DNS
Historia DNS'u

Pod koniec lat 60 eksperymentalna, rozległa sieć komputerowa ARPAnet finansowana przez Agencję ds. Zaawansowanych Projektów Badawczych (ARPA) Departamentu Obrony (DoD) Stanów zjednoczonych połączyła organizacje badawcze realizujące kontrakty rządowe w celu współdzielenia zasobów obliczeniowych.
Bardzo szybko sieć stała się medium wykorzystywanym także i w innych obszarach współpracy poprzez przesyłanie plików i wymianę poczty elektronicznej. Komunikacja między komputerami odbywała się w oparciu o adresy numeryczne, co dość szybko okazało się niewygodne i uciążliwe. Zdecydowanie łatwiejszym sposobem operowania adresami przez człowieka jest system nazw symbolicznych, które są łatwiejsze do zapamiętania, a także o wiele rzadziej ulegają zmianie niż adresy numeryczne. Pierwotnie system nazw symbolicznych oparty był na pliku HOSTS.TXT, który konserwowany był indywidualnie przez każdy ośrodek. Bardzo szybko okazało się, że utrzymywanie wielu kopii jednego pliku jest nieefektywne, co doprowadziło do rozpoczęcia w 1973 roku prac nad centralizacją systemu zakończonych w roku 1974. W wyniku konsultacji uzgodniono, że oficjalna kopia pliku HOSTS.TXT będzie utrzymywana i udostępniana przez Stanford Research Instutute (SRI) Network Information Center (NIC). System ten doskonale zdawał egzamin przez prawie 10 lat, do momentu gdy standardowy zestaw protokołów sieci ARPAnet o nazwie TCP/IP dołączono do systemu operacyjnego BSD UNIX. W wyniku tego bardzo dużo komputerów znajdujących się w sieciach lokalnych wielu organizacji uzyskało dostęp do sieci ARPAnet. Lawinowy przyrost hostów w sieci sprawił, że niemożliwe stało się centralne utrzymywanie pliku z nazwami komputerów i powstała konieczność wypracowania innego sposobu zarządzania systemem nazw symbolicznych. Rezultatem prac rozpoczętych w 1982 roku było opublikowanie do 1983 roku kilku dokumentów RFC (810, 811, 819, 830, 881, 882, 883) definiujących sam system nazw symbolicznych oraz sposób jego implementacji. System ten znany pod nazwą DNS (Domain Name System) wykorzystywany jest do dzisiaj.
Główne założenia DNS'u

Utrzymywanie pliku HOSTS.TXT w sieci ARPAnet było stosunkowo proste i mało kłopotliwe. Administratorzy wysyłali do NIC wprowadzone przez siebie zmiany i raz na jakiś czas (np. dwa razy w tygodniu) pobierali plik HOSTS.TXT z NIC. System ten zdawał egzamin dopóki sieć składała się z kilkuset hostów. Wraz ze wzrostem liczby hostów wzrosło obciążenie sieci i serwera związane z dystrybucją pliku. Wystąpiły problemy z utrzymaniem spójności pliku w zakresie unikalności nazw. Ponadto proces przeszukiwania dość dużego pliku przez lokalne komputery stanowił poważne źródło obciążenia.
Przystępując do tworzenia nowego systemu przyjęto szereg założeń, których celem było uniknięcie wszystkich dotychczasowych ograniczeń. Najważniejszą cechą systemu nazw symbolicznych jest niewątpliwie hierarchiczna struktura danych, która pozwala zarówno na decentralizację danych, jak i na decentralizację zarządzania danymi. Zarządzanie danymi odbywa się w miejscu ich powstawania w ściśle określonym zakresie, co w naturalny sposób gwarantuje spójność systemu. W podobny, naturalny sposób osiągnięto wysoki stopień odporności i wydajności systemu wprowadzając dodatkowe mechanizmy powielania i buforowania danych, które w połączeniu z trybem pracy typu klient-serwer czynią system w pełni skalowalny.
Struktura nazw DNS'u
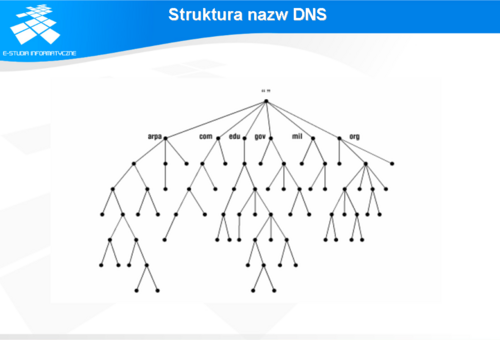
Kluczowym elementem projektu DNS jest hierarchiczna struktura nazw. Wszystkie nazwy są wieloczłonowe i rozpoczynają się od wspólnego korzenia (ang. root), reprezentowanego znakiem „.” (kropki). Poszczególne człony nazwy także oddzielane są od siebie znakiem kropki, np.:
www.pw.edu.pl. Nazwę zapisuje się począwszy od ostatniego członu, który najczęściej oznacza nazwę hosta w danej organizacji, w kierunku członów bardziej ogólnych tworzących nazwę domeny tej organizacji. Przyjęto oznaczać pełną nazwę hosta skrótem FQHN od ang. Full Qualified Host Name i podobnie pełną nazwę domeny FQDN od ang. Full Qualified Domain Name. Zgodnie z pierwotną specyfikacją poszczególne człony nazwy powinny spełniać następujące warunki: powinny składać się z liter, cyfr i znaku ‘-’, długość członu powinna wynosić min. 3 znaki, pierwszy znak powinien być zawsze literą, wielkość liter nie ma znaczenia. W późniejszym okresie dopuszczono stosowanie krótszych członów.
Domeny pierwszego poziomu

Pierwszym członem w nazwie domenowej jest tzw. domena pierwszego poziomu TLD (and. Top-Level Domain). Poniżej domeny pierwszego poziomu może znajdować się dowolnie dużo poddomen drugiego poziomu, poniżej których może znajdować się dowolnie wiele poddomen trzeciego poziomu, itd.
W pierwotnej specyfikacji znalazło się siedem domen pierwszego poziomu: .com, .edu, .mil, .gov, .net, .org, .int, oraz dwuliterowe domeny narodowe. Obsługa każdej z domen delegowana jest do odpowiedniej organizacji, odpowiedzialnej za daną domenę. Po kilkunastu latach od chwili ogłoszenia pierwszej specyfikacji zostały zgłoszone propozycje nowych domen pierwszego poziomu, z których zaakceptowano kolejnych siedem, z czego cztery .biz, .info, .name, .pro otrzymały status domen ogólnie dostępnych, natomiast pozostałe trzy .aero, .coop, .museum status domen sponsorowanych. Spośród domen znajdujących się w pierwotnej specyfikacji, w trzech: .com – firmy comercyjne, .net – firmy/organizacje zajmujące się ogólnie rozumianą technologią sieciową, .org – firmy/organizacje non-profit rejestracja nie podlega ograniczeniom, natomiast w pozostałych czterech rejestracja odbywa się według ściśle określonych kryteriów: .edu – jednostki oficjalnie uznane za edukacyjne w USA, .mil – Armia USA, .gov – instytucje rządowe USA, .int – organizacje oficjalnie zajmujące się obsługą Internetu na podstawie umów międzynarodowych. Nazwy domen pierwszego poziomu oraz związane z nimi zasady rejestracji zostały przeniesione i zaakceptowane w odniesieniu do domen drugiego poziomu domen narodowych. Ostatecznie zasady organizacji domen zostały dość mocno rozluźnione. Rozszerzono zestaw domen pierwszego poziomu, dopuszczono stosowanie dowolnych schematów tworzenia domen poniżej poziomu domen narodowych. W związku z tym pojawiły się domeny regionalne (w Polsce waw, czest, katowice), zmieniono nazwy niektórych domen (Wielka Brytania com -> co, edu -> ac), dopuszczono dowolne nazwy poniżej poziomu domen narodowych. Z wyjątkiem wspomnianych wyżej reguł rejestracji w 4 domenach pierwszego poziomu, które zaadoptowano także dla drugiego poziomu domen narodowych oraz takich wyjątków jak rejestracja w domenie .eu, gdzie stworzono bufor czasowy dla firm i organizacji posiadających osobowość prawną, rejestracja odbywa się w dowolny sposób na zasadzie „kto pierwszy ten lepszy”. Szczegóły dotyczące zasad funkcjonowania nazw domenowych można znaleźć na stronach ICANN (Internet Corporation For Assigned Names and Numbers):
http://www.icann.org/tlds/ - Top-Level Domains (gTLDs),
http://www.icann.org/topics/TLD-acceptance/ - Universal Acceptance of all Top-Level Domains
http://data.iana.org/TLD/tlds-alpha-by-domain.txt - List of Top Level Domains
Domena .arpa

