W przypadku systemów rozproszonych istotnym czynnikiem przy ich projektowaniu jest heterogeniczność.
Szczególnie widać to właśnie w przypadku procesów i ich wędrówki. Dopóki rozpatrujemy identyczne maszyny, czyli mamy do czynienia ze środowiskiem homogenicznym, dopóty nie istnieje wiele problemów związanych z różnicami wewnątrz środowiska maszyn i oprogramowania.
Możliwość wykonania identycznego kodu na różnych typach maszyn i właściwego przechowywania stanu procesu są kluczowe dla poprawnego wykonania operacji przeniesienia procesu. Stopień komplikacji wędrówki procesu w systemie zależy oczywiście od typu wędrówki. Jeżeli jest to przenośność słaba, problem sprowadza się do wygenerowania kodu dla odpowiednich typów platform. Nie ma tu natomiast przeniesienia segmentu wykonania, który może znacząco się różnić w zależności od architektury maszyny.
Przykładowym rozwiązaniem, które zastosowano m.in. dla języka Java jest zezwolenie na wędrówkę procesu tylko w określonych punktach jego wykonywania np. przy wywoływaniu metody, wtedy też aktualizowany jest tzw. stos wędrówki (ang. migration stack ). Stos wędrówki jest niczym innym jak kopią stosu programu ale przechowywaną w sposób niezależny od maszyny.
Za każdym razem kiedy proces wchodzi do podprogramu i z niego wychodzi odpowiednie dane ze stosu, identyfikator wywołanego podprogramu oraz etykieta powrotu (adres od którego należy kontynuować przetwarzanie po powrocie z podprogramu) są przetaczane (ang. marshaled ) i odkładane na stosie wędrówki. Stos wędrówki jest w razie wędrówki procesu przenoszony na maszynę docelową i tam odwrotnie przetaczany (ang. unmarshaled ), tak aby można było odtworzyć stos fazy wykonywania.

Podczas wędrówki procesu pojawia się pewna trudność w postaci stanu komunikacji przenoszonego procesu. Poza tym nasuwa się również pytanie, co zrobić z przyszłymi komunikatami, które będą nadchodzić do wspomnianego procesu.
Odpowiedzią na te problemy mogą być trzy następujące rozwiązania: przekierowywanie komunikatów (ang. message redirection ), zapobieganie utracie komunikatów (ang. message loss prevention ) oraz odzyskiwanie utraconych komunikatów (ang. message loss recovery ).
Pierwsze z wymienionych podejść, czyli przekierowywanie komunikatów działa w ten sposób, że komputer, z którego proces wywędrował musi zapamiętać wszystkie możliwe źródła komunikatów dla tego procesu. Ponadto maszyna źródłowa musi również znać adres docelowej maszyny, do której odbyła się wędrówka. Z kolei procesy-nadawcy niekoniecznie są informowani o fakcie wędrówki i mogą wysyłać komunikaty do starego miejsca procesu. Jeżeli w trakcie wędrówki procesu przychodziły komunikaty, są one zapamiętywane w starym miejscu i dostarczane do procesu-odbiorcy po ukończeniu operacji wędrówki. Wadą tego podejścia jest łańcuch pośredników rosnący w miarę, jak proces migruje na kolejne maszyny.
W podejściu polegającym na zapobieganiu utracie wiadomości proces który zamierza wędrować powiadamia o tym wszystkie procesy, z którymi utrzymuje komunikację, tak aby te mogły po ukończeniu komunikować się z nim bezpośrednio. W przeciwieństwie do poprzedniej metody unika się tu pośredników w komunikacji, dzięki czemu ruch w systemie jest mniejszy.
W ostatniej metodzie polegająca na odzyskiwaniu utraconych komunikatów, proces podlegający wędrówce nie wysyła do procesów, z którymi się komunikuje żadnych informacji o tym fakcie. Wszystkie wiadomości, które nadchodzą podczas procesu migracji są po prostu ignorowane i tracone. Proces po zakończeniu migracji nawiązuje ponownie komunikację z procesami, z którymi ją wcześniej utrzymywał i rozpoczynany jest proces odzyskiwania utraconych komunikatów. Metoda ta stosowana jest często w systemach, gdzie liczy się czas migracji procesu, gdyż jest ona stosunkowo szybka i prosta.
Wędrówka procesów w DEMOS/MP

W tej części zaprezentujemy przykładowy mechanizm migracji procesów zastosowany w rozproszonym systemie operacyjnym DEMOS/MP. Przykład ten zilustruje w skrócie zagadnienia jakie wiążą się z wędrówką procesów.
Operacja wędrówki procesu w systemie DEMOS/MP składa się z dwóch części: negocjacji oraz przemieszczenia procesu.
W fazie negocjacji komputer źródłowy wysyła propozycję wędrówki procesu do komputera docelowego. Wraz z propozycją wędrują również informacje niezbędne do podjęcia wędrówki. Jeżeli komputer docelowy ma wystarczającą ilość zasobów odsyła do komputera, który przysłał ofertę, odpowiedź z akceptacją wędrówki. W przeciwnym wypadku komputer źródłowy otrzymuje odmowę i trzeba na nowo zaplanować całą operację.
Ilustracja wędrówki procesów w DEMOS/MP
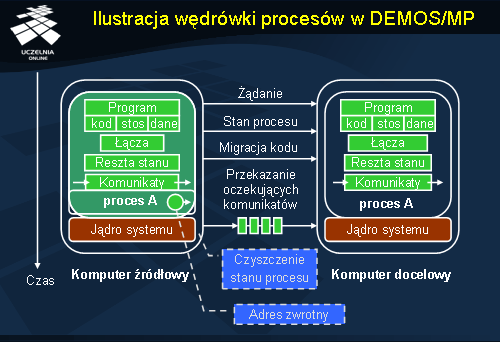
W drugiej fazie, przemieszczania procesu następuje kilka mniejszych kroków.
