Adresacja IP
Potrzeba adresowania
W przypadku sieci komputerowych, podobnie jak w przypadku tradycyjnych sposobów komunikacji, istnieje potrzeba określenia miejsca przeznaczenia, do którego powinna zostać wysłana porcja danych. Można to przyrównać do wysyłania listu do znanej nam (lub nieznanej) osoby. W obu przypadkach należy określić adres miejsca przeznaczenia. W przypadku tradycyjnego systemu pocztowego na kopercie wpisywane są dane adresata. Zwykle też podawane są dane nadawcy, w celu komunikacji zwrotnej. Oba adresy powinny być unikalne w innym przypadku korespondencja mogłaby nie trafiać do adresatów.
Również analogicznie jak w tradycyjnej poczcie pakiety transportowane są do określonej sieci, w której router jest odpowiednikiem urzędu pocztowego. Router decyduje również do którego hosta adresuje ramkę z danym pakietem, podobnie jak listonosz, który przynosi przesyłki do konkretnego adresata.
Adresacja w sieciach komputerowych

Analogicznie w sieciach komputerowych stosuje się adresację wymaganą przez stosowane protokoły. W zależności od rozpatrywanych warstw modelu ISO/OSI można wyróżnić adresację na poziomie warstwy łącza danych (L2) oraz adresację na poziomie warstwy sieci (L3). Pierwsza z nich dotyczy adresacji fizycznej interfejsu sieciowego, tzw. adres MAC (Media Access Control). Druga z nich odnosi się do adresacji logicznej.
Oba ww sposoby adresacji można porównać do danych wymienionych w dowodzie rejestracyjnym pojazdu, w którym pośród różnorodnych pól znajdują się: numer nadwozia (unikalnym dla każdego pojazdu i nadawany przez producenta karoserii) oraz adres właściciela i związane z tym numery tablic rejestracyjnych (zależne od miejsca zameldowania posiadacza pojazdu). Pierwsze pole jest unikalne i dzięki temu można określić czy dany pojazd nie został skradziony drugie z tych pól zmienia się w momencie zmiany miejsca zameldowania właściciela. Reasumując: adres MAC jest adresem identyfikującym konkretne urządzenia i nadawanym przez producenta, podobnie jak numer nadwozia pojazdu. Adres IP jest adresem logicznym i nadawany w zależności od tego do jakiej sieci zostało podłączone dane urządzenie sieciowe, analogicznie jak adres i numery rejestracyjne pojazdu. Oczywiście w obu przypadkach możliwe jest zmienianie tych adresów przy pomocy programów podobnie jak zmienia się (fałszuje) dane dotyczące pojazdu.
Przydzielenie adresów

Podobnie jak w przypadku rzeczywistych adresów tak samo w przypadku adresów IP musi być zapewniona ich unikalność. Nie dotyczy to adresów prywatnych, o których będzie mowa później. Z tego względu przydzielaniem adresów zajmują się powołane do tego celu organizacje. Pierwotnie zajmował się tym Internet Network Information Center (InterNIC). Organizacja ta obecnie nie istnieje. Jej rolę przejął Internet Assigned Numbers Authority (IANA). Zadaniem obu jest (było) przydzielanie unikalnych adresów.
Wersje adresacji IP
Struktura adresu IPv4

W przypadku adresacji IP adres składa się z części bitów przeznaczonych na identyfikację sieci, do której został przypisany dany interfejs hosta oraz z pozostałej liczby bitów przeznaczonych na adresację hosta w danej sieci.
Można to porównać do adresu listowego, który składa się z kodu identyfikującego miasto (część miasta) oraz dokładnego adresu identyfikującego precyzyjnie adresata. Kod umożliwia szybkie przesłanie przesyłki do właściwego urzędu pocztowego. Dokładny adres umożliwia listonoszowi (z danego urzędu pocztowego) doręczenie przesyłki. W przypadku IPv4 część adresu przeznaczona na identyfikator sieci jest zależna od długości maski sieciowej. Maska ta służy do wyznaczania adresu sieciowego, który jest (musi być) taki sam dla wszystkich interfejsów znajdujących się w tej samej podsieci. Netmaska podobnie jak adres IPv4 składa się z 32 bitów. Bity na najbardziej znaczących pozycjach powinny być ustawione na 1. Liczba tych jedynek pogrupowanych w oktety decyduje o tym ile bitów z adresu będzie odpowiadało za identyfikację sieci, np. dla maski 11111111.00000000.00000000.00000000 (dziesiętnie: 255.0.0.0) do zapisania adresu sieci będzie wykorzystywanych 8 najbardziej znaczących bitów adresu, zaś pozostałe 24 bity zostaną przeznaczone na adresy hostów w tej sieci. W przypadku maski, np.: 11111111.11111111.11111111.00000000 (netmaska zapisana dziesiętnie wynosi: 255.255.255.0), liczba bitów przeznaczonych na adresację sieci wynosi 24, zaś na adresację hosta pozostanie 8 bitów. Ze względu na wygodę zapisu i mniejszą możliwość pomyłek netmaski zapisuje się najczęściej w postaci notacji dziesiętnej.
Adresacja IP

