
Na potrzeby tego modułu, w celu uwypuklenia pewnych aspektów wprowadzonych wcześniej pojęć, pojęcia te zostaną ponownie zdefiniowane lub sformalizowane.
Dalsza część wykładu dotyczy podstawowego problemu synchronizacji procesów — wzajemnego wykluczania i poprawności jego rozwiązania. Przedstawione zostaną algorytmy oparte wyłącznie na zapisie i odczycie współdzielonych zmiennych — algorytm Petersona oraz Lamporta (tzw. algorytm piekarni). Następnie analizowane będą rozwiązania wykorzystujące złożone instrukcje atomowe: test & set oraz exchange .

Instrukcje wykonywane w systemie, niezależnie od procesu, wpływają również na stan systemu jako całości. Stan systemu stanowi pewne otoczenie każdego procesu (jest tym samym elementem stanu każdego z procesów), gdyż niektóre zasoby systemu są przez procesy współdzielone. W najprostszym przypadku można mówić o współdzielonych zmiennych, których wartości wynikają z wykonywania instrukcji różnych procesów. W ten sposób dochodzi do interakcji pomiędzy procesami.
W celu ujednolicenia opisu stan systemu będzie występował wyłącznie w kontekście procesu, a interakcja pomiędzy procesami będzie realizowana poprzez zmienne wejściowe i wyjściowe poszczególnych procesów.
Przedstawioną abstrakcję można również odwzorować na proces wielowątkowy. Proces taki odpowiadałby wówczas systemowi, udostępniając środowisko do wykonywania wątków. Zmiana stanu wynikałaby z realizacji instrukcji związanych z wątkami tego procesu.

W systemach z jedną jednostką przetwarzającą warunki te spełnia każdy rozkaz procesora, gdyż sprawdzanie wystąpienia przerwań oraz ewentualna ich obsługa wykonywana jest zawsze na końcu cyklu rozkazowego. Poza tym skutki wykonania takiej instrukcji są natychmiast widoczne dla instrukcji następnych.
W systemach wieloprocesorowych instrukcje mogą być wykonywane jednocześnie przez różne jednostki przetwarzające. Takie wykonanie instrukcji odbywa się w izolacji, co gwarantuje, że żadne częściowe (tymczasowe) wyniki nie są widoczne i tym samym nie wpływają na wykonanie innych instrukcji. Jeśli jednak jednocześnie wykonywane instrukcje operują na tych samych danych, konieczne jest najczęściej wykonanie ich w określonej sekwencji. W systemach wieloprocesorowych, opartych na wspólnej magistrali, efekt ten można uzyskać przez zablokowanie dostępu do magistrali systemowej na czas wykonywania instrukcji. W architekturach Intel, w tym celu przekazywany jest sygnał LOCK, który jest integralnie związany z cyklem rozkazowym w przypadku niektórych rozkazów (np. xchg) lub wynika z jawnego żądania ze strony wykonywanego programu, poprzez użycie prefiksu LOCK.
W przyjętych oznaczeniach ei (c , O ) oznacza wykonanie w ramach procesu Pi operacji c ∈C , w wyniku której czytane lub modyfikowane są operandy (argumenty) ze zbioru O = {o1 , o2 ,..., on } ⊆ D . Formalnie wykonanie operacji jest zatem elementem iloczynu kartezjańskiego C × 2D .
Stan procesu i zdarzenia

Z punktu widzenie współbieżnej i asynchronicznej realizacji przetwarzania przez wiele procesów istotne jest, kiedy jakaś instrukcja się wykona, zwłaszcza instrukcja, która wpływa na otoczenie procesu (potencjalnie zatem na inne procesy). Dlatego najbardziej istotny jest ten aspekt stanu procesu, który dotyczy wykonywania instrukcji i pośrednio wpływa na realizację innych procesów w systemie.
Na poziomie architektury procesora następną instrukcję do wykonania bezpośrednio wskazuje rejestr w procesorze, zwany licznikiem rozkazów lub wskaźnikiem instrukcji. Jednak następna wartość tego rejestru zależy od wykonywanego rozkazu oraz ustawienia flag w rejestrze, zwanym słowem stanu programu. Zawartość tego rejestru wynika z kolei z wcześniej wykonanych instrukcji oraz wartości ich operandów. Poza tym możliwość wykonania instrukcji uwarunkowana jest dostępnością takich zasobów jak pamięć, czy procesor.
Na potrzeby dalszej analizy zakłada się, że określony stan procesu jest unikalny, tzn. ten sam stan nigdy się nie powtórzy, pomimo że stan przetwarzania (stan rejestrów procesora, pamięci) będzie dokładnie taki sam jak wcześniej. Można przyjąć, że elementem stanu procesu jest rzeczywisty czas ostatniego zdarzenia lub licznik wykonanych instrukcji, który będzie się monotonicznie zwiększał.