Gdy już wybrany został proces do migracji i wiadomo gdzie ma się znaleźć, następuje jego oznaczenie jako procesu do migracji. To skutkuje m.in. tym, że proces taki usuwany jest z kolejki procesów do uruchomienia. Wiadomości, które przychodzą do procesu nadal będą odbierane i umieszczane w jego kolejce komunikatów.
W drugim kroku do komputera docelowego, a dokładniej do jądra systemu operacyjnego, który nim zarządza, zostaje wysłana wiadomość z żądaniem, aby przemieścić proces. Wiadomość ta zawiera wszystkie informacje potrzebne do wędrówki procesu: rozmiar i lokalizację kodu oraz dane dotyczące stanu itp.
Następnie zostaje utworzony specjalny proces na maszynie docelowej. Proces ten nie posiada jeszcze żadnego stanu. W międzyczasie rezerwowane są wymagane przez proces zasoby.
Skoro na komputerze docelowym jest już pewien proces zostaje na jego miejsce skopiowany stan oryginalnego procesu (przeniesienie odpowiednich danych).
Po tym zostaje ostatecznie przeniesiony cały program w postaci kodu, danych oraz stosu.
Kiedy kontrola trafi z powrotem do jądra systemu maszyny źródłowej i zostanie potwierdzony fakt przeniesienia procesu, stary komputer przesyła do nowego wszystkie wiadomości, które trzymał w kolejce od momentu rozpoczęcia wędrówki. W trakcie tej fazy komputer źródłowy zapamiętuje także informacje o nowym miejscu pobytu procesu.
W przedostatnim kroku fazy przenoszenia procesu jądro systemowe na maszynie źródłowej czyści stan oryginalnego procesu pozostawiając tylko wcześniej wspomniany adres maszyny docelowej. Adres ten będzie służył w przyszłości do komunikacji z przeniesionym procesem.
Na końcu kontrola ostatecznie wraca do maszyny docelowej, a nowy proces zostaje przywrócony do stanu sprzed momentu wędrówki.
Agenci programowi

Mimo braku precyzyjnej definicji agenta programowego (ang. software agent ), można go opisać jako pewne rozszerzenie pojęcia procesu, w tym sensie, że jest on zdolny do samodzielnego działania; jest autonomiczny i potrafi się również komunikować z innymi agentami. W miarę rozwoju badań nad agentami programowymi wyróżniono kilka ich typów.
Agenci współpracujący (ang. collaborative agent ) charakteryzują się tym, że dążą do osiągnięcia pewnego wspólnego celu poprzez współpracę ze sobą.
Agenci ruchomi (ang. mobile agents ) potrafią z kolei się przemieszczać między różnymi maszynami, zbierając np. różne dane.
Agenci interfejsu (ang. interface agents ) pomagają użytkownikom w używaniu różnych aplikacji, często ucząc się przy tym w celu poprawienia przyszłego działania.
Ostatnią przedstawioną tu klasą agentów są agenci informacji (ang. information agents ). Są oni odpowiedzialni za zarządzanie informacjami np. filtrowanie.
Ważnym elementem działania agentów programowych jest sposób ich komunikacji. Do tego celu służy tzw. kanał komunikacji agentów (ang. agent communication channel – ACC). ACC jest między innymi odpowiedzialne za niezawodność komunikacji i porządek komunikatów. Wraz z ACC pojawia się również język komunikacji agentów (ang. agent communication language – ACL). Język ten określa pewien standard wymiany informacji między agentami, protokół. Istotne w przypadku ACL jest rozdzielenie w komunikacie dwóch składników: jego celu i treści. Wyróżnia się pewną skończoną liczbę celów, na które agent-odbiorca może zareagować. Przykładowymi celami są zamówienie jakiegoś działania, pytanie o jakiś obiekt lub dostarczenie jakiejś oferty.
Szeregowanie procesów
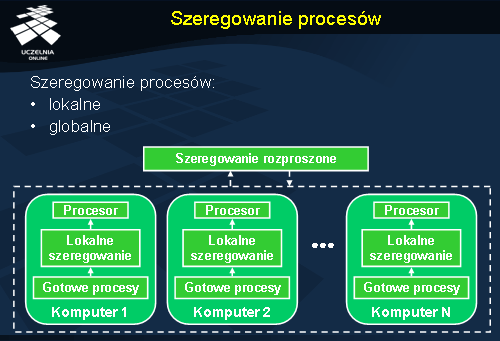 Szeregowanie procesów
Szeregowanie procesów (ang.
process scheduling ) jest integralną częścią zarządzania procesami. Ponieważ procesy możemy traktować jako pewne zasoby, również zarządzanie procesami możemy zaklasyfikować jako szczególny rodzaj zarządzania zasobami. Zrozumienie niektórych aspektów zarządzania zasobami pozwoli z pewnością uzasadnić potrzebę takich operacji jak wędrówka lub zdalne wykonywanie procesów.