Podział na notację klasową i bezklasową wynika ze stosowania numerów IPv4 i odpowiadających im netmasek. W przypadku notacji klasowej numery IP jak i maski mają ściśle określone zakresy. W przypadku adresacji bezklasowej dozwolonym numerom IPv4 mogą być przypisane dowolne (dozwolone) netmaski.
Adresacja z podziałem na klasy zostanie omówiona na następnym slajdzie, zaś adresacja bezklasowa w dalszej części wykładu.
Podział adresów IPv4 na klasy

Podział na poszczególne klasy adresów wynikał z próby optymalnego (na ówczesne czasy) przydzielania adresów. Stąd wyłoniono 5 klas adresów: A,B,C,D,E. Adresacja z podziałem na klasy została wprowadzona w celu określenia ile z bitów odpowiada za adres sieci, a ile za adres hosta.
Klasa A została przeznaczona dla dużych organizacji z bardzo dużą liczbą hostów. Pula adresowa sieci zawiera się w przedziale 1-126 i stanowi połowę wszystkich dostępnych adresów. Klasa B została przeznaczona dla dużej liczby organizacji z dużą liczbą hostów. Numery sieci w tej klasie zawierają adresy od 128 do 191, stąd dostępna liczba adresów stanowi 25 procent całej puli adresowej. Klasa C była zaplanowana przede wszystkim dla małych organizacji z liczbą hostów nie przekraczającą kilkuset sztuk. Klasa D służy do rozsyłania grupowego pakietów przy pomocy adresów IPv4. Klasa E została zarezerwowana przez IETF dla celów badawczych. Jak się później okazało podział ten nie pozwalał na efektywne zarządzanie pulą adresów. Stąd późniejsze próby przeciwdziałania temu zjawisku przez IETF , przez wprowadzenie mechanizmów, o których będzie mowa w dalszej części wykładu. Aby określić właściwie klasę adresu IP należy spojrzeć na pierwszą liczbę (w zapisie dziesiętnym) adresu lub na najbardziej znaczące bity (w zapisie binarnym).
Klasy adresów: klasy A
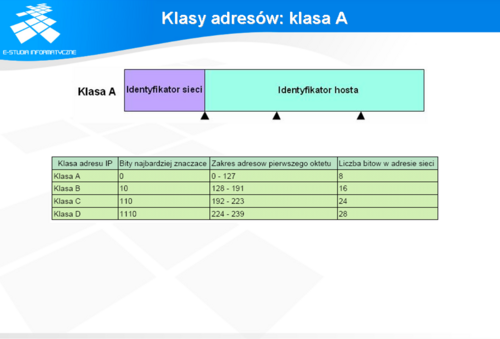
W klasie A tylko 8 bitów zostało przeznaczone na adresację sieci. Pierwszy najbardziej znaczący bit ma zawsze wartość 0, zatem do dyspozycji na numerację sieci klasy A pozostaje 2^7 adresów. Dzięki temu zakres adresów pierwszego oktetu zawiera się w przedziale od 0 do 126. Adres zaczynający się od 127 został zarezerwowany na adres pętli zwrotnej.
W sieci tej klasy pozostałe 24 bity są przeznaczone na część identyfikującą hosty. Daje to przestrzeń adresową ponad 16 milionową (16.777.216). Standardowa (naturalna) maska dla sieci tej klasy to 255.0.0.0
Klasy adresów: klasy B
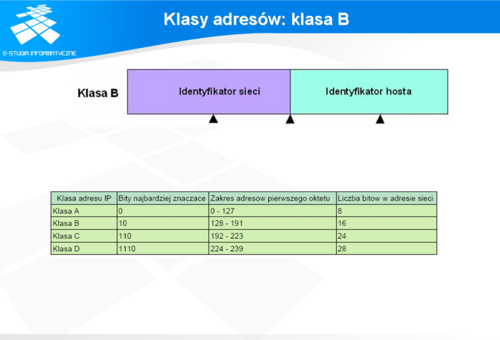
W klasie B 16 bitów zostało przeznaczone na adresację sieci. Pierwsze dwa najbardziej znaczące bity mają wartość 10. Dzięki temu zakres adresów pierwszego oktetu zawiera się w przedziale od 128 do 191. Zatem na zaadresowanie sieci pozostaje 14 bitów, co daje 16384 (2^14) adresów.
W sieci tej klasy pozostałe 16 bitów przeznaczone są na część identyfikującą hosty. Daje to przestrzeń adresową umożliwiającą wykorzystanie ponad 65 tysięcy adresów sieciowych. W każdej z sieci z tego zakresu, do dyspozycji jest ponad 65 tysięcy adresów na hosty. (65536). Standardowa (naturalna) maska sieciowa dla tej klasy wynosi: 255.255.0.0
Klasy adresów: klasy C
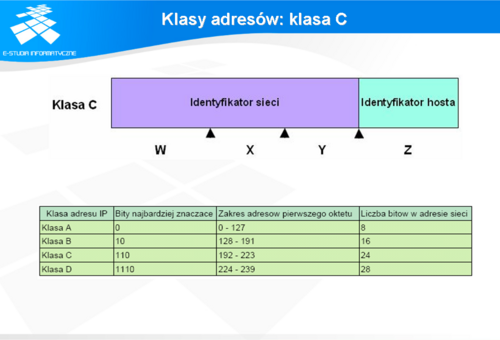
W klasie C 24 najbardziej znaczące bity zostały przeznaczone na adresację sieci. Pierwsze trzy najbardziej znaczące bity mają wartość 110 (2). Dzięki temu zakres adresów pierwszego oktetu zawiera się w przedziale od 192 do 223. Daje to razem 2097152 (2^21) adresów przeznaczonych na identyfikację sieci.
W sieci tej klasy pozostałe 8 bitów przeznaczone są na część identyfikującą hosty. Daje to przestrzeń adresową umożliwiającą zaadresowanie małych sieci składających z się z nie więcej niż 256 adresów. Standardowa (naturalna) maska sieciowa dla tej klasy wynosi: 255.255.255.0 Przykładowo jeśli adres hosta w sieci tej klasy wynosi: 194.29.145.84 co można zapisać binarnie: 11000010. 00011101. 10010001. 01010100 Standardowa netmaska 255.255.255.0 binarnie 11111111. 11111111. 11111111.00000000 Zatem adres sieci wyznaczony przez operacje iloczynu logicznego poszczególnych bitów adresu wynosi: 11000010. 00011101. 10010001.00000000 co w notacji dziesiętnej zapisane jest następująco: 194.29.145.84
Klasy adresów: klasy D
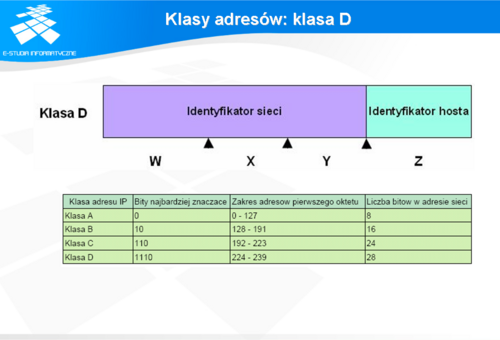
Klasa adresów D została zarezerwowana na potrzeby rozsyłania grupowego. Jest to bardziej efektywny sposób przesyłania danych do hostów niż rozgłaszanie poprzez adres 255.255.255.255. Ten ostatni sposób wymaga przetwarzania pakietów przez wszystkie hosty w domenie rozgłoszeniowej. Związane jest to z niepotrzebnym nakładem obliczeń. Zamiast tego można wykorzystywać adresację grupową, gdzie tylko określone hosty będą otrzymywały pakiety, które muszą przetworzyć.
Przykładem takich pakietów są pakiety wysyłane przez protokoły rotingu: - RIPv2 wysyła uaktualnienia na adres 224.0.0.9 - OSPF - wysyła pakiety „Hello” na adres 224.0.0.5
Zasady adresowania

