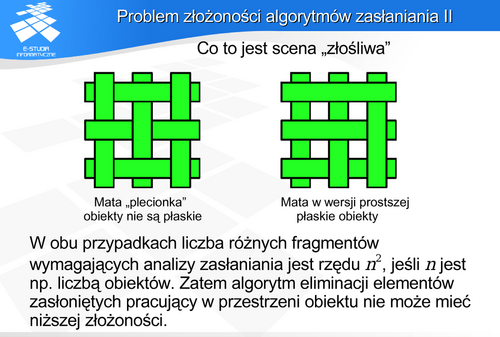
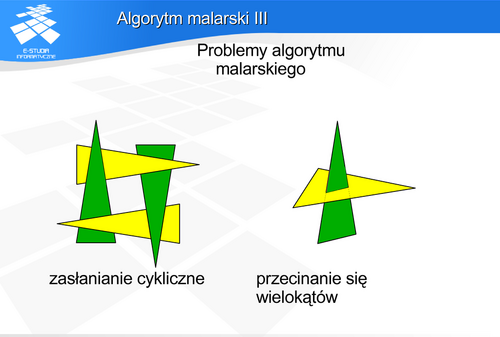
Jest to przykład problemu, dla którego nie jest znane jedno, uniwersalne rozwiązanie. Generalnie rzecz biorąc, zadanie to można traktować jako szeroko rozumiany problem sortowania. Z punkt widzenia obserwatora obiekty leżące dalej są zasłonięte przez obiekty leżące bliżej. Niestety to proste stwierdzenie nie przekłada się na równie prosty algorytm. Już samo określenie „jeden obiekt leżący dalej od drugiego” może prowadzić do niejednoznaczności, gdyż trudno przypisać jedną miarę odległości obiektowi zajmującemu pewien obszar w przestrzeni. Jak więc porównać położenia tych obiektów, a tym bardziej wyciągnąć wnioski o ich wzajemnym zasłanianiu. W skrajnym przypadku można wyobrazić sobie sytuację, że dwa obiekty zasłaniają się w taki sposób, że każdy jest częściowo zasłonięty przez drugi z nich. Do tego relacja częściowego zasłaniania nie jest relacją przechodnią. A zatem wyciągnięcie właściwego wniosku dotyczącego zasłaniania na podstawie wzajemnego położenia obiektów jest zadaniem trudnym.
Znanych jest bardzo wiele różnych algorytmów rozstrzygania widoczności. W latach siedemdziesiątych i osiemdziesiątych XX wieku powstało ich rzeczywiście dużo. Warto wspomnieć przynajmniej o kilku z nich.
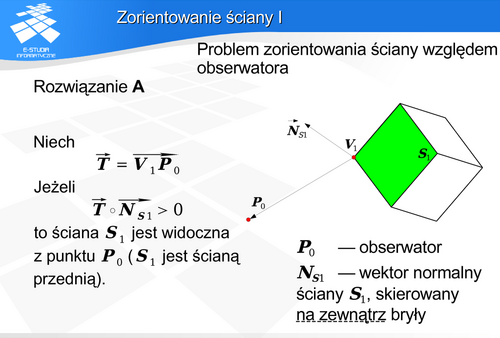
Zorientowanie ściany
Wielokąty ostatniej grupy są pomijalne, odpowiednie odcinki zostaną i tak narysowane jeśli pojawią się wielokąty widoczne.
W pierwszej i drugiej grupie występują wielokąty, które w całości podlegają określonym zasadom widoczności i przynależności do grupy. Nie może zachodzić przypadek, że tylko część wielokąta jest widoczna (a druga część zasłonięta). A zatem rozwiązanie zadania - wybór elementów widocznych w przypadku wielościanu wypukłego sprowadza się do określenia zbioru wielokątów należących do pierwszej grupy. I one powinny być (w całości) narysowane.
Można pokazać trzy (co najmniej) różne sposoby rozwiązanie tak zdefiniowanego zdania. Pierwszy sposób (Rozwiązanie A) polega na analizie położenia obiektów w przestrzeni. Definiowane są określone wektory a następnie jest wyznaczany iloczyn skalarny tych wektorów. Znak tego iloczynu określa przynależność do określonej grupy. Zwróćmy uwagę na fakt, że w tym przypadku nie ma w ogóle mowy o jakimkolwiek rzucie. Położenie obserwatora w przestrzeni w zupełności wystarczy.
