Io-1-wyk
Wprowadzenie do przedmiotu
Witam Państwa serdecznie na pierwszym wykładzie dotyczącym inżynierii oprogramowania. Dzisiejszy wykład będzie trochę przypominał oglądanie okolicy z lotu ptaka. Z tej perspektywy nie widać wielu, być może bardzo ważnych, szczegółów, ale za to ma się obraz całości. I ten obraz całości, w odniesieniu do inżynierii oprogramowania, będę się starał w trakcie dzisiejszego wykładu stworzyć.
Definicja
Zgodnie ze standardowym słownikiem inżynierii oprogramowania opracowanym przez IEEE, inżynieria oprogramowania jest to zastosowanie systematycznego, zdyscyplinowanego, ilościowego podejścia do rozwoju, eksploatacji i utrzymania oprogramowania.
Krótko mówiąc, jest to zastosowanie inżynierskiego podejścia do oprogramowania. Taka definicja jest krótka (i to jest jej zaletą), ale – niestety – nie wyjaśnia zbyt szczegółowo, co wchodzi w zakres inżynierii oprogramowania.
Computing Curricula 2001
Określeniem zakresu wiedzy dotyczącej różnych obszarów informatyki, w tym również inżynierii oprogramowania, od wielu lat zajmują się wspólnie dwa, największe na świecie, towarzystwa informatyczne: IEEE Computer Society i Association for Computing Machinery (w skrócie ACM). Oba powstały tuż po II Wojnie Światowej w Stanach Zjednoczonych i mają teraz (razem) około 180 tys. członków na całym świecie (dla porównania, Polskie Towarzystwo Informatyczne ma około tysiąca członków). Wydają wysokiej rangi czasopisma naukowe, organizują liczne i bardzo ważne konferencje oraz zawody dla studentów takie, jak IEEE Computer Society International Design Competition i ACM International Collegiate Programming Contest.
Pierwsze rekomendacje dotyczące studiów informatycznych powstały pod auspicjami ACM w 1968 roku. IEEE Computer Society opracowało swoje rekomendacje po raz pierwszy w 1977 roku.
Pod koniec lat 80-tych oba towarzystwa postanowiły połączyć swoje siły i wspólnie opracowały standard nauczania zwany Computing Curricula 1991. Dziesięć lat później powstała nowa wersja zwana Computing Curricula 2001.
Inżynieria oprogramowania jest jednym z czternastu obszarów informatyki wyodrębnionych w tym dokumencie.
Inżynieria oprogramowania
W ramach inżynierii oprogramowania jest osiem jednostek wiedzy o charakterze obligatoryjnym (czyli każdy informatyk musi to wiedzieć) i cztery opcjonalne.
Wśród obowiązkowych jednostek wiedzy mamy dwie dotyczące czynności poprzedzających samo kodowanie programu. Jest to specyfikacja wymagań, czyli ustalenie co budowany system ma robić i projektowanie oprogramowania, czyli – w dużym uproszczeniu – zaproponowanie jego struktury.
Kolejne dwie jednostki dotyczą walidacji i weryfikacji oprogramowania (czyli, inaczej mówiąc, kontroli jakości) i jego ewolucji, czyli utrzymania użyteczności programu i umiejętnego wprowadzania do niego koniecznych zmian.
Inżynieria oprogramowania obejmuje również takie jednostki wiedzy, jak procesy wytwarzania oprogramowania (rozpatruje się tutaj, m.in. różne modele cyklu życia oprogramowania, co ma potem wpływ na planowanie przedsięwzięć programistycznych) i zarządzanie przedsięwzięciami programistycznymi.
Ostatnie dwie obowiązkowe jednostki wiedzy dotyczą narzędzi i środowisk programistycznych oraz interfejsów programistycznych – w skrócie API od ang. Application Programming Interface
Wśród jednostek opcjonalnych są metody formalne (czyli o charakterze matematycznym), systemy specjalne (np. systemy czasu rzeczywistego sterujące pracą elektrowni, czy lotem samolotu), komponenty programistyczne i zagadnienia dot. niezawodności oprogramowania.
Polski standard kształcenia dla kierunku Informatyka, przyjęty przez Radę Główną Szkolnictwa Wyższego w czerwcu 2006 roku, obejmuje osiem jednostek wiedzy, które według Computing Curricula 2001 mają charakter obligatoryjny.
W ramach tego przedmiotu skoncentrujemy się na pierwszych sześciu obszarach, natomiast narzędzia, jak i API będą omawiane w ramach innych przedmiotów. Na przykład takie narzędzia jak kompilatory różnych języków programowania będą omawiane przy okazji prezentowania paradygmatów programowania, na których te języki się opierają. W ramach inżynierii oprogramowania będziemy prezentować tylko narzędzia wspomagające dotyczące takich zagadnień, jak zarządzanie konfiguracją, tworzenie modeli w języku UML, czy testowanie. Z kolei API będą prezentowane na przedmiotach związanych z różnymi obszarami informatyki. Na przykład API dotyczące wybranego systemu operacyjnego będzie prezentowane w ramach zajęć z systemów operacyjnych, API związane z pakietami graficznymi – na przedmiocie dotyczącym grafiki komputerowej itd.
Plan wykładu
W dalszej części wykładu chciałbym krótko omówić tematykę kolejnych wykładów, jakie nas czekają w ramach tego przedmiotu.
