innym kwantem czasu. W celu uniknięcia głodzenie procesów na niższych poziomach, mogą one być przenoszone po pewnym czasie na wyższy poziom.
Implementacja funkcji priorytetu zgodnie z matematycznym modelem wymaga odpowiednio częstego przeliczania priorytetu procesów. Takie rozwiązanie nawet w przypadku prostych obliczeniowo funkcji wymaga czasu procesora. Istotne jest zatem zastosowanie odpowiednich struktur danych w implementacji kolejki procesów gotowych, żeby wybór przyspieszyć. Z drugiej strony struktury te nie mogą być zbyt kosztowne w utrzymaniu, gdyż niweczy to zysk czasowy, wynikający z możliwości dokonania szybkiego wyboru. Przykładem może być utrzymywanie kolejki procesów gotowych, posortowanej wg. priorytetów. Wybór procesu do wykonania jest natychmiastowy — jest to proces z czoła kolejki. Wstawienie procesu do kolejki jest jednak operacją czasochłonną, chociaż algorytmicznie niezbyt złożoną.
Implementację algorytmu FCFS można oprzeć o kolejkę FIFO. Aktualizacja takiej kolejki jest prostą operacją, nie wymagającą czasochłonnych obliczeń. Kolejka dostarcza też natychmiastowo informację o kolejnym procesie do przydziału procesora.
Taka implementacja nie jest jednak dokładną realizacją modelu matematycznego, przedstawionego wcześniej, albo model matematyczny jest nieadekwatny do przedstawionej implementacji. Po wejściu w stan oczekiwania, a następnie ponownym uzyskaniu gotowości proces umieszczany jest na końcu kolejki. Jest więc traktowany tak, jak gdyby dopiero został przyjęty do systemu, podczas gdy model matematyczny definiuje funkcję priorytetu jako czas przebywania w systemie od momentu przyjęcia.
Kolejka priorytetowa jest powszechnie używaną strukturą w implementacji kolejki procesów gotowych w przypadku planowania uwzględniającego priorytety procesów. Jest ona łatwa w aktualizacji, gdyż priorytet jest najczęściej indeksem kolejki odpowiedniego poziomu. Niekiedy liczba poziomów priorytetu jest większa niż liczba poziomów kolejek, wówczas każda kolejka odpowiada pewnemu zakresowi priorytetów. Odwzorowanie priorytetu na poziom kolejki wymaga wówczas prostej operacji arytmetycznej np. dzielenia lub przesunięcia bitów w prawo.
Umieszczanie procesu w kolejce po jej zlokalizowaniu jest operacją wymagającą odpowiedniego powiązania deskryptorów procesów, co sprowadza się do operacji podstawienia kilku wskaźników.
Zlokalizowanie procesu gotowego o najwyższym priorytecie wymaga wyszukania odpowiedniej kolejki. Przyspieszenie tej operacji możliwe jest z wykorzystaniem wektora bitowego, w którym każdy bit odpowiada jednej kolejce, a jego wartość (0 lub 1) wskazuje, czy kolejka jest pusty, czy nie. Przy odpowiednim wsparciu w rozkazach procesora ustalenie indeksu z pierwszą kolejką niepustą sprowadza się do wykonania jednego lub kilku rozkazów maszynowych, zależnie od długości wektora.
Celem wykładu jest przedstawienie podejść do planowania przydziału procesora w najbardziej popularnych systemach operacyjnych: tradycyjnym systemie UNIX, systemie Linux i systemie Windows 2000/XP. W ramach prezentowanych podejść omawiane są struktury danych oraz koncepcje realizacji algorytmów przeliczania priorytetów, wyboru procesów lub wątków do wykonania oraz przeciwdziałania głodzeniu.
Wszystkie prezentowane podejścia stosują algorytm rotacyjny z wywłaszczaniem opartym na priorytetach dynamicznych, chociaż w systemach Linux i Windows wydzielone jest pasmo priorytetów czasu rzeczywistego, gdzie stosowane są priorytety statyczne. W wszystkich tych systemach dąży się do maksymalnego wykorzystania zasobów, w związku z czym jest preferencja dla zadań ograniczonych wejściem-wyjściem. Sposób faworyzowania zadań ograniczonych wejściem-wyjściem w każdym systemie jest jednak zupełnie inny.
Cechą wspólną implementacji prezentowanych rozwiązań jest stosowanie kolejki priorytetowej, czyli tablicy kolejek, których nagłówki lokalizowane są w tablicy na pozycjach odpowiadających poziomom priorytetów. Specyfiką rozwiązania w systemie Linux jest operowanie dwoma takimi kolejkami.
Algorytm rotacyjny z wywłaszczaniem polega na tym, że po upływie kwantu czasu (około 1 sekundy) następuje przełączenie kontekstu na inny proces o takim samym priorytecie. Jeśli nie ma procesu o takim samym priorytecie, proces kontynuuje działanie przez kolejny kwant czasu. Jeśli jednak przed upływem kwantu czasu pojawi się proces gotowy o wyższym priorytecie nastąpi wywłaszczenie, tym samym również przełączenie kontekstu. Wyjątkiem od tej reguły jest przypadek wykonywania programu jądra. Jądro w tradycyjnym systemie UNIX jest niewywłaszczalne, co oznacza, że nie można przerwać procesu, który działa w trybie jądra, nawet jeśli pojawi się proces o wyższym priorytecie. Proces może oczywiście wejść w stan oczekiwania, wówczas jądro stanie się dostępne dla innych procesów. Przełączenie kontekstu następuje zatem w następujących przypadkach:
Zakres priorytetu od 0 do 49 zarezerwowany jest dla procesów w trybie jądra, a pozostałe wartości są priorytetami procesów w trybie użytkownika.
W systemie dąży się do tego, aby procesy jak najszybciej opuszczały tryb jądra, gdyż jest to zasób krytyczny dla funkcjonowania systemu i niewywłaszczalny. Dlatego większość procesów, znajdujących się w trybie jądra jest uśpiona w oczekiwaniu na jakieś zdarzenia (np. zakończenie operacji wejścia-wyjścia). Jeśli jakiś proces jest budzony w wyniku zajścia oczekiwanego zdarzenia, otrzymuje on tzw. priorytet uśpienia tego zdarzenia, który jest oczywiście priorytetem poziomu jądra. Na przykład: priorytet uśpienia dla wyjścia z terminala wynosi 28, a priorytet uśpienia dla operacji dyskowej wynosi 20. Obudzony w ten sposób proces ma wyższy priorytet niż wykonywany proces poziomu użytkownika, więc następuje wywłaszczenie. Gdyby jednak wykonywany był kod jądra przez jakiś proces, wznowienie procesu oczekującego nastąpi dopiero po zwolnieniu jądra (opuszczeniu bądź wejściu w oczekiwanie) przez proces wykonywany.
Struktura qs jest tablicą kolejek, czyli odpowiednich wskaźników. Sama kolejka jest zbudowana na liście dwukierunkowej i łączy deskryptory procesów, dokładnie struktury proc, stanowiące część pełnego deskryptora procesu.
W systemie jest 1 proces o priorytecie z przedziału 0 – 3, 2 procesy o priorytecie z przedziału 4 – 7, 3 procesy o priorytecie z przedziału 8 – 11, nie ma procesu o priorytecie z przedziału 12 – 15 itd. Wektor whichqs wskazuje pozycje niepuste i umożliwia szybką lokalizację kolejki o najwyższym priorytecie, w której jest jakiś proces.
Parametr cpu jest wartością liczbową, która jako miara wykorzystania procesora jest zwiększana, gdy proces jest wykonywany oraz stopniowo zmniejszana, gdy proces nie wykorzystuje procesora.
Wartość nice może być zwiększana przez użytkownika zwykłego, co skutkuje zmniejszeniem priorytetu, natomiast zmniejszana (w celu zwiększenia priorytetu) może być przez nadzorcę. Domyślnie wartość nice ustawiana jest na 20.
Wyodrębnienie parametrów pri i usrpri wynika z różnicy wartości priorytetu w trybie użytkownika i w trybie jądra. W trybie jądra proces otrzymuje priorytet wyższy, wynikający np. z rodzaju operacji wejścia-wyjścia, jakiej zażądał. Przed powrotem do trybu użytkownika priorytet musi jednak wrócić do poprzedniej wartości. W trybie użytkownika zatem wartości parametrów pri i usrpri są takie same, a w trybie jądra wartość parametru pri jest mniejsza (wyższy priorytet), niż usrpri.
Przykład obrazuje zmiany priorytetów trzech procesów w systemie. Początkowy priorytet (załóżmy, że jest to baza + nice ) każdego z procesów wynosi 60, a miara wykorzystania procesora wynosi 0. 60 razy na sekundę następuje takt zegara, który zmienia parametr cpu. Proces P1 wykorzystuje jako pierwszy procesor (oś czasu skierowana jest w dół, ). Po 60 taktach następuje przeliczenie priorytetów. Parametr cpu1 osiąga wówczas wartość 60 i jest dzielony przez 2. Podobnie jest to robione dla pozostałych procesów, ale dla nich wartość parametru cpu jest cały czas 0, gdyż nie wykorzystywały one procesora. Połowa przeliczonej wartości parametru cpu dodawana jest do statycznej części priorytetu procesu P1 , co daje wynik 75. Wyższy priorytet mają zatem procesy P2 i P3 , czyli następuje przełączenie kontekstu na proces P2. Po kolejnych 60 taktach następuje przeliczenie priorytetów. W międzyczasie wartość cpu2 zwiększyła się do 60 i nie zmieniła się w przypadku pozostałych procesów. Po przemnożeniu przez współczynnik zaniku cpu1 wynosi 15, cpu2 — 30, a cpu3 — cały czas 0. Po dodaniu połowy wartości parametru cpu do statycznej części otrzymujemy usrpri1 o wartości 67, usrpri2 o wartości 75 i usrpri3 o wartości 60. Najwyższy priorytet ma więc proces P3, a po kolejnych 60 taktach priorytet procesu P1 ponownie wzrośnie do największego w systemie (wartość 63).
W systemie Linux, podobnie jak w innych współczesnych systemach operacyjnych (Windows 2000, współczesne implementacje systemów uniksopodobnych) uwzględniono szeregowanie procesów czasu rzeczywistego. Są to rozwiązania spełniające wymagania tzw. łagodnego (tolerancyjnego) czasu rzeczywistego, co znaczy, że system próbuje wykonywać je szybciej niż inne zadania, ale nie gwarantuje ich zakończenia w określonym czasie (przed linią krytyczną). Priorytety dla zadań czasu rzeczywistego (czyli klas SCHED_FIFO i SCHED_RR) są zawsze wyższe — mają mniejsze wartości — niż priorytety zadań zwykłych.
Wartość nice ma podobny charakter jak w systemie UNIX. Określa się jako składową statyczną priorytetu. W rzeczywistości nie jest ona liczbową wartością priorytetu, bo jest odwzorowywana na odpowiednią wartość z zakresu 100 – 139. W przeciwieństwie do tradycyjnego rozwiązania w systemie UNIX Linux oferuje zmiennej długości kwant czasu.
W przypadku procesów zwykłych priorytet może się zmieniać, podobnie jak to było w systemie UNIX, ale zasady zmiany są inne. Dlatego ogólnie określa się go jako dynamiczny (chociaż ma również składnik statyczny). Priorytety zadań czasu rzeczywistego nie zmieniają się. Biorąc pod uwagę fakt, że priorytety te są wyższe, niż priorytety procesów zwykłych, istnieje ryzyko, że jeśli proces czasu rzeczywistego otrzyma procesor, zagłodzi inne zadania. Dlatego możliwość zmiany priorytetu (i tym samym strategii szeregowania) w zakresie czasu rzeczywistego zastrzeżona jest dla nadzorcy.
Tablica priorytetów obejmuje 140 pozycji o wartościach od 0 (najwyższy priorytet) do 139 (najniższy priorytet). Wartości z zakresu 1 – 99 odpowiadają procesom czasu rzeczywistego, a większe wartości odpowiadają procesom zwykłym i odwzorowane są na odpowiednie wartości nice.
Mechanizm szeregowania w jądrze 2.6 (2.5) został dość istotnie przebudowany w stosunku do rozwiązań wcześniejszych i również rozwiązań stosowanych w innych systemach operacyjnych. Ma to swoje skutki między innymi w strukturach danych. Podobnie, jak w przypadku tradycyjnego systemu UNIX, a także Windows 2000/XP podstawową strukturą jest kolejka priorytetowa, zwana tablicą priorytetów. W przeciwieństwie jednak do systemu UNIX nie ma tu przeliczania priorytetu każdego procesu co określony czas, priorytet dynamiczny wyznaczany jest na bieżąco, np. po zakończeniu kwantu czasu. Takie podejście mogłoby jednak oznaczać głodzenie, bo nowo wyliczony priorytet mógłby być większy niż priorytet innych procesów gotowych i oczekujących już przez dłuższy czas na procesor. W tradycyjnym systemie UNIX tego problemu unikało się w ten sposób, że co sekundę były przeliczane priorytety wszystkich procesów, a w wyniku tego przeliczenia karane były procesy, które dużo korzystały z procesora i nagradzana takie, które dłużej czekały.
W celu niedopuszczenia do głodzenia w systemie Linux stosowane są dwie kolejki priorytetowe. Jedna kolejka jest dla zadań, które mają prawo korzystać z procesora, zwanych zadaniami aktywnymi, a druga jest dla tzw. zadań przeterminowanych, które chwilowo wykorzystały już przydzielone im limity.
Podobnie, jak w systemie UNIX, w celu szybkiej identyfikacji pozycji niepustych w kolejkach priorytetowych, wykorzystywany jest wektor bitowy. W przeciwieństwie jednak do UNIXa, każdy bit odpowiada dokładnie jednej pozycji, czyli jednemu priorytetowi.
Mechanizm szeregowania w jądrze 2.6 (2.5) został dość istotnie przebudowany w stosunku do rozwiązań wcześniejszych i również rozwiązań stosowanych w innych systemach operacyjnych. Ma to swoje skutki między innymi w strukturach danych. Podobnie, jak w przypadku tradycyjnego systemu UNIX, a także Windows 2000/XP podstawową strukturą jest kolejka priorytetowa, zwana tablicą priorytetów. W przeciwieństwie jednak do systemu UNIX nie ma tu przeliczania priorytetu każdego procesu co określony czas, priorytet dynamiczny wyznaczany jest na bieżąco, np. po zakończeniu kwantu czasu. Takie podejście mogłoby jednak oznaczać głodzenie, bo nowo wyliczony priorytet mógłby być większy niż priorytet innych procesów gotowych i oczekujących już przez dłuższy czas na procesor. W tradycyjnym systemie UNIX tego problemu unikało się w ten sposób, że co sekundę były przeliczane priorytety wszystkich procesów, a w wyniku tego przeliczenia karane były procesy, które dużo korzystały z procesora i nagradzana takie, które dłużej czekały.
W celu niedopuszczenia do głodzenia w systemie Linux stosowane są dwie kolejki priorytetowe. Jedna kolejka jest dla zadań, które mają prawo korzystać z procesora, zwanych zadaniami aktywnymi, a druga jest dla tzw. zadań przeterminowanych, które chwilowo wykorzystały już przydzielone im limity.
Podobnie, jak w systemie UNIX, w celu szybkiej identyfikacji pozycji niepustych w kolejkach priorytetowych, wykorzystywany jest wektor bitowy. W przeciwieństwie jednak do UNIXa, każdy bit odpowiada dokładnie jednej pozycji, czyli jednemu priorytetowi.
Jeśli przetwarzanie odbywa się w trybie jądra, to wywłaszczenie (przełączenie kontekstu) nie może nastąpić w dowolnym momencie, choć ogólnie jądro systemu Linux jest w pewnych warunkach wywłaszczalne. Wykrycie potrzeby przeszeregowania w trakcie wykonywania kodu jądra (np. w trakcie obsługi przerwania zegarowego) powoduje ustawienie znacznika need_resched i kontynuację przetwarzania w trybie jądra. Dopiero przy powrocie do trybu użytkownika następuje sprawdzenie znacznika podjęcia decyzji o przełączeniu kontekstu.
Wywłaszczenie nastąpi, gdy będzie gotowe zadanie o nie mniejszym priorytecie.
Przeliczenie priorytetu i związanego z nim kwantu czasu procesu następuje zaraz po upłynięciu kwantu czasu, a nie w wyniku specjalnej, okresowo uruchamianej procedury. Bardzo często jest tak, że nie wymaga się żadnych specjalnych przeliczeń. Priorytet i kwant czasu procesu pozostają bez zmian. Należy jednak zrobić coś z procesem, który wykorzystał swój kwant, a po przeliczeniu ma dość wyskoki priorytet, żeby dać szansę przetwarzania innym procesom o niższych priorytetach. W większości przypadków proces, który wykorzystał już swój kwant czasu, identyfikowany jest jako przeterminowany i trafia do odpowiedniej tablicy priorytetów. Procesy w tablicy priorytetów dla zadań przeterminowanych nie są uwzględniane przez planistę, jako kandydaci do przydziału procesora, do końca tzw. epoki .
W szczególnych przypadkach proces, który wykorzystał już swój kwant czasu, może trafić ponownie bezpośrednio do tablicy priorytetów dla zadań aktywnych. Zależy to od stopnia interaktywności zadania oraz stanu tablicy priorytetów dla zadań przeterminowanych. Jeśli nie ma zbyt długo oczekujących zadań przeterminowanych a stopień interaktywności wywłaszczanego procesu jest dostatecznie duży, po przeliczeniu priorytetu może on trafić na koniec kolejki właściwej dla swojego priorytetu w tablicy priorytetów dla zadań aktywnych.
Warto podkreślić, że proces, który zażąda operacji wejścia-wyjścia lub z innych powodów wejdzie w stan oczekiwania, nie traci swojego kwantu. Po uzyskaniu gotowości, ma szansę wykorzystać resztę przysługującego mu w danej epoce czasu procesora. Natomiast część kwantu czasu, pozostała do wykorzystania przez proces, jest dzielony na pół w momencie, gdy proces ten tworzy nowy proces (potomny). Połowa kwantu pozostaje więc do dyspozycji procesu macierzystego, a druga połowa jest początkowym kwantem czasu potomka.
Zamiana tablic jest operacją bardzo szybką, gdyż polega na zamianie wartości dwóch wskaźników, wskaźnika na tablicę priorytetów dla zadań aktywnych i tablicę priorytetów dla zadań przeterminowanych. Wszystkie przeterminowane zadania stają się ponownie aktywne.
Priorytet dynamiczny dotyczy procesów zwykłych. Dla procesów czasu rzeczywistego priorytet jest ustalony i ewentualnie modyfikowany w wyniku działań nadzorcy, a nie planisty.
W zależności od oceny interaktywności procesu, jego priorytet dynamiczny jest odpowiednio modyfikowany. Wyznaczenie kwantu czasu sprowadza się do przeskalowania wartości priorytetu dynamicznego z przedziału –20 – 19 (albo 100 do 139) na wartość kwantu czasu z przedziału 10 ms do 200 ms z uwzględnieniem proporcjonalności odwrotnej, gdyż mniejsza wartość priorytetu to wyższy poziom preferencji w dostępie do procesora.
W czasie wykonywania procesu (gdy proces korzysta z procesora), każdy takt zegara powoduje zmniejszenie wartości zmiennej sleep_avg o 1. Po obudzeniu procesu w stanie oczekiwania wartość ta jest z kolei zwiększana o czas oczekiwania.
Określanie charakteru aplikacji na podstawie porównywania czasu wykorzystania procesora oraz oczekiwania na zakończenie operacji wejścia-wyjścia może niekiedy prowadzić błędów:
Planista nie modyfikuje priorytetu procesów czasu rzeczywistego. Jeśli proces taki nie zwolni procesora (i jądra) w wyniku wejścia w stan oczekiwania, wywłaszczenie może nastąpić tylko przez proces o wyższym priorytecie (czyli inny proces czasu rzeczywistego). W przypadku klasy SCHED_RR wywłaszczenie może też nastąpić po upływie kwantu czasu, gdy jest gotowy inny proces o tym samym priorytecie. Jeśli nie ma takiego procesu, proces dotychczas wykonywany otrzymuje kolejny kwant czasu i kontynuuje działanie. Nieodpowiednie użycie klasy priorytetów czasu rzeczywistego może więc skutkować zawłaszczeniem procesora.
Ogólne podejście do szeregowania w Windows jest podobne do wcześniej przedstawionych. Wyróżniono dwa zakresu (pasma) priorytetów, z których wynika taż sposób zarządzania priorytetami wątków.
W paśmie zmiennych priorytetów stosowany jest algorytm rotacyjny oparty jest na priorytetach dynamicznych. Priorytet wątku w tym paśmie może ulec podwyższeniu po zakończeniu oczekiwania, a następnie jest stopniowo obniżany.
W paśmie priorytetów czasu rzeczywistego stosowany jest również algorytm rotacyjny, ale priorytety nie ulegają zmianie. Tak rozumiany czas rzeczywisty oznacza tylko bardziej przewidywalne zachowanie, nie gwarantuje natomiast utrzymania jakiegokolwiek reżimu czasowego.
W sumie wyróżniono 32 poziomy priorytetu, ale najniższy poziom zastrzeżony jest dla wątku bezczynności.
Wyróżniono kilka klas priorytetu, z których większość jest w paśmie priorytetów dynamicznych. Każda klasa reprezentowana jest przez pewną wartość priorytetu, która ustalana jest dla procesu. Wartość ta dziedziczona jest przez wątek procesu, ale jego priorytet bazowy może zostać w stosunku do klasy procesu skorygowany poprzez zastosowanie odpowiedniego modyfikatora. Oprócz podanych modyfikatorów w paśmie wątków czasu rzeczywistego możliwe są też wartości –7, -6, ..., -3, 3, 4, 5, 6. W wyniku zsumowania klasy priorytetu oraz modyfikatora nie można wyjść poza pasmo, czyli suma ta jest odpowiednio ograniczana.
Dwa zasadnicze pasma priorytetu, decydujące o sposobie przeliczania wartości priorytetów wątków, to:
Warto zwrócić uwagę, że modyfikatory THREAD_PRIORITY_TIME_CRITICAL oraz THREAD_PRIORITY_IDLE reprezentują odpowiednio najwyższy i najniższy dostępny priorytet w danym paśmie . Modyfikatory takie oznaczają odpowiednio 31 i 16 w paśmie czasu rzeczywistego oraz wartości 15 i 1 w paśmie priorytetów dynamicznych, niezależnie od klasy priorytetu.
Podobnie jak w systemach UNIX i Linux podstawową strukturą danych, ułatwiającą pracę planisty — zwanego w polskich tłumaczeniach dyspozytorem (ang. dispatcher) — jest kolejka priorytetowa. W celu przyspieszenia wyszukiwania kolejki o najwyższym priorytecie stosowany jest wektor bitowy, wskazujący kolejki niepuste.
Przykład pokazuje stan kolejki priorytetowej, za pomocą której identyfikowanych jest pięć wątków gotowych, należących do dwóch procesów.
Dwa wątki procesu P1 (TA i TB) oraz jeden wątek procesu P2 (TC) mają priorytet na poziomie 3, a pozostałe 2 wątki procesu P2 (TC i TE) mają priorytet na poziomie 2.
Przypadki przełączania kontekstu są typowe dla planowania rotacyjnego z wywłaszczaniem na podstawie priorytetu.
Wywłaszczenie przez wątek o wyższym priorytecie może być konsekwencją:
Wywłaszczony wątek umieszczany jest na początku kolejki procesów gotowych.
Upłynięcie kwantu czasu nie musi oznaczać przełączenia kontekstu, gdyż może się okazać, że nie ma w systemie wątku gotowego o równym lub wyższym priorytecie.
Realizacja szeregowania sprowadza się do wywołania jednej z dwóch procedur FindReadyThread lub ReadyThread.
Wywołanie FindReadyThread oznacza, że wątek wykonywany dobrowolnie zrzekł się procesora lub upłynął przydzielony mu kwant czasu. W związku z tym konieczne jest wybranie nowego wątku do wykonania.
Procedura ReadyThread uruchamiana jest dla konkretnego wątku, który wchodzi w stan gotowości lub któremu podwyższono priorytet, a jej celem jest zdecydować o dalszym losie tego wątku. Zależnie od wartości priorytetów, skutkiem wykonania procedury jest:
Algorytm pokazuje zasady wywłaszczania. Jeśli gotowy wątek Tg, dla którego uruchomiona została procedura, ma wyższy priorytet niż wątek wykonywany Tw , to następuje wywłaszczenie. W przeciwnym przypadku wątek Tg trafia na koniec właściwej dla jego priorytetu kolejki wątków gotowych. W przypadku wywłaszczenia wątek wywłaszczony trafia najczęściej na koniec kolejki wątków gotowych, właściwej dla swojego priorytetu. Wyjątkiem jest przypadek, gdy wątek wywłaszczony nie wykorzystał jeszcze pierwszego kwantu czasu, wówczas trafia na początek właściwej dla jego priorytetu kolejki.
Niech Tg oznacza wątek gotowy, Tw wątek wykonywany, a pri(T) priorytet wątku T.
Kwant czasu nie jest wyrażany w jednostka bezpośrednio związanych z czasem. Jednostka ma związek z taktem zegara, ale również nie jest to liczba taktów, gdyż każde przerwanie zegarowe zmniejsza liczbę jednostek o 3. Liczbę jednostek można zmieniać modyfikując w rejestrze Windows wartość HKLM\SYSTEM\CurrentControlSet\Control\PriorityControl\Win32PrioritySeparation.
Wykorzystanie kwantu czasu skutkuje podobnymi działaniami, jak w innych podejściach z wywłaszczaniem, opartych na priorytecie, czyli rozpoczyna się poszukiwanie innego wątku do wykonania. Ponieważ jednak stosowane jest podejście priorytetowe, poszukiwany wątek nie może mieć priorytetu niższego niż wątek, który stracił kwant czasu. Jeśli takiego wątku nie ma, wątek dotychczas wykonywany otrzymuje kolejny kwant czasu.
Jeśli następuje przełączenie kontekstu, ta prawdopodobnie znaleziony został wątek o takim samym priorytecie, jak dotychczas wykonywany. Gdyby w stanie gotowości był wątek o priorytecie wyższym, wcześniej nastąpiłoby wywłaszczenie i wątek wykonywany (o niższym priorytecie) nie doczekałby końca kwantu czasu.
W pewnych warunkach priorytet wątku, który wykorzystał swój kwant czasu może zostać obniżony (patrz następne slajdy). W wyniku tego obniżenia może zaistnieć stan, w którym innych wątek gotowy ma priorytet wyższy, niż wątek dla którego kwant czasu właśnie upłynął.
Wyrażenie kwantu w jednostkach nie związanych bezpośrednio z długością interwału zegara umożliwia zrealizowanie częściowego zanikania kwantu. Przykładem jest wejście w stan oczekiwania przed upłynięciem kwantu. Brak zanikania oznaczałby, że wątek nigdy nie utraci swojego kwantu, jeśli tylko będzie zgłaszał jakieś żądanie tuż przed jego upływem. Taki przywilej mają natomiast wątki w paśmie czasu rzeczywistego.
Wydłużenie kwantu zamiast zwiększenie priorytetu nie powoduje głodzenie przetwarzania w tle (zakładając ten sam priorytet). Ogranicza jedynie czas procesora dla takiego przetwarzania. Wyższy priorytet wątków związanych z obsługą okna mógłby oznaczać, że wątki w tle nie otrzymywałyby w ogóle procesora.
W zależności od zdarzenia, które spowodowało przejście wątku w stan oczekiwania, priorytet wątku, wchodzącego ponownie w stan gotowości, jest odpowiednio zwiększany. Zwiększenie priorytetu ma jednak charakter tymczasowy. Po upływie każdego kolejnego kwantu czasu jest on zmniejszany o 1, aż osiągnie poziom bazowy dla danego wątku.
System Windows faworyzuje procesy interaktywne. Stąd wysoki wzrost priorytetu w przypadku zakończenie oczekiwania na dane z klawiatury lub reakcję myszy. Są to typowe urządzenia, którymi posługuje się użytkownik interaktywny. Również inne wątki, które zakończyły oczekiwanie na urządzenie zewnętrzne, otrzymują wyższy priorytet, gdyż mogą być ograniczone wejściem-wyjściem. Po uzyskaniu procesora nawet na krótki czas mogą ponownie zażądać operacji wejścia-wyjścia. W ten sposób równoważone jest obciążenie systemu.
Wielkość podwyższenia jest definiowana przez moduł sterujący urządzenia wejścia-wyjścia.
Zdarzenia i semafory związane są z synchronizacją między procesami. Zwiększony o 1 priorytet będzie obowiązywał tylko przez 1 kwant czasu, gdyż zaraz po nim zostanie obniżony o 1, wracając tym samym do poziomu bazowego.
Zwiększenie kwantu czasu zostało już omówione. Warto zwrócić uwagę, że zwiększenie priorytetu jest tymczasowe, podczas gdy zwiększenie kwantu będzie obowiązywać tak długo, jak długo okno będzie na pierwszym planie.
Wątki, które obsługują okno (nie koniecznie pierwszoplanowe) mają zwiększany priorytet o 2, gdy pojawi się jakieś zdarzenie (jakiś komunikat) związane z tym oknem.
Skutkiem zbyt niskiego priorytetu wątku może być jego głodzenie w dostępie do procesora, jeśli zawsze będzie jakiś wątek gotowy o wyższym priorytecie. Zwiększenie jego priorytetu do największej możliwej wartości w paśmie zmiennych priorytetów daje mu możliwość „złapania” procesora chociaż na krótką chwilę. Jeśli upłynie przyznany czas, priorytet wraca do wartości bazowej, co może wymagać kolejnych kilku sekund oczekiwania, zanim wątek dostanie kolejną szansę na dostęp do procesora.
Działanie takie ma między innymi na celu przeciwdziałanie inwersji priorytetów poprzez uruchamianie wątków, które być może przetrzymują jakieś zasoby potrzebne innym wątkom o wyższych priorytetach.
Celem wykładu jest przedstawienie podejść do zarządzania jednym z kluczowych zasobów systemu komputerowego — pamięcią operacyjną. Ponieważ zarządzanie pamięcią operacyjną uwarunkowane jest rozwiązaniami na poziomie architektury komputera, wyodrębnione są zadania realizowane sprzętowo oraz zadania systemu operacyjnego, zmierzające do wykorzystania możliwości sprzętowych.
Wykład rozpoczyna się od przedstawienia podstawowych pojęć, związanych z zarządzaniem pamięcią. Następnie wskazana jest rola układów sprzętowych na poziomie architektury komputera w zarządzaniu pamięcią. Dalsza część dotyczy najważniejszego zadania w zarządzaniu pamięcią, realizowanego przez system operacyjny — przydziału, który ściśle wiąże się z podziałem pamięci. Pozostała część wykładu dotyczy zjawisk wewnątrz przydzielonych obszarów pamięci, czyli tworzenia obrazu procesu, jego ochrony oraz współdzielenia. Na końcu omawiane są techniki odwzorowania logicznej przestrzeni adresowej w fizyczną, wspomagające przy tym zarządzanie pamięcią, czyli stronicowanie i segmentacja.
Pamięć jest kluczowym (obok procesora) zasobem systemu komputerowego dla wykonywania programów. Zarządzanie pamięcią jest jednak dość skomplikowane, gdyż jest ona (poszczególne jej części) jednocześnie wykorzystywana przez wiele procesów często różnych użytkowników oraz przez jądro systemu operacyjnego. Stabilność pracy systemu komputerowego wymaga zatem odpowiedniej ochrony przestrzeni użytkowników, a tym bardziej jądra systemu.
Podstawowe zadania, realizowane w ramach zarządzania pamięcią obejmują przydział pamięci i jej odzyskiwanie, ochronę, udostępnianie w celu współdzielenia, transformację adresów oraz transfer danych pomiędzy poszczególnymi poziomami w hierarchii pamięci. Zadania te podzielone są pomiędzy układy sprzętowe na poziomie architektury komputera, a system operacyjny. Ze względu na efektywność realizacji, zadania takie jak ochrona, transformacja i w dużej części transfer danych realizowane są przez odpowiednie układy sprzętowe. Zadanie systemu operacyjnego sprowadza się do dostarczenia odpowiednich danych tym układom. Dane te wynikają z wcześniejszych decyzji o przydziale pamięci, co już należy do kompetencji systemu operacyjnego.
Dodatkowym elementem komplikującym zarządzanie pamięcią jest jej złożona struktura — począwszy od rejestrów procesora, poprzez pamięć podręczną i główną, a skończywszy na pamięci masowej. W hierarchii pamięci na wyższym poziomie znajdują się szybkie układy o niewielkiej pojemności, a w miarę schodzenia niżej zmniejsza się szybkość, a zwiększa pojemność.
Operowanie zawartością pamięci w takiej złożonej, hierarchicznej strukturze oparte jest na tzw. zasadzie okna , zgodnie z którą dane na wyższym (szybszym, ale mniej pojemnym) poziomie stanowią fragment danych, przechowywanych na niższym poziomie.
Zależnie od architektury, procesor adresuje w pamięci bajty, słowa, podwójne słowa itd., a zatem jednostki stosunkowo niewielkie. Takie jednostki obowiązują w transferze pomiędzy rejestrami procesora a pamięcią podręczną lub główną. Pomiędzy niższymi poziomami w hierarchii pamięci transferowane są większe jednostki:
Pamięć postrzegana jest najczęściej jako tablica bajtów, indeksowana przez adresy. Taki jest obraz pamięci zarówno na poziomie architektury komputera, jak i na poziomie systemu operacyjnego, czy też procesu działającego w systemie. Poszczególne komórki pamięci mogą być jednak inaczej identyfikowane na poziomie architektury, a inaczej na poziomie systemu operacyjnego. Te same komórki pamięci mogą być nawet różnie identyfikowane w poszczególnych procesach. Adresy, które identyfikują poszczególne komórki pamięci na poziomie architektury komputera, tworzą fizyczną przestrzeń adresową. Adresy fizyczne przekazywane są szyną adresową magistrali systemowej do układów elektronicznych pamięci. W szczególnym przypadku takimi samymi adresami można się posługiwać na poziomie systemu operacyjnego, ale takie podejście wprowadza sporo ograniczeń, szczególnie uciążliwych w konstrukcji systemów wielozadaniowych. Rozróżnianie przestrzeni fizycznej i logicznej oznacza, że w kontekście procesu komórka pamięci jest inaczej identyfikowana, niż to wynika z jej fizycznego adresu, co wymaga odpowiedniego przekształcenia adres logicznego na fizyczny, zwanego transformacją adresu. Za transformację odpowiada układ ściśle współpracujący z procesorem — jednostka zarządzania pamięcią (ang. memory management unit — MMU).
Adres logiczny służy do identyfikacji komórek pamięci również na poziomie maszynowym procesora, pracującego w kontekście konkretnego procesu. Adresy przechowywane w rejestrach, wykorzystywanych w różnych trybach adresowania (np. rejestrowym pośrednim, bazowym, indeksowym itp.), czy w liczniku programu (zwanym też wskaźnikiem instrukcji), są adresami logicznymi. Procesor rozumiany jest tu jako jednostka funkcjonalna, odpowiedzialna za przetwarzanie. W tym sensie oddzielony jest on od jednostki zarządzania pamięcią, chociaż we współczesnych rozwiązaniach jest z nią strukturalnie zintegrowany. Elementem kontekstu procesu jest zatem również stan jednostki zarządzania pamięcią.
Odwzorowanie adresu logicznego na fizyczny w najprostszym przypadku polega na dodaniu do adresu logicznego, wystawionego przez procesor, pewnej wartości, przechowywanej w rejestrze przemieszczenia w jednostce zarządzania pamięcią. Zawartość komórki pamięci, która w logicznym obrazie procesu zlokalizowana jest pod adresem 25, znajduje się w pamięci fizycznej pod adresem 1049. W ten sposób logiczny obraz procesu można skonstruować, abstrahując od jego fizycznej lokalizacji w pamięci, a przemieszczenie ustalać dopiero w czasie ładowania programu do pamięci lub podczas wykonania.
W systemie wielozadaniowym występuje konieczność ochrony przed zamierzoną lub przypadkową ingerencją jednego procesu w obszar innego procesu lub w obszar jądra systemu operacyjnego. Ochrona jądra systemu operacyjnego wskazana jest również w systemach jednozadaniowych, nie jest jednak elementem krytycznym, gdyż całość zasobów systemu przeznaczona jest na potrzeby jednego przetwarzania. Brak ochrony spowodować może jednak utratę kontroli nad systemem komputerowym w przypadku błędów w programie.
Ochrona pamięci wymaga weryfikacji adresów generowanych przez proces przy każdorazowym odniesieniu do pamięci. W celu weryfikacji adresów w kontekście danego procesu muszą być przechowywane informacje na temat dostępności obszarów pamięci (zakres adresów, tryb dostępu).
Przykład przedstawia mechanizm transformacji uzupełniony o weryfikację poprawności adresu. Uwzględniając fakt, że procesor wystawia adres logiczny, którego naturalnym dolnym ograniczeniem jest 0, wystarczy sprawdzić, czy adres ten nie wykracza poza górny limit, zgodnie z wielkością przydzielonego obszaru. Jeśli adres logiczny jest mniejszy od wartości granicznej jest poprawny i poddawany jest transformacji. W przeciwnym przypadku następuje zgłoszenie przerwania diagnostycznego.
Na poprzednich slajdach scharakteryzowano krótko najważniejsze zadania, które w zarządzaniu pamięcią realizowane są na poziomie architektury komputera. Zadania te realizowane są przez jednostkę zarządzania pamięcią, pod warunkiem, że udostępnione są odpowiednie dane do transformacji i weryfikacji adresów. W tym miejscu zaczyna się rola systemu operacyjnego.
Zakres adresów fizycznych, dostępnych dla procesu jest konsekwencją przydziału pamięci. Sposób przydziału wiąże się ściśle z podziałem, czyli wyznaczeniem przydzielanych jednostek pamięci lub określeniem zasad ich wyznaczania.
Można wyróżnić:
W ogólnym obrazie pamięci fizycznej można wyróżnić część, przeznaczoną na jądro systemu operacyjnego oraz część do dyspozycji procesów użytkownika, którą przydziela oczywiście zarządca pamięci (odpowiedni moduł systemu operacyjnego). Jądro zajmuje najczęściej początkowy lub końcowy obszar pamięci fizycznej, ale właściwa lokalizacja zależy od rozwiązań na poziomie architektury komputera.
Omawiane zagadnienia podziału i przydziału pamięci można odnieść zarówno do przestrzeni, przeznaczonej na procesy użytkownika, jak i do obszaru jądra systemu operacyjnego. Przestrzeń dla procesów użytkownika jest przydzielana w reakcji na żądania użytkowników, związane z tworzeniem procesów lub przydzielaniem im dodatkowej pamięci. Jądro przeznacza pewien obszar przydzielonej pamięci na tymczasowe potrzeby, wynikające z bieżąco realizowanych żądań zasobowych procesów lub obsługiwanych urządzeń.
Zjawiskiem związanym z podziałem i przydziałem pamięci jest fragmentacja. Pod pojęciem fragmentacji kryją się dwa osobne zjawiska określane jako fragmentacja zewnętrzna i fragmentacja wewnętrzna. Fragmentacja wewnętrzna dotyczy niewykorzystania pamięci wewnątrz przydzielonego bloku i najczęściej jest skutkiem operowania przez system większymi jednostkami, niż dokładność specyfikacji potrzeb ze strony aplikacji lub jądra systemu. Ten rodzaj fragmentacji jest charakterystyczny dla systemów z podziałem stałym.
Fragmentacja zewnętrzna oznacza podział na osobne części. Problem fragmentacji zewnętrznej ujawnia się najczęściej w zarządzaniu wolną przestrzenią. W niektórych podejściach do zarządzania pamięcią (np. w stronicowaniu) można też go odnieść do obszarów pamięci przydzielonych procesom. Pofragmentowanie wolnej przestrzeni bierze się stąd, że przydzielane są kolejne fragmenty pamięci, a następnie część z nich jest zwalniana, a część pozostaje zajęta.
W przedstawionym obrazie pamięci wolna przestrzeń jest podzielona na 4 fragmenty, z których żaden nie jest wystarczająco duży, żeby pomieścić w ciągłym obszarze pamięci blok danych na potrzeby procesu. Gdyby jednak udało się scalić wolne fragmenty w jeden duży obszar, wystarczyłoby miejsca na więcej niż 2 takie bloki.
Możliwość scalenia zależy od sposobu wiązania adresów. Sensowna realizacja scalenia wolnych fragmentów wymaga ustalania adresów fizycznych w czasie wykonania przy wsparciu jednostki zarządzania pamięcią.
Fragmentacja wewnętrzna wynika najczęściej z ograniczeń na rozmiar przydzielanej jednostki. Nie jest to jednak jedyny przypadek. W przedstawionym przykładzie przydział dokładnie tylu bajtów, ile wynosi zapotrzebowanie, powoduje, że koszt utrzymania bardzo małego obszaru wolnego jest niewspółmiernie duży, np.:
Dlatego wolny obszar przydzielany jest w całości, ale nie jest w pełni wykorzystany. Powstaje wiec fragmentacja wewnętrzna, wynikająca z decyzji zarządcy, a nie z konfiguracji systemu.
W podejściu z podziałem stałym nie można oczekiwać przydziału ciągłego obszaru pamięci o rozmiarze większym, niż to wynika z podziału, dokonanego na etapie konfiguracji systemu. Konsekwencją podziału stałego przestrzeni procesów użytkownika jest konieczność ograniczenia rozmiaru procesu do rozmiaru partycji. Z drugiej strony, mniejszym procesom również przydzielane są obszary pamięci, wynikające z takiego podziału, co oznacza marnowanie pamięci w związku z fragmentacją wewnętrzną.
W najprostszym przypadku partycje mają ten sam rozmiar. Realizacja żądania polega zatem na znalezieniu jakiejkolwiek wolnej partycji. W przedstawionym przykładzie realizacji żądań przydziału pamięci dla dwóch procesów obie wolne partycje zostają zajęte w całości, pomimo że potrzeby procesów są mniejsze.
Istotnym problemem może być przypadek zażądania przydziału obszaru większego, niż udostępniony przez system w wyniku podziału. W przypadku przydziału pamięci na dane (np. w jądrze) ograniczenia, wynikające z podziału stałego, można przewidzieć wcześniej i dostosować odpowiednio struktury danych. W przypadku programu można zastosować technikę, zwaną nakładkowaniem. Nakładkowanie polega na podziale kodu (nie danych) na części niezależne od siebie i wymianie w miarę potrzeb jednej części — nakładki (ang. overlay) — na inną.
W programie wydziela się część stałą, która zawsze znajduje się w pamięci oraz nakładki, które wiąże się z tzw. sekcją nakładkowania. Na każdą sekcję wydzielona jest pewna część pamięci. Nakładki w ramach tej samej sekcji podlegają wymianie — jedna nakładka usuwa inną. W programie może być kilka takich sekcji.
Z nakładkami wiążą się pewne ograniczenia. Stan nakładki usuwanej z pamięci nie jest nigdzie zapisywany, w związku z tym nie może ona ulegać zmianie — może zawierać tylko kod, ewentualnie stałe. Ograniczone są też możliwości przekazywania danych i sterowania pomiędzy nakładkami w tej samej sekcji, zatem nie można się odwołać z jednej nakładki do drugiej w tej samej sekcji. Przekazywanie danych i sterowania odbywa się najczęściej za pośrednictwem części stałej, czyli w tej części (ewentualnie w nakładce w innej sekcji) znajdują się wywołania podprogramów zlokalizowanych w nakładkach. Podział na nakładki wymaga dokładnej znajomości kodu i przepływu sterowania. Ponieważ nakładkowanie stosowane jest w przypadku dużych programów, podział na nakładki jest złożonym zadaniem. Może też być źródłem dodatkowych, trudno wykrywalnych błędów.
Nakładkowanie nie wymaga wsparcia ze strony jądra systemu operacyjnego, co najwyżej ze strony pewnych narzędzi do tworzenia kodu. Ze względu na uciążliwość technika ta stosowana jest jednak tylko w przypadku istotnych ograniczeń na rozmiar pamięci fizycznej w stosunkowo prostych architekturach. Zalecanym rozwiązaniem, wymagającym jednak wsparcia zarówno na poziomie architektury, jak i na poziomie systemu operacyjnego, jest pamięć wirtualna, która zostanie omówiona w następnym module.
Odpowiedzią na zróżnicowane pod względem wielkości żądania może być podział na partycje o różnych rozmiarach. Realizacja żądania wymaga znalezienie partycji, odpowiednio dobrze dopasowanej do wielkości zapotrzebowania. Może jednak powstać problem decyzyjny w przypadku, gdy najlepiej dopasowane partycje są zajęte, a wolne są partycje większe. Optymalizując przepustowość można przydzielić partycję większą (kosztem fragmentacji wewnętrznej), a optymalizując wykorzystanie pamięci należałoby wstrzymać przydział do momentu zwolnienia najlepiej dopasowanej partycji.
Istotą podziału dynamicznego jest operowanie stosunkowo niewielkimi jednostkami i przydzielanie bloków, stanowiących ciąg kolejnych jednostek w stosownej do zapotrzebowania liczbie. Przydzielany jest zatem ciągły obszar pamięci z dokładnością do rozmiaru jednostki. Jednostka może obejmować 1 bajt, ale częściej operuje się nieco większymi jednostkami, np. 16 bajtów (tzw. paragraf). W przypadku większych jednostek możliwa jest niewielka fragmentacja wewnętrzna.
W przypadku podziału dynamicznego po przydzieleniu odpowiedniego bloku reszta obszaru pozostaje wolna i jest do dyspozycji na potrzeby kolejnych żądań.
Wolne obszary mogą mieć różne rozmiary i trudno z góry ustalić, gdzie znajduje się odpowiedni obszar. Wyróżnia się 4 strategie poszukiwania odpowiedniego obszaru, tzw. dziury.
Pierwszy wolny blok jest zbyt mały, więc przydzielany jest następny wolny blok. Jest on jednak większy niż zapotrzebowanie, dlatego po przydzieleniu pozostanie jeszcze trochę wolnego miejsca. Jest to metoda szybka, biorąc pod uwagę średni czas wyszukiwania. Warto zwrócić uwagę, że blok dałoby się dopasować również w pozostałe wolne obszary, ale zgodnie z kierunkiem przeszukiwania nie były one w ogóle analizowane.
Poszukiwany jest taki obszar wolny, żeby po przydziale pozostało po nim jak najmniej wolnego miejsca. Wymaga to przeszukania wszystkich dziur (dlatego metoda jest stosunkowo powolna), chyba że znajdzie się obszar dokładnie odpowiadający zapotrzebowaniu lub pozostały do przeszukania obszar jest mniejszy niż zapotrzebowanie.
Znalezienie największego wolnego obszaru wymaga również przeszukania wszystkich wolnych dziur, chyba że znajdzie się dziurę większą niż połowa zakresu pamięci, jaki pozostał jeszcze do przeszukania lub obszar pozostały do przeszukania jest niewiększy niż dotychczas znaleziona największa dziura.,/p>
Metoda nie jest zbyt często stosowana, jednak jej idea jest taka, żeby pozostawiać stosunkowo duże wolne obszary, gdyż zarządzanie małymi obszarami jest często nieefektywne (o czym wspomniano przy omawianiu fragmentacji wewnętrznej).
Metoda bloków bliźniaczych (ang. buddy) polega na sukcesywnym dzieleniu dostępnego obszaru pamięci na połowy i przydziale najlepiej dopasowanego bloku, którego rozmiar jest potęgą przy podstawie 2. Jest przy tym ustalony minimalny rozmiar przydzielanego bloku (wykładnik L ).
Jest to metoda pośrednia pomiędzy przydziałem stałym a dynamicznym. Rozmiar partycji nie jest ustalony odgórnie, ale możliwość dopasowania go do żądanej wielkości jest ograniczona. Najmniej korzystny przypadek ma miejsce, gdy wielkość żądanego obszaru jest trochę większa niż potęga dwójki, gdyż prawie połowa przydzielonego bloku pozostaje niewykorzystana (fragmentacja wewnętrzna).
Takie podejście ułatwia jednak zarządzanie, gdyż przyspiesza wyszukiwanie odpowiedniego bloku. Wolne bloki o danym rozmiarze identyfikowane są poprzez listę, której czoło znajduje się w tablicy. Indeks tablicy odpowiada wykładnikowi potęgi dwójki, określającej rozmiar bloku.
Metoda bloków bliźniaczych stosowana jest w systemie Linux, przede wszystkim na wewnętrzne potrzeby jądra. Również podczas przydziału stron pamięci dla procesów zarządca stara się je grupować i w przypadku większych żądań przydzielać ciąg stron o kolejnych numerach, stanowiących bliźniaczy blok.
Przykład pokazuje realizację ciągu żądań przydziału pamięci w metodzie bloków bliźniaczych. Do dyspozycji jest obszar 1 MB (=1024 KB). W odpowiedzi na żądanie przydziału 100 KB następuje podział bloku 1 MB na 2 bloki po 512 KB, z których jeden jest dalej dzielony na 2 bloki po 256 KB, a jeden z tych bloków z kolei dzielony jest znowu na 2 bloki po 128 KB. Dalszy podział nie ma już sensu, gdyż 64 KB to za mało w stosunku do zapotrzebowania. Żądanie przydziału 240 KB będzie zaspokojone niemal natychmiast, ponieważ dokonany wcześniej podział wyodrębnił już jeden blok o rozmiarze 256 KB, a jego połowa byłaby zbyt małym obszarem. Kolejne żądanie — przydziału 64 KB — wymaga przepołowienie wydzielonego już bloku 128 KB. Następne żądanie — 250 KB, wymaga bloku 256 KB, który może powstać przez podział bloku 512 KB. Warto zwrócić uwagę, że gdyby ostanie żądanie dotyczyło bloku o rozmiarze trochę większym, np. 260 KB, przydzielony musiałby być cały blok 512 KB.
Dotychczas omawiane zagadnienia dotyczyły zarządzania pamięcią bez interpretowania jej zawartości. Jednak takie zagadnienia, jak ochrona, czy transformacja adresu zostały tylko zasygnalizowane. Zanim nastąpi ich rozwinięcie, omówienia wymagają kwestie, dotyczące obrazu procesu w pamięci. Ponieważ tworzenie obrazu procesu jest zagadnieniem z dziedziny translatorów, poruszone zostaną tylko najważniejsze zagadnienia, które mają wpływ na funkcjonowanie systemu operacyjnego.
Tworzenie obrazu procesu obejmuje kompilację, konsolidację i ładowanie. W zależności od podejścia do wiązania adresów (wynikających często z możliwości sprzętu), można też rozważać relokację procesu w pamięci. Osobnym zagadnieniem, choć już wcześniej wspomnianym jest ochrona. Cześć obrazu (np. kod programu, kod funkcji bibliotecznych, niektóre dane) może być wspólna dla kilku procesów. Takie podejście poprawia efektywność i otwiera drogę do współpracy procesów, ale przy ochronie pamięci wymaga odpowiedniego odseparowania fizycznej i logicznej przestrzeni adresowej.
Tworzenie obrazu procesu zaczyna się od programu źródłowego. Program taki jest kompilowany do przemieszczalnego modułu wynikowego, a następnie łączony (konsolidowany) z modułami bibliotecznymi, do których są odwołania w kodzie. Konsolidację można jednak odłożyć do czasu ładowania, a nawet wykonywania kodu. Konsolidacja przed ładowaniem określana jest jako statyczna, a w jej wyniku powstaje moduł absolutny. Konsolidacja w czasie ładowania lub wykonania określana jest jako konsolidacja dynamiczna.
Każdemu etapowi tworzenia obrazu procesu w pamięci towarzyszy odpowiednie przekształcanie adresów, począwszy od etykiet i innych symboli, a skończywszy na fizycznych adresach komórek pamięci.
Translacja oznacza odpowiednie przekształcenie kodu źródłowego, znajdującego się w ogólności w jednym z wielu plików (modułów) współtworzących program, na przemieszczalny kod wynikowy.
Na tym etapie można wyliczyć adresy obiektów i kodu znajdujących się w tym module względem początku modułu. Adresy odnoszące się do obiektów i kodu w innych modułach mogą zostać związane dopiero na etapie konsolidacji.
W konsolidacji łączy się wynikowe moduły przemieszczalne, powstałe na etapie kompilacji. Konsolidację statyczną przeprowadza na etapie tworzenia programu ładowalnego. Jeśli jednak te same funkcje wykorzystywane są w wielu programach ładowalnych, każdy plik dla takiego programu będzie zawierał kopie modułów bibliotecznych, obejmujących te funkcje.
W przypadku konsolidacji dynamicznej program ładowalny zawiera tylko informację o tym, jakie moduły biblioteczne potrzebne są do wykonania. Moduły te nie są natomiast kopiowane do pliku z programem, są natomiast dołączane podczas uruchamiania lub wykonania. Można w ten sposób zaoszczędzić miejsce na dysku lub zasoby sieci (pasmo) podczas transmisji takiego programu. Problem może się pojawić, gdy nastąpi przeniesienie programu w inaczej skonfigurowane środowisko, w którym nie wszystkie wymagane moduły biblioteczne są dostępne.
Adresy obiektów w modułach przemieszczalnych przeliczane są stosownie do odwzorowania danego moduły w przestrzeni logicznej programu (modułu absolutnego). Do adresów przemieszczalnych dodawane są więc wartości, wynikające z przesunięcia danego modułu przemieszczalnego względem początku modułu absolutnego. Wiązane są również adresy, które odnoszą się do innych modułów wynikowych.
Logiczna przestrzeń adresowa procesu obejmuje kod programu, dane i stos. W przestrzeni tej może być również zlokalizowana część bloku kontrolnego procesu, obejmująca te atrybuty, które potrzebne są tylko w trakcie przetwarzania w kontekście danego procesu (np. u-obszar w systemie UNIX). Część obrazu procesu w pamięci ładowana jest z pliku z programem — kod samego programu oraz dane inicjalizowane w kodzie. Pozostałe części obrazu są tylko opisane (np. rozmiar stosu) i tworzone są przez jądro systemu operacyjnego. Tworzony jest oczywiście również blok kontrolny. Jeśli system dostarcza wsparcia dla współdzielenia, to kod programu lub funkcji bibliotecznych może być współdzielony z innymi procesami.
Ładowanie absolutne oznacza, że lokalizacja procesu w pamięci znana jest zanim nastąpi załadowanie kodu do pamięci. W przypadku takiego ładowania adresy fizyczne mogą być związane na etapie kompilacji lub konsolidacji.
W przypadku ładowania relokowalnego adresy fizyczne ustalane są dopiero na etapie tworzenia obrazu procesu w pamięci, co oznacza, że wszystkie adresy muszą zostać odpowiednio przeliczone. Wymagane jest zatem wskazanie tych miejsc w programie ładowalnym, które zawierają adresy absolutne i dodania do nich przemieszczenia względem początku obszaru pamięci fizycznej. Oprócz czasochłonności samego przeliczania format pliku z programem ładowalnym musi więc dodatkowo uwzględniać identyfikację adresów, przez co staje się skomplikowany i powoduje wzrost rozmiaru samego pliku. Taka forma ładowania komplikuje przemieszczanie kodu w pamięci podczas wykonywania procesu oraz wymianę pomiędzy pamięcią główną a pamięcią pomocniczą, gdyż wymaga przeliczenia adresów przy każdej zmianie lokalizacji procesu w pamięci fizycznej.
Przy pewnym wsparciu na poziomie architektury komputera można jednak zrealizować ładowanie dynamiczne, w którym adresy fizyczne ustalane są przez jednostkę zarządzania pamięcią dopiero przy odwołaniu do pamięci. Adres wystawiony przez procesor poddawany jest więc odpowiedniej transformacji, zanim zostanie wystawiony na szynie adresowej magistrali systemowej. W takim przypadku można mówić o rozdzieleniu logicznej i fizycznej przestrzeni adresowej.
Jednym z celów współdzielenia pamięci jest poprawa efektywności jej wykorzystania. Dzięki współdzieleniu ten sam obszar pamięci fizycznej, zawierającej program lub dynamicznie ładowane moduły biblioteczne, można odwzorować w obrazy logiczne wielu procesów. Przy braku współdzielenia każdy proces musiałby mieć własną kopię kodu, przechowywaną w osobnym obszarze pamięci.
Pamięć jest najszybszym środkiem przekazywania informacji pomiędzy procesami. Dlatego drugim celem współdzielenia jest dostęp do wspólnego obszaru pamięci, za pośrednictwem którego procesy przekazują sobie sygnały synchronizujące oraz dane do przetwarzania.
Realizacja współdzielenia wymaga rozwiązania podobnych problemów z wiązaniem adresów, jakie pojawiają się przy relokacji, a ponadto uniemożliwia ochronę pamięci lub wprowadza ograniczenia w dostępie. Współdzielenie pamięci przy zachowaniu elastyczności dostępu wymaga rozdzielenia logicznej i fizycznej przestrzeni adresowej oraz możliwości niezależnego odwzorowania poszczególnych części logicznego obrazu procesu na obszar pamięci fizycznej.
Na jednym z pierwszych slajdów pojawiła się informacja na temat ochrony pamięci, ograniczonej do weryfikacji poprawności zakresu dla adresu wystawionego przez procesor. Obraz procesu jest jednak skomplikowany — w jego skład wchodzą między innymi kod programu, dane oraz stos. Stos może być zarówno zapisywany, jak i odczytywany. Dane, zależnie od rodzaju, mogą być albo tylko czytane, albo czytane i zapisywane. Kod programu na ogół nie jest modyfikowany, a jest to niedopuszczalne w przypadku jego współdzielenia. W związku z tym można wprowadzić dodatkowe restrykcje odnośnie dostępu do pamięci. Poszczególne części obrazu procesu muszą mieć pewne atrybuty, wskazujące na rodzaj zawartości i wynikające stąd prawa dostępu. Jednostka zarządzania pamięcią, weryfikująca poprawność dostępu, musi mieć z kolei informacje o realizowanym właśnie cyklu maszynowym. Dostęp do zawartości pamięci z kodem możliwy jest tylko w fazie (cyklu maszynowym) pobrania kodu rozkazu. W fazie tej nie jest z kolei możliwy dostęp do obszarów, które nie są oznaczone jako kod. W ten sposób niemożliwa jest również modyfikacja kodu programu. Obszar danych tylko do odczytu nie jest z kolei dostępny w cyklu maszynowym zapisu pamięci. Ogólnie obszar danych i stosu nie jest dostępny w fazie pobrania kodu rozkazu, co wynika z wcześniejszych wyjaśnień. Restrykcje takie wprowadzana są często na potrzeby bezpieczeństwa. Np. przejęcie sterowania w procesie poprzez tzw. przepełnienie bufora, możliwe jest dzięki temu, że zawartość obszaru danych lub stosu interpretowana jest jako ciąg instrukcji. Ochrona na tym poziomie wymaga jednak wyodrębnienia odpowiednich części programu i właściwego ich opisania, co wymaga wsparcia sprzętowego.
W dotychczas rozważanych aspektach istniało domniemanie, że obraz procesu zajmuje ciągły obszar pamięci fizycznej. Ewentualne odwzorowanie obrazu logicznego na fizyczny polegało na dodaniu do adresu logicznego przemieszczenia, wynikającego z przesunięcia początku obszaru pamięci procesu względem początku pamięci fizycznej.
Obraz procesu można jednak podzielić na odrębne części i dla każdej części zdefiniować odwzorowanie. Jednym z tego typu podejść jest stronicowanie (ang. paging), w którym obraz procesu oraz pamięć fizyczna dzielone są na równe obszary o ustalonej wielkości zwane stronami (ang. pages). W celu odróżnienia stron z obrazem procesu od stron pamięci fizycznej te ostatnie nazywa się ramkami (ang. frames).
Strony i tym samym ramki mają współcześnie rozmiar od kilku do kilkudziesięciu kilobajtów, są więc stosunkowo niewielkie w stosunku do rozmiary obrazu procesu, czy dostępnej pamięci fizycznej. Stronicowanie jest więc pewną formą podziału stałego, jednak obraz procesu może zająć kilka jednostek, wynikających z tego podziału. Procesowi można przydzielić ramki rozmieszczone w dowolnym miejscu dostępnego obszaru pamięci fizycznej (nie muszą to być kolejne, sąsiadujące ze sobą jednostki). W ten sposób kosztem pewniej fragmentacji wewnętrznej rozwiązuje się problem fragmentacji zewnętrznej.
Mniej znaczące bity w adresie logicznym traktowane są jako przesunięcie wewnątrz strony (tym samym ramki), podczas gdy pozostałe (bardziej znaczące) bity wyznaczają numer strony. W przedstawionym przykładzie adresu logicznego na przesunięcie przeznaczono 10 bitów, co oznacza, że rozmiar strony/ramki wynosi 210 = 1 KB.
Każda strona ma ustalony numer ramki. Informacja o numerach ramek dla poszczególnych stron znajduje się w tablicy stron. Tablica stron zlokalizowana jest w pamięci fizycznej i musi być dostępna dla jednostki zarządzania pamięcią, której zadanie w ramach transformacji adresu sprowadza się do zastąpienia numeru strony w adresie logicznym numerem ramki.
W systemach wielozadaniowych każdy proces ma własną tablicę stron, której adres zlokalizowany jest w odpowiednim rejestrze jednostki zarządzania pamięci i podlega zmianie przy przełączaniu kontekstu.
Po wystawieniu adresu logicznego przez procesor jednostka zarządzania pamięcią identyfikuje numer strony i traktując go jako indeks w tablicy stron, lokalizuje odpowiedni wpis. Następnie zamienia numer strony w adresie logicznym na odczytany numer ramki, przesunięcie pozostawiając bez zmian i wystawia taki adres na magistrali systemowej.
