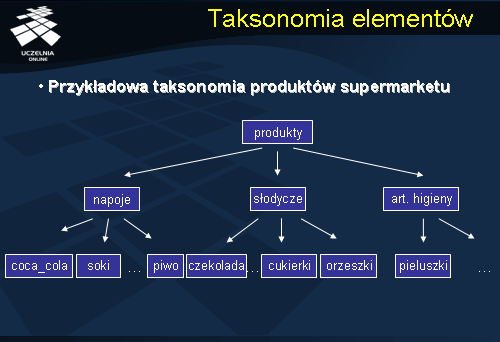
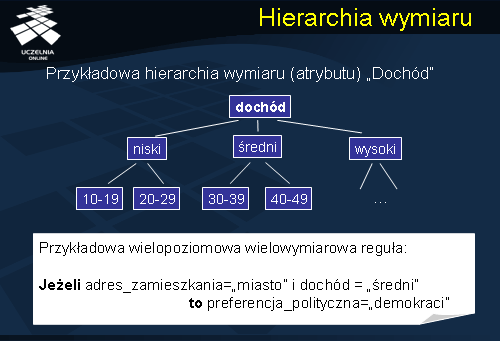
Teraz przejdziemy do omówienia podstawowego algorytmu odkrywania wielopoziomowych reguł asocjacyjnych. Ogólna idea algorytmu odkrywania wielopoziomowych reguł asocjacyjnych, polega na rozszerzeniu każdej transakcji Ti należącej do D, i=1, ..., n o zbiór poprzedników (nazwane grupy elementów) wszystkich elementów należących do transakcji. Pomijamy przy tym rozszerzeniu korzeń taksonomii i, ewentualnie, usuwamy z transakcji powtarzające się elementy. Następnie, w odniesieniu do tak rozszerzonej bazy danych można zastosować dowolny algorytm odkrywania jednopoziomowych reguł asocjacyjnych (np. Apriori). W kroku trzecim algorytmu usuwamy wszystkie trywialne wielopoziomowe reguły asocjacyjne.

Ze zbioru wygenerowanych reguł należy usunąć trywialne wielopoziomowe reguły asocjacyjne. Trywialną regułą asocjacyjną nazywamy regułę postaci wierzchołek -> poprzednik(wierzchołka), gdzie wierzchołek reprezentuje pojedynczy element lub nazwaną grupę elementów. Do usuwania trywialnych wielopoziomowych reguł asocjacyjnych wykorzystujemy taksonomie elementów, po czym usuwamy specjalizowane wielopoziomowe reguły asocjacyjne jedną regułą uogólnioną np.: ‘bułki -> napoje’ oraz ‘rogale -> napoje’ zastąp regułą ‘pieczywo -> napoje’.
Wady podstawowego algorytmu odkrywania WRA
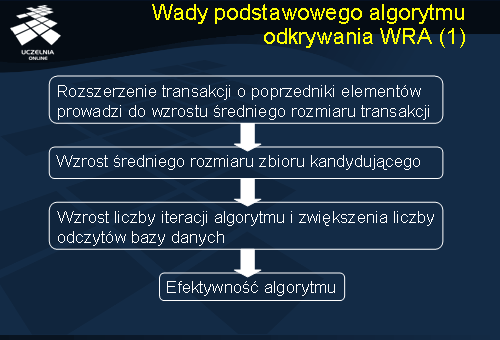
Przedstawiony podstawowy algorytm odkrywania wielopoziomowych reguł asocjacyjnych posiada szereg wad, które w istotny sposób wpływają na jego efektywność. Idea rozszerzenia transakcji o poprzedniki wszystkich elementów należących do transakcji prowadzi w oczywisty sposób do zwiększenia średniego rozmiaru transakcji, co z kolei prowadzi do zwiększenia średniego rozmiaru zbioru kandydującego. Wzrost średniego rozmiaru zbioru kandydującego prowadzi do zwiększenia liczby iteracji algorytmu, a co za tym idzie, do zwiększenia liczby odczytów bazy danych w fazie obliczania wsparcia zbiorów kandydujących, co istotnie pogarsza efektywność algorytmu. Wzrost średniego rozmiaru zbioru kandydującego prowadzi również do znacznego zwiększenia liczby zbiorów kandydujących, co w konsekwencji również istotnie pogarsza efektywność algorytmu.