Nazwa domeny .arpa to skrót od Address and Routing Parameter Area. Domena ta przeznaczona jest do obsługi infrastruktury Internetu. Administracją domeny zajmuje się IANA wspólnie z Internet Architecture Board. Wymagania oraz wytyczne dotyczące obsługi domeny .arpa znajdują się w RFC3172 (BCP 52). Obecnie w domenie .arpa zdefiniowane są następujące domeny drugiego poziomu:
in-addr.arpa, której zadaniem jest mapowanie numerów IPv4 na nazwy ip6.arpa, której zadaniem jest mapowanie adresów IPv6 na nazwy e164.arpa, której zadaniem jest mapowanie numerów telefonicznych zgodnych z E.164 na adresy URI (ang. Uniform Resource Identifier).
Przestrzeń numerów IP
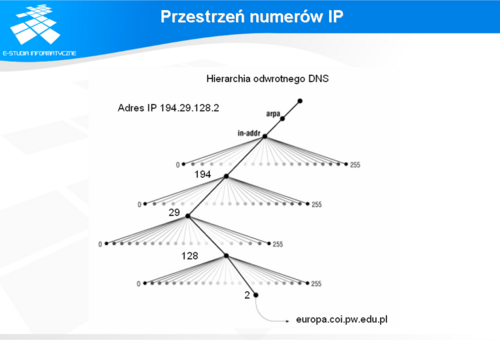
Na slajdzie zaprezentowana jest przestrzeń mapowania odwrotnego dla adresów IPv4.
Położenie domeny .arpa w przestrzeni nazw DNS
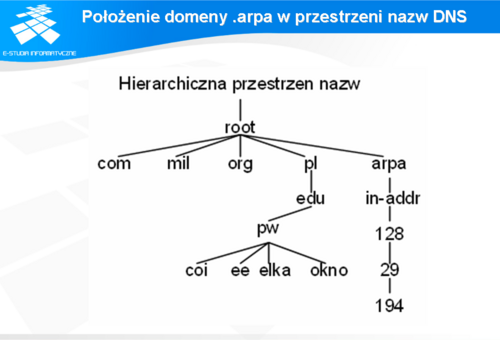
Slajd pokazuje położenie domeny .arpa w przestrzeni nazw DNS.
Zasada działania DNS
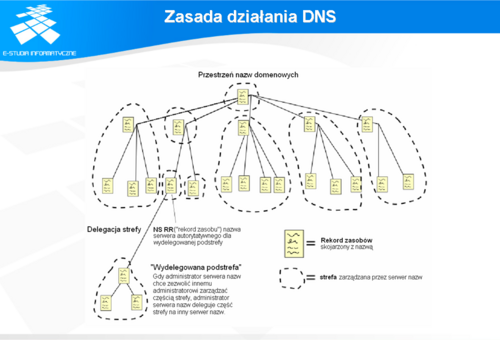
Drugą istotną cechą DNS, obok hierarchicznej struktury nazw jest rozproszona baza nazw. Idea delegowania obsługi fragmentu bazy danych organizacjom, w których te dane powstają okazała się prosta i niezwykle skuteczna.
Organizacje centralne, odpowiedzialne za funkcjonowanie Internetu obsługują lub zlecają obsługę domen pierwszego poziomu (np. domen narodowych), natomiast obsługa domen drugiego poziomu przekazywana jest organizacjom, do których należy dana domena, albo które specjalnie zostały do tego celu powołane. Następnie, organizacje obsługujące domeny drugiego poziomu, delegują obsługę domen trzeciego poziomu innym organizacjom, które zgodnie z przyjętymi zasadami mają do tego prawo, itd. Dzięki takiej strukturze zależności dane są wpisywane do bazy w miejscu, w którym powstają, co do minimum skraca czas od powstania do wprowadzenia nazwy do bazy, a to oznacza, że teoretycznie taka nazwa natychmiast jest widziana w Internecie. Aby taki system mógł działać potrzebne są specjalne serwery utrzymywane przez organizacje obsługujące jedną lub więcej domen. Serwery te przechowują właściwy dla danej organizacji fragment bazy i udostępniają posiadane informacje użytkownikom sieci, którzy o to poproszą. Na przykład domenę pw.edu.pl. należącą do Politechniki Warszawskiej obsługują serwery europa.coi.pw.edu.pl oraz io.pw.edu.pl. Jeżeli jakiś użytkownik będzie chciał połączyć się z serwerem www Politechniki www.pw.edu.pl i zapyta o adres IP tego serwera, to pośrednio albo bezpośrednio otrzyma odpowiedź właśnie z serwerów europa/io.coi.pw.edu.pl.
Serwery DNS

