Środowisko programisty
Forma zajęć
Laboratorium (30 godzin)
Opis
Przedstawienie środowiska programisty obejmujące: podstawowe narzędzia tekstowe, programy narzędziowe, wprowadzenie do systemów wspierających tworzenie oprogramowania i zarządzanie projektami programistycznymi. Przedstawienie elementów programowania w języku C.
Sylabus
Autor
- Krzysztof Ciebiera — Uniwersytet Warszawski
Zawartość
- Pliki, typy plików, poruszanie się po katalogach
- Tworzenie dokumentów matematycznych w języku LaTeX
- Narzędzia tekstowe typu grep, sort i inne
- Programy do zarządzania źródłami (np. svn)
- Programy do zarządzania zadaniami i błędami (np. mantis)
- Kompilatory, fazy kompilowania programów
- Odpluskwianie programów
Literatura
- Krzysztof Stencel, Systemy operacyjne, Wydawnictwo PJWSTK, 2005,
- Mendel Cooper, Advanced Bash-Scripting Guide.
- Dokumentacja bash, grep i sort.
- Version Control with Subversion.
- Dokumentacja systemów svn i mantis.
- B. Kernighan, D. Ritchie, Język ANSI C, Wydawnictwa Naukowo-Techniczne, Warszawa 2004.
- T. Oetiker, H. Partl, I. Hyna, E. Schlegl (tłum. J. Gołdasz, R. Kubiak, T. Przechlewski), Nie za krótkie wprowadzenie do systemu LaTeX2e.
- Dokumentacja systemu LaTeX.
- Dokumentacja make.
Wprowadzenie do Basha
Czym jest Bash?
Bash (Bourne-Again Shell) jest najpopularniejszą odmianą shell'a. Innymi znanymi są np. ksh (Korn Shell), csh (C Shell).
Shell możemy kojarzyć z linią poleceń, dzięki której możemy wpisywać komendy z klawiatury. Służą one na ogół do uruchamiania innych programów, poleceń lub wyświetlania informacji. Shell służy też do uruchamiania własnoręcznie napisanych skryptów.
Najprostsze skrypty są po prostu ciągiem poleceń, ale możemy też pisać bardziej skomplikowane mechanizmy, które w istocie rzeczy można nazwać wręcz programami. Składnia skryptów nie jest skomplikowana. Oprócz różnych programów użytkowych i systemowych jest zaledwie kilka reguł, których wystarczy się nauczyć, żeby swobodnie pisać skrypty składające poznane programy w celu wykonania zaplanowanych działań.
Shell jest podstawowym narzędziem pod system typu UNIX, ale nie tylko. Pod Windowsem mamy np. interpretator poleceń, a skryptami są np. pliki o rozszerzeniu bat. Niemniej możliwości i funkcjonalność takich skryptów pod Windowsem są znikome (w porównania do Basha pod Unixem) ze względu na ograniczenia składniowe, jak i dostępny zbiór poleceń użytkowych. Aby uzyskać możliwość uruchamiania skryptów napisanych w Bashu pod Windowsem możemy sobie zainstalować pakiet Cygwin.
Do czego się przydaje?
Skrypty pisze się, gdy chce się zautomatyzować lub uprościć jakąś czynność powtarzalną bądź nie. Czynności te, to
- kompilacja, budowanie aplikacji,
- przetwarzanie plików (tworzenie, usuwanie, szukanie, itp.),
- prosta obróbka (np. tekstowa) plików,
- administracja systemem (np. konfiguracja, uruchamianie demonów),
- i wiele innych...
Do czego się nie nadaje?
Bash jest interpreterem. Skryptów napisanych w bashu się nie kompiluje. Nie ma też żadnych skomplikowanych struktur danych (jak tablice wielowymiarowe, czy drzewa), ani konstrukcji znanych z języków wyższych poziomów (jak rekordy, klasy). W związku z tym skrypty nie nadają się na przykład do:
- zadań trudnych obliczeniowo, wymagających szybkiego działania,
- operacji skomplikowanych algorytmicznie lub matematycznie,
- operacji niskopoziomowych, jak dostęp do sprzętu.
Zaczynamy pracować
Zapoznanie z Linuxem
Po uruchomieniu systemu Linux powinno pojawić się okno logowania. Należy wpisać swój login i hasło. W przypadku problemów należy poprosić administratora o przydzielenie konta. Po zalogowaniu uruchamia się menedżer okien w środowisku graficznym. W zależności od dystrybucji i konfiguracji może to być jeden z wielu dostępnych menedżerów. Najpopularniejszymi są KDE i GNOME.
Podobnie jak w systemach z rodziny Windows możemy uruchamiać programy z dostępnego menu. Oprócz uruchamiania programów takich jak przeglądarki, czy edytory, nas najbardziej będzie interesować konsola/shell. W KDE jest to program konsole i możemy go wybrać albo z paska, albo z menu. Po uruchomieniu konsoli pojawia nam się okienko z linią komend. Migający kursor zaprasza nas do wpisywania komend. Wpiszmy komendę pwd.
bashtest@host:~$ pwd
/home/bashtest
bashtest@host:~$W wyniku wypisał się nasz katalog domowy /home/bashtest i z powrotem pojawiła się linia z kursorem zachęcającym do wpisania następnej komendy. Katalogi w Linuxie oddziela się znakiem /. Oznacza to, że nasz katalog domowy w stosunku do katalogu głównego / znajduję się w podkatalogu home, a następnie w katalogu bashtest. Komenda pwd wypisuje aktualny katalog, a ponieważ zaraz po uruchomieniu shella zaczynamy w katalogu domowym, więc w tym wypadku zwraca ona nasz katalog domowy.
Konsola z linią komend jest podstawowym narzędziem pracy do wykonywania poleceń basha. Ponadto do tworzenia skryptów, bądź też innych plików tekstowych będziemy używać edytorów. Najprostszymi edytorami, których można używać bezpośrednio z linii poleceń, są mcedit, joe, pico. Można używać też bardziej skomplikowanych edytorów jak emacs, vim, kate. Na przykład, aby edytować plik test.txt wpisujemy komendę:
bashtest@host:~$ mcedit test.txtWpisujemy jakiś tekst, wciskamy F10 i potwierdzamy zapis. Aby wyświetlić wprowadzony tekst, piszemy:
bashtest@host:~$ cat test.txt
Przykład możliwości Basha
Shell z linii komend umożliwia nam wykonywanie nawet bardzo skomplikowanych czynności. Spójrzmy na następujący przykład, który jest już bardziej skomplikowany. Załóżmy, że mamy projekt o nazwie ecmnet, którego źródła znajdują sie w katalogu o tej samej nazwie. Chcemy wysłać sobie mailem archiwum ze źródłami tego projektu. Chcemy również, aby w tym archiwum nie znalazły się pliki o rozszerzeniu bak, czy kończące się znakiem ~. Ponadto nazwa archiwum powinna zawierać aktualną datę z dokładnością co do sekundy.
Niektóre komendy mogą być w tym momencie niezrozumiałe, niemniej warto być świadomym możliwości, że tego typu czynności można wykonywać bardzo sprawnie. Skomentujmy po krótce przeznaczenie użytych poleceń, o których więcej szczegółów zostanie podanych w trakcie kursu. Zwróćmy uwagę również na możliwości edycyjne basha. Przy edycji komendy możemy używać klawiszy intuicyjnie tak, jak ma się to w zwykłych edytorach. Jednak w bashu są również typowe dla niego funkcje. Nie będziemy omawiać tutaj szczegółów. Pokażemy tylko parę przykładów, a zainteresowanych odsyłamy do dokumentacji basha.
Omówmy nasz przykład.
bashtest@host:~$ cp -a ecmnet/ /tmp/cp -a kopiuje rekurencyjnie katalog ecment do katalogu /tmp/ (jest to standardowy katalog, w którym trzyma się pliki tymczasowe). Zamiast pisać pełną nazwę katalogu wpisujemy tylko ec i wciskamy Tab, co powoduję automatyczne rozwinięcie do ecmnet/. Tab służy do rozwijania komend oraz nazw plików.
bashtest@host:~$ cd /tmp/Zmienia aktualny katalog na /tmp.
bashtest@host:/tmp$ find ecmnet/ -name "*.bak" -o -name "*~" bashtest@host:/tmp$ find ecmnet/ -name "*.bak" -o -name "*~" -execdir rm -f {} +
find potrafi wyszukiwać pliki rekurencyjnie w rozmaity sposób i nie tylko. W tym przypadku użyliśmy go do znalezienia plików o rozszerzeniu bak lub kończących się znakiem ~. W drugiej linii zmodyfikowaliśmy komendę tak, aby te znalezione pliki zostały od razu usunięte.
Aby wpisać drugą komendę wystarczy wcisnąć strzałkę do góry i dopisać brakujący kawałek. Za pomocą strzałek w górę i w dół możemy przeglądać historię wpisywanych poleceń.
bashtest@host:/tmp$ date +%Y%m%d%H%M%Sdate służy do wyświetlania aktualnej daty/godziny lub jej zmieniania. W tym przypadku wyświetlamy datę w odpowiednim formacie.
bashtest@host:/tmp$ tar cvz ecmnet/ | uuencode ecmnet-`date +%Y%m%d%H%M%S`.tgz | mail me@somehost
Tutaj mamy przykład potoku. Komenda tar służy do składania plików w jedno archiwum z kompresją lub bez. To, co wyprodukuje ta komenda, jest przekazywane komendzie uuencode, która służy do kodowania plików binarnych tak, aby mogły być użyte w mediach tekstowych. Wynik wywołania komendy date jest użyty do nazwania pliku archiwum. Ostateczny wynik dostaje komenda mail, która wysyła go na adres me@somehost.
Żeby nie pisać ponownie komendy date wraz z trudnym do wpisania formatem daty, wciskamy strzałkę do góry, aby uzyskać przed chwilą wpisaną komendę date. Następnie przechodzimy na początek komendy (Ctrl-A lub Home) i wciskamy Ctrl-K. Powoduje to usunięcie wszystkich znaków od pozycji kursora do końca linii i umieszczenie ich w buforze. Później, przy edycji, gdy ponownie dochodzimy do momentu wpisania komendy date, wciskamy Ctrl-Y i zostaje umieszczone to, co jest aktualnie w buforze.
bashtest@host:/tmp$ rm -rf ecmnet/Usuwa rekurencyjnie katalog ecmnet.
bashtest@host:/tmp$ cdZmienia katalog z powrotem na domowy katalog użytkownika.
Dokumentacja
W powyższym przykładzie widzimy, że główną siłą była znajomość komend i opcji, z jakimi trzeba ich użyć. Jeśli chodzi o uzyskiwanie informacji na temat opcji danej komendy, to z pomocą przychodzą nam dwa polecenia:
- man
- info
Na przykład, żeby dowiedzieć się co oznacza magiczne +%Y%m%d%H%M%S przy poleceniu date możemy napisać:
<flash>file=SrodowiskoProgramisty-bash02.swf|width=484|height=316|quality=low|loop=false</flash>
bashtest@host:~$ man date
Dostajemy tekstowy opis komendy date wraz z wszystkimi opcjami, który możemy sobie spokojnie poprzeglądać. Komenda info jest podobna do komendy man z tą różnicą, że daje jeszcze większą wygodę poruszania się i na ogół jest znacznie więcej informacji. W niektórych dystrybucjach linuxa większość informacji o dostępnych komendach użytkowych można uzyskać na przykład poprzez polecenie:
bashtest@host:~$ info coreutils
Dokładną dokumentację Basha uzyskujemy przez:
bashtest@host:~$ info bash
Przydatne jest też wywołanie
bashtest@host:~$ man -k słowoktóre wyświetla wszystkie polecenia związane z danym słowem. Więcej o czytaniu dokumentacji:
man man man info
Gdzie można znaleźć informacje o tym jakie w ogóle są komendy? Wiele z nich wymienionych jest w info coreutils. Innych komend można samemu spróbować poszukać w liście zainstalowanych pakietów danej dystrybucji. Takie szukanie jest jednak czasochłonne. Tak naprawdę lista wszystkich poleceń nie istnieje, gdyż co chwilę powstają nowe programy dające nowe możliwości lub ułatwiające życie.
W tym kursie przedstawimy podstawowe narzędzia, które powinny w praktyce wystarczyć do większości celów. Przy potrzebie bardziej wysublimowanych komend trzeba jednak będzie znaleźć odpowiednie narzędzie, lub też samemu napisać, używając bardziej zaawansowanych języków jak Perl, Python, C, czy Java.
Podstawowe mechanizmy
Przekierowanie wejścia-wyjścia
Każdy program ma trzy podstawowe strumienie wejścia-wyjścia:
- standardowe wejście,
- standardowe wyjście,
- standardowe wyjście diagnostyczne (strumień błędów).
Zazwyczaj zaraz po uruchomieniu strumienie te połączone są z terminalem, co dla wejścia oznacza, że wczytywane jest ono z klawiatury, a dla wyjścia oznacza, że wypisywane jest ono na ekran. Strumienie te możemy jednak przekierowywać do plików za pomocą symboli <, >, lub >>. Na przykład, aby przekierować wynik wywołania komendy ls -R do pliku wynik.txt piszemy:
bashtest@host:~$ ls -R > wynik.txtZnaczenie tych symboli przedstawione jest w poniższej tabeli.
-
Symbol Znaczenie < plik podstawienie pod standardowe wejścia pliku > plik wypisywanie wyjścia do pliku; jeśli plik istniał wcześniej to jest nadpisywany >> plik wypisywanie wyjścia do pliku; jeśli plik istniał wcześniej to wyjście jest dopisywane na jego końcu
Aby przekierować standardowe wyjście diagnostyczne używamy notacji 2> lub 2>>. Na przykład
rm "nie ma takiego pliku" 2>plik
Zobaczmy, jak można wykorzystywać przekierowania. Polecenie cat uruchamiane bez argumentów po prostu kopiuje wejście na wyjście. Przekierowując wyjście do pliku, możemy wprowadzić treść tego pliku z klawiatury. Aby zakończyć strumień wejścia wprowadzamy znacznik końca pliku (^D) z klawiatury wciskając Ctrl-D.
bashtest@host:~$ cat >test.txt To jest ^D bashtest@host:~$ cat >>test.txt test ^D bashtest@host:~$ cat <test.txt To jest test bashtest@host:~$
W ostatnim poleceniu taki sam wynik otrzymamy po prostu podając poleceniu cat nazwę pliku jako argument:
bashtest@host:~$ cat test.txt To jest test bashtest@host:~$
Potoki
W sytuacji gdy chcemy, aby wyjście jednego programu było zarazem wejściem dla drugiego, używając przekierowań, możemy użyć pliku tymczasowego. Można to zrobić znacznie prościej, używając potoków. Gdy połączymy dwa programy znakiem |, standardowe wyjście pierwszego programu będzie dostarczone w standardowym wejściu drugiego programu.
Aby wyświetlić plik w aktualnym katalogu, który został ostatnio zmodyfikowany, możemy posłużyć się komendą:
bashtest@host:~$ ls -t | head -1 test.txt
ls służy do wyświetlania plików. Argument -t powoduje, że wynik jest sortowany po dacie modyfikacji poczynając od najnowszego. head wyświetla tylko pierwsze linie wejścia, w tym przypadku jest to tylko jedna linia ze względu na opcję -1.
Potoki mogą łączyć więcej niż dwa programy. Na przykład:
bashtest@host:~$ tr j t <test.txt | uniq To test bashtest@host:~$ tr j t <test.txt | uniq | tr '\n' ' ' To test bashtest@host:~$
tr x y konwertuje wszystkie znaki x na y. uniq usuwa powtarzające się linie. \n oznacza znak końca linii. W wyniku ostatniej komendy otrzymujemy napis 'To test ' bez znaku końca linii przez co tekst zachęty pojawia się zaraz za nim.
Ciąg poleceń
Polecenia mogą być też uruchamiane jedno po drugim. Do rozdzielenia poleceń służy znak ;.
bashtest@host:~$ echo "test.txt: start"; cat test.txt; echo "test.txt: end" test.txt: start To jest test test.txt: end bashtest@host:~$
Komenda echo służy do wypisywania tekstu podanego w argumencie.
Oczywiście inny sposób na wykonanie kilku poleceń pod rząd to osobne wprowadzanie każdego z nich. Ciągi poleceń są głównie wykorzystywane w linii komend. W skryptach dla czytelności przeważnie każde polecenie piszemy w osobnej linii.
Wzorce nazw plików
W argumentach polecenia, gdy odwołujemy się do plików, możemy używać wzorców do określenia o jakie pliki nam chodzi. Służą do tego znaki:
* - kojarzy dowolny ciąg znaków (być może pusty),
? - kojarzy dokładnie jeden dowolny znak.
Jeśli w nazwie pliku pojawia się znak * lub ?, interpreter przegląda aktualny katalog w celu znalezienia wszystkich plików, które odpowiadają danemu wzorcowi. Na przykład
$ echo *.txtWyświetli nazwy plików z aktualnego katalogu kończące się na .txt.
$ cat *.tx?Wypisze zawartość wszystkich plików kończących się na .tx plus dowolny znak.
A oto jeszcze jeden przykład:
bashtest@host:~$ mkdir wzorce_test bashtest@host:~$ cd wzorce_test/ bashtest@host:~/wzorce_test$ touch a b ab abcd bbdd bashtest@host:~/wzorce_test$ ls a ab abcd b bbdd bashtest@host:~/wzorce_test$ echo ? a b bashtest@host:~/wzorce_test$ echo b* b bbdd bashtest@host:~/wzorce_test$ echo *b* ab abcd b bbdd bashtest@host:~/wzorce_test$ echo *b?* abcd bbdd bashtest@host:~/wzorce_test$ echo ?b?d abcd bbdd bashtest@host:~/wzorce_test$ echo a* a ab abcd bashtest@host:~/wzorce_test$ echo a? ab bashtest@host:~/wzorce_test$
Komenda touch tworzy plik, jeśli plik nie istnieje, w przeciwnym razie (jeśli plik istnieje), ustawia jego datę modyfikacji na aktualną datę systemową.
Znaki specjalne, apostrofy i cudzysłowy
Poznaliśmy niektóre znaki, które są interpretowane w specjalny sposób przez Basha (np. < > ; | * ?). Poznamy ich jeszcze znacznie więcej. Powstaje pytanie, co zrobić, jeśli chcemy użyć jednego z tych znaków w argumentach polecenia, np. w nazwie pliku. Są trzy sposoby na zrobienie tego.
Backslash (\)
Aby uzyskać dany znak poprzedzamy go znakiem \.
bashtest@host:~$ echo \aa\*\?\|\<\>\\
aa*?|<>\
bashtest@host:~$W ten sposób możemy użyć spacji w nazwie pliku, która normalnie służy do rozdzielania argumentów.
bashtest@host:~$ touch To\ jest\ jeden\ plik bashtest@host:~$ ls -l *\ * -rw-r--r-- 1 bashtest users 0 2006-08-05 10:44 To jest jeden plik bashtest@host:~$ rm To\ jest\ jeden\ plik bashtest@host:~$ ls -l *\ * ls: * *: Nie ma takiego pliku ani katalogu bashtest@host:~$
Apostrof (')
Wygodniejszym sposobem na wprowadzanie napisów zawierających znaki specjalne jest otoczenie danego ciągu znaków apostrofami.
bashtest@host:~$ echo 'aa*?|<>\' aa*?|<>\ bashtest@host:~$
Jedyny znak, który nie może się pojawić pomiędzy dwoma apostrofami jest apostrof, gdyż oznaczałby on wcześniejsze skończenie nieinterpretowanego łańcucha. Między dwoma znakami może się nawet pojawić znak końca linii (enter).
bashtest@host:~$ echo 'Pierwsza linia > Druga linia' Pierwsza linia Druga linia bashtest@host:~$
Cudzysłów (")
Cudzysłów działa analogicznie jak apostrof, z tą różnicą, że pomiędzy cudzysłowami niektóre znaki interpretowane są w specjalny sposób. Tymi znakami są $ ` \. Znaczenie znaków $ ` jeszcze poznamy. Znaki, które są specjalne pomiędzy cudzysłowami możemy wprowadzić używając \. Apostrof ma zwykłe znaczenie pomiędzy cudzysłowami.
bashtest@host:~$ echo "Znaki, które trzeba poprzedzić znakiem \\: '\$' '\`' '\"' '\\'" Znaki, które trzeba poprzedzić znakiem \: '$' '`' '"' '\' bashtest@host:~$
Znak \, postawiony przed innymi znakami niż wyżej wymienione, nadaje jemu zwykłe znaczenie.
bashtest@host:~$ echo "\a\b\c" \a\b\c bashtest@host:~$
Możemy tworzyć też dłuższe łańcuchy łącząc każdą z powyższych trzech metod.
bashtest@host:~$ echo "To 'słowo', "a\ to\ 'też "słowo"' To 'słowo', a to też "słowo" bashtest@host:~$
Zmienne
Bash umożliwia zapamiętywanie łańcuchów znakowych na zmiennej. Identyfikator zmiennej powinien zaczynać się z litery alfabetu angielskiego, a następnie z ciągu składającego się z liter, cyfr i znaku podkreślenia. Zmiennej przypisujemy wartość używając znaku =. Przy czym trzeba pamiętać, aby nie używać odstępów.
Do zmiennej odwołujemy się poprzedzając identyfikator znakiem $.
bashtest@host:~$ zm=wart bashtest@host:~$ echo $zm wart bashtest@host:~$ echo zm zm bashtest@host:~$ zm=słowo1 słowo2 bash: słowo2: command not found bashtest@host:~$ zm="słowo1 słowo2" bashtest@host:~$ echo $zm słowo1 słowo2 bashtest@host:~$
Używając zmiennych możemy uprościć przykład z sekcji Ciąg poleceń.
bashtest@host:~$ p=test.txt; echo "$p: start"; cat $p; echo "$p: end"
W ten sposób nazwa pliku podana jest tylko w jednym miejscu i wystarczy wykonać jedną zmianę, aby przykład działał dla innej nazwy pliku. Zauważmy, że możemy także odwoływać się do zmiennej wewnątrz cudzysłowów. Wewnątrz apostrofów nie jest to możliwe.
