
Taksonomie• wprowadzanie i wyprowadzanie danych może być realizowane w postaci odpowiedniej dla człowieka (klawiatura, ekran) lub właściwej dla współpracy z jakimś obiektem (np. czujnik temperatury grzejnik)
• podział na kategorie• określanie własności
• prosta• ma znaczenie historyczne - należy ją znać
• ilustruje strukturę komputera• stosunkowo mało znana, ale przyda się do wyjaśnienia kilku istotnych elementów podczas kursu

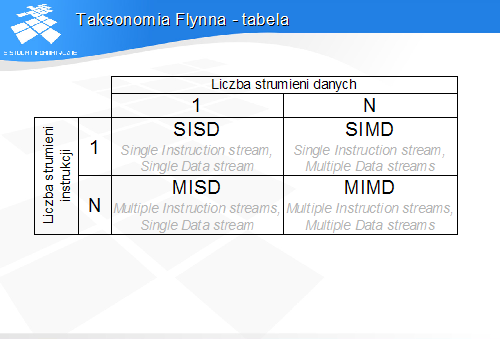

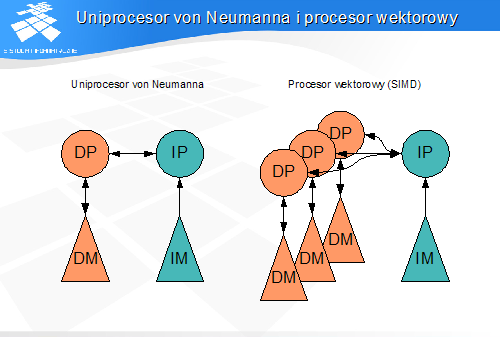
• pojedynczy strumień instrukcji i danych• przykład: uniprocesor von Neumanna• najbardziej rozpowszechniony typ architektury
• jeden strumień instrukcji, wiele strumieni danych• jedna instrukcja powoduje wykonanie tej samej operacji na wielu kompletach danych• przykład: procesor wektorowy lub macierzowy
• nie bardzo wiadomo, co to jest (procesor potokowy?)
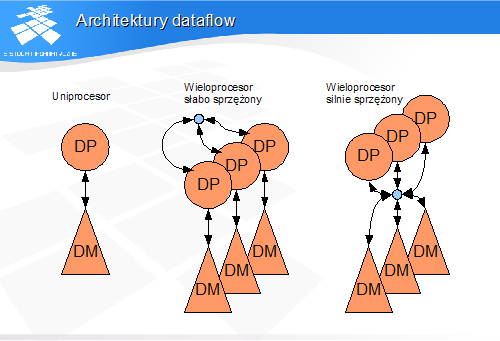
• przykład: wieloprocesor. wielokomputer
Klasa MISD jest dość problematyczna – trudno wskazać wzorcowego reprezentanta tego typu. Można przyjąć, że założenia MISD w pewnym sensie realizują maszyny potokowe, np. procesory graficzne.
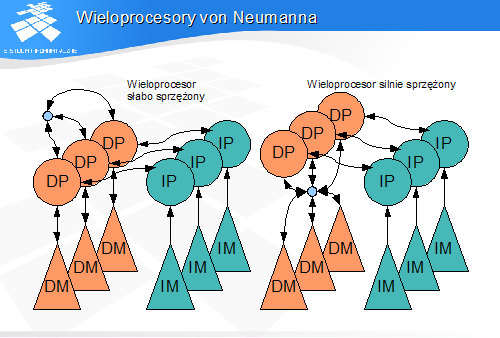
Do klasy MIMD należą tzw. wieloprocesory lub wielokomputery von Neumanna, czyli maszyny złożone z wielu połączonych uniprocesorów von Neumanna.
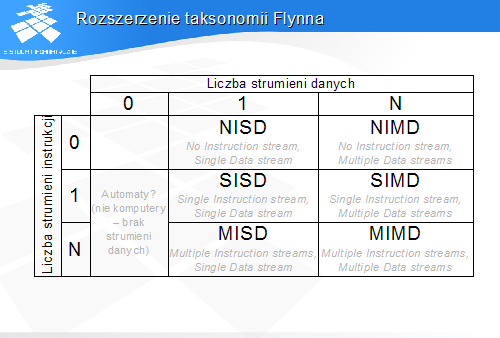

