W pewnym sensie będzie to rozwinięcie pierwszego wykładu, w ramach którego była mowa o zasadach skutecznego działania.
Witam serdecznie!
Na dzisiejszym wykładzie będzie mowa o kontroli jakości artefaktów. Większość artefaktów, czyli wytworów rąk ludzkich, wymaga kontroli jakości. Na slajdzie mamy pokazaną kontrolę jakości płytki krzemu w świetle zielonej lampy.
W trzeciej części wykładu zostanie zaprezentowana konkretna metoda dokonywania przeglądów oprogramowania zwana przeglądami Fagana.
Ostatnią część wykładu chciałbym poświęcić problemowi szacowania liczby defektów, jakie pozostały w kodzie lub w specyfikacji po przeprowadzeniu przeglądu.
Zacznijmy od pojęcia jakości.

Jeśli mówimy o jakości (a w przeglądach chodzi o zapewnienie jakości), to trzeba sobie zdawać sprawę, że jakość ma dwa oblicza: można mówić o jakości projektu i jakości wykonania. Jakość projektu, jest to zespół cech zależnych od pomysłów twórców. Jeśli mówimy o jachcie, to jakość projektu mogłaby dotyczyć jego szybkości, liczby miejsc w kajucie, wyposażenia tego jachtu w sprzęt nawigacyjny itd. Niektóre z rozwiązań mogą być tak bardzo innowacyjne, że zdecydowanie przyciągną uwagę potencjalnego klienta i będzie miał ochotę taki jacht kupić. Ale jest też druga strona jakości – jakość wykonania. Jeśli okaże się, że wykonanie jest słabe, że tu się coś nie domyka, a tam tapeta zaczyna się odklejać, to klient może się szybko zniechęcić. Podobnie jest z oprogramowaniem. Jakość projektu to będzie w tym przypadku wartość pomysłów dotyczących funkcjonalności systemu, ergonomiczność interfejsu użytkownika, założona przepustowość. Jeśli chodzi o jakość wykonania, to będą to wszelkiego rodzaju defekty, które spowodują, że system czegoś nie będzie mógł wykonać, że w pewnych warunkach się zawiesi itd.
W dalszej części wykładu będzie mowa o jakości w sensie jakości wykonania.
Osiem wymiarów jakości

Bardzo ciekawą klasyfikację atrybutów związanych z jakością zaproponował David Garvin z Harvard Business School. Według niego można mówić o ośmiu wymiarach jakości.
Pierwszy dotyczy szeroko rozumianej wydajności. W przypadku systemu informatycznego mogłaby to być np. szybkość przetwarzania liczona w transakcjach na minutę.
Drugim wymiarem jest niezawodność. Można ją rozumieć np. jako częstotliwość pojawiających się błędów w zachowaniu systemu albo jako średni czas międzyawaryjny.
Trzecim wymiarem jest wytrzymałość. W odniesieniu do sprzętu takiego jak telefon komórkowy, czy komputer to łatwo ją zinterpretować – jak długo ten sprzęt będzie działał. W przypadku oprogramowania jest trudniej, ale można by przyjąć, że chodzi w tym przypadku o to, jak długo system będzie mógł pracować bez istotnych modyfikacji funkcjonalnych. Jeśli dobrze został zaprojektowany (ma np. wbudowane mechanizmy dostosowania), to może być bardzo długo wykorzystywany (słyszałem o oprogramowaniu, które było wykorzystywane podobno przez 30 lat bez żadnych modyfikacji).
Czwartym wymiarem składającym się na jakość jest łatwość naprawy. Jest to w dużej mierze cecha projektu. Jeśli oprogramowanie zostało zaprojektowane modularnie z użyciem odpowiednich wzorców, to jego naprawa będzie pewnie dużo łatwiejsza niż oprogramowania o strukturze monolitycznej.
Estetyka w przypadku oprogramowania chyba najbardziej odnosi się do interfejsu użytkownika. Do samego kodu klient rzadko zagląda, zatem trudno byłoby tutaj mówić o wrażeniach estetycznych.
Cechy funkcjonalne David Garvin wymienia na 6. miejscu. W przypadku systemów informatycznych są one niezmiernie ważne i mogą odgrywać pierwszoplanową rolę przy wyborze systemu.
Na nasze postrzeganie jakość ma wpływ także reputacja wytwórcy. Jest to szczególnie widoczne w przemyśle samochodowym. W informatyce odgrywa to chyba znacznie mniejszą rolę.
Ósmym wymiarem (czy kryterium jakości) według Garvina jest zgodność ze standardami i innymi wymaganiami. W informatyce dopiero rodzą się standardy dotyczące różnego typu aplikacji (swego czasu trwały w Polsce intensywne prace sponsorowane przez Stowarzyszenie Księgowych w Polsce i Polskie Towarzystwo Informatyczne dotyczące standardu dla systemów finansowo-księgowych). Zazwyczaj, jeśli w jakimś obszarze standardy i wymagania prawne istnieją, to wchodzą do wymagań dotyczących budowanego systemu i MUSZĄ być honorowane.

