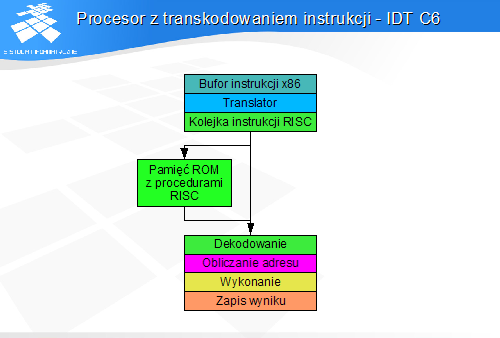
- Budowa potoku
- Problemy synchronizacji i opóźnienia w potokach
- Superpotok
- Opóźnienia w superpotoku
- Potokowe realizacje procesorów CISC
Potokowa jednostka wykonawcza - MIPS R3000

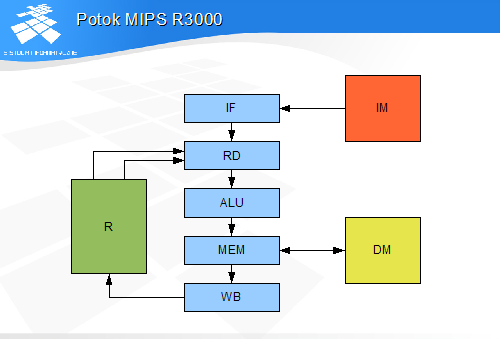
Potok R3000 składa się z pięciu stopni.
Stopień IF pobiera instrukcje z hierarchii pamięci instrukcji (zewnętrznej w stosunku do procesora).
Stopień RD odczytuje zawartości rejestrów źródłowych z zestawu rejestrów procesora.
Stopień ALU wykonuje operację arytmetyczną i ew. skok.
Stopień MEM dokonuje wymiany danych z hierarchią pamięci danych.
Stopień WB zapisuje wynik operacji arytmetycznej lub daną odczytaną z pamięci do rejestru.
Budowa i działanie potoku MIPS R3000
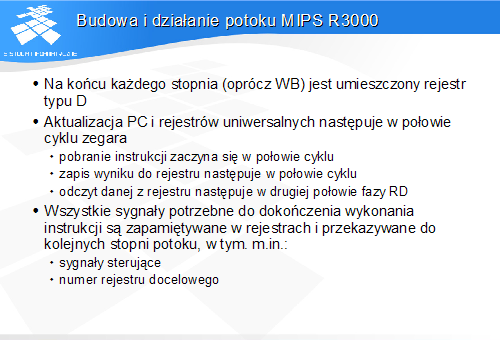
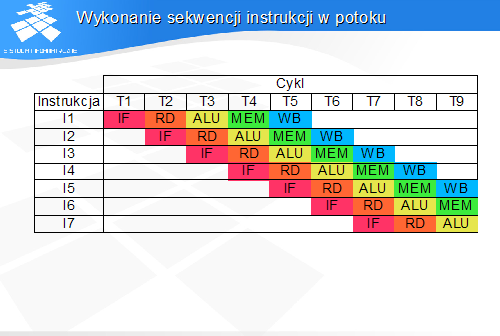
Diagram ilustruje wykonanie instrukcji przez potok procesora MIPS R3000. W każdym cyklu procesor rozpoczyna wykonanie nowej instrukcji i kończy wykonanie wcześniejszej instrukcji.
W każdym cyklu w potoku przebywa 5 instrukcji w różnych fazach wykonania.
Synchronizacja potoku

Podczas wykonania przedstawionej sekwencji instrukcji w potoku, druga instrukcja, znajdując się w stopniu RD odczytuje zawartość rejestru, który pierwsza instrukcja zaktualizuje w stopniu WB, a więc w trzy cykle później.
Podczas wykonania programu użytkowego może się zdarzyć, że wykonanie strumienia instrukcji zostanie przerwane, a następnie podjęte na nowo po jakimś czasie. W międzyczasie procesor będzie wykonywał inne sekwencje instrukcji, należące do procedur systemowych lub innego procesu użytkownika. W takiej sytuacji. przed przełączeniem kontekstu procesor zakończy wykonanie instrukcji pierwszej, nie rozpoczynając wykonania drugiej (a właściwie anulując efekty jej wykonania).
Po powrocie do przerwanego procesu rozpocznie się wykonanie go od drugiej instrukcji. W takiej sytuacji druga instrukcja pobierze z rejestru wynik zapisany przez pierwszą instrukcję.

