-
Kierowanie instrukcji do wykonania
-
po równoległym pobraniu grupy kilku (2 lub 4) instrukcji są one kierowane do wykonania równocześnie lub jedna po drugiej, do czasu rozpoczęcia wykonania wszystkich instrukcji z grupy; następnie rozpoczyna się kierowanie do wykonania instrukcji z następnej grupy
-
np. Alpha 21064
-
wydajność zależy od ustawienia instrukcji w grupy
-
łatwa konstrukcja stopnia szeregującego
-
tzw. okno instrukcji - w każdym cyklu stopień szeregujący ma do dyspozycji kilka instrukcji, z których co najmniej pierwsze kieruje do wykonania: w następnym cyklu następuje "dobieranie" instrukcji, tak. że w każdym cyklu można potencjalnie rozpocząć taką samą liczbę instrukcji
-
np. Intel Pentium (P5), SuperSPARC I
-
większa wydajność, opłacona komplikacją stopnia szeregującego
Superskalar z kolejnym rozpoczynaniem i niekolejnym kończeniem
-
Instrukcje są pobierane i dekodowane po kilka sztuk w kolejności programowej
-
Stopień szeregujący rozpoczyna wykonanie w kolejności programowej
-
Po skierowaniu instrukcji do potoków wstrzymanie jednego potoku nie powoduje wstrzymania pozostałych
-
instrukcje mogą być kończone w innej kolejności od programowej
-
Wzrost wydajność dzięki lepszemu wykorzystaniu potoków
-
Przykład: Cyrix 6x86 (ok. 1995r)
-
wydajność o ok 30% wyższa od Intel P5 przy podobnej strukturze
-
Problem:
-
zmiana kolejności kończenia instrukcji może wprowadzać problemy synchronizacyjne
Superskalar z niekolejnym wykonaniem instrukcji
-
Zdekodowane instrukcje są gromadzone w stopniu szeregującym
-
Skierowanie instrukcji do wykonania zachodzi wtedy, gdy są gotowe argumenty źródłowe
-
wykonanie może być rozpoczynane w kolejności innej niż programowa
-
Dwa rozwiązania szeregowania
-
centralny bufor instrukcji przed rozejściem na indywidualne potoki
-
kosztowny w realizacji
-
zapewnia równe obciążenie przy kilku identycznych potokach
-
np. Intel P6, AMD K6
-
bufory w pierwszych stopniach potoków wykonawczych (tzw. stacje rezerwacyjne - algorytm Tomasulo)
-
proste w realizacji, ale powoduje suboptymalne wykorzystanie potoków
-
np. AMD K5
-
Procesor w każdej chwili musi mieć ważną wartość PC, i tym samym instrukcję, do której program został wykonany
-
instrukcję uznaje się za ostatecznie wykonaną, jeśli również wszystkie instrukcje ją poprzedzające zostały wykonane
-
instrukcja po przejściu przez potoki wykonawcze trafia do stopnia RETIRE, gdzie oczekuje na zakończenie instrukcji poprzedzających
-
przed ostatecznym zakończeniem wykonania instrukcja nie może w sposób trwały modyfikować kontekstu procesora ani pamięci
-
Dwa ostatnie stopnie superskalara
-
oczekiwanie na zakończenie wykonania instrukcji poprzedzających
-
nieodwracalna modyfikacja kontekstu
-
Niemal wszystkie współczesne procesory do komputerów uniwersalnych wykonują instrukcje nie w kolejności
-
np. AMD K8, Intel Pentium 4, Intel Core
Synchronizacja superskalarna ze zmianą kolejności instrukcji
-
Rozpatrzmy wykonanie sekwencji instrukcji:
-
addu $4, $3, $2
-
addu $2, $5, $4
-
pierwsza instrukcja korzysta z argumentu źródłowego w rejestrze $2
-
rejestr ten jest rejestrem docelowym drugiej instrukcji
-
Problem: jaką wartość $2 pobierze pierwsza instrukcja?