Podstawą fizycznej realizacji systemu nazw są serwery DNS zaimplementowane w postaci specjalnych programów komputerowych. Jakkolwiek działanie wszystkich serwerów opiera się na kilku, bardzo podobnych aplikacjach, to ze względów praktycznych poszczególne serwery różnią się między sobą funkcjonalnością. Różnice te wynikają tylko i wyłącznie ze sposobu konfiguracji, odzwierciedlającej politykę danej firmy, a nie ze względu na stosowane oprogramowanie. To jak zostanie skonfigurowany dany serwer zależy przede wszystkim od zakresu przechowywanych danych oraz budowy sieci komputerowej firmy.
Główne (root) serwery DNS
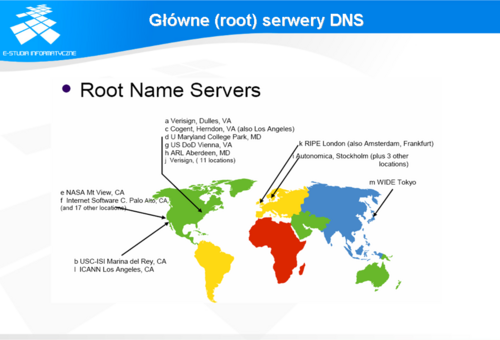
Podstawowym typem serwerów DNS są serwery główne. Z praktycznego punktu widzenia każdy serwer przechowujący dane źródłowe jest traktowany jako serwer główny dla danego poziomu w hierarchii nazw domenowych. Wśród tego typu serwerów szczególną funkcję pełnią tzw. „root serwery”, czyli serwery przechowujące informacje o serwerach głównych, obsługujących domeny pierwszego poziomu. Ze względu na dość specyficzną rolę, która ma krytyczne znaczenie dla sprawnego działania całego systemu nazw w Internecie, serwery te realizują tylko i wyłącznie tę jedną funkcjonalność. Wszystkie inne serwery DNS muszą znać adresy „root serwerów”, co jest podstawowym warunkiem umożliwiającym rozwiązanie wszystkich poprawnych nazw.
Master serwer
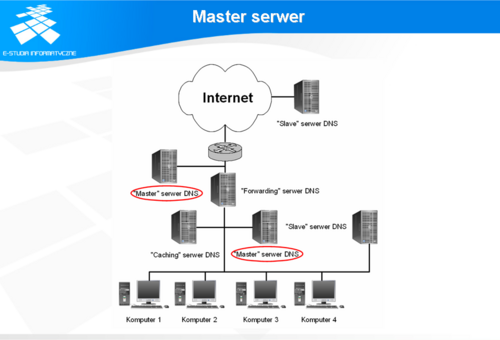
Na każdym poziomie systemu nazw instalowane są tzw. „master serwery”, przechowujące dane źródłowe dla konkretnego poddrzewa danego poziomu. W zależności od możliwości firmy, serwery te mogą ograniczać się jedynie do tej jednej funkcjonalności albo mogą świadczyć szerszy zakres usług w sieci, np. udzielać odpowiedzi bezpośrednio stacjom klienckim. Na ogół, w celu podniesienia poziomu bezpieczeństwa sieci, serwery te oprócz przechowywania danych źródłowych, świadczą jedynie usługi polegające na transferze pełnych danych do serwerów zapasowych oraz udzielaniu odpowiedzi dotyczących domen zależnych.
Slave serwer
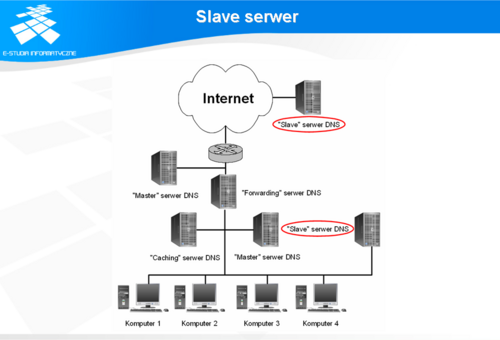
Serwery zapasowe także zaliczane są do serwerów głównych. W praktyce, klient jednakowo traktuje odpowiedzi uzyskane od serwera typu slave co i master. Zgodnie z normami, dopuszczalna liczba oficjalnych serwerów głównych (master i slave) wynosi pięć.
Praca serwera typu slave polega na transferowaniu informacji z serwera typu master zawsze wtedy, gdy serwer typu slave nie ma odpowiednich danych albo gdy dane uległy zmianie. Serwer typu slave okresowo porównuje wersję danych, które posiada z wersją danych znajdujących się na serwerze typu master. Jeżeli wersje różnią się między sobą (wersja master jest nowsza niż wersja slave), serwer typu slave dokonuje transferu danych z serwera typu master. Najnowsze serwery DNS umożliwiają bardziej efektywny sposób synchronizacji danych poprzez informowanie serwerów pomocniczych o zmianie wersji oraz transfer tylko tych danych, kóre uległy zmianie.
Bardzo częstym sposobem konfiguracji serwerów jest łączenie obu funkcji master i slave w jednym serwerze w ten sposób, że dany serwer pełni rolę serwera typu master dla domeny „A” oraz serwera typu slave dla domeny „B”, natomiast serwer typu master dla domeny „B” pełni rolę serwera typu slave dla domeny „A”. Sytuacje takie występują najczęściej w sieciach korporacyjnych oraz uniwersyteckich sieciach kampusowych.
Oprócz serwerów oficjalnych, w sieci można zainstalować rozsądnie dowolną liczbę serwerów typu slave. Dodatkowe serwery typu slave instalowane są najczęściej w poszczególnych segmentach sieci komputerowej i obsługują tylko i wyłącznie komputery należące do danego segmentu. Dzięki temu następuje zmniejszenie ruchu z Internetem poprzez ograniczenie zapytań do zewnętrznych serwerów DNS. Wszystkie podobne zapytania od pojedynczych stacji obsługiwane są przez wewnętrzny serwer typu slave, który tylko raz wysyła zapytanie do serwerów zewnętrznych, a potem przez pewien czas przechowuje uzyskane odpowiedzi w pamięci podręcznej i na tej podstawie udziela odpowiedzi. Innym przykładem wykorzystania serwerów typu slave jest instalacja takiego serwera na komputerze świadczącym inne usługi sieciowe, np. poczta elektroniczna, WWW. Praca serwerów usługowych związana jest z istnieniem wielu podrzędnych instancji serwera danej usługi, które tworzone są w momencie wystąpienia zapytania z sieci. Każda taka instancja jest potencjalnym klientem systemu nazw. W wyniku lokalnej obsługi zapytań występują nie tylko oszczędności pasma związane z łączem do Internetu ale także z łączem danego serwera do sieci lokalnej. W przypadku zbyt dużej liczby serwerów pomocniczych może wystąpić efekt odwrotny, polegający na zbyt dużym obciążeniu ruterów komunikacją między serwerem typu master a serwerami typu slave. Jeżeli konfiguracja sieci uzasadnia potrzebę instalacji tak dużej liczby serwerów pomocniczych, wtedy wybrane serwery typu slave pełnią rolę serwerów typu master dla pozostałych serwerów typu slave. Zależności pomiędzy serwerami konfiguruje się w taki sposób, aby możliwie maksymalnie ograniczyć ruch w sieci związany z transferem danych między serwerami. Wielostopniowa konfiguracja serwerów typu slave oznacza istotne zwiększenie stopnia złożoności systemu, co w konsekwencji oznacza zwiększenie bezwładności systemu oraz powoduje większe utrudnienia w utrzymaniu systemu w ruchu.
Cache serwer
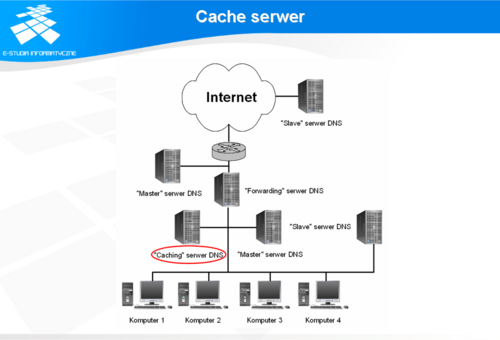
Jedną z funkcji serwerów DNS jest buforowanie danych, które zostały uzyskane w wyniku procesu wyszukiwania. Jeżeli serwer nie został skonfigurowany do przechowywania danych dla konkretnego fragmentu systemu nazw jako serwer typu master lub slave, to taki serwer nazywa się serwerem buforującym. Jego jedynym zadaniem jest wyszukiwanie danych i ich buforowanie. Podstawową informacją, na podstawie której serwer buforujący poszukuje danych jest baza adresów serwerów typu root.
Tego typu serwery przeznaczone są na ogół do obsługi segmentu sieci, którego są członkami.
Jedną z funkcji serwerów DNS jest buforowanie danych, które zostały uzyskane w wyniku procesu wyszukiwania. Jeżeli serwer nie został skonfigurowany do przechowywania danych dla konkretnego fragmentu systemu nazw jako serwer typu master lub slave, to taki serwer nazywa się serwerem buforującym. Jego jedynym zadaniem jest wyszukiwanie danych i ich buforowanie. Podstawową informacją, na podstawie której serwer buforujący poszukuje danych jest baza adresów serwerów typu root.
Tego typu serwery przeznaczone są na ogół do obsługi segmentu sieci, którego są członkami.
Forward serwer
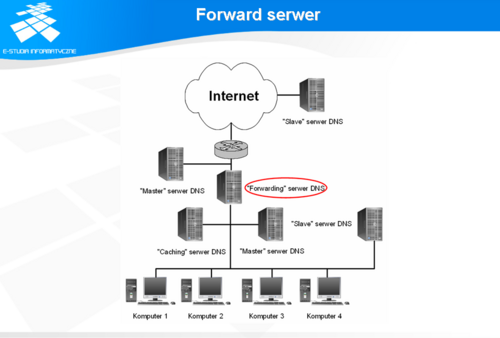
Funkcjonalność serwera typu forward nie wynika z konfiguracji, a ze sposobu jego użytkowania. Serwerem typu forward może być zarówno serwer typu master jak i slave, czy cache, który komunikuje się z serwerami zewnętrznymi w imieniu serwerów wewnętrznych. Jeżeli serwer wewnętrzny otrzyma zapytanie, które wymaga wyszukiwania w Internecie, przekazuje to zapytanie do konkretnego serwera, a ten dokonuje standardowego wyszukiwania danych komunikując się z serwerami zewnętrznymi. Tego typu konstrukcje stosuje się najczęściej w przypadku, gdy sieć wewnętrzna odseparowana jest od Internetu za pomocą FireWall’a i ze względów bezpieczeństwa serwery wewnętrzne komunikują się jedynie z serwerem typu forward, którego rolę pełni zwykły serwer DNS zainstalowany na hoście bastionowym w strefie zdemilitaryzowanej.
Sposób działania systemu nazw
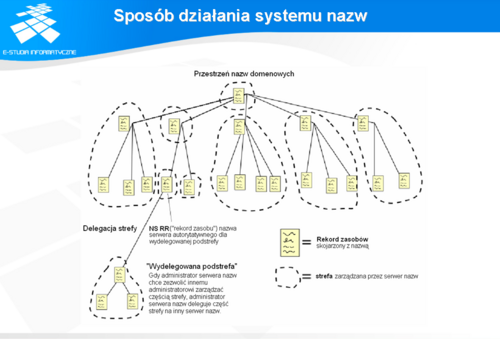
Działanie serwera DNS polega na wyszukiwaniu danych i ich buforowaniu oraz na ewentualnym przechowywaniu informacji stałych o ściśle określonym fragmencie systemu nazw. Na podstawie przechowywanych informacji, stałych lub buforowanych serwer DNS udziela odpowiedzi na otrzymane zapytania. Zapytania mogą mieć postać zapytań iteracyjnych albo rekurencyjnych.
W systemie operacyjnym każdego komputera znajduje się zestaw funkcji bibliotecznych przeznaczonych do komunikacji z serwerami nazw. Każda aplikacja wykorzystuje te funkcje do rozwiązywania nazw hostów, do których wysyła pakiety. W celu rozwiązania nazwy hosta, funkcje biblioteczne zadają pytanie serwerowi nazw, którego internetowy adres IP znajduje się w ściśle określonych plikach konfiguracyjnych systemu operacyjnego.
Rekursywny sposób rozwiązania nazw
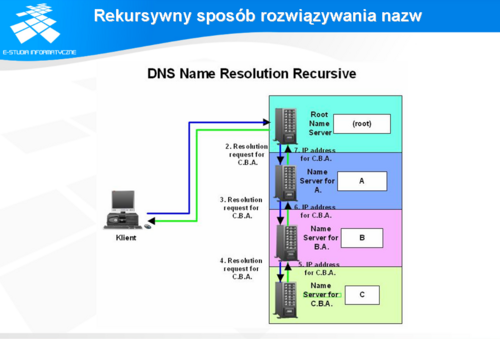
Proces rekurencyjny polega na tym, że serwer po otrzymaniu zapytania bierze na siebie cały ciężar znalezienia odpowiedzi na zapytanie przesłane od klienta. Na rysunku przedstawiono proces rozwiązywania nazwy składający się w całości z zapytań rekurencyjnych.
W praktyce jedynie lokalne serwery nazw dopuszczają zapytania rekurencyjne pochodzące tylko i wyłącznie od klientów znajdujących się w danym segmencie sieci, gdyż oprogramowanie resolvera nie potrafi samodzielnie szukać rozwiązań w przestrzeni nazw. Natomiast, lokalny serwer nazw po otrzymaniu od klienta pytania rekurencyjnego poszukuje odpowiedzi za pomocą pytań iteracyjnych.
Iteracyjny sposób rozwiązania nazw
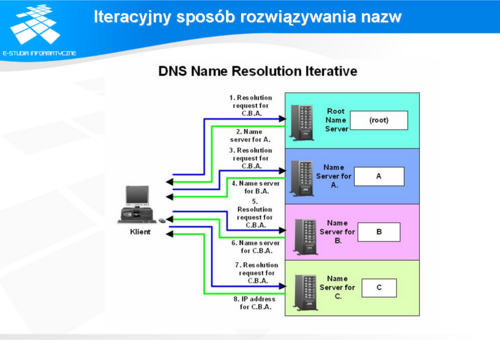
Iteracyjny sposób rozwiązywania nazw dla odmiany polega tym, że serwer zwraca najlepszą odpowiedź jaką ma w bazie albo w buforze. W skrajnym przypadku zwraca adres serwera typu root.
Na przykład, jeżeli trzeba rozwiązać nazwę www.pw.edu.pl klient wysyła zapytanie rekurencyjne do serwera DNS, którego adres znajduje się w plikach konfiguracyjnych systemu operacyjnego. Serwer DNS sprawdza, czy w buforze znajduje się informacja dotycząca tej nazwy. Jeżeli tak, to zwraca do klienta odpowiedź. Jeżeli nie ma takiej nazwy w bazie albo w buforze, to sprawdza, czy master wie jaki serwer obsługuje domenę pw.edu.pl, potem domenę edu.pl i na końcu pl. Jeżeli serwer nie ma takiej informacji w buforze, to wysyła zapytanie do jednego z serwerów głównych typu root. W odpowiedzi otrzyma informację w postaci adresu serwera DNS obsługującego domenę pl, do którego wyśle zapytanie. Serwer obsługujący domenę pl w odpowiedzi prześle adres serwera obsługującego domenę edu.pl, do którego nasz serwer wyśle kolejne zapytanie i od którego otrzyma adres serwera DNS obsługującego domenę pw.edu.pl, który z kolei, jak należy się spodziewać w odpowiedzi zwróci adres IP odpowiadający nazwie www.pw.edu.pl. Przedstawiony przykład opisuje skrajny przypadek, gdy żaden z serwerów DNS nie wie nic więcej poza adresem serwera domeny podrzędnej wchodzącej w skład nazwy. W praktyce, jeżeli jakiś serwer będzie miał w buforze szukany adres albo adres serwera obsługującego domenę tworzącą nazwę lub jej fragment, to zwróci tę informację przez co znacznie skróci proces poszukiwania rozwiązania. Oczywiście serwer DNS poszukując odpowiedzi gromadzi w buforze wszystkie otrzymane odpowiedzi przez ściśle określony czas. Jeżeli w tym czasie otrzyma zapytanie dotyczące, np. nazwy www.ee.pw.edu.pl, to rozpocznie przeszukiwanie od serwera obsługującego domenę pw.edu.pl. Natomiast poszukując rozwiązania dla nazwy www.fuw.edu.pl skieruje pierwsze zapytanie do serwera obsługującego domenę edu.pl.
Do systemu nazw DNS jest wykorzystywane różnorodne oprogramowanie