Z puli dostępnych wartości adresów część wartości jest wyłączona z adresów, które mogą być nadawane hostom.
Jednym z takich ograniczeń jest adres postaci 127.x.x.x. Został on zarezerwowany na potrzeby pętli zwrotnej. Kolejnym ograniczeniem jest adres, w którym identyfikator hosta skłąda się z liczb 255. Wynika, to z założenia, że ten rodzaj adresu przeznaczony jest do rozsyłania komunikatów typu broadcast. W przypadku adresacji bezklasowej ograniczenie to rozszerzone jest do ostatniego adresu w danej sieci, możliwych do wykorzystania adresów. Identyfikator hosta nie może składać się z samych zer, gdyż jest to adres sieci, w której znajduje się host. W przypadku adresacji bezklasowej ta zasada jest uogólniona do pierwszego adresu hosta. Aby spełniony był warunek unikalności całych adresów IP, identyfikator hosta nie może powtórzyć się w sieci. W przypadku przypadkowego nadania tego samego adresu IP w sieci, np. adresu interfejsu routera, wszystkie komputery w sieci będą próbowały wysłać do takiego mylnie zaadresowanego interfejsu pakiety. W wyniku takich zakłóceń może zostać całkowicie sparaliżowany transport pakietów.
Użyteczna liczba adresów

Ze względu na ograniczenia podane na poprzednim slajdzie faktyczna liczba użytecznych adresów, które można przypisać hostom w danej sieci jest zawsze o dwa mniejsza niż ta wynikająca z liczby bitów przeznaczonych na identyfikatory hostów.
Jeśli weźmiemy pod uwagę pulę adresów dla sieci 194.29.145.0 z netmaską 255.255.255.0, to zgodnie ze wzorem liczba dostępnych adresów wynosi 2^8 - 2, co daje 254 użyteczne adresy w zakresie dziesiętnym od 1 do 254. Adres 194.29.145.0 jest adresem sieci, zaś adres 194.29.145.255 jest adresem rozgłoszeniowym (ang. broadcast). Zwyczajowo nadaje się pierwszy poprawny identyfikator hosta interfejsowi routera obsługującego daną sieć.
Ograniczenia adresacji z wykorzystaniem klas

Protokół IPv4 został zaprojektowany na początku lat 80-tych XX w. W tamtym czasie spełniał on w wystarczającym stopniu wymagania co do liczby adresów niezbędnych do obsłużenia połączonych w sieci urządzeń. Jednak wraz z rozwojem sieci komputerowych wzrasta zapotrzebowanie na adresy IP.
Potrzeba co raz większej liczby adresów wymusiła potrzebę zarządzania dostępną pulą adresów. Problem ten szczególnie dotyczył adresów klasy C, która zakładała przydzielanie całej puli składającej się z 255 adresów. W przypadku, gdy sieć ta posiadała zaledwie kilkanaście hostów pozostałe ponad dwieście było niewykorzystanych. Jeszcze większa „rozrzutność” dotyczyła sieci klasy A, czy też B. Sytuacja odwrotna występowała w przypadku organizacji z dużą liczbą hostów. W tym przypadku istniała potrzeba używania większej puli adresów. W obu przypadkach wiązało się to z nieefektywnym wykorzystaniem przydzielonych adresów. Dodatkowym problemem były duże tablice routingu i związane z tym długie czasy przesyłania pakietów w sieciach.
Próby rozwiązania problemu niedoboru adresów IPv4

Ze względu na zmniejszającą się pulę dostępnych adresów podejmowane były różne kroki w celu rozwiązania tego problemu.
Jednym ze sposobów, zaproponowanym w 1985 roku, było tworzenie podsieci. Zakres adresów hostów w danej sieci był dzielony na mniejsze podsieci z mniejszą liczbą hostów, w każdej z nowo utworzonych. Metoda ta wymagała „pożyczenia” bitów z części adresu przeznaczonej dla identyfikacji hosta dla zaadresowania podsieci. Szczegółowo zostanie ona omówiona w dalszej części wykładu. Innym sposobem rozwiązania problemu brakujących adresów było, zaproponowanie w dokumencie RFC 1009 (w 1987 roku), tworzenie podsieci o zróżnicowanej długości masek adresów (ang. Variable Length Subnet Masks (VLSM). Przydzielona danej organizacji pula adresów jest następnie dzielona wewnątrz niej na mniejsze porcje. Podział ten jest następnie niewidoczny z zewnątrz sieci danej organizacji. Jeszcze inne rozwiązanie polegało na wprowadzeniu bezklasowego routingu międzydomenowego - CIDR (ang. Classless Inter-Domain Routing). Metoda CIDR podobnie jak metoda VLSM pozwala na podział puli adresów na mniejsze porcje. Przy czym w odróżnieniu do metody VLSM, metoda CIDR polega na podziale puli dostępnych adresów przez Internet Registry dla dostawcy Internetu (ISP) najwyższego poziomu, poprzez poziom pośredni niski, aż do odbiorcy usług Internetowych. W metodzie CIDR informacje na temat masek sieci są przekazywane przez poszczególne routery w trakcie aktualizacji tablic routingu. Szczegółowo routing pakietów zostanie omówiony w innej części materiałów. Kolejnym sposobem, który może być stosowany w sieciach lokalnych jest mechanizm adresów prywatnych. Nie wymaga on praktycznie żadnych nakładów poza wyborem numeracji. Pakiety pochodzące z takich adresów będą odfiltrowywane przez routery. W przypadku adresów prywatnych, aby była możliwa komunikacja w Internecie, wprowadzono mechanizm tłumaczenia adresów prywatnych na publiczne, tzw. NAT (ang. Network Address Translation). Dzięki temu organizacjom wystarczy pojedynczy publiczny adres IP, w przypadku braku serwerów WWW, pocztowych i innych. Przedstawione sposoby zostaną omówione dokładniej w dalszej części wykładu.
Adresy prywatne