W przypadku systemów informatycznych można powiedzieć, że ich jakość opiera się na czterech filarach:

O ważności problematyki dotyczącej kontroli jakości mogą świadczyć przetargi organizowane przez różne instytucje rządowe a dotyczące zapewnienia jakości. Na przykład w związku z budową systemu informatycznego do obsługi wyborów parlamentarnych i prezydenckich ogłoszono osobny przetarg o wartości ok. 1 mln zł na przetestowanie tego systemu.
Podobna sytuacja była przy budowie systemu informatycznego dla Głównego Inspektora Informacji Finansowej (jest to jedna z kluczowych pozycji w Ministerstwie Finansów). Ogłoszony przetarg na kontrolę jakości miał wartość kilkuset tysięcy złotych.
Podobnej skali przedsięwzięciem była kontrola jakości Systemu Zintegrowanej Taryfy Celnej ISZTAR2.
Jak więc widać, rodzi się rynek na usługi w zakresie kontroli jakości oprogramowania.
Przejdźmy teraz do omówienia podstawowych zagadnień dotyczących testowania. Jak już wspomniałem, ta problematyka będzie szerzej omówiona w trakcie osobnych dwóch wykładów.

Pierwsze pytanie, jakie można postawić, jest następujące: co to jest testowanie? Według Glena Myersa testowanie jest to wykonanie programu celem znalezienia błędu. Ta końcówka zdania „celem znalezienia błędu” jest bardzo ważna.
Wynika z niej, że udany test to taki, który wykrywa jeszcze nie wykryty błąd (jeśli test wykrywa błąd, o którym już wiemy, że istnieje, to nie jest to dla nas żadna ważna informacja).
Na tej podstawie można przyjąć, że miarą jakości przypadku testowego jest prawdopodobieństwo znalezienia jeszcze nie wykrytego błędu.
Pracochłonność testowania

Kolejne pytanie, jakie powstaje, to ile czasu potrzeba na testowanie? Inaczej mówiąc, jaką część całkowitej pracochłonności zajmuje testowanie?
Według Rogera Pressmana, jednego z uznanych ekspertów w dziedzinie inżynierii oprogramowania, w amerykańskich przedsięwzięciach informatycznych testowanie typowego projektu pochłania 30 do 40% ogólnej pracochłonności. Jest to całkiem sporo. Wynika z tego, że jeżeli 1000 godzin poświęcamy na specyfikację wymagań, projekt architektury systemu, kodowanie, napisanie dokumentacji, to dodatkowe 500 godzin zajmie testowanie takiego systemu.
W przypadku systemów krytycznych (takich, jak sterowanie samolotem albo pracą elektrowni jądrowej) testowanie zajmuje jeszcze więcej czasu i może sięgać nawet 80% całkowitej pracochłonności.
Rodzaje testowania
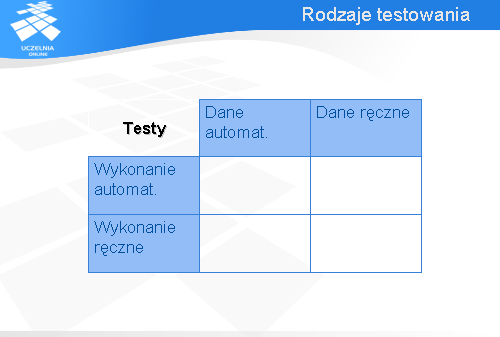
Część prac związanych z testowaniem może być zautomatyzowana. Jeśli mówimy o testowaniu, to mamy na myśli dwie grupy zadań:
Każda z tych czynności może być wykonana ręcznie (tzn. przez człowieka) lub automatycznie (przez komputer). Są więc możliwe cztery podejścia do testowania.

