
Można postawić pytanie: ‘Czym jest eksploracja danych?’. Zadaniem metod eksploracji danych, nazywanej również odkrywaniem wiedzy w bazach danych (ang. knowledge discovery in databases, database mining), jest automatyczne odkrywanie nietrywialnych, dotychczas nieznanych, zależności, związków, podobieństw lub trendów -- ogólnie nazywanych wzorcami (ang. patterns) -- w dużych repozytoriach danych. Odkrywane w procesie eksploracji danych wzorce mają, najczęściej, postać reguł logicznych, klasyfikatorów (np. drzew decyzyjnych), zbiorów skupień, wykresów, itp. Celem eksploracji najogólniej mówiąc jest analiza danych i procesów w celu lepszego ich poznania i zrozumienia. Automatyczna eksploracja danych otwiera nowe możliwości w zakresie interakcji użytkownika z systemem bazy i magazynem danych. Przede wszystkim umożliwia formułowanie zapytań na znacznie wyższym poziomie abstrakcji aniżeli pozwala na to standard SQL.
Typy zapytań do repozytoriów danych

Możemy wyróżnić trzy typy zapytań do repozytoriów danych w szczególności do systemów baz danych. Są to zapytania operacyjne, zapytania analityczne oparte o model OLAP oraz zapytania eksploracyjne. Typowym zapytaniem operacyjnym do bazy danych będzie: „Ile butelek wina sprzedano w I kwartale 2006 w sklepie Auchan w Poznaniu”? Bardziej zaawansowanym zapytaniem będzie zapytanie analityczne postaci: „Ile sprzedano butelek wina w sieci Auchan na terenie kraju z podziałem na województwa, gatunki win oraz kwartały, w ciągu ostatnich 5 lat?” Analiza danych w magazynie danych, zgodnie z modelem OLAP, jest sterowana całkowicie przez użytkownika. Użytkownik formułuje zapytania i dokonuje analizy danych zawartych w magazynie. Z tego punktu widzenia, OLAP można interpretować jako rozszerzenie standardu SQL o możliwość efektywnego przetwarzania złożonych zapytań zawierających agregaty. Niestety, analiza porównawcza zagregowanych danych, która jest podstawą modelu OLAP, operuje na zbyt szczegółowym poziomie abstrakcji i nie pozwala na formułowanie bardziej ogólnych zapytań.
Zapytania eksploracyjne

Jak już wspomnieliśmy zapytania eksploracyjne mają charakter znacznie bardziej ogólny i znacznie bardziej abstrakcyjny. Oto kilka przykładów zapytań eksploracyjnych:
Jakie inne jeszcze produkty, najczęściej, kupują klienci, którzy kupują wino?
Czym różnią się koszyki klientów kupujących wino i piwo?
W jaki sposób można scharakteryzować klientów kupujących wino?
Czy można dokonać predykcji, że dany klient kupi wino?
Jakie produkty kupują klienci supermarketu najczęściej wraz z winem?
Jakie oddziały supermarketu miały 'anormalną' sprzedaż w pierwszym kwartale 2004 r.?
Czy można przewidzieć przyszłe zachowania klientów?
Czy istnieje korelacja pomiędzy lokalizacją oddziału supermarketu a asortymentem produktów, których sprzedaż jest wyższa od średniej sprzedaży produktów?
Zapytań takich nie moglibyśmy zrealizować przy pomocy SQL czy nawet jego rozszerzeń w postaci zapytań analitycznych.

Zapytania eksploracyjne możemy definiować nie tylko w odniesieniu do danych pochodzących ze sprzedaży, ale niemalże w każdej dziedzinie życia. Weźmy pod uwagę zbiór danych opisujących pacjentów szpitala. W oparciu o ten zbiór danych możemy sformułować szereg zapytań eksploracyjnych np.: ‘Czy będziemy potrafili poprawnie zdiagnozować pacjenta?’, ‘Czy na podstawie określonych przesłanek (symptomów choroby) będziemy potrafili określić wystąpienie choroby?’, ’Przewidzieć poprawnie wynik terapii, określić jakie czynniki mogą wpłynąć na powikłania w procesie leczenia?’ czy też zaproponować najlepszą z możliwych terapię.
Czym jest eksploracja danych?