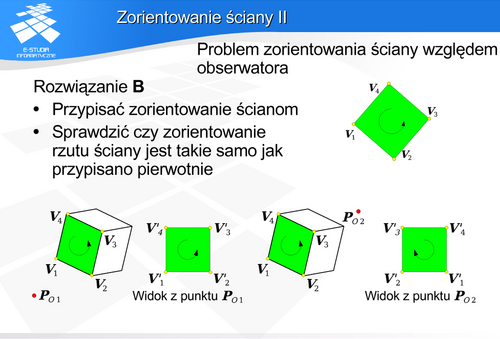
Porównywane jest zorientowanie ściany obiektu (w przestrzeni obiektu) i zorientowanie rzutu ściany (w przestrzeni rzutu). Jeśli oba zorientowania są jednakowe, to ściana jest widoczna (przednia).
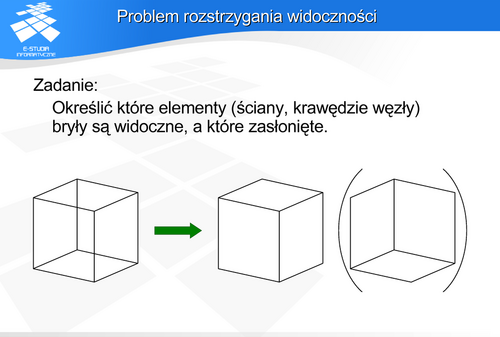
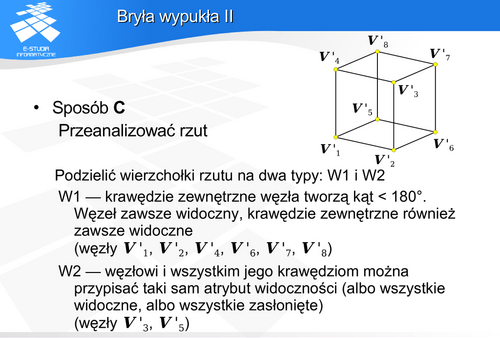
Bryła wypukła


Z drugiej strony często mówi się o precyzji obrazowej lub obiektowej danego algorytmu. Oznacza to, że algorytmy pracujące z precyzją obrazowa wykonują obliczenia z dokładnością urządzenia wyświetlającego (wynikającą z wyświetlania pojedynczego piksela). Algorytmy pracujące z precyzją obiektowa wykonują obliczenia z dokładnością związaną z definicją obiektów, a nie pikseli.
Bryła wypukła, złożoność algorytmów

Złożoność trzech wariantów algorytmów eliminacji elementów zasłoniętych dla wielościanu wypukłego jest liniowa. Jest to szczególny przypadek wśród algorytmów określania widoczności.
Bryła dowolna
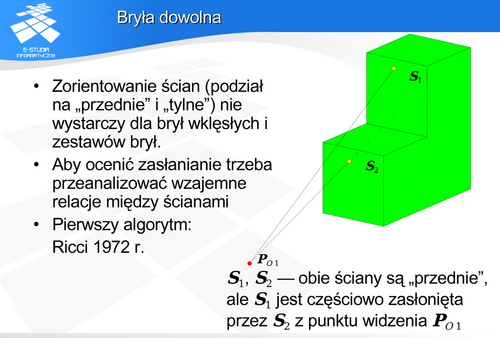
Pierwszy algorytm rozstrzygania widoczności dla dowolnych brył, przy założeniu że ściany są trójkątami (a przecież dowolny wielokąt zawsze może zostać rozłożony na zbiór trójkątów) podał Ricci w 1972 roku. Był to algorytm pracujący metodą „każdy z każdym” o kwadratowej złożoności obliczeniowej.

Jeśli na przykład rozpatrzymy scenę zawierającą wielościany, to o widoczności wierzchołków możemy np. wnioskować na podstawie widoczności ściany.: Jeśli ściana jest widoczna to również jej węzły są widoczne, Tego typu wnioski powinny być ostrożnie formułowane, gdyż nie wszystkie sytuacje są oczywiste (np. wniosek, że odcinek łączący widoczne węzły jest widoczny, nie zawsze jest prawdziwy).
