

Dążenie do jednolitości rozwiązań, ich klasyfikacji i uproszczenia, pojawiają w wielu dziedzinach inżynierii. Podstawowe pytanie, jakie stawiają sobie inżynierowie, dotyczy możliwości wielokrotnego wykorzystania raz sformułowanego rozwiązania danego problemu. Czy można zapisać to rozwiązanie w sposób ogólny, abstrahując od szczegółowych rozwiązań? Pozwoliłoby ująć tzw. dobre praktyki w postaci szablonów, które można stosować wielokrotnie, unikając typowych błędów.

Wzorce projektowe, choć obecnie znane przede wszystkim w kontekście inżynierii oprogramowania, wywodzą się z architektury. Twórcą tego pojęcia był amerykański architekt, Christopher Alexander, który postawił tezę, że piękno, funkcjonalność oraz inne cechy użytkowe lub konstrukcyjne można zapisać właśnie w postaci uogólnionych rozwiązań. Wzorce opisane przez Alexandra powstały na podstawie analizy decyzji podejmowanych przez architektów i budowniczych, którzy usiłowali osiągnąć określony efekt, z ich doświadczeń, błędów i odkryć.
Zdaniem Aleksandra, każdy wzorzec powinien być opisany przez następujące atrybuty:
Taki wzorzec jest gotowym schematem postępowania, który można zastosować w wielu sytuacjach, łącząc go także z innymi wzorcami.
Wprawdzie idee Alexandra nie odbiły się szerokim echem w świecie architektury, jednak stanowiły silny impuls dla rozwoju technik projektowania oprogramowania.
Aby przybliżyć pojęcie wzorca, przyjrzyjmy się dylematowi projektanta budowlanego, który zastanawia się nad wyborem konstrukcji mostu lub wiaduktu. Z każdym rozwiązaniem związane są pewne wymagania wstępne, dotyczące np. nośności gruntu, uwarunkowania konstrukcyjne, wpływające na koszt konstrukcji i konsekwencje, m.in. osiągnięta nośność, konieczność konserwacji etc. Analiza każdej konstrukcji oraz wyrażenie jej w sposób opisowy jest możliwe, ale dość skomplikowane i narażone na niedomówienia. Trzeba bowiem za każdym razem na nowo przemyśleć poszczególne elementy projektu, uwzględnić zadania, jakie stoją przed projektowaną budowlą, warunki klimatyczne etc.

Autorami pierwszej szeroko znanej publikacji poświęconej wzorcom w inżynierii oprogramowania byli E. Gamma, R. Helm, R.Johnson i J. Vlissides, znani jako Banda Czterech (Gang of Four) – w bliżej niesprecyzowanym nawiązaniu do nazwy grupy dawnych prominentów w komunistycznych Chinach. W swojej książce opisali 24 wzorce projektowe dotyczące konstrukcji, struktury i zachowania obiektów w systemach informatycznych. Ich zdaniem, poziom abstrakcji wzorca projektowego powinien znajdować się powyżej poziomu pojedynczej klasy.
Od tego czasu wzorce projektowe stały się jednym z podstawowych narzędzi projektowania systemów. Powstały nowe, specjalizowane wzorce poświęcone rozwiązaniom dla konkretnych technologii czy platform (np. wzorce dla J2EE).

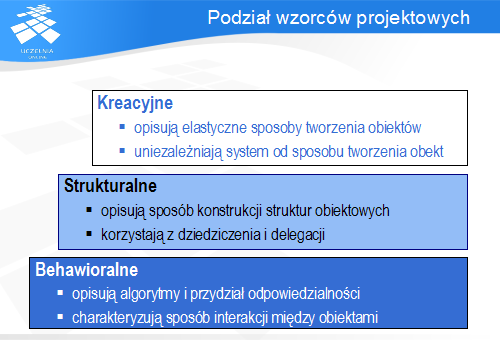
Banda Czterech zaproponowała podstawową systematykę wzorców, dzieląc je na trzy kategorie:

