Systemy plików – warstwa logiczna
Celem wykładu jest pokazanie systemu plików, jako abstrakcyjnego obrazu informacji, przechowywanej i udostępnianej przez system operacyjny. W zakresie tym mieszczą się podstawowe pojęcia związane z plikami (pojęcie samego pliku, typu oraz struktury) oraz ich logiczną organizacją (strefy i katalogi). Kluczowym elementem tego obrazu jest sposób dostępu do zawartości pliku.
Plan wykładu
Wykład rozpoczyna wprowadzenie do systemu plików, obejmujące zdefiniowanie podstawowych pojęć (plik, typ, struktura), atrybutów pliku oraz roli i zadań systemu operacyjnego w odniesieniu do systemu plików. Następnie omawiane są metody dostępu do plików oraz przykładowy interfejs operacji plikowych, ze szczególnym zwróceniem uwagi na sposób realizacji metod dostępu. Na końcu omawiana jest organizacja logiczna systemu plików, czyli ten element, który kształtuje obraz organizacji informacji, postrzegany przez użytkownika.
Pojęcie pliku
Pojęcie pliku (ang. file) jest bardzo ogólne i może być różnie rozumiane w zależności od punktu widzenia. Pojęcie to, podobnie jak system operacyjny , czy proces , trudno zdefiniować precyzyjnie w krótkiej i zwartej formie.
Intuicyjnie plik jest ciągiem danych (bitów, bajtów, rekordów itp.), których znaczenie (semantykę) określa jego twórca i jego użytkownik. Np. użytkownik, tworząc plik z programem w języku C, określa, że jest to plik, na podstawie którego kompilator potrafi wygenerować kod pośredni, a po dołączeniu odpowiednich bibliotek konsolidator (linker) potrafi wygenerować plik z programem binarnym.
Zamieszczone definicje podkreślają aspekt zewnętrzny (obraz informacji, jednostka magazynowania) oraz wewnętrzny (powiązane informacje).
Zadania systemu operacyjnego
System operacyjny udostępnia pliki w jakieś postaci logicznej (zwanej też wirtualną), np. sekwencji rekordów, tablicy bajtów itp., tzn. udostępnia operacje, z pomocą których można odpowiednio manipulować takim właśnie jednostkami. Wykonanie takiej operacji musi zostać przełożone na operacje dostępu do zawartości pliku, zgodnie z jego fizyczną strukturą, np. do zawartości sektora na dysku.
Zlecenie operacji na pliku wymaga jego zidentyfikowania. Dostarczanie wygodnych dla użytkownika identyfikatorów, to jedno z zadań systemu operacyjnego. Drugim zadaniem jest dostarczenie funkcjonalnie kompletnego interfejsu operacji plikowych oraz ich implementacji w celu realizacji dostępu.
Atrybuty pliku
Nazwa pliku tworzona jest dla wygody użytkownika. System operacyjny ma najczęściej jakiś inny, wewnętrzny mechanizm identyfikacji pliku (np. numer i-węzła w systemie UNIX, referencja w NTFS).
Typ pliku, jako atrybut, istotny jest w systemach, które rozróżniają typy plików na poziomie jądra systemu operacyjnego. W praktyce pewne typy plików muszą być rozpoznawane przez jądro, np. pliki z programem dla procesu.
Lokalizacja jest atrybutem, który w istotnym stopniu decyduje o różnicach w implementacji systemu plików.
Kontrola dostępu polega na weryfikacji uprawnień do wykonania operacji, żądanej przez użytkownika, np. odczytu pliku, zapisu pliku itp.
Czasy dostępu umożliwiają działanie niektórych narzędzi programistycznych, np. programu make. Przydatne są też czasami przy wyszukiwaniu pliku.
Typy plików
Problem rozpoznawania typów pliku można pozostawić użytkownikowi, wspomagając go ewentualnie przez przyjęcie pewnej konwencji nazewniczej.
Jeśli typ pliku rozpoznawany jest przez jądro systemu operacyjnego, to możliwa jest optymalizacja dostępu, zabezpieczenie przed popełnieniem pewnych błędów, związanych z niewłaściwą interpretacją zawartości pliku (np. próba wyświetlenia zawartości pliku z programem binarnym) itp.
W systemie UNIX, w którym większość zasobów reprezentowana jest przez pliki, wyróżnia się następujące typy: plik zwykły, katalog, dowiązanie symboliczne, urządzenie blokowe, urządzenie znakowe, łącze nazwane, gniazdo. Rozróżnienie to jest bardziej związane z rolą pliku w systemie niż z jego zawartością. Jeśli chodzi o plik zwykły, to nie ma on typu — z punktu widzenia jądra systemu operacyjnego jest to ciąg bajtów, niezależnie od rodzaju zawartości. Jedynie pliki zwykłe z prawem eXecute są w pewien sposób wyróżnione, tzn. muszą mieć odpowiednią strukturę (np. COFF lub ELF), wymaganą przez jądro systemu operacyjnego w celu prawidłowego uruchomienia procesu (chyba że są to skrypty powłoki). Jądro dostarcza zestaw elementarnych operacji dostępu do plików zwykłych. Właściwa interpretacja zawartości takiego pliku jest sprawą użytkownika lub aplikacji, a informacja o typie pliku, rozpoznawana na poziomie aplikacji, zwyczajowo zawarta jest w nazwie — w jej części po kropce, zwanej rozszerzeniem.
Struktura plików
Logiczna struktura pliku określa powiązanie informacji wewnątrz pliku (właściwym byłoby zatem określenie struktura informacji). Jako przykład można sobie wyobrazić plik z tabelą bazy danych, w którym:
-
pierwsze 4 bajty określają liczbę rekordów (krotek),
-
następne 2 — długość rekordu w bajtach,
-
kolejny bajt — długość nagłówka z definicją atrybutów,
-
reszta przeznaczona jest na dane, przy czym każdy rekord ma dodatkowo 2 bajty kontrolne.