Odwzorowanie L zdefiniowane jest przez program dla procesu, zakładając, że program jest deterministyczny. Odzwierciedla ono fakt, że zajście zdarzenia w określonym stanie prowadzi do następnego stanu. Opisując to z drugiej strony można stwierdzić, że stan następny uwarunkowany jest zajściem zdarzenia i stanem poprzedzającym to zajście. Odwzorowanie to nie jest określonej dla każdej pary ze zbioru Si × Ei . W przetwarzaniu sekwencyjnym stan determinuje następne zdarzenie, np. licznik rozkazów wskazuje następny rozkaz do wykonania.
Jak już zasygnalizowano na poprzednim slajdzie, użycie pojęcia wątek , obok powszechnie używanego w tym kontekście pojęcia proces , podkreśla fakt, że realizacja współbieżnego przetwarzania przebiega we wspólnej przestrzeni adresowej, czyli przy dostępie do współdzielonych danych. W tym module pojęcia proces i wątek będą utożsamiane.

Przetwarzanie sekwencyjne oznacza następstwo stanów i zdarzeń. Zarówno zdarzenia, jak i stany w procesie sekwencyjnym są liniowo uporządkowane zgodnie z kolejnością ich wystąpienia.

Zakładając, że w systemie z kilkoma równolegle działającymi procesorami operacje jednoczesne (nakładające się w czasie, ang. overlapping) nie powoduję konfliktu w dostępie do danych, model taki jest w dalszym ciągu adekwatny. Można pokazać, że przetwarzanie z jednoczesnym wykonaniem pewnych instrukcji jest równoważne wykonaniu sekwencyjnemu.
Jeśli występuje konflikt w dostępie do danych, tzn. dwie (lub więcej) instrukcje wykonywane jednocześnie mają wspólny operand, przy czym przynajmniej jedna z nich go modyfikuje, konieczne jest ich uszeregowanie w czasie. W wyniku tego uszeregowania instrukcje „w konflikcie” będą wykonane w pewnej sekwencji.
Niezależnie zatem od sposobu realizacji przetwarzania, instrukcje różnych procesów będą analizowane tak, jak gdyby przeplatały się one w czasie.
We współbieżnej realizacji zakłada się, że procesy działają asynchronicznie, tzn. liczba instrukcji poszczególnych procesów, wykonana w jednostce czasu, może być dla każdego z nich inna. Oznacza to, że nie ma pewności, w jakiej kolejności instrukcje różnych procesów będą następowały po sobie, chyba że kolejność tę wymuszą zastosowane mechanizmy synchronizacji.

Na stan początkowy przetwarzania składają się stany początkowe poszczególnych procesów.
Podobnie jak odwzorowanie L, odwzorowanie G nie jest określone dla każdej pary ze zbioru Σ × Δ. Nie każde zdarzenie może zatem wystąpić w określonym stanie przetwarzania współbieżnego. W przeciwieństwie do stanu procesu sekwencyjnego stan przetwarzania współbieżnego nie determinuje jednak jednoznacznie następnego zdarzenia, gdyż potencjalnie jakieś zdarzenie może wystąpić w każdym ze współbieżnych procesów. Liczba możliwych zdarzeń może być zredukowana poprzez zastosowanie mechanizmów synchronizacji.

