
Jest to ósmy wykład z cyklu.
Dowiedzieliśmy się już o takich zagadnieniach jak przygotowywanie specyfikacji wymagań, projektowaniu w języku UML, poznaliśmy wzorce projektowe… Obecny wykład pomoże zrozumieć metody zapanowania nad tymi wszystkimi artefaktami i ich zmianami, jakie mają miejsce w projektach informatycznych.
Zarządzanie konfiguracją oprogramowania to zestaw czynności pozwalających kontrolować zmiany. Robione to jest poprzez identyfikację elementów, które mogą się zmieniać, ustalenie relacji pomiędzy nimi, określenie mechanizmów zarządzania wersjami.
Dla osób, które do tej pory pracowały jedynie w pojedynkę, takie rzeczy mogą się wydawać abstrakcyjne. Dlatego aby wytłumaczyć ideę zarządzania konfiguracją oraz pokazać szereg problemów, jakie pojawiają się w przypadku pracy wielu osób, nad wieloma programami, dla wielu klientów…
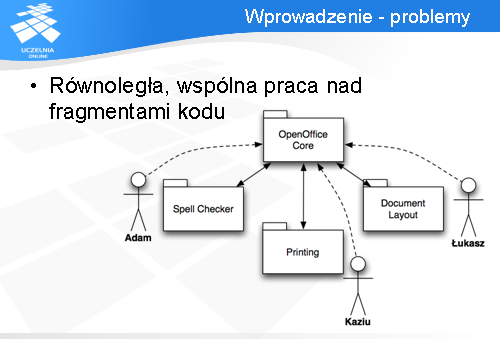
Załóżmy, że nad pewnymi artefaktami (np. moduł kodu) pracuje wiele osób jednocześnie.
Na diagramie mamy przykład, w którym nad programem (pakiet OpenOffice) pracują 3 osoby. Każda z nich rozwija samodzielnie swój moduł, lecz pewne elementy są wspólne (moduł ten został nazwany OpenOffice Core). Podczas pracy nad poszczególnymi modułami często zachodzi potrzeba zmiany modułu Core. Wtedy dochodzi do jednoczesnej pracy kilku osób nad tym samym artefaktem.
Tak więc drugim problemem jest równoległa praca wielu osób - system zarządzania konfiguracją musi wiedzieć, w jaki sposób pobrać zmiany od poszczególnych programistów, następnie je scalić w jedno, a spójną wersję rozpropagować dalej do pozostałych osób.
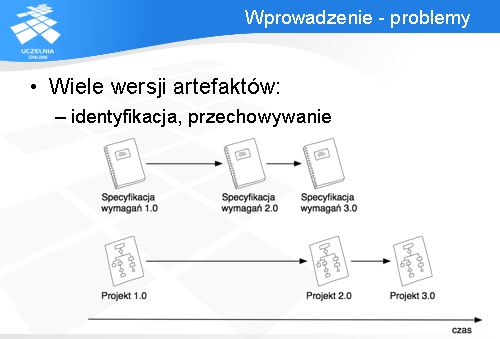
Każdy artefakt może ulegać ewolucji. Np. specyfikacja wymagań, lub projekt architektury zmienia się w zależności od aktualnej wiedzy analityka lub architekta.
Aby komunikacja w zespole i pomiędzy zespołem a klientem przebiegała bezproblemowo, musimy mieć możliwość:
Warto zauważyć, że zmiany wersji poszczególnych artefaktów nie są synchroniczne, czyli np. specyfikacja wymagań może powstać w wersji 2.0 pewnego dnia, natomiast projekt architektury w wersji 2.0 powstanie dopiero tydzień później.
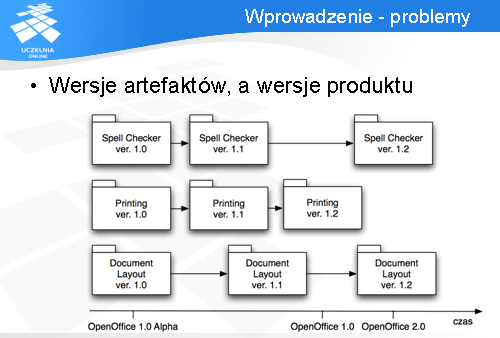
Podobnie zmieniają się wersje różnych modułów oprogramowania (czy też plików źródłowych).
Firma programistyczna musi wiedzieć, co znajduje się w określonej wersji produktu.