-
zakończenie wykonania drugiej instrukcji przed odczytem rejestru $2 przez pierwszą instrukcję spowoduje błędne wykonanie pierwszej instrukcji
-
Niejednoznaczność ta jest nazywana hazardem W-A-R (zapis po odczycie)
-
procesor musi zagwarantować poprawne wykonanie takiej sekwencji instrukcji
-
Rozpatrzmy wykonanie sekwencji instrukcji:
-
addu $4, $3, $2
-
addu $4, $8, $9
-
addu $2, $5, $4
-
trzecia instrukcja korzysta z argumentu źródłowego w rejestrze $4
-
rejestr ten jest rejestrem docelowym pierwszej i drugiej instrukcji
-
Problem: jaką wartość $4 pobierze trzecia instrukcja?
-
zakończenie wykonania drugiej instrukcji przed zakończeniem pierwszej spowoduje, że trzecia instrukcja pobierze wartość rejestru $4 zapisaną przez pierwszą instrukcję
-
Niejednoznaczność ta jest nazywana hazardem W-A-W (zapis po zapisie)
-
procesor musi zagwarantować poprawne wykonanie takiej sekwencji instrukcji
Hazardy W-A-R i W-A-W
-
Hazardy te nie wynikają z prostej zależności instrukcji
-
zależność między instrukcjami w przypadku WAR daje się zauważyć po odwróceniu kolejności instrukcji
-
zależności tego rodzaju nazywa się zależnościami wstecznymi, zależnościami fałszywym i lub antyzależnościami
-
Usunięcie hazardów WAR i WAW wymaga zrozumienia przyczyny ich powstania
Mechanizm powstawania hazardów WAR i WAW
Źródła hazardów WAR i WAW
-
Powodem powstawania hazardów jest wielokrotne używanie tych samych zmiennych (rejestrów procesora) do przechowywania różnych wartości
-
Wynika to z:
-
ograniczonej liczby rejestrów dostępnych w procesorze
-
dążenie do przejrzystego zapisu programu (użycie małej liczby zmiennych/rejestrów
-
pętlowej struktury programów - w kolejnych obiegach pętli zmienia się wartość zmiennych
-
Rozwiązanie:
-
zwiększenie liczby dostępnych rejestrów - najlepiej do nieskończoności
Usuwanie hazardów WAR i WAW
-
Ograniczona liczba rejestrów wynika z:
-
skończonej powierzchni krzemu w układzie procesora
-
zajętości pamięci przez kody instrukcji - w każdej instrukcji trzeba zapisać numery rejestrów
-
Rozwiązanie:
-
wyposażenie procesora w większą liczbę rejestrów, niż wynika to z modelu programowego
-
dynamiczne przypisywanie rejestrów fizycznych do numerów rejestrów modelu programowego
-
technika ta jest nazywana przemianowywaniem rejestrów (register renaming)
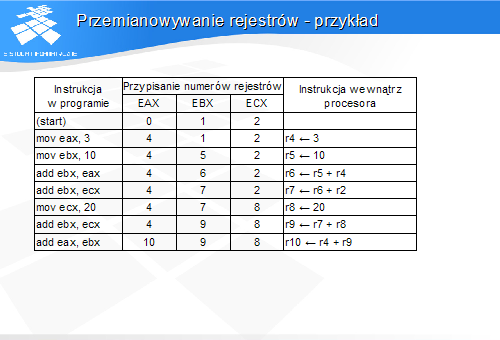
Przemianowywanie rejestrów - realizacja
-
Każda instrukcja opuszczająca stopień szeregujący otrzymuje „nowy" fizyczny rejestr docelowy, zastępujący numer rejestru modelu programowego
-
W kolejnych instrukcjach specyfikujących ten rejestr jako źródłowy numer rejestru źródłowego modelu programowego zostaje zastąpiony przez numer rejestru fizycznego przypisanego danemu rejestrowi modelu programowego
-
Rejestr fizyczny jest zwalniany przy zakończeniu wykonania następnej instrukcji o tym samym numerze rejestru docelowego w modelu programowym
-
Procesor musi uwzględniać (przywracać) kolejność programową instrukcji przy ich kończeniu
Przemianowywanie rejestrów - przykład