W niektórych przypadkach kolejność wystąpienia zdarzeń nie ma znaczenia, osiągamy ostatecznie taki sam stan. Są jednak przypadki, w których wystąpienie określonego zdarzenia na tyle istotnie wpływa na stan przetwarzania współbieżnego, że sterowanie w niektórych procesach może przebiegać zupełnie inną ścieżką. Zjawisko, w którym w zależności od kolejności pewnych zdarzeń system osiąga różne stany, określa się jako hazard (ang. race condition).

Przeplot może być analizowany w kontekście zrealizowanego już przetwarzania, a może być rozważany potencjalnie, jako ciąg dopuszczalnych zdarzeń i wynikających z nich stanów, na potrzeby weryfikacji poprawności lub innych własności. W tym drugim przypadku, uwzględniając niedeterminizm, należałoby raczej mówić o pewnym zbiorze możliwych przeplotów, czyli różnych uporządkowaniach tego samego lub zbliżonego zbioru zdarzeń. Różnice w samym zbiorze zdarzeń mogą wynikać z faktu, że w zależności od stanu przetwarzania, przebieg sterowania w poszczególnych procesach może być nieco inny, w związku z czym pewne instrukcje mogą zostać pominięte.
Z punktu widzenia analizy określonych własności, typu bezpieczeństwo, żywotność, zakleszczenie, istotny jest nie tyle przeplot ile stan systemu, który powstanie w wyniku zajścia zdarzeń w przeplocie. Kluczowe w tym kontekście jest pojęcie osiągalności stanów. Osiągalność jakiegoś stanu z innego stanu zachodzi wówczas, gdy istnieje przeplot, który prowadzi z jednego stanu do drugiego. Wyraża to formalnie definicja rekurencyjna, przedstawiona na slajdzie.

Procesy współpracujące ze sobą mogą się komunikować i rywalizować o dostępność zasobów, a z faktu wystąpienia interakcji między nimi może wynikać taka lub inna sekwencja osiąganych stanów a nawet realizowanych instrukcji (taki lub inny przepływ sterowania). Zdarzenie związane z jednym z procesów może mieć zatem wpływ na wybór instrukcji do wykonania w innym. Na przykład, jeden z procesów modyfikuje współdzieloną zmienną, od wartości której zależy spełnienie warunku wykonania instrukcji lub pętli w innym procesie.

Zmienne współdzielone z kolei dostępne są dla kilku (w szczególności wszystkich) procesów. Można rozważać różne schematy dostępności zmiennych współdzielonych, np. dostępność do zapisu w jednym procesie, a do odczytu w pozostałych procesach. W prezentowanych algorytmach własności takie nie będą wyrażane explicite, mogą jednak wynikać konstrukcji algorytmu. W algorytmach definicje zmiennych współdzielonych będą poprzedzane modyfikatorem shared .


W procesorach o architekturze RISC operacje arytmetyczne wykonywane są wyłącznie na rejestrach procesora, wobec czego podstawienie takie wymaga wcześniejszego załadowania zawartości komórki pamięci, przechowującej wartość zmiennej n, do odpowiedniego rejestru, dodania wartości 1 do zawartości tego rejestru, a następnie umieszczenia zmodyfikowanej wartości ponownie w pamięci pod adresem przypisanym zmiennej n . W tym celu wątek A korzysta z jakiegoś rejestru procesora, oznaczonego RA , a wątek B z rejestru RB . W szczególności może to być ten sam rejestr, ale raz występujący w kontekście wątku A, a raz w kontekście wątku B.
W procesorach o architekturze CISC powszechne są rozkazy typu odczyt modyfikacja zapis (ang. read-modify-write). Przykładem może być 16- lub 32-bitowa architektura intelowska z rozkazem inc , którego operand może być w pamięci. Rozkaz ten może być zatem użyty w przekładzie na kod maszynowy wysokopoziomowej instrukcja podstawienia n := n + 1.



Synchronizacja na najniższym poziomie polega na wykonaniu określonych (często specjalnych) instrukcji, które powodują zablokowanie postępu przetwarzania do czasu wystąpienia określonego zdarzenia w systemie, związanego również z instrukcją synchronizującą, ale w innym wątku.
Synchronizacja na wyższym poziomie polega na użyciu w programie specjalnych konstrukcji lub odpowiednim zdefiniowaniu struktur danych, które kompilator zamienia na właściwe instrukcje synchronizujące, udostępniane przez system operacyjny lub architekturę procesora.