Najpopularniejszą fizyczną implementacją serwera DNS jest program o nazwie BIND, który na ogół stanowi jeden z elementów składowych wszystkich systemów operacyjnych z rodziny UNIX i LINUX.
Obecnie dostępnych jest kilka implementacji serwerów DNS, które można pobrać z Internetu w postaci programów źródłowych lub w postaci binarnej dla konkretnej platformy programowo sprzętowej.
Konfiguracja klienta DNS
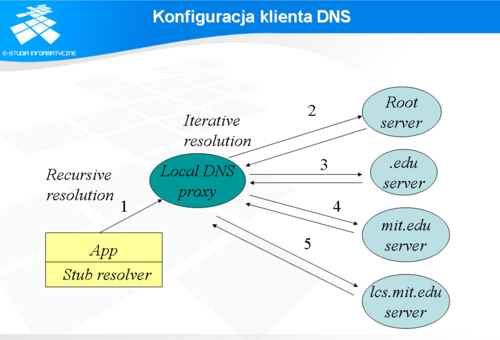
Aby aplikacje pracujące w danym systemie operacyjnym mogły korzystać z systemu nazw, należy w systemie operacyjnym skonfigurować reslover. Resolver tworzy zbiór programów bibliotecznych systemu operacyjnego, które odpowiadają za komunikację z serwerami DNS.
W przypadku systemów UNIX i LINUX konfiguracja wykonywana jest w postaci odpowiednich deklaracji w ściśle określonych plikach. Wpisy dokonywane są albo bezpośrednio za pomocą edytora tekstowego ed lub vi, lub innego kompatybilnego z tymi edytorami, albo za pomocą aplikacji graficznej dostarczonej z systemem. W przypadku dokonywania wpisów bezpośrednich, należy upewnić się czy sposób zapisu tekstu do pliku jest zgodny ze specyfikacją konkretnego systemu operacyjnego (znaki zakończenia linii oraz znaki zakończenia pliku). W przypadku systemów z rodziny M$ Windows konfigurację resolver’a wykonuje się albo za pomocą aplikacji graficznej, albo automatycznie z serwera DHCP, co jest znacznie częstszą praktyką.
Konfiguracja klienta DNS w systemie UNIX
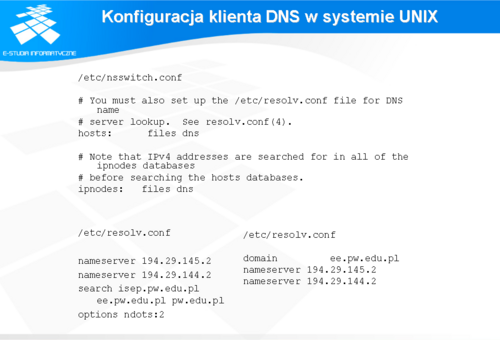
W systemach operacyjnych typu UNIX i LINUX konfigurację resolvera zaczyna się od ustawienia odpowiedniej deklaracji w pliku nsswitch.conf (NameServiceSWITCH.CONFiguration), który na ogół znajduje się w katalogu /etc. W pliku tym definiuje się serwisy oraz kolejność ich przeszukiwania w celu znalezienia konkretnej informacji. W przypadku rozwiązywania nazw istnieje wiele serwisów umożliwiających rozwiązanie nazwy: plik hosts (opcja „files”), dns, nis, nisplus, ldap i inne. W celu wymuszenia przeszukiwania serwerów DNS należy w pliku nsswitch.conf umieścić odpowiednią deklarację w opcjach hosts oraz ipnodes. Opcja ipnodes i związana jest z obsługą adresów IPv6.
Następnie należy wpisać odpowiednie deklaracje do pliku resolv.conf, który także na ogół znajduje się w katalogu /etc. W pliku tym powinna znajdować co najmniej jedna deklaracja „nameserver”, wskazująca adres IP serwera DNS. Serwer ten będzie każdorazowo pytany przez aplikacje uruchomione w danym systemie operacyjnym podczas poszukiwania rozwiązań dla nazw. W deklaracji tej możemy podać dowolny serwer w Internecie, jednak zazwyczaj podawany jest adres serwera właściwego dla danego segmentu sieci, ze względu na szybkość odpowiedzi, ale przede wszystkim, ze względu na fakt, że ten inny serwer może odmówić udzielenia odpowiedzi. Jeżeli na danym hoście uruchomiony jest serwer DNS, to jako adres IP serwera DNS podaje się numer IP: 127.0.0.1. Zgodnie z normami w pliku resolv.conf może znajdować się nie więcej niż 3 deklaracje typu „nameserver”. W pliku tym można zadeklarować domyślną nazwę domeny za pomocą deklaracji „domain”, co spowoduje, że do każdej nazwy nie zakończonej kropką automatycznie będzie dołączany zadeklarowany ciąg znaków. Jeżeli dana organizacja składa się z wielu jednostek posiadających własne domeny, lub komputery tej organizacji w zdecydowanej większości przypadków kontaktują się z nieliczną grupą ściśle określonych domen, to zamiast deklaracji „domain” można użyć deklaracji „search” z listą nazw domen. Podczas poszukiwania odpowiedzi nazwy domen podanych w opcji „search” będą dołączane według kolejności w liście do nazwy poszukiwanej, o ile ta nie kończy się znakiem kropki. Proces poszukiwań kończy się w chwili znalezienia pierwszej, poprawnej odpowiedzi.
Konfiguracja klienta DNS w systemie Windows
W systemach M$ Windows konfiguracji resolvera dokonuje się za pomocą aplikacji graficznej dostępnej, np. w następujący sposób:
START -> Panel sterowania -> Połączenia sieciowe -> Połączenie lokalne -> Właściwości -> Protokół internetowy (TCP/IP) -> Właściwości.
Za pomocą tej aplikacji można ustawić wszystkie parametry związane z komunikacją z siecią komputerową. Najczęściej wybieraną konfiguracją jest konfiguracja automatyczna. Ustawienia pochodzące z konfiguracji automatycznej można zmienić wpisując swoje własne parametry. Ponadto, podobnie jak w systemach UNIX i LINUX można zadeklarować domenę domyślną komputera oraz domeny używane podczas przeszukiwania.
Dynamiczny DNS
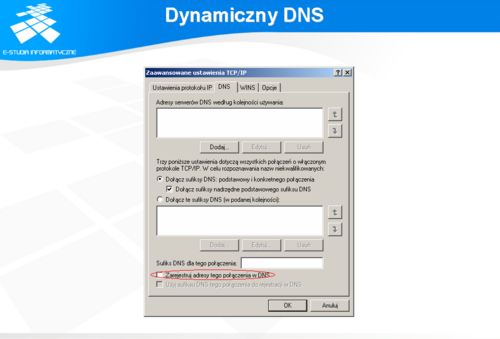
W przypadku, gdy dystrybucja adresów IP odbywa się w sposób całkowicie przypadkowy, konkretna stacja robocza może za każdym razem otrzymywać inny adres IP. Zatem, w celu zachowania spójności systemu nazw opracowano system tzw. dynamicznego DNS’u, w którym stacja robocza, po otrzymaniu z serwera DHCP wartości parametrów sieciowych może dokonać odpowiedniego wpisu do baz serwera DNS.
W zwykłych konfiguracjach opcja dynamicznego uaktualniania baz DNS jest zablokowana po stronie serwera. Natomiast, mechanizm ten jest bardzo intensywnie wykorzystywany w środowisku Active Directory firmy Microsoft, dlatego też opcja ta w domyślnej konfiguracji interfejsów sieciowych jest włączona. Staje się to przyczyną generowania zbędnego ruchu w sieci i niepotrzebnie absorbuje serwery DNS obsługą niedopuszczalnych zleceń. Zatem, opcję tą należy zawsze wyłączać, chyba że wymaga tego środowisko sieciowe, które w takim przypadku powinno być tak skonfigurowane, aby związany z tym ruch nie wychodził poza sieć lokalną.
Konfiguracja serwera DNS - zasady ogólne

