
Omówiony tutaj materiał będzie punktem odniesienia dla pozostałych wykładów dotyczących programowania ekstremalnego i refaktoryzacji, gdzie testowanie odgrywa kluczową rolę podczas weryfikacji poprawności przekształceń refaktoryzacyjnych.


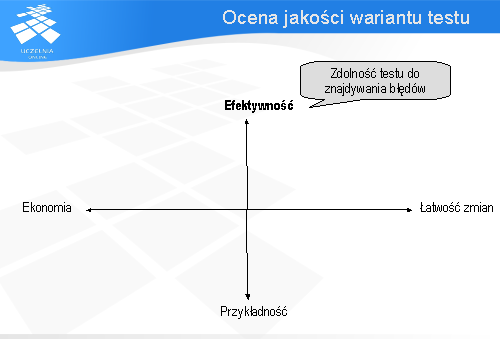
Oprogramowanie powinno być przetestowane by uzyskać pewność, że będzie działać prawidłowo w środowisku docelowym. Od testowania wymaga się by było ono efektywne i wydajne. Przez efektywne rozumie się skuteczne w znajdywaniu błędów. Wydajne natomiast oznacza wykonanie testów w sposób jak najszybszy i jak najtańszy.
Czas potrzebny na testowanie dla typowych projektów informatycznych waha się od 30% do 40% całkowitej pracochłonności. W przypadku systemów krytycznych wynosi nawet do 80%. Mimo to przetestowane programy zawierają błędy. Niestety nieprawidłowe działanie programu sporo kosztuje szczególnie gdy usterki znalezione zostaną dopiero po wdrożeniu systemu, podczas normalnego użytkowania. Powodów występowania błędów może być wiele jednak oznacza to, że nie przetestowano dokładnie systemu.


Testowanie to umiejętność wyboru, które warianty testów powinny być zaprojektowane i wykonane. Dla każdego systemu występuje astronomiczna liczba przypadków testowych. W praktyce jednak jest czas na wykonanie tylko niewielkiej części z nich. Mimo tego od wybranych wariantów, które mają być wykonane oczekuje się, że znajdą większość błędów występujących w programie.
Wybór przypadków testowych do wykonania jest więc bardzo ważnym zadaniem. Badania pokazały, że selekcja wariantów w sposób losowy nie jest efektywnym podejściem do testowania. Najlepszym podejściem jest wybranie „najlepszych przypadków testowych” do wykonania. Jak więc można określić, które warianty testów są najlepsze?
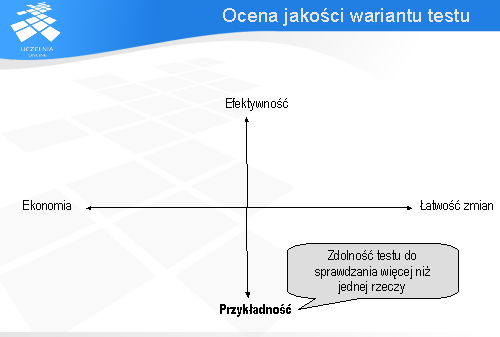
W kontekście automatyzacji testowania przypadki testowe można oceniać na podstawie czterech atrybutów:
efektywności (ang. effective), łatwości zmian (ang. evolvable), przykładności (ang. exemplary), i ekonomiczności (ang. economic).
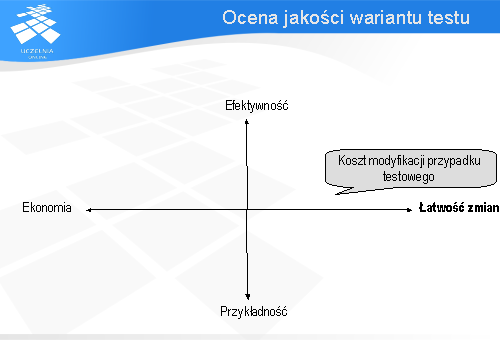

