-
Statyczne - zachodzi po zdekodowaniu instrukcji skoku, nie wymaga gromadzenia wiedzy o historii programu
-
przewidywanie realizacji skoku warunkowego
-
Dynamiczne - na podstawie wiedzy o historii wykonania programu
-
przewidywanie wystąpienia instrukcji skoku przed jej pobraniem
-
przewidywanie adresu docelowego skoków statycznych i dynamicznych
-
przewidywanie realizacji skoku warunkowego
Wszystkie metody przewidywania skoków można podzielić na statyczne i dynamiczne. Metody statyczne, w przeciwieństwie do dynamicznych, nie wymagają gromadzenia przez procesor informacji o historii wykonania programu. Metody statyczne ograniczają się więc do przewidywania sposobu wykonania skoku warunkowego po jego zdekodowaniu przez procesor, kiedy już wiadomo, że instrukcja skoku wystąpiła oraz jaki jest adres docelowy skoku.
Metody dynamiczne polegają na kolekcjonowaniu przez procesor informacji o wykonaniu programu. Na tej podstawie można przewidywać wszystkie wymienione wcześniej aspekty skoków.
Statyczne przewidywanie realizacji skoku
-
Przewidywanie przez kompilator lub programistę
-
kompilator języka wysokiego poziomu lub programista piszący program w asemblerze zna prawdopodobieństwo wykonania skoku warunkowego
-
informacja ta może zostać umieszczona w programie, o ile model programowy uwzględni dwa warianty skoków warunkowych
-
skoki prawdopodobne
-
skoki nieprawdopodobne
-
przykłady: Alpha AXP, Intel Pentium 4
-
Przewidywanie przez procesor
-
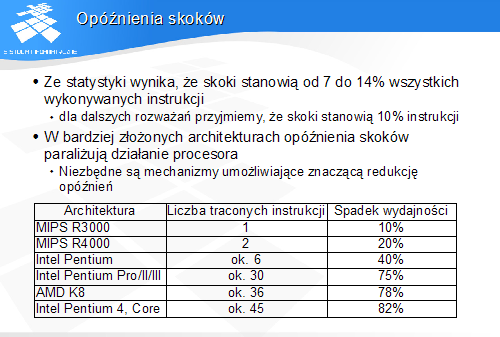
z analizy własności programów wynika, że ponad 60% skoków warunkowych w tył jest realizowanych, a skoków w przód - nierealizowanych
-
skoki warunkowe są zapisywane jako względne - bit znaku przemieszczenia może zostać użyty przez procesor jako znacznik prawdopodobieństwa skoku
Przy przewidywaniu statycznym przez kompilator lub programistę, instrukcje skoków warunkowych zostają a priori oznaczone jako prawdopodobne lub nieprawdopodobne. Na tej podstawie procesor będzie podejmował decyzję o sposobie spekulatywnego wykonania skoku po jego zdekodowaniu, a przed właściwym deterministycznym wykonaniem. Taki sposób przewidywania wymaga odmiennego kodowania instrukcji skoków prawdopodobnych i nieprawdopodobnych. Mechanizm taki posiadały m.in. procesory rodziny Alpha AXP i Intel 960. Podobny mechanizm, korzystający z tzw. prefiksów instrukcji, wprowadzono w architekturze Pentium 4.
Przewidywanie przez procesor polega na określaniu prawdopodobieństwa na podstawie kierunku skoku. Korzysta się tu ze szczególnej własności programów.
Dynamiczne przewidywanie wystąpienia skoku
-
Wymaga wprowadzenia do struktury procesora dodatkowych bloków sprzętowych, gromadzących informację o historii wykonania programu
-
Bufor docelowy skoków (BTB - Branch Target Buffer)
-
gromadzi informację o pewnej liczbie ostatnio wykonywanych skoków
-
działa na zasadzie podobnej do kieszeni
-
często realizowany w powiązaniu z kieszenią kodu
-
Przy każdej realizacji skoku adres, pod którym jest położona instrukcja skoku jest odnotowywany w BTB
-
na ogół razem z adresem docelowym skoku
-
Przy każdym pobraniu instrukcji stopień pobrania sprawdza, czy adres pobrania został wcześniej zanotowany jako adres instrukcji skoku
-
jeśli tak - stopień pobrania może w następnym cyklu "wykonać" skok
Przewidywanie dynamiczne wymaga umieszczenia w procesorze bloków służących do gromadzenia informacji o wykonaniu skoków.
