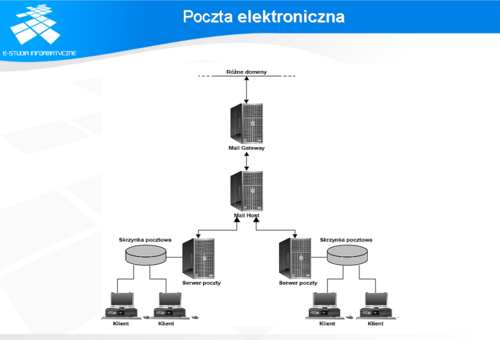
Po rozpoznaniu użytkownika przez serwer następuje przejście do kolejnego z wymienionych trybów pracy. Użytkownik może wysyłać do serwera polecenia:
SELECT - wybór skrzynki pocztowej; serwer musi odpowiedzieć ustawiając jedną z flag: <n> EXISTS - liczba wiadomości w skrzynce, <n> RECENT - liczba nowych wiadomości od czasu ostatniego jej czytania, OK [UIDVALIDITY <n>] - unikalny identyfikator skrzynki; jest on stały dla wszystkich sesji. Serwer może modyfikować tylko jedną skrzynkę na raz. Zmiana skrzynki powoduje, że poprzednia przestaje być dostępna. Jeśli wybrana skrzynka również okaże się niedostępna, to serwer nie będzie operował na żadnej skrzynce czekając znowu na komendę SELECT. Po wydaniu komendy SELECT skrzynka jest otwarta w trybie read-write. EXAMINE - działa tak samo jak SELECT, ale otwiera skrzynkę w trybie read-only, CRATE - tworzy nową skrzynkę o nazwie podanej jako argument, DELETE - usuwa skrzynkę o podanej nazwie, RENAME - zmienia nazwę podanej skrzynki na nową, SUBSCRIBE - dodaje skrzynkę do zbioru aktywnych lub inaczej zapisanych; klient IMAP4 może użytkownikowi pokazywać wiadomości, pojawiające się tylko w tych skrzynkach, do których użytkownik jest zapisany, UNSUBSCRIBE - działanie odwrotne, LIST - służy do pobierania z serwera listy elementów pasujących do wzorca, z miejsca wskazanego argumentem komendy, np.:
C: a005 list "~/Mail/" "%„ S: * LIST (\Noselect) "/" ~/Mail/foo S: * LIST () "/" ~/Mail/archive S: a005 OK LIST completed
Pierwszym argumentem zazwyczaj jest katalog ze skrzynkami pocztowymi. Drugi wyszukuje skrzynki zgodnie z maską; możliwe jest podawanie wzorców np, "%", który oznacza skrzynkę o dowolnej nazwie w katalogu podanym jako argument pierwszy, LSUB - komenda działa tak samo jak LIST z tym, że brane są pod uwagę tylko skrzynki oznaczone jako aktywne, APPEND - zapisuje do wskazanej skrzynki podany argument tesktowy (wiadomość).
Dodatkowe komendy protokołu IMAP

Jak widać możliwości, które oferuje serwer IMAP, są znacznie większe niż w protokole POP3. Daje on użytkownikowi duże możliwości zarządzania swoimi wiadomościami na serwerze. Dodatkowo możliwości te są poszerzone o zbiór komend dostępny w trybie czytania wiadomości z wybranej skrzynki:
CHECK - wymusza na serwerze sprawdzanie wszelkiego typu statusu lub stanów skrzynki, np. synchronizację zawartości skrzynki w pamięci serwera z zawartością zapisaną na dysku, CLOSE - usuwa wszystkie wiadomości z ustawioną flagą usunięta oraz zamyka wybraną wcześniej skrzynkę; serwer przechodzi do trybu oczekiwania wyboru skrzynki przez klienta, EXPUNGE - usuwa z aktualnej skrzynki wszystkie wiadomości z ustawioną flagę usunięta, SEARCH - przeszukuje wiadomości pod kątem zawierania wskazanego kryterium; dopuszczalne są logiczne wyrażenia: OR, AND i NOT; serwer zwraca identyfikator wiadomości spełniającej podane warunki przeszukiwania, FETCH - pozwala na pobranie z serwera danych związanych z daną wiadomością, między innymi przez komendy (są to tylko przykłady większej liczby komend tego typu): ALL - cała wiadomość, BODY - treść wiadomości, BODY[<section>] - treść ze wskazanej sekcji (przydatne przy wiadomościach typu multipart/mixed PARTIAL - pozwala na pobranie z serwera konkretnej liczby bajtów, od wskazanej pozycji wybranej wiadomości, ALTER - zapisuje zmiany wprowadzone w wiadomości w skrzynce, COPY - zapisuje wskazaną wiadomość do wskazanej skrzynki.
IMAP vs. POP3

Z punktu widzenia użytkownika, najważniejszą funkcją oferowaną przez serwery IMAP, jest możliwość dokładnego zarządzania wiadomościami na serwerze oraz możliwość szybkiego ich odbierania. W przeciwieństwie do serwerów POP3, serwery IMAP mogą wysyłać klientowi tylko nagłówki wiadomości bez ich treści. Dla użytkowników łączących się z siecią przez zwykłe modemy jest to ogromne udogodnienie. Mogą od razu kasować niechciane wiadomości bez przesyłania ich na swój lokalny komputer. Użytkownicy mogą sortować nadchodzące przesyłki i zapisywać je do różnych skrzynek zgodnie ze zdefiniowanymi przez siebie regułami.
Inną zaletą korzystania z serwerów IMAP jest możliwość rozsyłania wiadomości w grupie użytkowników bez potrzeby obciążania serwera pocztowego. Wystarczy, że zapisze on wiadomość w podanej skrzynce, którą będą mogli wybrać użytkownicy tej grupy w konfiguracji swoich klientów IMAP. W przypadku serwera POP3 konieczne w takim wypadku jest rozesłanie wiadomości do wszystkich użytkowników. W konfiguracji klienta POP3 można też stworzyć dodatkowe konto u każdego klienta w grupie, a klientom kazać odbierać pocztę również z tych dodatkowych kont. Jest to jednak rozwiązanie bardziej złożone niż w protokole IMAP.
Przesyłanie plików