-
Z długości nagłówka wynika, gdzie rozpoczynają się dane, z wielkości rekordu oraz informacji o strukturze, mówiącej o 2 dodatkowych bajtach dla każdego rekordu, można wyliczyć początek rekordu o podanym numerze itd.
Struktura logiczna wiąże się najczęściej z typem pliku, tzn. pewne typy pliku mogą mieć określoną strukturę, np. katalogi w systemie UNIX, plik z obrazem — JPEG lub GIF (Graphics Interchange Format) itd.
Struktura może być definiowana i rozpoznawana na poziomie jądra systemu operacyjnego lub może być rozpoznawana na poziomie aplikacji korzystającej z tego pliku. Definiowanie obsługi różnych struktur plików na poziomie jądra może być pomocne dla użytkownika (może wspomagać optymalizację dostępu), ale w systemie musi być wówczas zawarty kod do obsługi każdej z tych struktur, co może powodować nadmierny rozrost programu jądra.
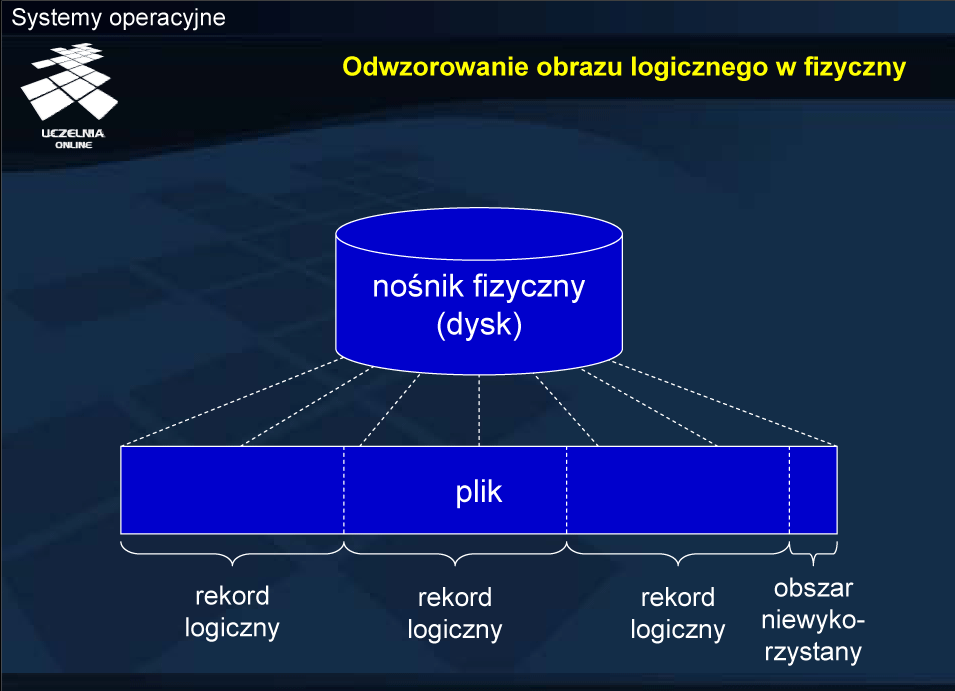
Odwzorowanie obrazu logicznego w fizyczny
Fizyczna struktura pliku wynika z własności urządzenia, na którym plik jest przechowywany. Większość urządzeń składowania danych (w tym plików) ma charakter blokowy. Zadaniem systemu operacyjnego jest zatem odwzorować jednostkę logiczną (np. rekord) na jednostkę fizyczną (np. sektor dysku). Operacja dostępu do rekordu może więc wymagać jednej lub kilku operacji dostępu do sektora dysku lub dostępu do bufora pamięci podręcznej, gdzie przechowane są tymczasowe zawartości niektórych obszarów przestrzeni dyskowej.
W związku z blokowym charakterem urządzeń składujących może wystąpić zjawisko fragmentacji wewnętrznej. Wynika ono z faktu, że rozmiar jednostki alokacji na urządzeniu, będący wielokrotnością (w liczbie jakieś potęgi dwójki: 1, 2, 4, 8, ...) rozmiaru sektora, nie musi dokładnie odpowiadać potrzebom aplikacji.
Metody dostępu do plików
Wyszczególnienie metod dostępu
W dostępie sekwencyjnym możliwe są następujące operacje: odczyt kolejnego rekordu, dopisanie rekordu na końcu pliku, przesunięcie wskaźnika bieżącej pozycji (bieżącego rekordu) na początek, ewentualnie przesuwanie wskaźnika o podaną liczbę jednostek w przód, czy w tył. Identyfikacja rekordu dla wykonywanej operacji wynika zatem z historii wcześniejszych operacji dostępu.
W przypadku dostępu bezpośredniego (określanego również jako swobodny) możliwe jest wskazanie dowolnego rekordu (lub innego fragmentu pliku), na którym ma zostać wykonana operacja dostępu. Rekord wskazywany jest poprzez podanie numeru lub przesunięcia względem początku pliku. Pliki o dostępie bezpośrednim są szczególnie użyteczne w przetwarzaniu informacji w dużych zbiorach danych (np. w bazach danych).
Dostęp indeksowy umożliwia identyfikowanie rekordów za pomocą kluczy indeksowych. Takie podejścia mają najczęściej na celu przyspieszenie wyszukiwania informacji na podstawie klucza. W praktyce stosowane są raczej w systemach zarządzania bazami danych, niż bezpośrednio w systemie operacyjnym. Pliki indeksowe przyjmują często postać skomplikowanych struktur typu B-drzewo lub B+-drzewo, czy tablice haszowe.
