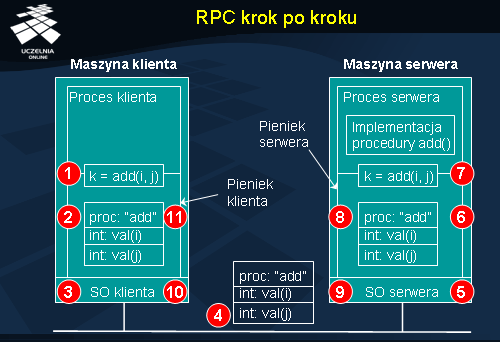
Na rysunku ukazano kolejne kroki wykonywania zdalnej procedury add, zachodzące od momentu wywołania przez klienta jego pieńka do momentu faktycznego wykonania procedury po stronie serwera. Poniżej wypunktowano te kroki, z uzupełnieniem ich o etap przesyłania wyniku do klienta.

Ponieważ funkcje pieńka klienta i serwera zależą wyłącznie od interfejsu procedury, kod programu realizujący pieńka można automatycznie wygenerować na podstawie definicji tego interfejsu. W praktyce wszystkie implementacje RPC dostarczają własnej odmiany języka do definiowania interfejsu. Jednym z takich języków jest IDL, od angielskiej nazwy
Interface Definition Language . Definicja interfejsu w języku IDL jest kompilowana na kod pieńków klienta i serwera. Pozwala to zwolnić programistę z obowiązku samodzielnego tworzenia pieńka i tym samym znacząco uprościć i przyspieszyć konstrukcję systemu rozproszonego.
RMI - koncepcja

Technologia obiektowa okazała się bardzo atrakcyjnym narzędziem budowy aplikacji. Jedną z najistotniejszych właściwości obiektu jest to, że jego stan jest ukryty przed światem zewnętrznym, natomiast dostęp do niego odbywa się tylko przez jego operacje, które udostępnia na zewnątrz. Operacje te tworzą interfejs obiektu. Takie podejście pozwala zmieniać w razie potrzeby implementację obiektu, pod warunkiem że interfejs obiektu pozostaje bez zmian.
Z czasem, gdy RPC stało się najpopularniejszą techniką komunikacji procesów w systemach rozproszonych, pojawił się pomysł, by połączyć je z przetwarzaniem obiektowym, pozwoli to bowiem podnieść poziom przezroczystości rozproszenia względem tradycyjnego RPC. Ten nowy model obiektowego RPC nazwano zdalnym wywoływaniem metod , w skrócie RMI , od angielskiej nazwy Remote Method Invocation.
W dalszej części wykładu skupimy się na stosunkowo prostym modelu RMI, w którym cały stan obiektu znajduje się w jednym miejscu, a więc nie jest rozproszony.
Organizacja zdalnego obiektu
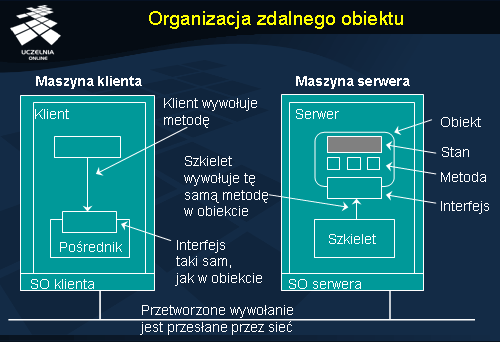
Kluczową cechą obiektu jest jego budowa. Obiekt tworzą dane, nazywane
stanem , oraz operacje, które manipulują tymi danymi, nazywane
metodami . Dostęp do danych obiektu odbywa się wyłącznie za pośrednictwem metod. Zbiór metod obiektu udostępnionych na zewnątrz to tak zwany
interfejs obiektu. Jeden obiekt może implementować kilka interfejsów, i na odwrót – jeden interfejs może być implementowany przez wiele obiektów. Podobnie jak w RPC, interfejs obiektu jest zazwyczaj definiowany w specjalnym języku deklaratywnym, IDL. Proces na maszynie serwera, który przechowuje dany obiekt, będziemy nazywać serwerem; pojęcia serwera i obiektu będziemy często używać zamiennie.
Rozgraniczenie pomiędzy interfejsami a obiektami je implementującymi ma w systemach rozproszonych kluczowe znaczenie. Możliwe jest bowiem umieszczenie interfejsu i obiektu na różnych maszynach . Taka organizacja jest powszechnie nazywana rozproszonym obiektem lub zdalnym obiektem . Należy zaznaczyć, że wbrew nazwie stan obiektu rozproszonego nie musi być rozproszony.
