-
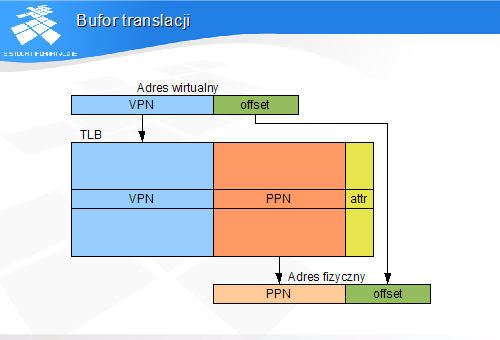
W przypadku chybienia konieczne jest załadowanie nowego deskryptora strony do bufora translacji
-
Deskryptory stron są przechowywane przez system operacyjny w tablicach umieszczonych w pamięci
-
w "CISCowych" jednostkach stronicowania pobraniem deskryptora z pamięci zajmuje się mikrokod jednostki stronicowania (x86, SPARC)
-
w "RlSCowych" jednostkach stronicowania chybienie TLB generuje błąd. obsługiwany przez system operacyjny-ładowaniem deskryptora zajmuje się system (MIPS. Alpha)
-
Do TLB nie ładuje się deskryptorów nieważnych
-
napotkanie nieważnego deskryptora generuje błąd dostępu
Implantacja pamięci wirtualnej na bazie stronicowania
-
Duża liczba stron umożliwia elastyczne określenie zbioru roboczego
-
wiele stron "chwilowo niepotrzebnych" może zostać przeniesionych do pamięci masowej
-
algorytm wymiany stron może korzystać z bitów znaczników dostępu (Acessed) i zapisu (Dirty) w deskryptorach stron
-
Stały rozmiar strony eliminuje fragmentację pamięci operacyjnej i masowej
-
w miejscu zwolnionym przez stronę zawsze można zaalokować nową stronę
-
brak konieczności uciąglania pamięci operacyjnej i masowej
-
Implementacja pamięci wirtulanej jest łatwa i efektywna
-
Stronicowanie zostało opracowane z myślą o implementacji systemu pamięci wirtualnej
Przechowywanie deskryptorów stron
-
Typowy przypadek:
-
procesor 32-bitowy
-
strony o rozmiarze 4 KB
-
przestrzeń adresowa zawiera 220 stron
-
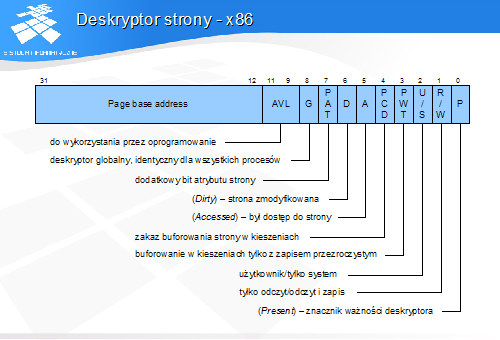
prosty deskryptor strony zajmuje 4 bajty
-
220 deskryptorów - 4 MB
-
W celu zmniejszenia zajętości pamięci deskryptory przechowuje się w pamięci strukturach tablicowo-drzewiastych
-
drzewo tablic (przykład - x86)
-
tablice zawierają po 1024 deskryptory
-
dwa poziomy tablic
-
deskryptor nieważny oznacza brak następnej tablicy - cały fragment przestrzeni adresowej jest nieważny
-
deskryptor ważny wskazuje tablicę deskryptorów
-
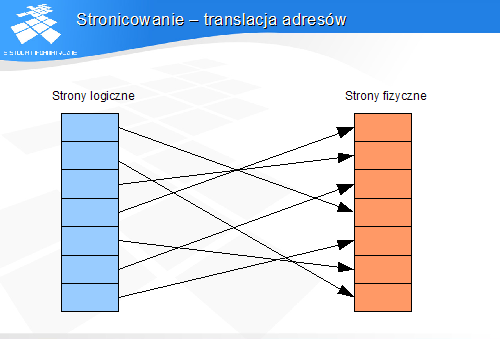
Odwzorowanie adresów wirtualnych w fizyczne jest unikatowe dla każdego procesu
-
Każdy proces ma własne tablice deskryptorów
-
Tablica pierwszego poziomu jest wskazywana przez specjalny rejestr procesora - rejestr bazowy tablic deskryptorów stron