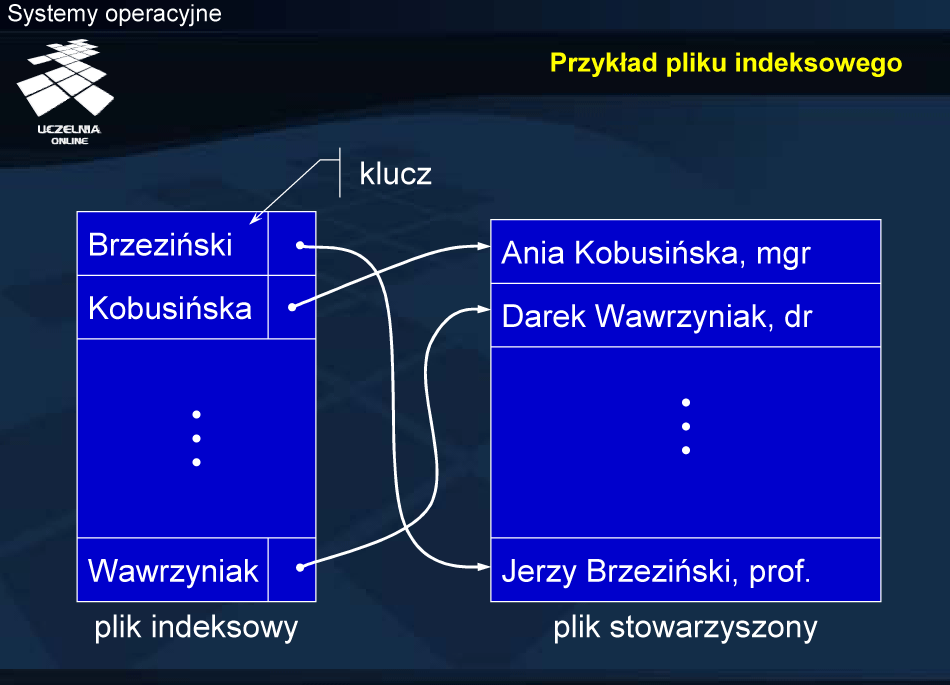
Przykład pliku indeksowego
Przykład obrazuje zasadę dostępu indeksowego. Plik indeksowy jest zorganizowany w taki sposób, żeby przyspieszyć wyszukiwanie klucza, np. przez odpowiednie posortowanie lub zbudowanie struktury drzewiastej. Z kluczem związana jest informacja o lokalizacji rekordu w pliku stowarzyszonym, czyli właściwym pliku z danymi.
Sam dostęp polega na znalezieniu na podstawie klucza w pliku indeksowym informacji o lokalizacji rekordu, a następnie wykorzystaniu tej informacji w uzyskaniu dostępu do właściwego rekordu w pliku stowarzyszonym.
Podstawowe operacje na plikach
Podstawowe operacje na plikach to tworzenie, usuwanie oraz dostęp do zawartości pliku. Dostęp do zawartości w najprostszym przypadku sprowadza się do zapisu lub odczytu fragmentu pliku.
Tworzenie pliku wymaga jawnego podania wartości niektórych atrybutów — nazwy, typu, czy atrybutów związanych z ochroną. Wartości innych atrybutów definiowane są w trakcie użytkowania pliku, np. czasy dostępu, rozmiar, czy lokalizacja.
W przypadku właściwych operacji dostępu typowy zestaw informacji sprowadza się do określenia „co i gdzie”, czyli co jest zapisywane i w którym miejscu pliku lub która część pliku jest odczytywana oraz gdzie trafia odczytana informacja.

Usuwanie fragmentów pliku może przysparzać problemów. Zasadniczą kwestią jest, co zrobić z miejscem po usuniętej częścią pliku. W najprostszym przypadku można odpowiednio przesunąć zwartość pliku, ale jest to operacja pracochłonna. W przypadku pliku składającego się z logicznych rekordów o stałym rozmiarze można przenieść ostatni rekord w miejsce usuwanego. Jeśli jednak rekordy są posortowane, metoda ta może się okazać niewłaściwa. Sposób wykonania takiej operacji zależy więc od struktury pliku. Z tego powodu system operacyjny umożliwia tylko usuwanie końcowego fragmentu pliku, wszelkie optymalizacje pozostawiając warstwie aplikacyjnej.
W interfejsie usług plikowych wyróżnia się pewne operacje dodatkowe, jak otwieranie, zamykanie i przesuwanie wskaźnika bieżącej pozycji. Otwieranie oraz komplementarne zamykanie związane jest efektywnością realizacji operacji plikowych. Wygodnym dla użytkownika identyfikatorem pliku jest nazwa. W złożonej, hierarchicznej strukturze katalogów (w tym miejscu odwołujemy się do intuicji słuchacza, gdyż struktury katalogowe zostaną omówione w dalszej części) lokalizowanie pliku na podstawie nazwy wymaga czasami przeszukania kilku katalogów. Identyfikowanie pliku przez nazwę przy każdej operacji dostępu wymagałoby potencjalnie każdorazowego przeszukiwania takiej złożonej struktury katalogowej, co znacząco wydłużyłoby czas dostępu. Otwarcie pliku oznacza alokację odpowiednich zasobów jądra (pozycji w tablicach otwartych plików), które przechowują niezbędne dane od efektywnej realizacji operacji dostępu. Z otwarciem pliku wiąże się utworzenie jakiegoś tymczasowego identyfikatora (deskryptora, uchwytu), za pomocą którego można bardzo szybko zlokalizować plik lub jego fragment.
Sens operacji przesuwania wskaźnika bieżącej pozycji zostanie wyjaśniony w dalszej części.
Interfejs dostępu do pliku w systemie uniksopodobnym
Interfejs dostępu do plików w systemach uniksopodobnych obejmuje operacje wyszczególnione na wcześniejszym slajdzie, jednak kilka funkcji wymaga komentarza.