Kontynuując rozważania nad tym ‘czym jest eksploracja danych?’, możemy podać alternatywne określenia technologii eksploracji danych. Najpopularniejszą alternatywną definicją jest definicja, że eksploracja danych to odkrywanie wiedzy w bazach danych KDD (Knowledge Discovery in Databases). Powstała również specjalna sekcja w ramach stowarzyszenia ACM poświęcona temu zagadnieniu - SIGKDD (Special Interest Group On Knowledge Discovery and Data Mining).

W początkowym okresie rozwoju eksploracji danych (data mining) powstało wiele alternatywnych „ciekawych” określeń np. archeologia danych, kopanie czy też drążenie w danych, eksploatacja złóż danych i wiele innych.
Rozważając czym jest eksploracja danych należy się również zastanowić czym ona nie jest. Czasami jest błędnie utożsamiana z systemami eksperckimi czy też analizą OLAP (Online Analytical Processing). Analiza danych sterowana zapytaniami (OLAP) zakłada, że użytkownik, po pierwsze, posiada pełną wiedzę o przedmiocie analizy, i, po drugie, potrafi sterować tym procesem. Eksploracja danych umożliwia analizę danych dla problemów, które, ze względu na swój rozmiar, są trudne do przeprowadzenia przez użytkownika, oraz tych problemów, dla których nie dysponujemy pełną wiedzą o przedmiocie analizy, co uniemożliwia sterowanie procesem analizy danych.

Powtórzmy definicję eksploracji danych, najogólniej mówiąc
Eksploracja danych (ang. Data Mining) jest to zbiór technik automatycznego odkrywania nietrywialnych zależności, schematów, wzorców, reguł (ang.patterns) w dużych zbiorach danych (bazach danych, hurtowniach danych).
Proces odkrywania wiedzy

Termin 'eksploracja danych' jest często używany jako synonim terminu 'odkrywanie wiedzy' w bazach i magazynach danych. W istocie należy rozróżnić dwa pojęcia: odkrywanie wiedzy i eksploracja danych. Zgodnie z definicją, termin 'odkrywanie wiedzy' ma charakter ogólniejszy i odnosi się do całego procesu odkrywania wiedzy, który stanowi zbiór kroków transformujących zbiór danych 'surowych' w zbiór wzorców, które mogą być, następnie, wykorzystane w procesie wspomagania podejmowania decyzji. W procesie odkrywania wiedzy wyróżniamy następujące etapy: etap pierwszy to etap
zapoznania się z wiedzą dziedzinową aplikacji (aktualna wiedza i cele aplikacji);
Integracja danych (ang. data integration) -- celem etapu jest integracja danych z różnych heterogenicznych i rozproszonych źródeł danych w jeden zintegrowany zbiór danych; Etapem trzecim jest etap
selekcji danych (ang. data selection) -- celem etapu jest selekcja danych istotnych z punktu widzenia procesu analizy danych;

