Algorytmy Knutha-Morrisa-Pratta i Morrisa-Pratta
Przedstawimy klasyczne algorytmy Knutha-Morrisa-Pratta (w skrócie KMP) oraz Morrisa-Pratta (w skrócie MP) dla problemu string-matchingu: obliczyć w w tekście \( y \) wszystkie (lub pierwsze) wystąpienia danego tekstu \( x \), zwanego wzorcem.
Algorytmy MP i KMP różnią się jedynie tym że jeden używa tablicy P a drugi P'. Tablica P' jest bardziej skomplikowana, będziemy się zatem głównie koncentrować na algorytmie MP, poza wersją on-line (gdzie waśnie P' ma przewagę).
Oznaczmy \( m=|x|, n=|y| \), gdzie \( m\le n \).
Zaczniemy od obliczania jedynie pierwszego wystąpienia. Algorytm MP przegląda tekst y od lewej do prawej, sprawdzając, czy jest zgodność na pozycji \( j+1 \) we wzorcu x oraz na pozycji \( i+j+1 \) w tekście y. Jeśli jest niezgodność, to przesuwamy potencjalny początek (pozycja i) wystąpienia x w y. Zakładamy, że algorytm zwraca na końcu wartość false, jeśli nie zwróci wcześniej true.
Algorytm Algorytm MP
i:=0; j:=0; while i <= n-m do begin while j < m and x[j+1]=y[i+j+1] do j=j+1; if j=m then return (true); i:=i+j-P[j]; j:=max(0,P[j]) end;
Uwaga: Algorytm działa podobnie gdy zamiast prefikso-sufiksów użyjemy tablicy P' silnych prefisko-sufksów. Algorytm w całości jest wtedy bardziej skomplikowany ze względu na trudniejszy preprocessing (liczenie P' jest trudniejsze od P).
Algorytm MP z tablicą P' zamiast P nazywamy algorytmem Knutha-Morrisa-Pratta i oznaczamy przez KMP.
Operacją dominującą w algorytmach KMP i MP jest operacja porównania symboli: \( x[j+1]=y[i+j+1] \). Algorytmy KMP i MP wykonują co najwyżej 2n-m porównań symboli. Zauważmy, że dla danej pozycji w tekście y jest ona co najwyżej raz porównana z pewną pozycją we wzorcu w porównaniu pozytywnym (gdy symbole są równe). Jednocześnie każde negatywne porównanie powoduje przesunięcie pozycji \( i \) co najmniej o jeden, maksymalna wartość i wynosi n-m, zatem mamy takich porównań co najwyżej n-m, w sumie co najwyżej 2n-m porównań.
Poniższa animacja pokazuje przykładowe działanie algorytmu KMP.
Algorytm dla \( x=ab \), \( y=aa..a \) wykonuje 2n-2porównania, zatem 2n-m jest dolną i jednocześnie górną granicą na liczbę porównań w algorytmie.
Obserwacja. W wersji on-line algorytmu okaże się, że jest zdecydowana różnica między użyciem P' i P; to właśnie jest motywacją dla wprowadzenia silnych prefikso-sufiksów.
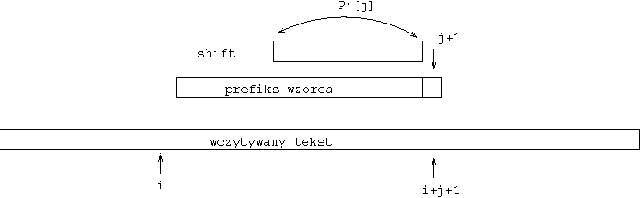
Rysunek 1: Jedna iteracja algorytmu KMP. Przesunięcie \( shift=j-P'[j] \) potencjalnego początku wystąpienia wzorca gdy \( x[j+1]\ne y[i+j+1] \).