Każdy wzorzec należący do katalogu zaproponowanego przez „Bandę Czterech” opisany jest przez zestaw atrybutów, dzięki którym jego właściwości są przedstawione w usystematyzowany, powtarzalny i obiektywny sposób. W ten sposób powstał szablon wzorca projektowego. Po kolei omówione zostaną pokrótce najważniejsze jego atrybuty.
Nazwa wzorca jest dobrana tak, aby szybko nasuwać skojarzenia z przeznaczeniem wzorca. Nazwy oryginalnie zostały sformułowane po angielsku, i tak też będą podawane w trakcie wykładu. Stosowanie spójnego, anglojęzycznego nazewnictwa ułatwia komunikację, dlatego pomijanie polskich tłumaczeń (choć w niektórych przypadkach naturalnych i nie powodujących wieloznaczności) wydaje się uzasadnione.
Cel wzorca krótko opisuje ostateczny skutek jego zastosowania.
Bardzo ważnym elementem jest opis struktury wzorca, przede wszystkim w zakresie powiązań pomiędzy uczestniczącymi w nim klasami w postaci diagramu klas UML. Aspekt dynamiczny (zachowanie poszczególnych uczestników wzorca) opisywany jest w atrybucie dotyczącym współdziałania.

Lista uczestników wzorca zawiera nie tylko nazwy ról klas wchodzących w jego skład, ale przede wszystkim zakres ich odpowiedzialności oraz sposób zachowania. Jest to uszczegółowienie informacji, które są umieszczone na diagramie struktury.
Często pomijaną, choć bardzo ważną, składową każdego wzorca jest informacja o konsekwencjach, jakie niesie jego zastosowanie, szczególnie negatywnych. Wykorzystanie wzorca często wymusza podejmowanie określonych decyzji w przyszłości i wyklucza niektóre rozwiązania, dlatego projektant powinien być świadomy ich związków z tym wzorcem.
Przykład pozwala lepiej zrozumieć charakter, przeznaczenie i strukturę wzorca.
Jeżeli wzorzec jest spokrewniony z innymi, przede wszystkim pod względem kontekstu oraz celu stosowania, wówczas są one wymienione jako wzorce pokrewne.

W celu lepszego przedstawienia idei wzorców, wybrane wzorce zostaną omówione na przykładzie projektu oprogramowania dla biblioteki. System taki składa się z rozmaitych modułów i realizuje różne funkcje, które nie są interesujące z punktu widzenia jakości projektu. Dlatego dla potrzeb przykładu zostanie on ograniczony do czterech odułów, spośród których opisane zostaną wybrane problemy i sposoby ich rozwiązania w oparciu o wzorce.
Te cztery moduły w systemie bibliotecznym to:


Przykład dotyczy właśnie katalogu rzeczowego. Wobec niego postawione są następujące wymagania:
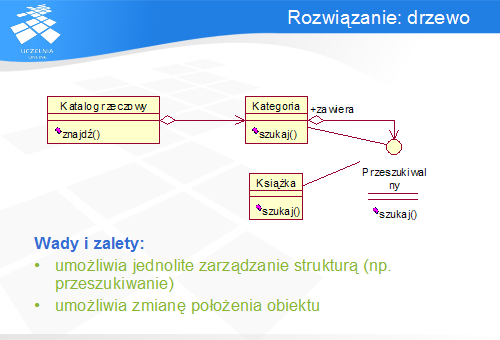
Naturalne rozwiązanie polega na stworzeniu wspólnego interfejsu, np. o nazwie Przeszukiwalny, który jest implementowany we wszystkich obiektach, które są częścią struktury i w których można szukać książek. Interfejs ten posiada dwie implementacje: Kategorię (która jest związana relacją agregacji z dowolną liczbą obiektów zależnych typu Przeszukiwalny, a zatem zarówno innych Kategorii, jak i Książek) oraz Książkę (reprezentującą element struktury, który nie posiada obiektów zależnych).
Obiekt klasy Katalog rzeczowy, który wywoła metodę szukaj () w kategorii znajdującej się w korzeniu drzewa katalogu, nie musi znać struktury tego drzewa, jego głębokości ani innych własności. Każda Kategoria, po wywołaniu jej metody szukaj (), realizuje ten sam algorytm: wykonuje wyszukiwanie na własnym obiekcie, a następnie wywołuje tę samą metodę na każdym jej obiekcie zależnym, co powoduje rekurencyjne przeszukanie drzewa w głąb.
Takie rozwiązanie umożliwia, zgodnie z podanymi wcześniej wymaganiami, jednolity sposób wyszukiwania, minimalizujący wiedzę, jaką o strukturze danych powinien posiadać klient. Możliwe jest także przeniesienie Książki z jednej Kategorii do innej w trakcie działania systemu (co nie byłoby możliwe w niektórych rozwiązaniach, np. związanych z dziedziczeniem).
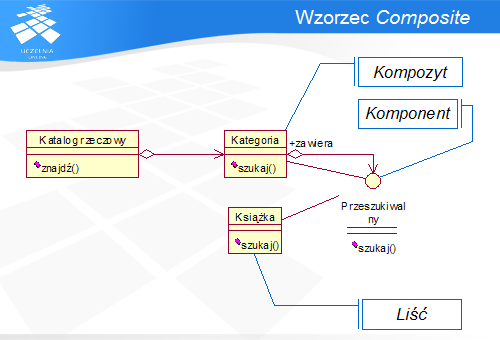