Własność uczciwości zostaje tylko zasygnalizowana i nie będzie w dalszej części analizowana w prezentowanych algorytmach.

Środki udostępniane przez poziom maszynowy procesora to głównie atomowy zapis oraz odczyt współdzielonych danych, określanych również jako współdzielone rejestry, czyli współdzielone komórki pamięci. Na poziomie architektury komputera mamy gwarancję atomowego transferu danych 8-, 16-, 32-bitowych itd. pomiędzy rejestrami procesora a pamięcią, co daje pewność, że dane są zapisywane lub odczytywane „w całości”. Procesor może też udostępnić bardziej złożone operacje atomowe na współdzielonych rejestrach lub bitach rejestrów. Do takiej grupy należą np. instrukcje test & set oraz exchange.
Synchronizacja za pomocą odpowiednich instrukcji opartych na rozwiązaniach w architekturze procesora oznacza konieczność permanentnego wykonywania określonej instrukcji, aż do uzyskania oczekiwanego efektu (odpowiednik odpytywania w interakcji jednostki centralnej z urządzeniem wejścia-wyjścia). Takie podejście przy przedłużającym się oczekiwaniu oznacza najczęściej marnowania czasu procesora, chyba że procesor jest dedykowany wyłącznie do wykonywania danego procesu. W systemach ogólnych, gdy liczba zadań znacznie przekracza liczbę jednostek przetwarzających, lepszym rozwiązaniem jest uśpienie procesu do czasu zajścia oczekiwanego zdarzeniu lub osiągnięcia określonego stanu. Wykonanie instrukcji synchronizującej oznacza odpowiednią zmianę stanu procesu, co jest z kolei sygnałem dla planisty, że proces nie jest gotowy i nie jest rozważany jako kandydat do przydziału procesora. Do tego typu mechanizmów należą semafory oraz mechanizmy standardu POSIX — zamki (inaczej rygle, muteksy) i zmienne warunkowe.
Ponadto języki programowania wysokiego poziomu dostarczają konstrukcji do wyrażania oczekiwań odnośnie sposobu współbieżnej realizacji instrukcji lub dostępu do współdzielonych danych. Jako przykłady mechanizmów z tej grupy podać można monitory, regiony krytyczne, obiekty chronione (w języku Ada 95), spotkania symetryczne (w języku CSP lub Occam), spotkania asymetryczne (w języku Ada-83).