Alternatywną formą odwoływania się do zmiennej jest ${zmienna}. Jest ona przydatna na przykład wtedy, gdy po wartości zmiennej chcemy dopisać inne znaki, które mogły by wejść w skład nazwy zmiennej.
bashtest@host:~$ zm=but bashtest@host:~$ echo $zmy bashtest@host:~$ echo ${zm}y buty bashtest@host:~$
Ciapki
Argumenty polecenia możemy tworzyć także poprzez inne polecenia. Do tego celu służą ciapki `...`. Polecenie podane w bloku otoczonym ciapkami jest uruchamiane i wynik tego polecenia (tzn., to co polecenie wypisało na standardowe wyjście) zastępuje dany blok. Po wykonaniu tych podmian, oryginalne polecenie jest interpretowane i uruchamiane. Oto prosty przykład utworzenia komendy whoami przez wywołanie trzy razy polecenia echo z różnymi argumentami.
bashtest@host:~$ `echo who``echo am``echo i` bashtest bashtest@host:~$ whoami bashtest bashtest@host:~$
Inny przykład.
bashtest@host:~$ cp "`ls *.txt | head -1`" /tmp
Powyższe polecenie przekopiuje pierwszy alfabetycznie plik o rozszerzeniu txt do katalogu /tmp. Trzeba pamiętać o użyciu apostrofów, gdyż może się okazać, że nazwa pliku zawiera spację, a wtedy w wyniku podmiany będzie utworzonych więcej argumentów. Spójrzmy na przykład.
bashtest@host:~$ cp `echo a b` c cp: cel `c' nie jest katalogiem
Tutaj polecenie cp dostało trzy argumenty a b c, zatem próbuje ono przekopiować wszystkie pliki/katalogi podane w wszystkich argumentach oprócz ostatniego do katalogu podanego w ostatnim argumencie.
bashtest@host:~$ cp "`echo a b`" c cp: nie można wykonać stat na `a b': Nie ma takiego pliku ani katalogu
Tutaj cp ma dwa argumenty i szuka pliku o nazwie 'a b', który nie istnieje.
Używając ciapek możemy inicjować zmienne wynikiem wykonania polecenia. Na przykład możemy zmiennej przypisać zawartość pliku:
bashtest@host:~$ zm=`cat test.txt`
Bash udostępnia też alternatywną formę wstawiania wyniku wywołania polecenia $( ... ). Czyli zamiast pisać
`polecenie`
możemy też napisać
$(polecenie)
Ta forma jest o tyle wygodniejsza od ciapek, że umożliwia w prosty sposób zagnieżdżanie, na przykład
bashtest@host:~$ zm=$(cat $(echo test).txt)
Bash - podstawowe komendy
Bash - pisanie skryptów
Atrybuty plików
W systemie typu Unix jest podział na użytkowników i grupy. Każdy użytkownik może przynależeć do kilku grup. Do wyświetlania przynależności do grup służy polecenie groups.
bashtest@host:~$ groups users bashtest@host:~$ groups bashtest root kubus bashtest : users root : root kubus : users cdrom floppy audio src video staff bashtest@host:~$
Bez argumentów wyświetla przynależność do grup aktualnego użytkownika. Z argumentami przynależność do grup podanych użytkowników. Na przykład użytkownik kubus przynależy do większej ilości grup, co daje mu większe prawa w systemie.
Każdy plik/katalog należy do dokładnie jednego użytkownika i grupy. Z każdym plikiem/katalogiem związane są trzy rodzaje praw dostępu:
r prawo do odczytu,
w prawo do modyfikacji (czyli do zapisu, bądź usunięcia),
x prawo do uruchomienia; w przypadku katalogu oznacza to prawo do zmiany bieżącego katalogu na ten katalog.
Prawa dostępu przydzielane są trzem kategoriom użytkowników:
- użytkownicy, do których należy dany plik,
- inni użytkownicy z grupy, do której należy dany plik,
- wszyscy pozostali użytkownicy.
Aby wyświetlić informacje o właścicielach i prawach dostępu możemy użyć polecenia ls z opcją -l:
bashtest@host:~$ ls -l razem 128 drwx------ 2 bashtest users 4096 2006-07-08 09:37 Mail d-wx--x--x 2 bashtest users 4096 2006-08-07 15:28 niedostępny_katalog ----rw---- 1 bashtest users 5 2006-08-07 15:30 plik_dla_pozostałych_userów -rwxr-xr-x 1 root root 109552 2006-08-07 15:32 program -rw-r--r-- 1 bashtest users 13 2006-08-01 15:18 test.txt bashtest@host:~$
Po lewej stronie są prawa dostępu. Literka po lewej mówi o typie pliku, kolejne trzy literki pokazują prawa dostępu dla pierwszej kategorii użytkowników, kolejne trzy o drugiej kategorii użytkowników i ostatnie trzy literki o ostatniej kategorii. W trzeciej i czwartej kolumnie pokazany jest użytkownik i grupa do której należy dany plik/katalog.
Mail i niedostępny_katalog są katalogami (literka d po lewej). Katalog Mail jest dostępny tylko dla użytkownika bashtest (2-4 literki rwx oznaczają ustawione wszystkie prawa dostępu: do odczytu, zapisu i uruchamiania). Katalog niedostępny_katalog nie ma ustawionych praw do odczytu, zatem nie można wyświetlić jego zawartości, ale można zmienić na niego bieżący katalog, gdyż ma ustawione prawa do uruchomienia. Plik plik_dla_pozostałych_userów mogą odczytywać i modyfikować tylko użytkownicy inni niż bashtest należący do grupy users. Plik program jest programem i można go uruchamiać.
Do zmiany właściciela służą polecenia chown i chgrp. Do zmiany praw dostępu służy polecenie chmod.
Pierwszy skrypt
Przygotujmy plik
hello_world.sh o następującej zawartości:
#!/bin/sh echo "Hello world"
Rozszerzenie sh jest standardowym rozszerzeniem skryptów napisanych w bashu. Nie jest ono konieczne, ale dobrze by było, żeby już sama nazwa pliku mówiła nam o jego typie. Pierwsza linijka jest podpowiedzią dla systemu, jak ma być uruchomiony ten plik. System użyje polecenia /bin/sh do interpretacji tego pliku.
Spróbujmy uruchomić ten plik.
bashtest@host:~$ hello_world.sh bash: hello_world.sh: command not found bashtest@host:~$
Takie polecenie nie zostało znalezione. System szuka danego polecenia wśród wszystkich katalogów zapamiętanych na zmiennej środowiskowej PATH. Zmienna środowiskowa jest to taka zmienna, która została zdefiniowana zanim jeszcze uruchomiliśmy interpreter. Własne zmienne środowiskowe, które zostaną przekazane programom przez nas uruchomionych można definiować za pomocą komendy export. Zobaczmy, co zawiera zmienna PATH.
bashtest@host:~$ echo $PATH /usr/local/bin:/usr/bin:/bin:/usr/bin/X11:/usr/games bashtest@host:~$
Jak widzimy, nie zawiera ona bieżącego katalogu, w którym znajduje się nasz skrypt. Przy uruchamianiu polecenia, które nie znajduje katalogu podanym w PATH, trzeba podawać również ścieżkę (względną, bądź bezwzględna) przed nazwą pliku. W tym przypadku musimy podać katalog bieżący, co najprościej można zrobić przy użyciu kropki.
bashtest@host:~$ ./hello_world.sh bash: ./hello_world.sh: Brak dostępu bashtest@host:~$
Tym razem dostaliśmy komunikat o złych prawach dostępu. Zobaczmy:
bashtest@host:~$ ls -l hello_world.sh -rw-r--r-- 1 bashtest users 29 2006-08-07 15:45 hello_world.sh bashtest@host:~$
Ten plik nie ma ustawionych praw do uruchamiania. Możemy to zrobić używając polecenia chmod. Aby ustawić prawa uruchamiania tylko dla użytkownika bashtest, możemy użyć opcji u+x. Jeśli chcemy ustawić prawa uruchamiania dla wszystkich, używamy opcji a+x. W tym przypadku ustawimy prawa uruchamiania tylko dla nas.
bashtest@host:~$ chmod u+x hello_world.sh bashtest@host:~$ ls -l hello_world.sh -rwxr--r-- 1 bashtest users 29 2006-08-07 15:45 hello_world.sh bashtest@host:~$
Teraz wygląda lepiej spróbujmy uruchomić nasz skrypt.
bashtest@host:~$ ./hello_world.sh
Hello world
bashtest@host:~$Udało się!
Komentarze
Komentarze zaczynają się od symbolu #. Wszystkie pozostałe znaki aż do końca linii są ignorowane. W pierwszej linii skryptu helo_world.sh mamy już taki komentarz, który jest zarazem informacją dla systemu. Dodajmy jeszcze dwa komentarze.
#!/bin/sh # Przykładowy skrypt wypisujący napis "Hello world" echo "Hello world" # Tutaj wypisujemy co trzeba
Argumenty
Skrypty - podobnie jak dowolne programy - możemy uruchamiać podając im argumenty. Następujące zmienne o specjalnych nazwach pozwalają odczytywać argumenty:
$# |
zwraca liczbę argumentów, |
$0 |
zwraca nazwę pliku bieżącego programu, |
$1, $2, ... |
zwraca odpowiednio pierwszy argument, drugi argument, itd., |
$@ |
rozwija się do listy wszystkich argumentów; przydatne jeśli chcemy przekazać wszystkie argumenty innemu programowi. Jeśli chcemy mieć pewność, że każdy argument będzie osobnym słowem, należy użyć cudzysłowów: "$@"; ma to znaczenie na przykład wtedy, gdy istnieje argument, który zawiera spację.
|
Aby operować na dalszych argumentach pomocne jest polecenie shift, które usuwa pierwszy argument, a pozostałe przesuwa o jeden w lewo. Aby n-krotnie wywołać polecenie shift wystarczy podać mu to n jako argument: shift n.
Na przykład dla skryptu test_arg.sh o zawartości
#!/bin/sh # Testowanie argumentów echo "Uruchomiłeś program `basename $0`" echo Wszystkie: $@ echo "Pierwsze trzy: '$1', '$2', '$3'" shift 2 echo "shift 2" echo "Wszystkie: $@" echo "Pierwsze trzy: '$1', '$2', '$3'"
mamy efekt
bashtest@host:~$ ./test_arg.sh Raz Dwa "To jest zdanie" Cztery Uruchomiłeś program test_arg.sh Wszystkie: Raz Dwa To jest zdanie Cztery Pierwsze trzy: 'Raz', 'Dwa', 'To jest zdanie' shift 2 Wszystkie: To jest zdanie Cztery Pierwsze trzy: 'To jest zdanie', 'Cztery', '' bashtest@host:~$
Wyrażenia
Jak w każdym liczącym się języku, w bashu możemy wyliczać wartości wyrażeń arytmetycznych. Możemy zrobić to na kilka sposobów.
expr
Najprostszym sposobem jest użycie polecenia expr. Trzeba przy tym pamiętać, żeby osobne tokeny (tzn. liczby i operatory arytmetyczne) były podawane w osobnych argumentach. Wynika to stąd, że expr potrafi też operować na łańcuchach znakowych (czym się nie będziemy w tej chwili zajmować), więc musi jakoś te łańcuchy dostawać, a jedyną droga to przez argumenty.
Dostępnych jest pięć operatorów arytmetycznych:
- dodawanie (+),
- odejmowanie (-),
- mnożenie (*),
- dzielenie (/),
- modulo - reszta z dzielenia (%).
Ponadto możemy wykonywać porównania <, <=, =, == (synonim =), !=, >=, >. W wyniku mamy 1, gdy relacja jest spełniona i 0 w przeciwnym przypadku.
Trzeba też pamiętać by znaki specjalne poprzedzać backslashem lub brać w cudzysłowy. Przykłady:
bashtest@host:~$ expr 2\*3 2*3 bashtest@host:~$ expr 2 \* 3 6 bashtest@host:~$ expr '2 * 3' 2 * 3 bashtest@host:~$ expr 2 \* \(7 - 1\) expr: argument nieliczbowy bashtest@host:~$ expr 2 \* \( 7 - 1 \) 12 bashtest@host:~$ a=5 bashtest@host:~$ a=`expr $a + 1` bashtest@host:~$ echo $a 6 bashtest@host:~$ expr 3 \<= 4 1 bashtest@host:~$ expr 3 '<=' 1 0 bashtest@host:~$
$(( ... )) i (( ... ))
Znacznie wygodniejszą formą pisania wyrażeń jest forma $(( wyrażenie )). W stosunku do expr w ciapkach ma prawie same zalety. Jest jeden problem, ta składnia może nie działać w innych shellach, czy w starszych wersjach Basha (ale kto teraz używa czegoś innego niż Bash). Pierwszą zaletą jest szybkość, tzn. użycie tej składni nie powoduje tworzenia nowego procesu (co ma miejsce w przypadku `expr ...`) i jest interpretowane bezpośrednio przez Basha. Po drugie przy odwoływaniu się do zmiennych nie musimy poprzedzać ich znakiem $, gdyż każdy identyfikator wewnątrz podwójnych nawiasów jest traktowany jak zmienna. Nie musimy także dbać o używanie odstępów i backslashowania znaków specjalnych. Trzecią zaletą jest bogatsza paleta operatorów arytmetycznych. Otóż wyrażenia arytmetyczne mogą tu zawierać dowolne operatory, które można znaleźć w języku C, np. inkrementacje/dekrementacje zmiennych (ID++, --ID), operacje bitowe (<<, &, ~), przypisania arytmetyczne (=, +=, *=), itp. Więcej o znaczeniu tych operacji i dozwolonych działaniach można znaleźć w kursie języka C lub w dokumentacji Basha.
Składni (( wyrażenie )) używamy wtedy, gdy nie potrzebujemy wyniku, czyli wtedy, gdy wyrażenie nie jest częścią instrukcji, tylko jest sama w sobie instrukcją. Najlepiej będzie, jak przyjrzymy się przykładom.
Kilka sposobów na zwiększenie zmiennej o 1:
bashtest@host:~$ a=0 bashtest@host:~$ a=$((a + 1)) bashtest@host:~$ ((a=a+1)) bashtest@host:~$ ((a++)) bashtest@host:~$ ((a += 1)) bashtest@host:~$ echo $a 4 bashtest@host:~$
Inne przykłady:
bashtest@host:~$ echo "1 + ... + $x = $((x * (x + 1) >> 1))" 1 + ... + 5 = 15 bashtest@host:~$ echo $((x++)) 5 bashtest@host:~$ echo $((++x)) 7 bashtest@host:~$ echo $((x += x > 0)) 8 bashtest@host:~$ echo "x = $x" x = 8 bashtest@host:~$
let
let jest wbudowanym poleceniem Basha i używamy go, podając mu jako argumenty wyrażenia do przetworzenia.
let wyrażenie1 wyrażenie2 ...równoważne jest ciągowi poleceń
((wyrażenie1)) ((wyrażenie2)) ...
Przykład:
bashtest@host:~$ x=0 bashtest@host:~$ let x+=2 "x += 4" bashtest@host:~$ echo $x 6 bashtest@host:~$
Trzeba pamiętać, że wyrażenie zawierające odstępy trzeba ujmować w cudzysłowy, aby formowały jeden argument.
Wczytywanie wejścia
W skryptach czasami jest potrzeba wczytania czegoś ze standardowego wejścia. Możemy chcieć pobrać od użytkownika jakąś informację. Możemy też chcieć wczytywać standardowe wejście i stopniowo je przetwarzać. Do tych celów jest polecenie read.
read wywołane bez argumentów wczytuje jedną linię ze standardowego wejścia na zmienną o nazwie REPLY. Jeśli podamy jeden argument, read,/code> wczyta tą linię na zmienną o nazwie takiej samej, jak zawartość argumentu. Jeśli podamy więcej argumentów reprezentujących nazwy zmiennych, <code>read na pierwsze zmienne będzie wczytywał pojedyncze słowa, a na ostatnią wczyta pozostałość bieżącej linii do jej końca. Prześledźmy to na przykładzie.
Dla skryptu
#!/bin/sh read echo $REPLY read a echo $a read a b c echo "a='$a', b='$b', c='$c'" read x echo "'$x'"
i dla wejścia
Pierwsza linia (pamiętać o cudzysłowach przy odwoływaniu się do $REPLY) Druga linia (teraz pamiętamy - "$a") Raz Dwa Trzy Cztery Czwarta linia jest pusta, a to jest piąta linia
otrzymamy wynik
Pierwsza linia (pamiętać o cudzysłowach przy odwoływaniu się do $REPLY) Druga linia (teraz pamiętamy - "$a") a='Raz', b='Dwa', c='Trzy Cztery'
Podawanie wejścia poleceniu w skrypcie
Gdy wykonujemy polecenie, czasami chcemy zadać mu konkretne wejście. Możemy to zrobić na przykład za pomocą komendy echo:
echo "Nasze wejście" | polecenie
Użycie echo dla wejść, które mają składać się z wielu linii jest jednak kłopotliwe. W tym celu w Bashu jest możliwość podania fragmentu skryptu jako wejście do polecenia. Służy do tego symbol specjalny <<. Takie "przekierowanie" << SŁOWO mówi, że wejście dla uruchamianego polecenia ma być czytane z aktualnego wejścia tak długo, aż zostanie napotkany napis SŁOWO. Na przykład wynikiem skryptu
#!/bin/sh echo "Moje ulubione liczby:" sort -n << LICZBY 120 10 2006 314159 0 LICZBY echo "Od najmniejszej do największej, rzecz jasna"
jest
Moje ulubione liczby: 0 10 120 2006 314159 Od najmniejszej do największej, rzecz jasna
Status wyjścia
Każdy program po ukończeniu zwraca swój kod wyjścia. Można go pobrać używając specjalnej zmiennej $?.
bashtest@host:~$ ls *.txt test.txt bashtest@host:~$ echo $? 0 bashtest@host:~$ ls *.nieznane ls: *.nieznane: Nie ma takiego pliku ani katalogu bashtest@host:~$ echo $? 2 bashtest@host:~$
Zgodnie z konwencją jeśli polecenie wykonało się z sukcesem, kodem wyjścia jest 0, a jeśli w wyniku wykonania pojawiły się błędy lub polecenie skończyło się porażką, zwracany jest kod różny od zera.
Normalnie własny skrypt kończy się ze statusem wyjścia równym zero. Możemy zakończyć skrypt w dowolnym miejscu z wybranym przez nas statusem wyjścia, stosując polecenie exit. Na przykład instrukcja exit 1 powoduje natychmiastowe zakończenie skryptu z kodem wyjścia 1.
Instrukcje warunkowe
if
Instrukcja if w najprostszej postaci ma następującą składnię:
if polecenie_warunek; then instrukcje fi
Jej działanie jest następujące. Wykonywane jest polecenie polecenie_warunek. Jeśli kod wyjścia tego polecenia jest 0, wykonywane są instrukcje między then, a fi. Jeśli kod wyjścia polecenia był niezerowy, wykonywanie instrukcji if jest zakończone i interpreter przechodzi do wykonywania instrukcji znajdujących się po słowie kluczowym fi.
Widzimy, że rolę warunków logicznych spełniają tu po prostu zwykłe polecenia, a prawda lub fałsz jest to odpowiednio status wyjścia równy zero lub status wyjścia różny od zera.
Składnia if z użyciem else:
if polecenie_warunek; then instrukcje1 else instrukcje2 fi
Jeśli warunek jest prawdziwy, wykonywane są instrukcje1, w przeciwnym razie wykonywane są instrukcje2. Przykład:
if cd $katalog; then echo "Jesteśmy w katalogu $katalog" else echo "Nie udało się wejść do katalogu $katalog" fi
Pełna składnia if jest następująca:
if warunek1; then instrukcje1 elif warunek2; then instrukcje2; ... else instrukcje_else; fi
Część z else jest opcjonalna. instrukcje1 są wykonane, jeśli jest spełniony warunek1, w przeciwnym razie, jeśli jest spełniony warunek2, to wykonywane są instrukcje2, itd. Na końcu, jeśli żaden warunek nie jest spełniony, wykonywane są instrukcje_else.
Wyrażenia logiczne
Powstaje pytanie, jak tworzyć polecenia, które sprawdzają jakieś sensowne warunki np. porównywanie liczb. Do tego celu służy polecenie test. Potrafi ono porównywać łańcuchy znakowe, liczby i sprawdzać istnienie plików.
Jeśli chodzi o porównywanie łańcuchów znakowych, mamy następujące możliwości. -z ŁAŃCUCH sprawdza, czy długość łańcucha jest równa zero, a -n ŁAŃCUCH, sprawdza, czy długość łańcucha jest różna od zera. Ponadto możemy porównywać dwa łańcuchy np. ŁAŃCUCH1 < ŁAŃCUCH2. Porównanie jest leksykograficzne. Możliwe operatory to ==, !=, <, >.
Do porównywania dwóch liczb są inne operatory: -eq, -ne, -lt, -le, -gt, -ge, których odpowiedniki matematyczne to =, <>, <, <=, >, >=.