Wzorzec określa metodę konstrukcji hierarchicznych struktur, którymi można zarządzać poprzez jeden węzeł – korzeń. Dzięki temu podstawowe operacje, takie jak wyszukiwanie elementów, nie wymagają żadnej wiedzy o strukturze drzewa.
Popularność tego wzorca wynika z oferowanej przez niego możliwości elastycznego zarządzania złożonymi strukturami. Ponadto wszystkie elementy struktury realizują ten sam algorytm, co ułatwia ich testowanie.
Mechanizm ten jest jednym z najczęściej wykorzystywanych wzorców projektowych, np. w systemach okienkowych. Strukturę drzewiastą tworzą wówczas składowe okienek: przyciski, etykiety, listy etc. Przesunięcie okienka na ekranie powoduje automatyczne przesunięcie wszystkich jego elementów.



W tym punkcie zajmiemy się właśnie problemem zaprojektowania systemu kart czytelnika.
Wymagania wobec nich są następujące:
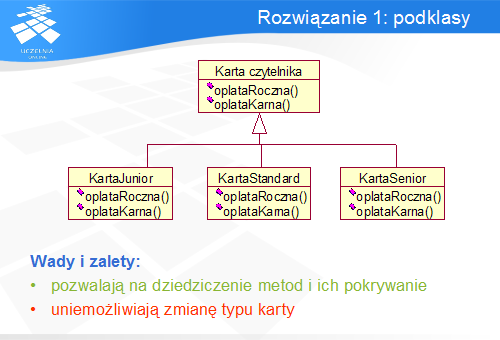
Pierwsze, niemal intuicyjne rozwiązanie polega na utworzeniu podklas reprezentujących rodzaje kart. Podklasy dziedziczą wspólne atrybuty i zachowanie po nadklasie stanowiącej ogólną Kartę Czytelnika, definiując jednak własny sposób wykonania niektórych metod (np. opłataRoczna () i opłataKarna ()). Z punktu widzenia zachowania programu jest to zatem rozwiązanie poprawne, które jednocześnie promuje ponowne użycie kodu poprzez wykorzystanie dziedziczenia.
Jednak stworzenie niezależnych klas uniemożliwia zmianę typu karty bez rekompilacji kodu. To oznacza, że zmiana typu karty Junior na Standard wiązałaby się z usunięciem jednego obiektu i utworzeniem drugiego poprzez przepisanie jego atrybutów. Dlatego to rozwiązanie w całości jest nie do zaakceptowania.
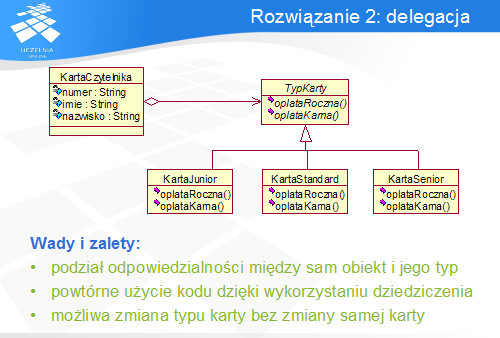
Drugie rozwiązanie polega na rozdzieleniu odpowiedzialności Karty Czytelnika na część przechowującą dane i część reprezentującą stan. Część przechowująca dane, nadal nazywana Kartą Czytelnika, posiada referencję do obiektu reprezentującego aktualny typ, dziedziczącego po klasie abstrakcyjnej lub implementującej interfejs. Dzięki temu zmiana typu wymaga jedynie utworzenia instancji innej klasy Typ Karty i przypisanie jej do Karty Czytelnika.