Przesyłanie plików przez użytkowników jest jedną z najczęściej wykonywanych operacji. Stanowią one znaczną część ruchu w sieciach komputerowych.
Protokoły do tego używane zapewniają dostęp do plików na innych komputerach dwiema drogami: albo przez kopiowanie (FTP, SCP) albo jako dostęp zintegrowany z systemem operacyjnym, gdzie operacje dostępu do zdalnych plików są dla użytkownika niewidoczne (NFS, CIFS). W obu jednak przypadkach protokoły muszą uwzględniać prawa dostępu do pliku (nie zawsze zapisywane w ten sam sposób jak w systemie lokalnym), różnice w nazwach plików, różnice w reprezentacjach binarnych (choć czasami konwersja formatów powodowałaby utratę danych i jest niemożliwa).
Protokół FTP
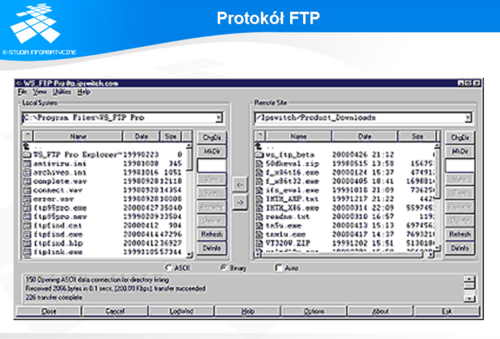
FTP (ang. File Transfer Protocol) był pierwszym z protokołów przeznaczonych specjalnie do transferu plików. Aby z niego korzystać, użytkownik musi mieć program klienta. Program klienta oferuje użytkownikowi dostęp interakcyjny. Program ten łączy się ze wskazanym serwerem FTP, próbując otworzyć sesję TCP na porcie 21. Przed wykonaniem jakichkolwiek operacji przesłania danych do lub z serwera, użytkownik musi podać identyfikator w postaci nazwy użytkownika i hasła.
Serwer i klient FTP używają odrębnego połączenia do przesyłania danych sterujących oraz odrębnych połączeń do transmisji każdego z czytanych lub zapisywanych plików z osobna. Połączenie sterujące jest otwarte tak długo jak trwa sesja FTP. Wszystkie komendy wysyłane do serwera oraz jego odpowiedzi są przesyłane w kodzie ASCII (tak samo jak w przypadku SMTP, POP3, IMAP). Do transmisji danych wykorzystywany jest protokół UDP. Klient lokalnie używa dowolnego, numeru portu niezajętego przez inną aplikację. Wysyła do serwera jego numer i czeka, aż serwer wybierze swój port. Następnie klient otwiera połączenie ze wskazanym portem i transmituje dane. Jest to tzw. tryb active pracy klienta. Serwer może również do tego celu użyć zastrzeżonego numeru portu TCP - 20. Alternatywą trybu active jest passive. W trybie tym to serwer pracuje tylko i wyłącznie na porcie 20. W trakcie pracy z serwerem użytkownik może specyfikować format zapisywanych lub odczytywanych danych (dane binarne, w kodzie ASCII). Oprócz tego może wydawać serwerowi cały szereg dodatkowych komend. Ich listę można uzyskać przez uruchomienie klienta ftp i wydaniu komendy help. Oprócz protokołu FTP istnieje TFTP (ang. Trivial FTP). W odróżnieniu od FTP protokół ten nie ma wbudowanych mechanizmów autoryzacji i nie ma możliwości pracy w trybie interakcyjnym z użytkownikiem. Dzięki temu pliki binarne klienta TFTP oraz serwera zajmują niewiele miejsca w pamięci. Korzystają z tego producenci urządzeń sieciowych, którzy na kliencie TFTP opierają możliwości instalowania nowszych wersji oprogramowania, bezdyskowe stacje robocze, które przy pomocy TFTP pobierają z serwera pliki z obrazem jądra.
Protokół NFS
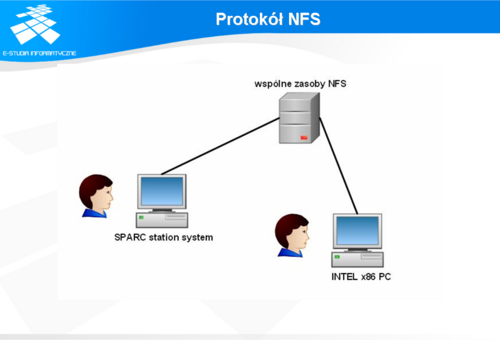
Sieciowy system plików (ang. Network File System) został opracowany przez firmę Sun Microsystems. System ten zapewnia użytkownikowi "przezroczysty" dostęp do plików i programów położonych na innych komputerach. Konieczne do tego jest jedynie uruchomienie serwera NFS oraz wyposażenie użytkownika w program klienta.
Klient może wysyłać do serwera polecenia otwarcia, zapisania, odczytania pliku. Serwer sprawdza czy użytkownik, który wysyła te polecenia ma prawo do wykonania tych operacji. Informacje o tym są pobierane przez serwer na podstawie identyfikatora użytkownika, który albo istnieje w lokalnych dla serwera plikach konfiguracyjnych (np. /etc/passwd i musi być identyczny na stacji użytkownika i serwerze w systemach UNIX) albo są dostępne przez serwisy takie jak NIS lub NIS+ (ang. Network Information Service). Oprócz tego serwer określa z jakimi prawami udostępniane są wskazane w konfiguracji zasoby. W szczególności może zabronić wykonywania programów z ustawionym bitem SUID [*]. Projektanci NFS oparli ten protokół o dwa wcześniej opracowane protokoły: RPC (ang. Remote Procedure Call) oraz XDR (ang. eXternal Data Representation). Mechanizm RPC daje możliwość podzielenia kodu aplikacji na kod serwera i klienta. Programista może wydzielić wybrane funkcje jako odległe i wskazać to kompilatorowi. Kompilator wówczas dołącza odpowiednie kody procedur RPC w trakcie kompilacji programu. RPC ukrywa przed programistą wszelkie szczegóły protokołów. Dzięki temu jest chętnie wykorzystywany do budowy systemów rozproszonych. Program klient wywołując zdalną procedurę sam tworzy odpowiedni rodzaj komunikatu i wysyła go do serwera. Nawiązanie połączenia jest zupełnie niewidoczne dla użytkownika. Drugi z protokołów, XDR, daje możliwość przekazywania danych w środowisku heterogenicznym bez konieczności ich konwersji do odpowiednich typów standardów sprzętowych. Jego główną zaletą jest automatyczna konwersja formatów danych między klientami a serwerami systemu NFS.
Usługi SCP
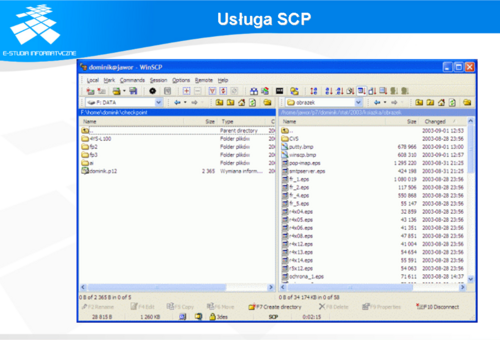
SCP (ang. Secure Copy) jest usługą najczęściej interpretowaną jako fragment oprogramowania SSH (opisanego w dalszej części). Wynika to stąd, że usługa ta jest instalowana w systemach przy okazji uruchamiania tego serwisu. Można z niej jednak korzystać bez instalacji całego SSH. W chwili obecnej dostępne są programy SCP działające zarówno w środowisku Windows (WinSCP, pscp) jak i wszelkiego typu systemach UNIX. Slajd przedstawia przykład działania programu WinSCP.
W swoim działaniu, z dotychczas wymienionych usług, SCP najbardziej przypomina FTP. Oferuje mechanizm autoryzacji użytkownika przed wykonaniem operacji odczytu lub zapisu plików. W przeciwieństwie jednak do FTP, SCP nie używa dwóch odrębnych kanałów do komunikacji i transferu danych. Poza tym nie pracuje w trybie interaktywnym z użytkownikiem, choć niektóre programy np. WinSCP pozwalają na to. To, co wyróżnia SCP, to stosowanie mechanizmów kryptograficznych przy wymianie danych między serwerem a klientem. Najczęściej są to te same mechanizmy, które oferuje SSH, gdyż to właśnie ta usługa jest wykorzystywana do zestawiania sesji, wymiany kluczy między serwerem a klientem, ustalaniu parametrów transmisji (kompresja przesyłanych danych lub jej brak, częstotliwość wymiany klucza).
Usługi terminalowe