Na przykład poniższe polecenia zwrócą prawdę (tj. status wyjścia równy 0):
test -z "" test abc \< def test 3 \> 17 test 3 -lt 17
Można także sprawdzać istnienie i typ plików, na przykład:
if test -a $plik; then echo "$plik istnieje" if test -f $plik; then echo "$plik jest zwykłym plikiem" elif test -d $plik; then echo "$plik jest katalogiem" fi fi
Polecenie
test warunekmożna też pisać w postaci
[ warunek ]
Taka forma jest po prostu wygodniejsza.
Warto wiedzieć, że instrukcja arytmetyczna (( ... )) też zwraca status. Zwraca 0, jeśli wartość wyrażenia jest niezerowa, i zwraca 1, jeśli wartość wyrażenia wynosi 0. Pozwala to w Bashu stosować w bardzo wygodny sposób porównania, dokładnie tak samo jak w C.
bashtest@host:~$ if (( 0 )); then echo prawda; else echo fałsz; fi fałsz bashtest@host:~$ if (( 1 )); then echo prawda; else echo fałsz; fi prawda bashtest@host:~$ if (( 3 < 4 )); then echo prawda; else echo fałsz; fi prawda bashtest@host:~$ if (( 0 < -1 )); then echo prawda; else echo fałsz; fi fałsz bashtest@host:~$ if (( 3 * 6 - 2 * 9 )); then echo prawda; else echo fałsz; fi fałsz bashtest@host:~$ if (( 1/0 )); then echo prawda; else echo fałsz; fi bash: ((: 1/0 : division by 0 (error token is " ") fałsz bashtest@host:~$
Najprostszymi poleceniami, które zwracają prawdę i fałsz, prostszymi nawet niż (( 1 )) i (( 0 )) są true i false, co przydaje się na przykład w pętlach.
Wyrażenia regularne
Po co są wyrażenia regulrane?
Częstym zadaniem, które wykonuje się podczas pracy z komputerem jest wyszukiwanie danego fragmentu tekstu w jakimś pliku, zmienianie go, sprawdzanie, czy dany tekst się w tym pliku znajduje. Generalnie potrzebujemy narzędzi do znajdywania wzorca o zadanej charakterystyce w jakimś większym tekście. Tą charakterystykę musimy jakoś podawać. W najprostszym przypadku podajemy po prostu tekst, jaki chcemy znaleźć. Na przykład, aby znaleźć wszystkie linie w pliku tekst.txt, w których znajduje się fragment est, wystarczy wykonać polecenie
grep est tekst.txtWtedy dla pliku tekst.txt o zawartości
To jest plik tekstowy.
Testujemy narzędzie grep.
Trzecia linia.
A to czwarta linia.
To jest piąta linia.w wyniku otrzymamy
To jest plik tekstowy.
Testujemy narzędzie grep.
To jest piąta linia.Zamiast wyszukiwać daną frazę, możemy chcieć znaleźć bardziej skomplikowane wzorce, jak na przykład wszystkie adresy email, które znajdują się w danym tekście, czy też wszystkie formy słowa pies. W tych celach potrzebne są bardziej zaawansowane możliwości podawania charakterystyki frazy, której chcemy szukać. Taką możliwość dają właśnie wyrażenia regularne.
Składnia
Znaki
Najprostsze wyrażenia regularne składają się z ciągu znaków. Niektóre znaki są specjalne, więc aby rozpoznać któryś z nich, trzeba poprzedzać go backslashem. Następujące znaki są specjalne: . ^ $ * ? [ ] \. Na przykład, aby wyszukać w tekście frazę \abc[?] używamy wyrażenia \\abc\[ \?\ ].
Klasy znaków
Przypuśćmy, że chcemy znaleźć wystąpienie jednego z łańcuchów psa, psu i psy. Zatem pierwsze dwa znaki są ustalone i są to ps. Natomiast przy trzecim znaku mamy pewną dowolność. Chcemy, aby trzeci znak mógł być równy a, u lub y. Do tego służą klasy znaków. Listę znaków, którą chcemy rozpoznać, umieszczamy pomiędzy nawiasami kwadratowymi: [auy]. Nasze wyrażenie wygląda więc tak: ps[auy].
bashtest@host:~$ grep ps[auy] <<KONIEC > psami > psom > psu > ps > KONIEC psami psu bashtest@host:~$
W klasach możemy podawać przedziały znaków używając myślnika. Na przykład [0-9] rozpoznaje dowolną cyfrę. Możemy podawać kilka przedziałów: [a-zA-Z] rozpozna dowolną literę angielską.
Jeśli umieścimy znak ^ na początku opisu klasy, będzie to oznaczać rozpoznawanie wszystkich znaków nie znajdujących się na liście. Na przykład [^xX] oznacza dowolny znak różny od x i X. Oczywiście możemy podawać też przedziały.
Jeśli chcemy umieścić na liście znak ], należy go podać jako pierwszy na liście. Aby umieścić ^, należy go umieścić w dowolnym miejscu, byle nie na początku. Wreszcie, aby umieścić -, należy go umieścić na końcu listy.
Ponadto mamy możliwość kojarzenia dowolnego znaku oprócz znaku końca linii. Do tego służy znak specjalny . (kropka).
Powtórzenia
Znak specjalny * próbuje dopasować poprzedzający go element zero lub więcej razy w szukanym tekście. Na przykład =* dopasowuje się do ciągu znaków równości (być może ciągu pustego).
Inny przykład, wyrażenie [a-zA-Z][a-zA-Z0-9_]* reprezentuje identyfikator, tzn. niepusty łańcuch znaków zaczynający się od litery i składający się z liter, cyfr oraz znaków podkreślenia.
Znak specjalny + jest podobny do * z tym, że próbuje on dopasować poprzedzający go element jeden lub więcej razy.
Znak specjalny ? mówi, że poprzedzający element może wystąpić, bądź też nie. Na przykład wyrażenie -?[0-9]+ oznacza dowolny niepusty ciąg cyfr, być może poprzedzony znakiem -. Czyli takie wyrażenie może służyć do rozpoznawania dowolnej liczby całkowitej (jeżeli dopuścimy to, że zapis dziesiętny liczby może mieć wiodące zera).
Ponadto ilość powtórzeń można podać bardziej w uniwersalny sposób:
| symbol powtórzenia | liczba powtórzeń poprzedzającego elementu |
|---|---|
{n} |
dokładnie n
|
{n,} |
co najmniej n
|
{,m} |
co najwyżej m
|
{n,m} |
co najmniej n i co najwyżej m
|
Pozycjonowanie
Znaczniki pozycjonujące są takimi symbolami, które nie są kojarzone z żadnym ciągiem znaków, ale z pozycją w tekście spełniającą pewne ustalone warunki.
Jeśli chcemy, aby wzorzec był dopasowywany od początku linii, wyrażenie zaczynamy znakiem ^. Jeśli chcemy, aby wzorzec był dopasowywany do końca linii, wyrażenie kończymy znakiem $. Gdy użyjemy oba znaki, wzorzec będzie dopasowywany do całej linii.
Na przykład, żeby znaleźć linie, w których znajduje się dokładnie jedna kropka, możemy użyć wyrażenia ^[^.]*\.[^.]*$. Użycie ^ na początku i $ na końcu oznacza, że zawsze będzie próba dopasowania całej linii. Następnie [^.]* oznacza dowolny ciąg znaków nie zawierający kropki, a \. oznacza wystąpienie kropki (trzeba użyć \, bo . jest znakiem specjalnym).
Aby znaleźć linię, która zaczyna się od dowolnej liczby spacji, liczby, później kropki, a następnie spacji i dużej litery, używamy wyrażenia ^ *[0-9][0-9]*\. *[A-Z]. Za pomocą tego wyrażenia zostaną znalezione na przykład
1. Wstęp 2.Wprowadzenie 13. Zakończenie
a nie zostaną znalezione takie linie
1 Trafienie 3. echo - komenda wbudowana 4 . Punkt czwarty 2006 ^ 1. Wstęp
Oprócz znaczników rozpoznających początek i koniec linii, mamy też szereg znaczników rozpoznających końce słowa:
\< znacznik mówiący, że w tym miejscu zaczyna się nowe słowo
\> znacznik mówiący, że w tym miejscu kończy się słowo
\b znacznik mówiący, że w tym miejscu jest krawędź słowa (nie zaczyna ani nie kończy się żadne słowo)
\B znacznik mówiący, że w tym miejscu nie znajduje się krawędź słowa
Dokładne definicje, co to jest brzeg słowa, są nieprzyjemnie skomplikowane i je pominiemy. Przyjrzyjmy się przykładowi. Dla frazy Jola jest lojalna następujące wyrażenia zostaną dopasowane do wycinka tej frazy:
\<jest\>\bjest\b\Best\b\Bes\B
a poniższe wyrażenia nie zostaną dopasowane:
\<est\>\best\b\Bes\b\>jest\<
Alternatywa
Jeśli chcemy, aby był rozpoznawany jeden z dwóch możliwych napisów, to możemy użyć alternatywy |, na przykład jeden|dwa rozpozna albo słowo jeden albo słowo dwa. Operator | może mieć jako argumenty też inne wyrażenia, na przykład [0-9]*|[a-z]*|[A-Z]*/ rozpoznaje albo ciąg cyfr, albo ciąg małych liter, albo ciąg dużych liter.
Priorytety i nawiasowanie
Największy priorytet mają operatory powtórzenia. Jeśli chcemy mieć wyrażenie oznaczające powtórzenie większej liczby elementów, to możemy zrobić to poprzez stosowanie nawiasów ( ... ). Na przykład wyrażenie ([a-z][a-z])* oznacza ciąg składający się z parzystej liczby małych literek.
Najmniejszy priorytet ma alternatywa. Jeśli chcemy wpisać wyrażenie, które rozpoznaje wszystkie słowa, które rozpoczynają się od Ta lub od Do, to nie możemy napisać Ta|Do[a-z]*, gdyż takie wyrażenie rozpoznaje albo słowo Ta, albo ciąg literek zaczynający się od Do. Z pomocą przychodzą nawiasy: (Ta|Do)[a-z]*.
Wyrażenia podstawowe i rozszerzone
Wyrażenia regularne dzielimy na podstawowe i rozszerzone. W wyrażeniach podstawowych znaki ?, +, {, |, (, ) nie mają specjalnego znaczenia, zamiast nich trzeba używać wersji z backslashem: \?, \+, \ {, \|, \ (, \ ). W wyrażeniach rozszerzonych możemy stosować wszystkie wymienione znaki specjalne.
Rozróżnienie takie powstało na skutek różnych narzędzi i zachowania kompatybilności między nimi. Niektóre narzędzia używają składni z podstawowymi, a niektóre z rozszerzonymi wersjami wyrażeń regularnych. Przy omawianiu poszczególnych komend powiemy, które używają jakiej składni.
Przykłady wykorzystania
grep
Polecenie grep jest podstawowym narzędziem do wyszukiwania wzorca w tekście z użyciem wyrażeń regularnych. grep używa podstawowych wyrażeń. Jeśli jest potrzeba użycia rozszerzonych wyrażeń można użyć wtedy w zastępstwie polecenia egrep.
Podstawowe użycie, to
grep wzorzecgdzie wzorzec jest wyrażeniem regularnym. Wzorzec jest wyszukiwany w standardowym wejściu i na standardowe wyjście są wypisywane linie zawierające wzorzec.
Można podać plik lub pliki jako argumenty:
grep wzorzec pliklub
grep wzorzec plik1 plik2 ...W przypadku jednego pliku, działanie jest takie samo jak bez argumentów, z tą różnicą, że dane są czytane z pliku, a nie ze standardowego wejścia.
W wersji z wieloma plikami wzorzec wyszukiwany jest w każdym pliku. Wyświetlane są linie zawierające wystąpienie wzorca poprzedzone nazwą pliku, w którym został on znaleziony.
Ponadto jest wiele opcji kontrolujących sposób szukania i wyświetlane informacje. Omówimy najprzydatniejsze z nich.
-e wzorzec
alternatywny sposób podania wzorca; przydatny, gdy wyrażenie regularne może zaczynać się od znaku -
-i
ignoruje rozróżnianie wielkich liter,
-c
zlicza tylko liczbę wystąpień wzorca,
-w
dopasowuje wzorzec tylko do całych słów,
-x
dopasowuje wzorzec tylko do całych linii,
-v
odwraca sens dopasowania i wyszukuje tylko linie w których nie udało się dopasować wzorca,
-q
nic nie wypisuje na standardowe wyjście i kończy działania na pierwszym dopasowaniu; przydatne, gdy polecenie grep chcemy użyć jako warunku.
grep zwraca zero jako kod wyjścia, gdy wzorzec uda się znaleźć i wartość niezerową w przeciwnym przypadku. Można to wykorzystać w połączeniu z opcją -q w instrukcjach warunkowych. Na przykład
if grep -qw TODO opis_prac.txt; then echo "Zostało jeszcze coś do zrobienia" fi
Jeśli chcemy z pliku usunąć linie, które pasują do wzorca możemy zrobić to w następujący sposób:
TMPFILE=/tmp/xyzabcd cp plik $TMPFILE grep -xv wzorzec $TMPFILE >plik rm -f $TMPFILE
expr
Polecenie expr oprócz obliczania wyrażeń arytmetycznych ma też podstawowe operacje na łańcuchach znakowych. Szczególnie przydatny jest operator :. Jego składnia to
expr łańcuch : wzorzecWzorzec jest wyszukiwany na początku łańcucha (czyli tak jakby zawsze na początku wzorca stał ^). Jeśli zostanie on znaleziony, wypisywana jest liczba dopasowanych znaków. W przeciwnym razie liczba dopasowanych znaków wynosi 0.
Jeżeli we wzorcu były używane nawiasy \( i \), zwracany jest łańcuch dopasowany w tym podwyrażeniu.
Status wyjścia jest równy zero tylko wtedy, gdy do wzorca uda się dopasować niepusty ciąg znaków.
Oto kilka przykładów:
- Wyświetlenie rozszerzenia pliku znajdującego się na zmiennej plik:
expr "$plik" : ".*\.\ ([^.]*\ )"
- Zmiana rozszerzenia z tar.gz na tgz pliku na zmiennej plik:
if expr "$plik" : ".*\.tar\.gz$"; then mv $plik `expr "$plik" : "\ (.*\.\ )tar\.gz"`tgz fi
oczywiście if jest zbędny jeśli wiemy, że nazwa pliku na pewno kończy się na .tar.gz.
sed
Najprościej rzecz ujmując sed jest edytorem strumieniowym. Czyta ze standardowego wejścia lub z pliku, jeśli został podany jako argument, następnie wykonuje operacje podane w komendach edycyjnych i wynik wyrzuca zawsze na standardowe wyjście.
Najczęściej sed jest używany z komendą edycyjną postaci s/wzorzec/zamiennik/, gdzie wzorzec jest podstawowym wyrażeniem regularnym, a zamiennik jest łańcuchem znakowym jakim będzie zastąpiony znaleziony wzorzec. W łańcuchu zamiennik możemy używać specjalnych sekwencji odnoszących się do znalezionego tekstu. \n, gdzie n jest liczbą, oznacza łańcuch skojarzony z n-tą parą nawiasów \( ... \). Znak & kojarzy z całym znalezionym łańcuchem.
Na przykład, aby zamienić każdy ciąg wykrzykników w jeden wykrzyknik można użyć komendy s/!\+/!/:
bashtest@host:~$ echo 'Hej!! Hej!!!! Tutaj!' | sed 's/!\+/!/' Hej! Hej!!!! Tutaj! bashtest@host:~$
Domyślnie sed wykonuje zastąpienie tylko przy pierwszym skojarzeniu wzorca w danej linii. Aby szukał wszystkich skojarzeń należy dodać przyrostek g do komendy edycyjnej:
bashtest@host:~$ echo 'Hej!! Hej!!!! Tutaj!' | sed 's/!\+/!/g' Hej! Hej! Tutaj! bashtest@host:~$
Aby zamienić znak . na znak , we wszystkich liczbach zmiennopozycyjnych możemy użyć komendy
s/\ ([0-9]\+\ )\.\ ([0-9]\+\ )/\1,\2/g
Użyliśmy tutaj odnośników. \1 oznacza grupę cyfr przed . w znalezionym łańcuchu, a \2 oznacza grupę cyfr po ..
Do rozdzielania komendy s nie trzeba wcale używać znaku /, ale może to być dowolny wybrany znak. Na przykład komenda
s+C:\\+/mnt/win/+g
zamieni wszystkie wystąpienia C:\ na /mnt/win/.
sed może też służyć do filtrowania wejścia. Opcja -n powoduje, że domyślnie nic nie jest wypisywane. Trzeba dodać przyrostek p do komendy, aby wynik został wypisany. Na przykład
sed -n 's/[a-zA-Z0-9]/&/p' opis.txt
wypisze tylko te linie pliku opis.txt, które zawierają znak alfanumeryczny.
Ponadto sed posiada znacznie więcej różnych użytkowych funkcji. Można poprzedzić komendę adresem. Na przykład sed '20s/.../.../' zadziała tylko w 20 linii. Adresem może być numer linii, wyrażenie regularne albo zakres. Są też inne komendy, na przykład sed '/^#/d' usunie wszystkie linie, które zaczynają się od znaku #.
Bash - skrypty złożone
Instrukcja wyboru
case jest instrukcją wyboru, która jest krótszą alternatywą dla instrukcji if, gdy testujemy jedną wartość. Jej składnia to:
case wartość in wzorzec1) instrukcje1 ;; wzorzec2) instrukcje2 ;; ... esac
Wzorce mają formę podobną do wzorców plików, tzn. może to być konkretna wartość, a może też zawierać znaki * i ?. case dopasowuje wartość do jednego z wzorców. Dla pierwszego dopasowanego wzorca wykonywane są odpowiadające mu instrukcje. Jeśli nie uda się dopasować do żadnego z wzorców, to nie są wykonywane żadne instrukcje.
#!/bin/sh case $1 in "") echo "Prawidłowe wywołanie to: $0 plik" exit 1 ;; *.txt) # jeśli plik tekstowy, to go uruchamiamy edytor pico $1 ;; *.sh) # jeśli skrypt to go uruchamiamy ./$1 ;; *) # to oznacza wszystkie wartości; dalsze wzorce nie mają już sensu echo "Nieznany rodzaj pliku '$1'" ;; esac
Pętle
while
Pętla while ma składnię
while warunek; do instrukcje done
Interpreter tak długo wykonuje instrukcje, jak długo jest spełniony warunek. Podobnie, jak przy instrukcji if, warunek jest poleceniem, które jest uruchamiane przy każdym obrocie pętli. Jeśli status wyjścia jest równy zero, to wykonywane są instrukcje podane w bloku pętli.
Przykład.
zm="" while [ "$zm" != koniec ]; do echo -n "Wpisz coś (słowo 'koniec' aby zakończyć): " read zm echo "Wpisałeś '$zm'" done
until
Pętla until jest bardzo podobna do pętli while:
until warunek; do instrukcje done
Różnica polega na tym, że pętla jest wykonywana tak długo, jak warunek jest nieprawdziwy (przeciwnie do tego jak ma się to w pętli while). Na przykład pętla z poprzedniego przykładu mogła by wyglądać tak:
until [ "$zm" == koniec ]; do ... done
for
Pętla for ma dwie formy. Pierwsza forma służy wykonywania bloku instrukcji dla każdej wartości argumentów z listy, a druga forma ma bardziej złożoną składnię i jest zapożyczona z języka C.
for dla list
Ta wersja ma postać:
for zm in lista; do instrukcje done
gdzie lista jest listą wartości. Listę podajemy w analogiczny sposób, jak argumenty poleceniu, czyli na przykład możemy używać wzorców nazw plików do podania wielu nazw plików naraz. Instrukcje w bloku są wykonywane dla każdej wartości znajdującej się na liście. W danym obrocie wartość z listy przypisywana jest na zmienną zm.
Przykład:
for f in *; do # * rozwija się do listy wszystkich plików/katalogów znajdujących się w bieżącym katalogu if [ -d "$f" ]; then echo "Katalog '$f'" elif [ -f "$f" ]; then echo "Plik '$f'" else echo "Inny typ '$f'" fi done
Listą może być też ciąg wartości. Na przykład, aby wyświetlić kwadraty wybranych liczb, możemy te liczby umieścić na liście:
for i in 1 5 100 99; do echo "Kwadrat $i = $((i * i))" done
Listą może też być wynik innego polecenia:
# Wyszukanie wszystkich tych plików o rozszerzeniu txt, # dla których ostatnia linia zawiera napis "Autor: Jan Kowalski" for f in `find . -name "*.txt" -type f`; do if [ "`tail -1 $f`" == "Autor: Jan Kowalski" ]; then echo "Plik '$f' posiada już podpis" fi done
Można także w liście umieścić argumenty skryptu:
# Wypisywanie argumentów skryptu n=1 for arg in "$@"; do echo "Argument $n: '$arg'" let "n++" done
Listę można utworzyć przez połączenie dwóch innych list, na przykład 0 "$@" jest listą składającą się z elementu 0 oraz z wszystkich argumentów skryptu.
for w stylu C
Bardziej skomplikowana wersja pętli for w stylu C ma postać:
for ((inicjacja; warunek; post_modyfikacja)); do instrukcje done
inicjacja, warunek i post_modyfikacja są wyrażeniami takimi jak wyrażenia używane w konstrukcjach $(( ... )) i (( ... )). Działanie jest następujące.
Na początku i tylko raz, jest uruchamiane wyrażenie inicjacja. To wyrażenie zazwyczaj ma za zadanie zainicjowanie zmiennych używanych do iterowania pętli.
Następnie przed każdą iteracją wyliczane jest wyrażenie warunek. Jeśli jest ono fałszywe, wykonywanie pętli kończy się. Jeśli jest ono prawdziwe, wykonywany jest blok instrukcje.
Po każdej iteracji wykonywane jest wyrażenie post_modyfikacja. To wyrażenie zazwyczaj ma za zadanie modyfikowanie zmiennych.