Pierwszy wariant dotyczy sytuacji, gdy wszystko jest realizowane automatycznie, zarówno opracowanie danych testowych, jak i wykonanie testów. To podejście jest bardzo atrakcyjne, ale póki co udaje się to robić tylko w bardzo ograniczonym zakresie. Generalnie nie można jeszcze – w przypadku komercyjnych przedsięwzięć – mówić o w pełni automatycznym testowaniu wszystkich możliwych właściwości systemu informatycznego.
Zaznaczmy zatem ten wariant kolorem szarym – być może w przyszłości będzie to, przynajmniej w dużym stopniu, możliwe, ale teraz nie ma jeszcze warunków (głównie wiedzy i narzędzi), żeby firmy informatyczne mogły na tym podejściu polegać.
Drugi wariant, to ręcznie przygotowywane dane i automatycznie wykonywane testy. Jest to podejście znajdujące coraz szersze uznanie i będące jedną z głównych praktyk zapewniania jakości w metodyce zwanej Programowaniem Ekstremalnym (w skrócie XP).
Można też myśleć o ręcznym wykonywaniu testów według danych przygotowanych przez komputer. Może to mieć sens tylko w wyjątkowych wypadkach. Jeśli chodzi o testowanie oprogramowania, to raczej takie podejście nie ma sensu, bowiem przy wymyślaniu testów potrzebna jest kreatywność i tutaj człowiek ma znaczną przewagę nad komputerem, natomiast samo wykonanie ma charakter czysto automatyczny (trzeba wprowadzić dane i zobaczyć, czy wyniki odpowiadają oczekiwaniom) – w tym zakresie komputer jest znacznie szybszy od człowieka i nie nuży się wykonywaniem tego typu zadań.
Zatem oznaczmy ten wariant kolorem czarnym, żeby pokazać, że raczej nie ma on praktycznego znaczenia.
Ostatni, czwarty, wariant polega na wykonywaniu wszystkiego przez człowieka. Jego zadaniem jest zarówno przygotowanie przypadków testowych, jak i ich wykonanie. W praktyce ten wariant jest szeroko stosowany.
Teraz główna dyskusja dotyczy w zasadzie tylko jednej kwestii: czy warto automatycznie wykonywać testy, czy nie. Jeśli chodzi o przygotowywanie danych testowych i oczekiwanych wyników, to raczej jest tutaj zgodność, że należy powierzyć to zadanie człowiekowi.
Plan wykładu
Pozostawmy problematykę dotyczącą testowania i przejdźmy do omówienia przeglądów, jako metody kontroli jakości.
Anomalia
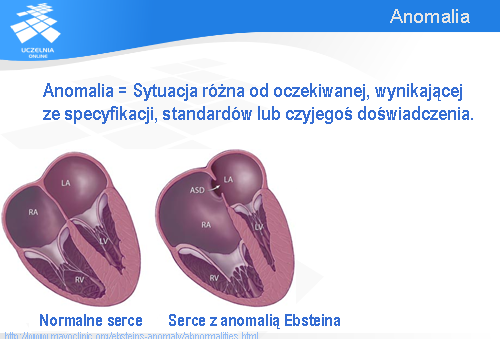
Zacznijmy od pojęcia anomalii. Na slajdzie pokazane są dwa serca. To z lewej jest normalne, to z prawej ma wadę zwaną anomalią Ebsteina. Między innymi widać na prawym zdjęciu znacznie powiększoną prawą komorę serca oznaczoną jako RA.
Na użytek wykładu przyjmiemy definicję anomalii zaproponowaną w standardzie IEEE 1028 dotyczącym przeglądów. Przez anomalię rozumie się sytuację różną od oczekiwanej, przy czym oczekiwania opierają się na specyfikacji, standardach lub na czyimś doświadczeniu. Ta definicja pasuje zarówno do anomalii anatomicznych, jak i do anomalii dotyczących oprogramowania.
Przegląd

