Nie każde uszeregowanie operacji wykonanych w systemie rozproszonym jest możliwe do zrealizowania w praktyce. Będziemy rozważać tylko
. Legalność oznacza, że odczyt wartości
, który znajdowałby się w uszeregowaniu procesu czytającego po zapisie wartości
. Co więcej: nie może być miedzy zapisem wartości
. Założenia te są dość intuicyjne jeżeli weźmiemy pod uwagę działanie pamięci lokalnej w węźle. Każda zmienna ma w pamięci swoją pojedynczą lokalizację i odczyt zwraca zawsze ostatnio zapisaną wartość.
Dla uproszczenia rozważań (nie redukując jednak ogólności rozważań) będziemy zakładać, że każdy zapis i odczyt dotyczy unikalnej wartości v . Innymi słowy, wartość zapisywana będzie jednoznacznie identyfikować konkretną operację zapisu.

Analiza modeli spójności odwołuje się do pojęcia historii. Historia reprezentuje zrealizowane wcześniej przetwarzanie, a więc uporządkowany zbiór wszystkich operacji, które zostały wykonane.
Przetwarzanie każdego z procesów jest reprezentowane jego lokalną historią hj , która jest liniowo uporządkowanym zbiorem operacji zleconych przez ten proces. Relacją porządkującą jest lokalny porządek zleceń wykonania kolejnych operacji.
Złożenie historii wszystkich procesów daje historię globalną , gdzie relacją porządkującą jest relacja zależności przyczynowej (zawierająca w sobie lokalne porządki poszczególnych procesów). Zbiór ten jest częściowo uporządkowany, ponieważ niektóre zdarzenia realizowane są współbieżnie.
Każdy z procesów postrzega w jakiś sposób zapisy, które zostały zgłoszone na innych węzłach. Uszeregowanie tych zapisów daje obraz historii w procesie . Obraz historii jest uporządkowany liniowo relacją lokalnego uszeregowania, które musi być legalne.
Złożenie wszystkich lokalnych obrazów historii daje obraz historii , który jest kolekcją zbiorów liniowo uporządkowanych.
Spójność sekwencyjna

Przetwarzanie jest zgodne z modelem spójności sekwencyjnej, jeżeli obraz historii w każdym z procesów spełnia oba zaprezentowane warunki. Pierwszy warunek mówi o tym, że lokalne uporządkowanie operacji powinno być zachowane w obrazie przetwarzania w każdym procesie. Dotyczy to oczywiście operacji wykonywanych w danym węźle oraz wszystkich zapisów, które zostały zgłoszone. Odczyty wykonywane na innych węzłach nie są brane pod uwagę, ponieważ są one realizowane jedynie lokalnie. Zapisy natomiast muszą być propagowane do wszystkich węzłów.
Drugi warunek mówi o tym, że wszystkie zapisy w systemie muszą być globalnie uszeregowane. Innymi słowy: istnieje jedna, globalnie ustalona kolejność wykonywania wszystkich zapisów, które zostały zlecone w systemie. Zostało to zdefiniowane w ten sposób, że dla każdej pary operacji zapisu w1 i w2 wszystkie węzły albo realizują najpierw w1 a później w2 , albo najpierw w2 a później w1 . W skrócie można więc powiedzieć, że spójność sekwencyjna wymusza globalne uporządkowanie zapisów.
Spójność sekwencyjna - przykład

Przykład przedstawia przetwarzanie w systemie, który gwarantuje spójność sekwencyjną. Ostateczna postać obrazów historii w procesach
p1 i
p2 spełnia oba warunki modelu. W szczególności warto zwrócić uwagę na globalne uporządkowanie operacji zapisu: oba procesy widzą najpierw zapis wartości 1 do zmiennej
x , a później wartości 2. W obrazach historii w procesie
p1 występuje dodatkowo odczyt, który nie występuje w obrazie historii procesu
p2 . Komunikat przesyłany z procesu
p2 do
p1 oznacza aktualizację danych.
Algorytm fast-read