Zasady skutecznego działania
Szefowie amerykańskich firm informatycznych skarżą się, że absolwenci amerykańskich uczelni nie potrafią się komunikować, mają niedostateczne przygotowanie do pracy w zespole i że brak im umiejętności skutecznego i produktywnego zarządzania ich pracą indywidualną. Prawdopodobnie tego typu zastrzeżenia można by usłyszeć również z ust pracodawców polskich. Dlatego zanim zaczniemy prezentować różne metody i narzędzia inżynierii oprogramowania postanowiłem najpierw przedstawić ogólne zasady skutecznego działania, które stanowią podstawę dla szczegółowych rozwiązań i bez rozumienia których trudno oczekiwać satysfakcjonujących efektów.
Zasady te będą oparte na słynnej książce Stephena Covey’ego „7 nawyków skutecznego działania”. Na slajdzie widzimy okładkę do jej wersji dźwiękowej. Książka ta została również wydana w języku polskim.
Zasady Covey’ego
Ogólnie mówiąc, Stephen Covey proponuje swoim czytelnikom rozwój osobowości od stanu zależności od innych osób, poprzez niezależność od innych do współzależności z innymi osobami.
Zależność od innych osób przejawia się nadmierną tendencją do obarczania tych innych zadaniem opieki nad sobą. Osoby zależne wierzą, że to inni są odpowiedzialni za ich wykształcenie, brak pracy, czy problemy rodzinne. Oni sami wydają się mieć niewielki wpływ na swoje życie. Taka postawa rzadko kiedy (jeśli kiedykolwiek) prowadzi do skutecznego działania.
Niezależność to wiara we własne siły i zaufanie do siebie. Osoby niezależne są przekonane, że angażując własną energię, zdolności i emocje są w stanie osiągnąć wiele, bardzo wiele.
Aby przejść od zależności do niezależności Stephen Covey proponuje wdrożenie w swoim życiu trzech zasad: trzeba być proaktywnym, trzeba zaczynać mając zawsze koniec (czyli skutki swoich działań) na względzie i trzeba tak zarządzać czasem, aby rzeczy pierwsze w sensie ważności były również pierwsze w przydzielaniu im naszego czasu. Aby być skutecznym nie wystarczy te zasady zrozumieć i zgodzić się z nimi – trzeba je tak głęboko wdrożyć, aby stały się naszymi nawykami.
Wyższym stopniem rozwoju osobowości od niezależności jest współzależność. Współzależność pozwala osiągnąć rzeczy, które byłyby dla pojedynczej osoby nie do osiągnięcia. Jest to przekonanie, że razem możemy więcej.
Rozwój polegający na przejściu od niezależności do współzależności opiera się na kolejnych trzech zasadach, które należy wdrożyć: trzeba myśleć o obopólnej korzyści, a nie tylko własnej, trzeba najpierw starać się zrozumieć partnera (klienta, szefa, pracownika) a dopiero potem oczekiwać by nas zrozumiano i trzeba dbać o synergię.
Do tego dochodzi jeszcze jedna, siódma zasada: ostrz piłę, czyli dbaj o ciągłe doskonalenia.
O tych siedmiu zasadach będzie mowa na następnym wykładzie. Każda z tych zasad skutecznego działania zostanie dość dokładnie przedstawiona. Jednak ostateczny efekt będzie zależał od tego, w jakim stopniu słuchacze zdecydują się przekuć te zasady w swoje nawyki.
Specyfikacja wymagań
Wykład ten będzie wprost nawiązywał do jednostki wiedzy „specyfikacja wymagań”.
Cykl życia
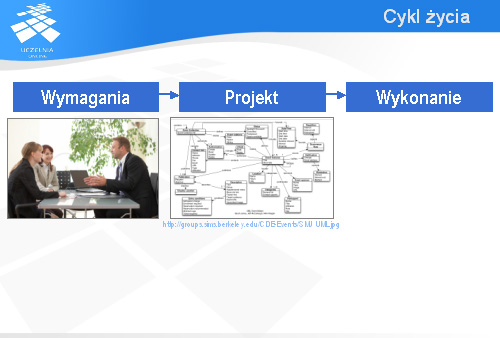
Inżynierskie podejście do wytworzenia jakiegoś produktu opiera się zazwyczaj na cyklu życia obejmującym przynajmniej trzy fazy: zebranie wymagań, opracowanie projektu i wykonanie produktu.
Jeśli, na przykład, ktoś myśli o przedsięwzięciu budowlanym, to najpierw trzeba zebrać wymagania inwestora dotyczące funkcji, jakie budynek ma pełnić i trzeba uwzględnić ograniczenia sformułowane w warunkach zabudowy.
W następnej fazie powstaje projekt architektoniczny, który pokazuje, jak zebrane wymagania i nałożone ograniczenia mają być spełnione.
I wreszcie dochodzi do fazy wykonania, dla której punktem wyjścia jest projekt opracowany na podstawie wymagań.
Podobnie powinno być z przedsięwzięciem programistycznym. Na początku należy zebrać wymagania dotyczące systemu, który ma być zbudowany.
Mając wymagania można przejść do opracowania projektu systemu. Na slajdzie widoczny jest projekt systemu informatycznego przedstawiony w języku UML.
W oparciu o projekt programiści tworzą kod systemu. Oczywiście, potem należy jeszcze sprawdzić, czy system nie zawiera defektów i czy spełnia wymagania, o które chodziło klientowi.
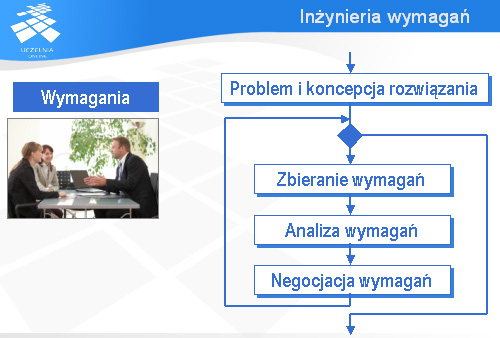
Inżynieria wymagań
Samo zbieranie i opracowanie wymagań jest tak ważnym i trudnym procesem, że mówi się wręcz o inżynierii wymagań. Rozumie się przez to fragment inżynierii oprogramowania odpowiedzialny za wymagania.
