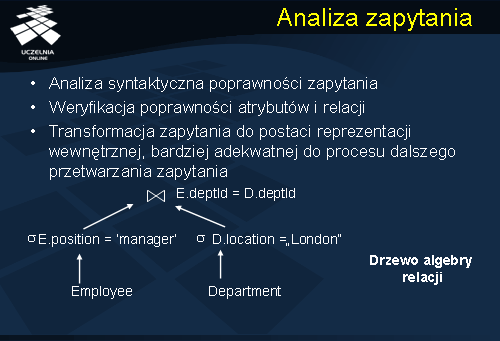
Kolejnym, ważnym, etapem dekompozycji zapytania jest etap analizy semantycznej zapytania. Celem analizy semantycznej zapytania jest odrzucenie niepoprawnie sformułowanych lub sprzecznych zapytań. Zapytanie jest niepoprawnie sformułowane, jeżeli jego elementy składowe nie prowadzą do generacji wyniku. Zapytanie jest sprzeczne, jeżeli jego predykaty nie mogą być spełnione przez żadną krotkę w bazie danych. Przykładem klauzuli, która jest sprzeczna jest wyrażenie: position = ‘manager’ and position = ‘assistant’.
Zakładając, że baza danych jest w 1NF, nie istnieje w bazie danych żadna krotka, któraby jednocześnie spełniała oba predykaty. Wartość sprzecznej klauzuli interpretujemy jako wartość FALSE. W związku z tym, wyrażenie zawierające sprzeczna klauzulę można uprościć. Przykładowo, wyrażenie
(position = ‘manager’ and position = ‘assistant’) or salary > 1000;
ze względu na sprzeczność klauzuli : „position = ‘manager’ and position = ‘assistant’” można uprościć do postaci „salary > 1000”

Rozwiązanie problemu zapytań niepoprawnie sformułowanych opiera się na konstrukcji tak zwanego grafu połączeń atrybutów. Graf połączeń atrybutów konstruujemy następująco. Dla każdej referencji do atrybutu tworzymy w grafie wierzchołek atrybutu lub wierzchołek 0. Następnie, tworzymy luk skierowany pomiędzy wierzchołkami reprezentującymi operację połączenia, oraz łuk skierowany pomiędzy wierzchołkiem atrybutu a wierzchołkiem 0, reprezentujący warunek selekcji. W kolejnym kroku nadajemy wagi lukom:
łuk: a -> b posiada wagę c, jeżeli luk reprezentuje warunek nierównościowy (a<= b+c),
łuk: 0 -> a posiada wagę -c, jeżeli luk reprezentuje warunek nierównościowy (a >= c).
łuki reprezentujące połączenia posiadają wagę 0.
Jeżeli graf połączeń atrybutów zawiera cykl, którego suma wag jest ujemna, zapytanie jest sprzeczne.
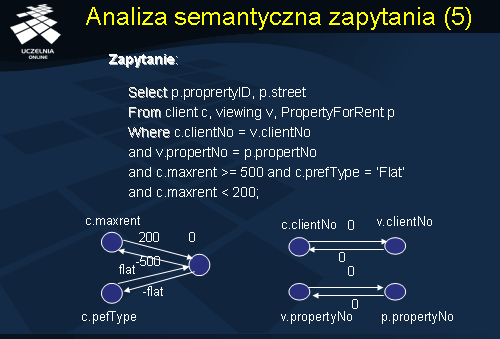
Dla ilustracji problemu zapytań sprzecznych rozważmy przykładowe zapytanie przedstawione na slajdzie. Skonstruujmy dla podanego zapytania graf połączeń atrybutów. Przypomnijmy, że graf połączeń atrybutów konstruujemy następująco. Dla każdej referencji do atrybutu tworzymy w grafie wierzchołek atrybutu lub wierzchołek 0. Następnie, tworzymy luk skierowany pomiędzy wierzchołkami reprezentującymi operację połączenia, oraz łuk skierowany pomiędzy wierzchołkiem atrybutu a wierzchołkiem 0, reprezentujący warunek selekcji. W kolejnym kroku nadajemy wagi lukom. Zauważmy, że zapytanie zawiera dwa warunki połączeniowe:
(1) c.clientNo = v.clientNo
(2) v.propertNo = p.propertNo
reprezentowane przez wierzchołki atrybutów: c.clientNo, v.clientNo, v.propertNo, p.propertNo. Wierzchołki te połączone są wzajemnie lukami o wagach 0. Podane zapytanie zawiera 3 predykaty selekcji (referencje do atrybutów):
c.maxrent >= 500
c.prefType = ‘Flat’
c.maxrent < 200
reprezentowane przez wierzchołki atrybutów: c.maxrent, c.prefType, i c.maxrent. Wierzchołki te połączone są wzajemnie lukami o wagach, odpowiednio, 200, -500, flat oraz –flat. Jak łatwo zauważyć, przedstawiony graf połączeń atrybutów zawiera cykl, którego suma wag jest ujemna (-300). Zatem, podane zapytanie jest sprzeczne.