Realizacja modelu spójności wymaga zaprojektowania odpowiedniego protokołu spójności. Przytoczony na przykładzie algorytm jest jednym z możliwych protokołów gwarantujących zachowanie spójności sekwencyjnej. Jak sama nazwa wskazuje preferuje on odczyty. Preferencja przejawia się tym, że odczyt nigdy nie jest blokowany – od razu zwracana jest lokalnie przechowywana wartość zmiennej.
Zapis algorytmu ma postać procedur obsługi zdarzeń. Zawartość pamięci reprezentowana jest w algorytmie jako tablica M , zwielokrotniona w postaci lokalnych tablic Mi w procesie pi.
Odczyt zwraca po prostu wartość przechowywaną na odpowiedniej pozycji w tablicy M . Zlecenie zapisu jest rozgłaszane (lub rozsyłane) do wszystkich procesów. Rozgłaszanie jest rozgłaszaniem niepodzielnym (ang. atomic broadcast ), co oznacza, że komunikat musi dotrzeć do wszystkich i to w tej samej kolejności. Warstwa komunikacji grupowej zajmie się więc w tym przypadku zapewnieniem uporządkowania operacji zapisu. Jest to wygodna (choć nie zawsze najbardziej efektywna) metoda implementacji protokołu spójności. Właściwa operacja modyfikacji zmiennej realizowana jest w procedurze obsługi odbioru wiadomości aktualizacyjnej. Dotyczy to również węzła, który inicjuje zapis. Jest to ważne, ponieważ zapisy mają być wszędzie realizowane w tej samej kolejności. Zapis powoduje wstrzymanie przetwarzania procesu, który go zleca, do czasu zakończenia niepodzielnego rozgłaszania. Wykonanie bieżącego zapisu może być więc poprzedzone wcześniejszym obsłużeniem zapisów zleconych na innych węzłach – o kolejności zadecyduje warstwa komunikacyjna. W procedurze obsługi odbioru wiadomości aktualizacyjnej, jeżeli komunikat dociera do procesu, który inicjował rozgłoszenie, następuje obudzenie procesu zlecającego (funkcja signal ). Proces był zawieszony w procedurze zapisu (funkcją wait ).
Algorytm fast-write

Protokół
fast-write dla spójności sekwencyjnej optymalizuje operacje zapisu wykonywane w systemie. Ich wykonanie nigdy nie jest blokujące, co pozwala na natychmiastową kontynuację obliczeń, być może powodującą wykonanie kolejnego zapisu. Blokowaniu natomiast podlega operacja odczytu. Sprawdza ona czy licznik
num , inkrementowany przy każdym zapisie osiągnął wartość 0, co oznacza poprawne zakończenie wszystkich operacji zapisu zleconych lokalnie. Proces może zlecić wiele zapisów, jeden za drugim, zwiększając w ten sposób zmienną
num . Warstwa komunikacyjna będzie próbowała dostarczyć odpowiednie komunikaty do wszystkich serwerów, a proces w tym czasie może realizować dalsze zadania. Odczyt wymaga zakończenia wykonywania wszystkich dotychczasowych operacji zapisu zleconych lokalnie. Bez tego oczekiwania mogłoby dojść do wygenerowania uszeregowania nielegalnego, np.: w(x)5 ? r(x)0. Obsługa zapisu wymaga w tym przypadku rozgłaszania niepodzielnego zachowującego porządek FIFO, gdyż w przeciwnym wypadku mogłoby dość do przestawienia kolejności zapisów zleconych przez pojedynczy proces, a więc doszłoby do naruszenia lokalnego uporządkowania. Protokół
fast-read nie wymagał stosowania niepodzielnego rozgłaszania FIFO, ponieważ przed zleceniem kolejnego zapisu poprzedni musiał być zakończony, co wymuszało zachowanie lokalnego porządku.
Przedstawione protokoły dla spójności sekwencyjnej pokazują, że jej realizacja jest kosztowna. Koszt objawia się w tym przypadku opóźnieniami, które wynikają z koniecznej synchronizacji procesów. W zależności od potrzeb można optymalizować operacje odczytu bądź zapisu, ale zawsze takie optymalizacje odbywają się kosztem drugiej operacji.
Spójność atomowa

Spójność atomowa jest silniejszym modelem niż spójność sekwencyjna. W jej przypadku brane są bowiem pod uwagę zależności czasowe pomiędzy zdarzeniami na różnych węzłach. Warunki, które muszą spełniać obrazy historii przetwarzania na poszczególnych węzłach są bardzo podobne do tych dla spójności sekwencyjnej. Drugi warunek jest identyczny. W pierwszym zamiast lokalnego porządku występuje zależność czasowa pomiędzy zdarzeniami. Oczywiście synchronizacja przetwarzania z uwzględnieniem zależności czasowych jest dużo bardziej kosztowna i wymaga dodatkowej komunikacji.
Spójność atomowa - przykład
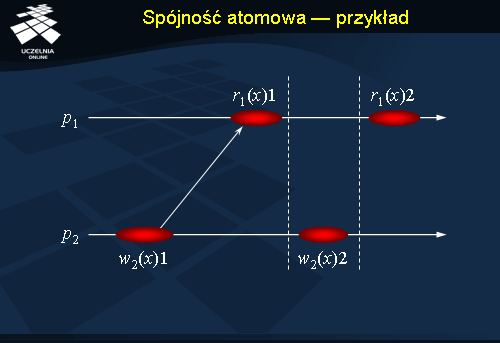
Rysunek przedstawia tą samą sytuację, która była prezentowana w przypadku spójności sekwencyjnej. W tym przypadku jednak uzyskanie takich samych obrazów historii przetwarzania wymaga „przesunięcia” zapisu w(x)2 tak, aby w czasie rzeczywistym występował po odczycie
r(x)1 w procesie
p1.
Spójność atomowa w praktyce nie jest realizowana. Jej znaczenie wiąże się głównie z wykorzystaniem do formalnej weryfikacji algorytmów.
Spójność przyczynowa