Przykład pokazuje sens stronicowania. W obrazie logicznym (po lewej) pod adresami do 0 do 11 znajdują się kody kolejnych znaków (liter alfabetu). W obrazie fizycznym kolejność jest zupełnie inna, a dane nie zajmują nawet ciągłego obszaru. Przykład adresowania litery g obrazuje transformację. Adres logiczny 6 (dziesiętnie) po zastąpieniu dwóch bardziej znaczących bitów (wartości 1) zgodnie z zawartością tablicy stron na pozycji 1 zamieniany jest na 10 (dziesiętnie).
Przykład ma charakter poglądowy, dlatego rozmiar strony wynosi zaledwie 4 bajty. W żadnym rzeczywistym rozwiązaniu nie jest to tak mała jednostka.
Transformacja adresu wymaga dodatkowego dostępu do pamięci w celu pobrania informacji o stronie z tablicy stron. Czas dostępu do właściwej zawartości (kod rozkazu, operandów) wydłuża się więc dwukrotnie. W celu zredukowania dodatkowego obciążenia czasowego stosowana jest pamięć asocjacyjna, zwana buforami TLB (ang. translation look-aside buffer), w której przechowywane są ostatnio pobrane wpisy z tablicy stron. Kluczem, na podstawie którego lokalizowana jest pozycja w buforze TLB, jest numer strony, a wartością na wyjściu jest numer ramki. Jeśli wpis o danym kluczu nie zostanie znaleziony w buforze TLB, następuje normalne odwołanie do tablicy stron, przy czym wpis przenoszony jest do bufor TLB. Wykorzystywana jest tutaj właściwość programów, zwana lokalnością odniesień do pamięci.
Przedstawiony wcześniej przykładowy podział 32-bitowego adresu logicznego na 10-bitowe przesunięcie oraz 22 bitowy numer strony oznaczałby, że potencjalnie może być potrzebnym 222 wpisów w tablicy stron. Zakładając, że każdy wpis wymaga 32 bitów (4 bajtów), na tablicę stron potrzebny byłby ciągły obszar pamięci fizycznej o rozmiarze 224 = 16 MB. Znalezienie tak dużego ciągłego obszaru może być kłopotliwe, a rozwiązaniem problemu może być zastosowanie podejścia wielopoziomowego, zwanego również hierarchicznym. W podejściu dwupoziomowym w adresie logicznym wyodrębnia się 3 zakresy bitów:
Podejście takie zastosowano między innymi w architekturze Intel IA-32. Zewnętrzną tablicę stron określa się jako katalog stron, a wewnętrzną po prostu jako tablicę stron. Na identyfikację pozycji w katalogu stron oraz w tablicy stron przeznaczone jest po 10 bitów z 32-bitowego adresu. Na przesunięcie na stronie pozostaje zatem 12 bitów, co oznacza, że rozmiar strony wynosi 4 KB. W architekturze Sparc zastosowano nawet podeście trzypoziomowe.
Podstawą stronicowania jest stały podział pamięci. Segmentacja (ang. segmentation) oparta jest z kolei na podziale dynamicznym. Obraz procesu dzielony jest na logiczne części, odpowiadające poszczególnym sekcjom programu — sekcji kodu, danych, stosu itp. Dla każdej sekcji definiowany jest odpowiedni segment. Na potrzeby segmentu przydzielane są dynamiczne partycje w pamięci. Segmenty danego procesu mogą być dowolnie rozmieszczone w pamięci, ale każdy segment zajmuje ciągły obszar pamięci.
Segment, przeznaczony na określoną sekcję programu, może mieć zróżnicowany rozmiar i zawartość, a także dowolne położenie w pamięci fizycznej. Dlatego opis segmentu (deskryptor) obejmuje takie dane, jak:
Strona miała rozmiar dokładnie dostosowany do przesunięcia, nie było więc ryzyka operowania przesunięciem naruszającym rozmiar strony. Dla segmentu rozmiar jest jednym z atrybutów niezależnych od przesunięcia. Możliwy jest zatem przypadek użycie przesunięcia, wykraczającego poza rozmiar segmentu. Taki przypadek musi być oczywiście wykryty i zasygnalizowany przez odpowiednie przerwanie diagnostyczne. Stosownie do atrybutów segmentu weryfikowany może być również cykl maszynowy oraz poziom (pierścień) ochrony.
Po poprawnej weryfikacji przesunięcie dodawane jest do adresu bazowego segmentu i powstaje adres fizyczny, wystawiany na magistrali systemowej.
W przeciwieństwie do stron, segmenty mogą mieć dość duży rozmiar, a więc znalezienie dla nich ciągłego obszaru pamięci fizycznej może być kłopotliwe. Chociaż możliwa jest relokacja segmentu, operacja może być czasochłonna. Zalety segmentacji i stronicowania można jednak połączyć, stosując obie techniki. Pamięć w takim podejściu postrzegana jest jako zbiór segmentów, które składają się z ramek. Przesunięcie wewnątrz segmentu traktowana jest jako adres w pamięci stronicowanej, czyli adres składający się z numeru strony oraz przesunięcia wewnątrz strony. Zamiast adresu bazowego segmentu w deskryptorze znajduje się adres tablicy stron danego segmentu, za pośrednictwem której ustalany jest numer ramki.
Nie jest to jedyny sposób transformacji adresu. W architekturze IA-32 (począwszy już od procesora 80386) zastosowano podejście, w którym każdy adres poddawany jest transformacji zgodnie z zasadą segmentacji, w wyniku czego powstaje adres liniowy. Jeśli procesor pracuje w trybie z pamięcią stronicowaną, adres liniowy poddawany jest dalszej transformacji, właściwej dla stronicowania dwupoziomowego.
Współdzielenie pamięci można zrealizować w sensowny sposób dopiero wówczas, gdy określony fragment logicznej przestrzeni adresowej można odwzorować na współdzielony fragment pamięci niezależnie od pozostałej części przestrzeni logicznej. Zarówno stronicowanie, jak i segmentacja udostępniają środki do takiego odwzorowania, gdyż wpisy w odpowiednich tablicach (stron lub segmentów) poszczególnych procesów mogą się odnosić do tego samego obszaru pamięci fizycznej. Weryfikacja poprawności odwołania, związana z ochroną, może być przeprowadzona na poziomie adresów logicznych.
Pamięć wirtualna jest organizacją zasobów pamięci, zrealizowaną w oparciu o tzw. przestrzeń wymiany w pamięci drugiego rzędu (na dysku). Pamięć operacyjna (fizyczna) jest dla tych zasobów tylko pewnym oknem, przechowującym część zawartości na potrzeby bieżącego przetwarzania.
Stosowanie pamięci wirtualnej ma wiele zalet nie tylko związanych z możliwością powiększenia zasobów pamięci ponad dostępną pamięć fizyczną. Umożliwia bardziej racjonalne wykorzystanie pamięci operacyjnej, gdyż programy tworzone są często z nadmiarem w stosunku do typowych potrzeb. Na przykład rozmiary tablic statycznych ustala się z nadmiarem w stosunku do typowych potrzeb, w kodzie uwzględnia się obsługę sytuacji wyjątkowych do których może nigdy nie dojść. Ten nadmiar nie musi być ładowany do pamięci. Zastosowanie pamięci wirtualnej może też zmniejszyć czas odpowiedzi, gdyż skraca czas ładowania kodu, który często odwzorowywany jest w przestrzeń adresową procesu bezpośrednio z pliku i sprowadzany w niewielkich porcjach na żądanie.
Celem wykładu jest przedstawienie zasady działania i problemów realizacji pamięci wirtualnej oraz omówienie algorytmów wymiany stron pomiędzy pamięcią operacyjną a pamięcią drugiego rzędu (obszarem wymiany).
Podstawą funkcjonowania pamięci wirtualnej jest mechanizm stronicowania na żądanie, od omówienia którego rozpoczyna się wykład. Działanie mechanizmu oparte jest na stronicowaniu i polega na sprowadzaniu do pamięci operacyjnej stron adresowanych przez procesor. Sprowadzenie strony jest zadaniem systemu operacyjnego i realizowane jest w przypadku wystąpienia błędu strony. Ponieważ pamięć operacyjna jest na ogół mniejsza od pojemności zasobów pamięci wirtualnej, sprowadzenie może wymagać usunięcia innej strony — dochodzi wówczas do wymiany. Realizacja pamięci wirtualnej oprócz wsparcia sprzętowego wymaga rozwiązania dwóch zasadniczych problemów na poziomie systemu operacyjnego:
Rozwiązanie problem wyboru ofiary bazuje na przesłankach o charakterze losowym i związane jest ściśle z algorytmem wymiany. Klasyfikacja i omówienie algorytmów wymiany stanowią ostatnią część wykładu.
Stronicowanie na żądanie związane jest przede wszystkim z wymianą stron pomiędzy pamięcią pierwszego rzędu (operacyjną, fizyczną) i drugiego rzędu (masową, dyskową). Dzięki wykorzystaniu pamięci masowej można rozszerzyć wirtualną przestrzeń adresową i tym samym zwiększyć stopień wieloprogramowości lub uruchamiać zadania, których rozmiar wykracza poza dostępną pamięć operacyjną. Kosztem wprowadzenia takiego mechanizmu jest złożoność zarządzania pamięcią i narzut czasowy związany z dostępem, wynikający z wykorzystania stosunkowo wolnej pamięci dyskowej.
Adresowanie stron odbywa się tak samo, jak w prostym stronicowaniu, omówionym w poprzednim module. W tablicy stron przechowywany jest jednak bit poprawności, informujący o stanie strony. Strona poprawna (ang. valid) to taka, która zlokalizowana jest w pamięci operacyjnej. Odniesienie do takiej strony nie wymaga jej sprowadzania. Jeśli zgodnie z wartością bitu poprawności strona jest uznana za niepoprawną, występuje błąd braku strony i zgłaszane jest odpowiednie przerwanie diagnostyczne. W ramach obsługi błędu strony następuje sprowadzenie strony z obszaru wymiany (ang. swap space), umieszczenie w wolnej ramce i ponowne wykonanie rozkazu. Takie działanie nazywa się leniwą wymianą (ang. lazy swapping).
Urządzeniem wymiany jest najczęściej dysk, na którym znajduje się plik wymiany lub specjalnie wyodrębniona strefa (tzw. partycja wymiany).
W dalszej części wykładu zamiennie będzie używane sformułowanie: adresowanie strony i odniesienie do strony, oznaczające wystawienie przez procesor adresu logicznego komórki, zlokalizowanej na tej stronie.
Zgodnie z zasadą transformacji adresu w pamięci stronicowanej, w celu zamiany numeru strony na numer ramki lokalizowany jest odpowiedni wpis w tablicy stron. Wpis może być jednak w danej chwili niepoprawny (ang. invalid), gdyż strona mogła zostać usunięta z pamięci — zastąpiona inną stroną. W przypadku odwołania się do strony, opisanej jako niepoprawna, następuje zgłoszenie błędu (przerwania diagnostycznego), które obsługuje system operacyjny. W ramach obsługi adresowana strona sprowadzana jest z obszaru wymiany do pamięci operacyjnej.
Po sprowadzeniu strony do pamięci operacyjnej odpowiedni bit poprawności w tablicy stron jest ustawiany. Przyjmijmy, że ustawienie bitu poprawności oznacza, że strona jest poprawna (ang. valid). Następnie rozkaz, który spowodował błąd strony, wykonywany jest ponownie przez procesor. To odniesienie do pamięci, które spowodowało wcześniej błąd strony powinno teraz wykonać się poprawnie.
Ramkę, która jest użyta do wymiany określa się jako ramkę ofiarę (ang. victim frame), chociaż to raczej strona jest ofiarą. W dalszej części używane będą zależnie od kontekstu terminy: ramka ofiara, strona ofiara, lub po prostu ofiara.
Brak bitu modyfikacji w tablicy stron oznacz konieczność zapisania strony na urządzeniu wymiany, jeśli strona to mogła być potencjalnie modyfikowana. Jeśli bit modyfikacji istnieje, ustawiany jest przed jednostkę zarządzania pamięcią zawsze, gdy wystąpił cykl maszynowy zapisu na tej stronie, nawet jeśli zapis niczego w stanie strony nie zmienił (np. nastąpiło wpisanie do komórki pamięci takiej samej wartości, jaka była tam wcześniej).
Jeśli bit modyfikacji nie jest ustawiony, to znaczy, że w obszarze wymiany jest aktualna kopia strony, która znajduje się również w pamięci. Zastąpienie takiej strony sprowadza się do jej nadpisania w pamięci. Przy ustawionym bicie modyfikacji strona zastępowana musi być najpierw zapisana w obszarze wymiany, co istotnie zwiększa koszt operacji wymiany.
Z punktu widzenia efektywności przetwarzania koszt wymiany można utożsamiać z czasem realizacji wymiany. W celu uproszczenia analizy przyjmuje się, że koszt usunięcia strony stanowi stałą część kosztu jej sprowadzenia. Koszt wynika zatem z czasu sprowadzania, który w ogólności zależy od:
Przyjmując funkcję kosztu sprowadzenia zbioru stron — h, koszt realizacji wymiany jest po prostu sumą kosztów w chwilach odniesienie do pamięci. Jeśli żadna strona nie jest sprowadzana, koszt wynosi 0. Jeśli sprowadzana jest jedna strona, koszt wynosi 1.
W przypadku dysku żądanie odczytu bloków czeka w kolejce, aż urządzenie dyskowe będzie wolne, czyli skończy obsługę wcześniej zgłoszonych żądań. Czas oczekiwania nie zależy od wielkości zgłaszanego żądania, ale wielkość ta ma wpływ na łączny czas dostępu, na który składa się czas wyszukiwania ścieżki, opóźnienie obrotowe, czas przesyłania. Czas dostępu dotyczy każdego sektora, można jedynie minimalizować czas wyszukiwania i opóźnienie obrotowe, gdyż sektory z zawartością strony są lokalizowane blisko siebie.
Jak wynika z własności funkcji kosztu dla dysku, sprowadzenie kilku stron w wyniku realizacji jednego żądania jest bardziej kosztowne niż sprowadzenie jednej strony, ale mniej kosztowne niż sprowadzanie poszczególnych stron w wyniku osobnych żądań.
Konieczność sprowadzenia strony pojawia się dopiero przy wystąpieniu błędu strony. Sprowadzanie stron w okolicznościach innych niż obsługa błędu strony nie ma sensu, ale jak wynika z zaprezentowanej analizy, w ramach obsługi błędu strony sensowne może być sprowadzenie kilku stron, przewidując przeszłe odniesienia. Koszt sprowadzenia jest więc ściśle uzależniony od liczby błędów strony i liczby transmisji stron.Liczba błędów strony wpływa również na długość kolejki żądań dostępu do dysku, co wydłuża czas oczekiwania. Można zatem wyciągnąć ogólny wniosek, że w celu redukcji kosztów wymiany należy minimalizować liczbę błędów strony, gdyż wpływa ona pośrednio lub bezpośrednio na wszystkie składowe kosztu.
Zasadnicze problemy wymiany stron dotyczą decyzji odnośnie usuwanej strony oraz zagwarantowania dostępności wszystkich stron wymaganych do realizacji cyklu rozkazowego.
Usunięcie z pamięci strony, która będzie potrzebna przyszłości, oznacza konieczność ponownego sprowadzenia jej do pamięci, a więc koszt, którego być może dałoby się uniknąć. Nasilenie tego zjawiska określane jest jako migotanie i oznacza drastyczny spadek efektywności działania systemu komputerowego, gdyż większość czasu cyklu przetwarzania proces spędza w stanie oczekiwania na gotowość urządzenia dyskowego. Rozwiązanie problemu wyboru ofiary oparte jest na przesłankach o charakterze losowym.
Problem wznawiania rozkazów wiąże się z koniecznością ponownego wykonania całego cyklu rozkazowego, w którym wystąpił błąd strony. Cykl rozkazowy może składać się z kilku cykli maszynowych, z których każdy może się wiązać z odniesieniem do innej strony pamięci. W niesprzyjających okolicznościach mogłoby dojść do sytuacji, w której w wyniku obsługi błędu strony następuje usunięcie z pamięci innej strony, adresowanej w tym samym cyklu rozkazowym. Wznowienie rozkazu ponownie zakończy się błędem strony w jednym z cykli maszynowych. W skrajnym przypadku rozkaz mógłby się nigdy nie wykonać. Problem wznawiania rozkazów można rozwiązać, zapewniając procesowi pewną minimalną liczbę ramek — nie mniejszą niż liczba różnych adresów, wystawianych na magistrali w jednym cyklu rozkazowym.
Problem z wyborem ofiary wynika z faktu, że nie znamy przyszłego ciągu odniesień do stron. Przyszłe odniesienia możemy jedynie przewidywać z pewnym prawdopodobieństwem na podstawie różnych przesłanek z odniesień w przeszłości. Większość typowych programów charakteryzuje się własnością lokalności. Często również optymalizatory kodu dokonują takiego rozmieszczenia obiektów, aby w trakcie wykonywania ujawniała się taka własność.
Lokalność można rozważać w dwóch aspektach: czasowym i przestrzennym. Lokalność czasową można sprowadzić do wielokrotnego odwołania w krótkim czasie do tej samej strony. Przypadek taki ma miejsce przy wykonywaniu programu, chyba że występują częste i dość dalekie (wychodzące poza stronę) skoki. Przypadek taki dotyczy również danych, np. tablic, a nawet pojedynczych zmiennych, gdyż programiści definiują często kilka zmiennych na potrzeby obsługi jakiegoś krótkiego fragmentu programu, np. pętli. Z punktu widzenia stronicowania oznacza to, że jeśli strona zostanie sprowadzona do pamięci operacyjnej, przyda się wielokrotnie w czasie wykonywania określonego fragmentu programu. Własność lokalności czasowej wykorzystywana jest często przy podejmowaniu decyzji o usunięciu strony z pamięci.
Lokalność przestrzenna sprowadza się do wnioskowania na podstawie odniesień do pewnych stron o przyszłych odniesieniach do innych stron. Podstawą takiego skojarzenia może być numeracja stron. Jeśli program lub większa struktura danych (tablica) zajmuje kilka kolejnych stron, to prawdopodobne jest, że po odniesieniu do pierwszej z tych stron nastąpi odniesienie do drugiej, a później do trzeciej. Skojarzenie takie można również oprzeć o obserwację wcześniejszych odniesień. Jeśli strona p2 często była adresowana zaraz po stronie p1 , to być może na stronie p1 jest skok do instrukcji, znajdującej się na stronie p2 . Ten rodzaj lokalności można wykorzystać przy podejmowaniu decyzji o usuwaniu, ale również przy sprowadzaniu stron, kiedy stosowane jest tzw. sprowadzanie wstępne (sprowadzanie kilku stron w wyniku jednego błędu strony).
Podstawą efektywnego funkcjonowania pamięci wirtualnej jest oczywiście precyzyjna identyfikacja zbioru stron aktywnych. Wykorzystanie tej informacji polega na utrzymaniu stron aktywnych w pamięci. Jeśli ze względu na zbyt duże potrzeby procesów strony aktywne muszą być usuwane z pamięci, to i tak trzeba ponieść koszt ich ponownego sprowadzenia. W tego typu sytuacji dochodzi najczęściej do migotania stron (szamotania, ang. trashing), jednak identyfikacja stron aktywnych umożliwia wykrycie takiego ryzyka i podjęcie pewnych działań zapobiegawczych.
Sama identyfikacja wynikać może z różnych przesłanek, a precyzja tej identyfikacji uzależniona jest od zasadności przyjętych przesłanek.
Klasyfikacja związana jest z okolicznościami, w jakich podejmowana jest decyzja o sprowadzeniu lub usunięciu strony. W algorytmach wymiany na żądanie zarówno sprowadzanie, jak i usuwanie wykonywane jest wówczas, gdy jest absolutna konieczność. W przypadku sprowadzania oznacza to, że jeśli strony nie ma w pamięci, to nie zostanie sprowadzona wcześniej, niż po wystąpieniu odniesienia do niej (zaadresowania jej przez procesor). W przypadku usuwania absolutna konieczność występuje dopiero wówczas, gdy brakuje miejsca w pamięci operacyjnej (nie ma wolnej ramki), a ze względu na występujące odniesienia do stron, znajdujących się poza pamięcią operacyjną, konieczne jest zwolnienie ramki na potrzeby sprowadzanej strony. Ponieważ strona do sprowadzenia jest jednoznacznie określona przez stan systemu (stan pamięci oraz adres wystawiony przez procesor), specyfika algorytmu tej klasy zależy od wyboru strony usuwanej z pamięci.
W klasie algorytmów wymiany ze sprowadzaniem na żądanie o specyfice algorytmu również decyduje sposób wyboru strony usuwanej, a często stron usuwanych. W tych algorytmach strona (lub kilka stron) może być usunięta w dowolnym momencie, niekoniecznie przy okazji obsługi błędu strony.
W klasie algorytmów ze wstępnym sprowadzaniem odniesienie do strony nieobecnej w pamięci operacyjnej skutkuje błędem strony, ale przy okazji jego obsługi może nastąpić sprowadzenie oprócz strony żądanej innych stron. Istotą algorytmów tej klasy jest wybór stron wstępnie sprowadzanych, można więc przyjąć dowolny sposób usuwania, łącząc w ten sposób ideę wstępnego sprowadzania z różnymi koncepcjami utrzymania stron w pamięci.
Klasyfikacja wiąże się z zakresem ramek uwzględnianych przy poszukiwaniu ofiary. W przypadku zastępowania lokalnego proces dysponuje pewną liczbą ramek, w których muszą się pomieścić jego strony. Błąd strony tego procesu skutkuje ewentualnym usunięciem innej jego strony. Można w ten sposób ograniczyć (ale nie zlikwidować) negatywny wpływ zbyt częstego generowania błędów strony przez proces na efektywność działania całego systemu.
W zastępowaniu globalnym poszukiwanie ramki ofiary dotyczy całej puli ramek niezależnie od bieżącego przydziału. Może więc dojść do podkradania ramek, kiedy jeden proces traci ramkę na rzecz innego. Takie podejście ułatwia adaptację liczby ramek używanych przez procesy do zróżnicowanych potrzeb, ale jest niebezpieczne dla efektywności całego systemu, gdy liczba ramek jest zbyt mała. Może wówczas dojść do zjawiska szamotania.
Klasyfikacja związana jest z adaptacją przydziału zasobów do zmieniających się potrzeb procesów. W przydziale statycznym proces otrzymuje pewną liczbę ramek na cały czas cyklu przetwarzania. W przydziale dynamicznym liczba ramek przydzielonych procesowi może się zmienić zależnie od intensywności generowania błędów strony. Jeśli liczba błędów strony, generowanych przez proces, jest stosunkowo duża to w zależności od możliwości, jakimi dysponuje system, można przydzielić dodatkowe ramki. Dodatkowe ramki mogą pochodzić z puli ramek odebranych procesom, które generowały mało błędów strony.
Zastępowanie globalne w naturalny sposób prowadzi do przydziału dynamicznego, nie ma natomiast sensu w przypadku przydziału statycznego. Przydział statyczny wymaga zastępowania lokalnego, ale w przypadku zastępowania lokalnego również można zastosować przydział dynamiczny. W ramach obsługi błędu strony wymiana jest lokalna, ale okresowo liczba ramek może się np. zwiększyć, co wyeliminuje na jakiś czas problem zastępowania w przypadku kolejnych błędów strony. Liczba ramek przydzielonych procesowi może też oczywiście się zmniejszyć.
Z przydziałem ramek wiąże się ustalanie ich liczby. Jest to szczególnie istotne w przydziale statycznym, ale dotyczy również początkowej liczby ramek w przydziale dynamicznym. Niezależnie od sposobu przydziału proces, który jest w pamięci powinien mieć do dyspozycji pewną minimalną liczbę ramek, gwarantującą uniknięcie problemu wznawiania rozkazów. Liczba ramek powinna być nie mniejsza, niż maksymalna liczba różnych adresów, jakie mogą być wystawione na magistrali w jednym cyklu rozkazowym.
Zakładając, że spełnione jest minimum dla każdego procesu przebywającego w pamięci, liczba ramek może być:
Algorytmy wymiany na żądanie stosowane są w systemach jednozadaniowych lub w systemach wielozadaniowych ze statycznym przydziałem ramek.
Algorytm MIN oparty jest na nierealnej przesłance, wymagającej znajomości przyszłego ciągu odniesień. Z drugiej strony jest to algorytm optymalny w tej klasie, dlatego wykorzystywany jest dla celów porównawczych. Można w ten sposób sprawdzać, ile tracimy, opierając się na przesłankach z historii dotychczasowych odniesień. Jest to zatem swego rodzaju miara zasadności tych przesłanek.
Algorytmy FIFO i LIFO oparte są na kolejności sprowadzania stron do pamięci. FIFO usuwa strony w kolejności ich sprowadzania LIFO w kolejności odwrotnej. FIFO sprawdza się dobrze w przypadku programów, w których jest prosty, sekwencyjny przepływ sterowania od początku programu do końca, z małą liczbą pętli, czy wywołań podprogramów. LIFO natomiast właściwy jest dla przypadków pętli, gdyż ponowne przejście sterowania do tej samej instrukcji nastąpi dopiero w następnej iteracji. Dla pętli istnieje jeszcze inny algorytm — LD (ang. loop detection), którego prezentację tu pominięto.
Algorytmy LRU, LFU i MFU oparte są na przesłankach, wymagających monitorowania odniesień do pamięci. Dla LRU istotny jest czas ostatniego odniesienia, a dla LFU i MFU liczba odniesień w przeszłości. LRU jest typowym algorytmem dla programów, charakteryzujących się lokalnością czasową odniesień do pamięci. Algorytmy LFU i MFU (tzw. algorytmy licznikowe) oparte są na zupełnie przeciwnych przesłankach: LFU usuwa stronę, do której było najmniej odniesień do początku przetwarzania lub od momentu sprowadzenia do pamięci (są to dwa warianty algorytmów licznikowych), a MFU usuwa stronę, do której było najwięcej odniesień.
Przedstawiony przykład pokazuje przebieg odniesień do stron o numerach od 1 do 5 w obrębie 4 początkowo pustych ramek. Pierwsze 4 odniesienia powodują błąd strony, ale nie występuje problem zastępowania, gdyż dostępne są wolne ramki. Dopiero odniesienie do strony nr 5 wymaga zwolnienia jakieś ramki. Wybór strony do usunięcia zależy od algorytmu wymiany.
Na kolejnych rysunkach pokazany jest stan poszczególnych ramek, zależnie od zastosowanego algorytmu. Przy okazji pokazane jest odniesienie do pamięci, które spowoduje kolejny błąd błąd strony i tym samym problem zastępowania.
Usunięcie tej samej strony w przypadku algorytmów LFU i LRU oraz MFU i LIFO jest przypadkowe i kolejna wymiana w przypadku tych algorytmów może wykazać różnice.
Warto też przy tej okazji zwrócić uwagę, że dla algorytmów licznikowych wybór może być niejednoznaczny, gdyż liczba odniesień do różnych stron może być taka sama. Jako kryterium rozstrzygnięcia można przyjąć czas sprowadzenia, czyli strony z taką samą wartością licznika usuwane są w kolejności FIFO.
Przy założeniu, że strony sprowadzane są pojedynczo nie ma tego problemu w algorytmach opartych na kolejności zdarzeń w czasie, czyli MIN, FIFO, LIFO i LRU.
W przypadku 3 ramek pierwsze 7 odniesień do stron kończy się błędem, ale kolejna 2 odniesienia przebiegają bez błędów, a później pojawiają się jeszcze 2 błędy. W sumie jest ich 9.
W przypadku 4 ramek początek jest bardziej optymistyczny, gdyż po 4 pierwszych odniesieniach z błędem, wypełnione ramki zdają się gwarantować stabilność przetwarzania. Jednak sprowadzenie strony nr 5 powoduje usunięcie strony numer 1, która sprowadzana jest jako następna, usuwając z kolei potrzebną później stronę nr 2 itd. Ostatecznie mamy 10 błędów strony pomimo zwiększenia liczby ramek . Paradoks ten, nazywany anomalią Belady’ego, dotyczy wybranych algorytmów, między innymi algorytmu FIFO. Anomalia nie ujawnia się być może zbyt często, ale może wzbudzać obiekcje co do efektów przydziału dodatkowych zasobów.
Jak już wcześniej wspomniano, kluczowa dla efektywności funkcjonowania systemu z pamięcią wirtualną jest minimalizacja liczby błędów strony. W celu ograniczenia kosztów czasowych dostępu do pamięci stosowane są odpowiednie algorytmy wymiany. Na przykładzie algorytmów FIFO i LRU wyjaśnione zostaną natomiast zagadnienia związane z kosztem działania samego algorytmu.
Implementacja algorytmu FIFO bazuje na kolejce FIFO, którą można łatwo zaimplementować za pomocą listy jednokierunkowej.
Warto zwrócić uwagę, że aktualizacja listy następuje w ramach obsługi błędu strony, gdyż stronę umieszczamy na liście po sprowadzeniu. W przypadku usuwania na żądanie, również usuwanie strony z listy wykonywane jest przy obsłudze błędu strony.
Rozwiązanie z licznikiem wymaga zwiększenia licznika odniesień do pamięci i stosownej aktualizacji opisu strony (lub ramki). Jest to operacja stosunkowo szybka w porównaniu z wyszukiwaniem strony do usunięcia w przypadku konieczności zwolnienia ramki. Pewnym problemem jest ryzyko przepełnienia licznika.
W przypadku rozwiązania opartego na stosie jest odwrotnie. Aktualizacja stosu zbudowanego na liście wymaga zmiany zaledwie kilku wskaźników, ale wyszukanie strony w głębi stosu jest bardziej czasochłonne. Wybór strony do usunięcia w przypadku konieczności zwolnienia ramki jest za to natychmiastowy.
Porównując oba podejścia należałoby zauważyć, że błąd strony jest zjawiskiem nieporównywalnie rzadszym niż odniesienie do strony. W przeciwnym przypadku stosowanie pamięci wirtualnej nie miałoby żadnego sensu. Preferowane byłoby zatem rozwiązanie licznikowe. Jednak implementacja tego rozwiązania na poziomie systemu operacyjnego wymaga przekazania sterowania do programu jądra przy każdym odniesieniu do strony. Nawet jeśli aktualizacja licznika i tablicy stron wymaga wykonania zaledwie kilku rozkazów, to i tak powoduje to kilkunastokrotne spowolnienie każdego dostępu do pamięci. Programowe rozwiązanie oparte na stosie byłoby jeszcze bardziej czasochłonne.
Mogłoby się zatem okazać, że koszt algorytmu LRU pochłania zysk, wynikający z trafności decyzji co do stron wymienianych. Konieczne jest zatem odpowiednie wsparcie na poziomie architektury komputera.
Implementacja na poziomie architektury komputera nie może być zbyt kosztowana, gdyż nie wiadomo, jaki algorytm wymiany będzie implementowany w systemie operacyjnym i czy w ogóle realizowana będzie pamięć wirtualna z wymianą stron. Jeśli zatem dostarczane jest wsparcie dla implementacji wymiany, powinno ono być na tyle uniwersalne, żeby można była je zaadaptować do różnych algorytmów.
W ramach wsparcia na poziomie architektury jednostka zarządzania pamięcią ustawia odpowiednie bity na właściwej pozycji w tablicy stron w przypadku wykrycia odniesienia do strony:
W dalszej części omówione zostaną 3 algorytmy, w których wykorzystywane jest omówione wspomaganie sprzętowe:
Poza tym, bity te wykorzystywane są w niektórych algorytmach wymiany ze sprowadzaniem na żądanie.
W algorytmie dodatkowych bitów odniesienia okresowo sprawdzane są bity odniesienia każdej ze stron i kopiowane do dodatkowej struktury, zwanej tablicą dodatkowych bitów odniesienia. Bity kopiowane są na najbardziej znaczącą pozycje, ale przed skopiowaniem następuje logiczne przesunięcie bitów w prawo na każdej pozycji. Bit najmniej znaczący jest tracony. Tablica przechowuje zatem informacje o wystąpieniu błędu strony w kilku ostatnich okresach kontrolnych. Ciąg samych zer oznacza, że nie było żadnego odniesienia w ostatnim czasie. Ogólnie im mniejsza wartość tym bardziej odległe w czasie jest ostatnie odniesienie lub mniejsza jest liczba odniesień. Horyzont czasowy tej informacji zależy od liczby bitów na każdej pozycji oraz długości okresu kontrolnego. Oczywiście im dłuższy okres kontrolny, tym mniej precyzyjna jest informacja, gdyż reprezentowana jest tylko przez 1 bit.
W przypadku konieczności wymiany poszukiwana jest strona, dla której wartość w tablicy jest najmniejsza, a ramka tej strona jest użyta do wymiany. Precyzja działania algorytmu wymaga uwzględnienia również bieżącej wartości bitu odniesienia na najbardziej znaczącej pozycji wektora. Można przyjąć, że tuż przed wybraniem strony ofiary następuje przesunięcie bitów w tablicy i skopiowanie bitów odniesienia.
Algorytm drugiej szansy (FINUFO, ang. First In Not Used First Out) jest jednym z tzw. algorytmów zegarowych (wskazówkowych), w których numery stron (lub ramek, w tym przypadku ramek danego procesu) tworzą listę cykliczną (tarczę zegara), a wskazówka wskazuje kandydatkę do usunięcia z pamięci w przypadku błędu strony. Jeśli jednak strona, wskazywana do usunięcia była ostatnio adresowana (ma ustawiony bit odniesienia), otrzymuje drugą szansę. Bit odniesienia dla tej strony jest kasowany, a wskazówka przesuwa się na stronę następną. Sprowadzana strona zastępuje więc stronę na wskazanej ostatecznie pozycji, po czym wskazówka przesuwa się do następnej strony.
W przedstawionym przykładzie wskazywana jest strona nr 5, ale bit odniesienia do tej strony jest ustawiony, więc po jego skasowaniu wskazówka przesuwa się na stronę nr 2. Dla tej strony bit odniesienie jest skasowany, więc nastąpi jej usunięcie, konkretnie ramka tej strony zostanie użyta do wymiany, a wskazówka przesunie się na stronę nr 4.
W niektórych publikacjach odróżnia się algorytm zegarowy od algorytmu drugiej szansy (FINUFO), przedstawiając ten drugi, jako algorytm FIFO, w którym strona na czole kolejki jest:
Algorytm zegarowy natomiast przedstawia się jako listę cykliczną ramek, w których wymieniane są strony zgodnie z położeniem wskazówki.
Ulepszenie algorytmu drugiej szansy w tym przypadku polega na uwzględnieniu bitu modyfikacji. W celu redukcji kosztów unika się po prostu wymiany stron modyfikowanych, które muszą być dodatkowo zapisane na urządzeniu wymiany. Wyszukiwanie strony do wymiany polega więc na analizie wartości 2-bitowej, złożonej z bitu odniesienia na bardziej znaczącej pozycji i bitu modyfikacji na mniej znaczącej pozycji. W przestawionym przykładzie „najlepsza” do usunięcia zgodnie z obiegiem wskazówki jest strona nr 6, gdyż ma wyzerowane oba bity.
Istotą algorytmów ze sprowadzaniem na żądanie jest zwalnianie ramek, uznanych za nie wykorzystywane, wcześniej niż to wynika z potrzeb realizacji samej wymiany. Celem wcześniejszego zwalniania jest uzyskanie ramek na potrzeby innych procesów, którym tych ramek brakuje. W skrajnych przypadkach niewystarczająca liczba ramek może być przyczyną zawieszenie procesu i przeniesienia całego obrazu w obszar wymiany. Uzyskanie wolnych ramek umożliwia z kolei aktywację procesu — wprowadzenie do pamięci operacyjnej niezbędnych jego stron.
Algorytm VMIN (ang. Variable-space MIN) jest optymalny w klasie algorytmów ze sprowadzaniem na żądanie, ale oparty jest na znajomości przyszłego ciągu odniesień do stron. Decyzja o usunięci strony z pamięci wynika z porównania kosztu ponownego sprowadzenia, oraz kosztu utrzymania do czasu następnego odniesienia. Jeśli koszt ponownego sprowadzania jest mniejszy, strona jest usuwana.
Algorytm WS (ang. Working Set) oparty jest na koncepcji zbioru roboczego , czyli zbioru stron, do których było odniesienie w ostatnim okresie czasu w przeszłości. Długość tego okresu mierzona liczbą odniesień, jest parametrem algorytmu. Algorytm WS wymaga monitorowania odniesień do pamięci, więc wymaga wsparcia sprzętowego. Wykorzystywany jest tutaj bit odniesienia.
Przybliżoną realizacją idei zbioru roboczego, wykorzystującą bit odniesienia, jest również algorytm WSClock.
Algorytmy PFF (ang. Page Fault Frequency) i VSWS (ang. Variable-Interval Sampled Working Set) dają efekt podobny do zbioru roboczego, przy czym oparte są na częstość generowania błędów strony.
Przedstawione definicje — zbioru roboczego oraz okna zbioru roboczego — oznaczają właściwie to samo. Pierwsza definiuje zbiór roboczy w oparciu o pojęcie okna, a druga definiuje okno w oparciu o pojęcie zbioru roboczego. Z punktu widzenia strony, pozostaje ona w zbiorze roboczym tak długo, jak długo ostatnie odniesienie do niej pozostaje w bieżącym oknie. Oznacza to, że od momentu ostatniego zaadresowania strony, pozostaje ona w zbiorze roboczym przez ? odniesień.
Ogólna (teoretyczna) koncepcja zbioru roboczego polega utrzymywaniu takiego zbioru dla każdego procesu. Strony, należące do zbioru roboczego, pozostawiane są w pamięci, natomiast ramki stron spoza zbioru roboczego są zwalniane. Zapotrzebowanie na ramki w systemie jest sumą mocy zbiorów roboczych wszystkich procesów. Jeśli liczba ta jest większa niż dostępna liczba ramek, może dojść do szamotania. Zadaniem zarządcy pamięci jest wówczas przeniesienie całego obrazu któregoś z procesów w obszar wymiany i odzyskanie jego ramek. Po uzyskaniu odpowiednio dużej liczby wolnych ramek (w przypadku zmniejszenia się zbiorów roboczych) można aktywować któryś z procesów zawieszonych. Wybór procesu do usunięcia lub aktywowania jest zadaniem planisty średnioterminowego.
Osobnym problemem jest dobór wielkości okna. Okno powinno być na tyle duże, żeby objąć tzw. strefę, czyli zbiór stron niezbędnych do wykonania określonego fragmentu programu (np. procedury). W praktyce zależy to od częstości generowania błędów strony przez proces.
Dla przykładowego ciągu odniesień przedstawiono 2 zbiory robocze przy rozmiarze okna 4 oraz 2 zbiory robocze przy rozmiarze okna 6. Ze względu na powtarzające się odniesienia moc zbioru roboczego (liczba elementów) może być mniejsza niż rozmiar okna, co widać w przypadku okna o rozmiarze 6.
Przykład pokazuje realizację ciągu odniesień z poprzedniego slajdu przy rozmiarze okna 5. Proces ma więc do dyspozycji 5 ramek. Początkowo wymiana przebiega tak samo, jak w przypadku FIFO lub LRU. Ciekawym momentem jest drugie odniesienie do strony nr 2. Formalnie strona nr 2 została właśnie usunięta ze zbioru roboczego, ale nastąpiło do niej odniesienie. Jest więc błąd strony, chociaż jego obsługa nie wymaga sprowadzania strony ponownie z pliku wymiany. Podobna sytuacja ma miejsce przy następnym odniesieniu do pamięci — do strony nr 4. Po kolejnym odniesieniu — ponownie do strony nr 4 — poza bieżącym oknem znajduje się ostatnie odniesienie do strony nr 5, więc strona ta jest usuwana ze zbioru roboczego i tym samym z pamięci operacyjnej. Po ostatnim odniesieniu do strony numer 4 zbiór roboczy redukuje się do 3 stron.
Precyzyjna identyfikacja zbioru roboczego mogłaby być zaimplementowana podobnie jak algorytm LRU. Zaprezentowana koncepcja jest adaptacją licznika odniesień do stron. Problemem podobnie, jak w przypadku LRU, jest monitorowanie odniesień do stron oraz złożoność struktur danych na potrzeby pamiętania licznika. Ze względu na koszt takiej realizacji algorytm WS implementowany jest w sposób przybliżony.
Czas wirtualny i tym samym czas odniesienia do strony wyznaczany jest w sposób przybliżony — z dokładnością do okresu kontrolnego, wyznaczanego przez czasomierz lub błąd strony. Wystąpienie odniesienia do strony sprawdzane jest na podstawie bitu odniesienia w tablicy stron. Bieżąca wartość licznika staje się wirtualnym czasem odniesienia dla tych stron, dla których bit odniesienia jest ustawiony. Brak odniesienia do strony może oznaczać, że ostatnie odniesienie jest już poza oknem i stronę należy usunąć. W tym celu sprawdzana jest różnica pomiędzy bieżącą wartością licznika (bieżącym czasem wirtualnym), a czasem ostatniego odniesienia, odczytanym dla danej strony/ramki z przeznaczonej na to tablicy.
Upływ czasu wirtualnego musi być rejestrowany oddzielnie dla każdego procesu i tylko wówczas, gdy jest on wykonywany. Przerwanie zegarowe powinno więc zwiększać licznik w tym procesie, w kontekście którego jest obsługiwane.
Pomimo uniknięcia konieczności monitorowania wszystkich odniesień do pamięci, implementacja tego algorytmu i tak jest kosztowana, gdyż po każdym przerwaniu zegarowym wymagane jest testowanie bitu odniesienia każdej ze stron procesu.
Jak sama nazwa wskazuje, algorytm łączy podejście oparte na zbiorze roboczym z koncepcją algorytmu zegarowego. Podobnie jak w przybliżonej realizacji algorytmu zegarowego, utrzymywany jest wirtualny czas ostatniego odniesienia do strony, mierzony osobno dla każdego procesu.
Warto zwrócić uwagę na dwie istotne cechy algorytmu:
Zasadniczą różnicą w stosunku do algorytmów wymiany na żądanie jest zastępowanie globalne. Podobieństwo do koncepcji zbioru roboczego przejawia się natomiast w usuwaniu pierwszej napotkanej strony, nie należącej do zbioru roboczego swojego procesu.
Postępowanie w drugiej części algorytmu jest podobne, jak w przypadku właściwego przybliżenia algorytmu WS, czyli strona, do której nie było odniesienia, weryfikowana jest pod kątem przynależności do zbioru roboczego. Wyszukiwanie kończy się jednak na znalezieniu pierwszej ramki ofiary. Brak takiej ramki (brak strony ofiary) zgodnie z ideą zbioru roboczego oznacza, że suma rozmiarów zbiorów roboczych wyczerpuje limit dostępnych ramek pamięci fizycznej i należy zwiesić jakiś proces.
W przykładzie wskazana do usunięcia jest strona nr 5, więc od ramki tej strony rozpocznie się poszukiwanie ofiary. Strona 5 ma ustawiony bit odniesienia więc z założenia jest w zbiorze roboczym i nie zostanie usunięta z pamięci. Wyzerowany zostanie jedynie bit odniesienia i ustawiony wirtualny czas odniesienia do strony na wartość aktualną dla bieżącego procesu, czyli 51. Dla uproszczenia przyjmijmy, że strony 2, 4 i 5 należą do tego samego procesu.
Kolejną kandydatką na liście jest strona nr 4. Bit odniesienia jest dla tej strony skasowany, ale ostatni czas użycia nie jest jeszcze poza oknem (45>51–10), więc strona pozostaje w pamięci, a czas jej użycia się nie zmienia. Następna na liście jest strona nr 2, której ostatnie użycie, zgodnie z wirtualnym czasem, jest poza oknem zbioru roboczego. Strona nr 2 we wskazanej ramce zostanie zastąpiona.
Algorytm dwuwskazówkowy stosowany jest w niektórych systemach rodziny UNIX, np. SVR4. Realizuje on strategię, określaną jako NRU (Not Recently Used), która w tym przypadku oznacza, że jeśli w czasie pomiędzy przejściem wskazówki wiodącej a nadejściem zamykającej nie został ustawiony bit odniesienia, to strona jest usuwana. Czas pomiędzy przejściem tych wskazówek zależy od tempa przeglądania oraz rozstawu wskazówek. Parametry te są natomiast ustawiane zależnie od liczby wolnych ramek w systemie.
Jeśli uruchomienie algorytmu nie doprowadzi do uzyskania wystarczająco dużej liczby wolnych ramek, następuje zawieszenie jakiegoś procesu i zwolnienie jego ramek.
Wskazówka wiodąca w przykładzie ustawiana jest na stronie nr 5, której bit jest zerowany. Wskazówka zamykająca ustawiona jest na stronie nr 3, dla której bit odniesienia nie został ustawiony, więc nastąpi jej usunięcie. Warto zwrócić uwagę, że bit odniesienie został ustawiony dla strony nr 7, więc po przejściu wskazówki zamykającej strona ta pozostanie w pamięci. W międzyczasie może zostać ustawiony bit odniesienia do strony nr 8. Jeśli jednak nie nastąpi to przed nadejściem zamykającej wskazówki, strona ta zostanie usunięta.
Algorytmy bazujące na zbiorze roboczym są trudne w implementacji, gdyż ze względu na brak możliwości monitorowania odniesień do stron muszą być realizowane w sposób przybliżony.
Podobne efekty przy mniejszym koszcie implementacji można uzyskać stosują podejście oparte na kontroli częstości błędów strony. Podejście jest łatwiejsze w implementacji, gdyż wymaga aktualizacji struktur danych tylko w przypadku wystąpienia błędu strony, którego obsługa jest i tak dość czasochłonna.
Ogólna idea polega na tym, żeby zabierać ramki procesom zgłaszającym mało błędów strony, a przydzielać procesom, które często generują błędy strony. W przypadku przekroczenia dolnego progu można rozważać dwie strategie postępowania: żwawą i opieszałą. W strategii żwawej zwalniane są wszystkie ramki, dla których bit odniesienia jest skasowany, a w strategii opieszałej zwalniana jest tylko jedna ramka.
Implementacja algorytmu może być oparta na:
Kontrola częstości błędów strony wymaga wykonania dodatkowego zadania okresowego, wyznaczanego przez czasomierz, niezależnego od błędu strony. Umożliwia to oparcie decyzji o przydziale lub odebraniu ramek na średniej z dłuższego okresu, w przeciwieństwie do implementacji opartej na sprawdzaniu okresu między kolejnymi błędami strony.
Sprawdzanie okresu między kolejnymi błędami strony nie wymaga dodatkowej kontroli poza obsługą błędu strony, gdyż czas odmierzany jest przez jądro na podstawie taktów zegara, niezależnie od zastosowanego podejścia do wymiany stron. Problemem może być jednak pewna destabilizacja przydziału ramek, wynikająca ze zbyt szybkiej reakcji na przypadkowe błędy strony występujące w krótkim czasie. W teorii automatycznej regulacji można by to podsumować jako dominację członu różniczkującego (duży czas wyprzedzenia).
W zależności od implementacji, algorytm PFF albo słabo (wolno) dostosowuje się do zmieniającej się strefy w procesie, albo reaguje zbyt gwałtownie. Wolne dostosowanie polega na tym, że po wejściu w nową strefę zbyt długo utrzymywane są strony ze starej strefy. Może to powodować chwilowy wzrost zapotrzebowania na ramki z wszystkimi negatywnymi skutkami, np. zawieszaniem procesów. Zbyt gwałtowana reakcja może spowodować usunięcie stron potrzebnych do dalszego przetwarzania.
Algorytm VSWS (zbioru roboczego ze zmiennym okresem próbkowania) przez odpowiednią parametryzację umożliwia lepsze dostosowanie do tego typu sytuacji. Jego istotą jest wcześniejsze lub późniejsze reagowanie na zmieniającą się strefę, zależnie od liczby błędów strony. Czas reakcji jest jednak obustronnie ograniczony, więc reakcja nie będzie ani zbyt szybka (gwałtowna), ani znacząco spóźniona.
Interwał czasu pomiędzy kolejnymi kontrolami należy do przedziału obustronnie domkniętego od Tmin do Tmax , przy czym konkretna wartość zależy od momentu osiągnięcia liczby nmax błędów strony. Jeśli liczba błędów strony jest duża i osiągnie wartość nmax przed upływem czasu Tmin, to kontrola następuje po czasie Tmin. Jeśli upłynął czas Tmin, to kontrola nastąpi zaraz po osiągnięciu nmax błędów strony, nie później jednak niż po czasie Tmax. A więc najpóźniej kontrola wystąpi po czasie Tmax, niezależnie do liczby błędów strony.
Przedstawione techniki służą do zmniejszenia czasu obsługi błędu strony. Są one szczególnie przydatne w algorytmach ze sprowadzaniem na żądanie.
Jeśli na potrzeby wymiany została znaleziona ramka, zawierająca zmodyfikowaną stronę, a w systemie dostępne są inne wolne ramki, to zamiast wymiany stron, wymagającej czasochłonnego zapisu, dla sprowadzanej strony przydzielana jest nowa ramka. Ramka z brudną stroną dołączana jest natomiast do puli ramek zwolnionych. W ten sposób następuje wymiana ramek zamiast wymiany stron.
Ramki zwolnione w przypadku stosowania algorytmów ze sprowadzaniem na żądanie nie zawsze są natychmiast wykorzystywane na potrzeby innych procesów. Można więc pozostawić zawartość strony bez zmian do czasu przydziału tej ramki. Jeśli jednak przed ponownym przydziałem wystąpi żądanie dostępu do usuniętej strony, to błąd strony można obsłużyć bez wykonywania czasochłonnej operacji wejścia-wyjścia, przydzielając ramkę ze stroną ponownie.
Czasami system jest niedociążony przez bieżące przetwarzanie. Taki chwilowy okres przestoju można wykorzystać do zapisu zmodyfikowanych stron. Kasowany jest wówczas bit modyfikacji i stronę łatwiej jest wymienić.
W przypadku zwalniania ramek stron modyfikowanych operację zapisu w obszarze wymiany można odłożyć w czasie, dołączając ramkę do specjalnej listy. W miarę dostępności zasobów system stopniowo będzie zapisywał strony w ramkach z tej listy w obszarze wymiany i dołączał ramki do puli oczyszczonych wolnych ramek, gotowych w każdej chwili do użycia.
Sens wstępnego sprowadzania wynika z analizy efektywności wymiany, przedstawionej wcześniej. W praktyce, skuteczność tego podejścia zależy od trafności decyzji o wstępnym sprowadzeniu. Na koszt wymiany wpływa również trafność decyzji o usuwaniu stron, ale sprowadzanie wstępne nie jest obligatoryjne, a więc daje potencjalny zysk, jednak obarczony ryzykiem. Przed omówieniem algorytmów warto przypomnieć, że sprowadzanie (również wstępne) przeprowadza się w wyniku wystąpienia błędu strony.
Algorytm DPMIN (ang. Demand Prepaging MIN) — jest optymalny w klasie algorytmów ze sprowadzaniem na żądanie, ale oparty jest (podobnie jak wcześniej przedstawione algorytmy optymalne) na znajomości przyszłego ciągu odniesień do stron. W wyniku wystąpienia błędu strony wszystkie dostępne ramki są wypełniane stronami, do których nastąpi odniesienie w najbliższej przyszłości.
Algorytm OBL (ang. One Block Lookahead) wykorzystuje założenie o lokalności przestrzennej odniesień do pamięci i wraz ze stroną, której zaadresowanie spowodowało błąd, sprowadza stronę następną (jeśli nie ma jej jeszcze w pamięci). Skojarzenie stron ma tu charakter statyczny.
Algorytm SL (ang. Spatial Lookahead) również wykorzystuje założenie o lokalności przestrzennej, ale informacja o powiązaniu stron budowana jest w czasie działania algorytmu, ma więc charakter dynamiczny.
Algorytm FDPA (ang. Fixed-space Demand Prepaging) opiera się na wskazówkach programisty lub wnioskach ze statycznej analizy kodu, przekazywanych do systemu poprzez wykonania specjalnych instrukcji. Instrukcje to dotyczą zarówno wskazania stron potrzebnych w przyszłości, jak i zbędnych. Algorytm uwzględnia więc również wskazówki odnośnie usuwania stron.
Krótka charakterystyka algorytmów DPMIN i OBL przy opisie wcześniejszego slajdu jest wystarczająca, natomiast omówienia wymaga algorytm SL.
Celem tablicy pred jest przechowywanie informacja o numerze strony, którą należy sprowadzić wstępnie w przypadku błędu braku strony. Jeśli więc wystąpi błąd strony przy odniesieniu do strony p , to wstępnie sprowadzona zostanie również strona, której numer jest na pozycji p w tablicy pred — pred[p]. Początkowo przyjmujemy, że będzie to strona następna, tak jak w przypadku OBL.
Zmienna u przechowuje numer strony, do której odniesienie spowodowało ostatnio obsłużony błąd strony. Jeśli zatem następny błąd strony występuje przy adresowaniu strony p (p jest kolejną sprowadzaną stroną po stronie u ), to być może jest jakiś związek pomiędzy tymi stronami i w przyszłości również warto po wystąpieniu błędu strony przy dostępie do strony u wstępnie sprowadzić stronę p . Numer strony — p — powinien zostać zapisany w tablicy pred na pozycji odpowiadającej stronie u. Należy się jednak upewnić, że dotychczasowe skojarzenie dla strony u jest nieodpowiednie. Jeśli zatem przy sprowadzaniu strony u nie było wstępnego sprowadzenia innej strony lub strona wstępnie sprowadzona nie została użyta, skojarzenie dla u lepiej zmienić.
Na końcu następuje wstępne sprowadzenie strony, wynikające z bieżącego skojarzenia dla p . To, czy skojarzenie jest właściwe, okaże się przy wystąpieniu następnego błędu strony. W tym celu wartość p podstawiana jest do zmiennej u.
W wyniku analizy kodu w odpowiednich miejscach w programie pojawiają się instrukcje dla systemu operacyjnego, informujące o przyszłych potrzebach (lub ich braku) w odniesieniu do pewnych stron. Zgodnie z tymi instrukcjami w tablicy stron lub innej strukturze ustawiane są odpowiednie bity. W toku realizacji wymiany bity te są kasowane.
Bit P oznacza, że strona będzie w najbliższej przyszłości potrzebna, a jego wykasowanie nastąpi przy odwołaniu do strony po jej sprowadzaniu do pamięci.
Bit D oznacza, że strona nie będzie na razie potrzebna. Gdyby jednak strona została usunięta z pamięci i ponownie sprowadzana w wyniku błędu strony, bit ten zostanie skasowany.
System sprowadza oczywiście strony na żądanie i dokonuje wymiany w przypadku braku wolnych ramek. Usuwane są strony z ustawionym bitem D , a gdy takich nie ma, zgodnie z innym algorytmem, np. LRU lub w praktyce z którymś z jego przybliżeń. Algorytm usuwania nie jest tu najbardziej istotny poza preferencją dla stron „wskazanych” przez bit D.
Strona z ustawionym bitem P może być zarówno w pamięci, jak i poza nią. Będąc poza pamięcią, strona taka czeka na sprowadzenie. Bit P ustawiony dla strony przebywającej w pamięci operacyjnej oznacza, że stronę tę wstępnie sprowadzono, ale nie było do niej jeszcze odniesienia, dlatego nie powinna być usunięta przy wymianie.
System stara się sprowadzać do pamięci wszystkie strony z ustawionym bitem P w miarę dostępnych ramek. W bilansie ramek uwzględnia się zwolnienie ramek przez strony z ustawionym bitem D. Jak już wcześniej wspomniano, gdyby bit D ustawiony był dla strony sprowadzanej, to zostanie wykasowany.
W niektórych systemach (między innymi IBM OS/2) podjęto próbę realizacji segmentacji na żądanie. Zarządzanie wymianą segmentów jest jednak znacznie bardziej skomplikowane, gdyż sprowadzenie segmentu do pamięci może wymagać upakowania i/lub przesunięcia w obszar wymiany jednego lub kilku segmentów znajdujących się w pamięci fizycznej. Optymalizacja decyzji w takim przypadku jest więc procedurą czasochłonną. W przypadku stronicowania czas sprowadzenia stron do pamięci oraz zapisu na dysku jest zmienną losową, w przypadku segmentacji, ze względu na zróżnicowany rozmiar segmentów, sam czas przesyłania danych i tym samym czas oczekiwania w kolejce do dysku jest trudniej przewidzieć.
Celem wykładu jest omówienie zagadnień obsługi urządzeń wejścia-wyjścia (zwanych również urządzeniami zewnętrznymi lub peryferyjnymi) i realizacji związanych z tym mechanizmów w jądrze systemu operacyjnego. Problem obsługi urządzeń wejścia-wyjścia jest o tyle skomplikowany, że są to urządzenia bardzo zróżnicowane pod wieloma względami, stosunkowo wolne (w porównaniu z jednostką centralną) i stanowią najczęściej zmieniający się element konfiguracji systemu komputerowego. Z drugiej strony urządzenia wejścia-wyjścia stanowią „zmysły” komputera, dlatego większość z nich jest bardzo istotna dla użytkownika i jego interakcji z systemem. Można wręcz powiedzieć, że zwykły użytkownik postrzega komputer właśnie poprzez urządzenia wejścia-wyjścia. Efektywność i wygoda obsługi tych urządzeń, zwłaszcza w systemach interaktywnych, decyduje więc o ogólnym wrażeniu z jakości pracy z komputerem.
Treść wykładu obejmuje:
Urządzenia wejścia-wyjścia są bardzo zróżnicowane pod każdym względem. Przedstawione wyszczególnienie dotyczy zastosowań. Warto podkreślić, że urządzenia składowania danych sterowane są wyłącznie przez jednostkę centralną. Są więc właściwie niezależne od zdarzeń poza systemem komputerowym, z wyjątkiem szczególnych przypadku wyjęcia dyskietki, płyty CD itp.
Urządzenia transmisji na odległość oprócz reakcji na sygnały sterujące ze strony jednostki centralnej reagują również na zdarzenia zewnętrzne, związane z przekazywaniem danych z innych jednostek. Należy tu też podkreślić, że każda komunikacja z urządzaniem zewnętrznym jest jakąś transmisją danych. Urządzenia transmisji danych na odległość służą do wymiany danych z innymi komputerami, więc chodzi tu o transmisję danych pomiędzy urządzeniami o podobnym charakterze, a nie transmisję pomiędzy jednostką centralną, a zintegrowanym z nią urządzeniem.
Urządzenia do komunikacji z człowiekiem w ogólności też reagują zarówno na zdarzenia wewnętrzne, jak i zewnętrzne. Zdarzenia zewnętrzne dotyczą przede wszystkim urządzeń wejściowych i związane są z działaniami człowieka (użytkownika). Są to więc zdarzenia, które zachodzą niezbyt często w porównaniu z szybkością pracy jednostki centralnej, a moment ich zajścia jest trudny do przewidzenia.
Urządzenia wejścia-wyjścia są bardzo zróżnicowane pod każdym względem. Przedstawione wyszczególnienie dotyczy zastosowań. Warto podkreślić, że urządzenia składowania danych sterowane są wyłącznie przez jednostkę centralną. Są więc właściwie niezależne od zdarzeń poza systemem komputerowym, z wyjątkiem szczególnych przypadku wyjęcia dyskietki, płyty CD itp.
Urządzenia transmisji na odległość oprócz reakcji na sygnały sterujące ze strony jednostki centralnej reagują również na zdarzenia zewnętrzne, związane z przekazywaniem danych z innych jednostek. Należy tu też podkreślić, że każda komunikacja z urządzaniem zewnętrznym jest jakąś transmisją danych. Urządzenia transmisji danych na odległość służą do wymiany danych z innymi komputerami, więc chodzi tu o transmisję danych pomiędzy urządzeniami o podobnym charakterze, a nie transmisję pomiędzy jednostką centralną, a zintegrowanym z nią urządzeniem.
Urządzenia do komunikacji z człowiekiem w ogólności też reagują zarówno na zdarzenia wewnętrzne, jak i zewnętrzne. Zdarzenia zewnętrzne dotyczą przede wszystkim urządzeń wejściowych i związane są z działaniami człowieka (użytkownika). Są to więc zdarzenia, które zachodzą niezbyt często w porównaniu z szybkością pracy jednostki centralnej, a moment ich zajścia jest trudny do przewidzenia.
Zróżnicowanie urządzeń wejścia-wyjścia przejawia się między innymi w dużej liczbie klasyfikacji, wynikających z różnych kryteriów.
Ze względu na tryb transmisji wyodrębnia się urządzenie znakowe i blokowe. W przypadku urządzeń blokowych w wyniku operacji wejścia-wyjścia następuje przekazanie bloku o ustalonym rozmiarze np. 512 B. W przypadku urządzeń znakowych po przekazaniu bajta lub słowa konieczne jest zlecenie następnej operacji wejścia-wyjścia w celu odebrania kolejnej takiej jednostki. Urządzenia takie mają czasami wewnętrzny bufor, umożliwiający przekazywanie nieco większych porcji danych.