Proces zbierania i opracowywania wymagań ma najczęściej charakter cykliczny.
Powinien być poprzedzony sformułowaniem problemu (lub problemów), które budowany system informatyczny ma rozwiązać i nakreśleniem bardzo ogólnej wizji rozwiązania.
Zasadnicza część procesu zbierania i opracowywania wymagań składa się z trzech faz. Pierwszą fazą powinno być zbieranie wymagań. Często wymagania pochodzą od wielu różnych osób i na dodatek należy uwzględniać ograniczenia wynikające np. z różnych przepisów prawa.
Drugą fazą powinna być analiza wymagań. Wymagania mogą być wzajemnie sprzeczne, niejednoznaczne itp. – im wcześniej się takie wady wykryje tym lepiej dla całego przedsięwzięcia.
Po analizie wymagań potrzebna jest ich negocjacja. Wykryte defekty, takie jak np. sprzeczności między wymaganiami, należy usunąć. Zazwyczaj wymaga to negocjacji z wieloma zainteresowanymi osobami i może być bardzo trudne.
Jeśli osoby odpowiedzialne za przedsięwzięcie uznają, że wymagania mają już odpowiednią jakość i można na ich podstawie przejść do pracy nad projektem, to proces zbierania i analizy wymagań można zakończyć.
Generalnie wymagania można podzielić na funkcjonalne i pozafunkcjonalne. Wymagania funkcjonalne opisują funkcje, jakie ma realizować system. Przykładem może być wymaganie, aby budowany system księgarni internetowej automatycznie wysyłał do wydawcy zamówienia na te tytuły, których liczba w magazynie spadnie poniżej 20 sztuk. Wymagania pozafunkcjonalne dotyczą takich aspektów, jak wydajność (np. szybkość wykonania poszczególnych operacji), czy niezawodność.
Wykład nt. specyfikacji wymagań
W trakcie wykładu poświęconego specyfikacji wymagań przedstawiona zostanie metoda specyfikacji wymagań funkcjonalnych zwana przypadkami użycia. Metoda ta staje się coraz bardziej popularna, również w polskich firmach informatycznych. Zaprezentowane zostaną także dobre praktyki dotyczące dokumentu specyfikacji wymagań, zbierania wymagań, ich analizy i negocjacji oraz opisywania wymagań. Ta problematyka zostanie rozwinięta w ramach przedmiotu obieralnego „Zaawansowana inżynieria oprogramowania”.
Plan wykładu
Kolejny wykład będzie poświęcony kontroli jakości artefaktów.
Kontrola jakości artefaktów
Jest on bezpośrednio związany z jednostką wiedzy dotyczącą walidacji. Zagadnienia te nabierają szczególnego znaczenia w przypadku budowy tzw. systemów krytycznych, czyli systemów, których awaria może doprowadzić do utraty zdrowia, a nawet życia ludzkiego lub spowodować ogromne straty materialne.
Artefakty
W trakcie pracy nad systemem informatycznym powstaje cały szereg różnego typu artefaktów: specyfikacja wymagań, testy akceptacyjne, kod programu, podręcznik użytkownika i wiele innych. Oczywiście, muszą to być produkty dobrej jakości – nie mogą zawierać poważnych defektów.
Dlatego potrzebna jest kontrola jakości tych artefaktów.
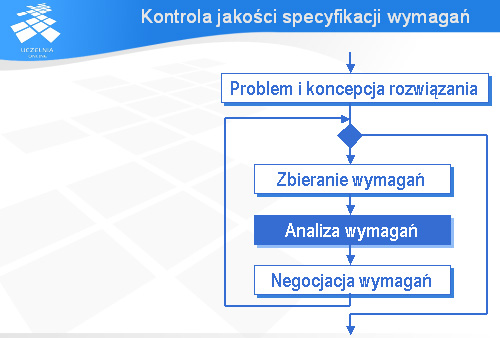
Kontrola jakości specyfikacji wymagań
Wiele osób myśli o kontroli jakości, jako ostatniej fazie pracy nad jakimś artefaktem. Nie jest to, ogólnie rzecz biorąc, najlepsze podejście. Omawiając proces zbierania i analizy wymagań przedstawiłem iteracyjny cykl życia, w którym analiza wymagań – i związana z nią kontrola jakości tych wymagań – są wykonywane wielokrotnie.
W praktyce kontrola jakości najczęściej przyjmuje postać testowania lub przeglądów. Testowanie można wykonać tylko w odniesieniu do działającego systemu lub jego prototypu. Przeglądy są bardziej ogólne: można je stosować zarówno do kodu, jak i do specyfikacji wymagań. Istotą przeglądu jest analiza artefaktów. Analiza ta może być przeprowadzona przez pojedynczą osobę (nazywamy to recenzją) lub też przez zespół osób (najpopularniejszym przykładem tego typu przeglądów są inspekcje).
Wykład nt. kontroli jakości
W trakcie wykładu poświęconego kontroli jakości artefaktów przedstawię krótko najważniejsze pojęcia dotyczące jakości i testowania, zaprezentuję sposób przeprowadzania inspekcji zgodny ze standardem IEEE 1028 i pokażę, jak można oszacować liczbę defektów, jakie zakradły się do artefaktu (łącznie z tymi, które nie zostały w trakcie kontroli jakości wykryte).