Kiedy klient dowiązuje się (ang. bind ) do obiektu, implementacja interfejsu obiektu po stronie klienta, nazywana pośrednikiem (ang. proxy ), jest ładowana do przestrzeni adresowej klienta. Pośrednik jest tym samym, co pieniek klienta w modelu RPC. Jedynym jego zadaniem jest przetwarzanie wywołań metod zdalnego obiektu do postaci komunikatu sieciowego oraz odtwarzanie wyników tych wywołań z odbieranych od serwera komunikatów.
Rzeczywisty obiekt znajduje się na maszynie serwera. Obiekt ten udostępnia taki sam interfejs, jak pośrednik klienta. Rolę pieńka serwera pełni tak zwany szkielet (ang. skeleton ), który przetwarza odbierane z sieci wiadomości na wywołania metod oraz wyniki tych wywołań na wiadomości sieciowe, odsyłane klientowi.
Kod pośrednika oraz szkieletu jest, podobnie jak w przypadku RPC, jest automatycznie generowany na podstawie definicji interfejsu obiektu.
Odniesienie do obiektu

Zasadnicza różnica pomiędzy tradycyjnym modelem RPC a modelem RMI tkwi w tym, że RMI wprowadza pojęcie globalnego w skali systemu adresu obiektu, nazywanego odniesieniem obiektowym (ang. object reference ). Takie odniesienie może być swobodnie przesyłane pomiędzy procesami pracującymi na różnych maszynach, na przykład w postaci parametru wywołania.
Ponadto, odniesienie najczęściej jest implementowane tak, by jego wnętrze było nieczytelne, tzn. by proces nie mógł odczytać z niego, gdzie znajduje się obiekt. Pozwala to zwiększyć stopień przezroczystości rozproszenia zasobów systemu.
Jednym z najważniejszych problemów projektowych jest ustalenie, jakie informacje adresowe zostaną zapisane w odniesieniu. Przykładowo, jeśli w odniesieniu znajdzie się adres IP serwera oraz numer portu, na którym obiekt (serwer) oczekuje na zgłoszenia, takie odniesienie będzie bardzo wrażliwe na ewentualną awarię serwera. Gdyby do niej doszło, zdalny obiekt może po wznowieniu pracy używać innego numeru portu, a to by oznaczało, że wszystkie dotychczasowe odniesienia do niego stają się nieważne.
Przykładowe rozwiązanie tego problemu polega na uruchomieniu na maszynie serwera wyróżnionego procesu, będącego rejestrem obiektów, oczekującego na wywołania na dobrze znanym numerze portu, zarezerwowanym tylko dla siebie. Rejestr przyjmowałby wywołania do obiektów, identyfikował wywoływany obiekt i przekazywał mu wywołanie. W odniesieniu znalazłby się wówczas tylko adres procesu-rejestru oraz identyfikator wywoływanego obiektu. Takie podejście (zastosowane zresztą w systemie DCE) pozwala częściowo uniezależnić odniesienie od dokładnego adresu obiektu, konkretnie od numeru portu. Nie umożliwia jednak przenoszenia procesu serwera wraz z jego obiektami na inną maszynę.
Oczywistym rozwiązaniem wydaje się być zastosowanie serwera lokalizacji , pamiętającego adres maszyny, na której aktualnie działa poszukiwany obiekt. Odniesienie zawierałoby wówczas wyłącznie adres serwera lokalizacji oraz identyfikator pozwalający odnaleźć szukany obiekt. Jednak i to podejście ma poważne ograniczenia, związane głównie z kwestią przeciążenia serwera lokalizacji, a tym samym z kwestią skalowalności systemu.
Rodzaje obiektów

Należy podkreślić, że pojęcie
obiektu w modelu RMI dotyczy głównie
wrażenia , jakie system dostarcza aplikacji klienta. Najważniejsze jest to, by klientowi wydawało się, że pracuje z obiektem. Kwestia rzeczywistej realizacji tej abstrakcji obiektu jest drugorzędna. Chociaż najprostszym podejściem wydaje się być takie, w którym zdalne obiekty są realizowane przez obiekty języka programowania, w ogólności tak być nie musi. Obiekt zdalny może zostać zaimplementowany w dowolny sposób, pod warunkiem, że klient będzie miał złudzenie pracy z obiektem. W przypadku zdalnych obiektów realizowanych w nieobiektowych językach programowania, za dostarczanie klientowi tego złudzenia odpowiada
adapter obiektu (ang.
Object adapter ). Jego rolą jest dostosowanie rzeczywistej implementacji obiektu do postaci, której oczekuje klient.