Przykłady algorytmów


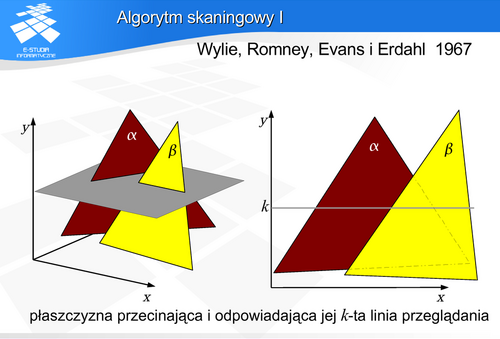
Kolejne linie poziome obrazu można rozpatrywać jako przecięcie ekranu i pewnej płaszczyzny prostopadłej do ekranu. Taka płaszczyzna przetnie wszystkie obiekty sceny. Każda linia obrazu może być rozpatrywana niezależnie. Problem rozstrzygania widoczności można zatem uprościć do niezależnej analizy każdej linii, przechodząc z analizy położenia wielokątów w przestrzeni trójwymiarowej do analizy położenia odcinków na płaszczyźnie.

Analiza widoczności polega na analizie kolejnych odcinków między punktami przecięć w tablicy krawędzi. Punkty takiego pojedynczego odcinka należą do pewnego zbioru rzutów wielokątów.
Jeśli ten zbiór jest pusty, to odcinek ten (tzn. odpowiadające mu piksele urządzenia wyświetlającego) należy wypełnić barwą tła.
Jeśli zbiór jest jednoelementowy, to znaczy, że piksele tego odcinka należą dokładnie do jednego rzutu wielokąta. A to oznacza, że nie zachodzi żadne zasłanianie i piksele odpowiadające temu odcinkowi należy wypełnić barwą rzutu danego wielokąta.
Jeśli zbiór rzutów jest dwu lub więcej elementowy, to do wypełniania należy użyć barwy tego wielokąta, który jest najbliżej obserwatora. Oczywiście w tym przypadku wybór elementu najbliższego jest bardzo prosty, gdyż rozpatrujemy przecięcia wielokątów i płaszczyzny tnącej, czyli zbiór odcinków na płaszczyźnie.
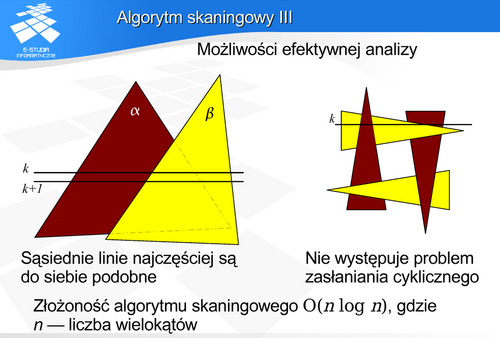
Złożoność algorytmu jest taka jak sortowania i wynika z pierwszej fazy algorytmu. Modyfikacje usprawniające (takie jak na przykład uproszczona analiza sąsiednich linii) nie wpływają na złożoność asymptotyczną, ale mogą w określonych sytuacjach przyspieszyć działanie algorytmu.
Algorytm skaningowy rozwiązuje również problem zasłaniania cyklicznego. Ponieważ w pojedynczym kroku analizujemy jedną linię obrazową czyli jedno przecięcie płaszczyzną tnącą, to zasłanianie cykliczne nie stanowi problemu, gdyż na tej płaszczyźnie nie może zachodzić zasłanianie cykliczne odcinków.
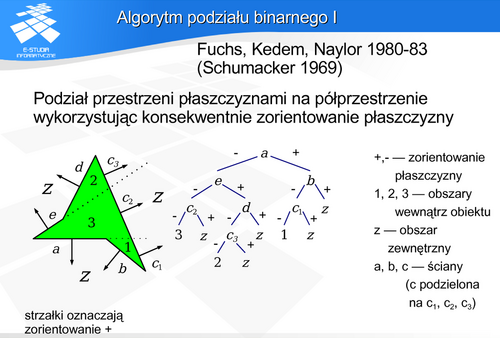
Rozpatrzmy przypadek jak na rysunku. Każdej płaszczyźnie można przypisać zorientowanie (zaznaczone strzałkami, zwrot zgodny ze strzałkami został w drzewie zaznaczony + , zwrot przeciwny został oznaczony - ). Kolejność analizy (budowy drzewa podziału) – to znaczy wybór kolejnych płaszczyzn jest dowolny. Może to oczywiście wpłynąć na kształt drzewa, wpływa także na konieczność podziału ścian wielościanu. Na przykład ściana  na rysunku została podzielona na fragmenty
na rysunku została podzielona na fragmenty  ,
,  i
i  , co wynika z wcześniejszego podziału przestrzeni. Algorytm podziału binarnego w takiej postaci może zostać także wykorzystany do sprawdzenia czy dany punkt należy do wnętrza wielościanu.
