

Plan wykładu wygląda następująco. Na początku dowiecie się Państwo czym jest proces weryfikacji i walidacji oraz jakie są jego cele. Przedstawione zostaną ponadto dwie najważniejsze techniki weryfikacji i walidacji. Omówione zostanie także pojęcie testowania oprogramowania oraz ograniczenia tejże techniki, co w konsekwencji doprowadzi do sformułowania aksjomatów testowania. Dalej zapoznani zostaniecie z rodzajami testów oraz metodą czarnej i białej skrzynki. Wreszcie na koniec omówione zostaną relacje testowania z debugowaniem i inspekcjami kodu.

Dzięki postępowi technologicznemu wciąż rośnie złożoność programów. Niestety za tym idą błędy, które kosztują coraz więcej i to nie tylko pieniędzy. W lipcu 1988 roku krążownik USS Vincennes patrolował wody Zatoki Perskiej egzekwując embargo nałożone przez Stany Zjednoczone na Iran. Został zaatakowany około godziny 10:00 przez łodzie irańskie. Odpowiedział w ich kierunku ogniem. W tym czasie nad nieoczekiwanym polem bitwy przelatywał pasażerski samolot cywilny Airbus 320 wiozący 290 cywilów z lotniska Bandar Abbas do Abu Dhabi. Na skutek błędu w systemie śledzenia obiektów zainstalowanym na krążowniku USS Vincennes samolot ten został uznany za irański samolot wojskowy F-14 i zestrzelony przez załogę statku. Zginęli wszyscy pasażerowie samolotu Airbus – 290 osób.
Jako inny tragiczny przykład spowodowany błędem w oprogramowaniu może posłużyć przypadek śmierci pacjentów chorych na raka, którzy otrzymali nadmierne dawki promieniowania. Therac-25, maszyna służąca do terapii raka, na skutek sytuacji wyścigu, czyli błędnej implementacji współbieżności zadań, podawała nadmierne dawki promieniowania chorym pacjentom. Wielu z nich zmarło na skutek takiej „kuracji”, pozostali odnieśli trwały uszczerbek na zdrowiu. Leczenie z wykorzystaniem tej maszyny było prowadzone przez dwa lata zanim zauważony został błąd.


Rakieta udawała się w swój pierwszy rejs, po dziesięciu latach budowy, które kosztowały siedem miliardów dolarów. Ją samą i ładunek wyceniono na pięćset milionów dolarów. Rakieta i jej cztery satelity nie były ubezpieczone.

Jak widać błędy mogą mieć fatalne skutki. Dlatego też, ważne jest by już podczas wytwarzania produktu można było stwierdzić czy tworzony system jest zgodny ze specyfikacją oraz czy spełnione są oczekiwania klienta. To jest nazywane procesem weryfikacji i walidacji. Oba aspekty są ważne, ponieważ fakt zgodności ze specyfikacją nie oznacza, że system jest technicznie poprawny i odwrotnie.
Proces weryfikacji i walidacji jest szczególnie ważny w przypadku wytwarzania oprogramowania. Przez ostatnie 20 - 30 lat produkcja oprogramowania ewoluowała z małych zadań tworzonych przez grupki kilku ludzi do wielkich systemów, w których udział biorą setki czy nawet tysiące programistów. Z powodu tych zmian proces weryfikacji i walidacji również musiał ulec zmianie. Początkowo weryfikacja i walidacja była nieformalnym procesem wykonywanym przez inżyniera oprogramowania. Jednakże ciągły wzrost złożoności oprogramowania oznaczał, że stosowanie tych technik musi ulec zmianie. Inaczej nie możnaby było polegać na wynikowym produkcie.
Czymże jest ów proces walidacji i weryfikacji? Jak sama nazwa wskazuje składa się z dwóch składowych: weryfikacji i walidacji. Na etapie weryfikacji sprawdzane jest czy produkty danej fazy wytwarzania są zgodne z nałożonymi na nią założeniami. Natomiast nie jest sprawdzane czy specyfikacja jest prawidłowa, co jest przedmiotem walidacji. Weryfikacja nie wykryje błędów związanych z nieprawidłową specyfikacją wymagań. Walidacja natomiast sprawdza czy oprogramowanie wykonuje to czego wymaga od niego użytkownik, czyli jest odpowiedzialna za znalezienie błędów w specyfikacji systemu.