Obiekty są również klasyfikowane ze względu na ich trwałość. Obiekty trwałe (ang. persistent ) charakteryzują się tym, że istnieją nawet wtedy, gdy nie znajdują się aktualnie w przestrzeni adresowej procesu serwera. Innymi słowy, są niezależne od bieżącego serwera i mogą przetrwać jego awarię. W praktyce oznacza to, że stan takich obiektów musi zostać przechowany w pamięci trwałej. W przeciwieństwie do nich, obiekty ulotne (ang. transient ) istnieją tylko tak długo, jak długo działa utrzymujący je serwer.
Wywołanie statyczne i dynamiczne

Wywołania statyczne dokonywane są przez klienta za pomocą statycznego pośrednika (pieńka). Wywołania dynamiczne zaś nie wykorzystują statycznego pośrednika. Polegają natomiast na użyciu po stronie klienta ogólnej funkcji, umożliwiającej dynamiczne utworzenie wywołania. Innymi słowy, korzystając z wywołań dynamicznych, klient w dużej mierze sam robi to, co zrobiłby za niego jego pośrednik.
Na slajdzie ukazano ogólną funkcję invoke, umożliwiającą dynamiczne utworzenie dowolnego wywołania zdalnej metody. W ramach jej parametrów należy określić szukany obiekt, wywoływaną w nim metodę, oraz wartości parametrów wejściowych i ewentualnie wyjściowych.
Przykładowo, dla wywołania statycznego postaci:
MójObiekt.MojaMetoda(i)
odpowiadające mu wywołanie dynamiczne wyglądałoby następująco:
Invoke(MójObiekt, ID(MojaMetoda), i, NULL).
W wielu sytuacjach wykorzystanie wywołań dynamicznych okazuje się koniecznością. Dzieje się tak na przykład w systemach, które przekierowują wywołania, powielają je do większej liczby odbiorców czy też w przeglądarkach obiektów.
Przekazywanie parametrów
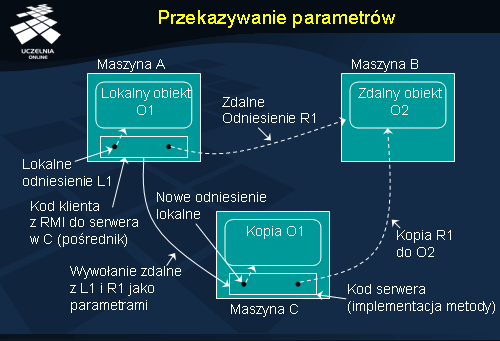
Dopóki przekazywanym parametrem nie będzie obiekt, stosuje się rozwiązania podobne do tych, które przedstawiono przy okazji tradycyjnego RPC. W modelu RMI pojawia się jednak nowy typ parametru, mianowicie obiekt.
Obiekty przekazywane są na dwa sposoby. Dla obiektów zdalnych, czyli takich, które powinny znajdować się tylko w jednej lokalizacji i być dostępne zdalnie, jedyną możliwością jest przekazanie przez odniesienie . Przekazywana jest kopia odniesienia do zdalnego obiektu. Proces otrzymujący kopię odniesienia posiada więc wskazanie na ten sam zdalny obiekt. Na przedstawionym rysunku widać, jak proces działający w maszynie A wywołuje zdalną metodę procesu maszyny C i przekazuje jako parametr odniesienie R1 do zdalnego obiektu O2. Od tej chwili na obiekt O2 wskazują dwa identyczne odniesienia. Wszelkie wywołania metod obiektu O2 mają zawsze charakter zdalny.
Dla obiektów lokalnych, a więc takich, które nie są dostępne zdalnie, jedyną opcją jest przekazanie ich przez wartość (in. przez kopię). Stan takich obiektów jest w całości kopiowany i przesyłany jako parametr metody. Na rysunku widać, jak lokalny obiekt O1 zostaje przekazany jako parametr wywołania zdalnego, dokonywanego przez proces maszyny A na obiekcie w maszynie C – w serwerze maszyny C tworzona jest kopia obiektu O1, a późniejsze wywołania metod obiektu O1 mają charakter lokalny.