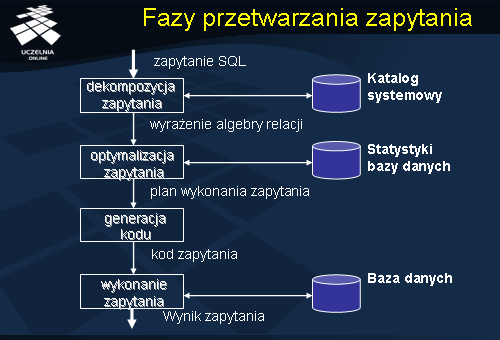
Generalnie, problem optymalizacji zapytań jest problemem bardzo trudnym. Istnie bardzo wiele podejść do optymalizacji. De facto, istnieje tyle podejść ile jest na rynku systemów zarządzania bazami danych. Złożoność problemu optymalizacji wynika z konieczności uwzględniania w procesie optymalizacji bardzo wielu czynników, które, dodatkowo, w trakcie wykonywani zapytania mogą ulegać modyfikacjom i zmianom (np. charakterystyka relacji i atrybutów, obciążenie stanowisk w systemie, fluktuacja obciążenia sieci, itp.). Należy stwierdzić, że problem optymalizacji zapytań nie został tak naprawdę jeszcze rozwiązany. Jest to szczególnie widoczne w przypadku dużych zapytań i aplikacji występujących w systemach wspomagania podejmowania decyzji. Ciągle trwają prace badawcze nad dalszą poprawą efektywności metod optymalizacji wykonywania zapytań, szczególnie, dla nowych typów danych (zbiory, sekwencje, grafy, dokumenty XML). Możliwe kierunki poprawy efektywności obejmują: opracowanie nowych reguł algebraicznej transformacji złożonych zapytań, opracowanie nowych metod znajdowanie kolejności wykonywania operacji binarnych ( w tym szczególnie, operacji połączenia), oraz opracowanie nowych metod szacowania kosztów i rozmiarów wyników pośrednich zapytania. Po tym krótkim przedstawieniu problemów związanych z optymalizacją zapytań, wróćmy do reguł transformacji wyrażeń reprezentujących zapytania.
Operacje

Każdy plan wykonania zapytania jest częściowo uporządkowanym zbiorem operacji. W skład tego zbioru operacji wchodzą: operacja skanowania, selekcji, projekcji, połączenia, produktu kartezjańskiego, operacje grupowania i agregacji. Problem znalezienia najlepszego planu wykonania zapytania obejmuje, z jednej strony, określenie kolejności wykonania operacji wchodzących w skład zapytania, z drugiej, określenia metody wykonania poszczególnych operacji. Przykładowo, mamy dwie metody dostępu do relacji: bezpośrednie skanowanie (odczyt) relacji lub dostęp do relacji poprzez skanowanie indeksu założonego na relacji. Podstawowa reguła optymalizacji mówi, że wszystkie operacje unarne (projekcja i selekcja) należy przesunąć w dół drzewa zapytania, tzn. wykonywać w pierwszej kolejności. Operacje te charakteryzują się silną własnością redukcji (filtrowania) przetwarzanych danych. Redukując rozmiar przetwarzanych danych, operacje unarne prowadzą do poprawy efektywności wykonywania operacji binarnych. Dlatego, operacje binarne (połączenie, produkt kartezjański) należy przesunąć w kierunku korzenia drzewa zapytania. Dla operacji binarnych, np. połączenia, poza określeniem kolejności ich wykonywania, należy wybrać również metodę ich wykonania (dla połączenia - nested loop, sort-merge, hash-join). Najczęściej, na końcu planu wykonania zapytania znajdują się operacje grupowania i agregacji.
Prawa algebry relacji