Efektem takiego projektu jest czytelniejszy podział odpowiedzialności, który jednocześnie posiada zalety brakujące w poprzednim rozwiązaniu.
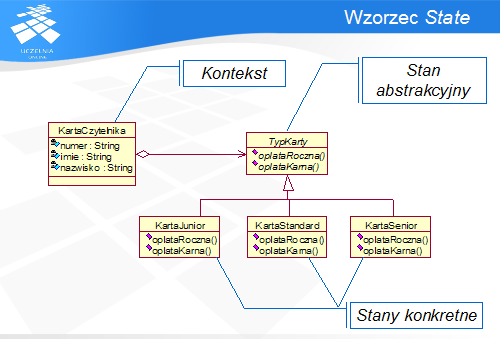
Rozwiązanie to jest znane jako wzorzec State. Wzorzec ten, podobnie jak inne wzorce, do opisania klas uczestniczących w nim posługuje się nazwami ról, jakie one w nim pełnią. KartaCzytelnika jest nazwana Kontekstem, abstrakcyjny TypKarty – Stanem Abstrakcyjnym, a jego podklasy – Stanami Konkretnymi.
Obiekt Kontekst, chcąc wykonać metodę zależną od typu karty, deleguje ją do aktualnie związanego z nim obiektu reprezentującego Typ Karty, zwykle przekazując referencję do siebie jako argument takiej metody. W ten sposób obiekt Typu Karty może odwołać się do kontekstu, na którego rzecz wykonuje odpowiednią operację (np. pobrać dane z obiektu KartaCzytelnika, wywołać jego metody etc.)

Podobnie jak w poprzednim przypadku, we wzorcu uczestniczą 3 klasy.
Obiekt Kontekst posiada referencję do obiektu typu Stan Abstrakcyjny, wskazującą na bieżący stan. W obiekcie Stan zdefiniowane są wszystkie metody, których zachowanie zależy od stanu obiektu Kontekst, natomiast Stany konkretne definiują te metody.

Zastosowanie wzorca pozwala modyfikować zachowanie obiektów tak jakby zmieniała się ich klasa – i to jest najważniejszy cel i skutek zastosowania tego wzorca. Drugim efektem jest hermetyzacja stanu w postaci niezależnych klas, która pozwala na atomiczną (niepodzielną) zmianę tego stanu, bez wprowadzania stanów niespójnych czy nieoznaczonych.
Ciekawa obserwacja dotyczy możliwości współdzielenia obiektów typu State. Jeżeli nie one przechowują informacji (a w większości przypadków może ona być zapamiętana w obiekcie Kontekst), a jedynie definiują zachowanie, wówczas – paradoksalnie – obiekty te, reprezentujące stan, są bezstanowe i mogą być współdzielone między wiele obiektów typu Kontekst.