Funkcja unlink usuwa dowiązanie do pliku. W systemie unikskopodobnym plik może mięć kilka nazw, zwanych dowiązaniami twardymi. Funkcja unlink usuwa wskazane dowiązanie, co nie musi oznaczać fizycznego usunięcia pliku. Fizyczne usunięcie pliku następuje dopiero w wyniku usunięcia ostatniego dowiązania.
Funkcja creat (bez litery e na końcu), jak nazwa wskazuje, służy do tworzenia pliku. W tym samym calu można jednak wykorzystać funkcję open, która również umożliwia utworzenie pliku, ale udostępnia więcej parametrów i tym samym daje większe możliwości w zakresie obsługi przypadków szczególnych.
W opisie interfejsu pominięto między innymi funkcję fcntl, oraz kilka funkcji dostępu do specyficznych atrybutów plików.
System uniksopodobny — tworzenie pliku
System uniksopodobny — otwieranie pliku
System uniksopodobny — zamykanie deskryptora pliku
System uniksopodobny — usuwanie dowiązania do pliku
System uniksopodobny — skracanie pliku
System uniksopodobny — odczyt zawartości pliku
W parametrach funkcji read nie ma wskazania na odczytywany fragment pliku. Takie podejście jest właściwe dla dostępu sekwencyjnego.
System uniksopodobny — zapis zawartości pliku
Podobnie jak w przypadku funkcji read, w parametrach funkcji write również nie ma wskazania, który obszar pliku ma być zapisywany. Wpływ na miejsce zapisywania może mieć tryb otwarcia. W przypadku otwarcia pliku z flagą O_APPEND następuje zawsze dopisywanie na końcu. Jeśli flaga nie została użyta, w wyniku wykonania funkcji może nastąpić nadpisanie dotychczasowej zawartości, przy czym plik zachowuje się tak, jak przy dostępie sekwencyjnym.
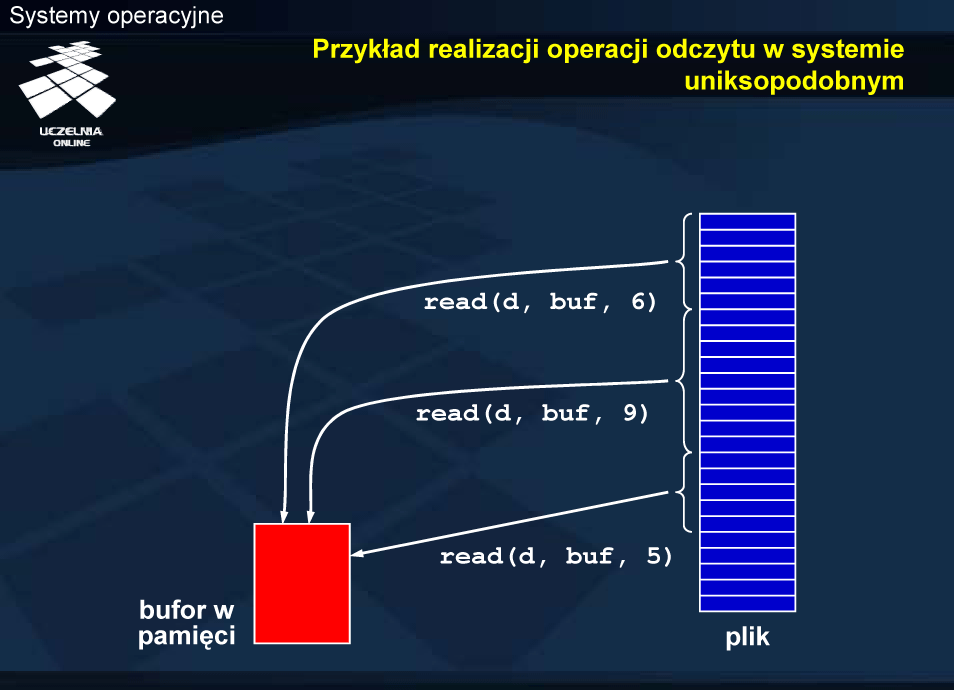
Przykład realizacji operacji odczytu w systemie uniksopodobnym
Przykład pokazuje efekt trzech kolejnych operacji odczytu pliku po jego otwarciu. Przyjmując od góry początek pliku, pierwsze wykonanie read umieści w buforze pamięci pierwsze sześć bajtów, następne nadpisze te sześć bajtów kolejnymi dziewięcioma z pliku, ostatnie wykonanie częściowo nadpisze zwartość bufora kolejnymi pięcioma bajtami. Jest to typowy przykład dostępu sekwencyjnego. Po wykonaniu operacji stan otwarcia pliku zmienia się w tak, że następna operacja dotyczy kolejnego fragmentu pliku.
Przykład realizacji operacji zapisu w systemie uniksopodobnym
Podobnie realizowana jest operacja zapisu. Wynikiem kolejnych trzech wywołań funkcji write będzie zapisanie łącznie 20 kolejnych bajtów w pliku. Jeśli w zapisywanym obszarze pliku były już jakieś dane, zostaną nadpisane. Jeśli plik byłby krótszy niż 20 bajtów, nastąpi jego powiększenie.
System uniksopodoby — zmiana wskazania bieżącej pozycji
Z każdym otwartym plikiem związany jest wskaźnik bieżącej pozycji. Wskaźnik ten identyfikuje miejsce, od którego rozpocznie się kolejna operacja zapisu lub odczytu. Po każdej operacji wskaźnik bieżącej pozycji przesuwa się o tyle bajtów, na ilu operacja była wykonana.