Ponieważ nie wiadomo, czy wykonanie programu zostanie zawieszone, a następnie wznowione pomiędzy instrukcją pierwszą i drugą – nie można jednoznacznie określić, jaką wartość rejestru $4 pobierze druga instrukcja. Sytuacja taka jest nazywana hazardem.
Program musi być wykonywany deterministycznie – niezbędne jest usunięcie wszelkich niedeterminizmów i zagwarantowanie jednoznaczności wykonania.

Najprostszą metodą usunięcia hazardu RAW jest uznanie sekwencji instrukcji powodującej hazard za nielegalną i niedozwoloną. Stosowny zapis w dokumentacji powinien określać minimalny odstęp pomiędzy instrukcją wyliczającą wynik i instrukcją korzystającą z tego wyniku jako z argumentu źródłowego.
Metoda ta jest niepraktyczna, gdyż na ogół instrukcje programów tworzą sekwencje – łańcuchy, w których kolejne instrukcje korzystają z wyników instrukcji poprzedzających. W praktyce programiści musieliby więc umieszczać w programach dużo instrukcji pustych dla zapewnienia odpowiednich odstępów pomiędzy instrukcjami generującymi hazardy.

Hazard w potoku można stosunkowo łatwo wykryć, umieszczając w stopniu RD komparatory, porównujące numery rejestrów źródłowych odczytywanych przez stopień RD z numerami rejestrów docelowych instrukcji przebywających w stopniach ALU i MEM. (Przypomnijmy, że stopień RD może oczytać rejestr zapisywany w tym samym cyklu w stopniu WB.)
W razie wykrycia hazardu, instrukcja odczytu zostaje zatrzymana w stopniu RD, a do stopnia ALU zostaje wstrzyknięta instrukcja pusta. Instrukcja odczytu opuści stopień RD, kiedy zniknie ostrzeżenie o hazardzie, czyli w chwili, kiedy instrukcja zapisu znajdzie się w stopniu WB.
Działanie potoku MIPS R3000 - przypomnienie


Najbardziej efektywna metoda usuwania hazardu RAW wymaga nieco większych nakładów sprzętowych, w postaci rozbudowy stopnia odczytu i przeprowadzenia dodatkowych ścieżek danych ze stopni ALU i MEM do stopnia RD.
Na ścieżkach tych są przesyłane numery rejestrów docelowych oraz wartości danych z wyjść stopni. W przypadku operacji arytmetycznych będą to gotowe wyniki, które później zostaną zapisane do rejestrów docelowych.
W ten sposób w stopniu RD można pobrać jako argumenty źródłowe wartości rejestrów, zanim zostaną one zapisane do rejestrów procesora.
Obejście - działanie
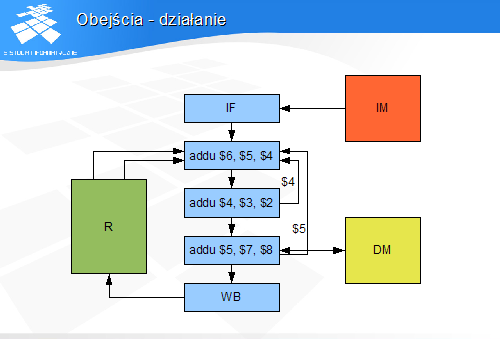
W przedstawionym przykładzie obejścia ze stopni ALU i MEM zawierają wartości, które w przyszłości zostaną zapisane do rejestrów $5 i $4. Instrukcja przebywająca w stopniu RD specyfikuje jako argumenty źródłowe właśnie te rejestry.
Logika stopnia RD spowoduje, że wartości argumentów zostaną pobrane nie z rejestrów $4 i $5, a z obejść.
Opóźnienie wynikające z dostępu do pamięci