Dosyć często zdarza się sytuacja, w której użytkownicy chcieliby mieć możliwość korzystania z zasobów innych komputerów pracujących w odległych miejscach, nie posiadając dostępu do konsoli tych maszyn. Jednym ze sposobów zapewniających ten rodzaj pracy są serwisy WWW, np. wyszukiwarki internetowe. Poprzez odpowiedni interfejs oferują one dostęp do bazy adresów oraz możliwość ich przeszukiwania. Nie zawsze jednak chodzi tylko o tego typu dostęp. Często np. studenci chcą korzystać z kompilatorów zainstalowanych na serwerach uczelnianych, pracownicy ze specjalistycznego oprogramowania używanego w firmie, itd. Wówczas nieocenione stają się możliwości korzystania z opisanych poniżej protokołów oferujących dostęp do wszystkich poleceń na odległym systemie.
Protokół TELNET
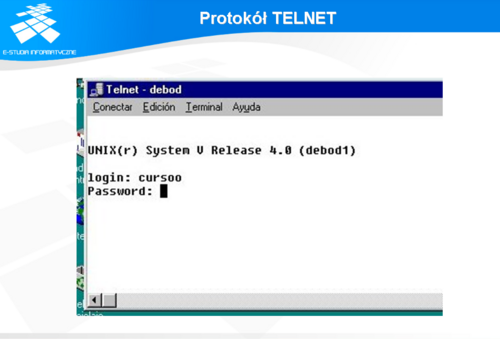
Protokół ten umożliwia użytkownikowi zestawienie sesji TCP między dwoma odległymi systemami. Na jednym z nich musi pracować proces serwera TELNET. Użytkownik musi być wyposażony w program klienta. Użytkownik może wskazać serwer TELNET podając jego nazwę lub numer IP. Serwer przeprowadza autoryzację użytkownika. W tym celu musi on podać nazwę użytkownika i hasło. Jednak przesyłane dane, pomiędzy klientem i serwerem, nie są w żaden sposób zabezpieczone przed podsłuchem.
Po nawiązaniu sesji TCP klient przesyła do serwera informacje o wszystkich naciśniętych klawiszach. Zwrotnie przyjmuje znaki, które przysłał serwer i wyświetla je na terminalu użytkownika. Ponieważ serwer TELNET musi obsługiwać wiele sesji jednocześnie, zazwyczaj jeden proces serwera oczekuje na nowe połączenia na porcie 23 TCP. Dalej przekazuje on obsługę połączenia tworzonemu w tym celu procesowi podrzędnemu. Dla użytkownika, po nawiązaniu sesji przy pomocy TELNET, praca z odległym systemem przebiega w sposób przypominający pracę na lokalnej konsoli.
Funkcje sterujące protokołu TELNET

Największy problem, z jakim mieli do czynienia autorzy tego protokołu, to różnorodność systemów operacyjnych na jakich może działać klient i serwer. Heterogeniczność środowisk niesie za sobą różną interpretację znaków pochodzących z klawiatury, możliwość używania 7 bitowego lub 8 bitowego zbioru znaków ASCII.
W celu rozwiązania problemu TELNET definiuje tzw. sieciowy terminal wirtualny (ang. Network Virtual Terminal - NVT). Dzięki niemu klient i serwer posługują się tym samym interfejsem w komunikacji między sobą. Poza tym protokół umożliwia negocjowanie opcji (oprócz zbioru opcji standardowych) oraz nie wymaga, aby dane wejściowe klienta pochodziły z klawiatury, a dane wyjściowe były wyświetlane na ekranie. Sieciowy terminal wirtualny wykorzystuje mechanizm tzw. pseudoterminali w systemach operacyjnych. Oferują one działającym programom dostęp do systemu przekazując znaki przesyłane przez klienta tak jakby pochodziły z klawiatury. Bez tego mechanizmu budowa serwerów TELNET byłaby niemożliwa. To, czy wiersze tekstu powinny się kończyć znakiem CR, LF, czy też CR-LF, który z klawiszy (lub ich sekwencji) daje możliwość przerwania programu, zależy od systemu operacyjnego. Dlatego też polecenia użytkownika są tłumaczone na format NVT i wysyłane do serwera. Wirtualny terminal po stronie serwera tłumaczy je na format swojego systemu operacyjnego. Podobnie dzieje się przy przesyłaniu odpowiedzi serwera do klienta. Umożliwienie przerywania działających programów jest bardzo istotne. Dzięki temu program, działający bez kontroli, wywołany przez użytkownika, może zostać zatrzymany bez zbędnego obciążania serwera. NVT do tego celu używa funkcji sterujących pokazanych na slajdzie.
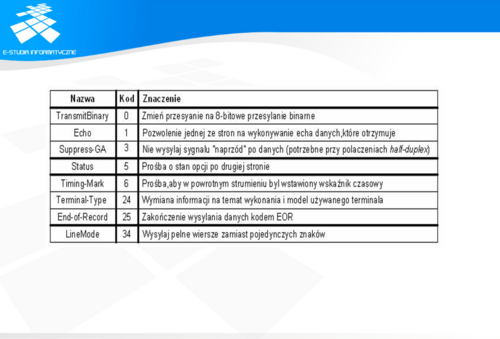
Projektanci NVT zdecydowali o rozdzieleniu poleceń od zwykłych danych przesyłanych w kodzie ASCII między klientem a serwerem. Dzięki temu definiowanie nowych funkcji kontrolnych jest bardzo przejrzyste i elastyczne. Nie ma kłopotu z interpretacją, czy znak powinien być potraktowany jako dane czy jako funkcja kontrolna.
Aby zapanować nad programem, który nie działa prawidłowo na odległej maszynie, to jednak czasami nie wystarczające. W przypadku, gdy program użytkownika wykonuje nieskończone pętle, nie czytając danych z wejścia i nie generując danych na wyjściu, w pewnym momencie bufory systemu operacyjnego mogą się zapełnić. Serwer nie będzie mógł wówczas zapisać większej ilości danych w buforze pseudoterminalu. Musi więc zaprzestać czytania danych z połączenia TCP, co spowoduje zapełnienie buforów połączenia. To z kolei zmusi serwer do proponowania zerowej wielkości okna, czyli zaprzestania przepływu danych. Przy opisanych dotychczas możliwościach nie ma metody wysłania programowi polecenia IP. Dlatego też TELNET przesyła sygnały poza kolejką normalnych danych. W przypadku wysyłania funkcji kontrolnej protokół wysyła dodatkowo funkcję SYNCH i dodaje zarezerwowany bajt DMARK (ang. Data Mark). W nagłówku TCP ustawia flagę URG. Dzięki temu sygnał dociera natychmiast do serwera. Bajt DMARK oznacza, że część SYNCH zawiera strumień danych (zawsze pilnych). Najbardziej złożoną częścią protokołu TELNET jest możliwość negocjacji opcji. Dzięki nim połączenie może być rekonfigurowane np. z trybu half-duplex do trybu full-duplex lub też określony zostaje rodzaj terminalu użytkownika. Najczęściej używane opcje zawiera tabela na slajdzie. Opcje są negocjowane na zasadzie zgłaszania próśb. Strona odbierająca prośbę (komunikat WILL X) o użycie danej opcji albo ją akceptuje (komunikat DO X) albo odrzuca (komunikat DON'T X). Mechanizm ten pozwala na negocjację opcji bez jakichkolwiek informacji o drugiej stronie. Dzięki temu jest możliwa współpraca starszych i nowszych wersji klientów i serwerów. Niewątpliwą zaletą TELNET jest jego popularność oraz w miarę prosta implementacja, z czego korzysta wielu producentów urządzeń sieciowych do zdalnego zarządzania swoimi produktami. Wadą jest przesyłanie znak po znaku tego co wpisuje użytkownik (jeśli nie zostaną wynegocjowane odpowiednie opcje) oraz zupełny brak zabezpieczeń przed podsłuchiwaniem treści przesyłanych między serwerem a klientem.
Protokół SSH
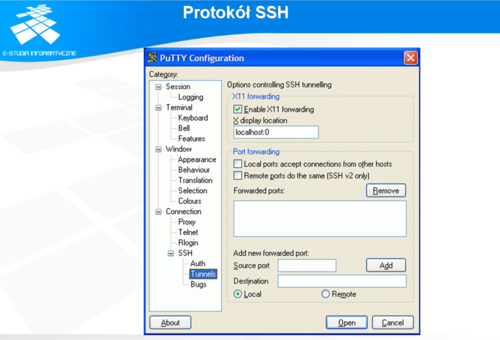
Secure Shell jest usługą funkcjonalnie zbliżoną do usługi TELNET. Tak samo jak w przypadku TELNET użytkownik musi posiadać program klienta łączącego się z procesem serwera. Po połączeniu ze zdalnym systemem użytkownik ma możliwość korzystania z dostępnych na nim poleceń i programów. SSH zawiera również możliwość negocjowania niektórych opcji połączenia oraz ustalanie parametrów wirtualnych terminali. Jednak na tym podobieństwa się kończą. Autorzy SSH stworzyli protokół wymiany danych, odporny na podsłuch sieciowy. Cała komunikacja między dwoma zdalnymi systemami jest szyfrowana. Do tego celu użyli silnych kryptograficznie i ogólnie dostępnych algorytmów ( w niektórych krajach, np. USA niektóre z nich są opatentowane i niestety ich eksport poza granice tego kraju jest prawnie zakazany). Z tej zalety SSH szeroko korzystają i doceniają administratorzy systemów oraz ci użytkownicy, którym zależy na bezpieczeństwie przesyłanych danych. W szczególności dotyczy to haseł dostępu do systemów.
Program klienta w celu połączenia z serwerem musi zestawić sesję TCP z maszyną serwera. Standardowo proces serwera oczekuje na połączenia na porcie 22 TCP. Po takim połączeniu przekazuje obsługę do procesu potomnego, sam czekając dalej na nowe połączenia. Po zestawieniu połączenia TCP klient i serwer SSH ustalają między sobą między innymi rodzaj algorytmu szyfrującego, zasady kompresji przesyłanych danych, możliwość przesyłania informacji generowanych przez aplikacje działające w środowiskach graficznych. Odbywa się to na zasadzie wysłania informacji o obsługiwanych algorytmach i opcjach przez klienta do serwera. Następnie klient otrzymuje listy obsługiwanych algorytmów i opcji od serwera. Wówczas klient wybiera (jeśli użytkownik wyraźnie tego nie określił) rodzaj stosowanego algorytmu. Zanim jednak klient wyśle do serwera dalsze informacje, przy pomocy algorytmu Diffiego-Hellmana ustalany jest wspólny symetryczny klucz w niezabezpieczonym kanale. Klucz ten służy do zabezpieczania przesyłanych danych w dalszej komunikacji. Klucz ten posiada każda ze stron, ale nie jest on nigdy przesyłany między nimi. Przykład możliwych do wyboru opcji przedstawia rys. 7.4.
Generowanie kluczy SSH