• komputer musi przetwarzać dane
• same dane mogą nieść informacje o potrzebnym przetwarzaniu• są to tzw. maszyny sterowane przepływam danych (dataflow)

• zawiera dane oraz "metkę" (tag), opisującą zawartość• metka jest odpowiednikiem instrukcji, opisującej, co należy zrobić z danymi
• ok. 1985 roku firma NEC produkowała mikroprocesor dataflow
• nie ma to nic wspólnego ze sprzętem komputerowym
Komputer sterowany przepływem danych nie ma jawnych instrukcji. Operuje on na tzw. „tokenach”, czyli obiektach złożonych z danych i opisujących je znaczników – metek.
Metka zastępuje instrukcję. Na podstawie metki procesor sterowany przepływem danych przekształca cały token- zarówno dane jak i metkę, tworząc nowy token.
O ile maszyny dataflow nie są współcześnie konstruowane, to samo podejście dtaflow jest używane do opisu procesów informacyjnych.
Taksonomia Flynna - podsumowanie

• tutaj przedstawimy tylko jeden

• Procesory instrukcji (IP) - pobierają i analizują instrukcje• Procesory danych (DP) - wykonują operacje na danych• Hierarchie pamięci instrukcji (IM) - przechowują instrukcje• Hierarchie pamięci danych (DM) - przechowują dane - argumenty operacji i wyniki
• nawet jeśli w rzeczywistej strukturze komputera jest inaczej
W modelach architektur przyjmuje się, że liczba hierarchii pamięci jest równa liczbie procesorów danego typu. Oznacza to, że model architektury ze wspólną hierarchią pamięci dla kilku procesorów jest przedstawiany jako model z kilkoma hierarchiami pamięci i możliwością dostępu każdego procesora do każdej hierarchii pamięci.

• Procesory z hierarchiami pamięci• Procesory instrukcji z procesorami danych• Procesory jednego rodzaju pomiędzy sobą
• 1 - 1• 1 - N• N - N ("każdy ze swoim", czyli N połączeń 1 - 1)• N x N ("każdy z każdym")

Rysunek przedstawia prosty model w taksonomii Skillicorna (jest to model uniprocesora von Neumanna). Procesory są oznaczone symbolicznie kołami, a hierarchie pamięci – trójkątami. Strzałki reprezentują połączenia i kierunki przesyłania informacji.
Strzałki pionowe z prawej strony procesorów i hierarchii pamięci reprezentują żądania dostępów, a strzałki po prawej stronie – przepływ instrukcji i danych. Na kolejnych rysunkach podwójne strzałki zostaną zastąpione pojedynczymi, reprezentującymi kierunki przepływu danych i instrukcji, z pominięciem żądań dostępu.

• Procesor przesyła do hierarchii pamięci żądania pobrania instrukcji• Hierarchia pamięci instrukcji zwraca instrukcje
• procesor instrukcji przesyła instrukcje w postaci zrozumiałej dla procesora danych• procesor danych zwraca informacje o stanie przetwarzania oraz informacje dotyczące przebiegu wykonania programu
• procesor przesyła żądania odczytu i zapisu danych• hierarchia pamięci przesyła dane - argumenty operacji
Procesor instrukcji przesyła do hierarchii pamięci instrukcji żądanie pobrania instrukcji. W odpowiedzi otrzymuje instrukcje. instrukcje przesyłane są po zdekodowaniu do procesora danych, który wykonuje operacje na danych.
Procesor danych przesyła do hierarchii pamięci żądania operacji odczytu i zapisu. Dane pomiędzy procesorem danych i hierarchią pamięci danych przesyłane są w dwóch kierunkach (strzałka po prawej stronie).
Procesor danych przesyła do procesora instrukcji informacje o stanie przetwarzania, umożliwiające procesorowi instrukcji decydowanie o dalszym przebiegu wykonania programu w zależności od wyników przetwarzania danych.
Modele w taksonomii Skillicoma