, co wynika z wcześniejszego podziału przestrzeni. Algorytm podziału binarnego w takiej postaci może zostać także wykorzystany do sprawdzenia czy dany punkt należy do wnętrza wielościanu.

procedure przeglądaj_BSP (drzewo)
begin
end;
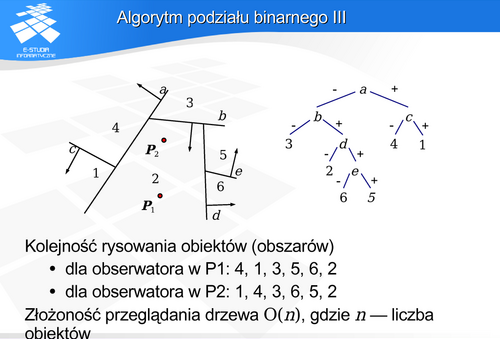
Oczywiście drzewo nie uwzględnia położenia obserwatora, natomiast położenie to wpływa na drogę przejścia przez drzewo. Rysunek pokazuje różne kolejności rysowania obiektów dla dwóch różnych położeń obserwatora.
Ciekawym przypadkiem jest sytuacja, gdy obserwator znajduje się wewnątrz obszaru. Wtedy drzewo binarnego podziału pokazuje właściwą kolejność bez względu na kierunek patrzenia obserwatora !
Algorytm drzewa binarnego podziału przestrzeni był bardzo długo traktowany jako niezwykle elegancka ciekawostka, ze względu na skomplikowanie tworzenia drzewa podziału. Dopiero silny rozwój gier komputerowych w latach 90 dwudziestego wieku spowodował, że algorytm ten przeżywa swój renesans. Zauważono bowiem, że warto na użytek gier rozdzielić etap tworzenia drzewa od etapu przeglądania. Jeśli przyjmiemy, że w każdym elemencie podziału znajduje się jeden obiekt sceny, to samo przeglądanie algorytmem INORDER± ma złożoność liniową ze względu na liczbę obiektów i to niezależnie od zbalansowania drzewa.
Drzewo zostaje zatem utworzone przez twórców gry w momencie generowania „mapy” gry. Natomiast przeglądane jest w momencie realizacji (wirtualnego poruszania się gracza/bohatera po świecie gry). Co więcej, sprawę można dodatkowo uprościć dzieląc mapę na obszary, w których jest ustalona kolejność rysowania obiektów, a następnie zapisać gotowe schematy kolejności dla poszczególnych obszarów. W tym przypadku podczas realizacji gry nawet przeglądanie drzewa nie jest potrzebne.
Warto dodać, że w latach 1992-1995 (Teller, Luebke, Georges) powstała metoda wyboru potencjalnych elementów widocznych (ang.PVS – Potentially Visible Set) pozwalająca określić przybliżony zakres widoczności obiektów. Metoda ta jest często łączona z generacją drzewa BSP.
 .
.
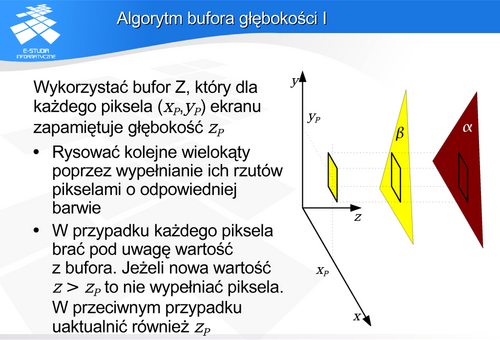
Na początku pracy algorytmu bufor Z jest wypełniany maksymalną wartością współrzędnej z, jaka może wystąpić w analizowanym obszarze. Jednocześnie wszystkie piksele obrazu przyjmują barwę tła. Następnie rysowane są wielokąty (w dowolnej kolejności) – to znaczy wypełniane są ich rzuty odpowiednią barwą. Podczas wypełniania zwykła procedura wypełniająca jest poszerzona o sprawdzenie głębokości odpowiadającej danemu pikselowi. Piksel jest wypełniony tylko wtedy, kiedy jego z jest mniejsze niż wartość zapisana w buforze.
Mechanizm ten powoduje, że podczas wypełniania kolejnych wielokątów szukany jest piksel, którego współrzędna z jest najmniejsza – to znaczy szukany jest punkt leżący najbliżej obserwatora – czyli punkt rzeczywiście widoczny.