Szeregowanie procesów związane jest z polityką odpowiedzialną za podejmowanie decyzji, od których zależą: lokalne uszeregowanie procesów (tj. uszeregowanie w ramach pojedynczego procesora) oraz strategia rozproszenia obciążenia pomiędzy różne maszyny obecne w systemie. Nie będziemy podczas tego wykładu zagłębiać się w problematykę lokalnego szeregowania procesów, a skupimy się na szeregowaniu globalnym. Należy zaznaczyć, że samo szeregowanie lokalne nie jest w stanie zagwarantować uszeregowania optymalnego z punktu widzenia globalnego systemu. Do rozwiązania problemów globalnego szeregowania procesów stosuje się zasadniczo dwa typy algorytmów. Mianowicie wyróżniamy algorytmy podziału obciążenia (ang. load sharing ) oraz algorytmy równoważenia obciążenia (ang. load balancing ). Warto podkreślić, iż oba podejścia zakładają wędrówkę procesów.
Zdalne operacje na procesach

W przypadku systemów scentralizowanych dostępny jest zawsze pewien podstawowy zestaw operacji, które można wykonać na procesach. Za pomocą tych operacji możemy wpływać na stan procesów. Wśród nich znajdziemy operacje takie jak utworzenie nowego procesu, zakończenie procesu, zawieszenie procesu, wznowienie procesu itp.
Rozproszone systemy operacyjne ze względu na swoją architekturę, oprócz lokalnych operacji powinny posiadać dodatkowy zestaw w postaci zdalnych operacji (ang. remote operations ) na procesach. Są to m.in. utworzenie, zakończenie, zawieszenie wykonywania, wznowienie, zdalne uruchomienie procesu, migracja procesu, tworzenie połączeń komunikacyjnych.
W idealnym przypadku wszystkie te operacje powinny być niewidoczne dla użytkownika.
Zdalne wykonywanie procesów
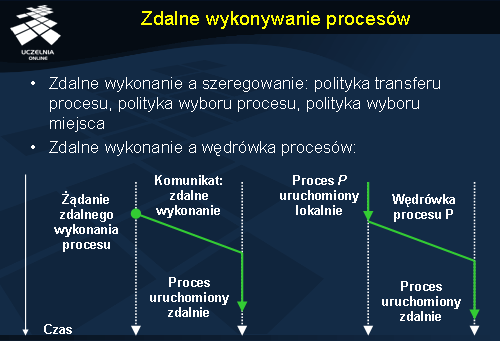 Zdalne wykonywanie procesów
Zdalne wykonywanie procesów (ang.
remote execution ) i wędrówka procesów są dwoma podstawowymi mechanizmami używanym przy szeregowaniu zadań. Główną cechą, która odróżnia zdalne wykonywanie procesu od wędrówki procesów jest to, że proces uruchomiony zdalnie nie może już migrować.
Szeregowanie procesów spełnia w kontekście operacji zdalnego wykonywania procesów kilka zadań: określa politykę transferu procesu (ang. transfer policy ) w celu zadecydowania czy proces ma być uruchomiony zdalnie czy lokalnie, określa politykę wyboru procesu (ang. selection policy ) aby zadecydować który proces powinien być przeniesiony oraz określa politykę wyboru miejsca (ang. location policy ), w którym ma być uruchomiony wybrany proces.
Podział obciążenia
 Podział obciążenia
Podział obciążenia jest metodą, która pozwala na wykorzystanie mocy obliczeniowej maszyn, które w danej chwili nic nie przetwarzają. Algorytmy dokonujące podziału obciążenia zwiększają efektywność tylko lokalnie, wewnątrz pewnej grupy użytkowników i ich procesów. Metoda ta bazuje głownie na migracji procesów na bezczynne maszyny.
Algorytm podziału obciążeń ma do rozwiązania przede wszystkim dwie kwestie. Po pierwsze, kiedy przeprowadzić wędrówkę procesu na zdalną bezczynną maszynę. Po drugie, jak znaleźć zdalny bezczynny procesor. W pierwszym przypadku odpowiedź wydaje się stosunkowo prosta: kiedy moc obliczeniowa maszyny przestaje wystarczać potrzebom procesów użytkownika. Natomiast odpowiedzi na drugie pytanie może być wiele m.in.: można skorzystać ze specjalnego serwera, który zbiera informacje o wolnych zasobach, można też skorzystać z mechanizmu komunikacji grupowej do rozgłaszania informacji o bezczynnych procesorach, w końcu można np. skorzystać z informacji przechowywanych lokalnie.
Systemy, które używają podziału obciążenia mogą korzystać z różnych struktur komunikacyjnych do szeregowania procesów.
W przypadku użycia scentralizowanej struktury występuje pewna wyróżniona maszyna, która zbiera informacje o bezczynnych komputerach i na tej podstawie może szeregować procesy. Wadą takiego podejścia są oczywiście podatność na awarię oraz trudność w śledzeniu stanu wszystkich procesorów przez jedną maszynę.
Zamiast scentralizowanej struktury można użyć rozproszonej. Mamy wtedy kilka maszyn, z których każda stara się znaleźć odpowiednie miejsca do wykonania swoich procesów. W tym wypadku niezbędna staje się synchronizacja między maszynami. Rozproszone podejście do podziału obciążeń likwiduje wspomniane wady scentralizowanego algorytmu, jakkolwiek jest bardziej czasochłonne ze względu na koordynację działań komputerów, biorących udział w operacji.
Hierarchiczny algorytm podziału obciążenia

W prezentowanym tutaj algorytmie wykorzystuje się hierarchię procesorów w postaci ściętego drzewa (ang.
truncated tree ). Na najniższym poziomie drzewa wyróżnia się procesory, które są robotnikami. Na wyższym poziomie znajdują się procesory-zarządcy, którzy mają pod sobą robotników. Na najwyższym poziomie są z kolei procesory odpowiedzialne za globalną alokację.