Podstawowe reguły transformacji wyrażeń reprezentujących zapytania wynikają z praw algebry relacji i obejmują, m. in. reguły przemienności i łączności operacji oraz reguły dystrybutywności. Przykładowe reguły przemienności i łączności operacji oraz reguły dystrybutywności operacji przedstawiono na slajdzie. Zgodnie z przedstawioną regułą dystrybutywności, wyrażenie będące połączeniem relacji R oraz relacji, będącej sumą relacji S i T, transformujemy do sumy relacji będących połączeniem relacji R z S i R z T. Reguła ta pozwala przesunąć operator sumy za operator połączenia. Ponieważ koszt operacji połączenia silnie zależy od rozmiarów łączonych relacji, zastosowanie transformacji, opartej o regułę dystrybutywności, transformuje wyjściowe wyrażenie do sumy relacji będących połączeniem mniejszych relacji, co powinno skutkować niższym kosztem wykonania całego wyrażenia. Reguła łączności operacji połączenia pozwala zmienić kolejność łączonych relacji. Łącząc, w pierwszej kolejności, mniejsze relacje, zmniejszamy rozmiary częściowych wyników operacji połączenia, co również powinno prowadzić do zmniejszenia kosztu wykonania całego wyrażenia.

Kolejny slajd przedstawia reguły transformacji dla operacji selekcji. Szczególne znaczenie ma pierwsza reguła dotycząca koniunkcji predykatów selekcji:
selekcja C AND C’(R) = selekcja C(selekcja C’(R))
Reguła ta wynika z komutatywności operatora selekcji i pozwala zmienić kolejność wykonywania operacji selekcji. W pierwszej kolejności zawsze wykonywana jest operacja selekcji o większym współczynniku selektywności, bardziej redukująca rozmiar relacji R. Zwróćmy uwagę na regułę nr 3:
selekcja C (R połączenie S) = selekcja C (R) połączenie S (jeżeli C zawiera tylko atrybuty relacji R)
oraz regułę nr 4:
selekcja C (R połączenie S) = (selekcja C (R)) połączenie (selekcja C (S)) (jeżeli C zawiera atrybuty obu relacji R i S)
Transformacja oparta o te reguły pozwala przesunąć operator selekcji przed operator połączenia, redukując rozmiary łączonych relacji, co prowadzi do zmniejszenia kosztu wykonania zapytania. Podobna uwaga dotyczy ostatnich trzech przedstawionych reguł, które pozwalają przesunąć operator selekcji przed operatory binarne sumy, iloczynu i różnicy.

Kolejny slajd przedstawia podstawową regułę transformacji wykorzystującą własność komutatywności operacji selekcji i projekcji. Przesuwając operator projekcji przed operator selekcji zmniejszamy rozmiar argumentu operatora selekcji.
Rozważmy dwa przykłady ilustrujące działanie przedstawionych dotychczas reguł transformacji. Dane są relacje R(A, B, C, D) i S(E, F, G).
Jaką regułę transformacji należy zastosować w odniesieniu do pierwszego wyrażenia?
Odpowiedź – regułę: selekcja z relacji R przed połączeniem z relacją S, tj. „selekcja C (R połączenie S) = selekcja C (R) połączenie S” (jeżeli C zawiera tylko atrybuty relacji R). Po zastosowaniu powyższej reguły, przedstawione wyrażenie zostanie przetransformowane do postaci: „selekcja F=3 (S) połączenie R”.
Rozważmy drugie z podanych wyrażeń. Jaką regułę transformacji należy zastosować w odniesieniu do tego wyrażenia? Odpowiedź – złożenie dwóch reguł: reguły dotyczącej kaskady selekcji oraz reguły dotyczącej dystrybutywności selekcji i połączenia. Po zastosowaniu powyższych reguł, przedstawione wyrażenie zostanie przetransformowane do postaci: „(selekcja G=9 (S)) połączenie (selekcja A=5 (R))”.

Kolejny slajd przedstawia podstawowe reguły transformacji wyrażeń zawierających projekcje. Pierwsza reguła transformacji wynika z reguły dystrybutywności operacji połączenia względem projekcji. Przesuwając operator projekcji przed operator połączenia zmniejszamy rozmiar argumentu operatora połączenia. Druga reguła transformacji dotyczy kaskady projekcji, które mogą być łączone w jedną operację projekcji. Rozważmy przykład ilustrujący działanie przedstawionych reguł transformacji. Dane są relacje R(A, B, C, D) i S(E, F, G). W jaki sposób można uzyskać przedstawioną na slajdzie transformację? Jakie będą predykaty projekcji w wynikowym wyrażeniu? Z przedstawionych powyżej reguł wynika, że predykaty projekcji w wynikowym wyrażeniu mają następującą postać:
projekcjaA,B,G(R połączenie S) = projekcja A, B, G ((projekcja A,B,D (R)) połączenie D=E (projekcja E,G(S)))
Przepisywanie zapytań: podzapytania