-
jest to rejestr systemowy, niedostępny dla użytkownika
-
jest on przeładowywany podczas przełączania procesów
-
w x86 rejestr ten nosi oznaczenie CR3
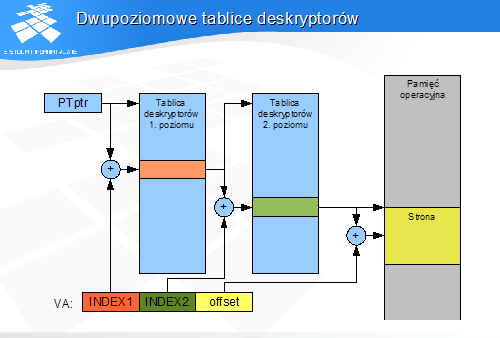
Dwupoziomowe tablice deskryptorów
Dwupoziomowe tablice deskryptorów (x86)
-
Adres wirtualny dzieli się na 3 pola
-
INDEX1 - 10 bitów
-
INDEX2 - 10 bitów
-
OFFSET - 12 bitów
-
Najbardziej znaczące bity adresu wybierają deskryptor z tablicy pierwszego poziomu
-
jeden deskryptor opisuje 222 = 4 MB przestrzeni adresowej
-
deskryptor nieważny oznacza, że proces nie ma dostępu do całego 4-megabajtowego obszaru przestrzeni adresowej
-
deskryptor ważny wskazuje tablicę drugiego poziomu
-
Tablica drugiego poziomu jest indeksowana wartością INDEX2
-
tablica zawiera deskryptory stron
-
Każda tablica ma rozmiar 4 KB, czyli zajmuje jedną stronę
Dwupoziomowe tablice stron - zajętość pamięci
-
Przestrzeń adresowa procesu dzieli się na część użytkownika i systemową
-
Część systemowa jest wspólna dla wszystkich procesów
-
tablice drugiego poziomu opisujące część systemową są wspólne dla wszystkich procesów
-
Każdy proces ma własną tablicę pierwszego poziomu
-
Każdy proces ma własne tablice drugiego poziomu opisujące przejrzeń adresową w części użytkownika
-
Typowy proces zajmuje do kiludziesięciu MB w czterech obszarach
-
potrzeba od czterech do kilkunastu tablic drugiego poziomu plus jednej pierwszego poziomu
-
typowa zajętość pamięci przez tablice - 20..80 KB. czyli niewiele ponad 1/1000 zajętości pamięci przez proces
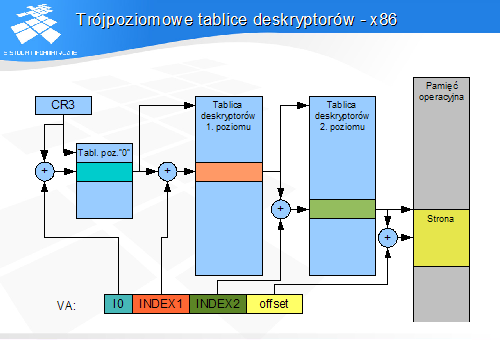
Trójpoziomowe tablice deskryptorów
-
Zmiany alokacji w części systemowej o zasięgu przekraczającym 4 MB powodują konieczność modyfikowania tablic pierwszego poziomu
-
Przy dwupoziomowej strukturze tablic oznacza to konieczność modyfikacji wielu tablic pierwszego poziomu
-
Rozwiązanie - tablice trójpoziomowe
-
"nowy" pierwszy poziom dzieli przestrzeń adresową na kilka obszarów (np.4)
-
zmiany w systemowych tablicach drugiego (wcześniej pierwszego) poziomu nie wymagają zmian na pierwszym poziomie
-
zmienia się tylko zawartość tablic, a nie położenie
Trójpoziomowe tablice deskryptorów - x86
Stronicowanie w procesorach 64-bitowych