Pamięć spójna przyczynowo musi zachowywać porządek przyczynowy operacji. Jeżeli więc operacja
o2 zależy przyczynowo od
o1 , to we wszystkich lokalnych obrazach przetwarzania operacje te powinny występować właśnie w tej kolejności. W praktyce można to wyrazić następująco:
Zapisy potencjalnie powiązane przyczynowo muszą być widziane przez wszystkie procesy w takim samym porządku . Zapisy współbieżne mogą być na różnych maszynach oglądane w różnej kolejności .
Implementacja spójności przyczynowej musi przechowywać informacje o zależnościach przyczynowych pomiędzy operacjami. Można do tego celu wykorzystać wektorowe znaczniki czasu.
Spójność przyczynowa - przykłady

Na slajdzie pokazano przykładowe przetwarzanie w systemie zachowującym przyczynowe uporządkowanie operacji. Każdy z procesów w swoim obrazie przetwarzania musi umieścić wszystkie lokalne operacje oraz wszystkie operacje zapisu, zachowując przy tym warunek legalności. Pierwsze zapisy do zmiennej
x realizowane przez oba procesy
p1 i
p2 są realizowane współbieżnie, nie są od siebie zależne przyczynowo. W efekcie ich wyniki mogą być obserwowalne na węzłach w różnej kolejności. Tak też się stało w tym przypadku. Proces
p1 odczytuje z
x wartość 1, co oznacza, że zapis tej wartości musiał wystąpić po zapisie
w(x)2 (inaczej naruszony byłby warunek legalności – odczytywana byłaby wartość nadpisana). W procesie
p2 następuje odczyt z
x wartości 2, co oznacza, że odpowiedni zapis musiał trafić po
w(x)1 . W efekcie procesy
p1 i
p2 widzą oba zapisy do
x w różnej kolejności. Jest to jak najbardziej dopuszczalne, ponieważ zapisy te były realizowane współbieżnie.
Warto zauważyć, że powyższa realizacja nie jest spójna sekwencyjnie. W modelu sekwencyjnym wszystkie zapisy powinny być postrzegane przez wszystkie procesy w tej samej kolejności.
Protokół dla spójności przyczynowej

Slajd przedstawia przykładowy protokół realizujący model spójności przyczynowej. Do jego implementacji wykorzystano rozgłaszanie zachowujące uporządkowanie przyczynowe (funkcja
causal_broadcast ), a więc cały ciężar realizacji protokołu spada w tym przypadku na warstwę komunikacji grupowej. Warto zwrócić uwagę, że zarówno operacje odczytu jak i zapisu nie wymagają w tym przypadku blokowania, synchronizującego przetwarzanie z operacjami na innych węzłach. Zarówno zapis jak i odczyt może być wykonywany z pełną szybkością. Przetwarzanie lokalne zmiennych zawsze generuje realizacje zachowujące legalność ponieważ zapisy od razu są odnotowywane w pamięci, co powoduje, że następujące po nich odczyty zwracają zapisaną wartość. Komunikaty rozgłoszeniowe są ignorowane przez węzły, które wysyłają odpowiednie aktualizacje.
Spójność PRAM

Spójność PRAM (ang.
pipelind RAM ) jest modelem słabszym od spójności przyczynowej. Dla zapewnienia spójności PRAM wystarczy w obrazach historii każdego procesu zachować lokalny porządek wykonywania operacji każdego innego procesu. Nazwa
pipelined oczywiście nie jest tu przypadkowa – chodzi o potok zleceń płynących od danego procesu. Potok ten musi zachowywać oryginalne uporządkowanie.
Spójność PRAM - przykład
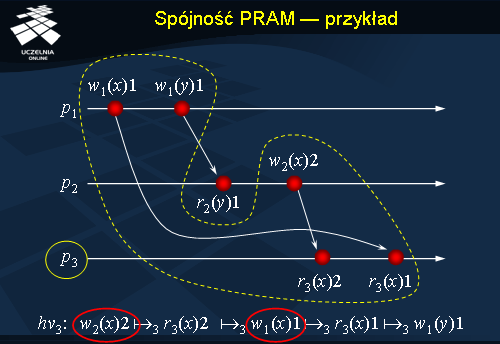
Na slajdzie pokazano przykładowe przetwarzanie w systemie zachowującym spójność PRAM. Zaznaczone operacje są uwzględniane w obrazie historii procesu p3 . Zapisy w(x)1 i w(x)2 realizowane są przez różne procesy, w związku z czym mogą być wykon ywane w procesie p3 w dowolnej kolejności. W przypadku przetwarzania z rysunku zapis w(x)2 dociera do p3 przed zapisem zapisem w(x)1 . Z punktu widzenia modelu spójności PRAM ważne jest jednak to, że zapisy w(x)1 i w(y)1 są widziane w kolejności, w której były wykonywane przez p1.
Warto zauważyć, że zapisy w(x)1 i w(x)2 są od siebie zależne przyczynowo. Łączy je odczyt zmiennej y zapisywanej przez p1 . W obrazie historii w procesie p3 operacje te występują jednak w odwrotnej kolejności. W związku z tym przedstawione przetwarzanie nie zachowuje spójności przyczynowej.
Protokół dla spójności PRAM