Przedstawiony problem jest szczególnym przypadkiem hazardu RAW. Tym razem instrukcja zapisująca wynik jest instrukcją ładowania danej z pamięci.
Kiedy instrukcja odczytująca rejestr $4 znajduje się w stopniu RD, instrukcja zapisująca rejestr jest w stopniu ALU. Dostęp do pamięci nastąpi w stopniu MEM. Obejście ze stopnia ALU nie może więc zawierać wyniku instrukcji ładowania.
Wynik ten będzie dostępny na obejściu ze stopnia MEM, kiedy instrukcja ładowania znajdzie się w stopniu MEM. Nie ma możliwości przyspieszenia tej operacji, a obejścia nie są w stanie usunąć hazardu.

Eliminacja hazardu wymaga wprowadzenia opóźnienia pomiędzy instrukcją ładowania i instrukcją korzystającą z załadowanych danych. Można to zrobić na dwa sposoby – poprzez zaznaczenie takiej konieczności w dokumentacji lub przy użyciu opisanego wcześniej mechanizmu wykrywania hazardu, powodującego wstrzykiwanie do potoku instrukcji pustych.
W obu przypadkach w pracy procesora pojawi się opóźnienie.
W MIPS R3000 zastosowano metodę administracyjną – programiście nie wolno użyć danej ładowanej z pamięci w instrukcji następującej bezpośrednio po instrukcji ładowania. W nowszych implementacjach architektury MIPS, w tym w wersji architektury oznaczonej jako MIPS32, usunięto to zastrzeżenie, a eliminację hazardu dba sprzęt.

Podobny problem występuje w odniesieniu do instrukcji skoków. Skok jest realizowany w stopniu ALU, kiedy instrukcja następująca bezpośrednio po instrukcji skoku znajduje się już w stopniu RD. Zmiana PC dokonana w stopniu ALU wpływa natychmiast na działanie stopnia IF, który pobiera instrukcję spod adresu docelowego skoku. W potoku znalazła się jednak już jedna instrukcja za instrukcją skoku.
Instrukcja ta może zostać anulowana (zmieniona w instrukcję pustą), ale nie ma możliwości odzyskania cyklu straconego na jej pobranie i wykonanie. Struktura potoku wprowadza opóźnienie w wykonaniu instrukcji skoku. W przypadku R3000 opóźnienie to wynosi jeden cykl.
Redukcja opóźnienia skoków w potoku

We wczesnych procesorach RISCowych stosowano prosty sposób redukcji opóźnienia skoków. Polega on na zmianie definicji instrukcji skoku ze „skocz” na „wykonaj jedną instrukcję, a potem skocz”. W ten sposób działanie procesora potokowego polegające na pobieraniu „zbędnej” instrukcji zostaje usankcjonowane, a wykonanie instrukcji następującej za instrukcją skoku staje się normą.
Z badań statystycznych wynika, że w większości przypadków daje się znaleźć w programie przed instrukcją skoku taką instrukcję, której wykonanie nie wpływa na wykonanie skoku. Instrukcja taka może zostać przez programistę lub kompilator przesunięta za instrukcję skoku.
Wydajność potoku

W idealnym przypadku procesor potokowy powinien pracować bez zatrzymań, zaczynając i kończąc wykonanie kolejnej instrukcji w każdym cyklu.
W rzeczywistości opisane wcześniej opóźnienia wynikające z konieczności usuwania hazardów w potoku oraz opóźnienia w dostępach do hierarchii pamięci powstające poza potokiem powodują, że rzeczywista szybkość wykonywania instrukcji w procesorach o krótkich potokach wynosi przeciętnie około 1.2 cyklu procesora na instrukcję.