Sekcja krytyczna jest fragmentem kodu w programie każdego z procesów, który ze względu na poprawność nie może być wykonywany współbieżnie. Wykonywanie sekcji krytycznej przez jeden proces wyklucza możliwość wykonywania swoich sekcji krytycznych przez inne procesy (stąd nazwa wzajemne wykluczanie). Sekcja krytyczna każdego procesu może być inna. Najczęściej jest to fragment kodu związany z modyfikacją jakieś współdzielonej zmiennej lub z dostępem do jakiegoś zasobu, który może być używany w trybie wyłącznym. Przykładem operacji, która powinna być wykonywana w sekcji krytycznej jest zwiększanie o 1 wartości zmiennej n w przykładzie przedstawionym wcześniej. Podobnym przykładem, z różnym kodem w sekcji krytycznej jest zwiększanie licznika o 1 przez jeden proces, a zmniejszanie o 1 przez drugi proces. Z tego typu przypadkiem w praktyce można mieć do czynienia w niektórych rozwiązaniach jednego z klasycznym problemów synchronizacji — problemu producenta i konsumenta.
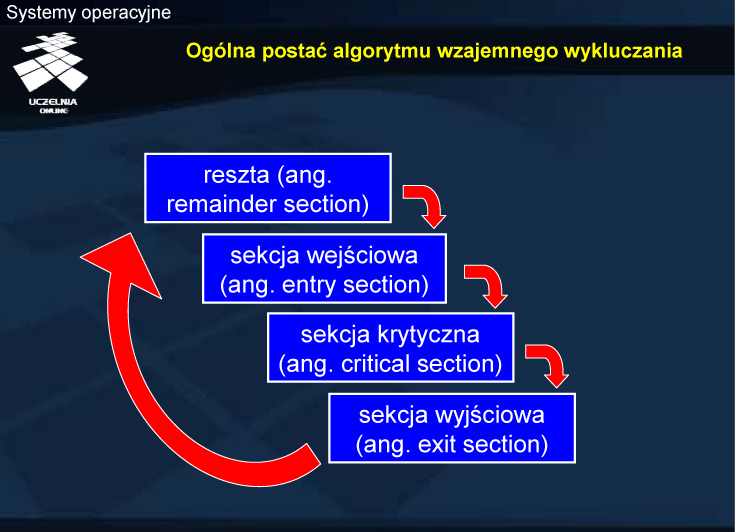
W celu wyeksponowania protokołu dostępu, algorytmy prezentowane na kolejnych slajdach rozpoczynają się od sekcji wejściowej. Ponadto, abstrahuje się od kwestii aplikacyjnych, z których mogłoby wynikać, że w procesie jest kilka niezależnych sekcji krytycznych, związanych z dostępem do różnych zmiennych współdzielonych lub zasobów. Istotą jest realizacja protokołu dostępu !
W algorytmach tych nie wyróżnia się również procesu, który byłby arbitrem dla procesów rywalizujących o sekcję krytyczną. Wszystkie decyzje odnośnie wejścia do sekcji krytycznej podejmowane są na podstawie informacji, znajdujących się we współdzielonym obszarze pamięci. Podejścia z arbitrem wbrew pozorom nie ułatwiają rozwiązania problemu, gdyż wymagają pewnych środków komunikacji międzyprocesowej, których implementacja na bazie pamięci współdzielonej wymaga z kolei odpowiednich mechanizmów synchronizacji, w szczególności gwarancji wzajemnego wykluczania. W pewnym sensie jednak rozwiązania bazujące na mechanizmach systemowych (np. semaforach) opierają się na arbitrażu ze strony jądra systemu operacyjnego, które decyduje o przejściu procesu zablokowanego w stan gotowości.

Warunkiem bezpieczeństwa jest wzajemne wykluczanie, co oznacza, że nigdy w systemie nie może zaistnieć stan, w którym dwa (lub więcej) procesy byłyby w swojej sekcji krytycznej.
Warunek postępu oznacza, że jeśli nie ma żadnego procesu w sekcji krytycznej, a są procesy w sekcji wejściowej, to jeden z nich w skończonym czasie (po zajściu skończonej liczby zdarzeń w systemie) wejdzie do sekcji krytycznej.
Warunek postępu nie gwarantuje, że konkretny proces wejdzie do sekcji krytycznej. Może się zdarzyć tak, że w momencie przejścia do sekcji wyjściowej, proces opuszczający sekcję krytyczną do sygnał do wejścia procesom oczekującym w sekcji wejściowej, w wyniku którego jakiś proces wejdzie do sekcji krytycznej, a inny (przy zachowaniu warunku bezpieczeństwa) oczywiście nie wejdzie. Przy kolejnym sygnale ze strony procesu wychodzącego z sekcji krytycznej pominięty poprzednio proces ponownie może nie uzyskać prawa wejścia, podczas gdy inny proces wykonujący swoją sekcję wejściową prawo takie dostanie. Sytuacja może się powtarzać w nieskończoność. Postęp jest zachowany bo jakiś proces wchodzi do sekcji krytycznej, ale istnieje proces permanentnie pomijany.
Warunek ograniczonego czekania gwarantuje właśnie, że każdy proces ubiegający się o wejście do sekcji krytycznej w końcu (w skończonym czasie, po skończonej liczbie zdarzeń w systemie) uzyska prawo wejścia do niej. Warto podkreślić, że nie wszystkie algorytmy gwarantuję tę własność.