Zamieszczony w tym module opis konfiguracji serwera DNS stanowi niezbędne minimum jakie należy wykonać, aby uruchomić poszczególne typy serwerów. Opis ten jest zgodny z implementacjami BIND w wersji 8 oraz 9 (widoki dotyczą tylko wersji 9). Natomiast, położenie plików konfiguracyjnych oraz sposób uruchamiania i zatrzymywania serwera został przedstawiony na podstawie systemu operacyjnego SUN Solaris. Przyjęto również założenie, że stosowne oprogramowanie aplikacyjne znajduje się już w systemie operacyjnym.
Podstawowym plikiem konfiguracyjnym systemu BIND 8/9 jest plik „named.conf”, znajdujący się zazwyczaj w katalogu /etc. Natomiast pliki z bazami danych, buforami, logami itp. umieszczane są w domyślnym katalogu bazowym /var/named. Katalog ten może zostać zmieniony odpowiednią deklaracją w pliku „named.conf”. Również nazwy wszystkich plików konfiguracyjnych mogą zostać ustawione dowolnie przez administratora systemu, jak i położenie tych plików wewnątrz katalogu bazowego. Pliki z bazami danych, to: baza root serwerów (root.cache), baza odwzorowania nazwy dla loopback (localhost.zone), baza odwrotnego odwzorowania dla loopback (localhost.rev), bazy odwzorowania dla poszczególnych stref. Podane w nawiasach nazwy plików zostały ustalone dla potrzeb niniejszego opisu.
W zależności od systemu operacyjnego istnieją różne sposoby konfigurowania procesu automatycznego uruchamiania się serwera DNS. W systemie SUN Solaris v.9 i niższe), serwer DNS uruchamiany jest jako jeden z procesów za pomocą skryptu startowego /etc/rc2.d/S72inetsvc poleceniem „/usr/sbin/in.named &”.
Konfiguracja serwera DNS - serwer typu cache
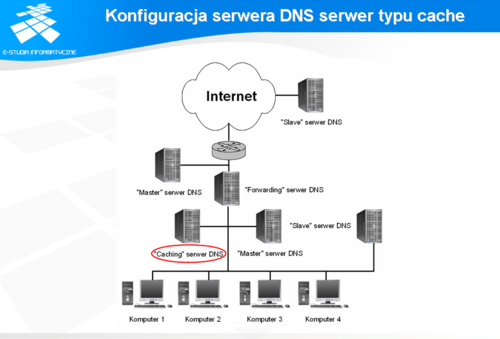
Buforowanie danych jest naturalną, jedną z podstawowych funkcjonalności serwera DNS, dlatego aby uruchomić serwer DNS dowolnego typu należy zawsze zacząć od uruchomienia serwera buforującego.
Na konfigurację serwera buforującego składają się: baza root serwerów (root.cache), baza odwzorowania nazwy dla loopback (localhost.zone), baza odwrotnego odwzorowania dla loopback (localhost.rev), przy czym BIND v.9 nie wymaga stosowania pliku z bazą root serwerów, którą tworzy samodzielnie.
named.conf - 1

Slajd przedstawia pierwsza część pliku named.conf, zawierającą deklaracje „options” oraz „logging”.
Deklaracja „options” służy do ustawienia opcji podstawowych, jak np. położenie plików oraz innych opcji, o znaczeniu globalnym, obowiązujących we wszystkich innych deklaracjach, chyba że zostaną one jawnie zmienione w obszarze konkretnej deklaracji szczegółowej. W naszym przypadku pokazano deklaracje dwóch opcji: directory – określającą położenie katalogu bazowego, pid-file - określającą położenie pliku z numerem procesu serwera. Deklaracje te nie są wymagane, jeżeli wartości opcji są zgodne z wartościami domyślnymi. Jednak ze względów bezpieczeństwa zaleca się jawne deklarowanie wszystkich istotnych zmiennych, aby uniknąć sytuacji wieloznacznych. Szczegółowy wykaz opcji można znaleźć w dokumentacji systemowej.
Deklaracja logging dotyczy sposobu obsługi komunikatów systemowych. Jeżeli zostanie pominięta, to serwer poprzestanie na generowaniu standardowych komunikatów wynikających z działania w konkretnym systemie operacyjnym. Przedstawiona deklaracja pokazuje najprostszą możliwą konfigurację systemu logowania, zgodnie z którą wszystkie komunikaty będą zapisywane w pliku „/var/named/log”. W procesie uruchamiania serwera DNS logi z komunikatami stanowią nieocenioną pomoc w odnajdywaniu błędów w konfiguracji systemu. System BIND posiada możliwość bardzo precyzyjnej konfiguracji sposobu obsługi komunikatów, z którego szczegółowy opis można znaleźć w dokumentacji.
named.conf - 2

Slajd przedstawia drugą część minimalnej wersji pliku „named.conf”, zawierającą deklaracje dotyczące bazy root serwerów oraz mapowania prostego i odwrotnego dla interfejsu loopback. Wszystkie deklaracje wykonane są zgodnie ze składnią stosowaną do opisu stref.
Deklaracja root serwerów składa się z deklaracji typu „hint” oraz nazwy pliku zawierającego bazę root serwerów. Typ „hint” oznacza, że baza ma charakter bufora. Podobnie wygląda sprawa deklaracji dla interfejsów loopback, przy czym w tym przypadku występują deklaracje typu master, a pliki z bazami są zbudowane zgodnie ze składnią plików opisujących zwykłe strefy.
root.cache