Główną strukturą jet tu bufor docelowy skoków, gromadzący informacje o wystąpieniach skoków i ich adresach docelowych.
Sam bufor docelowy służy do przewidywania wystąpienia skoku przed jego pobraniem i zdekodowaniem oraz do określenia adresu docelowego takiego skoku.
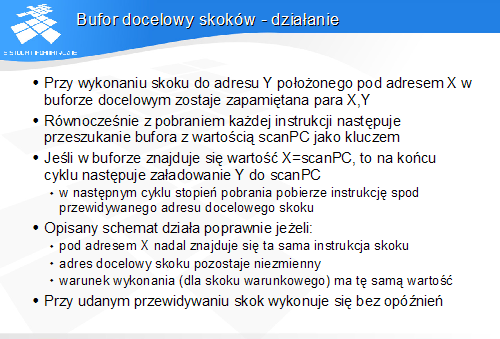
Bufor docelowy skoków - działanie
-
Przy wykonaniu skoku do adresu Y położonego pod adresem X w buforze docelowym zostaje zapamiętana para X,Y
-
Równocześnie z pobraniem każdej instrukcji następuje przeszukanie bufora z wartością scanPC jako kluczem
-
Jeśli w buforze znajduje się wartość X=scanPC, to na końcu cyklu następuje załadowanie Y do scanPC
-
w następnym cyklu stopień pobrania pobierze instrukcję spod przewidywanego adresu docelowego skoku
-
Opisany schemat działa poprawnie jeżeli:
-
pod adresem X nadal znajduje się ta sama instrukcja skoku
-
adres docelowy skoku pozostaje niezmienny
-
warunek wykonania (dla skoku warunkowego) ma tę samą wartość
-
Przy udanym przewidywaniu skok wykonuje się bez opóźnień
Bufor docelowy bez dodatkowych mechanizmów sprzętowych przewiduje skoki wyłącznie jako bezwarunkowe. Samo przewidywanie opiera się na spełnieniu przez wykonywany program kilku założeń. W przypadku niespełnienia wymienionych założeń, przewidywanie się nie powiedzie.
Bufor docelowy - ograniczenia
-
Bufor docelowy w podstawowej formie nie może przewidywać:
-
skoków dynamicznych
-
skoków warunkowych przy różnych wartościach warunku w kolejnych wykonaniach
-
Zastosowanie skoków dynamicznych:
-
powroty z procedur - b. częste, niezbędne
-
wskaźniki na funkcje, w tym metody wirtualne - zależne od przyjętego stylu programowania
-
jedna z możliwych realizacji konstrukcji typu switch - zależne od kompilatora
-
Skoki dynamiczne mogą być przewidywane w buforze docelowym jako statyczne
-
działa to dość dobrze dla wskaźników na funkcje
-
Potrzebny inny mechanizm przewidywania powrotów z procedur
Z przytoczonych wcześniej założeń wynika, że bufor docelowy nie może przewidywać skoków o zmiennym adresie docelowym, ani nie radzi sobie z przewidywaniem skoków warunkowych wykonywanych w różny sposób.
Ponieważ powroty z procedur są jednymi z najczęściej wykonywanych instrukcji, procesor powinien być wyposażony w inny mechanizm umożliwiający ich przewidywanie.