Niezależnie od wykonywanych operacji dostępu wskaźnik ten można przesunąć za pomocą funkcji lseek. Wskazanie miejsca docelowego polega na podaniu przesunięcia względem początku pliku, końca pliku lub pozycji bieżącej. Wartość dodatnia oznacza przesunięcie w kierunku końca pliku, a ujemna w kierunku początku pliku.
Funkcja lseek jest uzupełnieniem funkcji read i write, umożliwiającym bezpośredni dostęp do plików. W przypadków plików sekwencyjnych, do których należą np. pliki urządzeń, czy łącza (potoki, kolejki FIFO) funkcja lseek nie ma zastosowania. W ten sposób udało się zachować jednolitość interfejsu dostępu do plików — nie trzeba było wyodrębniać dwóch rodzajów funkcji do odczytu i do zapisu.
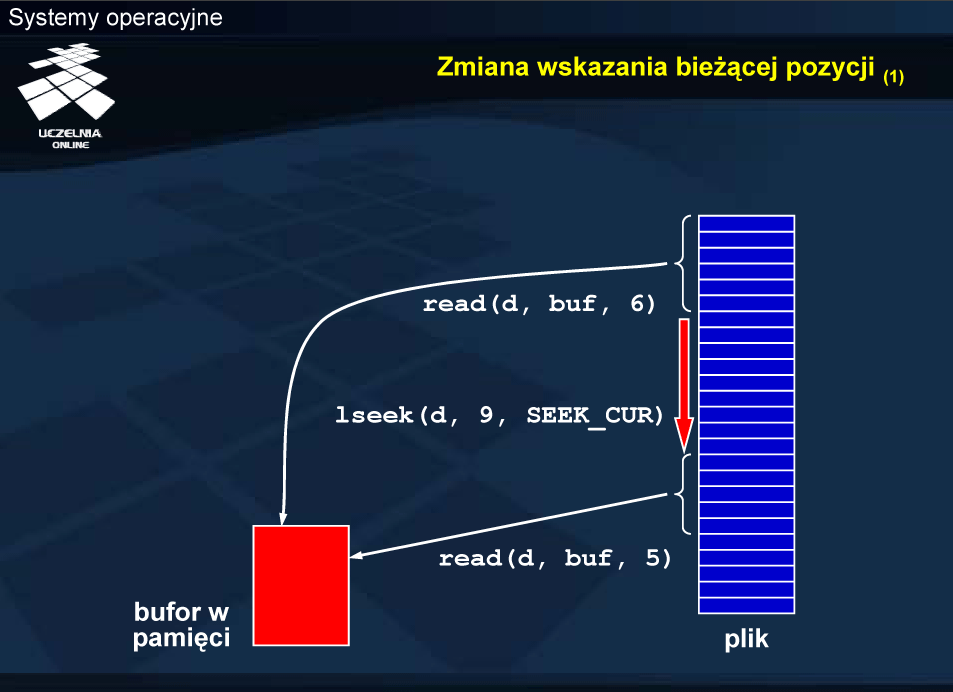
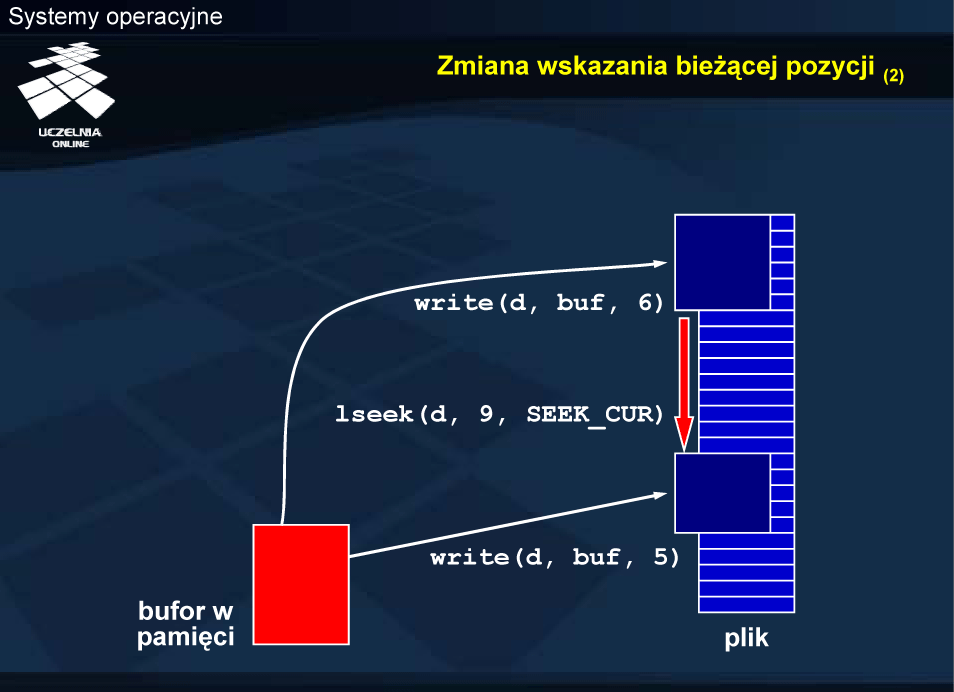
Zmiana wskazania bieżącej pozycji
Przedstawiony schemat ilustruje przykładową realizację operacji odczytu z przesunięciem wskaźnika bieżącej pozycji o 9 bajtów w kierunku końca pliku. Skutkiem jest pominięcie tych 9 bajtów.
W przypadku zapisu skutkiem przesunięcia jest pominięcie 9 bajtów, czyli pozostawienie tego fragmentu bez zmian.