Zgodnie ze standardem IEEE 1028 przegląd (po angielsku „review”) jest to proces lub spotkanie, w trakcie którego artefakt związany z oprogramowaniem (np. kod) jest prezentowany różnym osobom w celu skomentowania lub uzyskania jego zatwierdzenia. Inaczej mówiąc, przegląd jest to ocena artefaktu (np. kodu lub specyfikacji) realizowana przez grupę osób.
Inspekcja (po angielsku „inspection”) jest to wizualne sprawdzenie artefaktu celem wykrycia lub zidentyfikowania anomalii dotyczących oprogramowania. Inspekcje są przeprowadzane przez osoby z tego samego szczebla zarządzania (szefowie nie biorą w nich udziału), a prowadzą je specjalnie przeszkoleni (niezależni) moderatorzy (po angielsku „facilitators” lub „Inspection leaders”).
Rola przeglądów
Przeglądy i inspekcje spełniają dwie funkcje: z jednej strony służą zapewnieniu jakości, a z drugiej są sposobem przekazywania informacji o tworzonym oprogramowaniu. Jeśli nawet ktoś nie tworzył danego modułu, ale brał udział w jego inspekcji, to na pewno będzie więcej wiedział na temat tego modułu niż ktoś, kto w ogóle nie miał styczności z tym modułem. Podobnie jest z inspekcją specyfikacji. Ponadto, jeśli programista w trakcie inspekcji specyfikacji nie wykrył jakiegoś błędu, to później z większym zrozumieniem odniesie się do tego błędu, gdy go wykryje na etapie np. kodowania.
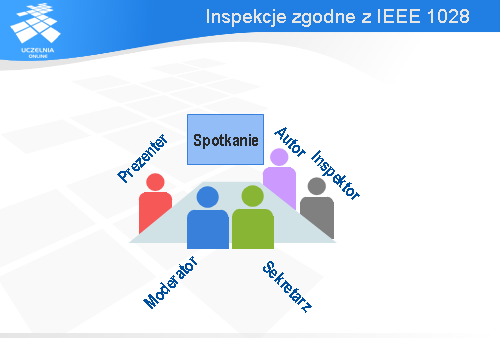
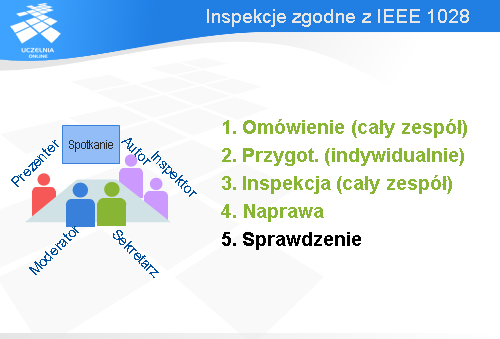
Chciałbym przedstawić inspekcje w wersji zgodnej ze standardem IEEE 1028 z 1997 roku. Jak już wspomniałem, spotkanie inspekcyjne jest prowadzone przez moderatora. Jego zadaniem jest zaplanowanie inspekcji, sprawne jej przeprowadzenie i zebranie danych związanych z inspekcją. Zgodnie ze standardem IEEE 1028 oprócz moderatora są jeszcze cztery inne role.
Zadaniem prezentera jest przedstawienie artefaktu (np. kodu lub specyfikacji wymagań) w zrozumiały sposób i podkreślenie najistotniejszych elementów.
Zadaniem autora artefaktu jest przygotowanie go do inspekcji, wyjaśnienie ewentualnych wątpliwości, jakie mogą się pojawić się w trakcie inspekcji i usunięcie defektów wykrytych w trakcie inspekcji.