Przykład. Kilka sposobów wypisania liczb od 1 do 10:
i=1 while ((i <= 10)); do echo -n "$i " let "i++" done echo for i in 1 2 3 4 5 6 7 8 9 10; do echo -n "$i " done echo for i in `seq 1 10`; do echo -n "$i " done echo for ((i = 1; i <= 10; i++)); do echo -n "$i " done echo
Polecenie seq służy do generowanie ciągów arytmetycznych.
break i continue
Wewnątrz pętli dostępne są dwa dodatkowe polecenia:
break,continue.
break powoduje natychmiastowe przerwanie wykonywanej pętli. continue powoduje zakończenie aktualnej iteracji pętli i przejście do następnej iteracji.
while true; do read a if [ "$a" = "koniec" ]; then break elif [ "$a" = "dalej" ]; then continue fi echo "Wpisałeś '$a'" done
Funkcje
Wewnątrz skryptu można pisać własne funkcje, które spełniają rolę podprogramu. Ma to miejsce na przykład wtedy, gdy pewną czynność chcemy wykonać wielokrotnie w różnych miejscach skryptu i chcemy uniknąć kopiowania kodu. Funkcję deklarujemy w skrypcie w następujący sposób:
nazwa_funkcji () { instrukcje }
Wywoływanie funkcji i argumenty
Zadeklarowana funkcja dostępna jest dla potrzeb skryptu jak nowe polecenie. Wywołujemy ją używając jej nazwy. Możemy przekazywać argumenty w ten sam sposób, w jaki przekazujemy je poleceniom.
# Przykład pokazujący deklarację i wywołanie funkcji z parametrami wypisz_argumenty () { echo -n "Jest $# argumentów:" for i in "$@"; do echo -n " '$i'" done echo } wypisz_argumenty wypisz_argumenty "$@" wypisz_argumenty raz dwa trzy cztery pięć
Zasięg deklaracji
Deklaracja funkcji jest instrukcją, w wyniku której dostępne staje się nowe polecenie. Czyli na przykład można deklarować funkcję wewnątrz bloków, a nie można używać funkcji, których deklaracja następuje później.
f # błąd - funkcja nie jest zadeklarowana if [ "$USER" = bashtest ]; then f () { echo "Pierwsza wersja f" } else f () { echo "Druga wersja f" } fi f # funkcja f może być zadeklarowana na dwa sposoby, zależnie od tego jaki użytkownik uruchomił skrypt
Status wyjścia
Ponieważ funkcja zachowuje się jak polecenie, to może też zwracać status wyjścia. Domyślnie zwracane jest zero. Aby wyjść z funkcji z zadanym statusem służy polecenie return.
pytanie_tak_nie () { while true; do if [ $# -ge 1 ]; then echo -n "$1 (tak/nie)? " fi read odp if [ "$odp" = tak ]; then return 0 elif [ "$odp" = nie ]; then return 1 fi done } if pytanie_tak_nie "Czy chcesz usłyszeć pytanie"; then until pytanie_tak_nie "Czy chcesz zakończyć ten skrypt"; do : # : jest wbudowaną pustą instrukcją done fi
Podshelle
Uruchamianie skryptów wiąże się z tworzeniem nowego procesu. Wszystko, co dostaje skrypt, to środowisko i argumenty. Tworząc nowy proces, możemy mu przekierować wejście i wyjście. Ponadto, jeśli uruchamiamy inny skrypt, to nie widzi on zmiennych, które zadeklarowaliśmy (chyba, że je wyeksportowaliśmy do środowiska). Po powrocie z wywołania innego skryptu bądź programu mamy pewność, że zadeklarowane zmienne nie zostały zmienione, podobnie jak argumenty skryptu. Wiemy też, że katalog bieżący jest niezmieniony.
Tego typu własności mogą być pożądane, gdy chcemy wykonać ciąg poleceń w skrypcie. Istnieje możliwość zrobienia tego bez pisania pliku z nowym skryptem. Można to zrobić w aktualnym skrypcie używając konstrukcji z nawiasami:
( instrukcje )
Instrukcje między nawiasami są uruchomione w nowym shellu. Dziedziczy po naszym skrypcie wszystkie zmienne:
bashtest@host:~$ a=2; ( echo $a; a=3; echo $a ); echo $a 2 3 2 bashtest@host:~$ ( cd /tmp ); echo $PWD /home/bashtest bashtest@host:~$
Konstrukcja ( ... ) przydaje się też do grupowania poleceń po to, aby używać przekierowań lub potoku do całej grupy instrukcji.
( if [ ! -d "$1" ]; then echo "$1 nie jest katalogiem exit 1 # wychodzi tylko z podshella fi cd "$1" for i in *.txt; do if [ -f "$i" ]; then echo "==== Do zrobienia w pliku '$i' ====" grep TODO "$i" fi done ) | less
Powyższy kawałek skryptu wyszuka w katalogu podanym w pierwszym argumencie wszystkie pliki o rozszerzeniu txt i dla każdego z nich wyświetli główkę oraz wszystkie linie zawierające tekst TODO. Wynik będzie można przejrzeć programem less.
Uruchamianie nowych procesów nie jest zbyt szybkie. Jeśli zależy nam na szybkości, należy unikać tworzenia nowych procesów. Na przykład
cat plik | grep wzorzec
można zastąpić poleceniem
grep wzorzec plikktóre uruchamia tylko jeden proces, a nie dwa, jak w poprzednim wywołaniu (dodatkowy proces to polecenie cat).
Warto wiedzieć, że wiele poleceń jest wbudowanych w Basha i nie są dla nich uruchamiane nowe procesy. Takie polecenia to na przykład: cd, echo, test. Jeśli chcemy zgrupować polecenia, to zamiast używać konstrukcji ( ... ) można używać { ... }. Różnica jest taka, że nie jest uruchamiany nowy shell, a co się z tym wiąże, wszelkie modyfikacje dokonane wewnątrz tego bloku są widoczne po wyjściu z tego bloku.
bashtest@host:~$ a=2; { echo $a; a=3; echo $a; }; echo $a; 2 3 3 bashtest@host:~$
Referencje
W jaki sposób dobrać się do zmiennej, której nazwa znajduje się na innej zmiennej. Otóż możemy użyć do tego polecenia eval:
eval argumentyDziała ono tak, że tworzona jest instrukcja składająca się z podanych argumentów. Niby nic w tym specjalnego, ale jest to w pewien sposób użyteczne. Na przykład, gdy w argumentach znajduje się wywołanie do zmiennej (np. $zmienna), wtedy wpierw wstawiana jest wartość zmiennej, potem tworzona jest instrukcja i dopiero na końcu jest wykonywana. Pozwala nam to tworzyć polecenia, w których skład wchodzą wartości zmiennych.
bashtest@host:~$ a=wartość bashtest@host:~$ echo $a wartość bashtest@host:~$ b=a bashtest@host:~$ echo $b a bashtest@host:~$ eval echo \$$b wartość bashtest@host:~$
Taki sposób przechowywania informacji o zmiennej (tzn. pamiętanie tylko nazwy zmiennej) nazywamy referencjami. W ten sposób możemy przekazywać zmienne funkcjom.
dopisz_y () { for z in "$@"; do eval $z=\$\{$z\}y done } a=dom b=kąt dopisz_y a b echo "a=$a" # wypisze a=domy echo "b=$b" # wypisze b=kąty
Widzimy, że tutaj odwołanie do zmiennej wymaga nawet użycia formy ${...}. Zauważmy, że gdybyśmy mieli w czwartej linii taką instrukcję
eval $z=\$${z}y
to nie byłoby to poprawne. Otóż dla z=a wartością $z jaki i ${z} było by a, więc polecenie utworzone przez eval do wykonania brzmiałoby a=$ay.
Pliki specjalne
W systemie Linux dostępne są tak zwane pliki specjalne. Na przykład /dev/null. Jest to taki plik, który zawsze, jak z niego czytamy, jest plikiem pustym, a wszystko, co do niego wpiszemy, znika. Ten plik jest przydatny gdy chcemy, aby wyjście polecenia nie zostało nigdzie wyświetlone.
polecenie 2>/dev/null >/dev/nullIgnorowanie wyjścia jest przydatne, gdy interesuje nas tylko status wyjścia.
Innym plikiem specjalnym jest /dev/zero. Wszystko co się wpisze do tego pliku, również znika, ale gdy czytamy z tego pliku otrzymujemy zawsze bajty, których wartość binarna wynosi 0. Ten plik można wykorzystać do utworzenia pliku o określonej wielkości. Na przykład, aby utworzyć plik 1m.dat składający się dokładnie z jednego megabajta znaków możemy użyć polecenia
dd if=/dev/zero of=1m.dat bs=1M count=1
Polecenie dd służy do kopiowania z jednego pliku do drugiego określonej liczby bajtów.
Inne pliki specjalne znajdują się w katalogu /proc. W katalogu tym są najróżniejsze informacje o systemie, o procesach. Podamy tu dla przykładu dwa pliki: /proc/cpuinfo, /proc/meminfo. Pierwszy wyświetla informacje o procesorach znajdujących się w danym komputerze, a drugi wyświetla informacje o dostępnej pamięci operacyjnej.
Składanie dokumentów - Latex
Wprowadzenie
Co to jest Latex
Latex wywodzi się z Tex'a. Zarówno Tex jak i Latex mają analogiczne przeznaczenie, przy czym Latex jest znacznie wygodniejszy. A zatem czym jest Latex?
Latex służy do wytwarzania przejrzyście wyglądających dokumentów tekstowych takich jak książki, artykuły, czy nawet prezentacje. Docelowym formatem jest wydruk, czy też pliki w różnych formatach, takich jak PDF, Postscript, czy też HTML. Szczególnie wygodne jest tworzenie dokumentów technicznych, matematycznych, ale z powodzeniem może też być stosowany do pisania dokumentacji programów albo zbioru opowiadań.
Latex, podobnie jak języki programowania, ma swój własny język, w którym pisze się treść dokumentu oraz posiada narzędzia (można by powiedzieć "kompilatory"), które przetwarzają pliki źródłowe i generują pliki docelowe. W językach programowania zazwyczaj jedną z istotnych rzeczy jest zbiór bibliotek z gotowymi implementacjami różnych typowych czynności. Również w Latexu jest dużo gotowych pakietów pozwalających w szybki sposób tworzyć najróżniejsze elementy i rodzaje dokumentów.
Filozofia Latexa jest taka, aby skupiać się na tym co merytorycznie ma zawierać dany dokument, a jak najmniej poświęcać uwagi na to, jak ma to wyglądać. Innymi słowy wprowadzamy tylko strukturę i zawartość dokumentu, a latex za nas robi resztę roboty, aby wyjściowy dokument wyglądał jak należy. Oczywiście mamy dużą możliwość ingerencji w wygląd, ale zazwyczaj jest to tylko dobieranie jakiegoś szablonu lub potrzeba uzyskania niestandardowego efektu. Jest to zupełnie inna filozofia, niż w wielu innych edytorach tekstowych, szczególnie w różnych aplikacjach biurowych, gdzie prawie na każdym kroku musimy od decydować, jaki ma być wygląd, wielkość liter, czcionka, odstępy, sposób wyświetlania tytułów itp.
Dystrybucje
Podstawą możliwości cieszenia się twórczością w Latexu jest posiadanie wszystkich narzędzi, pakietów, czcionek, itp. Gotowe zbiory są dostępne w różnych dystrybucjach. Oprócz tych narzędzi, początkujący użytkownicy mogą skorzystać z gotowych środowisk do obrabiania dokumentów Latexu.
Podstawową dystrybucją jest TeX Live. Jest ona dostępna pod wiele różnych platform. Jest łatwą w instalacji kompletną paczką narzędzi, programów, czcionek.
Użytkownicy Linuxa w swoich dystrybucjach zazwyczaj mają dostępny pakiet TeTeX, którego instalacja udostępnia wszelkie niezbędne narzędzia. Pod Linuxem wygodnym środowiskiem graficznym jest Kile.
Dla użytkowników Windowsa jest też bogata dystrybucja ProTeXt oparta na innej dystrybucji MiKTex i ponadto zawierająca kilka wydonych narzędzi, jak na przykład środowisko graficzne TeXnicCenter.
Typowa sesja
Z poziomu linii komand, droga do utworzenia dokumentu wynikowego składa się z wykonania kilku poleceń [pokaż] .
Plikom latexowym nadajemy rozszerzenie tex. Do kompilacji plik latexowego służy polecenie latex:
$ latex dok.tex
Polecenie wyrzuca szereg skomplikowanych napisów, którymi nie należy się przejmować do momentu, gdy nie są to informacje o błędzie w dokumencie.
W wyniku kompilacji powstaje szereg plików. Są to pliki pomocnicze, pliki z logami i najważniejszy plik o rozszerzeniu dvi (ang. device independent). Plik ten można już oglądać w postaci graficznej za pomocą polecenia xdvi:
$ xdvi dok.dvi
Ten format ma swoje ograniczenia, np. nie umożliwia dodawania obrazków, więc nie jest docelowym formatem. Aby utworzyć plik typu PostScript służy polecenie dvips:
$ dvips -o dok.ps dok.dviPolecenie to na podstawie pliku dvi tworzy plik ps. Aby obejrzeć ten plik, możemy użyć polecenie gv:
$ gv dok.psMożemy też utworzyć plik pdf. Najprostszym sposobem jest kompilacja za pomocą polecenia pdflatex zamiast latex:
$ pdflatex dok.tex
W wyniku powstaje kilka plików, ale najważniejsze jest, że powstaje też plik pdf. Przy tworzeniu w ten sposób plików o formacie pdf są pewne ograniczenia co do zawartości pliku latexowego. Warto mieć tą świadomość, gdy naszym celem jest plik pdf.
Struktura dokumentu
Plik źródłowy jest plikiem tekstowym zawierającym polecenia latexa, właściwą treść i inne symbole kontrolujące zawartość dokumentu. Polecenie latexa jest ciągiem liter (małych i dużych) zaczynającym się od znaku \. Polecenie może mieć argumenty. Argument umieszczany jest pomiędzy klamrami { i } (ale nie jest to konieczne, gdy argument składa się z jednego znaku; klamry ogólnie służą do grupowania). Argumenty opcjonalne umieszczane są pomiędzy nawiasami kwadratowymi [ i ] .
Plik musi mieć odpowiednią strukturę. Składa się z dwóch części:
- preambuły i
- części głównej.
Preambuła powinna zaczynać się od polecenia \documentclass{...} określającego rodzaj dokumentu. Najczęstszym rodzajem jest article. Polecenie też przyjmuje argumenty opcjonalne. Najczęściej używane to
a4paper- ustawia rozmiar papieru na A4,10pt, 11pt, 12pt- rozmiar tekstu.
Następnie mogą znaleźć się polecenia dotyczące stylu całego dokumentu i deklaracje dodatkowych pakietów. Pakiet dołączamy za pomocą polecenia \usepackage{...}.
Część główna ma postać:
\begin{document} Treść dokumentu... \end{document}
A oto przykładowy dokument, który zawiera deklaracje pakietów potrzebnych do obsługi języka polskiego:
% Preambuła \documentclass[a4paper,11pt]{article} \usepackage[polish]{babel} \usepackage[OT4]{fontenc} \usepackage[utf8]{inputenc} % Część główna \begin{document} Treść. \end{document}
Znak % oznacza komentarz. Po wystąpieniu % wszystkie znaki do końca linii są ignorowane przez kompilator.
Pakiet inputenc mówi, w jaki sposób są wprowadzone w pliku tekstowym znaki międzynarodowe. Współcześnie coraz częściej używa się kodowania UTF-8, które jest użyte w tym przykładzie. Jest ono wspierane już przez większość edytorów. Możemy podać też inne sposoby kodowania, a przykład często spotykany standard ISO-8859-2 (Latin-2). Aby go użyć należy podać latin2 jako argument opcjonalny (zamiast utf8).
Podstawy
Paragrafy
Podstawowym rodzajem treści dokumentu jest tekst, czyli wyrazy, zdania i całe paragrafy.
|
To jest pierwszy paragraf. Nie ma znaczenia liczba odstępów między wyrazami. Dobrym nawykiem jest umieszczanie zdań w osobnych liniach. Aby zacząć następny (drugi już) paragraf wystarczy dodać co |
|

Sekcje
Dla zwiększenia czytelności powinno dzielić się dokument na części. Podstawowym podziałem są sekcje.
|
Początkowe zdanie.
\section{Wstęp} Treść wstępu. \section{Sekcja główna} Treść sekcji głównej i mniejsze sekcje wchodzące w jej skład. \subsection{Podpunkt pierwszy} Treść pierwszego podpunktu. \subsubsection{Podpodpunkt} Treść podpodpunktu. \subsection{Podpunkt drugi} Treść drugiego podpunktu. |
|

Tytuł
Każdy szanujący się dokument powinien zaczynać się od tytułu, autora i ewentualnie daty powstania. Dlatego na początku części głównej można umieścić następujący kod.
|
\title{Wprowadzenie do \LaTeX-a} \author{Jan Kowalski} \date{\today} \maketitle |

|
Jak widzimy w tym przykładzie w argumentach poleceń można też używać inne polecenia.
Czcionki
Możemy też zmieniać krój czcionki oraz jego rozmiar.
|
To \emph{słowo} jest wyróżnione (tak właśnie \LaTeX{} rozumie wyróżnianie słów). \texttt{To zdanie jest napisane czcionką maszynową.} Z kolei to {\sf słowo} i to \textsf{słowo} jest napisane czcionką bezszeryfową. {\Large Ten akapit jest trochę większy. W tym akapicie {\small niektóre słowa} są mniejsze. |

|
Widzimy, że rozmiar i krój mogą być zagnieżdżone. Nie można zagnieżdżać krojów. Istotny jest zawsze ostatnio wybrany krój. Pełną listę krojów i rozmiarów można znaleźć w dokumentacji latexa.
W powyższym przykładzie używaliśmy symbolów grupowania { i }. Wszystko co występuje pomiędzy tymi symbolami nazywamy grupą. Grupy służą do składania w jeden element większej ilości elementów (np. przy tworzeniu argumentów) albo do ograniczenia zasięgu użytych komend. W tym przykładzie grupy służy nam do ograniczenia zasięgu użytego kroju, czy też rozmiaru.
Innym przykładem jest użycie pustej grupy po komendzie \LaTeX. Jest to zrobione po to, aby wymusić odstęp przed następnym słowem rozumie.
Układ
Przenoszenie wyrazów
Weźmy pod uwagę plik źródłowy przykład.tex:
\documentclass[a4paper,12pt]{article}
\usepackage[polish]{babel}
\usepackage[OT4]{fontenc}
\usepackage[utf8]{inputenc}
\pagestyle{empty}
\begin{document}
W tym akapicie występuje problem związany z przenoszeniem słowa dzwonnica.
To słowo trudno jest złamać tak, aby odstępy w linii nie były za duże lub za małe.
W związku z tym przy kompilacji generowane jest ostrzeżenie.
\end{document}W wyniku kompilacji
$ latex przykład.tex
dostaniemy ostrzeżenie
Overfull \hbox (6.78139pt too wide) in paragraph at lines 7--12
W wyniku otrzymujemy taki akapit:

|
Aby temu zaradzić możemy na przykład zaproponować łamanie linii między słowami słowa i dzwonnica. Służy do tego komenda \linebreak. Modyfikujemy siódmą linię pliku źródłowego na
W tym akapicie występuje problem związany z przenoszeniem słowa\linebreak dzwonnica.
Kompilacja odbywa się już bez problemów, a wynikowy akapit wygląda teraz tak:

|
Teraz w pierwszej linii odstępy są trochę większe, co pogarsza wygląd estetyczny. Lepiej by było pewnie przeformułować jakoś to zdanie, żeby latex nie miał problemów z dzieleniem wyrazów.
Jeśli nie zależy nam aż tak bardzo na jakości, możemy pozwolić na użycie większych odstępów między wyrazami dodając w preambule polecenie \sloppy.
Czasami dzielenie wyrazów w niektórych słowach (np. w skrótach) nie jest pożądane.
|
Pisanie w \LaTeX-u znacznie się różni od tego co mamy w edytorach WYSIWYG. |
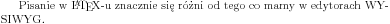
|
W takim wypadku można zablokować łamanie wyrazu poprzez użycie polecenie \mbox{...}.
|
Pisanie w \LaTeX-u znacznie się różni od tego co mamy w edytorach \mbox{WYSIWYG}. |
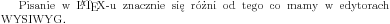
|
Łamanie linii i strony
Do łamania linii służy polecenie \\. Powoduje ono przejście do nowej linii. Do złamania strony służy polecenie \newpage. Żeby zacząć akapit bez wcięcia używamy \noindent.
W języku polskim nie zostawia się jednoliterowych spójników na końcu wiersza. Jednak latex może zdecydować, że linia zostanie złamana właśnie zaraz po spójniku. Aby temu zapobiec można użyć niełamliwych spacji, które wprowadza się za pomocą znaku tyldy ~.
|
\noindent Pierwsza linia.\\ Druga linia. Tutaj z kolei użyjemy niełamliwego odstępu, który często Tutaj z kolei użyjemy niełamliwego odstępu, który często |

|
Odstępy
Latex posiada sporo poleceń umożliwiających zmieniać domyślny układ graficzny. Tutaj pokażemy proste polecenia służące do wstawiania odstępu.
Do wstawienia odstępu poziomego służy polecenie \hspace{...}. Argumentem powinna być liczba zakończona przyrostkiem oznaczającym jednostki. Przykładowe jednostki to cm - centymetr, in - cal. Możemy też jako argument użyć polecenia \stretch{...}. Powoduje ono wstawienia takiego odstępu, aby aktualna linia została rozciągnięta na całą dostępną szerokość. Jeśli użyjemy więcej takich odstępów, to są one skalowane proporcjonalnie do wartości argumentów polecenia \stretch.