Protokół spójności dla modelu PRAM jest bardzo podobny do protokołu spójności dla spójności przyczynowej. Jedna różnica polega na zastąpieniu rozgłaszania zachowującego porządek przyczynowy (
causal_broadcast ) rozgłaszaniem zachowującym kolejność wysyłania komunikatów rozgłoszeniowych danego procesu (ang.
FIFO broadacst ). Oczywiście realizacja funkcji
FIFO_broadcast jest znacznie „tańsza” niż realizacja funkcji
causal_broadcast , ale też model PRAM oferuje mniej niż spójność przyczynowa. W tym przypadku również operacje zapisu i odczytu nie są blokowane, co oczywiście pozytywnie wpływa na efektywność.
Spójność podręczna

Spójność podręczna (ang.
cache consistency ) jest modelem, w którym zachowany jest globalny porządek operacji zapisu do poszczególnych zmiennych. Część wspólna zbiorów
OW i
O|x reprezentuje wszystkie zapisy w systemie dotyczące zmiennej
x . Obrazy historii przetwarzania we wszystkich procesach powinny umieszczać te zapisy w tej samej kolejności. Model ten nie wymaga, aby zachowane było lokalne uporządkowanie operacji o ile dotyczą one różnych zmiennych. Jest to więc model, który jest całkowicie niezależny do spójności PRAM i spójności przyczynowej.
Spójność podręczna - przykłady
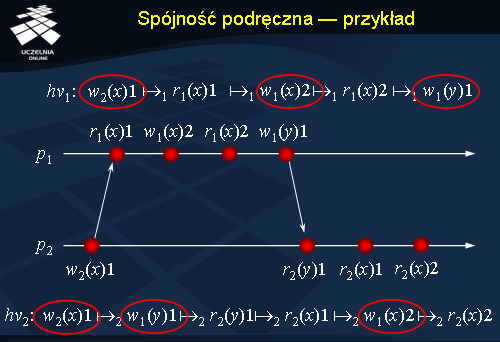
Slajd przedstawia przykładowe przetwarzanie w systemie zachowującym spójność podręczną. Jak ławo zauważyć operacje zapisu wykonywane na zmiennej
x są widziane przez oba procesy w tej samej kolejności. Zmienna
y nie wnosi tu nic nowego, ponieważ jest tylko jeden zapis. Warto jednak zwrócić uwagę na uporządkowanie wszystkich zapisów w obrazach historii przetwarzania. Widać z niego, że nie jest zachowywany porządek lokalny. Proces
p2 widzi zapis do zmiennej
y przez zapisem
w(x)2 , odwrotnie niż proces
p1 . Tym bardziej więc nie jest zachowywany porządek przyczynowy, co widać w sekwencji operacji
w1(x)2 ?
w1(y)1 ?
r2(y)1 ?
r2(x)1 .
Protokół dla spójności podręcznej
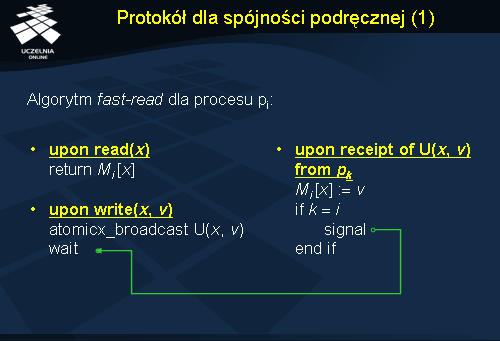
Protokół spójności
fast-read dla spójności podręcznej przypomina analogiczny protokół dla spójności sekwencyjnej. W tym przypadku następuje również blokowanie podczas realizacji zapisu, ponieważ zapisy te muszą być uporządkowane względem innych zapisów do tych samych zmiennych. W przeciwieństwie do poprzedniego protokołu nie występuje tu jednak pełna wersja rozgłaszania niepodzielnego, porządkującego globalnie wszystkie komunikaty, ale jego wersja uproszczona, porządkująca komunikaty aktualizujące wybraną zmienną. W literaturze rozgłoszenie takie nie jest jakoś specjalnie nazywane, stąd w zapisie protokołu użyto nazwy
atomicx_broadcast , dla odróżnienia od
atomic_broadcast . Oczywiście realizacja
atomicx_broadcast jest mniej kosztowna od pełnego niepodzielnego rozgłaszania, stąd protokół
fast-write dla spójności podręcznej powinien charakteryzować się większą wydajnością od analogicznego protokołu dla spójności sekwencyjnej. Rozgłoszenie
atomicx_broadcast może być koordynowane współbieżnie przez różne procesy, o ile dotyczy różnych zmiennych. Jego implementacja może więc być bardziej rozproszona, a więc lepiej wykorzystująca dostępne zasoby.
Przez analogię można również skonstruować protokół
fast-write dla spójności podręcznej, który strukturalnie jest identyczny z protokołem
fast-write dla spójności sekwencyjnej. W tym przypadku również blokowanie zostaje przeniesione do operacji odczytu. Blokowaniu podlegają jednak jedynie operacje odczytu, które odwołują się do zmiennych, dla których nie dokończono jeszcze realizacji ostatnich operacji zapisu. W celu stwierdzenia, które operacje wymagają synchronizacji, protokół przechowuje tablicę liczników
num , w której
i-ta pozycja reprezentuje liczbę aktualnie realizowanych zapisów na
i-tej zmiennej. Wyzerowanie licznika powoduje zniesienie blokowania oczekującego zapisu.
W protokole fast-write zapisy nie są blokowane. W związku z tym jest możliwość zlecenia wielu zapisów, które będą realizowane w tle. W szczególności możliwe jest zlecenie wielu zapisów do tej samej zmiennej. Zapisy do tych samych zmiennych powinny być jednak porządkowane, dlatego do rozgłaszania zleceń zapisu użyto rozgłaszania uporządkowanego FIFO, ale nie w pełnej wersji, a jedynie w odniesieniu do poszczególnych zmiennych. Podobnie jak poprzednio, implementacja rozgłaszania porządkującego zapisy do pojedynczych zmiennych jest prostsza do zrealizowania od rozgłaszania porządkującego wszystkie komunikaty.
Spójność procesorowa