• uniprocesor dataflow• wieloprocesor dataflow• uniprocesor von Neumanna (SISD)• procesor wektorowy (SIMD)• wieloprocesor słabo sprzężony (MIMD)• wieloprocesor silnie sprzężony (MIMD)
• ma sens tylko dla procesorów danych• słabe - przez kanał komunikacji pomiędzy procesorami• silne - poprzez wzajemny dostęp do hierarchii pamięci (praktycznie wspólna hierarchia pamięci)

• kolejne warstwy mają coraz większe pojemności i czasy dostępu
Taksonomia Skillicorna posługuje się pojęciem hierarchii pamięci w miejsce dużo bardziej popularnego pojęcia pamięci. Słowo „hierarchia” dobrze oddaje budowę pamięci współczesnego komputera, w którym znajduje się kilka bloków funkcjonalnych służących do przechowywania programów i danych.
Idealny komputer powinien mieć jak największą i jak najszybszą pamięć. Pojemność pamięci wpływa na jej fizyczne rozmiary, a te – na czas dostępu. Nie można więc zbudować dowolnie dużej i jednocześnie szybkiej pamięci.
Problem ten rozwiązuje się przez wyodrębnienie wielu warstw o zróżnicowanej pojemności i szybkości, tworzących razem hierarchię pamięci. Kolejne warstwa w miarę oddalania się od procesora mają coraz większe pojemności i coraz dłuższe czasy dostępu.

Rejestry fizycznie znajdują się wewnątrz procesora, dzięki czemu dostęp do nich jest bardzo szybki.
Kieszenie, wprowadzone po raz pierwszy około 1968 roku, zapewniają buforowania danych pomiędzy procesorem i pamięcią operacyjną w celu przyspieszenie dostępu do pamięci.
Warstwa pamięci wirtualnej, powstała również około 1968 roku, zapewnia rozszerzenie pamięci operacyjnej.
Z punktu widzenia użytkownika do hierarchii pamięci należy zaliczyć wszelkie zasoby służące przechowywaniu danych. Logiczne staje się więc uzupełnienie rysunku o lokalny system plików komputera oraz o zasoby zdalne, w postaci nośników wymiennych i serwerów sieciowych.
Sterowanie hierarchią pamięci
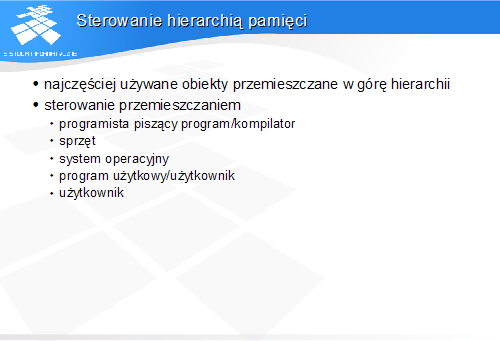
• programista piszący program/kompilator• sprzęt• system operacyjny• program użytkowy/użytkownik• użytkownik
O ile zasada działania hierarchii pamięci dotyczy wszystkich warstw, to mechanizmy sterujące przemieszczaniem danych pomiędzy poszczególnymi warstwami są różne.
O umieszczeniu danych w rejestrach decyduje programista piszący program w języku asemblerowym lub kompilator języka wysokiego poziomu.
Styk warstwy kieszeni i pamięci operacyjnej jest sterowany na poziomie sprzętu. Stykiem pamięci operacyjnej i wirtualnej steruje system operacyjny przy użyciu jednostki zarządzania pamięcią.
O umieszczeniu danych w pamięci wirtualnej decyduje użytkownik – otwierając plik danych lub uruchamiając program.
Przemieszczaniem danych pomiędzy lokalnym systemem plików i nośnikami wymiennymi lub zasobami sieciowymi steruje użytkownik.