Podział na urządzenia sekwencyjne i bezpośrednie wiąże się z łatwością uzyskania dostępu do wybranego zakresu danych na urządzeniu. Większość urządzeń wejścia-wyjścia pracuje w sposób sekwencyjny, czyli przekazuje dane do jednostki centralnej w postaci pewnego strumienia bez możliwości ograniczenia do pewnego zakresu. Jednostka centralna może co najwyżej dokonać filtracji po odebraniu tych danych. Podobnie w przypadku przekazywania danych do urządzenia, nie ma możliwości wskazania kolejności przetwarzania czy zmiany kolejności ułożenia poszczególnych części. Jednym z niewielu urządzeń o dostępie bezpośrednim jest dysk. Przed zainicjalizowaniem właściwej operacji dostępu można odpowiednio ustawić pozycję głowicy oraz wskazać sektor do zapisu lub odczytu. Podobne podejście można by potencjalnie stosować w przypadku napędów taśmowych. Zasadnicza trudność wiąże się jednak z czasem pozycjonowania, wymagającym długotrwałego przewijania taśmy. Dlatego napędy taśmowe są urządzeniami o dostępie sekwencyjnym.
W przypadku urządzeń synchronicznych wymagany czas pracy urządzenia można w miarę precyzyjnie przewidzieć. Taki czas jest jednak zmienna losową, ale o stosunkowo niewielkim rozproszeniu wartości. Na przykładzie dysku można powiedzieć, że po ustawieniu pozycji głowicy sam czas odczytu sektora do się precyzyjnie określić, ale opóźnienie obrotowe ma charakter losowy. Elementem losowym, zwiększającym czas dostępu są również przypadki błędu w odczycie sektora. Precyzyjne przewidywanie nie jest możliwe w przypadku urządzeń „synchronizowanych” zdarzeniami zewnętrznymi. Dla jednostki centralnej zdarzenia te zachodzą całkowicie asynchronicznie, nie da się więc przewidzieć momentu, w którym urządzenie będzie wymagało obsługi ze strony jednostki centralnej.
Pewne urządzenia mogą współbieżnie obsługiwać zlecenia wielu procesów. Dla urządzenie nie ma znaczenia jaki proces czy użytkownika obsługuje. Pojęcie procesu na poziomie architektury nawet nie istnieje. Ma to natomiast znaczenia dla użytkownika. Dla użytkownika nie ma znaczenia, czy dysk zapisując jego dane, wplecie pomiędzy operacje zapisu poszczególnych sektorów, operacje zapisu lub odczytu innych sektorów, wynikające z osobnego zlecenia. Co najwyżej nastąpi opóźnienie realizacji całego zlecenia zapisu, jest to jednak raczej nieodczuwalne. Trudno jednak taki przeplot zaakceptować na wydruku — jest mało prawdopodobne, żeby wydruk był czytelny.
W zakresie szybkości działania nie jest łatwo wyodrębnić konkretne klasy. Celem tej klasyfikacji jest podkreślenie dużego zróżnicowania w zakresie szybkości przetwarzania danych przez urządzenie. Oczywiście wszystkie urządzenia wejścia-wyjścia są wolne w porównaniu z jednostką centralną.
Kierunek przekazywania danych dotyczy danych przetwarzanych, a nie sygnałów sterujących, czy informacji o stanie urządzenia. Drukarka jest typowym urządzeniem wyjściowym, ale można odczytać jej stan (np. informację o braku papieru, tonera itp.). Nie służy ona natomiast do wprowadzania danych.
Chociaż można sobie wyobrazić urządzenie wejścia-wyjścia sterowane bezpośrednio przez procesor główny, współcześnie takich rozwiązań raczej się nie stosuje. Urządzenia mają swoje sterowniki (ang. device controller), czyli układy elektroniczne, odpowiedzialne za kontrolę ich pracy. Dzięki sterownikowi możliwa jest równoległa praca jednostki centralnej i urządzenia wejścia-wyjścia.
Interakcja jednostki centralnej z urządzeniem wejścia-wyjścia sprowadza się do zapisu lub odczytu odpowiednich rejestrów sterownika. Sterownik może być umieszczony na płycie głównej (np. karta graficzna) lub na płytce urządzenia (np. sterownik dysku, sterownik drukarki). Sterownik na płycie głównej lub ta jego część, która przystosowana jest do współpracy z magistralą systemu komputerowego, nazywany jest adapterem. W przypadku niektórych urządzeń komunikacja pomiędzy sterownikiem, a adapterem na płycie odbywa się za pośrednictwem specjalnej magistrali (np. magistrali SCSI). Procesor ma wówczas bezpośredni dostępu do rejestrów adaptera, który komunikuje się ze sterownikiem. W przypadku, kiedy sterownik nie jest zintegrowany z adapterem, komunikacja pomiędzy urządzeniem zewnętrznym a jednostką centralną może odbywać się przez odpowiedni port standardowy, np. port szeregowy (RS-232, USB) lub port równoległy. W tym przypadku procesor również nie ma bezpośredniego dostępu do rejestrów sterownika i wszystkie operacje zapisu oraz odczytu musi wykonać za pośrednictwem sterownika portu i jego rejestrów.
Zadaniem systemu operacyjnego jest między innymi ułatwienie dostępu do urządzeń, przez ujednolicenie i uproszczenie interfejsu, czyli ukrycie szczegółów realizacji urządzenia. Odpowiada za to przede wszystkim moduł sterujący (moduł obsługi urządzenia, ang. device driver).
Podsystem wejścia-wyjścia realizuje zadania niezależne od konkretnych urządzeń: dostarcza ogólny interfejs i realizuje buforowanie. Celem projektowym interfejsu wejścia-wyjścia jest dostarczanie aplikacji interfejsu funkcji (API), umożliwiających wykonywanie operacji wejścia-wyjścia w sposób jednolity, niezależny od urządzenia lub grupy, do której należy urządzenie. Typowy interfejs obejmuje między innymi funkcje:
Sposób implementacji tych funkcji zależy od specyfiki urządzenia. Implementacja taka dostarczana jest przez moduł sterujący. Moduł sterujący dostarcza też procedur, które nie są dostępne w interfejsie dla aplikacji, ale wywoływane są np. w ramach obsługi przerwania, zgłaszanego przez urządzenie.
Moduły sterujące dostarczane są dla typowych systemów operacyjnych (np. Windows XP, Solaris, Linux) przez twórców systemów operacyjnych lub wytwórców urządzeń wejścia-wyjścia. Moduł sterujący jest taką częścią oprogramowania systemowego, które może wymagać modyfikacji i uzupełnień, zależnie od urządzeń dołączanych do komputera. Jądro systemu operacyjnego musi więc dostarczyć odpowiednie mechanizmy, umożliwiające dołączanie nowych modułów. W skrajnym przypadku sposobem dołączania nowego modułu jest rekompilacja jądra. Metoda taka stosowana była w klasycznym systemie UNIX, dlatego elementem standardowego oprogramowania tych systemów był między innymi kompilator języka C.
Sterownik urządzenia dostępny jest dla jednostki centralnej poprzez odpowiedni zbiór rejestrów. Procesor ma bezpośredni dostęp do rejestrów tych sterowników, które podłączone są do magistrali systemowej. Oznacza to, że w niektórych przypadkach procesor ma dostęp tylko do rejestrów sterownika portu, do którego podłączone jest urządzenie. Przez ten port następuje wymiana informacji pomiędzy jednostką centralną a właściwym sterownikiem urządzenia.
Liczba i wielkość rejestrów sterownika zależą od konkretnych rozwiązań. W typowym sterowniku można jednak wyróżnić następujące rejestry:
Różnica pomiędzy odwzorowaniem rejestrów w przestrzeni pamięci i w przestrzeni wejścia-wyjścia polega na przekazaniu do odpowiedniego dekodera adresowego innych sygnałów sterujących (podłączeniu innych linii magistrali sterującej). W przypadku odwzorowania w pamięci przekazywane są sygnały zapisu/odczytu pamięci, a w przypadku odwzorowania w przestrzeni wejścia-wyjścia przekazywane są sygnały zapisu/odczytu wejścia-wyjścia.
Niektóre urządzenia udostępniają część swoich rejestrów w przestrzeni adresowej wejścia-wyjścia, a część w przestrzeni adresowej pamięci (np. karta graficzna).
Zasadniczą kwestią w interakcji z urządzeniem zewnętrznym jest sposób przekazywania informacji o stanie urządzenia pomiędzy procesorem a sterownikiem oraz danych pomiędzy sterownikiem a pamięcią.
W przypadku odpytywania procesor jest odpowiedzialny zarówno za monitorowanie stanu sterownika (np. w celu stwierdzenia zakończenia operacji) jak i transfer danych. Procesor jest więc zobligowany do ciągłego lub okresowego sprawdzania rejestru stanu sterownika, co wymaga odpowiedniej konstrukcji modułu sterującego. Podejście tego typu określa się jako aktywne czekanie . Odpytywanie może być stosowane w przypadku urządzeń synchronicznych, wykonujących krótkotrwałe operacje wejścia-wyjścia.
W przypadku sterowania przerwaniami procesor jest odpowiedzialny za transfer danych, ale nie musi monitorować w sposób ciągły stanu sterownika. Inicjalizuje on pracę sterownika a o jej zakończeniu lub zaistnieniu określonego stanu informowany jest przez przerwanie, które zgłasza sterownik. W oprogramowaniu systemowym należy zatem uwzględnić procedurę obsługi przerwania a jej adres umieścić na właściwej pozycji wektora przerwań.
W przypadku zastosowania układu DMA, po zainicjalizowaniu pracy urządzenia przez procesor, przekazywanie danych pomiędzy sterownikiem a pamięcią realizowane jest przez specjalizowany układ (DMA), który wykonuje swoje zadanie bez angażowania procesora. Zależnie od architektury, zadanie takie może również wykonywać procesor wejścia-wyjścia, który może nawet dysponować własną, prywatną pamięcią.
Diagram pokazuje przebieg czasowy interakcji procesora ze sterownikiem w trybie odpytywania. Po zainicjalizowaniu operacji wejścia-wyjścia procesor wielokrotnie odczytuje rejestr stanu sterownika, zanim nastąpi stwierdzenie zakończenia operacji.
Interakcja pomiędzy procesorem a sterownikiem w najprostszym przypadku mogłaby się opierać na 2 bitach. W zaprezentowanym rozwiązaniu sam stan sterownika reprezentowany jest przez 2 bity (gotowości i zajętości).
Dla uproszenia dalszej prezentacji przyjęto, że ustawienie bitu gotowości po zakończeniu operacji oznacza pomyślne zakończenie. Brak ustawienia bitu gotowości oznacza błąd, co z kolei jest sygnalizowane przez odpowiednie bity kodu błędu w rejestrze stanu. W przypadku operacji wyjścia bit gotowości oznacza zatem, że udało się przekazać zawartość rejestru danych do urządzenia i ją przetworzyć.
Sterownik urządzenia czeka na zlecenie od procesora, sprawdzając bit gotowości zlecenia zapisu. Należy w tym miejscu podkreślić różnicę pomiędzy bitem gotowości urządzenia w rejestrze stanu oraz bitem gotowości zlecenia (nazywanym krótko bitem zlecenia) w rejestrze sterowania. Procesor, realizując program modułu sterującego, sprawdza, czy urządzenie jest dostępne (czy bity gotowości i zajętości są skasowane). Dla uproszczenia przyjęto, że robi to również w trybie odpytywania. Biorąc pod uwagę fakt, że procesor oczekuje na zakończenie operacji wejścia-wyjścia, odczytując rejestr stanu, nie wydaje się możliwe, aby urządzenie było zajęte, a procesor realizował kolejne zlecenie. Sytuacja taka mogłaby ewentualnie mięć miejsce w systemach wieloprocesorowych lub w przypadku odpytywania okresowego.
Operacja wyjścia polega na zapisaniu rejestru danych wyjściowych, a następnie ustawieniu bitu gotowości polecenia zapisu. Po wydaniu zlecenia procesor przechodzi w tryb odpytywania rejestru stanu w celu sprawdzenie bitu gotowości, a sterownik realizuje zlecenie. Po zrealizowaniu zlecenia sterownik ustawia bit gotowości (na co czeka procesor) oraz kasuje bit zajętości i przechodzi do oczekiwania na kolejne zlecenie.
Interakcja w przypadku operacji wejścia wygląda podobnie z tą różnicą, że procesor przed zleceniem operacji nie zapisuje rejestru danych, tym samym sterownik go nie odczytuje. Po wykonaniu operacji sterownik zapisuje rejestr danych wejściowych, który odczytuje procesor po stwierdzeniu gotowości urządzenia.
Program obsługi urządzenia, wykonywany przez procesor, polegający na testowaniu i ustawianiu odpowiednich bitów, zapisie i odczycie rejestrów danych, ewentualnie interpretacji kodów błędu jest zawarty w module sterującym. Jak wynika z wcześniejszej analizy, dopóki urządzenie nie zakończy pracy, procesor wykonuje program modułu, polegający na testowaniu bitu gotowości (ewentualnie bitów błędu). Z punktu widzenia przetwarzania aplikacyjnego jest to czas marnowany na oczekiwaniu. Pomimo, że sterownik może funkcjonować równolegle z procesorem, tylko jedno z tych urządzeń działa w danej chwili efektywnie.
W przypadku sterowania przerwaniami operacja wejścia-wyjścia przebiega w dwóch fazach:
W międzyczasie centralny procesor może realizować przetwarzanie użytkowe. Proces, który zlecił wykonanie operacji zostaje najczęściej zablokowany w oczekiwaniu na zakończenie, ale dostępny może być inny proces gotowy. W ten sposób można równoważyć obciążenie systemu, co było głównym celem wprowadzenie wielozadaniowości i związanej z nią koncepcji procesu. Nawet gdyby nie było żadnego procesu gotowego, to procesor może wykonać pewne zadania systemowe, np. zapisać profilaktycznie na urządzeniu wymiany zawartość brudnych ramek pamięci fizycznej. W ostateczności będzie wykonywana pętla bezczynności, zwana również wątkiem bezczynności. Pętla bezczynności jest oczekiwaniem na przerwanie, a więc specyficznym odpytywaniem linii wejściowej przerwań w procesorze.
Po zakończeniu pracy urządzenia wejścia-wyjścia sterownik, oprócz ustawienia odpowiednich bitów stanu, zgłasza przerwanie. Pośrednikiem w przekazywaniu przerwania do procesora jest sterownik przerwań. Ma on kilka linii wejściowych i jedną wyjściową, za pośrednictwem której przekazuje sygnał na odpowiednie wejście procesora. Obsługa urządzenia po zakończeniu pracy realizowana w reakcji na przerwanie. Zanim nastąpi obsługa konieczne jest zidentyfikowanie źródła przerwania. Nie zawsze też całość obsługi urządzenia realizowana jest w procedurze obsługi przerwania. Niektóre czynności mogą zostać odroczone i wykonane poza procedurą obsługi przerwania.
Zlecenie sterownikowi operacji wejścia-wyjścia przebiega podobnie, jak w przypadku odpytywania. Tutaj jednak możliwy jest przypadek, że urządzenie nie jest dostępne dla procesu, gdyż wykonuje operację, zleconą przez inny proces. W takiej sytuacji musi nastąpić umieszczenie zlecenia lub zlecającego procesu w kolejce. Można również przyjąć ogólne podejście z kolejkowaniem operacji, niezależnie od stanu sterownika. Zadaniem modułu sterującego jest po prostu pobrać kolejne zadanie z kolejki.
Po zleceniu operacji następuje zapisanie informacji o tej operacji w tablicy urządzeń i powrót do przetwarzania aplikacyjnego. Jest to jedna część realizacji operacji wejścia-wyjścia. Implementacja tej części określana jest w module sterującym jako górna połowa. (Nieco inaczej termin górna i dolna połowa rozumiany jest w systemie Linux).
Oprogramowanie odpowiedzialne za obsługę przerwania może być różnie zorganizowane w zależności od rozwiązań na poziomie architektury komputera. Najczęściej wyodrębnia się podprogram obsługi przerwania (ang. interrupt handler) oraz wywoływany przez niego podprogram obsługi urządzenia (ang. device handler).
Podprogram obsługi przerwania wykonuje pewne zadania ogólne, niezależne od źródła przerwania oraz identyfikuje źródło przerwania. Właściwą obsługę urządzenia realizuje podprogram obsługi urządzenia, określany jako dolna połowa modułu sterującego. Wykonanie dolnej połowy polega na odczytaniu odpowiednich informacji z tablicy urządzeń, a następnie sprawdzeniu stanu sterownika (stanu zakończenia operacji) i przekazaniu danych i/lub informacji statusowych do procesu zlecającego wykonanie operacji.
Jeśli w kolejce do urządzenia znajdują się kolejne żądania, wybierane jest jedno z nich i zlecana jest następna operacja wejścia-wyjścia.
Procedura obsługi przerwania musi być wykonana dość szybko ze względu na blokowanie obsługi innych przerwań. Pewne czasochłonne zadania, związane z przetwarzaniem danych w ramach operacji wejścia-wyjścia, mogą być wykonane później, poza obsługą przerwania. Określa się je jako czynności odroczone, a w systemie Linux nazywa dolną połową, podczas gdy górna połowa oznacza część kodu, wykonywaną bezpośrednio w reakcji na przerwanie. Przykładem czynności odroczonych jest interpretacja zawartości ramki, odebranej przez kartę sieciową. Zawartość bufora karty musi być skopiowana możliwie szybko, a dalsze przetwarzanie, np. sprawdzenie poprawności, interpretacja adresów itp., mogą być wykonane nieco później.
W przedstawionym schemacie przepływu sterowania górna połowa modułu kończy się po wydaniu zlecenia dla urządzenia wejścia-wyjścia, po czym jest powrót do przetwarzania aplikacyjnego. Gotowość urządzenia sygnalizowana jest przez przerwanie, oznaczone „błyskawicą” i sterowanie przechodzi do dolnej połowy modułu sterującego. Po obsłużeniu przerwania kontynuowane jest przetwarzania aplikacyjne. W tym przypadku możliwe jest jednoczesne przetwarzanie użytkowe i praca urządzenia wejścia-wyjścia.
Przerwania wielokrotne są zjawiskiem naturalnym w przypadku jednoczesnej obsługi wielu urządzeń. Przykładem wystąpienia przerwań wielokrotnych jest odbiór danych z łącza komunikacyjnego w czasie obsługi drukarki.
Ogólnie można wyróżnić kilka podejść do obsługi przerwań wielokrotnych:
Przerwania wielokrotne są zjawiskiem naturalnym w przypadku jednoczesnej obsługi wielu urządzeń. Przykładem wystąpienia przerwań wielokrotnych jest odbiór danych z łącza komunikacyjnego w czasie obsługi drukarki.
Ogólnie można wyróżnić kilka podejść do obsługi przerwań wielokrotnych:
W czasie obsługi przerwania 1 zgłaszane jest kolejne przerwanie, ale reakcja na nie następuje dopiero po zakończeniu procedury obsługi przerwania 1. Zaznaczono to jako powrót do przetwarzania aplikacyjnego, ale zanim nastąpi wykonanie kolejnej instrukcji programu użytkownika, wykonana zostanie procedury obsługi przerwania 2.
Zgłoszenie kolejnego przerwania podczas obsługi przerwania 1 powoduje przerwanie bieżącej procedury i przejście do obsługi przerwania 2. Po zakończeniu procedury obsługi przerwania 2 kontynuowana jest obsługa przerwania 1, a po jej zakończeniu sterowanie wraca do programu użytkownika.
W czasie obsługi przerwania o średnim priorytecie następuje zgłoszenie przerwania o wysokim priorytecie, a następnie przerwania o niskim priorytecie. W pierwszym przypadku postępowanie jest zgodne ze schematem dla obsługi zagnieżdżonej, a w drugim dla obsługi sekwencyjnej.
Podejście priorytetowe jest oczywiście powszechnie stosowane w obsłudze przerwań.
Podejście z wieloma liniami przerwań wymagałoby tylu linii przerwań, ile jest urządzeń mogących zgłosić przerwanie. Linii tych może być niemal zawsze albo za dużo albo za mało, podejście jest więc trudne do zrealizowania w systemie ogólnego zastosowania.
Odpytywanie programowe wymaga odczytania i zinterpretowania stanu każdego urządzenia. Można się oczywiście ograniczyć do tych urządzeń, dla których w tablicy urządzeń jest odnotowany fakt realizacji operacji. Wymaga to jednak przeglądania tablicy urządzeń, ogólnie jest więc czasochłonne.
Odczyt wektora wymaga umieszczenia odpowiednich informacji (numeru urządzenia, adresu urządzenia lub numeru przerwania) na magistrali. Informacja może zostać wystawiona po potwierdzeniu otrzymania przerwania przez procesor (odpytywanie sprzętowe). Sygnał potwierdzający otrzymanie przerwania propagowany jest łańcuchowo przez urządzenia aż do napotkania tego, które zgłosiło przerwanie. Innym sposobem jest uzyskanie wyłączności dostępu do magistrali i wystawienie odpowiedniego wektora przed zgłoszeniem przerwania (arbitraż na magistrali).
Rozwiązaniem hybrydowym jest użycia sterownika przerwań. Ma on wiele linii wejściowych i jedną wyjściową, podłączoną do odpowiedniego wejścia procesora. Po stwierdzeniu przerwania wystarczy odpytać sterownik przerwań, na której linii nastąpiło zgłoszenie. Sterownik przerwań ma jednak taką samą wadę, jak procesor, jeśli chodzi o liczbę wejściowych linii przerwań. Dlatego podejście to łączy się z odpytywaniem programowym. Wiele urządzeń może zgłaszać przerwanie o tym samym numerze. Obsługa przerwania rozpoczyna się od zidentyfikowania numeru przerwania, a następnie odpytywane są wszystkie urządzenie, które zgłaszają przerwanie o tym numerze. W praktyce wygląda to tak, że z każdym numerem przerwanie związany jest łańcuch modułów sterujących. W ramach obsługi przerwania uruchamiana jest odpowiednia procedura kolejnego modułu, a jaj zadaniem jest stwierdzenie, czy urządzenie przez nią obsługiwane uzyskało stan gotowości.
Priorytety urządzeń wiążą się z priorytetami przerwań od nich, ale problem można uogólnić na priorytety innych zdarzeń, na które jądro musi reagować. W związku z powyższym wyróżnia się poziomy pracy jądra związane z reakcją na pewne zdarzenia. Na określonym poziomie pracy (poziomie priorytetu) jądro reaguje tylko na zdarzenia o wyższym priorytecie. Obsługa przerwania rozpoczyna się od odpowiedniego podniesienia poziomu pracy. W zaprezentowanym przykładzie (zbliżonym do rozwiązań w systemach rodziny UNIX):
Na każdym wyższym poziomie jądro oczywiście nie reaguje również na zdarzenia przypisane do niższego poziomu.
W konkretnych implementacja tych poziomów może być więcej. W systemie Windows 2000/XP występują 32 tzw. poziomy zgłoszeń przerwań. W systemach Linux i Solaris do obsługi przerwań wykorzystywane są wątki jądra i ich priorytet decyduje o realizacji określonej procedury.
W celu porównania efektywności przetwarzania w systemie z odpytywaniem oraz z przerwaniami należy wrócić do podstawowego cyklu zmian stanów procesu. Stan procesu zmienia się cyklicznie z wykonywanego na oczekujący, następnie gotowy i znowu wykonywany . Na poziomie architektury procesor oraz urządzenia wejścia-wyjścia są albo bezczynne, albo zajęte obsługą. Niech Tc oznacza zatem całkowity czas przetwarzania przez procesor, a Td całkowity czas realizacji operacji wejścia-wyjścia. Czasy te są niezależne od sposobu obsługi urządzeń. Składnikiem, zależnym od sposobu obsługi urządzeń jest narzut czasowy — To. Narzut ten wynika ze zwłoki w reakcji procesora na zgłoszenie gotowości urządzenia lub z oczekiwania na dostępność urządzenia.
W odpytywaniu występuje opóźnienie, wynikające z różnicy czasu pomiędzy ustawieniem bitu gotowości, a odczytaniem rejestru stanu sterownika przez procesor. Narzut czasowy w przypadku odpytywania wynika wyłącznie z tego opóźnienia.
W przypadku przerwań narzut wynika z:
WW systemie jednozadaniowym czas cyklu przetwarzania — Tt — jest sumą:
Różnica pomiędzy odpytywaniem a sterowaniem przerwaniami jest tylko w narzucie czasowym, który jest mniejszy w przypadku odpytywania.
Rozważając system wielozadaniowy, jeśli proces uzyska procesor, odpytywanie jest dla niego korzystniejsze, gdyż narzut czasowy jest mniejszy, a oczekiwanie na gotowość urządzenia jest z jego punktu widzenia czasem marnowanym (nie ma wówczas postępu w realizacji programu).
Na potrzeby systemu wielozadaniowego analizowany jest łączny czas przetwarzania zbioru procesów. W przypadku odpytywania nie ma jednoczesności przetwarzania, a więc czas ten jest sumą czasów przetwarzania poszczególnych procesów.
Analiza w trybie sterowania przerwaniami zrobiona jest przy założeniu, że łączny czas procesora, potrzebny do realizacji przetwarzania jest większy, niż łączny czas realizacji operacji wejścia-wyjścia. Zbiór zadań jako całość ograniczony jest więc procesorem.
W wariancie optymistycznym zawsze po wejściu w stan oczekiwania procesu zlecającego operację wejścia-wyjścia jest jakiś inny proces gotowy. Oznacza to, że w czasie, gdy proces oczekuje na dostępność urządzenia lub przydział procesora, procesor wykonuje inne zadanie. Jedynie sama obsługa przerwania angażuje procesor i w tym czasie nie może on wykonywać przetwarzania aplikacyjnego.
W wariancie pesymistycznym wszystkie procesy w tym samym czasie zlecają wykonanie operacji wejścia-wyjścia na tym samym urządzeniu, a urządzenie przydzielane jest temu procesowi, którego zlecenie jest najbardziej czasochłonne.
Czas skumulowanej obsługi przerwań, nawet w wariancie pesymistycznym, musiałby być znaczący, żeby kwestionować ogólną zasadność obsługi urządzeń wejścia-wyjścia sterowanej przerwaniami. Takie podejście mogłoby jedynie mieć sens w przypadku bardzo szybkich urządzeń, które potrafią zrealizować operację wejścia-wyjścia w czasie kilkunastu lub kilkudziesięciu cykli rozkazowych.
Układ DMA ma „kompetencje” procesora w zakresie dostępu do pamięci, w związku z czym może rywalizować z procesorem o dostęp do magistrali systemowej w celu przejęcia sterowania systemem komputerowym.
Układ DMA wykorzystywany jest w celu realizacji transferu większych bloków danych, np. w przypadku dysku lub karty sieciowej.
Procesor zleca układowi DMA transmisję danych, przekazując następujące parametry:
W celu realizacji zlecenia układ DMA przejmuje kontrolę nad magistralą, gdy nie jest ona potrzebna procesorowi lub „wykrada” cykl magistrali procesorowi i realizuje przesłanie słowa. Fakt zakończenia transmisji bloku danych układ DMA sygnalizuje procesorowi, zgłaszając przerwanie.
Pomimo ograniczeń w jednoczesnej pracy procesora i układu DMA, wynikającej z konieczności zapewnienia wyłącznego dostępu do magistrali, realizacja transferu bloku z udziałem DMA daje poprawę efektywności. Przekazanie bloku słowo po słowie przez procesor, przeplatane z realizacją przetwarzania aplikacyjnego, wymaga przerwania, powrotu z przerwania, zmiany zawartości niektórych rejestrów (przechowania i odtworzenia odpowiednich wartości). Poza tym procesor korzysta z pamięci podręcznej i nie zawsze wymagany jest dostęp do magistrali systemowej w cyklu rozkazowym.
Układ DMA może być różnie umiejscowiony w architekturze komputera. W pierwszej z przedstawionych konfiguracji wszystkie podstawowe układy, czyli procesor, pamięć, urządzenia wejścia-wyjścia oraz DMA współdzielą magistralę systemową. Układ DMA musi wówczas rywalizować o magistralę z procesorem zarówno przy dostępie do pamięci, jak i przy dostępie do urządzeń wejścia-wyjścia. W pozostałych konfiguracjach rywalizacja z procesorem występuje tylko przy dostępie do pamięci. W drugiej konfiguracji DMA jest ściśle zintegrowany z urządzeniem, które obsługuje. Może też obsługiwać kilka takich urządzeń. W trzeciej konfiguracji wyodrębniono magistralę wejścia-wyjścia, dostępną za pośrednictwem układu DMA.
Ogólnym celem buforowania jest niwelowanie różnic, co oddaje angielskie znaczenie tego terminu (ang. buffer = zderzak). Niwelowanie różnic polega na wykorzystaniu szybkiej pamięci operacyjnej do gromadzenia danych, zanim zostaną one przekazane do urządzenia.
Różnice mogą dotyczyć szybkości pracy urządzeń. Typowy przypadek dotyczy szybkiego producenta, przekazującego dane, z których przetwarzaniem nie nadąża odbiorca — konsument. Czasami, w celu równoważenia obciążenia urządzenia szybsze otrzymują więcej pracy do wykonania, w związku z czym nie mogę natychmiast reagować na żądania urządzeń powolnych. Wówczas również przydaje się buforowanie.
Inny przypadek dotyczy efektywności transmisji danych pomiędzy urządzeniami blokowymi. Bloki przekazywane przez jedno urządzenie mogą mieć innych rozmiar, niż bloki akceptowane przez inne urządzenie. W celu uniknięcia zbędnych operacji wejścia-wyjścia dane gromadzi się w buforze w celu „uformowania” jednostki o właściwym rozmiarze.
Nieco odmiennym przypadkiem jest semantyka kopii. Przypadek ten wiąże się z synchronizacją współbieżnego dostępu, a dokładniej koniecznością uniknięcia długotrwałego blokowania dostępu do danych. W tym celu robi się kopie danych w pamięci, które następnie można przekazać do urządzenia, podczas gdy proces może operować na danych oryginalnych.
Przykładem dopasowania szybkiego producenta do stosunkowo małej przepustowości konsumenta jest drukowanie. Drukarka jest urządzeniem powolnym, podczas gdy komputer potrafi przygotować dane do wydruku dość szybko, nawet w przypadku dokumentu ze skomplikowanym formatowaniem, rysunkami itp. Strumień, który ma być przekazany do drukarki jest więc gromadzony w pamięci, co umożliwia po stosunkowo krótkim czasie kontynuacje pracy z drukowanym właśnie dokumentem.
W obsłudze drukarki stosowany jest dodatkowo tzw. spooler, co zostanie omówione z dalszej części.
Przykładem dopasowania jednostek transmisji jest zapis na dysku danych odbieranych z sieci. Po wyodrębnieniu z ramki sieciowej danych aplikacyjnych może się okazać, że ich objętość jest mniejsza niż rozmiar sektora. Dane można oczywiście zapisać, tzn. zapisać sektor dysku, przy czym część sektora będzie zwierać wartości przypadkowe lub 0. Po otrzymaniu kolejnej ramki dane w sektorze można uzupełnić, ale operacja taka wymaga wczytania sektora do pamięci — do bufora, uzupełnienia świeżo otrzymanymi danymi i ponownego zapisu. Buforowanie zatem i tak jest niezbędne na potrzeby realizacji operacji dyskowych. Tym nie mniej, lepiej przetrzymać niepełną zawartość bufora w pamięci i poczekać na uzupełnienie danymi z następnej ramki. W tym przypadku mamy do czynienia ze składaniem. Przy transmisji danych z dysku przez sieć w opisanej sytuacji może być z kolei potrzeba fragmentowania danych, czyli dzielenia w buforze na mniejsze części, dopasowane do pojemności ramki.
Przykładem buforowania w celu zagwarantowania semantyki kopii jest zapis na dysku pliku, który podlega modyfikacji. Przypadek taki ma często miejsce, kiedy chcemy zachować bieżący stan dokumentu na wypadek awarii lub przed jakąś poważną modyfikacją, której może się nie udać wycofać. Transfer danych bezpośrednio z przestrzeni procesu oznacza ryzyko zapisania danych niespójnych. Ryzyko niespójności w tym przypadku polega na tym, że w trakcie realizacji operacji zapisu (wyjścia) plik w pamięci jest modyfikowany i część zapisanych zmian dotyczy zawartości sprzed modyfikacji, a część po modyfikacji. Można w ten sposób zapisać na dysku drugą połowę wprowadzanego właśnie zdania, pomimo że zlecenie zapisu zostało wydane przed rozpoczęciem wprowadzania tego zdania.
Można by oczywiście zablokować dostęp do obszaru pamięci z bieżącą zawartością pliku, ale zmusza to użytkownika do przerwania pracy na czas zapisu na dysku. Można zatem wykonać znacznie szybszą operację skopiowania odpowiedniego obszaru pamięci do bufora w jądrze, gdzie będzie gwarancja niezmienności danych.
Buforowanie można zrealizować na kilka sposobów, w zależności od zastosowania i intensywności korzystania z buforów. Całkowita rezygnacja z buforowania oznacza konieczność utrzymania urządzeń wyjściowych w gotowości do natychmiastowego działania lub blokowania pracy urządzeń wejściowych. Można zastosować bufor pojedynczy, który ma jednak pewne ograniczenie — albo jest w danej chwili czytany, albo zapisywany. W celu umożliwienia jednoczesnej pracy obu komunikującym się urządzeniom konieczne jest użycie co najmniej bufor podwójnego. Jedna z dwóch pozycji bufora jest w danej chwili zapisywana, a druga odczytywana, po czym następuje zmiana. W przypadku dużych tymczasowych rozbieżności w szybkości pracy urządzeń konieczny może być bufor cykliczny, w którym jest kilka pozycji. Producent zapełnia kolejne pozycje, a gdy dojdzie do końca, rozpoczyna ponownie od początku. Podobnie konsument pobiera dane z poszczególnych pozycji. Warunkiem poprawności takiego buforowania jest blokada producenta przed nadpisaniem pozycji, której konsument jeszcze nie odczytał oraz blokowanie konsumenta przed odczytaniem pozycji, której producent jeszcze nie zapisał (wielokrotnym odczytaniem tej samej pozycji). Tego typu problem rozważany będzie w module dotyczącym synchronizacji procesów.
Przechowywanie podręczne jest pewną formą buforowania (raczej utrzymywania danych w pamięci), której celem jest poprawa efektywności realizacji operacji wejścia-wyjścia poprzez udostępnianie danych w pamięci zamiast wykonywania operacji na urządzeniu.
W przypadku zlecenia odczytu danych z urządzenia są one przekazywane procesowi z bufora w pamięci podręcznej, z pominięciem operacji wejścia. Wymaga to utrzymania aktualnych danych w buforze pamięci podręcznej, a więc w wyniku operacji zapisu na urządzeniu musi nastąpić stosowana zmiana zawartości tego bufora. Operacja wyjścia może się ograniczyć do modyfikacji zawartości bufora. Właściwa operacja wyjścia na urządzeniu może nastąpić później i uwzględnić kilka zleceń zapisu ze strony procesów aplikacyjnych.
Tego typu technika stosowana jest powszechnie w obsłudze systemu plików, co będzie omawiane w następnych modułach. Jest ona również stosowana w obsłudze pamięci wirtualnej, ale w tym przypadku odnosi się do zawartość pamięci, urządzenie wymiany jest zatem wtórnym miejscem gromadzenia danych.
Spooling jest akronimem od angielskiego określenia sequential peripheral operation on line , co można przetłumaczyć, oddając sens sformułowania, jako na bieżąco realizowana operacja sekwencyjna na urządzeniu wejścia-wyjścia.
Operacja sekwencyjna jest tutaj rozumiana jako operacja na urządzeniu o dostępie wyłącznym. Następna operacja może się rozpocząć dopiero po zakończeniu poprzedniej. Konieczne jest więc zagwarantowanie ciągłości strumienia danych, przekazywanych do urządzenia w ramach operacji wyjścia. Strumień taki nie może się przeplatać z innym strumieniem. Typowym przykładem urządzenia, obsługiwanego z wykorzystaniem techniki spoolingu, jest drukarka. Przeplatanie strumieni w przypadku takiego urządzenia oznacza wydruk, który może być zupełnie nieczytelny (pomieszanie linii, słów, znaków lub zupełna abstrakcja w przypadku grafiki).
Spooling polega więc na buforowaniu strumienia danych, przekazywanych do urządzenia dostępnego w trybie wyłącznym i rozpoczęciu operacji dopiero po zapamiętaniu całego strumienia. Ze względu na objętość strumienia buforowanie takie odbywa się najczęściej na dysku (tzw. spooler). Przekazywanie danych ze spoolera do urządzenia realizuje jeden proces lub wątek, co zapewnia sekwencyjność tej operacji.
Alternatywą dla spoolingu byłoby blokowanie urządzenia, tzn. jawny przydział urządzenia żądającemu procesowi i blokowanie dostępu innym procesom do czasu zwalniania. Takie rozwiązanie stwarza jednak problem uzależnienie zajętości urządzenia od „kaprysu” procesu. Jeśli proces przekaże tylko część strumienia, a drukowanie reszty będzie musiał odłożyć w czasie, drukarka pozostanie cały czas zajęta. W przypadku spoolingu drukowanie nie rozpocznie się, dopóki cały strumień nie zostanie zbuforowany, dzięki czemu przedłużające się przekazywanie danych nie blokuje innych procesów w dostępie do drukarki.
Chociaż podsystem wejścia-wyjścia udostępnia interfejs dla obsługi wszystkich urządzeń wejścia-wyjścia, wykorzystanie niektórych z tych urządzeń w taki „surowy” sposób jest niewygodne. Karta sieciowa na przykład jest urządzeniem, które staje się dopiero wówczas użyteczne, gdy otrzymuje dane z odpowiednimi informacjami adresowymi i kontrolnymi, stosownie do używanych protokołów sieciowych. Dysk służy do przechowywania danych w sektorach, ale logicznie dane zorganizowane są w pliki, które mogą zajmować wiele sektorów. Musi gdzieś być zatem pamiętana informacja o sektorach (lub innych jednostkach alokacji) zajmowanych przez plik.
Zarządzanie taką informacją na poziomie aplikacji naraża system na sporo błędów. Dwa różne procesy mogłyby na przykład przydzielić sobie ten sam blok dyskowy. Poza tym zadaniem jądra systemu operacyjnego jest stworzenie środowiska wygodnego dla użytkowników, ułatwiającego wykonywanie programów. Tego typu usługi są wiec realizowane przez oprogramowanie systemowe, które na bazie modułu sterującego urządzenia fizycznego tworzy pewne urządzenia wirtualne, oferujące często zupełnie inny model wykorzystania zasobów urządzeń zewnętrznych.
Dwoma nadmienionymi już przykładami są: protokoły komunikacji sieciowej i system plików. Stos protokołów udostępnia usługi transmisji danych na bazie fizycznej karty sieciowej. Dla aplikacji urządzeniem jest połączenie sieciowe a nie karta. System plików udostępnia logiczny obraz informacji w postaci hierarchicznej struktury katalogów oraz plików identyfikowanych przez nazwy, a moduł organizacji fizycznej systemu plików odwzorowuje ten obraz na zbiór sektorów fizycznego dysku. Dla aplikacji urządzeniem jest więc plik o określonej nazwie, a nie dysk.
Celem wykładu jest pokazanie systemu plików, jako abstrakcyjnego obrazu informacji, przechowywanej i udostępnianej przez system operacyjny. W zakresie tym mieszczą się podstawowe pojęcia związane z plikami (pojęcie samego pliku, typu oraz struktury) oraz ich logiczną organizacją (strefy i katalogi). Kluczowym elementem tego obrazu jest sposób dostępu do zawartości pliku.
Wykład rozpoczyna wprowadzenie do systemu plików, obejmujące zdefiniowanie podstawowych pojęć (plik, typ, struktura), atrybutów pliku oraz roli i zadań systemu operacyjnego w odniesieniu do systemu plików. Następnie omawiane są metody dostępu do plików oraz przykładowy interfejs operacji plikowych, ze szczególnym zwróceniem uwagi na sposób realizacji metod dostępu. Na końcu omawiana jest organizacja logiczna systemu plików, czyli ten element, który kształtuje obraz organizacji informacji, postrzegany przez użytkownika.
Pojęcie pliku (ang. file) jest bardzo ogólne i może być różnie rozumiane w zależności od punktu widzenia. Pojęcie to, podobnie jak system operacyjny, czy proces, trudno zdefiniować precyzyjnie w krótkiej i zwartej formie.
Intuicyjnie plik jest ciągiem danych (bitów, bajtów, rekordów itp.), których znaczenie (semantykę) określa jego twórca i jego użytkownik. Np. użytkownik, tworząc plik z programem w języku C, określa, że jest to plik, na podstawie którego kompilator potrafi wygenerować kod pośredni, a po dołączeniu odpowiednich bibliotek konsolidator (linker) potrafi wygenerować plik z programem binarnym.
Zamieszczone definicje podkreślają aspekt zewnętrzny (obraz informacji, jednostka magazynowania) oraz wewnętrzny (powiązane informacje).
System operacyjny udostępnia pliki w jakieś postaci logicznej (zwanej też wirtualną), np. sekwencji rekordów, tablicy bajtów itp., tzn. udostępnia operacje, z pomocą których można odpowiednio manipulować takim właśnie jednostkami. Wykonanie takiej operacji musi zostać przełożone na operacje dostępu do zawartości pliku, zgodnie z jego fizyczną strukturą, np. do zawartości sektora na dysku.
Zlecenie operacji na pliku wymaga jego zidentyfikowania. Dostarczanie wygodnych dla użytkownika identyfikatorów, to jedno z zadań systemu operacyjnego. Drugim zadaniem jest dostarczenie funkcjonalnie kompletnego interfejsu operacji plikowych oraz ich implementacji w celu realizacji dostępu.
Nazwa pliku tworzona jest dla wygody użytkownika. System operacyjny ma najczęściej jakiś inny, wewnętrzny mechanizm identyfikacji pliku (np. numer i-węzła w systemie UNIX, referencja w NTFS).
Typ pliku, jako atrybut, istotny jest w systemach, które rozróżniają typy plików na poziomie jądra systemu operacyjnego. W praktyce pewne typy plików muszą być rozpoznawane przez jądro, np. pliki z programem dla procesu.
Lokalizacja jest atrybutem, który w istotnym stopniu decyduje o różnicach w implementacji systemu plików.
Kontrola dostępu polega na weryfikacji uprawnień do wykonania operacji, żądanej przez użytkownika, np. odczytu pliku, zapisu pliku itp.
Czasy dostępu umożliwiają działanie niektórych narzędzi programistycznych, np. programu make. Przydatne są też czasami przy wyszukiwaniu pliku.
Problem rozpoznawania typów pliku można pozostawić użytkownikowi, wspomagając go ewentualnie przez przyjęcie pewnej konwencji nazewniczej.
Jeśli typ pliku rozpoznawany jest przez jądro systemu operacyjnego, to możliwa jest optymalizacja dostępu, zabezpieczenie przed popełnieniem pewnych błędów, związanych z niewłaściwą interpretacją zawartości pliku (np. próba wyświetlenia zawartości pliku z programem binarnym) itp.
W systemie UNIX, w którym większość zasobów reprezentowana jest przez pliki, wyróżnia się następujące typy: plik zwykły, katalog, dowiązanie symboliczne, urządzenie blokowe, urządzenie znakowe, łącze nazwane, gniazdo. Rozróżnienie to jest bardziej związane z rolą pliku w systemie niż z jego zawartością. Jeśli chodzi o plik zwykły, to nie ma on typu — z punktu widzenia jądra systemu operacyjnego jest to ciąg bajtów, niezależnie od rodzaju zawartości. Jedynie pliki zwykłe z prawem eXecute są w pewien sposób wyróżnione, tzn. muszą mieć odpowiednią strukturę (np. COFF lub ELF), wymaganą przez jądro systemu operacyjnego w celu prawidłowego uruchomienia procesu (chyba że są to skrypty powłoki). Jądro dostarcza zestaw elementarnych operacji dostępu do plików zwykłych. Właściwa interpretacja zawartości takiego pliku jest sprawą użytkownika lub aplikacji, a informacja o typie pliku, rozpoznawana na poziomie aplikacji, zwyczajowo zawarta jest w nazwie — w jej części po kropce, zwanej rozszerzeniem.
Logiczna struktura pliku określa powiązanie informacji wewnątrz pliku (właściwym byłoby zatem określenie struktura informacji). Jako przykład można sobie wyobrazić plik z tabelą bazy danych, w którym:
Z długości nagłówka wynika, gdzie rozpoczynają się dane, z wielkości rekordu oraz informacji o strukturze, mówiącej o 2 dodatkowych bajtach dla każdego rekordu, można wyliczyć początek rekordu o podanym numerze itd.
Struktura logiczna wiąże się najczęściej z typem pliku, tzn. pewne typy pliku mogą mieć określoną strukturę, np. katalogi w systemie UNIX, plik z obrazem — JPEG lub GIF (Graphics Interchange Format) itd.
Struktura może być definiowana i rozpoznawana na poziomie jądra systemu operacyjnego lub może być rozpoznawana na poziomie aplikacji korzystającej z tego pliku. Definiowanie obsługi różnych struktur plików na poziomie jądra może być pomocne dla użytkownika (może wspomagać optymalizację dostępu), ale w systemie musi być wówczas zawarty kod do obsługi każdej z tych struktur, co może powodować nadmierny rozrost programu jądra.
Fizyczna struktura pliku wynika z własności urządzenia, na którym plik jest przechowywany. Większość urządzeń składowania danych (w tym plików) ma charakter blokowy. Zadaniem systemu operacyjnego jest zatem odwzorować jednostkę logiczną (np. rekord) na jednostkę fizyczną (np. sektor dysku). Operacja dostępu do rekordu może więc wymagać jednej lub kilku operacji dostępu do sektora dysku lub dostępu do bufora pamięci podręcznej, gdzie przechowane są tymczasowe zawartości niektórych obszarów przestrzeni dyskowej.
W związku z blokowym charakterem urządzeń składujących może wystąpić zjawisko fragmentacji wewnętrznej. Wynika ono z faktu, że rozmiar jednostki alokacji na urządzeniu, będący wielokrotnością (w liczbie jakieś potęgi dwójki: 1, 2, 4, 8, ...) rozmiaru sektora, nie musi dokładnie odpowiadać potrzebom aplikacji.
W dostępie sekwencyjnym możliwe są następujące operacje: odczyt kolejnego rekordu, dopisanie rekordu na końcu pliku, przesunięcie wskaźnika bieżącej pozycji (bieżącego rekordu) na początek, ewentualnie przesuwanie wskaźnika o podaną liczbę jednostek w przód, czy w tył. Identyfikacja rekordu dla wykonywanej operacji wynika zatem z historii wcześniejszych operacji dostępu.
W przypadku dostępu bezpośredniego (określanego również jako swobodny) możliwe jest wskazanie dowolnego rekordu (lub innego fragmentu pliku), na którym ma zostać wykonana operacja dostępu. Rekord wskazywany jest poprzez podanie numeru lub przesunięcia względem początku pliku. Pliki o dostępie bezpośrednim są szczególnie użyteczne w przetwarzaniu informacji w dużych zbiorach danych (np. w bazach danych).
Dostęp indeksowy umożliwia identyfikowanie rekordów za pomocą kluczy indeksowych. Takie podejścia mają najczęściej na celu przyspieszenie wyszukiwania informacji na podstawie klucza. W praktyce stosowane są raczej w systemach zarządzania bazami danych, niż bezpośrednio w systemie operacyjnym. Pliki indeksowe przyjmują często postać skomplikowanych struktur typu B-drzewo lub B+-drzewo, czy tablice haszowe.
Przykład obrazuje zasadę dostępu indeksowego. Plik indeksowy jest zorganizowany w taki sposób, żeby przyspieszyć wyszukiwanie klucza, np. przez odpowiednie posortowanie lub zbudowanie struktury drzewiastej. Z kluczem związana jest informacja o lokalizacji rekordu w pliku stowarzyszonym, czyli właściwym pliku z danymi.
Sam dostęp polega na znalezieniu na podstawie klucza w pliku indeksowym informacji o lokalizacji rekordu, a następnie wykorzystaniu tej informacji w uzyskaniu dostępu do właściwego rekordu w pliku stowarzyszonym.
Podstawowe operacje na plikach to tworzenie, usuwanie oraz dostęp do zawartości pliku. Dostęp do zawartości w najprostszym przypadku sprowadza się do zapisu lub odczytu fragmentu pliku.
Tworzenie pliku wymaga jawnego podania wartości niektórych atrybutów — nazwy, typu, czy atrybutów związanych z ochroną. Wartości innych atrybutów definiowane są w trakcie użytkowania pliku, np. czasy dostępu, rozmiar, czy lokalizacja.
W przypadku właściwych operacji dostępu typowy zestaw informacji sprowadza się do określenia „co i gdzie”, czyli co jest zapisywane i w którym miejscu pliku lub która część pliku jest odczytywana oraz gdzie trafia odczytana informacja.
Usuwanie fragmentów pliku może przysparzać problemów. Zasadniczą kwestią jest, co zrobić z miejscem po usuniętej częścią pliku. W najprostszym przypadku można odpowiednio przesunąć zwartość pliku, ale jest to operacja pracochłonna. W przypadku pliku składającego się z logicznych rekordów o stałym rozmiarze można przenieść ostatni rekord w miejsce usuwanego. Jeśli jednak rekordy są posortowane, metoda ta może się okazać niewłaściwa. Sposób wykonania takiej operacji zależy więc od struktury pliku. Z tego powodu system operacyjny umożliwia tylko usuwanie końcowego fragmentu pliku, wszelkie optymalizacje pozostawiając warstwie aplikacyjnej.
W interfejsie usług plikowych wyróżnia się pewne operacje dodatkowe, jak otwieranie, zamykanie i przesuwanie wskaźnika bieżącej pozycji. Otwieranie oraz komplementarne zamykanie związane jest efektywnością realizacji operacji plikowych. Wygodnym dla użytkownika identyfikatorem pliku jest nazwa. W złożonej, hierarchicznej strukturze katalogów (w tym miejscu odwołujemy się do intuicji słuchacza, gdyż struktury katalogowe zostaną omówione w dalszej części) lokalizowanie pliku na podstawie nazwy wymaga czasami przeszukania kilku katalogów. Identyfikowanie pliku przez nazwę przy każdej operacji dostępu wymagałoby potencjalnie każdorazowego przeszukiwania takiej złożonej struktury katalogowej, co znacząco wydłużyłoby czas dostępu. Otwarcie pliku oznacza alokację odpowiednich zasobów jądra (pozycji w tablicach otwartych plików), które przechowują niezbędne dane od efektywnej realizacji operacji dostępu. Z otwarciem pliku wiąże się utworzenie jakiegoś tymczasowego identyfikatora (deskryptora, uchwytu), za pomocą którego można bardzo szybko zlokalizować plik lub jego fragment.
Sens operacji przesuwania wskaźnika bieżącej pozycji zostanie wyjaśniony w dalszej części.
Interfejs dostępu do plików w systemach uniksopodobnych obejmuje operacje wyszczególnione na wcześniejszym slajdzie, jednak kilka funkcji wymaga komentarza.
Funkcja unlink usuwa dowiązanie do pliku. W systemie unikskopodobnym plik może mięć kilka nazw, zwanych dowiązaniami twardymi. Funkcja unlink usuwa wskazane dowiązanie, co nie musi oznaczać fizycznego usunięcia pliku. Fizyczne usunięcie pliku następuje dopiero w wyniku usunięcia ostatniego dowiązania.
Funkcja creat (bez litery e na końcu), jak nazwa wskazuje, służy do tworzenia pliku. W tym samym calu można jednak wykorzystać funkcję open, która również umożliwia utworzenie pliku, ale udostępnia więcej parametrów i tym samym daje większe możliwości w zakresie obsługi przypadków szczególnych.
W opisie interfejsu pominięto między innymi funkcję fcntl, oraz kilka funkcji dostępu do specyficznych atrybutów plików.
creatunlinkreadwritetruncatelseekopenclosecreat open closeunlink truncatereadPodobnie jak w przypadku funkcji read, w parametrach funkcji write również nie ma wskazania, który obszar pliku ma być zapisywany. Wpływ na miejsce zapisywania może mieć tryb otwarcia. W przypadku otwarcia pliku z flagą O_APPEND następuje zawsze dopisywanie na końcu. Jeśli flaga nie została użyta, w wyniku wykonania funkcji może nastąpić nadpisanie dotychczasowej zawartości, przy czym plik zachowuje się tak, jak przy dostępie sekwencyjnym.
writePrzykład pokazuje efekt trzech kolejnych operacji odczytu pliku po jego otwarciu. Przyjmując od góry początek pliku, pierwsze wykonanie read umieści w buforze pamięci pierwsze sześć bajtów, następne nadpisze te sześć bajtów kolejnymi dziewięcioma z pliku, ostatnie wykonanie częściowo nadpisze zwartość bufora kolejnymi pięcioma bajtami. Jest to typowy przykład dostępu sekwencyjnego. Po wykonaniu operacji stan otwarcia pliku zmienia się w tak, że następna operacja dotyczy kolejnego fragmentu pliku.
Podobnie realizowana jest operacja zapisu. Wynikiem kolejnych trzech wywołań funkcji write będzie zapisanie łącznie 20 kolejnych bajtów w pliku. Jeśli w zapisywanym obszarze pliku były już jakieś dane, zostaną nadpisane. Jeśli plik byłby krótszy niż 20 bajtów, nastąpi jego powiększenie.
Z każdym otwartym plikiem związany jest wskaźnik bieżącej pozycji. Wskaźnik ten identyfikuje miejsce, od którego rozpocznie się kolejna operacja zapisu lub odczytu. Po każdej operacji wskaźnik bieżącej pozycji przesuwa się o tyle bajtów, na ilu operacja była wykonana.
Niezależnie od wykonywanych operacji dostępu wskaźnik ten można przesunąć za pomocą funkcji lseek. Wskazanie miejsca docelowego polega na podaniu przesunięcia względem początku pliku, końca pliku lub pozycji bieżącej. Wartość dodatnia oznacza przesunięcie w kierunku końca pliku, a ujemna w kierunku początku pliku.
Funkcja lseek jest uzupełnieniem funkcji read i write, umożliwiającym bezpośredni dostęp do plików. W przypadków plików sekwencyjnych, do których należą np. pliki urządzeń, czy łącza (potoki, kolejki FIFO) funkcja lseek nie ma zastosowania. W ten sposób udało się zachować jednolitość interfejsu dostępu do plików — nie trzeba było wyodrębniać dwóch rodzajów funkcji do odczytu i do zapisu.
Przedstawiony schemat ilustruje przykładową realizację operacji odczytu z przesunięciem wskaźnika bieżącej pozycji o 9 bajtów w kierunku końca pliku. Skutkiem jest pominięcie tych 9 bajtów.
W przypadku zapisu skutkiem przesunięcia jest pominięcie 9 bajtów, czyli pozostawienie tego fragmentu bez zmian.
System plików daje abstrakcyjny obraz informacji, gromadzonej w systemie komputerowym. Fizycznie, informacja ta może być przechowywana na różnych nośnikach: taśmach, dyskach, płytach kompaktowych, a nawet w pamięci operacyjnej. Strefa jest najczęściej obszarem związanym z fizycznym urządzeniem przechowującym plik. Czasami na urządzeniu (np. dysku) wydziela się różne strefy, postrzegane jako logiczne urządzenia.
Pliki w strefie znajdują się w katalogach, które z kolei najczęściej tworzą strukturę hierarchiczną. Z daną strefą związany jest na ogół zbiór danych o odpowiedniej strukturze do identyfikacji hierarchii katalogów oraz lokalizacji bloków z zawartością plików. Informacje takie określa się jako metadane. Inicjalizacja metadanych nazywana jest formatowaniem logicznym, albo tworzeniem systemu plików.
Warto podkreślić, że jest to logiczny obraz, który może się różnie przekładać na fizyczne rozlokowanie danych na dostępnych urządzeniach.
W przedstawionym przykładzie wyróżniono dwie strefy, w których umieszczone są pliki i katalogi. W jednej z nich katalog główny zawiera podkatalog oraz plik, a w drugiej podkatalog zawiera 2 pliki.
Jak już wspomniano, strefa odpowiada najczęściej urządzeniu fizycznemu. Podział na strefy może być też jednak zrobiony w celu wyodrębnienia kilku logicznych urządzeń (dysków) na jednym urządzeniu fizycznym lub powiązania kilku fizycznych urządzeń w jedną logiczną całość.
Wpis w katalogu tworzony jest zawsze, gdy jakiś obiekt z danymi ma być identyfikowany przez nazwę za pośrednictwem systemu plików. Obiektem takim jest plik. Plik może mieć kilka alternatywnych nazw, z których każda ma swój wpis. Swoje wpisy mają też podkatalogi w przypadku struktury hierarchicznej. Wpis taki można również usunąć lub przemianować. Wszystkie te operacje dotyczą modyfikacji katalogu. Katalog na ogół częściej jest przeszukiwany niż modyfikowany. Przeszukiwanie polega na poszukiwaniu wpisu, identyfikowanego przez nazwę lub tworzeniu wykazu wszystkich wpisów, spełniających określone kryteria.
Współcześnie najczęściej katalogi są logicznie powiązane w strukturę drzewa, która narzuca naturalną hierarchiczność. W przeszłości stosowane był niekiedy prostsze struktury, np. jednopoziomowa, dwupoziomowa. Można sobie również wyobrazić bardziej skomplikowane struktury, np. graf acykliczny, czy graf dowolny.
Wszystkie pliki identyfikowane są przez nazwy, znajdujące się na tym samym poziomie. Wymaga się zatem, żeby nazwy te były unikalne. Jest to poważne ograniczenie zwłaszcza w systemach wielodostępnych.
Krokiem w kierunku ułatwienia wielodostępu przy „płaskiej” strukturze katalogów jest struktura dwupoziomowa. Każdy użytkownik ma swój katalog, więc wybierane przez niego nazwy, nie kolidują z nazwami, wybranymi przez innych użytkowników. Podejście takie zastosowano w systemie CP/M.
Typowym podejściem jest organizacja katalogów w formie drzewa. Każdy katalog zawiera wpisy odpowiadające plikom oraz innym katalogom. Nazwy w każdym katalogu muszą być unikalne, mogą się natomiast powtarzać w innych katalogach.
Graf acykliczny oznacza, że ten sam obiekt może mieć wpis (dowiązanie) w kilku katalogach. W prezentowanym przykładzie obiekt (katalog) programy ma wpis w nadkatalogu darek oraz nadkatalogu jacek. Podobnie jeden z plików ma dwie różne nazwy — art.txt i do_czyt — w różnych katalogach.
Tego typu organizacja logiczna plików i katalogów stosowana jest w systemach uniksopodobnych, ale wielokrotne dowiązanie nie jest możliwe dla katalogów. Poza tym dowiązanie te muszą być w tej samej strefie (logicznym urządzeniu).
Dowolny graf raczej nie jest stosowany w systemach plików, gdyż dopuszcza cykl, który utrudnia orientację w trakcie poruszania się po takiej strukturze. Hierarchia jest najlepszą formą organizacji informacji, akceptowalną przez ludzki mózg i tym samym wygodną dla użytkownika.
Celem wykładu jest prezentacja różnych podejść do implementacji systemu plików. Podejścia opierają się na założeniu, że urządzeniem składowania danych jest dysk i dotyczą one przede wszystkim organizacji przestrzeni dyskowej. Podkreślane są wady i zalety tych podejść w kontekście różnych form dostępu do danych w plikach.
Zasadniczą kwestią, przedstawianą w ramach wykładu, jest organizacja przestrzeni dyskowej, obejmująca powiązanie pliku z blokami dyskowymi oraz zarządzanie blokami wolnymi. Poruszona jest też implementacja katalogu. W kolejnej części omawiany jest sposób realizacji operacji plikowych oraz wynikający z tego problem integralności danych. Na koniec zasygnalizowana jest problematyka współbieżnego dostępu do pliku.
Przestrzeń dyskowa na potrzeby systemu plików zorganizowana jest w jednostki alokacji, zwane krótko blokami. Blok jest wielokrotnością sektora dysku.
W zakresie przydziału miejsca dla pliku na dysku, czyli powiązania bloków z plikiem, omówione są trzy podejścia: przydział ciągły, listowy i indeksowy, przy czym ten ostatni wymaga dodatkowo określenia sposobu powiązania bloków indeksowych. Podejściem opartym na idei przydziału listowego jest tablica alokacji plików (FAT).
Wolna przestrzeń jest dopełnieniem przestrzeni przydzielonej dla plików w ramach danej strefy dysku. Jednak efektywna identyfikacja wolnych bloków na potrzeby tworzenia nowych plików lub rozszerzania istniejących wymaga utrzymywania komplementarnej informacji. Wyróżnia się cztery rodzaje takich struktur: wektor bitowy, lista powiązana, grupowanie, zliczanie, przy czym idee niektórych podejść można łączyć.
Dla katalogu przydzielane są bloki tak, jak dla innych plików dyskowych. Jest to zatem również plik, ale jego struktura jest odpowiednio definiowana przez system. Specyficzne są również operacje dostępu. W przypadku niewielkiej liczby wpisów katalog może być zwykłą listą (czy tablicą). Czas wyszukiwania zależy wówczas liniowo do liczby wpisów, co staje się nie akceptowalne w przypadku rozrastających się katalogów. Dla dużych katalogów lepiej jest zastosować jakąś strukturę przyspieszającą wyszukiwanie informacji, np. B/B+-drzewo lub tablicę haszową.
Przydział ciągły oznacza, że zawartość pliku umieszczona jest w kolejnych według jakieś jednoznacznej numeracji blokach (jednostkach alokacji). Numeracja związana jest z fizycznym położeniem bloku na urządzeniu.
W przydziale listowym poszczególne bloki powiązane są wskaźnikami. W przypadku listy jednokierunkowej w każdym bloku przechowywany jest wskaźnik (czyli numer, indeks) bloku następnego. Dzięki temu zawartości pliku może być rozmieszczona w blokach, dowolnie rozproszonych w dostępnej przestrzeni dyskowej.