Spójność procesorowa nie wprowadza kompletnie nowej jakości. Jest to po prostu połączenie spójności PRAM i podręcznej. Definicja modelu spójności zawiera warunki, które były wymieniane w definicjach modeli PRAM i spójności podręcznej. W skrócie pamięć jest spójna procesorowo, jeżeli lokalny porządek zlecania operacji w poszczególnych procesach jest zachowany w obrazach historii przetwarzania wszystkich procesów (PRAM), oraz gdy zapisy do poszczególnych zmiennych są globalnie uporządkowane (spójność podręczna).
Spójność procesorowa - przykład

Rysunek przedstawia przykładowe wykonanie w systemie zachowującym spójność procesorową. Jak widać z rysunku w obrazach historii obu procesów zapisy do zmiennej
x widziane są w tej samej kolejności. Uporządkowanie zleceń z poszczególnych procesów również jest zachowane. Nie oznacza to jednak, że istnieje jeden, globalny porządek wykonywania operacji zapisu (co oznaczałoby efektywnie, że spełnione są wymagania modelu sekwencyjnego). Zapisy
w(x)1 i
w(y)1 występują w obrazach historii procesów w odwrotnej kolejności.
Protokół dla spójności procesorowej

Slajd przedstawia protokół spójności typu
fast-write dla spójności procesorowej. Struktura protokołu jest identyczna z poprzednimi protokołami
fast-write . Różnica polega na specyficznej metodzie rozgłaszania zleceń aktualizacji danych. Rozgłaszanie to, oznaczone jako
FIFO_atomicx_broadcast porządkuje globalnie wszystkie zapisy pojedynczych procesów oraz porządkuje globalnie zapisy odnoszące się do tych samych zmiennych. Zapisy nie są blokowane. Aktualizacje realizowane są po odebraniu komunikatu aktualizacyjnego. Odczyty mogą być blokowane, gdy dotyczą zmiennej, której aktualizacja zlecona przez ten węzeł jest jeszcze realizowana.
Naruszanie porządku przyczynowego
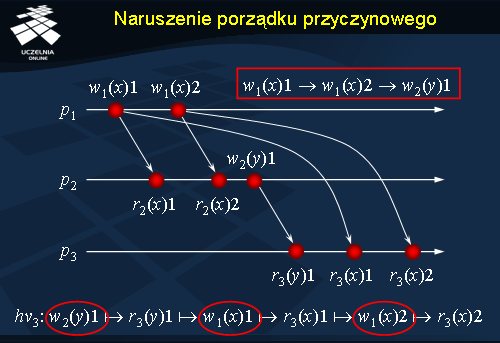
Przykład na slajdzie pokazuje realizację w systemie zachowującym spójność procesorową, w której naruszona jest jednak spójność przyczynowa. Proces
p3 dokonuje na początku odczytu ze zmiennej
y , której aktualizacja dociera do tego procesu jako pierwsza. Następnie docierają do tego procesu dwie aktualizacje zmiennej
x , które są obserwowane kolejnymi odczytami. Okazuje się jednak, że zapis
w(y)1 w procesie
p2 jest przyczynowo zależny od wcześniejszych zapisów do zmiennej
x realizowanych przez proces
p1 . Zależność ta nie jest jednak uwzględniana przy propagacji zapisów do procesu
p3 . Wskazuje to jednoznacznie na rozróżnialność spójności przyczynowej i procesorowej.
Relacje pomiędzy modelami spójności