Głównymi celami weryfikacji i walidacji jest wykrycie błędów w systemie oraz sprawdzenie czy system spełnia oczekiwania klienta. Oznacza to nie tylko znalezienie błędów wynikających ze złej implementacji specyfikacji, ale także nieprawidłowo wyspecyfikowanych oczekiwań klienta. Może się zdarzyć, że klient oczekuje funkcjonalności, która wogóle nie została uwzględniona w specyfikacji, lub też opis jest niejednoznaczny.
Weryfikacja i walidacja powinna być wykonywana na każdym etapie tworzenia oprogramowania. Wiele firm waliduje produkt dopiero na końcu czego efektem są wyższe koszty usuwania znalezionych błędów. Często zdarza się też, że gdy ostatnią fazą jest weryfikacja i walidacja to brakuje zasobów na ich przeprowadzenie, ponieważ poprzednie fazy wytwarzania pochłonęły ich więcej aniżeli wynikało to z harmonogramu. Dlatego też, przeprowadzenie weryfikacji i walidacji na każdym etapie pozwala na przynajmniej częściowe sprawdzenie systemu (póki są zasoby) oraz zmniejsza koszt usunięcia błędu, ponieważ usterki znajdywane są szybciej co ułatwia ich usunięcie.

Istnieje wiele różnych technik weryfikacji oprogramowania. Do dwóch najważniejszych należą: inspekcje kodu oraz dynamiczne testowanie oprogramowania.
Inspekcje kodu związane są z analizą statycznej reprezentacji systemu w celu wykrycia potencjalnych problemów w niej występujących. Proces ten może być częściowo zautomatyzowany. Wtedy kod programu analizowany jest najpierw przez automat, który znajduje potencjalne nieprawidłowości. Podejrzane fragmenty kodu są następnie analizowane przez użytkownika by stwierdzić czy znalezione przez automat naruszenia mają rzeczywiście miejsce.
Dynamiczne testowanie oprogramowania jest drugą z technik, która polega na uruchomieniu aplikacji, zasileniu jej pewnymi danymi testowymi i sprawdzeniu jakie zachowanie generowane jest przez system. Następnie zaobserwowane zachowanie jest porównywane z oczekiwanym.
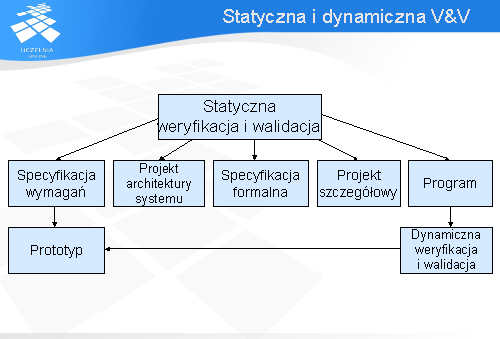
Poniższy slajd pokazuje możliwości zastosowania technik statycznej i dynamicznej analizy systemu.
Jak widać statyczna weryfikacja i walidacja może być zastosowana praktycznie na wszystkich etapach wytwarzania oprogramowania. Wykorzystując statyczne techniki możliwe jest sprawdzenie systemu od specyfikacji wymagań, projektu architektury systemu, specyfikacji formalnej aż po program skończywszy, podczas gdy dynamiczną techniką można sprawdzić tylko przy okazji specyfikacji wymagań i na końcu po napisaniu części systemu. Analiza wymagań w sposób dynamiczny jest możliwa po uprzednim napisaniu prototypu, który spełnia analizowane wymagania.