Analogiczne polecenie, które służy do wstawiania odstępów pionowych jest \vspace{...}.
|
\noindent Centymetr: $|$\hspace{1cm}$|$. Cal: $|$\hspace{1in}$|$.\\ 0\hspace{\stretch{1}}1\hspace{\stretch{3}}4\\ \vspace{3cm} Większe odstępy między liniami mogą być przydatne. |

|
W przykładzie tym użyliśmy znaków $. Znak ten rozpoczyna i kończy tryb matematyczny, dzięki czemu możemy wstawiać różne ciekawe znaki. Zobacz także cześć poświęconą matematyce.
Znaki specjalne
Symbole specjalne
Niektóre znaki są interpretowane przez kompilator w specjalny sposób, więc nie można wstawić ich bezpośrednio, aby je uzyskać w tekście. Są to $ & % # _ { } ~ ^ \. Większość można otrzymać poprzedzając je znakiem \. Do trzech trzeba użyć trybu matematycznego. Polecenie \ (spacja poprzedzona \) oznacza pełnowymiarową spację.
\$ \& \% \# \_ \{ \} $\tilde{\ }$ $\hat{\ }$ $\backslash$ |
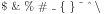
|
Cudzysłowy
W latexu cudzysłów " może mieć specjalne znaczenie (np. w trybie języka polskiego). Do tworzenia różnych cudzysłowów należy używać znaków , ' `. Jeżeli chcemy mieć podwójny cudzysłów, to wystarczy, że wprowadzimy dany znak dwa razy pod rząd.
|
Cudzysłowy angielskie: `x', ``tekst w cudzysłowach''. W języku polskim używamy ,,takich'' cudzysłowów. |
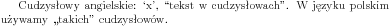
|
Myślniki
Są trzy rodzaje myślników: -, --, ---. Pierwszy jest najkrótszy i jest stosowany jako łącznik lub do przenoszenia wyrazów. Drugi jest trochę dłuższy i używamy go np. do zakresów liczbowych. Trzeci jest najdłuższy i jest czasami stosowany jako zwykły myślnik.
|
Łącznik: np. 52-ego. Pauza: np. 12--17. Myślnik --- na przykład taki. |
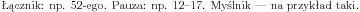
|
Złożone elementy
Bardziej złożone polecenia zapisywane są w postaci środowiska:
\begin{polecenie} Treść... \end{polecenie}
Środowiska można zazwyczaj zagnieżdżać.
Listy
Do tworzenia list z punktami służą środowiska enumerate, itemize i description,.
|
\begin{enumerate} \item Pierwszy punkt listy wyliczeniowej: \begin{itemize} \item wypunktowanie, \item bez numerów. \end{itemize} \item W drugim punkcie jest podlista z opisami: \begin{description} \item[C/C++] język programowania; przez wielu programistów uważany za dosyć brzydki, \item[Java] tajne źródła podają, że to też jest język programowania. \end{description} \end{enumerate} |

|
Tabele
Do tworzenia tabel służy środowisko tabular. To środowisko wymaga argumentu, który specyfikuje kolumny. Najprostsza specyfikacja składa się z ciągu liter określających sposób justowania ewentualnie przedzielonych znakiem | oznaczającym, że w tym miejscu ma być pionowa linia. Sposoby justowania to:
- l - równaj do lewej,
- c - centruj,
- r - równaj do prawej.
Wiersze w tabeli oddziela się poleceniem nowej linii \\, natomiast poszczególne kolumny oddzielamy znakiem &.
|
\begin{tabular}{r|cl} bardzo & prosta & tabela\\ \hline to & jest & drugi wiersz\\ & a to trzeci \end{tabular} |

|
Wyrównanie
Do równania tekstu do lewej, bądź prawej służą środowiska flushleft i flushright. Do centrowania służy środowisko center.
|
\begin{flushleft} do\\ lewej \end{flushleft} \begin{center} do\\ środka \end{center} \begin{flushright} do\\ prawej \end{flushright} |
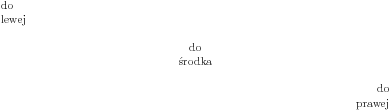
|
Przypisy
Przypisy wstawiamy poleceniem \footnote. Należy je wstawiać zaraz po wyrazie, po którym ma być przypis.
|
W tym akapicie\footnote{Innego akapitu tutaj nie ma.} jest przypis. Treść przypisu jest umieszczana na końcu strony. |

|
Odsyłacze
W większych dokumentach, aby ułatwić czytelnikowi poruszanie się po nich, dobrze jest używać odsyłaczy. Kierują one czytelnika do innej części dokumentu, na przykład do danego paragrafu, tabeli, strony. Służą do tego polecenia \label{...}, \ref{...} i \pageref{...}.
Polecenie \label{etykieta} ustawia miejsce odniesienia o nazwie etykieta w danym miejscu kodu. Istotne jest, aby polecenie to wstawiać zaraz za miejscem, do którego chcemy się odsyłać.
Polecenie \ref{etykieta} odnosi się do miejsca wskazanego przez etykietę. W tekście polecenie to wstawia odpowiedni numer paragrafu, tabeli, itp., zależnie od tego jaki jest rodzaj wskazywanego elementu.
Polecenie \pageref{etykieta} również odnosi się do miejsca deklaracja etykiety, co w tekście jest widoczne jako numer strony, w której występuje miejsce odniesienia.
|
\section{Wstęp} \ldots \section{Użycie odsyłaczy}\label{odsylacze} W \LaTeX-u użycie odsyłaczy\ldots \section{Dzielenie dokumentu na części} \ldots Do odnoszenia się do innych części można używać odsyłaczy, patrz sekcja~\ref{odsylacze}. |

|
Zauważmy, że podczas pierwszej kompilacji otrzymamy zapewne wśród komunikatów takie informacje:
No file odsyłacze.aux. LaTeX Warning: Reference `odsylacze' on page 1 undefined on input line 13. [1] (./odsyłacze.aux) LaTeX Warning: There were undefined references. LaTeX Warning: Label(s) may have changed. Rerun to get cross-references right.
Podczas pierwszej kompilacji tworzony jest plik odsyłacze.aux, który zawiera w sobie informacje o odsyłanych miejscach. Aby latex poprawnie wyliczył sobie i wstawił do tekstu odpowiednie odnośniki, niezbędna jest powtórna kompilacja.
Wstawki
Niektóre obiekty ( na przykład tabele czy rysunki) nie chcielibyśmy, aby były dzielone pomiędzy strony. Dodatkowo chcielibyśmy, aby można było dodawać im podpis, numerować je i mieć możliwość użycia odsyłaczy. Służą do tego środowiska table i figure. Środowiska te mają jeden opcjonalny argument. Zawartość takiego środowiska będzie wstawiona w tekście możliwie najbliżej miejsca, w którym zostało ono użyte. Zasady umiejscawiania wstawki są dosyć skomplikowane i efekty mogą być czasami irytujące. Warto więc zapoznać się w dokumentacji z zasadą działania wstawek.
Wewnątrz środowiska możemy użyć polecenia \caption{...}, które dodaje podpis.
|
Przykład mnożenia pisemnego liczb 23 i 37 można zobaczyć poniżej w tabeli \ref{mnozenie}. \begin{table}[!hbp] \centering \begin{tabular}{cl@{}l@{}l} & & 2 & 3\\ $\times$ & & 3 & 7\\ \hline $=$ & 1 & 6 & 1\\ $+$ & 6 & 9\\ \hline $=$ & 8 & 5 & 1 \end{tabular} \caption{Mnożenie pisemne}\label{mnozenie} \end{table} Tabela ta powinna być wstawiona gdzieś w tym akapicie. \LaTeX{} zrobi to automatycznie tak, aby było to możliwie blisko, zaraz po użyciu środowiska {\tt table}. |

|
W tym przykładzie użyliśmy środowiska figure. Wewnątrz środowiska użyliśmy polecenia /centering, które powoduje, że obiekt będzie centrowany. Etykieta powinna znaleźć się zaraz po podpisie. Użyliśmy też argumentu opcjonalnego środowiska !hbp, który sugeruje latexowi, gdzie umieszczać wstawkę. ! mówi, aby pominąć niektóre parametry kontrolujące (dzięki temu bywa, że efekt jest bardziej zadowalający). h mówi, żeby spróbować umieścić wstawkę w miejscu jej pojawienia. Jeśli to się nie powiedzie to użycie b mówi, żeby spróbować umieścić wstawkę na dole strony. Jeśli wszystko zawiedzie, to p mówi, żeby wstawka znalazła się na stronie zawierającej tylko wstawki.
Zwróćmy też uwagę na użycie symbolu @ w specyfikacji kolumn tabeli. Otóż @{...} podaje tekst, który ma być użyty do rozdzielania kolumn. W tym przypadku tekst jest pusty, co daje efekt taki, że między kolumnami nie ma w ogóle odstępu.
Matematyka
Wprowadzanie wzorów matematycznych jest najsilniejszą stroną latexa. Możliwości są olbrzymie, dlatego przedstawimy kilka wybranych elementów, które pozwolą już wprowadzać większość formuł. Użytkownicy wprowadzający bardzo skomplikowane wzory chętnie skorzystają zapewne z dokumentacji oraz z dodatkowego pakietu ams-latex.
Tryb matematyczny
Aby pisać wzory, trzeba używać trybu matematycznego. Jeśli chcemy wstawić wzór wewnątrz akapitu, stosujemy składnie $...$. Można też eksponować wzór w osobnej linii. Przydatne jest to wtedy, gdy wzory są bardziej skomplikowane. Służy do tego składnia \[...\].
|
\noindent Suma $\sum_{k=1}^n k$, czyli suma liczb od 1 do $n$ wynosi $\frac{n(n+1)}{2}$: \[ \sum_{k=1}^n k = \frac{n(n+1)}{2}. \] Tą prostą równość można udowodnić na wiele sposobów. |
|
Widzimy, że formuły wewnątrz akapitu są trochę inaczej składane niż formuły eksponowane.
Tryb matematyczny znacznie różni się od trybu tekstowego. Na przykład odstępy są automatycznie wyliczane. Możemy zawsze użyć specjalnych komend powiększających odstępy takich jak \,, czy \quad.
Wzorom eksponowanym możemy nadawać etykiety, aby móc później się do nich odwoływać.
|
\noindent Mamy dwie własności \begin{equation} x^2 \ge 0\label{eq:kwadrat_nieujemny} \end{equation} oraz \begin{equation} (a-b)^2 = a^2 + b^2 - 2ab.\label{eq:a_minus_b_kwadrat} \end{equation} Wstawiając $a-b$ za $x$ w (\ref{eq:kwadrat_nieujemny}), po rozpisaniu ze wzoru (\ref{eq:a_minus_b_kwadrat}) otrzymujemy nierówność: \[ a^2 + b^2 \ge 2ab. \] |
|
Grupowanie
Wiele konstrukcji wymaga (tak jak polecenia), aby ich elementy stanowiły zwartą całość. Dlatego często trzeba używać operatorów grupowania {...}, gdyż jeśli ich nie użyjemy, efekty mogą odbiegać od tego co chcemy uzyskać.
\[a^x+y \quad a^{x+y} \quad 2^16 \quad 2^{16}\] |
\[a^x+y \quad a^{x+y} \quad 2^16 \quad 2^{16}\] |
Elementy
Pokażemy kilka przykładowych składników formuł.
Operatory _ i ^ służą do tworzenia indeksów dolnych i górnych.
\[ (x_1+x_2)^2 = x_1^2 + 2x_1x_2 + x_2^2 \] |
\[ (x_1+x_2)^2 = x_1^2 + 2x_1x_2 + x_2^2 \] |
Przy użyciu odpowiednich poleceń mamy dostępnych znacznie więcej symboli, jak na przykład litery greckie.
\[ \alpha + \beta + \gamma = 180^\circ \] |
\[ \alpha + \beta + \gamma = 180^\circ \] |
Podstawy takie jak pierwiastek \sqrt, ułamki \frac, nierówności \le.
\[ \sqrt{ab} \le \frac{a+b}{2} \] |
\[ \sqrt{ab} \le \frac{a+b}{2} \] |
Zmienne można dekorować dodając im różne znaczki lub je pogrubić.
\[ \dot{y} \quad \ddot{y} \quad f'(\hat{x}) \quad y \quad \mathbf{x} \quad \vec{x} \quad \widehat{xyz} \] |
\[ \dot{y} \quad \ddot{y} \quad f'(\hat{x}) \quad y \quad \mathbf{x} \quad \vec{x} \quad \widehat{xyz} \] |
Dostępnych jest wiele funkcji matematycznych (takich jak sin, lim) z użyciem poleceń. Funkcje mają być pisane czcionką prostą, stąd bierze się potrzeba użycia specjalnych poleceń.
\[ \lim_{h\to 0}\frac{\sin h}{h}=1 \] |
\[ \lim_{h\to 0}\frac{\sin h}{h}=1 \] |
Możemy mieć potrzebę stosowanie większych nawiasów we wzorach. Efekt ten można uzyskać, używając specjalnych poleceń, które określają rozmiar i stronę nawiasu. Za takim poleceniem powinien znaleźć się znak nawiasu, którego chcemy użyć.
\[ A[l] \le A\biggl[\frac{l+r}{2}\biggr] = O\Bigl(\sum A[i]\Bigr) \]
|
\[ A[l] \le A\biggl[\frac{l+r}{2}\biggr] = O\Bigl(\sum A[i]\Bigr) \] |
Oczywiście mamy naprawdę sporo symboli matematycznych. Prawie wszystko, co powymyślali matematycy.
\[ A \subseteq B \Leftrightarrow \forall x\ x\in A\Rightarrow x\in B \] |
\[ A \subseteq B \Leftrightarrow \forall x\ x\in A\Rightarrow x\in B \] |
Macierze
W trybie matematycznym środowiskiem pozwalającym tworzyć tablice i macierze jest array. Jest ono analogiczne do środowiska tabular z trybu tekstowego.
\[ {\left( \begin{array}{cc} 2 & 1\\ 1 & 3 \end{array} \right)}^2 = \left( \begin{array}{cc} 5 & 5\\ 5 & 10 \end{array} \right) \] |
\[ {\left( \begin{array}{cc} 2 & 1\\ 1 & 3 \end{array} \right)}^2 = \left( \begin{array}{cc} 5 & 5\\ 5 & 10 \end{array} \right) \] |
Tutaj do powiększenia nawiasów użyliśmy poleceń \left i \right. Dobierają one rozmiar automatycznie.
Środowiska array można użyć też do wzoru z przypadkami.
\[ |x| = \left\{ \begin{array}{ll} x & \textrm{ dla }x\ge 0,\\ -x & \textrm{ dla }x < 0. \end{array} \right. \] |
\[ |
Jako argument komendy \right daliśmy ., co oznacza, że w ogóle nie będzie prawego nawiasu. Ponadto zauważmy, że aby wstawić zwykły tekst wewnątrz formuły używa się polecenia \textrm{...}.
Równania wielolinijkowe
Normalnie nie można wprowadzać wzorów, które mają więcej niż jedną linię. W tym celu można użyć środowiska array, albo użyć trybu matematycznego eqnarray.
\begin{eqnarray}
{(\sin x)}' & = & \cos x\\
{(\cos x)}' & = & -\sin x\\
{(x^n)}' & = & n x^{n-1}\nonumber
\end{eqnarray} |
\begin{eqnarray} {(\sin x)}' & = & \cos x\\ {(\cos x)}' & = & -\sin x\\ {(x^n)}' & = & n x^{n-1}\nonumber \end{eqnarray} |
Widzimy, że równania w kolejnych linijkach są numerowane. Jeśli nie chcemy mieć numerów, możemy użyć wersji z *, tzn. \begin{eqnarray*}...\end{eqnarray*}, albo stosować polecenie \nonumber.
Co dalej?
Możliwości latexa są znacznie większe niż to co zostało tutaj przedstawione, a to za sprawą bogatej biblioteki pakietów, jakie zostały napisane. Przedstawimy po krótce najważniejsze z nich.
Tworzenie prezentacji - klasa beamer
Latex świetnie nadaje się do tworzenie prezentacji w postaci slajdów dzięki klasie dokumentów beamer. Posiada on dużo różnych możliwości.
- Klasa jest napisana z myślą o prostym i szybkim tworzeniu slajdów.
- Bardzo łatwo tworzy się nakładki, tzn. takie slajdy, w których elementy pojawiają się jeden po drugim.
- Posiada bogatą bibliotekę gotowych, praktycznych i dobrze dopracowanych wyglądów prezentacji, które można w bardzo prosty sposób zmieniać.
- No i oczywiście można korzystać z wszystkich atutów latexa.
Załączanie grafiki - pakiet graphicx
Podstawową sprawą jest możliwość dodawania grafiki. Służy do tego pakiet graphicx. Grafikę wstawia się za pomocą polecenia
\includegraphics{plik}
Polecenie to posiada szereg opcji. Są też ograniczenia co do formatu graficznego. Jeśli dokumentem docelowym ma być plik PS, to jedynym dozwolonym formatem jest EPS. Jeśli dokumentem docelowym ma być PDF, to dozwolone formaty to PDF, PNG, JPEG i GIF.
Wbudowana grafika - pakiet pgf
Grafikę można też tworzyć bezpośrednio w latexu za pomocą gotowych pakietów. Wadą takiego podejścia jest jednak brak wizualnego tworzenia. Zaletą jest jednak to, że możemy z łatwość łączyć rysunki z latexem. Na przykład z łatwością możemy umieszczać na rysunku skomplikowane formuły matematyczne.
Spośród kilku pakietów przeznaczonych do tego celu jednym z najbardziej dopracowanych jest pakiet pgf (skrót od Portable Graphics Format). Ponadto jedną z jego podstawowych zalet jest, że dokumenty napisane z jego użyciem, można eksportować zarówno do plików PS jak i PDF.
Zarządzanie wersjami - Subversion
Wprowadzenie
Narzędzia zarządzające wersjami (zwane też systemami kontroli wersji) mają na celu wspomaganie pamiętania źródeł projektu wraz z jego historią i możliwymi wersjami.
Czego możemy się spodziewać od zarządzania wersjami?
Przyjrzyjmy się, czego możemy się spodziewać od zarządzania wersjami z punktu widzenia zarządzającego projektem programistycznym. Otóż w skład projektu wchodzą pliki źródłowe programu. Pliki te są modyfikowane na ogół przez wielu programistów. W najprostszym przypadku chcemy, aby te pliki znajdowały się w jednym miejscu. Takie miejsce nazwiemy repozytorium. Często jest ono umieszczane na zdalnym serwerze dostępnym dla wszystkich programistów. W takim repozytorium powinny być najświeższe wersje źródeł. W ten sposób programiści mieliby dostęp do ostatniej wersji i na niej mogli by pracować. Zmiany przez nich nanoszone powinny być umieszczane w repozytorium, aby pozostali programiści mieli do nich wgląd. Skoro mamy wgląd do ostatniej wersji, to czemu by nie mieć wglądu do wszystkich wersji, jakie się uprzednio pojawiły, najlepiej wraz z historią dokonanych zmian. W ten sposób można by przeglądać historię projektu. Pozwoliłoby to na odtworzenie poprzednich wersji, co jest przydatne w przypadkach, gdy ostatnio naniesione zmiany zostały wprowadzone przez pomyłkę lub spowodowały, że aktualna wersja programu przestała działać. Ponadto czasami mile widziana by była też możliwość rozwijania kilku wersji na raz, bądź też praca równoległa nad różnymi częściami projektu. Oczywiście zmiany w różnych częściach projektu powinny dać się zintegrować w celu ostatecznego utworzenia produktu. Powinna być możliwa równoległa praca nad źródłami, wykonywana przez wielu programistów na raz, nawet wtedy, gdy dwie osoby pracują nad jednym plikiem. Do tego jeden programista, który modyfikuje jakieś pliki, powinien mieć w tych plikach możliwość obejrzenia zmian dokonanych w międzyczasie przez innych. Nawet powinien mieć możliwość uaktualniania plików, nad którymi pracuje, o zmiany innych programistów, nie tracąc przy tym swoich zmian. Większość powyższych wymagań jest realizowana w systemach kontroli wersji. Wygoda i szybkość realizacji tych operacji jest wyznacznikiem jakości takich systemów.
Do czego może się to przydawać?