Plan wykładu
Kolejny wykład będzie poświęcony językowi UML.
Język UML
UML jest wykorzystywany m.in. przy projektowaniu systemów informatycznych. Jest też wiele narzędzi komercyjnych i darmowych wspomagających tworzenie modeli w języku UML (wśród narzędzi komercyjnych dużą popularnością cieszy się Rational Rose, a jednym z bardziej popularnych darmowych narzędzi jest ArgoUML).
www.uml.org
UML jest stosunkowo nowym językiem. Jego pierwsza wersja została zaakceptowana w 1997 roku. Na slajdzie jest pokazana strona internetowa dotycząca języka UML, która jest utrzymywana przez międzynarodową organizację OMG zatwierdzającą kolejne wersje tego języka. Osoby znające język angielski znajdą na tej stronie wiele cennych informacji na temat języka UML.
Diagramy UML
Język UML obejmuje wiele różnego typu diagramów, które pozwalają w sposób graficzny modelować różne aspekty systemów informatycznych (i nie tylko informatycznych). Tytułem wprowadzenia do języka UML przedstawione zostaną bardzo proste przykłady diagramu stanów, diagramu przypadków użycia i diagramu sekwencji. Zarówno te wymienione diagramy, jak i pozostałe zostaną bardziej szczegółowo omówione w trakcie wykładu poświęconego językowi UML.
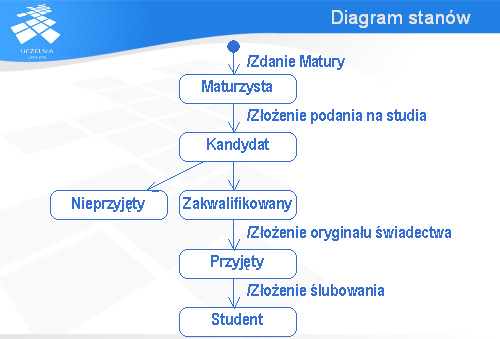
Diagram stanów
Pierwszym diagramem, który chciałbym pokazać jest diagram stanów. Na slajdzie widzimy diagram pokazujący „przeistaczanie” się maturzysty w studenta – za chwilę dokładniej go omówimy.
Kluczowym elementem na diagramach stanów są oczywiście stany. Stan jest reprezentowany za pomocą owalu z nazwą stanu w środku.
Między stanami są przejścia reprezentowane za pomocą strzałki. W przypadku diagramu pokazanego na slajdzie widać, że będąc w stanie „Maturzysta” można przejść do stanu „Kandydat”, ale nie odwrotnie.
Z przejściem może być związana akcja. W przykładzie pokazanym na slajdzie widać, że przejście od stanu „Maturzysta” do stanu „Kandydat” wiąże się ze złożeniem podania na studia.
Akcje są poprzedzane znakiem ukośnej kreski – tym samym, jaki jest wykorzystywany jako symbol dzielenia.
Początek jest zaznaczany małym ciemnym kółkiem. Stąd zaczyna się „chodzenie” po stanach.
Zgodnie z diagramem przedstawionym na slajdzie, najpierw trzeba zdać maturę i wtedy zdobywa się status maturzysty (w odniesieniu do świata rzeczywistego jest to uproszczenie, ale modele mają to do siebie, że zawsze w jakiś sposób upraszczają rzeczywistość). Po złożeniu podania na studia stajemy się kandydatami. Wskutek akcji, czy zdarzeń nie pokazanych na diagramie Kandydat uzyskuje status Zakwalifikowanego (można się domyślać, że trzeba tutaj pozytywnie przejść przez procedurę kwalifikacyjną) lub też staje się Nieprzyjęty. Po złożeniu podania Zakwalifikowany staje się Przyjętym, a po złożeniu ślubowania uzyskuje on upragniony status Studenta.
Diagram przypadków użycia
Przejdźmy teraz do diagramów przypadków użycia. Są one wykorzystywane do pokazania kto co może zrobić.
Jednym z głównych elementów występujących na diagramach przypadków użycia są tzw. aktorzy. Na slajdzie pokazano symbol, jakim się oznacza aktorów w języku UML. Aktor jest to rola, jaką człowiek lub ewentualnie urządzenie może odgrywać w kontakcie z opisywanym systemem informatycznym.
Na slajdzie widzimy trzech aktorów: Maturzystę, Zakwalifikowanego i Nieprzyjętego.
Aktor może mieć do czynienia z przypadkiem użycia opisującym pewien cel (np. o charakterze biznesowym), który aktor chce osiągnąć w kontakcie z systemem informatycznym. Nazwy przypadków użycia zapisuje się w elipsach tak, jak pokazano to na slajdzie.
Zgodnie z przedstawionym diagramem, Maturzysta może złożyć podanie, natomiast zarówno Zakwalifikowany, jak i Nieprzyjęty mogą obejrzeć wyniki rekrutacji.
Diagram sekwencji
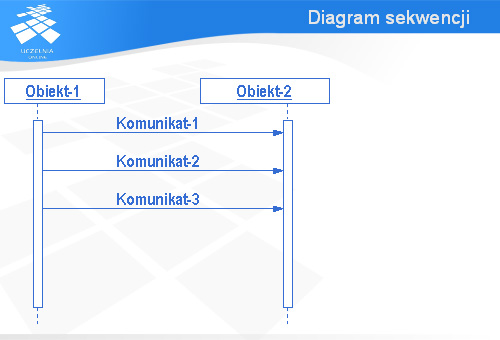
Trzecim rodzajem diagramów języka UML, jaki chciałbym przedstawić są diagramy sekwencji. Diagramy te służą do ilustrowania komunikacji między obiektami.