Poziom pewności zależy od wielu czynników. Jednym z najważniejszych jest przeznaczenie oprogramowania, czyli określenie jaką funkcję ma ono pełnić dla organizacji. Poziom pewności zależy od tego jak krytyczne jest to oprogramowanie dla organizacji.
Oczekiwania użytkownika, to drugi z czynników wpływających na poziom pewności. Użytkownicy mogą mieć niskie oczekiwania w stosunku do pewnych rodzajów oprogramowania lub fragmentów systemu, co może oznaczać mniej restrykcyjne weryfikowanie i walidowanie.
Wreszcie sam rynek dostarcza informacji o tym jak wysoki poziom pewności powinien posiadać system. Może się okazać, że wcześniejsze wypuszczenie produktu na rynek jest ważniejsze niż znajdywanie błędów w programie

Bardzo ważną sprawą podczas wytwarzania oprogramowania jest odpowiednie planowanie. Ta sama zasada tyczy się również fazy weryfikacji i walidacji. Im wcześniej rozpocznie się planowanie tym lepiej. Najlepiej je zacząć już na etapie analizy wymagań. To umożliwia lepsze zrozumienie jak ma działać budowany system. Plan powinien identyfikować równowagę pomiędzy statyczną weryfikacją a testowaniem. Obydwie techniki powinny być wykorzystywane w procesie weryfikacji i walidacji. Metody statyczne nie sprawdzą wszystkich cech produktu jak np. wydajność systemu. Do tego celu idealnie nadaje się testowanie. Odwrotna sytuacja też jest niedopuszczalna. Statyczne techniki umożliwiają sprawdzenie między innymi poprawności specyfikacji i wykrycie brakujących wymagań, jak również identyfikację takich, które są niejednoznaczne co przy pomocy testowania jest niemożliwe.
Czy plan powinien uwzględniać testy wszystkich możliwych elementów systemu? W praktyce testuje się tylko jego wybrane fragmenty w myśl zasady Pareto, że 20% kodu generuje 80% błędów.
Celem planowania testów jest bardziej definiowanie standardów dla testowania aniżeli opisywanie samych testów jakim poddany będzie produkt.

Dokument planu testów powinien zawierać opis procesu testowania, czyli w jaki sposób będzie przeprowadzany, oraz kto będzie za niego odpowiedzialny. Plan testów oprogramowania powinien być tak skonstruowany by móc umożliwić śledzenie wymagań. W przypadku gdy dane wymaganie ulegnie zmianie, szybko będzie można zaktualizować także plan co zmniejszy szansę pomyłki podczas weryfikacji i walidacji systemu. Wszystkie testy powinny być powiązane z wymaganiami użytkownika. Nie warto testować cech systemu, o których nie ma żadnej informacji w jego specyfikacji. Oczywiście plan nie może obyć się bez harmonogramu. Powinno być w nim zawarte co i kiedy jest testowane oraz kto ma to przeprowadzić. Sposób w jaki test będzie wykonywany, jakie techniki mają być wykorzystane oraz jak przeprowadzana jest rejestracja testu jest bardzo ważny. Bez logów i informacji dla jakich danych test nie przeszedł niemożliwe jest usunięcie błędu. Sama informacja, że są błędy nie zda się na wiele. W planie testów powinno być też opisane środowisko testowe, na jakim sprzęcie wykonane zostanie uruchomienie systemu, oraz z jakiego systemu operacyjnego i innego oprogramowania system ma korzystać.
Szczegóły dotyczące dokumentowania planu testów można znaleźć w standardzie IEEE 829 (Std 829-1998). Celem tego wykładu jest jedynie zaznajomienie Państwa z podstawowymi hasłami dotyczącymi zagadnień testowania.