W przydziale indeksowym numery bloków dyskowych z danymi skupione są w jednym miejscu, w tzw. bloku indeksowym. Jeśli jeden blok indeksowy jest zbyt mały, żeby pomieścić numery wszystkich bloków z danymi, tworzone są kolejne bloki indeksowe i organizowane w schemat listowy, wielopoziomowy lub kombinowany.
W przedstawionym przykładzie przydziału ciągłego atrybut lokalizacja pliku implementowany jest za pomocą dwóch wartości: numeru (indeksu) pierwszego bloku oraz liczby bloków, która wynika z rozmiaru pliku. Pierwszy plik (zielony) zajmuje więc 10 bloków począwszy od bloku 1, drugi plik (czerwony) zajmuje 11 bloków począwszy od bloku nr 13 (czyli do 23 włącznie), a trzeci plik (żółty) zajmuje 9 bloków od bloku nr 27.
Niewątpliwą zaletą przydziału jest efektywność. Dotyczy ona zarówno złożoności czasowej operacji dostępu, jak i złożoności struktur danych. W przypadku wielu operacji dostępu do tego samego pliku można oczekiwać niewielkich ruchów głowic dyskowych, a więc krótkiego czasu wyszukiwania. Łatwo można zlokalizować dowolny fragment pliku. Identyfikacja bloków pliku nie wymaga żadnych dodatkowych danych poza dwoma wartościami całkowitymi (numerem pierwszego bloku i rozmiarem).
Wadą rozwiązania jest trudność obsługi fragmentacji zewnętrznej. W przedstawionym przykładzie pomiędzy pierwszym i drugim plikiem (zielonym i czerwonym) są dwa bloki wolne, a pomiędzy drugim i trzecim plikiem (czerwonym i żółtym) są trzy bloki wolne. Potencjalnie można by jeszcze znaleźć miejsce na plik o rozmiarze pięciu bloków, ale nie stanowią one ciągłego obszaru. Przenoszenie bloków natomiast jest operacją w ogólności czasochłonną. Można ją wykonać od czasu do czasu w ramach optymalizacji przestrzeni dyskowej, ale nie sposób robić tego przy każdym problemie alokacji bloków.
Nie ma też dobrej ogólnej metody na rozszerzanie pliku.
Wymienione wady dyskwalifikują to podejście w systemach plików, w których często wykonywane są modyfikacje zawartości i towarzyszące temu skracanie lub rozszerzanie pliku. Podejście można natomiast stosować w systemach, gdzie modyfikacje są sporadyczne.
W przedstawionym przykładzie atrybut lokalizacja w katalogu (lub w związanej z nim strukturze) składa się z dwóch indeksów — indeksu pierwszego i ostatniego bloku (alternatywnie rozmiar pliku). Jednak pozostałe indeksy ukryte są blokach z danymi. W każdym bloku musi być zarezerwowane miejsce na indeks następnego bloku. Pierwszy plik (zielony) rozpoczyna się od bloku 1. W bloku pierwszym oprócz danych (treści pliku) przechowywany jest indeks bloku następnego, czyli 3. W bloku 3 z kolei przechowywany jest indeks bloku następnego, czyli 28 itd.
Przydział listowy rozwiązuje problem fragmentacji zewnętrznej i wynikających z niej ograniczeń na przydział bloków.
Łatwo realizowalny jest dostęp sekwencyjny, jeśli przebiega się plik od początku do końca. Problem może powstać, gdy trzeba się cofnąć. Jeśli dane są w poprzednim bloku, należy rozpocząć wyczytywanie bloków od początku. W przypadku próby dostępu bezpośredniego niejednokrotnie również należy rozpocząć przeglądanie bloków od początku, dlatego ten rodzaj dostępu jest problematyczny w realizacji.
Kosztem realizacji tego typu podejścia jest konieczność przeznaczenia pewnej ilości miejsca w bloku na przechowywanie wskaźnika do bloku następnego.
W przypadku uszkodzenia sektora dysku jest ryzyko utraty bloku. W przypadku przydziału listowego może to mieć większe konsekwencje, gdyż utrata bloku oznacza również utratę indeksu bloku następnego i tym samym wszystkich pozostałych bloków aż do końca pliku.
FAT jest odmianą przydziału listowego, w której sama lista powiązań jest oddzielna od bloków z danymi. Indeks następnego bloku nie jest przechowywany w bloku z danymi, tylko na odpowiadającej temu blokowi pozycji w tablicy FAT. Dzięki temu w jednej operacji dostępu do dysku można wczytać do pamięci większy fragment łańcucha powiązań i sprawniej zrealizować dostęp bezpośredni.
Zaprezentowany przykład jest adaptacją przykładu z przydziałem listowym. Tablica FAT na pozycji nr 1 zawiera wartość 3, co oznacza, że następnym blokiem po bloku nr 1 jest blok nr 3. Na pozycji 3 w tablicy FAT jest wartość 28, a więc blok nr 28 jest następnym blokiem pliku.
Przerywanymi liniami na rysunku zaznaczona te powiązania pomiędzy blokami, które wynikają z przedstawionego obok fragmentu tablicy FAT.
Atrybut lokalizacja w przypadku przydziału indeksowego musi przede wszystkim identyfikować blok indeksowy. Blok ten w całości wypełniony jest indeksami bloków z danymi. W przykładzie dla pierwszego pliku (zielonego) blok nr 3, jako blok indeksowy zawiera numery bloków 1, 8, 27 i 28, jako bloków z danymi. Podobnie w przypadku pozostałych plików, przy czym blok indeksowy pliku drugiego (czerwonego) identyfikuje tylko 2 bloki.
Blok indeksowy jest jednym z bloków przydzielanych w ramach zarządzania przestrzenią dyskową. Jego rozmiar jest skończony, w związku z czym skończona jest również liczba indeksów, którą można w nim przechować. Na przykład przy bloku 1KB i indeksie 4-bajtowym, w bloku można przechować 256 indeksów.
Jeśli liczba indeksów w jednym bloku nie jest wystarczająca, przydzielany jest kolejny blok indeksowy. Bloki indeksowe pliku należy jakoś powiązać. Można je powiązać w listę (schemat listowy), w drzewo (schemat wielopoziomowy) lub przyjąć rozwiązanie łączące kilka drzew o różnych głębokościach (schemat kombinowany).
W schemacie listowym ostatni wskaźnik (indeks) w blok indeksowym wskazuje na następny blok indeksowy dla danego pliku. Jeśli zatem blok indeksowy może pomieścić 256 wskaźników, to 255 odnosi się do bloków z danymi, a 1 do następnego bloku indeksowego.
W schemacie wielopoziomowym na pierwszym poziomie jest jeden blok indeksowy, a każdy wskaźnik w tym bloku określa następny blok indeksowy itd. Dopiero ostatni poziom zawiera wskaźniki do bloków z danymi. W przypadku 256 wskaźników w jednym bloku oraz indeksie 2-poziomowym można zaadresować 2562=65536 bloków z danymi, a przy indeksie 3-poziomowym 2563=16777216 bloków z danymi.
W schemacie kombinowanym część wskaźników w głównym bloku indeksowym określa bezpośrednio bloki z danymi, część wskazuje na kolejny blok indeksowy, adresujący bloki danych (indeks 2-poziomowy), część jest początkiem indeksu 3-poziomowego.
Podejście indeksowe umożliwia szybszą lokalizację bloku pliku, zawierającego wskazany fragment, niż w przypadku przydziału listowego. Przydział ten sprawdza się zatem zarówno przy dostępie sekwencyjnym jak i bezpośrednim. Koszt i ryzyko są podobne, jak w przypadku przydziału listowego.
Zarządzanie wolną przestrzenią sprowadza się do identyfikacji bloków, które nie są przydzielone i mogą zostać wykorzystane dla nowo tworzonych lub rozszerzanych plików. Wolne bloki można wykorzystać do tymczasowego przechowywania danych na potrzeby zarządzania. Dlatego część stosowanych rozwiązań przypomina przydział bloków na potrzeby plików. Można więc powiedzieć, że w tych podejściach wolna przestrzeń jest plikiem składającym się z wolnych bloków.
W wektorze bitowym każdy blok dyskowy (jednostka alokacji) reprezentowany jest przez jeden bit. Wartość 1 tego bitu oznacza, że dany blok jest wolny (można ewentualnie przyjąć odwrotną logikę). Efektywna implementacja takiego podejścia wymaga dostępności odpowiednich rozkazów manipulowania bitami w procesorze.
Lista powiązana tworzy z wolnych bloków plik zgodnie z koncepcją przydziału listowego. Powiązanie wolnych bloków polega więc na tym, że w bloku poprzednim znajduje się indeks bloku następnego, a indeks pierwszego bloku znajduje się w specjalnym miejscu w systemie plików.
Przydział wolnego bloku polega na tym, że przydzielany jest blok, wskazywany jako pierwszy w superbloku, a indeks pierwszego bloku w superbloku zmieniany jest zgodnie z wpisem w bloku przydzielonym. W efekcie wskazuje zatem łańcuch, który zaczyna się od następnego wolnego bloku.
W przykładzie blok nr 2 zawiera indeks bloku 5, ten z kolei indeks bloku 6 itd.
Grupowanie jest odpowiednikiem przydziału indeksowego z listową strukturą bloku indeksowego. Pierwszy wolny blok, wskazany w superbloku, zawiera indeksy n innych wolnych bloków, z których n -1 dotyczy bloków do natychmiastowej alokacji, a n -ty blok zawiera indeks następnego bloku grupującego n -1 indeksów kolejnych wolnych bloków oraz indeks następnego bloku grupującego.
W przedstawionym przykładzie blok nr 2 grupuje indeksy bloków 5, 6, 15, 9, przy czym blok nr 9 jest kolejnym blokiem grupującym.
Zliczanie jest odpowiednikiem przydziału ciągłego. W przypadku kilku kolejnych (przylegających do siebie) wolnych bloków pamiętany jest tylko indeks pierwszego z nich oraz liczba wolnych bloków znajdujących się bezpośrednio za nim. Wykaz wolnych obszarów jest ciągiem wpisów, składających się z indeksu bloku oraz licznika. Zysk z tego podejścia ujawnia się, gdy występują duże ciągłe obszary wolne, np. wolna przestrzeń zaczynająca się od bloku 15.
Podejście taki mogłoby być połączone np. z listą powiązaną lub grupowaniem.
Katalog jest ciągiem wpisów, obejmującym przed wszystkim nazwę, gdyż przeszukiwanie katalogu odbywa się najczęściej po nazwie. Poza nazwą w katalogu mogą być inne atrybuty lub informacje o lokalizacji odpowiedniego obiektu opisującego plik.
Lista liniowa jest najprostszą formą implementacji katalogu. Jest to po prostu ciąg wpisów. Przeszukiwanie takiego katalogu odbywa się w czasie liniowo zależnym od liczby wpisów. W przypadku małych katalogów rzeczywisty czas jest na tyle krótki, że jakakolwiek optymalizacja nie jest potrzebna. W przypadku większych katalogów korzyść z formy haszowej lub indeksowej może okazać się znacząca.
Pozycja danego wpisu wyznaczana jest zgodnie z wartością funkcji haszującej dla nazwy danego pliku. Działanie przykładowej funkcji haszującej mogłoby polegać na zsumowaniu kodów znaków tworzących nazwę, a następnie wyznaczeniu wartości modulo liczba pozycji z tej sumy. Wykorzystując tę samą funkcję przy wyszukiwaniu wpisu, można go szybko zlokalizować. Funkcja haszująca nie gwarantuje unikalności (nie jest to funkcja różnowartościowa), należy się więc liczyć z konfliktami, gdy ta sama wartość zostanie wyznaczona dla dwóch różnych nazw. W zależności od sposobu rozwiązywania konfliktów, potrzebne mogą być dodatkowe struktury.
Inną formą przyspieszania lokalizacji wpisu jest struktura drzewiasta, oparta np. na B/B+-drzewie. Struktura drzewiasta w zakresie czasu wyszukiwania daje efekt podobny jak posortowanie, jest przy tym łatwiejsza w aktualizacji. Wierzchołki w B/B+-drzewie kojarzone są z blokami dyskowymi, co umożliwia optymalizację transferu danych pomiędzy jednostką centralną a urządzeniem przy dostępie do indeksu.
Operacja dostępu do danych w pliku wymaga ich sprowadzenia z urządzenia do pamięci operacyjnej, gdzie można je testować, zmieniać, po czym zażądać ponownego ich zapisania na urządzeniu.
Czytanie i pisanie bezpośrednio z / na dysk podczas wszystkich operacji dostępu do plików jest nieefektywne ze względu na czas reakcji dysku oraz relatywnie małą szybkość transmisji dyskowych.
Minimalizacja dostępów do dysku możliwa jest przez utrzymywanie puli wewnętrznych buforów, zwanych podręczną pamięcią buforową (ang. buffer cache), które zawierają dane z ostatnio używanych bloków dyskowych.
Dane w jednym buforze odpowiadają danym z jednego bloku dyskowego. Realizacja dostępu wymaga sprawdzenia dostępności bloku w podręcznej pamięci buforowej. Jeśli blok się tam znajduje, nie ma potrzeby wykonywania operacji dyskowej. W przeciwnym przypadku następuje sprowadzenie żądanego bloku z urządzenia do bufora. Sprowadzenie takie może oznaczać usunięcie (zastąpienie) dotychczasowej zawartości bufora. Jeśli zawartość ta była modyfikowana, wcześniej musi nastąpić zapis usuwanych danych we właściwym bloku dyskowym. Blok, dostępny w buforze, może być czytany oraz zapisywany, zależnie od praw dostępu do pliku, trybu otwarcia i rodzaju wykonywanych operacji. Modyfikacja zawartości bufora wymaga ponownego zapisu zawartości na dysku. Zapis taki może być wykonany natychmiast lub w późniejszym czasie, zależnie od trybu otwarcia. Póki nie nastąpi zwolnienie bufora na potrzeby nowo sprowadzanych danych, jego zawartość może być wykorzystywana przy kolejnych operacjach dostępu, gdyż bufor ten zawiera najświeższe dane. Konieczność natychmiastowego zapisu bloku dyskowego może być podyktowana bezpieczeństwem lub względami spójności. Niebezpieczeństwo wynika z możliwości utraty zawartości podręcznej pamięci buforowej w przypadku awarii komputera, zaniku zasilania itp. Problem spójności może powstać, jeśli do dysku jest dostęp bez pośrednictwa systemu operacyjnego, który buforuje dane. Przypadek taki może dotyczyć dysków w sieciowych systemach plików.
Schemat realizacji dostępu do odczytu w uproszeniu wygląda tak, że najpierw lokalizowany jest blok (lub bloki), zawierający czytany fragment. Sama lokalizacja w zależności od metody przydziały bloków może wymagać odczytu dodatkowych bloków, które też zostaną umieszczone w podręcznej pamięci buforowej. Po zlokalizowaniu bloku sprawdza się, czy znajduje się on w buforowej pamięci podręcznej. Jeśli nie ma go w pamięci podręcznej, następuje odczyt z urządzenia i umieszczenie zawartości w odpowiednim buforze. Ostatni etap polega na kopiowaniu danych z bufora pamięci podręcznej pod adres w przestrzeni procesu aplikacyjnego, wskazany w parametrach operacji.
Schemat postępowania jest podobny jak przy odczycie. Warto zwrócić uwagę, że dostęp do zapisu oznacza konieczność wcześniejszego odczytania bloku, ponieważ operacja zapisu może dotyczyć tylko fragmentu tego bloku.
Problem integralności może powstać wówczas, gdy w wyniku operacji następuje zmiana kilku bloków. Rozważmy przykład systemu plików z przydziałem indeksowym, w którym następuje rozszerzenie pliku. Rozszerzenie oznacza dołączenie kolejnego bloku danych i tym samym zmiany w plikach indeksowych oraz w identyfikacji bloków wolnych. Gdyby żadna z tych zmian nie została utrwalona, można przyjąć, że ze względu na awarię operacja nie udała się. Jeśli jednak tylko część tych zmian zostanie utrwalona na dysku, może się okazać, że blok jest zarówno w wykazie wolnych jak i przydzielonych jednostek lub też nie ma go w żadnym z tych wykazów.
Pierwszy z przejawów braku integralności nie jest szczególnie niebezpieczny dla stanu systemu plików. Oznacza on po prostu tymczasową (do momentu wykrycia i usunięcia) utratę bloku. Usunięcie niespójności polega po prostu na dołączeniu bloku do wykazu bloków wolnych.
Poważniejsze w skutkach mogą być następne dwa przypadki. Obecność bloku w wykazie bloków wolnych jak i zajętych sama w sobie nie jest jeszcze problem i może być łatwo naprawiona przez usunięcie bloku z wykazu bloków wolnych. Jednak w wyniku żądania przydziału, błędnie identyfikowany blok może zostać zaalokowany ponownie i dochodzimy do kolejnego przejawu niespójności — duplikacji przydzielonego bloku.
Podobnie wygląda przypadek wielokrotnego powtórzenia się bloku w wykazie bloków wolnych. Jest ryzyko, że ten sam blok zostanie wielokrotnie przydzielony, ale wczesne wykrycie i usunięcie duplikacji nie powoduje żadnych dalszych konsekwencji. Warto zwrócić uwagę, że ten przejaw niespójności nie może się zdarzyć w przypadku użycia wektora bitowego do zarządzania wolną przestrzenią.
Poważniejsze w skutkach jest wielokrotne powtórzenie bloku w wykazie bloków przydzielonych plikom (tzw. skrzyżowanie), bo dostęp do każdego z plików (czy różnych fragmentów tego samego pliku) może spowodować niezależne modyfikacje. Próbą rozwiązania problemu może być powielenie bloku i przydzielenie w każdym miejscu wystąpienia osobnej kopii. Może się jednak okazać, że nie będzie to właściwa kopia w żadnym z tych miejsc.
Semantyka spójności staje się istotna w przypadku współbieżnego dostępu do pliku wielu procesów, przy czym skutkiem dostępu są modyfikacje pliku. Semantyka spójności określa więc, w jaki sposób takie zmiany wpływają na obraz pliku w innych procesach.
Zgodnie z semantyką spójności systemu UNIX wszelkie zmiany są natychmiast dostępne dla następnych operacji odczytu, niezależnie od procesu. Wszystkie procesu korzystają po prostu z tej samej podręcznej pamięci buforowej.
Semantyka sesji oznacza, że wraz z otwarciem pliku tworzona jest sesja dostępu i wszelkie zmiany pliku w sesji staną się dostępne dopiero po jej zamknięciu. Jeśli zatem proces w czasie otwarcia sesji przez inny proces, otworzy swoją sesję, uzyska lokalną wersję pliku, która nie będzie uwzględniać dokonanych zmian w sesji współbieżnej. Dopiero otwarcie sesji po jej zamknięciu przez inny proces umożliwia dostęp do zmian.
Semantyka stałych plików dzielonych oznacza uniknięcie problemu, raczej niż jego rozwiązanie.
Zachowanie poprawnej struktury pliku przy współbieżnym realizowaniu operacji wymaga często koordynacji działań procesów, które mają dostęp do tego pliku. Koordynację taką w najprostszym przypadku można uzyskać poprzez wyłączność dostępu do pliku na czas wykonywania operacji. Blokada wyłączna jest często nadmiarowa, podobnie jak blokowanie całego pliku.
Wyróżnia się zatem blokadę
Inną kwestią jest ziarnistość blokad. Bardzo często wystarczy zablokować tylko modyfikowany lub czytany fragment pliku.
Więcej szczegółów związanych z synchronizacją znajduje się w następnych modułach.
Tabela pokazuje, które rodzaje blokad mogą współistnieć, a które się wykluczają. Jak już wcześniej wspomniano, blokada do odczytu może współistnieć z inna blokadą do odczytu — współbieżny odczyt jest dopuszczalny. Żeby natomiast uniknąć odczytu danych częściowo tylko zmodyfikowanych lub nie dopuścić do hazardu w przypadku współbieżnych modyfikacji (patrz następny moduł) blokada wyłączna wyklucza inne blokady.
Celem wykładu jest zaprezentowanie wybranych implementacji systemu plików, omówienie struktur najważniejszych metadanych dla tych systemów, oraz przedyskutowanie pewnych konsekwencji przyjętych założeń projektowych.
Geneza systemu plików wiąże się z jakimś systemem operacyjnym, ale współcześnie niektóre systemy operacyjne udostępniają wiele różnych systemów plików. Przykładem może być system Linux, w którym na różnych partycjach mogą współistnieć takie systemy plików, jak ext2, ext3, RaiserFS, itd. Istnieje też możliwość dostępu do systemów plików, opartych na strukturze FAT, zastosowanej w DOS oraz Windows 95/98, NTFS, czy też sieciowych systemów plików, np. NFS. Możliwość współistnienia wielu systemów plików możliwa jest dzięki dodatkowej warstwie w implementacji obsługi systemu plików, zwanej wirtualnym systemem plików (VFS).
W module zaprezentowane zostaną systemy plików CP/M, MS DOS (oparty na strukturze FAT), ISO 9660 (podstawowy systemów plików dla CD ROM), typowy system uniksowy, oraz NTFS (stosowany w nowszych rozwiązaniach firmy Microsoft).
Plik w systemie CP/M opisany jest przez blok kontrolny (FCB). Bloki FCB wszystkich plików znajdują się w katalogu, przy czym jest tylko jeden katalog dla danej partycji. W systemie CP/M nie ma więc hierarchicznej struktury katalogów. Implementacyjnie struktura ta jest jednopoziomowa, a logicznie dwupoziomowa, gdyż atrybutem każdego pliku jest kod użytkownika. Każdy użytkownik widzi więc tylko swoje pliki. Rozróżnienie plików poprzez kod użytkownika umożliwia zatem nadawanie im tych samych nazw.
System plików CP/M projektowany był na potrzeby obsługi dyskietek o stosunkowo niewielkich rozmiarach (180 KB). Dane (zawartość pliku) znajdują się w 128-bajtowych sektorach, jednostką alokacji jest jednak blok o rozmiarze 1KB (8 sektorów). Do zarządzania wolną przestrzenią używany jest wektor bitowy, przechowywany w pamięci, zajmujący 23 bajty, wyliczany każdorazowo po restarcie lub zmianie nośnika.
Katalog oraz obszar danych mają w strukturze partycji ustalony rozmiar. Oznacza to, że maksymalna liczba plików oraz ich łączny rozmiar definiowane są na etapie formatowania partycji.
Jak wynika ze struktury wpisu katalogowego, nazwa pliku składa się z 8 znaków, oraz 3 znaków rozszerzenia, kojarzonych z typem pliku. Jeden taki wpis identyfikuje 16 jednostek alokacji, czyli maksymalnie 16 KB. Rzeczywisty rozmiar obszaru danych, objętych wpisem, podany jest z dokładnością do 128 bajtów (liczba sektorów). Jeśli rozmiar pliku nie jest wielokrotnością 128 bajtów, wymagany jest jakiś specjalny bajt w zawartości pliku, sygnalizujący jego koniec.
W przypadku plików większych niż 16 KB konieczne jest opisanie ich za pomocą większej liczby jednostek katalogowych. Dla tego samego pliku istnieje zatem kilka wpisów, w których jest ten sam kod użytkownika oraz nazwa wraz z rozszerzeniem. Każdy wpis identyfikuje inny zakres bloków z danymi, a właściwa kolejność wpisów określona jest przez wartość pola extent.
Koncepcje przydziału kilku pozycji do opisu jednego pliku wykorzystano również na potrzeby przechowywania długich nazw plików w systemach MS Windows 95/98 oraz na potrzeby pomieszczenia dużej liczby atrybutów w systemie plików NTFS.
Rozmiar wpisu katalogowego jest taki sam, jak bloku kontrolnego w systemie CP/M. Dzięki temu w systemie MS DOS istnieje alternatywna możliwość korzystania z bloków FCB.
System DOS dopuszcza wielopoziomową, hierarchiczną strukturę katalogów. Katalog implementowany jak każdy plik, ale zawiera w treści 32-bajtowe opisy innych plików lub katalogów. Wpis dla katalogu w nadkatalogu zawiera flagę, informującą, że jest to katalog, w związku z czym jego zawartość ma być traktowana i interpretowana w szczególny sposób.
Wielkość jednostki alokacji można dobrać na etapie konfiguracji (formatowania logicznego). Wielkość ta wahała się od 512 B do kilku kilobajtów w miarę zwiększania się wielkości dysków. Bloki plików, a także bloki wolne lub zawierające uszkodzone sektory, identyfikowane są poprzez odpowiednie wartości na odpowiadających im pozycjach w tablicy FAT.
Na etapie formatowani logicznego definiowany jest podział partycji, z którego wynika między innymi rozmiar tablicy FAT oraz katalogu głównego. Rozmiar tablicy FAT określa liczbę jednostek alokacji, pośrednio zatem również rozmiar jednostki alokacji, gdyż wielkość obszaru danych też jest ustalona przy formatowaniu. Oczywiście liczba jednostek alokacji nie może być większa, niż wynika to z rozmiaru elementu tablicy FAT. Element tablicy FAT musi po prostu „pomieścić” numer dowolnego bloku. Przykładowo, w przypadku 16-bitowej struktury FAT do dyspozycji jest 216=65536 numerów jednostek (w praktyce kilka numerów mniej, ze względu na kody specjalne). Przeznaczanie zatem więcej niż 128 KB (65536·16 bitów) na tę strukturę nie ma sensu, bo większej liczy jednostek i tak nie da się obsłużyć.
Ze struktury partycji wynika też, że ustalony jest rozmiar katalogu głównego. Liczba wpisów w katalogu głównym ma zatem górne ograniczenia, a w przypadku nie wykorzystania tych wpisów miejsce jest marnowane. Jeśli chodzi rozmiar podkatalogu, jest on ustalany dynamicznie z dokładnością do jednostki alokacji w miarę zwiększania lub zmniejszania liczby wpisów.
Tablica FAT jest newralgicznym elementem systemu plików. Jej uszkodzenie może spowodować całkowita utratę powiązań bloków i tym samym praktycznie zniszczyć system plików. Dlatego utrzymywana jest również kopia tej tablicy. Wątpliwości może budzić lokalizacja takiej kopii. Jeśli tablice sąsiadują ze sobą, to w przypadku zarysowania dysku przez głowicę istnieje ryzyko uszkodzenia obu tablic.
Podobnie, jak w systemie CP/M, nazwa składa się maksymalnie z 8 znaków, oraz 3 znaków rozszerzenia. Flagi są bitami, określającymi specjalne atrybuty pliku: plik ukryty, plik systemowy, plik tylko do odczytu, podkatalog, plik archiwalny, etykieta. W katalogu przechowany jest numer pierwszego bloku, czyli początek listy w tablicy FAT. Przeznaczone jest na to maksymalnie 16 bitów, a wiec taka struktura jest właściwa dla rozwiązań opartych najwyżej na 16-bitowej tablicy FAT.
FAT 32-bitowy wymaga pewnych rozszerzeń w strukturze wpisu katalogowego. Wykorzystane zostały wszystkie bajty, nieużywane w wersji opartej na FAT 12/16. Indeks pierwszego bloku podzielony jest na 2 części po 16 bitów w każdej. Dlatego nadaje się do zastosowania w rozwiązaniach opartych na FAT 32.
ISO 9660 jest standardem systemu plików dla płyt CD (również DVD), wykorzystującym wszystkie udogodnienia, które wynikają z faktu niezmienności zapisanych danych, takie jak sortowanie katalogów, czy przydział ciągły. Jego powszechnie znanymi rozszerzeniami są standardy Rock Ridge oraz Joliet.
Ciekawostką jest podwójne (grubo- i cienkokońcówkowe) reprezentowanie wszystkich liczb całkowitych — chodziło o to, aby nie dyskryminować jednego czy drugiego uporządkowania, ponieważ mogłoby to utrudnić zaakceptowanie standardu.
Standard nie definiuje przeznaczenia pierwszych 16 bloków. Obszar ten jest do dyspozycji twórcy, może np. służyć do umieszczenia programu rozruchowego w przypadku ładowania systemu operacyjnego z płyty.
Uwzględniając różnorodność zastosowań płyt kompaktowych, w deskryptorze głównego wolumenu znajduje się mnóstwo informacji o jej zawartości, autorze, wytwórcy, prawach autorskich itd. Można tam umieścić dowolne informacje, przydatne raczej tylko dla użytkownika, zapisane z użyciem dużych liter, cyfr i wybranych znaków interpunkcyjnych.
Z zakresu metadanych w deskryptorze znajduje się rozmiar bloku logicznego (2048, ale dopuszcza się więcej, np. 4096, 8192 itd.), liczba bloków na płycie, czas utworzenia i przeterminowania zawartości płyty. Jedną z najważniejszych informacji jest opis katalogu głównego, tzn. blok początkowy i rozmiar, zgodnie z zasadą przydziału ciągłego.
Wpis katalogowy może mieć zmienną długość, co przejawia się w obecności trzech pól: wielkości wpisu katalogowego , wielkości rozszerzenia oraz długości nazwy. Nazwy dłuższe niż 15 znaków należą już do rozszerzeń standardu. W standardzie ISO 9660 przewidziano taką możliwość, umieszczając właśnie pole wielkości rozszerzenia w katalogu. Struktura rozszerzenia jest już przedmiotem definicji standardu rozszerzającego.
Atrybuty lokalizacja i rozmiar są wartościami 32 bitowymi, ale ze względu na podwójną reprezentację zajmują 8 bajtów. Podobnie nr CD jest wartością 16-bitową, a zajmuje 4 bajty. Z wartościami całkowitymi 1-bajtowymi nie ma tego problemu, gdyż nie ma tam czego porządkować.
W polu flagi wyróżniono między innymi następujące bity:
Standard ISO uwzględnia operowanie zbiorami płyt, możliwe jest więc, że wpis katalogowy opisuje plik, zlokalizowany na innej płycie. Stąd pole reprezentujące numer płyty CD z lokalizacją pliku.
Opis implementacji uniksowego systemu plików ograniczony zostanie do najważniejszych koncepcji, na których opierają się różne odmiany tego systemu, stosowane w rodzinie systemów uniksowych. Podstawą implementacji jest i-węzeł, grupujący wszystkie atrybuty pliku z wyjątkiem nazwy. I-węzły tworzą tablicę, której rozmiar limituje liczbę plików w systemie. I-węzeł pośrednio lub bezpośrednio identyfikuje bloki danych pliku. Wolna przestrzeń jest identyfikowana przez grupowanie, przy czym pierwszy węzeł (blok) z indeksami wolnych bloków zlokalizowany jest w całości w bloku nadrzędnym. W pewnych odmianach stosowany jest wektor bitowy. Wektor bitowy w tych odmianach używany jest również do identyfikacji wolnych i-węzłów.
Dwa główne element partycji stanowią: tablica i-węzłów oraz bloki danych. W niektórych odmianach na jednej partycji wyodrębnia się kilka sekcji, z których każda ma strukturę zbliżoną do przedstawionej na slajdzie. Celem takiego rozdystrybuowania jest zmniejszenie strat w wyniku potencjalnych awarii oraz poprawa efektywności poprzez skrócenie czasu wyszukiwania dla głowic dyskowych.
Jak wynika ze struktury partycji, liczba i-węzłów jest ustalona, podobnie jak liczba bloków danych. Zawartość systemu plików podlega zatem takim samym ograniczeniom, jak w systemie CP/M, ale istnieje hierarchiczna struktura katalogów (drzewo katalogów, a uwzględniając pliki — graf acykliczny).
Ograniczenia na rozmiar katalogu wynikają wyłącznie z dostępności bloków danych, gdyż katalog zajmuje przestrzeń dyskową na takich samych zasadach, jak plik. Jego zawartość jest jednak interpretowana przez system zgodnie z zasadami budowy katalogów w danej implementacji. Jeden, ustalony i-węzeł opisuje korzeń drzewa katalogów.
Z każdym plikiem związany jest 1 i-węzeł. Zawiera on podstawowe atrybuty pliku w modelu uniksowym, czyli:
Pozostała część i-węzła wypełniona jest indeksami bloków z danymi. Część indeksów w i-węźle (10 – 12, zależnie od odmiany) wskazuje bezpośrednio bloki z danymi. Ponadto są jeszcze 3 indeksy, z których jeden wskazuje blok indeksowy 1-poziomowy, jeden — blok indeksu 2-poziomowego, a jeden — blok indeksu 3-poziomowego.
Katalog składa się z wpisów, kojarzących nazwę z i-węzłem. W tradycyjnym podejściu nazwa ograniczona była do 14 znaków, ale oczywiście w toku rozwoju systemów uniksowych wielkość tę zwiększano i współcześnie dopuszcza się nawet 256 znaków.
W katalogu istnieją też wpisy specjalne o nazwie . (kropka) i .. (dwie kropki), skojarzone z numerem i-węzła odpowiednio katalogu bieżącego i nadrzędnego. Wyjątkiem w tym zakresie jest korzeń drzewa katalogów, który nie ma nadkatalogu.
W projekcie systemu NTFS uwzględniono różne cele projektowe, związane głównie z efektywnością i bezpieczeństwem, takie jak obsługa dużych wolumenów, tolerancja na awarie, kryptograficzne zabezpieczenie danych, czy kompresja danych.
Plik w modelu NTFS jest zbiorem atrybutów, w szczególności atrybutu dane. Wartość każdego atrybutu traktowana jest jako strumień bajtów. Potencjalnie w pliku może być kilka strumieni danych.
Podstawową strukturą w implementacji jest główna tablica plików (MFT – master file table)
Tablica MFT ma ustalone położenie na partycji NTFS, ale ponieważ sama jest plikiem, może być powiększana w ramach strefy MFT. Strefa MFT potencjalnie dostępna jest też dla bloków danych, ale wykorzystywana jest dopiero wówczas, gdy brakuje miejsca we właściwym obszarze danych. Dla bezpieczeństwa 16 rekordów MFT, identyfikujących ważne dla systemu pliki (zawierające metadane) ma swoją kopię w środkowej części partycji.
Przestrzeń dyskowa podzielona jest na bloki (zwane klastrami lub gronami), których rozmiar jest ustalony i jest wartością z zakresu 512 B – 64 KB, zależnie od wielkości wolumenu. Typowa wartość to 4 KB. Każdy blok identyfikowany jest przez pewien logiczny numer (LCN), związany z fizyczną lokalizacją bloku.
Rozmiar rekordu MFT ustalany jest na etapie tworzenia systemu plików (formatowania logicznego) na ogół ma wielkość 1 KB. Rekord MFT poza nagłówkiem, składa się z atrybutów. Atrybut traktowany jest jako strumień bajtów, oczywiście odpowiednio interpretowany. Nagłówek atrybutu znajduje się zawsze w rekordzie MFT. Jeśli wartość atrybutu jest niewielka, może również zmieścić się w samym rekordzie. Jest to tzw. atrybut rezydentny . Jeśli wartość jest zbyt duża, umieszczana jest w obszarze danych, a w rekordzie MFT zamiast wartości znajduje się wskaźnik do tego obszaru. W przypadku niewielkiej objętości danych jest szansa umieszczenia całego pliku w rekordzie MFT.
Numer sekwencyjny jest składnikiem referencji pliku i ma na celu eliminację pomyłek, wynikających z przechowania jakieś starej referencji do już usuniętego pliku. Zwiększenie numeru sekwencyjnego o 1 oznacza, że stara referencja, nawet jeśli odnosi się do tego samego rekordu, będzie nieaktualna, gdyż będzie zawierać już nieobowiązujący numer sekwencyjny.
Pojęcia rekord bazowy i rekord rozszerzeń odnoszą się do przypadku, w którym jeden rekord MFT jest niewystarczający do przechowania wszystkich atrybutów i na potrzeby tego samego pliku przydzielany jest następny rekord.
Nie wszystkie atrybuty są obecne w każdym rekordzie MFT. Niektóre z atrybutów są są zawsze rezydentne, w przypadku innych uzależnione jest to od wielkości strumienia.
Atrybut informacje standardowe jest obligatoryjnym atrybutem każdego rekordu MFT, zawierającym informacje o właścicielu, flagi, czasy, licznik dowiązań itp. Ma on ustalony rozmiar i jest atrybutem rezydentnym.
Nazwa pliku zapisana jest kodzie Unicode (UTF-16). W rekordzie może wystąpić kilka atrybutów nazwa pliku, np. w przypadku twardych dowiązań lub dla zachowania zgodności nazw z systemem MS DOS. Atrybut ten jest zawsze rezydentny.
W pliku zwykłym istnieje anonimowy atrybut dane , który oznacza domyślny strumień danych, udostępniany w ramach operacji na pliku. Można jednak utworzyć dodatkowy, nazwany atrybut dane , którego strumień dostępny będzie przez jawne podanie nazwy tego atrybutu. Atrybut ten nie występują w przypadku katalogu, chyba że zostanie jawnie utworzony nazwany atrybut tego typu.
Atrybuty korzeń indeksu, alokacja indeksu oraz mapa bitowa indeksu wykorzystywane są w implementacji katalogów.
Atrybut lista atrybutów zawiera listę atrybutów wraz z ich lokalizacją w rekordach rozszerzeń w MFT w przypadku, gdy jeden rekord MFT jest niewystarczający do pomieszczenie informacji o wszystkich atrybutach.
Mały plik to taki, dla którego wartość atrybutu dane mieści się w rekordzie MFT. Rekord taki w najprostszym przypadku składa się z atrybutów: informacje standardowe, nazwa pliku, dane. W przypadku większego pliku, wartość atrybutu dane musi zostać przeniesiona do bloków danych poza tablicą MFT, a bloki te muszą zostać opisane odpowiednio w rekordzie MFT.
Opis polega na odwzorowaniu wirtualnych numerów bloków danego pliku (virtual cluster number — VCN), czyli numerów kolejnych bloków stanowiących strumień danych, na logiczne numery bloków dyskowych (logical cluster number — LCN). Nagłówek tabeli takiego odwzorowania zawiera zakres numerów VCN objętych opisem w tabeli, a poszczególne pozycje samej tabeli zawierają opisy tzw. przebiegów (ang. run). Przebieg jest ciągiem kolejny bloków wg. numeracji LCN. Opis takiego przebiegu składa się zatem z numeru LCN pierwszego bloku oraz liczby bloków wchodzących w skład przebiegu.
Przykład: strumień danych pliku umieszczony jest w 30 blokach, porozkładanych w 3 przebiegach różnej wielkości. Pierwszy przebieg obejmuje 8 bloków zlokalizowanych pod numerami LCN 1500 – 1507, drugi 10 bloków o numerach 1800 – 1809, a trzeci 12 bloków o numerach 2000 – 2011. Numery VCN dla takiego pliku są z zakresu 0 – 29 i taka informacja znajdzie się w nagłówku tabeli. Pozycje tej tabeli zawierają zatem: pierwsza 1500 i 8, druga 1800 i 10, trzecia 2000 i 12.
W przypadku mocno pofragmentowanego pliku liczba przebiegów może być tak duża, że ich opis nie zmieści się w jednym rekordzie MFT. W rekordzie bazowym musi zatem zostać utworzony atrybut lista atrybutów ze wskazaniem na dodatkowe rekordy MFT (rekordy rozszerzeń), w których umieszczony zostanie opis kolejnego zakresu przebiegów. W przedstawionym przykładzie rekord bazowy uzupełniono o 2 rekordy rozszerzeń.
Potencjalnie mogłoby się pojawić potrzeba utworzenia tak dużej liczby rekordów rozszerzeń, że w rekordzie bazowym nie wystarczy miejsca na ich opisanie. Rozwiązaniem jest wówczas przeniesienie atrybutu lista atrybutów z rekordu MFT do bloku dyskowego. Atrybut ten stanie się wówczas nierezydentny.
Atrybut dane jest tym, który zajmuje zwykle najwięcej miejsca. Każdy inny atrybut, którego wielkość jest znacząca, przechowywany jest według tej samej zasady.
Katalog jest sekwencją wpisów, zawierających najczęściej wyświetlane atrybuty pliku. Atrybuty te kopiowane są z rekordów MFT plików, wchodzących w skład katalogu. Przyspiesza to sporządzenie listingu zawartości katalogu, gdyż nie trzeba „sięgać” do rekordu MFT każdego pliku.
Istotnym atrybutem rekordu MFT, opisującego katalog, jest korzeń indeksu (index root). W przypadku małych katalogów atrybut ten zawiera po prostu sekwencję wpisów. W przypadku większych katalogów, wpisy zorganizowane są w strukturę B+-drzewa, w której kluczem jest nazwa pliku. Atrybut korzeń indeksu jest korzeniem tego drzewa (nazwa atrybutu staje się adekwatna do jego znaczenia), a dodatkowe atrybuty alokacja indeksu oraz mapa bitowa indeksu opisują odpowiednio lokalizację bloków z węzłami struktury indeksowej oraz ich wypełnienie.
W przypadku małego katalogu, wpisy katalogowe, posortowane według nazwy, umieszczona są w samym rekordzie MFT.
W przypadku dużego katalogu atrybut korzeń indeksu, jako korzeń B+-drzewa zawiera klucze (nazwy plików) oraz wskaźniki na węzły B+-drzewa z następnymi kluczami. Zgodnie z przykładem, VCN 0 jest wskaźnikiem na blok wypełniony nazwami, które w porządku leksykograficznym są wcześniejsze niż nazwa 1 . Podobnie, VCN 1 jest numerem bloku-węzła z nazwami w zakresie leksykograficznym od nazwa 1 do nazwa 2 itd. Węzły na kolejnych poziomach zbudowane są według tej samej zasady. Liście z kolei wypełnione są właściwymi wpisami, obejmującymi oprócz nazw, referencje, rozmiary oraz czasy dostępu.
Odwzorowanie numerów VCN bloków-węzłów na obszar danych zapewnia następny atrybut — alokacja indeksu, zbudowany tak samo, jak to opisano dla atrybutu dane.
Wszystkie informacje, w tym metadane na temat samego systemu plików, przechowywane są w plikach. Jak już wspomniano, sama tablica MFT jest plikiem i pierwszy rekord tej tablicy opisują ją samą jako plik o nazwie $MFT. $MFTMIRR jest plikiem, zawierającym kopię wpisów dla metadanych i zlokalizowanym w środkowej części partycji.
Na wypadek konieczności odtwarzania spójności systemu plików wszystkie modyfikacje metadanych (również tych, zlokalizowanych w innych rekordach MFT, opisujących normalne pliki i katalogi) rejestrowane są w tzw. dzienniku (kronice), przechowywanym w pliku $LOGFILE. W pliku tym rejestrowane są właściwie wszystkie zmiany atrybutów, z wyjątkiem atrybutu dane.
Plik $VOLUME zawiera ogólne informacje o wolumenie (np. rozmiar, etykieta, wersja systemu plików).
Plik $DEFATTR zawiera definicję typów atrybutów, możliwych do stosowania w systemie plików.
Wpis o nazwie $ zawiera opis korzenia drzewa katalogów.
Plik $BITMAP zawiera mapę bitową z informacją o wolnych i zajętych blokach dyskowych.
Celem wykładu jest przedstawienie zagadnień współbieżnego wykonywania wątków lub procesów, zwłaszcza w przypadku, gdy wchodzą one we wzajemne interakcje. Omówiony zostanie też jeden z podstawowych problemów synchronizacji — problem wzajemnego wykluczania oraz jego rozwiązania oparte na środkach dostępnych na poziomie architektury komputera.
Na potrzeby tego modułu, w celu uwypuklenia pewnych aspektów wprowadzonych wcześniej pojęć, pojęcia te zostaną ponownie zdefiniowane lub sformalizowane.
Wykład obejmuje omówienie modelu systemu współbieżnego, opartego na dwóch zasadniczych pojęciach:instrukcji atomowej i przeplocie. Pokazane zostaną przykładowe przeploty operacji dwóch współbieżnych procesów, z których nie wszystkie dają wyniki, zgodne z oczekiwaniami programisty. Na bazie tych pojęć zostanie wyjaśnione, jak rozumiana jest poprawność programu współbieżnego oraz na czym polega synchronizacja. Następnie dokonana zostanie klasyfikacja mechanizmów synchronizacji procesów, z których część zostanie omówiona w niniejszym module, a pozostała część w następnym.
Dalsza część wykładu dotyczy podstawowego problemu synchronizacji procesów — wzajemnego wykluczania i poprawności jego rozwiązania. Przedstawione zostaną algorytmy oparte wyłącznie na zapisie i odczycie współdzielonych zmiennych — algorytm Petersona oraz Lamporta (tzw. algorytm piekarni). Następnie analizowane będą rozwiązania wykorzystujące złożone instrukcje atomowe: test & set oraz exchange.
Przetwarzanie w systemie współbieżnym polega na wykonywaniu instrukcji różnych procesów. Wykonanie instrukcji (akcja) skutkuje zmianą stanu procesu i określane jest jako zdarzenie.
Instrukcje wykonywane w systemie, niezależnie od procesu, wpływają również na stan systemu jako całości. Stan systemu stanowi pewne otoczenie każdego procesu (jest tym samym elementem stanu każdego z procesów), gdyż niektóre zasoby systemu są przez procesy współdzielone. W najprostszym przypadku można mówić o współdzielonych zmiennych, których wartości wynikają z wykonywania instrukcji różnych procesów. W ten sposób dochodzi do interakcji pomiędzy procesami.
W celu ujednolicenia opisu stan systemu będzie występował wyłącznie w kontekście procesu, a interakcja pomiędzy procesami będzie realizowana poprzez zmienne wejściowe i wyjściowe poszczególnych procesów.
Przedstawioną abstrakcję można również odwzorować na proces wielowątkowy. Proces taki odpowiadałby wówczas systemowi, udostępniając środowisko do wykonywania wątków. Zmiana stanu wynikałaby z realizacji instrukcji związanych z wątkami tego procesu.
Programowanie współbieżne opiera się na dwóch zasadniczych pojęciach: instrukcji atomowej i przeplocie. Instrukcja atomowa to taka instrukcja, która wykonywana jest w sposób niepodzielny. W trakcie jej wykonywania nie są obsługiwane żadne przerwania.
W systemach z jedną jednostką przetwarzającą warunki te spełnia każdy rozkaz procesora, gdyż sprawdzanie wystąpienia przerwań oraz ewentualna ich obsługa wykonywana jest zawsze na końcu cyklu rozkazowego. Poza tym skutki wykonania takiej instrukcji są natychmiast widoczne dla instrukcji następnych.
W systemach wieloprocesorowych instrukcje mogą być wykonywane jednocześnie przez różne jednostki przetwarzające. Takie wykonanie instrukcji odbywa się w izolacji, co gwarantuje, że żadne częściowe (tymczasowe) wyniki nie są widoczne i tym samym nie wpływają na wykonanie innych instrukcji. Jeśli jednak jednocześnie wykonywane instrukcje operują na tych samych danych, konieczne jest najczęściej wykonanie ich w określonej sekwencji. W systemach wieloprocesorowych, opartych na wspólnej magistrali, efekt ten można uzyskać przez zablokowanie dostępu do magistrali systemowej na czas wykonywania instrukcji. W architekturach Intel, w tym celu przekazywany jest sygnał LOCK, który jest integralnie związany z cyklem rozkazowym w przypadku niektórych rozkazów (np. xchg) lub wynika z jawnego żądania ze strony wykonywanego programu, poprzez użycie prefiksu LOCK.
W przyjętych oznaczeniach ei (c , O ) oznacza wykonanie w ramach procesu Pi operacji c ∈C, w wyniku której czytane lub modyfikowane są operandy (argumenty) ze zbioru O = {o1 , o2 ,..., on} ⊆ D. Formalnie wykonanie operacji jest zatem elementem iloczynu kartezjańskiego C × 2D.
Z punktu widzenie współbieżnej i asynchronicznej realizacji przetwarzania przez wiele procesów istotne jest, kiedy jakaś instrukcja się wykona, zwłaszcza instrukcja, która wpływa na otoczenie procesu (potencjalnie zatem na inne procesy). Dlatego najbardziej istotny jest ten aspekt stanu procesu, który dotyczy wykonywania instrukcji i pośrednio wpływa na realizację innych procesów w systemie.
Na poziomie architektury procesora następną instrukcję do wykonania bezpośrednio wskazuje rejestr w procesorze, zwany licznikiem rozkazów lub wskaźnikiem instrukcji. Jednak następna wartość tego rejestru zależy od wykonywanego rozkazu oraz ustawienia flag w rejestrze, zwanym słowem stanu programu. Zawartość tego rejestru wynika z kolei z wcześniej wykonanych instrukcji oraz wartości ich operandów. Poza tym możliwość wykonania instrukcji uwarunkowana jest dostępnością takich zasobów jak pamięć, czy procesor.
Na potrzeby dalszej analizy zakłada się, że określony stan procesu jest unikalny, tzn. ten sam stan nigdy się nie powtórzy, pomimo że stan przetwarzania (stan rejestrów procesora, pamięci) będzie dokładnie taki sam jak wcześniej. Można przyjąć, że elementem stanu procesu jest rzeczywisty czas ostatniego zdarzenia lub licznik wykonanych instrukcji, który będzie się monotonicznie zwiększał.
Przedstawiona definicja jest nieco bardziej sformalizowaną postacią definicji przedstawionej wcześniej na potrzeby zarządzania zasobami systemu.
Odwzorowanie L zdefiniowane jest przez program dla procesu, zakładając, że program jest deterministyczny. Odzwierciedla ono fakt, że zajście zdarzenia w określonym stanie prowadzi do następnego stanu. Opisując to z drugiej strony można stwierdzić, że stan następny uwarunkowany jest zajściem zdarzenia i stanem poprzedzającym to zajście. Odwzorowanie to nie jest określonej dla każdej pary ze zbioru Si ×Ei. W przetwarzaniu sekwencyjnym stan determinuje następne zdarzenie, np. licznik rozkazów wskazuje następny rozkaz do wykonania.
Jak już zasygnalizowano na poprzednim slajdzie, użycie pojęcia wątek, obok powszechnie używanego w tym kontekście pojęcia proces, podkreśla fakt, że realizacja współbieżnego przetwarzania przebiega we wspólnej przestrzeni adresowej, czyli przy dostępie do współdzielonych danych. W tym module pojęcia proces i wątek będą utożsamiane.
Przetwarzanie sekwencyjne oznacza następstwo stanów i zdarzeń. Zarówno zdarzenia, jak i stany w procesie sekwencyjnym są liniowo uporządkowane zgodnie z kolejnością ich wystąpienia.
Na potrzeby analizy systemu współbieżnego przyjęte zostaje założenie, że zdarzenia zachodzą w sposób natychmiastowy i pojedynczo, stan natomiast może trwać przez pewien interwał czasu. Oznacza to, że operacje wykonywane są sekwencyjnie, co odpowiada systemowi współbieżnemu z jedną jednostką przetwarzającą.
Zakładając, że w systemie z kilkoma równolegle działającymi procesorami operacje jednoczesne (nakładające się w czasie, ang. overlapping) nie powoduję konfliktu w dostępie do danych, model taki jest w dalszym ciągu adekwatny. Można pokazać, że przetwarzanie z jednoczesnym wykonaniem pewnych instrukcji jest równoważne wykonaniu sekwencyjnemu.
Jeśli występuje konflikt w dostępie do danych, tzn. dwie (lub więcej) instrukcje wykonywane jednocześnie mają wspólny operand, przy czym przynajmniej jedna z nich go modyfikuje, konieczne jest ich uszeregowanie w czasie. W wyniku tego uszeregowania instrukcje „w konflikcie” będą wykonane w pewnej sekwencji.
Niezależnie zatem od sposobu realizacji przetwarzania, instrukcje różnych procesów będą analizowane tak, jak gdyby przeplatały się one w czasie.
We współbieżnej realizacji zakłada się, że procesy działają asynchronicznie, tzn. liczba instrukcji poszczególnych procesów, wykonana w jednostce czasu, może być dla każdego z nich inna. Oznacza to, że nie ma pewności, w jakiej kolejności instrukcje różnych procesów będą następowały po sobie, chyba że kolejność tę wymuszą zastosowane mechanizmy synchronizacji.
Kontynuując rozumowanie, przedstawione na poprzednich slajdach, można powiedzieć, że na stan przetwarzania współbieżnego składają się stany poszczególnych procesów, a zmiana tego stanu spowodowana jest zdarzeniem w jednym z tych procesów.
Na stan początkowy przetwarzania składają się stany początkowe poszczególnych procesów.
Podobnie jak odwzorowanie L, odwzorowanie G nie jest określone dla każdej pary ze zbioru Σ × Δ. Nie każde zdarzenie może zatem wystąpić w określonym stanie przetwarzania współbieżnego. W przeciwieństwie do stanu procesu sekwencyjnego stan przetwarzania współbieżnego nie determinuje jednak jednoznacznie następnego zdarzenia, gdyż potencjalnie jakieś zdarzenie może wystąpić w każdym ze współbieżnych procesów. Liczba możliwych zdarzeń może być zredukowana poprzez zastosowanie mechanizmów synchronizacji.
Analizując konkretną realizację przetwarzania można określić jakie stany i jakie zdarzenia miały miejsce, kiedy miały miejsce (w jakiej kolejności). Analizując program dla przetwarzania współbieżnego, pewne stany i zdarzenia należy przewidzieć, gdyż każde wykonanie takiego programu może przebiegać nieco inaczej. Ponieważ w większości przypadków dopuszczalnych jest wiele zdarzeń różnych procesów, w przypadku przetwarzania asynchronicznego nie wiadomo, które dokładnie zdarzenie zajdzie jako kolejne. Stąd niedeterminizm takiego przetwarzania.
W niektórych przypadkach kolejność wystąpienia zdarzeń nie ma znaczenia, osiągamy ostatecznie taki sam stan. Są jednak przypadki, w których wystąpienie określonego zdarzenia na tyle istotnie wpływa na stan przetwarzania współbieżnego, że sterowanie w niektórych procesach może przebiegać zupełnie inną ścieżką. Zjawisko, w którym w zależności od kolejności pewnych zdarzeń system osiąga różne stany, określa się jako hazard (ang. race condition).
Przeplot jest takim globalnym uporządkowaniem akcji w systemie, które zachowuje porządek wynikający z programu każdego ze współbieżnych procesów. Używając zależności teoriomnogościowych, można stwierdzić, że Y1≤xn→i⊆→ lub dokładniej, że relacja → jest liniowym rozszerzeniem przechodniego domknięcia sumy mnogościowej Y1≤xn.
Przeplot może być analizowany w kontekście zrealizowanego już przetwarzania, a może być rozważany potencjalnie, jako ciąg dopuszczalnych zdarzeń i wynikających z nich stanów, na potrzeby weryfikacji poprawności lub innych własności. W tym drugim przypadku, uwzględniając niedeterminizm, należałoby raczej mówić o pewnym zbiorze możliwych przeplotów, czyli różnych uporządkowaniach tego samego lub zbliżonego zbioru zdarzeń. Różnice w samym zbiorze zdarzeń mogą wynikać z faktu, że w zależności od stanu przetwarzania, przebieg sterowania w poszczególnych procesach może być nieco inny, w związku z czym pewne instrukcje mogą zostać pominięte.
Z punktu widzenia analizy określonych własności, typu bezpieczeństwo, żywotność, zakleszczenie, istotny jest nie tyle przeplot ile stan systemu, który powstanie w wyniku zajścia zdarzeń w przeplocie. Kluczowe w tym kontekście jest pojęcie osiągalności stanów. Osiągalność jakiegoś stanu z innego stanu zachodzi wówczas, gdy istnieje przeplot, który prowadzi z jednego stanu do drugiego. Wyraża to formalnie definicja rekurencyjna, przedstawiona na slajdzie.
Procesy niezależne to takie, w przypadku których nie można mówić o bezpośrednim wpływie jednego z nich na stan innego. Procesy takie mogą oczywiście rywalizować o zasoby, zarządzane przez system operacyjny. Niedostatek tych zasobów (np. czasu procesora, pamięci fizycznej, dostępności drukarki itp.) może spowodować spowolnienie przetwarzania jedno z nich na rzecz drugiego. W każdym z procesów wystąpi jednak prędzej czy później określona sekwencja stanów, niezależnie od przeplotu operacji tych procesów.
Procesy współpracujące ze sobą mogą się komunikować i rywalizować o dostępność zasobów, a z faktu wystąpienia interakcji między nimi może wynikać taka lub inna sekwencja osiąganych stanów a nawet realizowanych instrukcji (taki lub inny przepływ sterowania). Zdarzenie związane z jednym z procesów może mieć zatem wpływ na wybór instrukcji do wykonania w innym. Na przykład, jeden z procesów modyfikuje współdzieloną zmienną, od wartości której zależy spełnienie warunku wykonania instrukcji lub pętli w innym procesie.
Niektóre zmienne mogą być dostępne w obrębie tylko jednego procesu. Nie mogą one być oni czytane ani modyfikowane przez inne procesy. Takie zmienne będą określane jako lokalne , a w algorytmach ich definicje poprzedzane będą modyfikatorem local.
Zmienne współdzielone z kolei dostępne są dla kilku (w szczególności wszystkich) procesów. Można rozważać różne schematy dostępności zmiennych współdzielonych, np. dostępność do zapisu w jednym procesie, a do odczytu w pozostałych procesach. W prezentowanych algorytmach własności takie nie będą wyrażane explicite, mogą jednak wynikać konstrukcji algorytmu. W algorytmach definicje zmiennych współdzielonych będą poprzedzane modyfikatorem shared.
Za pośrednictwem danych (zmiennych) wejściowych proces uzyskuje informacje od innych procesów z jego otoczenia. Za pośrednictwem danych wyjściowych z kolei proces przekazuje informację do innych procesów z otoczenia. Zbiory danych wejściowych i wyjściowych nie muszą być rozłączne — pewne zmienne mogą być zarówno wejściowymi dla danego procesu, jak i wyjściowymi. Takie dane będą określane jako wejściowo-wyjściowe.
W przedstawionym programie instrukcja podstawienia n := n + 1 wykonywana jest współbieżnie przez 2 wątki: A oraz B, a n jest zmienną współdzieloną przez te wątki. Innymi słowy, zmienna n znajduje się w obszarze pamięci współdzielonym przez te wątki i jest dla nich zmienną wejściowo-wyjściową. Instrukcja podstawienia wymaga wykonania operacji arytmetycznej, w związku z czym może być różnie przetłumaczona na kod maszynowy, czyli na sekwencję instrukcji wykonywanych atomowo.
W procesorach o architekturze RISC operacje arytmetyczne wykonywane są wyłącznie na rejestrach procesora, wobec czego podstawienie takie wymaga wcześniejszego załadowania zawartości komórki pamięci, przechowującej wartość zmiennej n, do odpowiedniego rejestru, dodania wartości 1 do zawartości tego rejestru, a następnie umieszczenia zmodyfikowanej wartości ponownie w pamięci pod adresem przypisanym zmiennej n. W tym celu wątek A korzysta z jakiegoś rejestru procesora, oznaczonego RA , a wątek B z rejestru RB. W szczególności może to być ten sam rejestr, ale raz występujący w kontekście wątku A, a raz w kontekście wątku B.
W procesorach o architekturze CISC powszechne są rozkazy typu odczyt modyfikacja zapis (ang. read-modify-write). Przykładem może być 16- lub 32-bitowa architektura intelowska z rozkazem inc , którego operand może być w pamięci. Rozkaz ten może być zatem użyty w przekładzie na kod maszynowy wysokopoziomowej instrukcja podstawienia n := n + 1.
Dwa różne przeploty operacji wątków A i B prowadzą do innych wyników. Przeplot pierwszy daje wynik zgodny z oczekiwaniami, a w przeplocie drugim wątek B czyta zmienną n po jej modyfikacji w wątku A, ale przed udostępnieniem zmodyfikowanej wartości dla otoczenia. Można zatem powiedzieć, że w momencie pobrania wartości zmiennej n przez wątek B modyfikacja miała lokalny charakter w wątku A. Innymi słowy, przedstawiony sposób modyfikacji nie jest wykonaniem instrukcji atomowej i po dwóch pierwszych operacjach wątku A nastąpiło przełączenie kontekstu na wątek B.
W przypadku procesora typu CISC można wykonać atomowo operację zwiększenia o 1 bez ryzyka niepożądanego przeplotu. Niezależnie od kolejności wykonania operacji przez oba procesy wynik jest zgodny z oczekiwaniami. Wykonanie takiej operacji w systemie wieloprocesorowym wymagałoby jednak użycia prefiksu LOCK przed instrukcją inkrementacji w programie dla wątków. W przeciwnym przypadku istnieje ryzyko, że w trakcji realizacji operacji przez jeden procesor, drugi procesor rozpocznie wykonywanie konfliktowej operacji.
Jak wydać na przedstawionym wcześniej przykładzie, nie wszystkie przeploty operacji współbieżnych procesów (wątków) są dopuszczalne z punktu widzenie oczekiwań programisty. Swobodę przeplotu należy zatem czasami ograniczyć poprzez zastosowanie mechanizmów synchronizacji w celu kontroli przepływu sterowania pomiędzy współbieżnymi procesami.
Synchronizacja na najniższym poziomie polega na wykonaniu określonych (często specjalnych) instrukcji, które powodują zablokowanie postępu przetwarzania do czasu wystąpienia określonego zdarzenia w systemie, związanego również z instrukcją synchronizującą, ale w innym wątku.
Synchronizacja na wyższym poziomie polega na użyciu w programie specjalnych konstrukcji lub odpowiednim zdefiniowaniu struktur danych, które kompilator zamienia na właściwe instrukcje synchronizujące, udostępniane przez system operacyjny lub architekturę procesora.