W literaturze zaproponowano szereg wariantów podstawowego algorytm odkrywania wielopoziomowych reguł asocjacyjnych: Cumulate, Stratify, Estimate, oraz EstMerge, których celem jest poprawa efektywności fazy znajdowania zbiorów częstych.
Przedstawione podejście do odkrywania wielopoziomowych reguł asocjacyjnych nastręcza jeszcze jeden istotny problem. Zauważmy, że przedstawione w powyższym algorytmie odkrywania wielopoziomowych reguł asocjacyjnych podejście zakłada jednakowy próg minimalnego wsparcia dla wszystkich poziomów abstrakcji taksonomii elementów. Identyczny próg minimalnego wsparcia odnosi się do nazwanej grupy elementów "napoje"' jak i pojedynczego elementu "orzeszki ziemne firmy Felix w opakowaniu 50-gramowym"'. Ma to swoje istotne zalety. Po pierwsze, użytkownik podaje tylko jedną wartość minimalnego wsparcia i minimalnej ufności. Po drugie, upraszcza i optymalizuje procedurę znajdowania zbiorów częstych. Zauważmy bowiem, że dowolny wierzchołek wewnętrzny taksonomii jest nadzbiorem swoich następników - w fazie znajdowania zbiorów częstych można pominąć analizę zbiorów zawierających elementy, których poprzedniki w taksonomii elementów nie są zbiorami częstymi (algorytm Stratify).
Wymienione wyżej wady podejścia zakładającego jednakowy próg minimalnego wsparcia dla wszystkich poziomów taksonomii elementów stanowiły motywację opracowania podejścia, którego podstawowym założeniem jest zmniejszanie wartości minimalnego wsparcia dla kolejnych, idąc od korzenia, poziomów taksonomii. Algorytmy odkrywania wielopoziomowych reguł asocjacyjnych o zmiennym progu minimalnego wsparcia Multi_AssocRedSup. Punktem wyjścia przy konstrukcji algorytmów odkrywania wielopoziomowych reguł asocjacyjnych o zmiennym progu minimalnego wsparcia jest założenie, że dla każdego poziomu taksonomii elementów definiujemy niezależny próg minimalnego wsparcia. Im niższy poziom taksonomii, tym mniejszy próg minimalnego wsparcia.
Zmienny próg minimalnego wsparcia

Punktem wyjścia przy konstrukcji algorytmów odkrywania wielopoziomowych reguł asocjacyjnych o zmiennym progu minimalnego wsparcia jest założenie, że dla każdego poziomu taksonomii elementów definiujemy niezależny próg minimalnego wsparcia. Im niższy poziom taksonomii, tym mniejszy próg minimalnego wsparcia. Wymienione wyżej wady podejścia zakładającego jednakowy próg minimalnego wsparcia dla wszystkich poziomów taksonomii elementów stanowiły motywację opracowania podejścia, którego podstawowym założeniem jest zmniejszanie wartości minimalnego wsparcia dla kolejnych, idąc od korzenia, poziomów taksonomii. Algorytmy odkrywania wielopoziomowych reguł asocjacyjnych o zmiennym progu minimalnego wsparcia Multi_AssocRedSup. Punktem wyjścia przy konstrukcji algorytmów odkrywania wielopoziomowych reguł asocjacyjnych o zmiennym progu minimalnego wsparcia jest założenie, że dla każdego poziomu taksonomii elementów definiujemy niezależny próg minimalnego wsparcia. Im niższy poziom taksonomii, tym mniejszy próg minimalnego wsparcia. Próg minimalnego wsparcia dla poziomu i wynosi minsup = 0.2, natomiast dla poziomu i+1 wynosi 0.1. Wsparcie zbiorów "coca_cola"' oraz "piwo"' wynosi 0.11, zatem, oba zbiory są częste. Wsparcie zbioru "napoje"' wynosi 0.22 i jest większe niż minsup dla poziomu i. Zatem, zbiór "napoje"' jest również zbiorem częstym. Gdyby przyjąć jednakowy próg minimalnego wsparcia, na przykład minsup = 0.2, wówczas tylko zbiór "napoje" byłby zbiorem częstym.
Ogólny algorytm odkrywania WRA o zmiennym progu minsup