Kolejnym etapem procesu odkrywania wiedzy jest
etap czyszczenia danych (ang. data cleaning) - celem etapu jest usunięcie niepełnych, niepoprawnych lub nieistotnych danych ze zbioru eksplorowanych danych; Kolejny etap to etap
konsolidacja i transformacja danych (ang. data transformation, data consolidation) - celem etapu jest transformacja wyselekcjonowanych danych do postaci wymaganej przez metody eksploracji danych; Następny krok to
wybór metody lub metod eksploracji danych, która zostanie wykorzystana w procesie pozyskiwania wiedzy;
Wybór algorytmów – wybór konkretnych algorytmów rozwiązujących dany problem; Etap
Eksploracji danych (ang. data mining) odkrywa potencjalnie użytecznych wzorców ze zbioru wyselekcjonowanych danych.
Ocena wzorców (ang. pattern evaluation - celem etapu jest ocena i identyfikacja interesujących wzorców.
Wizualizacja wzorców (ang. knowledge representation) - celem etapu jest wizualizacja otrzymanych interesujących wzorców w taki sposób, aby umożliwić użytkownikowi interpretację i zrozumienie otrzymanych w wyniku eksploracji wzorców, reguł, skupień itp. Wykorzystanie pozyskanej wiedzy i wdrożenie jej w życie. Najczęściej, niektóre etapy procesu odkrywania wiedzy są wykonywane łącznie. Przykładowo, etapy czyszczenia danych oraz integracji danych stanowią integralną część budowy hurtowni danych, natomiast etapy selekcji danych oraz transformacji i konsolidacji danych mogą być zrealizowane poprzez zbiór zapytań. Wzorce odkryte na etapie eksploracji danych są prezentowane użytkownikowi, ale mogą być zapamiętane w bazie danych lub hurtowni danych dla dalszej eksploracji.
Mieszanka wielu dyscyplin

Eksploracja danych jest dziedziną informatyki, która integruje szereg dyscyplin badawczych, takich jak: systemy baz danych i hurtownie danych, statystyka, sztuczna inteligencja, obliczenia równoległe, optymalizacja i wizualizacja obliczeń. Powyższa lista dyscyplin nie jest pełna. Eksploracja danych wykorzystuje również szeroko techniki i metody opracowane na gruncie systemów wyszukiwania informacji, analizy danych przestrzennych, rozpoznawania obrazów, przetwarzania sygnałów, technologii Web, grafiki komputerowej, bioinformatyki. Różnorodność i wielość metod eksploracji danych, wywodzących się często z różnych dyscyplin badawczych, utrudnia potencjalnym użytkownikom identyfikację metod, które są najodpowiedniejsze z punktu widzenia ich potrzeb w zakresie analizy danych.
Co można eksplorować?

Można postawić trywialne pytanie ‘Co można eksplorować?’. Odpowiedź jest równie trywialna jak pytanie, eksplorować możemy dowolny zbiór danych w postaci relacyjnych baz danych, hurtowni danych, repozytorium danych czy innych zaawansowanych systemów informatycznych w postaci obiektowych czy obiektowo-relacyjnych baz danych, przestrzennych baz danych, przebiegów czasowych i temporalnych baz danych, WWW, i innych. Najważniejszy jest odpowiedni dobór metody eksploracji do analizowanego zbioru informacji.
Metody eksploracji danych