Dokument RFC 1918 podaje trzy pule adresów prywatnych, po jednej dla poszczególnych klas A,B,C. Pakiety z adresami prywatnymi nie są przepuszczane przez routery sieciowe.
W klasie A są to adresy z zakresu 10.0.0.0 - 10.255.255.255 W klasie B do dyspozycji jest pula adresów 172.16.0.0 - 172.31.255.255 W klasie C są to adresy 192.168.0.0 192.168.255.255
Dodatkowo stosując netmaski i zmiennej długości (VLSM) można te pule zmniejszać lub też zwiększać w zależności od potrzeb.
Netmaski o zmiennej długości
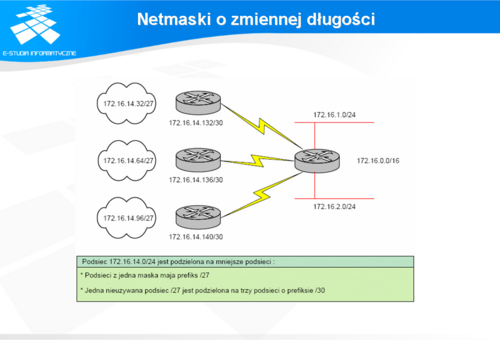
W poprzedniej części wykładu poruszane było zagadnienie optymalnego przydzielania adresów IPv4 przy pomocy VLSM lub też CIDR. Obie te metody sprowadzają się do stosowania netmaski o zmiennej długości, która pozwala dzielić dostępną pulę adresów wg. założonych potrzeb.
Przy maskach standardowych liczba bitów ustawionych na 1 na pozycjach najbardziej znaczących stanowi 8,16 lub 24 bity. W przypadku jeśli standardową netmaskę dla sieci klasy C (255.255.255) zmodyfikujemy przez pożyczenie jednego lub tez kilku bitów z części przeznaczonej na identyfikację hosta, to zamiast sieci, w której można zaadresować 254 hosty otrzymamy sieci w których można będzie zaadresować tylko 126 hostów. W przypadku działania odwrotnego - próby konsolidacji adresów pożyczamy bity z części sieciowej na adresację hostów. Tworzone w ten sposób adresy zapisujemy w skrócie poprzez numer sieci i liczbę bitów ustawionych na 1 w netmasce sieciowej. I tak jeśli pożyczymy 2 bity z adresu hosta z sieci 192.168.1.0 i przeznaczymy je na adresację sieci, to uzyskamy adres: 192.168.1.0/26, gdzie 26 oznacza maskę sieciowa z 26 bitami ustawionymi na 1 ( w zapisie dziesiętnym 255.255.255.192) Obie te czynności, czyli tworzenie podsieci i nadsieci zostaną omówione na przykładach w dalszej części wykładu.
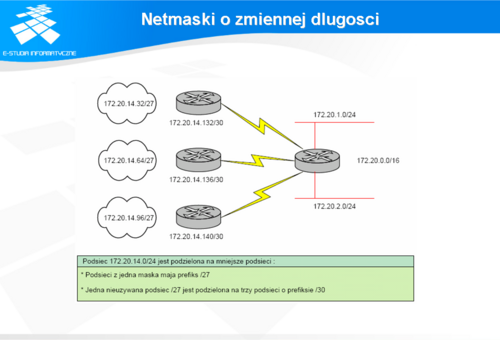 Tworzenie podsieci (przykład)
Tworzenie podsieci (przykład)