Alokacja procesorów w momencie, gdy pojawi się praca wymagająca m procesów przebiega następująco. System zostaje powiadomiony o potrzebie zaalokowania m procesorów. Każdy procesor-zarządca zna w przybliżeniu liczbę robotników, którymi zarządza. Jeśli liczba wolnych robotników-procesorów jest wystarczająca (większa od m ), to procesory te zostają zarezerwowane i praca może zostać wykonana. W przeciwnym wypadku, kiedy zarządca nie ma takiej liczby robotników, przekazuje żądanie w górę hierarchii zarządców do momentu napotkania najwyższego węzła-szefa. Jeżeli taki węzeł stwierdzi, że nie ma on wystarczającej liczby procesorów, to przekazuje żądanie do swoich sąsiadów na tym samym poziomie drzewa.
Algorytm hierarchiczny - przykład
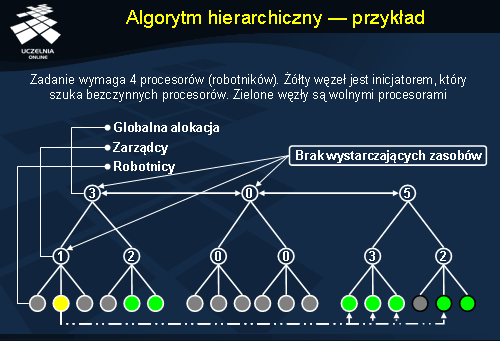
W zilustrowanym przykładzie wystąpiło zadanie, które wymaga 4 procesorów. Niestety zarządca procesora, który jest inicjatorem zadania (oznaczony żółtym kolorem) nie ma pod sobą wystarczającej liczby wolnych procesorów. Zleca więc zadanie zarządcy, który jest wyżej w hierarchii od niego i który to zajmuje się globalną alokacją. Ten niestety też nie ma pod sobą wystarczającej liczby wolnych procesorów, pyta więc kolejno innych globalnych zarządców do momentu aż znajduje zarządcę z odpowiednią liczbą wolnych procesorów. Wtedy rezerwowane są znalezione wolne procesory i zadanie może być wykonane.
Pierścieniowy algorytm podziału obciążenia
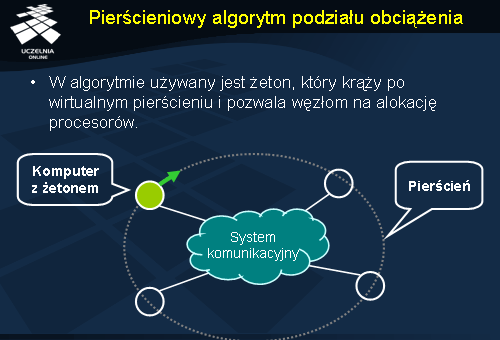
Algorytm ten oparty jest na pierścieniowej strukturze procesorów. Jeżeli pojawi się zadanie wymagające
m procesów, system musi zarezerwować w tym celu
m procesorów. Po pierścieniu procesorów krąży tzw. żeton (ang
. token ). W momencie gdy procesor, która ma zadanie do wykonania, ma żeton, może rozpocząć poszukiwanie bezczynnych procesorów. W pierwszym kroku zarządca (procesor, który ma żeton) rozsyła komunikaty do innych węzłów aby dowiedzieć się, czy są one dostępne. Jeżeli jakiś węzeł jest dostępny, odsyła informację do zarządcy, a ten rezerwuje dany procesor. Procesor jest zwalniany jeżeli w określonym czasie nie otrzyma żądania wykonania procesu. Ponadto jeśli liczba dostępnych procesorów jest zbyt mała dla zarządcy, są one zwalniane. Po tych czynnościach zarządca przekazuje żeton do swojego następnika w pierścieniu. Gdy poszukiwanie się powidło i zarządca ma wystarczającą liczbę dostępnych węzłów, rozdziela między nie odpowiednio procesy, a po zakończeniu zadania wszystkie procesory są zwalniane.
Podział obciążenia w systemie Condor

Condor jest systemem służącym do szeregowania zadań, który umożliwia użycie bezczynnych węzłów. Algorytm szeregujący procesy działa następująco. Każdy komputer ma swój indeks
i , który początkowo jest równy zero. Indeks każdego komputera jest aktualizowany w następujący sposób: gdy przydzielone zostają mu zdalne zasoby obliczeniowe, jego indeks jest powiększany, natomiast gdy takie zasoby na skutek jego żądania nie zostają mu przydzielone, jego indeks maleje. W systemie znajduje się centralny koordynator, który przelicza priorytety każdego komputera używając wspomnianych indeksów. Zadanie ze stacji
i ma wywłaszczający priorytet w stosunku do zadania ze stacji
j , jeżeli indeks stacji
i jest mniejszy od indeksu stacji
j . Następnie koordynator sprawdza, czy jakiś komputer ma nowe zadania do zdalnego wykonania. Jeśli komputer z wyższym priorytetem ma zadanie do wykonania, ale nie ma wolnych innych komputerów, koordynator wywłaszcza zdalnie uruchomioną pracę na stacji o niższym priorytecie i tworzy
punkt kontrolny przerwanego zadania (ang.
checkpoint ). Punkt kontrolny jest operacją zapamiętania stanu procesu tak aby można go było kontynuować w przyszłości. Po tej operacji komputer z wyższym priorytetem uruchamia swoje zadanie na nowo dostępnym komputerze.