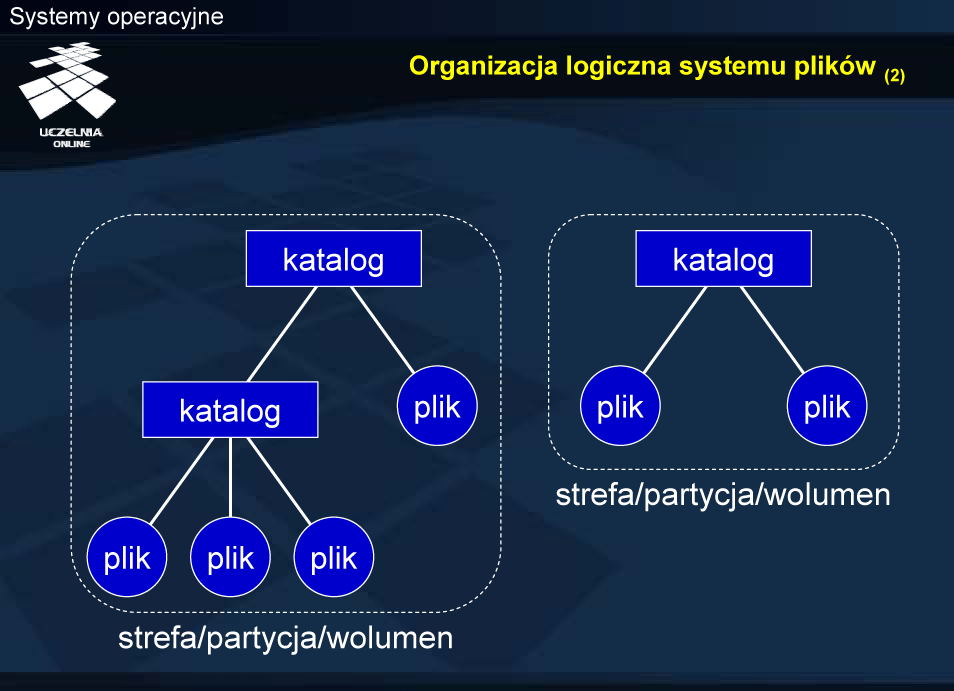
Organizacja logiczna systemu plików
System plików daje abstrakcyjny obraz informacji, gromadzonej w systemie komputerowym. Fizycznie, informacja ta może być przechowywana na różnych nośnikach: taśmach, dyskach, płytach kompaktowych, a nawet w pamięci operacyjnej. Strefa jest najczęściej obszarem związanym z fizycznym urządzeniem przechowującym plik. Czasami na urządzeniu (np. dysku) wydziela się różne strefy, postrzegane jako logiczne urządzenia.
Pliki w strefie znajdują się w katalogach, które z kolei najczęściej tworzą strukturę hierarchiczną. Z daną strefą związany jest na ogół zbiór danych o odpowiedniej strukturze do identyfikacji hierarchii katalogów oraz lokalizacji bloków z zawartością plików. Informacje takie określa się jako metadane . Inicjalizacja metadanych nazywana jest formatowaniem logicznym , albo tworzeniem systemu plików.
Warto podkreślić, że jest to logiczny obraz, który może się różnie przekładać na fizyczne rozlokowanie danych na dostępnych urządzeniach.
W przedstawionym przykładzie wyróżniono dwie strefy, w których umieszczone są pliki i katalogi. W jednej z nich katalog główny zawiera podkatalog oraz plik, a w drugiej podkatalog zawiera 2 pliki.
Podział strefy
Jak już wspomniano, strefa odpowiada najczęściej urządzeniu fizycznemu. Podział na strefy może być też jednak zrobiony w celu wyodrębnienia kilku logicznych urządzeń (dysków) na jednym urządzeniu fizycznym lub powiązania kilku fizycznych urządzeń w jedną logiczną całość.
Operacje na katalogu
Wpis w katalogu tworzony jest zawsze, gdy jakiś obiekt z danymi ma być identyfikowany przez nazwę za pośrednictwem systemu plików. Obiektem takim jest plik. Plik może mieć kilka alternatywnych nazw, z których każda ma swój wpis. Swoje wpisy mają też podkatalogi w przypadku struktury hierarchicznej. Wpis taki można również usunąć lub przemianować. Wszystkie te operacje dotyczą modyfikacji katalogu. Katalog na ogół częściej jest przeszukiwany niż modyfikowany. Przeszukiwanie polega na poszukiwaniu wpisu, identyfikowanego przez nazwę lub tworzeniu wykazu wszystkich wpisów, spełniających określone kryteria.
Struktura logiczna katalogów
Współcześnie najczęściej katalogi są logicznie powiązane w strukturę drzewa, która narzuca naturalną hierarchiczność. W przeszłości stosowane był niekiedy prostsze struktury, np. jednopoziomowa, dwupoziomowa. Można sobie również wyobrazić bardziej skomplikowane struktury, np. graf acykliczny, czy graf dowolny.
