Dalsze algorytmy dla języków regularnych. Problemy rozstrzygalne
W tym wykładzie przedstawimy algorytmy konstrukcji gramatyki regularnej, automatu skończenie stanowego oraz wyrażeń regularnych opisujących ten sam język \(\displaystyle L\). Omówimy także problemy rozstrzygalne algorytmicznie w klasie języków regularnych.
Dalsze algorytmy języków regularnych
Dowód twierdzenia z ostatniego wykładu, w którym udowodniliśmy równoważność rozpoznawania języka \(\displaystyle L\) i generowania tego języka przez gramatykę regularną daje podstawę do określenia dwóch algorytmów. Algorytmu konstruującego automat skończony w oparciu o daną gramatykę regularną i oczywiście akceptujący język generowany przez tę gramatykę oraz algorytmu budowy gramatyki regularnej dla zadanego automatu. Bez utraty ogólności przyjmujemy, że automat jest deterministyczny.
Idea działania algorytmu Automat2GReg jest następująca: każdy symbol nieterminalny \(\displaystyle v\) tworzonej gramatyki odpowiada pewnemu stanowi \(\displaystyle s_v\) automatu. Jeśli w automacie pod wpływem litery \(\displaystyle a\) następuje przejście ze stanu \(\displaystyle s_v\) do stanu \(\displaystyle s_w\), to do zbioru praw gramatyki dodawane jest prawo \(\displaystyle s_v \rightarrow as_w\). Ponadto, jeśli stan \(\displaystyle s_w\) jest stanem końcowym, to dodajemy także prawo \(\displaystyle s_w \rightarrow 1\), aby w danym miejscu wywód słowa mógł zostać zakończony.
Algorytm Automat2GReg - buduje gramatykę regularną dla zadanego automatu skończonego.
1 Wejście: \(\displaystyle \mathcal{A}=(S, A, f, s_0, T)\) - automat niedeterministyczny.
2 Wyjście: \(\displaystyle G=(V_N, V_T, P, v_0)\) - gramatyka regularna taka, że \(\displaystyle L(G)=L(\mathcal{A})\).
3 \(\displaystyle V_N \leftarrow \{v_0,v_1,...,v_{|S|-1}\}\);
4 \(\displaystyle V_T \leftarrow A\);
5 \(\displaystyle v_0 \leftarrow s_0\);
6 \(\displaystyle P \leftarrow \emptyset\);
7 for each \(\displaystyle s_i\in S\) do
8 for each \(\displaystyle a\in A\) do
9 if \(\displaystyle f(s_i,a)\neq\)NULL then
10 \(\displaystyle s_j \leftarrow f(s_i,a)\); \(\displaystyle \triangleright\) funkcja \(\displaystyle f\) jest określona na \(\displaystyle (s_i,a)\)
11 \(\displaystyle P \leftarrow P \cup \{s_i \rightarrow as_j\}\);
12 if \(\displaystyle s_j \in T\) then
13 \(\displaystyle P \leftarrow P \cup \{s_j \rightarrow 1\}\);
14 end if
15 end if
16 end for
17 end for
18 return \(\displaystyle G\);
Oznaczmy przez \(\displaystyle E(\mathcal{A})\) ilość krawędzi w grafie \(\displaystyle n\)-stanowego automatu niedeterministycznego \(\displaystyle \mathcal{A}\). Złożoność czasowa liczona względem \(\displaystyle E(\mathcal{A})\) jest liniowa i równa \(\displaystyle O(E(\mathcal{A}))\). Również złożoność pamięciowa jest liniowa i wynosi \(\displaystyle O(|S|+E(\mathcal{A}))\).
Przykład 1.1
Niech dany będzie automat \(\displaystyle \mathcal{A}\) pokazany na rysunku 1. Zbudujemy gramatykę, która będzie generowała język akceptowany przez \(\displaystyle \mathcal{A}\).
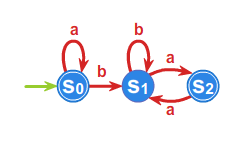
Ponieważ \(\displaystyle f(s_0,a)=s_0\), a ponadto \(\displaystyle s_0\) jest stanem końcowym, do \(\displaystyle P\) dodajemy produkcje \(\displaystyle v_0 \rightarrow av_0\) oraz \(\displaystyle v_0 \rightarrow 1\). Dodajemy także produkcję \(\displaystyle v_0 \rightarrow bv_1\), gdyż mamy \(\displaystyle f(s_0,b)=s_1\).
Fakt, że \(\displaystyle f(s_1,b)=s_1\) oraz \(\displaystyle f(s_1,a)=s_2\) sprawia, że do \(\displaystyle P\) dodajemy: \(\displaystyle v_1\ \rightarrow bv_1\), \(\displaystyle v_1 \rightarrow av_2\).