Plik zawierający bazę root serwerów składa się z dwóch typów rekordów. Jeden typ to rekordy stosowane do opisu delegacji domeny:
. 3600000 IN NS A.ROOT-SERVERS.NET. oraz drugi do opisu mapowania nazwy na numer IP: A.ROOT-SERVERS.NET. 3600000 A 198.41.0.4
W programie BIND v9. plik ten można pominąć, gdyż program sam potrafi uzyskać aktualna bazę root serwerów. Jest to o tyle wygodne, że administrator nie musi śledzić zmian adresów root serwerów.
W przypadku konfiguracji własnego root serwera, co czasami może być przydatne ze względów bezpieczeństwa lub do budowy serwisu nazw wewnątrz sieci odłączonej od Internetu, należy zadeklarować strefę „.” jako strefę typu „master” oraz przygotować plik z opisem strefy w standardowy sposób, opisany w dalszej części wykładu.
localhost.zone i localhost.rev
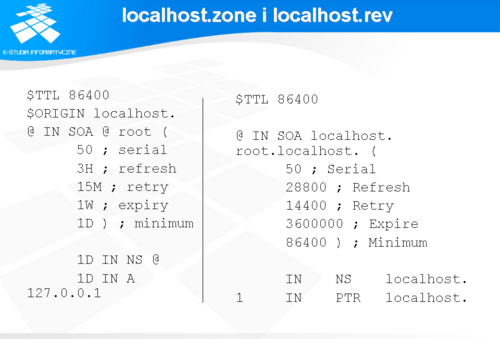
Na slajdzie przedstawiono przykładowe implementacje plików localhost.zone i localhost.rev.
Pliki te włączane są do konfiguracji serwerów DNS w celu zachowania ciągłości odwzorowania wszystkich nazw i adresów IP. Stałym elementem sieciowych systemów operacyjnych jest sieć zwrotna (loopback) zapewniająca komunikację procesów wewnętrznych systemu operacyjnego i uruchomionych w nim aplikacji między sobą za pomocą standardowych mechanizmów sieciowych. Organizacja tej sieci odbywa się na bazie nazw i adresów zarezerwowanych i nikt nie jest odpowiedzialny za ich obsługę. Zatem, obsługa taka musi być zorganizowana we własnym zakresie. Budowa plików jest bardzo prosta i dla każdego serwera DNS może być taka sama. Dane te można również umieszczać w plikach z bazami danych stref, jednak jest to niewygodne, a w przypadku serwerów buforujących, które nie mają plików strefowych i tak trzeba je stworzyć.
log
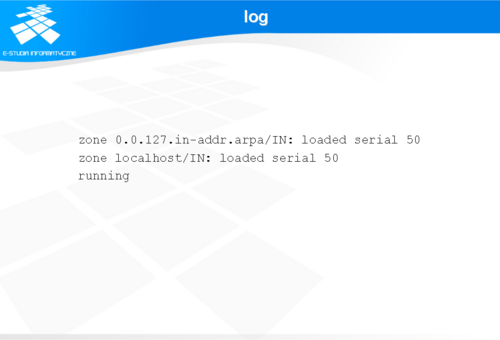
Slajd przedstawia komunikaty wygenerowane podczas poprawnego uruchomienia serwera typu cache.
Jak widać serwer przeczytał i załadował do pamięci jedyne zadeklarowane strefy dla interfejsu loopback.
Serwer DNS został uruchomiony za pomocą polecenia: /usr/sbin/in.named
W przypadku stwierdzenia błędów w konfiguracji, serwer należy albo zatrzymać poleceniem: kill –KILL <PID procesu serwera>
albo dokonać restartu serwera za pomocą podobnego polecenia: kill –HUP <PID procesu serwera>
Szczegółowy opis komunikatów można znaleźć w dokumentacji programu BIND.
Konfiguracja serwera DNS serwer typu master

Określenie „serwer typu master” używane jest w kontekście konkretnej domeny. Stąd serwer typu master dla konkretnej domeny, to serwer DNS, który posiada źródłowe bazy odwzorowania nazw na adresy IP.
W celu skonfigurowania serwera DNS jako master serwera dla konkretnej domeny, należy do pliku named.conf dodać odpowiednią deklarację typu „zone”, zawierającą opcję „type master” oraz opcję określającą nazwę pliku z bazą danych dla domeny. Deklaracja „zone” może zawierać dodatkowo inne dodatkowe opcje podnoszące funkcjonalność lub zwiększające bezpieczeństwo systemu. Szczegółowy opis opcji dodatkowych można znaleźć w dokumentacji do systemu BIND. Opis pliku z bazą danych dla domeny zostanie przedstawiony na kolejnych slajdach.
Konfiguracja serwera DNS serwer typu reverse

Konfiguracja serwera typu „revers”, czyli odwzorowania odwrotnego dotyczy sytuacji, gdy adres IP odwzorowywany jest na nazwę. Także i w tym przypadku rozróżniane są serwery typu master i slave, których konfiguracja odbywa się w kontekście konkretnej strefy numeracyjnej.
Deklaracja obsługi danej strefy jako serwer typu master wykonywana jest tak samo jak dla odwzorowania zwykłego, czyli przez odpowiedni wpis w pliku named.conf. Postać deklaracji jest taka sama jak dla deklaracji typu „zone”, przy czym jako nazwę strefy podaje się numer sieci zapisany w odwrotnej kolejności i uzupełniony nazwą domeny specjalnej „in.addr.arpa” stosowanej do obsługi infrastruktury Internetu. Plik zawierający bazę danych dla strefy tworzony jest w podobny sposób jak pliki odwzorowania zwykłego, z pewnymi ograniczeniami, co zostanie przedstawione na następnych slajdach.
Konfiguracja serwera DNS serwer typu slave

W przypadku serwera typu „slave” do znanych już opcji dochodzi opcja „masters”, która pokazuje serwer lub serwery główne dla danej domen/strefy, z których serwer będzie transferował dane.
Wartość opcji type zmienia się na slave, co jest jednoznacznie związane z funkcjonalnością serwera dla danej domeny/strefy. Natomiast ciągi znaków w opcji „file” są nazwami plików, w których serwer będzie przechowywał bazy uzyskane w wyniku transferu danych z serwerów typu master. Pliki te tworzone są automatycznie. Ich wewnętrzna zawartość, co do sposobu deklaracji dość mocno odbiega od oryginału, jednak co do treści pokrywa się całkowicie z treścią zawartą w bazie źródłowej.
Widoki (ang. views)
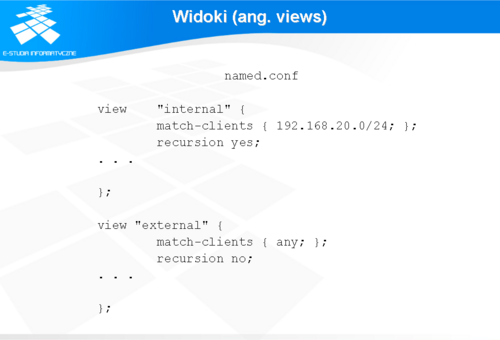
W momencie wprowadzenia do konfiguracji sieci mechanizmu mapowania adresów (NAT) pojawił się problem obsługi tego typu konstrukcji przez serwery DNS.
Zazwyczaj fizyczna i logiczna budowa sieci firmowej przewiduje dwie główne części: strefę zdemilitaryzowaną (DMZ), do której jest dostęp z Internetu, i w której znajdują się Internetowe serwery usługowe oraz sieć wewnętrzną, do której nie ma dostępu z Internetu, a dostęp do Internetu jest filtrowany. W sieci wewnętrznej, w takich przypadkach stosowana jest numeracja oparta na adresach prywatnych. Konfiguracja systemu nazw zakłada, że sieć wewnętrzna firmy ma dostęp do usług Internetowych oraz Intranetowych, natomiast użytkownicy Internetu mają dostęp tylko do takich usług i informacji jakie przewiduje polityka bezpieczeństwa firmy. W przypadku serwerów DNS realizowane jest to za pomocą tzw. widoków. W konfiguracji serwera definiuje się dwie sekcje (views) o różnej zawartości. Pierwsza sekcja przeznaczona jest do obsługi ściśle określonych hostów, natomiast druga do obsługi reszty sieci, z Internetem włącznie.
Budowa plików z opisem stref

Pliki zawierające bazę danych dla domeny, czy strefy składają się z różnego typu rekordów i deklaracji zapisanych w postaci tekstowej.
Najważniejszym rekordem w bazie jest rekord SOA (ang. Start Of Authority), który zgodnie ze swoją rolą zawsze znajduje się jako pierwszy. Wszystkie rekordy rozpoczynają się nazwą opisywanego obiektu, deklaracją typu sieci, deklaracją typu rekordu. Po tych deklaracjach umieszczana jest wartość rekordu, która może mieć postać złożoną (rekordy typu SOA i MX). Ponieważ w praktyce dominującym typem sieci jest Internet, oznaczany symbolem IN, normy dopuszczają traktowanie tego oznaczenia jako domyślne i pomijanie w opisie rekordu. Istotną zasadą budowy rekordu jest możliwość pominięcia nazwy obiektu w kolejnym rekordzie dotyczącym tego obiektu. Fakt ten należy wyraźnie zaznaczyć zapisując pozostałe parametry rekordu z zachowaniem wolnej przestrzeni na początku rekordu. Na następnych slajdach zostaną przedstawione podstawowe i najczęściej spotykane sposoby użycia rekordów. Szczegółowych opisów należy szukać w dokumentacji serwerów DNS.
Rekord SOA