Jedną z najczęściej wykonywanych operacji jest tworzenie z podsieci na podstawie przydzielonej puli adresów.
Weźmy dla przykładu adres sieci 192.168.1.0 Standardowo w ramach takiej sieci mamy do dyspozycji 256 adresów, z których można wykorzystać 254 na zaadresowanie poszczególnych interfejsów. Załóżmy, że chcielibyśmy je wykorzystać w taki sposób, żeby rozdzielić całą pulę adresów na kilka mniejszych i przydzielić te adresy hostom, które znajdują się w 8 pracowniach komputerowych. Trzeba przy tym założyć, że w pracowniach tych będzie nie więcej niż 30 komputerów. Aby zaadresować 8 podsieci potrzeba 3 bity (2^3=8) bity te trzeba pożyczyć z części przeznaczonej na adresację hosta. Przy takich wymaganiach netmaska będzie miała 27 bitów, tzn. 11111111. 11111111. 11111111.11100000 i jej postać dziesiętna zapis. 255.255.255.224. Cały zakres adresów można opisać jako: 193.168.1.0/27 Przy użyciu takiej maski sieciowej adresy poszczególnych sieci będą miały postać: 192.168.1.0, 192.168.1.32, 192.168.1.64, 192.168.1.96, 192.168.1.128, 192.168.1.160, 192.168.1.192, 192.168.1.224 Ostatni adres będący adresem broadcastowym w każdej z tych sieci będzie miał postać: 192.168.1.31, 192.168.1.63, 192.168.1.95, 192.168.1.127, 192.168.1.159, 192.168.1.191, 192.168.1.224, 192.168.1.255 Odpowiednie pierwsze adresy użyteczne do zaadresowania hostów w tych sieciach będą następujące: 192.168.1.1, 192.168.1.33, 192.168.1.65, 192.168.1.97, 192.168.1.129, 192.168.1.161, 192.168.1.193, 192.168.1.225 Administratorzy często dokonują podziału sieci na mniejsze segmenty w celu zmniejszenia komunikatów rozgłoszeniowych w domenach.
Tworzenie nadsieci (przykład)
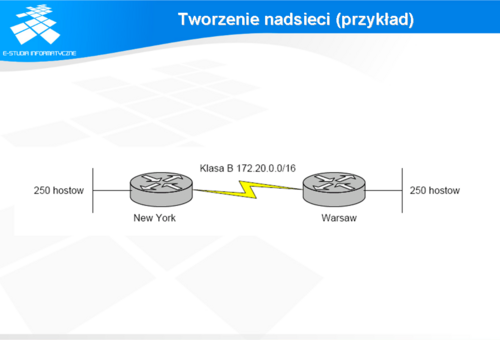
Tworzenie nadsieci potrzebne jest wówczas, gdy potrzebna jest większa dostępna liczba adresów przeznaczonych na hosty, które powinny być umieszczone w jednej sieci logicznej niż liczba adresów w danej klasie adresowej.
Przy tworzeniu nadsieci pożycza się bity z części przeznaczonej na adresację sieci w celu zaadresowania większej liczby hostów. Załóżmy, że w danej sieci powinno się znaleźć 500 hostów. Do zaadresowania takiej liczby komputerów potrzebujemy 9 bitów (2^9 = 512). W przypadku sieci klasy C zachodzi potrzeba pożyczenia tego jednego dodatkowego bitu z części 3 oktetu adresu. Weźmy dla przykładu adres, który był rozpatrywany w przypadku tworzenia podsieci: 192.168.1.0 Widać, że ten adres sam nie wystarczy, żeby uzyskać sieć złożoną z 500 hostów. Aby uzyskać dodatkowy bit, netmaska tej sieci będzie miała postać: 11111111. 11111111. 11111110.00000000, co w zapisie dziesiętnym daje: 255.255.254.0 Zapis sieci w tym przypadku będzie wyglądał następująco: 192.168.0.0/23. Pierwszy użyteczny adres hosta w tej sieci będzie miał postać: 192.168.0.1, zaś adres rozgłoszeniowy będzie następujący: 192.168.1.255 Ważnym aspektem przy tworzeniu nadsieci, z punktu metody CIDR, jest wybieranie adresów sieci sąsiadujących w taki sposób, żeby sąsiadujące sieci (obsługiwane przez ten sam router) miały adresy o takich samych znaczących bitach. Umożliwia to późniejszą agregację tras przez routery. Router, który obsługuje trasę złożoną z sieci o zmiennej długości zbudowaną wg powyższych zaleceń rozgłasza daną zagregowaną trasę jedną podsiecią.