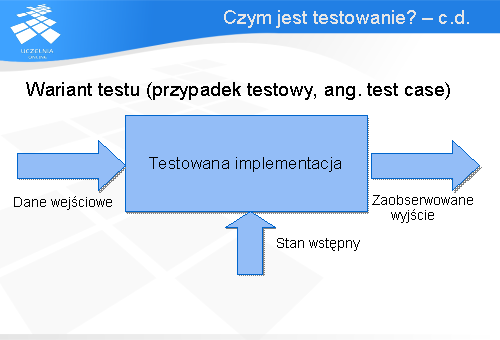
W ramach projektowania testu wyodrębnia się i analizuje powinności testowanego systemu. Następnie projektuje się warianty testu. Na wariant testu zwany inaczej przypadkiem testowym składają się następujące elementy:
- stan wstępny, czyli stan testowanego systemu bądź jego fragmentu jaki występuje tuż przed testem
- Dane wejściowe lub warunki testu
- Oczekiwane wyniki
Wynik oczekiwany określa, co testowana implementacja powinna wyprodukować z danych testowych.
Natomiast rzeczywiste wyjście, czyli wynik wykonania testu na testowanej implementacji (systemie lub jego fragmencie) nazywany jest zaobserwowanym wyjściem.
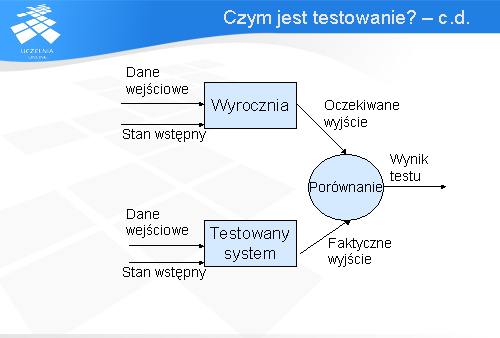
Po zaprojektowaniu wariantów testu przychodzi czas na ich przeprowadzenie. Wykonanie przypadku testowego można opisać przy pomocy następujących kroków. Testowany system bądź jego fragment są ustawiane w stanie wstępnym. Następnie podawane są dane wejściowe do testowanej implementacji.
Te same dane podawane są wyroczni. Wyrocznia jest środkiem do wytwarzania wyników oczekiwanych. Najczęściej wyroczniami są wyjścia ustalone przez projektanta testu. Może to być także wynik wykonania systemu zaufanego.
Następnie zaobserwowane wyjście jest porównywane z wyjściem oczekiwanym z wyroczni w celu ustalenia czy test ujawnił błąd czy też nie. Za udany test uważa się taki, który wykryje przynajmniej jeden błąd.

Testowanie powinno być wykorzystywane wraz z technikami statycznej weryfikacji w celu osiągnięcia pełnego pokrycia dla weryfikacji i walidacji.
W przypadku wymagań niefunkcjonalnych testowanie jest jedyną techniką walidacji. Wymagania takie jak wydajność systemu czy obciążenie można sprawdzić tylko i wyłącznie przy pomocy testowania.


Czy w takim razie jeśli system podzielony zostanie na mniejsze podsystemy, które zostaną przetestowane wyczerpująco i okaże się, że są bezbłędne to oznaczać to będzie, że jest bezbłędny?
To pytanie skłoniło Elaine Weyuker do sformułowania aksjomatów testowania, które określają granice testowania. Niestety nie można założyć, że z poszczególnych poprawnych części zawsze powstaje poprawna całość. Granice testowania określone zostały przez trzy aksjomaty: aksjomat antyekstensjonalności, antydekompozycji oraz aksjomat antykompozycji.
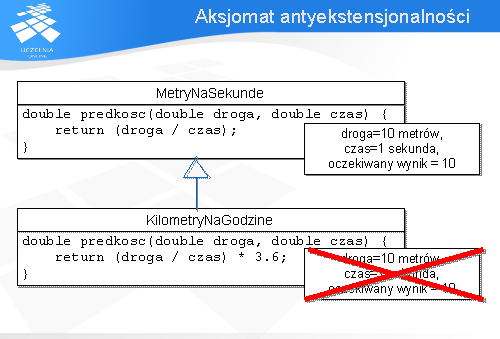
Pierwszy z nich, aksjomat antyekstensjonalności, czyli nierozszerzalności mówi, że zestaw testów pokrywający jedną implementację danej specyfikacji nie musi pokrywać jej innej implementacji. Zestaw testów odpowiedni dla metody nadklasy może nie być odpowiedni jeśli metoda została odziedziczona i zasłonięta.
Na przykład zestaw testów przygotowany dla algorytmu sortowania quicksort może nie osiągnąć 100% pokrycia dla sortowania heapsort. Jako inny przykład związany z dziedziczeniem może posłużyć metoda obliczająca prędkość. Zestaw testów dla wariantu podającego wynik w metrach na sekundę będzie nieadekwatny dla metody przykrytej przez klasę, w której wynik podawany jest w kilometrach na godzinę.