Równoważenie obciążenia
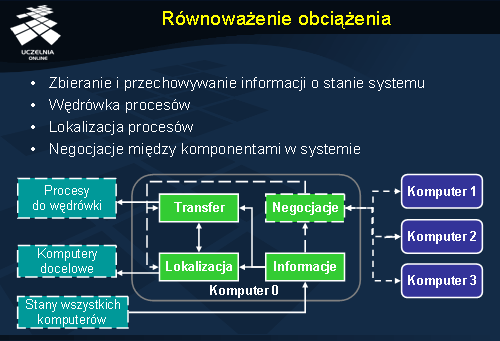
Równoważenie obciążenia jest stosunkowo rozległą dziedziną związaną m.in. z zarządzaniem procesami, dlatego tutaj skupimy się na kluczowych jego własnościach. Dalej przedstawimy również kilka przykładów algorytmów równoważenia obciążenia.
Głównym zadaniem równoważenia obciążenia jest uszeregowanie procesów w systemie rozproszonym w taki sposób, aby zrównoważyć w nim obciążenie pracą. Do tego celu wykorzystywana jest m.in. wcześniej zaprezentowana wędrówka procesów. W przeciwieństwie do podziału obciążenia w tym przypadku nie ma wymogu, aby procesory, na które migrowane są zadania były wcześniej bezczynne. Procesory mogą być częściowo obciążone, a mimo to nadal są brane pod uwagę przy wędrówce procesów.
W przypadku algorytmów równoważenia obciążenia można wyróżnić grupę komponentów, z których każdy jest odpowiedzialny za pewien element ich polityki. Kilka takich komponentów zostało zaprezentowanych przy okazji omawiania zdalnego uruchamiania procesów. Były to: polityka transferu procesu, polityka wyboru procesu oraz polityka wyboru miejsca. Nie są to wszystkie elementy, które można tu wymienić. W przypadku dynamicznego równoważenia obciążenia jest jeszcze np. komponent odpowiedzialny za negocjacje, który pozwala współpracować różnym komponentom na różnych komputerach poprzez składanie ofert, ich żądanie i przyjmowanie. Innym komponentem jest komponent odpowiedzialny za zbieranie i przechowywanie informacji o stanie systemu (obciążenie procesora, długość kolejek, informacje o procesach itd.).
Klasyfikacja metod równoważenia obciążenia
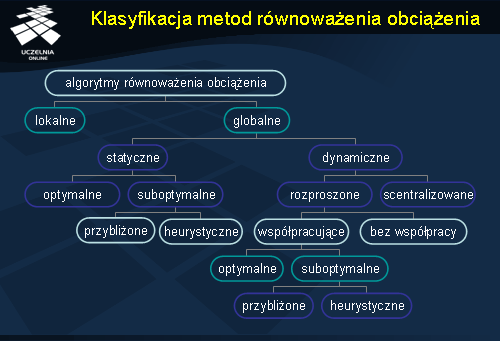
Na rysunku została przedstawiona przykładowa klasyfikacja algorytmów równoważenia obciążenia.
Na najwyższym poziomie wyróżniono lokalne (ang. local ) i globalne (ang. global ) równoważenie obciążenia. Ze względu na temat wykładu my zajmiemy się tą drugą klasą algorytmów.
Po zejściu na niższy poziom zauważymy dwa kolejne typy algorytmów: statyczne (ang. static ) i dynamiczne (ang. dynamic ). Algorytmy statyczne charakteryzują się przede wszystkim tym, że zadania są tutaj przypisywane do procesorów a priori tzn. przed rozpoczęciem ich wykonywania. Po rozpoczęciu wykonywania, proces nie może już ulec przemieszczeniu.
Algorytmy statyczne można podzielić na: algorytmy optymalne (ang. optimal ) oraz suboptymalne (ang. sub-optimal ).
W wypadku wyboru gałęzi z dynamicznym równoważeniem obciążenia, dostaniemy dwa odgałęzienia w postaci algorytmów scentralizowanych (ang. centralized ) i rozproszonych (ang. distributed ). W pierwszym przypadku odpowiedzialność za szeregowanie procesów ponosi jedna wybrana maszyna. Z drugiej strony w rozproszonych algorytmach decyzja podejmowana jest przez kilka węzłów obliczeniowych.
Wśród rozproszonych dynamicznych algorytmów szeregowania procesów można wyróżnić dwie dodatkowe kategorie: algorytmy, które bazują na współpracy pomiędzy węzłami oraz algorytmy, które tej współpracy nie wykorzystują.
Obok przedstawionych kryteriów klasyfikacyjnych algorytmów równoważenia obciążenia, istnieją też inne, nie przedstawione na rysunku:
– algorytmy adaptacyjne (ang. adaptive ), czyli takie które potrafią wykorzystać poprzednie stany systemu przy podejmowaniu decyzji, a nie tylko bieżący stan, jak to robią algorytmy nieadaptacyjne;
– algorytmy, które stosują strategię zapoczątkowania równoważenia obciążenia przez serwer (ang. server-iitiative ) – serwer szuka zbyt obciążonych maszyn i np. wysyła część zadań na inne mniej zajęte maszyny – lub przez źródło (ang. source-initiative ), które jest zbyt obciążone pracą;
– algorytmy, które wykorzystują negocjowanie;
– algorytmy bez wywłaszczania (ang. non-pre-emptive ) tzn. takie, które przydzielają tylko nowoutworzone zadania. Algorytmy z wywłaszczaniem mogą z kolei przerywać procesy w trakcie wykonywania i je przenosić.