Przykłady
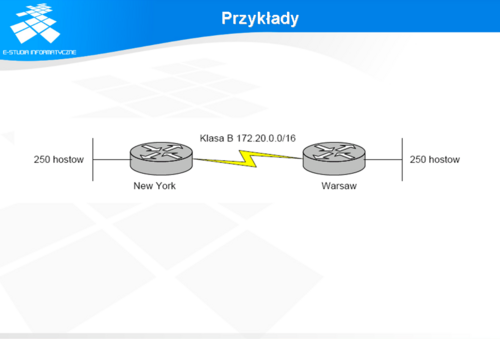
Tworzenie sieci o zmiennej długości netmasek najlepiej chyba zilustruje poniższy przykład. Ze względu na fakt, że adresy użyte tutaj są adresami z puli.
Przykład 2
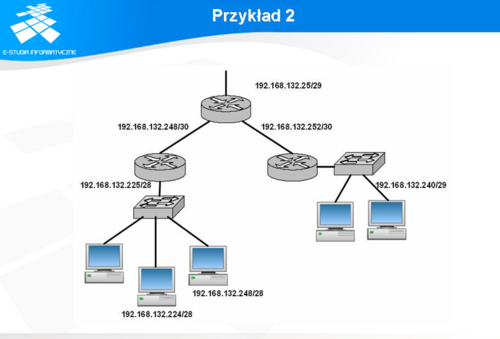
Inny przykład dotyczy sytuacji, gdy ISP udostępnił na potrzeby klienta pulę 32 adresów IPv4 z zakresu: 192.168.132.224/27
Załóżmy również, że jest to lokalny dostawca Internetu, który obsługuje zaledwie kilku klientów (maksymalnie do 6). Sam dostawca Internetu udostępnia na potrzeby jednego z klientów adres 192.168.132.29/29. Jak widać z długości netmaski interfejsu routera w podsieci tej znajduje się 8 innych adresów (32-29 bitów= 3 --> 2^3) , z czego 6 (2^3-2) są to adresy użyteczne. Zakres adresów w tej sieci, to 192.168.132.24...31/29. W ramach dostępnych adresów uzyskanych od ISP część z nich zostanie przyznanych na adresację łączy pomiędzy routerami, a część na obsługę hostów. Załóżmy, że firma ma dwie lokalizacje. Router obsługujący te sieci musi zatem łączyć się z poszczególnymi podsieciami w lokalizacjach poprzez interfeisy WAN. I tak pierwsze 16 adresów z dostępnej puli będzie obsługiwało jedną z lokalizacji. Aby to zrealizować wykorzystana zostanie pula adresów: 192.168.132.224-239. Aby zaadresować 16 hostów w tej sieci potrzebne są 4 bity. Zatem netmaska tej sieci będzie składała się z 28 bitów (32-4). Zatem całą tak wydzieloną pulę adresów można zapisać jako 192.168.132.224/28. Pierwszy użyteczny adres w tej lokalizacji będzie 192.168.132.225 z netmaską 255.255.255.240, zaś adres rozgłoszeniowy 192.168.132.239. Pozostałe 16 adresów zostanie podzielone w taki sposób, żeby obsłużyć drugą lokalizację, w której będzie maksymalnie 6 hostów i na obsługę 2 sieci rozległych. Zatem adresy z zakresu 192.168.132.240-247/29 będą obsługiwały drugą lokalizację. Do dyspozycji będzie 8 adresów zatem natmaska będzie 29 bitowa: 255.255.255.248 Pierwszy użyteczny adres hosta w tej sieci będzie: 192.168.132.241 zaś adres rozgłoszeniowy: 192.168.132.247. Pozostałe 8 adresów zostanie rozdzielonych na adresy interfesjów sieciowych łączących poszczególne lokalizacje z routerem, który je obsługuje. I tak jedno z łączy WAN będzie miało adresy: 192.168.132.248/30. Wystarczy to do zaadresowania 2 interfejsów routerów adresami: 192.168.132.249/30 oraz 192.168.132.250. Adres rozgłoszeniowy będzie 192.168.132.251, zaś maska sieciowa 255.255.255.252 Drugie z łączy WAN będzie miało adresy: 192.168.132.252/30. Wystarczy to do zaadresowania 2 interfejsów routerów adresami: 192.168.132.253/30 oraz 192.168.132.254/30. Adres rozgłoszeniowy będzie 192.168.132.255, zaś maska sieciowa 255.255.255.252
Adresy IPv6

Założenia protokołu IPv6 zostały szczegółowo omówione w poprzednim module. Jedną z najważniejszych i bardzo istotną zmianą w stosunku do IPv4 jest przeznaczenie większej liczby bitów na określenie adresu. W przypadku adresów IPv4 tylko 32 bity były przeznaczone na adres. Kwestia niedoborów adresów wśród sieci i hostów mogłaby w zasadzie być jeszcze przez jakiś czas rozwiązywana poprzez stosowanie metod omówionych w pierwszej części moduł w odniesieniu do protokołu IPv4. Jednak rozwój metod komunikacji (GPRS, EDGE, UMTS) oraz wprowadzanie na rynek nowych urządzeń z funkcją komunikacji sieciowej wymusza zastosowanie efektywniejszych metod przesyłania datagramów. Jednym z bardziej istotnych elementów jest możliwość nieograniczonego przydzielania adresów IP.
Zwiększenie przestrzeni adresowej z 2^32 (IPv4) do 2^128 (IPv6) oznacza przyrost możliwych do przypisania adresów z ok. 4,3x10^9 do ok. 3,4x10^38. W przeliczeniu na powierzchnię daje to ok. 6,7x10^17 adresów/mm^2 powierzchni Ziemi. Jest to więc bardzo duża liczba adresów, która powinna zapewnić swobodne korzystanie dla większości znanych zastosowań. Adres IPv6 zapisywany jest postaci heksadecymalnej. Preferowany jest zapis, w którym co 16 bitów (4 cyfry heksadecymalne) wstawiany jest separator w postaci dwukropka. Przykładem takiego adresu może być: 0432:5678:abcd:00ef:0000:0000:1234:4321. Notacja pozwala opuszczać wiodące zera, zatem adres ten można zapisać również jako: 432:5678:abcd:ef:::1234:4321 Specyfikacja pozwala również w przypadku występowania mieszanej infrastruktury (IPv6 z Ipv4) na podkreślenie tego faktu poprzez zapis ostatnich 32 bitów podobnie jak to było zapisywane w wersji IPv4, np.: 0:0:0:0:0:0:13.1.68.3 0:0:0:0:0:FFFF:129.144.52.38 lub wersji skróconej:
13.1.68.3
FFFF:129.144.52.38
Ze względu na fakt, że spora część ruchu odbywa się w dalszym ciągu w oparciu o IPv4 pakiety IPv6 są tunelowane wewnątrz IPv4.
IPv6: typy adresów