Metody eksploracji danych, ze względu na cel eksploracji i typy wzorców odkrywanych w procesie eksploracji danych, można podzielić, bardzo ogólnie, na 7 zasadniczych klas:
Odkrywanie asocjacji - najszersza klasa metod obejmująca, najogólniej, metody odkrywania interesujących zależności lub korelacji, nazywanych ogólnie asocjacjami, pomiędzy danymi w dużych zbiorach danych. Wynikiem działania metod odkrywania asocjacji są zbiory reguł asocjacyjnych lub wzorców sekwencji opisujących znalezione zależności i/lub korelacje. Klasyfikacja i predykcja - obejmuje metody odkrywania modeli (tak zwanych klasyfikatorów) lub funkcji opisujących zależności pomiędzy zadaną klasyfikacją obiektów a ich charakterystyką. Odkryte modele klasyfikacji są, następnie, wykorzystywane do klasyfikacji nowych obiektów o nieznanej klasyfikacji. Grupowanie (analiza skupień, klastrowanie) - obejmuje metody analizy danych i znajdowania skończonych zbiorów klas obiektów posiadających podobne cechy. Wykrywanie punktów osobliwych - obejmuje metody wykrywania (znajdowania) obiektów osobliwych, które odbiegają od ogólnego modelu danych (klasyfikacja i predykcja) lub modeli klas (analiza skupień). Często, metody wykrywania punktów osobliwych stanowią integralną część innych metod eksploracji danych, na przykład, metod grupowania. Analiza przebiegów czasowych - obejmuje metody analizy przebiegów czasowych w celu znalezienia: trendów, podobieństw, anomalii oraz cykli. Opisy koncepcji/klas - obejmuje metody znajdowania zwięzłych opisów lub podsumowań ogólnych własności klas obiektów. Znajdowane opisy mogą mieć postać reguł charakteryzujących lub reguł dyskryminacyjnych. W tym drugim przypadku, opisują różnice pomiędzy ogólnymi własnościami tak zwanej klasy docelowej (klasy analizowanej) a własnościami tak zwanej klasy (zbioru klas) kontrastującej (klasy porównywanej). Analiza trendów i odchyleń - obejmuje metody analizy danych zmiennych w czasie w celu znalezienia różnic pomiędzy aktualnymi a oczekiwanymi wartościami danych, anomalnych zmian wartości danych w czasie, itp. Eksplorację tekstu oraz Eksplorację WWW .
Metody eksploracji: klasyfikacja
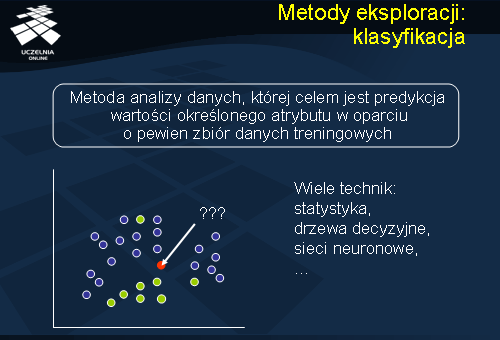
Przejdziemy obecnie do omówienia niektórych wybranych metod eksploracji danych. Rozpoczniemy od krótkiego omówienia metody klasyfikacji. Klasyfikacja jest metodą analizy danych, której celem jest predykcja wartości określonego atrybutu w oparciu o pewien zbiór danych treningowych. Obejmuje metody odkrywania modeli (tak zwanych klasyfikatorów) lub funkcji opisujących zależności pomiędzy zadaną klasyfikacją obiektów a ich charakterystyką. Odkryte modele klasyfikacji są, następnie, wykorzystywane do klasyfikacji nowych obiektów o nieznanej klasyfikacji.
Metody eksploracji: grupowanie
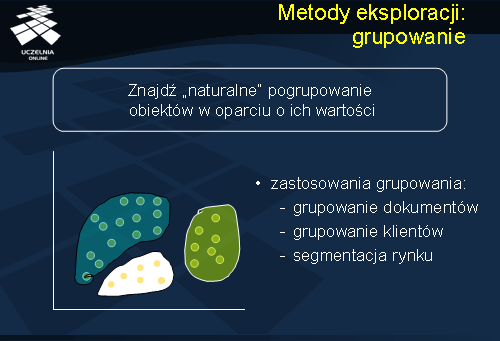
Kolejną metodą jest grupowanie (klastrowanie) - obejmuje metody analizy danych i znajdowania skończonych zbiorów klas obiektów posiadających podobne cechy. W przeciwieństwie do metod klasyfikacji i predykcji, klasyfikacja obiektów (podział na klasy) nie jest znana a-priori, lecz jest celem metod grupowania. Metody te grupują obiekty w klasy w taki sposób, aby maksymalizować podobieństwo wewnątrzklasowe obiektów i minimalizować podobieństwo pomiędzy klasami obiektów. Grupowanie znalazło szereg zastosowań w różnych dziedzinach życia np. grupowanie dokumentów, grupowanie klientów czy określenia segmentacji rynku.
Metody eksploracji: odkrywanie asocjacji

Kolejną metoda eksploracji danych jest odkrywanie asocjacji. Odkrywanie asocjacji jest jedną z najciekawszych i najbardziej popularnych technik eksploracji danych. Celem procesu odkrywania asocjacji jest znalezienie interesujących zależności lub korelacji, nazywanych ogólnie asocjacjami, pomiędzy danymi w dużych zbiorach danych. Wynikiem procesu odkrywania asocjacji jest zbiór reguł asocjacyjnych opisujących znalezione zależności lub korelacje między danymi. Sztandarowym przykładem reguły asocjacyjnej jest reguła wygenerowana w odniesieniu do bazy danych supermarketu: „klienci, którzy kupują pieluszki, kupują również piwo”. Celem tej analizy jest znalezienie naturalnych wzorców zachowań konsumenckich klientów poprzez analizę produktów, które są przez klientów supermarketu kupowane najczęściej wspólnie np.: „klienci, którzy kupują chleb, masło i ser, kupują również wodę mineralną i ketchup”.