Każdy obiekt jest reprezentowany przez prostokąt zawierający jego nazwę i tzw. linię życia obiektu.
Komunikaty przesyłane między obiektami są reprezentowane za pomocą strzałki, nad którą pisze się nazwę komunikatu. Strzałka pokazuje kierunek przepływu komunikatu. Na pokazanym slajdzie komunikat jest wysyłany przez Obiekt-1 i trafia do Obiekt-2.
Diagramy sekwencji zazwyczaj zawierają więcej niż jeden komunikat. Komunikaty są wysyłane w kolejności „od góry do dołu”. Na slajdzie widać trzy komunikaty. Najpierw będzie wysłany Komunikat-1, potem Komunikat-2 i na końcu Komunikat-3. Tak się złożyło, że wszystkie te komunikaty są wysyłane przez Obiekt-1 i trafiają do Obiekt-2.
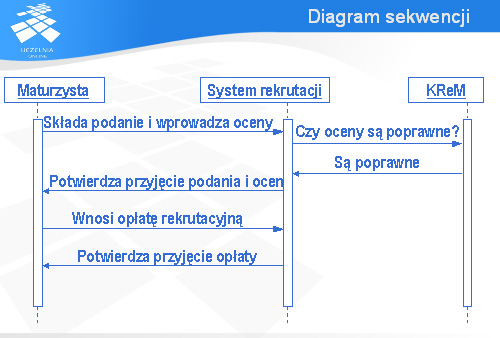
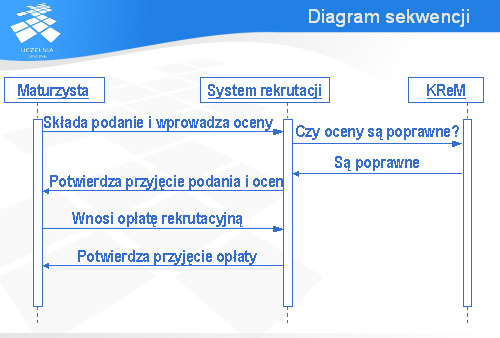
Diagram pokazany na tym slajdzie opisuje komunikację między trzema obiektami: Maturzystą, Systemem rekrutacji na studia i obiektem o nazwie KReM (chodzi tutaj o Krajowy Rejestr Matur – system informatyczny udostępniający wyniki matur z Okręgowych Komisji Egzaminacyjnych). Zgodnie z tym diagramem maturzysta chcący dostać się na studia najpierw składa podanie i wprowadza swoje oceny. Następnie system rekrutacji wysyła do KReM-u zapytanie, czy wprowadzone oceny są poprawne. KReM przesyła komunikat, z którego wynika, że oceny są poprawne. Wtedy system rekrutacji wysyła do maturzysty komunikat z potwierdzeniem przyjęcia podania i ocen. Teraz maturzysta wnosi opłatę rekrutacyjną, a system rekrutacji potwierdza przyjęcie tej opłaty.
Zaletą diagramów sekwencji jest pokazanie jakby z globalnego punktu widzenia (czyli patrząc na wszystkie interesujące nas obiekty), jak wygląda komunikacja między obiektami. Pomaga to zrozumieć działanie opisywanego systemu i jest to informacja, której nie dostarczają inne rodzaje diagramów języka UML.
Diagramy języka UML
Jak widać, język UML oferuje różnego rodzaju diagramy, z których każdy opisuje inne aspekty systemu. Jak już wcześniej wspomniano, tych rodzajów diagramów jest więcej i będą one omówione w trakcie wykładu poświęconego językowi UML.
Plan wykładu
Kolejny wykład będzie dotyczył metod formalnych.
Metody formalne
Zgodnie z Computing Curricula 2001, metody formalne są jednostką opcjonalną. Mają one ścisły związek z walidacją oprogramowania. Niektórzy podchodzą do nich sceptycznie, inni upatrują w nich nadzieję na istotne podniesienie jakości tworzonego oprogramowania, jakości rozumianej jako zgodność implementacji ze specyfikacją.
Zasadnicza koncepcja związana z metodami formalnymi polega na tym, by wykazywać poprawność programów nie w oparciu o testy czy przeglądy, lecz na gruncie matematycznym, poprzez dowodzenie właściwości programów.
Silnia
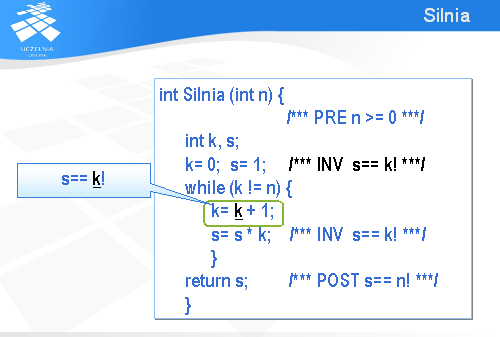
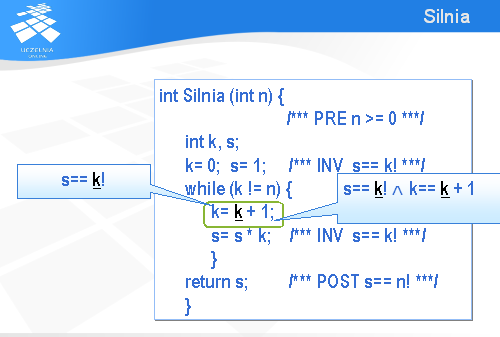
Spróbujmy udowodnić, że przedstawiona na slajdzie funkcja zapisana w języku C oblicza wartość n!.