Ostatni z atrybutów ekonomiczność (ang. Economic) określa koszt wykonania, analizy i debugowania przypadku testowego. Im większa jego wartość tym taniej jest dany wariant wykonać i analizować.
W praktyce trzeba często równoważyć wpływ tych czterech czynników na siebie. Przykładowo wariant testu, który testuje wiele rzeczy będzie najczęściej kosztował sporo na etapie wykonania, analizy i ewentualnego debugowania tego testu. Będzie także najprawdopodobniej wymagał sporego nakładu pracy na jego pielęgnację w przypadku, gdy testowany system ulegnie zmianie. Niestety wysoka wartość dla atrybutu przykładności powoduje obniżenie na skali ekonomiczności i łatwości zmian.
Można więc powiedzieć, że testowanie to nie tylko zapewnienie, że warianty testu znajdą większość błędów, ale także zapewnienie, że te przypadki testowe są dobrze zaprojektowane i nie kosztują sporo.
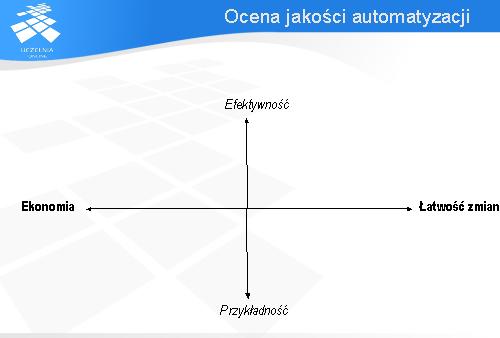
Automatyzacja testów znacznie różni się od testowania. Bywa bardzo kosztowna, droższa nawet od ręcznego wykonania testów. Bardzo ważną rolę odgrywa tutaj wybór wariantów testów, które mają być zautomatyzowane. Decyzja ta wpływa na to czy zyskuje się na automatyzacji testów czy też traci. Jakość automatyzacji nie określa się tak samo jak jakość wariantów testów.
To czy dany przypadek testowy jest zautomatyzowany czy wykonywany ręcznie nie wpływa na jego zdolność znajdywania błędów - efektywność (ang. effective), ani na przykładność (ang. exemplary). Nie ma znaczenia jak dobrze zostanie zautomatyzowany wariant testu, który nie wykrywa żadnego błędu. Po automatyzacji nadal nie wykryje błędu! Będzie za to wykonywany szybciej.
Automatyzacja testów wpływa na dwa atrybuty: ekonomiczność (ang. economic), oraz łatwość zmian (ang. evolvable). Po zaimplementowaniu zautomatyzowany przypadek testowy jest na ogół bardziej ekonomiczny, ponieważ koszt związany z jego wykonaniem tego testu jest znacznie mniejszy od przeprowadzenia go ręcznie. Niestety zautomatyzowane testy kosztują więcej jeśli chodzi o ich stworzenie i utrzymanie. Im lepsze podejście do automatyzacji testów, tym tańsze będzie ich tworzenie w dłuższej perspektywie czasu. Jeśli w trakcie automatyzacji nie bierze się pod uwagę konieczności przyszłej pielęgnacji testów, ich późniejsza aktualizacja może kosztować co najmniej tyle samo (jeśli nie więcej) co wykonanie tych testów ręcznie.
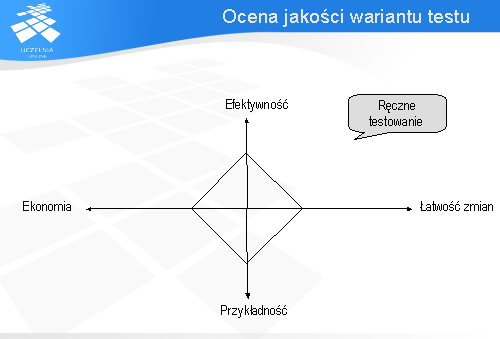
Wpływ automatyzacji na atrybuty opisujące jakość wariantu testu zobrazowane zostaną na poniższym diagramie. Załóżmy, że dla wariantu testu wykonanego ręcznie wartości atrybutów przyjmują wartości pokazane na diagramie przy pomocy linii ciągłej.
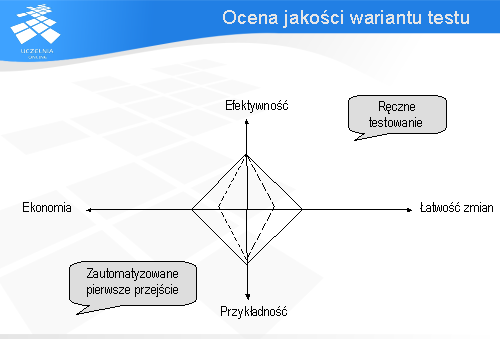
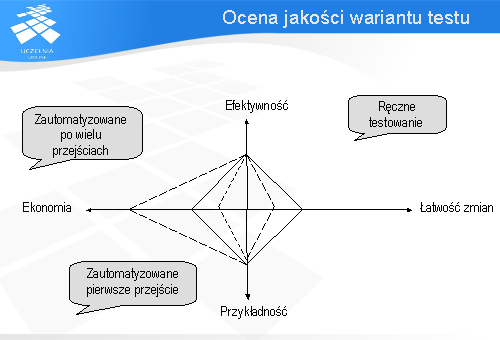
Dopiero gdy zautomatyzowany przypadek testowy wykonany zostanie wiele razy stanie się bardziej ekonomiczny od tego samego wariantu testu wykonanego ręcznie.
By uzyskać efektywny i wydajny zbiór zautomatyzowanych testów trzeba zbudować zbiór dobrych przypadków testowych, czyli takich które maksymalizują cztery omówione wcześniej kryteria oceny. Z tych wariantów następnie wybiera się te, które powinny być poddane automatyzacji.

Osobą, która tworzy i pielęgnuje artefakty związane ze zautomatyzowanymi testami jest test automator. Zadaniem testera natomiast jest przygotowanie „dobrych” wariantów testów, które następnie oceniane są pod kątem automatyzacji. Test automatorem bywa często sam tester, choć może być nim także osoba spoza zespołu odpowiedzialnego za testowanie. Przykładowo jeśli w skład zespołu testerów wchodzą osoby, które są użytkownikami systemu to posiadają oni nieocenioną wiedzę biznesową, ale nie mają umiejętności technicznych potrzebnych do automatyzacji tych testów. Do tego celu można wykorzystać programistów, by wspomogli te osoby w procesie implementacji i pielęgnacji zautomatyzowanych testów. W takim przypadku programista jest test automatorem.
Podobnie jak możliwe jest uzyskanie dobrych lub słabych jakościowo przypadków testowych, możliwe jest uzyskanie różnej jakości zautomatyzowanych wariantów testu. To od umiejętności test automatora zależy jak łatwo będzie dodać lub poprawić istniejące zautomatyzowane warianty testów, oraz jakie korzyści będą płynąć z automatyzacji.