Jest to konieczne w momencie kiedy zadzwoni do nas klient z problemem. W tej sytuacji musimy potrafić jednoznacznie powiedzieć, które wersje plików źródłowych wchodzą w skład jego produktu. Jeżeli tego nie wiemy, to w jakiej wersji kodu zaczniemy szukać błędu zgłoszonego przez niego?
Czyli wymagamy od systemu zarządzania konfiguracją, aby zapamiętał, że przykładowo OpenOffice w wersji 1.0 składał się z modułów: Spell Checker 1.1, Printing 1.2 oraz Document Layout 1.1.
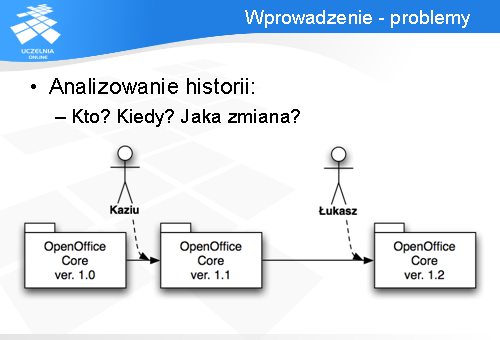
Aby zapanować nad dużym zespołem programistycznym, musimy mieć możliwość śledzenia wszystkich zmian w artefaktach projektu, czyli musimy posiadać informację kto, kiedy i jaką zmianę wprowadził.
Jest to potrzebne w wielu sytuacjach:
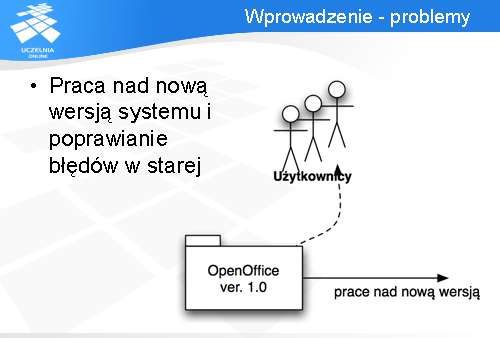
Problem pojawia się również w momencie kiedy jedną wersję systemu (np. OpenOffice 1.0) udostępnimy użytkownikom i zaczniemy pracować nad nową wersją (czyli zaczniemy dodawać nową funkcjonalność, która na początku nie będzie jeszcze stabilna). Co w momencie kiedy użytkownicy zauważą błędy? Powinniśmy je jak najszybciej poprawić i udostępnić nowe wydanie wersji OpenOffice 1.0 (może ona być oznaczona np. 1.0.1), lecz nie chcemy włączać tam nowych funkcji, które są przeznaczane dla wersji 2.0 i nie są jeszcze stabilne.
Czyli system zarządzania konfiguracją musi dawać możliwość równoległej pracy nad różnymi wersjami produktu - chcemy mieć możliwość pracy nad nową wersją, ale również możliwość poprawienia drobnego błędu w starej wersji.
Wprowadzenie

Jest wiele narzędzi, które wspomagają zarządzanie konfiguracją oprogramowania, darmowe np. CVS, Subversion, czy komercyjne np. Microsoft SourceSafe.
Każde z tych narzędzi działa na podobnej zasadzie - za pomocą odpowiednich komend umożliwiają wprowadzanie zmian do centralnego repozytorium, pamiętają zmiany artefaktów, umożliwiają synchronizowanie wersji różnych osób, oraz tworzenie rozgałęzień i łączenie gałęzi.
Samo narzędzie jednak nie wystarcza. W każdej firmie potrzebny jest zestaw procedur, które instruują w jaki sposób korzystać z tego narzędzia, czyli w jaki sposób należy wprowadzać zmiany w kodzie, wydawać nową wersję, poprawiać defekty w udostępnionych wersjach, czy też łączyć zmiany z różnych wersji.
Po tym krótkim wprowadzeniu zostanie przedstawiony najpopularniejszy system zarządzania konfiguracją oprogramowania: CVS. Po kolei zostaną omówione podstawowe operacje na repozytorium. Następnie zostanie przedstawiona przykładowa struktura plików projektu, pozwalająca uniknąć bałaganu (przydatne zwłaszcza początkującym osobom przystępującym do pracy grupowej).
Samo przedstawienie operacji to jeszcze za mało - użytkownik musi wiedzieć, w jaki sposób wykorzystać te operacje do osiągnięcia zamierzonych celów. Dlatego na końcu zostaną przedstawione wybrane wzorce zarządzania konfiguracją.