W odniesieniu do reguł asocjacyjnych znalezionych w bazie supermarketu reguły te można wykorzystać przykładowo do opracowania akcji promocyjnych, programów lojalnościowych, planowaniu kampanii promocyjnych, planowanie rozmieszczeń stoisk sprzedaży w supermarketach, opracowania koncepcji katalogu oferowanych produktów i wiele innych.
Metody eksploracji: odkrywanie wzorców sekwencji

Kolejną metodą eksploracji danych jest problem odkrywania wzorców sekwencji polega, najogólniej mówiąc, na analizie bazy danych zawierającej informacje o zdarzeniach, które wystąpiły w określonym przedziale czasu, w celu znalezienia zależności pomiędzy występowaniem określonych zdarzeń w czasie. Przykładem wzorca sekwencji, który można znaleźć w bazie danych wypożyczalni filmów video, jest następujący wzorzec zachowania klientów wypożyczalni: ‘Klient, który wypożyczył tydzień temu film pod tytułem Gwiezdne wojny, w ciągu tygodnia wypożyczy film pt.Imperium kontratakuje, a następnie, w ciągu kolejnego tygodnia, wypożyczy film pt. Powrót Jedi'. Zauważmy, że zdarzenia wchodzące w skład wzorca sekwencji nie muszą występować bezpośrednio jedno po drugim - mogą być przedzielone wystąpieniem innych zdarzeń. W odniesieniu do przedstawionego powyżej wzorca sekwencji, oznacza to, że klient, pomiędzy wypożyczeniem filmu pt. Imperium kontratakuje a Powrót Jedi, wypożycza zwykle jeszcze inny film, ale podana sekwencja opisuje typowe zachowanie większości klientów wypożyczalni.
Innym przykładem może być kurs akcji BPH, który podczas ostatnich trzech sesji wzrósł o 0.5%, 0.9%, 0.1%, na następnej sesji spadnie o 0.5%. Również w nawiązaniu do koszyka zakupów, jeżeli do współwystępowania produktów dołożymy element czasowy będziemy mieli do czynienia z problemem odkrywania wzorców sekwencji następującej postaci. „klienci, którzy kupili farbę emulsyjną, kupią w najbliższym czasie pędzel płaski, a jeszcze później rozpuszczalnik’.

Metoda odkrywania wzorców sekwencji znalazła zastosowanie w wielu dziedzinach: analiza koszyka zakupów, telekomunikacja, medycyna (znajdowanie skutecznej terapii), ubezpieczenia i bankowość, planowanie inwestycji giełdowych, przewidywanie sprzedaży, WWW, itd. W przypadku analizy koszyka zakupów, metodę odkrywania wzorców sekwencji stosuje się w celu znalezienia typowych wzorców zachowań klientów w czasie. Dotyczy to handlu hurtowego lub półhurtowego, gdy potrafimy zidentyfikować pojedynczego klienta i jego koszyk zakupów. W takim przypadku, z każdym rekordem opisującym zakupy pojedynczego klienta jest związana, dodatkowo, informacja o kliencie (identyfikator klienta) i o dacie zakupów (etykieta czasowa rekordu). Na podstawie danych opisujących zakupy danego klienta, uporządkowanych zgodnie z wartościami etykiet czasowych można uzyskać profil klienta i próbować przewidzieć jego zachowanie w czasie.
Metody eksploracji: odkrywanie charakterystyki

