Pokazane zostanie odwzorowanie obiektów występujących w programie w obiekty obecne w pamięci podczas wykonania programu.
Następnie zbudujemy model programowy prostego procesora, nadający się do implementacji podstawowych mechanizmów języka wysokiego poziomu.
Na końcu zostanie pokazane przejście od modelu przykładowego procesora do rzeczywistego modelu programowego procesorów rodziny x86.
Języki wysokiego poziomu

Wkrótce po upowszechnieniu komputerów ustabilizowały się metody ich programowania. Obecnie powszechnie używa się języków wysokiego poziomu - proceduralnych i obiektowych. Współczesne komputery są budowane z myślą o programowaniu ich w takich właśnie językach, a ich struktura logiczna jest zaprojektowana tak, aby mogły one łatwo i wydajnie wykonywać programy powstałe przez translację zapisu algorytmów w językach wysokiego poziomu.
Pomimo odrębnych paradygmatów programowania, języki obiektowe od strony implementacji nie różnią się znacząco od języków proceduralnych. Możny przyjąć, że komputer, który daje się efektywnie programować w języku C będzie podobnie skutecznie wykonywał programy napisane w innych podobnych językach proceduralnych i obiektowych, takich jak np. Pascal, C++ czy Java.
Program w języku wysokiego poziomu

Przykładowy program w języku C zawiera podstawowe obiekty i mechanizmy występujące w typowych programach.
Główna procedura programu wywołuje inne procedury, przekazując do nich argumenty i odbierając wartości.
W programie występują dane o różnym zasięku i czasie życia: zmienne zewnętrzne x, y i p; zmienne lokalne i argumenty procedur ora zmienna wskazywana przez zmienną wskaźnikową p.

Poszczególne rodzaje obiektów – instrukcje i dane – będą odwzorowane w odrębne sekcje, czyli klasy pamięci.
Wywoływanie procedur wymaga zrealizowania mechanizmów przekazywania argumentów, przekazywania i zwracania sterowania oraz zwracania wartości funkcji.

Klasa kodu będzie zawierała instrukcje tworzące program.
Klasa danych statycznych zawiera dane zadeklarowane na poziomie zewnętrznym.
Klasa danych automatycznych zawiera argumenty wywołania i zmienne lokalne procedur.
Klasa danych kontrolowanych zawiera dane dynamiczne jawnie tworzone i usuwane przez programistę.
Kod (sekcja TEXT)

Kodu programu w postaci ciągów instrukcji jest odwzorowany w sekcję kodu, występującą często pod nazwą TEXT.
Sekcja ta nie zmienia swoich rozmiarów ani zawartości przez cały czas wykonywania programu. Jest ona tworzona przed rozpoczęciem wykonywania programu, a niszczona po jego zakończeniu. Z punktu widzenia wykonywanego programu „żyje” ona ciągle, a więc jest statyczna.
Oprócz samych instrukcji sekcja może zawierać stałe niezbędne do działania programu, w tym m.in. adresy ciągów instrukcji odpowiedzialnych za poszczególne ścieżki instrukcji złożonych typu switch oraz stałe (literały) występujące w programie, które nie mogą być zapisane bezpośrednio jako argumenty natychmiastowe.
Dane statystyczne (STATIC)

Sekcja danych statycznych, podobnie jak sekcja kodu, ma stały rozmiar i istnieje przez cały czas wykonania programu. W sekcji tej mogą jednak występować obiekty o różnych dozwolonych rodzajach dostępu i odmiennych sposobach inicjowania. Wygodnie jest podzielić sekcję danych statycznych na trzy „podsekcje” o różnych atrybutach.



Kolejność rozmieszczenia sekcji w przestrzeni adresowej oraz wartości ich adresów początkowych zależy od decyzji projektanta systemu operacyjnego. Adresy bliskie zera pozostają wolne, a dostęp do nich nie jest dozwolony. Dzięki temu próby odwołań przy użyciu niezainicjowanych zmiennych wskaźnikowych lub wskaźników o wartości NULL (zwykle równej 0) są wychwytywane i sygnalizowane jako błędy wykonania.
Poszczególne sekcje ne muszą sąsiadować ze sobą w przestrzeni adresowej. Przestrzeń adresowa – to tylko zbiór adresów,a adresy nie muszą być odwzorowane w fizyczne lokacje pamięci, stąd puste obszary przestrzeni adresowej pomiędzy sekcjami nie zajmują pamięci komputera.
Licznik instrukcji (PC - program counter)