System CVS
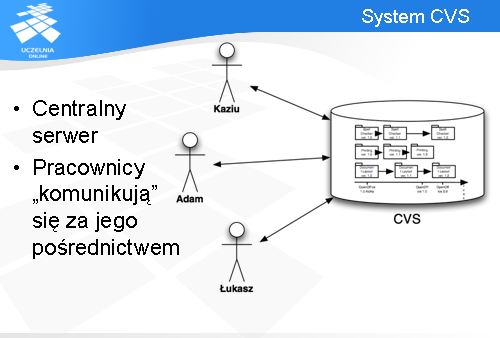
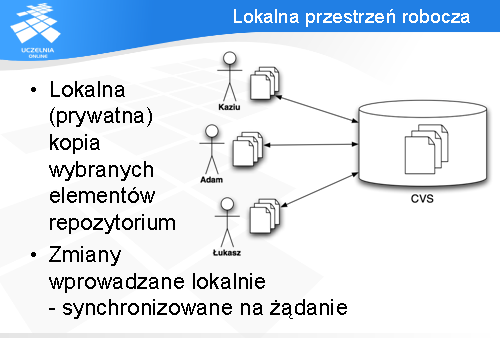
Każdy użytkownik repozytorium posiada na swoim komputerze prywatną kopię elementów z repozytorium, na których pracuje. Kopia taka nazywana jest lokalną przestrzenią roboczą i stanowi zbiór plików i folderów pobranych z repozytorium.
Wszelkie prace odbywają się najpierw lokalnie i są wysyłane na żądanie do repozytorium. Dopiero w momencie, kiedy zmiany się tam znajdą są one widoczne dla pozostałych osób.
Zacznijmy od poznania sposobu pracy z repozytorium CVS, czyli poszczególnych komend, jakie możemy wykonać.
Pierwsza czynność programisty, to pobieranie artefaktów.
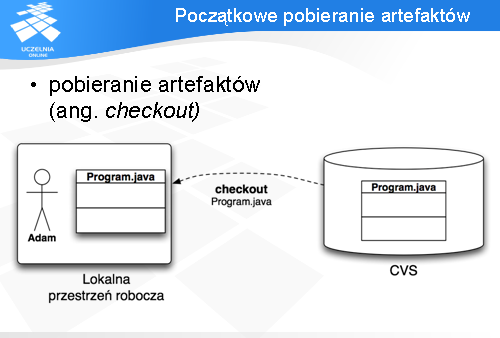
Zanim programista ma możliwość współpracy z repozytorium musi utworzyć na swoim komputerze przestrzeń roboczą i pobrać do niej wybrane artefakty z repozytorium.
Czyni to raz, np. na początku prac implementacyjnych. Wcześniej ktoś musi umieścić tam pewien szkielet plików i folderów, ale o tym później.
Do pobierania artefaktów służy komenda checkout. Jako parametr tej komendy podajemy nazwę „modułu”, który chcemy pobrać, czyli nazwę jednego z katalogów przechowywanych w repozytorium (w szczególności może to być zawartość całego repozytorium oznaczana przez „.”)

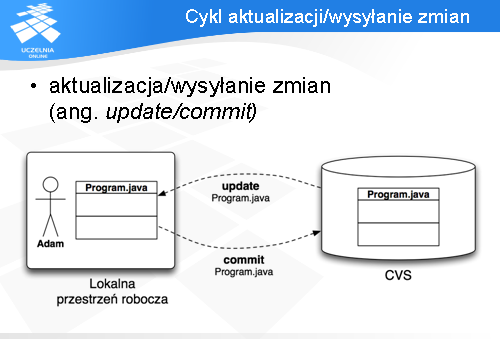
Cykl synchronizacji z repozytorium najlepiej przedstawić na diagramie.
Pobieranie zmian z serwera i wprowadzanie do lokalnej przestrzeni roboczej robione jest przez polecenie „update”.
Natomiast w drugą stronę - wysłanie lokalnych zmian do repozytorium wykonuje się dzięki poleceniu „commit”.
Ze zmianami wysyłanymi do repozytorium (polecenie „commit”) można skojarzyć komentarz. Nadawanie komentarzy jest dobrą praktyką, gdyż ułatwia innym osobom z zespołu szybkie zorientowanie się w dużej liczbie zmian.