System transferu wiadomości - organizacja
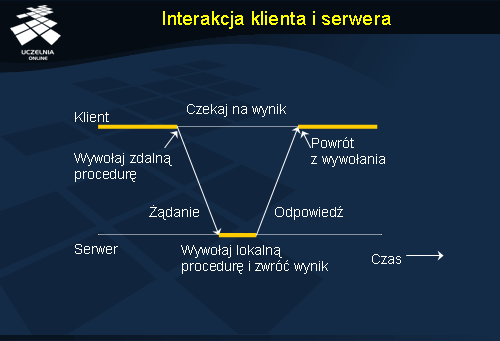
Istnieje szereg zastosowań, dla których modele RPC i RMI okazują się niewystarczające. Dotyczy to szczególnie aplikacji, w których nie można zakładać, że odbiorca wiadomości jest aktywny podczas jej przesyłania. Ponadto, synchroniczny charakter wywołań procedur czy metod, przy których klient jest blokowany do momentu otrzymania wyniku, często stanowi zbyt wielkie ograniczenie.
Odpowiedzią na te ograniczenia są systemy transferu wiadomości . Niniejsza część wykładu prezentuje komunikację zorientowaną na wiadomości. Omawia dostępne rodzaje komunikacji oraz ich przykładowe realizacje.
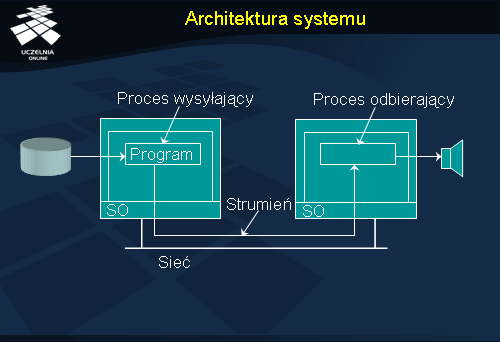
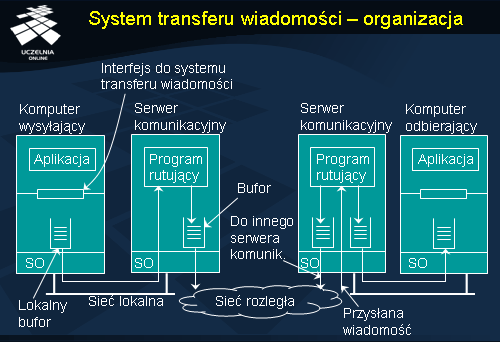
Na rysunku przedstawiono ogólną organizację systemu, w którym przesyłane są wiadomości. Aplikacje są zawsze wykonywane na komputerach końcowych, udostępniających interfejs, przez który wiadomości mogą być wysyłane. Komputery końcowe są połączone ze sobą za pośrednictwem sieci serwerów komunikacyjnych, odpowiedzialnych za przekazywanie (i routowanie) wiadomości. Zarówno komputery końcowe, jak i serwery komunikacyjne posiadają bufory, w których zapamiętują przesyłane wiadomości.
Rodzaje komunikacji

Z punktu widzenia trwałości wiadomości wyróżniamy dwa rodzaje komunikacji. Komunikacja jest trwała (ang. persistent ), jeśli wysłana wiadomość jest pamiętana w systemie komunikacyjnym do momentu jej dostarczenia do odbiorcy. Odnosząc się do rysunku z poprzedniego slajdu można powiedzieć, że wiadomość jest pamiętana w jednym serwerze komunikacyjnym tak długo, aż zostanie dostarczona do następnego serwera komunikacyjnego. Nie ma zatem potrzeby, aby aplikacja wysyłająca kontynuowała działanie po przekazaniu wysyłanej wiadomości systemowi. Przykładem z życia codziennego usługi realizującej trwałą komunikację jest tradycyjna poczta.
W komunikacji nietrwałej (ang. transient ) wiadomość jest pamiętana przez system komunikacyjny tylko tak długo, jak długo działają nadawca lub odbiorca. Odnosząc się znów do rysunku na poprzednim slajdzie, można bardziej precyzyjnie powiedzieć, że jeśli jeden serwer komunikacyjny nie będzie w stanie dostarczyć wiadomości do następnego serwera lub do odbiorcy, wiadomość zostanie porzucona. Ten sposób komunikacji przypomina działanie tradycyjnej telefonii z funkcją poczty głosowej lub automatycznej sekretarki.