-
Adres logiczny - 64 bity
-
Adres wirtualny - krótszy od logicznego, np. 52 bity
-
dozwolony zakres adresów wirtualnych leży na początku i na końcu przestrzeni logicznej
-
są to tzw. adresy kanoniczne, w których pewna liczba najbardziej znaczących bitów ma tę samą wartość (0 albo 1)
-
odwołania do adresów niekanonicznych generują błąd dostępu
-
Długi adres wirtualny wymaga budowy struktur tablicowo-drzewiastych o dużej liczbie poziomów
Wielopoziomowe tablice deskryptorów - AMD64
Redukcja chybień bufora translacji
-
Chybienie bufora translacji powoduje konieczność przejrzenia struktur danych w pamięci (tzw. table walk)
-
Ponieważ chybienia są rzadkie, dane z tablic deskryptorów rzadko znajdują się w kieszeniach
-
konieczne wykonanie 2.4 dostępów do pamięci operacyjnej - we współczesnych procesorach jest to równoważne wykonaniu nawet kilkuset instrukcji
-
Wysoki koszt chybienia powoduje konieczność redukcji liczby chybień
-
Chybienia wynikają z ograniczonej pojemności bufora translacji
-
większa pojemność - mniejsza szybkość
-
liczbę chybień można zmniejszyć zmniejszając liczbę używanych deskryptorów
-
Duża liczba potrzebnych deskryptorów wynika z niewielkich rozmiarów stron
-
Małe rozmiary stron wynikają z potrzeby wirtualizacji
-
Brak wirtualizacji oznacza brak konieczności podziału przestrzeni adresowej na strony
-
Obszary nie podlegające wirtualizacji:
-
jądro systemu
-
cala pamięć fizyczna komputera odwzorowana w przestrzeni systemu
-
urządzenia wejścia-wyjścia, np. sterownik graficzny (pamięć obrazu)
-
Obszary te mogą być opisane mniejszą liczbą deskryptorów "dużych" stron
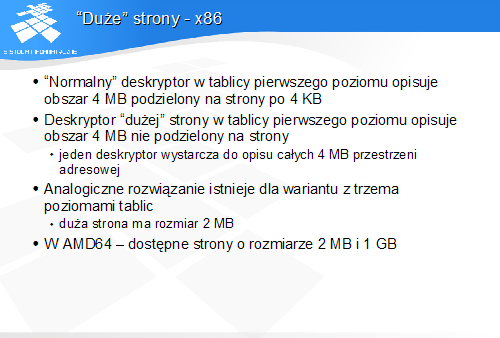
"Duże" strony - x86
-
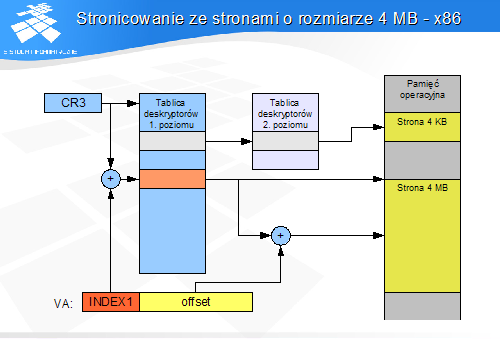
"Normalny" deskryptor w tablicy pierwszego poziomu opisuje obszar 4 MB podzielony na strony po 4 KB
-
Deskryptor "dużej" strony w tablicy pierwszego poziomu opisuje obszar 4 MB nie podzielony na strony
-
jeden deskryptor wystarcza do opisu całych 4 MB przestrzeni adresowej
-
Analogiczne rozwiązanie istnieje dla wariantu z trzema poziomami tablic
-
duża strona ma rozmiar 2 MB
-
W AMD64 - dostępne strony o rozmiarze 2 MB i 1 GB
Stronicowanie ze stronami o rozmiarze 4MB - x86