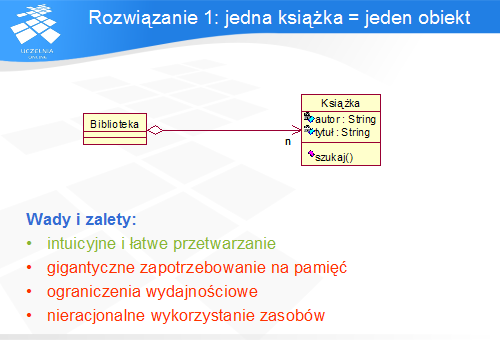
Pierwsze rozwiązanie jest intuicyjne i naturalne: każdej fizycznej karcie książki odpowiada jeden obiekt, tworzony w momencie, gdy jest potrzebny. Ten model charakteryzuje się prostym sposobem przetwarzania: w odpowiedzi na zapytanie (np. wyszukiwanie) obiekt zarządzający (biblioteka) tworzy niezbędną liczbę obiektów reprezentujących karty książki.
Jednak takie rozwiązanie posiada wszystkie wady związane z wydajnością: duże wymagania pamięciowe, ograniczenia wydajnościowe i nieracjonalne gospodarowanie zasobami. Należy zatem je odrzucić i szukać bardziej zaawansowanego mechanizmu.
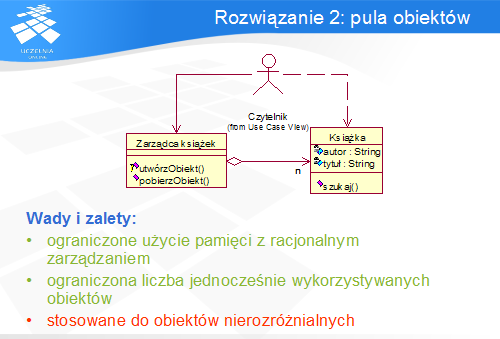
Rozwiązaniem, które usuwa wady poprzedniego, jest pula obiektów. Obiekt zarządzający tworzeniem obiektów-książek nie tworzy ich za każdym razem, gdy zażąda tego klient. Przechowuje on grupę aktywnych obiektów (właśnie pulę), które są przydzielane klientom w miarę ich potrzeb, a po wykorzystaniu zwracane do puli.
W ten sposób rozwiązany jest problem racjonalnego wykorzystania zasobów, ponieważ obiekty mogą być wykorzystywane wielokrotnie. Wydajność takiego rozwiązania zależy od liczby aktywnych obiektów i charakterystyki czasowej nadchodzących żądań.
Jednak nie rozwiązuje to wszystkich problemów: pula zasobów służy do zarządzania grupą obiektów nierozróżnialnych (np. reprezentujących niektóre zasoby), natomiast karty książek posiadają indywidualne dane, które odróżniają je od siebie. Bezpośrednie zastosowanie tego wzorca nie jest zatem możliwe i należy szukać lepszego rozwiązania.
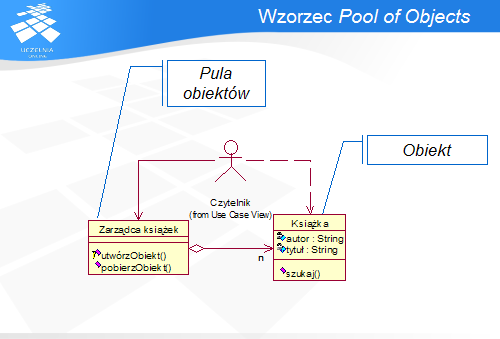
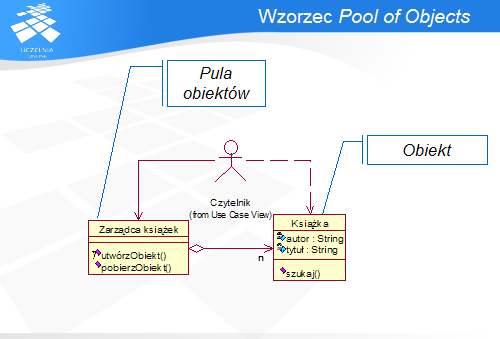
Najważniejsze dwie funkcje Puli obiektów to zdefiniowanie punktu dostępu do obiektów (zarówno do ich tworzenia, jak i zwrotu) oraz zarządzanie cyklem ich życia: tworzeniem, inicjalizacją i usuwaniem.
Klient może otrzymać instancję klasy Obiekt wyłącznie za pomocą Puli obiektów i w ten sam sposób zwalnia przydzielony obiekt.