Komendy „update” i „commit” można wykonać na określonych fragmentach projektu: na wybranym pliku, całym katalogu, lub całym projekcie - w zależności od potrzeby.
Zaleca się, aby taki cykl synchronizacji powtarzany był jak najczęściej - co najmniej raz dziennie. Po przyjściu do pracy programista powinien wykonać komendę „update”, aby ściągnąć bieżące zmiany, a następnie przed wyjściem z pracy wykonać „commit”.
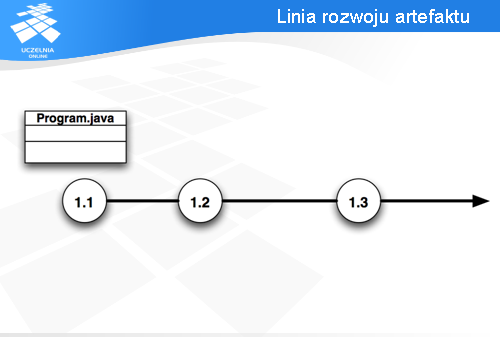
Serwer pamięta historię wszystkich zmian wszystkich artefaktów. Powiedzmy, że przechowujemy plik Program.java. Repozytorium będzie pamiętać każdą wersję tego pliku (a dokładniej - różnice pomiędzy tymi wersjami), jak również datę każdej operacji i osobę, która dokonała zmiany.
Każda wersja jest oznaczona numerem. W CVSie są to numery 1.1, 1.2, 1.3, itd. Numeracja jest inna jeżeli nie pracujemy na głównej gałęzi, ale więcej informacji o tym będzie za chwilę.
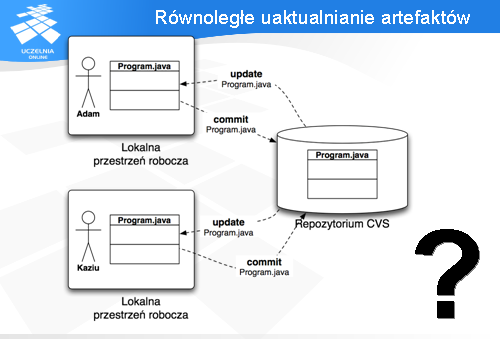
Do tej pory wszystko wydaje się proste. Pobieramy pliki, pracujemy na nich, a następnie wysyłamy i pobieramy zmiany.
Zadanie repozytorium CVS wydaje się dużo trudniejsze, jeżeli dopuścimy możliwość równoległej pracy wielu osób. Każda z tych osób może pracować jednocześnie na tym samym pliku, nawet zmieniać te same fragmenty pliku.
Spróbujmy przyjrzeć się jak działają operacje update/commit, aby zrozumieć, jak CVS zachowa się w takich sytuacjach.
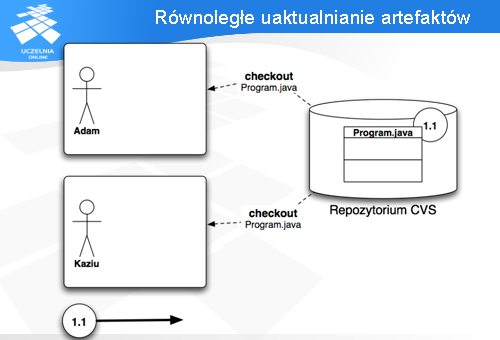
Najlepiej prześledzić to na przykładzie. Na slajdzie widać 4 główne części:
Oboje zaczynając pracę nad plikiem Program.java, muszą stworzyć sobie jego kopię lokalną (polecenie „checkout”).
Równie dobrze mogliby wykonać to polecenie na całym katalogu, lub projekcie, ale dla prostoty tego przykładu ograniczymy się jedynie do jednego pliku.
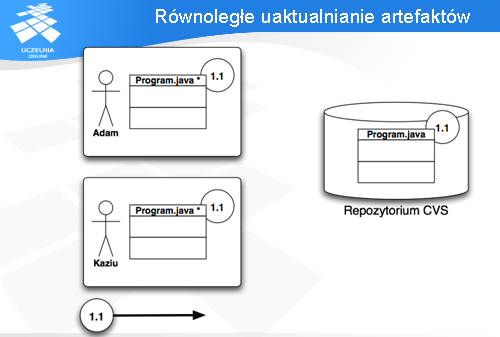
W rezultacie każdy z nich otrzymuje plik Program.java w najnowszej wersji (1.1).