Omówione modele spójności przy dostępie ogólnym są w pewnych zależnościach między sobą. Idąc od dołu, a więc od modeli najmniej restrykcyjnych mamy model PRAM, gwarantujący zachowanie porządku lokalnego wykonywanych operacji przez poszczególne procesy. Rozszerzając zachowywany porządek lokalny modelu PRAM o uporządkowanie przyczynowe dostajemy spójność przyczynową. Spójność podręczna wymaga uporządkowania, które jest całkowicie ortogonalne w stosunku do wymagań spójności PRAM czy przyczynowej. Łącząc własności spójności PRAM i spójności podręcznej dostajemy spójność procesorową. Jeżeli wszystkie zapisy w systemie są globalnie uporządkowane, a więc obserwowane przez wszystkie procesy w tej samej kolejności, to dostajemy model sekwencyjny, który jest silniejszy zarówno od spójności przyczynowej jak i procesorowej. Ostatecznie uwzględnienie w uporządkowaniu globalnym kolejności występowania zdarzeń w czasie rzeczywistym prowadzi do modelu atomowego, który jest z kolei silniejszy od modelu sekwencyjnego.
Dostęp synchroniczny - założenia

Drugą grupę modeli spójności w ramach modeli nastawionych na dane tworzą modele przy dostępie synchronizowanym. Modele te próbują zaradzić niedogodnościom modeli przy dostępie swobodnym, w których albo protokół okazywał się być nieefektywny (spójność atomowa i sekwencyjna), albo oferowane własności uszeregowania zapisów były niewystarczające do działania aplikacji. Niekiedy może się okazać nawet, że modele słabsze (spójność przyczynowa, PRAM czy podręczna) są wystarczające do konkretnych algorytmów, ale wykazanie tej wystarczalności jest zadaniem bardzo trudnym. Powoduje to zrozumiałą niechęć programistów do stosowania słabszych modeli spójności.
Rozwiązaniem zaproponowanym przez twórców niektórych systemów z rozproszoną pamięcią dzieloną jest propozycja kompromisu pomiędzy wygodą programowania takich systemów a efektywnością ich pracy. Modele przy dostępie ogólnym nie wymagają żadnej zmiany kodu algorytmu – program powinien działać poprawnie bez modyfikacji, niestety nieefektywnie. Jeżeli zrezygnować z pełnej transparentności i wymusić na programiście oznakowanie kodu dodatkowymi instrukcjami podpowiadającymi systemowi jakie są oczekiwania co do spójności danych, to implementacja odpowiedniego protokołu spójności może się okazać dużo bardziej efektywna. Jeżeli tylko dodatkowe instrukcje i ich umiejscowienie będzie proste, to rozwiązanie takie ma szansę na popularyzację.
Kolejne slajdy prezentują modele spójności przy dostępie synchronizowanym. Model systemu pozostaje taki jak poprzednio. Działania wykonywane są więc przez zbiór n procesów rozlokowanych na n węzłach. Procesy wykonują operacje na zbiorze zmiennych współdzielonych, których repliki znajdują się na każdym węźle. Dodatkowo istnieje zbiór S obiektów synchronizujących. W zależności od modelu wykorzystywane są następujące obiekty synchronizujące: zamki i bariery. Na zamkach wykonywane są dwie operacje: acquire – zajęcie (nabycie) zamka i release – zwolnienie zamka. Dla bariery wykonuje się operację synchronizacji na barierze. Synchronizacja taka polega na wstrzymaniu przetwarzania procesów zgłaszających się do bariery do czasu zgłoszenia się wszystkich procesów.
Spójność słaba
Pierwszym modelem spójności przy dostępie synchronizowanym była
spójność słaba (ang.
weak consistency ). W modelu tym rozróżniono po raz pierwszy dwa typy operacji: operacje dostępu do danych współdzielonych i operacje na zmiennych synchronizujących. Podstawową motywacją dla wprowadzenia jawnej operacji synchronizującej było umożliwienie opóźnienia propagacji aktualizacji do innych węzłów do czasu aż to będzie faktycznie potrzebne. W modelu sekwencyjnym praktycznie każda, najmniejsza operacja zmusza system do podejmowania kroków zmierzających do uspójnienia danych. Niekiedy jednak logika algorytmu wskazuje, że dane będą odczytywane później, po zaktualizowaniu większej grupy zmiennych. W spójności słabej zapisy do zmiennych współdzielonych nie muszą być od razu propagowane. Można je zbuforować i przesłać łącznie podczas wykonywania operacji synchronizującej.
W spójności słabej wyróżnia się jeden typ operacji synchronizującej. Definicja spójności słabej mówi, że:
1) Operacje na zmiennych synchronizujących są spójne atomowo (w nowszym podejściu sekwencyjnie). Wykonując operację synchronizującą proces może więc uzyskać gwarancję, że jego wcześniejsze modyfikacje na pewno dotrą do pozostałych procesów.
2) Nie można wykonać (zakończyć) operacji dostępu do zmiennej synchronizującej przed globalnym zakończeniem wcześniejszych operacji dostępu do zmiennych współdzielonych. Chodzi o to, żeby operacja synchronizująca swoim działaniem objęła wszystkie wcześniej wykonane operacje danego procesu.
3) Nie można wykonać (zakończyć) operacji dostępu do zmiennej współdzielonej przed globalnym zakończeniem wcześniejszych operacji dostępu do zmiennych synchronizujących. Motywacją w tym przypadku jest uniemożliwienie np. odczytywania danych, jeżeli dane te nie zostały jeszcze zaktualizowane, ponieważ operacja synchronizująca cały czas jest jeszcze wykonywana.
Spójność słaba - przykład