Statyczne równoważenie obciążenia

Statyczny model równoważenia obciążenia, jak zostało wcześniej wspomniane, zakłada że zadania są przypisywane do odpowiednich procesorów przed ich uruchomieniem. Decyzja o uruchomieniu procesów na odpowiednich maszynach podejmowana jest w sposób deterministyczny lub probabilistyczny . W deterministycznym podejściu algorytmy używają informacji o własnościach węzłów obliczeniowych i charakterystyce procesów, które mają być uszeregowane na tych węzłach. Probabilistyczny model szeregowania korzysta tylko ze statycznych informacji o węzłach, czyli z informacji, które się w ogólności nie zmieniają (np.: topologia sieci, moc obliczeniowa węzła).
Typowymi kryteriami, których używa się podczas rozwiązywania problemu są m.in.: minimalizowanie czasu ukończenia procesów, minimalizacja zużycia zasobów obliczeniowych, maksymalizacja przepustowości systemu.
Podsumowując model deterministyczny i probabilistyczny można powiedzieć, że ten pierwszy jest trudny do optymalizacji, a jego koszt implementacji często przewyższa koszt implementacji drugiego modelu.
Algorytm A*
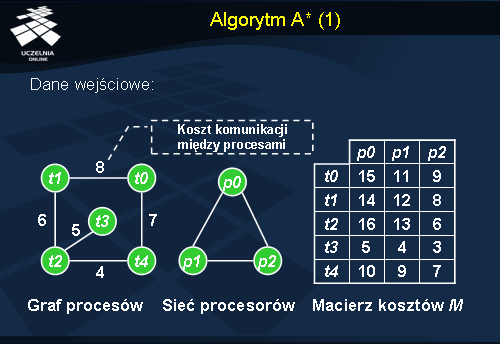
Algorytm A* jest algorytmem, który może posłużyć m.in. do statycznego równoważenia obciążenia. Poniżej opiszemy politykę wyboru miejsca, w którym ma być uruchomiony dany proces, gdyż cały algorytm polega na odpowiednim przypisaniu procesów do procesorów.
Zakładamy, że system składa się z n procesorów i m procesów. Dla każdego procesu mamy podany koszt jego uruchomienia na każdym procesorze (macierz kosztów na slajdzie). Algorytm używa struktury drzewa do znalezienia najlepszego rozwiązania. Proces poszukiwania rozwiązania zaczyna się od korzenia drzewa, miejsca w którym jeszcze żaden proces nie jest przypisany do procesora. Każdy poziom w drzewie oznacza przypisanie jednego procesu do określonego procesora. Liście drzewa oznaczają kompletne rozwiązanie, czyli przypisanie wszystkich procesów do procesorów. Podczas schodzenia w głąb drzewa dla każdego węzła n w drzewie obliczany jest koszt C(n ). Ta wartość jest oceną najtańszego rozwiązania zawierającego dany węzeł, biorąc pod uwagę koszt komunikacji i uruchomienia. Koszt C(n ) tworzy suma dwóch składników: f(n ) – koszt bieżącego, częściowego rozwiązania z pierwszymi k zadaniami przypisanymi do procesorów; g(n ) – dolne ograniczenie szacowanego kosztu ścieżki w drzewie, poczynając od węzła n do liścia, który reprezentuje pełne rozwiązanie. Za każdym razem algorytm wybiera węzeł z dołu bieżącego drzewa o minimalnym koszcie i rozpatruje przypisanie kolejnego procesu. Algorytm zatrzymuje się gdy dotrze do rozwiązania. Do obliczenia f(n ) jest brany procesor z największym obciążeniem komunikacyjnym (koszt komunikacji podany jest na grafie procesów) i obliczeniowym. Wartość g(n ) jest kosztem komunikacji pomiędzy najbardziej obciążonym węzłem, a węzłami, którym nie przypisano do tej pory zadań. Dla uproszczenia wszystkie procesy reprezentowane są jako graf nieskierowany, gdzie każdy węzeł oznacza proces, a krawędź wymagania komunikacyjne. Poza tym zakłada się, że każdy procesor może komunikować się ze wszystkimi innymi procesorami w systemie i nie muszą one być połączone koniecznie bezpośrednio ze sobą.
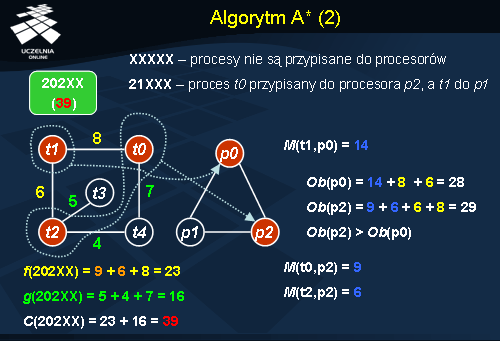
Prześledzimy teraz działanie algorytmu A* dla sieci procesów i procesorów zaprezentowanych na poprzednim slajdzie. Macierz kosztów
M również bierzemy z poprzedniego slajdu.
Dla uproszczenia prezentacji przykładu, zakładamy następującą notację przypisania procesów do procesorów: procesy uporządkowane są w ciąg według swoich identyfikatorów (t0 , t1 , t2 , …, tn ), a każdemu procesowi z ciągu, który ma być wykonany na pewnym procesorze, odpowiada identyfikator tego procesora. W ten sposób uzyskujemy ciąg identyfikatorów (na slajdzie numerów) procesorów przypisanych do kolejnych procesów. Dodatkowo jeżeli proces nie ma przypisanego żadnego procesora oznaczamy to w ciągu literą „X”.