Aksjomat antydekompozycji mówi, że pokrycie uzyskane dla testowanego modułu nie zawsze jest uzyskane dla modułów przez niego wywoływanych. Zestaw testów pokrywający klasę lub metodę nie musi pokrywać obiektów serwera tej klasy lub metody. W przykładzie, który Państwo widzicie następujące warianty testów dla klasy korzystającej z klasy Math spowodują 100% pokrycie instrukcji tej klasy:
Natomiast nie spowodują one wykonania wszystkich instrukcji w klasie Math. Otóż nie wykonana zostanie ani razu instrukcja wyrzucająca wyjątek DzieleniePrzezZero, ponieważ w klasie klienta sprawdzanie jest wystąpienie warunku dla 0. Zatem pokrycie instrukcji dla klasy Math wyniesie tylko 50%, co jest zgodne z aksjomatem antydekompozycji.


Posiadając przypadki testowe warto jest wiedzieć jak dokładnie sprawdzają one kod analizowanego systemu. Modele pokrycia kodu umożliwiają zmierzenie ile kodu jest sprawdzane przez testy. Do najpopularniejszych modeli pokrycia należą: pokrycie instrukcji oraz pokrycie gałęzi.
Instrukcja jest uznana za pokrytą jeśli test wymusi jej wykonanie przynajmniej raz. Zatem pokrycie instrukcji wynosi 100% jeśli każda instrukcja w analizowanym fragmencie kodu jest przynajmniej raz wykonana przez testy.
Drugim popularnym modelem jest pokrycie gałęzi. Wynosi ono 100% w przypadku gdy każda gałąź w analizowanym fragmencie kodu jest przynajmniej raz odwiedzona. Każda instrukcja warunkowa musi mieć przynajmniej raz prawdziwy i przynajmniej raz fałszywy warunek by można było uznać, że zostało uzyskane pokrycie gałęzi dla analizowanego fragmentu programu.
Pokrycie instrukcji - przykład

Przedstawiona tutaj metoda wyświetla napis „liczba parzysta” w przypadku gdy podany argument wywołania metody jest liczbą parzystą. Ponadto metoda ta wypisuje liczby od 0 do 4, w przypadku gdy argument liczba jest mniejszy od 5.
By uzyskać pełne pokrycie instrukcji (100%) należy zapewnić, że liczba jest parzysta oraz, że jest mniejsza od 5. Wtedy wyświetlony zostanie napis „liczba parzysta” oraz wykonana zostanie pętla. Takie warunki spełnia przypadek testowy dla argumentu liczba = 4.
Pokrycie gałęzi - przykład

W przypadku pokrycia gałęzi warunek w instrukcji warunkowej if musi być przynajmniej raz prawdziwy i przynajmniej raz fałszywy. Tak samo jest dla warunku w pętli for.
W pierwszym przypadku, dla instrukcji warunkowej if, by możliwe było spełnienie prawdziwości i fałszywości warunku musi być podana liczba parzysta i liczba nieparzysta.
Dla drugiego przypadku wystarczy podać liczbę mniejszą od 5. Warunek pętli i tak będzie fałszywy gdy w wyniku wykonywania pętli iterowana zmienna liczba osiągnie wartość 5. W związku z tym potrzebne są dwa warianty testu: liczba = 4 i liczba = 13.
Czarne strony pokrycia kodu