Problem wyspecyfikowania intencji programisty odnośnie dopuszczalnych przeplotów wiąże się z warunkami poprawności programów współbieżnych. Ogólnie formułuje się dwie podstawowe własności:
Dodatkowo sformułować można własność uczciwości (lub inaczej sprawiedliwości, ang. fairness) programów współbieżnych. Własność ta jest uszczegółowieniem własności żywotności i precyzuje czas oczekiwania na wystąpienie określonego stanu.
Własność uczciwości zostaje tylko zasygnalizowana i nie będzie w dalszej części analizowana w prezentowanych algorytmach.
Wśród mechanizmów synchronizacji można wyodrębnić dwie zasadnicze klasy:
Środki udostępniane przez poziom maszynowy procesora to głównie atomowy zapis oraz odczyt współdzielonych danych, określanych również jako współdzielone rejestry, czyli współdzielone komórki pamięci. Na poziomie architektury komputera mamy gwarancję atomowego transferu danych 8-, 16-, 32-bitowych itd. pomiędzy rejestrami procesora a pamięcią, co daje pewność, że dane są zapisywane lub odczytywane „w całości”. Procesor może też udostępnić bardziej złożone operacje atomowe na współdzielonych rejestrach lub bitach rejestrów. Do takiej grupy należą np. instrukcje test & set oraz exchange.
Synchronizacja za pomocą odpowiednich instrukcji opartych na rozwiązaniach w architekturze procesora oznacza konieczność permanentnego wykonywania określonej instrukcji, aż do uzyskania oczekiwanego efektu (odpowiednik odpytywania w interakcji jednostki centralnej z urządzeniem wejścia-wyjścia). Takie podejście przy przedłużającym się oczekiwaniu oznacza najczęściej marnowania czasu procesora, chyba że procesor jest dedykowany wyłącznie do wykonywania danego procesu. W systemach ogólnych, gdy liczba zadań znacznie przekracza liczbę jednostek przetwarzających, lepszym rozwiązaniem jest uśpienie procesu do czasu zajścia oczekiwanego zdarzeniu lub osiągnięcia określonego stanu. Wykonanie instrukcji synchronizującej oznacza odpowiednią zmianę stanu procesu, co jest z kolei sygnałem dla planisty, że proces nie jest gotowy i nie jest rozważany jako kandydat do przydziału procesora. Do tego typu mechanizmów należą semafory oraz mechanizmy standardu POSIX — zamki (inaczej rygle, muteksy) i zmienne warunkowe.
Ponadto języki programowania wysokiego poziomu dostarczają konstrukcji do wyrażania oczekiwań odnośnie sposobu współbieżnej realizacji instrukcji lub dostępu do współdzielonych danych. Jako przykłady mechanizmów z tej grupy podać można monitory, regiony krytyczne, obiekty chronione (w języku Ada 95), spotkania symetryczne (w języku CSP lub Occam), spotkania asymetryczne (w języku Ada-83).
Problem wzajemnego wykluczania (ang. mutual execlusion) w ogólności formułowany jest dla n procesów, przy czym dla wygody prezentacji niektórych algorytmów numeracja przyjęta jest od 0 do n - 1 , a nie od 1 do n.
Sekcja krytyczna jest fragmentem kodu w programie każdego z procesów, który ze względu na poprawność nie może być wykonywany współbieżnie. Wykonywanie sekcji krytycznej przez jeden proces wyklucza możliwość wykonywania swoich sekcji krytycznych przez inne procesy (stąd nazwa wzajemne wykluczanie). Sekcja krytyczna każdego procesu może być inna. Najczęściej jest to fragment kodu związany z modyfikacją jakieś współdzielonej zmiennej lub z dostępem do jakiegoś zasobu, który może być używany w trybie wyłącznym. Przykładem operacji, która powinna być wykonywana w sekcji krytycznej jest zwiększanie o 1 wartości zmiennej n w przykładzie przedstawionym wcześniej. Podobnym przykładem, z różnym kodem w sekcji krytycznej jest zwiększanie licznika o 1 przez jeden proces, a zmniejszanie o 1 przez drugi proces. Z tego typu przypadkiem w praktyce można mieć do czynienia w niektórych rozwiązaniach jednego z klasycznym problemów synchronizacji — problemu producenta i konsumenta.
W ogólnej strukturze algorytmu wzajemnego wykluczania wyróżnia się 4 część:
W celu wyeksponowania protokołu dostępu, algorytmy prezentowane na kolejnych slajdach rozpoczynają się od sekcji wejściowej. Ponadto, abstrahuje się od kwestii aplikacyjnych, z których mogłoby wynikać, że w procesie jest kilka niezależnych sekcji krytycznych, związanych z dostępem do różnych zmiennych współdzielonych lub zasobów. Istotą jest realizacja protokołu dostępu !
W algorytmach tych nie wyróżnia się również procesu, który byłby arbitrem dla procesów rywalizujących o sekcję krytyczną. Wszystkie decyzje odnośnie wejścia do sekcji krytycznej podejmowane są na podstawie informacji, znajdujących się we współdzielonym obszarze pamięci. Podejścia z arbitrem wbrew pozorom nie ułatwiają rozwiązania problemu, gdyż wymagają pewnych środków komunikacji międzyprocesowej, których implementacja na bazie pamięci współdzielonej wymaga z kolei odpowiednich mechanizmów synchronizacji, w szczególności gwarancji wzajemnego wykluczania. W pewnym sensie jednak rozwiązania bazujące na mechanizmach systemowych (np. semaforach) opierają się na arbitrażu ze strony jądra systemu operacyjnego, które decyduje o przejściu procesu zablokowanego w stan gotowości.
Zasadnicze założenie na potrzeby analizy poprawności rozwiązania problemu wzajemnego wykluczania to skończony czas przebywania procesu w swojej sekcji krytycznej.
Warunkiem bezpieczeństwa jest wzajemne wykluczanie, co oznacza, że nigdy w systemie nie może zaistnieć stan, w którym dwa (lub więcej) procesy byłyby w swojej sekcji krytycznej.
Warunek postępu oznacza, że jeśli nie ma żadnego procesu w sekcji krytycznej, a są procesy w sekcji wejściowej, to jeden z nich w skończonym czasie (po zajściu skończonej liczby zdarzeń w systemie) wejdzie do sekcji krytycznej.
Warunek postępu nie gwarantuje, że konkretny proces wejdzie do sekcji krytycznej. Może się zdarzyć tak, że w momencie przejścia do sekcji wyjściowej, proces opuszczający sekcję krytyczną do sygnał do wejścia procesom oczekującym w sekcji wejściowej, w wyniku którego jakiś proces wejdzie do sekcji krytycznej, a inny (przy zachowaniu warunku bezpieczeństwa) oczywiście nie wejdzie. Przy kolejnym sygnale ze strony procesu wychodzącego z sekcji krytycznej pominięty poprzednio proces ponownie może nie uzyskać prawa wejścia, podczas gdy inny proces wykonujący swoją sekcję wejściową prawo takie dostanie. Sytuacja może się powtarzać w nieskończoność. Postęp jest zachowany bo jakiś proces wchodzi do sekcji krytycznej, ale istnieje proces permanentnie pomijany.
Warunek ograniczonego czekania gwarantuje właśnie, że każdy proces ubiegający się o wejście do sekcji krytycznej w końcu (w skończonym czasie, po skończonej liczbie zdarzeń w systemie) uzyska prawo wejścia do niej. Warto podkreślić, że nie wszystkie algorytmy gwarantuję tę własność.
Pierwsze podejście do rozwiązania problemu wzajemnego wykluczania w oparciu o pamięć współdzieloną polega na wykorzystaniu współdzielonej zmiennej wejściowo-wyjściowej numer, wskazującej numer (identyfikator) procesu, który ma prawo wejść do sekcji krytycznej. Podejście rozważane jest w kontekście dwóch procesów, mogłoby jednak być uogólnione na większą ich liczbę. Drugi z procesów wykonuje analogiczne operacje, przy czym w miejscu numeru i występuje j i odwrotnie. Kod dla Pj wygląda zatem następująco:
while numer ≠ j do nic; sekcja krytycznaj; numer := i; resztaj;
Zmienna numer, ze względu na fakt współdzielenia, jest inicjalizowana globalnie wartością, która jest numerem jednego z procesów. Proces o tym numerze będzie mógł jako pierwszy wejść do sekcji krytycznej, podczas gdy wszystkie pozostałe procesy, ubiegające się o wejście, utkną w pętli while.
Ponieważ dopiero w sekcji wyjściowej proces ustawia numer następnego procesu do wejścia do sekcji krytycznej, nie ma ryzyka naruszenie warunku bezpieczeństwa. Podejście to wymusza jednak naprzemienność zajmowania sekcji krytycznej przez dwa procesy. Nie jest zatem spełniony warunek postępu, gdyż proces Pi, wychodząc z sekcji krytycznej, nie może zająć jej ponownie, zanim nie zrobi tego proces Pj. Może więc dojść do takiego stanu, w którym proces Pi po opuszczeniu sekcji krytycznej ponownie wchodzi do sekcji wejściowej i nie może zająć sekcji krytycznej. Jeśli z programu procesu Pj wynika, że nie będzie on już wchodził do sekcji krytycznej, proces Pi nie wejdzie tam nigdy.
Podejście bazuje na współdzielonej tablicy znacznik, przy czy każdy z dwóch procesów modyfikuje w niej pozycję odpowiadającą swojemu numerowi. Traktując poszczególne pozycje tablicy znacznik w odseparowaniu można stwierdzić, że dla procesu Pi znacznik[i ] jest zmienną wyjściową, a dla Pj jest zmienną wejściową. Odwrotna zależność dotyczy oczywiście zmiennej znacznik[j].
W rozwiązaniu tym proces sygnalizuje zamiar lub docelowo fakt wejścia do sekcji krytycznej, ustawiając znacznik na swojej pozycji na true. W celu stwierdzenia dostępności sekcji krytycznej sprawdza wartość znacznika na pozycji odpowiadającej rywalowi (dla Pi rywalem jest Pj i odwrotnie). Jeśli znacznik na pozycji rywala ma wartość false, proces przerywa pętlę while i tym samym wchodzi do sekcji krytycznej.
Własność bezpieczeństwa łatwo można wykazać metodą nie wprost. Zakładając, że dwa procesy mogą jednocześnie wykonywać sekcję krytyczną, każdy z nich musiał odczytać wartość false z pozycji tablicy znacznik, odpowiadającej rywalowi. Wcześniej jednak każdy z nich ustawił wartość true na swojej pozycji. Przeplot z punktu widzenia każdego z procesów musi zatem uwzględniać fakt, że nie została ustawiona wartość true na pozycji rywala. Dla Pi oznacza to, że podstawienie true pod znacznik[j] wykonało się po zakończeniu przez niego pętli while. Dla Pj sytuacja jest odwrotna, więc Pi musiałby wykonać pętlę po podstawieniu true pod znacznik[j].
Własność postępu nie jest spełniona, gdyż mogą nastąpić podstawienia true pod odpowiednie pozycje znacznika, czyli:
znacznik[i] := true;
znacznik[j] := true;
W takim stanie systemu oba procesy utkną w pętli while w swoich sekcjach wejściowych i żaden nie wejdzie do sekcji krytycznej. Stan taki będzie stabilny, tzn. nie zmieni się, jeśli nie nastąpi jakaś interwencja z zewnątrz (spoza zbioru procesów). Jest to przykład zakleszczenia (ang. deadlock).
Przedstawione podejście jest podobne do poprzedniego. Różnica polega na tym, że zamiast tylko testować znacznik na pozycji odpowiadającej procesowi rywalizującemu po ustawieniu wartości true na własnej pozycji, proces dodatkowo wykonuje kolejno dwa podstawienia — wartości false oraz true — na swojej pozycji w tablicy znacznik. Pomiędzy tymi podstawieniami może być pewna zwłoka czasowa. W ten sposób stwarza szansę rywalowi, że „wplecie” się z odczytem znacznika (w nagłówku pętli while) pomiędzy te dwa podstawienia, odczyta false i wejdzie do sekcji krytycznej. Przykładowy przeplot w najprostszym przypadku byłby następujący:
{Pi} znacznik[i] := true; {Pj} znacznik[j] := true; {Pi} while znacznik[j] do {Pi} znacznik[i] := false; {Pj} while znacznik[i] do ... // wyjście z pętli {Pj} sekcja krytycznaj
Nie ma tu zatem zakleszczenia, gdyż przy asynchroniczności przetwarzania cały czas istnieje potencjalna szansa, że jeden z procesów opuści sekcję wejściową i wejdzie do sekcji krytycznej. Z drugiej strony nie ma pewności, że tak się kiedyś stanie. Stan taki nie jest stabilny — może (ale nie musi) się zmienić — i nazywany jest uwięzieniem (ang. livelock). Pojęcie uwięzienia można kojarzyć z głodzeniem procesu. Głodzenie dotyczy jednak określonego procesu, którego obsługa — najczęściej ze względu na niski priorytet — jest odkładana na dalszy plan, przy czym w systemie ciągle jest rywal o wyższym priorytecie. Uwięzienie z kolei dotyczy ogółu rywalizujących procesów, można zatem powiedzieć, że jest to głodzenie wszystkich współpracujących procesów.
Rozwiązanie to jest wynikiem połączenia podejścia 1 i 2. Za pośrednictwem tablicy znacznik procesy informują się nawzajem o swoim stanie, a za pośrednictwem zmiennej numer rozstrzygają ewentualny konflikt. Jeśli zatem wartość w tablicy znacznik na pozycji odpowiadającej procesowi rywalizującemu jest ustawiona na false, to nie ubiega się on o sekcję krytyczną. Następuje wówczas opuszczenie pętli while, tym samym sekcji wejściowej i wejście do sekcji krytycznej. W przypadku, gdy dwa rywalizujące procesu ustawią wartość true na swoich pozycjach w tablicy znacznik, rozstrzygnięcie sporu zależy od wartości zmiennej numer. Ten z procesów, który później ustawi w niej numer rywala, ten musi poczekać, aż rywal wyjdzie z sekcji krytycznej.
Przedstawione rozwiązanie znane jest pod nazwą algorytmu Petersona. Algorytm ten można uogólnić na n procesów, stosując podejście „wieloetapowe”. Na każdym etapie eliminowany jest jeden proces. Zmienna numer musi być wówczas tablicą n-1 - elementową, a tablica znacznik przechowuje numer etapu, na którym jest dany proces.
Idea algorytm piekarni, zaproponowanego przez Lamporta, opiera się na przydzielaniu kolejnego numeru w kolejce oczekujących petentów i wpuszczaniu petenta z najniższym numerem. Algorytm stosowany jest w niektórych urzędach, bankach oraz przychodniach lekarskich.
Etap algorytmu, w którym przydzielany jest numer, nazywany jest przejściem przez drzwi. Jest to część sekcji wejściowej. Proces, przechodząc przez drzwi, odczytuje numer wszystkich pozostałych, wybiera maksymalny z nich, zwiększa go o 1 i w ten sposób ustala swój własny numer. Proces, który wykonuje resztę, ma numer 0. Numery przydzielone procesom przechowywane są w tablicy współdzielonej numer . Pozycja i -ta tej tablicy jest zmienną wyjściową procesu Pi , a wszystkie pozostałe pozycje tablicy są dla niego zmiennymi wejściowymi. Wynika to z rozwinięcia operacji max, która w pełnej postaci mogłaby wyglądać następująco:
tmp := numer[0]; for k := 1 to n -1 do if numer[k] > tmp then tmp := numer[k]; numer[i] := tmp;
Dodatkowo można by jeszcze wykluczyć przypadek k = i w pętli. Początkowo tablica numer wypełniona jest oczywiście wartościami 0
W celu kontroli przydziału numeru każdy proces ustawia na swojej pozycji w tablicy wybieranie wartość true na czas ustalania swojego numeru. Początkowo tablica wypełniona jest oczywiście wartościami false.
Analizując szczegóły operacji na zmiennych współdzielonych, można zauważyć, że wszystkie zmienne są modyfikowane przez 1 proces, a czytane przez pozostałe. Są to tzw. współdzielone rejestry typu „jeden zapisujący wielu odczytujących” (ang. single-writer-multiple-readers shared registers).
Po ustaleniu numeru zaczyna się właściwa sekcje wejściowa, w której dokonuje się rozstrzygnięcie odnośnie zajęcia sekcji krytycznej. W tym celu proces Pi sprawdza zamiary kolejnych rywali, analizując współdzielone tablice począwszy od pozycji 0 z pominięciem własnej pozycji. Jeśli analizowana pozycja odnosi się do procesu, który jest w trakcie wybierania numeru, wykonywana jest pętla oczekiwania na zakończenie wyboru (linia 3). Wykazanie konieczności takiego oczekiwania jest jednym z zadań ćwiczeniowych.
Po ewentualnym zakończeniu wyboru następuje sprawdzenie stanu potencjalnego rywala. Jeśli ma on przydzielony numer 0, to znaczy, że wykonuje resztę i nie jest zainteresowany sekcją krytyczną — pętla while w linii 4 kończy się i rozpoczyna się kolejna iteracji pętli for. To samo dzieje się, gdy numer rywala jest większy. Możliwy jest jednak przypadek, gdy dwa procesu uzyskają te same numery. Rozstrzygający jest wówczas numer procesu, który z założenia jest unikalny. Stąd porównanie:(numer [k],k ) < (numer [i],i) ≡ numer [k] < numer [i] ∨ (numer [k] = numer [i] ∧ k < i ), które można by również zapisać jako (numer [k] · n + k) < (numer [i] · n + i ).
Jeśli w ten sposób procesowi Pi uda się zakończyć pętlę for , to znaczy, że nie ma w systemie procesu ubiegającego się o sekcję krytyczną, którego numer byłby mniejszy (lub równy przy mniejszym identyfikatorze) od Pi i możne on opuścić sekcję wejściową, zajmując tym samym sekcję krytyczną.
Po wyjściu z sekcji krytycznej, proces sygnalizuje brak zainteresowania rywalizacją, wpisując wartość 0 jako swój numer.
Atomowo wykonywana operacja test & set polega na odczytaniu dotychczasowej wartości zmiennej logicznej (w praktyce jakiegoś bitu), a następnie ustawieniu wartości tej zmiennej na true. Jeśli wartość była już true, wykonanie operacji niczego nie zmieni.
W systemie jednoprocesorowym efekt atomowości (niepodzielności) można uzyskać poprzez zablokowanie przerwań na czasy wykonywania operacji. W implementacji musiałyby się zatem znaleźć rozkazy blokowania przerwań na początku i odblokowania na końcu, właściwe dla danej architektury.
W architekturze IA-32 (Intel) tego typu operacje realizowane są na poziomie maszynowym przez rozkazy: bts, btr, btc, poprzedzone ewentualnie prefiksem lock.
Atomowo wykonywana operacja exchange polega na zamianie wartości dwóch zmiennych logicznych. Podobnie, jak w przypadku test & set, w systemie jednoprocesorowym efekt atomowości operacji można uzyskać poprzez zablokowanie przerwań na czas jej wykonywania.
W architekturze IA-32 (Intel) operacja exchange realizowana jest na poziomie maszynowym przez rozkaz: xchg, dotyczy jednak nie bitów a zawartości całych rejestrów. Pewnym ograniczeniem jest fakt, że jeden z operandów musi być w rejestrze procesora, ale nie przeszkadza to np. w zastosowaniu tego. rozkazu do rozwiązania problemu wzajemnego wykluczania. Jeśli któryś z operandów rozkazu xchg jest w pamięci, następuje blokada magistrali niezależnie od użycia prefiksu lock.
Rozwiązanie polega na wykorzystaniu współdzielonej zmiennej zamek, której wartość true oznacza zajętość sekcji krytycznej.
Na zmiennej wykonywana jest operacja test & set , która ustawia true (być może ponownie) i zwraca poprzednią wartość zmiennej. Jeśli poprzednia wartość była false, to znaczy, że w sekcji krytycznej nie było żadnego procesu i może ona zostać zajęta. W przeciwnym przypadku nie nastąpiła zmiana wartości zmiennej zamek (było true i jest nadal true), a jedynie ustalenie wartości tej zmiennej. Z wartości tej wynika oczywiście, że sekcja krytyczna jest zajęta i należy dalej kontynuować wykonywanie pętli while.
Taki algorytm może być stosowany dla dowolnej liczby współpracujących procesów. Nie gwarantuje on jednak ograniczonego czekania, gdyż nie ma żadnej pewności, że konkretny proces będzie mógł wykonać na swoje potrzeby operację test & set akurat wówczas, gdy zmienna zamek będzie miała wartość false.
Rozwiązanie z użyciem procedury exchange jest bardzo podobne. Wykorzystywana jest jednak dodatkowa zmienna lokalna klucz. Wartość zmiennej klucz zamieniana jest z wartością zmiennej zamek. Ponieważ na początku sekcji wejściowej pod klucz podstawiana jest wartość true, ta wartość trafia następnie do zmiennej zamek. Z zamka do klucza trafia z kolei dotychczasowa wartość zamka. Jeśli wartość ta jest false, można przerwać pętlę repeat - until i wejść do sekcji krytycznej. Jeśli wartością tą jest true, wykonanie operacji exchange niczego nie zmieni, a za pośrednictwem klucza proces dowie się, że sekcja krytyczna jest niedostępna.
Z realizacją wzajemnego wykluczania w taki sposób wiążą się te same kwestie, które poruszono przy rozwiązaniu z użyciem test & set.
Celem wykładu jest przedstawienie mechanizmów synchronizacji, które mogą być implementowane zarówno na poziomie architektury komputera, jak i przy wsparciu systemu operacyjnego, polegającego na odpowiednim zarządzaniu synchronizowanymi procesami. Należą do nich semafory oraz mechanizmy zdefiniowane w ramach standardu POSIX, czyli zamki oraz zmienne warunkowe.
Celem wykładu jest przedstawienie mechanizmów synchronizacji, które mogą być implementowane zarówno na poziomie architektury komputera, jak i przy wsparciu systemu operacyjnego, polegającego na odpowiednim zarządzaniu synchronizowanymi procesami. Należą do nich semafory oraz mechanizmy zdefiniowane w ramach standardu POSIX, czyli zamki oraz zmienne warunkowe.
Semafor, jako mechanizm synchronizacji procesów, został zaproponowany przez Dijkstrę.
Semafor jest zmienną całkowitą, która z logicznego punktu widzenia (z punktu widzenia aplikacji) przyjmuje wartości nieujemne (≥0) lub — w przypadku semaforów binarnych — logiczne. Zmienna semaforowa musi mieć nadaną początkową wartość (oczywiście nieujemną).
Po nadaniu początkowej wartości zmiennej semaforowej można na niej wykonywać tylko dwa rodzaje operacji:
P — opuszczanie semafora (hol. proberen),
V — podnoszenie semafora (hol. verhogen).
Operacja opuszczania powoduje zmniejszenie wartości zmiennej semaforowej, a operacja podnoszenia jej zwiększenie. Wykonując operację semaforową, proces może zastać zablokowany (przejść w stan oczekiwania). Typowym przypadkiem jest blokowanie w operacji opuszczania semafora. Operacja opuszczania nie zakończy się do czasu, aż wartość zmiennej semaforowej będzie na tyle duża (być może zostanie zwiększona w międzyczasie), że zmniejszenie jej wartości w wyniku tej operacji nie spowoduje przyjęcia wartości ujemnej. W przypadku semaforów dwustronnie ograniczonych blokowanie może wystąpić również w przypadku podnoszenia semafora.
Typowym semaforem jest semafor binarny, który może mieć dwa stany: true (podniesiony otwarty) i false (opuszczony zamknięty). Wielokrotne podnoszenie takiego semafora nie zmieni jego stanu — skutkiem będzie stan otwarcia. W niektórych rozwiązaniach przyjmuje się, że próba podniesienia otwartego semafora sygnalizowana jest błędem.
W przeciwieństwie do semafora binarnego, semafor ogólny „pamięta” liczbę operacji podniesienia. Przy wartości początkowej 0 można zatem bez blokowania procesu wykonać tyle operacji opuszczenia semafora, ile razy został on wcześniej podniesiony. Stąd określenie — semafor zliczający.
Semafor uogólniony (semafor zliczający) można zwiększać lub zmniejszać o dowolną podaną wartość pod warunkiem, że w wyniku zmniejszenia zmienna semaforowa nie osiągnie wartości ujemnej. Jeśli zatem wartość parametru, o którą ma być zmniejszona zmienna semaforowa jest większa od wartości tej zmiennej, następuje zablokowanie procesu.
Dla semafora dwustronnie ograniczonego (semafor ogólny) definiuje się górne ograniczenie, po osiągnięciu którego następuje blokowanie procesu również w operacji podnoszenia.
W implementacji na poziomie maszynowym semafor ogólny jest zmienną całkowitą nieujemną (teoretycznie nieograniczoną od góry), na której wykonywane są operacje P i V. Takie podejście do implementacji wynika zatem bezpośrednio z definicji.
W celu wyeksponowania przepływu sterowania i wskazania instrukcji, które muszą być wykonane niepodzielnie, implementację operacji P można przedstawić następująco:
procedure P(var s : Semaphore)begin próbuj: zablokuj_obsługę_przerwań; if s = 0 then begin odblokuj_obsługę_przerwań; goto próbuj end; else begin s := s – 1; odblokuj_obsługę_przerwań end; end;
Ciąg instrukcji pomiędzy zablokowaniem, a odblokowaniem przerwań wykonywany jest niepodzielnie. Istotne jest zatem niepodzielne sprawdzenie i zmniejszenie wartości zmiennej s (pod warunkiem, że jest większa od 0).
Skok do linii zaetykietowanej jako próbuj oznacza aktywne czekanie.
Zasada implementacji jest dokładnie taka sama, jak w przypadku semafora ogólnego, różnią się tylko wartości zmiennej s.
Celem implementacji na poziomie systemu operacyjnego jest zlikwidowanie aktywnego czekania i związanego z tym marnotrawstwa czasu procesora.
Zamiast permanentnego testowania zmiennej semaforowej, stan procesu zmieniany jest na oczekujący, w związku z czym planista przydziału procesora nie uwzględnia go, wybierając proces do wykonania. Z semaforem wiąże się kolejka procesów oczekujących na jego podniesienie. W definicji struktury danych na potrzeby semafora użyto abstrakcyjnej konstrukcji list of. Kolejkę taką można zbudować w oparciu o odpowiednie pola do wskazywania procesów, przechowywane w deskryptorze procesu. W strukturze semaforowej jest wówczas tzw. głowa listy, czyli wskaźnik na deskryptor pierwszego z oczekujących procesów.
W samej implementacji operacji opuszczania interesujący jest sposób modyfikacji pola wartość struktury semaforowej. Jest ono zmniejszane bezwarunkowo i może osiągnąć wartość ujemną. Interpretacja wartości tego pola jest następująca:
Zwiększenie wartości zmiennej semaforowej (pole wartość struktury semafora) jest operacją oczywistą, ale wartość ta mogła być ujemna, co oznacza, że w kolejce są procesy oczekujące na podniesienie semafora. Wówczas z kolejki wybierany jest jeden z procesów, który jest z niej usuwany, a następnie jest budzony (jego stan z oczekujący zmienia się na gotowy).
W podobny sposób można zrealizować semafor binarny, z tą różnicą, że jeśli pole wartość jest równe 1 (co oznacza otwarcie), a wykonywana jest operacja podnoszenia, to stan semafora nie ulega zmianie, czyli:
procedure V(var s : Semaphore) begin if s.wartość < 1 then s.wartość := s.wartość + 1; if s.wartość ≥ 0 then begin wybierz i usuń jakiś / kolejny proces z kolejki s.L; zmień stan wybranego procesu na „gotowy” end; end;
Nieco bardziej skomplikowany jest przypadek implementacji semaforów uogólnionych. Pozostawia się to jako ćwiczenie. Warto mieć jednak na uwadze dwa kryteria przy podnoszeniu semafora:
Wzajemne wykluczanie z użyciem semafora polega na opuszczaniu tego semafora w sekcji wejściowej i podnoszeniu w sekcji wyjściowej. Jeśli wartość początkowa semafora jest równa 1 (lub jest to semafor binarny, ustawiony początkowo na true), po wykonaniu jednej operacji opuszczania wartość zmiennej semaforowej osiągnie 0 i kolejne operacje opuszczania spowodują zablokowanie procesów. W ten sposób pozostałe procesy utkną w sekcji wejściowej do czasu, aż nie nastąpi podniesienie semafora. Podniesienie z kolei nastąpi dopiero po wyjściu z sekcji krytycznej i umożliwi jednemu z oczekujących procesów zakończenie operacji opuszczania.
Algorytm taki można zastosować dla dowolnego zbioru procesów, ale gwarancja spełnienia warunku ograniczonego czekania zależy od sposobu implementacji operacji semaforowych. Jeśli procesy, zablokowane pod semaforem, budzone są w kolejności FIFO, warunek ograniczonego czekania jest spełniony. Gdyby semafor implementowany był na poziomie maszynowym, jak to przedstawiono wcześniej, nie ma gwarancji ograniczonego czekania.
Mechanizmy synchronizacji są częścią standardu POSIX związaną z obsługą wielowątkowości. Mechanizmy te powstały zatem na potrzeby synchronizacji wątków i w takim kontekście będą rozważane w dalszej części.
Jeśli zmienne mają być użyte do synchronizacji, muszą znajdować się w obszarze pamięci dostępnym dla synchronizowanych wątków. We wszystkich operacjach zmienne synchronizujące udostępniane są przez wskaźniki. Użycie zmiennej synchronizującej musi być poprzedzone jej inicjalizacją.
Zamki są podobne do semaforów binarnych i używane są do zapewnienie wzajemnego wykluczania. Zmienne warunkowe używane są wówczas, gdy stan przetwarzania uniemożliwia wątkowi dalsze działanie i wątek musi wejść w stan oczekiwania.
Ponieważ interfejs operacji synchronizujących w standardzie POSIX wyspecyfikowany jest w języku C, w takiej samej formie będzie zaprezentowany na kolejnych slajdach.
Zamek jest obiektem typu pthread_mutex_t i do wszystkich operacji na nim jest przekazywany przez wskaźnik. Przed użyciem zamek powinien zostać zainicjalizowany. Najprostszy sposób, to podstawienie odpowiedniej stałej inicjalizującej przy jego definicji. Nieco bardziej złożone jest użycie odpowiedniej funkcji.
Jak już wspomniano, działanie zamka zbliżone jest do działania semafor binarnego. Operacja zaryglowania (zajmowania zamka, ang. lock) jest odpowiednikiem opuszczania semafora, a operacja odryglowania (zwalniania zamka, ang. unlock) jest odpowiednikiem podnoszenia semafora. Jednak z zamkiem, w przeciwieństwie do semafora binarnego, wiąże się zasada własności. Ten wątek, który zajmie zamek (zarygluje, wykona lock), musi go zwolnić (odryglować, wykonać unlock). Podnieść i opuścić semafor może natomiast dowolny proces.
Biorąc pod uwagę te analogie funkcja pthread_mutex_lock powoduje zajęcie (zaryglowanie) zamka, wskazywanego przez parametr, jeśli zamek ten jest zwolniony. W przeciwnym przypadku następuje zawieszenie wątku w oczekiwaniu na zwolnienie (odryglowanie). Zwolnienie zamka z kolei następuje w wyniku wywołania funkcji pthread_mutex_unlock przez ten wątek, który wcześniej zamek zajął. Funkcja pthread_mutex_trylock służy również do zajmowania zamka, ale nie powoduje zablokowania wątku w przypadku, gdy zamek jest zajęty. Zwracany jest wówczas tylko odpowiedni status zakończenia operacji, po którym można rozpoznać efekt.
pthread_mutex_tpthread_mutex_lock(pthread_mutex_t *m) —zajęcie zamkapthread_mutex_inlock(pthread_mutex_t *m) — zwolnienie zamkapthread_mutex_trylock(pthread_mutex_t *m) — próba zajęcia zamka w sposób nie blokujący wątku w przypadku niepowodzeniaImplementacja zamka jest zbliżona do implementacji semafora binarnego z tą różnicą, że w celu weryfikacji własności w odpowiedniej strukturze musiałby być przechowywany identyfikator wątku, który zajął zamek. Próba zwolnienia zamka poprzez wywołanie funkcji pthread_mutex_unlock wymagałaby zatem weryfikacji właściciela i ewentualnego zwrócenia błędu.
pthread_mutex_lock
pthread_mutex_unlock
pthread_mutex_trylock
Zmienna warunkowa jest obiektem typu pthread_cond_t i podobnie, jak w przypadku zamaka:
Zmienna warunkowa nie jest używana samodzielnie. Ze względu na ryzyko hazardu (różnicy w działaniu w zależności od kolejności operacji w przeplocie) pewne operacje na zmiennej warunkowej muszą być wykonywane sekcji krytycznej, chronionej przez zamek.
Wywołanie funkcji pthread_cond_wait powoduje wejście wątku w stan oczekiwania na sygnał, który z kolei musi wysłać inny wątek, wywołując funkcję pthread_cond_signal lub pthread_cond_broadcast. Na czas oczekiwania następuje zwolnienie zamka, do którego wskaźnik przekazywany jest jako drugi parametr funkcji pthread_cond_wait. Jak można się domyślać funkcja ta wywoływana jest w sekcji krytycznej. Dokładniej zostanie to omówiony przy schematach synchronizacji w dalszej części.
Funkcja pthread_cond_signal budzi jeden z oczekujących wątków, a pthread_cond_broadcast budzi wszystkie oczekujące wątki. Obudzenie wątku nie musi oznaczać natychmiastowego uzyskania stanu gotowości, podobnie jak sygnał budzika nie oznacza natychmiastowego wstania z łóżka. Wątek budzony musi jeszcze ponownie zająć zamek, który zwolnił na czas oczekiwania. Jeśli zamek jest zajęty musi poczekać na jego zwolnienie.
W kontekście przedstawionych wcześniej implementacji semaforów i zamków powyższy opis jest dość oczywisty. Warto tylko zwrócić uwagę na dwie sprawy:
pthread_cond_waitpthread_cond_signalpthread_cond_broadcastDziałanie zmiennej warunkowej kojarzone jest niekiedy z semaforem. W operacjach semaforowych używa się czasami takich samych nazw, czyli wait — opuszczanie oraz signal — podnoszenie.
Zasadnicza różnica pomiędzy zmienna warunkową a semaforem polega na tym, że sygnał na zmiennej warunkowej budzi oczekujący wątek lub jest ignorowany, jeśli żaden wątek nie oczekuje na tej zmiennej. Efekt operacji podnoszenia semafora jest natomiast odzwierciedlany w stanie semafora i może być „skonsumowany” przez późniejsza operację opuszczenia. W przypadku zmiennej warunkowej istnieje zatem ryzyko hazardu — jeśli wątek nie zdąży usnąć na zmiennej warunkowej, można stracić sygnał, który miał go obudzić.
Można rozważać dwa typowe schematy synchronizacji z użyciem zmiennych warunkowych:
W schemacie 1 wątek sprawdza warunek kontynuacji przetwarzania i jeśli jest niespełniony, wchodzi w stan oczekiwania. Jakakolwiek zmiana interesujących go aspektów stanu, będąca skutkiem aktywności innych wątków, powinna spowodować jego obudzenie. Obudzenie nie oznacza jednak, że oczekiwany stan musi wystąpić, w związku z czym wątek ponownie sprawdza warunek kontynuacji przetwarzania. Cała pętla wykonuje się w sekcji krytycznej, chronionej przez zamek, który zwalniany jest na czas oczekiwania. Z tego samego zamka korzysta wątek sygnalizujący, zatem zwolnienie jest konieczne w celu umożliwienia mu dostępu do fragmentów kodu, związanych z modyfikacją stanu przetwarzania.
Brak sekcji krytycznej podczas sprawdzania warunku kontynuacji przetwarzania, nawet jeśli sprawdzanie nie wiąże się ze modyfikacją współdzielonych zmiennych, mógłby z kolei prowadzić do hazardu i utraty sygnału. Wykazanie niepoprawności takiego podejścia pozostawia się jako ćwiczenie.
Wątek sygnalizujący w schemacie 1 budzi wątek oczekujący każdorazowo, gdy dokona modyfikacji tych aspektów stanu (tych zmiennych współdzielonych), które interesują watek oczekujący. Obudzenie może okazać się niepotrzebne, gdyż pomimo dokonanych modyfikacji, nie jest to jeszcze taki stan, na jaki czeka wątek budzony. Tę wiedzę ma jednak tylko wątek oczekujący i to on musi zweryfikować stan, ewentualnie ponownie wejść w stan oczekiwania.
Omówienie schematu 2 rozpoczynamy od wątku sygnalizującego. Znając oczekiwania wątku współpracującego, uśpionego na zmiennej warunkowej, wątek sygnalizujący może mu wysłać sygnał wówczas, gdy sprawdzi, że oczekiwany stan zaistniał.
Wątek oczekujący ma pewność, że zostanie obudzony dopiero wówczas, gdy przetwarzanie osiągnie oczekiwany stan. Po opuszczeniu funkcji pthread_cond_wait nie musi on ponownie sprawdzać warunku. Musi natomiast wykonać pthread_mutex_unlock, gdyż wychodząc z pthread_cond_wait zajmuje ponownie zamek. Schemat ten jest bardziej ryzykowny w użyciu, gdyż ten sam warunek sprawdzany jest w dwóch lub większej liczbie miejsc. Jakiekolwiek korekty w programie, dotyczące warunku, wymagają zatem modyfikacji kodu w kilku miejscach i któreś z tych miejsc można przeoczyć. Poza tym przy większej liczbie współpracujących wątków kolejność zajmowania sekcji krytycznej może być nieokreślona i narazić na zmianę stanu przetwarzania pomiędzy obudzeniem wątku, a ponownym zajęciem przez niego sekcji krytycznej. Z tego powodu w ogólnym przypadku ten schemat nie jest zalecany. Może on być stosowany w prostych rozwiązaniach z dość precyzyjnie przewidywalnym przeplotem operacji współbieżnych wątków.
Wysłanie sygnału przez wątek sygnalizujący (wywołanie pthread_cond_signal) na ogół odbywa się w sekcji krytycznej i najczęściej jest ostatnią operacją wykonywaną w tej sekcji. Warto zwrócić uwagę, że dopiero opuszczenie sekcji krytycznej (wywołanie funkcji pthread_mutex_unlock) umożliwia przejście wątku budzonego w stan gotowości, czyli właściwe opuszczenie funkcji pthread_cond_wait. Wątek sygnalizujący nie musi jednak natychmiast wyjść z sekcji krytycznej. Potencjalnie nawet mógłby dokonać kolejnych modyfikacji współdzielonych zmiennych, w wyniku których oczekiwany warunek byłby ponownie niespełniony, co kwestionowałoby zasadność schematu 2. Szerszą dyskusję na ten temat można znaleźć w literaturze przy okazji omawiania monitorów.
Można również rozważać wysłanie sygnału po wyjściu z sekcji krytycznej. Nie jest to błąd, ale zmniejsza przewidywalność decyzji planisty przydziału procesora.
Problem producenta i konsumenta dotyczy przekazywania danych — w szczególności strumienia danych — pomiędzy procesami z wykorzystaniem bufora o ograniczonej pojemności. Bufor może być zapełniony, co zmusza producenta do ograniczenia swojej aktywności, lub może być pusty, co blokuje konsumenta.
Problem czytelników i pisarzy jest ilustracją synchronizacji dostępu do współdzielonych danych, które mogą być czytane lub modyfikowane. Modyfikacja danych wymaga wyłączności dostępu do danych, podczas gdy ich odczyt może być wykonywany współbieżnie. Jest to namiastka problemu, z jakim stykają się twórcy systemów zarządzania bazami danych, projektując mechanizmy współbieżnego wykonywania transakcji.
Problem pięciu filozofów wiąże się z dostępem procesu do wielu różnych zasobów (w tym przypadku dwóch) w tym samym czasie. Skutkiem braku odpowiedniej koordynacji może być zakleszczenie (ang. deadlock), zagłodzenie któregoś procesu (ang. starvation) lub uwięzienie (ang. livelock).
Problem śpiących fryzjerów jest odzwierciedleniem zagadnień interakcji klienta z serwerem (np. w komunikacji sieciowej), w której początkowo aktywną stroną jest klient żądający obsługi, a po zaakceptowaniu żądania występuje aktywność zarówno po stronie klienta jaki i serwera. Ze względu na ograniczoną pojemność kolejki oczekujących żądań, próba nawiązania interakcji ze strony klienta może być odrzucona.
Bufor dla współpracy producenta i konsumenta ma pojemność ograniczoną do pewnej (ustalonej) liczby jednostek przekazywanego produktu. W literaturze spotkać można również nieco uproszczoną wersję tego problemu, w którym nie ma ograniczenia na rozmiar bufora. Nie ma wówczas potrzeby blokowania producenta, konieczne jest tylko blokowanie konsumenta, żeby „nie wyprzedził” producenta.
W przypadku jednego producenta i jednego konsumenta rozwiązanie wymaga dwóch semaforów ogólnych. Stan semafora wolne określa liczbę wolnych pozycji w buforze, a stan komplementarnego semafora zajęte określa liczbę pozycji zajętych. Przy założeniu, że początkowo bufor jest pusty, wartość semafora wolne wynosi n (n wolnych pozycji), a semafora zajęte 0 (żadna pozycja w buforze nie jest zajęta).
Producent ma lokalną zmienną i, która wskazuje kolejną pozycję do zapełnienia w buforze. W przypadku wielu producentów zmienna ta musiałaby być przez nich współdzielona. Zmienna zwiększana jest cyklicznie (modulo n) po każdym wstawieniu elementu do bufora. Tak funkcjonujący bufor określą się jako ograniczony bufor cykliczny.
Wstawienie elementu do bufora poprzedzone jest operacją opuszczenia semafora wolne. Brak wolnego miejsca oznacza wartość 0 zmiennej semaforowej wolne i tym samym uniemożliwia opuszczenie. W ten sposób producent blokowany jest w dostępie do bufora, co chroni bufor przed przepełnieniem. Semafor wolne zostanie podniesiony przez konsumenta, gdy zwolni on miejsce w buforze.
Jeśli producentowi uda się umieścić kolejny element w buforze, sygnalizuje to przez podniesienie semafora zajęte. Ile razy podniesie go producent, tyle razy będzie mógł go opuścić konsument.
Konsument działa symetrycznie w stosunku do producenta. Podobnie jak producent, utrzymuje on lokalną zmienną i, która wskazuje mu pozycję z kolejnym elementem do pobrania. Zmienna ta musiałaby być współdzielona w przypadku wielu konsumentów.
Przed uzyskaniem dostępu do bufora konsument wykonuje operację opuszczenia semafora zajęte, który zwiększa producent po umieszczeniu w buforze kolejnego elementu. Jeśli semafor zajęte jest równy 0, bufor jest pusty i konsument nie ma tam czego szukać. Utknie on zatem w operacji opuszczania.
Jeśli konsument uzyska dostęp do bufora, pobierze element i tym samym zwolni miejsce. Fakt ten zasygnalizuje poprzez podniesieni semafora wolne, co z kolei umożliwi wykonanie kolejnego kroku producentowi.
W problemie można rozważać dwa rodzaje użytkowników (procesów) — czytelników i pisarzy — lub użytkowników wcielających się w rolę czytelnika lub pisarza. Rozróżnienie takie jest o tyle istotne, że w niektórych rozwiązaniach (zwłaszcza w środowisku rozproszonym) przyjęcie stałej liczby czytelników i pisarzy ma istotny wpływ na konstrukcję protokołu synchronizacji.
Można rozważać dwa warianty problemu:
Zaprezentowane rozwiązanie faworyzuje czytelników, a dopuszcza głodzenie pisarzy. Synchronizacja opiera się na dwóch binarnych semaforach i współdzielonej zmiennej l_czyt (liczba czytelników w czytelni). Semafor mutex_r służy do synchronizacji dostępu do zmiennej l_czyt. Semafor mutex_w służy z kolei do blokowania pisarzy.
W prezentowanym rozwiązaniu czytelnik może wejść do czytelni zawsze, gdy nie ma w niej pisarza. Czytelnik zamyka zatem semafor mutex_r, chroniący zmienną l_czyt, po czym zwiększa ją o 1. Jeśli po zwiększeniu o 1 zmienna równa jest 1, to znaczy, że jest on pierwszym czytelnikiem, który zajął czytelnię. Musi on zatem zamknąć wejście pisarzom poprzez opuszczenie semafora mutex_w. Mogłoby się okazać jednak, że w czytelni nie było wprawdzie czytelników, ale był właśnie pisarz. Operacja opuszczenia semafora mutex_w powstrzyma czytelnika przed dostępem do czytelni do czasu wyjścia z niej pisarza (patrz następny slajd).
Jeśli do czytelni wchodzą kolejni czytelnicy, nie wykonują już operacji na semaforze mutex_w. Zamknął go już pierwszy czytelnik.
Przy wyjściu czytelnika z czytelni zmniejszana jest wartość zmiennej l_czyt. Operacja chroniona jest oczywiście przez semafor mutex_r, gwarantujący realizację w sekcji krytycznej. Gdyby po zmniejszeniu zmiennej l_czyt okazało się, że jest ona równa 0, to znaczy, że z czytelni wyszedł ostatni czytelnik i można dać szansę pisarzowi. Podnoszony jest zatem semafor mutex_w.
Może się jednak tak zdarzyć, że w czytelni zawsze będzie jakiś czytelnik. Zanim wyjdzie jeden czytelnik, następny może już wejść do czytelni. Można w ten sposób doprowadzić do głodzenia pisarzy.
Jednym zadaniem pisarza jest zakończyć sukcesem operację opuszczania semafora mutex_w. Jeśli pisarzowi się to uda, na czas pisania semafor będzie opuszczony. Kolejny pisarz utknie oczywiście na semaforze mutex_w. Pierwszy z czytelników, próbujących wejść do czytelni, również utknie na semaforze mutex_w. W wyniku zablokowania w opuszczaniu semafora mutex_w, do czasu odblokowania nie zostanie podniesiony semafor mutex_r, co spowoduje zablokowanie na nim pozostałych czytelników.
Synchronizacja w problemie pięciu filozofów odbywa się na dwóch poziomach:
Potrzeba synchronizacji na poziomie lokalnym wynika z faktu, że każdy widelec jest współwłasnością dwóch filozofów, a używany w danej chwili może być tylko przez co najwyżej jednego z nich. Globalna koordynacja z kolei jest wymagana, gdyż każdy filozof w celu przejścia do stanu „jedzenie” potrzebuje dwóch widelców. Uzyskanie tylko jednego z nich może oznaczać przetrzymywanie zasobu bez wyraźnej perspektywy zwolnienia go po osiągnięciu stanu „sytości”, do czego potrzeba drugiego.
Problem dostępu do widelców w synchronizacji pięciu filozofów można rozwiązać za pomocą tablicy semaforów binarnych — widelec . Semafor na każdej pozycji tablicy reprezentuje jeden widelec. Zmiana stanu z myślenia na jedzenie wymaga jednak dwóch widelców. Istnieje zatem ryzyko zakleszczenia lub uwięzienia, co jest istotą problemu pięciu filozofów. Problem zakleszczenia omawiany będzie w następnym module, ale uprzedzając całościowe omówienie zagadnień zakleszczenia, można powiedzieć, że najprostszym podejściem jest niedopuszczeni do powstania cyklu w oczekiwaniu na widelce. Można w tym celu stosować różne techniki:
W przedstawionym w dalszej części rozwiązaniu przyjęto pierwsze z wymienionych podejść, w związku z czym potrzebny jest semafor ogólny dopuść o wartości początkowej 4.
Przed podjęciem próby zdobycia widelców filozof opuszcza semafor dopuść . Jeśli byłby piątym procesem, dopuszczonym do rywalizacji, jest ryzyko powstania cyklu i zakleszczenia. Semafor dopuść dopuszcza jednak tylko czterech filozofów, w związku z czym nie ma ryzyka cyklu.
Fotel w salonie fryzjerskim jest stanowiskiem, obsługiwanym przez fryzjera. Zakłada się, że fryzjerów jest nie mniej niż foteli. W przypadku braku klienta fryzjer śpi. Jeśli jednak kolejka klientów nie jest pusta, fryzjerzy obsługują kolejnych klientów w miarę dostępnych foteli. Sama obsługa oznacza jednoczesną aktywność zarówno klienta, jak i fryzjera.
Problem można rozważać w kilku wariantach:
Rozwiązanie opiera się na jednym semaforze binarnym i trzech ogólnych. Poza tym, w zmiennej l_czek pamiętana jest liczba klientów oczekujących na obsługę i zajmujących miejsca w poczekalni. Semafor binarny mutex służy głównie do synchronizacji dostępu do zmiennej l_czek.
Klient zamyka semafor mutex w celu ochrony operacji na zmiennej l_czek, po czym sprawdza, czy jest wolne miejsce w poczekalni. Jeśli nie ma miejsca, otwiera semafor mutex i kończy niepowodzeniem próbę skorzystania z usługi. Jeśli natomiast jest wolne miejsce w poczekalni, to będąc cały czas w sekcji krytycznej, chronionej przez mutex, zmniejsza o 1 zmienną l_czek (zajmuje miejsce w poczekalni), podnosi semafor klient, dając w ten sposób sygnał fryzjerowi i opuszcza sekcję krytyczną. Po opuszczeniu sekcji krytycznej czeka na wolnego fryzjera na semaforze fryzjer — czeka na sygnał na tym semaforze, czyli na jego podniesienie. Kiedy pojawi się wolny fryzjer, podniesie on ten semafor i klient przejdzie do fazy strzyżenia.
Fryzjer czeka na klienta na semaforze klient, który jest podnoszony przez klienta po uzyskaniu miejsca w poczekalni. Po zakończeniu tej operacji fryzjer wie, że ma klienta więc czeka na wolny fotel opuszczając semafor fotel. Jeśli operacja się zakończy to jest fotel dla klienta i można przejść do obsługi. Najpierw zmniejszana jest zmienna l_czek, bo zwalnia się miejsce w poczekalni. Następnie poprzez podniesienie semafora fryzjer, przekazywany jest klientowi sygnał, że może wyjść ze stanu czekania i przejść do właściwej obsługi. Po zwolnieniu semafora mutex fryzjer też przechodzi do obsługi, po zakończeniu której zwalnia fotel (podnosi semafor fotel).
Zasada funkcjonowania monitora podobna jest do mechanizmów POSIX. Właściwie raczej mechanizmy POSIX wzorowane są na monitorach, gdyż koncepcja monitora została zaproponowana przez Hoare’a wcześniej, niż powstał standard POSIX.
Synchronizacja związana jest w tym przypadku z definicją określonej struktury, która (podobnie jak definicja klasy w podejściach obiektowych) obejmuje deklaracje zmiennych instancji oraz implementacje metod dostępu — wejść. Zmienne dostępne są tylko wewnątrz monitora, tzn. operacje na nich mogą być wykonywane tylko w ramach wejść. Wejścia z kolei stanowią publiczny interfejs dostępu do monitora. W ich implementacji można się odwoływać tylko do zmiennych monitora oraz parametrów.
Wejście wykonywane jest przy wyłącznym dostępie do monitora — wyklucza zatem aktywność jakiegokolwiek innego procesu wewnątrz monitora, czyli wyklucza możliwość współbieżnego wykonywana kodu monitora przez kilka procesów. Możliwe jest jednak udostępnienie monitora w przypadku, gdy proces wejdzie w stan oczekiwania na zmiennej warunkowej.
Częścią definicji monitora są zmienne warunkowe, na których proces może jawnie usnąć, a następnie zostać obudzony. Podobnie jak w przypadku mechanizmów POSIX, na czas uśpienia monitor jest zwalniany. W ten sposób uśpiony proces może kiedyś zostać obudzony przez inny proces, który wyśle sygnał na danej zmiennej. Warto jednak podkreślić, że zmienne warunkowe, jako wewnętrzne zmienne monitora, dostępne są tylko w ramach wejść. Zarówno usypianie jak i budzenie procesu jest częścią implementacji jakiegoś wejścia.
Każde wejście w definicji monitora może mieć parametry tak, jak normalna procedura. Wśród deklaracji zmiennych mogą się pojawić szczególne zmienne — warunkowe, na których w implementacji poszczególnych wejść można wykonywać operacja wait i signal . Podobnie jak w mechanizmach POSIX, wait powoduje uśpienie procesu w oczekiwaniu na sygnał i udostępnienie monitora innym procesom, a signal budzi jeden z procesów, śpiących na zmiennej warunkowej lub jest ignorowany, jeśli nie ma procesu do obudzenia.
Różnica w stosunku do mechanizmów standardu POSIX jest zatem taka, że zajęcie i zwolnienie zamaka wykonywane jest niejawnie. Sam zamek w związku z tym również nie jest jawnie deklarowany. W ten sposób można się ustrzec błędów związanych z pominięciem tego typu operacji synchronizującej. Należy jedynie zadbać o poprawność definicji struktury danych, a w zakresie tym można liczyć na wsparcie ze strony narzędzi programistycznych, np. kompilatora.
Podstawą rozwiązania problemu czytelników i pisarzy za pomocą monitora jest odpowiednio zdefiniowany bufor cykliczny. Bufor ten w prezentowanym rozwiązaniu chroniony jest przez monitor, tzn. właściwy bufor — określony jako pula miejsc — stanowi część monitora, w związku z czym dostępny jest bezpośrednio tylko w ramach wejść. Poza tym w monitorze zadeklarowane są zmienne na potrzeby obsługi dostępu do puli:
Synchronizacja dostępu wymaga jeszcze zmiennych warunkowych, na których byłyby usypiane procesy w przypadku zapełniania lub całkowitego opróżnienia bufora. W rozwiązaniu wykorzystano dwie zmienne warunkowe:
Wejście wstaw wywoływane jest przez producenta. Przed umieszczeniem elementu w puli danego bufora należy sprawdzić, czy jest wolne miejsce, czyli czy bieżące wypełnienie bufora — licz — nie jest takie, jak jego pojemność — n. Jeśli wartości są równe, bufor jest całkowicie zapełniony i proces producenta usypiany jest na zmiennej warunkowej pełny. Obudzony zostanie dopiero przez konsumenta po pobraniu elementu.
Jeśli w buforze jest wolne miejsce, na pozycji wskazanej przez zmienną wej umieszczany jest element, wstawiany przez producenta, po czym zmienna wej jest zwiększana cyklicznie o 1. Zwiększana jest też o 1 zmienna licz, gdyż przybył jeden element.
Na końcu wysyłany jest sygnał dla (być może) oczekującego konsumenta, że pojawiło się coś w buforze, co można skonsumować. Jeśli nikt nie czekan na zmiennej warunkowej pusty, sygnał zostanie zignorowany.
mplementacja wejścia pobierz jest analogiczna. Sprawdzane jest, czy bufor nie jest pusty, czyli czy liczba elementów — licz — nie jest równa 0. Jeśli licz jest równe 0, następuje uśpienie konsumenta.
Jeśli bufor nie jest pusty, konsument pobiera z pozycji, indeksowanej przez wyj element, który staje się wartością parametru wyjściowego. Zmienna wyj zwiększana jest cyklicznie, żeby wskazywała kolejny element, po czym następuje zmniejszenie zmiennej licz, gdyż w buforze zwolniła się miejsce po pobranym elemencie.
Na końcu wysyłany jest sygnał do producentów, którzy mogą czekać na zwolnienie miejsca w buforze.
Przyjmując, że początkowy stanu bufor jest pusty, w ramach inicjalizacji następuje wyzerowanie wszystkich zmiennych, związanych z kontrolą dostępu do puli.
Użycie monitora odpowiedzialnego za buforowanie w samym kodzie producenta lub konsumenta jest już bardzo proste. Wystarczy po wyprodukowaniu elementu wywołać odpowiednie wejście — wstaw, a chcąc skonsumować kolejny element, wywołać pobierz . Ponieważ bufor jest chroniony przez monitor, cała odpowiedzialność za synchronizację spoczywa na twórcy tego monitora, minimalizując ryzyko błędu w programie dla producenta i konsumenta.
W przedstawionym schemacie synchronizacji monitor czytelnia nie chroni czytelni. Monitor w tym przypadku pełni rolę koordynatora dostępu do czytelni. Jeśli w programie któregoś procesu przed wejściem do czytelni nie znalazłyby się operacje na monitorze, będące w rzeczywistości pytaniami o pozwolenie na wejście, to czytelnia i tak stałaby się dostępna, tylko w sposób nie skoordynowany, zatem z ryzykiem naruszeniem poprawności.
Gdyby czytelnia była chroniona wewnątrz monitora i dostępna byłaby poprzez wejścia typu: czytaj, pisz, to nadmiernie ograniczona byłaby współbieżność dostępu dla czytelników, gdyż wykluczaliby się oni wzajemnie.
W rozwiązaniu pominięto implementację monitora czytelnia. Implementację tę pozostawia się jako ćwiczenie.
shared czytelnia: Monitor;Przedstawiona definicja dotyczy właściwie warunkowego regionu krytycznego. Blokowanie i wznawianie procesów w przypadku regionów krytycznych odbywa się na podstawie warunku logicznego, w przeciwieństwie do monitora, gdzie jawnie wysyłany jest sygnał. Jeśli więc warunek nie jest spełniony, proces jest usypiany tak samo, jak przez jawne wywołanie wait w przypadku monitora. Również w przypadku, gdy warunek stanie się prawdziwy, proces zostanie obudzony. W przypadku monitora wymagane jest jawne wykonanie signal. Oczywiście w czasie oczekiwania na spełnienie warunku, podanego po frazie when, region krytyczny jest dostępny dla innych procesów.
shared v: T;
region v when B do S;
W przedstawionym rozwiązaniu buf jest zmienną typu rekord, obejmującą pulę pozycji i zmienne do jej obsługi (podobnie, jak w przypadku monitora). Na zmiennej buf będzie wykonywany region krytyczny.
Zasada działania tego rozwiązania jest zbliżona do monitora. Jak już wspomniano przy ogólnej definicji regionu krytycznego, różnicą jest tylko sposób opisu fragmentu kodu, wykonywanego w trybie wyłącznym oraz sposób blokowania producentów i konsumentów w dostępie do bufora.
Wzajemne wykluczanie dotyczy fragmentu kodu objętego konstrukcją region, zatem trzech operacji podstawienia, modyfikujących składowe rekordu buf. Takie same operacje w przypadku monitora znajdowały się w implementacji wejścia wstaw.
Usypianie i budzenie odbywa się niejawnie w zależności od wypełnienia bufora. Taki sam warunek sprawdzany był w przypadku monitora, ale usypianie a następnie budzenie wymagało jawnego użycia w kodzie instrukcji wait i signal .
Działanie konsumenta jest analogiczne. Warto zwrócić uwagę, że konsument wykonuje inny region krytyczny (z innym warunkiem i innym kodem wykonywanym w trybie wyłączny) na tej samej zmiennej — buf. Wykonywanie kodu konsumenta wyklucza zatem wykonywanie kodu producenta i odwrotnie.
Wzmianka o zakleszczeniu (ang. deadlock, inne tłumaczenia: blokada, impas, zastój) pojawiła się przy okazji synchronizacji procesów. W tym module, zjawisko zakleszczenie zostanie omówione w odniesieniu do zasobów systemu komputerowego. Przy odpowiednim uogólnieniu pojęcia zasób, w zakresie tym mieszczą się również zagadnienia zakleszczenia, związane z synchronizacją procesów.
Na wstępie warto przybliżyć nieformalnie, na czym to zjawisko polega. Proces w systemie, ze względu na działania innych procesów lub brak takich działań, nie może kontynuować przetwarzania, gdyż niedostępny jest jakiś niezbędny zasób. W odniesieniu do wspomnianego zakleszczenia w wyniku synchronizacji procesów — proces może czekać na jakiś sygnał synchronizujący (podniesienie semafora, zwolnienie zamka, obudzenie na zmiennej warunkowej itp.). Proces, potencjalnie udostępniający zasób (podnoszący semafor, zwalniający zamek itp.), z podobnych powodów może również zostać zablokowany i nie wykonać oczekiwanej operacji. Jeśli w ten sposób pewna grupa procesów blokuje się wzajemnie, to mamy do czynienia z zakleszczeniem.
Wykład rozpoczyna się od przypomnienia klasyfikacji zasobów systemu (odzyskiwalne i nieodzyskiwalne). Następnie omawiane są warunki konieczne wystąpienia zakleszczenia oraz ich interpretacje w kontekście obu rodzajów zasobów. Dalej omawiana jest grafowa reprezentacja stanu systemu, ułatwiająca jego analizę pod kątem zjawisk związanych z zakleszczeniem. Na końcu omawiane są zdarzenia w systemie istotne dla analizy zakleszczenia, na bazie których sformułowana jest definicja zakleszczenia.
Model systemu na potrzeby analizy problemu zakleszczenia obejmuje procesy i zasoby. Zasób, dokładniej jego rodzaj lub typ, może być reprezentowany przez wiele jednorodnych jednostek, np. pamięć jako zasób może być reprezentowana w formie jednostek zwanych stronami, paragrafami, bajtami, zależnie od sposobu przydziału (alokacji). Traktowanie jednostek jako jednorodne lub różnorodne (jednostki różnych typów zasobów) zależy czasami do sposobu wykorzystania zasobu przez proces. Jeśli w systemie są dwie różne drukarki, np. laserowa, umożliwiający tylko wydruk czarno-biały oraz atramentowa, drukująca kolorowo, to tylko od oczekiwań procesów lub użytkowników zależy, czy są to jednorodne, czy różnorodne egzemplarze. Jeśli procesy żądają po prostu wydruku, niezależnie od jakości i kolorów, egzemplarze można traktować jako jednorodne. Jeśli natomiast pojawiają się żądania wydruku kolorowego, każda z tych drukarek jest innym rodzajem zasobu.