Wraz z ulepszaniem technologii półprzewodnikowej wzrasta dopuszczalna częstotliwość pracy układów. Przy skracaniu cyklu pracy procesora potokowego można zaobserwować, że powyżej pewnej częstotliwości granicznej przestają działać niektóre bardziej złożone stopnie, a ponadto dostęp do hierarchii pamięci w jednym cyklu staje się niemożliwy.
Każda architektura potoku, wraz z otoczeniem (hierarchią pamięci) ma określoną częstotliwość graniczną, powyżej której albo procesor przestaje działać, albo stopnie wymiany z pamięcią muszą czekać dodatkowy cykl na zakończenie operacji. W efekcie przyspieszenie zegara jest albo niemożliwe, albo przynosi spadek wydajności zamiast jej wzrostu.
Dalsze przyspieszanie wymaga zmiany struktury potoku poprzez zwiększenie liczby stopni. Uzyskuje się w ten sposób architekturę zwaną superpotokiem.
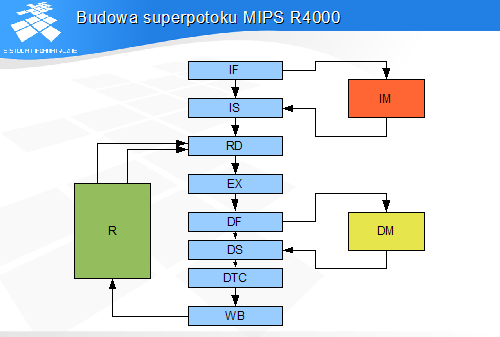


Ponieważ ogólny kształt superpotoku nie różni się od pooku, w superpotoku występują takie same problemy synchronizacyjne i opóźnienia, jak w krótkim potoku.
Większa liczba stopni i związane z tym większe odległości pomiędzy stopniami implikują konieczność wyposażenie superpotoku w większą liczbę obejść w celu likwidacji hazardu RAW. Również nieusuwalne opóźnienia ładowania danych i skoków mierzone w cyklach zegara są w tym przypadku większe.
Opóźnienie danych w superpotokach

Wskutek większej odległości pomiędzy stopniem finalizującym odwołanie do danych (DTC) i stopniem odczytu argumentów, opóźnienie danych jest 3-krotnie większe, niż w krótkim potoku. Ponieważ z koncepcji RISC wynika, że dane lokalne znajdują się na ogół w rejestrach procesora, opóźnienie danych będzie krytyczne głównie przy odwołaniach do struktur danych w pamięci (np. operacje na tablicach).
Sekwencja ładowania rejestrów będzie występowała również na końcu procedur, w tym przypadku jednak kilka instrukcji wykonywanych w epilogu po ładowaniu rejestrów skutecznie zamaskuje opóźnienie.

Zwiększone opóźnienie skoków oznacza, że gdyby procesor superpotokowy miał używać instrukcji skoku opóźnionego, slot opóźnienia miałby rozmiar równy 2, czyli po instrukcji skoku procesor wykonywałby jeszcze dwie kolejne instrukcje. Takie rozwiązanie nie jest właściwe, gdyż prawdopodobieństwo znalezienia drugiej instrukcji, która mogłaby zostać przesunięta za skok jest niewielkie. Istotny byłby również brak zgodności programowej z wcześniejszymi realizacjami o krótszych potokach.
Z tych przyczyn nie używa się skoków opóźnionych z opóźnieniem większym od jednej instrukcji. Po każdej instrukcji skoku procesor R4000 musi anulować kolejną instrukcję, pobraną jako drugą po instrukcji skoku – pierwsza jest wykonywana, tak jak w R3000.
Architektury projektowane od razu z myślą o realizacji superpotokowej nie mają instrukcji skoku opóźnionego. Ze względu na duże opóźnienie skoków są one wyposażane w układy przyspieszające wykonanie skoków, omówione w oddzielnym module.
Wydajność superpotoków


Modele programowe zgodne z założeniami koncepcji CISC nie pasują do koncepcji potoku, opracowanej równocześnie z koncepcją modelu programowego RISC. Aby procesory CISC mogły konkurować z procesorami RISC pod względem wydajności, konieczne stało się opracowanie potokowych realizacji procesorów CISC.
Są to możliwe dwa rodzaje realizacji. Pierwsza polega na skonstruowaniu potoku mogącego wykonywać instrukcje CISC. Druga zakłada, że po pobraniu instrukcje CISC będą translowane na sekwencje instrukcji podobnych do RISC, które będą następnie wykonywane w nieco zmodyfikowanym potoku.
Potok CISC