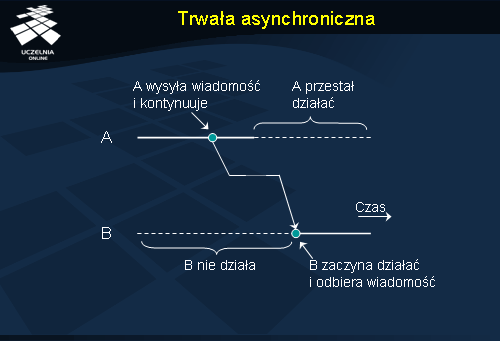
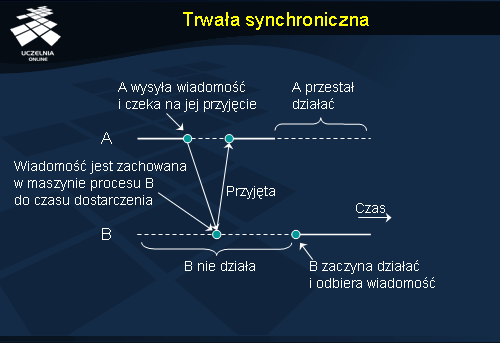
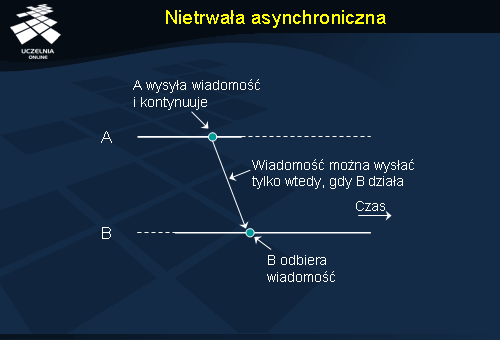
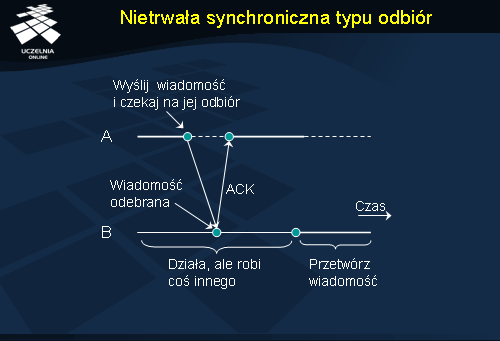
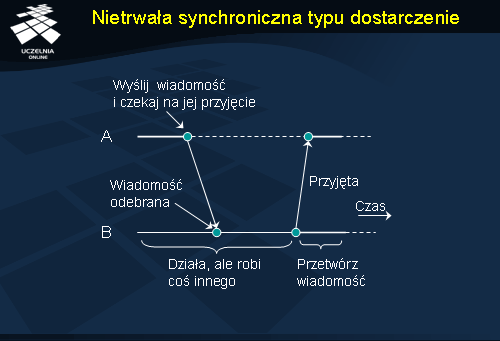
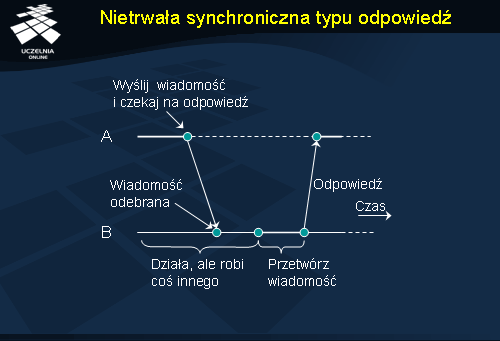
Druga linia podziału usług komunikacyjnych ma związek z czasem trwania operacji wysłania wiadomości. Cechą charakterystyczną komunikacji asynchronicznej jest to, że nadawca kontynuuje przetwarzanie natychmiast po przedłożeniu wysyłanej wiadomości w systemie. Wiadomość zostaje zapamiętana w komputerze wysyłającym lub w najbliższym serwerze komunikacyjnym. Nadawca nie jest zatem w ogóle blokowany w oczekiwaniu na jakiekolwiek potwierdzenie, przez co operacja wysłania trwa bardzo krótko. W komunikacji synchronicznej zaś nadawca jest blokowany do momentu, aż wiadomość znajdzie się w buforze komputera odbiorcy lub zostanie dostarczona do samego odbiorcy. Istnieje kilka odmian komunikacji synchronicznej, a w najsilniejszej z nich nadawca jest blokowany do momentu otrzymania potwierdzenia przetworzenia wiadomości przez odbiorcę. W dalszej części omówione zostały różne formy komunikacji, łączące różne poziomy trwałości i synchronizmu.
Trwała asynchroniczna
W trwałej asynchronicznej komunikacji wiadomość jest trwale zapamiętana w komputerze wysyłającym lub w najbliższym serwerze komunikacyjnym. Poczta elektroniczna jest jednym z przykładów tego typu komunikacji. Na rysunku pokazano zasadę działania trwałej komunikacji asynchronicznej. Podczas samego transferu wiadomości ani nadawca, ani odbiorca nie musi pozostawać aktywny, gdyż wiadomość jest trwale zapamiętana w systemie komunikacyjnym.