Wstępne dane są zabezpieczone wybranym symetrycznym algorytmem szyfrującym, ale algorytm opiera swoje działanie na idei szyfrowania asymetrycznego. W systemach tych do szyfrowania lub deszyfrowania potrzebne są dwa odrębne klucze: prywatny i publiczny. Wiadomość zaszyfrowana kluczem publicznym może być odczytana tylko przez kogoś, kto posiada klucz prywatny z tej pary kluczy. Klucze prywatny i publiczny powinny być wygenerowane przez użytkownika programem ssh-keygen w systemach UNIX. Jeżeli są wygenerowane to, klient SSH przekazuje serwerowi, której ze znanych mu par klucz-użytkownik ma użyć. Są to klucze publiczne. Serwer, jeżeli nie znajdzie informacji zabraniającej mu na zestawiania połączeń z komputerem użytkownika, wyśle klientowi numer losowy (ang. challenge) zaszyfrowany kluczem publicznym użytkownika. Ponieważ klucz prywatny jest zabezpieczony tzw. wyrażeniem przejściowym, więc tylko użytkownik znający to wyrażenie będzie w stanie odczytać wiadomość od serwera. W ten sposób użytkownik potwierdzi swoją tożsamość.
W przypadku, gdy klucze publiczny i prywatny nie zostały wygenerowane, serwer SSH wyśle klientowi zapytanie o nazwę użytkownika i jego hasło. W obu przypadkach informacje te będą przesyłane w postaci zaszyfrowanej wybranym algorytmem szyfrującym. Dodatkowo serwer może tworzyć tzw. skróty (ang. Message Digest) wysyłanych wiadomości. Skrót to nic innego jak skompresowana informacja o treści wiadomości. Jeżeli coś zostanie w treści zmienione, skrót ulegnie również zmianie. Do tego celu SSH używa dwóch algorytmów: MD-5 lub SHA-1. Bardziej bezpieczne i zalecane w używaniu SSH jest stosowanie szyfrowania asymetrycznego, czyli kluczy. Wprawdzie wymagają one od użytkownika poświęcenia kilku minut na poprawne skonfigurowanie, lecz w dłuższym używaniu są wygodniejsze. W celu ułatwienia ich stosowania, autorzy SSH umożliwiają uruchomienie programu ssh-agent, który może za nas przeprowadzać proces podawania wyrażenia przejściowego do odczytania klucza. Oprócz wymienionych dotychczas zalet wynikających ze stosowania SSH jest jeszcze jedna bardzo istotna. Mianowicie przy pomocy tego protokołu można przekierowywać lokalne numery portów na inne na zdalnej maszynie.
Usługi terminalowe systemów MS Windows
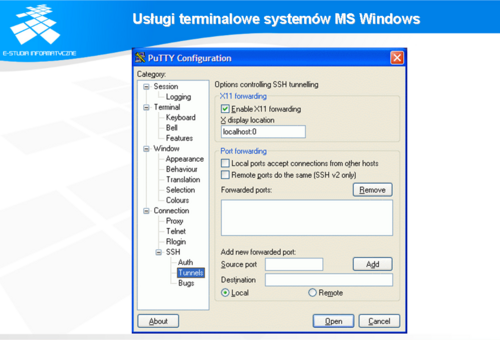
Remote Desktop Protocol podobnie jak SSH czy TELNET daje możliwość zdalnego dostępu do serwera. O ile jednak opisane wcześniej protokoły służą głównie do pracy z terminalami tekstowymi, to RDP jest wykorzystywany głównie w usługach Terminal Services systemów firmy Microsoft. SSH daje możliwość tunelowania połączeń do serwera XWindows i często ten mechanizm jest wykorzystywany przez użytkowników. Jednak jest to dodatkowa cecha SSH. RDP służy do wirtualnego przenoszenia całego środowiska graficznego użytkownika na lokalny komputer. Przykład konfiguracji klienta RDP przedstawia slajd.
Protokół RDP nie wprowadza dużego dodatkowego obciążenia dla lokalnego komputera. W zasadzie zadaniem lokalnej maszyny jest tylko i wyłącznie obsługa aplikacji wyświetlającej wyniki działania programów uruchomionych na serwerze. Ta cecha sprawia, że: RDP idealnie nadaje się do centralnego zarządzania instalowanym oprogramowaniem, daje możliwość wprowadzania oszczędności w firmach na sprzęcie, gdyż użytkownicy mniej wydajnych maszyn mogą uruchamiać duże aplikacje na serwerze, aplikacja, zainstalowana na serwerze Windows NT Terminal Server lub następnych wersjach systemu Windows, może być wykorzystywana przez dowolnego użytkownika, który ma aplikację klienta Terminal Services. Nie ma w związku z tym konieczności przeprowadzania uaktualnień dużej liczby systemów do najnowszych wersji, administrator musi dbać o uaktualnienia oprogramowania tylko na jednym komputerze.