Automatyzacja testowania umożliwia wykonanie wielu czynności znacznie wydajniej niż w przypadku gdyby były przeprowadzane ręcznie. Najbardziej oczywistą korzyścią płynącą z automatycznego testowania jest wykonanie testów regresyjnych dla nowej wersji programu. Wysiłek konieczny na ten typ testowania jest minimalny, pod warunkiem, że testy zostały zautomatyzowane dla wcześniejszej wersji aplikacji. W zaledwie kilka minut można wtedy wybrać odpowiednie warianty testów i je wykonać.
Jako zaletę można zaliczyć także uruchamianie więcej testów częściej. Dzięki temu, że testy wykonują się szybciej można je wykonywać częściej. To prowadzi do większej pewności, że tworzony system działa zgodnie z oczekiwaniami klienta.
Niektóre testy bardzo trudno wykonać ręcznie lub jest to wręcz niemożliwe. Do tego typu testów należą m.in. testy wydajnościowe. Próba wykonania testu, w którym 500 osób próbuje w tym samym czasie wstawić pewną informację do bazy może być dość kosztowna i trudna do zsynchronizowana w przypadku gdyby miała być przeprowadzona przez testerów.
Odciążając testerów od konieczności wykonywania testów i porównywania uzyskanego wyjścia z oczekiwanym, które są dość nudnymi zajęciami umożliwia im skupienie się na projektowaniu lepszych testów.
Na automatyzacji zyskują także same testy. Poprawia się ich spójność i powtarzalność. Testy, które są powtarzane automatycznie będą powtarzane dokładnie tak samo (przynajmniej wejście, gdyż wyjście może się różnić w zależności od np. czasu). To daje poziom regularności, który jest trudno uzyskać przez testowanie ręczne. Te same testy mogą być wykonywane w różnych konfiguracjach sprzętowych, na różnych systemach operacyjnych z wykorzystaniem różnych baz danych. To daje spójność pomiędzy platformami dla produktów wieloplatformowych, która jest niemożliwa do osiągnięcia w przypadku ręcznego testowania. Narzucenie dobrego reżimu automatyzacji testów może zapewnić spójne standardy zarówno dla testowania jak i programowania. Przykładowo narzędzie może sprawdzić, że ten sam typ cechy został zaimplementowany w ten sam sposób we wszystkich aplikacjach.
Dzięki temu, że automatyczne testy można wykonywać szybciej czas potrzebny na testowanie może zostać skrócony, co oznacza, że produkt może zostać szybciej wypuszczony na rynek.
Testowanie może także odbywać się w nocy. Testy uruchamiane są gdy testerzy kończą pracę. Nie trzeba czekać na wyniki. Będą dostępne następnego dnia rano.

Z automatyzacją testowania wiąże się wiele problemów i ograniczeń. James Bach na podstawie swojego wieloletniego doświadczenia podaje, że większość błędów wykrywana jest podczas ręcznego wykonywania testowania, bo aż 85% z nich. Tylko 15% błędów znajdywanych jest przez automatyczne przypadki testowe. By móc zautomatyzować dany wariantu testu trzeba najpierw upewnić się, że jest prawidłowy. Nie ma sensu tworzyć automatu dla niepoprawnych przypadków testowych. Testowanie wariantu testu polega najczęściej na wykonaniu go najpierw ręcznie, a następnie przeanalizowaniu uzyskanych wyników. Dopiero tak sprawdzony wariant jest automatyzowany. Największa szansa na znalezienie błędu jest podczas pierwszego wykonania testu. Raz wykryty i poprawiony błąd na ogół nie powtarza się, za wyjątkiem sytuacji, w których testowany fragment programu podlega modyfikacjom. Wtedy istnieje szansa na wprowadzenie błędu podczas zmian w kodzie aplikacji.
Testy poddawane automatyzacji muszą być dobrej jakości. Narzędzie wykonujące testy może tylko określić czy oczekiwane wyjście pasuje do faktycznie zaobserwowanego. Nie poda czy wariant testu jest prawidłowy. Jeśli przypadek testowy jest mało efektywny to prawdopodobieństwo znalezienia błędu dla takiego wariantu po jego automatyzacji będzie również niewielkie. Automat może najwyżej zwiększyć wydajność takiego testu tzn. zmniejszyć koszt i czas potrzebny do wykonania wariantu testu.
Zautomatyzowane testy są mniej podatne na zmiany niż testy wykonywane ręcznie. Wymagają więcej wysiłku na etapie wytworzenia oraz w ich późniejszej pielęgnacji. Modyfikacje programu wymagają także dostosowania zautomatyzowanych testów. Mogą one nie być wprowadzone ze względów ekonomicznych. Może okazać się, że zmiana wariantów testów jest nieopłacalna jeśli nie pomyślano o ich pielęgnacji podczas ich automatyzacji.
Koszt wytworzenia automatycznych testów też nie jest bez znaczenia. Średnio wynosi on 2 do 10 razy wysiłku związanego z ręcznym wykonywaniem testów. W niektórych przypadkach koszt ten nawet wzrastał do 30 razy. W związku z tym ważne jest by automatyzować tylko te testy, dla których ma to ekonomiczny sens, czyli takie, które będą wiele razy uruchamiane. Dzięki temu koszt związany z ich wytworzeniem się zwróci.
Automatyczne testy to tylko program posłusznie wykonujący instrukcje. Niestety tylko tester jest w stanie stwierdzić, czy wykonywany przypadek testowy zawiera błąd. Także tylko on jest w stanie poprawić wariant testu by sprawdzał dodatkowe rzeczy jeśli uzna, że ów wariant nie jest dostatecznie szczegółowy.

Nie jest możliwe ani także oczekiwane by automatyzować wszystkie czynności związane z testowaniem jak również same testy. Zawsze znajdą się takie przypadki, które łatwiej będzie wykonać ręcznie lub też takie, których automatyzacja jest nieekonomiczna. Testy których najczęściej nie warto automatyzować to testy wykonywane rzadko. Jeśli test jest wykonywany tylko kilka razy to koszt związany z jego automatyzacją może nie zwrócić się. To właśnie wielokrotne uruchamianie takiego testu amortyzuje koszt związany z jego automatyzacją.
W przypadku gdy testowany program często ulega zmianie może okazać się, że nie warto automatyzować testów sprawdzających te jego fragmenty, które często podlegają modyfikacji. Wraz ze zmianami w programie wiąże się potrzeba dostosowywania testów co zwiększa koszt związany z ich utrzymaniem i może okazać się nieopłacalne.
Również nie warto automatyzować testów, które łatwe są do zweryfikowania przez człowieka, ale trudne lub niemożliwe dla automatu. Przykładowo sprawdzenie schematu kolorów, czy też układu (ang. layout) kontrolek w interfejsie użytkownika, albo określenie czy prawidłowy dźwięk wydobywa się w momencie wywołania określonego zdarzenia w systemie są dość trudne do sprawdzenia przez program, a nie sprawiają większych problemów testerowi.
Jeśli testy wymagają fizycznej interakcji ze strony użytkownika systemu to także powinny być wykonywane ręcznie. Przykładem takiego testu, jest sytuacja kiedy by wykonać test należy przeciągnąć kartę przez czytnik kart.