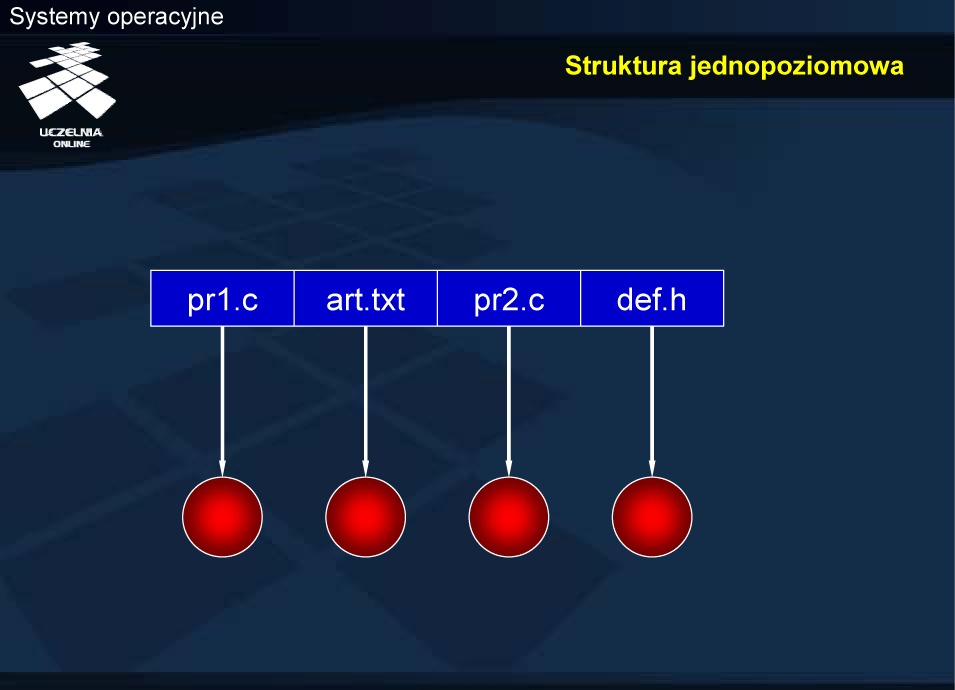
Struktura jednopoziomowa
Wszystkie pliki identyfikowane są przez nazwy, znajdujące się na tym samym poziomie. Wymaga się zatem, żeby nazwy te były unikalne. Jest to poważne ograniczenie zwłaszcza w systemach wielodostępnych.
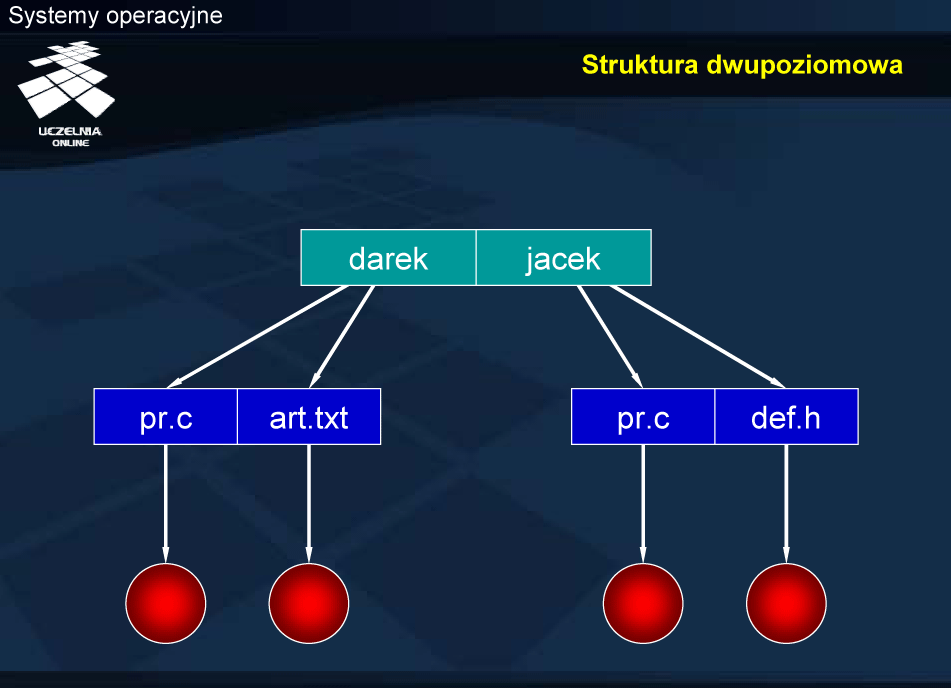
Struktura dwupoziomowa
Krokiem w kierunku ułatwienia wielodostępu przy „płaskiej” strukturze katalogów jest struktura dwupoziomowa. Każdy użytkownik ma swój katalog, więc wybierane przez niego nazwy, nie kolidują z nazwami, wybranymi przez innych użytkowników. Podejście takie zastosowano w systemie CP/M.
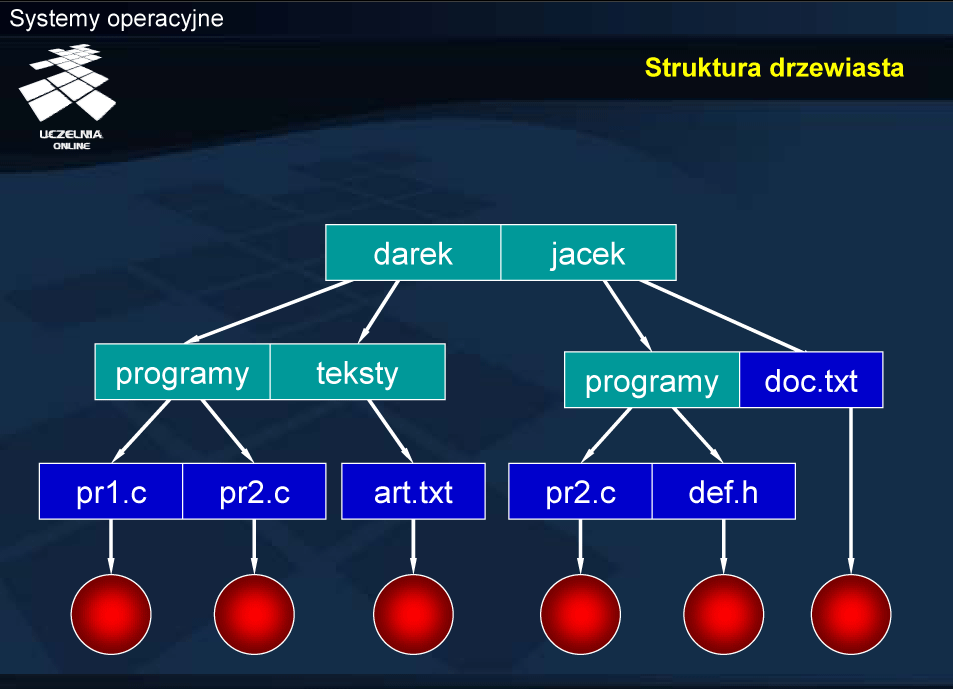
Struktura drzewiasta
Typowym podejściem jest organizacja katalogów w formie drzewa. Każdy katalog zawiera wpisy odpowiadające plikom oraz innym katalogom. Nazwy w każdym katalogu muszą być unikalne, mogą się natomiast powtarzać w innych katalogach.