Przewidywanie adresów powrotów z procedur
-
Szczególnie potrzebne w procesorach CISC
-
odczyt śladu ze stosu jest czasochłonny
-
Założenie: adres powrotu jest ostatnim zapamiętanym śladem
-
implikuje to wymaganie, że każdej instrukcji skoku ze śladem odpowiada instrukcja powrotu
-
przewidywanie adresu powrotu nie działa dla par: PUSH-RET, CALL-POP
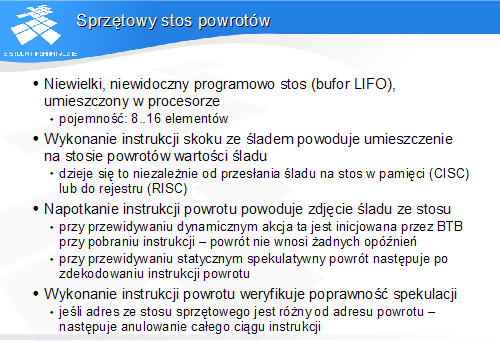
Sprzętowy stos powrotów
-
Niewielki, niewidoczny programowo stos (bufor LIFO), umieszczony w procesorze
-
pojemność: 8..16 elementów
-
Wykonanie instrukcji skoku ze śladem powoduje umieszczenie na stosie powrotów wartość i śladu
-
dzieje się to niezależnie od przesłania śladu na stos w pamięci (CISC) lub do rejestru (RISC)
-
Napotkanie instrukcji powrotu powoduje zdjęcie śladu ze stosu
-
przy przewidywaniu dynamicznym akcja ta jest inicjowana przez BTB przy pobraniu instrukcji - powrót nie wnosi żadnych opóźnień
-
przy przewidywaniu statycznym spekulatywny powrót następuje po zdekodowaniu instrukcji powrotu
-
Wykonanie instrukcji powrotu weryfikuje poprawność spekulacji
-
jeśli adres ze stosu sprzętowego jest różny od adresu powrotu -następuje anulowanie całego ciągu instrukcji
Sprzętowy stos powrotów - efektywność
-
Stos powrotów działa skutecznie dla fragmentów programu, w których zagłębianie procedur nie przekracza pojemności stosu
-
Każda "niesparowana" instrukcja CALL lub RETURN powoduje de synchronizację stosu
-
wszystkie następne powroty będą przewidywane błędnie, aż do zapełnienia całego stosu nowymi śladami
Dynamiczne przewidywanie realizacji skoku
-
Sam bufor docelowy przewiduje skoki warunkowe jako bezwarunkowe
-
skok niezrealizowany po zrealizowanym jest przewidziany błędnie
-
Lepsze przewidywanie realizacji skoków wymaga implementacji predyktora, decydującego o tym, czy procesor ma traktować skok jako realizowany czy nierealizowany
-
Skróty i konwencje:
-
T (Taken) - skok realizowany
-
NT (Not Taken) - skok nierealizowany
-
PT (Predict Taken) - skok przewidywany jako realizowany (na grafach - kolor zielony)
-
PNT (Predict Not Taken) - skok przewidywany jako nierealizowany-na grafach kolor czerwony)
-
Automaty decydujące o sposobie spekulatywnego wykonania przewidywanego skoku warunkowego na podstawie historii wykonania programu
-
Działanie predyktorów
-
deterministyczne wykonanie (rozstrzygnięcie skoku) przez procesor powoduje modyfikację stanu predyktora
-
spekulatywne wykonanie skoku na podstawie stanu predyktora
-
Klasyfikacja predyktorów
-
wg konstrukcji elementarnego automatu predyktora
-
wg sposobu wiązania instrukcji skoku z automatem predyktora:
-
jednopoziomowe - prawdopodobieństwo bezwarunkowe
-
dwupoziomowe - prawdopodobieństwo warunkowe
-
trójpoziomowe - p. warunkowe z adaptacją schematu przewidywania
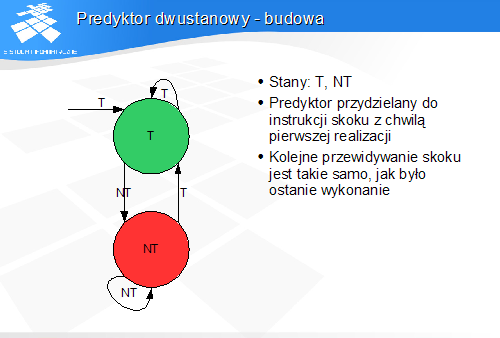
Predyktor dwustanowy - budowa
-
Stany: T, NT
-
Predyktor przydzielany do instrukcji skoku z chwilą pierwszej realizacji
-
Kolejne przewidywanie skoku jest takie samo, jak było ostanie wykonanie
Predyktor dwustanowy - charakterystyka
-
Błędne przewidywanie skoku zamykającego pętlę zagnieżdżoną przy pierwszym i ostatnim wykonaniu
-
istotne przy pętlach iterowanych niewielką liczbę razy
-
Błędne przewidywanie po każdym odstępstwie od typowego wykonania
-
100% błędne przewidywanie skoków realizowanych co drugi raz
Podczas ostatniej iteracji pętli zagnieżdżonej predyktor przewiduje zamknięcie pętli, i jest to oczywiście przewidywanie błędne. Przy wyjściu z pętli predyktor myli się. Po wyjściu z pętli predyktor dwustanowy ustawia przewidywanie skoku zamykającego pętle na NT(PNT). Przy powtórnym wejściu w pętlę predyktor przewiduje opuszczenie pętli, podczas, gdy pętla się zamyka. Po błędzie predyktora następuje zmiana stanu na T(PT). Predyktor myli się więc przy pierwszym i ostatnim obiegu pętli.