Pierwszą czynnością jaką należy wykonać to określenie co będzie testowane. Przez warunek testu rozumie się element lub zdarzenie, które może być zweryfikowane przez testy. Jest wiele różnych warunków testu dla systemu, jak również dla różnych rodzajów testowania, takich jak testowanie wydajnościowe, czy też testy bezpieczeństwa itd.
Warunki testu to opisy okoliczności, które można by sprawdzić. Przykładowo: sprawdzenie zachowania się systemu gdy wykonywany będzie przelew na konto o wartości ujemnej.
Istnieje wiele różnych technik testowania, które ułatwiają testerom identyfikację warunków testu w sposób usystematyzowany (przykładowo analiza wartości granicznych).






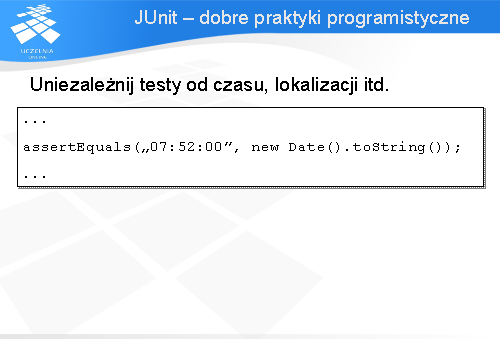
Ostatnią czynnością jest porównanie uzyskanego wyjścia z oczekiwanym. Może się to odbywać w sposób nieformalny przez testera, który sprawdza czy to co uzyskał zgadza się z tym czego oczekiwał, lub też w sposób rygorystyczny przez sprawdzenie zaobserwowanego wyjścia z opisem zawartym w procedurze testowej. Porównanie części wyników może odbywać się w trakcie wykonywania testów jak np. sprawdzenie czy pojawił się komunikat proszący o potwierdzenie podczas wykonywania przypadku testowego sprawdzającego czy można wykonać przelew o wartości ujemnej. W innym przypadku gdy np. chcemy sprawdzić czy zawartość bazy danych uległa zmianie może okazać się konieczne zaczekanie do końca wykonywania wariantu testu.
W najprostszym przypadku porównanie polega na sprawdzeniu czy uzyskane wyjście jest takie same jak oczekiwane. Jeśli są identyczne to przypadek testowy nie wykrył błędu. Jest to oczywiście najprostszy wariant. Faktyczne dane mogą nie być identyczne, ale podobne do tych oczekiwanych. Można powiedzieć, że porównanie polega na określeniu czy faktyczne wyjście pasuje (ang. match) do oczekiwanego wyjścia. Narzędzia automatyzujące tę czynność dokonują tylko porównania a nie weryfikacji. W związku z tym są w stanie wykryć tylko różnice. Zadaniem testera jest weryfikacja, czy w przypadku gdy wykryto niezgodność wyjść jest to akceptowalne, czy też powoduje, że test nie przeszedł.

Pierwsze dwie aktywności jakimi są: identyfikacja warunków testu, oraz zaprojektowanie przypadków testowych, wymagają pracy twórczej. To od nich zależy jakość testów. Niestety trudno poddają się automatyzacji. Ponadto na ogół wykonywane są tylko raz na początku nie uwzględniając oczywiście przypadków, w których popełniono błąd na etapie projektowania testów. Natomiast uruchomienie przypadków testowych oraz porównanie oczekiwanego wyjścia z faktycznym to typowo odtwórcze czynności, które wymagające sporo wysiłku. Powtarzane są one wiele razy w przeciwieństwie do projektowania, które wykonywane jest tylko raz na początku.

W związku z tym ostatnie dwie czynności idealnie nadają się do automatyzacji. Na następnych slajdach zostaną omówione krótko sposoby automatyzacji każdej z nich.

Wspomaganie automatyzacji projektowania przypadków testowych opiera się na narzędziach, które najczęściej automatycznie generują tylko dane wejściowe do testów. Nawet w przypadku narzędzi, które w stanie są podać także oczekiwane wyjścia nie można oczekiwać cudownych wyników. Nie zastąpią one czynności twórczych związanych z projektowaniem przypadków testowych, do których najlepiej nadaje się tester. Największym problemem związanym z wykorzystaniem tych narzędzi to fakt, że generują dużą liczbę testów. Nie potrafią rozróżnić, które z nich są ważne, co często skutkuje wytworzeniem dużej liczby mało istotnych testów. Część z tych narzędzi ma wbudowane algorytmy do minimalizacji ich liczby według kryteriów zadanych przez testera, co mimo wszystko w efekcie daje nadal zbyt wiele testów. W związku z tym należy korzystać z rozwagą z tego typu rozwiązań. Kolejną poważną wadą tych narzędzi jest fakt, że nie wykryją brakujących aspektów lub wymagań, ani też ich złej specyfikacji. To domena testerów, którzy posiadają wiedzę dziedzinową i potrafią określić kiedy dana powinność jest nie wyspecyfikowana lub źle zdefiniowana.
Narzędzia te generują dane wejściowe na podstawie trzech artefaktów: kodu aplikacji, na podstawie interfejsu użytkownika, oraz wykorzystując specyfikację systemu.

Generowanie danych testowych na podstawie kodu aplikacji oparte jest na analizie struktury kodu programu. Narzędzia znajdują instrukcje warunkowe i starają się określić dla jakich wejść poszczególne gałęzie są wykonywane.
To podejście jest niekompletne gdyż w ten sposób generowane są tylko dane wejściowe, a test potrzebuje jeszcze oczekiwanego wyjścia. Tego nie uzyska się na podstawie analizy kodu aplikacji. Tą informację można znaleźć w specyfikacji wymagań. Nie uda się także wykryć tym sposobem złych lub brakujących wymagań.