Oczywiście wiele tych cech jest wspólnych dla RDP, SSH czy TELNET. O ile jednak wyżej opisane protokoły były znane od dosyć dawna, to usługi terminalowe w systemach Windows mają znacznie krótszą historię. W ostatnich latach stały się nawet bardzo istotne w heterogenicznych środowiskach sieciowych dzięki programom takim jak:
rdesktop - pozwala klientom UNIX na łączenie się z serwerami Windows Terminal, SAMBA - pozwalająca udostępniać w zasoby systemów UNIX dla systemów Windows, Citrix - komercyjne rozwiązania firmy Citrix identyczne z Windows Terminal Services, choć wykorzystują one własny protokół ICA. Przy ich wykorzystaniu każdy użytkownik może logować się do zdalnego systemu Windows, tak jakby to robił lokalnie. Serwer dla każdego połączenia tworzy oddzielną sesję, a sesjami takimi zarządza niezależnie. Użytkownik może sesję przerwać wylogowując się z serwera lub tylko od sesji się odłączyć. Druga możliwość pozwala na późniejszy do niej powrót. W międzyczasie wygląd pulpitu użytkownika nie ulega zmianie.
Opis protokołu RDP
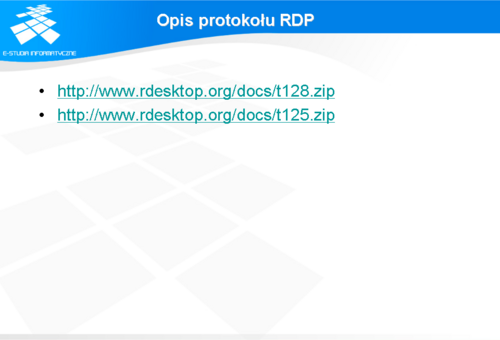
Firma Microsoft oparła implementację RDP o protokół wymiany danych między aplikacjami - T.128. Jest on również znany jako T.SHARE. Standard został opracowany przez ITU-T. Pod adresem
http://www.rdesktop.org/docs/t128.zip i
http://www.rdesktop.org/docs/t125.zip można znaleźć dokumenty ITU-T o tym protokole. Oprócz tego, dodatkowych informacji można szukać w dokumentach RFC905 i RFC2126.
Najważniejszą cechą rodziny protokołów T.120 jest możliwość przesyłu danych w kilku wirtualnych kanałach (do wykorzystania jest 64000 kanałów w jednym połączeniu). Dane są w nich transmitowane równolegle, a przy tym niezależnie. Dzięki temu dane warstwy prezentacji są niezależne od informacji pochodzących z portów szeregowych, klawiatury, myszy. W wersji usług terminalowych udostępnionych wraz z Windows NT4.0 Server wszystkie sesje były typu "punkt-punkt". RDP jednak, jako rozszerzenie T.Share pozwala na sesje typu multicast. RDP został zaprojektowany w sposób pozwalający mu wykorzystywać protokoły takie jak TCP/IP, NetBios, IPX do komunikacji. Czyni go to niezależnym od użytej technologii sieciowej i pozwala na używanie w różnorodnych środowiskach. Dane pochodzące z aplikacji, przesyłane przy pomocy RDP, są obsługiwane niemal identycznie jak inne programy nie korzystające z RDP. Jedynym dodatkiem jest stos tego protokołu. W stosie tym następuje podział danych na fragmenty, przekierowanie do odpowiedniego kanału, szyfrowanie, podział danych na ramki i przesłanie do protokołów warstw niższych. Odbiór danych odbywa się w przeciwnym kierunku. W systemach Windows złożoność tego procesu ukryto przed programistami udostępniając im odpowiedniego typu API (ang. Application Programming Interace).
Opis protokołu RDP

Warto zwrócić uwagę na dwa elementy stosu RDP. Skład się on z kilku części. Każda z nich jest odpowiedzialna za odrębne funkcje. Najważniejsze z nich to:
MCSMUX - (ang. Multipoint Communication Service), GCC - (ang. Generic Conference Control). Oba elementy są częścią rodziny standardów ITU-T T.120. MCS składa się z dwóch takich standardów: T.122 - definiuje serwisy, T.125 - specyfikuje rodzaj protokołu transmisji danych. MCSMUX kontroluje przypisania kanałów wirtualnych, ustawienia poziomu priorytetów, wielkość wysyłanych segmentów danych. W zasadzie tworzy on abstrakcyjną warstwę, która wiele stosów RDP prezentuje jako jedną całość z perspektywy GCC. GCC jest odpowiedzialne za zarządzanie kanałami. Pozwala na otwieranie nowych, kasowanie starych sesji oraz kontroluje zasoby dostarczane przez MCS.
Serwisy informacyjne

Sieć Internet z całą pewnością nie byłaby tak atrakcyjna dla użytkowników, gdyby nie zgromadzone w niej informacje i , co ważniejsze, możliwość łatwego dotarcia do nich. Oczywiście możliwość wymiany danych np. poczty elektronicznej, plików jest dużym ułatwieniem w pracy, bez którego dzisiaj trudno się obejść.
Czasami jednak rozsyłanie tych samych plików do setek użytkowników lub opisywanie pewnych rzeczy jest znacznie trudniejsze niż np. po prostu narysowanie ich. Oczywiście rysunek trzeba zaprezentować innym użytkownikom sieci. Tu z pomocą przychodzi protokół HTTP (ang. Hypertext Transfer Protocol) oraz znana dobrze wszystkim usługa WWW (ang. World Wide Web). Dzięki nim oraz językowi służącemu do tworzenia stron WWW - HTML (ang. Hypertext Markup Language) użytkownicy mogą łatwo przedstawiać wyniki swoich prac, poglądy, firmy przedstawiać produkty itd. W zasadzie można powiedzieć, że rozwój sieci Internet w ostatnich latach był motywowany przez rosnącą popularność serwisów WWW oraz wykorzystywanie protokołu HTTP do przesyłania danych przez inne aplikacje niż tylko przeglądarki stron WWW. Oprócz HTTP, nieco wcześniej powstał inny protokół NNTP (ang. Network News Transfer Protocol). Dzięki niemu użytkownicy mogą wymieniać poglądy i opinie przy pomocy tekstowych wiadomości. Podobnie jak w przypadku WWW są one umieszczane na serwerach i czytane przy pomocy programów-klientów.
Protokół HTTP
Zanim zostanie przedstawiony protokół HTTP należy przypomnieć, że pomiędzy nim a WWW istnieje różnica i nie są to dwa tożsame pojęcia. WWW składa się z trzech rzeczy: protokołu HTTP, języka HTML i systemu nazewnictwa URI (ang. Uniform Resource Identifier). Protokół HTTP jest używany do komunikacji między komponentami WWW, czyli np. przeglądarkami stron, serwerami proxy. Przy pomocy HTTP informacje są przesyłane w wielu różnych formatach, językach i kodowaniach znaków. Składnia wiadomości jest oparta o przedstawiony wcześniej MIME i nie jest w żaden sposób interpretowana przez protokół.
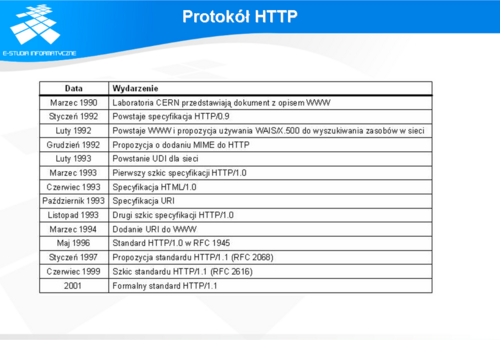
Historię rozwoju protokołu przedstawia tabela na slajdzie. Z tabeli tej widać, że protokół ma stosunkowo krótką historię rozwoju. Mimo to we współczesnych sieciach odgrywa on kluczową rolę.
Zalety protokołu HTTP