Ogólny algorytm odkrywania wielopoziomowych reguł asocjacyjnych o zmiennym progu minimalnego wsparcia jest algorytmem schodzącym (ang. top-down algorithm). W pierwszym kroku jest obliczane wsparcie elementów występujących na najwyższym poziomie taksonomii (pomijamy korzeń taksonomii). Elementy, których wsparcie jest większe od zadanego progu minimalnego wsparcia dla danego poziomu są dodawane do listy zbiorów częstych. W kolejnych krokach jest obliczane wsparcie dla elementów występujących na kolejnych, niższych poziomach taksonomii, aż nie zostanie osiągnięty poziom liści taksonomii. Do znajdowania zbiorów częstych na danym poziomie taksonomii można zastosować dowolny algorytm odkrywania zbiorów częstych.
Generowanie zbiorów częstych

Istnieje szereg wariantów nakreślonego powyżej ogólnego algorytmu odkrywania wielopoziomowych reguł asocjacyjnych o zmiennym progu minimalnego wsparcia. Warianty te różnią się przyjętą strategią przeszukiwania przestrzeni zbiorów kandydujących:
Strategia niezależnych poziomów jest strategią wyczerpującą, która zakłada, że poziomy taksonomii są wzajemnie niezależne. Oznacza to, że w fazie generowania zbiorów kandydujących każdy wierzchołek taksonomii jest analizowany niezależnie od swoich poprzedników lub następników. Innymi słowy, wszystkie wierzchołki taksonomii reprezentują ten sam poziom abstrakcji, to jest, reprezentują niezależne elementy (podobnie jak w przypadku odkrywania binarnych reguł asocjacyjnych). W konsekwencji, strategia niezależnych poziomów analizuje wsparcie każdego zbioru kandydującego niezależnie od tego, czy jego poprzednik w taksonomii elementów jest zbiorem częstym czy też nie. Niestety, prowadzi to do analizy wielu zbiorów kandydujących, które z definicji nie są zbiorami częstymi.
Strategia krzyżowej filtracji zbioru k-elementowego zakłada, że analizie poddawane są tylko te zbiory kandydujące, których elementy są następnikami zbiorów częstych k-elementowych. Przykładowo, jeżeli zbiór „piwo, pieczywo” jest zbiorem częstym, to zbiorami kandydującymi poddawanymi analizie są, na przykład, zbiory „piwo_żywiec, bułki_kajzerki” lub „piwo_lech, rogale”. Ta strategia, z kolei, prowadzi do automatycznego odrzucenia wielu interesujących częstych zbiorów kandydujących, takich, dla których poprzedniki elementów należących do tych zbiorów nie są częste. Przykładowo, załóżmy, że wsparcie nazwanej grupy elementów „piwo_żywiec”, występującej na i-tym poziomie taksonomii, jest większe od prógu minimalnego wsparcia zdefiniowanego dla tego poziomu taksonomii, natomiast wsparcie nazwanej grupy elementów "piwo"', występującej na i-1-tym poziomie taksonomii, jest mniejsze aniżeli próg minimalnego wsparcia dla poziomu i-1 taksonomii. Strategia krzyżowej filtracji zbioru k-elementowego automatycznie odrzuci zbiór częsty „piwo_żywiec, art. higieny”, który może być zbiorem częstym.
Strategia krzyżowej filtracji pojedynczego elementu jest próbą kompromisu pomiędzy wspomnianymi wcześniej strategiami przeszukiwania przestrzeni zbiorów kandydujących. Zbiór kandydujący jest analizowany na i-tym poziomie jeżeli jego poprzednik na poziomie i-1 jest zbiorem częstym. Innymi słowy, jeżeli zbiór x na poziomie i jest częsty, to analizie są poddawane jego następniki. Przykładowo, jeżeli zbiór „piwo” nie jest częsty, to w dalszej analizie pomija się zbiory „piwo_żywiec" oraz „piwo_lech”. Strategia ta posiada jednak podobną wadę jak strategia krzyżowej filtracji zbioru k-elementowego, to jest, może ona prowadzić do automatycznego odrzucenia interesujących częstych zbiorów kandydujących, takich, dla których poprzedniki elementów należących do tych zbiorów nie są częste. Próbą rozwiąania tego problemu było zaproponowanie zmodyfikowanej wersji strategii krzyżowej filtracji pojedynczego elementu, nazwanej kontrolowaną strategią krzyżowej filtracji pojedynczego elementu (ang. controlled level-cross filtering strategy by single item).
Wielowymiarowe reguły asocjacyjne