Jest to zaznaczone w ich lokalnych przestrzeniach roboczych - tam też widać wersję pliku lokalnego.
Następnie zarówno Adam jak i Kaziu wprowadzają swoje zmiany do pliku Program.java. Na diagramie oznaczyłem zmienione pliki symbolem gwiazdki przy ich nazwie.
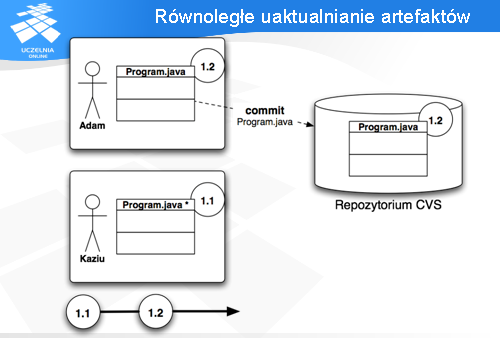
Adam próbuje wykonać polecenie „commit” - udaje się to bez problemu. Serwer przechowuje jego zmiany, jednocześnie nadając nową wersję plikowi Program.java (1.2) - widać to na dolnej osi.
Równocześnie CVS zaznacza, że w przestrzeni roboczej również mamy już wersję 1.2.
Znika również gwiazdka przy nazwie pliku, co oznacza, że nie mamy już żadnych zmian lokalnych, które by nie były na serwerze.
Przychodzi kolej na Kazia. On również chce zapisać swoje zmiany w repozytorium i próbuje wykonać operację „commit”.
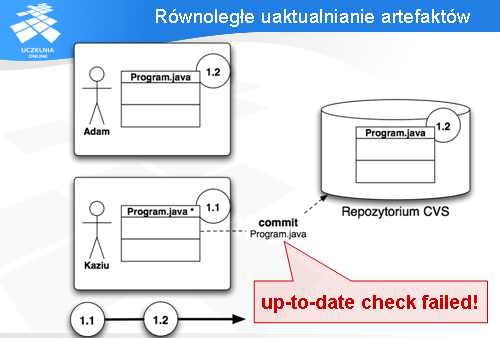
Niestety, serwer CVS wykrywa, że Kaziu pracował na starszej wersji pliku. Miał on w swojej przestrzeni roboczej wersję 1.1, podczas gdy na serwerze była już wersja 1.2.
CVS protestuje komunikatem „up-to-date check failed”, co oznacza w wolnym tłumaczeniu: „masz nieaktualną przestrzeń roboczą
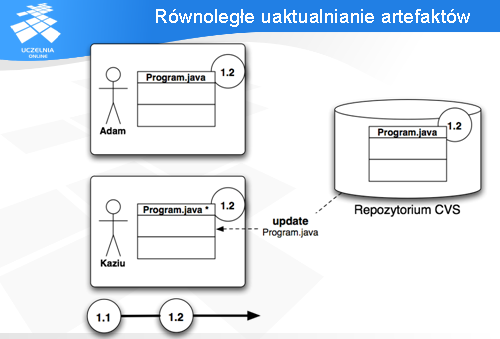
W takich sytuacjach należy najpierw pobrać najnowsze zmiany z CVSa i uaktualnić lokalny plik do nowej wersji komendą „update”.
„Update” pobiera z CVSa zmiany pomiędzy wersją 1.1, a 1.2 i wprowadza je do lokalnej przestrzeni roboczej Kazia, lecz nadal zachowuje jego własne zmiany - co jest zaznaczona gwiazdką.
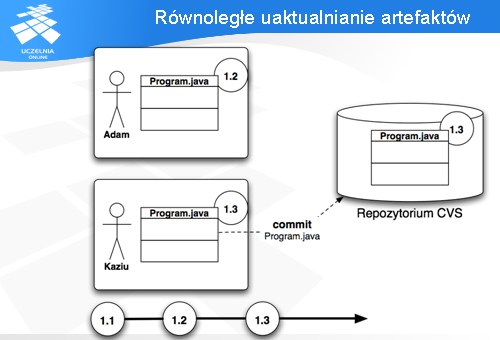

Powstaje pytanie - jak CVS radzi sobie z wykonaniem komendy „update” w momencie kiedy występują zmiany zarówno po stronie serwera, jak i lokalnie? Musi on w jakiś sprytny sposób połączyć 2 różne pliki w jedno.
Sposób jest dosyć prosty - CVS próbuje scalić zmiany.