Dany mamy ciąg (2 0 2 X X) przypisania procesów do procesorów (proces t0 przypisany do procesora p2 , t1 do p0 , t2 do p2 ). Chcemy teraz obliczyć koszt takiego przypisania C(2 0 2 X X). Musimy więc obliczyć dwie wartości: koszt f(2 0 2 X X) oraz koszt g(2 0 2 X X). Na slajdzie podano koszt wykonania poszczególnych procesów na odpowiednich procesorach (np. M(t1 , p0 ) = 14 ). Obciążenie procesora (oznaczone jako funkcja Ob(identyfikator_procesora )) obliczane jest poprzez zsumowanie kosztów wykonania przypisanych mu procesów i kosztów komunikacji z innymi przypisanymi już procesami. Po obliczeniu obciążenia procesorów p0 oraz p2 widzimy, że procesor p2 jest bardziej obciążony, dlatego to p2 jest brane pod uwagę przy obliczaniu kosztu f . f(2 0 2 X X) liczymy sumując koszty wykonania procesów na tym procesorze (M(t0 , p2 ) + M(t2 , p2 )) oraz maksymalny koszt komunikacyjny tego procesora (dla procesora p2 i ciągu przypisań (2 0 2 X X) będzie to 8). Koszt g(2 0 2 X X) liczymy z kolei sumując koszty komunikacji pomiędzy procesami na najbardziej obciążonym procesorze p2 (są to procesy t0 i t2 ), z nieprzypisanymi dotąd procesami czyli t3 i t4 . Po zsumowaniu kosztów f(2 0 2 X X) = 23 oraz g(2 0 2 X X) = 16 uzyskujemy całkowity koszt przypisania C(2 0 2 X X) = 39.
Dynamiczne równoważenie obciążenia

Algorytmy dynamicznego równoważenia obciążenia, w przeciwieństwie do algorytmów statycznych, starają się równoważyć obciążenie dynamicznie podczas gdy procesy są już być może uruchomione. Nadrzędnym celem algorytmów dynamicznego równoważenia obciążenia jest znalezienie najlepszego z pewnego punktu widzenia umiejscowienia w systemie wszystkich procesów. Decyzje podejmowane są na podstawie bieżącego stanu systemu rozproszonego, co jest jedną z podstawowych trudności w tym wypadku.
Informacje o stanie systemu mogą być przechowywane w sposób scentralizowany lub rozproszony. Dodatkową cechą algorytmów dynamicznego równoważenia obciążenia są relacje między komponentami decyzyjnymi w różnych węzłach systemu. Mogą one ze sobą współpracować w celu podjęcia wspólnej decyzji lub komponenty mogą same podejmować decyzje. W drugim przypadku decyzje wpływają tylko na lokalną wydajność i mogą być sprzeczne z decyzjami innych, generując konflikty zasobowe.
Algorytm Bryanta i Finkela

Jest to dynamiczny algorytm, działający w środowisku fizycznie rozproszonym. Przebiega następująco. Komputer
K1 wysyła zapytanie do jednego ze swoich najbliższych sąsiadów, komputera
K2 . Zapytanie to ma na celu dwie rzeczy: informuje komputer
K2 , o tym że
K1 chciałby utworzyć parę, która stanowiłaby stabilne środowisko odpowiednie do wędrówki procesów; poza tym zapytanie zawiera listę procesów oraz czasy jakie zajęło ich wykonywanie na
K1 (ta informacja jest użyta w późniejszym etapie do oszacowania czasu potrzebnego na dokończenie wykonania procesu).
K2 po otrzymaniu zapytania może wykonać następujące czynności:
a) odrzucić zapytanie – w tym momencie K1 zmuszone jest do wysłania zapytanie do innego sąsiada;
b) utworzyć parę z K1 – K1 i K2 odrzucają wtedy wszystkie nadchodzące do nich zapytania dopóki nie zakończą współpracy ze sobą;
c) odłożyć zapytanie K1 do czasu gdy K2 znajdzie się w stanie umożliwiającym wędrówkę, ponieważ K2 może aktualnie przeprowadzać wędrówkę innego procesu – K1 musi poczekać do czasu, gdy K2 utworzy z nim parę lub go odrzuci (w tym czasie K1 nie może wypytywać innych komputerów).
Po utworzeniu pary, komputer z większym obciążeniem (np. K1 ) wybiera proces do wędrówki na drugi komputer. Jako kryterium dla tej operacji używa się wskaźnika poprawy czasu reakcji k(i ) (ang. response time ), który równa się czasowi reakcji T1(i ) procesu na maszynie źródłowej podzielonemu przez sumę czasu reakcji T2(i ) tego procesu na maszynie docelowej i czasu T12(i ) jego przeniesienia na tę maszynę (np. z K1 na K2 ). T1(i ) może być obliczone poprzez oszacowanie czasu TE(i ) potrzebnego na ukończenie procesu; czas potrzebny na ukończenie procesu jest równy czasowi T zużytemu do tej pory. Algorytm obliczania T1(i ) przedstawiono szczegółowo na ilustracji.
W wypadku gdy k(i )< 1 dla wszystkich procesów na K1 , K1 informuje K2 o tym fakcie i para jest zrywana. W przeciwnym razie proces, który rokuje najlepsze nadzieje na poprawienie efektywności wykonywania, jest wybierany do wędrówki. Cała ta procedura wykonywana jest do czasu, gdy nie można poprawić wydajności żadnego procesu na K2 .