Zmienna numer , ze względu na fakt współdzielenia, jest inicjalizowana globalnie wartością, która jest numerem jednego z procesów. Proces o tym numerze będzie mógł jako pierwszy wejść do sekcji krytycznej, podczas gdy wszystkie pozostałe procesy, ubiegające się o wejście, utkną w pętli while.
Ponieważ dopiero w sekcji wyjściowej proces ustawia numer następnego procesu do wejścia do sekcji krytycznej, nie ma ryzyka naruszenie warunku bezpieczeństwa. Podejście to wymusza jednak naprzemienność zajmowania sekcji krytycznej przez dwa procesy. Nie jest zatem spełniony warunek postępu, gdyż proces Pi , wychodząc z sekcji krytycznej, nie może zająć jej ponownie, zanim nie zrobi tego proces Pj . Może więc dojść do takiego stanu, w którym proces Pi po opuszczeniu sekcji krytycznej ponownie wchodzi do sekcji wejściowej i nie może zająć sekcji krytycznej. Jeśli z programu procesu Pj wynika, że nie będzie on już wchodził do sekcji krytycznej, proces Pi nie wejdzie tam nigdy.

W rozwiązaniu tym proces sygnalizuje zamiar lub docelowo fakt wejścia do sekcji krytycznej, ustawiając znacznik na swojej pozycji na true. W celu stwierdzenia dostępności sekcji krytycznej sprawdza wartość znacznika na pozycji odpowiadającej rywalowi (dla Pi rywalem jest Pj i odwrotnie). Jeśli znacznik na pozycji rywala ma wartość false, proces przerywa pętlę while i tym samym wchodzi do sekcji krytycznej.
Własność bezpieczeństwa łatwo można wykazać metodą nie wprost . Zakładając, że dwa procesy mogą jednocześnie wykonywać sekcję krytyczną, każdy z nich musiał odczytać wartość false z pozycji tablicy znacznik , odpowiadającej rywalowi. Wcześniej jednak każdy z nich ustawił wartość true na swojej pozycji. Przeplot z punktu widzenia każdego z procesów musi zatem uwzględniać fakt, że nie została ustawiona wartość true na pozycji rywala. Dla Pi oznacza to, że podstawienie true pod znacznik[j] wykonało się po zakończeniu przez niego pętli while. Dla Pj sytuacja jest odwrotna, więc Pi musiałby wykonać pętlę po podstawieniu true pod znacznik[j].
Własność postępu nie jest spełniona, gdyż mogą nastąpić podstawienia true pod odpowiednie pozycje znacznika, czyli:
znacznik[i] := true;
znacznik[j] := true;
W takim stanie systemu oba procesy utkną w pętli while w swoich sekcjach wejściowych i żaden nie wejdzie do sekcji krytycznej. Stan taki będzie stabilny, tzn. nie zmieni się, jeśli nie nastąpi jakaś interwencja z zewnątrz (spoza zbioru procesów). Jest to przykład zakleszczenia (ang. deadlock).

Nie ma tu zatem zakleszczenia, gdyż przy asynchroniczności przetwarzania cały czas istnieje potencjalna szansa, że jeden z procesów opuści sekcję wejściową i wejdzie do sekcji krytycznej. Z drugiej strony nie ma pewności, że tak się kiedyś stanie. Stan taki nie jest stabilny — może (ale nie musi) się zmienić — i nazywany jest uwięzieniem (ang. livelock). Pojęcie uwięzienia można kojarzyć z głodzeniem procesu. Głodzenie dotyczy jednak określonego procesu, którego obsługa — najczęściej ze względu na niski priorytet — jest odkładana na dalszy plan, przy czym w systemie ciągle jest rywal o wyższym priorytecie. Uwięzienie z kolei dotyczy ogółu rywalizujących procesów, można zatem powiedzieć, że jest to głodzenie wszystkich współpracujących procesów.

Przedstawione rozwiązanie znane jest pod nazwą algorytmu Petersona . Algorytm ten można uogólnić na n procesów, stosując podejście „wieloetapowe”. Na każdym etapie eliminowany jest jeden proces. Zmienna numer musi być wówczas tablicą n-1 - elementową, a tablica znacznik przechowuje numer etapu, na którym jest dany proces.