Przyjrzyjmy się paru przykładom. Przy pisaniu programu zdarza się nam, że wprowadzamy bezsensowną modyfikację, która bardziej coś psuje niż ulepsza. Wtedy chcemy powrócić do stanu z przed dokonanych zmian. Normalnie należałoby zrobić kopię, zanim zaczęliśmy wprowadzać naszą zmianę. A co, jak byśmy chcieli się cofnąć do jeszcze innej wersji? Pewnie wypadało by robić kopię co jakiś czas. Takie rzeczy znacznie ułatwiają systemy kontroli wersji. Inna sytuacja. Mamy gdzieś błąd w programie i trzeba go poszukać. Błąd jest na tyle złośliwy, że narzędzia do śledzenia kodu są niewystarczające. Wtedy dopisujemy wypisywanie różnych informacji albo nawet całe nowe programy testujące, które mają na celu znalezienie najprostszych przypadków, kiedy ten błąd występuje. Po żmudnej pracy dodaliśmy dużo kodu debugującego do naszego programu i w końcu znaleźliśmy błąd, który usuwamy. Co zrobić teraz z całym tym kodem debugującym? Można go wykomentować, ale wtedy źródła robią się bardzo brzydkie. Jeśli ktoś inny też będzie zaglądał do tego kodu, to pewnie o wiele wygodniej będzie mu się pracować, gdy nie będzie całego tego śmietnika. Zatem najlepiej jest usunąć cały kod debugujący. Alternatywnie można by przepisać źródła inaczej, aby programy testujące nie mieszały się z kodem, ale to zazwyczaj wymaga dużo pracy. Załóżmy, że usunęliśmy kod debugujący, ale po krótkich dalszych modyfikacjach okazuje się, że znowu jest gdzieś bug. Co wtedy zrobić? Napisać kod debugujący od nowa? Za pomocą narzędzia zarządzania wersjami sprawa wygląda dosyć prosto. Otóż w momencie stwierdzenia, że mamy błąd w programie, zapamiętujemy aktualną wersję. Następnie wprowadzamy kod debugujący. Po znalezieniu błędu w repozytorium zapamiętujemy wersję z kodem debugującym. Przywracamy wersję bez kodu debugującego i poprawiamy tam błąd. Po dalszych modyfikacjach, jak pojawi się nowy błąd, to zazwyczaj (zależnie od możliwości systemu i zmian dokonanych w kodzie) możemy wprowadzić kod debugujący odtwarzając go z repozytorium, przy czym modyfikacje, które zrobiliśmy ostatnio zostają zachowane. Takie możliwości daje również kontrola wersji! Rozważmy teraz kolejną sytuację. Załóżmy, że piszemy nową funkcję naszego programu. Przy czym jest to złożone zajęcie. Modyfikacje w kodzie okazują się być dosyć duże. Na tyle duże, że postanawiamy zawiesić tą modyfikację i powrócić do niej za jakiś czas. W międzyczasie jednak chcemy dalej zająć się prostszymi elementami programu i go trochę pozmieniać. Później, jak wrócimy do naszej większej modyfikacji, chcemy jednak, aby te prostsze elementy były również uwzględnione. Normalnie trzeba by się zastanawiać, jak to wszystko zrobić, a z kontrolą wersji takie procesy są zupełnie naturalne. Oczywiście jedną z funkcji, którą umożliwia zarządzanie wersjami jest możliwość pracy w wiele osób. Jest to dużo wygodniejsze niż przesyłanie między sobą zaktualizowanych plików, które często prowadzi do błędów, gdyż łatwo się pomylić i wysłać nie ten plik, albo nie tą wersję pliku.
Narzędzia
Informacje o różnych narzędziach zarządzających wersjami można znaleźć na stronie Better SCM Initiative. Najbardziej rozpowszechniony jest CVS, jednak ze względu na jego ograniczenia, dzisiaj lepiej używać nowych, młodszych narzędzi, które nie mają już wad swojego poprzednika. My będziemy używać bardzo popularnego Subversion znanego też pod nazwą SVN. Subversion składa się z kilku poleceń, które umożliwiają tworzenie, modyfikowanie repozytorium oraz komunikację z repozytorium w celu uaktualniania, pobieranie różnych wersji, czy też historii zmian. Zatem praca polega na wpisywaniu poleceń. Istnieją też wygodne interfejsy graficzne, jak na przykład RapidSVN, jednak nie będziemy ich omawiać.Początek projektu
Tworzenie repozytorium
Wpierw trzeba zdecydować, gdzie repozytorium ma się znajdować - czy na serwerze zdalnym, czy też w lokalnym systemie plików. SVN udostępnia różne protokoły do komunikacji z serwerem wraz autoryzacją. My jednak będziemy stosować tutaj repozytorium lokalne bez autoryzacji. Utwórzmy wpierw katalog (z poziomu root'a):host:~# mkdir -p /var/local/reposhost:~# svnadmin create /var/local/reposhost:~# chgrp -R staff /var/local/repos host:~# chmod -R g+rw /var/local/repos
Co zawiera repozytorium?
Wiedza o tym, co przechowuje repozytorium i w jaki sposób, nie jest potrzebna do korzystania z narzędzia, jednakże może ułatwić zrozumienie działania niektórych poleceń SVNa. Dzięki temu będzie można lepiej zrozumieć, dlaczego są dostępne właśnie takie polecenia i jak za pomocą nich dokonać operacji, które sobie zaplanowaliśmy. Można w miarę w intuicyjny sposób przedstawić, co SVN pamięta w swoim repozytorium. W uproszczony sposób przedstawia to poniższy rysunek. SVN pamięta wszystkie kolejne wersje poczynając od numeru 0. Wersja 0 jest wersją powstałą tuż po utworzeniu repozytorium i zawiera ona tylko katalog główny, który z początku jest pusty. Dla każdej wersji pamiętana jest cała struktura plików i katalogów, jakie zawiera dana wersja. Ponadto dla każdego pliku lub katalogu jest pamiętana informacja, w jaki sposób dany zbiór się tutaj znalazł. Otóż możliwe są trzy sposoby.
SVN pamięta wszystkie kolejne wersje poczynając od numeru 0. Wersja 0 jest wersją powstałą tuż po utworzeniu repozytorium i zawiera ona tylko katalog główny, który z początku jest pusty. Dla każdej wersji pamiętana jest cała struktura plików i katalogów, jakie zawiera dana wersja. Ponadto dla każdego pliku lub katalogu jest pamiętana informacja, w jaki sposób dany zbiór się tutaj znalazł. Otóż możliwe są trzy sposoby.
- Zbiór został właśnie dodany w tej wersji. W przypadku pliku trzeba więc zapamiętać całą zawartość, a w przypadku katalogu wszystkie pliki i katalogi w nim się znajdujące.
- Plik został zmodyfikowany. W takim wypadku wystarczy zapamiętać tylko zmiany, które zostały dokonane (można to robić całkiem efektywnie) oraz poprzednią wersję pliku, który był wyjściem dla dokonania tych zmian. Na ogół jest to wersja poprzednia, jak mamy to na rysunku, ale w ogólności podstawą, dla której dokonano modyfikacji, może być plik z dowolnej wcześniejszej wersji.M
- Zbiór jest kopią jakiegoś innego zbioru. Wtedy wystarczy pamiętać tylko nazwę zbioru, którego jest on kopią. Kopia może dotyczyć całego katalogu wraz z jego zawartością. Później zobaczymy, że operacja kopiowania ma wiele ciekawych zastosowań.
Przykładowy projekt
Przepuśćmy, że mamy już zaczęty projekt. Naszym przykładowym projektem będzie projekt o nazwie słownik, którego celem jest napisanie bardzo uproszczonego słownika ortograficznego. Utworzyliśmy już kilka plików i porozmieszczaliśmy je w katalogach w następujący sposób:
slownik/
bin/
data/
slowa.txt
src/
Makefile
sprawdz.c- W katalogu
binbędą umieszczane pliki wykonywalne. Na razie mamy jeden program o nazwiesprawdz. Makefilepowinien być napisany tak, aby plik wykonywalny o nazwiesprawdzbył umieszczany właśnie w katalogubin. - W katalogu
databędą pliki z danymi. Na razie mamy tam plikslowa.txt, który ma zawierać wszystkie poprawne wyrazy języka polskiego. - W katalogu src znajdują się źródła programów
(sprawdz.c)orazMakefile. Działanie programu sprawdz.c ma być następujące. Wczytuje on ze standardowego wejścia wszystkie słowa i wypisuje na standardowe wyjście wszystkie te słowa, które nie występują w słowniku, czyli w plikuslowa.txt.PlikMakefilema być taki, aby wynikowy program sprawdz był umieszczany w katalogubin.
slowa.txt Zawiera tylko parę przykładowych słów dla testów.
abecadło
słowo
coś
raz
dwa
trzyMakefile.
CC=gcc CFLAGS=-Wall DEST=../bin/sprawdz all: $(DEST) $(DEST): sprawdz.c $(CC) $(CFLAGS) -o $@ $^ $(LDFLAGS) clean: rm -f $(DEST)
sprawdz.c. Jest to prosta implementacja. Duże i małe litery nie są rozróżniane. Kontrola błędów jest tylko na podstawowym poziomie.
#include <stdio.h> #include <stdlib.h> #include <string.h> const char * SLOWNIK = "slowa.txt"; int slow; char **slownik; void wczytaj_slownik(FILE *f) { char buf[128]; slow = 0; while (fscanf(f, "%127s", buf) > 0) { if (slow == 0) slownik = (char **) malloc(sizeof(char *)); else slownik = (char **) realloc(slownik, (slow + 1) * sizeof(char *)); slownik[slow] = (char *) malloc((strlen(buf) + 1) * sizeof(char)); strcpy(slownik[slow], buf); slow++; } } int inicjuj_slownik() { FILE *f = fopen(SLOWNIK, "r"); if (!f) { fprintf(stderr, "Nie można otworzyć pliku '%s' do odczytu\n", SLOWNIK); return 0; } wczytaj_slownik(f); fclose(f); return 1; } int w_slowniku(char *s) { int i; for (i = 0; i < slow; i++) if (!strcmp(s, slownik[i])) return 1; return 0; } void obrob_wejscie() { char buf[128]; while (scanf("%127s", buf) > 0) if (!w_slowniku(buf)) printf("%s\n", buf); } int main() { if (!inicjuj_slownik()) return 1; obrob_wejscie(); return 0; }
Wybór struktury katalogów
Dany projekt możemy wrzucić do repozytorium w takiej postaci, w jakiej go trzymamy. Jednakże ze względu na specyfikę Subversion, zostało powszechnie przyjęte stosowanie dodatkowych katalogów. Wiąże się to z tym, że w trakcie trwania projektu będziemy chcieli od czasu do czasu robić kopię wszystkich plików. Zdarza się to na przykład wtedy, gdy mamy już gotową, działającą wersję i chcemy ją sobie zapamiętać. Później możemy powprowadzać dalsze zmiany, ale dzięki kopii zawsze będziemy mogli odtworzyć tą daną wersję. Zazwyczaj przyjmuje się następującą strukturę katalogów:
trunk/ tags/ branches/
- W katalogu
trunkbędzie główna ścieżka rozwoju projektu. W tym katalogu będą trzymane wszystkie zbiory i tutaj będzie umieszczana większość zmian. - W katalogu
tagsbędą umieszczane kopie projektu. Będziemy tam kopiować określone wersje projektu, na ogół takie, które osiągnęły już pewien planowany stopień rozwoju. Przyjmuje się, że dla takich kopii nie wprowadza się już żadnych zmian (mimo, że system nie zabrania takowych). - W katalogu
branchespodobnie jak wtagsbędziemy umieszczać kopie projektu, ale w tym przypadku z zamiarem wprowadzenia zmian w tej kopii. Są to tak zwane gałęzie i o ich przeznaczeniu powiemy więcej później.
slownik/
trunk/
bin/
data/
src/
tags/
branches/slownik/ bin/ data/ src/
slownik w katalogu głównym repozytorium. Moglibyśmy pliki projektu umieścić od razu w katalogu głównym repozytorium:
trunk/ ... tags/ branches/
Umieszczenie projektu w repozytorium.
Ustaliliśmy, jak chcemy trzymać nasz projekt, więc trzeba przeorganizować to, co aktualnie mamy do postaci, w jakiej chcemy mieć to w repozytorium. W katalogu domowym użytkownika ala mamy:
slownik/ bin/ data/ src/
ala@host:~$ mkdir -p do_repozytorium/slownik ala@host:~$ cp -a slownik/ do_repozytorium/slownik/trunk ala@host:~$ mkdir -p do_repozytorium/slownik/tags ala@host:~$ mkdir -p do_repozytorium/slownik/branches ala@host:~$
staff:
ala@host:~$ groups users staff ala@host:~$
ala@host:~$ svn import do_repozytorium/ file:///var/local/repos/ -m "Import pierwszej wersji" Adding do_repozytorium/slownik Adding do_repozytorium/slownik/trunk Adding do_repozytorium/slownik/trunk/src Adding do_repozytorium/slownik/trunk/src/sprawdz.c Adding do_repozytorium/slownik/trunk/src/Makefile Adding do_repozytorium/slownik/trunk/bin Adding do_repozytorium/slownik/trunk/data Adding do_repozytorium/slownik/trunk/data/slowa.txt Adding do_repozytorium/slownik/branches Adding do_repozytorium/slownik/tags Committed revision 1. ala@host:~$
file://. Dodatkowo użyliśmy opcji -m, której argumentem jest komentarz, który będzie zapamiętany jako opis wprowadzonej zmiany w repozytorium. W rezultacie otrzymaliśmy wersję o numerze 1. Wersja ta różni się tym od wersji 0, że dodaliśmy katalog slownik. Upewnijmy się jeszcze, że właściwe katalogi znajdują się w repozytorium za pomocą komendy list:
ala@host:~$ svn list -R file:///var/local/repos slownik/ slownik/branches/ slownik/tags/ slownik/trunk/ slownik/trunk/bin/ slownik/trunk/data/ slownik/trunk/data/slowa.txt slownik/trunk/src/ slownik/trunk/src/Makefile slownik/trunk/src/sprawdz.c ala@host:~$
ala@host:~$ rm -rf do_repozytorium/
ala@host:~$Podstawowe operacje
Kopia robocza
Aby móc pracować na wersji znajdującej się w repozytorium, trzeba pobrać kopię roboczą. Posiadanie kopii roboczej pozwala na łatwe wprowadzanie zmian do repozytorium, porównywanie z wersją w repozytorium, czy też aktualizowanie zbiorów o zmiany znajdujące się już w repozytorium. Tworzymy sobie katalogsvn, w którym będziemy przechowywać kopie robocze.
ala@host:~$ mkdir svn ala@host:~$ cd svn/ ala@host:~$
checkout lub w skrócie co. Pobierzemy sobie z repozytorium główną wersję, czyli tą znajdującą się w katalogu trunk:
ala@host:~/svn$ svn co file:///var/local/repos/slownik/trunk slownik A slownik/src A slownik/src/sprawdz.c A slownik/src/Makefile A slownik/bin A slownik/data A slownik/data/slowa.txt Checked out revision 1. ala@host:~/svn$
slownik a w nim te pliki, które są w pierwszej wersji naszego projektu. Można zobaczyć, że SVN utworzył również ukryty katalog o nazwie .svn:
ala@host:~/svn$ cd slownik/ ala@host:~/svn/slownik$ ls -a . .. bin data src .svn ala@host:~/svn/slownik$
Wprowadzanie zmian
Modyfikacja plików
Popracujmy teraz na kopii roboczej znajdujące się w katalogusvn/slownik. Wprowadźmy jakieś proste modyfikacje.
W pliku dane/slowa.txt usuńmy słowo abecadło i dodajmy przed słowem raz słowo zero. Plik slowa.txt po modyfikacjach.
słowo
coś
zero
raz
dwa
trzysrc/Makefile dodajmy opcję -g do zmiennej CFLAGS.
CC=gcc CFLAGS=-Wall -g DEST=../bin/sprawdz all: $(DEST) $(DEST): sprawdz.c $(CC) $(CFLAGS) -o $@ $^ $(LDFLAGS) clean: rm -f $(DEST)
Sprawdzanie dokonanych zmian
Do podsumowania stanu naszej kopii roboczej służy komenda
status:
ala@host:~/svn/slownik$ svn status
M src/Makefile
M data/slowa.txt
ala@host:~/svn/slownik$M zostały zmodyfikowane.
Do sprawdzenia, jakich zmian dokonaliśmy, służy komenda diff:
ala@host:~/svn/slownik$ svn diff Index: src/Makefile =================================================================== --- src/Makefile (revision 1) +++ src/Makefile (working copy) @@ -1,5 +1,5 @@ CC=gcc -CFLAGS=-Wall +CFLAGS=-Wall -g DEST=../bin/sprawdz all: $(DEST) Index: data/slowa.txt =================================================================== --- data/slowa.txt (revision 1) +++ data/slowa.txt (working copy) @@ -1,6 +1,6 @@ -abecadło słowo coś +zero raz dwa trzy ala@host:~/svn/slownik$
Wycofywanie zmian
Jeśli uznamy, że wprowadzone zmiany nie są w jakiś sposób właściwe i będziemy chcieli się cofnąć do wersji sprzed zmian, z pomocą przychodzi na komenda revert. Na przykład stwierdziliśmy, że zmiany wslowa.txt są bez sensu. Przywracamy wersję z przed zmian następująco:
ala@host:~/svn/slownik$ svn revert data/slowa.txt Reverted 'data/slowa.txt' ala@host:~/svn/slownik$
diff lub za pomocą komendy status:
ala@host:~/svn/slownik$ svn status M src/Makefile ala@host:~/svn/slownik$
revert wymaga jako argumentów zbiorów, dla których chcemy przywrócić wersję z przed zmian.
Wprowadzanie zmian do repozytorium
Wprowadźmy dalsze zmiany. Przejdźmy do katalogu
src. Tym razem zmodyfikujmy plik sprawdz.c. Zmiana funkcjonalnie polega na tym, że będziemy rzadziej przydzielać pamięć tablicy slownik, nie tak jak dotychczas powiększać o jeden z każdym nowym słowem, ale jak tylko rozmiar będzie przekraczał potęgę dwójki, to będziemy zwiększać rozmiar tablicy dwa razy. Oto zmiany, jakich dokonamy. Po pierwsze dodamy funkcję potega2 zwracająca, czy liczba jest potęgą dwójki:
int potega2(int n) { return (n & (n - 1)) == 0; }
void wczytaj_slownik(FILE *f) { char buf[128]; slow = 0; while (fscanf(f, "%127s", buf) > 0) { if (slow == 0) slownik = (char **) malloc(sizeof(char *)); else if (potega2(slow)) slownik = (char **) realloc(slownik, (slow * 2) * sizeof(char *)); slownik[slow] = (char *) malloc((strlen(buf) + 1) * sizeof(char)); strcpy(slownik[slow], buf); slow++; } }
ala@host:~/svn/slownik/src$ svn diff sprawdz.c Index: sprawdz.c =================================================================== --- sprawdz.c (revision 1) +++ sprawdz.c (working copy) @@ -7,6 +7,11 @@ int slow; char **slownik; +int potega2(int n) +{ + return (n & (n - 1)) == 0; +} + void wczytaj_slownik(FILE *f) { char buf[128]; @@ -14,8 +19,8 @@ while (fscanf(f, "%127s", buf) > 0) { if (slow == 0) slownik = (char **) malloc(sizeof(char *)); - else - slownik = (char **) realloc(slownik, (slow + 1) * sizeof(char *)); + else if (potega2(slow)) + slownik = (char **) realloc(slownik, (slow * 2) * sizeof(char *)); slownik[slow] = (char *) malloc((strlen(buf) + 1) * sizeof(char)); strcpy(slownik[slow], buf); slow++; ala@host:~/svn/slownik/src$
ala@host:~/svn/slownik/src$ make
gcc -Wall -g -o ../bin/sprawdz sprawdz.c
ala@host:~/svn/slownik/src$ala@host:~/svn/slownik/src$ cd .. ala@host:~/svn/slownik$ svn status M src/sprawdz.c M src/Makefile ? bin/sprawdz ala@host:~/svn/slownik$
Makefile i sprawdz.c, a plik wykonywalny sprawdz w katalogu bin ma status nieznany (literka ?). Nie chcemy, żeby plik wykonywalny był w repozytorium, więc ignorujemy ten status.
Teraz wprowadźmy te zmiany do repozytorium. Służy do tego komenda commit lub w skrócie ci. Jej argumentem są pliki, dla których zmiany chcemy dodać do repozytorium. Ponadto należy dodać komentarz krótko charakteryzujący zmiany, które wprowadziliśmy. Można to zrobić używając opcji -m. W przypadku braku tej opcji zostanie uruchomiony edytor z prośbą o podanie komentarza.
Ponieważ charakterystyka zmian dla pliku Makefile i sprawdz.c jest różna, a SVN nie umożliwia różnych komentarzy dla osobnych plików, więc zrobimy dwa commity. Wpierw Makefile:
ala@host:~/svn/slownik$ cd src/ ala@host:~/svn/slownik/src$ svn ci Makefile -m "Dodanie opcji -g" Sending Makefile Transmitting file data . Committed revision 2. ala@host:~/svn/slownik/src$
src, czyli jeden plik sprawdz.c:
ala@host:~/svn/slownik/src$ svn ci -m "Szybsza alokacja tablic" Sending src/sprawdz.c Transmitting file data . Committed revision 3. ala@host:~/svn/slownik/src$
ala@host:~/svn/slownik/src$ cd ..
ala@host:~/svn/slownik$ svn status
? bin/sprawdz
ala@host:~/svn/slownik$Dodawanie zbiorów
Umiemy wprowadzać modyfikacje plików, a jak dodawać nowe pliki lub katalogi? Służy do tego komendaadd. Na przykład załóżmy, że postanowiliśmy pisać również dokumentację i umieszczać ją w katalogu doc. Na razie utworzymy tam jeden plik dokumentacja.txt o zawartości:
Dokumentacja projektu slownik ============================= Tutaj będzie dokumentacja
ala@host:~/svn/slownik$ svn status ? doc ? bin/sprawdz ala@host:~/svn/slownik$
ala@host:~/svn/slownik$ svn add doc
A doc
A doc/dokumentacja.txt
ala@host:~/svn/slownik$dokumentacja.txt został zaplanowany do dodania. Nie zostały umieszczone one w repozytorium, aby tak się stało trzeba użyć operacji komendy ci:
ala@host:~/svn/slownik$ svn ci -m "Dodanie dokumentacji" Adding doc Adding doc/dokumentacja.txt Transmitting file data . Committed revision 4. ala@host:~/svn/slownik$
Usuwanie zbiorów
Możemy chcieć też usuwać zbiory z projektu. Służy do tego komenda delete lub w skrócie del:
ala@host:~/svn/slownik$ svn del data/slowa.txt D data/slowa.txt ala@host:~/svn/slownik$
data/slowa.txt. Plik został usunięty z naszej kopii roboczej. Teraz, żeby usunięcie zostało dokonane także w repozytorium, trzeba by użyć commita. Powiedzmy jednak, że to była pomyłka i nie chcemy usuwać tego pliku. Możemy wycofać tą zmianę (dodawanie i usuwanie zbiorów też jest modyfikacją, tylko że struktury), używając komendy revert. Komenda ta oprócz cofania modyfikacji w plikach może być używana do cofania zaplanowanych dodawań, czy usunięć zbiorów.
ala@host:~/svn/slownik$ svn revert data/slowa.txt Reverted 'data/slowa.txt' ala@host:~/svn/slownik$
Praca równoległa
Zademonstrujemy teraz jak sobie radzi SVN, gdy więcej niż jeden użytkownik pracuje nad danym projektem. Przypuśćmy, że jest drugi użytkownik o loginie
bartek. Żeby pracować nad projektem musi pobrać on swoją wersję roboczą:
bartek@host:~$ mkdir svn bartek@host:~$ cd svn/ bartek@host:~/svn$ svn co file:///var/local/repos/slownik/trunk slownik A slownik/doc A slownik/doc/dokumentacja.txt A slownik/src A slownik/src/sprawdz.c A slownik/src/Makefile A slownik/bin A slownik/data A slownik/data/slowa.txt Checked out revision 4. bartek@host:~/svn$
sprawdz.c przyspieszyć wyszukiwanie słów w słowniku. Wpierw trzeba dopisać sortowanie słów w słowniku i tym się zajmie Bartek. Gdy tablica slownik jest posortowana, można do wyszukiwania słów zastosować wyszukiwanie binarne i tym zajmie się Ala.