Generalnie rzecz biorąc HTTP jest protokołem bardzo prostym. Mimo to, jest bardzo uniwersalny. Jego główne cechy to:
używanie URI do identyfikacji zasobów w sieci, stosowanie mechanizmu "zapytanie-odpowiedź" przy wymianie danych, brak nawiązywania sesji między klientem a serwerem, zawieranie informacji o zasobach, które mogą być użyte na różne sposoby. Oczywiście za tymi czterema punktami kryje się nieco bardziej skomplikowany mechanizm. URI pozwala na umieszczenie zasobu (pliku) gdziekolwiek w sieci Internet. Separuje jednocześnie nazwę od rodzaju zasobu, który się pod nią kryje. W zasadzie, zasób może mieć nazwę przydzieloną na zawsze, co nie oznacza, że jego zawartość i sposób reprezentacji nie może w tym czasie ulec zmianie. Z punktu widzenia protokołu URI jest sformatowanym ciągiem znaków. Można powiedzieć, że URI wskazuje na zasób, niezależnie jakiego typu i niezależnie w jakim miejscu w sieci się znajduje. W tym sensie URI jest kombinacją URL (ang. Uniform Resource Locator) i URN (ang. Uniform Resource Name). Bardziej znanym jest URL. Powiązanie między tymi trzema mechanizmami lokalizacji zasobów jest następujące: jeśli zasób X został umieszczony pod adresem www.foo.com/X i adresem www.companyx.com/pub/X to są to dwa adresy URL. Każdy z nich jest URI zasobu X. URL w związku z tym wskazuje na położenie kopii zasobu. Jeżeli zasobem X jest książka o nadanym numerze ISBN (ang. International Society of Book Numbers) to jej URN jest właśnie ten numer.
Adres URL

Adres URI jest uważany za bezwzględny, jeśli ciąg znaków, który go reprezentuje, zaczyna się od tzw. schematu i dalej znaków reprezentujących zasób osiągalny w sieci przy pomocy tego schematu. Schemat to nic innego jak wskazanie protokołu, który ma być użyty do pobrania zasobu. Pierwsza specyfikacja HTTP/0.9 uwzględniała schematy: file, news, http, telnet, gopher. Mimo, że określenie protokołu wskazuje wyraźnie jego nazwę to, do pobrania zasobu mogą być również użyte inne protokoły. Typowe pobranie strony HTML z sieci powoduje skorzystanie z systemu DNS do odnalezienia numeru IP serwera i z protokołu TCP do nawiązania z nim sesji. Najbardziej znanym schematem jest HTTP.
Każdy z protokołów ma inną składnię i mechanizm nazywania zasobów. Poprzez oddzielenie protokołu i ciągu znaków lokalizującego zasób, mechanizm nazywania w WWW pozwala na pobieranie tego samego pliku przy pomocy różnych protokołów. Mechanizm ten był bardzo potrzebny i często wykorzystywany w początkowych czasach funkcjonowania WWW. Dzięki temu również WWW stało się tak uniwersalnym interfejsem do pobierania zasobów, które zazwyczaj są tylko dostępne przez np. FTP. Przykładem wykorzystania tego jest rtsp://clips.foo.com/audio/X lub telnet://ox.mycompany.com.pl. Kiedy przeglądarka spotyka się z takim odwołaniem do zasobu, interpretuje rodzaj protokołu do pierwszego wystąpienia znaku ":" a następnie uruchamia połączenie przy jego pomocy - RTSP (ang. Real Time Streaming Protocol) lub TELNET.
Transfer danych

Jak już zostało wspomniane, protokół HTTP nie używa sesji połączeniowej do wymiany danych między klientem i serwerem. Cała komunikacja jest oparta o mechanizm "zapytanie - odpowiedź". Zapytanie wysłane przez klienta do serwera nie musi być odebrane przez oryginalny serwer, do którego było kierowane. Może je obsłużyć dowolny serwer posiadający żądany zasób lub np. serwer proxy. Dla klienta jest to zupełnie niewidoczne. Serwer odbierający zapytanie odsyła odpowiedź.
Protokół HTTP specyfikuje kilka metod, których może użyć klient do pobierania, modyfikacji, tworzenia i usuwania zasobu. Są to: Metody zdefiniowane w HTTP/1.0 GET - najpopularniejsza metoda pobierania zasobów z serwera HEAD - metoda służy do pobierania metadanych o zasobie POST - w przeciwieństwie do GET i HEAD, ta metoda służy do uaktualniania zawartości zasobu Metody implementowane w niektórych wersjach HTTP/1.0 PUT - metoda działa podobnie jak POST w sensie modyfikowania zasobów wyspecyfikowanych w URI DELETE - metoda służy do usuwania zasobu LINK i UNLINK - metody pozwalają na tworzenie lub usuwanie powiązań między wskazanym w URI zasobem a innymi zasobami.
Odpowiedź serwera
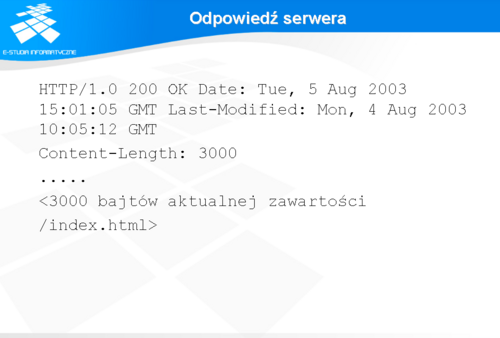
Odpowiedź serwera składa się z :
numeru kodu odpowiedzi, mówiącego o sukcesie lub błędzie, przyczyny powstania takiej odpowiedzi, opcjonalnych nagłówków, opcjonalnej zawartości żądanego zasobu. W zaprezentowanym przykładzie oprócz wymaganych informacji zostały dodane jeszcze pola dodatkowe informujące o dacie ostatniej modyfikacji zasobu oraz jego wielkości. Pola te nie zawsze mają charakter tylko informacyjny. Klient może, oprócz przedstawionego zapytania, w opcjonalnych nagłówkach podać metodę, która ma być zastosowana do zasobu przy spełnieniu określonych warunków. Na przykład, klient może nie chcieć odpowiedzi od serwera, jeżeli żądany dokument nie był modyfikowany od ostatniego czasu, kiedy był przez niego pobrany. Serwer traktuje zasoby trochę jak "czarne skrzynki". Najczęściej taką skrzynką jest plik ze swoją zawartością, którą serwer czyta i wysyła w odpowiedzi klientowi. Dzięki takiemu podejściu - nie interpretowaniu treści zasobu, a tylko sprawdzaniu treści zapytania - serwer może dla tego samego zasobu udzielać różnych odpowiedzi w zależności od rodzaju zapytania, czasu w którym serwer je otrzymał, zmian jakie wprowadzono do zasobu. W praktyce rola serwera i klienta jest bardzo często wymienna. W sieci funkcjonuje całe mnóstwo serwisów i urządzeń zdolnych obsługiwać zapytania kierowane przez programy użytkowników. Obecność w sieci serwerów proxy, różnego rodzaju bram, tuneli nie wpływa na podstawowy sposób, w jaki HTTP wymienia informację między serwerem a klientem. Serwery proxy pozwalają na łatwe dotarcie do informacji przez użytkownika bez generowania nadmiernego ruchu w sieci Internet i obciążaniu serwerów źródłowych. Natomiast, użytkownikowi końcowemu zapewnia to większy komfort pracy.
COOKIES