Dzięki wykorzystaniu wzorca Pool of Objects, Obiekty są tworzone w ograniczonej liczbie instancji i wielokrotnie wykorzystywane ponownie. Pozwala to usunąć bardzo istotny koszt związany z ich tworzeniem. Jest on szczególnie dokuczliwy, gdy liczba żądań jest duża, a czas wykorzystania obiektu bardzo krótki, np. w przypadku przetwarzania zapytań zwracających listę obiektów. Pula obiektów może także wykorzystywać skomplikowane algorytmy heurystyczne w celu przewidywania zapotrzebowania na obiekty i dostosowywania do potrzeb liczby Obiektów przechowywanych w puli, co dodatkowo przyczynia się do optymalizacji wykorzystania zasobów.
Ponadto, wzorzec ten poprawia także hermetyzację Obiektu: jego tworzeniem i konfiguracją zajmuje się Pula obiektów, natomiast Klient jedynie korzysta z usług oferowanych Obiekt.
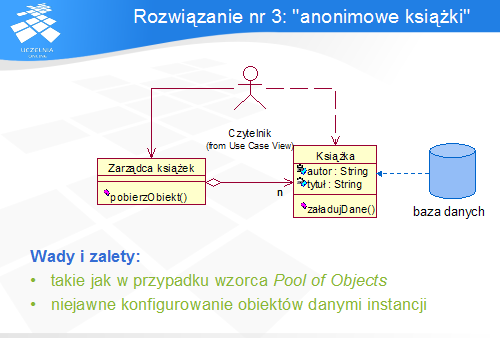
Powiedzieliśmy wcześniej, że wzorzec Pool of Objects nie spełnia wszystkich wymagań zdefiniowanych w specyfikacji tego modułu.
Na tym slajdzie przedstawiono inny mechanizm – "anonimowych książek", stanowiący rozwinięcie wzorca Puli obiektów. Pula przechowywała nierozróżnialne obiekty gotowe do użycia, zatem niemożliwe było przechowywanie w nich informacji specyficznej. Natomiast w przypadku obiektów anonimowych pula zawiera obiekty "nieaktywne", pozbawione specyficznych danych, wymagające inicjacji przed przekazaniem Klientowi. Polega ona właśnie na załadowaniu do obiektu informacji specyficznych, np. odczytanych z bazy danych. W ten sposób klient otrzymuje dokładnie taki obiekt, jakiego oczekuje, nie powodując zwiększenia zużycia zasobów.
Zalety tego rozwiązania są więc identyczne jak w przypadku puli obiektów, a jednocześnie możliwe jest także konfigurowanie obiektów danymi specyficznymi.
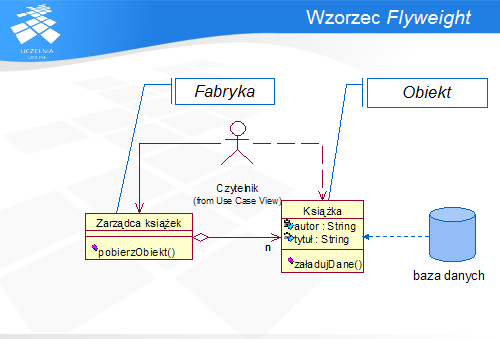
Idea tej koncepcji jest zawarta we wzorcu Flyweight, którego celem jest właśnie ograniczenie liczby instancji wymaganych do obsługi nadchodzących żądań, przy zapewnieniu ich indywidualnych cech. We wzorcu rola pełniona przez Zarządce jest nazywana Fabryką, natomiast Książka jest Obiektem.
Istotą wzorca jest podział danych przechowywanych w Obiektach na dane wewnętrzne (współdzielone) i zewnętrzne (unikatowe dla każdego obiektu). Dane wewnętrzne nie są modyfikowane przy inicjacji obiektu, natomiast dane zewnętrzne są dostarczane dla każdego obiektu z zewnątrz przed przekazaniem obiektu Klientowi.