No dobrze, więc postawmy się wpierw w sytuacji Bartka, który pisze sortowanie. Przypuśćmy, że zmodyfikował on plik sprawdz.c w swojej kopii roboczej dopisując sortowanie z użyciem dostępnej funkcji qsort.
#include <stdio.h> #include <stdlib.h> #include <string.h> const char * SLOWNIK = "slowa.txt"; int slow; char **slownik; int potega2(int n) { return (n & (n - 1)) == 0; } void wczytaj_slownik(FILE *f) { char buf[128]; slow = 0; while (fscanf(f, "%127s", buf) > 0) { if (slow == 0) slownik = (char **) malloc(sizeof(char *)); else if (potega2(slow)) slownik = (char **) realloc(slownik, (slow * 2) * sizeof(char *)); slownik[slow] = (char *) malloc((strlen(buf) + 1) * sizeof(char)); strcpy(slownik[slow], buf); slow++; } } int inicjuj_slownik() { FILE *f = fopen(SLOWNIK, "r"); if (!f) { fprintf(stderr, "Nie można otworzyć pliku '%s' do odczytu\n", SLOWNIK); return 0; } wczytaj_slownik(f); fclose(f); return 1; } int w_slowniku(char *s) { int i; for (i = 0; i < slow; i++) if (!strcmp(s, slownik[i])) return 1; return 0; } void obrob_wejscie() { char buf[128]; while (scanf("%127s", buf) > 0) if (!w_slowniku(buf)) printf("%s\n", buf); } int main() { if (!inicjuj_slownik()) return 1; obrob_wejscie(); return 0; }
bartek@host:~/svn/slownik$ svn diff Index: src/sprawdz.c =================================================================== --- src/sprawdz.c (revision 4) +++ src/sprawdz.c (working copy) @@ -27,6 +27,12 @@ } } +static int +cmpstringp(const void *p1, const void *p2) +{ + return strcmp(* (char * const *) p1, * (char * const *) p2); +} + int inicjuj_slownik() { FILE *f = fopen(SLOWNIK, "r"); @@ -36,6 +42,7 @@ } wczytaj_slownik(f); fclose(f); + qsort(slownik, slow, sizeof(char *), cmpstringp); return 1; } bartek@host:~/svn/slownik$
bartek@host:~/svn/slownik$ svn up At revision 4. bartek@host:~/svn/slownik$
bartek@host:~/svn/slownik$ svn ci -m "Sortowanie słownika" Sending src/sprawdz.c Transmitting file data . Committed revision 5. bartek@host:~/svn/slownik$
Aktualizacja
Wróćmy do Ali. Ala ma napisać przeszukiwanie binarne. Sprawa wydaje się prosta, gdyż w standardowej bibliotece mamy dostępną funkcję
bsearch. Ala zmodyfikowała funkcję w_slowniku w programie sprawdz.c tak, że wygląda ona następująco:
int w_slowniku(char *s) { return bsearch(&s, slownik, slow, sizeof(char *), ???) != NULL; }
ala@host:~/svn/slownik/src$ svn diff Index: sprawdz.c =================================================================== --- sprawdz.c (revision 3) +++ sprawdz.c (working copy) @@ -41,11 +41,7 @@ int w_slowniku(char *s) { - int i; - for (i = 0; i < slow; i++) - if (!strcmp(s, slownik[i])) - return 1; - return 0; + return bsearch(&s, slownik, slow, sizeof(char *), ???) != NULL; } void obrob_wejscie() ala@host:~/svn/slownik/src$
??? powinna pojawić się funkcja porównująca elementy tablicy zgodna z typem, który jest spodziewany w nagłówku bsearch. Ala się zastanawia jak to zrobić, ale na razie zostawia ten problem. Sprawdzi wpierw, czy Bartek już coś wprowadził do repozytorium. Jak już wspomnieliśmy komenda update służy do aktualizacji kopii roboczej. Ala wykonuje to polecenie:
ala@host:~/svn/slownik/src$ svn up G sprawdz.c Updated to revision 5. ala@host:~/svn/slownik/src$
sprawdz.c i ma ona numer 5. Plik sprawdz.c został zaktualizowany , ale nasze zmiany nie zostały zapomniane. Świadczy o tym literka G mówiąca, że zmiany z repozytorium zostały naniesiony do pliku.
#include <stdio.h> #include <stdlib.h> #include <string.h> const char * SLOWNIK = "slowa.txt"; int slow; char **slownik; int potega2(int n) { return (n & (n - 1)) == 0; } void wczytaj_slownik(FILE *f) { char buf[128]; slow = 0; while (fscanf(f, "%127s", buf) > 0) { if (slow == 0) slownik = (char **) malloc(sizeof(char *)); else if (potega2(slow)) slownik = (char **) realloc(slownik, (slow * 2) * sizeof(char *)); slownik[slow] = (char *) malloc((strlen(buf) + 1) * sizeof(char)); strcpy(slownik[slow], buf); slow++; } } static int cmpstringp(const void *p1, const void *p2) { return strcmp(* (char * const *) p1, * (char * const *) p2); } int inicjuj_slownik() { FILE *f = fopen(SLOWNIK, "r"); if (!f) { fprintf(stderr, "Nie można otworzyć pliku '%s' do odczytu\n", SLOWNIK); return 0; } wczytaj_slownik(f); fclose(f); qsort(slownik, slow, sizeof(char *), cmpstringp); return 1; } int w_slowniku(char *s) { return bsearch(&s, slownik, slow, sizeof(char *), ???) != NULL; } void obrob_wejscie() { char buf[128]; while (scanf("%127s", buf) > 0) if (!w_slowniku(buf)) printf("%s\n", buf); } int main() { if (!inicjuj_slownik()) return 1; obrob_wejscie(); return 0; }
int w_slowniku(char *s) { return bsearch(&s, slownik, slow, sizeof(char *), cmpstringp) != NULL; }
ala@host:~/svn/slownik/src$ cd .. ala@host:~/svn/slownik$ svn up At revision 5. ala@host:~/svn/slownik$ svn ci -m "Użycie przeszukiwania binarnego" Sending src/sprawdz.c Transmitting file data . Committed revision 6. ala@host:~/svn/slownik$
bartek@host:~/svn/slownik$ svn up U src/sprawdz.c Updated to revision 6. bartek@host:~/svn/slownik$
Przeglądanie zmian
Do przeglądania logów ze zmian służy komendalog. Na przykład, aby przejrzeć historię zmian pliku src/sprawdz.c podajemy go jako argument:
ala@host:~/svn/slownik$ svn log src/sprawdz.c ------------------------------------------------------------------------ r6 | ala | 2006-08-30 23:05:39 +0200 (Wed, 30 Aug 2006) | 1 line Użycie przeszukiwania binarnego ------------------------------------------------------------------------ r5 | bartek | 2006-08-30 22:33:32 +0200 (Wed, 30 Aug 2006) | 1 line Sortowanie słownika ------------------------------------------------------------------------ r3 | ala | 2006-08-30 14:35:50 +0200 (Wed, 30 Aug 2006) | 1 line Szybsza alokacja tablic ------------------------------------------------------------------------ r1 | ala | 2006-08-30 14:22:39 +0200 (Wed, 30 Aug 2006) | 1 line Import pierwszej wersji ------------------------------------------------------------------------ ala@host:~/svn/slownik$
sprawdz.c.
Konflikty
Przy pracy równoległej nie zawsze jest tak dobrze, że aktualizacja jest bezproblemowa. W sytuacji, gdy dwaj użytkownicy modyfikują tą samą część tego samego pliku, może dojść do tak zwanych konfliktów. Prześledźmy to na przykładzie.
Powstawanie konfliktów
Przypuśćmy, że Ala i Bartek jednocześnie dodają nowe słowa do słownika, czyli do pliku
data/slowa.txt.
Bartek modyfikuje plik następująco:
abecadło
słowo
coś
zero
raz
dwa
trzy
ananas
banan
japkozero, ananas, banan i japko, a następnie wprowadza do repozytorium:
bartek@host:~/svn/slownik$ svn ci -m "Nowe słowa" Sending data/slowa.txt Transmitting file data . Committed revision 7. bartek@host:~/svn/slownik$
abecadło słowo coś raz dwa trzy cztery banan jabłko kokos
cztery, banan, jabłko i kokos. Aktualizuje swoją kopie roboczą:
ala@host:~/svn/slownik$ svn up C data/slowa.txt Updated to revision 7. ala@host:~/svn/slownik$
slowa.txt został zaktualizowany do wersji 7, ale z konfliktami, o czym świadczy literka C. Zobaczmy co się stało.
ala@host:~/svn/slownik$ cd data/ ala@host:~/svn/slownik/data$ ls slowa.txt slowa.txt.mine slowa.txt.r6 slowa.txt.r7 ala@host:~/svn/slownik/data$
slowa.txt. Znaczenie ich jest następujące:
slowa.txt.minezawiera plikslowa.txtz naszej kopii roboczej sprzed dokonania aktualizacji,slowa.txt.r6zawiera plikslowa.txtw wersji 6 z repozytorium, czyli w wersji, na której pracowaliśmy przed aktualizacją,slowa.txt.r7zawiera plikslowa.txtw wersji 7 z repozytorium, czyli wersji, która jest ostatnią w repozytorium.
slowa.txt wygląda tak:
abecadło słowo coś zero raz dwa trzy <<<<<<< .mine cztery banan jabłko kokos ======= ananas banan japko >>>>>>> .r7
Rozwiązywanie konfliktów
Stajemy przed trudnym zadaniem, które polega na zdecydowaniu, co powinno powstać w wyniku zmian Ali i Bartka. To zadanie może być czasami dosyć oczywiste (jak to jest w tym przypadku), ale może też być nieoczywiste i wymagać bezpośredniej komunikacji między Alą, a Bartkiem. W tym przypadku z punktu widzenia Ali, Bartek chciał dodać trzy słowa na końcu pliku. Jedno, którego my nie dodaliśmy -
ananas, jedno, które my też dodaliśmy - banan oraz jedno, które my też dodaliśmy, a Bartek wprowadził z błędem. Jasne jest, że powinny znaleźć się wszystkie nowe słowa, ale te napisane bez błędów, zatem plik slowa.txt powinien wyglądać tak:
abecadło słowo coś zero raz dwa trzy cztery ananas banan jabłko kokos
resolved:
ala@host:~/svn/slownik/data$ svn resolved slowa.txt Resolved conflicted state of 'slowa.txt' ala@host:~/svn/slownik/data$ ls slowa.txt ala@host:~/svn/slownik/data$
ala@host:~/svn/slownik/data$ svn diff Index: slowa.txt =================================================================== --- slowa.txt (revision 7) +++ slowa.txt (working copy) @@ -5,6 +5,8 @@ raz dwa trzy +cztery ananas banan -japko +jabłko +kokos ala@host:~/svn/slownik/data$
ala@host:~/svn/slownik/data$ svn ci -m "Nowe słowa" Sending data/slowa.txt Transmitting file data . Committed revision 8. ala@host:~/svn/slownik/data$
Etykiety i gałęzie
Oznaczanie wybranych wersji
W pewnym stadium projektu uzyskujemy wersję, która spełnia stawiane przez nas wymagania. Taką wersję warto sobie zapamiętać. Najprościej jest zapamiętać numer wersji w repozytorium danej wersji. Jednak ten numer trzeba by wtedy gdzieś opisać. Dlatego najwygodniej jest zrobić kopię tej wersji pod nazwą mówiącą, co to jest za wersja. Kopiowanie umożliwia komendacopy.
Przykładowo spójrzmy na nasz projekt. Uzyskaliśmy szybką wersję programu sprawdz.c i chcemy ją sobie oznaczyć jako wersja o symbolicznym numerze 1.0. Później jeszcze dokonaliśmy jakichś zmian w słowniku slowa.txt, ale to nas nie interesuje i chcemy, aby w tej wersji 1.0 znalazły się słowa nie zawierające ostatnich dodań. Żeby sprawdzić, o jaki numer wersji chodzi, możemy posłużyć się komendą log:
ala@host:~/svn/slownik$ svn log | head -13 ------------------------------------------------------------------------ r7 | bartek | 2006-08-31 14:19:26 +0200 (Thu, 31 Aug 2006) | 1 line Nowe słowa ------------------------------------------------------------------------ r6 | ala | 2006-08-30 23:05:39 +0200 (Wed, 30 Aug 2006) | 1 line Użycie przeszukiwania binarnego ------------------------------------------------------------------------ r5 | bartek | 2006-08-30 22:33:32 +0200 (Wed, 30 Aug 2006) | 1 line Sortowanie słownika ------------------------------------------------------------------------ ala@host:~/svn/slownik$
tags, którego zadaniem jest tak naprawdę przechowywanie kopii wybranych przez nas wersji.
ala@host:~/svn/slownik$ svn copy -r 6 file:///var/local/repos/slownik/trunk \ > file:///var/local/repos/slownik/tags/1.0 -m "Utworzenie etykiety '1.0'" Committed revision 9. ala@host:~/svn/slownik$
slownik/tags/1.0, który jest kopią katalogu slownik/trunk, ale z wersji o numerze 6. Gdybyśmy pominęli opcję -r 6 byłaby to kopia z ostatniej wersji, czyli z wersji o numerze 8. Widzimy teraz, czemu warto było na początku umieścić cały projekt w dodatkowym katalogu trunk - po to, aby wygodnie można było robić jego kopie.
Powstały katalog 1.0 w katalogu slownik/tags nazywamy etykietą. Za pomocą tej etykiety (czyli tak naprawdę katalogu) możemy się później odwoływać w celu uzyskania konkretnej wersji.
Komenda copy jest bardzo tania i nie musimy sie martwić, że jeśli wykonamy za dużo kopii, to zapchamy dostępną przestrzeń dyskową. SVN nie kopiuję całego drzewa katalogów plik po pliku, a jedynie zapamiętuje w sposób leniwy informację, że dany katalog jest kopią takiego katalogu z takiej wersji. Robi to w czasie i pamięci O(1).
Eksportowanie
Aby docenić wartość etykiet, spróbujmy wyeksportować paczkę z daną wersją z repozytorium. Chodzi oczywiście o wersję z etykietą 1.0. Do wyciągania z repozytorium plików bez tworzenia już żadnych katalogów administracyjnych (np. katalogów .svn tak jak ma się to przy komendzie
checkout) służy komenda export:
ala@host:~$ svn export file:///var/local/repos/slownik/tags/1.0 slownik-1.0 A slownik-1.0 A slownik-1.0/doc A slownik-1.0/doc/dokumentacja.txt A slownik-1.0/src A slownik-1.0/src/sprawdz.c A slownik-1.0/src/Makefile A slownik-1.0/bin A slownik-1.0/data A slownik-1.0/data/slowa.txt Exported revision 9. ala@host:~$
slownik-1.0 z żądaną przez nas wersją, która zawiera wyłącznie interesujące nas pliki. Jeśli byśmy nie mieli etykiety, to dokładnie ten sam efekt osiągnęlibyśmy poleceniem:
ala@host:~$ svn export -r 6 file:///var/local/repos/slownik/trunk slownik-1.0
Rozgałęzianie projektu
W trakcie tworzenia projektu możemy chcieć wprowadzać równolegle kilka różnych modyfikacji. Jedne modyfikacje mogą być bardziej skomplikowane i trwać dłużej, inne mogą być znacznie prostsze i można je wprowadzać bardzo szybko. Możliwe jest, że dodanie pewnej nowej funkcjonalności może trwać tygodniami, a kod programu, który będzie powstawał podczas takiej zmiany, nie będzie funkcjonalny, tzn. może się nawet nie kompilować. Tu pojawia się problem, gdyż jeśli więcej osób pracuje nad projektem, to pozostali autorzy powinni mieć dostępny kod stabilny. Mogą oni chcieć wprowadzać prostsze zmiany, skompilować sobie program i przetestować go. Jedne rozwiązanie jest takie, że osoby odpowiedzialne, za wprowadzenie większej zmiany, będą ją robiły u siebie lokalnie i nie będą nic wprowadzały do repozytorium dopóki, dopóty modyfikacja nie będzie w pełni gotowa. W ten sposób jednak, przy wprowadzaniu tej większej modyfikacji, pozbawiamy możliwości korzystania z kontroli wersji w Subversion. Właściwym podejściem w takiej sytuacji jest stworzenie kopii projektu w repozytorium i nanoszenie modyfikacji pracując na tej kopii. W ten sposób praca nad nową funkcjonalnością nie będzie kolidowała z główną ścieżką projektu, a dodatkowo można wprowadzać zmiany do repozytorium. Później przy zakończeniu tej modyfikacji, można nanieść zmiany, które zostały wprowadzone w tej kopii, do właściwych źródeł projektu. Taką kopię nazywamy gałęzią. Prześledźmy to na przykładzie naszego projektu. Chcemy wprowadzić modyfikację polegającym na tym, że program sprawdz sprawdzałby swoje argumenty i w przypadku, gdy zostałyby one podane czytałby wejście z plików podanych w argumentach zamiast ze standardowego wejścia. Zakładając, że ta modyfikacja będzie większa, chcemy wprowadzać ją w nowej gałęzi. Możliwe są dwa sposoby przejścia do pracy w gałęzi. Wpierw omówimy jak wygląda pierwszy sposób opisując tylko jak wyglądają odpowiednie polecenia. Następnie omówimy drugą metodę stosując ją bezpośrednio na naszym projekcie. Aby utworzyć gałąź można użyć polecenia:$ svn copy file:///var/local/repos/slownik/trunk \ > file:///var/local/repos/slownik/branches/uzycie_argumentow -m "Utworzenie gałęzi 'uzycie_argumentow'"
$ svn co file:///var/local/repos/slownik/branches/uzycie_argumentow slownik-uzycie_argumentowslownik-uzycie_argumentow powinniśmy teraz mieć już odpowiednią gałąź. Możemy pracować w tym katalogu. Naniesione zmiany będą wprowadzane w repozytorium w katalogu branches/uzycie_argumentow, a zatem główna ścieżka projektu trunk pozostanie nienaruszona.
Omówmy teraz drugą metodę w praktyce na uproszczonym przykładzie. Pracujemy cały czas na kopii roboczej głównej ścieżki projektu, tj. kopii roboczej katalogu trunk. Załóżmy, że zaczeliśmy modyfikować już program sprawdz.c pod kątem dodania obsługi argumentów. Przypuśćmy, że Ala zmieniła funkcję main następująco:
int main(int argc, char *argv[]) { if (!inicjuj_slownik()) return 1; if (argc == 0) /* po staremu */ obrob_wejscie(); else { /* tutaj obrobimy pliki znajdujące się w argumentach */ } return 0; }
ala@host:~/svn/slownik$ svn copy file:///var/local/repos/slownik/trunk \ > file:///var/local/repos/slownik/branches/uzycie_argumentow -m "Utworzenie gałęzi 'uzycie_argumentow'" Committed revision 10. ala@host:~/svn/slownik$
branches/uzycie_argumentow, ale aktualna kopia robocza jest wzięta z katalogu trunk. Według pierwszej metody trzeba by utworzyć nową kopię roboczą z odpowiedniego katalogu, ale wtedy stracilibyśmy swoje zmiany. Można by je oczywiście ewentualnie nanieść jeszcze raz. Jest na szczęście prostsza metoda. Otóż możemy przełączyć kopię roboczą na inny katalog w repozytorium za pomocą komendy switch:
ala@host:~/svn/slownik$ svn switch file:///var/local/repos/slownik/branches/uzycie_argumentow . At revision 10. ala@host:~/svn/slownik$
ala@host:~/svn/slownik$ svn diff Index: src/sprawdz.c =================================================================== --- src/sprawdz.c (revision 10) +++ src/sprawdz.c (working copy) @@ -59,10 +59,14 @@ printf("%s\n", buf); } -int main() +int main(int argc, char *argv[]) { if (!inicjuj_slownik()) return 1; - obrob_wejscie(); + if (argc == 0) /* po staremu */ + obrob_wejscie(); + else { + /* tutaj obrobimy pliki znajduące się w argumentach */ + } return 0; } ala@host:~/svn/slownik$
ala@host:~/svn/slownik$ svn ci -m "Przygotowanie obróbki argumentów" Sending src/sprawdz.c Transmitting file data . Committed revision 11. ala@host:~/svn/slownik$
bartek@host:~/svn/slownik$ svn update U data/slowa.txt Updated to revision 11. bartek@host:~/svn/slownik$
slowa.txt. Jest to jeszcze zaległa aktualizacja, w której Ala dodawała nowe słowa. Jak się można było spodziewać, plik src/sprawdz.c nie został zaktualizowany. Jest to logiczne, gdyż Ala zmieniała tak naprawdę plik w repozytorium slownik/branches/uzycie_argumentow/src/sprawdz.c, a nie slownik/trunk/src/sprawdz.c.