Inspektor jest to główna rola. Zadaniem inspektora jest wykrycie anomalii, jakie być może zakradły się do badanego artefaktu. Zazwyczaj w inspekcji bierze udział kilku inspektorów reprezentujących różne punkty widzenia. W roli inspektora może być analityk, reprezentant klienta, specjalista od bezpieczeństwa systemów informatycznych itp.
Ostatnią, piątą rolą jest rola sekretarza. Sekretarz ma dokumentować wykryte anomalie, podjęte decyzje, rekomendacje itp. Rolę sekretarza i moderatora może pełnić ta sama osoba.
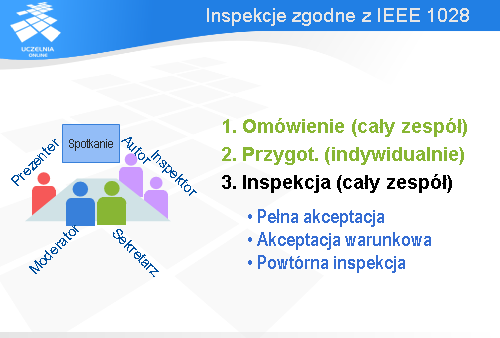
Każda inspekcja powinna być poprzedzona działaniami przygotowawczymi ze strony kierownictwa oraz czynnościami o charakterze planistyczno-organizacyjnymi, za które odpowiada moderator.
Cały proces składa się z pięciu kroków. Najpierw ma miejsce omówienie. Spotyka się cały zespół biorący udział w inspekcji i autor przedstawia ogólne omówienie artefaktu, natomiast moderator podaje – dla orientacji – dane dotyczące minimalnego czasu, jaki będzie potrzebny na przygotowanie się inspektorów do inspekcji oraz jak wiele anomalii wykryto we wcześniejszych tego typu przedsięwzięciach.
Potem każdy z inspektorów pracuje indywidualnie i ocenia dany artefakt (tzn. czyta kod, czy też specyfikację). Oczywiście, w trakcie czytania zauważa różne anomalie, które dokumentuje na formularzach przygotowanych przez moderatora i przekazuje te formularze moderatorowi. Moderator zbiera informację o anomaliach i przesyła je dalej do autora. Ponadto moderator lub prezenter ustalają sposób prezentacji artefaktu w trakcie spotkania, jakie się ma odbyć.
W trzecim kroku dochodzi do drugiego spotkania inspekcyjnego, w którym bierze udział cały zespół inspektorów. Moderator otwiera spotkanie, sprawdza, czy wszyscy inspektorzy są przygotowani do inspekcji i prezentowane są uwagi natury ogólnej dotyczące artefaktu. Następnie prezenter przedstawia artefakt i zaczyna się omawianie dostrzeżonych anomalii.
Na końcu podejmowana jest decyzja w sprawie artefaktu. Są trzy możliwości:
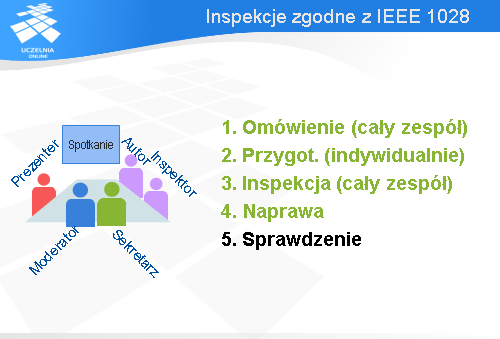
W czwartym kroku ma miejsce korekta wykrytych anomalii.
Na końcu dochodzi do sprawdzenia, przez moderatora lub inną wyznaczoną osobę, czy korekty zostały poprawnie wprowadzone. Jeśli nie wykryto żadnych anomalii, to ten krok jest pusty. Jeśli była decyzja, że potrzebna jest jeszcze jedna inspekcja, to ten krok zamienia się w kolejną inspekcję.
Inspekcja Fagana