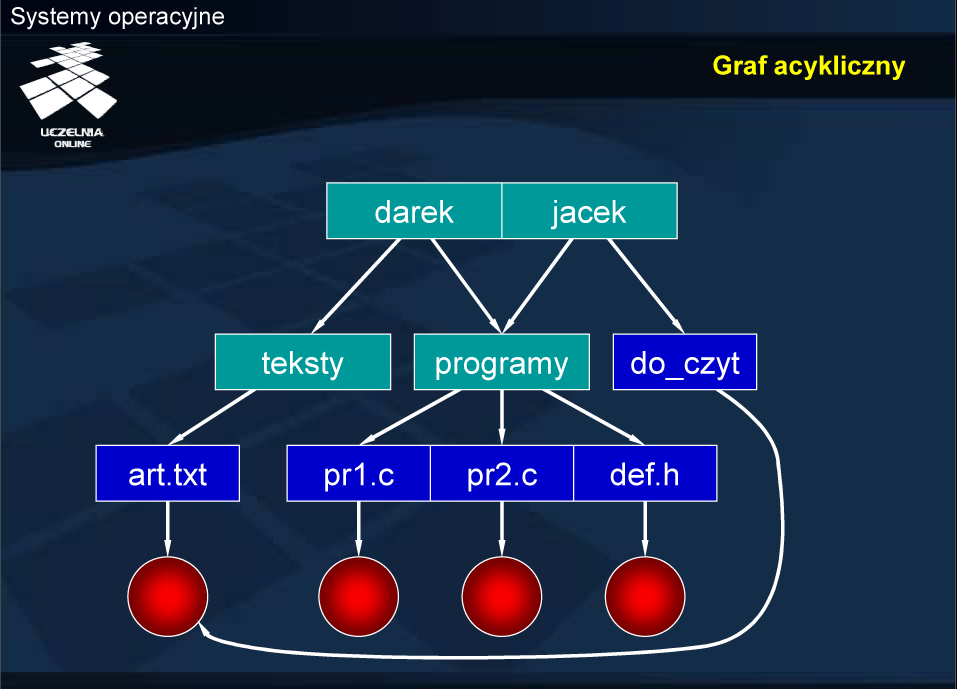
Graf acykliczny
Graf acykliczny oznacza, że ten sam obiekt może mieć wpis (dowiązanie) w kilku katalogach. W prezentowanym przykładzie obiekt (katalog) programy ma wpis w nadkatalogu darek oraz nadkatalogu jacek . Podobnie jeden z plików ma dwie różne nazwy — art.txt i do_czyt — w różnych katalogach.
Tego typu organizacja logiczna plików i katalogów stosowana jest w systemach uniksopodobnych, ale wielokrotne dowiązanie nie jest możliwe dla katalogów. Poza tym dowiązanie te muszą być w tej samej strefie (logicznym urządzeniu).
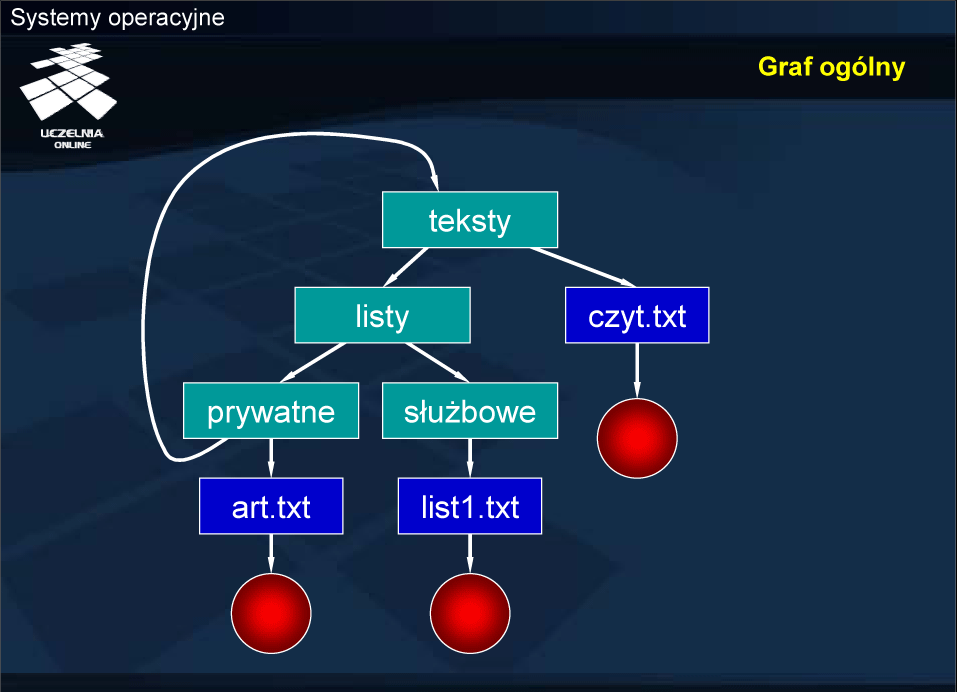
Graf ogólny
Dowolny graf raczej nie jest stosowany w systemach plików, gdyż dopuszcza cykl, który utrudnia orientację w trakcie poruszania się po takiej strukturze. Hierarchia jest najlepszą formą organizacji informacji, akceptowalną przez ludzki mózg i tym samym wygodną dla użytkownika.