Kolejnym podejściem jest generowanie testów na podstawie interfejsu użytkownika. Generatory potrafią analizować interfejs okienkowy jak również kod html jeśli testowana aplikacja oparta jest na stronach www. Narzędzie takie identyfikuje kontrolki i następnie sprawdza czy dla każdej z nich istnieje funkcja pomocy. Innym przykładem testu jaki może być wygenerowany jest sprawdzenie czy można edytować pola przeznaczone tylko do odczytu. Dla stron www narzędzie sprawdza wszystkie hiperłącza występujące na stronie. W ten sposób jest w stanie zweryfikować czy któryś z nich prowadzi do nieistniejącej strony. Nie jest oczywiście w stanie sprawdzić czy prowadzi do dobrej strony.
Przy pomocy tego podejścia można wygenerować dane wejściowe i częściowo oczekiwane wyjście w dość ogólnym i negatywnym sensie. Dla wcześniejszego przykładu hiperłącz na stronie możliwe jest wygenerowanie sprawdzenia czy hiperłącze istnieje (co daje prawidłowy wynik) oraz czy prowadzi do nieistniejącej strony (nieprawidłowy wynik). Sama informacja, że test przechodzi nie gwarantuje, że podane hiperłącze jest prawidłowe, natomiast jeśli test wykryje martwe łącze to jest to informacja o błędzie.


Dla każdego testu określane jest oczekiwane wyjście. Najlepszym rozwiązaniem jest sprecyzowanie zawczasu jak ma się zachowywać system. Jeśli nie jest ono wyspecyfikowane zanim przypadek testowy zostanie wykonany, wtedy w celu sprawdzenia czy program działa prawidłowo faktyczne wyjście uzyskane z pierwszego wykonania wariantu testu staje się oczekiwanym wyjściem, oczywiście po uprzednim dokładnym przeanalizowaniu go przez testera. To wymaga wiedzy dziedzinowej od osoby weryfikującej faktyczne wyjście. Podejście, w którym wynik pierwszego wykonania testu jest uznawany za oczekiwane wyjście nazywa się testowaniem referencyjnym (ang. reference testing).
Problemem podczas specyfikacji oczekiwanego wyjścia jest zdecydowanie co ma być ze sobą porównane. Jeśli wybranych zostanie niewiele elementów to może okazać się, że wybrano zbyt ogólne oczekiwane wyjście. Spowoduje, to że błąd może zostać nie wykryty, ponieważ porównywane dane wyjściowe nie będą zawierały informacji o błędnym zachowaniu. Zbyt szczegółowe wyjście z kolei spowoduje, że test automatyczny będzie trudniejszy do zmodyfikowania oraz bardziej skomplikowany co zwiększa ryzyko wystąpienia błędu w takim wariancie.
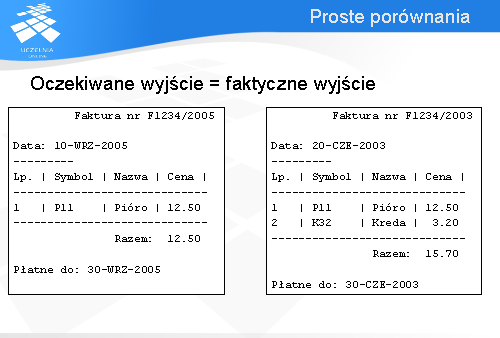
Najprostszą metodą porównań dostępną w narzędziach automatyzujących wykonanie testów jest tzw. proste porównanie. Dzięki tej metodzie faktyczne wyjście uznawane jest za pasujące do oczekiwanego wyjścia tylko w przypadku jeśli są one identyczne. Nie może być różnic między tym co zaobserwowano w wyniku wykonania programu, a tym jak program powinien się zachowywać. W przeciwnym przypadku zgłoszone zostaną różnice i test nie powiedzie się.
Jeśli wariant testu miałby sprawdzić czy generowane przez program faktury mają prawidłowy układ, należałoby uprzednio przygotować jako oczekiwane wyjście fakturę zawierającą te same dane, które będą podane w ramach testu. W przeciwnym wypadku nawet jeśli program generuje faktury o prawidłowej budowie test nie powiedzie się ze względu na różnicę w podanych danych.
Innym rozwiązaniem są złożone porównania polegające na pominięciu informacji szczegółowych dotyczących niektórych pól faktury. Na rynku jest kilka narzędzi, które posiadają taką funkcjonalność. Podawane są pola, które mają być pominięte, lub dla których ma być wykonane sprawdzenie typu. Jeśli np. pole z datą posiada nieprawidłowy format to zgłaszany jest błąd. Nie jest dokonywane sprawdzenie czy data jest identyczna z tą podaną w oczekiwanym wyjściu. Brak złożonych porównań nie przekreśla przydatności narzędzia. Można w dość prosty sposób zaimplementować sobie taką funkcjonalność.
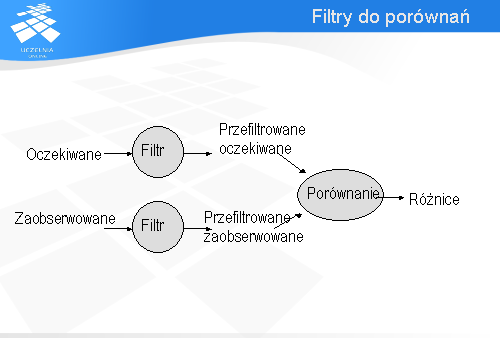
Praktycznie stosowanym rozwiązaniem dla problemu, w którym nie można zastosować złożonych porównań (np. używane narzędzie nie wspiera tej metody) jest zastosowanie filtrów. Zasada działania jest następująca. Zanim zaobserwowane wyjście jest porównane z oczekiwanym, oba wyjścia przechodzą przez filtr, którego zadaniem jest usunięcie niepotrzebnych informacji. Po ich odfiltrowaniu następuje porównanie ze sobą wyjść przy pomocy metody prostego porównania.
Oczywiście filtr może się okazać tak naprawdę łańcuchem filtrów, gdzie każdy z nich usuwa pojedynczą informację z danych, które mają być porównane. Oprócz usuwania filtr może także sortować dane lub dokonywać ich zamiany na inną postać.
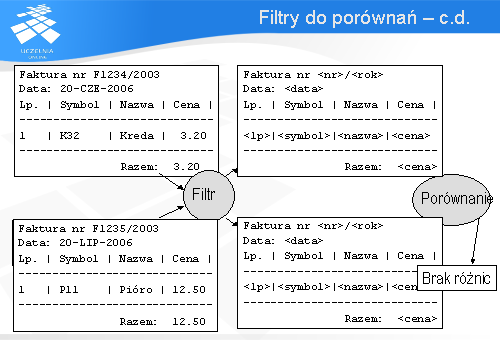
Dla przykładu z fakturą zarówno oczekiwane wyjście jak i zaobserwowane przepuszczono przez zestaw filtrów. Każdy z nich odfiltrowywał jeden rodzaj pola z dokumentów. Zastosowano filtry odpowiedzialne za wycięcie dat, numerów faktur, symboli, nazw oraz cen towarów. W wyniku uzyskano szablony faktur, które następnie porównano ze sobą przy pomocy prostego porównania.