Ponieważ \(\displaystyle f(s_2, a)=s_1\) do \(\displaystyle P\) dodajemy: \(\displaystyle v_2 \rightarrow av_1\) oraz \(\displaystyle v_2 \rightarrow 1\), gdyż \(\displaystyle s_2 \in T\).
Symbolem początkowym nowej gramatyki jest symbol \(\displaystyle v_0\). Ostatecznie gramatyka ma postać:
Zwróćmy uwagę na wygodny zapis produkcji gramatyki, jaki został użyty powyżej. Produkcje o tej samej lewej stronie (wspólnym symbolu
nieterminalnym) zapisywane są razem, a prawe strony tych produkcji oddzielane są pionowymi kreskami.
Przedstawiony poniżej algorytm GReg2Automat konstruuje automat skończenie stanowy, akceptujący język generowany przez
zadaną gramatykę.
Zauważmy, że gramatyka podana na wejściu algorytmu nie może zawierać produkcji postaci \(\displaystyle v \rightarrow x\), gdzie \(\displaystyle v \in V_N\), \(\displaystyle x \in (V_N \cup V_T)\). Jeśli gramatyka zawiera takie produkcje, to możemy się ich łatwo pozbyć, zgodnie z Twierdzeniem 2.2 z Wykładu 7 (patrz twierdzenie 2.2 wykład 7), uzyskując oczywiście gramatykę równoważną.
Idea działania algorytmu jest podobna do poprzedniej - każdy tworzony stan automatu odpowiadać będzie pewnemu symbolowi nieterminalnemu gramatyki wejściowej. Zależnie od postaci produkcji gramatyki, niektóre stany będą stanami końcowymi.
Zapis \(\displaystyle f \leftarrow\displaystyle \emptyset\) w linii 7. symbolicznie oznacza, że funkcja przejść nie jest jeszcze określona.
W pętli 8.-15. pozbywamy się produkcji, w których występuje więcej niż jeden terminal; każdą taką produkcję "rozbijamy" na sekwencję
produkcji postaci \(\displaystyle v \rightarrow aw\), gdzie \(\displaystyle v,w \in V_N,\ a \in V_T\).
Algorytm GReg2Automat - buduje automat dla zadanej gramatyki regularnej.
1 Wejście: \(\displaystyle G=(V_N, V_T, P, v_0)\) - gramatyka regularna.
2 Wyjście: \(\displaystyle \mathcal{A}=(S, A, f, v_0, T)\) - automat taki, że \(\displaystyle L(\mathcal{A})=L(G)\).
3 \(\displaystyle S \leftarrow\displaystyle V_N\);
4 \(\displaystyle A \leftarrow V_T\);
5 \(\displaystyle T \leftarrow \emptyset\); \(\displaystyle \triangleright\) nie ma jeszcze stanów końcowych
6 \(\displaystyle s_0 \leftarrow v_0\);
7 \(\displaystyle f \leftarrow \emptyset\); \(\displaystyle \triangleright\) funkcja \(\displaystyle f\) nie jest określona dla żadnego argumentu
8 for each \(\displaystyle (v_i \rightarrow a_1a_2...a_nv_j) \in P\) do
9 if \(\displaystyle n>1\) then
10 \(\displaystyle V_N \leftarrow V_N \cup \{v^{a_1}, ..., v^{a_{n-1}}\}\); \(\displaystyle \triangleright\) rozbijamy produkcję na kilka prostszych
11 \(\displaystyle P \leftarrow P \backslash \{v_i \rightarrow a_1a_2...a_nv_j\}\); \(\displaystyle \triangleright\) w tym celu usuwamy produkcję z \(\displaystyle P\)
12 \(\displaystyle P \leftarrow P \cup \{v_i \rightarrow a_1v^{a_1}, v^{a_{n-1}} \rightarrow a_nv_j\}\); \(\displaystyle \triangleright\) w zamian dodając ciąg krótszych
13 \(\displaystyle P \leftarrow P \cup \{v^{a_1} \rightarrow a_2v^{a_2}, \ldots, v^{a_{n-2}} \rightarrow a_{n-1}v^{a_{n-1}} \}\);
14 end if
15 end for
16 \(\displaystyle \triangleright\) wszystkie produkcje są postaci \(\displaystyle u\rightarrow a v\) lub \(\displaystyle u\rightarrow 1\), gdzie \(\displaystyle u,v\in V_N\), \(\displaystyle a\in V_T\)
17 for each \(\displaystyle (s_i \rightarrow as_j) \in P\) do
18 \(\displaystyle f(s_i, a) \leftarrow s_j\);
19 end for
20 for each \(\displaystyle (v_i \rightarrow 1) \in P\) do
21 \(\displaystyle T \leftarrow T \cup \{v_i\}\);
22 end for
23 return \(\displaystyle \mathcal{A}=(S, A, f, s_0, T)\);
Przykład 1.2
Jako wejście algorytmu rozważmy gramatykę z przykładu 1.1 (patrz przykład 1.1.) Używając algorytmu Greg2Automat, zbudujemy dla niej automat akceptujący język przez nią generowany.
