

Rejestry procesora mogą pełnić różne role w programach.
Akumulatorem nazywamy rejestr, który może być użyty jako argument źródła i równocześnie przeznaczenia dla operacji arytmetycznej lub logicznej.
Rejestr służący do uzyskania adresu danej umieszczonej w pamięci nazywa się ogólnie rejestrem adresowym. Jeśli rejestr może być użyty w trybie adresowania rejestrowym pośrednim, jest on nazywany rejestrem bazowym.
Rejestr może również służyć do odliczania iteracji pętli. Rejestr przewidziany do takiego zastosowania nazywa się licznikiem pętli.
Architektury zestawu rejestrów
Szczególną postacią architektury bezrejestrowej jest architektura MOVE. W architekturach tego typu procesor wykonuje tylko jedną lub co najwyżej kilka instrukcji, których argumentami mogą być wyłącznie stałe lub adresy pamięci. operacje arytmetyczne i logiczne są realizowane poprzez przesłania do specjalnych lokacji pamięci, służących jako rejestry argumentów. Adresy tych lokacji są używane do wyboru operacji wykonywanej przez jednostkę arytmetyczną.

Architektury tego typu nie są stosowane w komputerach uniwersalnych, były one natomiast popularne w mikrokontrolerach.

Rysunek przedstawia zestaw rejestrów jednostki wykonawczej mikrokontrolera rodziny HC08. Argumenty i zmienne lokalne procedur są tu adresowana względem wskaźnika stosu, a wielofunkcyjny rejestr HX służy jako rozszerzenie akumulatora dla operacji mnożenia i dzielenia, rejestr adresowy i licznik pętli. Podstawowym akumulatorem jest rejestr A.
Mały zestaw rejestrów wymusza umieszczanie niektórych zmiennych roboczych (tymczasowych) w pamięci.
Mały zestaw rejestrów specjalizowanych

Ponieważ kompilator używa czasem instrukcji, których argumenty muszą być umieszczone w konkretnych rejestrach, rejestry nie mogą być użyte do przechowywania danych programu (argumentów i zmiennych lokalnych procedur). Służą one jedynie do przechowywania tymczasowych wyników obliczeń oraz jako argumenty instrukcji, z którymi są domyślnie związane.
Pomimo, że pojemność zestawu rejestrów jest znacząca, kompilator nie jest w stanie efektywnie korzystać z rejestrów.

Stosunkowo najbardziej uniwersalnymi rejestrami są SI i DI, ale ich użycie jest ograniczone przez fakt, że nie jest dostępny ich najmniej znaczący bajt. Niektóre bardziej zaawansowane kompilatory dla x86 używały tych dwóch rejestrów do alokacji zmiennych lokalnych procedury.

Przykładem jest tu 32-bitowa wersja x86, zapoczątkowana przez model 80386 w roku 1985. Rejestry odziedziczone po wersji 16-bitowej zostały rozszerzone do 32 bitów. Wprowadzono również nowy zestaw trybów adresowania, umożliwiający wykorzystanie do adresowania wszystkich rejestrów. Wprowadzenie nowych instrukcji mnożenia umożliwiło zmniejszenie „przywiązania rejestrów do instrukcji. W ten sposób, pomimo, że na pierwszy rzut oka model programowy wygląda bardzo podobnie do wcześniejszych wersji, kompilator może używać rejestrów znacznie elastyczniej niż we wcześniejszych procesorach tej rodziny.
Duży zestaw rejestrów uniwersalnych

Odwołania do pamięci zostają skupione w prologu i epilogu procedury, gdzie zachodzi przeładowanie ramki stosu pomiędzy rejestrami i stosem w pamięci.
Ponieważ zestaw rejestrów mieści kilka ramek stosu, odwołania do pamięci zachodzą przy przepełnieniu lub niedopełnieniu stosu w rejestrach, co ma miejsce raz na kilka poziomów wywołań procedur.
W architekturach ze stosowym zestawem rejestrów rejestry są zorganizowane w postaci niewielkiego stosu. Ponieważ operacje są domyślnie wykonywane na wierzchołku stosu, procesory o takich zestawach rejestrów mają zwykle instrukcje bezargumentowe lub jednoargumentowe.
Taka architektura zestawu rejestrów znacząco upraszcza konstrukcję kompilatora, jest ona jednak bardzo trudna do efektywnej realizacji przy typowych współczesnych strukturach jednostek wykonawczych.
Tryby adresowania