Pozostała nam jeszcze jedna klasa reguł asocjacyjnych, rozpatrywanych w kontekście wymiarowości przetwarzanych danych. Aby przybliżyć pojęcie analizy wielowymiarowej, rozważmy, dla przykładu, problem analizy i generowania raportów opisujących sprzedaż wina w sieci supermarketów. Załóżmy, że sprzedaż wina jest mierzona ilością butelek sprzedanych w określonym przedziale czasu. Miarą analizy jest zatem ilość sprzedanych butelek wina. Wartość tej miary jest, najczęściej, funkcją następujących „wymiarów” analizy: czasu, rodzaju wina oraz oddziału supermarketu. Może się zatem zdarzyć, że różne wymiary analizy będą posiadały tą samą dziedzinę wartości. Na przykład, dla wymiarów „adres supermarketu” i „adres klienta”, dziedziną wartości będzie zbiór adresów reprezentowanych przez łańcuchy znaków. Reguła może być zatem wielowymiarowa nawet, jeżeli dane występujące w regule reprezentują tę samą dziedzinę wartości.
Wielowymiarową regułą asocjacyjną nazywamy regułę, w której dane w niej występujące reprezentują różne dziedziny wartości. Atrybuty (wymiary) mogą być dwojakiego rodzaju ciągłe (ilościowe) lub kategoryczne (nominalne). Reguły wielowymiarowe określają współwystępowanie wartości danych ciągłych i/lub kategorycznych.
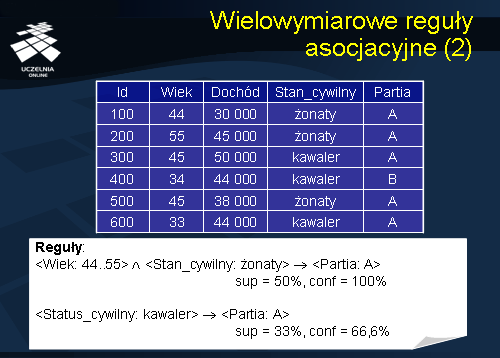
Dla zilustrowania wielowymiarowych reguł asocjacyjnych rozważmy przykład umieszczony na slajdzie. Dana jest baza danych sondażowych przedstawiających wyniki głosowania określonych osób, o określonych parametrach i określonej partii politycznej. Przykładowo osoba o identyfikatorze 100, lat 44, dochodzie 30 000, stan cywilny żonaty – głosował na partię A. W prezentowanej bazie danych można przedstawić następujące otrzymane reguły wielowymiarowe postaci:
<Wiek: 44..55> i <Stan_cywilny: żonaty> -> <Partia: A> sup = 50%, conf = 100%
<Status_cywilny: kawaler> -> <Partia: A>sup = 33%, conf = 66,6%
Problemy

Z wielowymiarowymi regułami asocjacyjnymi wiąże się szereg problemów. Po pierwsze dane ciągłe (np. atrybut „zarobek” w analizowanym przez nas przykładzie) może być bardzo różnorodny. Gdybyśmy brali pod uwagę wszystkie możliwe wartości jakie może przyjąć ten atrybut, znalezienie jakichkolwiek zależności między atrybutami byłoby bardzo ograniczone, lub wręcz niemożliwe. Dane ciągłe wymagają odpowiedniego przygotowania zwanego dyskretyzacją. Szerzej na temat dyskretyzacji powiemy w dalszej części wykładu.
Drugim problemem są brakujące dane w bazie danych czyli wartości puste (null values), w tym wypadku przyjmujemy dwie strategie. Albo pomijamy rekordy zawierające brakujące dane, albo próbujemy uzupełnić brakujące dane.
Jeżeli decydujemy się na uzupełnienie danych musimy przyjąć założenie o świecie otwartym lub zamkniętym. W przypadku założenia o świecie otwartym zakładamy, że dane mogą przyjąć dowolne wartości. W drugim przypadku, zakładamy że wartości jakie przyjmuje atrybut są atrybutami występującymi w bazie danych. W takim przypadku możemy wykorzystać algorytm znajdowania zależności funkcyjnych w bazie danych. Korzystając z wiedzy z odkrytych zależności funkcyjnych możemy uzupełnić brakujące dane.
Transformacja problemu