Niewątpliwą zaletą płynącą ze stosowania filtrów jest możliwość pracy tylko nad wybranymi fragmentami wyjścia. Dla przykładu z fakturą porównywany był tylko jej układ. Filtry usunęły szczegółowe informacje dot. nr faktury oraz zakupionych towarów.
Dobrze zaimplementowane filtry można ponownie wykorzystać. Usuwanie wybranych typów danych może być wielokrotnie użyte przy okazji innych testów.
Ponieważ każdy filtr wykonuje prostą czynność implementacja ich nie powinna nastręczyć większych problemów. Złożone porównanie jest podzielone na wiele małych kroków, co także ułatwia automatyzację testu gdyż można zastosować proste porównanie.
Niestety stworzenie filtrów wymaga umiejętności programistycznych. Na szczęście raz stworzone filtry można ponownie wykorzystać. Kolejną wadą może być konieczność ich modyfikacji w przypadku gdy format wyjścia ulegnie zmianie.
By filtry mogły być ponownie wykorzystane muszą być dobrze udokumentowane. Inaczej nie będzie wiadomo w jaki sposób można ich użyć.

Przed wykonaniem wariantu testu konieczne jest ustawienie systemu w odpowiedni stan wyspecyfikowany w przypadku testowym. Angielska nazwa tej fazy to pre-processing. Do przykładów zaliczyć można dodawanie krotek do bazy danych, które są niezbędne do wykonania testu, logowanie użytkownika w systemie itp. Przed wykonaniem każdego przypadku testowego uruchamiany jest pre-processing. Różne warianty testów mają różne stany do ustawienia. Często jednak zdarza się, że wiele przypadków testowych wymaga ustawienia systemu w ten sam stan. Warto, więc zautomatyzować tę czynność, a powstały w ten sposób skrypt (czy też program) wykorzystywać ponownie w ramach tych przypadków testowych, które wymagają ustawienia tego samego stanu systemu.
Po wykonaniu każdego wariantu testu wykonywany jest post-processing, w ramach którego przywracany jest stan systemu sprzed wykonania testu. Można powiedzieć, że wykonywane jest „sprzątanie” po testowaniu. Podobnie jak w przypadku pre-processing’u wiele wariantów testu sprząta w podobny sposób czyniąc tę czynność wartą automatyzacji i do ponownego wykorzystania.
Przedstawione wcześniej pojęcia związane z automatyzacją wykonywania testów skonfrontuję teraz z popularną biblioteką JUnit 3.8.x służącą do tworzenia automatycznych przypadków testowych. W chwili tworzenia wykładu dostępna jest testowa wersja 4.x tej biblioteki. Jednak ze względu na brak dokumentacji do niej oraz fakt, że można ją wykorzystać tylko z wersją języka Java 1.5 nie będzie omówiona w ramach tego wykładu. Zainteresowani mogą znaleźć dodatkowe informacje na stronie http://www.junit.org/ .
Rodzina bibliotek xUnit dostępna jest na wiele platform programistycznych i dla wielu różnych języków programowania. JUnit to wariant biblioteki przeznaczony dla języka Java. Z jego pomocą uprzednio zaimplementowane testy mogą być automatycznie uruchamiane. Biblioteka ta udostępnia także szereg klas i metod ułatwiających tworzenie automatycznych testów. Między innymi implementuje szereg asercji służących do porównań oczekiwanego wyjścia z faktycznie zaobserwowanym. Są to tzw. proste porównania. Należy więc pamiętać o konieczności stosowania filtrów w przypadkach kiedy chcemy usunąć pewne informacje z oczekiwanego i zaobserwowanego wyjścia. Ponadto biblioteka wspiera automatyczne wykonywanie pre- oraz post-processing’u.
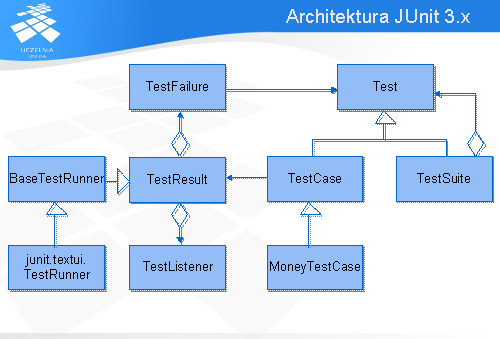
Biblioteka składa się z wielu klas i interfejsów jednak omówione zostaną tylko najważniejsze z nich. Klasą bazową dla wszystkich przypadków testowych jest klasa TestCase . W zamyśle autorów klasa miała reprezentować pojedynczy przypadek testowy. Choć jest to oczywiście możliwe, w praktyce w ramach tej klasy umieszcza się zbiór przypadków testowych, które mają te same metody do pre- i post- processing. Klasa TestCase udostępnia metody służące do prostych porównań, zwaneasercjami , o których mowa będzie w dalszej części wykładu.
Klasy reprezentujące przypadki testowe mogą być grupowane w zbiory wariantów testowych reprezentowane przez klasę TestSuite . Dzięki temu możliwe jest utworzenie hierarchii drzewiastej testów, co daje ich lepsze uporządkowanie i łatwiejsze zarządzanie nimi. Jak widać na powyższym diagramie zbiór przypadków testowych może zawierać także inny zbiór wariantów testów.
Wyniki wykonania testów przechowywane są w obiekcie klasy TestResult . Pojedynczy błąd reprezentowany jest przez obiekt klasy TestFailure . Istnieje wiele dodatków do biblioteki JUnit umożliwiających prezentowanie wyników testów w wielu różnych formatach m. in. pdf, html. Z tej możliwości korzystają również środowiska programistyczne (IDE) dopisując własne rozszerzenia integrujące bibliotekę ze swoimi interfejsami.
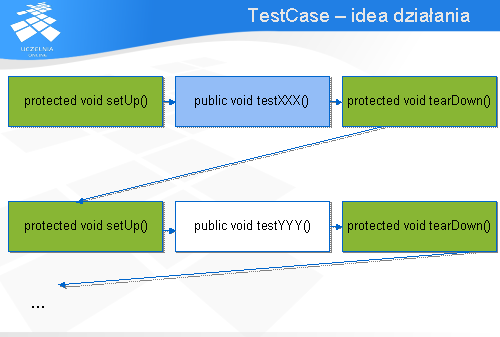
Wariant testu ma pewną strukturę. Pojedynczy przypadek testowy reprezentowany jest przez klasęTestCase . W praktyce jednak obiekt tej klasy grupuje te warianty testów, dla których wykonywane są te same metody pre- jak i post-processing. Pojedynczy przypadek testowy prezentowany jest przez metodę rozpoczynającą się od nazwy „test”. Metoda pre-processing powinna być zaimplementowana w metodziesetUp , a post-processing w metodzie tearDown .
Warianty testu wykonywane są następująco. Najpierw uruchamiana jest metoda setUp . Następnie wykonywany jest jeden przypadek testowy przez uruchomienie metody rozpoczynającej się od słowa „test”, po czym sterowanie przechodzi do metody tearDown , która odpowiada za post-processing. Jeśli w klasie zaimplementowano więcej niż jeden wariant testu (występuje więcej metod publicznych rozpoczynających się od słowa „test”) to ponownie wykonywana jest metoda setUp , następnie kolejna metoda rozpoczynająca się od słowa „test”, i ponownie tearDown .