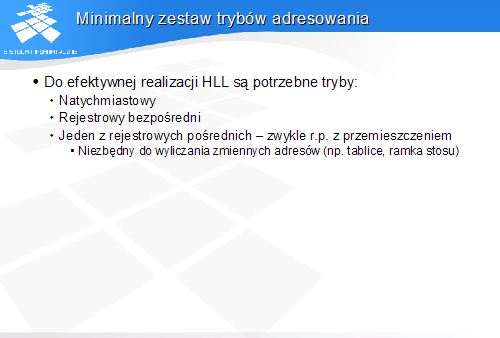
Można zauważyć, że w celu umożliwienia efektywnej implementacji języków wysokiego poziomu procesor powinien posiadać trzy tryby adresowania.
Tryb natychmiastowy służy do ładowania do rejestrów stałych, w tym również adresów danych statycznych. Tryb rejestrowy bezpośredni umożliwia użycie zawartości rejestru jako argumentu operacji. Do adresowania danych w pamięci wystarczy jeden z trybów rejestrowych pośrednich. W ten sposób uzyskujemy możliwość adresowania zmiennym adresem, wyliczonym uprzednio w rejestrze. Adresowanie danych stałym adresem może być potraktowane jako szczególny przypadek adresowania ze zmiennym adresem. Najwygodniejszym trybem adresowania pamięci jest tryb rejestrowy pośredni z przemieszczeniem.
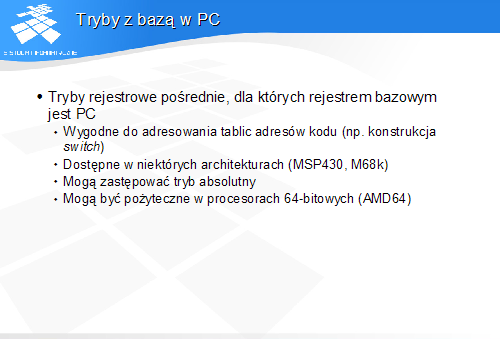
Tryby rejestrowe pośrednie z bazą w liczniku instrukcji umożliwiają adresowanie danych względem adresu bieżącej instrukcji. Mogą one być używane do adresowania danych wplecionych w kod i logicznie należących do kodu programu (np. tablice adresów). W procesorach 64-bitowych tryby te umożliwiają ograniczenie długości adresów absolutnych zawartych w zapisie instrukcji, gdyż dane, przynajmniej statyczne, są zwykle położone niezbyt daleko od kodu programu. (W przeciwnym razie zamiast 32-bitowych przemieszczeń względem PC do adresowania danych należałoby używać 64-bitowych adresów absolutnych.)
Problem obliczania zmieniających się z każdą instrukcją przemieszczeń danych liczonych względem PC przejmuje na siebie asembler.


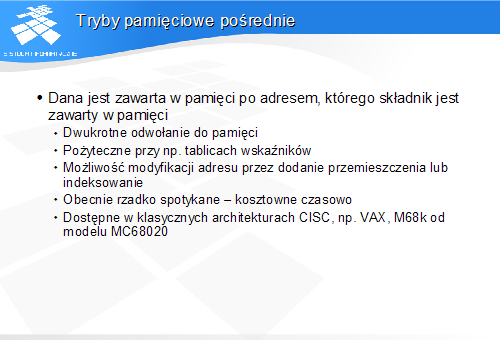
W trybach pamięciowych pośrednich jeden z elementów adresu jest pobierany z pamięci, a uzyskany adres jest wykorzystywany do odwołania do danej w pamięci. Odwołanie do danej wymaga więc dwukrotnego sięgnięcia do pamięci.
W trybach pamięciowych pośrednich występują dwa adresy efektywne, do obliczenia których można korzystać z operacji indeksowania lub dodawania przemieszczenia. Pierwszy adres, wyznaczony z jednego z omówionych wcześniej trybów adresowania pamięci, jest używany do odczytania wartości, służącej jako adres bazowy dla drugiego adresu. Do pozyskanego w ten sposób adresu bazowego można następnie dodać przemieszczenie lub przeskalowaną zawartość rejestru indeksowego.
Tryby pamięciowe pośrednie były charakterystyczne dla złożonych architektur CISC. Obecnie są one rzadko spotykane, gdyż opisana sekwencja operacji może być łatwo, a zarazem w sposób bardziej elastyczny, zrealizowana na drodze programowej.
Model operacji warunkowych