Rekord SOA (ang. Start Of Authority) jest rekordem zasobów, informujących, że dany serwer jest serwerem informacji źródłowych o danej strefie.
Zgodnie z budową rekordu, rekord SOA zaczyna się nazwą obiektu, który opisuje. Może tu występować jawna nazwa domeny, koniecznie zakończona kropką albo zamiast jawnej nazwy może zostać użyty znak „@” oznaczający nazwę domeny źródłowej zgodnej z deklaracją w pliku named.conf. Następnymi parametrami jest symbol sieci „IN” oraz typ rekordu SOA, po którym występuje wartość, bardzo rozbudowana w przypadku tego rekordu. Składowe pola wartości rekordu to: nazwa serwera typu master obsługującego daną domenę, adres e-mail osoby odpowiedzialnej za domenę (ze względu na inne znaczenie symbolu „@” w plikach DNS, w adresie występuje znak „.”; ponieważ adres ten nie jest obsługiwany automatycznie, a służy jedynie jako informacja dla innych administratorów, przyjmuje się, że administrator sieci będzie umiał przekształcić ten ciąg znaków na poprawny adres e-mail), grupa wartości w nawiasach „(…)” numer seryjny: numer oznaczający wersję danych w bazie; im wyższy numer tym nowsze dane; numer ten używany jest przez serwery zapasowe; jeżeli numer seryjny danych o domenie w serwerze zapasowym jest niższy niż ten na serwerze głównym, to serwer zapasowy dokonuje transferu danych dla tej domeny; odświeżanie: czas w sekundach określający jak często serwer zapasowy powinien sprawdzać na serwerze typu master konkretnej domeny aktualność danych, ponowienie: czas w sekundach, po którym należy ponowić próbę sprawdzenia aktualności danych, jeżeli poprzednia próba zakończyła się niepowodzeniem, wygasanie: czas w sekundach wygasania domeny, po którym serwer zapasowy przestaje udzielać informacji o domenie, jeżeli próba kontaktu z serwerem typu master dla danej domeny zakończyła się niepowodzeniem, buforowanie negatywne: pierwotnie wartość ta oznaczała czas w sekundach, przez jaki serwery mogą buforować dane dotyczące konkretnej domeny zarówno w przypadku odpowiedzi pozytywnych jak i negatywnych; zmiana nastąpiła od wersji 8.2 programu BIND; obecnie wartość ta określa czas w sekundach buforowania odpowiedzi negatywnych; do określania czasu buforowania odpowiedzi pozytywnych służy zmienna TTL, której deklaracja występuje jako pierwszy wpis w pliku dla danej domeny, przed rekordem SOA. Obecnie normy dopuszczają stosowanie skróconego formatu czasu: 120m – 120 minut, 1H – jedna godzina, 3D – trzy dni, 1W – jeden tydzień.
Rekord MX

Rekord typu MX określa nazwę serwera pocztowego, obsługującego daną domenę lub konkretny host.
Wartością rekordu, jest wartość składająca się z dwóch elementów: priorytetu, nazwy serwera pocztowego. Jeżeli jakiś serwer pocztowy chce dostarczyć przesyłkę do adresata w konkretnej domenie, sprawdza w systemie nazw jaki serwer obsługuje pocztę dla domeny adresata. Dla danej domeny może być więcej niż jeden serwer pocztowy. O kolejności w jakiej serwer wysyłający będzie kontaktował się z serwerami odbierającymi decyduje pole priorytetu. Konfiguracje takie stosuje się w przypadku instalacji klastrowych serwerów pocztowych, bądź w przypadku konfiguracji z wieloma serwerami pośredniczącymi.
NS

Rekordy typu NS służą do definiowania serwerów DNS obsługujących daną domenę (a) albo jej poddomenę (c). Adres serwera DNS może zostać wpisany w formie pełnej, kwalifikowanej nazwy domenowej, koniecznie zakończonej „.” (a) (c), co jest najczęściej stosowane albo w postaci adresu IP (b). Jeżeli adres serwera zostanie podany w postaci nazwy domenowej, to w tym samym pliku dodawane są tzw. rekordy „sklejające” (ang. glue records), których zadaniem jest:
przyśpieszenie poszukiwań, nie dopuszczanie do zapętleń w wyniku stosowania odwołań. Bardzo często obsługa domen odbywa się na zasadzie hostingu, gdy np. dostawca Internetu utrzymuje serwery DNS dla swoich klientów. Normy nie narzucają miejsca usytuowania serwera DNS dla danej domeny. Serwer ten może być gdziekolwiek w Internecie. Praktyka pokazuje, że najlepiej, gdy serwer DNS znajduje się możliwie blisko szeroko rozumianego administratora domeny. Ponadto dobrą praktyką jest umieszczenie serwera zapasowego w innym segmencie sieci niż master serwer. Szczególnie korzystne jest umiejscowienie serwera zapasowego poza siecią firmową.
Przykład pliku z definicją strefy mapowanie proste (nazwa -> ip)
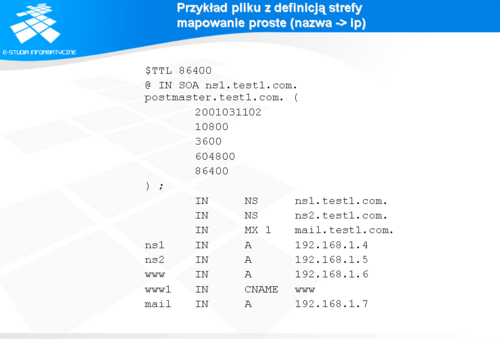
Slajd pokazuje początek typowego pliku z definicją domeny. Zgodnie z normami, plik otwiera rekord SOA i towarzysząca mu deklaracja TTL dla pozytywnego buforowania.
Następnie, występują deklaracje serwerów DNS oraz serwera pocztowego. W dalszej kolejności znajdują się głównie rekordy mapowania typu nazwa -> adres IP. Rekordy oznaczane są w za pomocą symbolu „A” (ang. address). W przypadku mapowania nazwy na adres IPv6, stosuje się oznaczenie „AAA”. W tego typu plikach często spotykanym rekordem jest rekord typu „CNAME” (ang. canonical name). Rekord ten używany jest do mapowania nazw za pomocą innych nazw. Przykładem stosowania tego typu konstrukcji są wirtualne serwery WWW, które mają jeden adres IP, ale obsługują serwery wirtualne różnych organizacji, gdzie identyfikacja serwera odbywa się poprzez nazwę. Można oczywiście dla każdej nazwy serwera wirtualnego dokonać deklaracji za pomocą rekordu typu „A”. Jednak w przypadku zmiany adresu IP znacznie prościej jest zmienić ten adres w jednym miejscu, zmniejszając tym samym ryzyko pomyłki. Normy dopuszczają stosowanie wielokrotnych odwołań typu „CNAME”. Należy jednak zachować umiar i ostrożność w stosowaniu takich konfiguracji. Ponadto normy dopuszczają także inne typy rekordów. W praktyce albo zaniechano ich stosowania, albo ich wykorzystanie jest marginalne. Spośród tych rekordów należy wspomnieć rekord opisowy oznaczany symbolem „TEXT”. Jego pierwotnym przeznaczeniem był opis zdefiniowanego wcześniej obiektu. W opisie podawano różne szczegóły dotyczące, np. typu komputera, systemu operacyjnego, lokalizacji, itp. Informacje te były przeznaczone dla użytkowników ale od kiedy niemal jedynymi ich odbiorcami stali się hakerzy, administratorzy unikają ich stosowania.
Przykład pliku z definicją strefy mapowanie odwrotne (ip -> nazwa)
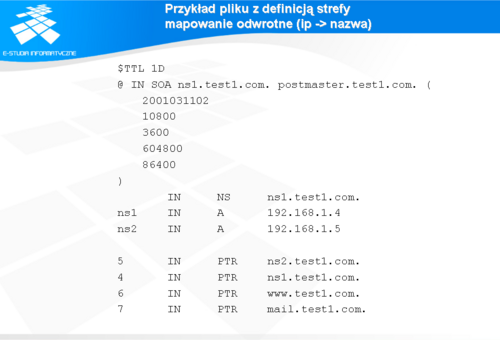
Plik opisujący mapowanie odwrotne, czyli adres IP -> nazwa skonstruowany jest identycznie jak plik z opisem mapowania nazwa -> adres IP przedstawiony na slajdzie poprzednim.
Różnica polega na tym, że zasadniczym elementem pliku są rekordy typu „PTR” (ang. pointer). Wartością rekordów „PTR” jest pełna, kwalifikowana nazwa domenowa hosta (FQHN) posiadającego konkretny adres IP. Często się zdarza, że zakres dany numeracyjny w całości dotyczy hostów z jednej domeny. Jednak równie często, występuje sytuacja odwrotna, gdy zakres numeracyjny podzielony jest pomiędzy kilka, kilkunaście, a nawet kilkadziesiąt firm. W takich przypadkach konfigurowane są specjalne deklaracje umożliwiające lokalną administrację przydzielonym zakresem numerów IP. Szczegóły można znaleźć w RFC 2317.
Uruchomienie serwera DNS i diagnostyka