Z cech maszyny von Neumanna wynika pośrednio obecność w procesorze rejestru, służącego do wskazywania kolejnych wykonywanych instrukcji. Ponieważ zawartość tego rejestru jest inkrementowana po pobraniu każdej instrukcji, rejestr ten nosi nazwę licznika instrukcji.
Podczas wykonywania instrukcji rejestr PC wskazuje następną instrukcję po aktualnie wykonywanej. Taka wartość PC jest określana jako nextPC (PC następnej instrukcji).
Podczas wykonywania instrukcji skoku do rejestru licznika instrukcji jest ładowana nowa wartość.
Procedury - wywołanie i powrót
Procesor przystosowany do wykonywania programu napisanego w języku wysokiego poziomu musi umożliwiać łatwą implementację przekazywania sterowania pomiędzy procedurami. W tym celu potrzebne są dwie instrukcje – skoku ze śladem i powrotu według śladu.
Instrukcja skoku ze śladem wykonuje skok po uprzednim zapamiętaniu wartości rejestru PC. Podczas wykonywania instrukcji skoku ze śladem PC wskazuje następną instrukcję po instrukcji skoku, i taka właśnie wartość PC podlega zapamiętaniu. Instrukcja skoku ze śladem służy do przekazania sterowania do procedury (wywołania procedury).
Instrukcja powrotu według śladu jest instrukcją skoku, której adres docelowy jest uprzednio zapamiętany m adresem śladu wywołania, czyli adresem wskazującym następną instrukcję po ostatnio wykonanej instrukcji skoku ze śladem.
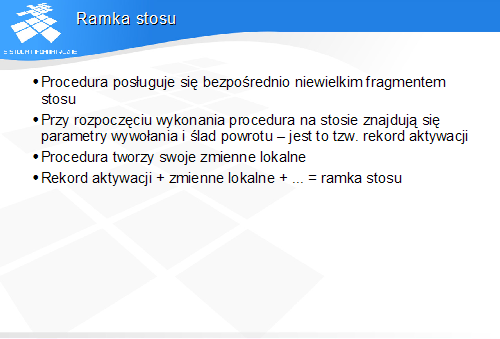
Stos

Pierwszy model procesora zawiera minimum mechanizmów niezbędnych do wykonania zaprezentowanego wcześniej programu w języku C. Modelowy procesor jest wyposażony w rejestr licznika instrukcji oraz rejestr przechowujący wynik obliczeń, służący jednocześnie jako rejestr argumentu źródłowego. Rejestr taki jest nazywany akumulatorem.
Model procesora obsługuje stos i realizuje podstawowe operacje na stosie, jednak implementacja stosu pozostaje nieokreślona.
Procesor wykonuje dostępy do danych wyspecyfikowanych przez podanie nazw lub wartości. Oczywiście ten aspekt modelu jest wysoce nierealistyczny i ma charakter tymczasowy.
Model procesora I - instrukcje
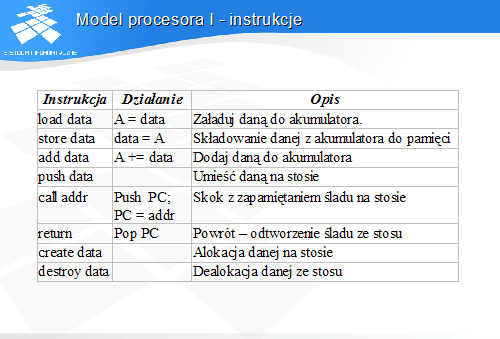
Tabela zawiera opis instrukcji pierwszego modelu procesora.
Procesor wykonuje pięć instrukcji dotyczących stosu. PUSH umieszcza wartość na stosie. Instrukcja skoku ze śladem przekazuje sterowanie do procedury po uprzednim zapamiętaniu śladu na stosie. Instrukcja powrotu według śladu odtwarza ślad ze stosu jednocześnie usuwając go. Instrukcja alokacji danej CREATE przypomina instrukcję PUSH, lecz nie nadaje danej na wierzchołku stosu żadnej wartości. Instrukcja DESTROY usuwa daną z wierzchołka stosu.