Pokrycie kodu równe 100% nie zawsze jest możliwe do osiągnięcia. Fragmenty kodu, których nie można uruchomić (np. martwy kod) spowodują zaniżenie wartości pokrycia mimo iż system może być przetestowany gruntownie. W przykładzie pokazanym na slajdzie instrukcja wyświetlająca napis „martwy kod” nigdy nie zostanie wykonana, ponieważ występuje po instrukcji powrotu z metody. Jest to przykład tzw. martwego kodu. Wiele języków w tym m.in. Java sygnalizuje wystąpienie takich konstrukcji programu, jednak nie wszystkie np. kompilator C tego nie zauważa.
Mimo swoich słabości modele pokrycia są szeroko stosowanym narzędziem przez osoby testujące oprogramowanie. Umożliwiają one skutecznie oszacować ile systemu zostało sprawdzone przez testy. Nie oceniają jednak efektywności samych przypadków testowych.


W powyższym przykładzie dla funkcji dodawanie powstał mutant, który zamiast dodawać mnoży argumenty funkcji. Przypadek testowy dla obu argumentów przyjmujących wartość zero nadal przechodzi. Nie wykrywa zmiany, ponieważ mnożenie dwóch zer daje liczbę 0 co jest takim samym wynikiem jak dodanie ze sobą dwóch zer. Ten przypadek testowy powinien być poprawiony lub usunięty z listy przypadków testowych, ponieważ nie jest w stanie wykryć błędu, który wprowadził mutant.
Dla przypadku gdy oba argumenty przyjmują wartość 1 błąd wprowadzony przez mutanta zostanie wykryty. Ten przypadek testowy jest uznany za dobry.
Niestety testowanie mutacyjne nie jest szeroko wykorzystywane w praktyce ze względu na dość duży czas potrzebny na jego przeprowadzenie. Trzeba wykonać mutację na kodzie, przekompilować go i następnie uruchomić dla niego testy. To wszystko zajmuje sporo czasu jeśli weźmie się pod uwagę rozmiar obecnie wytwarzanego oprogramowania.

Testy można podzielić ze względu na przedmiot testowania. Standard IEEE 610.12 z roku 1990 definiuje testy jednostkowe, integracyjne oraz systemowe.
Testy jednostkowe wykonuje programista w środowisku laboratoryjnym. Celem tych testów jest sprawdzenie pojedynczej jednostki oprogramowania jaką jest klasa, metoda, czy też zbiór współpracujących ze sobą klas (tzw. klaster klas).
Przetestowane jednostki kodu są następnie łączone w większą całość. Podczas integracji przeprowadzane są testy integracyjne. Ich zadaniem jest sprawdzenie łączonych fragmentów kodu. Weryfikowana jest współpraca integrowanych jednostek między sobą. Celem jest określenie czy po zintegrowaniu otrzymany podsystem nadaje się do dalszego testowania. Proces łączenia i testowania jest powtarzany aż do powstania całego systemu. Testy te wykonywane są przez grupę programistów w środowisku laboratoryjnym odpowiedzialną za łączone moduły.
Testy systemowe wykonywane są po pomyślnej integracji jednostek wchodzących w skład systemu będącego przedmiotem testowania. Wykonywane są przez programistów lub niezależny zespół w kontrolowanym środowisku laboratoryjnym. Sprawdzają one czy system jako całość spełnia wymagania funkcjonalne i jakościowe postawione przez klienta.
Przetestowany system trafia następnie do użytkowników końcowych (klienta), gdzie następnie poddawany jest kolejnym testom. Tym razem to użytkownik lub reprezentant klienta sprawdza system. Testy przeprowadzane są w środowisku docelowym lub jak najbardziej zbliżonym do niego. Sprawdzane jest czy system spełnia oczekiwania klienta.
Testowanie należy przeprowadzać zaczynając od testów jednostkowych (zaczynając od metod przechodząc następnie w klasy, klastry, pakiety itd.), przez testy integracyjne na testach systemowych skończywszy. Niestety większość firm testuje tylko na poziomie systemowym nie doceniając niższych warstw testowania co zwiększa koszty związane z usuwaniem błędów, bo wykrywane jest mniej błędów, a te znalezione trudniej jest zlokalizować i poprawić.
Testowanie regresyjne