Aby przedstawić pewne dane charakteryzujące pracochłonność inspekcji i mogące pomóc w prawidłowym jej zaplanowaniu odwołam się do inspekcji Fagana. Był to historycznie pierwszy rodzaj inspekcji przeprowadzanych w odniesieniu do oprogramowania. Koncepcja ta narodziła się w połowie lat 70-tych w firmie IBM. W tamtych czasach cykl życia oprogramowania był w firmie IBM podzielony na trzy fazy: projekt, kod i testy. Projekt obejmował tzw. specyfikacje zewnętrzne (dzisiaj nazywamy to specyfikacją wymagań), specyfikacje wewnętrzne dotyczące interfejsów modułów kodu i specyfikacje logiki przetwarzania. Oznaczmy przez I1 inspekcje projektu, czyli inspekcje specyfikacji logiki przetwarzania. Jeszcze będziemy się do nich odwoływać. Kodowanie było podzielone na dwie fazy: samo kodowanie w sensie pisania programu i testowanie jednostkowe. Niech I2 oznacza inspekcje kodu.
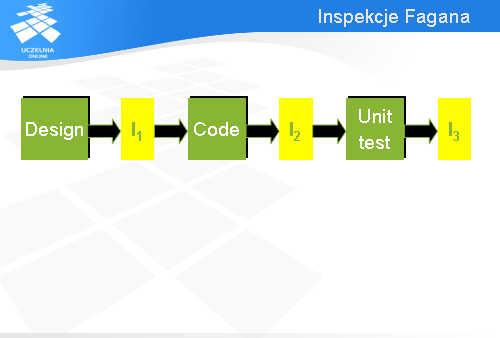
Fagan wprowadził inspekcje dotyczące projektu rozumianego jako specyfikacja logiki przetwarzania (Design) i przeprowadzane zaraz po tej fazie (I1 oznacza tę właśnie inspekcję), inspekcje kodu (Code) oznaczone na slajdzie przez I2 i dodatkowe inspekcje oprogramowania przeprowadzane po testowaniu jednostkowym (na slajdzie oznaczone jako I3).
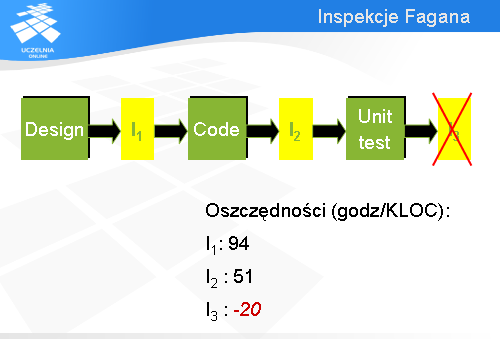
Z zebranych przez Fagana danych wynika, że wprowadzenie inspekcji projektu (I1) pozwoliło zaoszczędzić średnio 94 godziny na każdym tysiącu linii kodu. Inspekcje kodu (I2) dały oszczędności w wysokości 51 godzin na tysiąc linii kodu. Natomiast inspekcje przeprowadzane po testach jednostkowych spowodowały dodatkowe obciążenie w wysokości 20 godzin na tysiąc linii kodu. Zatem nie warto prowadzić inspekcji po testach jednostkowych.