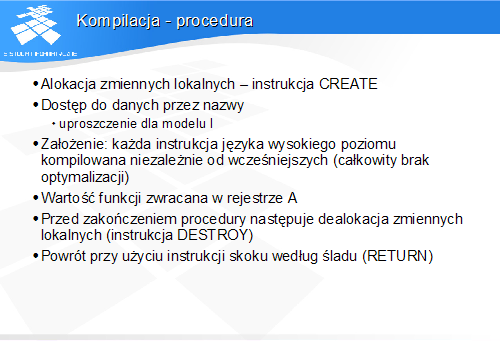

Pierwsza instrukcja procedura należy do prologu procedury i służy przygotowaniu środowiska jej działania – w tym przypadku alokacji jednej zmiennej lokalnej.
Rysunek przedstawia zawartość stosu po zakończeniu prologu.
Kolejne cztery instrukcje stanowią ciało procedury. Ostatnia z nich przygotowuje wartość zwracaną przez procedurę.
Ostatnie dwie instrukcje stanowią epilog procedury. Służą one do dealokacji zmiennej lokalnej i powrotu do procedury wywołującej.
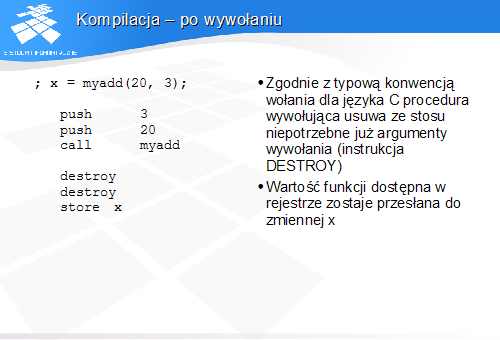

Najczęściej implementowany rodzaj stosu nazywa się stosem pełnym schodzącym. Przy takiej implementacji SP zawiera adres danej ostatnio umieszczonej na stosie, a stos rośnie w kierunku malejących adresów.
Model procesora II

Druga wersja modelu procesora stanowi urealnioną odmianę modelu pierwszego.
Stos został zaimplementowany w pamięci, co wymagało umieszczenia w procesorze rejestru SP. Posługując się rejestrem SP zdefiniowano jawnie operacje wykonywane przez instrukcje odnoszące się do stosu.
Model wciąż korzysta z dostępu do danych przez nazwy. Ten element zostanie dookreślony w trzecim modelu.
Model procesora II – instrukcje
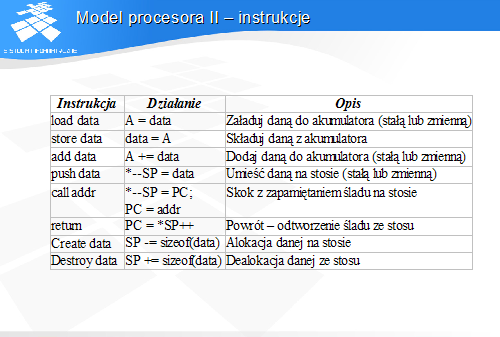

Adresowanie obiektów poprzez podania ich przemieszczenia względem SP nie jest jednak w ogólnym przypadku wygodne, gdyż podczas wykonywania procedur wywołujących inne procedury wartość SP może się zmieniać. Tym samym zmieniałyby się przemieszczenia liczone względem SP.
Adresowani względem SP nie nastręcza problemów w procedurach nie wywołujących innych procedur, czyli tzw. liściach.
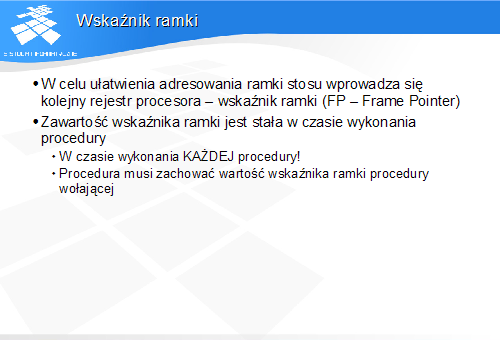
Wskaźnik ramki wskazuje ramkę bieżącej procedury. Oznacza to, że każda procedura ustanawia własną wartość wskaźnika ramki. Każda procedura spodziewa się również, że jej wartość wskaźnika ramki nie zostanie zmieniona. Oznacza to, że procedura musi przed powrotem odtworzyć wskaźnik ramki procedura wołającej.