Etap algorytmu, w którym przydzielany jest numer, nazywany jest przejściem przez drzwi. Jest to część sekcji wejściowej. Proces, przechodząc przez drzwi, odczytuje numer wszystkich pozostałych, wybiera maksymalny z nich, zwiększa go o 1 i w ten sposób ustala swój własny numer. Proces, który wykonuje resztę, ma numer 0. Numery przydzielone procesom przechowywane są w tablicy współdzielonej numer . Pozycja i -ta tej tablicy jest zmienną wyjściową procesu Pi , a wszystkie pozostałe pozycje tablicy są dla niego zmiennymi wejściowymi. Wynika to z rozwinięcia operacji max, która w pełnej postaci mogłaby wyglądać następująco:
Dodatkowo można by jeszcze wykluczyć przypadek k = i w pętli. Początkowo tablica numer wypełniona jest oczywiście wartościami 0.
W celu kontroli przydziału numeru każdy proces ustawia na swojej pozycji w tablicy wybieranie wartość true na czas ustalania swojego numeru. Początkowo tablica wypełniona jest oczywiście wartościami false.
Analizując szczegóły operacji na zmiennych współdzielonych, można zauważyć, że wszystkie zmienne są modyfikowane przez 1 proces, a czytane przez pozostałe. Są to tzw. współdzielone rejestry typu „jeden zapisujący wielu odczytujących” (ang. single-writer-multiple-readers shared registers).