Bartek wprowadzi jakieś drobne modyfikacje. Powiedzmy, że pododaje słowa kluczowe static przed wszystkimi symbolami globalnymi (zmienne i funkcje oprócz main). Zamieszczamy diffa, aby pokazać zmiany.
bartek@host:~/svn/slownik$ svn diff Index: src/sprawdz.c =================================================================== --- src/sprawdz.c (revision 11) +++ src/sprawdz.c (working copy) @@ -2,17 +2,17 @@ #include <stdlib.h> #include <string.h> -const char * SLOWNIK = "slowa.txt"; +static const char * SLOWNIK = "slowa.txt"; int slow; char **slownik; -int potega2(int n) +static int potega2(int n) { return (n & (n - 1)) == 0; } -void wczytaj_slownik(FILE *f) +static void wczytaj_slownik(FILE *f) { char buf[128]; slow = 0; @@ -33,7 +33,7 @@ return strcmp(* (char * const *) p1, * (char * const *) p2); } -int inicjuj_slownik() +static int inicjuj_slownik() { FILE *f = fopen(SLOWNIK, "r"); if (!f) { @@ -46,12 +46,12 @@ return 1; } -int w_slowniku(char *s) +static int w_slowniku(char *s) { return bsearch(&s, slownik, slow, sizeof(char *), cmpstringp) != NULL; } -void obrob_wejscie() +static void obrob_wejscie() { char buf[128]; while (scanf("%127s", buf) > 0) bartek@host:~/svn/slownik$
bartek@host:~/svn/slownik$ svn ci -m "Dodanie brakujących static" Sending src/sprawdz.c Transmitting file data . Committed revision 12. bartek@host:~/svn/slownik$
ala@host:~/svn/slownik$ svn update At revision 12. ala@host:~/svn/slownik$
sprawdz.c.
void obrob_wejscie(FILE *f) { char buf[128]; while (fscanf(f, "%127s", buf) > 0) if (!w_slowniku(buf)) printf("%s\n", buf); } int main(int argc, char *argv[]) { if (!inicjuj_slownik()) return 1; if (argc == 0) obrob_wejscie(stdin); else { int i; for (i = 1; i <= argc; ++i) { FILE *f = fopen(argv[i], "r"); if (!stdin) { fprintf(stderr, "Nie można otworzyć pliku '%s'\n", argv[i]); return 1; } obrob_wejscie(f); fclose(f); } } return 0; }
ala@host:~/svn/slownik/src$ svn ci -m "Dodanie obrabiania plików w argumentach" Sending src/sprawdz.c Transmitting file data . Committed revision 13. ala@host:~/svn/slownik/src$
Scalanie
Ala zamknęła nanoszenie zmian w gałęzi. Modyfikacja została ostatecznie zakończona. Teraz przyszedł czas na naniesienie zmian z gałęzi do głównej ścieżki projektu. Taką operacją nazywamy scalaniem. Wpierw trzeba przejść do wersji roboczej, która odpowiada katalogowi trunk. Można to zrobić poprzez zrobienie checkout odpowiedniego katalogu z repoztorium. W naszym przykładzie użyjemy ponownie komendyswitch:
ala@host:~/svn/slownik$ svn switch file:///var/local/repos/slownik/trunk . U src/sprawdz.c Updated to revision 13. ala@host:~/svn/slownik$
sprawdz.c zawiera teraz tylko modyfikacje Bartka (bez kodu z obsługą argumentów). W tej kopii roboczej naniesiemy jeszcze raz zmiany, które Ala nanosiła pracowicie w gałęzi uzycie_argumentow. Oczywiście nie trzeba już tu pisać kodu ponownie, a jedynie pobrać odpowiednie zmiany z repozytorium. W tym celu musimy znać wersję sprzed zmian w danej gałęzi i wersję, w której już wszystkie zmiany są naniesione. SVN mając ustalone dwie wersje, potrafi zobaczyć jaka jest między nimi różnica i nanieść te zmiany do bieżącej kopii roboczej. Do tego służy komenda merge. Wersja, w której już wszystkie zmiany w gałęzi są wprowadzone to w tym przypadku po prostu ostatnia wersja znajdująca się w repozytorium, którą reprezentuje słowo HEAD. Musimy jeszcze znaleźć numer wersji, w której nie było jeszcze naniesionych żadnych zmian, czyli najlepiej wersję, w której dana gałąź powstała. Numer ten mogliśmy sobie zapamiętać, ale w przypadku, gdy go zapomnimy z pomocą przychodzi komenda log.
ala@host:~/svn/slownik$ svn log file:///var/local/repos/slownik | grep -B 2 "uzycie_argumentow" r10 | ala | 2006-09-06 13:51:10 +0200 (Wed, 06 Sep 2006) | 1 line Utworzenie gałęzi 'uzycie_argumentow' ala@host:~/svn/slownik$
log z argumentem z lokalizacją znajdujacą się w repozytorium, gdyż chcieliśmy otrzymać komunikaty dotyczące wszystkich zmian w projekcie slownik, a nie tylko te, które są w katalogu trunk. W wyniku widzimy, że szukaną wersją początku gałęzi jest 10. Teraz mamy już wszystkie dane, aby użyć komendy merge.
ala@host:~/svn/slownik$ svn merge -r 10:HEAD file:///var/local/repos/slownik/branches/uzycie_argumentow C src/sprawdz.c ala@host:~/svn/slownik$
sprawdz.c. Taka sytuacja może często się pojawiać w wyniku scalania większych zmian. Konflikty trzeba poprawić. W tym przypadku konflikt jest dosyć oczywisty. Pojawił on się w nagłówku funkcji obrob_wejscie:
<<<<<<< .working static void obrob_wejscie() ======= void obrob_wejscie(FILE *f) >>>>>>> .merge-right.r13
static, a my dodaliśmy argument. Jasne zatem jest, że po scaleniu nagłówek funkcji powinien wyglądać tak:
static void obrob_wejscie(FILE *f)
ala@host:~/svn/slownik$ svn resolved src/sprawdz.c Resolved conflicted state of 'src/sprawdz.c' ala@host:~/svn/slownik$
ala@host:~/svn/slownik$ svn ci -m "Dodanie zmian z gałęzi 'uzycie_argumentow'" Sending src/sprawdz.c Transmitting file data . Committed revision 14. ala@host:~/svn/slownik$
Automatyzacja kompilacji - make
Wstęp
Przypuśćmy, że piszemy program w C, który składa się z kilku plików, a mianowicie
main.c, komunikat.c, komunikat.h, test.c, test.h. Dla przykładu niech to będą bardzo proste źródła.
main.c: #include "test.h" int main() { test(); return 0; }
komunikat.c:
#include "komunikat.[geshifilter-code]h[/geshifilter-code]" const char *komunikat = "test";
komunikat.h:
#ifndef KOMUNIKAT_H #define KOMUNIKAT_H extern const char *komunikat; #endif
test.c:
#include <stdio.h> #include <math.h> #include "test.h" #include "komunikat.h" void test() { printf("%s\n", komunikat); printf("sin(2)=%f\n", sin(2)); }
test.h:
#ifndef TEST_H #define TEST_H extern void test(); #endif
Kompilujemy je stopniowo. Wpierw tworzymy pliki *.o z plików *.c, a następnie je linkujemy. Czyli kolejne polecenia kompilacji wyglądają następująco:
gcc -Wall -c komunikat.c -o komunikat.o gcc -Wall -c main.c -o main.o gcc -Wall -c test.c -o test.o gcc -lm komunikat.o main.o test.o -o program
Dla ułatwienia kompilacji możemy sobie te polecenia zapisać do skryptu i uruchamiać ten skrypt za każdym razem, gdy zmodyfikujemy jakieś źródła. Skrypt ma jednak parę wad. Po pierwsze jeśli dodamy lub usuniemy pliki źródłowe C, to będziemy musieli przeedytować skrypt. Możemy z tym problemem sobie poradzić, jeśli w danym katalogu znajdują się tylko pliki źródłowe należące do danego programu. Wtedy wystarczy przerobić skrypt.
for f in *.c; do gcc -Wall -c $f -o ${f%c}o done gcc -lm *.o -o program
Druga wada skryptu jest taka, że kompilujemy za każdym razem wszystkie źródła, a przecież wystarczy skompilować tylko te co się zmieniły i powtórzyć linkowanie plików *.o w jeden program. Taki skrypt jesteśmy w stanie napisać, ale zrobiłoby się to bardzo skomplikowane.
Po za tym co jak będziemy chcieli zmienić opcje kompilacji, linkowania, itp. Będziemy musieli rozbudować nasz skrypt znacznie. Tymczasem gotową automatyzację udostępnia program make i skupimy się dalej na wykorzystaniu tego narzędzia do ułatwienia życia przy rekompilacji programu.
Pierwszy makefile
Program make czyta co ma zrobić z pliku o nazwie makefile, zatem cała sztuka użycia make sprowadza się do umiejętności pisania pliku makefile.
Najważnieszą składowa pliku makefile są reguły. Reguła wygląda następująco:
cel: zależności
polecenieReguła określa w jakis sposób należy budować cel. Znaczenie poszczególnych składników.
cel
nazwa pliku, który ma powstać z tej reguly,
zależności
lista plików od których zależy cel, tzn. zmiana któregokolwiek z tych plików oznacza, że cel też się zmieni,
polecenie
jest to polecenie za pomocą, którego ma zostać wytworzony cel.
Uwaga! Istotne jest, aby polecenie było wcięte za pomocą jednego znaku tabulacji, a nie przypadkiem spacji. Jest to dosyć kłopotliwe, ale cóż, każde narzędzie miewa swoje widzimisie.
Dla przykładu reguła
komunikat.o: komunikat.c komunikat.h gcc -Wall -c komunikat.c -o komunikat.o
mówi w jaki sposób tworzyć plik komunikat.o. Zależy on od dwóch plików źródłowych komunikat.c i komunikat.h.
W jaki sposób znajdować pliki zależna? Można posłużyć się opcją -MM polecenia gcc.
gcc -MM plik.cPowyższe polecenie wyrzucie linię
plik.o: plik.c inne pliki źródłowe
pokazującą jakie są jeszcze inne pliki źródłowe, od których zależy dany plik. Forma wyjścia nie jest przypadkowa. Jest taka, aby było można ją łatwo wstawić do pliku code>makefile.M
Z pomocą gcc -MM lub bez tworzymy nasz pierwszy makefile, który wygląda tak:
program: komunikat.o main.o test.o gcc -lm komunikat.o main.o test.o -o program komunikat.o: komunikat.c komunikat.h gcc -Wall -c komunikat.c -o komunikat.o main.o: main.c test.h gcc -Wall -c main.c -o main.o test.o: test.c test.h komunikat.h gcc -Wall -c test.c -o test.o
Teraz w wyniku wykonania polecenia make mamy taki efekt:
$ make gcc -Wall -c komunikat.c -o komunikat.o gcc -Wall -c main.c -o main.o gcc -Wall -c test.c -o test.o gcc -lm komunikat.o main.o test.o -o program
Zostały utworzone odpowiednie pliki *.o oraz program wykonywalny program.
W jaki sposób zadziałał make? Otóż jeśli nie podamy mu żadnego argumentu, to próbuje on utworzyć cel występujący w pierwszej regule pliku makefile. W tym celu tworzy wpierw wszystkie pliki od których on zależy, jeśli takowe jeszcze nie istnieją. Do tworzenia plików *.o używa dalszych reguł. Tworzenie celu kończy się porażką jeżeli zajdzie jeden z przypadków:
- plik, od którego zależy cel, nie zostanie znaleziony,
- nie będzie można znaleźć reguły, do utworzenia danego pliku,
- polecenie podane w regule skończy się porażką.
Ponadto make potrafi stwierdzać, czy jest potrzeba ponownego wykonania poleceń kompilacji. Wykonajmy go jeszcze raz:
$ make -f simple.mak make: `program' jest aktualne.
co oznacza, że plik wykonywalny program jest aktualny i nie trzeba nic uruchamiać.
Teraz zmodyfikujmy jakiś plik. Zasymulujemy to poleceniem touch:
$ touch komunikat.h
Uruchamiamy make jeszcze raz:
$ make -f simple.mak gcc -Wall -c komunikat.c -o komunikat.o gcc -Wall -c test.c -o test.o gcc -lm komunikat.o main.o test.o -o program
Tym razem ponownie zostały utworzone te pliki wynikowe, które zależały od komunikat.h, a mianowicie są to komunikat.o i test.o. Oczywiście zostało też ponowione linkowanie.
Reguły jak polecenia
Dodamy regułę, która będzie czyścić niepotrzebne pliki:
program: komunikat.o main.o test.o gcc -lm komunikat.o main.o test.o -o program komunikat.o: komunikat.c komunikat.h gcc -Wall -c komunikat.c -o komunikat.o main.o: main.c test.h gcc -Wall -c main.c -o main.o test.o: test.c test.h komunikat.h gcc -Wall -c test.c -o test.o clean: rm -f program komunikat.o main.o test.o
Nowa reguła nie ma zależności, a jest jedynie cel, który w wyniku polecenia w tej regule i tak nie jest tworzony. Nie mniej takie reguły są przydatne. Są to takie reguły-polecenia. Żeby je wykonać należy wywołać polecenie make z nazwą celu jako argument:
$ make clean rm -f program komunikat.o main.o test.o
Problem jest jednak taki, że jeśli będzie np. istniaj plik o nazwie clean to taka reguła nie zostanie wykonana, gdyż cel będzie już istniał, a wszystkie pliki, od których on zależy (wszystkie, czyli żadne) są aktualne. Żeby wskazać, że dana reguła jest tak na prawdę tylko wywołaniem polecenia, należy dodać regułę z celem o specjalnej nazwie .PHONY.
program: komunikat.o main.o test.o gcc -lm komunikat.o main.o test.o -o program komunikat.o: komunikat.c komunikat.h gcc -Wall -c komunikat.c -o komunikat.o main.o: main.c test.h gcc -Wall -c main.c -o main.o test.o: test.c test.h komunikat.h gcc -Wall -c test.c -o test.o .PHONY: clean clean: rm -f program komunikat.o main.o test.o
Zmienne i funkcje
Zmienne
Nasz makefile jest na razie dosyć brzydki. Co jeśli będziemy chcieli dodać nowy plik wynikowy o rozszerzeniu .o? Będziemy musieli go dodać w kilku miejscach, co jest jednak dosyć żmudne.
Z pomocą przychodzą zmienne. Jeśli zadeklarujemy zmienną objects
objects=komunikat.o main.o test.o to będziemy mogli tej zmiennej użyć w dalszej części przez wywołanie $(objects). W ten sposób znacznie uprościmy makefile: objects=komunikat.o main.o test.o program: $(objects) gcc -lm $(objects) -o program komunikat.o: komunikat.c komunikat.h gcc -Wall -c komunikat.c -o komunikat.o main.o: main.c test.h gcc -Wall -c main.c -o main.o test.o: test.c test.h komunikat.h gcc -Wall -c test.c -o test.o .PHONY: clean clean: rm -f program $(objects)
Funkcje
make udostępnia szereg wbudowanych funkcji, aby ułatwić nieco życie. Szczegółowe zestaw dostępnych funkcji jest opisany w dokumentacji, my dla przykładu pokażemy zastosowanie funkcji patsubst.
Wprowadziliśmy zmienną objects, która zawiera listę wszystkich plików wynikowych *.o, które wchodzą w skład programu. Jednakże jest tak, że każdemu plikowi źródłowemu o rozszerzeniu .c odpowiada dany plik wynikowy. Powinniśmy raczej zadeklarować zmienną
sources=komunikat.c main.c test.c
pamiętającą wszystkie pliki źródłowe, a na ich podstawie powinniśmy utworzyć zmienną objects. Możemy zastosować funkcję patsubst:
objects=$(patsubst %.c,%.o,$(sources))
Składnia tej funkcji jest następująca:
$(patsubst wzorzec_wejściowy,wzorzec_wynikowy,lista_wyrazów)
We wzorcach znak % spełni podobną rolę jak * we wzorcach nazw plików. patsubst działa mniej więcej tak, że każdy wyraz z listy kojrzy ze wzorcem wejściowym i zamienia go tak, aby pasował do wzorca wyjściowego, pozostawiając niezmienione części, które zostały przypasowane do znaku %.
W tym przypadku, gdy zamieniamy tylko sufiksy, a listą jest wartość zmiennej patsubst ma skróconą wersję:
$(sources:.c=.o)
Użyjemy właśnie jej.
sources=komunikat.c main.c test.c objects=$(sources:.c=.o) program: $(objects) gcc -lm $(objects) -o program komunikat.o: komunikat.c komunikat.h gcc -Wall -c komunikat.c -o komunikat.o main.o: main.c test.h gcc -Wall -c main.c -o main.o test.o: test.c test.h komunikat.h gcc -Wall -c test.c -o test.o .PHONY: clean clean: rm -f program $(objects)
Jeżeli byśmy wiedzieli, że w skład programu wchodzą wszystkie pliki *.c znajdujące się w aktualnym katalogu, to moglibyśmy zmienić deklarację zmiennej sources z użyciem funkcji wildcard
sources=$(wildcard *.c)
Zmienne automatyczne
Innym udogodnienie są zmienne automatyczne o specjalnych nazwach, które są dostępne w regułach, a dokłdnie w treści polecenia dotyczącego danej reguły. Oto przykładowe trzy:
$@
daje nazwę celu
$<
daje nazwę pierwszej zależność
$^
daje nazwy wszystkich zależności
Z użyciem tych zmiennych można trochę skróć nasz makefile:
sources=komunikat.c main.c test.c objects=$(sources:.c=.o) program: $(objects) gcc -lm $^ -o $@ komunikat.o: komunikat.c komunikat.h gcc -Wall -c $< -o $@ main.o: main.c test.h gcc -Wall -c $< -o $@ test.o: test.c test.h komunikat.h gcc -Wall -c $< -o $@ .PHONY: clean clean: rm -f program $(objects)
Reguły schematy
Zauważmy, że po ostatnich zmianach polecenia do kompilacja programu .c w plik wynikowy .o wyglądają identycznie. Zatem może da się je jakoś raz zadeklarować. Otóż tak, z pomocą przychodzą reguły schematy.
Deklarowanie reguły schematu
Reguły schematy używane są do podowania sposobu kompilacji z jednego typu w drugi typ. W naszym przypadku mamy jeden sposób na tworzenie pliku wynikowego .o z pliku .c. Można w tym celu użyć reguły schematu, która jako cel i zależności ma wzorce.
%.o: %.c gcc -Wall -c $< -o $@
Zauważmy, że przy deklarowaniu takich reguł, zmienne automatyczne stają się niezbędne. Moglibyśmy teraz usunąć te trzy reguły, które służą nam do tworzenia pliku *.o i zastąpić je powyższą regułą. Jednak wtedy stracimy zależności. Otóż można zrobić tak. Zostawić same zależności bez poleceń, które są i tak zadane przez regułę schemat.
sources=komunikat.c main.c test.c objects=$(sources:.c=.o) program: $(objects) gcc -lm $^ -o $@ komunikat.o: komunikat.c komunikat.h main.o: main.c test.h test.o: test.c test.h komunikat.h %.o: %.c gcc -Wall -c $< -o $@ .PHONY: clean clean: rm -f program $(objects)
Użycie wbudowanych reguł schematów
Takie kompilowanie programów napisanych w C wydaje się być standardowe. Okazuje się, że dla takich czynności make ma już wbudowane reguły schematy i nie trzeba już ich deklarować. Usuńmy nasz schemat i zobatrzmy co zrobi make dla takiego pliku makefile:
sources=komunikat.c main.c test.c objects=$(sources:.c=.o) program: $(objects) gcc -lm $^ -o $@ komunikat.o: komunikat.c komunikat.h main.o: main.c test.h test.o: test.c test.h komunikat.h .PHONY: clean clean: rm -f program $(objects)
wykonujemy:
$ make clean rm -f program komunikat.o main.o test.o $ make cc -c -o komunikat.o komunikat.c cc -c -o main.o main.c cc -c -o test.o test.c gcc -lm komunikat.o main.o test.o -o program
No nie do końca otrzymaliśmy to o co nam chodziło. Został użyty kompilator cc, a nie gcc. Pondto znikła opcja -Wall. Można jednak konfigurować wbudowaną regułę za pomocą zmiennych. W dokumentacji make możemy przeczytać, że wbudowana jest reguła
%.o: %.c $(CC) $(CFLAGS) $(CPPFLAGS) -c -o $@ $<
Zmienna CC oznacza nazwę kompilatora programów napisanych w C, zmienna CFLAGS oznacza opcję tego kompilatora, a CPPFLAGS oznacza opcje preprocesora. Wystarczy nadać tym zmiennym odpowiednią wartość, aby uzyskać porządany efekt.
CC=gcc CFLAGS=-Wall sources=komunikat.c main.c test.c objects=$(sources:.c=.o) program: $(objects) gcc -lm $^ -o $@ komunikat.o: komunikat.c komunikat.h main.o: main.c test.h test.o: test.c test.h komunikat.h .PHONY: clean clean: rm -f program $(objects)