W przypadku gdy przetestowany wcześniej system uległ modyfikacji czy to na skutek poprawy błędu, czy też w wyniku zmiany wymagań ze strony klienta, należy go ponownie przetestować. Do tego celu mogą służyć opracowane wcześniej testy. Testowanie takie nazywa się testowaniem regresyjnym. Jest to ponowne wykonanie opracowanych wcześniej testów by sprawdzić czy wprowadzone modyfikacje w programie nie spowodowały powstania błędu. Uproszczona forma testowania regresyjnego zwana testem na dym (ang. smoke test) sprawdza czy w wyniku modyfikacji program nadal się uruchamia. Testowanie regresyjne może być przeprowadzone jeśli modyfikacje systemu nie były znaczące. W przeciwnym przypadku konieczna jest także modyfikacja samych wariantów testu.

Przy przygotowywaniu wariantów testu stosowane są generalnie dwie techniki: metoda białej skrzynki oraz metoda czarnej skrzynki.
Metoda białej skrzynki opiera się na analizie kodu, który ma być testowany. Sprawdzana jest jego wewnętrzna struktura. Na podstawie tych informacji konstruowane są przypadki testowe. Niestety wykorzystując tylko tą metodę łatwo jest pominąć pewne przypadki testowe, gdyż analiza samego kodu nie poda nie zaimplementowanych wariantów zachowania systemu. Ta metoda nadaje się do testów jednostkowych, oraz integracyjnych, dla których znajomość kodu źródłowego jest konieczna.
Testowanie metodą czarnej skrzynki nazywane też inaczej testowaniem funkcjonalnym opiera się na analizie powinności testowanego systemu np. na podstawie specyfikacji wymagań. W ten sposób nie pominie się testowania istotnych zachowań systemu. Ta metoda nadaje się do wszystkich rodzajów testowania, jednak nie wyklucza stosowania metody białej skrzynki. Ze względu na duży koszt związany z testowaniem metodą czarnej skrzynki stosuje się obie metody. Testowanie metodą białej skrzynki wykorzystywane jest wszędzie tam gdzie testy wykonane metodą czarnej skrzynki są zbyt kosztowne. W pozostałych przypadkach testy tworzone są w oparciu o powinności systemu.
Profil błędu
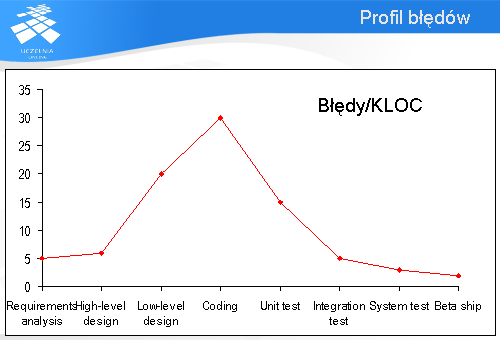
Poznając rodzaje testów nasuwa się pytanie, do którego etapu warto testować? Przedstawiony na tym slajdzie wykres uzasadnia konieczność stosowania różnych rodzajów testowania. Na wykresie pokazana jest ilość błędów przypadających na 1000 linii kodu źródłowego w zależności od fazy wytwarzania oprogramowania.
Warto zauważyć, że na każdym etapie wykrywane są błędy. Najwięcej przypada na etap kodowania. Najmniej powinno przypadać po oddaniu systemu do produkcji. Nasuwa się wniosek, że testowanie jednostkowe nie wykrywa wszystkich błędów, podobnie jak testy systemowe. W związku z tym każdy z rodzajów testowania jest konieczny do uzyskania produktu, który spełni oczekiwania klienta.
Koszt poprawiania błędu