Algorytm Baraka i Shiloha

Algorytm Baraka i Shiloha jest algorytmem do globalnego równoważenia obciążenia. W algorytmie tym zakłada się, że każdy komputer przechowuje informację o obciążeniu pewnej stałej liczby innych komputerów. Co pewien czas informacje o obciążeniach wymieniane są losowo pomiędzy parami komputerów. Przy użyciu tych informacji, algorytm stara się zminimalizować rozbieżności w obciążeniu poszczególnych komputerów.
W skład algorytmu wchodzą trzy komponenty składowe.
1) Algorytm do obliczania obciążenia procesora, który służy do szacowania lokalnego obciążenia komputera. Lokalne obciążenie obliczane jest co pewien określony czas, a następnie jest uśredniane w danym okresie czasu. W algorytm tym wykorzystywany jest również tzw. wektor obciążenia, L , w którym przechowywane są lokalnie informacje o obciążeniach komputerów. Na pierwszej pozycji wektora L przechowywana jest informacja o lokalnym obciążeniu komputera. Kolejne pozycje wektora L zawierają wartości obciążenia innych komputerów. Wartość L[j ] oznacza pozycję j w wektorze obciążenia i zawiera szacowane obciążenie komputera j.
2) Kolejnym komponentem jest algorytm wymiany informacji między komputerami, który jest odpowiedzialny za przekazywanie informacji o obciążeniach między komputerami. Wymiana informacji polega w skrócie na przesłaniu pewnej części wektora obciążenia L do innych komputerów, tak aby były dobrze poinformowane o stanie obciążenia.
Poniżej opiszemy bardziej szczegółowo działanie algorytmu wymiany informacji.
Co pewien czas każdy komputer wykonuje kilka operacji. Aktualizuje informację o wartości swojego obciążenia w wektorze L , a następnie wybiera losowy komputer i i wysyła do niego pierwszą połowę swojego wektora obciążenia, Lr . Po otrzymaniu części wektora obciążenia, każdy komputer oszacowuje obciążenie każdego innego komputera poprzez połączenie otrzymanego wektora ze swoim własnym wektorem obciążenia L . Należy nadmienić, że porządek wartości w wektorze L implikuje wiek informacji. Łączenie połowy wektora obciążenia podczas jego podziału jest pewną formą starzenia danych (ang. aging ). W kolejnym kroku algorytm stara się oszacować obciążenie komputera używając w tym celu średniej liczby procesów, które żądają usługi w pewnej jednostce czasu. Wartość tego obciążenia jest użyta następnie do określenia czasu reakcji (ang. response time ) procesora. Do komputera, który ma najmniejszy czas reakcji można teraz przenieść proces. Specjalny proces działa dodatkowo na każdym komputerze i sprawdza czy są procesy, które mogą być poddane wędrówce.
3) Ostatnim komponentem w podejściu Baraka i Shiloha jest migracja procesów, której nie będziemy jednak tutaj już przedstawiać.
Algorytm Baraka i Shiloha jest algorytmem optymalnym globalnie przy założeniu, że wektor L ma rozmiar, który jest równy liczbie wszystkich komputerów w sieci.
Algorytm Baraka i Shiloha - przykład
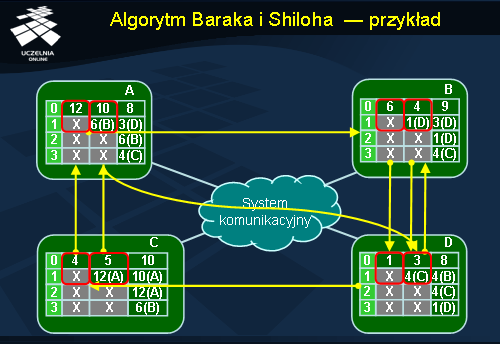
W przykładzie zaprezentowanym na ilustracji przedstawiono schemat wymiany informacji w algorytmie Baraka i Shiloha. Zakładamy istnienie sieci 4 komputerów:
A ,
B ,
C oraz
D . Każdy z nich przechowuje wektor obciążenia o rozmiarze 4. Wartość wektora należy odczytywać z tabel pionowo, kolejne wiersze odpowiadają kolejnym pozycjom wektora. Każdy komputer posiada kilka wartości swojego wektora obciążenia dla różnych momentów w czasie, co widoczne jest w postaci kolumn w tabeli. Np. trzecia kolumna w tabeli na komputerze
A ([8, 3, 6, 4]) oznacza wektor obciążenia uzyskany w wyniku wymiany informacji z innym komputerem. Strzałka skierowana od wektora na jednym komputerze do wektora na drugim komputerze oznacza, że ten pierwszy wybrał drugiego w celu wymiany informacji.
Prześledźmy teraz przykład wymiany informacji o obciążeniu. Wartości oznaczone jako X na rysunku są wartościami obciążenia, które nie są dla nas istotne i oznaczają dowolną liczbę. Posłużymy się w tym celu komputerem A . Obciążenie komputera A wynosi 12. W pewnym momencie działania algorytmu równoważenia obciążenia komputera A wybrał losowo komputer B w celu wymiany z nim informacji. Wektor Lr , który zostanie przekazany z komputera B do A ma postać [6 X]. Po połączeniu lokalnego wektora z otrzymanym od B wektorem Lr , na komputerze A uzyskujemy nowy wektor [10 6 X X]. W kolejnym kroku komputer A wybiera do wymiany komputer D . W międzyczasie aktualizowana jest również informacja o wartość lokalnego obciążenia, która teraz dla A wynosi 8. Z komputera D , komputer A otrzymuje wektor Lr równy [3, 4]. Ostatecznie wektor obciążenia L na A wynosi [8, 3, 6, 4].