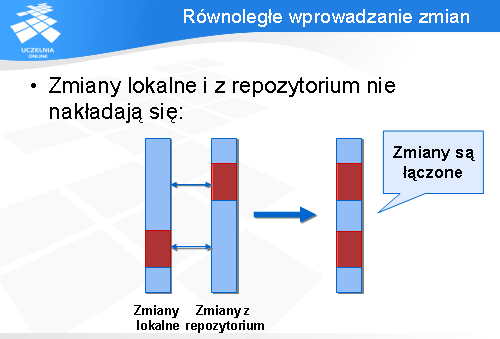
Każdy plik tekstowy jest postrzegany przez CVS jako zbiór linii. Jeżeli linie zmienione lokalnie oraz w repozytorium stanowią rozłączne obszary, wtedy nic nie stoi na przeszkodzie, aby CVS automatycznie scaliło zmiany. W wyniku powstaje plik, który zawiera zarówno zmiany lokalne, jak i globalne.
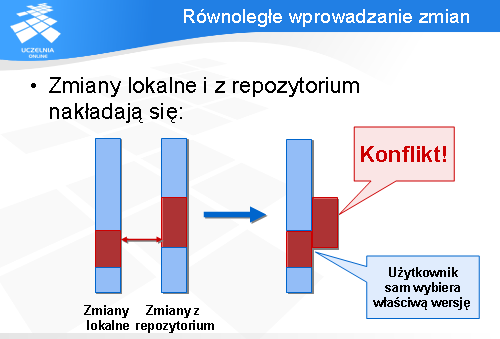
Sytuacja się komplikuje, jeżeli zmienione linie lokalne i zdalne nakładają się. Wtedy CVS nie jest w stanie ich automatycznie połączyć - prosi o pomoc użytkownika.
Wtedy w pliku wynikowym przechowywane są obie wersje i są one oznaczane jako tzw. konflikt. W takiej sytuacji użytkownik musi samodzielnie wybrać właściwą wersję.
Rozwiązywanie konfliktu
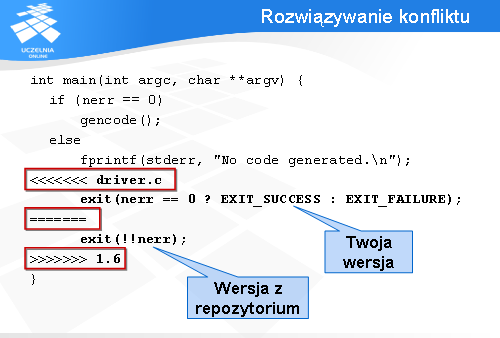
CVS oznacza konflikt w następujący sposób. Po wykonaniu komendy „update” prowadzącej do konfliktu w pliku wynikowym mamy dwa bloki tekstu:
Zadaniem użytkownika w tej sytuacji jest wybór odpowiedniej wersji (czasem to będzie jakieś połączenie obu wersji), oraz usunięcie wszelkich znaków specjalnych oznaczających konflikt, a zostawienie jedynie poprawnej części pliku.
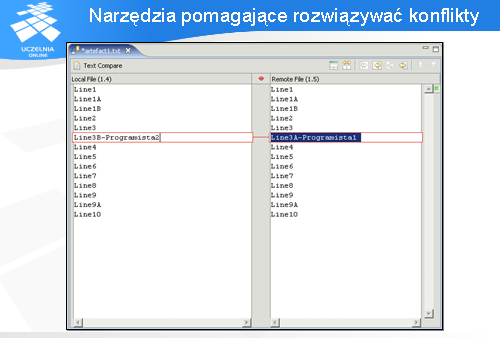
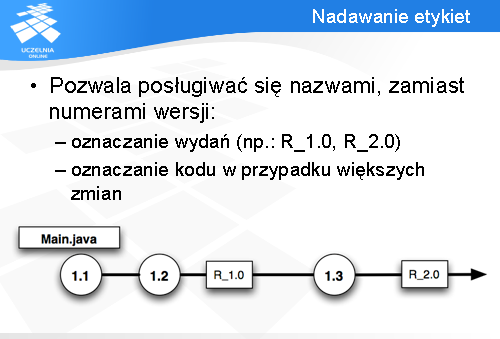
Z tego powodu systemy do zarządzania konfiguracją oprogramowania (również CVS) pozwalają posługiwać się etykietami, zamiast numerami. Etykiety są przydzielane świadomie przez programistę, wtedy kiedy uważa on to za stosowne (np. w sytuacjach wspomnianych wcześniej). Są one pamiętane przez repozytorium i za ich pomocą można pobrać określoną wersję plików, które nas interesują.