W zastosowaniu do skoku wykonywanego naprzemiennie predyktor myli się w każdym wykonaniu.
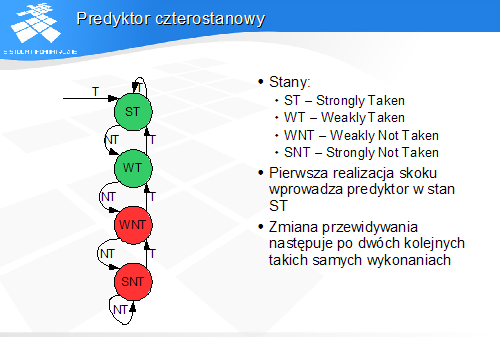
Predyktor czterostanowy
-
Stany:
-
ST - Strongly Taken
-
WT - Weakly Taken
-
WNT - Weakly Not Taken
-
SNT - Strongly Not Taken
-
Pierwsza realizacja skoku wprowadza predyktor w stan ST
-
Zmiana przewidywania następuje po dwóch kolejnych takich samych wykonaniach
Predyktor czterostanowy działa jak dwubitowy licznik rewersyjny z nasyceniem. W stanach ST i WT mamy przewidywanie PT, a w stanach WNT i SNT PNT.
Predyktor czterostanowy - charakterystyka
-
Błędne przewidywanie skoku zamykającego pętle przy ostatnim wykonaniu
-
istotne przy pętlach iterowanych niewielką liczbę razy
-
Poprawne przewidywanie po każdym jednokrotnym odstępstwie od typowego wykonania
-
Skoki realizowane co drugi raz przewidywane poprawnie w 50%
Po serii obiegów pętli predyktor skoku zamykającego pętlę jest w stanie SNT. Przy wyjściu z pętli predyktor błędnie przewiduje zamknięcie, po czym przechodzi w stan WT. Przy następnym wejściu w pętlę predyktor poprawnie przewiduje zamknięcie.
Skok naprzemienny jest przewidywany zawsze tak samo, czyli predyktor myli się w co drugim wykonaniu. Dzieje się tak dzięki temu, że początkowo predyktor ustawie się w stan ST (ew. SNT), po czym oscyluje pomiędzy ST i WT (lub SNT i WNT).