• dostęp do pamięci następuje poprzez podanie przez procesor numeru komórki• numer komórki nazywamy ADRESEM
• zazwyczaj komputer będzie pobierał kolejne instrukcje programu z kolejnych komórek pamięci• komórki te będą wybierane przez zwiększający się adres, który powinien być przechowywany i inkrementowany w procesorze• adres ten jest przechowywany w specjalnym rejestrze - tzw. liczniku instrukcji (Program Counter - PC)
Architektura von Neumanna jest określona przez zestaw cech. Model maszyny von Neumanna wprowadza specyficzny mechanizm dostępu do pamięci – poprzez adres.
Z takiej organizacji pamięci i z faktu przechowywania w niej programu wynika z kolei obecność rejestru licznika instrukcji.
Warianty organizacji hierarchii pamięci w realizacjach maszyn von Neumanna

• nie będą to modele Skillicorna!!!
Kolejne rysunki posługują się symbolami zapożyczonymi z taksonomii Skillicorna w sposób sprzeczny z zasadami budowy modeli wprowadzonymi przez tę taksonomię.
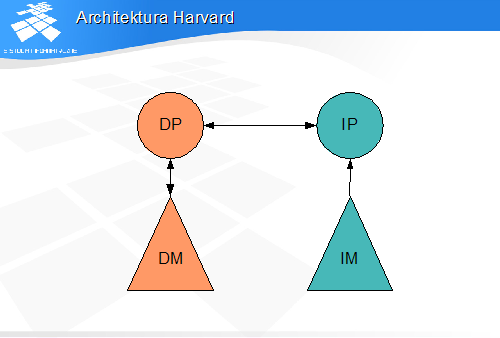

• często uznawana za architekturę nie-vonneumannowską ze względu na dyskusyjność zachowania postulatu o jednakowym składowaniu instrukcji i danych
• czyli brak możliwości programowania• komputer dostarczany ze stałym programem• dopuszczalne tylko w zastosowaniach wbudowanych
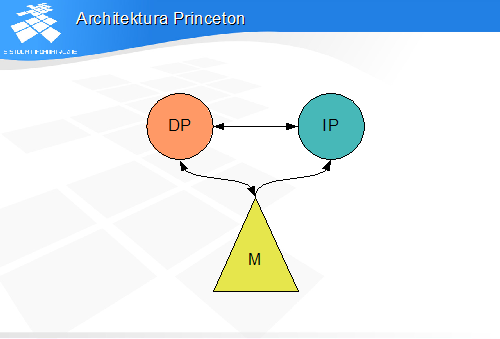

• tzw. von Neumann bottleneck
• obiekt zapisany przez procesor danych do hierarchii pamięci jako dany może być następnie pobrany przez procesor instrukcji jako instrukcja• możliwość programowania - potrzebna w komputerach uniwersalnych• program może sam siebie modyfikować (automodyfikacja)
- nie zawsze jest to pożądana cecha
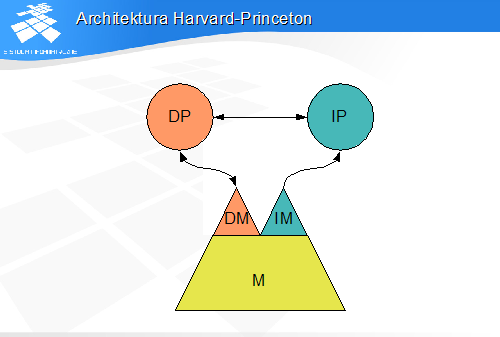

• szybkie działanie dzięki równoległości dostępów jak w architekturze Harvard
• programowalność - niezbędna w komputerach uniwersalnych

• brak możliwości automodyfikacji
• jeden program (proces) może modyfikować drugi• możliwość ładowania programu np. z pliku
• automodyfikacja jest niebezpieczna
• w tym wszystkie współczesne komputery PC