Ciekawe są też dane dotyczące wydajności inspekcji. Krok omówienia był wykonywany w inspekcjach dotyczących projektu (I1) z prędkością 500 linii kodu na godzinę. Przy drugiej inspekcji (I2) to omówienie było już zbędne, bo inspektorzy znali produkt. Przygotowanie do inspekcji przebiegało z prędkością około 100 linii kodu na godzinę w przypadku pierwszej inspekcji i 125 linii kodu na godzinę jeśli chodzi o drugą inspekcję. W trakcie samego spotkania inspekcyjnego prędkość inspekcji wynosiła 130 linii kodu na godzinę dla inspekcji I1 i 150 dla inspekcji I2.
Ponadto Fagan zaobserwował, że spotkanie inspekcyjne nie powinno trwać dłużej niż 2 godziny, bo wtedy bardzo mocno spada wydajność. Jeśli chodzi o liczbę spotkań, to nie powinno być ich więcej niż 2 dziennie.



Zacznijmy od wstrzykiwania defektów – koncepcja tej metody jest bardzo prosta. W pierwszym kroku do artefaktu, który chcemy poddać kontroli jakości dodajemy n defektów.
W drugim kroku przekazujemy tak spreparowany artefakt do kontroli jakości. Inspektorzy, na przykład korzystając z wcześniej przedstawionej procedury, szukają w tym artefakcie defektów.
Po zakończeniu ich pracy dostajemy raport, który zawiera całą listę znalezionych defektów. Przeglądamy tę listę i stwierdzamy, że k spośród wszystkich znalezionych defektów są to defekty przez nas dodane, natomiast m defektów jest zupełnie nowych.
Zakładając, że wykrycie każdego z n przez nas wstawionych defektów jest tak samo trudne jak wykrycie pozostałych, możemy oszacować liczbę wszystkich defektów (nie licząc defektów przez nas wstawionych) na podstawie przedstawionego, prostego wzoru: liczba defektów jest w przybliżeniu równa liczbie nowo wykrytych defektów, m, pomnożonej przez liczbę dodanych przez nas defektów, n, i podzielonej przez liczbie „naszych” defektów, jakie udało się wykryć inspektorom. Oczywiście, ten wzór można stosować, o ile liczba k > 0. Przy k = 0 inspekcję (czy inną formę kontroli jakości) należałoby powtórzyć.
Szacowanie liczby nie wykrytych defektów