Ograniczenia predyktorów jednopoziomowych
-
Brak możliwości trafnego przewidzenia wszystkich iteracji skoku zamykającego pętlę
-
szczególnie istotne przy pętlach iterowanych niewielką liczbę razy. często spotykanych w oprogramowaniu
-
Brak możliwości trafnego przewidzenia skoków wykonywanych cyklicznie
-
np. dwa razy realizowany, następnie dwa razy nierealizowany
Predyktory dwupoziomowe
-
Przechowują informację o prawdopodobieństwie warunkowym
-
"jak wykona się skok, jeśli ostatnio raz był zrealizowany i trzy razy niezrealizowany"
-
Predyktor elementarny nie jest bezpośrednio związany z instrukcją skoku
-
wybór predyktora zachodzi na podstawie adresu instrukcji skoku i historii wykonań
-
Rejestr historii:
-
rejstr przesuwający o długości 8..16 bitów, zawierający historię wykonań (T/NT) dla ostatnich wykonań pojedynczego lub wielu skoków
-
Predyktory dwupoziomowe i trójpoziomowe są nazywane korelatorami skoków
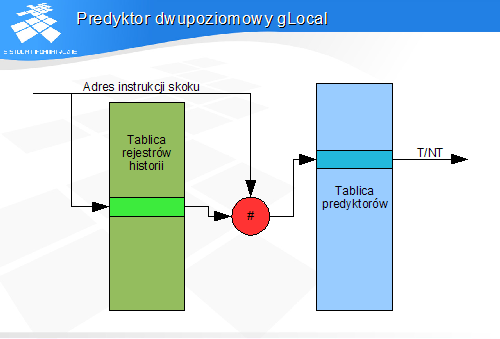
Predyktor dwupoziomowy gLocal
W schemacie gLocal adres instrukcji skoku wybiera rejestr historii związany z danym skokiem. Zawartość rejestru historii i adres skoku są argumentami funkcji mieszającej, której wartość wybiera jeden z dwu- lub czterostanowych predyktorów.
Jako funkcji mieszającej najczęściej używa się operacji XOR.
Predyktor udziela odpowiedzi na pytanie o prawdopodobieństwo skoku na bazie poprzednich wykonań tego skoku.
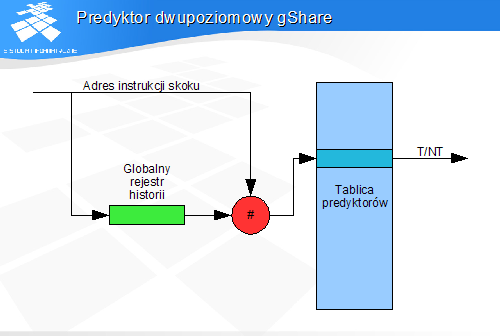
Predyktor dwupoziomowy gShare
W schemacie gShare historia wykonań wszystkich skoków przechowywane jest w jednym rejestrze. Zawartość rejestru historii i adres skoku są argumentami funkcji mieszającej, której wartość wybiera jeden z dwu- lub czterostanowych predyktorów.
Predyktor udziela odpowiedzi na pytanie o prawdopodobieństwo skoku na bazie poprzednich wykonań wszystkich ostatnio wykonywanych skoków.
Predyktory dwupoziomowe - własności

-
Powolne „uczenie się" predyktora
-
trafne przewidywanie wymaga często wielu tysięcy wykonań skoku
-
Możliwość poprawnego przewidywania sekwencji wykonań o długości równej co najmniej długości rejestru historii
-
w tym możliwość poprawnego przewidywania zamknięć pętli iterowanych np. 8 razy
-
Niewrażliwość na pojedyncze nieregularności wykonania
-
Trafność przewidywania typowo około 95% lub więcej
-
Predyktor gLocal lepiej przewiduje pętle iterowane niewielką liczbę razy
-
Predyktor gShare lepiej przewiduje rozejścia zależne od wartości danych
-
o ile kilka kolejnych rozejść jest ze sobą powiązanych
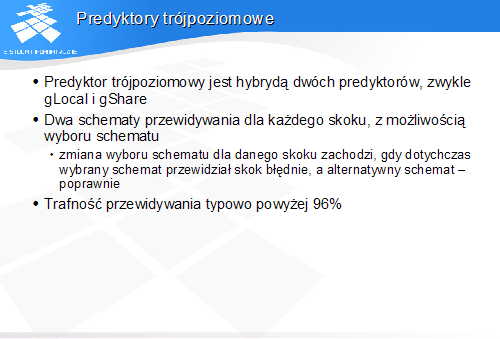
Predyktory trójpoziomowe
-
Predyktor trójpoziomowy jest hybrydą dwóch predyktorów, zwykle gLocal i gShare
-
Dwa schematy przewidywania dla każdego skoku, z możliwością wyboru schematu
-
zmiana wyboru schematu dla danego skoku zachodzi, gdy dotychczas wybrany schemat przewidział skok błędnie, a alternatywny schemat-poprawnie