Algorytm ma tylko jedną wadą – potrzebuje pamięci o rozmiarze obrazu pozwalającej zapisać odległość dla każdego piksela. Jeszcze do niedawna (koniec dwudziestego wieku) był to warunek trudny do spełnienia. Realizacja algorytmu wymagała dodatkowo wykonania podziału obrazu na fragmenty, które mogły być razem z odpowiadającym mu buforem zmieszczone do pamięci. Dzisiaj nie stanowi to żadnego problemu.
Prostota algorytmu sprzyja również implementacji sprzętowej. Stacje graficzne i większość dobrych kart graficznych ma dzisiaj możliwość sprzętowej realizacji bufora głębokości.
Algorytm rysowania wykresu funkcji z=f(x,y)

Powierzchnia będąca wykresem funkcji  należy do szczególnej klasy obiektów trójwymiarowych, dla której można pokazać uproszczony algorytm rozstrzygania widoczności.
należy do szczególnej klasy obiektów trójwymiarowych, dla której można pokazać uproszczony algorytm rozstrzygania widoczności.
Można przyjąć, że dziedziną D funkcji dla rozpatrywanego fragmentu powierzchni jest prostokąt ![[x_{min},x_{max}] X [y_{min},y_{max}]](images/EXTERN_0006.png) . Jeśli dziedzinę D podzielimy równomierną siatką za pomocą linii równoległych odpowiednio do osi
. Jeśli dziedzinę D podzielimy równomierną siatką za pomocą linii równoległych odpowiednio do osi  i osi
i osi  , to punkt
, to punkt ![[x_i,y_j]](images/EXTERN_0009.png) będzie węzłem takiej siatki (dla
będzie węzłem takiej siatki (dla  oraz
oraz  , gdzie
, gdzie  ,
,  określają liczbę linii siatki dla każdej współrzędnej). Punkt
określają liczbę linii siatki dla każdej współrzędnej). Punkt ![[z_{ij},x_i,y_j]](images/EXTERN_0014.png) dla
dla  jest węzłem siatki rozpiętej na powierzchni będącej wykresem punkcji. Taki przykład najczęściej występuje w zastosowaniach praktycznych, gdzie wartości węzłowe pochodzą na przykład z pomiarów lub symulacji. Przybliżoną powierzchnię rysujemy łącząc węzły odcinkami.
jest węzłem siatki rozpiętej na powierzchni będącej wykresem punkcji. Taki przykład najczęściej występuje w zastosowaniach praktycznych, gdzie wartości węzłowe pochodzą na przykład z pomiarów lub symulacji. Przybliżoną powierzchnię rysujemy łącząc węzły odcinkami.
Watkins w 1974 roku zaproponował algorytm maskowania pozwalający rysować kolejne krzywe (łamane) siatki rozpiętej na powierzchni będącej wykresem funkcji. Można zauważyć dotychczas narysowany fragment (pierwszym takim fragmentem jest obszar powierzchni pomiędzy pierwszymi dwoma krzywymi/łamanymi) może zasłaniać wszystkie później rysowane elementy powierzchni. A zatem do realizacji algorytmu wystarczy zdefiniować bufor górny (ograniczenie górne  we współrzędnych rzutu) i bufor dolny (ograniczenie dolne
we współrzędnych rzutu) i bufor dolny (ograniczenie dolne  we współrzędnych rzutu), a następnie w każdym kroku sprawdzać położenie rysowanego elementu (odcinka) względem buforów. Jeśli element jest powyżej ograniczenia górnego lub poniżej dolnego to jest rysowany, w przeciwnym przypadku (między ograniczeniami) to nie jest rysowany. Oczywiście każdy narysowany element powiększa (rozszerza w danym kierunku) odpowiednie ograniczenie.
we współrzędnych rzutu), a następnie w każdym kroku sprawdzać położenie rysowanego elementu (odcinka) względem buforów. Jeśli element jest powyżej ograniczenia górnego lub poniżej dolnego to jest rysowany, w przeciwnym przypadku (między ograniczeniami) to nie jest rysowany. Oczywiście każdy narysowany element powiększa (rozszerza w danym kierunku) odpowiednie ograniczenie.