Procesy
p1 i
p2 wykonują zapisy do zmiennej
x współbieżnie, bez żadnej synchronizacji ze sobą. Następnie oba procesy wykonują operację synchronizującą, która powinna spowodować wymianę informacji pomiędzy węzłami odnośnie nowych operacji, o których druga strona nie wie. W efekcie zlecone wcześniej zapisy trafiają do drugiego serwera. Odczyty, które następują po synchronizacji odzwierciedlają w takiej sytuacji zapisy wykonane na zdalnym serwerze.
Spójność zwalniana

Kolejny model spójności to spójność zwalniania (ang.
release consistency ). Model ten udoskonalił spójność słabą poprzez rozróżnienie dwóch oddzielnych operacji synchronizujących wykonywanych na zamkach. Operacje te w swojej logice działają podobnie do semaforów, umożliwiając realizację wzajemnego wykluczania. Dodatkowo podczas ich wykonywania następuje propagacja zmian do pozostałych serwerów. Operacja bariery służy do globalnej synchronizacji całej pamięci na wszystkich węzłach.
Rozróżniamy dwa istotnie różne protokoły spójności dla spójności zwalniania; protokoły, które były niekiedy mylnie nazywane modelami spójności. Otóż w protokole eager release węzeł, który wykonuje operację zwalniania zamka rozsyła jednocześnie informację aktualizującą do wszystkich pozostałych serwerów. Do czasu wykonania operacji release żadna komunikacja nie jest potrzebna. Sama informacja aktualizacyjna może mieć postać aktualizacji bezpośrednio danych lub może powodować unieważnienie replik.
Drugi protokół to lazy release , w którym stosuje się właśnie podejście leniwe . W przeciwieństwie do protokołu eager nie wysyła się aktualizacji do wszystkich, bo najprawdopodobniej wszyscy ich nie potrzebują. Aktualizacja danych jest tu opóźniona do czasu wykonania następnej operacji acquire . W tym momencie bowiem wiadomo, kto tych danych potrzebuje. Synchronizacja następuje więc pomiędzy dwoma konkretnymi serwerami: tym, który dokonywał ostatnich modyfikacji (posiada więc aktualną kopię) i tym, który potrzebuje te dane. Jest to rozwiązanie bardzo oszczędne komunikacyjnie, ponieważ angażuje tylko węzły, które muszą być w tej sytuacji angażowane. Niestety pewnym problemem staje się w tym podejściu kumulacja informacji o wcześniejszym przetwarzaniu. Każdy kolejny węzeł musi bowiem uczestniczyć w przenoszeniu informacji o modyfikacjach, zarówno tych, które on sam dokonał, jak i tych wykonanych przez wszystkie węzły, które uczestniczyły w przetwarzaniu.
Spójność zwalniana - przykład

Rysunek pokazuje przykładowe przetwarzanie w systemie stosującym spójność zwalniania. Odczyty realizowane przez proces
p2 przed operacją
acquire zwracają wartości początkowe dla zmiennych
x i
y , gdyż protokół aktualizuje dane tylko podczas wykonywania operacji synchronizujących. Proces
p2 wykonuje operację
acquire na zamku, który wcześniej zajmowany był przez proces
p1 , co powoduje przesłanie aktualizacji z
p1 do
p2 . Dzięki temu kolejne odczyty, zarówno zmiennej
x jak i
y odzwierciedlają modyfikacje dokonane przez proces
p1 . Jeżeli stosowany jest protokół unieważniania, to odwołanie do strony, gdzie znajduje się zmienna
x lub zmienna
y spowoduje pobranie aktualnej wersji tej strony z węzła
p1.
Podsumowując: węzeł, który zwalnia blokadę przekazuje węzłowi, który przejmuje blokadę informacje o wszystkich modyfikacjach, których węzeł docelowy nie zna. Do reprezentacji historii przetwarzania i wydzielania fragmentów historii nieznanych innym węzłom stosuje się wektorowe etykiety czasowe.
Operacje synchronizujące mogą być wykonywane współbieżnie na wielu serwerach, ponieważ istnieje wiele zamków.
Spójność zakresu