Klasa TestCase posiada wiele metod służacych do prostych porównań zwanych asercjami. Dzięki nim można łatwo zweryfikować relacje między oczekiwanym wyjściem a faktycznym. Asercje te są metodami polimorficznymi mającymi postacie dla wielu typów danych w języku Java. Każda z asercji posiada wariant, dla którego istnieje możliwość podania komunikatu wyświetlanego gdy wykryte zostaną różnice pomiędzy wyjściem oczekiwanym a zaobserwowanym. Oczywiście jest to parametr opcjonalny i może być pominięty. Asercje składają się z następujących grup metod:

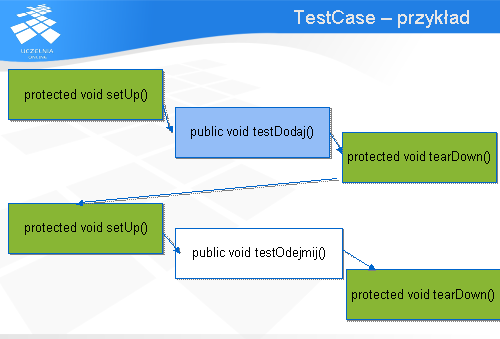
Na dwóch kolejnych slajdach przedstawiony zostanie przykład implementacji wariantów testujących klasę Pieniadze . Klasa ta reprezentuje kwotę pieniężną i udostępnia dwie metody: dodawania i odejmowania obiektów klasy Pieniądze . Wynikiem ich wykonania są obiekty klasy Pieniądze . Udostępniana jest również metoda equals , która podaje czy dany obiekt jest tożsamy obiektowi klasyPieniądze . Obiekty uznawane są za tożsame jeśli reprezentują tą samą kwotę pieniężną.

Dla klasy Pieniądze przygotowano dwa warianty testów po jednym dla każdej z metod: testDodaj oraztestOdejmij . Metoda setUp przygotowuje obiekt do testów. Jak widać przygotowanie to polega na utworzeniu instancji klasy. Metoda tearDown implementuje post-processing, czyli „sprzątanie” po testach. Jak widać zwalniana jest pamięć przydzielona dla obiektu klasy Pieniądze , a dokładniejGarbage Collector dostaje informację, że obiekt klasy Pieniądze nie jest już wykorzystywany i można zwolnić pamięć przez niego zajmowaną.
Metoda testDodaj implementuje wariant testu sprawdzający działanie metody dodaj w klasie Pieniądze. Wykonywane jest proste porównanie polegające na sprawdzeniu czy w wyniku dodawania dwóch kwot pieniężnych 4 oraz 8 uzyska się w wyniku obiekt klasy Pieniądze o wartości 12.
Analogicznie zaimplementowany jest przypadek dla odejmowania – metoda testOdejmij . Tutaj sprawdzane jest czy w wyniku odejmowania 4 od 3 otrzyma się obiekt klasy Pieniadze o wartości 1.
Wykonanie przez obiekt klasy TestRunner wariantów testów zaimplementowanych w klasiePieniadzeTest obrazuje powyższy slajd. Najpierw wykonywana jest metoda setUp ustawiająca obiekt klasy Pieniądze na kwotę 4. Następnie wykonywany jest pierwszy przypadek testowy zaimplementowany w metodzie testDodaj . Po wykonaniu przypadku testowego wykonywana jest metodatearDown , która „sprząta” po testach. Ponieważ w klasie są dwie metody „test” uruchamiana jest ponownie metoda setUp przygotowująca obiekt klasy Pieniądze dla drugiego wariantu testu. Wykonywany jest następnie przypadek testowy przez wywołanie metody testOdejmij . Na koniec ponowne wywołanie metody tearDown „ sprząta” system po testach.