-
Trafność przewidywania typowo powyżej 96%
Redukcja opóźnienia danych z pamięci
-
W architekturach superskalarnych samo rozsunięcie instrukcji ładującej daną i instrukcji korzystającej z danej nie maskuje opóźnienia
-
Niezbędne pobieranie danych z pamięci do kieszeni lub buforów "na zapas" (Data Prefetch)
-
Realizacje:
-
pobieranie inicjowane przez oprogramowanie
-
automatyczne (spekulatywne) pobieranie przez procesor
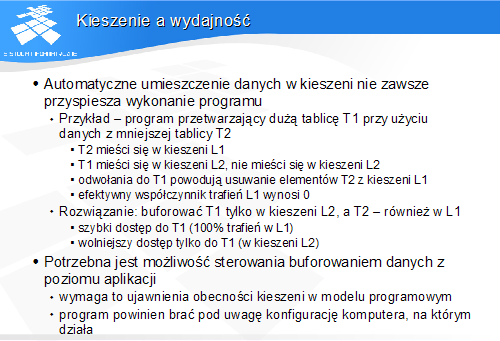
Kieszenie a wydajność
-
Automatyczne umieszczenie danych w kieszeni nie zawsze przyspiesza wykonanie programu
-
Przykład - program przetwarzający dużą tablicę T1 przy użyciu danych z mniejszej tablicy T2
-
T2 mieści się w kieszeni L1
-
T1 mieści się w kieszeni L2, nie mieści się w kieszeni L2
-
odwołania do T1 powodują usuwanie elementów T2 z kieszeni L1
-
efektywny współczynnik trafień L1 wynosi 0
-
Rozwiązanie: buforować T1 tylko w kieszeni L2, a T2 - również w L1
-
szybki dostęp do T1 (100% trafień w L1)
-
wolniejszy dostęp tylko do T1 (w kieszeni L2)
-
Potrzebna jest możliwość sterowania buforowaniem danych z poziomu aplikacji
-
wymaga to ujawnienia obecności kieszeni w modelu programowym
-
program powinien brać pod uwagę konfigurację komputera, na którym działa
Instrukcje pobierania danych
-
Instrukcje nie mają skutku w modelu programowym - nie modyfikują kontekstu procesora
-
Implementacja opcjonalna - prostsze procesory mogą je wykonywać jako puste
-
Instrukcje mają charakter sugestii (podpowiedzi), umożliwiających optymalizację działania procesora Jeden argument - adres pamięci
-
Wykonanie instrukcji polega na przesłaniu danych z pamięci do kieszeni lub bufora, ew. zmianie stanu linii kieszeni
-
instrukcja "pobrania do zapisu" tylko alokuje linie w kieszeni, które mają być całkowicie zapełnione nowymi danymi - bez późniejszego zapisu danych ich wartość będzie nieokreślona!
-
Czas i sposób wykonania mogą zależeć od bieżącego obciążenia interfejsu pamięci i kieszeni
Instrukcje PREFETCH - x86
-
PREFETCHNTA - pobranie danych z pominięciem kieszeni (do niewidocznego bufora danych w procesorze)
-
dane będą użyte jednorazowo i nie powinny powodować usunięcia innych obiektów z kieszeni
-
PREFETCHTO - pobranie danych do kieszeni poziomu 1. i ew. innych poziomów
-
PREFETCHT1 - pobranie danych do kieszeni poziomu 2 i ew. następnych
-
dane nie mieszczą się w L1 i nie powinny jej zajmować
-
PREFETCHT2 - pobranie danych do kieszeni poziomu 3. i ew. następnych
-
dane nie mieszczą się w L2 i nie powinny jej zajmować
Automatyczne pobieranie danych przez procesor
-
Odpowiedni moduł sprzętowy wykrywa wzorce odwołań do pamięci realizowanych przez program
-
Na podstawie rozpoznanego wzorca procesor samoczynnie wykonuje operację pobierania danych analogiczną do inicjowanej przez instrukcje PREFETCH
-
Mechanizm zaimplementowany min. w procesorach serii Pentium 4 i Core