Pierwszym krokiem jest związanie z tą funkcją warunku wstępnego (po angielsku – precondition ) i końcowego (ang. postcondition ). Ponieważ parametr n został zadeklarowany jako liczba całkowita, to wystarczy dodać jako warunek wstępny, że ma być to liczba nieujemna. Stąd też umieściliśmy w tekście programu komentarz PRE zawierający warunek „n >= 0”. Warunek końcowy (POST) określa relację, jaka ma być prawdziwa na końcu wykonania podprogramu. W przypadku omawianego programu na końcu zmienna s powinna mieć wartość n!.
No to teraz wystarczy tylko dowieść, że jeżeli na początku wykonania podprogramu n >= 0, to na końcu s będzie równe n!. Łatwo powiedzieć, trudno zrobić. W przypadku naszego programu najtrudniejszym elementem jest pętla while . Dowodzenie poprawności programu zawierających pętle odbywa się metodą niezmienników (ang. invariant ). Niezmiennik jest to zdanie, które jest prawdziwe za każdym razem, kiedy powtarzane jest wykonanie instrukcji zawartych w pętli. Dokładnie mówiąc, niezmiennik powinien być prawdziwy tuż przed pierwszym wykonaniem instrukcji zawartych w pętli, tuż przed drugim wykonaniem, przed trzecim itd. Zasadniczy problem polega na tym by znaleźć (wymyślić) taki niezmiennik, który zawsze będzie prawdziwy i jednocześnie pomoże nam w udowodnieniu warunku końcowego POST.

Nasz podprogram jest bardzo prosty i nietrudno zauważyć, że niezmiennik (INV) ma postać następującego zdania: s równa się k!. Najpierw udowodnimy, że to zdanie jest faktycznie niezmiennikiem, a potem pokażemy, jak go wykorzystać do udowodnienia warunku końcowego.
Pierwsze wystąpienie inwariantu (tuż przed wykonaniem instrukcji while ) jest prawdziwe, bowiem na mocy definicji funkcji silnia, 0! jest równe 1
Instrukcja „k= k+1” jest o tyle kłopotliwa, że występuje w niej dwa razy ten sam symbol k i za każdym razem oznacza inną wartość.
Żeby usunąć tę niejednoznaczność oznaczmy przez k z podkreśleniem początkową wartość k, jaka była przed wykonaniem tej instrukcji przypisania, a k bez podkreślenia niech oznacza nową wartość, jaka będzie po wykonaniu tej instrukcji.
Zatem z pierwszego inwariantu wynika, że przed wykonaniem tej instrukcji przypisania mamy s równe „k z podkreśleniem” silnia.
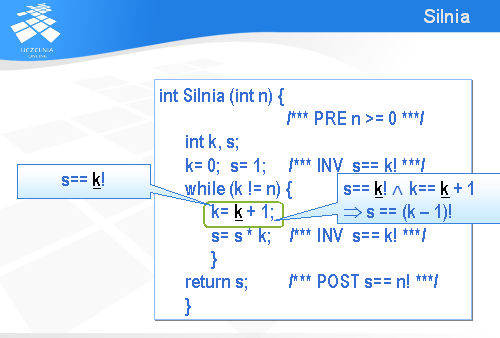
Po wykonaniu omawianej instrukcji przypisania dojdzie nam jeszcze zdanie mówiące, że nowa wartość k jest równa starej wartości powiększonej o 1.
Czyli po wykonaniu tej instrukcji przypisania będziemy mieli s równe (k-1)!.
W kolejnej instrukcji przypisania mamy podobną niejednoznaczność, jak poprzednio: dwa razy występuje symbol s i za każdym razem oznacza inną wartość.
Podobnie jak poprzednio przyjmiemy, że s z podkreśleniem oznacza „starą” wartość, a s bez podkreślenia „nową” wartość zmiennej s.
Zatem na mocy poprzednio dowiedzionego faktu można powiedzieć, że tuż przed wykonaniem tej instrukcji przypisania stara wartość s jest równa (k-1)!.
Po wykonaniu tej instrukcji będzie można dopisać do poprzedniego zdania jeszcze jedno: nowa wartość s jest równa starej pomnożonej przez k.
Jeżeli zastąpimy starą wartość s przez (k – 1)!, to okaże się, że nowa wartość s jest równa k!.
I w ten sposób dowiedliśmy, że jeżeli na początku wykonania instrukcji while prawdą jest, że s jest równe k!, to po wykonaniu obu instrukcji przypisania nadal s będzie równe k!. Zatem faktycznie jest to niezmiennik tej pętli.
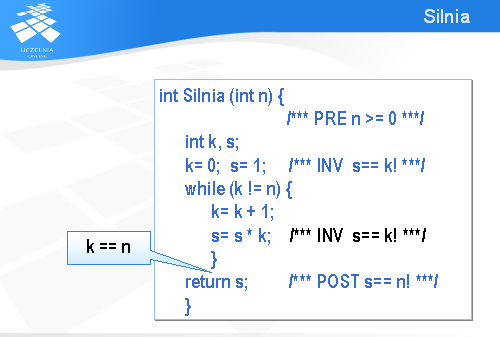
Aby dowieść prawdziwość warunku końcowego (POST) wystarczy zauważyć, że zaraz po wykonaniu instrukcji while prawdziwy jest inwariant „s jest równe k!” oraz prawdziwe jest zaprzeczenie warunku występującego w instrukcji while , czyli k jest równe n.
Podstawiając niezmiennik n w miejsce k dostajemy warunek końcowy i w ten sposób kończy się dowód poprawności tego podprogramu.