Większość instrukcji występuje w postaci dwuargumentowej, a w zapisie symbolicznym instrukcji jako pierwszy podaje się argument docelowy, a następnie argumenty źródłowe. W instrukcjach arytmetycznych i logicznych argument docelowy jest jednocześnie pierwszym argumentem źródłowym.
Procesory x86 umożliwiają adresowanie pamięci sumą zawartości rejestru i stałej (przemieszczenia). Taki tryb adresowania jest wygodny do adresowania obiektów w ramce stosu. Możliwe jest adresowanie zarówno względem wskaźnika stosu, jak i względem wskaźnika ramki.
Potrzebne instrukcje x86
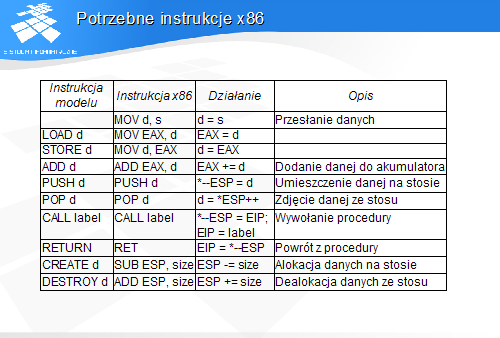
Tabela zawiera zestawienie instrukcji modelu II i ich odpowiedników w x86. instrukcje LOAD i STOR są zastąpione pojedynczą, dwuargumentową instrukcją przesłania MOV.
Operacje CREATE i DESTROY są realizowane jako odjęcie i dodanie stałej określającej rozmiar obiektów do wskaźnika stosu.
Kompilacja dla x86, adresowanie względem SP

Składnia zapisu przykładowego programu jest zgodna z asemblerami rodziny NASM.
Sekwencja wywołania dla x86 jest taka sama, jak w dotychczasowych modelach.
Alokacja i dealokacj zmiennej r w procedurze wywoływanej polega na wykonaniu prostej operacji na wskaźniku stosu. Podczas wykonania ciała procedury wskaźnik stosu wskazuje zmienną r. Dostępy do obiektów lokalnych są realizowane przy użyciu adresowania względem wskaźnika stosu.
Po powrocie z procedury następuje usunięcie argumentów. Polega ono na przesunięciu wskaźnika stosu o rozmiar argumentów – w tym przypadku o 8 (dwa argumenty po 32 bity).
Wartość funkcji zostaje zapamiętana w zmiennej statycznej x. Zapis [x] oznacza komórkę pamięci o adresie x. Ponieważ x jest zmienną statyczną, jej adres jest stałą. która może zostać zapisana symbolicznie.
Kompilacja dla x86, adresowanie względem FP
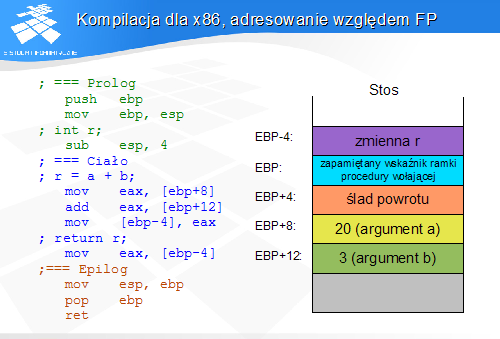
W wersji korzystającej ze wskaźnika ramki w prologu procedura następuje zapamiętanie wskaźnika ramki procedury wołającej i ustanowienie własnej wartości wskaźnika ramki. Ostatnia instrukcja prologu służy do alokacji zmiennej lokalnej.
Można zauważyć, że każda procedura będzie miała niemal identyczny prolog, zawierający trzy instrukcje. Jedyna różnica pomiędzy różnymi procedurami polega na odmiennych rozmiarach alokowanych zmiennych lokalnych.
Rysunek przedstawia ramkę stosu procedury podczas wykonywania ciała procedury. pomiędzy śladem powrotu i zmiennymi lokalnymi znajduje się zapamiętany wskaźnik ramki procedury wołającej. Na rysunku zaznaczono adresy poszczególnych obiektów ramki stosu liczone względem rejestru wskaźnika ramki (EBP).
Epilog każdej procedury jest identyczny i zawiera trzy instrukcje. Począwszy od modelu 80186 dwie instrukcje (MOV ESP, EBP; POP EBP) mogą być zastąpione pojedynczą, bezargumentową instrukcją LEAVE.
Stos – inne realizacje