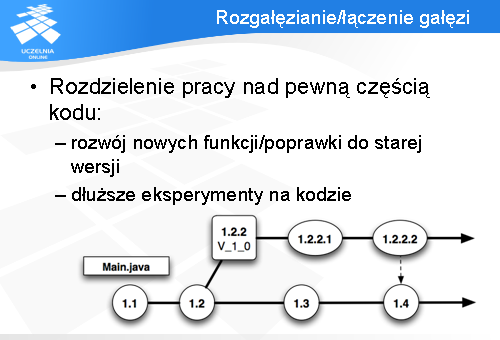
CVS umożliwia tworzenie rozgałęzień poprzez komendę „branch” i łączenia poprzez „merge”.
Daje to możliwość wyłączenia fragmentu kodu z głównej linii rozwoju, osobnego operowania na tej wydzielonej gałęzi, a następnie scalenia zmian z główną gałęzią. Dobrze przedstawia to diagram ze slajdu.
W CVS-ie każda gałąź ma swoją nazwę (np. V_1_0), oraz numer złożony z numeru pliku podstawowego (np. 1.2), oraz numeru parzystego oznaczającego numer gałęzi (2, 4, 6,…). W rezultacie otrzymujemy 1.2.2 jako numer gałęzi z przykładowego diagramu.
Kolejne numery wersji plików z gałęzi, mają na początku numer, oraz kolejno 1,2,3, na końcu.
Po wykonaniu niezbędnych zmian na gałęzi i przetestowaniu ich mamy możliwość scalenia tych zmian z bazowym kodem poprzez wykonanie komendy „merge”.

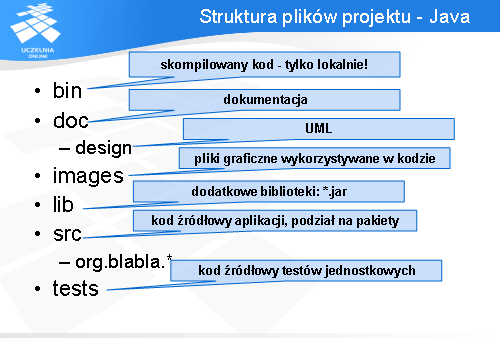
Dla języka Java, najczęstsza struktura plików projektu wygląda następująco:
Znajomość samych operacji nie wystarcza jednak do rozwiązania wszystkich problemów, o których była mowa na początku wykładu. Jest z tym podobnie jak z językami programowania - znajomość konstrukcji języka nie jest wystarczająca do budowania dużych systemów informatycznych.
Literatura udostępnia wiele dobrych praktyk i rad dotyczących posługiwaniem się repozytorium kodu. Część z nich wyodrębniono jako „wzorce zarządzania konfiguracją”. Wybrane wzorce zostaną przedstawione w dalszej części wykładu.

Cztery najważniejsze wzorce, to:
Nazwy te w tej chwili mogą być dla Państwa niezrozumiałe, lecz za moment powinno być wszystko jasne.
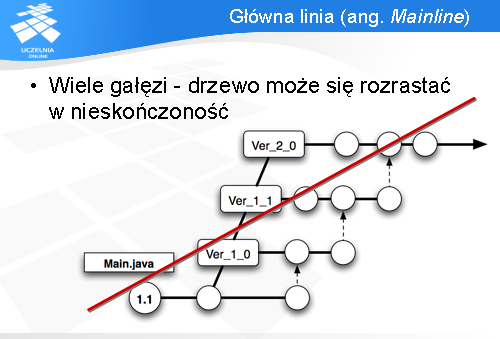
Repozytoria umożliwiają dzielenie artefaktów na wiele gałęzi. Jednak duża liczba tych gałęzi utrudnia panowanie nad repozytorium. Przy takiej strukturze repozytorium, jak na diagramie, programiści mieliby problemy z odnalezieniem właściwej gałęzi do pracy. Dodatkowo, po wydaniu nowej wersji produktu, musieliby pamiętać, aby przełączyć się do gałęzi z nową wersją.
Dlatego nie jest pożądane, aby drzewo rozrastało się w głąb.