Mamy \(\displaystyle S=\{s_0, s_1, s_2\}\). W liniach 17. -- 19. określana jest funkcja przejścia: \(\displaystyle f(s_0, a)=s_0\), \(\displaystyle f(s_0, b)=s_1\), \(\displaystyle f(s_1, b)=s_1\), \(\displaystyle f(s_1, a)=s_2\) oraz \(\displaystyle f(s_2, a)=s_1\).
Pętla w liniach 20. - 22. przebiega po dwóch produkcjach: \(\displaystyle v_0 \rightarrow 1\) oraz \(\displaystyle v_2 \rightarrow 1\), dodaje zatem do zbioru \(\displaystyle T\) stanów końcowych stany \(\displaystyle s_0\) oraz \(\displaystyle s_2\). Szukany automat to automat z poprzedniego przykładu; przedstawiony jest na rysunku 1.
Automat powstały w wyniku działania algorytmu GReg2Automat nie musi być automatem deterministycznym (wystarczy, że w zbiorze
produkcji znajdą się dwie produkcje postaci \(\displaystyle v_i \rightarrow av_j\) oraz \(\displaystyle v_i \rightarrow av_k\) dla pewnego \(\displaystyle a \in A\)), jednak po jego determinizacji i minimalizacji otrzymujemy minimalny automat deterministyczny akceptujący język, który jest generowany przez gramatyke podaną na wejście algorytmu.
Złożoność czasowa jak i pamięciowa algorytmu wynosi \(\displaystyle O(p)\), gdzie \(\displaystyle p\) jest liczbą produkcji występujących w zbiorze praw \(\displaystyle P\) gramatyki.
Przedstawimy teraz algorytmy związane z wyrażeniami regularnymi. Pierwszy z nich prowadzi do konstrukcji automatu skończenie stanowego, rozpoznającego język opisany wyrażeniem regularnym. Drugi, mając na wejściu automat, konstruuje wyrażenie regularne opisujące język rozpoznawany przez ten automat.
Rozpoczynamy od algorytmu prowadzącego do konstrukcji automatu na podstawie wyrażenia regularnego.
Niech \(\displaystyle a \in A, r,s \in \mathcal{WR}\). Najpierw pokażemy, że językom odpowiadającym wyrażeniom regularnym , \(\displaystyle 1\), \(\displaystyle a\), \(\displaystyle r+s\), \(\displaystyle rs\) oraz \(\displaystyle r^*\) można przyporządkować automaty akceptujące te języki, a
następnie podamy algorytm konstruowania automatu rozpoznającego dowolne wyrażenie regularne.
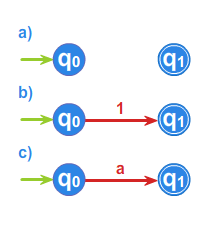
Na rysunku 2 przedstawione są trzy automaty. Automat a) rozpoznaje język pusty, automat b) - język \(\displaystyle \{1\}\), a automat c) - język \(\displaystyle \{a\}\), dla \(\displaystyle a \in A\).
Niech dane będą automaty: \(\displaystyle M_1\), akceptujący język opisywany wyrażeniem \(\displaystyle r\) oraz \(\displaystyle M_2\), akceptujący język opisywany wyrażeniem \(\displaystyle s\). Na rysunku 3 przedstawiono konstrukcje automatów akceptujących wyrażenia regularne \(\displaystyle r+s\) (automat a)), \(\displaystyle (rs)\) (automat b)) oraz \(\displaystyle r^*\) (automat c)).
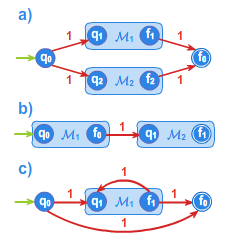
W automacie a) stan \(\displaystyle q_0\) jest stanem początkowym, stan \(\displaystyle f_0\) -stanem końcowym, stany \(\displaystyle q_1,q_2\) oraz \(\displaystyle f_1,f_2\) oznaczają odpowiednio stany początkowe automatów \(\displaystyle M_1\) i \(\displaystyle M_2\) oraz stany
końcowe automatów \(\displaystyle M_1\) i \(\displaystyle M_2\).
W automacie b) stan \(\displaystyle q_0\) jest jednocześnie jego stanem początkowym oraz stanem początkowym automatu \(\displaystyle M_1\), stan \(\displaystyle f_1\) jest stanem końcowym automatu b) i jednocześnie stanem końcowym automatu \(\displaystyle M_2\).
Stan \(\displaystyle f_0\) jest stanem końcowym w \(\displaystyle M_1\), a \(\displaystyle q_1\) - początkowym w \(\displaystyle M_2\).
W automacie c) stan \(\displaystyle q_0\) jest jego stanem początkowym a \(\displaystyle f_0\) końcowym. Stany \(\displaystyle q_1\) oraz \(\displaystyle f_1\) to odpowiednio początkowy i końcowy stan automatu \(\displaystyle M_1\).
Wyrażenia regularne można przedstawiać w postaci drzewa, w którym liśćmi są litery, słowo puste 1 lub zbiór pusty , a węzły symbolizują operacje na wyrażeniach regularnych, czyli sumę, konkatenację lub iterację, czyli gwiazdkę Kleene'ego.
Przykład 1.3
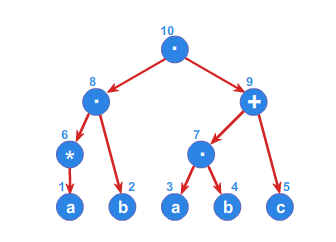
Rozważmy wyrażenie regularne \(\displaystyle r=(a^*b)(ab+c)\). Drzewo odpowiadające \(\displaystyle r\) przedstawione jest na rysunku 4. Korzeniem jest wierzchołek z małą wchodzącą strzałką.
Powyższe konstrukcje będą stosowane podczas iteracyjnej budowy automatu. Algorytm do tego celu będzie wykorzystywał drzewo odpowiadające wyrażeniu regularnemu w następujący sposób: drzewo będzie przeszukiwane metodą post-order (zaczynając od korzenia),
tzn. najpierw rekurencyjnie przeszukiwane są poddrzewa danego węzła \(\displaystyle x\), a na końcu sam węzeł \(\displaystyle x\). Dzięki temu, wchodząc do węzła \(\displaystyle x\) drzewa etykietowanego daną operacją na wyrażeniu regularnym oba poddrzewa \(\displaystyle P\) i \(\displaystyle L\) wierzchołka \(\displaystyle x\) będą już reprezentowane przez automaty \(\displaystyle \mathcal{A}_P\) oraz \(\displaystyle \mathcal{A}_L\). Teraz wystarczy zastosować jedną z konstrukcji z rysunku 2 lub 3. Procedurę powtarzamy do momentu, aż przechodzenie drzewa zakończy się w korzeniu. Szukanym przez nas automatem będzie automat "odpowiadający" korzeniowi drzewa.
Poniżej przedstawiony jest algorytm konstrukcji automatu w oparciu o wyrażenie regularne. Jego istotną część składową stanowi procedura
PostOrder, której pseudo-kod jest przedstawiony poniżej. Wykorzystamy także dwie procedury, mianowicie CreateAutomata(type) oraz JoinAutomata(type,\(\displaystyle \mathcal{M}_1,\mathcal{M}_2\)). Zmienna type może przyjmować wartości '\(\displaystyle a\)', '\(\displaystyle b\)' lub '\(\displaystyle c\)'. Funkcja zwraca automat CreateAutomata(type)
przedstawiony (zależnie od zmiennej type) na rysunku 2. Procedura JoinAutomata(type,\(\displaystyle \mathcal{M}_1,\mathcal{M}_2\)) natomiast konstruuje na podstawie automatów \(\displaystyle \mathcal{M}_1\), \(\displaystyle \mathcal{M}_2\) automat z rysunku 2, przy czym dla przypadku type=\(\displaystyle c\) automat \(\displaystyle \mathcal{M}_2\) jest bez
znaczenia. Ostatnią wykorzystaną procedurą będzie BuildTree(r), tworząca drzewo (binarne) dla wyrażenia regularnego. Zakładamy, że studentowi doskonale jest znana Odwrotna Notacja Polska i budowa takiego drzewa nie będzie dla niego stanowiła problemu. Dla ustalenia uwagi zakładamy, że symbol \(\displaystyle *\) prowadzi zawsze do lewego dziecka.
Poniżej przedstawiamy oznaczenia standardowych funkcji operujących na drzewach. Funkcja \(\displaystyle \textsc{Root}(T)\) zwraca korzeń drzewa \(\displaystyle T\), funkcje \(\displaystyle \textsc{LeftChild}(T,v)\) oraz \(\displaystyle \textsc{RightChild}(T,v)\) zwracają lewe i prawe dziecko wierzchołka \(\displaystyle v\) (ew. NULL, gdy brak lewego lub prawego dziecka), natomiast funkcja \(\displaystyle \textsc{Label}(T,v)\) zwraca etykietę wierzchołka \(\displaystyle v\) drzewa \(\displaystyle T\). Funkcja \(\displaystyle \textsc{IsLeaf}(T,v)\) zwraca wartość \(\displaystyle \textbf{true}\), gdy \(\displaystyle v\) jest liściem w drzewie \(\displaystyle T\) oraz \(\displaystyle \textbf{false}\) w przypadku
przeciwnym.
Algorytm Wr2Automat -- buduje automat rozpoznający język
opisywany wyrażeniem regularnym
1 Wejście: \(\displaystyle r\) -- wyrażenie regularne.
2 Wyjście: \(\displaystyle \mathcal{A}=(S, A, f, s_0, T)\) -- automat rozpoznający język opisywany wyrażeniem \(\displaystyle r\).
3 \(\displaystyle T\leftarrow \textsc{BuildTree}(r)\);
4 \(\displaystyle v_0 \leftarrow \textsc{Root}(T)\);
5 \(\displaystyle \mathcal{A} \leftarrow\) PostOrder(\(\displaystyle T,v_0\));
6 return \(\displaystyle \mathcal{A}\);
Przykład 1.4
Zastosujemy algorytm Wr2Automat do konstrukcji automatu dla wyrażenia regularnego \(\displaystyle w=(a^*b)(ab+c)\).
Automat \(\displaystyle \mathcal{A}_{10}\) jest zwrócony przez algorytm jako automat akceptujący język opisywany wyrażeniem \(\displaystyle r=(a^*b)(ab+c)\). Automat ten przedstawiony jest na rysunku 5.
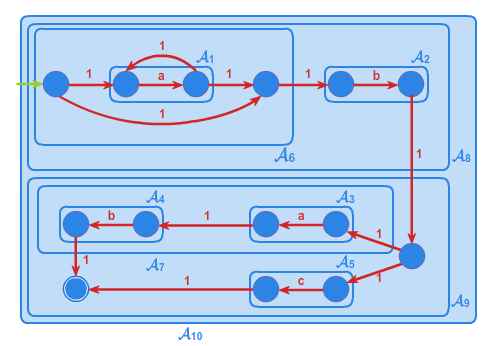
Ramkami zaznaczono i opisano automaty budowane w trakcie działania procedury PostOrder.
Rezultat działania algorytmu Wr2Automat może nie być zadawalający, gdyż wynikiem działania algorytmu nie jest automat deterministyczny, lecz automat z pustymi przejściami. Automat ten można więc poddać procesowi usunięcia przejść pustych oraz determinizacji, co można przeprowadzić przy pomocy omówionych wcześniej algorytmów UsuńPustePrzejścia oraz Determinizuj.
Algorytm Procedure PostOrder
1 procedure PostOrder (\(\displaystyle T\): drzewo, \(\displaystyle v\): wierzchołek)
2 if IsLeaf(\(\displaystyle T,v\)) then
3 if \(\displaystyle v\)=NULL then
4 \(\displaystyle \mathcal{A}_v \leftarrow\) CreateAutomata('\(\displaystyle a\)');
5 else
6 if Label(\(\displaystyle T,v\))='1' then
7 \(\displaystyle \mathcal{A}_v \leftarrow\) CreateAutomata('\(\displaystyle b\)');
8 else
9 \(\displaystyle \mathcal{A}_v \leftarrow\) CreateAutomata('\(\displaystyle c\)'); \(\displaystyle \triangleright\) Label\(\displaystyle (T,v)\in A\)
10 end if
11 end if
12 return \(\displaystyle \mathcal{A}_v\);
13 else
14 \(\displaystyle \mathcal{A}_L \leftarrow\) PostOrder(\(\displaystyle T\), LeftChild\(\displaystyle (T,v)\));
15 \(\displaystyle \mathcal{A}_P \leftarrow\) PostOrder(\(\displaystyle T\), RightChild\(\displaystyle (T,v)\));
16 if Label(\(\displaystyle T,v\))='\(\displaystyle +\)' then
17 \(\displaystyle \mathcal{A}_{LP}\leftarrow\)JoinAutomata('\(\displaystyle a\)'\(\displaystyle ,\mathcal{A}_L,\mathcal{A}_P\));
18 end if
19 if Label(\(\displaystyle T,v\))='\(\displaystyle \cdot\)' then
20 \(\displaystyle \mathcal{A}_{LP}\leftarrow\)JoinAutomata('\(\displaystyle b\)'\(\displaystyle ,\mathcal{A}_L,\mathcal{A}_P\));
21 end if
22 if Label(\(\displaystyle T,v\))='\(\displaystyle *\)' then
23 \(\displaystyle \mathcal{A}_{LP}\leftarrow\)JoinAutomata('\(\displaystyle c\)'\(\displaystyle ,\mathcal{A}_L,\mathcal{A}_P\));
24 end if
25 return \(\displaystyle \mathcal{A}_{LP}\);
26 end if
27 end procedure
Procedura tworzenia drzewa dla wyrażenia regularnego działa w czasie liniowym ze względu na długość napisu reprezentującego wyrażenie
regularne -- napis ten można najpierw przekształcić do równoważnego mu, zapisanego w Odwrotnej Notacji Polskiej, a następnie, przechodząc
od lewej strony do prawej, konstruować po kolei fragmenty drzewa.
Przechodzimy teraz do algorytmów konstruujących wyrażenie regularne na podstawie zadanego automatu. Pierwszą metodę, można owiedzieć
klasyczną i omawianą w większości podręczników, prezentujemy poniżej. Drugą, nieco prostszą i wygodniejszą w zastosowaniu, przedstawimy w ćwiczeniach do tego wykładu.
Niech dany będzie automat \(\displaystyle \mathcal{A}=(S, A, f, s_1, T)\). Zbudujemy wyrażenie regularne opisujące język akceptowany przez \(\displaystyle \mathcal{A}\).
Konstrukcja polega na obliczeniu zbiorów \(\displaystyle R_{ij}^k\) (definicja poniżej), gdzie \(\displaystyle i,j=1,...,|S|\), co jest równoważne konstrukcji pewnych wyrażeń regularnych \(\displaystyle r_{ij}^k\). Szukany język będzie odpowiadał sumie pewnych zbiorów \(\displaystyle R_{ij}^k\), a zatem opisywany będzie przez wyrażenie regularne postaci \(\displaystyle r_{ij_1}^k + ... + r_{ij_t}^k\) dla pewnych \(\displaystyle j_l\), \(\displaystyle i\) oraz \(\displaystyle k\).
Załóżmy, że zbiór stanów automatu jest postaci \(\displaystyle S=\{s_1, s_2, ..., s_n\}\). Wprowadźmy porządek na
zbiorze \(\displaystyle S\), przyjmując:
Zbiory \(\displaystyle R_{ij}^k\) definiujemy w następujący sposób:
\(\mbox{(1)}\)
Intuicyjnie, zbiór \(\displaystyle R_{ij}^k\) to ogół wszystkich słów \(\displaystyle w\) takich, że \(\displaystyle f(s_i, w)=s_j\), a ponadto jeśli \(\displaystyle w=a_1a_2...a_m\), to \(\displaystyle \forall 1 \leqslant j \leqslant m-1 f(s_i, a_1a_2...a_j) = s_l \wedge l \leqslant k\).
Zamiast obliczać zbiory \(\displaystyle R_{ij}^k\) wygodniej będzie od razu zapisywać odpowiadające im wyrażenia regularne, które oznaczać
będziemy poprzez \(\displaystyle r_{ij}^k\). Przez analogię mamy wzór rekurencyjny:
\(\mbox{(2)}\)
Pozostaje wyjaśnić jak wyglądają wyrażenia \(\displaystyle r_{ij}^0\). Jeśli \(\displaystyle R_{ij}^k=\{a_1,a_2,\dots,a_s\}\) to
\(\mbox{(3)}\)
Twierdzenie 1.1
Niech \(\displaystyle \mathcal{A}\) oraz \(\displaystyle R_{ij}^k\) będą zdefiniowane jak powyżej i niech zbiór stanów końcowych dla \(\displaystyle \mathcal{A}\) ma postać \(\displaystyle T=\{s_{j_1}, s_{j_2}, ..., s_{j_t}\}\). Wtedy
Powyższą metodę ujmiemy formalnie w ramy algorytmu (algorytm Automat2WR1).
Algorytm Automat2WR1 -- buduje wyrażenie regularne opisujące język akceptowany przez automat skończony.
1 Wejście: \(\displaystyle \mathcal{A}=(S=\{s_1, s_2, ..., s_n\}, A, f, s_1, T)\).
2 Wyjście: \(\displaystyle w\) - wyrażenie regularne opisujące język \(\displaystyle L=L(\mathcal{A})\).
3 for \(\displaystyle i\leftarrow 1\) to \(n\) do
4 for \(\displaystyle j\leftarrow 1\) to \(\displaystyle n\) do
5 oblicz \(\displaystyle r_{ij}^0\) \(\displaystyle \triangleright\) stosujemy wzór (3);
6 end for
7 end for
8 for \(\displaystyle k \leftarrow 1\) to \(\displaystyle n\) do
9 for \(\displaystyle i\leftarrow 1\) to \(\displaystyle n\) do
10 for \(\displaystyle j\leftarrow 1\) to \(\displaystyle n\) do
11 \(\displaystyle r_{ij}^k \leftarrow r_{ik}^{k-1}(r_{kk}^{k-1})^*r_{kj}^{k-1} + r_{ij}^{k-1}\); \(\displaystyle \triangleright\) dokonujemy katenacji słów
12 end for
13 end for
14 end for
15 \(\displaystyle r \leftarrow\) ""; \(\displaystyle \triangleright\) podstaw pod \(\displaystyle r\) słowo puste
16 for \(\displaystyle i\leftarrow 1\) to \(\displaystyle n\)
17 if \(\displaystyle \ s_i \in T\)
18 if r=""
19 \(\displaystyle r\leftarrow r_{1i}^{n}\); \(\displaystyle \triangleright\) stosujemy Twierdzenie 1.1
20 else
21 \(\displaystyle r \leftarrow r + r_{1i}^{n}\);
22 end if
23 end if
24 end for
25 return \(\displaystyle r\);
Podczas obliczania wyrażeń \(\displaystyle r_{ij}^k\) należy je w miarę możliwości upraszczać, gdyż, szczególnie przy dużej liczbie stanów,
nieskracane, mogą rozrastać się do bardzo dużych rozmiarów.
Przykład 1.5
Znajdziemy wyrażenie regularne opisujące język akceptowany przez automat z rysunku 6.
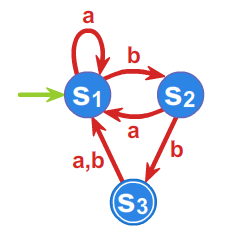
Mamy \(\displaystyle |S|=3\), \(\displaystyle i,j \in \{1, 2, 3\}\), \(\displaystyle k \in \{0, 1, 2, 3\}\), \(\displaystyle T=\{s_3\}\). Szukamy zatem wyrażenia regularnego \(\displaystyle r = r_{13}^3\).
Najpierw musimy obliczyć \(\displaystyle r_{ij}^0\) dla wszystich \(\displaystyle i,j \in \{1,2,3\}\). Mamy na przykład \(\displaystyle r_{31}^0=a+b\), gdyż z definicji zachodzi: \(\displaystyle R_{31}^0 = \{a \in A:\ f(s_3, a)=s_1\}=\{a, b\}\).
Gdy mamy wyliczone wszystkie \(\displaystyle r_{ij}^0\), przystępujemy do obliczeń dla \(\displaystyle k=1\).
Na przykład:
co po zredukowaniu daje
Obliczone wyrażenia \(\displaystyle r_{ij}^k\) dla \(\displaystyle k=0,1,2\) oraz dla wszystkich \(\displaystyle i,j\) przedstawione są w tabeli 1.
| \(\displaystyle k=0\) | \(\displaystyle k=1\) | \(\displaystyle k=2\) | |
| \(\displaystyle r_{11}^k\) | \(\displaystyle a+1\) | \(\displaystyle a^*\) | \(\displaystyle a^*b(a^+b)^*a^++a^*\) |
| \(\displaystyle r_{12}^k\) | \(\displaystyle b\) | \(\displaystyle a^*b\) | \(\displaystyle a^*b(a^+b)^*\) |
| \(\displaystyle r_{13}^k\) | \(\phi\) | \(\phi\) | \(\displaystyle a^*b(a^+b)^*b\) |
| \(\displaystyle r_{21}^k\) | \(\displaystyle a\) | \(\displaystyle a^+\) | \(\displaystyle (a^+b)^*a^+\) |
| \(\displaystyle r_{22}^k\) | \(\displaystyle 1\) | \(\displaystyle a^+b+1\) | \(\displaystyle (a^+b)^*\) |
| \(\displaystyle r_{23}^k\) | \(\displaystyle b\) | \(\displaystyle b\) | \(\displaystyle (a^+b)^*b\) |
| \(\displaystyle r_{31}^k\) | \(\displaystyle a+b\) | \(\displaystyle a^++ba^*\) | \(\displaystyle (1+(a^+b+ba^*b)(a^+b)^*)a^++ba^*\) |
| \(\displaystyle r_{32}^k\) | \(\phi\) | \(\displaystyle a^+b+ba^*b\) | \(\displaystyle (a^+b+ba^*b)(a^+b)^*\) |
| \(\displaystyle r_{33}^k\) | \(\displaystyle 1\) | \(\displaystyle 1\) | \(\displaystyle (a^+b+ba^*b)(a^+b)^*b+1\) |
Tabela 1. Obliczone wartości \(\displaystyle r_{ij}^k\) dla automatu z rys. 6
Ponieważ \(\displaystyle T=\{s_3\}\), szukanym wyrażeniem regularnym będzie \(\displaystyle r=r_{13}^3\). Obliczamy zatem:
Problemy rozstrzygalne algorytmicznie
Kończąc część wykładu prezentującą języki regularne, wskażemy problemy rozstrzygalne algorytmicznie w zakresie tej rodziny języków formalnych. Ponieważ pojęcia rozstrzygalności i nierozstrzygalności możemy uznać za znane (były wprowadzone na innych wykładach) nie
będziemy tutaj ich definiować ani kreślić tła teorii rozstrzygalności.
W obrębie rodziny języków regularnych wszystkie podstawowe problemy są algorytmicznie rozstrzygalne. Uzasadnienia są proste. Część z nich opiera się na lemacie o pompowaniu, a część wynika bezpośrednio z algorytmicznej struktury automatu skończenie stanowego, czy też gramatyki regularnej.
Twierdzenie 2.1
W klasie języków regularnych \(\displaystyle \mathcal{REG}(A^{*})\) następujące problemy są rozstrzygalne:
- problem niepustości języka, \(\displaystyle L\neq \emptyset,\)
- problem nieskończoności języka, \(\displaystyle card\, L=\aleph _{0},\)
- problem równości języków, \(\displaystyle L_{1}=L_{2},\)
- problem należenia słowa do języka, \(\displaystyle w\in L.\)
Dowód
1. Aby uzasadnić ten fakt zauważmy, że wystarczy sprawdzić niepustość skończonego podzbioru języka \(\displaystyle L,\) co wynika z równoważności:
gdzie \(\displaystyle N\) stała z lematu o pompowaniu. Implikacji \(\displaystyle \Leftarrow\) jest oczywista. Natomiast fakt, że do niepustego języka należy słowo o długości ograniczonej przez \(\displaystyle N\) , wynika z lematu o pompowaniu. Jeśli mianowicie \(\displaystyle w\in L\) i \(\displaystyle \mid w\mid \geqslant N\) , to rozkładamy słowo \(\displaystyle w\) następująco:
Przyjmując teraz wartość \(\displaystyle i=0\) , uzyskujemy:
Po skończonej ilości powtórzeń powyższego rozkładu uzyskamy słowo należące do języka, o długości ograniczonej przez \(\displaystyle N\) .
2. Wystarczy udowodnić nastepującą równoważność:
Jeśli \(\displaystyle L\) jest językiem nieskończonym, to znajdziemy w \(\displaystyle L\) słowo \(\displaystyle w\) dowolnie długie. Niech \(\displaystyle \mid w\mid \geqslant N\) . Jeśli słowo \(\displaystyle w\) nie spełnia ograniczenia \(\displaystyle \mid w\mid <2N\) , to podobnie jak poprzednio korzystamy z lematu o pompowaniu i po skończonej ilości kroków otrzymamy słowo krótsze od \(\displaystyle 2N\) . Istotne jest, że wykorzystując lemat o pompowaniu, możemy założyć, że usuwane słowo \(\displaystyle u\) ma długość ograniczoną przez \(\displaystyle N\) . Zatem oznacza to, że ze słowa dłuższego od \(\displaystyle 2N\) nie dostaniemy słowa krótszego od \(\displaystyle N\) .
Jeśli teraz do języka \(\displaystyle L\) należy słowo \(\displaystyle w\) o długości większej lub równej \(\displaystyle N\) , to znów z lematu o pompowaniu wnioskujemy, że
Istnieje więc nieskończony podzbiór języka \(\displaystyle L\) , a więc i sam język \(\displaystyle L\) jest nieskończony.
3. Rozważmy \(\displaystyle L=(L_{1}\cap \overline{L_{2}})\cup (\overline{L_{1}}\cap L_{2})\) . Język \(\displaystyle L\) jest regularny, co wynika z domkniętości klasy \(\displaystyle \mathcal{L}_{3}\) na operaje boolowskie. Równoważność
sprowadza problem równości języków do problemu niepustości omówionego powyżej.
4. Konstruujemy automat \(\displaystyle \mathcal{A} \displaystyle =(S,f,s_0,T)\) rozpoznający język \(\displaystyle L\) i sprawdzamy, czy \(\displaystyle f(s_{0},w)\in T.\)
Na podstawie dowodu powyższego twierdzenia nietrudno jest określić algorytmy rozstrzygające przedstawione problemy. Poniżej prezentujemy
algorytm rozstrzygający problem należenia słowa do języka regularnego zadanego automatem. Bez straty ogólności możemy założyć, że automat jest deterministyczny.
Algorytm NależenieDoJęzyka -- sprawdza, czy dane słowo należy do języka \(\displaystyle L\) akceptowanego przez zadany automat \(\displaystyle \mathcal{A}\)
1 Wejście: \(\displaystyle \mathcal{A}=(S, A, f, s_0, T)\) - automat akceptujący język \(\displaystyle L\) oraz \(\displaystyle w=w_1w_2\ldots w_n \in A^*\) - słowo.
2 Wyjście: Odpowiedź true (tak) lub false (nie).
3 \(\displaystyle k \leftarrow |w|\);
4 \(\displaystyle s \leftarrow s_0\);
5 for \(\displaystyle i\leftarrow 1\) to \(k\) do
6 \(\displaystyle s \leftarrow f(s,w_i)\);
7 end for
8 if \(\displaystyle s \in T\) then
9 return true;
10 else
11 return false;
12 end if
Algorytm działa w czasie \(\displaystyle O(|w|)\) i posiada złożoność pamięciową \(\displaystyle O(|A| \cdot |S|)\), co spowodowane jest koniecznością przechowywania funkcji przejść automatu \(\displaystyle \mathcal{A}\).
Jeśli język zadany jest nie automatem, a gramatyką regularną, to gramatykę można przekształcić na automat poznanym na początku wykładu algorytmem GReg2Automat, następnie zdeterminizować ten automat i podać go jako wejście dla algorytmu NależenieDoJęzyka.
Jeśli język zadany jest wyrażeniem regularnym, to mając wyrażenie regularne, można zbudować odpowiadający mu automat przy pomocy algorytmu WR2Automat. A zatem, na przykład, z powyższego twierdzenia wynika, iż problem równoważności wyrażeń regularnych jest rozstrzygalny.