Dowodzenie poprawności programów
Do lat 90-tych dowodzenie poprawności programów odbywało się jedynie dla bardzo krótkich programów. W ciągu ostatniej dekady nastąpił istotny postęp i powstały bardzo efektywne weryfikatory. Jednakże dowodzenie poprawności programu jest wciąż bardzo pracochłonne. Ciekawe dane pozyskano w ramach projektu VSE (Verification Support Environment) finansowanego przez Unię Europejską. Jak pisze prof. Wolfgang Reif, dowiedzenie poprawności programu zawierającego ok. 7 tys. wierszy wymagało pracochłonności około 2 osobolat, a sama specyfikacja formalna miała ok. 5 tys. wierszy tekstu. Jak więc widać, formalna specyfikacja programów może być bardzo obszerna i jej wytworzenie oraz sprawdzenie jej poprawności jest zadaniem samym w sobie.
Wykład nt. metod formalnych
W trakcie wykładu dotyczącego metod formalnych omówię tzw. specyfikacje aksjomatyczne i związane z nimi implementacje niestandardowe, mające charakter anomalii. Przedstawię też sieci Petriego jako chyba najbardziej popularne narzędzie modelowania oprogramowania. Jest to notacja matematyczna o charakterze graficznym wykorzystywana do modelowania nie tylko systemów informatycznych, ale także np. systemów transportowych.
Plan wykładu
Kolejny wykład będzie poświęcony wzorcom projektowym
Wzorce projektowe
Wzorce projektowe są podstawą współczesnego projektowania oprogramowania.
Informatyka zawdzięcza koncepcję wzorców profesorowi Christopherowi Alexandrowi. Zgodnie z jego koncepcją wzorzec jest to sprawdzona koncepcja, która opisuje problem powtarzający się wielokrotnie w określonym kontekście, działające na niego siły oraz podaje istotę rozwiązania tego problemu w sposób abstrakcyjny.
W ramach wykładu powiemy o Bandzie Czterech, czyli tych, którzy wprowadzili wzorce do inżynierii oprogramowania, omówiony zostanie katalog wzorców projektowych i przedstawione zostaną wybrane wzorce projektowe oraz ich zastosowania.
Plan wykładu
W cyklu wykładowym poświęconym inżynierii oprogramowania nie może zabraknąć wykładu dotyczącego zarządzania konfiguracją.
Zmiany w oprogramowaniu i towarzysząca im ewolucja kodu są praktycznie nie do uniknięcia. Właściwe zarządzanie konfiguracją jest podstawą skutecznej ewolucji oprogramowania i jedną z kluczowych praktyk zarządzania przedsięwzięciem informatycznym.
Jeżeli przedsięwzięcie jest małe w sensie rozmiaru kodu oprogramowania, pracochłonności jego wytworzenia i liczby zaangażowanych osób, to zarządzanie zmianą może być bardzo proste. Wystarczy, że proponowana przez klienta zmiana spotka się z akceptacją programistów (może też być odwrotnie: stroną proponującą zmianę mogą być programiści, a akceptującą – klient) .
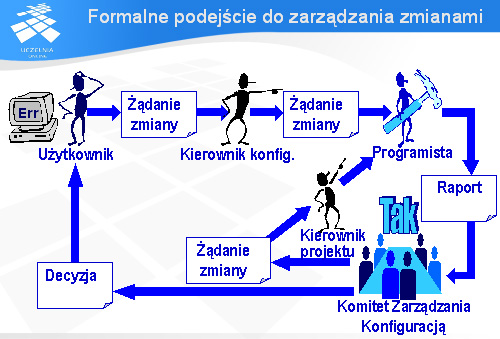
Formalne podejście do zarządzania zmianami
Niestety, jest szereg przedsięwzięć programistycznych, które wymagają bardziej formalnego podejścia do zarządzania zmianami. Duże firmy, prowadzące tak duże przedsięwzięcia, jak budowa elektronicznej centrali telefonicznej, korzystają dość często z podejścia prezentowanego na slajdzie, gdzie żądanie zmiany przechodzi dość długi proces od użytkownika zgłaszającego żądanie zmiany (np. usterkę w oprogramowaniu), poprzez kierownika konfiguracji, programistę oceniającego - na polecenie kierownika konfiguracji - ryzyko i koszty wprowadzenia proponowanej zmiany, specjalny Komitet Zarządzania Konfiguracją, który podejmuje ostateczną decyzję w sprawie proponowanej zmiany i Kierownika projektu, który przydziela jednemu z programistów zadanie wprowadzenia zaproponowanej zmiany do oprogramowania.
Koncepcja systemu zarządzania konfiguracją
Załóżmy teraz, że trzech programistów dostało trzy różne zadania modyfikacji tego samego programu. Ponieważ (jak to często bywa) klientowi bardzo się spieszy, programiści ci mają pracować równolegle. Oczywiście, jeżeli zaczną oni bezpośrednio i dość chaotycznie manipulować kodem programu, to nic dobrego z tego nie wyniknie.
Aby temu zaradzić korzysta się z systemów zarządzania konfiguracją, które chronią oprogramowanie przed chaotycznymi modyfikacjami i umożliwiają współbieżne modyfikowanie różnych składników oprogramowania w sposób kontrolowany.
Wykład nt. zarządzania konfiguracją
W trakcie wykładu omówiony zostanie jeden z najbardziej popularnych systemów zarządzania konfiguracją zwany CVS. Przedstawiona także zostanie struktura plików projektu oraz wzorce zarządzania konfiguracją.
Plan wykładu
Kolejne dwa wykłady będą poświęcone testowaniu oprogramowania.
Testowanie oprogramowania
Testowanie ma ścisły związek z weryfikacją, a także z walidacją oprogramowania i dostarcza danych, które mogą być wykorzystane do określenia niezawodności oprogramowania.