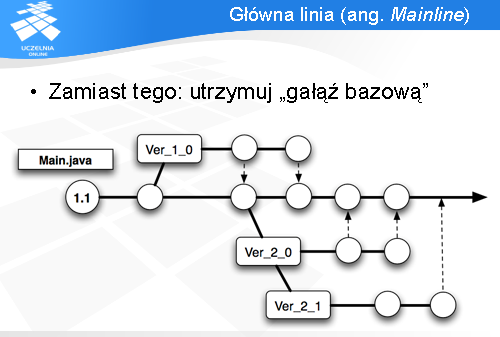
Dużo lepszą praktyką jest utrzymywanie „gałęzi” bazowej, tzw. „głównej linii”. Główne prace implementacyjne powinny odbywać się właśnie tam. Jeżeli potrzebne jest rozgałęzienie i prowadzenie równoległych prac nad kawałkiem kodu (np. w momencie wydania nowej wersji), to wszystkie zmiany powinny docelowo być scalone z główną linią.
Takie podejście pozwala zapanować nad rozrastaniem się drzewa gałęzi i odciąża wszystkich programistów od potrzeby pamiętania, w którym miejscu drzewa obecnie się znajdujemy.
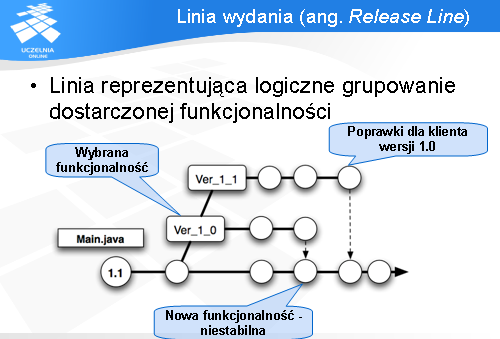
Kolejny wzorzec to „linia wydania”.
Każdemu wydaniu systemu (np. nowa wersja oprogramowania) powinno towarzyszyć rozgałęzienie. Dzięki temu część funkcjonalności, która była zawarta w tym wydaniu jest „oddzielona” i można na niej prowadzić równolegle pracę. Jest to niezbędne jeżeli chcemy pozwolić na tworzenie nowej funkcjonalności (na początku niestabilnej) w głównej gałęzi, a jednocześnie poprawiać błędy w wydanej wersji systemu.
Wtedy wszystkie błędy poprawiane są w gałęzi. W razie potrzeby można tą strukturę bardziej zagnieżdżać - czyli zrobić gałąź dla gałęzi - gdy przykładowo chcemy wydać wersję 1.1 oprogramowania, co jest pokazane na diagramie.

Następny wzorzec to „gałąź przed wydaniem”.
Problem powstaje, kiedy większy zespół pracuje nad wydaniem. Jeżeli część z tych osób skończy pracę kilka dni wcześniej niż inni - wtedy chcieliby zapewne zacząć już pracę nad nowymi funkcjami, lecz nie mogą tego robić w głównej gałęzi - zakłóciliby pracę osób, które pracują nad wydaniem. W takiej sytuacji zalecane jest stworzenie dodatkowej gałęzi. Na tej gałęzi pracują osoby przygotowujące wydanie, natomiast pozostałe osoby mogą swobodnie pracować w głównej gałęzi.
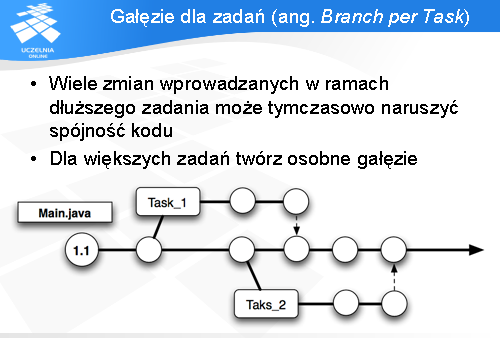
Ostatni wzorzec to: „gałęzie dla zadań”.
Problem, z jakim można się często spotkać w praktyce to praca nad dłuższymi zadaniami, która mocno zaburza pozostały kod. Wykonywanie tych zadań na głównej gałęzi byłoby uciążliwe, gdyż w międzyczasie, przed ukończeniem tego zadania zdarza się, że jakiś fragment się nie kompiluje, lub nie działa tak jak powinien. W celu umożliwienia pracy nad takimi zadaniami należy dla każdego stworzyć osobną gałąź. Po skończeniu zadania i upewnieniu się, iż zmiany nie zaburzają istniejącego kodu można scalić je do głównej gałęzi.
Podsumowując: