Architektura Komputerów/Wykład 6: Jednostka wykonawcza procesora
Plan wykładu
Procesor jednocyklowy
Procesor wielocyklowy z jednostką sterującą
Procesor potokowy
Procesor jednocyklowy
Procesory o prostym modelu programowym można zrealizować w postaci układu sekwencyjnego, który podczas każdej instrukcji zmienia stan tylko jeden raz - na końcu instrukcji
Całe wykonanie instrukcji odbywa się w układzie kombinacyjnym
Założenia dla modelu procesora:
model programowy MIPS (RISC) z uproszczeniami
architektura Harvard - rozdzielone pamięci programu i danych
pamięć programu jest pamięcią stałą (ROM), czyli układem kombinacyjnym
instrukcje o długości 32 bitów zapisane w pamięci o szerokości słowa równej 32 bity
adresowanie pamięci - bajtowe
wymuszone wyrównanie naturalne danych i instrukcji
Formaty instrukcji
op - główny kod operacyjny
rs - rejestr źródłowy
rt - rejestr źródłowy lub przeznaczenia
rd - rejestr przeznaczenia
shamt - wartość przesunięcia bitowego dla instrukcji przesunięć
func - rozszerzenie kodu operacyjnego
offset - stała 16-bitowa - argument operacji, przemieszczenie
pamięci lub przmieszczenie skoku
Modelowy procesor ma możliwość wykonywania instrukcji MIPS w dwóch spośród trzech formatów – R oraz I. W obu formatach występują pola głównego kodu operacyjnego i dwa numery rejestrów. Pozostała część słowa instrukcji jest różna dla obu formatów.
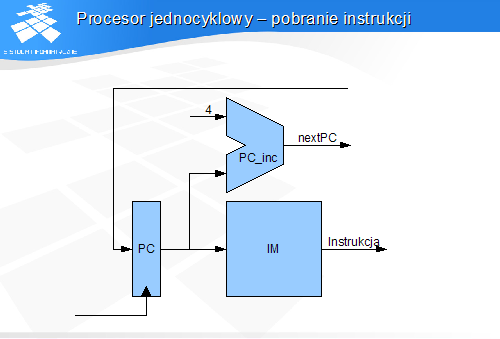
Procesor jednocyklowy - pobranie instrukcji
PC – licznik instrukcji
PC_inc – inkrementer licznika instrukcji
IM – pamięć intrukcji
Inc PC – zinkrementowana wartość PC
nextPC – ścieżka zawierająca następną zawartość PC
Licznik instrukcji PC zrealizowany jako rejestr typu D
Zawartość licznika instrukcji jest podawana na:
wejście adresowe pamięci programu IM
wejście inkremementera PC_inc - układu kombinacyjnego generującego wartość PC+4 - potencjalny adres następnej instrukcji
Na wyjściu pamięci instrukcji pojawia się binarny obraz instrukcji w postaci słowa 32-bitowego
Poszczególne części tego słowa zawierają (w zależności od formatu):
kod operacyjny instrukcji (jedno lub dwa pola)
0, 1, 2 lub 3 numery rejestrów (docelowy, źródłowe)
16-bitową stałą natychmiastową, używaną jako argument operacji lub przemieszczenie adresu
5-bitową wartość przesunięcia bitowego
Procesor jednocyklowy - układ sterujący
Na wejście układu sterującego jest podawana część słowa instrukcji
główny kod operacyjny- pole OPC
(tylko dla instrukcji w formacie R) pole FUN
Układ sterujący generuje sygnały sterujące pozostałymi częściami procesora, w tym m.in.
sygnały sterujące multiplekserami
sygnały zezwolenia na odczyt i zapis pamięci danych
sygnał zezwolenia na zapis rejestru docelowego
kod operacji dla jednostki arytmetyczno-logicznej
sygnał zezwolenia na skok warunkowy
sygnał sterujący pracą układu rozszerzania danej natychmiastowej
Układ sterujący jest wielowyjściowym układem kombinacyjnym. Generuje on sygnały sterujące wszystkimi częściami procesora.
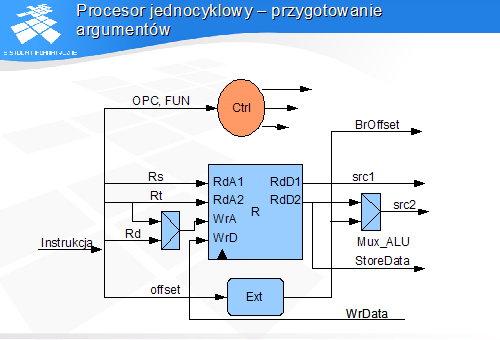
Procesor jednocyklowy - przygotowanie argumentów
Argumenty rejestrowe:
pierwszy argument - rejestr o numerze Rs
drugi argument - rejestr o numerze Rt (tylko w formacie R)
Argument natychmiastowy (format I) - uzyskiwany przez rozszerzenie 16-bitowego pola stałej do 32 bitów w układzie rozszerzenia Ext
instrukcje arytmetyczne, skoki warunkowe, odwołania do pamięci -rozszerzenie bitem znaku
instrukcje logiczne - rozszerzenie zerami
Wybór drugiego argumentu realizowany przez multiplekser Mux_ALU, w zależności od formatu instrukcji
Jednostka arytmetyczna otrzymuje na wejściach dwa argumety 32-bitowe
Numer rejestru docelowego pochodzi z pola Rt lub Rd
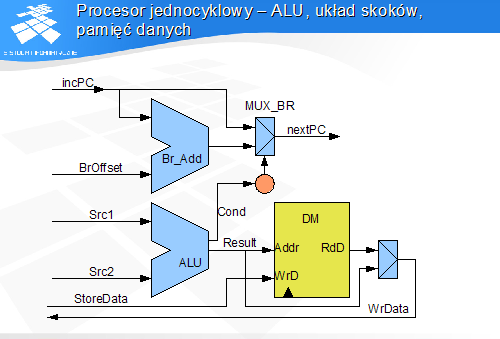
Procesor jednocyklowy - ALU, układ skoków, pamięć danych
Procesor jednocyklowy - ALU, układ skoków
Jednostka arytmetyczno-logiczna wykonuje na argumentach wejściowych operację określoną przez wykonywaną instrukcję
przy instrukcjach odwołań do pamięci jest to sumowanie zawartości rejestru bazowego z przemieszczeniem, którego wynikiem jest adres odwołania
przy instrukcjach skoków warunkowych ALU porównuje dwa argumenty sprawdzając określoną relację, a wartość logiczną relacji wystawia na wyjście warunku skoku COND
Architektura wielocyklowa minimalizuje liczbę bloków funkcjonalnych poprzez wielokrotne wykorzystanie bloków podczas każdej instrukcji
Implikuje to konieczność rozbicia wykonania instrukcji na kilka faz - cykli
w każdej fazie każdy blok wykonuje jedną czynność
liczba faz wynosi od dwóch do kilkunastu, w zależności od budowy procesora i złożoności danej instrukcji
poszczególne instrukcje mają różne czasy wykonania
Do sterowania wykonaniem służy skomplikowany układ sterujący, będący złożonym automatem synchronicznym
Komplikacja dróg przepływu danych implikuje wzrost liczby multiplekserów
Wspólna pamięć programu i danych
architektura Princeton
programowalność
dwu- lub trzykrotne użycie pamięci podczas wykonania instrukcji
Wielokrotne wykorzystanie sumatora
do inkrementacji PC
do wykonania operacji arytmetycznej
do wyliczenia adresu docelowego skoku
Wielofazowe wykonanie powoduje konieczność zapamiętania pobranej instrukcji
służy do tego tzw. rejestr instrukcji (IR-instruction register), umieszczony w jednostce sterującej
w fazie pobrania rejestr ten jest ładowany obrazem instrukcji pobranym z pamięci
Procesor wielocyklowy - studiu implementacji
Każda instrukcja wykonuje się w kilku cyklach zegara
przyjmijmy średnią liczbę cykli równą 3
Czas cyklu zależy od najdłuższej ścieżki propagacji sygnałów
przyjmując parametry analogiczne jak dla modelu procesora jedocyklowego: 20 ns + 3 x 5 ns = 35 ns → fmax około 30 MHz
Średni czas wykonania instrukcji - 3 x 35 ns = 105 ns
realizacja wielocyklowa jest nieco wolniejsza od jednocyklowej
niższe koszty rekompensują niższą wydajność
Procesor wielocyklowy - analiza
Wykonanie każdej instrukcji wymaga wykonania sekwencji operacji
niektóre operacje mogą być puste dla niektórych instrukcji
Przyjmijmy sekwencję faz wykonania:
pobranie instrukcji
zdekodowanie instrukcji
pobranie argumentów
wykonanie operacji
zapis wyniku
Procesory wielocyklowe mają modele programowe CISC
argumenty mogą pochodzić z rejestrów lub z pamięci danych
wynik zapisywany do rejestru lub pamięci
instrukcje mają różne długości - pobieranie i dekodowanie ma charakter iteracyjny
Procesor wielocyklowy - budowa
W praktyce pamięć jest umieszczona na zewnątrz procesora i jest ona połączona z procesorem tzw. szyną
Do współpracy procesora z pamięcią służy jednostka interfejsu szyny, umieszczona wewnątrz
Bloki procesora (przykład):
Jednostka sterująca
zestaw rejestrów
jednostka arytmetyczno - logiczna
jednostka interfejsu szyny
Procesor wielocyklowy - działanie
W poszczególnych fazach wykonania instrukcji pracuje tylko część bloków wykonawczych procesora:
pobranie instrukcji - interfejs szyny
dekodowanie instrukcji - tylko jednostka sterująca
odczyt argumentów - rejestry lub interfejs szyny
wykonanie operacji - jednostka arytmetyczno - logiczna
zapis wyniku - rejestry lub interfejs szyny
Przez większość czasu większość bloków procesora jest bezczynna
Procesor wielocyklowy - optymalizacja struktury
Liczba faz potrzebnych do wykonania instrukcji zależy od możliwości przesyłania danych wewnątrz procesora
przy jednej ścieżce danych samo pobranie dwóch argumentów z rejestrów zajmuje dwie fazy. a wykonanie prostej instrukcji - min. 6 faz
Liczbę faz można zwiększyć poprzez zwiększenie liczby
niezależnych ścieżek danych wewnątrz procesora
np. przez bezpośrednie połączenie rejestrów z jednostką arytmetyczną
przy trzech ścieżkach danych wykonanie instrukcji z argumentami w rejestrach zajmuje 3 fazy pobrania, dekodowania i wykonania
większa liczba ścieżek oznacza możliwość szybkiego wykonania bardziej złożonych instrukcji z wieloma argumentami (np. ze złożonymi trybami adresowania)
w fazie, w której interfejs szyny byłby bezczynny (zwykle faza dekodowania), samoczynnie wykonuje on cykl pobrania instrukcji spod adresu zawartego w scanPC i zapisania jej do rejestru prefetch
jednocześnie inkrementowany jest rejestr scanPC
jednostka sterująca może zwykle pominąć fazę pobrania, pobierając następną instrukcję z rejestru prefetch
nie wymaga to oddzielnej fazy
Efekt: pominięcie fazy pobrania instrukcji
Prefetch - implementacja, problemy
Mechanizm prefetch zrealizowano m.in. w mikroprocesorach MC68000 (rok 1979)
przed rozpoczęciem wykonania instrukcji procesor pobiera następną instrukcję
W procesorach CISC instrukcje mają różne długości
mechanizm prefetch pobiera do rejestru tylko jedno słowo z pamięci
przy dłuższych instrukcjach konieczna jest kontynuacja pobierania
Po wykonaniu skoku scanPC różni się od nextPC, a w rejestrze prefetch znajduje się instrukcja położona za instrukcją skoku
należy skopiować wartość nextPC do scanPC i unieważnić zawartość rejestru prefetch
przy wykonywaniu następnej instrukcji po skoku nie można pominąć fazy pobrania - jednostka sterująca musi czekać na pobranie instrukcji z pamięci
Kolejka instrukcji
Instrukcje procesorów CISC mają różne długości
Podczas wykonania instrukcji jednostka interfejsu szyny może być bezczynna przez kilka faz
mogłaby ona pobrać kilka kolejnych słów. o ile byłoby gdzie je przechować
jeśli w kolejce jest wolne miejsce, jednostka intefejsu szyny pobiera do niej kolejne słowo w każdym cyklu bezczynności i inkrementuje scanPC
Po wykonaniu skoku należy unieważnić zawartość kolejki i skopiować nextPC do scanPC
Kolejki instrukcji stosowano m.in. w procesorach MC68010, Intel 8086, 80286, i386
Opóźnienie skoków w procesorach z kolejką insrukcji
Niemożność pominięcia fazy pobrania po wykonaniu skoku oznacza, że instrukcja skoku wykonuje się dłużej, niż instrukcje nie modyfikujące PC
Różnica pomiędzy czasem wykonania instrukcji skoku i czasem wykonania innych instrukcji nazywa się opóźnieniem skoku (branchpenalty)
Statystycznie skoki stanowią od 7 do 14% wszystkich instrukcji wykonywanych przez procesor
opóźnienie skoków jest poważnym problemem obniżającym wydajność procesora
Należy dążyć do redukcji opóźnienia wynikającego z wykonania skoków
Redukcja opóźnienia skoków w procesorach
Opóźnienie skoków wynika z konieczności przeładowywania kolejki instrukcji
Opóźnienie można ograniczyć przez ograniczenie liczby skoków w programie