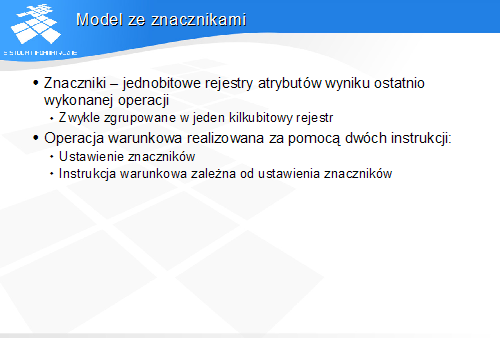
Model ze znacznikami wprowadza dwufazową realizację operacji warunkowych, przy czym instrukcje procesora realizujące obie fazy mogą być rozsunięte w czasie.
W pierwszej fazie w wyniku wykonania operacji arytmetycznej lub logicznej zostają ustawione znaczniki – jednobitowe rejestry atrybutów wyniku. W drugiej fazie następuje wykonanie operacji zależne od stanu znaczników.
Znaczniki

Znacznik przeniesienia pomocniczego wspomaga realizację operacji na liczbach zapisanych w kodzie BCD. Przechowuje on wartość przeniesienia pomiędzy tetradami pojedynczego bajtu reprezentującymi cyfry dziesiętne.
Znacznik parzystości był używany do podstawowej kontroli poprawności transmisji danych znakowych w kodzie ASCII, w tym do kontroli danych odczytywanych z taśm perforowanych. Nawet w procesorach 32- i 64-bitowych znacznik parzystości zawsze dotyczy wyłącznie najmniej znaczącego bajtu wyniku operacji.


Instrukcja ustawienia danej (np. SETcc w x86) wpisuje do rejestru wartość logiczną warunku wyrażoną jako stałą całkowitą.
W niektórych architekturach większość instrukcji jest wykonywanych jako warunkowe.
Warunki wykonania instrukcji
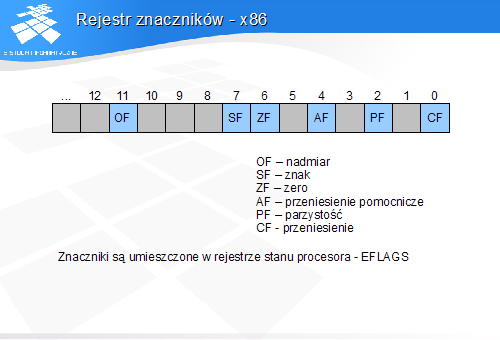
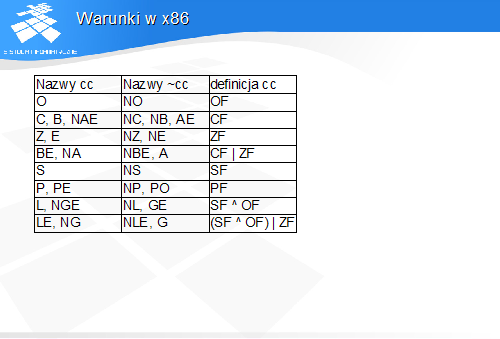
Tabela zawiera nazwy symboliczne warunków dostępnych w x86 i specyfikację odpowiadających im wyrażeń logicznych na znacznikach.
Należy zwrócić uwagę na istnienie wielu nazw tych samych warunków, co ułatwia ich użycie w programach.
Stosowane w nazwach warunków skróty A, B, G i L (above, below, greater, less) oznaczają odpowiednio relacje większości i mniejszości dla liczb bez znaku (A, B) i ze znakiem (G, L).

Taki model operacji warunkowych jest prosty i wydajny w implementacji. jest on stosowany w prostych architekturach RISCowych.
Model z predykatami