Wartym podkreślenia jest fakt, że w IPv6 nie ma adresów rozgłoszeniowych (ang. broadcastowych). Ich funkcje w pełni zastąpiły adresy rozsyłania grupowego. W specyfikacji RFC 1884 wymienione są 3 typy adresów:
- kierowanego (ang. Unicast) - identyfikator pojedynczego interfesju. Pakiety wysyłane na ten adres trafiają do określonego w nim hosta - uniwersalnego (ang. Anycast) - identyfikator zbioru interfejsów, które zwykle należą do różnych węzłów sieci. Pakiet wysłany na ten adres jest dostarczany tylko na jeden z interfejsów z tego zbioru. Zwykle jest to adres interfejsu najbliższego w rozumieniu metryki (Pojęcie metryki będzie omawiane w module poświęconym routingowi). - grupowego (ang. Multicast) - podobnie jak w przypadku poprzednim: identyfikator jest przypisany do zbioru interfejsów. Pakiet zawierający ten adres jest dostarczany na każdy z interfejsów należących do zbioru.
IPv6: specjalne pule adresów

Wśród adresów IPv6 są pewne specjalne pule adresów. Część z nich zostanie wymieniona poniżej
/128 – adres zerowy, wykorzystywany tylko w oprogramowaniu.
1/128 – adres pętli zwrotnej, zapisany inaczej: 0:0:0:0:0:0:0:1 (odpowiednik 127.0.0.1 z IPv4).
/96 – adresy kompatybilne z adresem IPv4 hosta korzystającego z IPv6 i IPv4.
ffff:0:0/96 – adresy kompatybilne z adresem IPv4 hosta korzystającego wyłącznie z IPv4, część adresu (32 najmniej znaczące bity) jest taka sama jak w IPv4
fe80::/10 – adresy typu "link-local" wykorzystywane wewnątrz sieci lokalnych, w procesie autokonfiguracji. ff00::/8 – adresy multicast
Podsumowanie

W module tym zostały przedstawione podstawowe wiadomości na temat adresacji IP. Podane zostały klasy adresowe w IPv4 oraz zostało omówione adresowanie bezklasowe. Omówione zostały również problemy związane z brakiem wystarczającej puli adresów IPv4 i stosowane od początku lat 90-tych próby rozwiązania tego problemu.
Omówiony został również format adresów IPv6. Adresowanie w warstwie sieciowej (L3) jest jednym z kluczowych zagadnień związanych z przesyłaniem pakietów przez routery. Informacjom na temat routingu poświęcony będzie osobny moduł.