Analizując stan systemu zakłada się, że procesy kiedyś kończą swoje przetwarzanie. Istotnym pytaniem jest, co się dzieje z zasobami tych procesów po zakończeniu. W zależności od odpowiedzi na to pytanie rozróżnia się zasoby:
Przy tej okazji warto przypomnieć, że zasoby klasyfikuje się również jako współdzielone i wyłączne oraz wywłaszczalne i niewywłaszczalne. Jak się jednak okaże przy omawianiu warunków koniecznych wystąpienia zakleszczenia, problem dotyczy tylko zasobów wyłącznych i niewywłaszczalnych. Natomiast odzyskiwalność lub nieodzyskiwalność zasobów wpływa na sposób analizy stanu systemu i postępowania w rozwiązywaniu problemu zakleszczenia.
Założenie o stałej liczbie jednostek zasobów odzyskiwalnych jest konieczne w celu analizy możliwości systemu w zakresie obsługi żądań. Założenie to jest adekwatne dla typowych realiów funkcjonowania systemów komputerowych (nikt w trakcie działania systemu nie dokłada dynamicznie pamięci, czy procesora). Dynamiczne rozszerzenie dostępnych zasobów (np. dołożenie pamięci dyskowej) wymaga rekonfiguracji w związku z tym reinicjalizacji algorytmów zarządzania zasobami.
Proces może zażądać kilka jednostek zasobu w jednym zamówieniu, skierowanym do zarządcy zasobu. Można też rozważać system, w którym zamówienie ze strony procesu obejmuje jednostki zasobów różnych typów. Zarządca będzie utożsamiany z jądrem systemu operacyjnego. Po użyciu, a najpóźniej po zakończeniu swojego działania proces zwalnia te zasobu — oddaje je ponownie do dyspozycji zarządcy, który z kolei może przydzielić je innym procesom.
W stosunku do zasobów odzyskiwalnych używa się też terminu szeregowo - zwrotne (ang. serially reusable), w celu podkreślenia, że zasób może być wykorzystywany przez wiele procesów, ale nie w tym samym czasie.
W przypadku zasobów nieodzyskiwalnych warto podkreślić fakt, że ich egzemplarze są tworzone przez jakiś proces. Zasobem takim nie jest np. papier do drukarki, pomimo że ulega zużyciu. Po pierwsze — nie jest to zasób, którym w typowych systemach komputerowych zarządza system operacyjny. Po drugie — dostępność tego zasobu nie zależy w żaden sposób od bieżącego stanu jakiegokolwiek procesu. Żaden z procesów nie może go wyprodukować. W analizie zakleszczenia chodzi natomiast o ustalenie niezbędnych działań związanych z procesami, zmierzających do precyzyjnego zidentyfikowania przyczyny zakleszczenia i ewentualnego jej usunięcia lub niedopuszczenia do powstania.
Podobnie jak w przypadku zasobów odzyskiwalnych proces ubiega się o jednostki, składając zamówienie do zarządcy, albo realizując jakiś specyficzny protokół synchronizacji. Z punktu widzenia zarządcy lub innych współpracujących procesów przydział oznacza zużycie. Proces może natomiast wytworzyć jednostki danego zasobu i udostępnić je innym procesom, które tego zażądają. Na potrzeby analizy stanu zakleszczenia zakłada się, że jeśli proces, który tworzy dany zasób, nie jest zablokowany w oczekiwaniu na inne zasoby systemu, może wyprodukować nieograniczoną liczbę jednostek, czyli taką liczbę, jakiej oczekują inne procesu.
Jednoczesne zaistnienie wszystkich warunków koniecznych nie musi oznaczać wystąpienia zakleszczenia. Niespełnienie natomiast któregoś z tych warunków oznacza brak ryzyka zakleszczenia, co jest podstawą metod zapobiegania zakleszczeniom.
Graf przydziału zasobów jest wygodną formą graficzną reprezentacji stanu sytemu na potrzeby analizy zjawisk związanych z zakleszczeniem. Poza tym można wykazać na podstawie pewnych własności tego grafu, że wystąpił pewien szczególny stan, np. właśnie stan zakleszczenia lub zagrożenia, co w połączeniu z powszechnie znanymi algorytmami analizy grafów ułatwia wykrywanie takich stanów.
Graf przydziału zasobów odzyskiwalnych (krótko graf zasobów odzyskiwalnych, graf przydziału lub graf alokacji) jest to skierowany graf dwudzielny, w którym jedną grupę wierzchołków tworzą procesy, a drugą zasoby. Krawędzie skierowane od procesów do zasobów reprezentują zamówienia, a krawędzie skierowane od zasobów (ich jednostek) do procesów reprezentują przydział.
Przedstawiony graf reprezentuje stan systemu z dwoma procesami P1 i P2 oraz dwoma rodzajami zasobów: Z1 i Z2 . Zasób Z1 składa się z jednego egzemplarza a zasób Z2 z dwóch. Krawędź skierowana od jednostki zasobu Z2 do wierzchołka procesu P1 oznacza, że jednostka ta przydzielona jest procesowi P1. Podobnie druga jednostka zasobu Z2 przydzielona jest procesowi P2. Jedyna jednostka zasobu Z1 przydzielona jest procesowi P2. Z faktu, że żadna krawędź skierowana nie wychodzi z wierzchołka procesu P2, wynika, że nie potrzebuje on innych zasobów do kontynuacji przetwarzania. Krawędź skierowana od wierzchołka proces P1 do wierzchołka zasobu Z1 oznacza zamówienie procesu P1 na jednostkę zasobu Z1. Ponieważ nie ma wolnej jednostki zasobu Z1, proces P1 musi czekać na jej zwolnienie.
Jak wspomniano przy omawianiu współbieżności, stan systemu zmienia się pod wpływem zdarzeń, związanych z działaniem procesów. Z punktu widzenia zagadnień związanych z realizacją dostępu do zasobów istotne są zdarzenia: zamówienia jednostki zasobu, nabycia zamówionej jednostki i zwolnienia nabytej jednostki. Zamówienie oraz zwolnienie są zdarzeniami, które wynikają z przetwarzania procesu. Nabycie jest zdarzeniem w procesie Pi , którego wystąpienie uwarunkowane jest dostępnością jednostek zasobu. Brak wolnych jednostek uniemożliwia zajście tego zdarzenia i powoduje wstrzymanie (zablokowanie) procesu.
Skutkiem wystąpienia zdarzenia w systemie jest zmiana stanu i związana z tym transformacja grafu przydziału.
Jeśli zawsze zamawiana jest jedna jednostka zasobu, w grafie zasobów odzyskiwalnych występuje zawsze pojedyncza krawędź zamówienia. Mówi się wówczas o żądaniach pojedynczych.
W przypadku żądania kilku jednostek w jednym zamówienia możne wystąpić kilka równoległych krawędzi zamówienia.
W pierwszym z przedstawionych stanów dopuszczalne jest zdarzenie zwolnienia jednostek zasobów przydzielonych procesowi P2 , gdyż proces P1 jest wstrzymany ze względu na niedostępność jednostki zasobu Z1 . Zakładając, że jednostki zwalniane są pojedynczo i najpierw zwolniona zostaje jednostka zasobu Z1 , uzyskujemy następny stan reprezentowany przez kolejny graf przydziału. W stanie tym dopuszczalne są już dwa zdarzenia:
Niezależnie od tego, które z wymienionych zdarzeń zajdzie jako pierwsze, w osiągniętym stanie dopuszczalne jest drugie zdarzenie. Transformację można by więc kontynuować aż do osiągnięcia stanu zwolnienia wszystkich jednostek zasobów Z1 i Z2 , przechodząc przez różne stany pośrednie, zależnie od kolejności zdarzeń dopuszczalnych. Narysowanie całej takiej sieci przejść pozostawia się jako ćwiczenie.
Przedstawiony przykład obrazuje funkcjonowanie procesu w systemie z dwoma jednostkami zasobu odzyskiwalnego. Proces Pi, ubiegając się o jednostki zasobu, zmieniają swój stan. Możliwe stany procesu są następujące:
W stanie si4 proces nie może zażądać kolejnej jednostki, ponieważ przekroczyłby możliwości systemu. Może natomiast zwolnić jedną jednostkę, wracając do stanu si2. W stanie si2 również może zwolnić jedną jednostkę. W stanie si2 dopuszczalne są więc dwa zdarzenia — zwolnienie jednostki lub zamówienie następnej.
Przykład kolejny obrazuje funkcjonowanie dwóch procesów — Pi oraz Pj, rywalizujących o zasoby. Zmiany stanu procesu Pi pokazane są w poziomie, a procesu Pj w pionie. Stan systemu, na który składa się stan sik proces Pi oraz stan sjl procesu Pj, oznaczony został jako σkl.
Wobec rywalizacji dwóch procesów o zasoby pewne stany jednego procesu są nieosiągalne, jeśli określony stan osiągnął drugi proces. Na przykład: stan σ42 oznaczałby, że proces Pi ma przydzielone dwie jednostki zasobu, a Pj — jedną jednostkę, podczas gdy system dysponuje w sumie dwoma jednostkami.
Na slajdzie przedstawiona jest kontynuacja grafu przejść między stanami, przy czym dla poprawy czytelności zrobiona została „zakładka”, polegająca na powtórzeniu stanów σ02, σ12, σ22, σ32, które pojawiły się również na slajdzie poprzednim.
Na bazie rozważanego modelu przetwarzania współbieżnego zdefiniowane zostanie zakleszczenie procesu. Wcześniej jednak wymagane jest zdefiniowanie wstrzymania procesu.
Przykładem stanu systemu, w którym wstrzymany jest proces Pi jest σ32 w poprzednim przykładzie. Jedyne dopuszczalne zdarzenia w tym stanie związane są z procesem Pj , który może zwolnić przydzieloną jednostkę, albo zażądać następnej. W stanie σ41 zablokowany jest z kolei proces Pj , gdyż zażądał on pierwszej jednostki zasobu, podczas gdy obie przydzielone są procesowi Pi. Pj musi więc czekać na zwolnienie przynajmniej jednej z jednostek przez Pi.
Przykładem zakleszczenia z kolei jest stan σ33, w którym żadne zdarzenie nie jest dopuszczalne. Jest to zatem zakleszczenie obu procesów, czyli całego systemu.
Odnosząc zjawisko zakleszczenia do grafu przydziału, należy wyodrębnić pewne własności tego grafu, ułatwiające stwierdzenie stanu zakleszczenia.
Własnością systemu, która przejawia się w grafie przydziału, podlegającym analizie, jest natychmiastowość przydziału. Oznacza ona, że jeśli zamawiane egzemplarze zasobu są dostępne (wolne), to są przydzielane bez żadnej zwłoki. Stan systemu, w którym przydzielono wszystkie dostępne egzemplarze, zamówione przez procesy, określany będzie jako zupełny (ang. expedient). Graf przedstawiony na slajdzie nie reprezentuje takiego stanu, gdyż jedna z dwóch jednostek zasobu Z2 pozostaje wolna, a ubiegają się o nią dwa procesy.
Rozważmy graf składający się z wierzchołków i łuków, rozumianych jako uporządkowane pary wierzchołków. Podstawą definiowania istotnych dla zakleszczenia własności jest osiągalność wierzchołków. Wierzchołek u jest osiągalny z wierzchołka v wtedy i tylko wtedy, gdy istnieje w grafie skierowanym ścieżka rozpoczynająca się w wierzchołku v a kończąca w wierzchołku u.
Cykl w grafie oznacza, że istnieje ścieżka rozpoczynająca się i kończąca w tym samym wierzchołku, czyli jakiś wierzchołek jest osiągalny z samego siebie.
Supeł w grafie oznacza podzbiór wierzchołków, w którym każdy wierzchołek jest osiągalny z każdego innego, a jednocześnie z żadnego z tych wierzchołków nie jest osiągalny wierzchołek poza supłem. Jak łatwo zauważyć, supeł implikuje cykl.
W przedstawionym grafie jest cykl, obejmujący wierzchołki v2, v3 i v4. Nie ma tu natomiast supła, gdyż żaden wierzchołek nie jest osiągalny z wierzchołka v5, w związku z czym wierzchołek v5 nie może należeć do supła, ale wierzchołek v5 jest osiągalny z każdego innego wierzchołka.
W obu przedstawionych przykładach jest supeł. W przykładzie pierwszym obejmuje on wszystkie wierzchołki. W przykładzie drugim supeł tworzą wierzchołki v2, v3 i v4.
Przedstawiony graf reprezentuje stan systemu, w którym wystąpiło zakleszczenie. Każdy z procesów czeka na jakąś jednostkę zasobu Z1 lub Z2 , która jest zajęta przez inny proces. Nie ma jednak w systemie procesu, który mógłby się zakończyć, bo żaden nie ma wszystkich żądanych jednostek. Cechą szczególną grafu, reprezentującego ten stan jest cykl (P1 –Z1 – P2 –Z2 ).
W tym grafie występuje również supeł.
W grafie przedstawionym na slajdzie również jest cykl, obejmujący te same procesy i zasoby, co na poprzednim slajdzie. Różnica polega na tym, że występują dwie jednostki zasobu Z2, z których jedna przydzielona jest procesowi P3. Proces P3 ma zatem (na razie) przydzielone niezbędne egzemplarze (właściwie jeden egzemplarz zasobu Z2), więc być może się zakończy. Jeśli P3 niczego więcej nie zażąda i rzeczywiście się zakończy, zwolni jednostkę zasobu Z2, która będzie mogła zostać przydzielona procesowi P2. Przy takim scenariuszu, pomimo cyklu w grafie przydziału, nie dojdzie do zakleszczenia. W bieżącym stanie systemu nie można zatem stwierdzić zakleszczenia, co jednak nie wyklucza faktu, że może istnieć stan osiągalny systemu, w którym zakleszczenie wystąpi.
Kontynuując analizę poprzedniego przykładu, gdyby w trakcie przetwarzania procesu P3 okazało się, że do jego zakończenia potrzebna jest dodatkowo jedna jednostka zasobu Z1 , uzyskujemy stan przedstawiony na slajdzie. Jest to stan zakleszczenia. Interesującą własnością grafu przydziału, opisującego ten stan, jest supeł.
W grafie nie ma supła, jest tylko cykl. Proces P2 w jednym zamówieniu żąda 2 jednostek zasobu Z2. Nawet gdyby P3 się zakończył i zwolnił przydzieloną mu jednostkę zasobu Z2, i tak nie wystarczy to do zaspokojenia żądań pozostałych procesów. Wystąpiło więc zakleszczenie.
Przykład jest podobny do poprzedniego, ale proces P2 jednocześnie żąda jednostek dwóch różnych zasobów Z2 i Z3. Tak jak w poprzednim przypadku, nawet gdyby P3 się zakończył i zwolnił przydzieloną mu jednostkę zasobu Z2, i tak nie odblokuje to procesu P2, bo cały czas niedostępna jest jednostka zasobu Z3. Również występuje tu zakleszczenie.
Spostrzeżenia z poprzednich przykładów są podstawą do wyciągnięcia pewnych wniosków, prezentowanych najczęściej w formie twierdzeń.
W przypadku zasobów pojedynczych (posiadających tylko jedną jednostkę) warunkiem koniecznym i dostatecznym wystąpienia zakleszczenia jest cykl w grafie przydziału. Warto podkreślić, że ze względu na liczebność egzemplarzy dopuszczalne są w tym przypadku tylko żądania pojedyncze.
W przypadku systemu, gwarantującego natychmiastowy przydział, gdy analizowany stan jest zupełny, supeł w grafie przydziału jest warunkiem dostatecznym (ale nie koniecznym ) zakleszczenia.
W przypadku zasobów, posiadających kilka jednorodnych egzemplarzy, przydzielanych natychmiastowo w wyniku pojedynczych żądań, warunkiem koniecznym i dostatecznym zakleszczenia jest supeł w grafie przydziału. Cykl w tym przypadku jest tylko warunkiem koniecznym, co wynika z faktu, że jest warunkiem koniecznym powstania supła.
Konstrukcja grafu zasobów nieodzyskiwalnych jest niemal taka sama jak w przypadku grafu zasobów odzyskiwalnych. Różnica w stosunku do grafu zasobów odzyskiwalnych sprowadza się do interpretacji krawędzi, konkretnie krawędzi skierowanej od wierzchołka zasobu do wierzchołka procesu. Krawędź ta — nazywana krawędzią produkcji — oznacza, analogicznie do przypadku zasobu odzyskiwalnego, możliwość uwolnienia jednostki zasobu, co w tym przypadku interpretowane jest jako utworzenie takiej jednostki. W związku z tym krawędź produkcji skierowana jest od wierzchołka zasobu, a nie od kropki, reprezentującej jego egzemplarz. Poza tym, od zasobu mogą wychodzić krawędzie skierowane do różnych procesów, gdyż ten sam zasób może mieć wielu producentów. W systemie z zasobami odzyskiwalnymi też było to możliwe, jednak krawędzie wychodziły od różnych kropek, gdyż egzemplarz używany był w trybie wyłącznym.
W przypadku dostępu do zasobów nieodzyskiwalnych występują te same zdarzenia, które wyszczególnione zostały dla zasobów odzyskiwalnych. Różnica dotyczy jednak kontekstu zachodzenia tych zdarzeń. W przypadku zasobów nieodzyskiwalnych proces nabywający nie musi ich produkować (ani produkujący nabywać), podczas gdy w przypadku zasobów odzyskiwalnych po nabyciu jednostek przez proces oczekiwało się ich zwolnienia. W przypadku zasobów odzyskiwalnych zdarzenie d zachodziło zatem na ogół w następstwie zdarzenia a w tym samym procesie. W przypadku zasobów nieodzyskiwalnych odpowiadające sobie zdarzenia a i d będą zachodzić na ogół w różnych procesach.
W systemie z zasobami zużywalnymi zrealizowanie zamówienia oznacza usunięcie jednostki zasoby, czyli kropki reprezentującej tę jednostkę w grafie. Jeśli chodzi o tworzenie, to ograniczeniem jest przypadek, gdy proces tworzący czeka na realizację własnego zamówienia.
Przykład pokazuje współpracę dwóch procesów za pośrednictwem zasobu nieodzyskiwalnego Z1, który można utożsamiać np. z semaforem uogólnionym. Proces P2 potencjalnie podnosi ten semafor. Podniesienie o 1 jest pierwszym zdarzeniem w systemie. Drugim zdarzeniem jest próba opuszczenia go o 2, co powoduje zablokowanie procesu P1. Następnie następuje podniesienie o 2 (oczywiście przez proces P2), co umożliwia nabycie (czyli rzeczywiste opuszczenie) przez proces P1.
Analiza graf przydziału zasobów nieodzyskiwalnych jest trudniejsza, niż w przypadku zasobów odzyskiwalnych. Chociaż można wskazać pewne własności, które umożliwiałyby wykrycie np. stanu zakleszczenia, dotyczą one szczególnych przypadków. Trudno np. rozważać system z zasobami pojedynczymi. Jedyną sensowną metodą jest redukcja grafu przydziału, co zostanie przedstawione w następnym module. Ale i takie podejście nie zawsze gwarantuje precyzyjne określenia rzeczywistego stanu.
W przedstawionym przykładzie procesy P3 i P4 są zablokowane ze względu na niedostępność jednostek odpowiednio zasobu Z3 i Z4. Jednostki tych zasobów mogą zostać wyprodukowane odpowiednio przez procesy P1 i P2 pod warunkiem odblokowania tych procesów. Dalszy przebieg przetwarzania zależy od kolejności zdarzeń w systemie lub decyzji zarządcy zasobów. Przydzielając jednostkę zasobu Z1 procesowi P1 a jednostkę zasobu Z2 procesowi P2 (lub odwrotnie), system wchodzi w stan zakleszczenia, niezależnie od tego czy zasoby Z1 i Z2 są odzyskiwalne, czy nie. Przydzielenie jednostek obu zasobów jednemu z procesów doprowadzi do zakleszczenia drugiego. Na przykład, jeśli P1 uzyska jednostki obu zasobów wyprodukuje Z3, co odblokuje P3, a dalej umożliwi wyprodukowanie jednostki zasobu Z1. Dla P2 zabraknie jednak jednostki zasobu Z2. W przypadku zasobów odzyskiwalnych, odpowiednie jednostki zostałyby po prostu zwolnione po zakończeniu procesów — jednostka zasobu Z2 wróciłaby wówczas do systemu. Zgodnie z definicją zakleszczenia, każdy z procesów da się odblokować (nie ma więc zakleszczenia), ale odblokowanie P1 powoduje zakleszczenie P2 i P4, a odblokowanie P2 powoduje zakleszczenie P1 i P3.
Wyszczególnione własności podobne są do tych, które omówione zostały dla zasobów odzyskiwalnych.
Zasadniczo można wyróżnić dwa rodzaje podejść do rozwiązania problemu zakleszczenia. Jedno polega na niedopuszczeniu do powstania zakleszczenia, drugie dopuszcza zakleszczenie, ale jego istotą jest wykrywanie (detekcja, ang. deadlock detection) i usuwanie tego stanu. Niedopuszczenie do zakleszczenia sprowadza się do zapobiegania (ang. deadlock prevention) lub unikania (ang. deadlock avoidance). Zapobieganie jest metodą dość zachowawczą, polegającą na przeciwdziałaniu zajściu jednego z warunków koniecznych wystąpienia zakleszczenia. Unikanie jest z kolei metodą pośrednią pomiędzy zapobieganiem a detekcją. Jej istotą jest przewidywanie przyszłych zdarzeń w systemie i sprawdzanie, czy w osiągalnych stanach występuje zakleszczenie. Stosuje się przy tym takie same metody, jak w przypadku wykrywania. Jeśli stan zakleszczenia jest osiągalny, to mamy do czynienie ze stanem niebezpiecznym (stanem zagrożenia), którego należy unikać, realizując żądania procesów. Przewidywanie przyszłych zdarzeń wymaga jednak pewnych przesłanek. Najczęściej muszą być znane maksymalne potencjalne potrzeby zasobowe współpracujących procesów.
Algorytmy wykrywania zakleszczenia, omawiane w tym module, opierają się na dwóch reprezentacjach stanu systemu, macierzowej i grafowej. Reprezentacja w postaci grafu przydziału zasobów została już omówiona w poprzednim module. Tutaj zostanie jedynie omówiona reprezentacja uproszczona w postaci grafu oczekiwania. Zostanie też omówiona reprezentacja macierzowa, oparta na wektorach i macierzach, zorientowana przede wszystkim na aspekty ilościowe w dostępności procesów do zasobów.
Zapobieganie zakleszczeniom polega na narzuceniu restrykcji na generowanie zamówień lub na ich realizację. Restrykcje te mają na celu zagwarantowanie, że nie będzie spełniony któryś z warunków koniecznych zakleszczenia. Może to jednak prowadzić do słabego wykorzystania zasobów i ograniczenia przepustowości systemu.
Unikanie zakleszczeń polega na takiej realizacji zamówień, żeby zawsze zagwarantować odpowiednią liczbę wolnych zasobów, niezbędnych dla zakończenia zadań. Strategia unikania zakleszczeń wymaga znajomości przyszłego zbioru zamówień procesów na zasoby. Innymi słowy, przed przydzieleniem pierwszego zasobu procesowi system musi wiedzieć, jakie zasoby będą żądane przez proces w dalszej kolejności, aż do momentu ich całkowitego zwolnienia. Oczywiście zamówienia mogą być realizowalne tylko w zakresie wcześniejszych deklaracji. Przekroczenie zadeklarowanych ograniczeń musi spowodować odrzucenie zamówienia.
Wykrywanie zakleszczeń wymaga okresowego uruchomienia odpowiedniego algorytmu. Jest to dodatkowe obciążenie dla systemu, gdyż w wielu przypadkach efektem będzie stwierdzenie braku zakleszczenia.
Likwidowanie zakleszczeń polega na zmuszeniu jakiegoś procesu (lub kilku procesów) do ustąpienia w rywalizacji o zasoby. Może to oznaczać:
Likwidowanie zakleszczeń w przypadku zasobów nieodzyskiwalnych polega na usuwaniu procesów. Nie można to mówić o wywłaszczaniu, ponieważ zasoby są zużywane zaraz po przydzieleniu. Z tego samego powodu, w ramach zapobiegania nie ma sensu przeciwdziałać warunkowi koniecznemu, mówiącemu o braku wywłaszczeń.
W związku z tym, że zasoby nie są zwalniane po przydzieleniu nie ma pojęcia stanu bezpiecznego, który jest podstawą unikania zakleszczenia. A więc w przypadku zasobów nieodzyskiwalnych również tego podejścia nie stosuje się.
W poprzednim module została omówiona reprezentacja stanu systemu w postaci grafu przydziału zasobów. Na potrzeby detekcji zakleszczenia lub zagrożenia reprezentację tę można jednak uprościć do grafu oczekiwania, w którym występują tylko procesy, a skierowane krawędzie wskazują, które procesy od których oczekują zwolnienia jednostek zasobów.
Reprezentacja macierzowa opiera się na wektorach i macierzach reprezentujących stan zasobów oraz żądania procesów. W odpowiednich strukturach macierzowych pamiętane są liczby jednostek zasobów poszczególnych typów, związanych z poszczególnymi procesami. Typom zasobów odpowiadają kolumny, a procesom wiersze.
Reprezentacja macierzowa ułatwia określenie w zwartej formie pewnych relacji na liczbach jednostek zasobów. Może to poprawić czytelność kodu programu, aczkolwiek w praktyce macierze, opisujące stan systemu, mogą zawierać dużo pustych miejsc (tzw. macierze rzadkie). Reprezentacja takiej macierzy w postaci tablicy oznacza spore marnotrawstwo pamięci.
Uogólniając, macierze lepiej nadają się do wyrażania zależności ilościowych, co jest szczególnie przydatne przy analizie zasobów odzyskiwalnych. Zależności pomiędzy konkretnymi procesami natomiast łatwiej odczytać z grafu, co z kolei częściej przydaje się przy analizie zasobów nieodzyskiwalnych.
Z grafu przydziału zasobów można uzyskać graf oczekiwania przez usunięcie wierzchołków zasobowych i złączenie odpowiednich krawędzi. Jeśli zatem z usuwanego wierzchołka wychodzi krawędź przydziału lub produkcji, a dochodzi krawędź zamówienia, w grafie oczekiwania pojawi się krawędź skierowana od procesu zamawiającego do procesu przetrzymującego (lub produkującego) jednostkę zasobu.
Uproszenie grafu przydziału do grafu oczekiwania ułatwia bezpośrednie zastosowanie znanych algorytmów wykrywania cykli lub supłów (węzłów, zatok) w grafie.
Zakres informacji, opisujących stan systemu, musi obejmować zasoby, jakimi w ogóle dysponuje system, zasoby przydzielone poszczególnym procesom, żądania zasobowe procesów, ewentualnie na potrzeby analizy bezpieczeństwa — deklaracje odnośnie maksymalnych żądań. Na tej podstawie można uzyskać inne przydatne informacje, np. liczbę wolnych jednostek zasobów poszczególnych typów.
Macierz C wynika z konfiguracji systemu i nie jest elementem bieżącego stanu.
Macierze R i A związane są bieżącym stanem systemu.
Macierz F wynika z C oraz A (jest to różnica tych dwóch macierzy).
Z pierwszej formuły wynika, że procesom nie można przydzielić w sumie więcej jednostek zasobów poszczególnych typów, niż liczba jednostek, zarządzana przez system.
Druga formuła właściwie definiuje wektor wolnych jednostek. Wszystkie jednostki, nie będące w posiadaniu któregoś z procesów, są wolne.
Trzecia formuła mówi, że proces nie może żądać więcej jednostek, niż jest w dyspozycji systemu. Zatem to, co już ma przydzielone i to, co jeszcze zamawia, łącznie nie może przekroczyć liczby jednostek, którymi dysponuje system.
Przedstawiona formuła oznacza, że jest jakiś podzbiór procesów P’, oczekujących na zamówione zasoby, ale nawet gdyby wszystkie procesy spoza tego zbioru zakończyły działanie, to i tak dla każdego procesu ze zbioru P’ jakiś zasób Zj nie będzie dostępny w wystarczającej liczbie jednostek.
Zadaniem algorytmu jest przede wszystkim ustalenie, czy wystąpiło zakleszczenie. Jeśli zakleszczenie wystąpiło, można również uzyskać informację o procesach, które zostały zakleszczone. Stwierdzenie natomiast braku zakleszczenia dotyczy wyłącznie bieżącego stanu (analizowanego przez algorytm) i oznacza, że stan zakończenia przetwarzania wszystkich procesów jest osiągalny. Nie oznacza to jednak, że przy pewnej sekwencji zamówień w przyszłości i ich natychmiastowej (nie kontrolowanej) realizacji do zakleszczenia nie dojdzie.
Oprócz macierzy, opisujących stan systemu, czyli C, R, A i F, potrzebne są jeszcze zmienne pomocnicze. W miarę analizy, żądania pewnych procesów można uznać za możliwe do zrealizowania. Procesy takie uznane zostaną zatem za zakończone, co zostanie odnotowane w wektorze K. Jednostki zasobów, przetrzymywane przez te procesy, wrócą do systemu i zostaną uznana za wolne. Łączna liczba wolnych jednostek, uwzględniająca jednostki odzyskane po zakończonych procesach, przechowywana będzie w wektorze W.
Wektor W przechowuje informację o liczbie jednostek poszczególnych rodzajów zasobów dostępną dla procesów. Początkowo zatem jego wartość inicjalizowana jest zawartością wektora F. W analizie istotne są tylko te procesy, które mogą zwolnić jakieś jednostki. Wartość na pozycji, odpowiadającej tym procesom, w tablicy K jest false. Z kolei procesy, które w tablicy K mają wartość true, uznane są za zakończone lub nieistotne.
W bloku decyzyjnym poszukiwany jest proces, który może zwolnić jakieś jednostki (nie jest uznany za zakończony), a którego zamówienie może zostać zaspokojone dostępnymi w systemie jednostkami (przechowywanymi w wektorze W).
Jeśli taki proces się znajdzie, zostaje on uznany za zakończony, a zwalniane przez niego jednostki zasobów dołączane są do wektora W. Następuje powrót do bloku decyzyjnego i poszukiwanie kolejnego procesu.
Jeśli warunek (koniunkcja) w bloku decyzyjnym jest nie spełniony, to albo nie ma kolejnego procesu „do zakończenia”, albo dla żadnego z procesów nie zakończonych nie ma wystarczającej liczby jednostek któregoś z zasobów. Sprawdzane jest to w kolejnym bloku decyzyjnym. Jeśli w wektorze K są wartości false, to odpowiednie procesy są nie zakończone, zatem zakleszczone: ∀Pi: (K [i] = false ⇒ Pi jest zakleszczony).
Jeśli wszystkie procesy udało się doprowadzić do zakończenie (∀Pi : K [i] = true) nie ma zakleszczenia.
Jak wynika z opisu stanu, przydział nie przekracza liczby jednostek, którymi dysponuje system. Żaden z procesów nie przekracza też tej liczby w swoich żądaniach.
Roboczy wektor W początkowo przechowuje wolne jednostki poszczególnych typów zasobów. Liczba wolnych jednostek wystarczająca jest dla zrealizowania żądania procesu P3. W przypadku pozostałych procesów brakuje jednostek któregoś zasobu. Dla procesu P1 brakuje jednostek zasobu Z1, a dla procesów P2 i P4, jednostek zasobu Z3. Po zakończeniu procesu P3 przydzielone mu jednostki trafiają do systemu i do dyspozycji zarządcy są odpowiednio 2, 2, 1 jednostki. Taka liczba jest wystarczająca dla procesu P4, ale uzyskany po jego zakończeniu stan wolnych jednostek (odpowiednio 2, 4, 2) nie wystarczy ani dla procesu P1 (z mało jednostek zasobu Z1), ani dla procesu P2 (za mało jednostek zasobu Z3). Procesy P1 i P2 są więc zakleszczone.
Redukcja grafu przydziału jest metodą uniwersalną — nadaje się do stosowania w przypadku zasobów odzyskiwalnych i nieodzyskiwalnych, jak również w systemach, gdzie współistnieją zasoby obu tych klas. Redukowalność grafu jest też używana czasami w definicjach stanu zakleszczenia.
Redukcja polega na usuwaniu wierzchołków procesów wraz z incydentnymi krawędziami w tych przypadkach, w których żądania procesu można zrealizować. Usunięcie wierzchołka procesu oznacza zwolnienie jednostek zasobów odzyskiwalnych i utworzenie w odpowiedniej liczbie jednostek zasobów nieodzyskiwalnych.
Przykład pokazuje redukcję grafu zasobów odzyskiwalnych. Zamówienie procesu P2 może być zrealizowane, więc odpowiedni wierzchołek ulega redukcji. Po zredukowaniu P2, jednostka zasobu Z1 staje się wolna i można zredukować P1. W wyniku redukcji nie pozostał żaden proces, więc nie ma zakleszczenia.
Jak już wspomniano w poprzednim module, problem sprawiają czasami zasoby nieodzyskiwalne. Przykład powyższy był już analizowany, a wynikiem była niejednoznaczność co do zakleszczonych procesów. Interpretacja wyniku redukcji nastręcza tych samych problemów. Redukując przez P1 nie da się zredukować procesów P2 i P4 , a redukując przez P2 nie da się zredukować P1 i P3.
Likwidacja zakleszczenia polega na powiększeniu przydziału zasobowego pewnych procesów, kosztem innych. W ten sposób przynajmniej część procesów uda się zakończyć. W celu odzyskania zasobów, przetrzymujące je procesy można usunąć z systemu. Tracony jest wówczas cały efekt dotychczasowego przetwarzania i to jest zasadniczy koszt tego podejścia. Najlepiej usunąć procesy, które tworzą cykl. Sam wybór procesu może być uzależniony od czasu działania w systemie (im dłużej proces działa, tym potencjalnie więcej jest do stracenia) lub priorytetu procesu. Nie ma natomiast sensu usuwać procesów, które są wprawdzie zakleszczone, ale nie współtworzą cyklu, gdyż żaden z zakleszczonych procesów nie czeka na przetrzymywane przez nie zasoby. W skrajnym przypadku można usunąć wszystkie zakleszczone procesy.
Alternatywą dla usuwania procesów jest odbieranie zasobów. Z odbieraniem zasobów wiąże się problem odtworzenia stanu. Jeśli stan zasobu jest istotny dla przetwarzania procesu, należy stan ten zapamiętać, albo ponowić ciąg instrukcji zmierzających do osiągnięcia tego stanu. Zapamiętanie stanu zasobu jest mniej lub bardziej kłopotliwe w zależności od rodzaju zasobu, a dokładniej od złożoności pamięciowej takiej operacji. Nie stanowi na ogół problemu zapamiętanie stanu procesora — jest to kwestia zapamiętania od kilkudziesięciu do kilkuset bajtów. Można zachować stan pamięci fizycznej pod warunkiem dostępności przestrzeni wymiany. Znaczenie bardziej kłopotliwe może być zapamiętanie stanu urządzeń wejścia-wyjścia, gdyż efekty ich pracy, widziane są na zewnątrz, a więc wymykają się spod kontroli systemu operacyjnego.
Problemem związanym z ponownym wykonaniem pewnego fragmentu przetwarzania jest uniknięcie głodzenia, czy wręcz uwięzienia, gdyż zakleszczenie może wystąpić ponownie.
W podejściach polegających na unikaniu stosowane są takie same algorytmy, jak w przypadku wykrywania, ale nie w odniesieniu do stanu bieżącego, ale do stanów osiągalnych ze stanu bieżącego. Bazując na informacji o potencjalnych przyszłych zamówieniach, przewidywany jest najgorszy możliwy stan osiągalny systemu i analizowany pod kątem wystąpienia zakleszczenia. Jeśli nie ma zakleszczenia, stan uważany jest za bezpieczny, w przeciwnym przypadku jest to stan zagrożenia. Opisywane podejście sprowadza się właśnie do unikania takich stanów.
Biorąc pod uwagę maksymalne deklaracje zasobowe poszczególnych procesów, można wyznaczyć maksymalne potrzeby zasobowe, do zaspokojenia których musi być przygotowany zarządca zasobów. Zakładając przypadek pesymistyczny, w którym pojawią się zamówienia właśnie z tymi maksymalnymi żądaniami, można stwierdzić (używając algorytmu wykrywania zakleszczenia), czy wystąpi wówczas zakleszczenie. Stwierdzenie zakleszczenia oznacza, że stan bieżący nie jest bezpieczny. W przeciwnym razie można wyznaczyć jedną lub kilka sekwencji w realizacji zamówień, w której proces wcześniejszy zwalnia po swoim zakończeniu zasoby dla procesów następnych.
Bazując na macierzowej reprezentacji stanu, można wykorzystać zaprezentowany wcześniej algorytm detekcji zakleszczenia. Jeśli stan jest bezpieczny, to kolejność, w jakiej procesy wybierane są do realizacji jest właśnie ciągiem bezpiecznym.
Z maksymalnego zapotrzebowania oraz bieżącego przydziału wynika, że proces P1 może zażądać jeszcze 5 jednostek (deklaruje 10, a 5 już ma), proces P2 może zażądać jeszcze 2 jednostek, a proces P3 jeszcze 7 jednostek. Do rozdysponowania pozostały jeszcze 3 jednostki, gdyż 9 zostało przydzielonych (5+2+2). W wariancie pesymistycznym żądań zasobowych te 3 wolne jednostki wystarczą dla procesu P2. Po zakończeniu P2 odzyskane zostaną przydzielone mu jednostki, łącznie będzie więc 5 wolnych jednostek. Taka liczba jednostek będzie wystarczająca dla P1, a po odzyskaniu przydzielonych mu jednostek ich liczba wzrośnie do 10. Oczywiście uwzględniając ograniczenia na wielkość zamówień, uzyskane jednostki muszą być wystarczające dla P3. Ciąg bezpieczny to P2, P1 , P3.
Po zrealizowaniu żądania procesu P3 stan systemu jest następujący:
W systemie pozostały 2 wolne jednostki, którymi można zaspokoić potencjalne potrzeby procesu P2. Po zakończeniu P2 liczba jednostek do rozdysponowania zwiększy się do 4, ale może się to okazać niewystarczające zarówno dla P1, jak i dla P3. Gdyby któryś z nich zażądał więcej niż 4 jednostek (co jest zgodne z ich deklaracjami), doszłoby do zakleszczenia. Zrealizowanie żądania procesu P2 wprowadza system w stan niebezpieczny. Stan ten nie oznacza jednak jeszcze zakleszczenia — jest to dopiero zagrożenie. Przy sprzyjającym zbiegu okoliczności (sprzyjającej sekwencji żądań) zakleszczenia można uniknąć.
Stosowalność algorytmu podlega tym samym ograniczeniom, o których była mowa w przypadku algorytmu wykrywania zakleszczenia, opartym na reprezentacji grafowej. Poza tym, podejścia polegające na unikaniu stosowane są dla zasobów odzyskiwalnych.
Z grafu wynika, że zarówno proces P1 jak i P2 może zażądać jednostki zasobu Z2 do realizacji przetwarzania.
Graf po lewej stronie obrazuje stan systemu po zrealizowania zamówienia procesu P1 na jednostkę zasobu Z2, a graf po prawej obrazuje stan systemu po zrealizowaniu takiego samego zamówienia na rzecz procesu P2. Nie tworząc nawet grafu oczekiwania, łatwo można dostrzec cykl w stanie systemu po lewej stronie. W przypadku pojedynczych zasobów odzyskiwalnych jest to warunek konieczny i dostateczny zakleszczenia, a więc zagrożenie (na razie, ponieważ P2 nie zażądał jeszcze jednostki zasobu Z2).
Tego ryzyka nie ma w stanie systemu po prawej. Nawet jeśli proces P1 zażąda jednostki zasobu Z2, nie będzie zakleszczenia.
Prezentowany algorytm — tzw. algorytm bankiera — jest sformalizowaną i nieco uogólnioną formą rozumowania przedstawionego we wcześniejszym przykładzie, dotyczącym ciągu bezpiecznego.
Oprócz macierzy, opisujących stan systemu, czyli C, R, A i F, oraz pomocniczych W i K, potrzebne są jeszcze macierze, związane z maksymalnymi deklaracjami zasobowymi. Deklaracje odnośnie maksymalnego zapotrzebowania procesów na jednostki zasobów poszczególnych typów, przechowywane są w macierzy D.
Macierz B = D – A. Maksymalne potrzeby odjąć bieżący przydział daje liczbę jednostek, której zażądania zarządca może się jeszcze spodziewać.
Algorytm uruchamiany jest w reakcji na złożenie zamówienia przez proces.
Najpierw następuje weryfikacja poprawności zamówienia w stosunku do deklaracji. Jeśli żądana liczba zasobów jest większa, niż nie zrealizowana część deklaracji, jest błąd przekroczenia deklarowanych ograniczeń.
Następnie sprawdzana jest dostępność żądanej liczby jednostek zasobów. Jeśli nie ma tylu jednostek, ilu żąda proces, żądanie jest oczywiście okładane do czasu zwolnienia odpowiedniej liczby jednostek przez inne procesy.
Jeśli wymagana liczba jednostek jest dostępna, następuje tymczasowa realizacja zamówienia. Jest to swego rodzaju symulacja, chociaż w prezentacji modyfikowane są wszystkie macierze, opisujące bieżący stan. Następnie sprawdza się, czy uzyskany w ten sposób stan jest bezpieczny. Jeśli jest to stan bezpieczny, zamówienie zostaje zaakceptowane (macierze są już zaktualizowane). W przypadku wykrycia zagrożenia, realizacja zamówienia jest odkładana, co wymaga wycofania zmian w opisie stanu systemu.
Sprawdzenie bezpieczeństwa polega na uruchomieniu takiego samego algorytmu, jak w przypadku detekcji zakleszczenia, przy czym zamówieniami są maksymalne potrzeby zasobowe, wynikające z deklaracji i bieżącego przydziału — czyli macierz B. Analizowany jest zatem przypadek skrajny, w którym wszystkie procesy oczekują realizacji swoich deklaracji w stopniu maksymalnym.
Wartości macierzy B wynikają z różnicy pomiędzy D i A.
System dysponuje wolnymi zasobami w liczbie: 3 jednostek zasobu Z1 oraz 3 jednostek zasobu Z2 (przydzielone jest 5 z 8). Taka liczba jest wystarczająca tylko do zaspokojenia maksymalnych potrzeb procesu P3. Jeśli jednak P3 się zakończy, zwolni przydzielone zasoby i liczba wolnych jednostek wzrośnie do 3, 4 (odpowiednio zasobu Z1 i Z2). Jak wynika z ostatniej kolumny, wystarczy to procesowi P4 lub P5. Po P4 i P5 obsłużyć można P1 i na końcu P2. Istnieją zatem 2 ciągi bezpieczne.
Przykład działania algorytmu sprawdzania bezpieczeństwa zaprezentowano na następnym slajdzie.
Roboczy wektor W początkowo przechowuje wolne jednostki poszczególnych typów zasobów, czyli 3, 3.
po zakończeniu procesu P3 : 3+0=3, 3+1=4,
po zakończeniu procesu P4 : 3+1=4, 4+0=4,
po zakończeniu procesu P5 : 4+0=4, 4+2=6,
po zakończeniu procesu P1 : 4+2=6, 6+2=8,
po zakończeniu procesu P2 : 8+2=8, 6+0=8.
System jest w stanie bezpiecznym, a ciąg bezpieczny to: P3 , P4 , P5, P1 , P2 (lub P3, P5, P4, P1, P2).
Tabela prezentuje stan systemu po przydzieleniu jednej jednostki zasobu Z1 procesowi P2 . Zmieniła się liczba wolnych jednostek oraz maksymalne potrzeby procesu P2. Zamówienie takie można zrealizować, pod warunkiem, że zaprezentowany stan jest bezpieczny.
Przykład działania algorytmu sprawdzania bezpieczeństwa zaprezentowano na następnym slajdzie.
Roboczy wektor W początkowo przechowuje wolne jednostki poszczególnych typów zasobów, czyli 2, 3.
po zakończeniu procesu P3 : 2+0=2, 3+1=4,
po zakończeniu procesu P4 : 2+1=3, 4+0=4,
po zakończeniu procesu P5 : 3+0=3, 4+2=6
Dla procesów P1 i P2 brakuje jednostek zasobu Z1 . Stan nie jest bezpieczny. Przy maksymalnych deklarowanych żądaniach zasobowych jednostek wystarczy tylko dla procesów P3 , P4 i P5.
Zgodnie z zasadą unikania zakleszczenia, nie można zrealizować zamówienia procesu P2.
Zapobieganie, podobnie jak unikanie, jest podejściem polegającym na niedopuszczaniu do zakleszczenia. W przeciwieństwie do unikania, decyzja o akceptacji lub odłożeniu realizacji zamówienia podejmowana jest wyłącznie w oparciu o bieżący stan systemu. Nie są tu uwzględniane żadne dane na temat przyszłych zachowań procesów. Podejście takie musi być zatem bardziej zachowawcze — w większym stopniu i często nadmiarowo ograniczające aktywność procesów.
Zapobieganie polega na kontrolowaniu zaistnienia warunków koniecznych. Wystarczy nie dopuścić do spełnienia jednego z nich, a nie dojdzie do zakleszczenia.
Ze względu na sposób korzystania z niektórych zasobów nie można podjąć żadnych kroków w celu przeciwdziałania warunkowi wzajemnego wykluczania.
Podejście ma wiele wad. Uzyskanie wszystkich zasobów przed rozpoczęciem przetwarzania może oznaczać przetrzymywanie zasobów, które przez długi czas nie będą wykorzystywane (np. rezerwacja przestrzeni dyskowej dla stopniowo powiększanego pliku). W konsekwencji mamy do czynienia ze słabym wykorzystaniem zasobów, blokowanie dostępu innym procesom i tym samym zmniejszenie przepustowości systemu.
Sama realizacja praktyczna tego podejścia może być kłopotliwa, gdyż na początku przetwarzania wymagana jest wiedza o zasobach, niezbędnych do realizacji całego przetwarzania, podczas gdy pewne potrzeby ujawniają się dopiero w trakcie samego przetwarzania (np. zapotrzebowanie na dynamicznie alokowaną pamięć, czy przestrzeń dyskową).
Problemem może też być głodzenie procesu ze względu na fakt, że nigdy nie będą jednocześnie dostępne wszystkie zasoby żądane przez proces.
Wywłaszczenie musi zostać zrealizowane we właściwym momencie. Sensowny jest moment, kiedy proces zamawia zasób, ale zasób ten nie jest natychmiast dostępny. Zwalniane są wówczas zasoby przez niego przetrzymywane (od tego momentu są wolne) i dopisywane do bieżącego zamówienia. Wznowienie procesu nastąpi po zrealizowaniu całego zamówienia.
Inny dogodny moment ma miejsce, kiedy proces zamawia zasób, który jest przetrzymywany przez inny oczekujący proces. Zasób ten (lub zasoby) jest wówczas odbierany procesowi oczekującemu i przydzielany zamawiającemu. Jeśli zasób nie jest dostępny, ale jest przetrzymywany przez proces nie zablokowany w oczekiwaniu (domniemamy, że proces działa i używa tego zasobu), proces zamawiający sam przechodzi w stan oczekiwania. W stanie oczekiwania proces może stracić swoje zasoby, o ile pojawią się żądania od inny procesów. Wznowienie procesu następuje po odzyskaniu zasobów utraconych w czasie oczekiwania i uzyskaniu zasobów nowo zamawianych.
Wcześniejsze warunki konieczne związane są z projektem systemu lub charakterystyką zasobów. Cykl wynika natomiast z funkcjonowania samych procesów aplikacyjnych, więc znaczenie łatwiej można to kontrolować. Przeciwdziałanie cyklowi jest więc najczęściej stosowaną metodą zapobiegania zakleszczeniom.
Opisana metoda wymaga, żeby jednostki zasobów, oznaczone tym samym numerem, zamawiane były w jednym zleceniu dla zarządcy.
Ze względu na różnice w charakterystyce zasobów, pewne metody można stosować w przypadku określonych rodzajów zasobów, ale nie można w przypadku innych rodzajów. Przykłady tego typu przewijały się w omawianych podejściach do rozwiązywania problemu zakleszczenia. Podejście zintegrowane polega na tym, żeby zasoby o podobnej charakterystyce łączyć w grupy, a liniowe uporządkowanie grup z kolei ułatwia przeciwdziałanie cyklowi przy alokacji.
Zadanie Uruchamiamy współbieżnie dwa egzemplarze następującego procesu:
var
y : integer := 0;
process P1;
var
x, i: integer;
begin
for i := 1 to 5 do
begin
x := y;
x := x + 1;
y := x
end;
end;Jaką wartość będzie miała zmienna y po zakończeniu działania obu?
Zadanie Uruchamiamy współbieżnie dwa następujące procesy:
process P1;
begin
repeat
sekcja_lokalna;
protokół_wstępny;
rejon_krytyczny;
protokół_końcowy
until false
end;
process P2;
begin
repeat
sekcja_lokalna;
protokół_wstępny;
rejon_krytyczny;
protokół_końcowy
until false
end;Chcemy zapewnić, że w tym samym czasie co najwyżej jeden z nich wykonuje fragment programu oznaczony jako rejon_krytyczny. Jakie instrukcje należy umieścić w protokołach, aby zrealizować ten cel? Zakładamy, że nie dysponujemy żadnymi mechanizmami synchronizacyjnymi.
Rozwiązanie W rozwiązaniu będziemy korzystać ze zmiennych globalnych i lokalnych. Zmienna lokalna może znajdować się w prywatnej przestrzeni adresowej procesu. Pozostałe procesy nie mają do niej dostępu, nie mogą jej zatem ani odczytywać ani modyfikować. Inaczej sytuacja wygląda ze zmiennymi globalnymi. Są one współdzielone między procesami, co oznacza, że w dowolnej chwili każdy z nich może takie zmienne zmodyfikować lub je odczytywać. Co dzieje się, gdy dwa wykonujące się równolegle procesy w tej samej chwili chcą uzyskać dostęp do tej samej zmiennej, a zatem do tej samej komórki (tych samych komórek) pamięci? Konflikt rozwiązuje sprzęt za pomocą arbitra pamięci. Jest to układ sprzętowy, który realizuje wzajemne wykluczanie przy dostępie do pojedynczych komórek pamięci. Jednoczesne odwołania do tej samej komórki pamięci zostaną w jakiś nieznany z góry sposób uporządkowane w czasie i wykonane. W dalszej części rozważań zakładamy istnienie arbitra pamięci i jego poprawne działanie.
Spróbujmy najpierw rozwiązać problem wprowadzając zmienną globalną ktoczeka. Będzie ona przyjmować wartości 1 lub 2. Wartość 1 oznacza, że proces pierwszy musi teraz poczekać a prawo wejścia do rejonu krytycznego ma proces drugi. Treść procesów wygląda następująco:
var
ktoczeka: 1..2 := ?;
process P1;
begin
repeat
sekcja_lokalna;
while ktoczeka = 1 do
{ instrukcja pusta };
rejon_krytyczny;
ktoczeka := 1;
until false
end;
process P2;
begin
repeat
sekcja_lokalna;
while ktoczeka = 2 do
{ instrukcja pusta };
rejon_krytyczny;
ktoczeka := 2
until false
end;Czy jest to rozwiązanie poprawne? Własność bezpieczeństwa jest zachowana — nigdy oba procesy nie będą jednocześnie w rejonie krytycznym. A co z własnością żywotności? Przypomnijmy o założeniu, że proces nie przebywa nieskończenie długo w rejonie krytycznym. Zatem po wyjściu z niego (które na pewno w końcu nastąpi) rozpocznie się wykonanie sekcji_lokalnej. I tu pojawia się problem, bo o tym fragmencie programu nic założyć nie możemy. Jeśli proces utknie w tym fragmencie kodu (bo nastąpi błąd, zapętlenie, itp.) to drugi z procesów będzie mógł wejść do sekcji krytycznej jeszcze co najwyżej raz. Kolejna próba zakończy się wstrzymaniem procesu „na zawsze". Zatem przedstawione rozwiązanie nie ma własności żywotności. Inną wadą tego rozwiązania jest zbyt ścisłe powiązanie ze sobą procesów. Muszą one korzystać z sekcji krytycznej naprzemiennie, a przecież potrzeby obu procesów mogą być różne. Jeśli ponadto działają one z różną „szybkością" (bo na przykład sekcja lokalna jednego z nich jest bardziej złożona od sekcji lokalnej drugiego), to proces „szybszy" będzie równał tempo pracy do wolniejszego.
Spróbujmy zatem zaatakować problem inaczej. Wprowadźmy dwie logiczne zmienne globalne: jest1 oznaczającą, że proces P1 jest w sekcji krytycznej i analogiczną zmienną jest2 dla procesu P2. Przed wejściem do rejonu krytycznego proces sprawdza, czy jego partner jest już w rejonie krytycznym. Jeśli tak, to czeka. Gdy rejon krytyczny będzie wolny to proces ustawia swoją zmienną sygnalizując, że jest w rejonie krytycznym, po czym wchodzi do niego.
var jest1: boolean := false; jest2: boolean := false;
process P1;
begin
repeat
sekcja_lokalna;
while jest2 do
{ instrukcja pusta };
jest1 := true;
rejon_krytyczny;
jest1 := false;
until false
end;
process P2;
begin
repeat
sekcja_lokalna;
while jest1 do
{ instrukcja pusta };
jest2 := true;
rejon_krytyczny;
jest2 := false
until false
end;Zauważmy, że to rozwiązanie nie uzależnia już procesów od siebie. Jeśli jeden z nich nie chce korzystać z sekcji krytycznej lub awaryjnie zakończy swoje działanie w sekcji lokalnej, to drugi może swobodnie wchodzić do rejonu krytycznego, ile razy zechce. Nie ma też problemu z żywotnością. Jeśli jakiś proces utknął w pętli w protokole wstępnym, to drugi proces musi znajdować się gdzieś między przypisaniem jest2 := true a przypisaniem jest2 := false. Po skończonym czasie wyjdzie zatem z rejonu krytycznego i ustawi swoją zmienną jest na false pozwalając partnerowi wyjść z jałowej pętli i wejść do rejonu krytycznego. Niestety, przy pewnych złośliwych przeplotach może się zdarzyć, że do rejonu krytycznego wejdą oba procesy:
jest1 = false, jest2= false
P1: P2
while jest2 do
{warunek jest teraz falszywy
więc nie czeka w pętli}
while jest1 do
{warunek jest teraz falszywy
więc nie czeka w pętli}
jest1 := true;
rejon_krytyczny;
jest2:= true;
rejon_krytyczny;
{ oba procesy są w rejonie krytycznym }Przyczyną takiej sytuacji było zbyt późne ustawienie zmiennych logicznych. Proces już był w rejonie krytycznym (bo przeszedł przez wstrzymującą go pętlę), a jeszcze nie poinformował partnera o tym, że jest w rejonie krytycznym. Zgodnie z definicją poprawności (musi być dobrze dla każdego przeplotu) stwierdzamy, że powyższy program jest niepoprawny. Spróbujmy zatem zmienić kolejność czynności i najpierw ustawmy zmienne logiczne, a potem próbujmy przechodzić przez pętle. Teraz zmienne logiczne oznaczają chęć wejścia do rejonu krytycznego:
var chce1: boolean := false; chce2: boolean := false;
process P1;
begin
repeat
sekcja_lokalna;
chce1 := true;
while chce2 do
{ instrukcja pusta };
rejon_krytyczny;
chce1 := false;
until false
end;
process P2;
begin
repeat
sekcja_lokalna;
chce2 := true;
while chce1 do
{ instrukcja pusta };
rejon_krytyczny;
chce2 := false
until false
end;Teraz mamy program bezpieczny. Faktycznie w rejonie krytycznym może znajdować się co najwyżej jeden proces. Ale ... nie ma żywotności! Z łatwością można doprowadzić do zakleszczenia:
chce1 = false, chce2 = false
P1: P2
chce1 := true;
chce2 := true;
while chce2 do; while chce1 do
{ i oba procesy są w pętlach nieskończonych }Zatem znowu program jest niepoprawny. Można próbować ratować sytuację zmuszając procesy do chwilowej rezygnacji z wejścia do sekcji i ustąpienia pierwszeństwa partnerowi:
var chce1: boolean := false; chce2: boolean := false;
process P1;
begin
repeat
sekcja_lokalna;
chce1 := true;
while chce2 do
begin
chce1 := false;
chce1 := true
end;
rejon_krytyczny;
chce1 := false;
until false
end;
process P2;
begin
repeat
sekcja_lokalna;
chce2 := true;
while chce1 do
begin
chce2 := false;
chce2 := true
end;
rejon_krytyczny;
chce2 := false
until false
end;Niestety znów istnieje (bardzo) złośliwy przeplot, który powoduje brak żywotności:
chce1 = false, chce2 = false
P1: P2
chce1 := true;
chce2 := true;
while chce2 do
{warunek policzony i prawdziwy}
chce1:=false;
chce1 := true;
while chce1 do
{warunek policzony i prawdziwy}
chce2 := false;
chce2 := true
{ itd. }Nie pomoże argumentacja, że taki przeplot jest „w zasadzie" nieprawdopodobny. Zgodnie z definicją poprawności, skoro istnieje scenariusz powodujący brak żywotności, to program jest niepoprawny.
Poprawne rozwiązanie znane pod nazwą algorytmu Petersona jest połączeniem pierwszego pomysłu z przedostatnim. Utrzymujemy zmienne chce1 i chce2, które oznaczają chęć wejścia procesu do rejonu krytycznego. W razie gdy oba procesy chcą wejść do rejonu krytycznego rozstrzygamy konflikt za pomocą zmiennej ktoczeka:
var chce1: boolean := false; chce2: boolean := false; ktoczeka: 1..2 := ?
process P1;
begin
repeat
sekcja_lokalna;
chce1 := true;
ktoczeka := 1;
while chce2 and (ktoczeka = 1) do
{ instrukcja pusta };
rejon_krytyczny;
chce1 := false;
until false
end;
process P2;
begin
repeat
sekcja_lokalna;
chce2 := true;
ktoczeka := 2;
while chce1 and (ktoczeka = 2) do
{ instrukcja pusta };
rejon_krytyczny;
chce2 := false
until false
end;Wady algorytmu Petersona:
Problem 1 Wzajemne wykluczanie. Stosujemy notację z wykładu oraz zakładamy, że bufor jest nieograniczony.
Pomysł polega na umieszczeniu początkowo w buforze jednego egzemplarza komunikatu Bilet. Proces wejdzie do sekcji krytycznej o ile w buforze jest komunikat, w przeciwnym razie będzie czekał. Wchodząc do sekcji krytycznej oczywiście wyjmuje komunikat z buforu a umieszcza go w nim zwalniając sekcję.
type
Komunikaty = (Bilet)
var
b: buffer;
process P (i: integer);
var
k: Komunikaty;
begin
repeat
sekcja_lokalna;
GetMessage (b, k)
rejon_krytyczny;
SendMessage (b, k)
until false
end;
begin
SendMessage (b, Bilet);
cobegin P(1); P(2) coend
endZwróćmy uwagę, że dla poprawności tego rozwiązania kluczowa jest żywotność operacji pobrania z bufora. Ponieważ pracujemy w modelu rozproszonym zmienne nie mogą być współdzielone między żadnymi procesami (w tym także zmienne występujące w głównym programie, który traktujemy jako jeszcze jeden proces, muszą być rozłączne ze zmiennymi, które występują w procesach). Wyjątkiem są zmienne buforowe, które zawsze są globalne. Rozwiązanie to nie zmieni się, jeśli uruchomimy więcej procesów:
type
Komunikaty = (Bilet)
var
b: buffer;
process P (i: integer);
var
k: Komunikaty;
begin
repeat
sekcja_lokalna;
GetMessage (b, k)
rejon_krytyczny;
SendMessage (b, k)
until false
end;
const
ileP = ...;
var i: integer;
begin
SendMessage (b, Bilet);
cobegin for i := 1 to ileP do P(i) coend
endCzasami zachodzi jednak konieczność ograniczenia liczby procesów jednocześnie przebywających w sekcji krytycznej niekoniecznie do jednego procesu, ale ogólnie do pewnej ustalonej wielkości M < ileP. Wtedy wystarczy umieścić w buforze odpowiednią liczbę „biletów wstępu".
Inne możliwe rozwiązanie polega na wprowadzeniu dodatkowego procesu Dozorcę, który będzie nadzorował wykorzystanie sekcji krytycznej. Proces, który chce skorzystać z sekcji krytycznej musi wysłać zamówienie do dozorcy i oczekiwać na potwierdzenie. Do komunikacji wykorzystamy zatem dwa bufory: jeden do wysyłania komunikatów do dozorcy, a drugi do odbierania zezwoleń (dlaczego muszą to być dwa oddzielne bufory?):
type
Komunikaty = (Chce, Mo»esz, Zwalniam)
var
zam, zezw: buffer;
process P (i: integer);
var
k: Komunikaty;
begin
repeat
sekcja_lokalna;
SendMessage (zam, Chce);
GetMessage (zezw, k);
rejon_krytyczny;
SendMessage (zam, Zwalniam);
until false
end;
const
M = ...;
process Dozorca;
var
k: Komunikaty;
ileWolnych: integer := M;
iluChce: integer := 0;
begin
repeat
GetMessage (zam, k);
case k of
Chce: if ileWolnych > 0 then
begin
dec (ileWolnych);
SendMessage (zezw, Mo»esz)
end
else
inc (iluChce)
Zwalniam: if iluChce > 0 then
begin
SendMessage (zezw, Mo»esz);
dec (iluChce)
end else
inc (ileWolnych)
end
until false
end;
const
ileP = ...;
var i: integer;
begin
cobegin Dozorca; for i := 1 to ileP do P(i) coend
endTen algorytm ma pewną subtelność: procesy nie muszą wchodzić do sekcji krytycznej w kolejności jej zamawiania. Może się zdarzyć, że zezwolenie „przeznaczone" dla jednego procesu odbierze proces, który zgłosił zapotrzebowanie później. Na mocy żywotności operacji pobierania z bufora nie dojdzie jednak do zagłodzenie żadnego procesu.