Przejdę teraz do omówienia metody 2-krotnego łowienia.
2-krotne łowienie
Metoda ta została opracowana w latach 50-tych przez biologów i dopiero w połowie lat 90-tych została przeniesiona na grunt inżynierii oprogramowania.
Załóżmy, że chcemy oszacować liczbę ryb w stawie. Moglibyśmy wówczas zastosować następującą procedurę.
Najpierw łowimy pewną próbkę ryb.
Potem złowione ryby oznaczamy w jakiś sposób.
Następnie je wszystkie wypuszczamy z powrotem do wody.
Po pewnym czasie jeszcze raz łowimy ryby.
I teraz liczymy ile wśród złowionych ryb jest ryb, które wcześniej oznakowaliśmy.
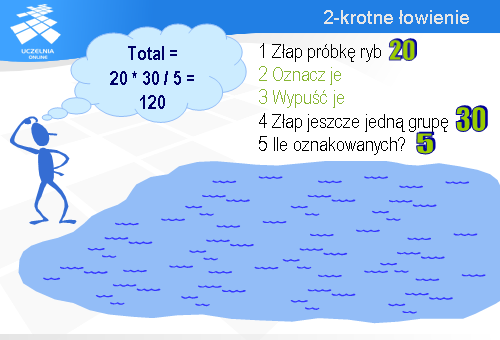
Załóżmy, że za pierwszym razem złapaliśmy 20 ryb, a za drugim 30, z czego 5 było oznakowanych.
Oznacza to, że wszystkich ryb jest 6 razy więcej niż oznakowanych. A ponieważ oznaczyliśmy 20 ryb, stąd wniosek, że wszystkich ryb w stawie powinno być około 120.
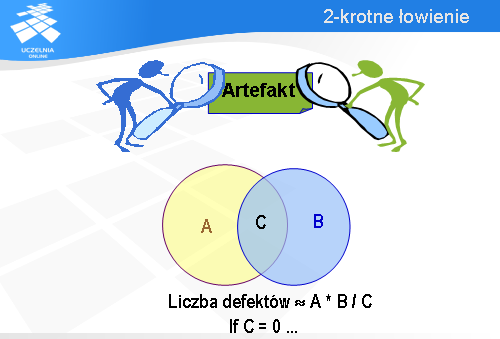
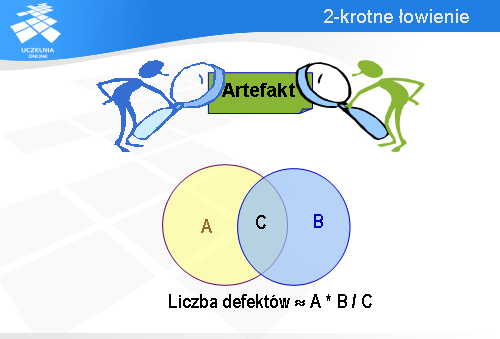
Rozumowanie to można łatwo przenieść na grunt kontroli jakości. Rybami będą w tym przypadku defekty, których liczbę chcielibyśmy oszacować. Załóżmy, że mamy dwóch recenzentów danego artefaktu. Każdy z nich będzie łowił defekty, podobnie jak poprzednio łowiliśmy ryby.
Niech zbiór A reprezentuje defekty znalezione przez lewego recenzenta.
I analogicznie, niech zbiór B reprezentuje defekty znalezione przez prawego recenzenta.
Część wspólną tych zbiorów oznaczmy przez C.
W tej sytuacji zbiór A odpowiada rybom złowionym za pierwszym razem, które zostały przez nas oznaczone. Natomiast zbiór B jest jakby drugim połowem. Zatem, rozumując podobnie jak poprzednio, liczbę wszystkich defektów można oszacować mnożąc liczność zbioru A przez stosunek liczności zbioru B do liczności części wspólnej, oznaczonej tutaj jako C.
Oczywiście, wzór ten można stosować tylko wtedy, gdy część wspólna nie jest pusta.
Jeśli mielibyśmy więcej niż dwóch recenzentów, to moglibyśmy postąpić następująco. Znajdujemy recenzenta, który znalazł najwięcej unikatowych defektów i znalezione przez niego defekty traktujemy jako zbiór A. Natomiast defekty wykryte przez wszystkich pozostałych recenzentów traktujemy jako zbiór B. I dalej obliczenia są prowadzone jak poprzednio.
Plan wykładu
Czas na podsumowanie wykładu.
Na początku wykładu podałem definicję jakości. Według Crosby’ego jakość jest to zgodność z wymaganiami. Takie rozumienie jakości zostało przeniesione do standardu ISO 9001:2000.
Cztery filary zapewnienia jakości

Powiedziałem też, że testowanie i przeglądy należą do głównych filarów, na których opiera się jakość oprogramowania.
Rodzaje testowania

Omawiając testowanie powiedziałem, że z praktycznego punktu widzenie największe znaczenie ma „ręczne” przygotowywanie danych testowych. Jeśli chodzi o wykonywanie testów, to są dwie szkoły: jedni twierdzą, że nie opłaca się automatyzować wykonywania testów, a drudzy wręcz przeciwnie.
Inspekcje zgodne z IEEE 1028
Przedstawiłem też inspekcje zgodne ze standardem IEEE 1028 i omówiłem krótko wyniki pomiarów inspekcji dokonanych przez Fagana w połowie lat 70-tych w firmie IBM.
Wstrzykiwanie defektów

W ostatniej części wykładu omówiłem dwie metody szacowania liczby nie wykrytych defektów. Pierwsza metoda polegała na wstrzykiwaniu defektów i liczeniu jaką ich część udało się wykryć w czasie kontroli jakości.
2-krotne łowienie
Dziękuję za uwagę i radzę zawsze pamiętać o kontroli jakości.