W literaturze można znaleźć wiele definicji testowania. Zgodnie z określeniem zawartym w jednej z książek Roberta Bindera, testowanie oprogramowania jest to wykonanie kodu dla kombinacji danych wejściowych i wewnętrznych stanów systemu w celu wykrycia błędów. Warto zwrócić uwagę, na ostatnią część zdania – „w celu wykrycia błędów”. Wynika z tego jasno, że celem testowania nie jest pokazanie, że w oprogramowaniu nie ma błędów – wręcz przeciwnie; w testowaniu chodzi o to by wykryć jak najwięcej błędów. Im więcej błędów się wykryje tym sprawniejszy jest proces testowania, ale też tym gorzej to świadczy o procesie tworzenia kodu.
Wykłady nt. testowania
Będą dwa wykłady na temat testowania. Pierwszy z nich będzie wprowadzeniem w problematykę testowania, natomiast w ramach drugiego wykładu przedyskutowane zostanie – bardzo ważne z praktycznego punktu widzenia – zagadnienie automatyzacji wykonywania testów.
Plan wykładu
Przedostatni wykład będzie poświęcony bardzo głośnej ostatnio metodyce programowania zwanej Programowaniem Ekstremalnym (po angielsku Extreme Programming ).
Programowanie Ekstremalne
Programowanie Ekstremalne jest to zestaw praktyk dotyczących m.in. specyfikacji wymagań, weryfikacji i walidacji, ewolucji kodu, różnych procesów związanych z rozwojem oprogramowania a także z zarządzaniem przedsięwzięciem programistycznym.
Kryzys oprogramowania
Kryzys oprogramowania po raz pierwszy pojawił się w latach 60-tych ubiegłego wieku. Zaobserwowano wówczas główne zagrożenia czyhające na śmiałków chcących w sposób komercyjny zajmować się wytwarzaniem oprogramowania. Okazało się, że w bardzo wielu przedsięwzięciach programistycznych dochodzi do przekroczenia terminu i budżetu, programiści są różnymi metodami zachęcani do pracy w nadgodzinach, co ujemnie się odbija na ich życiu prywatnym, a na dodatek jakość powstającego oprogramowania jest kiepska i nie satysfakcjonuje użytkowników końcowych.
Reakcja na kryzys oprogramowania
Pierwszą reakcją na kryzys oprogramowania było wprowadzenie dyscypliny do przedsięwzięć informatycznych. Wierzono, że poprzez wprowadzenie formalnych procesów i ustandaryzowanej dokumentacji uda się zwalczyć kryzys oprogramowania. W rezultacie powstały metodyki przypominające wspaniałe katedry gotyckie: budziły szacunek i podziw dla kunsztu ich twórców, jednak na co dzień mało kto z nich korzystał. Głównym winowajcą były zmiany. W niektórych przedsięwzięciach zmiany są tak częste, że klasyczne metodyki okazują się zbyt ciężkie, by można było za tymi zmianami nadążyć. W miarę upływu lat zaczęto zdawać sobie sprawę, że potrzeba czegoś lżejszego.
Lekkie metodyki tworzenia oprogramowania
W połowie lat 90-tych zaczęły się pojawiać tzw. lekkie metodyki oprogramowania, które były bardziej zorientowane na nadążanie za zmianami niż kurczowe trzymanie się planu. Jedną z nich jest Programowanie Ekstremalne.
Główne zalety Programowania Ekstremalnego
W Programowaniu Ekstremalnym najważniejsza jest komunikacja ustna. Jedyne artefakty, jakie muszą powstawać zostały ograniczone do kodu programu i testów. Ponadto Programowanie Ekstremalne pociąga obietnicą braku nadgodzin. Nic dziwnego, że wielu ludziom taka propozycja wydaje się bardzo atrakcyjna. Jednak bardzo wiele osób zapomina, że Programowanie Ekstremalne ma również szereg konkretnych wymagań mających postać praktyk, które muszą być stosowane, aby przedsięwzięcie zakończyło się sukcesem. O tych praktykach będzie mowa w trakcie wykładu poświęconego Programowaniu Ekstremalnemu.
Plan wykładu
Ostatni wykład będzie poświęcony ewolucji oprogramowania.
Ewolucja oprogramowania
W trakcie wykładu zostaną omówione przyczyny ewolucji oprogramowania, prawa Lehmana, rozwój jądra systemu Linux, który jest zaprzeczeniem praw Lehmana, czynniki wpływające na koszt pielęgnacji oprogramowania, typowy proces pielęgnacji oprogramowania i refaktoryzacja, jako technika obniżenia kosztów pielęgnacji.
Podsumowanie
W trakcie tego wykładu spojrzeliśmy z lotu ptaka na rozpoczynający się cykl wykładów na temat inżynierii oprogramowania. Z przedstawionej prezentacji wynika, że będą omówione wszystkie obowiązkowe jednostki wiedzy oprócz programowania za pomocą API, a ponadto będzie także jeden wykład poświęcony metodom formalnym. Dyskusja zagadnień dotyczących inżynierii oprogramowania, którą właśnie zaczęliśmy, będzie kontynuowana w ramach przedmiotu obieralnego pt. „Zaawansowana inżynieria oprogramowania”.
Dziękuję za uwagę. Mam nadzieję, że mimo wysokiego poziomu abstrakcji i pobieżności prezentacji parę istotnych szczegółów dotyczących inżynierii oprogramowania udało się Państwu dostrzec i ten ogólny obraz pomoże lepiej sobie przyswoić zagadnienia, o których będzie mowa na kolejnych wykładach. Serdecznie na nie zapraszam.