Czynności wykonywane podczas uruchamiania serwera DNS są w dużej mierze podobne do procesu diagnostyki serwera w sytuacji wystąpienia awarii. W celu sprawdzenia poprawności działania serwera lub w celu usunięcia ewentualnych błędów w konfiguracji należy sprawdzić:
poprawność uruchamiania programu serwera (ps –ef, /var/adm/messages), komunikaty w pliku z logami (/var/name/log), poprawność mapowania z wewnątrz i z zewnątrz sieci (nslookup, dig, itp..).
log
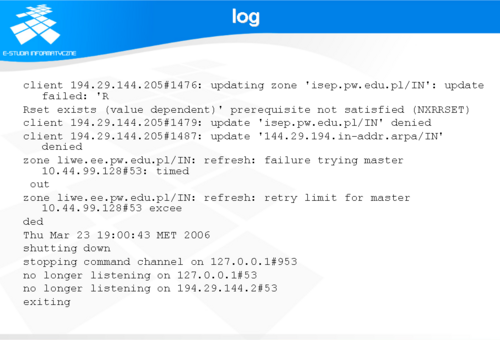
Pliki z logami, zarówno systemowymi , jak i pochodzącymi od samej aplikacji stanowią bardzo istotną pomoc podczas uruchamiania i monitorowania serwera DNS.
Na slajdzie przedstawiono fragment takich logów z programu BIND. Podczas czytania logów należy zachować pewną ostrożność, gdyż komunikaty nie zawsze są wystarczająco czytelne. Często jakiś komunikat o błędzie może być objawem błędu, który leży znacznie głębiej niż parametry zawarte w komunikacie.
nslookup
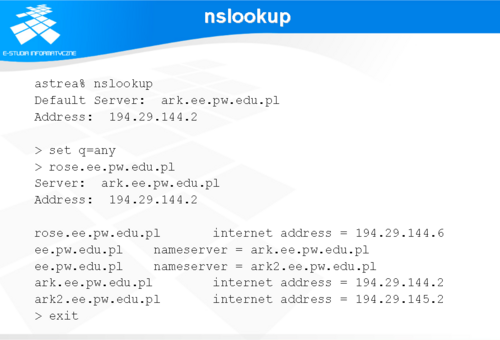
Najstarszym program służącym do diagnostyki systemu nazw jest program „nslookup”. Obecnie wykorzystywane są do tego celu inne programy jak dig, czy host. Jednak nslookup należy do podstawowych dystrybucji wszystkich sieciowych systemów operacyjnych.
Program ten wywołany bez opcji uruchamia się w trybie interakcyjnym wypisując parametry domyślnego serwera DNS. Polecenie „set” służy do konfiguracji zakresu odpowiedzi. W przykładzie ze slajdu ustawiono wartość opcji „querytype” (w skrócie „q”) na „any”, co oznacza, że program w odpowiedzi na postawione zapytanie wyświetli wszystkie informacje, które będzie w stanie uzyskać o danym obiekcie. Zakres odpowiedzi można ograniczyć do wybranych elementów. Szczegóły można znaleźć w manualu do polecenia nslookup (man nslookup). W wyniku zapytania o nazwę hosta rose.ee.pw.edu.pl, program wyświetlił parametry serwera, który udzielił odpowiedzi, parametry adresowe hosta oraz parametry adresowe serwerów DNS obsługujących domenę do której należy host. Z programu wychodzimy poleceniem „exit”.
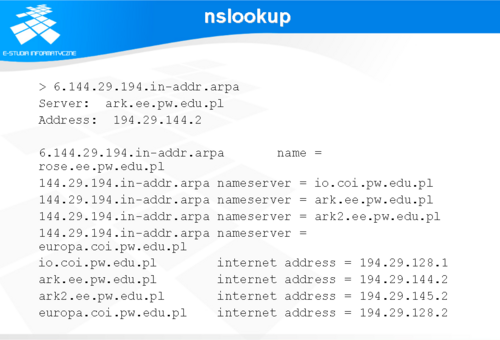
Slajd przedstawia odpowiedź na zapytanie dotyczące mapowania odwrotnego. Charakterystyczne jest to, że zapytanie sformułowane jest zgodnie z budową domeny in-addr.arpa, czyli od ostatniego elementu adresu IP do pierwszego.
W przedstawionych przykładach zaprezentowano typowe podczas testowania zapytania o mapowanie proste i odwrotne. Jeżeli w obu przypadkach odpowiedzi pokrywają się można uznać, że system działa poprawnie. Na ogół tego typu testowanie przeprowadza się nie tylko podczas uruchamiania serwera DNS, ale także po dokonaniu nowych wpisów w bazach.
Przykładowa konfiguracja serwera DNS
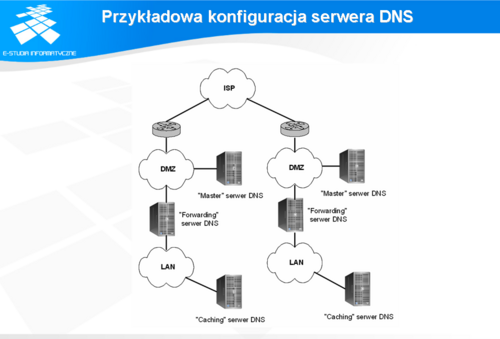
Jako przykład zostanie przedstawiona konfiguracja serwerów DNS w firmie z dwoma oddziałami, niezależnie podpiętymi do Internetu. Sieć każdego oddziału oraz sposób podpięcia do Internetu jest identyczny. W sieci każdej z tych sieci wyróżniamy dwie części: DMZ (strefa zdemilitaryzowana) oraz sieć lokalną (LAN), oddzielone od siebie ścianą ogniową. Oddziały połączone są dodatkowo łączem prywatnym.
W części DMZ jednego oddziału znajduje się serwer DNS typu master obsługujący domenę firmy, a w drugim oddziale znajduje się serwer DNS typu slave dla tej samej domeny. W sieci lokalnej każdego oddziału znajduje się serwer DNS typu typu master dla domeny wewnętrznej danego oddziału oraz typu slave dla domeny drugiego oddziału. Serwery w sieciach lokalnych skonfigurowane są tak, że wszystkie zapytania dotyczące Internetu kierowane są do serwera DNS znajdującego się w części DMZ danego oddziału.
Konfiguracja podstawowa

Wszystkie cztery serwery należy w fazie początkowej skonfigurować jednakowo, w sposób jaki konfiguruje się serwer buforujący. W pliku /etc/named.conf powinny znaleźć się bloki „options”, „logging” oraz „zone” dla sieci wewnętrznej (loopback). W zależności od wersji programu BIND można dodać lub nie blok „zone” dla root serwerów.
Ponadto zgodnie z wpisami w pliku named.conf należy w katalogu /var/named albo innym, w zależności od wartości deklaracji „directory” bloku „options” umieścić pliki wymienione w blokach „zone”. Po uruchomieniu, serwery będą samodzielnie wysyłały zapytania do Internetu. Na tym etapie, w konfiguracji serwerów wewnętrznych można dodać w bloku „options” deklarację: „forwarders { <ip serwera zewnętrznego>; };”, w której należy podać numer IP serwera zewnętrznego, znajdującego się w strefie DMZ danego oddziału. W wyniku tego zabiegu, wszystkie zapytania generowane przez serwery wewnętrzne powinny być obsługiwane przez serwery znajdujące się w strefie DMZ.
Konfiguracja serwerów w DMZ

Jeżeli serwery DNS skonfigurowane jako serwery buforujące działają poprawnie, można przystąpić do konfiguracji szczegółowej poszczególnych stref.
W celu ustalenia uwagi oddziały firmy oznaczono literami „A” oraz „B”. W strefie DMZ oddziału „A” znajduje się serwer DNS typu master dla domeny firmowej (konfiguracja DMZ A), natomiast w strefie DMZ oddziału „B” znajduje się serwer typu slave dla domeny firmowej (konfiguracja DMZ B). Wewnątrz sieci lokalnych (LAN) obu oddziałów znajdują się serwery, z których każdy jest serwerem typu master dla domeny danego oddziału i serwerem typu slave dla domeny drugiego oddziału. W przypadku serwerów wewnętrznych można użyć nazw domen w postaci <nazwa oddziału>.<domena firmy> albo w postaci skróconej <nazwa oddziału>, czyli tak jakby nazwy oddziałów były nazwami domen pierwszego poziomu. W praktyce nie powinno to mieć większego znaczenia, gdyż struktura wewnętrzna firmy nie powinna być widziana z Internetu.
Podsumowanie