Spójność zakresu (ang.
scope consistency ) jest dalszą modyfikacją przetwarzania obserwowanego w spójności zwalniania. Wymiana informacji następuje tu tak samo jak w przypadku protokołu
lazy release , a więc przy wywoływaniu operacji
acquire . Zmienia się jednak zakres tej informacji. O ile spójność zwalniania wymagała przesłania
wszystkich informacji nieznanych węzłowi docelowemu, o tyle w spójności zakresu przesyłane są tylko te modyfikacje, które zostały wykonane od ostatniej operacji
acquire na żądanym zamku. Najprawdopodobniej bowiem to właśnie te dane są potrzebne zajmującemu blokadę procesowi, a nie te, które były modyfikowane wcześniej czy później. Oczywistą konsekwencją tego rozwiązania jest zmniejszenie rozmiarów przesyłanych komunikatów. Informacja aktualizacyjna przesyłana jest tylko do węzła, który jej potrzebuje i w takim zakresie, jakiego potrzebuje.
Spójność zakresu - przykład
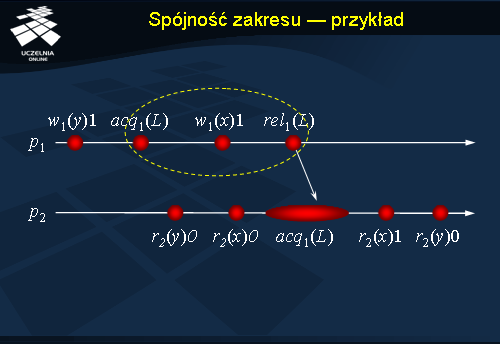
Rysunek przedstawia przykładowe przetwarzanie tożsame z tym, które było prezentowane w przypadku spójności zwalniania. W systemie stosującym spójność zakresu również nastąpi synchronizacja danych w momencie wykonywania operacji
acquire . Jednakże proces
p2 nie zostanie poinformowany o modyfikacjach zmiennej
y , ponieważ była ona modyfikowana przed zakresem wyznaczonym operacją
acquire . Poprawny dostęp do zmiennej
y wymagałby w tym przypadku: przesunięcia operacji
acquire przed zapis do
y lub użycie innej zmiennej synchronizującej i wskazanie nowego zakresu, do którego można by się odwołać w procesie
p2 .
Spójność wejścia

W spójności zwalniania i spójności zakresu zmienne synchronizujące są luźno związane ze zmiennymi współdzielonymi. To programista w swojej głowie ustala, że np. dostęp do zmiennej
x chroniony będzie zamkiem
L1 , a do zmiennej
y zamkiem
L2 . Inaczej jest w przypadku spójności wejścia, gdzie programista ma obowiązek jawnego powiązania każdego obiektu współdzielonego z jakąś zmienną synchronizującą. Dzięki takiemu rozwiązaniu następuje jeszcze bardziej precyzyjny transfer aktualizacji pomiędzy serwerami, ponieważ system wie na podstawie zlecanych operacji synchronizujących które obiekty ma aktualizować. Niestety wadą tego modelu jest konieczność definiowania wielu zmiennych synchronizacyjnych i konieczność ustalania powiązań między nimi.
Dodatkową cechą spójności wejścia jest wyróżnienie dwóch typów operacji acquire : zajęcie zamka może być w trybie wyłącznym lub dzielonym. Umożliwia to realizację współbieżnego odczytu tych samych danych na wielu węzłach, co nie było możliwe w przypadku spójności zwalniania i zakresu.
Własność lokalności

W analizie modeli spójności używa się niekiedy pojęcia
lokalności (ang.
locality ), której definicja zawarta jest na slajdzie. Lokalność jest cechą modeli spójności atomowej i podręcznej. W przypadku spójności podręcznej jest to dość naturalne, bo definicja modelu odnosi się właśnie do pojedynczych obiektów. Jeżeli więc zapisy do każdego pojedynczego obiektu są globalnie uporządkowane, to cały system zachowuje spójność podręczną.
Własność lokalności - przykład

Przykład na slajdzie (prezentowany dalej na kolejnych dwóch slajdach) ma na celu zaprezentowanie, że spójność sekwencyjna nie ma własności lokalności. W przykładzie proces
p1 dokonuje zapisów do 4 zmiennych:
x1 ,
x2 ,
y1 i
y2 . Proces
p2 jedynie czyta te zmienne. Jak łatwo zauważyć obraz historii przetwarzania w procesie
p2 zawiera inną kolejność operacji zapisu do zmiennych
x2 i
y1 niż obraz w procesie
p1 . Nie jest zachowana więc spójność sekwencyjna. Pomimo, że... (nast. slajd)

Rysunek przedstawia fragment przetwarzania z poprzedniego slajdu dotyczący operacji na zmiennych
x1 i
x2 . Jak widać z obrazów historii przetwarzania operacje na takim podzbiorze zmiennych są spójne sekwencyjnie. Ale... (nast. slajd)

Rysunek przedstawia inny fragment przetwarzania z wcześniejszego slajdu dotyczący operacji na zmiennych
y1 i
y2 . Jak widać z obrazów historii przetwarzania operacje na takim podzbiorze zmiennych również są spójne sekwencyjnie. Niestety na podstawie analizy dla tych dwóch podzbiorów zmiennych nie możemy powiedzieć, że system jako całość zachowuje spójność sekwencyjną. Oznacza to, że spójność sekwencyjna nie ma własności lokalności.
Wracając do pełnego przykładu – spójność atomowa posiada własność lokalności, ponieważ uwzględniane są uporządkowania operacji w czasie rzeczywistym. W takim przypadku kolejność operacji w(x2)1 i w(y1)1 z procesu p1 musiałaby być zachowana w obrazie historii w procesie p2 .