Kolejną metodą eksploracji danych jest odkrywanie charakterystyk. Metoda ta polega na znajdowaniu zwięzłych opisów (charakterystyk) podanego zbioru danych, czy też znajdowaniu zależności funkcyjnych pomiędzy zmiennymi opisującymi zbiór danych. Przykładem wykorzystania odkrywania charakterystyk może być opis pacjentów chorujących na anginę. Celem jest określanie powszechnych symptomów wskazanej choroby, czyli w przypadku anginy możemy podać następującą charakterystykę ‘pacjenci chorujący na anginę cechują się temperaturą ciała większą niż 37.5C, bólem gardła i osłabieniem organizmu’.
Podobnie jak inne metody, odkrywanie charakterystyk znalazło zastosowanie w różnych dziedzinach życia. Przykładowo może to być znajdowanie zależności funkcyjnych pomiędzy zmiennymi, określanie profilu klienta, czyli jego zbiór cech charakterystycznych, czy też znajdowanie charakterystyki pacjenta związanego z odpowiednią terapią itd.
Problemy odkrywania wiedzy

Z odkrywaniem wiedzy wiążą się niestety również problemy. W dużych bazach danych czy też hurtowniach danych mogą zostać odkryte tysiące reguł, a ich analiza jest bardzo czasochłonna często niemożliwa do realizacji w rozsądnym czasie. Dochodzi do tego czynnik ludzki, człowiek nie potrafi zrozumieć i przeanalizować dużych zbiorów informacji. Specyficzne wymagania użytkowników, różni użytkownicy systemu bazy danych są zainteresowani różnymi typami reguł z różnych relacji. Wreszcie problemy efektywnościowe - odkrywanie reguł jest procesem bardzo złożonym obliczeniowo i wymaga dużego nakładu pracy.
Dziedziny zastosowań

Eksploracja znalazła zastosowanie niemalże w każdej dziedzinie życia.
W świecie nauki: odkrywanie nowych obiektów (astronomia), bioinformatyka, przemysł farmaceutyczny, …
W świecie biznesu: reklama, CRM (Customer Relationship Management), inwestycje, finanse, ubezpieczenia, telekomunikacja, …
Web: Przeglądarki (Google), handel elektroniczny – Amazon, eBay, Allegro
Administracja: wykrywanie przestępstw, wykrywanie nadużyć podatkowych, etc.
Handel i marketing: identyfikacja „profilu klienta” dla przewidywania, którzy klienci odpowiedzą na marketing korespondencyjny, wykrywanie schematów zakupów i planowanie lokalizacji artykułów.
Finanse i bankowość: identyfikacja schematów wykorzystywania np. kradzionych kart kredytowych
przewidywanie dochodowości portfela akcji, znajdowanie korelacji wśród wskaźników finansowych.
Telekomunikacja: wykrywanie schematów alarmowych w sieciach telekomunikacyjnych.
Medycy do oceny tarapii itd
Uwagi końcowe
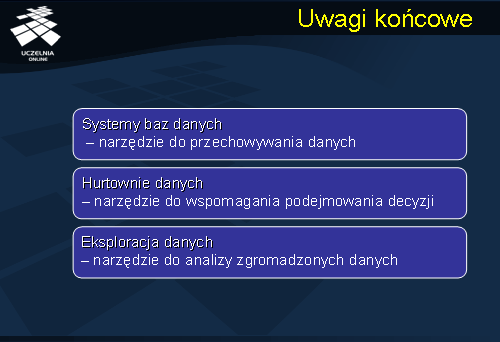
Na zakończenie możemy usystematyzować pojęcia - narzędzia przechowywania i przetwarzania danych. Podstawowym narzędziem do przechowywania i wyszukiwania danych są Systemy baz danych. Następnym poziomem abstrakcji są systemy Hurtowni danych – są to zarówno narzędzia do przechowywania danych, ale również do analizy danych w szczególności analizy porównawczej są to głównie narzędzie do budowy aplikacji wspomagania podejmowania decyzji. Wreszcie Eksploracja danych, która jest zbiorem narzędzi do analizy zgromadzonych danych, jej celem jest również opracowanie zaleceń służących wspomaganiu podejmowania decyzji.