Obsługa procesów zgodnie z kolejnością zgłoszeń wymagałaby wykorzystania dodatkowych informacji umieszczanych w bilecie.
Problem 2. Producenci i konsumenci Problem producentów i konsumentów ma kilka odmian. W notacji z wykładu najłatwiej zapisać rozwiązanie w wersji z nieograniczonym buforem. Wszelkie komentarze są tu chyba zbyteczne:
var
b: buffer;
process Producent;
var
p: Porcja;
begin
repeat
Produkuj (p);
SendMessage (b, p)
until false
end;
process Konsument;
var
p: Porcja;
begin
repeat
GetMessage (b, p);
Konsumuj (p)
until false
end;
begin
cobegin Producent; Konsument coend
endPowyższe rozwiązanie jest także poprawne dla wielu producentów i wielu konsumentów. Trudniej jest uzyskać rozwiązanie w wariancie problemu z buforem o pojemności M porcji. Trzeba wtedy „symulować" ograniczoność bufora w sposób podobny do pierwszego rozwiązania problemu wzajemnego wykluczania. W osobnym buforze umieszczamy „bilety", z których każdy reprezentuje jedno wolne miejsce w buforze. Producent przed umieszczeniem porcji w buforze pobiera bilet:
type
Bilety = (Bilet);
var
b: buffer;
bpom: buffer;
process Producent;
var
p: Porcja;
bil: Bilety;
begin
repeat
Produkuj (p);
GetMessage (bpom, bil);
SendMessage (b, p)
until false
end;
process Konsument;
var
p: Porcja;
begin
repeat
GetMessage (b, p);
SendMessage (bpom, Bilet)
Konsumuj (p)
until false
end;
var
i: 1..M;
begin
for i := 1 to M do SendMessage (bpom, Bilet);
cobegin Producent; Konsument coend
endJeszcze innego rozwiązania wymaga żądanie, żeby producent przekazywał porcję „bezpośrednio" do konsumenta (tzn. że możliwa jest produkcja kolejnej porcji dopiero gdy konsument odbierze dane). Konsument musi wtedy potwierdzać fakt odebrania komunikatu:
type
Potw = (Potwierdzenia);
var
b: buffer;
bpom: buffer;
process Producent;
var
p: Porcja;
pot: Potw;
begin
repeat
Produkuj (p);
SendMessage (b, p);
GetMessage (bpom, pot)
until false
end;
process Konsument;
var
p: Porcja;
begin
repeat
GetMessage (b, p);
SendMessage (bpom, Potwierdzenie)
Konsumuj (p)
until false
end;
begin
cobegin Producent; Konsument coend
endProblem 3. Czytelnicy i Pisarze Wydaje się, że rozwiązanie tego problemu można ująć następującym algorytmem. Czytelnik, który chce czytać sprawdza, czy w czytelni nie ma pisarza. Jeśli nie ma, to rozpoczyna czytanie. Pisarz, który chce pisać czeka aż czytelnia będzie pusta i rozpoczyna pisanie. Implementując taki algorytm dobrze jest wprowadzić dodatkowy proces Czytelnia synchronizujący dostęp do czytelni. Proces ten przechowuje informacje o tym, kto jest w czytelni i decyduje, kogo można wpuścić. Do komunikacji wprowadzimy trzy bufory: jeden do komunikacji z czytelnią, jeden do wysyłania zezwoleń dla pisarzy, jeden do wysyłania zezwoleń dla czytelników:
type
Komunikaty = (ChceCzytac, ChcePisac, Wychodze);
Zezwolenia = (Wejdz)
var
czytelnia, czyt, pis: buffer;
process Czytelnik (i: integer);
var
z: Zezwolenia;
begin
repeat
Sekcja_lokalna;
SendMessage (czytelnia, ChceCzytac);
GetMessage (czyt, z);
CZYTANIE;
SendMessage (czytelnia, Wychodze)
until false
end;
process Pisarz (i: integer);
var
z: Zezwolenia;
begin
repeat
sekcja_lokalna;
SendMessage (czytelnia, ChcePisac);
GetMessage (pis, z);
PISANIE;
SendMessage (czytelnia, Wychodze)
until false
end;
process Czytelnia;
var
dc, dp : integer; { liczba odp. czytelnikow i pisarzy
w czytelni. Dla symetrii dp jest
typu integer, choć mogłaby być typu
boolean }
ac, ap : integer; { liczba czyt. i pis., którzy się
pojawili, więc ac - dc czytelników
oczekuje na wejście do czytelni }
kom: Komunikaty;
begin
dc := 0; dp := 0;
repeat
GetMessage (czytelnia, kom);
case kom of
ChceCzytac: begin
inc (ac);
(*) if dp = 0 then
begin
inc (dc);
SendMessage (czyt, Wejdz);
end
end;
ChcePisac: begin
inc (ap);
if dp + dc = 0 then
begin
inc (dp);
SendMessage (pis, Wejdz)
end
end
Wyjdz : if dp > 0 then { wychodzi pisarz }
begin
dec (dp); dec (ap);
if dc < ac then
while dc < ac do
begin
SendMessage (czyt, Wejdz)
inc (dc)
end
else if dp < ap then begin
inc (dp);
SendMessage (pis, Wejdz)
end
end else { wychodzi czytelnik }
begin
dec (dc); dec (ac);
if (dc = 0) and (dp < ap) then begin
inc (dp);
SendMessage (pis, Wejdz)
end
end
end {case}
until false
end;Zwróćmy uwagę na sposób obsługi wychodzenia z czytelni. Pisarz, który wychodzi sprawdza najpierw, czy czekają czytelnicy. Jeśli tak, to wpuszcza wszystkich czekających. Dopiero gdy upewni się, że nie ma oczekujących czytelników sprawdza, czy czekają pisarze i jeśli tak, to wpuszcza jednego z nich. Odwrotna kolejność mogłaby spowodować zagłodzenie czytelników w razie ciągłego zgłaszania się pisarzy. Analogicznie czytelnik, który jako ostatni wychodzi z czytelni wpuszcza jednego z oczekujących pisarzy (jeśli są). Czytelnicy na pewno w tym momencie nie czekają (skoro w czytelni byli czytelnicy to nowi czytelnicy mogli od razu wejść do czytelni).
Niestety zachowanie odpowiedniej kolejności wpuszczania do czytelni przy wychodzeniu z niej nie wystarcza do uniknięcia zagłodzenia. W powyższym rozwiązaniu czytelnicy mogą z łatwością zagłodzić pisarzy: wystarczy, że czytelnia będzie wiecznie okupowana przez czytelników. Aby temu zapobiec czytelnia przestaje wpuszczać nowych czytelników, gdy pojawi się oczekujący pisarz. W tym celu warunek z wiersza oznaczonego gwiazdką zmieniamy na ap= 0.
Rozwiązanie tego problemu można znacznie uprościć zakładając, że liczba miejsc w czytelni jest ograniczona i wynosi M. Wtedy ponownie wykorzystujemy pomysł „biletów" na wejście do sekcji krytycznej: czytelnik przed rozpoczęciem czytania musi pobrać jeden bilet, a pisarz musi uzyskać komplet biletów. Dodatkowy proces jest wtedy niepotrzebny, wystarczy też jeden bufor:
type
Bilety = (Bilet);
var
czytelnia : buffer;
process Czytelnik (i: integer);
var
bil: Bilety;
begin
repeat
Sekcja_lokalna;
GetMessage (czytelnia, bil);
CZYTANIE;
SendMessage (czytelnia, Bilet)
until false
end;
process Pisarz (i: integer);
var
bil: Bilety;
i: 1..M;
begin
repeat
sekcja_lokalna;
for i := 1 to M do
GetMessage (czytelnia, bil);
PISANIE;
for i := 1 to M do
SendMessage (czytelnia, Bilet)
until false
end;Niestety powyższe rozwiązanie nie jest poprawne. Może dojść do zakleszczenia, jeśli dwóch pisarzy będzie jednocześnie próbować dostać się do czytelni. Wtedy jeden z nich może zabrać część biletów, a drugi pozostałe i obydwaj będą czekać w nieskończoność na pozostałe bilety blokując siebie i inne procesy. Prostym rozwiązaniem tego problemu jest umieszczenie pierwszej pętli pisarza w sekcji krytycznej:
type
Bilety = (Bilet);
var
czytelnia, pis : buffer;
process Czytelnik (i: integer);
var
bil: Bilety;
begin
repeat
Sekcja_lokalna;
GetMessage (czytelnia, bil);
CZYTANIE;
SendMessage (czytelnia, Bilet)
until false
end;
process Pisarz (i: integer);
var
bil: Bilety;
i: 1..M;
begin
repeat
sekcja_lokalna;
GetMessage (pis, bil);
for i := 1 to M do
GetMessage (czytelnia, bil);
SendMessage (pis, bil);
PISANIE;
for i := 1 to M do
SendMessage (czytelnia, Bilet)
until false
end;Oczywiście początkowo w buforze czytelnia musi być M biletów, a w buforze pis — jeden bilet.
Problem 1. Implementacja różnych odmian semaforów.
(a) Implementacja semafora dwustronnie ograniczonego.
var S : semaphore := K; {wartosc poczatkowa, 0 <= K <= N} T : semaphore := N - K; procedure PD; {operacja P na semaforze dwustronnie ograniczonym} begin P(S); V(T); end; procedure VD; {operacja V na semaforze dwustronnie ograniczonym} begin P(T); V(S); end;
Uwaga. Warto zauważyć, że zmiana kolejności wywołań w procedurze VD prowadzi do niepoprawnego rozwiązania (bardzo często podawanego przez studentów). Najlepiej to widać na przykładzie zastosowania powyższego schematu do rozwiązania problemu producentoów i konsumentóow z ograniczonym buforem.
Zastosowanie — producent i konsument, bufor cykliczny.
var bufor : array[0..N-1] of porcja; {bufor cykliczny} Wolne : semaphore := N; {bufor inicjalnie pusty} Zajete : semaphore := 0; process Producent; process Konsument; var k : integer := 0; var k : integer := 0; p : porcja; p : porcja; begin begin while true do begin while true do begin produkuj(p); P(Zajete); P(Wolne); p:= bufor[k]; bufor[k]:= p; V(Wolne); V(Zajete); k:= (k + 1) mod N; k:= (k + 1) mod N konsumuj(p) end end end; end;
(b) Implementacja semafora uogólnionego.
Należy zdefiniować dwie operacje, nazwijmy je PG(n) oraz VG(n), oznaczające odpowiednio opuszczenie oraz podniesienie semafora uogólnionego.
W przedstawionym, prostym i zwiezłym, rozwiazaniu semafor (tzn. zmienna pomocnicza) przyjmuje czasowo wartości ujemne (sic!). Sposób działania procesów (wstrzymywanie procesów) jest jednak całkowicie prawidłowy (i o to przecież chodzi). Rozwiązanie, w którym zmienna pomocnicza nie przyjmuje wartości ujemnych jest znacznie bardziej złożone (por. Z. Weiss, T. Gruźlewski).
var mutex : binary semaphore := 1; {wylaczny dostep} ochrona : binary semaphore := 1; {ochrona wspolnej zmiennej} Sczekaj : semaphore := 0; {oczekiwanie} ile : integer; {aktualna wartosc semafora} procedure PG(n : integer); {operacja P na semaforze uogolnionym} begin P(mutex); {co najwyzej jeden proces czeka na P} P(ochrona); ile:= ile - n; if ile < 0 then {wstrzymanie} begin V(ochrona); P(Sczekaj); end else V(ochrona); V(mutex) end; procedure VG(n : integer); {operacja V na semaforze uogolnionym} begin P(ochrona); ile:= ile + n; if (ile >= 0) and (ile < n) then {ktos czeka i juz sie doczekal} V(Sczekaj); V(ochrona); end;
Problem 2. Czytelnicy i pisarze.
Rozwiązanie klasycznego problemu przy użyciu semaforów, bez żadnych priorytetów, czyli bez zagłodzenia. Treści obu rodzajów procesów są prawie identyczne — z dokład-nością do nazw zmiennych plus spełnienie wymagania, że tylko jeden pisarz może prze-bywać w czytelni.
Schemat działania procesu danej grupy jest następujący: jeśli nie ma procesów z grupy przeciwnej, to wchodzę do czytelni (pisarze pojedynczo), w przeciwnym przypadku czekam (na odpowiednim semaforze). Po zakończeniu korzystania z czytelni przez wszystkie procesy, które uzyskały takie prawo, ostatni wychodzący proces wpuszcza wszystkie oczekujące procesy ż grupy przeciwnej (podnosząc semafor odpowiednia liczbę razy).
Do realizacji powyższego schematu należy użyć:
var jest_cz, akt_cz, czeka_p, jest_p : integer := (0, 0, 0, 0); Ochrona : binary semaphore := 1; {ochrona wspolnych zmiennych} Czytelnia : binary semaphore := 1; {dostep dla jednego pisarza} Czytelnicy : semaphore := 0; {czekajacy czytelnicy} Pisarze : semaphore := 0; {czekajacy pisarze} process Czytelnik; begin while true do begin wlasne_sprawy; P(Ochrona); jest_cz:= jest_cz + 1; {licznik wszystkich czytelnikow} if jest_p = 0 then begin {nie ma pisarza, mozna czytac} akt_cz:= akt_cz + 1; {licznik czytelnikow w czytelni} V(Ochrona) end else begin {sa pisarze ... } V(Ochrona); P(Czytelnicy) { ... czytelnicy czekaja} end; CZYTAM; P(Ochrona); akt_cz:= akt_cz - 1; jest_cz:= jest_cz - 1; if akt_cz = 0 then {wychodzi ostatni czytelnik} while jest_p > akt_p do begin {wpuszczamy wszystkich pisarzy} akt_p:= akt_p + 1; {zaznaczajac, ze sa oni aktywni} V(Pisarze); end; V(Ochrona) end end;
Treści obu rodzajów procesów są prawie identyczne — zamiast CZYTAM pisarz wykonuje P(Pisarze); PISZE; V(Pisarze).
Czytelnicy i pisarze — priorytet dla pisarzy (zagłodzenie czytelników).
Rozwiązanie dające priorytet pisarzom można uzyskać modyfikując przedstawione powyżej rozwiązanie. Interesujące cechy poniższego rozwiązania:
Osoby zainteresowane innym rozwiązaniem tego problemu odsyłam do książki: W. Iszkowski, M. Maniecki, "Programowanie współbieżne", WNT 1982. Bardzo pouczające jest pełne zrozumienie przedstawionego tam rozwiązania (zwłaszcza sekwencji trzech operacji P).
var jest_cz, akt_cz, jest_p : integer := (0, 0, 0); Ochrona : binary semaphore := 1; {ochrona wspolnych zmiennych} Czytelnia : binary semaphore := 1; {dostep dla pisarza/czytelnikow} Czytelnicy : binary semaphore := 0; {czekajacy czytelnicy} process Pisarz; begin while true do begin wlasne_sprawy; P(Ochrona); jest_p:= jest_p + 1; V(Ochrona); P(Czytelnia); PISANIE; V(Czytelnia); P(Ochrona); jest_p:= jest_p - 1; if (jest_p = 0) and (jest_cz > 0) then {wchodza czytelnicy} begin P(Czytelnia); {czytelnie zajmuja czytelnicy; troche nieladne} V(Czytelnicy) {uwaga: dziedziczenie sekcji krytycznej} end else V(Ochrona) end end; process Czytelnik; begin while true do begin wlasne_sprawy; P(Ochrona); jest_cz:= jest_cz + 1; {licznik wszystkich czytelnikow} if jest_p = 0 then begin {nie ma pisarza, mozna czytac} akt_cz:= akt_cz + 1; {licznik czytelnikow w czytelni} if akt_cz = 1 then P(Czytelnia); {pierwszy czytelnik musi zajac} V(Ochrona) end else begin {sa pisarze ... } V(Ochrona); P(Czytelnicy) { ... czytelnicy czekaja} akt_cz:= akt_cz + 1; if jest_cz > akt_cz then V(Czytelnicy) {wpuszczam nastepnego} else V(Ochrona) {a ostatni zwalnia} end; CZYTAM; P(Ochrona); akt_cz:= akt_cz - 1; jest_cz:= jest_cz - 1; if akt_cz = 0 then {wychodzi ostatni czytelnik} V(Czytelnia); { - moze wejsc pisarz} V(Ochrona) end end;
Możliwe jest również zapisanie treści obu procesów w sposób jeszcze bardziej zbliżony do poprawnego rozwiązania (beż priorytetów) — ale mniej ciekawy :-). Pozostawiamy to zainteresowanym czytelnikom.
Zadanie 1.
W systemie działa N grup procesów. Każdy proces cyklicznie wykonuje procedurę własne_sprawy, a następnie procedurę OBLICZ, którą w tym samym czasie mogą wykonywać tylko procesy należące do tej samej grupy. Pierwszy proces z grupy może rozpocząć wykonywanie procedury OBLICZ tylko wówczas, gdy nikt inny jej nie wykonuje. Po zakończeniu wykonywania procedury OBLICZ procesy czekają aż wszystkie wykonujące ją procesy zakończą jej wykonywanie. Po zakończeniu procedury przez ostatni z wykonujących ją procesów działanie powinny rozpocząć oczekujące procesy z kolejnej grupy. Zapisz treść procesu process P (gr : 1..N) używając samaforów.
Uwagi wstępne.
W tym zadaniu synchronizacja działania procesów dotyczy dwóch kwestii: zapewnienia poprawnego wykonywania procedury OBLICZ oraz wspólnego zakończenia (jednego cyklu) przetwarzania.
Rozwiązanie tego zadania wymaga użycia następujących semaforów:
Niezbędne informacje o stanie systemu obejmują:
Rozwiązanie
var Ochrona : binary semaphore := 1; {ochrona wspolnych zmiennych} Pierwsi : binary semaphore := 0; {tu czekaja pierwsi z grup} Reszta : array[1..N] of binary semaphore := {all 0}; { tu pozostali} Koniec : binary semaphore := 0; {a tu procesy, ktore juz zakonczyly} kto : integer := 0; {numer dzialajacej grupy; 0 - brak} dziala : integer := 0; {liczba dzialajacych procesow} ile : array[1..N] of integer := {all 0}; {ile procesow czeka} ilegrup : integer := 0; {ile grup czeka} ilekon : integer := 0; {ilu czeka po zakonczeniu obliczen} process P (gr : 1..N); begin while true do begin wlasne_sprawy; P(Ochrona); if kto = 0 then kto:= gr {nikogo nie ma, moge dzialac} else if kto <> gr then begin {dziala moja grupa -> wchodze, wpp. czekam} inc(ile[gr]); if ile[gr] = 1 then begin {jestem pierwszy z grupy} inc (ilegrup); V(Ochrona); {zwalniam dostep do zmiennych} P(Pierwsi); { i grzecznie czekam} dec (ilegrup); kto:= gr; {a teraz dziala moja grupa} end else begin {kolejny proces z grupy} V(Ochrona); P(Reszta[gr]); {czekam razem z kolegami z grupy} end; dec(ile[gr]); {juz sie doczekalem} end; inc(dziala); {i zaraz zaczne dzialac} if ile[gr] > 0 then V(Reszta[gr]) {budze nastepnego} else V(Ochrona); {lub zwalniam dostep} OBLICZ; P(Ochrona); dec(dziala); if dziala > 0 then begin {koledzy jeszcze pracuja} inc(ilekon); { wiec musze poczekac} V(Ochrona); P(Koniec); dec(ilekon) {dziedziczenie sekcji!} end; if ilekon>0 then V(Koniec) {zwalniam czekajacego,} else { a ostatni proces z grupy} if ilegrup >0 then V(Pierwsi) { budzi pierwszego z innej grupy} else begin kto:= 0; { lub zwalnia, bo nikt nie czeka} V(Ochrona) end end end;
Komentarze do rozwiązania zadania 1.
W obydwu miejscach (czekanie na rozpoczęcie działania, czekanie po zakończeniu działania) procesy są budzone potokowo, czyli jeden proces budzi następny, przekazując mu sekcję krytyczną, a dopiero ostatni proces zwalnia sekcję krytyczną (tu: dostęp do zmiennych),
Pytanie: czy można (w tym rozwiązaniu lub w ogóle) zmienić sposób budzenia, tak aby jeden proces budził wszystkich? Czy dostaniemy poprawne i sprawne rozwiązanie, a jeśli tak, to jakie są wady i zalety obu podejść?
Przyjmujemy, że obowiązującą definicją semaforów jest definicja klasyczna. Analizę dla praktycznej definicji pozostawiamy czytelnikowi.
Rozważmy najpierw kwestię wspólnego kończenia pracy przez wszystkie procesy z grupy. Przyjmijmy, że ostatni proces budzi wszystkich, czyli wykonuje instrukcję postaci: for i:= 1 to ilekon do V(Koniec); i kończy działanie. Semafor Koniec (ogólny, a nie binarny) ma poprawną wartość i każdy czekający proces może kontynuować pracę. Co się jednak stanie, gdy jakiś proces 'zaśpi'? Następna grupa zaczyna działać i może skończyć zanim ten 'śpioch' opuści podniesiony dla niego semafor. Konsekwencje: proces z nowej grupy nie czeka na kolegów, natomiast proces ze starej grupy ciągle czeka.
Konieczność dziedziczenia sekcji przy budzeniu pierwszego procesu z kolejnej grupy jest chyba oczywista. Gdyby nie było dziedziczenia, inny proces mógłby na podstawie stanu systemu (m.in, zmienna kto) stwierdzić, że może pracować i rozpocząć działanie. Chwilę później uprawniona grupa również rozpoczęłaby działanie. Nie możemy tego naprawić, gdyż nie wiemy który z oczekujących procesów zostanie obudzony.
Rozważmy teraz kwestię rozpoczęcia pracy przez grupę procesów z tej samej grupy. Pierwszy proces z grupy mógłby, po obudzeniu, budzić wszystkich swoich kolegów. Drobna wada (cecha?) takiego rozwiązania, to zrzucenie pewnej pracy na jeden z procesów, a nie równomierne obłożenie obowiązkami wszystkich (sprawność całości w zasadzie bez zmian). Odpowiednio operując licznikami (inaczej niż w przedstawionym rozwiązaniu!) można uniknąć sytuacji opisanej powyżej, czyli niepoprawnej pracy systemu.
Pozostaje jeszcze inna kwestia: proces może zostać wstrzymany zaraz po zwolnieniu dostępu do zmiennych >(V(0chrona)), a bezpośrednio przed wykonaniem operacji P, A wówczas mogłoby się zdarzyć, że pierwszy proces z grupy zostanie obudzony i podniesie semafor. Przy (nieco) niewłaściwej (a być może trudnej do zauważenia) modyfikacji liczników mogłoby się zdarzyć, że wszystkie procesy z grupy zakończyłyby działanie nie czekając na spóźnialskiego kolegę, który z kolei mógłby rozpocząć pracę w dowolnym terminie (bo semafor jest podniesiony).
Uwaga końcowa: przedstawione rozwiązanie jest poprawne, niezależnie od przyjętej definicji semaforów, jest jednakowo sprawne i bardziej sprawiedliwie dzieli obowiązki między wszystkie procesy.
Zadanie 2.
W systemie działa pewna liczba procesów zajmujących się przetwarzaniem danych. Każda praca jest wykonywana dokładnie przez K procesów (K > 1). Każdy proces (w nieskończonej pętli) zgłasza się do pracy, otrzymuje numer kolejny z przedziału od 1 do K, a następnie czeka na zgłoszenie się wszystkich K procesów. Ostatni (K-ty) proces inicjuje przetwarzanie (function inicjuj () : DANE)). Zainicjowane dane są następnie przetwarzane sekwencyjnie przez wszystkie procesy z tej grupy, począwszy od pierwszego procesu (tj, procesu, który przy zgłoszeniu otrzymał numer 1) aż do ostatniego (procedure przetwarzaj (var dane : DANE; nr : 1. .K)). Po zakończeniu przetwarzania każdy proces ponownie zgłasza się do pracy. Zakończenie całej pracy następuje po zakończeniu jej przetwarzania przez wszystkie procesy z grupy.
Równocześnie może być wykonywanych co najwyżej MAX prac (opisanych wyżej; MAX > 1). Przetwarzanie różnych prac może (i powinno) odbywać się równolegle, przy czym przetwarzanie danej pracy przez i-ty proces z danej grupy może rozpocząć się dopiero po zakończeniu przetwarzania poprzedniej pracy przez i-ty proces z poprzedniej grupy.
Zapisz przy użyciu semaforów treść procesów działających w tym systemie. Podaj początkowe wartości wszystkich semaforów.
Uwagi wstępne.
Zapewnienie wymaganej synchronizacji procesów oznacza konieczność użycia dwóch dwuwymiarowych tablic semaforów: semafory Faza służą do zapewnienia sekwencyjnego przetwarzania każdej pracy, natomiast semafory Dalej służą do właściwej synchronizacji procesów realizujących różne prace (nie za szybko).
Ograniczenie liczby jednocześnie wykonywanych prac może być zrealizowane (inaczej niż w przedstawionym rozwiązaniu) przy użyciu semafora ogólnego, zainicjowanego na liczbę prac dozwolonych do jednoczesnego wykonywania. Przedstawiona wersja rozwiązania jest nieco bardziej złożona, przedstawiam ją jednak dlatego, że wielu studentów wybierających tego typu rozwiązanie popełniało wiele podstawowych błędów synchronizacyjnych, Ponadto w tym drugim rozwiązaniu każdy proces musiałby najpierw opuścić semafor, a po stwierdzeniu, że nie jest ostatnim z grupy (tu akurat ostatni, a nie pierwszy proces to robi) musiałby podnosić niesłusznie opuszczony semafor. Alternatywne rozwiązanie jest w sumie nieco krótsze, ale mniej eleganckie i nieco bardziej złożone.
Przykładowe rozwiązanie.
const K = ...; MAX = ...; var Faza : array[1..K, 1..MAX] of binary semaphore = {all 0}; Dalej : array[1..K, 1..MAX] of binary semaphore = {K*1; others 0}; Prace : binary semaphore = 0; {tylko MAX prac, reszta czeka} Ochrona : binary semaphore = 1; {standardowa ochrona zmiennych} dane : array[1..MAX] of DANE; {przetwarzane dane} ilePrac : integer = 0; {liczba prac w toku} ileCzeka : integer = 0; {liczba procesow czekajacych na Prace} praca : integer = 1; {indeks w dane dla nastepnej pracy} ileProcesow : integer = 0; {liczba procesow do nastepnej pracy} process Proces; var nr : integer; {numer kolejny (1..K)} nrPracy : integer; {numer pracy (1..MAX)} begin while true do begin P(Ochrona); if ilePrac = MAX then begin {MAX prac w toku, czekamy} inc(ileCzeka); V(Ochrona); P(Prace); dec(ileCzeka) {sekcja odziedziczona} end; inc(ileProcesow); nr:= ileProcesow; {moj numer kolejny} nrPracy:= praca; {numer pracy} if nr = K then begin {grupa w komplecie} inc(ilePrac); praca:= praca mod MAX + 1; {nastepna praca} ileProcesow:= 0; {jeszcze nie ma do niej nikogo} dane[nrPracy]:= inicjuj(); V(Ochrona); V(Faza[1, nrPracy]); {pierwszy z mojej grupy do roboty} end else if ileCzeka > 0 then V(Prace) else V(Ochrona); P(Faza[nr, nrPracy]); {poprzednik z grupy zakonczyl} P(Dalej[nr, nrPracy]); {nie za szybko (poprzednia praca)} przetwarzaj( dane[nrPracy], nr ); {kolejne prace moga juz byc kontynuowane} V(Dalej[nr, nrPracy mod MAX + 1]); if nr < K then begin V(Faza[nr+1, nrPracy]) {nastepny z grupy do roboty} else begin {zakonczenie pracy} P(Ochrona); dec(ilePrac); if ileCzeka > 0 then V(Prace) else V(Ochrona) end end end;
Gdyby przyjąć (dospecyfikować), że rozpoczęcie pracy następuje już od zbierania procesów do jej wykonania, to wspomniane wcześniej alternatywne rozwiązanie nie-spełniałoby wymagań tego zadania, A wówczas przedstawione rozwiązanie byłoby (chyba) optymalne.
Zadanie 1 (Stolik dwuosobowy)
W systemie działa N par procesów. Procesy z pary są nierozróżnialne. Każdy proces cyklicznie wykonuje własne_sprawy, a potem spotyka się z drugim procesem z pary (randka) w kawiarni przy stoliku dwuosobowym. W kawiarni jest tylko jeden stolik. Procesy mogą zająć stolik tylko wtedy gdy obydwa są gotowe do spotkania, ale odchodzą od niego pojedynczo (w różnym czasie kończą wykonywanie procedury randka).
P(j : 1. .N) używając do synchronizacji semaforów.P(j : 1. .N) i monitor KAWIARNIA synchronizujący ich działanie.Rozwiązanie a
var NA_PARĘ : array [1..N] of binary semaphore := (0,...,0); para : array [1..N] of boolean := (False, ...,False); NA_STÓŁ : binary semaphore := 1; przy_stole : integer := 0; OCHRONA : binary semphore := 1; process P(j:1..N) begin repeat własne_sprawy; P(OCHRONA); if not para[j] then begin para[j] := True; V(OCHRONA); P(NA_PARĘ[j]); end else begin para[j] := False; V(OCHRONA); P(NA_STÓŁ); przy_stole := 2; V(NA_PARĘ[j]); end; randka; P(OCHRONA); dec(przy_stole); if przy_stole = 0 then begin V(OCHRONA); V(NA_STÓŁ); end else V(OCHRONA); until false; end;
Rozwiązanie b
monitor KELNER var NA_PARĘ : array [1..N] of condition; NA_STÓŁ : condition; przy_stole : integer; export procedure CHCĘ_STOLIK(j:integer) begin if empty(NA_PARĘ[j]) then wait(NA_PARĘ[j]) else begin if przy_stole > 0 then wait(NA_STÓ); przy_stole := 2; signal(NA_PAR[j]); end; end; export procedure ZWALNIAM begin dec(przy_stole); if przy_stole = 0 then signal(NA_STÓŁ); end; begin przy_stole := 0; end. process P(j:1..N) begin repeat własne_sprawy; KELNER.CHCĘ_STOLIK(j); randka; KELNER.ZWALNIAM; until false; end
Należy zwrócić uwagę na następujące różnice:
OCHRONA) dlatego, że procedur monitora nie może wykonywać wiele procesów jednocześniewait jest zawsze blokująca w przeciwieństwie do operacji P, która zależy od wartości semafora. Dlatego w rozwiązaniu a jest: P(NA_STÓŁ), a w rozwiązaniu b: if przy_stole > 0 then wait(NA_STÓŁ);signal na pustej kolejce nic nie robi w przeciwieństwie do operacji V, która wykonana na semaforze na którym żaden proces nie czeka powoduje jego podniesienie (zostawienie otwartej drogi)Zadanie 2 (Implementacja monitora przy pomocy semaforów)
Należy napisać odpowiedniki operacji monitorowych korzystając z semaforów:
waitsignalRozwiązanie a
Wersja prostsza: zakładamy, że signal jest ostatnią instrukcją w procedurze monitora.
var MONITOR: binary semaphore := 1; {żeby zapewnić wzajemne wykluczanie przy wykonywaniu procedur monitora} KOLEJKA: binary semaphore := 0; ilu_czeka: integer := 0; 1) P(MONITOR); 2) inc(ilu_czeka); V(MONITOR); P(KOLEJKA); dec(ilu_czeka); 3) if ilu_czeka > 0 then V(KOLEJKA) else V(MONITOR); 4) V(MONITOR);
Dziedziczenie sekcji krytycznej jest konieczne, aby zachować semantykę operacji monitorowych - po wykonaniu signal wykonuje się zwolniony proces.
Rozwiązanie b
Wersja pełna: signal może się pojawić w dowolnym miejscu w procedurze.
var MONITOR: binary semaphore := 1; {żeby zapewnić wzajemne wykluczanie przy wykonywaniu procedur monitora} KOLEJKA: binary semaphore := 0; STOS: binary semaphore := 0; ilu_czeka_k: integer := 0; ilu_czeka_s: integer := 0; 1) P(MONITOR); 2) inc(ilu_czeka_k); if ilu_czeka_s > 0 then begin dec(ilu_czeka_s); V(STOS); end else V(MONITOR); P(KOLEJKA); 3) if ilu_czeka_k > 0 then begin dec(ilu_czeka_k); inc(ilu_czeka_s); V(KOLEJKA); P(STOS); end; 4) if ilu_czeka_s > 0 then begin dec(ilu_czeka_s); V(STOS); end else V(MONITOR);
Procesy wykonujące wait i kończące procedurę monitora zwalniają procesy które wykonały signal (oczekujące na semaforze STOS).
Należy zwrócić uwagę, że nie jest to dokładna implementacja, ponieważ za pomocą semaforów nie można zasymulować kolejki (procesy wykonujące wait) ani stosu (procesy wykonujące signal) - procesy oczekujące na semaforze są zwalniane w kolejności zapewniającej żywotność, ale nie możemy powiedzieć dokładnie w jakiej.
Zadanie 1 (Bar)
Napisz monitor BAR synchronizujący pracę barmana obsługującego klientów przy kolistym barze z N stołkami. Każdy klient realizuje następujący algorytm:
var i : integer; begin repeat BAR.CZEKAJ_NA_STOŁEK_I_PIWO(i); <pije piwo na stołku i-tym> BAR.ZWALNIAM(i); until false; end;
Barman nalewa piwo nowo przybyłym klientom w kolejności wyznaczonej przez stołki przez nich zajmowane (chodzi "w kółko"):
var i : integer; begin repeat BAR.KTO_NASTĘPNY(i); <podejście do stołka i-tego i nalanie piwa> BAR.ZACZNIJ_PIĆ(i); until false; end;
Rozwiązanie
monitor BAR; var ilu_w: integer; { ilu klientów jest w barze } WEJŚCIE: condition; { tu klienci czekaj¡ na wej±cie do baru } stołek: array [0..N-1] of (wolny, nieobsłużony, obsłużony); { stan stołka: nieobsłużony - siedzący na nim klient czeka na piwo obsłużony - siedzący na nim klient pije piwo } czeka: array [0..N-1] of condition; { tu klient czeka na nalanie piwa } ilu_czeka: integer; { ilu klientów czeka na nalanie piwa } BARMAN: condition; { tu czeka barman, jeżeli nie ma nic do roboty } export procedure CZEKAJ_NA_STOŁEK_I_PIWO(var i: integer); begin if ilu_w = N then wait(WEJŚCIE); { nie ma wolnych stołków } inc(ilu_w); inc(ilu_czeka); i := 0; while stołek[i] <> wolny do { klient szuka wolnego stołka } i := (i + 1) mod N; stołek[i] := nieobsłużony; { i-ty stołek był wolny, klient go zajmuje } if ilu_czeka = 1 then signal(BARMAN); { zwalnia barmana, jeżeli ten czeka } wait(czeka[i]); { czeka na stołku i-tym na piwo } end; export procedure ZWALNIAM(i: integer); begin dec(ilu_w); stołek[i] := wolny; signal(WEJŚCIE); end; export procedure KTO_NASTĘPNY(var i:integer); begin if ilu_czeka = 0 then wait(BARMAN); { nie ma nieobsłużonych klientów } i := (i + 1) mod N; { barman szuka klienta począwszy od następnego miejsca po tym, które ostatnio obsługiwał } while stołek[i] <> nieobsłużony do i := (i + 1) mod N; end; export procedure ZACZNIJ_PIĆ(i: integer); begin stołek[i] := obsłużony; dec(ilu_czeka); signal(czeka[i]); end; begin for i:=0 to N do stołek[i] := wolny; end.
Uwagi
CZEKAJ_NA_STOŁEK_I_PIWO wykonuje wait( czeka [i] ) po signal (BARMAN). Zgodnie z semantyką operacji signal po wykonaniu signal (BARMAN) zaczyna działać barman, który sprawdzając kolejkę czeka [i] stwierdziłby, że jest ona pusta, ponieważ klient nie wykonał jeszcze wait(czeka[i])! Ten sam problem wystąpiłby, jeżeli przyjęlibyśmy założenie, że nalanie piwa jest wewnętrzną czynnością w monitorze, czyli procedury KTO_NASTĘPNY i ZACZNIJ_PIĆ złączylibyśmy w jedną.Zadanie 2 (Ładowanie cegieł)
Grupa N (N > 0) robotników ma załadować stertę cegieł na samochód. Każdy z nich musi wiedzieć od kogo ma odbierać cegły i komu podawać, czyli musi znać numery obu swoich sąsiadów (należy przyjąć, że sterta cegieł ma numer 0, a samochód N + 1). Pracę można rozpocząć dopiero wtedy, gdy zgłoszą się wszyscy robotnicy. Po zakończeniu załadunku robotnicy przychodzą po wypłatę. Każdy podaje swoją stawkę za pracę, na podstawie której wylicza się stawkę średnią, którą otrzymują wszyscy. Każdy robotnik działa według schematu:
procedura Robotnik (i: integer); const moja_stawka = ...; var lewy, prawy, wypłata: integer: begin repeat M.CHCĘ_PRACOWAĆ (i, lewy, prawy); podawaj_cegły (lewy, prawy); M.WYPŁATA (moja_stawka, wypłata); odpoczynek (wypłata); until false; end;
Należy napisać monitor M. Nie wolno deklarować żadnych struktur rozmiaru N lub większego.
Rozwiązanie niepoprawne
Podajemy rozwiązanie niepoprawne, ponieważ studenci najczęściej próbują je rozwiązać w taki właśnie sposób:
monitor M; var ilu, ostatni, stawka: integer; na_pozostałych: condition; export procedure CHCĘ_PRACOWAŁ (i: integer, var lewy, prawy: integer); begin inc(ilu); lewy := ostatni; ostatni := i; if ilu < N then wait(na_pozostałych) else ostatni:=N+1; prawy := ostatni; ostatni := i; dec(ilu); if not empty(na_pozostałych) then signal(na_pozostałych); end; export procedure WYPŁATA(moja_stawka: integer, var wypłata: integer); begin inc(ilu); if ilu = 1 then ostatni := 0; stawka := stawka + moja_stawka; if ilu < N then wait(na_pozostałych) else stawka := stawka div N; wypłata : = stawka; signal(na_pozostałych); end; begin ilu := 0; ostatni := 0; stawka := 0; end.
Każdy z procesów musi poznać swoich sąsiadów: lewego, czyli proces, który zgłosił się bezpośrednio przed nim (wystarczy zapamiętać numer ostatniego procesu, który wykonywał procedurę) i prawego, czyli proces, który zgłosił się bezpośrednio po nim - ten właśnie warunek nie jest spełniony.
Przeanalizujmy następujący scenariusz:
N = 4, kolejność zgłaszania się robotników: 2 4 3 1
2 4 3 1 lewy:=0 ostatni:=2 wait lewy:=2 ostatni:=4 wait lewy:=4 ostatni:=3 wait lewy:=3 ostatni:=1 ostatni:=N+1 prawy:=N+1 ostatni:=1; signal prawy:=1 (?!) ostatni:=2 signal prawy:=2 (?!) ostatni:=4; signal prawy:=4 (?!) ostatni:=3 signal (pusty)
Rozwiązanie poprawne
Aby poznać numer prawego sąsiada nie używając dodatkowych struktur danych należy odwrócić kolejność procesów wykorzystując do tego operację signal. Przypominamy, że signal wstrzymuje działanie procesu do momentu, gdy zwalniany przez niego proces opuści monitor. Procesy wstrzymane przy wykonaniu operacji signal zwalniane są w kolejności odwrotnej do tej w jakiej ją wykonywały.
export procedure CHCĘ_PRACOWAĆ(i: integer, var lewy, prawy: integer); begin inc(ilu); lewy := ostatni; ostatni := i; if ilu < N then begin export procedure CHCĘ_PRACOWAĆ(i: integer, var lewy, prawy: integer); begin inc(ilu); lewy := ostatni; ostatni := i; if ilu < N then begin wait(na_pozostałych); signal(na_pozostałych); prawy := ostatni; ostatni := i; end else begin prawy := N + 1; ilu := 0; signal(na_pozostałych); end; end;
Przeanalizujmy to na naszym przykładzie:
2 4 3 1 lewy:=0 ostatni:=2 wait lewy:=2 ostatni:=4 wait lewy:=4 ostatni:=3 wait lewy:=3 ostatni:=1 prawy:=N+1 signal signal signal signal (pusty) prawy:=1 ostatni:=3 prawy:=3 ostatni:=4 prawy:=4 ostatni:=2
Należy zwrócić uwagę, że nie potrzeba osobnych kolejek do wstrzymywania procesów czekających na pracę i na wypłatę, ponieważ nie ma niebezpieczeństwa, że procesy z tych dwóch grup się przemieszają.
Zadanie 1 (Biuro)
W pewnym biurze grupa urzędników obsługuje grupę klientów. Każdy urzędnik ma unikatowy identyfikator z zakresu od 1 do N. Algorytmy urzędników i klientów są następujące:
process Urzędnik (u:integer, r:1..2) process Klient begin var u1,u2:integer; repeat begin BIURO.CHCĘ_PRACOWAĆ(u,r); repeat rozmawiam_z_klientem; BIURO.CHCĘ_ZAŁATWIĆ_SPRAWĘ(u1,u2); BIURO.SKOŃCZYŁEM; rozmawiam_z_urządnikiem(u1,u2); odpoczywam; BIURO.ZAŁATWILEM; until false; własne_sprawy; end; until false; end;
Rozwiązanie
monitor BIURO var ile_krzeseł: integer; ilu_u2: integer; { ilu jest gotowych urzędników II } u: array [1..2] of condition; { tu czekają urzędnicy I i II } k: condition; { tu czekają klienci } z_kim1, z_kim2: integer; { identyfikatory urzędników } export procedure CHCĘ_PRACOWAĆ(ranga: 1..2, id: integer); begin if ranga = 1 then begin { czeka, jeżeli nie ma klientów lub wystarczającej liczby krzeseł } if empty(k) or ile_krzeseł < 2 then wait u[1]; ile_krzeseł := ile_krzeseł - 2; z_kim1 := id; { zapisuje swój identyfikator } z_kim2 := 0; { informuje, ze nie będzie drugiego urzędnika } signal(k); { zwalnia klienta } end else begin { czeka, jeżeli nie ma klientów lub wystarczającej liczby krzeseł lub oczekującego urzędnika II } if empty(k) or ile_krzeseł < 3 or empty(u[2]) then begin inc(ilu_u2) wait u[2]; dec(ilu_u2); end; { jeżeli jest pierwszym urzędnikiem, to zapisuje swój identyfikator i budzi drugiego urzędnika } if z_kim1 = 0 then begin ile_krzeseł := ile_krzeseł - 3; z_kim1 := id; signal(u[2]); end { jeżeli jest drugim urzędnikiem, to zapisuje swój identyfikator i budzi klienta } else begin z_kim2 := id; signal(k); end; end; export procedure CHCĘ_ZAłATWIĆ_SPRAWĘ(var id1, id2: integer); begin { klient czeka jeżeli } if (empty(u[1]) or ile_krzeseł < 2) and { nie ma urzędnika I lub 2 krzeseł } (ilu_u2 < 2 or ile_krzeseł < 3) { nie ma dwóch urzędników II lub 3 krzeseł } then wait(k) else if not empty(u[1]) then signal(u[1]) { budzi urzędnika I } else signal(u[2]); { budzi pierwszego urzędnika II } id1 := z_kim1; { odczytuje identyfikatory } id2 := z_kim2; z_kim1 := 0; end; export procedure SKOŃCZYŁEM/ZAŁATWIŁEM; begin inc(ile_krzeseł); { jeżeli może dojść do rozmowy, to zwalnia odpowiedniego urzędnika } if not empty(k) then if not empty(u[1]) and ile_krzeseł >= 2 then signal(u[1]) else if ilu_u2 >= 2 and ile_krzeseł >= 3 then signal(u[2]); end; begin ile_krzeseł := K; ilu_u2 := 0; z_kim1 := 0; end.
Uwagi
Schemat rozwiązania jest następujący: kiedy nie może dojść do rozmowy (z powodu braku jednej ze stron lub miejsc do siedzenia), wtedy proces czeka w odpowiedniej kolejce. Jeżeli pojawi się brakujący urzędnik pierwszej rangi, to zwalnia klienta. Jeżeli pojawi się brakujący urzędnik drugiej rangi, to zwalnia drugiego urzędnika, który zwalnia klienta. Jeżeli pojawi się brakujący klient, to zwalnia urzędnika i jeżeli jest to urzędnik drugiej rangi, to zwalnia swojego kolegę, który zwolniłby klienta, ale tego nie robi, bo kolejka klientów jest pusta (gdyby nie była, to nie brakowało by klienta - patrz: początek zdania). Jeżeli pojawiają się brakujące krzesła, to zwalniani są odpowiedni urzędnicy, którzy zwalniają klienta.
Warto zwrócić uwagę na przekazywanie identyfikatorów klientowi. Jeżeli to klient zwalnia urzędników, to identyfikatory zostają przekazane w momencie, kiedy klient wykonuje signal.
Priorytetowym wymaganiem w tym zadaniu jest obsłużenie jak największej ilości klientów. Aby je spełnić należy w pierwszej kolejności wybierać urzędników pierwszej rangi, ponieważ zajmują oni mniej krzeseł. Oczywiście może dojść do zagłodzenia drugiej grupy urzędników, ale jest to zagłodzenie wynikające z treści zadania.
Zadanie 2 (Zasoby)
W systemie są dwie grupy procesów korzystające z N zasobów typu A i M zasobów typu B (N + M > 1). Procesy z pierwszej grupy cyklicznie wykonują własne sprawy, po czym wywołują procedurę zamieńAB, która konsumuje jeden zasób A i produkuje jeden zasób B. Procesy z grupy drugiej cyklicznie wykonują własne sprawy, po czym wywołują procedurę zamień, która konsumuje jeden zasób dowolnego typu i produkuje zasób przeciwny. Zsynchronizuj procesy za pomocą monitora tak, aby:
zamieńAB i zamień były wywoływane przez procesy jedynie pod warunkiem dostępności odpowiednich zasobówzamieńAB parami, tzn. proces z grupy pierwszej może rozpocząć jej wykonanie jedynie wtedy, gdy jest inny proces z grupy pierwszej, gotowy do jej wykonania (i oczywiście niezbędne zasoby)Monitor powinien udostępniać jedynie procedury wywoływane przez procesy przed i po rozpoczęciu korzystania z zasobów.
Rozwiązanie
monitor Zasoby; var ileA, ileB, iluNaA: Integer; zasóbA, zasób, partner: condition; export procedure ChceA; begin inc(iluNaA); if iluNaA mod 2 = 1 then { pierwszy z pary } wait (partner); { czeka na partnera } else begin { drugi z pary } if ileA < 2 then { jeżeli nie ma dwóch zasobów A } wait (zasóbA); { czeka na co najmniej dwa zasoby A } ileA := ileA - 2; signal (partner) { zwalnia partnera } end dec(iluNaA); end; export procedure ChceZasób (var z: Zasob); begin if (ileB = 0) and (ileA = 0 or not empty(zasóbA)) then wait (zasób); { czeka na cokolwiek } if ileB > 0 then { najpierw B, żeby produkować A } begin z := B; dec (ileB) end else begin z := A; dec (ileA) end end; export procedure Wyprodukowalem (z: Zasób); begin if z = B then { jeżeli wyprodukowano B } begin inc (ileB); signal (Zasób) end else begin inc (ileA); if empty (ZasóbA) then { tylko jeżeli nie ma par w pierwszej grupie } signal (Zasób) { to zwalniamy swoją grupę } else { czeka para na zasób A } if ileA > 1 then { zwalniamy ja jeśli można lub } signal (ZasóbA) { czekamy na drugi egzemplarz zasobu A } end end; begin iluNaA := 0; ileA := N; ileB := M; end.
Uwagi
Aby nie zagłodzić procesów pierwszej grupy, proces który wyprodukował A, zwalnia procesy drugiej grupy tylko wtedy, gdy nie ma pary gotowych procesów z grupy pierwszej, nawet jeżeli jest tylko jeden zasób, który na razie jest dla tej pary bezużyteczny.
Na potrzeby kilku następnych ćwiczeń zakładamy dostępność następujących typów danych oraz operacji na nich:
wait_queuesleep(q) wstawiająca wykonujący ją proces do kolejki qprocesów zawieszonych, zmieniająca jego stan na wstrzymany oraz inicjująca przełączenie kontekstu wakeup(q) zmieniająca stan wszystkich procesów zawieszonych w kolejce q na gotowy i przenosząca je do kolejki procesów gotowych disable_interrupts wyłącza przerwania enable_interrupts włącza przerwania Czy synchronizacja globalnych struktur danych w jednoprocesorowym systemie operacyjnym z jądrem niewywłaszczalnym (takim jak tradycyjne jądro Uniksa) jest w ogóle potrzebna?
Nawet w niewywłaszczalnym jądrze działającym na komputerze jednoprocesorowym może być w danej chwili aktywnych wiele procesów. Oczywiście wykonuje się jeden z nich, a pozostałe oczekują na procesor lub jakiś zasób. Dzieje się tak, gdyż proces mógł rozpocząć wykonanie funkcji systemowej, po czym zrzec się dobrowolnie procesora (bo na przykład musi poczekać na zajście jakiegoś zdarzenia na przykład zainicjowanej operacji wejścia-wyjścia).
Takie jądro nazywamy wielowejściowym.
Wszystkie te procesy współdzielą tę samą kopię struktur danych jądra, więc jądro musi dbać o zachowanie ich spójności. Szczęśliwie niewywłaszczalność bardzo mu w tym pomaga. Przypomnijmy niewywłaszczalność jądra oznacza, że proces wykonujący się w trybie jądra nie może zostać wywłaszczony przez inny proces, nawet jeśli upłynie przeznaczony dla niego kwant czasu. Proces może jednak dobrowolnie oddać procesor. Ponieważ dzieje się to w konkretnym punkcie programu wykonywanego przez proces, więc proces może zadbać o pozostawienie jądra w stanie spójnym. Dzięki temu jądro może na przykład swobodnie manipulować wskaźnikami listy dwukierunkowej bez blokowania dostępu do niej, gdyż nie grozi wywłaszczenie po modyfikacji wskaźnika w przód, a przed modyfikacją wskaźnika w tył.
Są jednak dwa powody, w których synchronizacja w jednoprocesorowym systemie z niewywłaszczalnym jądrem jest jednak niezbędna:
Jak zapewnić spójność struktur danych, z których korzystają podprogramy obsługi przerwań?
Wyłączając przerwania na czas modyfikacji tych struktur danych, z których może również korzystać podprogram obsługi przerwania. W ten sposób kod modyfikujący kluczowe struktury danych jest w istocie sekcją krytyczną.
Należy jednak przy tym pamiętać, że:
Rozważmy następujący przykład. W pewnym systemie operacyjnym pula wolnych buforów wejścia-wyjścia jest przechowywana w jednokierunkowej liście bufcache. Rozpoczynając operację wejścia-wyjścia jądro wywołuje funkcję GetBuffer, która znajduje pierwszy wolny bufor i usuwa go z listy wolnych buforów. Jeśli w puli nie ma wolnych buforów, to proces jest wstrzymywany w kolejce procesów zawieszonych nobuffers. Po zakończeniu operacji wejścia-wyjścia podprogram obsługi przerwania wywołuje procedure ReleaseBuffer (b). Dane są następujące deklaracje:
type Buffer = ^ record next: Buffer; data: array[0..BUFFERSIZE] of byte; ... end; var bufcache: Buffer; {pierwszy bufor w puli buforów}
Zaimplementuj funkcję GetBuffer oraz ReleaseBuffer.
function GetBuffer: Buffer; begin while bufcache = nil do sleep (nobuffers); disable_interrupts; GetBuffer := bufcache; bufcache := bufcache^.next; enable_interrupts; end; procedure ReleaseBuffer (b: Buffer); begin b^.next := bufcache; bufcache := b; wakeup (nobuffers) end;
Wyłączenie przerwań w GetBuffer jest tu kluczowe! Niestety, nie daje ono jeszcze poprawności rozwiązania, pojawia się bowiem tzw. problem zagubionej pobudki. Zaobserwuj, co się stanie, jeśli przerwanie pojawi się po sprawdzeniu warunku pętli, a przed uśpieniem. Proces zostanie wówczas uśpiony, choć tak naprawdę jest dla niego bufor. Co więcej, pobudka dla niego (w postaci wakeup z ReleaseBuffer została wygenerowana ... zanim został on uśpiony!
Odłóżmy na razie rozwiązanie tego problemu i nie przejmując się nim przyjrzyjmy się drugiej sytuacji wymagającej synchronizacji w jądrze niewywłaszczalnym na jednoprocesorze. Zauważmy jeszcze tylko, że o ile disable_interrupt blokuje także przerwania zegarowe nie dopuszczając tym samym do wywłaszczenia procesu z powodu upływu kwantu czasu oraz o ile w trakcie obsługi przerwań blokowane są przerwania, to rozwiązania to zadziała poprawnie (z dokładnością do zagubionej pobudki) także w systemie z jądrem wywłaszczalnym (ale nie na wieloprocesorze).
Jak zapewnić spójność struktur danych w czasie wykonywania operacji blokującej?
Przypuśćmy, że w poprzednim zadaniu bufory znalezione przez GetBuffer są jedynie blokowane i nie usuwa się ich z puli wolnych buforów. Zmodyfikuj treść funkcji GetBuffer i procedury ReleaseBuffer. Nie przejmuj się problemem zagubionej pobudki.
Tym razem w ogóle nie musimy blokować przerwań, a właściwą synchronizację zapewni dodatkowe pole blocked związane z każdym buforem oraz niewywłaszczalność jądra.
function GetBuffer: Buffer; var found: boolean; p: Buffer; begin found := false; while not found do begin p := bufcache; while (p <> nil) and not found do if p^.blocked then p := p^.next else begin found := true; GetBuffer := p; p^.blocked := true end; if not found then sleep (nobuffers) end; end; procedure ReleaseBuffer (p: Buffer); begin p^.blocked := false; wakeup (nobuffers) end;
Choć struktura danych nie straci spójności, to jednak jeszcze dobitniej widać tu problem zagubionej pobudki, który drastycznie ujawni się, gdy podczas poszukiwania wolnego bufora zostanie zwolniony bufor, który już sprawdzaliśmy.
Zauważmy przy okazji, że w jądrze wywłaszczalnym oraz na wieloprocesorze powyższe rozwiązanie nie zapewni spójności danych.
W praktyce powyższe rozwiązanie zapisalibyśmy unikając przeszukiwania, gdy wiadomo, że buforów brakuje. Wystarczy, aby jądro utrzymywało globalną zmienną freebuffers zliczającą wolne bufory. Dla uproszczenia załóżmy, że operacje zwiększania i zmniejszanie tej zmiennej są atomowe:
function GetBuffer: Buffer; p: Buffer; begin while freebuffers = 0 do sleep (nobuffers); freebuffers--; p := bufcache; while p^.blocked do p := p^.next; GetBuffer := p; p^.blocked := true end; procedure ReleaseBuffer (p: Buffer); begin p^.blocked := false; freebuffers++; wakeup (nobuffers) end;
W dalszym ciągu jest to rozwiązanie, które nie zadziała ani z jądrem wywłaszczalnym ani z wieloprocesorem, a w przypadku jądra wywłaszczalnego mamy problem z zagubioną pobudką.
Czy można poradzić sobie jakoś z problemem zagubionej pobudki?
Nie. Proces musi odblokować przerwania zanim zostanie uśpiony, ale odblokowanie przerwań przed uśpieniem może spowodować, że przerwanie pojawi się zanim proces zostanie uśpiony. Chyba, że zmienimy semantykę operacji sleep. Niech teraz sleep atomowo zmienia stan procesu, przenosi go do kolejki procesów zatrzymanych i odblokowuje przerwania. Dzięki temu można go wywołać przy wyłączonych przerwaniach, a nasz ostatni program wyglądałby tak:
function GetBuffer: Buffer; p: Buffer; begin disable_interrupts; while freebuffers = 0 do begin sleep (nobuffers); disable_interrupts; end; freebuffers--; enable_interrupts; p := bufcache; while p^.blocked do p := p^.next; GetBuffer := p; p^.blocked := true end; procedure ReleaseBuffer (p: Buffer); begin p^.blocked := false; freebuffers++; wakeup (nobuffers) end;
Teraz już nie trzeba zakładać niepodzielności operacji zwiększania i zmniejszania zmiennej freebuffers.
Zaimplementuj operacje P i V na semaforze ogólnym w systemie jednoprocesorowym bez wywłaszczania. Załóż, że żadna procedura obsługi przerwania nigdy nie manipuluje semaforem.
type semaphore = record count: integer; wait: wait_queue; end; procedure P (var s: semaphore); { tryb jądra} begin while (s.count <= 0) do sleep (s.wait); s.count--; end; procedure V (var s: semaphore); { tryb jądra } begin inc (s.count); wakeup (s.wait); end;
Oczywiście w systemie z jądrem wywłaszczalnym i na wieloprocesorze rozwiązanie jest niepoprawne - brakuje nawet bezpieczeństwa, bo wiele procesów może wykonywać jednocześnie procedurę P.
Niektóre procesory (na przykład MIPS R4000, Alpha AXP firmy Digital oraz mikrokontrolery rodziny ARM) oferują parę specjalnych rozkazów:
load-locked (adres) przekazuje w wyniku wartość z komórki pamięci o podanym adresie i ustawia znacznik sprzętowy związany z konkretnym procesorem. Ten znacznik sprzętowy oznacza, że jedynie procesor wykonujący load-locked(adres) ma prawo wykonać na tym adresie operację store-condstore-cond (adres, wartość)wpisuje wartość do pamięci, o ile jest ustawiony znacznik wykonującego procesora. Jeśli zapis się udał, to przekazuje w wyniku true, w przeciwnym razie wynikiem jest false. Znacznik jest zerowany.Zaimplementuj blokadę wirującą dla wieloprocesora za pomocą pary rozkazów load-locked i store-cond. (Implementacja za pomocą xchng oraz test-and-set była na wykładzie). Załóż, że spin_lock jest niewywłaszczalny.
var lock: boolean := false; procedure spin_lock (var lock: boolean); begin repeat while load-locked (lock) do {nic}; until store-cond (lock, true) end; procedure spin_unlock (var lock: boolean); begin lock := false; end;
Czy blokady wirujące w kodzie jądra mają sens:
Blokady wirujące mają sens na wieloprocesorze, gdzie oczekiwanie w sposób aktywny na zasób zablokowany przez aktualnie wykonujący się (na innym procesorze) proces, może okazać się efektywniejsze niż wstrzymywanie procesu.
W systemach jednoprocesorowych z jądrem wywłaszczalnym blokady wirujące są nieefektywne, choć jeszcze niczego nie psują. Natomiast w jądrze niewywłaszczalnym "zawieszenie" się na blokadzie wirującej oznacza zakleszczenie.
Z tego powodu operacje spin_lock oraz spin_unlock są w takich systemach implementowane jako operacje puste.
Spróbujmy teraz uzupełnić poprzednią implementację semafora o wzajemne wykluczanie realizowane za pomocą blokad wirujących. Czy otrzymamy w ten sposób poprawną implementację semafora?
type semaphore = record count: integer; wait: wait_queue; lock: boolean; end; procedure P (var s: semaphore); { tryb jądra} begin spin_lock(s.lock); while (s.count <= 0) do begin spin_unlock(s.lock); sleep (s.wait); spin_lock(s.lock); end; s.count--; spin_unlock(s.lock); end; procedure V (var s: semaphore); { tryb jądra } begin spin_lock (s.lock); s.count++; wakeup (s.wait); spin_unlock (s.lock) end;
W systemie jednoprocesorowym jest OK (o ile operacje na blokadach wirujących są implementowane jako puste w przypadku jądra niewywłaszczalnego). Natomiast w systemie wieloprocesorowym mamy znów problem z zagubioną pobudką - tym razem jednak na nieco innym poziomie niż poprzednio.
Żeby sobie z tym problemem poradzić potrzebujemy niepodzielną operacje spin_unlock i sleep. Implementacja semafora w wieloprocesorowym jądrze Linuksa korzysta na przykład z wariantu funkcji sleep, której jednym z parametrów jest semafor s. Operacja sleep jest wywoływana bez zwalniania blokady wirującej i dopiero po faktycznym umieszczeniu procesu w odpowiedniej kolejce tuż przed przełączeniem kontekstu, wywołuje ona spin_unlock (s.lock).