odpowiednie techniki programowania
użycie instrukcji iteracyjnych
Wykrywanie krótkich pętli (MC68010)
seria M68k nie ma instrukcji iteracyjnych
krótkie pętle mieszczą się w trzech słowach 16-bitowych
jedno słowo instrukcji zawartej w pętli
dwa słowa instrukcji zamknięcia pętli
po wykryciu w kolejce krótkiej pętli kolejka zmienia się w bufor cykliczny i wykonanie pętli następuje bez pobierania instrukcji z pamięci
Inne rozwiązania zostaną omówione później
Praca procesora jednocyklowego
Podczas wykonywania pojedynczej instrukcji następuje propagacja sygnałów przez połączone układy kombinacyjne
Po jednokrotnej zmianie stanu wyjścia każdego układu, stan wyjścia pozostaje stały do zakończenia wykonania instrukcji
Każdy układ aktywnie "pracuje" tylko przez krótki czas, przez pozostały czas utrzymuje ustaloną wartość na wyjściu
Do utrzymywania ustalonych wartości można użyć rejestrów
Procesor jednocyklowy można podzielić na fragmenty o podobnych czasach propagacji sygnałów, np.:
PC i pamięć programu
zestaw rejestrów i układ rozszerzania danej
ALU i sumator skoków
pamięć danych
układ zapisu wyniku
Od procesora jednocyklowego do potoku
W miejscach "linii cięcia" umieszczamy rejestry typu D
Wykonanie instrukcji
po zmianie PC, po czasie potrzebnym na propagację sygnałów przez pamięć programu, zapamiętujemy stan wszystkich sygnałów (zinkrementowana wartość PC i wyjście pamięci programu) w rejestrze, poprzez podanie zbocza zegara
po przepropagowaniu sygnałów przez każdy kolejny fragment procesora zapamiętujemy wszystkie sygnały wychodzące z tego bloku w rejestrze umieszczonym na końcu danego bloku
po przepropagowaniu sygnałów z ostatniego bloku na wejścia PC i zestawu rejestrów podajemy zbocze zegara kończące wykonanie instrukcji
Przepływ sygnałów pozostał bez zmian, dodano 4 rejestry
Wykonanie instrukcji zajmuje 5 faz, czas wykonania instrukcji nieco wzrósł, potrzeba 5 przebiegów synchronizujących - gdzie jest zysk?
Po zapamiętaniu stanu wyjść fragmentu procesora, fragment ten staje się bezczynny
nie jest już potrzebny do wykonania danej instrukcji, a wynik jego pracy jest zapamiętany w rejestrze
Zwolniony fragment można wykorzystać do wykonania następnej instrukcji
wystarczy w tym celu użyć jednego, wspólnego przebiegu zegarowego do sterowania wszystkich rejestrów
Wykonanie pojedynczej instrukcji zajmuje 5 cykli zegarowych
czas tych cykli jest znacznie krótszy niż w wariancie jednocyklowym
W każdym cyklu procesor rozpoczyna wykonanie nowej instrukcji
W każdym cyklu procesor kończy wykonanie kolejnej instrukcji
Widziana na zewnątrz wydajność - jedna instrukcja na cykl
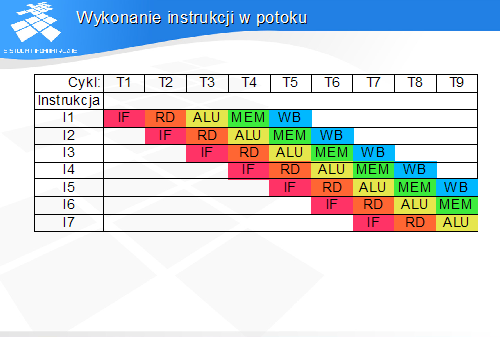
Struktura przykładowego potoku - stopnie
IF (instruction fetch) - pobranie instrukcji
RD (read) - dekodowanie i odczyt argumentów z rejestrów
ALU (arithmetic-logic unit) - obliczenie wyniku w jednostce arytmetyczno - logicznej
MEM (memory) -wymiana danych z pamięcią WB (write back) - zwrotny zapis wyniku do rejestrów
Wykonanie instrukcji w potoku
Procesor potokowy
Uzyskaną strukturę nazywamy procesorem potokowym lub potokiem
Efektywna teoretyczna wydajność procesora potokowego wynosi jeden cykl na instrukcję
Przyjmując wcześniejsze wartości parametrów czasowych:
czas cyklu wynosi ok. 30 ns
czas wykonania pojedynczej instrukcji - 150 ns
częstotliwość wykonywania instrukcji - ok. 33 MHz
Niemal wszystkie procesory budowane od połowy lat 80-tych XX wieku bazują na potokowych jednostkach wykonawczych
Zrównoleglenie wykonania instrukcji oprócz podwyższenia wydajności powoduje również powstanie problemów synchronizacyjnych, którymi zajmiemy się w następnym wykładzie