Z punktu widzenia komunikacji w sieci, HTTP jest protokołem poziomu aplikacji, używa protokołów warstw niższych ( w rzeczywistości tylko jednego - TCP). Ponieważ nie da się wygenerować odpowiedzi serwera dopóki nie otrzyma on zapytania od klienta, dlatego też kierunek zapytań zawsze zaczyna się od klienta do serwera. Następnie wysyłane są odpowiedzi. Każda taka wymiana komunikatów jest traktowana przez serwer zupełnie oddzielnie. Protokół HTTP nie posiada mechanizmów, które potrafiłyby przenosić informację o wcześniejszych odwołaniach klienta do serwera i jego odpowiedziach. Z tego punktu widzenia HTTP jest protokołem bezstanowym i nie zarządza sesjami.
Powód, dla którego postanowiono tak zrobić, jest bardzo prosty. W czasach powstawania WWW tworzono jeszcze kilka innych, konkurencyjnych systemów. Wszystkie one miały zapewnić dostęp do dużych zasobów w Internecie. Gdyby dodać do protokołu przechowywanie informacji o każdej sesji, to mogłoby się okazać, że serwery muszą przechowywać duże zbiory danych o swoich użytkownikach. WWW tym samym stałby się rozwiązaniem słabo skalowalnym . Nie znaczy to, że serwery, przeglądarki klientów lub inne aplikacje korzystające z HTTP do wymiany danych nie zarządzają sesjami. Serwer WWW może zapamiętywać adresy IP klientów, którzy pobierali z niego dane, jak również inne informacje, które klient wysyła w nagłówkach. Dzieje się to jednak na poziomie oprogramowania serwera i klienta. Problem utrzymywania sesji zaczął być bardzo odczuwalny, gdy serwis WWW musiał przechowywać jakieś informacje o wcześniejszych odwołaniach, np. sklepy internetowe, banki elektroniczne, itd. Rozwiązaniem najczęściej stosowanym są ciasteczka (ang. cookies). Przy każdym wysyłaniu zapytania do serwera, aplikacja użytkownika dołącza ciasteczko z informacjami o nim.
Sesje HTTP
Problem, jaki niesie za sobą model wymiany wiadomości w HTTP, jest związany z obciążeniem, którego nie generuje ten protokół jako taki, ale TCP. Jak wiemy, TCP potrzebuje wymiany kilku pakietów do otwarcia sesji. HTTP może przesyłać swoje dane dopiero po otwarciu sesji TCP. Użytkownicy wykorzystujący WWW bardzo często po odebraniu odpowiedzi serwera zmieniają go na inny. Tak się dzieje np. gdy korzystamy z wyszukiwarek internetowych. TCP nie zamyka od razu połączenia po stronie serwera, a system operacyjny użytkownika nie wysyła do niego informacji, że sesja nie będzie już używana. Tym sposobem zarówno klient jak i serwer mogą mieć sporą liczbę otwartych, nieużywanych sesji TCP. Wbrew temu co może się wydawać, zmniejszenie czasu nieaktywności sesji przed jej zamknięciem nie jest rozwiązaniem. Opóźnienia w sieci mają charakter losowy i często dane docierają w różnym czasie do odbiorcy. Jeżeli czas nieaktywności będzie zbyt krótki, sesja będzie zamknięta przed odebraniem danych. Użytkownik wówczas będzie otwierał nową sesję, która znowu po chwili będzie zamknięta. Serwer będzie obciążany samymi operacjami zamykania/otwierania sesji. Czas oczekiwania użytkownika na odpowiedź serwera będzie wydłużany o czas potrzebny na zestawienie sesji TCP, co czasami może trwać kilka sekund. Otwieranie i zamykanie sesji jest w sumie najbardziej kosztowną operacją dla serwera. Poza tym w sieci pojawia się ogromna liczba krótkich pakietów IP. Zwiększają one jej obciążenie zmniejszając tym samym szansę na przesłanie większej liczby danych. Sytuacja ta jest dość często spotykana w sieciach.
Najnowsza specyfikacja HTTP/1.1 pozwala na utrzymywanie "sesji HTTP" między przeglądarką a serwerem. Niektóre implementacje HTTP/1.0 pozwalały na używanie nagłówka Keep-Alive. W HTTP/1.1 zostało to przekształcone do tzw. stałego połączenia (ang. persistent connection). Mechanizm ten pozwala klientowi na poinformowaniu serwera, że jest zainteresowany utrzymaniem stałego połączenia z nim, poza pojedynczą wymianę wiadomości. Należy pamiętać, że ta wymiana może składać się z kilkunastu ramek TCP. W przypadku HTTP/1.0 mimo to istnieje problem określenia, jak długo połączenie ma być utrzymywane, gdy serwer odsyła dynamicznie generowaną odpowiedź np. przez skrypt. Nie zawiera ona wówczas nagłówka podającego jej wielkość. Klient może jedynie stwierdzić, że otrzymał całość, gdy serwer zamyka połączenie. Na szczęście poprzez rozszerzenia nagłówka HTTP, serwer może określać jak długo połączenie będzie utrzymywane po otrzymaniu ostatniego zapytania. Może również określić maksymalną liczbę zapytań, które klient może wysłać w danym połączeniu.
Metadane w HTTP

Metadane są informacjami związanymi z przedmiotem, którego dotyczą, ale nie są jego częścią. W przypadku HTTP metadane są przesyłane w nagłówkach. Oczywiście nie do każdego zasobu da się takie metadane stworzyć, np. w przypadku dynamicznie generowanych odpowiedzi serwer nie umieszcza informacji o jej wielkości gdyż obliczenie tego wprowadzałoby dodatkowe opóźnienie. Należy jednak pamiętać, że takie dane mają charakter nie tylko informacyjny. Często mogą one istotnie zmienić odpowiedzi serwera, kolejne zapytania klienta.
Najczęściej wykorzystywanymi informacjami są: rodzaj kodowania, dane mówiące, jak duży jest zasób pobierany przez klienta. Dzięki temu może się on łatwo zorientować, kiedy otrzymał całą odpowiedź, czas ostatniej modyfikacji żądanego zasobu. Informacja ta jest bardzo ważna dla serwerów cache jak i przeglądarek WWW. Posiadając ją są w stanie stwierdzić, czy kopia którą ewentualnie już mają jest aktualna, czy też należy pobrać zasób jeszcze raz.
Usługa Usenet news