W pewnym systemie z czterema typami zasobów A, B, C i D działa równocześnie pięć procesów: P1, P2, ..., P5. W pewnej chwili stan przydziału zasobów jest następujący:
| Przydzielone | Maksymalne | Dostępne | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | A | B | C | D | A | B | C | D | |
| P1 | 0 | 0 | 1 | 2 | 0 | 0 | 1 | 2 | 2 | 1 | 0 | 0 |
| P2 | 2 | 0 | 0 | 0 | 2 | 7 | 5 | 0 | ||||
| P3 | 0 | 0 | 3 | 4 | 6 | 6 | 5 | 6 | ||||
| P4 | 2 | 3 | 5 | 4 | 4 | 3 | 5 | 6 | ||||
| P5 | 0 | 3 | 3 | 2 | 0 | 6 | 5 | 2 | ||||
Potrzebne?(0, 1, 0,0) zgłoszone przez proces P3?Potrzebne jest różnicą macierzy Maksymalne i Przydzielone. Zatem aktualna wartość macierzy Potrzebne to:
| Potrzebne | ||||
|---|---|---|---|---|
| A | B | C | D | |
| P1 | 0 | 0 | 0 | 0 |
| P2 | 0 | 7 | 5 | 0 |
| P3 | 6 | 6 | 2 | 2 |
| P4 | 2 | 0 | 0 | 2 |
| P5 | 0 | 3 | 2 | 0 |
| Przydzielone | Potrzebne | Dostępne | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | A | B | C | D | A | B | C | D | ||
| P1 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | 0 | P1 | 2 | 1 | 0 | 0 |
| P2 | 2 | 0 | 0 | 0 | 0 | 7 | 5 | 0 | P4 | 2 | 1 | 1 | 2 |
| P3 | 0 | 0 | 3 | 4 | 6 | 6 | 2 | 2 | P5 | 4 | 4 | 6 | 6 |
| P4 | 2 | 3 | 5 | 4 | 2 | 0 | 0 | 2 | P2 | 4 | 7 | 9 | 8 |
| P5 | 0 | 3 | 3 | 2 | 0 | 3 | 2 | 0 | P3 | 6 | 7 | 9 | 8 |
| Przydzielone | Potrzebne | Dostępne | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | B | C | D | A | B | C | D | A | B | C | D | ||
| P1 | 0 | 0 | 1 | 2 | 0 | 0 | 0 | 0 | P1 | 2 | 0 | 0 | 0 |
| P2 | 2 | 0 | 0 | 0 | 0 | 7 | 5 | 0 | P4 | 2 | 0 | 1 | 2 |
| P3 | 0 | 1 | 3 | 4 | 6 | 5 | 2 | 2 | P5 | 4 | 3 | 6 | 6 |
| P4 | 2 | 3 | 5 | 4 | 2 | 0 | 0 | 2 | 4 | 6 | 9 | 8 | |
| P5 | 0 | 3 | 3 | 2 | 0 | 3 | 2 | 0 | |||||
Zatem żądanie nie zostanie zrealizowane, choć zasoby potrzebne procesowi P3 są dostępne.
W pewnym systemie z trzema typami zasobów A, B i C działa równocześnie pięć procesów: P1, P2, ..., P5. W pewnej chwili stan przydziału zasobów jest następujący:
| Przydzielone | Maksymalne | Dostępne | |||||||
|---|---|---|---|---|---|---|---|---|---|
| A | B | C | A | B | C | A | B | C | |
| P1 | 0 | 0 | 1 | 0 | 0 | 1 | 0 | 5 | 3 |
| P2 | 1 | 0 | 0 | 1 | 7 | 5 | |||
| P3 | 1 | 3 | 5 | 2 | 6 | 10 | |||
| P4 | 0 | 6 | 3 | 0 | 6 | 5 | |||
| P5 | 0 | 0 | 1 | 0 | 6 | 5 | |||
Potrzebne?(0, 4, 2) zgłoszone przez proces P2?Analogicznie do poprzedniego zadania.
Wykaż, że strategia SJF jest optymalna ze względu na średni czas obrotu dla ustalonego (w chwili 0) zbioru procesów w klasie strategii bez wywłaszczania.
Bez straty ogólności rozwiązania przyjmijmy, że procesy są ponumerowane zgodnie z rosnącymi czasami zapotrzebowania na kolejną fazę procesora, tzn. ti <= tj dla i < j, gdzie ti jest czasem trwania kolejnej fazy dla procesu Pi.
Rozpatrzymy teraz dowolną kolejność wykonania procesów, w której istnieje 1 <= i < n takie, że
Pi+1 wykonuje się przed Pi. Zamiana miejscami tych procesów powoduje zmianę czasów zakończenia jedynie procesu Pi oraz Pi+1. Proces Pi kończy się teraz o ti+1 wcześniej niż poprzednio, a proces Pi+1 o ti później. Zatem suma czasów obrotów wszystkich procesów zmienia się o ti - ti+1 <= 0. Średni czas obrotu jest więc teraz nie gorszy niż poprzednio.
Widać zatem, że możemy zawsze zlikwidować "inwersję" w ciągu procesów nie pogarszając średniego czasu obrotu zadania. Wynika z tego, że przydział procesora w kolejności wzrastających numerów procesów jest nie gorszy niż jakakolwiek inna kolejność. Czyli SJF jest optymalny.
W pewnym systemie jednoprocesorowym na wykonanie czekają następujące procesy:
| Proces | Czas przybycia | Zapotrzebowanie na CPU |
|---|---|---|
| P1 | 0 | 10 |
| P2 | 0 | 5 |
| P3 | 0 | 4 |
| P4 | 6 | 8 |
| P5 | 6 | 3 |
Jaki jest średni czas obrotu procesu dla strategii PS?
Do chwili 6 wykonują się procesy P1, P2 i P3 i każdy wykorzystuje procesor przez 2 jednostki czasu.
Następnie działają wszystkie procesy aż do zakończenie procesu P3, co nastąpi w chwili 16. Do tego czasu każdy proces wykorzysta procesor przez kolejne 2 jednostki czasu. W chwili 20 skończą się procesy P2 i P5. Pozostałe procesy P1 i P4 potrzebują jeszcze 5 jednostek czasu procesora, skończą się więc w chwili 30. Otrzymujemy zatem:
| Proces | Czas przybycia | Czas zakończenia | Czas obrotu |
|---|---|---|---|
| P1 | 0 | 30 | 30 |
| P2 | 0 | 20 | 20 |
| P3 | 0 | 16 | 16 |
| P4 | 6 | 30 | 24 |
| P5 | 6 | 20 | 14 |
Średni czas obrotu wynosi 104/5 = 20,8
W pewnym systemie jednoprocesorowym na wykonanie czekają cztery procesy. Zapotrzebowanie na CPU każdego z nich wynosi 10. Jaki będzie średni czas obrotu dla tej grupy procesów przy strategiach szeregowania:
Wyciągnij wnioski z tego przykładu.
Okazuje się zatem, że dla procesów o podobnym charakterze obliczeniowym, które nie wymagają szybkiego czasu reakcji, najprostsza implementacyjnie strategia FCFS daje także najlepszy czas obrotu! W dodatku narzut na przełączanie kontekstu jest tu najmniejszy.
Studenci rejestrujący się na pewien przedmiot muszą uzyskać zgodę prowadzącego i opłacić czesne. Oba te wymagania można wypełniać niezależnie od siebie w różnych miejscach kampusu. Limit miejsc wynosi 20 osób i przestrzega go zarówno prowadzący, jak i sekcja finansowa. Przypuśćmy, że opisany powyżej system rejestracji spowodował, że 19 studentów zarejestrowało się na przedmiot bez problemu, a o ostatnie miejsce rywalizuje dwóch studentów, z których jeden opłacił już czesne, ale nie uzyskał jeszcze zgody prowadzącego, a drugi uzyskał zgodę prowadzącego, ale nie opłacił czesnego. Który z warunków koniecznych powstawania zakleszczenia usuwa każde z następujących rozwiązań problemu:
W tym zadaniu dwóch feralnych studentów gra rolę procesów ubiegających się o dwa zasoby: miejsce na liście prowadzącego oraz miejsce na liście w sekcji finansowej. Zasoby te są niepodzielne.
Pewien bankier dysponuje kwotą 100 000 zł. Udziela on kredytu dwóm kredytobiorcom - każdemu po 50 000 zł. Po pewnym czasie obaj kredytobiorcy informują bankiera, że potrzebują jeszcze po 10 000 zł na dokończenie interestów i wtedy dopiero będą mogli oddać dług. Bankier radzi sobie z tym zakleszczeniem pożyczając potrzebną gotówkę z innego źródła i przekazując ją kredytobiorcom (zwiększając oprocentowanie kredytu:-). Który z warunków koniecznych powstawania zakleszczeń został usunięty przez bankiera?
Rozważmy następujące stategie przydziału pamięci w sposób ciągły:
Pokaż trzy przykłady ciągów działań, dla których każda z tych stategii okaże się lepsza od pozostałych. W każdym przykładzie podaj zapotrzebowanie na pamięć, określ kiedy pamięć jest zajmowana i zwalniana, a także podaj wielkość pamięci traconej w wyniku fragmentacji.
Przy okazji przyjrzyjmy się wadom i zaletom poszczególnych strategii. Porównajmy algorytmy, starając się dla każdego wskazać, w jakich sytuacjach będzie miał przewagę nad innymi, a w jakich będzie się zachowywał gorzej. Weźmy pod uwagę także narzut systemowy każdej z nich (np. sposób przechowywania informacji o wolnych obszarach pamięci i czas przeglądania tych danych).
Dostępna pamięć to spójny blok 2000B (2 kawałki po 1000B). Ciąg żądań:
X:=alloc(900B), Y:=alloc(900B), release(X), Z:=alloc(1000B)
Podany ciąg żądań zostanie bez czekania obsłużony tylko przez metodę stref statycznych. W przypadku stref dynamicznych - mimo, że pozostanie 1100B wolnej pamięci, to nie może ona być wykorzystana do spełnienia ostatniego żądania ze względu na fragmentację zewnętrzną.
Dostępna pamięć to spójny kawałek wielkości 400B. Ciąg żądań:
X:=alloc(200B), Y:=alloc(100B), release(X),
X:=alloc(50B), Z:=alloc(150B), W:=alloc(100B)
W przypadku metody pierwszy pasujący ten ciąg zostanie obsłużony bez czekania. Ze względu na fragmentację zewnętrzną (100B), w przypadku metody najlepszy pasujący ostatnie żądanie nie zostanie wykonane od razu. W strategii stref statycznych musielibyśmy mieć strefy wielkości 200B (żeby móc obsłużyć największe żądanie). W takiej sytuacji nie można przydzielić dwóch ostatnich fragmentów,
a fragmentacja wewnętrzna wynosi 250B.
Jak poprzednio dostępna pamięć to spójny blok wielkości 400B. Ciąg żądań:
X:=alloc(200B),Y:=alloc(100B), release(X),
X:=alloc(50B), Z:=alloc(50B), W:=alloc(200B)
W przypadku metody najlepiej pasujący ten ciąg zostanie obsłużony bez czekania. Ze względu na fragmentację zewnętrzną (200B) w przypadku metody pierwszy pasujący ostatnie żądanie nie zostanie wykonane od razu. Dla stref statycznych jest tak samo jak w poprzednim punkcie.
Rozważmy teraz system, w którym pamięć podzielona jest na strony. Załóżmy, że tablica stron jest przechowywana w pamięci głównej, czas dostępu do tej pamięci wynosi t.
Rozwiązanie
Przypuśćmy, że zawartość tablicy stron dla aktualnie wykonywanego procesu jest następująca:
| Numer strony | Numer ramki |
|---|---|
| 0 | - |
| 1 | 4 |
| 2 | - |
| 3 | 2 |
| 4 | 1 |
| 5 | 0 |
Strony i ramki są numerowane od zera, adresy są adresami bajtów w pamięci, a strona ma rozmiar 1024 bajty.
Jakim adresom fizycznym odpowiadają podane adresy wirtualne (nie należy obsługiwać błędów braku strony):
W pewnym systemie ze stronicowaniem: strona ma rozmiar 512 bajtów, pozycja w tablicy stron (adres) zajmuje 4 bajty, a tablica stron dowolnego poziomu zajmuje 1 stronę.
64KB > 8KB, czyli do zarządzania pamięcią o rozmiarze 8KB wystarczy stronicowanie 1-poziomowe.
Załóżmy, że funkcja mem(x) przekazuje liczbę 32-bitową, znajdującą się pod adresem x wyrażonym w bajtach. Napisz funkcję f(x), która dla założeń z poprzedniego zadania i 3 poziomów stronicowania przekształca adres liniowy w adres fizyczny. Przyjmij, że zmienna R przechowuje adres bazowy katalogu 3-ciego poziomu.
Struktura adresu liniowego dla podanych założeń
| 2 zarezerwowane bity | indeks 3 poziomu (7 bitów) |
indeks 2 poziomu (7 bitów) |
indeks 1 poziomu (7 bitów) |
przesunięcie (najmłodsze 9 bitów) |
Skorzystamy z poniższych makr:
#define PAGE_SIZE 512
#define CATALOG_BITS 7
#define DIRECTORY_BITS 7
#define TABLE_BITS 7
#define OFFSET_BITS 9
#define CATALOG_FIRST_BIT (DIRECTORY_BITS+TABLE_BITS+OFFSET_BITS)
#define DIRECTORY_FIRST_BIT (TABLE_BITS+OFFSET_BITS)
#define TABLE_FIRST_BIT (OFFSET_BITS)
#define SIZE_OF_CATALOG_ENTRY 4
#define SIZE_OF_DIRECTORY_ENTRY 4
#define SIZE_OF_TABLE_ENTRY 4
#define OFFSET_MASK ~(~0 << OFFSET_BITS)
#define getbits(x, start_position, field_size) ((x >> start_position) & (~(~0 << field_size)))
Makro getbits przekazuje pole o długości field_size wycięte z x od pozycji start_position, dosunięte to prawej strony. Przyjmujemy, że zerową pozycją bitu jest prawy koniec x.
Na przykład, getbits(x, 4, 3) przekazuje 3 bity - z pozycji 4, 5 i 6 dosunięte do prawej strony wyniku.
Oto funkcja f tłumacząca adres liniowy na adres fizyczny:
u32 f(u32 lin_addr) {
u32 address, offset;
/* wyznaczam indeks w katalogu stron najwyższego (tzn. trzeciego) poziomu */
offset = getbits(lin_addr, CATALOG_FIRST_BIT, CATALOG_BITS);
/* wyznaczam adres katalogu stron drugiego poziomu */
address = mem(R + SIZE_OF_DIRECTORY_ENTRY * offset);
/* wyznaczam indeks w katalogu stron drugiego poziomu */
offset = getbits(lin_addr, DIRECTORY_FIRST_BIT, DIRECTORY_BITS);
/* wyznaczam adres tablicy stron (pierwszy poziom) */
address = mem(address + SIZE_OF_DIRECTORY_ENTRY * offset);
/* wyznaczam indeks w tablicy stron */
offset = getbits(lin_addr, TABLE_FIRST_BIT, TABLE_BITS);
/* wyznaczam adres strony */
address = mem(address + SIZE_OF_TABLE_ENTRY * offset);
address *= PAGE_SIZE;
return address + (lin_addr & OFFSET_MASK);
}
Algorytm bliźniaków
Funkcja alloc_pages() (wykorzystywana między innymi przez kmalloc()) służy do przydzielania spójnych fragmentów pamięci na potrzeby jądra w systemach uniksowych.
Pamięć jest przydzielana i zwalniana w blokach o rozmiarze 2i ramek (i=0..MAX_ORDER-1).
Zarządzanie przydziałem i zwalnianiem wolnych fragmentów pamięci jest oparte na algorytmie bliźniaków (w literaturze angielskojęzycznej: buddy algorithm).
System przechowuje tablicę list adresów wolnych obszarów pamięci fizycznej o różnych
rozmiarach. Pierwsza lista zawiera obszary pamięci o wielkości jednej strony, a ostatnia o wielkości 2MAX_ORDER-1 stron. Każdy taki fragment pamięci, mimo że może składać się z wielu stron, jest spójnym blokiem pamięci fizycznej.
Zajmowanie obszaru o rozmiarze 2i
Szukanie obszaru do przydzielenia zaczyna się od listy i-tej. Jeśli nie jest ona pusta, to wyjmemy z niej jeden element i przekazujemy go
jako wynik funkcji. Jeśli lista jest pusta, to szukamy najbliższej niepustej listy zawierającej większe obszary pamięci i z niej wyjmujemy jeden element. Ponieważ znaleziony obszar jest większy od poszukiwanego, więc należy go podzielić. Dzielimy go zatem na połowy dopóty, dopóki otrzymany fragment jest żądanej wielkości. Pozostałe po dzieleniu obszary wstawanie są do odpowiednich list.
Zwalnianie obszaru o rozmiarze 2i
Zwalniany obszar musiał być kiedyś przydzielony, czyli musiał być wydzielony z bloku dwa razy większego. Być może jego bliźniak (czyli druga połowa tego większego bloku) też jest wolny i dwa bliźniacze obszary będzie można połączyć w jeden większy spójny obszar. Jeśli to się uda, to można szukać bliźniaka dla tego większego fragmentu itd. Postępuje się tak aż do momentu, kiedy szukany bliźniak okaże się być zajęty (lub cała dostępna pamięć jest wolna) i dodaje się utworzony blok do odpowiedniej listy, a także aktualizuje informacje o przynależności obszarów do pozostałych list.
Analiza
Zaletą algorytmu bliźniaków jest to, że jest on elastyczny i zapobiega fragmentacji, ponieważ te same fragmenty pamięci są wykorzystywane w obszarach o różnym rozmiarze. Jego wadą może wydawać się wydajność z uwagi na konieczność dzielenia i scalania obszarów.
Z drugiej strony dzięki indeksowaniu tablicy obszarów potęgami dwójki, większość operacji arytmetycznych polega na przesunięciu dwójkowym lub zamianie bitu, więc są one bardzo szybkie.
Zadanie
Przyjmiemy dla uproszczenia, że MAX_ORDER=5. W rzeczywistości jest to większa wartość: we współczesnych systemach Linux wynosi ona 11. Początkowo cała dostępna pamięć jest wolna i tworzy spójny obszar o rozmiarze 16 ramek o adresach od 0 do 15.
Jaka będzie odpowiedź, jeżeli zmienimy kolejność kroków (4) i (5)?
Jaki ciąg zleceń powoduje najgorsze możliwe zachowanie algorytmu bliźniaków?
| 4 | -> 0 | 3 | | 2 | | 1 | | 0 |
Sytuacja po operacji A:=allocate(1) :
| 4 | | 3 | -> 8 | 2 | -> 4 | 1 | -> 2 | 0 | -> 1
Sytuacja po operacji B:=allocate(2) :
| 4 | | 3 | -> 8 | 2 | -> 4 | 1 | | 0 | -> 1
Sytuacja po operacji C:=allocate(2) :
| 4 | | 3 | -> 8 | 2 | | 1 | -> 6 | 0 | -> 1
Sytuacja po operacji release(A) :
| 4 | | 3 | -> 8 | 2 | | 1 | -> 0, 6 | 0 |
Fragmenty o adresach 0 i 6 nie są bliźniakami, ponieważ nie tworzą spójnego obszaru.
Sytuacja po operacji D:=allocate(2) :
| 4 | | 3 | -> 8 | 2 | | 1 | -> 6 | 0 |
Jeśli zamienimy kolejność ostatnich 2 operacji, to otrzymamy:
Sytuacja po operacji D:=allocate(2) :
| 4 | | 3 | -> 8 | 2 | | 1 | | 0 | -> 1
Sytuacja po operacji release(A) :
| 4 | | 3 | -> 8 | 2 | | 1 | -> 0 | 0 |
Oblicz optymalny rozmiar strony minimalizujący fragmentację wewnętrzną.
(Wg. Brinch Hansena)
Niech p oznacza rozmiar strony (w słowach), a s przeciętny rozmiar programu (w słowach). Na każdą stronę potrzeba jednej pozycji w tablicy stron, a więc s/p pozycji. Średnio jest marnowana połowa (ostatniej) strony, a więc p/2. Optymalny rozmiar strony (minimalizujący fragmentację wewnętrzną) można zatem opisać wzorem:
f(p)=(p/2 + s/p)/s = p/2s + 1/p
f(p)' = 1/2s - 1/(p ^ 2)
f(p)' = 0 dla p = sqrt(2s), f(sqrt(2s)) = sqrt(2/s)
Wnioski: duża strona oznacza większe straty wynikające z niewykorzystania reszty ostatniej strony, ale mniejsze straty wynikające z rozmiaru tablicy stron. Warto też skomentować rozmiar strony w kontekście czasu poświęcanego na transmisje wejścia-wyjścia: im większa strona, tym narzuty w przeliczeniu na bajt są mniejsze) oraz w kontekście "fragmentacji logicznej" (ściągamy do pamięci większą stronę, potencjalnie ryzykujemy, że zawiera ona więcej niepotrzebnych bajtów).
(Jeszcze raz algorytm bliźniaków)
Zakładając, że MAX_ORDER=6 i początkowo cała wolna pamięć tworzy spójny obszar o rozmiarze 32 ramki, opisz stan pamięci po wykonaniu każdej z następujących operacji:
getpages(2); getpages(1); getpages(2); getpages(2);
freepages(8,2); freepages(4,1); freepages(0,2)Funkcja getpages(i) przydziela blok o rozmiarze i ramek, natomiast funkcja freepages(k,i) zwalnia blok rozpoczynający się od strony o numerze k i o rozmiarze i ramek. Ramki są numerowane od 0. Spośród dwóch obszarów uzyskanych w wyniku podziału zajmowany jest ten o mniejszym adresie.
Sytuacja początkowa:
| 5 | -> 0 | 4 | | 3 | | 2 | | 1 | | 0 |
Sytuacja po operacji getpages(2) :
| 5 | | 4 | -> 16 | 3 | -> 8 | 2 | -> 4 | 1 | -> 2 | 0 |
Sytuacja po operacji getpages(1) :
| 5 | | 4 | -> 16 | 3 | -> 8 | 2 | -> 4 | 1 | | 0 | -> 3
Sytuacja po operacji getpages(2) :
| 5 | | 4 | -> 16 | 3 | -> 8 | 2 | | 1 | -> 6 | 0 | -> 3
Sytuacja po operacji getpages(2) :
| 5 | | 4 | -> 16 | 3 | -> 8 | 2 | | 1 | | 0 | -> 3
Sytuacja po operacji freepages(6,2) :
| 5 | | 4 | -> 16 | 3 | -> 8 | 2 | | 1 | -> 6 | 0 | -> 3
Sytuacja po operacji freepages(4,1) :
| 5 | | 4 | -> 16 | 3 | -> 8 | 2 | | 1 | -> 6 | 0 | -> 3, 4
Fragmenty o adresach 3 i 4 nie są bliźniakami mimo, że tworzą spójnego obsza, ponieważ nie można z nich zbudować obszaru dwa razy większego o wyrównanym adresie.
Sytuacja po operacji freepages(0,2) :
| 5 | | 4 | -> 16 | 3 | -> 8 | 2 | | 1 | -> 0, 6 | 0 | -> 3, 4
Niech index_of_page oznacza indeks strony w tablicy ramek, index_of_buddy oznacza indeks bliźniaka, a order rząd, gdzie rozmiar wolnego obszaru w systemie bliźniaków to 2^order ramek. W jaki sposób obliczamy indeks bliźniaka? Wypełnij puste pola podanej tabeli:
index_of_page: 0 1 2 3 0 2 0 index_of_buddy: order: 0 0 0 0 1 1 2
Indeks bliźniaka wylicza się za pomocą formuły:
index_of_buddy = index_of_page XOR (1 << order).
index_of_page: 0 1 2 3 0 2 0 index_of_buddy: 1 0 3 2 2 0 4 order: 0 0 0 0 1 1 2
Zapisz formułę wyznaczającą dla obszaru o indeksie index_of_page rzędu order indeks zawierającego go bliźniaka rzędu order + 1. Sprawdź jej działanie dla przykładowych danych.
index_of_parent = index_of_page & ~(1 << order)
index_of_page: 0 1 2 3 0 2 0 index_of_parent: 0 0 2 2 0 0 0 order: 0 0 0 0 1 1 2
Rozważmy pamięć wirtualną ze stronicowaniem na żądanie. Tablica stron jest przechowywana w rejestrach. Obsługa przerwania braku strony zajmuje 8 milisekund, gdy jest dostępna pusta ramka lub strona usuwana z pamięci nie była modyfikowana i 20 milisekund, gdy usuwana strona była modyfikowana. Czas dostępu do pamięci wynosi 1 mikrosekundę.
Załóżmy, że 70% usuwanych stron to strony, które były modyfikowane. Jaki jest maksymalny akceptowalny współczynnik przerwań braku strony, aby efektywny czas dostępu do pamięci nie przekraczał 2 mikrosekund?
Rozwiązanie
2 mikrosekundy >= (1 - p) * 1 mikrosekunda + p * (0.3 * 8 milisekund + 0.7 * 20 milisekund) p <= 0.00006
Rozważmy następujący ciąg odwołań do stron:
4, 5, 3, 1, 4, 5, 2, 4, 5, 3, 1, 2
Zakładając, że dostępna dla procesów pamięć fizyczna składa się z:
które początkowo są wolne, podaj, które strony i w jakiej kolejności zostaną usunięte oraz jaka jest w każdej chwili zawartość pamięci przy zastosowaniu następujących strategii usuwania stron:
Rozwiązanie
4 5 3 1 4 5 2 4 5 3 1 2
* * * * * * * * * *
4 5 3 1 4 5 2 4 5 3 1 2
4 5 3 1 4 5 2 4 5 3 1
4 5 3 1 4 5 2 4 5 3 4 5 3 1 4 5 2 4 5 3 1 2
* * * * * * * * *
4 4 4 1 1 1 2 2 2 2 2 2
5 5 5 4 4 4 4 4 3 3 3
3 3 3 5 5 5 5 5 1 1 4 5 3 1 4 5 2 4 5 3 1 2
* * * * * * *
4 4 4 4 4 4 4 4 4 4 1 1
5 5 5 5 5 5 5 5 3 3 3
3 1 1 1 2 2 2 2 2 2 4 5 3 1 4 5 2 4 5 3 1 2
* * * * * * * *
4 5 3 1 4 5 2 4 5 3 1 2
4 5 3 1 4 5 2 4 5 3 1
4 5 3 1 4 5 2 4 5 3
4 5 3 1 1 1 2 4 5 4 5 3 1 4 5 2 4 5 3 1 2
* * * * * * * * * *
4 4 4 4 4 4 2 2 2 2 1 1
5 5 5 5 5 5 4 4 4 4 2
3 3 3 3 3 3 5 5 5 5
1 1 1 1 1 1 3 3 3Anomalia Belady'ego: wystąpiło więcej błędów braku strony mimo, że jest więcej dostępnej pamięci.
4 5 3 1 4 5 2 4 5 3 1 2
* * * * * *
4 4 4 4 4 4 4 4 4 4 1 1
5 5 5 5 5 5 5 5 5 5 5
3 3 3 3 3 3 3 3 3 3
1 1 1 2 2 2 2 2 2Pewien proces wygenerował następujący ciąg odwołań do stron:
1, 4, 1, 2, 5, 3, 1, 2, 6, 4, 3, 2
Zakładając, że dostępna dla procesów pamięć fizyczna składa się z 4 ramek, które początkowo są wolne, podaj, które strony i w jakiej kolejności zostaną usunięte oraz jaka jest w każdej chwili zawartość pamięci przy zastosowaniu następujących strategii usuwania stron:
Rozwiązanie
1 4 1 2 5 3 1 2 6 4 3 2
* * * * * * * *
1 4 1 2 5 3 1 2 6 4 3 2
1 4 1 2 5 3 1 2 6 4 3
4 1 2 5 3 1 2 6 4
4 1 2 5 3 1 2 6 1 4 1 2 5 3 1 2 6 4 3 2
* * * * * * * * *
>1.>1.>1.>1.>1. 3. 3. 3.>3. 3 3. 3
4. 4. 4. 4.>4 1. 1. 1. 1 1 2.
2. 2. 2 >2 >2. 2 4. 4.>4.
5. 5 5 5 6.>6.>6. 6. oznacza ustawiony bit
Rozważmy następujący ciąg odwołań do stron:
2, 4, 3, 4, 4, 4, 3, 4, 2, 1, 5, 2, 5
Podaj zawartość pola roboczego oraz liczbę przerwań braku strony dla wskazanego ciągu odwołań w strategii pola roboczego z okienkiem o rozmiarze:
Rozwiązanie
2 4 3 4 4 4 3 4 2 1 5 2 5
* * * * * * *
2 2 2 4 4 4 4 4 3 4 2 1 5
4 4 3 3 3 3 4 2 1 5 2
3 2 1 5 2
2 4 3 4 4 4 3 4 2 1 5 2 5
* * * * * *
2 2 2 2 4 4 4 4 4 3 4 2 1
4 4 4 3 3 3 3 3 4 2 1 5
3 3 2 2 1 5 2
1 5Rozważmy dwuwymiarową tablicę A:
var A: array [1..page_size] of array [1..page_size] of byte;
Ile przerwań braku strony wygeneruje wykonanie każdego z podanych dwóch algorytmów zerowania tablicy A?
for i:= 1 to page_size do
for j:= 1 to page_size do
A[i, j] := 0;
for i:= 1 to page_size do
for j:= 1 to page_size do
A[j, i] := 0;Można założyć, że:
Rozwiązanie
Algorytm pierwszy wygeneruje page_size przerwań braku strony, a drugi: page_size2.
Wniosek: struktura programu może mieć istotny wpływ na efektywność wykonywania tego programu w systemie z pamięcią wirtualną.
Algorytm WSClock zarządzania pamięcią działa następująco. Jeśli są puste ramki, to przydziela pierwszą wolną.
Jeśli nie ma, to przegląda cyklicznie wszystkie ramki (począwszy od miejsca, w którym ostatnio zakończono przeglądanie). Jeśli do strony zapamiętanej w ramce było odwołanie od ostatniego sprawdzenia, to za czas tego odwołania przyjmuje się czas bieżący. Jeśli do strony nie było odwołania od ostatniego sprawdzenia, to można usunąć tę stronę, jeśli od czasu ostatniego sprawdzenia minęło co najmniej T jednostek czasu. Jeśli strona była modyfikowana podczas pobytu w pamięci operacyjnej, to inicjuje się usunięcie strony i szuka się dalej. Jeśli w wyniku przejrzenia wszystkich ramek nie znajdzie się żadnej wolnej, to:
Dane są następujące deklaracje:
const lramek = ...;
maxproc = ...;
T = ...;
type ramki = 0..lramek-1;
procesy = 0..maxproc;
function Zegar: real; (* wirtualny zegar *)
procedure UsuńStronę (nrramki: ramki);
(* inicjuje przesłanie strony z danej ramki z pamięci operacyjnej do pomocniczej *)
function CzekajNaRamkę: ramki;
(* wstrzymuje działanie procesu aż do chwili najbliższego zakończenia usuwania
strony z pamięci operacyjnej do pomocniczej - przekazuje numer zwolnionej ramki *)
function UsuńProces: procesy
(* przekazuje numer procesu wyznaczonego do usunięcia *)Należy zadeklarować wszystkie potrzebne struktury danych oraz napisać procedurę WSClock implementującą strategię zarządzania pamięcią WSClock i przekazującą numer wolnej ramki w pamięci operacyjnej.
Uwaga: jeśli na porządne zapisanie tego algorytmu nie wystarczy czasu, to należy przynajmniej dokładnie omówić działanie algorytmu WSClock.
Rozwiązanie
type wramki = -1 .. lramek -1; (* wolne ramki; -1 <=>; NIL *)
var PaO: array [ramki] of
record
było_odwołanie: boolean;
czas_odwołania: real;
modyfikowana: boolean;
trwa_transmisja: boolean; (* strona jest usuwana,
była modyfikowana *)
proces: procesy;
następna_wolna: wramki; (* następna wolna *)
end;
strzałka: ramki;
wolna: wramki; (* wskaźnik do listy wolnych *)
usuwane: integer; (* liczba usuwanych stron zmodyfikowanych;
transmisja mogła zostać zainicjowana podczas
poprzednich wywołań procedury WSClock *)
czekający: integer; (* liczba procesów czekających na stronę *)
bieżący_proces: integer; (* numer bieżącego procesu *)
procedure ZwolnijRamkę (nrramki: ramki);
begin
PaO[nrramki].następna_wolna := wolna; wolna := nrramki;
with PaO[nrramki] do
begin
proces := 0; trwa_transmisja := false; było_odwołanie := false
end
end;
procedure WSClock (var nrramki: ramki);
var znaleziono: boolean;
ostatni: nrramki;
nrproc: procesy;
begin
if wolna <> -1 then begin
nrramki := wolna; wolna := PaO[wolna].następna_wolna
end
else begin
znaleziono := false;
ostatni := strzałka;
repeat
strzałka := (strzałka + 1) mod lramek;
with PaO[strzałka] do
if not trwa_transmisja then
if było_odwołanie then begin
było_odwołanie := false; czas_odwołania := Zegar(bieżący_proces);
end
else if Zegar(bieżący_proces) - czas_odwołania > T then
if modyfikowana then begin
usuwane := usuwane + 1;
trwa_transmisja := true;
UsuńStronę(strzałka)
end else begin
znaleziono := true;
proces := bieżący_proces;
nrramki := strzałka;
end
until znaleziono or (strzałka = ostatni);
if not znaleziono then begin
if czekający >= usuwane then begin
nrproc := UsuńProces;
for ostatni:=0 to lramek-1 do
with PaO[ostatni] do
if proces = nrproc then
if modyfikowana then begin
trwa_transmisja:=true;
usuwane := usuwane + 1;
UsuńStronę(ostatni)
end
else ZwolnijRamkę(ostatni);
end;
if wolna <> -1 then begin
nrramki := wolna; wolna := PaO[wolna].następna_wolna
end
else begin czekający := czekający + 1; nrramki := CzekajNaRamkę end
end;
end
end (* WSClock *)Dodatkowe pytania:
Rozważmy plik złożony ze 100 bloków. Załóżmy, że struktury danych opisujące położenie pliku na dysku są w pamięci operacyjnej. Przyjmijmy także, że blok fizyczny poprzedzający pierwszy blok pliku na dysku jest zajęty, a blok fizyczny położony za ostatnim blokiem pliku jest wolny. Ile operacji dyskowych wymaga:
Rozwiązanie
| alokacja ciągła | alokacja listowa | alokacja indeksowa | |
| a | 201=100+101 | 1 | 1 |
| b | 101=50+51 | 52=50+1+1 | 1 |
| c | 1 | 102=100+1+1 | 1 |
| d | 198=99+99 albo 0 | 1 | 0 |
| e | 98=49+49 | 52=51+1 | 0 |
| f | 0 | 100=99+1 | 0 |
I-węzeł pliku w systemach ext2 i ext3 zawiera numery pierwszych 12 bloków z danymi oraz numery jednego bloku pośredniego, jednego bloku podwójnie pośredniego i jednego bloku potrójnie pośredniego (tablica i-block).
Plik o rozmiarze logicznym 15000 B został umieszczony na partycji, dla której rozmiar bloku ustalono na 1 KB.
Policz ile operacji dyskowych wymaga:
fragmentu pliku o wielkości 1000 B (uwaga: nie 1 KB) położonego:
W obu przypadkach plik jest otwarty, ale żaden blok danych nie został jeszcze sprowadzony do pamięci. W pamięci znajduje się jedynie i-węzeł pliku. Możemy założyć, że wszystkie bloki pliku są zapisane (plik nie jest dziurawy).
Jak zmienią się odpowiedzi bez ostatniego założenia?
W jakiej sytuacji uzyskamy najmniejszą liczbę operacji dyskowych?
Rozwiązanie
Gdyby był to pierwszy zapis do bloku o numerze 14 (na przykład w sytuacji, gdy dopisywane jest 1000B na końcu pliku), to jeszcze doszedłby zapis bloku pojedynczo pośredniego, bo trzeba by przydzielić blok fizyczny na ten blok logiczny i wstawić jego adres do bloku indeksowego. Nie potrzeba natomiast odczytywać wcześniej bloku o numerze 14, więc liczba operacji dyskowych również wyniosłaby 5 (2 odczyty i 3 zapisy).
Najmniejsza liczba operacji odczytu i zapisu będzie w sytuacji, w której dokonujemy pierwszego zapisu do obydwu bloków i nie został jeszcze przydzielony blok z adresami pośrednimi (tylko 3 operacje zapisu). W tej sytuacji trzeba jednak przydzielić 3 nowe bloki dyskowe.
Załóżmy, że rozmiar bloku w systemie plików ext3 został ustalony na 1KB. Ile maksymalnie, a ile minimalnie bloków dyskowych może być potrzebne do zapamiętania pliku o rozmiarze 2GB?
Wskazówka: Pliki mogą być rozrzedzone (dziurawe).
Rozwiązanie
Przypadek maksymalnej liczby bloków dyskowych odpowiada np. plikowi całkowicie zapisanemu. Dla takiego pliku trzeba alokować wszystkie bloki z danymi, a więc także wszystkie bloki indeksowe.
Plik ma rozmiar 2 GB, co daje 2GB /1KB = 2M bloków z danymi.
Każdy blok pośredni może pomieścić 1024/4=256 numerów bloków.
Gdyby wszystkie bloki były indeksowane przez bloki pośrednie, to potrzeba na to 2M /256 = 8 K bloków pośrednich. Ponieważ adresy pierwszych 12 bloków znajdują się w i-węźle ostatni z tych bloków będzie indeksował 256 - 12 = 244 bloki z danymi.
Bloki pośrednie dzielą się na 1 blok samodzielny i 31 * 256 + 255 bloków indeksowanych przez bloki podwójnie pośrednie (ostatni niepełny). Te ostatnie z kolei dzielą się na 1 blok samodzielny i 31 bloków indeksowanych przez blok potrójnie pośredni (oczywiście niepełny).
Łącznie potrzeba: 2 M bloków z danymi, 8 K bloków pośrednich, 32 bloki podwójnie pośrednie i 1 blok potrójnie pośredni.
Przypadek minimalnej liczby bloków dyskowych odpowiada np. plikowi, który powstał przez zapisanie jednego bajtu pod adresem 2^31-1 (za pomocą operacji lseek()). W tym przypadku trzeba alokować po jednym bloku pośrednim każdego poziomu i jeden na blok danych (łącznie 3 + 1 = 4 bloki).
Kiedy rozmiar pliku w i-węźle systemu ext2 był opisywany liczbą 32-bitową i jej najstarszy bit był zarezerwowany, plik mógł mieć wielkość co najwyżej 2GB. We współczesnych systemach ext2 i ext3 32-bitowe pole i-węzła o nazwie i-blocks przechowuje rozmiar pliku wyrażony w liczbie 512 bajtowych porcji. Rozmiar bloków na dysku zależy od konfiguracji. Dopuszczalne są bloki o wielkości 512 B, 1KB, 2KB, 4KB, a nawet 8KB (o ile architektura na to pozwala). Numery bloków fizycznych są 32-bitowe.
Wiedząc to wszystko i biorąc pod uwagę sposób adresowania bloków uzupełnij poniższą tabelkę dla systemów ext2/3:
| rozmiar bloku | maksymalny rozmiar pliku | maksymalny rozmiar partycji |
| 1 KB | ||
| 2 KB | ||
| 4 KB | ||
| 8 KB |
Rozwiązanie
| rozmiar bloku | maksymalny rozmiar pliku | maksymalny rozmiar partycji |
| 1 KB | 16 GB | 4 TB |
| 2 KB | 256 GB | 8 TB |
| 4 KB | 2 TB | 16 TB |
| 8 KB | 2 TB | 32 TB |
Maksymalny rozmiar pliku jest ograniczony przez:
min(((b/4)3 + (b/4)2 + b/4 + 12)*b, 241),
gdzie b jest rozmiarem bloku.
Pierwsza część ograniczenia wynika ze sposobu adresowania, czyli maksymalnej liczby bloków jaką możemy zaadresować mając
3 poziomowe indeksowanie.
Druga część to ograniczenie wynikające z 32-bitowej postaci i-blocks oznaczającej liczbę 512 bajtowych porcji pliku:
232 * 29 = 241, czyli 2TB.
Dla b=210 maksymalny rozmiar pliku to
min(((28)3 + ...) * 210, 241)= w przybliżeniu 234
Dla b=211 maksymalny rozmiar pliku
to min(((29)3 + ...) * 211, 241)= w przybliżeniu 238
Dla b=212 maksymalny rozmiar pliku
to min(((210)3 + ...) * 212, 241) =241
Maksymalny rozmiar partycji jest zdeterminowany przez 32-bitowe numery bloków na dysku. Na przykład dla bloku o rozmiarze 1 KB:
232 * 210=242, czyli partycja może mieć wielkość co najwyżej 4 TB.
Napisz funkcję int bmap(struct inode *inode, int block), która tłumaczy logiczny numer bloku w pliku na fizyczny numer bloku na dysku, w systemach plików ext2/3.
Dane: wskaźnik do i-węzła pliku i logiczny numer bloku w pliku.
Wynik: fizyczny numer bloku na dysku w przypadku sukcesu lub 0, gdy nie znaleziono bloku.
Załóżmy, że są dostępne następujące makrodefinicje:
#define EXT2_BLOCK_SIZE 4096 #define EXT2_NDIR_BLOCKS 12 #define EXT2_IND_BLOCK EXT2_NDIR_BLOCKS #define EXT2_DIND_BLOCK (EXT2_IND_BLOCK + 1) #define EXT2_TIND_BLOCK (EXT2_DIND_BLOCK + 1) #define EXT2_N_BLOCKS (EXT2_TIND_BLOCK + 1)
Ponadto można założyć, że są dostępne następujące funkcje pomocnicze:
Jest to makro, które przekazuje numer bloku zapisany na pozycji nr w tablicy bloków pliku w i-węźle wskazywanym przez inode. Parametr nr powinien zatem należeć do przedziału [0..EXT2_N_BLOCKS-1] (czyli [0..14]). Makro to jest używane przy pobieraniu adresu fizycznego jednego z bloków bezpośrednich, bloku pojedynczego, podwójnego bądź potrójnego pośredniego.
Funkcja ta przekazuje wskaźnik do nagłówka bufora, do którego wczytano blok o numerze fizycznym i z urządzenia dev.
Funkcja ta przekazuje liczbę zapisaną w bloku z bufora o nagłówku bh, w komórce o numerze nr. Po odczytaniu zwalnia bufor (wykonując brelse()). Jest używana przy odczytywaniu adresów w blokach pojedynczych, podwójnych i potrójnych pośrednich.
Rozwiązanie
Warto wprowadzić dwie zmienne pomocnicze:
Jej wartością jest stale liczba adresów mieszczących się w bloku (czyli rozmiar_bloku/rozmiar_adresu).
Jej wartością jest stale logarytm przy podstawie 2 z wartości zmiennej N. Zmienna ta jest wykorzystywana przy wykonywaniu różnych operacji na bitach.
Przy przekształcaniu adresów zachodzi potrzeba obliczenia liczby bloków, które mieszczą się w poszczególnych strefach pośredniości. Oto jak radzi sobie z tym problemem algorytm bmap():
Maksymalna liczba bloków dająca się zaadresować w i-węźle jest sumą wymienionych czterech liczb.
Implementacja funkcji bmap():
{
/* Sprawdz czy parametr wywołania, block, jest poprawny */
if (block < 0) return 0; /* Nie znaleziono bloku */
if (block >= maksymalna liczba bloków możliwa do zaadresowania
w i-węźle) return 0;
/* Numer block jest poprawny; dalsze działanie zależy od
poziomu pośredniości, w którym znajduje się block */
DIR:
/* Poziom bezpośredni */
/* Blok jest w poziomie bezpośrednim, gdy jego numer jest
mniejszy od liczby blokow bezpośrednich */
if (block < EXT2_NDIR_BLOCKS) return inode_bmap(inode,block);
/* Blok jest w strefach pośrednich;pomijamy bloki bezpośrednie*/
block -= EXT2_NDIR_BLOCKS;
IND:
/* Pierwszy poziom pośredniości */
/* Blok jest w pierwszym poziomie pośredniości, gdy zmienna
block w tej chwili jest mniejsza od liczby bloków
dostępnych poprzez pojedynczy blok pośredni */
if (block < N)
{
/* Pobierz numer bloku pojedynczego pośredniego */
i = inode_bmap(inode, EXT2_IND_BLOCK);
if (i == 0) return 0;
/* Wczytaj blok o numerze i ( bread(inode->i_dev, i) ),
a nastepnie przekaż go jako pierwszy argument
do funkcji pomocniczej block_bmap */
return block_bmap( bread(inode->i_dev, i), block );
}
/* Blok jest w poziomie pośredniości wyższym od pierwszego;
pomijamy bloki w pierwszym poziomie pośredniości */
block -= N;
DIND:
/* Drugi poziom pośredniości */
if (block < liczba bloków dostępnych poprzez blok
podwójny pośredni)
{
/* Blok jest w drugim poziomie pośredniości */
/* Pobierz numer bloku podwójnego pośredniego */
i = inode_bmap(inode, EXT2_DIND_BLOCK);
if (i == 0) return 0;
/* Pobierz numer bloku pojedynczego pośredniego,
w którym znajduje się szukany blok; ten blok pojedynczy
pośredni ma numer block/N (część całkowita
ilorazu */
i = block_bmap(bread(inode->i_dev,i), block >> N_bits);
if (i == 0) return 0;
/* W bloku o numerze i, na pozycji (block mod N)
znajduje się szukany adres bloku */
return block_bmap(bread(inode->i_dev,i), block & (N - 1));
}
/* Pomijamy bloki w strefie drugiej pośredniości */
block -= liczba bloków dostępnych poprzez podwójny blok pośredni;
TIND:
/* Trzeci poziom pośredniości */
/* Pobierz numer bloku potrójnego pośredniego */
i = inode_bmap(inode, EXT2_TIND_BLOCK);
if (i == 0) return 0;
/* Pobierz numer bloku podwójnego pośredniego, w którym znajduje się szukany blok;
ten blok podwójny pośredni ma numer równy całości z dzielenia liczby block przez
kwadrat liczby N */
i = block_bmap( bread(inode->i_dev, i), block >> (N_bits * 2));
if (i == 0) return 0;
/* Z bloku i pobierz numer bloku pojedynczego pośredniego, w
którym znajduje się szukany blok; ten numer można otrzymać
biorąc część całkowitą z ilorazu block przez N,
a następnie z tego wyniku resztę modulo N */
i = block_bmap( bread(inode->i_dev,i), (block >> N_bits) & (N - 1) );
if (i == 0) return 0;
/* Teraz w bloku i na pozycji block mod N znajduje
się szukany adres bloku */
return block_bmap(bread(inode->i_dev, i), block & (N - 1))
}Jak widać ten klasyczny w świecie uniksowym sposób adresowania jest dobrze przystosowany do niewielkich plików lub plików rozrzedzonych. Jego zastosowanie w przypadku dużych plików wiąże się ze wzrastającymi nakładami. Konwersja numeru bloku o wysokim numerze, korzystająca z bloków
pośrednich (zwłaszcza podwójnie i potrójnie) jest dosyć kosztowna, wymaga od jądra kilku dostępów do bloków dyskowych (to może prowadzić do oczekiwania w stanie uśpienia podczas wykonania funkcji bmap).
Nasuwa się wniosek, że system plików ext3 dochodzi do granic swoich możliwości. Maksymalna wielkość partycji, czyli 16 TB (ew. 32 TB) jest już często przekraczana (np. w macierzach RAID), a ze względu na 32-bitowe numery bloków dyskowych więcej osiągnąć się nie da. Od 2006 roku trwają prace nad dwoma zasadniczymi zmianami dla ext3 dostępnymi w postaci łat a także obecnymi w jego następcy, czyli w systemie ext4.
Pierwsza i najważniejsza zmiana polega na zwiększeniu wielkości numeru bloku do 48 bitów, a druga na zamianie mechanizmu pośredniego adresowania bloków na tzw. ekstenty (ang. extent), czyli ciągłe zbiory (zakresy) bloków danych.
struct ext4_extent {
__le32 ee_block; /* first logical block extent covers */
__le16 ee_len; /* number of blocks covered by extent */
__le16 ee_start_hi; /* high 16 bits of physical block */
__le32 ee_start_lo; /* low 32 bits of physical block */
};Pojedynczy ekstent opisuje:
W strukturze i-węzła tablica i-block, która w systemach ext2/3 jest wykorzystywana do zapisywania numerów bloków, w ext4 służy do zapisania czterech ekstentów i jednego nagłówka ekstentu. W przypadku dużych plików system ext4 tworzy drzewo ekstentów. Dodatkowa struktura - indeks ekstentu - zawiera pozycję początkową ekstentu w pliku i numer bloku na dysku. Mechanizm ekstentów jest obecny także w innych popularnych systemach plików m. in w XFS, JFS, Reiser4, a nawet w NTFS.
Wiedząc, że w systemie ext4 numery logiczne bloków są 32-bitowe, a numery fizyczne bloków są 48 bitowe wypełnij tabelkę jak w zadaniu 3 dla rozmiaru bloku: 1, 2 i 4 KB.
Rozwiązanie
| rozmiar bloku | maksymalny rozmiar pliku | maksymalny rozmiar partycji |
| 1 KB | 4 TB | 256 PB |
| 2 KB | 8 TB | 512 PB |
| 4 KB | 16 TB | 1 EB |
232 * 210 = 242
232 * 211 = 243
232 * 212 = 244
248 * 210 = 258
248 * 211 = 259
248 * 212 = 260
Ustalmy, że rozmiar bloku wynosi 4KB. Porównaj, ile bloków dyskowych jest potrzebne do zapamiętania pełnego pliku (bez dziur) o rozmiarze 512MB w systemie ext3 i ext4.
Rozwiązanie
ext3:
Plik ma rozmiar 512 MB, co daje 512 MB/ 4 KB = 128 K bloków z danymi.
Każdy blok pośredni może pomieścić 4096/4=1024 numery bloków.
Gdyby wszystkie bloki były indeksowane przez pewien blok pośredni, to trzeba by na to 128 K/ 1024 = 128 bloków pośrednich. W rzeczywistości potrzeba 128 bloków pośrednich z tym, że ostatni jest niepełny i zawiera 1024 - 12 = 1012 numerów bloków z danymi. Ze 128 bloków pośrednich jeden jest wskazywany w i-węźle, a adresy pozostałych 127 bloków znajdują się w bloku podwójnie pośrednim.
Do przechowywania pliku wielkości 512MB potrzeba zatem 128 K bloków z danymi, 128 bloków pośrednich i 1 blok podwójnie pośredni. Oprócz bloków z danymi potrzeba dodatkowo 129 bloków, czyli 128 * 4KB + 4KB = 516KB.
ext4:
Jak poprzednio: 128 K bloków z danymi i w optymistycznej sytuacji (jeżeli plik nie jest pofragmentowany) nic więcej.
Za pomocą jednego ekstentu można zaadresować maksymalnie 215 * 4 KB = 128 MB danych, a zatem 4 ekstenty mieszczące się w i-węźle adresują cały plik.
Związek między procesem a systemem plików opisany jest przez dwa pola w strukturze danych procesu (task_struct):
W strukturze files_struct znajduje się tablica indeksowana liczbami naturalnymi, które odpowiadają deskryptorom otwartych plików. Wartościami poszczególnych pozycji w tej tablicy są dowiązania do systemowej tablicy otwartych plików.
Systemowa tablica otwartych plików
Każde wywołanie funkcji open() powoduje utworzenie nowej pozycji w systemowej tablicy otwartych plików. Natomiast wywołanie funkcji dup() i fork() powoduje, że do jednej pozycji mogą odnosić się różne deskryptory. Pozycja w systemowej tablicy otwartych plików jest opisana przez strukturę file. Pole f_count tej struktury odpowiada liczbie dowiązań do danej pozycji.
I-węzeł pliku
I-węzeł każdego otwartego pliku znajduje się w pamięci operacyjnej. Dla każdego pliku jest tylko jedna kopia i-węzła w pamięci niezależnie od tego ile razy dany plik był otwierany. Pole i_count w i-węźle informuje ile razy dla danego pliku wykonano funkcję open().
Uwaga: Przedstawiony tutaj opis jest oczywiście niepełny. Zawiera tylko wyrywkowe informacje pomocne przy wykonywaniu poniższych zadań.
Załóżmy, że pewien proces, który nie tworzył procesów potomnych, korzysta z n otwartych plików przy czym wszystkie one są różne (odpowiadają im różne i-węzły). Załóżmy również, że ten proces jest jedynym procesem w systemie posiadającym otwarte pliki. Czy jest możliwa sytuacja, w której liczba deskryptorów otwartych plików dla tego procesu jest:
Jeśli taka sytuacja jest możliwa, to kiedy może wystąpić? Opisz jak można taką sytuację wykryć znając jedynie zbiór obiektów plików file dla danego procesu, a nie wiedząc nic o liczbie deskryptorów plików otwartych przez ten proces.
Rozwiązanie
Proces P działa według następującego schematu (tablica plik[0..5] zawiera nazwy ścieżkowe plików):
fd=open(plik[0], ...);
for i in 1..5 do
{
if (!fork()) break;
fd=open(plik[i], ...);
}Jak będą wyglądały tablice deskryptorów plików procesu P i jego potomków?
Jak będzie wyglądała systemowa tablica otwartych plików (jakie wartości będą miały pola f_count)?
Rozwiązanie
Procesy potomne dziedziczą otwarte deskryptory ojca. Pierwszy proces potomny dziedziczy otwarty plik[0]. W momencie tworzenia drugiego procesu otwarte są pliki plik[0] i plik[1] itd.
Tablica deskryptorów procesu ojca:
| deskryptor | 0 | 1 | 2 | ... | j | j+1 | j+2 | j+3 | j+4 | j+5 |
| plik | STDIN | STDOUT | STDERR | ... | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] | plik[5] |
Tablica deskryptorów pierwszego potomka:
| deskryptor | 0 | 1 | 2 | ... | j |
| plik | STDIN | STDOUT | STDERR | ... | plik[0] |
Tablica deskryptorów piątego potomka:
| deskryptor | 0 | 1 | 2 | ... | j | j+1 | j+2 | j+3 | j+4 |
| plik | STDIN | STDOUT | STDERR | ... | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] |
Systemowa tablica otwartych plików:
| plik | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] | plik[5] |
| f_count | 6 | 5 | 4 | 3 | 2 | 1 |
(trudniejszy wariant poprzedniego zadania)
Proces P działa według następującego schematu (tablica plik[0..4] zawiera nazwy ścieżkowe plików):
fd=open(plik[0], ...);
for i in 1..4 do
{
fd=open(plik[i-1]);
if (!fork()) break;
fd=open(plik[i], ...);
dup(fd);
}Ile będzie pozycji odpowiadających plikom: plik[0], ..., plik[4]:
Jakie będą wartości liczników:
Rozwiązanie
Liczba pozycji odpowiadających poszczególnym plikom:
| plik | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] |
| tablica deskryptorów procesu P | 2 | 3 | 3 | 3 | 2 |
| tablica otwartych plików | 2 | 2 | 2 | 2 | 1 |
| tablica i-węzłów | 1 | 1 | 1 | 1 | 1 |
Wartości liczników w tablicy otwartych plików:
| plik | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] | ||||
| f_count | 5 | 5 | 8 | 4 | 6 | 3 | 4 | 2 | 2 |
Wartości liczników w tablicy i-węzłów:
| plik | plik[0] | plik[1] | plik[2] | plik[3] | plik[4] |
| i-count | 2 | 2 | 2 | 2 | 1 |
W omawianych systemach plików pierwszy blok partycji jest zarezerwowany dla sektora startowego. Reszta partycji jest podzielona na grupy bloków tego samego rozmiaru o ustalonej strukturze. Liczba grup zależy od rozmiaru partycji i od wielkości bloku. Głównym ograniczeniem jest to, że mapa bitowa opisująca stan zajętości bloków wewnątrz grupy musi zmieścić się w jednym bloku.
Jak widać na rysunku również mapa bitowa opisująca zajętość i-węzłów oraz superblok zajmują po jednym bloku. Pozostałe struktury są zmiennej długości.
Superblok zawiera informacje o całym systemie plików (m. in rozmiar bloku, łączną liczbę bloków i i-węzłów, łączną liczbę wolnych bloków i i-węzłów). Deskryptor grupy przechowuje podstawowe informacje dotyczące grupy, takie jak liczbę wolnych bloków oraz i-węzłów w danej grupie, numery bloków map bitowych i numer pierwszego bloku tablicy i-węzłów.
Tablica i-węzłów to zbiór bloków, w ramach których przydzielane są i-węzły. Ich liczba jest ustalana podczas tworzenia systemu plików.
Różnice w strukturze partycji pomiędzy kolejnymi wersjami systemu plików od ext2 do ext4 są niewielkie. W oryginalnej wersji systemu ext2, kopia superbloku oraz deskryptory grup znajdowały się w każdej grupie (redundacja miała na celu zabezpieczenie danych przed awarią). W nowszych wersjach wprowadzono możliwość pominięcia kopii w niektórych grupach. Kopie superbloku i deskryptorów grup znajdują się wtedy w grupach o numerach 0, 1 oraz będących potęgą 3, 5 lub 7.
Zauważmy, że dla bardzo dużych partycji taki sposób organizacji staje się nieefektywny, ponieważ zbyt wiele miejsca jest przeznaczone na (redundantne) metadane. Chodzi tutaj przede wszystkim o deskryptory grup, których liczba rośnie wraz z rozmiarem partycji (szczegółowe wyjaśnienie w zadaniu 7). Dlatego w późniejszych wersjach systemu ext3 i w systemie ext4 wprowadzono tak zwane metagrupy. Metagrupa jest zbiorem grup, o tak dobranym rozmiarze, aby deskryptory grup w obrębie jednej metagrupy mieściły się w pojedynczym bloku dyskowym. Deskryptory grup danej metagrupy są przechowywane w jej pierwszej grupie i dodatkowo - w drugiej i w ostatniej.
Dla partycji ext2 o wielkości 4 GB rozmiar bloku został ustalony na 4 KB. Załóżmy, że rozmiar deskryptora grupy wynosi 48 B, rozmiar i-węzła na dysku wynosi 128 B, a na grupę przypada 4096 i-węzłów.
Rozwiązanie
W sumie 528 KB, co stanowi 0.4% rozmiaru grupy: 528 KB / 128 MB =0.4% (rozmiar metadanych dzielony przez rozmiar grupy - dane i metadane).
W obrębie całego dysku straty będą takie same - 0.4% (pomijamy rozmiar bloku startowego).
Załóżmy, że w pewnym systemie plików ext2:
Jak należy skonfigurować system plików na tej partycji, żeby metadane nie zajęły więcej niż 2% partycji?
Opisz szczegółowo ile będzie grup dyskowych, ile bloków zajmie jedna grupa, co będzie się znajdowało w kolejnych blokach dyskowych partycji, jakie metadane będą przechowywane w kolejnych (ilu) blokach, ile bloków będzie przypadało średnio na jeden plik. Blok startowy można zaniedbać w rozważaniach.
Rozwiązanie
(4+x) * 64 * 4KB /8GB = (4+x)*32 /1M < 0.02
x < 651.36, czyli np. x=650
Czyli i-węzłów będzie 650*32=20 800 (w mapie bitowej da się opisać więcej, bo 32K, więc taka konfiguracja jest możliwa)
0111 1111 1101 1010 0110 ...
1011 0000 0000 0000 0000 ...
1101 1111 1111 1111 1111 ...
Rozwiązanie
Jaki jest maksymalny rozmiar partycji dla systemu plików, w którym pierwsza grupa przechowuje wszystkie deskryptory grup danej partycji. Przyjmijmy, że deskryptor grupy ma rozmiar 64B, a blok dyskowy - 4 KB. Jaki byłby w takiej sytuacji rozmiar metagrupy?
Rozwiązanie
Dla bloku o rozmiarze 4 KB grupa będzie miała rozmiar 8 * 212 * 212 = 227, czyli 128 MB.
Zatem w grupie zmieści się nie więcej niż 227/64 = 221 deskryptorów grup, a więc partycja może mieć rozmiar co najwyżej 221 * 227 = 248, czyli 256TB (a nawet jeszcze mniej, bo nie wzięliśmy pod uwagę superbloku, map bitowych i tablicy i-węzłów, które znajdują się w każdej grupie).
Wniosek: w przypadku dużych partycji konieczne staje się zastosowanie metagrup. Dla podanych założeń jedna metagrupa zawierałaby 212/64 =64 grupy.
| Załącznik | Wielkość |
|---|---|
| struktura-partycji.gif | 9.9 KB |
{kind=link}
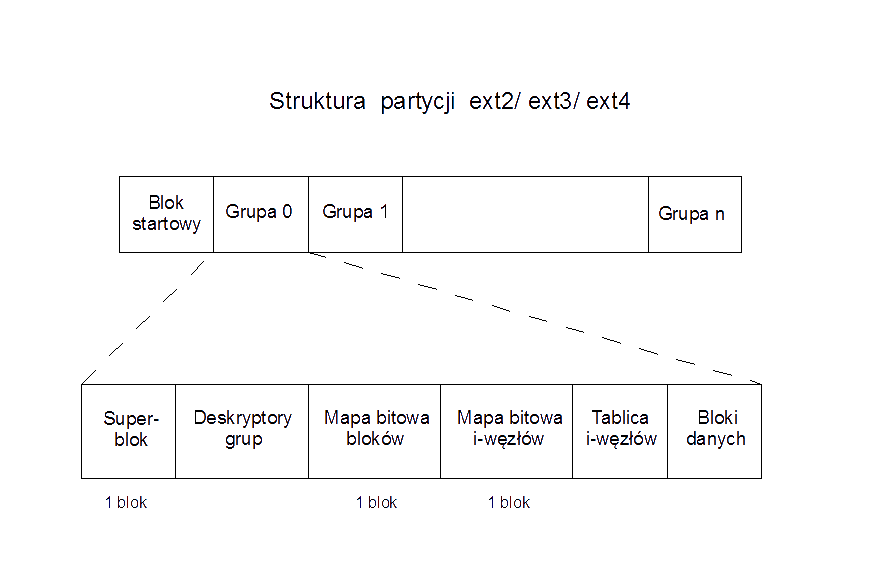{kind=link}