Problem odkrywania reguł wielowymiarowych jest problemem trudnym. Do każdego nowego problemu możemy podejścia w dwojaki sposób. Podejście pierwsze polegałoby na opracowaniu nowych specyficznych algorytmów rozwiązywania tego problemu. Podejście drugie, nazwane przez nas klasycznym podejściem rozwiązania problemów jest transformacja problemu odkrywania wielowymiarowych reguł asocjacyjnych do problemu znajdowania binarnych reguł asocjacyjnych. W pierwszym kroku dokonujemy dyskretyzacji atrybutów ciągłych, czyli dzielimy zbiór możliwych wartości przyjmowanych przez atrybut, na przedziały wartości. Przykładowo, atrybut „wiek” możemy podzielić na przedziały odpowiednio [20, 29], [30,39], itd. Innym rozwiązaniem jest tworzenie rekordów postaci boolowskiej. W tym wypadku atrybuty kategoryczne traktujemy w ten sposób, że każda wartość atrybutu kategorycznego stanowi osobny „produkt”. Natomiast, w przypadku atrybutów ciągłych każdy przedział atrybutu stanowi osobny „produkt”.
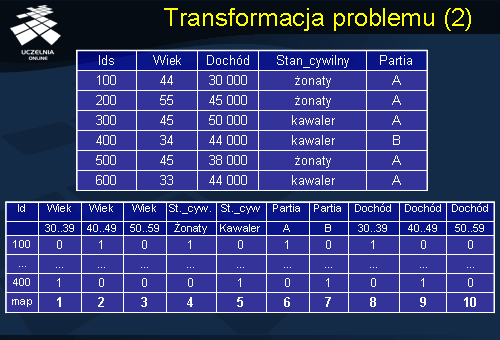
Rozważmy przykład ilustrujący transformację problemu odkrywania wielowymiarowych reguł asocjacyjnych do problemu odkrywania binarnych reguł asocjacyjnych. Dana jest relacja przedstawiona na slajdzie opisująca wyniki głosowania określonych osób na określone partie. Proces transformacji rozpoczyna się od procesu dyskretyzacji atrybutów ciągłych. W naszym przypadku będzie to atrybut wiek oraz atrybut dochód. Wcześniej wspomniany atrybut wiek poddajemy dyskretyzacji, czyli dzielimy na przedziały [30..39],[40..49],[50..59]. Podobnie dyskretyzujemy atrybut ciągły dochód dzielimy na trzy przedziały wartości [30..39],[40..49],[50..59]. Następnie transformujemy oryginalną relacje do postaci rekordów w postaci boolowskiej. Transformacja polega na utworzeniu osobnego atrybutu dla każdego przedziału wartości dla atrybutu ciągłego oraz utworzeniu osobnego atrybutu dla każdej wartości atrybutu kategorycznego. Stąd w naszej nowej relacji, która będzie zawierała rekordy w postaci boolowskiej, otrzymujemy następujące atrybuty: trzy atrybuty odpowiadające trzem przedziałom wartości atrybutu wiek; następnie dwa atrybuty odpowiadające wartościom atrybutu kategorycznego stan cywilny; następnie dwa atrybuty odpowiadające wartościom atrybutu kategorycznego partia, wreszcie trzy atrybuty odpowiadające trzem przedziałom atrybutu dochód. Dodajemy wiersz „map”, w którym mapujemy kolumny, nadając im poszczególne identyfikatory.

Następnie numerujemy wszystkie atrybuty, w naszym przypadku mamy 10 atrybutów ponumerowanych od 1 do 10. Następnie tworzymy nową tablicę przedstawioną na slajdzie składającą się z dwóch kolumn: kolumna Id oraz kolumna Produkty. Kolumna Id odpowiada identyfikatorom rekordów z oryginalnej relacji, natomiast kolumnę Produkty tworzymy w następujący sposób – wpisujemy dla danego rekordu numery atrybutów dla których dany rekord posiada wartość 1. Po dokonaniu transformacji wszystkich rekordów otrzymujemy następująca tablicę przedstawioną na slajdzie. Otrzymana tablica łudząco przypomina nam znaną tablicę, którą eksplorowaliśmy w celu znalezienia binarnych reguł asocjacyjnych. Możemy zastosować dowolny z algorytmów odkrywania binarnych reguł asocjacyjnych w celu znalezienia wszystkich zbiorów częstych i wszystkich reguł asocjacyjnych. Zakładamy próg minimalnego wsparcia = 30%.
Transformacja problemu - znajdowanie zbiorów częstych