Przejdziemy obecnie do przedstawienia bardziej specyficznych reguł transformacji zapytań. Dane jest zapytanie przedstawione na slajdzie. Jak łatwo zauważyć, przedstawione zapytanie zawiera skorelowane podzapytanie zagnieżdżone. Zapytania zawierające skorelowane podzapytania zagnieżdżone są kosztowne w realizacji, gdyż wymagają sprawdzenia, dla każdej krotki zapytania zewnętrznego, czy spełniony jest dla tej krotki warunek podzapytania skorelowanego. Klasyczna metoda transformacji takich zapytań polega na przepisaniu zapytania w taki sposób, aby usunąć zagnieżdżenie (ang. unnesting). Usunięcie zagnieżdżenia polega na zastąpieniu zagnieżdżenia operacją połączenia.

Kolejny slajd przedstawia przepisanie zapytania ze slajdu nr 21, w którym zastąpiono podzapytanie zagnieżdżone operacją połączenia. Pozostałe warunki selekcji podzapytania zagnieżdżonego zostały przeniesione o zapytania zewnętrznego. Usunięcie zagnieżdżenia zdecydowanie poprawia czas realizacji zapytania.
Transformacja zapytań zagnieżdżonych

Rozważmy inny przykład zapytania zawierającego skorelowane podzapytanie zagnieżdżone przedstawiony na slajdzie. Przykład ten ilustruje, że nie zawsze jest możliwe przetransformowanie zapytania do postaci bez zagnieżdżenia, i że, de facto, dla każdego typu zapytania, zawierającego skorelowane podzapytanie zagnieżdżone, należałoby zdefiniować specyficzne reguły transformacji. Celem zapytania przedstawionego na slajdzie jest znalezienie nazwy najdroższego produktu w kolorze niebieskim, i nazwy jego producenta.

Na kolejnych slajdach przedstawiono transformację zapytania ze slajdu nr 23 do postaci nie zawierającej skorelowanego podzapytania zagnieżdżonego. Pierwszym krokiem transformacji jest znalezienie uzupełnienia zapytania ze slajdu 23. Przedstawione na slajdzie zapytanie znajduje nazwy niebieskich produktów, i nazwy ich producentów, dla których istnieją produkty niebieskie o wyższej cenie. Zauważmy, że zapytanie cały czas jest zapytaniem zawierającym skorelowane podzapytanie zagnieżdżone. Transformujemy podane zapytanie do postaci, w której podzapytanie zastąpiono operacją połączenia.

Transformujemy podane zapytanie do postaci, w której podzapytanie zastąpiono operacją połączenia. Jak już wspominaliśmy, operacja usunięcia podzapytania prowadzi do istotnej minimalizacji czasu wykonania zapytania. Przedstawione na slajdzie zapytanie zwraca w wyniku dokładnie to czego nie szukamy.

Ostatnim krokiem transformacji jest odjęcie od zbioru wszystkich niebieskich produktów tych niebieskich produktów, dla których istnieją produkty niebieskie o wyższej cenie. W wyniku wykonania operacji EXCEPT znajdujemy poszukiwany zbiór najdroższych niebieskich produktów. Zauważmy, że wynikowe zapytanie nie zawiera skorelowanego podzapytania i jego koszt będzie niższy niż oryginalnego zapytania ze slajdu 23. Zauważmy, jednakże, że przedstawiona transformacja nie jest trywialna.
Redukcja rozmiarów relacji

Jak już wspomnieliśmy, zagadnienie optymalizacji jest zagadnieniem trudnym i istnieje bardzo wiele, specyficznych, reguł transformacji dla różnych typów zapytań. Co więcej, nie zawsze jest możliwe przetransformowanie zapytań w taki sposób, aby nie zawierało podzapytań (szczególnie dla podzapytań skorelowanych). W szczególnych przypadkach, gdy czas realizacji zapytania jest nieakceptowany, można zastosować technikę redukcji rozmiarów relacji uczestniczących w zapytaniu opartą o sekwencję operacji półpołączenia. Technika ta jest wykorzystywana do optymalizacji zapytań rozproszonych w systemach rozproszonych baz danych.