Wzorzec składa się z dwóch obiektów:
Obiektu, który umożliwia skonfigurowanie go danymi specyficznymi, oraz Fabryki obiektów, która stanowi (z punktu widzenia klienta) logiczny konstruktor obiektów. Fabryka ta posiada pamięć (pulę obiektów), w której przechowuje utworzone wcześniej, anonimowe instancje. Zajmuje się także zapisem i odtwarzaniem (serializacją i deserializacją) stanu zewnętrznego obiektu.



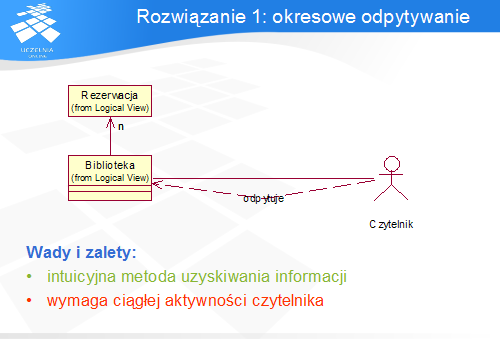
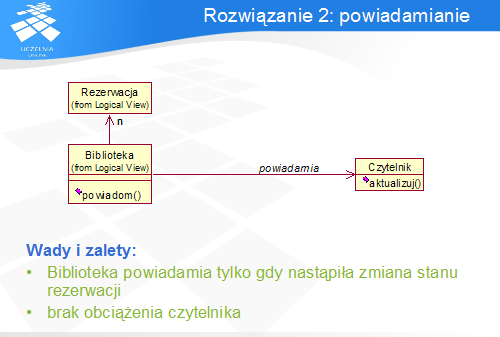
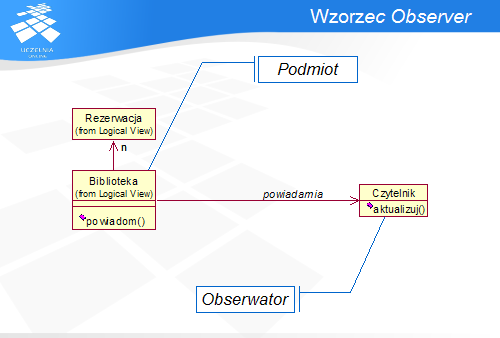
Rozwiązanie to znane jest jako wzorzec o nazwach Observer lub Listener. Biblioteka pełni rolę Podmiotu – obiektu, którego stan jest obserwowany, natomiast Czytelnik jest jego Obserwatorem. Czytelnik wyraża zainteresowanie powiadomieniami, rejestrując się Bibliotece jako Obserwator. W efekcie Biblioteka wywołuje wspólną metodę wszystkich Obserwatorów (aktualizuj ()) na rzecz każdego zarejestrowanego Obserwatora.

We wzorcu udział biorą udział dwa obiekty: Podmiot i Obserwator. Odpowiedzialność Podmiotu polega na przechowywaniu referencji do Obserwatorów, ich dodawaniu i usuwaniu, a także ich powiadamianiu o zmianach. Obserwator posiada interfejs służący do powiadamiania przez Podmiot, oraz aktualizuje swój stan lub wykonuje inne czynności na podstawie powiadomienia.
W języku Java rola obiektu obserwowanego jest reprezentowana przez klasę java . util . Observable , natomiast obserwatory implementują interfejs java . util . Observer. Znacznie upraszcza to zadanie implementacji wzorca w tym języku.

Jednym z najważniejszych konsekwencji zastosowania wzorca Observer jest ograniczenie powiązań i zależności pomiędzy obserwatorami i obiektem obserwowanym. Wprawdzie obiekt obserwowany posiada referencje do obserwatorów, jednak jego wiedza jest ograniczona tylko do znajomości interfejsu Obserwator, który deklaruje jedną metodę. Także Obserwatory nie muszą znać Podmiotu w momencie wywołania ich metody aktualizuj (), ponieważ otrzymują powiadomienia asynchroniczne.
Dzięki ogólności interfejsu Obserwator obiekty uczestniczące we wzorcu mogą należeć do różnych warstw abstrakcji. Wzorzec pozwala zachować spójność pomiędzy warstwami aplikacji, ponieważ informacje o zmianach w jednej warstwie są przekazywane natychmiast do pozostałych obiektów.