Network News Transfer Protocol - NNTP służy do transmisji artykułów związanych z "elektronicznymi grupami" usługi news. Programy klienckie użytkowników wykorzystują ten protokół do komunikacji z lokalnymi serwerami news, a serwery do wymiany wiadomości między sobą.
Usługa news służy do wymiany wiadomości między użytkownikami, podobnie jak poczta elektroniczna. Jednak między tymi dwoma serwisami istnieją zasadnicze różnice. Poczta elektroniczna służy do wymiany listów e-mail między dwoma osobami lub w kręgu niedużej grupy ludzi. Przykładem może być firma, która może utworzyć listę e-mailową związaną z danym tematem. Użytkownicy zainteresowani otrzymywaniem wiadomości z tej listy mogą się na nią zapisać. Pierwsza niedogodność płynąca z tego rozwiązania to wysyłanie oddzielnej kopii tego samego listu do każdej z zapisanych osób. Zwiększa to niepotrzebnie obciążenie serwera i sieci. Druga, ważniejsza, to sposób zarządzania listą. Jeśli nie jest automatyczny, to administrator listy musi ręcznie dodawać lub usuwać użytkowników. Oczywiście listą może zarządzać program, który odbiera listy kierowane na specjalny adres. Nie likwiduje to jednak problemu do końca, zwłaszcza gdy użytkownik zapomni zmienić swój adres e-mail na liście zanim zmieni go w rzeczywistości. Wówczas serwer będzie próbował wysyłać listy pod nieistniejące adresy, a lista zapisanych osób będzie rosła. Opisane problemy stają się ogromne w dużej skali. Dlatego też w 1979 został opracowany system USENET. W 1983 powstał standard, który dokładnie go określa. Kluczowe dla systemu jest założenie o utrzymywaniu centralnej bazy danych wiadomości zamiast oddzielnych kopii dla każdego zapisanego do systemu użytkownika. Baza składa się ze zbioru tzw. grup wiadomości (ang. newsgroups). Każda z nich jest związana z zapisaną dla niej listą wiadomości. Nazwa grupy jest związana z hierarchią, w której została założona (system podobny do DNS), np. comp.unix.databases. System bazy artykułów oferuje do nich dostęp, indeksowanie, usuwanie przestarzałych wiadomości, śledzenie powiązań między artykułami. Administrator serwera news może ustalić politykę określającą maksymalny "wiek" artykułu. Po jego osiągnięciu system usuwa go.
Rodzaje nagłówków

Podobnie jak w przypadku listu e-mail, artykuł zawiera szereg nagłówków:
adres e-mail autora, temat wiadomości, czas utworzenia, liczbę linii tekstu, identyfikator, nazwy innych grup news, do których został wysłany. Jeden centralny serwer news mógłby wprawdzie teoretycznie obsługiwać wszystkie grupy wiadomości na całym świecie oraz wszystkich użytkowników korzystających z tej usługi. Jednak nietrudno się domyśleć jaka byłaby jej jakość. Dlatego też artykuły są replikowane między serwerami news. Uczelnia może mieć swój serwer, który będzie udostępniał artykuły z popularnych grup dla studentów. Nie ma konieczności pobierania artykułów ze wszystkich grup dostępnych w USENET-cie. Oprócz tego mogą tam być grupy tylko i wyłącznie dla studentów tej uczelni. Serwer nie będzie ich wysyłał do innych serwerów news. Użytkownicy czytają i wysyłają artykuły przez programy, które komunikują się z lokalnym serwerem. Udostępnia on im interfejs do tworzenia i czytania wiadomości, pokazuje niezbędne nagłówki, listy dostępnych artykułów w danej grupie. Poza tym większość takich programów zapamiętuje w lokalnych plikach, jakie wiadomości zostały już przeczytane oraz które grupy news są przez użytkownika odwiedzane. Grupy news są identyfikowane w sieci Internet przez nazwę, tak samo jak serwisy WWW. Większość przeglądarek internetowych pozwala na ich czytanie.
Protokół NNTP
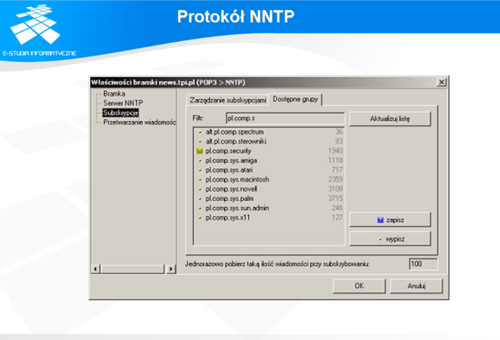
NNTP został zaproponowany jako zastępstwo starego UUCP (ang. UNIX-to-UNIX Copy Protocol) w 1986 r.
Aplikacja, służąca do odczytywania artykułów z serwera news, otwiera połączenie TCP z serwerem na porcie 119. Podobnie jak FTP i SMTP serwer zwraca trzycyfrowy kod, z opcjonalną wiadomością tekstową do komend wydawanych przez klienta. W zależności od rodzaju odpowiedzi może ona mieć jeszcze dodatkowe parametry. Numer i typ dodatkowych parametrów jest dołączany przez serwer do każdej odpowiedzi, co ułatwia klientowi ich interpretację. Podczas przetwarzania komend serwer pamięta nazwę bieżącej grupy news oraz numer artykułu pobranego przez klienta.
Polecenia protokołu NNTP

NNTP ma bogaty zbiór poleceń spełniających różne funkcje. Jednym ze zbiorów takich komend są polecenia dostarczające generalnych informacji o serwerze i dostępnych grupach news, np.:
lista obsługiwanych przez serwer poleceń, lista dostępnych grup wraz z informacją o pierwszym i ostatnim artykule w każdej z nich oraz informacją o tym, czy użytkownicy mogą wysyłać artykuły na daną grupę, lista grup utworzonych od danej daty/czasu, lista artykułów wysłanych w danej grupie od danej daty/czasu. Dostarczanie informacji o zmianach w czasie pozwala aplikacjom użytkowników na odświeżanie dostępnych dla nich list artykułów bez potrzeby przechowywania ich na serwerze. Inne zbiory komend służą do przemieszczania się między grupami (identyfikowane są przez nazwy), między artykułami, przejście od aktualnego do poprzedniego lub następnego artykułu. Oprócz tego są też komendy zwracające tylko nagłówki artykułu albo jego całość. Za każdym razem artykuł jest identyfikowany przez numer wiadomości albo numer w danej grupie news. Oczywiście NNTP dostarcza również komend do tworzenia nowych artykułów. Użytkownik może wysłać prośbę o wysłanie wiadomości. Jeżeli serwer odpowie pozytywnie, klient wysyła jego treść podobnie jak w przypadku SMTP. Artykuł kończy się pojedynczym znakiem "." w ostatniej linii. W tym czasie serwer generuje unikalny identyfikator dla wiadomości i dodaje ją do listy artykułów danej grupy. NNTP jest wyposażone w komendę służącą do kopiowania wiadomości między serwerami. Jest to chyba jedna z bardziej istotnych komend w NNTP. Dzięki niej artykuły są wymieniane między serwerami, a użytkownicy korzystający z różnych serwerów mogą je czytać. Serwery nie udostępniają swojej bazy artykułów komukolwiek, a tylko wyznaczonym w konfiguracji innym serwerom news (administratorzy usługi news często nazywają to rozwiązanie feed-em). Serwery wymieniające między sobą feed-a sprawdzają, przed skopiowaniem wiadomości o danym identyfikatorze, czy nie mają jej już w bazie. Jeżeli tak, to nie kopiują jej ponownie. Poza tym, serwery w ramach feed-u mogą sobie udostępniać tylko artykuły pojawiające się na określonych w konfiguracji grupach. Dzięki temu małe firmowe serwery mogą utrzymywać grupy news interesujące ich pracowników bez potrzeby kopiowania dziennie kilku terabajtów danych grup typu alt.binaries. Szybkość kopiowania artykułów między serwerami jest bardzo różna. Czasami może się zdarzyć, że serwer otrzyma daną wiadomość po kilkudziesięciu godzinach. Zależy to od obciążenia łącza do tego serwera jak i jego samego. Należy również pamiętać, że każda grupa wiadomości rządzi się swoimi, często różnymi, prawami. Większość z nich posiada swoje archiwum lub stronę WWW, gdzie jest publikowany regulamin pisania artykułów do danej grupy. Regulaminu tego powinni przestrzegać autorzy artykułów tej grupy.