Przypadki testowe można łączyć w zbiory wariantów testów (ang. test suite ) reprezentowane przez obiekty klasy TestSuite . JUnit umożliwia tworzenie takich zbiorów dwoma metodami: statyczną i dynamiczną.
Metoda statyczna w przeciwieństwie do metody dynamicznej wymaga „ręcznego” podania, które metody reprezentują przypadki testowe. Możliwe są dwa warianty utworzenia zbiorów testów tą drogą. Pierwszy polega na przeciążeniu metody runTest interfejsu Test implementowanego przez klasęTestCase . TestRunner biblioteki JUnit tak naprawdę nie rozróżnia obiektów TestCase od TestSuite . Odwołuje się do nich przez interfejs Test wywołując metodę runTest . Rozwiązanie polega na przeciążeniu tej metody i wywołanie w niej metod implementujących przypadki testowe wchodzące w skład tworzonego zbioru. W przykładzie pokazanym na slajdzie tworzony jest zbiór zawierający tylko jeden przypadek testowy jakim jest wariant weryfikujący działanie metody dodaj . Drugie rozwiązanie opiera się na wykorzystaniu klasy TestSuite . Do obiektu tej klasy dodawane są warianty testów przez wywołanie metody addTest . Proszę zwrócić uwagę w jaki sposób tworzone są obiekty reprezentujące poszczególne warianty testu. Otóż tworzone są obiekty klasy PieniadzeTest a jako argument wywołania konstruktora podawana jest nazwa metody implementująca wariant testu.






Wtedy w przypadku wystąpienia błędy podczas inicjacji, oprócz informacji o niemożności przeprowadzenia testu, wyświetlona zostanie dodatkowa informacja podająca powód, dla którego wariant testu nie mógł zostać wykonany.




Odmienną sytuacją jest przypadek, kiedy wariant testu sprawdza czy dany wyjątek jest wyrzucany przy określonych danych wejściowych. Nie wyrzucenie wyjątku oznacza błąd w programie. Biblioteka JUnit udostępnia dwa możliwe rozwiązania. Można wykorzystać metodę fail i umieścić ją zaraz pod metodą, która powinna spowodować wyrzucenie określonego wyjątku. Jeśli metoda ta nie zrobi tego to fail zakończy działanie przypadku testowego z informacją o błędzie. Należy jeszcze zabezpieczyć się przed ewentualnością wyrzucenia nieprawidłowego wyjątku. Metoda powinna być otoczona klauzulą try .. catch .. przechwytującą tylko dozwolone wyjątki. Wszystkie pozostałe zostaną odebrane przez bibliotekę JUnit, która poinformuje użytkownika o błędzie.
Drugim rozwiązaniem jest zastosowanie klasy ExceptionTestCase reprezentującej wariant testu, w którym wyrzucenie wyjątku spowoduje przejście testu. Obiekt tej klasy należy dodać do zbioru przypadków testowych, a w konstruktorze klasy podać nazwę metody zawierającej implementację wariantu testu, oraz wyrzucany wyjątek.

Często popełnianym błędem jest pisanie przypadków testowych zawierających efekty uboczne lub też zakładających pewną kolejność wykonywania się wariantów testu. Jednym z założeń przyświecających twórcom biblioteki JUnit jest niezależność poszczególnych przypadków testowych. Każdy z nich jest poprzedzony wywołaniem metody setUp , która ustawia stan testowanego systemu, oraz metody tearDown , która przywraca stan jaki był przed wykonaniem testu. Wszelkie sposoby ustawienia stanu systemu powinny być przeniesione z wariantów testu do metody setUp bądźtearDown .
Testowane powinny być metody biorące udział w interakcji z innymi obiektami. Do takich zalicza się metody publiczne i chronione. Czasem może zdarzyć się konieczność przetestowania metody prywatnej ze względu na jej nie trywialne zachowanie. W takim przypadku należy zastanowić się czy nie należy przerobić projektu klasy. Może to oznaczać, ze metoda ta powinna mieć mniej restrykcyjny zasięg. Jeśli oczywiście taka metoda ma być prywatna to jedynym rozwiązaniem jest wykorzystanie mechanizmu refleksji dostępnego w języku Java.

Na wykładzie przedstawiono wady i zalety wynikające z automatyzacji testów. Do niewątpliwych zalet należy zaliczyć zmniejszenie kosztu związanego z testowaniem nawet do 80% wysiłku spędzonego na ręcznym testowaniu kodu. Oszczędność ta umożliwia dokładniejsze sprawdzenie programu. Należy jednak pamiętać, że testy automatyczne nie dają efektywniejszych wariantów testu od ich „ręcznych odpowiedników”. Jedynie umożliwiają ich szybsze wykonanie. W związku z tym warianty testów, poddane automatyzacji muszą być dobrej jakości.
Na wykładzie przedstawione zostały czynności wchodzące w skład testowania. Dla każdej z nich podano potencjalne możliwości automatyzacji. Czynnościami, które warto automatyzować są: wykonywanie testów oraz porównywanie wyników testów z oczekiwanymi. W przypadku pozostałych opłacalność automatyzacji jest dyskusyjna.
Jako przykład narzędzia służącego do automatyzacji testów przedstawiono bibliotekę JUnit 3.8.x. Umożliwia ona wykonywanie testów i porównywanie uzyskanych wyników w sposób automatyczny.