Wyniki badań przeprowadzonych przez Boehma w latach osiemdziesiątych jak i obecnie prowadzone badania potwierdzają, że koszt poprawy błędu rośnie wykładniczo w zależności od etapu wytwarzania oprogramowania. Najmniej kosztuje poprawa na etapie analizy, najwięcej po wdrożeniu systemu do produkcji.
Jeśliby błąd związany z rokiem 2000 usunąć na etapie implementacji to koszt z tym związany byłby tysiąckrotnie niższy w stosunku do kosztu związanego z jego poprawą po wdrożeniu systemu.
W większości procesów wytwarzania testowanie systemu jest wykonywane na samym końcu. Oznacza to, że jest ono szczególnie narażone na przekroczenie kosztów i harmonogramu, co oznacza po prostu, że czas potrzebny na testowanie jest obcinany, ponieważ wcześniejsze fazy przekroczyły termin i budżet.
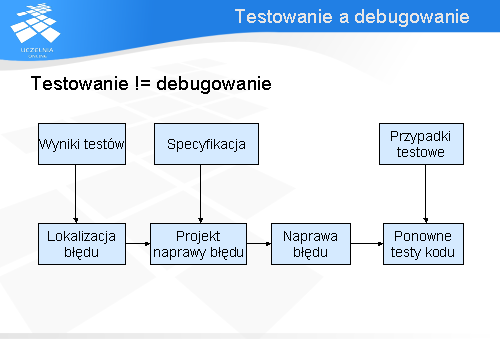
Testowanie jest często mylone z debugowaniem. Powyższy schemat ilustruje z jakich części składa się debugowanie. Na samym początku po wykonaniu testów wyniki ich wykonania są analizowane by znaleźć te warianty, które wykryły błąd. Na podstawie logów z wykonania testu lokalizowana jest usterka. Następnie w oparciu o specyfikację systemu, tworzony jest projekt jego naprawy. Zawiera on listę czynności, które muszą być wykonane by usterka była poprawiona. Miejsce, w którym błąd jest zaszyty zostanie następnie poprawione zgodnie z wcześniej ustalonym projektem. Zmodyfikowany system jest ponownie testowany by sprawdzić czy zmiany nie wprowadziły nowych błędów, a także po to by zweryfikować czy modyfikacja została przeprowadzona prawidłowo.
Jak widać testowanie i debugowanie to dwa osobne procesy. Testowanie koncentruje się na znajdywaniu błędów podczas gdy debugowanie zajmuje się ich lokalizacją i usuwaniem.
Inspekcja a testowanie




Na koniec wykładu pragnę podsumować zagadnienia, które poznali Państwo w ciągu tej godziny.
Po pierwsze zdefiniowane zostało czym jest weryfikacja, a czym walidacja oprogramowania. Weryfikacja to znajdywanie błędów związanych z nieprawidłową implementacją wymagań. Walidacja to sposób na znajdywanie błędów związanych z nieprawidłową definicją wymagań.
Testowanie polega na wykonaniu kodu dla kombinacji danych wejściowych i stanów w celu wykrycia błędów. Proszę zauważyć, że jest to technika dynamiczna – wymaga uruchomienia systemu (lub jego fragmentu), a jej cel to wykazanie, że system zawiera błędy.
Niestety na mocy trzech aksjomatów testowania nie można założyć, że z poszczególnych poprawnych części zawsze powstaje poprawna całość.
Testowanie jako technika weryfikacji i walidacji, skupia się na wykryciu błędu podczas gdy debugowanie koncentruje się na lokalizacji i naprawie tych błędów.
Inspekcje i testowanie to komplementarne techniki weryfikacji, które mogą być stosowane razem.