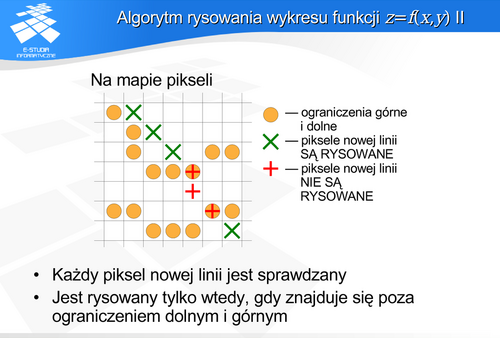
W tym celu rozpatrzmy tę samą sytuację ale na mapie pikseli. Ograniczenia górne i dolne w tym przypadku odpowiadają zestawowi pikseli, które w kolejnych kolumnach określają minimalną i maksymalną wysokość. Rysując każdy nowy piksel wystarczy sprawdzić jego położenie względem tego minimum lub maksimum. A to jest operacją bardzo prosta. Jeśli nowy piksel jest powyżej maksimum (lub poniżej minimum) to jest rysowany, jeśli pomiędzy minimum i maksimum, to rysowany nie jest. Oczywiście rysowany piksel przesuwa odpowiednie maksimum (lub minimum).
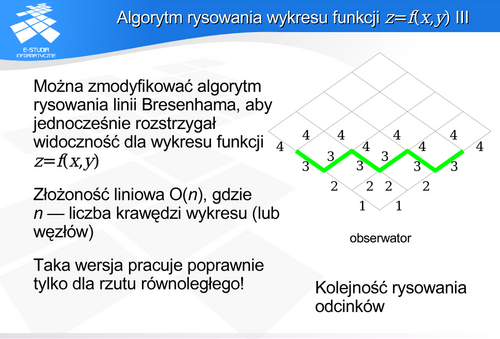
Dodatkowo należy zwrócić uwagę na kolejność wyboru do rysowania odcinków siatki. Jeśli byłyby one rysowane w naturalnej kolejności związanej z rodzinami linii dla stałego x, i dla stałego y, to mogłyby wystąpić problemy z wzajemnym zasłanianiem. Dobrym rozwiązaniem jest kolejność typu ZIG-ZAG (tzn. odcinki na przemian z każdej rodziny) lub kolejność zaproponowana na rysunku.
Warto dodatkowo zwrócić uwagę na fakt, że taka wersja algorytmu poprawnie pracuje tylko dla rzutu równoległego wykresu funkcji. Analiza rysowania na mapie pikseli z uwzględnieniem minimum i maksimum kolumny pokazuje, że dla odcinków rysowanych w rzucie perspektywicznym wystąpią błędy.
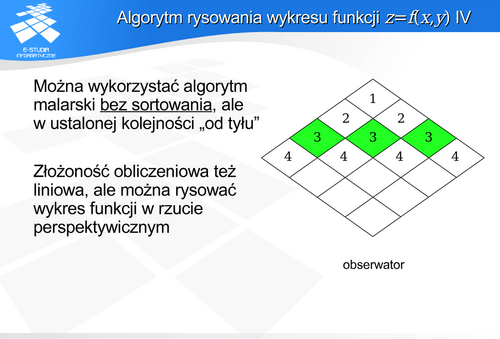
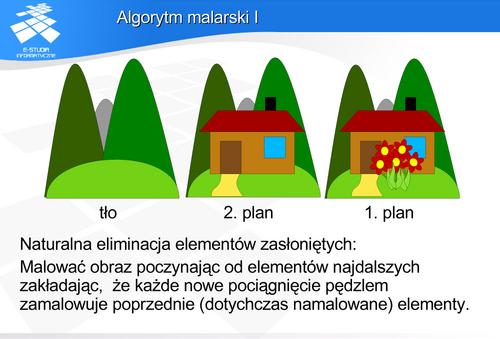
Zastosowanie algorytmu malarskiego ma dodatkową zaletę: algorytm ten poprawnie rysuje powierzchnię będącą wykresem funkcji także dla rzutu perspektywicznego.
Algorytm rysowania powierzchni będącej wykresem funkcji dwóch zmiennych jest przykładem algorytmu rozstrzygania widoczności dla szczególnej klasy obiektów trójwymiarowych. Drugim przykładem tego typu zadania jest algorytm rysowania figur obrotowych. Szczegóły tego algorytmu czytelnik może znaleźć w książce M.Jankowskiego Elementy grafiki komputerowej.
Problem złożoności algorytmów zasłaniania

Dla algorytmów pracujących w przestrzeni rzutu (z precyzją obrazową) złożoność będzie liniowa.