Po ewentualnym zakończeniu wyboru następuje sprawdzenie stanu potencjalnego rywala. Jeśli ma on przydzielony numer 0, to znaczy, że wykonuje resztę i nie jest zainteresowany sekcją krytyczną — pętla while w linii 4 kończy się i rozpoczyna się kolejna iteracji pętli for . To samo dzieje się, gdy numer rywala jest większy. Możliwy jest jednak przypadek, gdy dwa procesu uzyskają te same numery. Rozstrzygający jest wówczas numer procesu, który z założenia jest unikalny. Stąd porównanie:(numer [k],k ) < (numer [i],i ) ≡ numer [k] < numer [i] ∨ (numer [k] = numer [i] ∧ k < i ), które można by również zapisać jako (numer [k] · n + k ) < (numer [i] · n + i ).
Jeśli w ten sposób procesowi Pi uda się zakończyć pętlę for , to znaczy, że nie ma w systemie procesu ubiegającego się o sekcję krytyczną, którego numer byłby mniejszy (lub równy przy mniejszym identyfikatorze) od Pi i możne on opuścić sekcję wejściową, zajmując tym samym sekcję krytyczną.
Po wyjściu z sekcji krytycznej, proces sygnalizuje brak zainteresowania rywalizacją, wpisując wartość 0 jako swój numer.
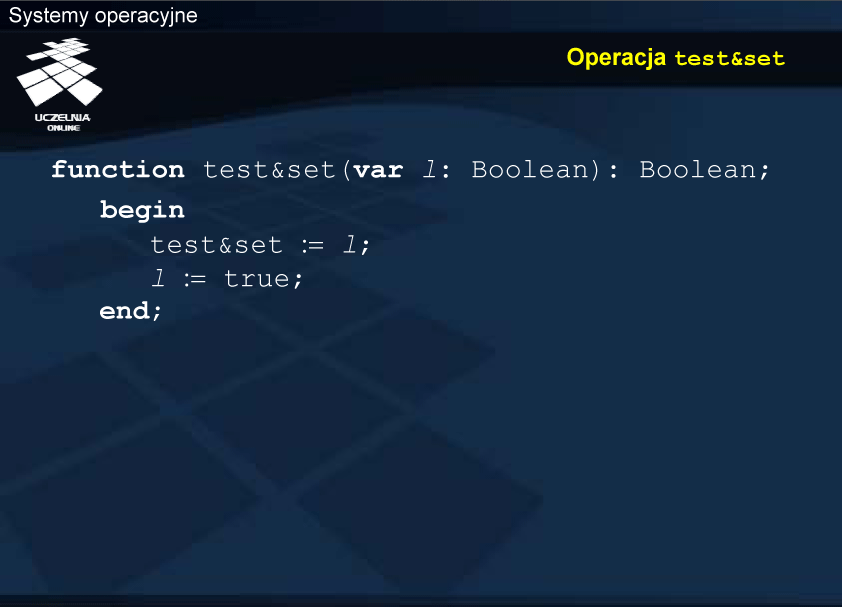
W systemie jednoprocesorowym efekt atomowości (niepodzielności) można uzyskać poprzez zablokowanie przerwań na czasy wykonywania operacji. W implementacji musiałyby się zatem znaleźć rozkazy blokowania przerwań na początku i odblokowania na końcu, właściwe dla danej architektury.
W architekturze IA-32 (Intel) tego typu operacje realizowane są na poziomie maszynowym przez rozkazy: bts , btr , btc , poprzedzone ewentualnie prefiksem lock.
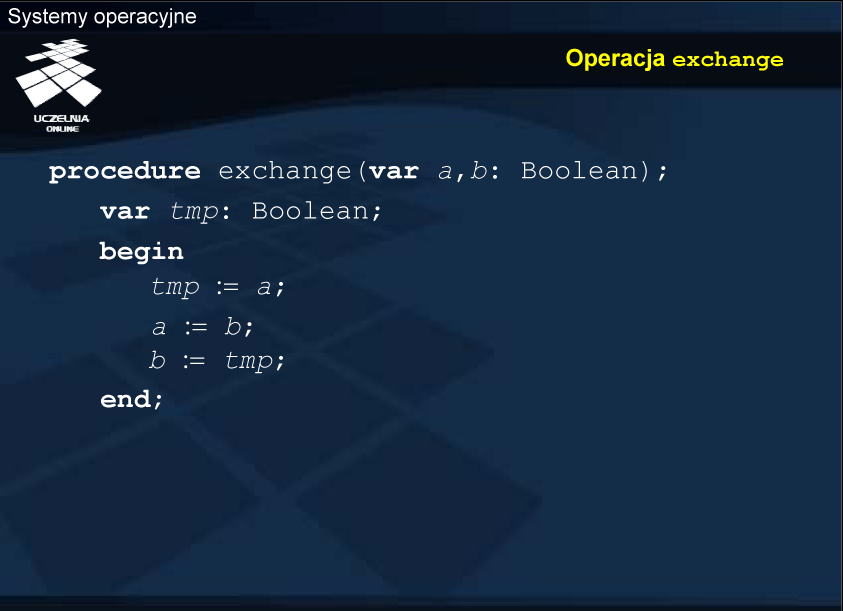
W architekturze IA-32 (Intel) operacja exchange realizowana jest na poziomie maszynowym przez rozkaz: xchg , dotyczy jednak nie bitów a zawartości całych rejestrów. Pewnym ograniczeniem jest fakt, że jeden z operandów musi być w rejestrze procesora, ale nie przeszkadza to np. w zastosowaniu tego. rozkazu do rozwiązania problemu wzajemnego wykluczania. Jeśli któryś z operandów rozkazu xchg jest w pamięci, następuje blokada magistrali niezależnie od użycia prefiksu lock.

Na zmiennej wykonywana jest operacja test & set , która ustawia true (być może ponownie) i zwraca poprzednią wartość zmiennej. Jeśli poprzednia wartość była false, to znaczy, że w sekcji krytycznej nie było żadnego procesu i może ona zostać zajęta. W przeciwnym przypadku nie nastąpiła zmiana wartości zmiennej zamek (było true i jest nadal true), a jedynie ustalenie wartości tej zmiennej. Z wartości tej wynika oczywiście, że sekcja krytyczna jest zajęta i należy dalej kontynuować wykonywanie pętli while .
Taki algorytm może być stosowany dla dowolnej liczby współpracujących procesów. Nie gwarantuje on jednak ograniczonego czekania, gdyż nie ma żadnej pewności, że konkretny proces będzie mógł wykonać na swoje potrzeby operację test & set akurat wówczas, gdy zmienna zamek będzie miała wartość false.

Z realizacją wzajemnego wykluczania w taki sposób wiążą się te same kwestie, które poruszono przy rozwiązaniu z użyciem test & set.